
http_accounting ๆฏ Nginx ็ไธไธช็ฌฌไธๆนๆจกๅ๏ผไผๆฏ้5ๅ้่ชๅจ็ป่ฎก Nginx ๆๆๅก็ๆต้๏ผ็ถๅๅ้็ป syslogใ
ๆต้ไปฅย accounting_idย ไธบๆ ็ญพๆฅ็ป่ฎก๏ผ่ฟไธชๆ ็ญพๅฏไปฅ่ฎพ็ฝฎๅจย server {}ย ็บงๅซ๏ผไนๅฏไปฅ่ฎพ็ฝฎๅจย location /urlpath {}ย ็บงๅซ๏ผ้ๅธธ็ตๆดปใ ็ป่ฎก็ๅ
ๅฎนๅ
ๆฌๅๅบๅญ่ๆฐ๏ผๅ็ง็ถๆ็ ็ๅๅบไธชๆฐใ
ๅ ฌๅธๅๅ ๆฏๆไธๅฅๅบไบ rrd ็็ณป็ป๏ผๆฅๆถ้ๅค็่ฟไบ syslog ๆฐๆฎๅนถไฝๅบ้ข่ญฆๅคๆญใๅผๅธธๆฅ่ญฆใไธ่ฟไปๅคฉไธ่ฎจ่ฎบ่ฟไธช๏ผ่ๆฏ่ฏๅพ็จๆ็ฎๅ็ๆนๅผ๏ผๅฟซ้็ๆๅฎ็ฑปไผผ็ไธญๅฟๅนณๅฐใ
่ฟ้ๅฝ็ถๆฏ logstash ็ๆไฝณ็จๆญฆไนๅฐใ
logstash.confย ็คบไพๅฆไธ๏ผ
input {
syslog {
port => 29124
}
}
filter {
grok {
match => [ "message", "^%{SYSLOGTIMESTAMP:timestamp}\|\| pid:\d+\|from:\d{10}\|to:\d{10}\|accounting_id:%{WORD:accounting}\|requests:%{NUMBER:req:int}\|bytes_out:%{NUMBER:size:int}\|(?:200:%{NUMBER:count.200:int}\|?)?(?:206:%{NUMBER:count.206:int}\|?)?(?:301:%{NUMBER:count.301:int}\|?)?(?:302:%{NUMBER:count.302:int}\|?)?(?:304:%{NUMBER:count.304:int}\|?)?(?:400:%{NUMBER:count.400:int}\|?)?(?:401:%{NUMBER:count.401:int}\|?)?(?:403:%{NUMBER:count.403:int}\|?)?(?:404:%{NUMBER:count.404:int}\|?)?(?:499:%{NUMBER:count.499:int}\|?)?(?:500:%{NUMBER:count.500:int}\|?)?(?:502:%{NUMBER:count.502:int}\|?)?(?:503:%{NUMBER:count.503:int}\|?)?"
}
date {
match => [ "timestamp", "MMM dd HH:mm:ss", "MMM d HH:mm:ss" ]
}
}
output {
elasticsearch {
embedded => true
}
}
