
1、下载scala2.11.5版本,下载地址为:http://www.scala-lang.org/download/2.11.5.html
2、安装和配置scala:
第一步:上传scala安装包 并解压


第二步 配置SCALA_HOME环境变量到bash_profile
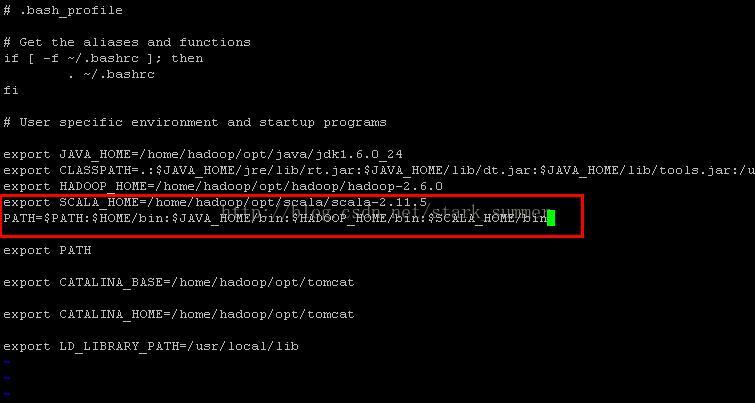
第三步 source 使配置环境变量生效:

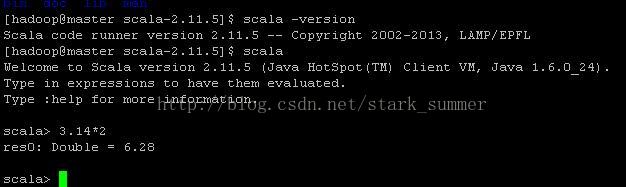
第四步 验证scala:
3、下载spark 1.2.0,具体下载地址:http://spark.apache.org/downloads.html
4、安装和配置spark:
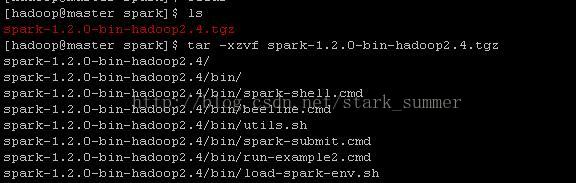
第一步 解压spark:
第二步 配置SPARK_HOME环境变量:
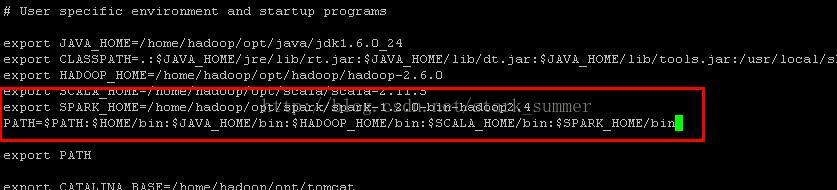
第三步 使用source生效:

进入spark的conf目录:
第四步 修改slaves文件,首先打开该文件:


slaves修改后:

第五步 配置spark-env.sh
首先把spark-env.sh.template拷贝到spark-env.sh:

然后 打开“spark-env.sh”文件:

spark-env.sh文件修改后:

5、启动spark伪分布式帮查看信息:
第一步 先保证hadoop集群或者伪分布式启动成功,使用jps看下进程信息:
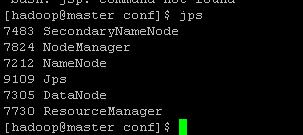
如果没有启动,进入hadoop的sbin目录执行 ./start-all.sh
第二步 启动spark:
进入spark的sbin目录下执行“start-all.sh”:
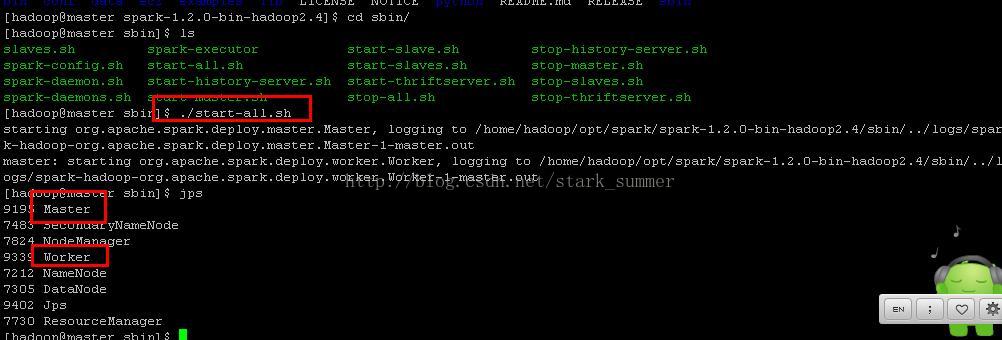
此刻 我们看到有新进程“Master” 和"Worker"
我们访问“http://master:8080/”,进如spark的web控制台页面:
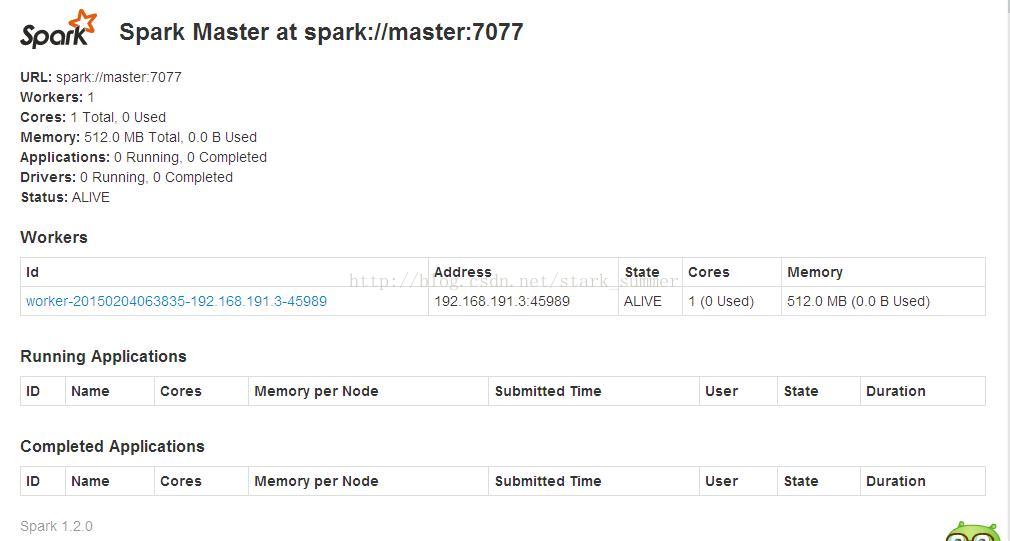
从页面上可以看到一个Worker节点的信息。
我们进入spark的bin目录,使用“spark-shell”控制台:

通过访问"http://master:4040",进入spark-shell web控制台页面:

6、测试spark伪分布式:
我们使用之前上传到hdfs中的/data/test/README.txt文件进行mapreduce
取得hdfs文件:

对读取的文件进行一下操作:

使用collect命令提交并执行job:
readmeFile.collect

查看spark-shell web控制台:

states:
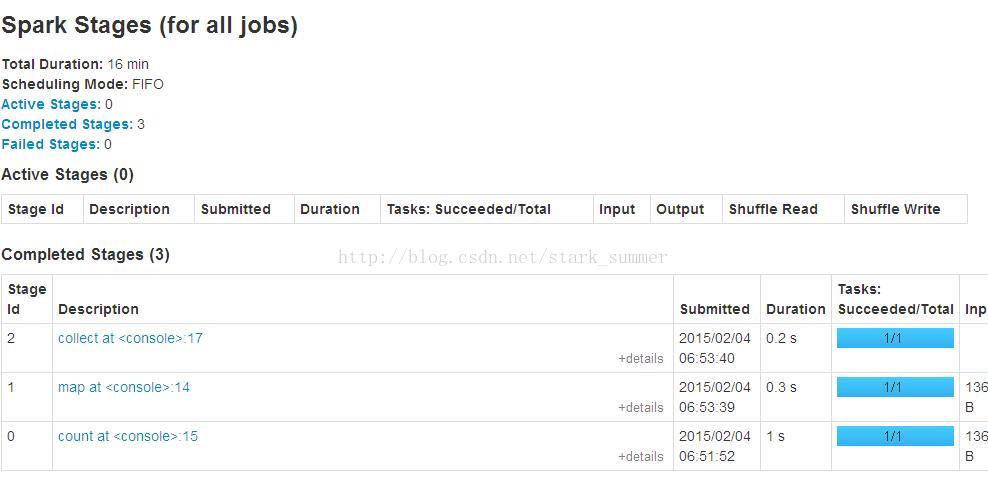
端口整理:
master端口是7077
master webui是8080
spark shell webui端口是4040