็ถๅ่ฟ่กย java -jar logstash-1.3.3-flatjar.jar agent -f logstash.confย ๅณๅฏๅฎๆๆถ้ๅ
ฅๅบ๏ผ ๅ่ฟ่กย java -jar logstash-1.3.3-flatjar.jar webย ๅณๅฏๅจ9292็ซฏๅฃ่ฎฟ้ฎๅฐ Kibana ็้ขใ
็ถๅๆไปฌๅผๅง้ ็ฝฎ็้ขๆ่ชๅทฑ้่ฆ็ๆ ทๅญ๏ผ
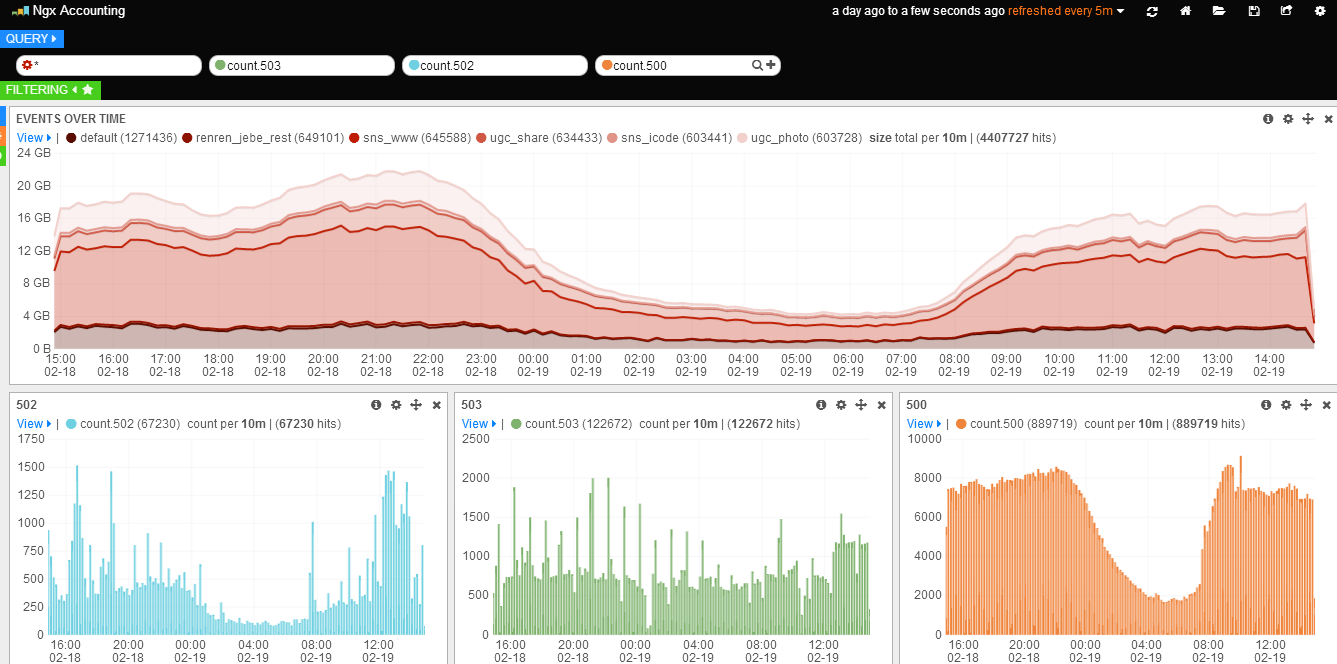
- Top-N ็ๆต้ๅพ
็นๅป Query ๆ็ดขๆ ๅทฆ่พน็ๆ่ฒๅ็น๏ผๅผนๅบๆ็ดขๆ ้
็ฝฎๆก๏ผ้ป่ฎคๆฏย luceneย ๆ็ดขๆนๅผ๏ผๆนๆtopNย ๆ็ดขๆนๅผใ็ถๅๅกซๅ
ฅๅๆๅญๆฎตไธบ accountingใ
็นๅป Event Over Time ๆฑ็ถๅพๅณไธ่ง็ฌฌไบไธช็ย Configureย ๅฐๅพๆ ๏ผๅผนๅบๅพ่กจ้
็ฝฎๆก๏ผ
- ๅจย
Panelย ้้กนๅกไธญไฟฎๆนยChart valueย ็ยcountย ไธบยtotal๏ผValue Fieldย ่ฎพ็ฝฎไธบ size๏ผๅพ้ยSecondsย ้กน๏ผ่ฝฌๆข size ็็ดฏๅ ๅผๆๆฏ็งๅธฆๅฎฝ(ไธ็ถ interval ๅๅไผๅฏผ่ด็ดฏๅ ๅผๅๅ)๏ผ - ๅจย
Styleย ้้กนๅกไธญไฟฎๆนยChart Optionsย ็ยBarsย ๅพ้้กนไธบยLines๏ผY Formatย ไธบ bytes๏ผ - ๅจย
Queriesย ้้กนๅกไธญไฟฎๆนยCharted Queriesย ไธบยselected๏ผ็ถๅ็นไธญๅณไพงๅๅบ็่ฏทๆฑไธญๆ้่ฆ็้ฃ้กน(ๅฝๅๅชๆไธไธช๏ผๅฐฑๆฏ*)ใ
ไฟๅญ้ๅบ้ ็ฝฎๆก๏ผๅณๅฏ็ๅฐ่ฏฅๅพ่กจๅผๅง่ชๅจๆดๆฐใ
- 50x ้่ฏฏ็ๆๆฏๅพ
็นๅป Query ๆ็ดขๆ ๅณ่พน็ + ๅท๏ผๆทปๅ ๆฐ็ Query ๆ็ดขๆ ๏ผ็ถๅๅจๆฐๆ็ดขๆ ้่พๅ
ฅ้่ฆๆ็ดข็ๅ
ๅฎน๏ผๆฏๅฆย count.500๏ผ
้ผ ๆ ็งปๅจๅฐๆต้ๅพๆๅทฆไพง๏ผไผ็งปๅบ Panel ๅฟซๆท้้กน๏ผ็นๅปๆๅบไธ็ + ๅท้้กนๆทปๅ ๆฐ็ Panel๏ผ
- ้ๆฉ Panel ็ฑปๅไธบย
histogram๏ผ - ้ๆฉ Queries ็ฑปๅไธบย
selected๏ผ็ถๅ็นไธญๅณไพงๅๅบ็่ฏทๆฑไธญๆ้่ฆ็้ฃ้กน(็ฐๅจๅบ็ฐไธคไธชไบ๏ผ้ไธญๆไปฌๅๆทปๅ ็ยcount.500)ใ
ไฟๅญ้ๅบ๏ผๅณๅฏ็ๅฐๆฐๅคๅบๆฅไธ่ก๏ผๅทฆไพงไธๅไนไธ(้ป่ฎคๆฏspan4๏ผๆทปๅ ็ๆถๅๅฏไปฅ้ๆฉ)็ไฝ็ฝฎๆไบไธไธชๆฑ็ถๅพใ
้ๅค่ฟไธชๆญฅ้ชค๏ผๆทปๅ 502/503 ็ๆฑ็ถๅพใ
- ไปช่กจ็่ฎพ็ฝฎๅญๆกฃ
้กต้ขๅณไธ่ง้ๆฉย Saveย ๅฐๅพๆ ไฟๅญๅณๅฏใไนๅๅไธ็้ขๅ๏ผๅฐฑๅฏไปฅ็นๅปๅณไธ่ง็ย Loadย ๅฐๅพๆ ่ชๅจๅ ่ฝฝใ
ไธ้ข่ฟไธช grok ๅ็ๅพ้พ็๏ผไธ่ฟไผผไนไนๆฒกๆๆดๅฅฝ็ๅๆณ๏ฝไธไธๆญฅไผ็ ็ฉถๅจ่ฟไธชๅบ็กไธๅๅนถ skyline ้ข่ญฆใ
2014 ๅนด 5 ๆ 10 ๆฅๆดๆฐ๏ผ
ๅจย logstash/docsย ไธๅ็ฐไธไธช filter ๅซ kv๏ผๅพ้ๅ่ฟไธชๅบๆฏ๏ผๅฏไปฅๅคงๅคง็ฎๅ grok ๅทฅไฝ๏ผๆฐ็ filter ้ ็ฝฎๅฆไธ๏ผ
filter {
grok {
match => [ "message", "^%{SYSLOGTIMESTAMP:timestamp}\|\| pid:\d+\|from:\d{10}\|to:\d{10}\|accounting_id:%{WORD:accounting}\|requests:%{NUMBER:req:int}\|bytes_out:%{NUMBER:size:int}\|%{DATA:status}"
}
kv {
target => "code"
source => "status"
field_split => "|"
value_split => ":"
}
ruby {
code => "n={};event['code'].each_pair{|x,y|n[x]=y.to_i};event['code']=n"
}
}
ไธๆๅพไธบไปไน filter/mutate ไธๆไพ่ฝฌๆข Hash ็ๅ่ฝ๏ผๆไปฅๅช่ฝๆ่ฟ่กๅๅจ filter/ruby ้้ขใkv ๆชๅบๆฅ็ value ้ป่ฎค้ฝๆฏๅญ็ฌฆไธฒ็ฑปๅใ
2014 ๅนด 5 ๆ 28 ๆฅๆดๆฐ๏ผ
ๅ็ฐ้ป่ฎค็ LVS ๆฃๆฅๅฏผ่ด็ 400 ไผ่ฎฐๅฝๅฐ้ป่ฎค็ accounting ็ป(โdefaultโ)้๏ผ่ฝ็ถไธๅ ๅธฆๅฎฝ๏ผๅดๅ ไธๅฐ่ฏทๆฑๆฐใ่ฟ็ฑปๆฅๅฟๅฏไปฅๅจ logstashๅฑ้ขๅฐฑๅนฒๆ๏ผ
filter {
grok {
match => [ "message", "^%{SYSLOGTIMESTAMP:timestamp}\|\| pid:\d+\|from:\d{10}\|to:\d{10}\|accounting_id:%{WORD:accounting}\|requests:%{NUMBER:req:int}\|bytes_out:%{NUMBER:size:int}\|%{DATA:status}"
}
if [accounting] == 'default' {
drop { }