相关推荐
**Spark伪分布式环境搭建指南** Spark是一款高性能的分布式计算框架,广泛应用于大数据处理领域。它提供了高度优化的引擎,支持多种计算模型,如批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)...
虽然文档中未详细展开Hadoop的安装步骤,但提及了Hadoop版本为2.6.0,这是构建伪分布式或单节点Spark环境的关键组件。Hadoop的安装步骤可能包括下载对应版本的Hadoop包、解压以及配置环境变量等。 ### Spark安装 ...
### Hadoop3.1.3安装与单机/伪分布式配置知识点详解 #### 一、实验目的和要求 - **掌握Hadoop3.1.3的安装与配置**:包括单机模式和伪分布式模式。 - **理解Hadoop的工作原理**:特别是其在不同模式下的运行机制。 ...
- [Ubuntu 14.04 下 Hadoop2.4.1 单机/伪分布式安装配置教程](http://www.linuxidc.com/Linux/2015-02/113487.htm) - [CentOS 6.3 下 Hadoop 伪分布式平台搭建](http://www.linuxidc.com/Linux/2016-11/136789.htm...
伪分布式模式允许在一个机器上模拟多节点集群。可以通过以下命令启动: ```bash ./bin/run-example org.apache.spark.examples.SparkPi local[2,2,1024] ``` 这里的 `[2,2,1024]` 表示启动两个 Worker,每个 Worker ...
总结,Spark Standalone模式的安装部署是一个基础但重要的实践环节,它涉及到了Linux环境管理、文件配置以及分布式系统的基础操作。通过这次实验,可以深入理解Spark集群的工作原理,为后续的数据处理和分析打下坚实...
#### 四、伪分布式Hadoop环境的安装与配置 1. **Hadoop安装与配置** - 安装路径:`/opt/hadoop-2.7.4` - 配置文件包括但不限于: - `hadoop-env.sh`: 设置JAVA_HOME - `hdfs-site.xml`: 配置HDFS相关的参数,...
- **Hadoop3.0**:分布式计算框架,为Spark提供底层支持。 - **JDK8**:Java开发工具包,Hadoop和Spark都需要。 - **Scala2.11.tgz**:编程语言,Spark的核心语言之一。 - **Spark-2.3.0-bin-hadoop2.7.tgz**:大...
### 云服务器上搭建大数据伪分布式环境 #### 一、云服务器上...以上就是在阿里云服务器上搭建Hadoop伪分布式环境、Hive和Spark的基本步骤。通过这些步骤,你可以搭建一个完整的、可用于数据处理和分析的大数据环境。
测试Spark伪分布式环境通常包括以下几个步骤: - **读取HDFS文件**: - 使用`sc.textFile`方法读取HDFS上的文件: ```scala val readmeFile = sc.textFile("hdfs://Master.Hadoop:9000/user/hadoop/input/file1....
让我们深入探讨Hadoop及其伪分布式模式,以及与之相关的JDK。 Hadoop是由Apache软件基金会维护的一个开源项目,它基于Java语言编写,旨在实现可靠、可扩展的数据存储和处理。核心组件包括Hadoop Distributed File ...
- **选择运行模式**: Spark可以本地模式、伪分布式模式和完全分布式模式运行。对于开发和测试,通常使用本地模式;生产环境通常选择分布式模式。 **3. Spark与Hadoop的关系** Spark可以与Hadoop生态系统集成,但本...
总结起来,单机伪分布式的Hadoop-spark配置是一个基础但重要的技能,它可以帮助开发者在本地环境中快速验证代码和测试算法。通过熟悉Hadoop和Spark的配置文件、理解其核心概念以及熟练掌握相关API,可以在大数据领域...
5. **测试运行**:通过`hadoop fs -ls`命令检查HDFS是否正常工作,运行MapReduce示例程序如WordCount,验证伪分布式环境的正确性。 6. **关闭Hadoop**:使用`stop-dfs.sh`和`stop-yarn.sh`停止Hadoop服务。 在单机...
在分布式环境中,通常需要多台服务器来运行Kafka集群,但为了测试或学习目的,可以使用单机上的伪分布式设置,这使得开发者能够在本地环境中快速搭建Kafka实例,而无需复杂的网络配置。 标签中的“kafka”、...
三、Hbase 伪分布式搭建(使用自带的 ZooKeeper)1. 环境Hbase-1.2.62. 详细步骤2.1 安装 Hbase下载并解压 Hbase,配置环境变量:tar -zxvf hbase-1.2.6-bin.tar.gzmv hbase-1.2.6 /usr/local/hbasehbase_home/...
对于没有安装 Hadoop 的情况,推荐遵循指定的 Hadoop 安装教程,如“Hadoop 安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04”。该教程不仅包含 Hadoop 的安装,也涵盖了 Java JDK 的安装,这是运行 Hadoop 和 ...
6. **Spark部署模式**:Spark可以部署为单机模式、单机伪分布式、集群分布式(完全分布式),但没有列分布式这一说法。 7. **Spark Streaming输入数据流**:Kafka、Twitter和TCP套接字都是Spark Streaming常见的...
单机模式下,Spark 只使用单台机器的资源,而伪分布式模式下,Spark 可以模拟分布式环境,但所有的计算都是在单台机器上完成的。 Starting a Cluster 在 standalone 模式下,需要手动启动 master 和 slave 节点。...