} else {
kv {
target => "code"
source => "status"
field_split => "|"
value_split => ":"
}
ruby {
code => "n={};event['code'].each_pair{|x,y|n[x]=y.to_i};event['code']=n"
}
}
}
ๅฆๅค่ฏดๆไธไธ๏ผngx_http_accounting_moduleย ไธญ่ฎพๅฎย http_accounting_idย ่ฟๆญฅๆฏ้ขๅ
ๅค็็๏ผๆไปฅๅช่ฝๅๅบๅฎๅญ็ฌฆไธฒ๏ผไธ่ฝ็จย $hostย ไน็ฑป็ nginx.conf ๅ้ใ
ย



็ธๅ ณๆจ่
ๅจโ05ๅฐ็ก ่ฐท_Nginx_hit1qr_nginxๅฐ็ก ่ฐท_nginx_โ็่ฏพ็จไธญ๏ผไฝ ๅฐๅ จ้ขๅญฆไน ๅฐไปฅไธๅ ๅฎน๏ผๅ ๆฌ่ฏฆ็ป็้ ็ฝฎ็คบไพๅๅฎ้ ๆไฝๆๅฏผ๏ผๅธฎๅฉไฝ ๆไธบไธๅ็็ป็ Nginx ไฝฟ็จ่ ใ้่ฟๆทฑๅ ฅๅญฆไน ๅๅฎ่ทต๏ผไฝ ๅฐ่ฝๅคๅ ๅๅฉ็จ Nginx ็ๅผบๅคง...
4. **ไบไปถๅค็**๏ผๆฝๅ็ๆฐๆฎๅฐไฝไธบLogstashไบไปถ่ฟ่กๅค็๏ผๅฏไปฅ่ฟไธๆญฅ้่ฟ่ฟๆปคๅจ๏ผๅฆgrokใmutate็ญ๏ผ่ฟ่กๆธ ๆดใ่ฝฌๆข๏ผ็ถๅ้่ฟ่พๅบๆไปถ๏ผๅฆelasticsearchใstdout็ญ๏ผๅ้ๅฐ็ฎๆ ็ณป็ปใ 5. **็ๆฌๅ ผๅฎนๆง**๏ผๅจๆฌไพ...
openresty_nginx_logstash_kibana_elasticsearch_centos6 ๅฆไฝๅจcentos6ไธๅฎ่ฃ ๏ผopenresty + nginx + logstash + kibana + elasticsearch๏ผ ไธไบๅธฎๅฉๅๅฏๅ็้พๆฅ๏ผ ๅฎ่ฃ openresty ๅ่ฎพๆบๅจไธๅทฒ็ปๅฎ่ฃ ไบnginxใ ...
centos7ไธๅฎ่ฃ rpm็ฆป็บฟๅฎ่ฃ logstash-6.2.4ๅlogstash-output-jdbcๆไปถ ๅ ๅซlogstash rpmๅ ๅๅทฒๆๅ ๅฅฝ็logstash-output-jdbcๆไปถ
ๅจๅคงๆฐๆฎๅค็ๅๆฅๅฟๅๆ้ขๅ๏ผLogstashๆฏไธไธชๅนฟๆณไฝฟ็จ็ๅทฅๅ ท๏ผๅฎ่ฝๅคๆถ้ใ่งฃๆๅ่ฝฌๅๅ็ง็ฑปๅ็ๆฐๆฎใๅจๆฌๅบๆฏไธญ๏ผๆไปฌๅ ณๆณจ็ๆฏๅฆไฝๅฉ็จLogstashๅฐMySQLๆฐๆฎๅบไธญ็ๆฐๆฎ้ซๆๅฐๅฏผๅ ฅๅฐElasticsearch๏ผES๏ผไธญใ่ฟไธช่ฟ็จ...
nginx็ๆญฃๅ่กจ่พพๅผ๏ผlogstash็จใgrokๆฏไธ็ง้็จ็ปๅๅคไธช้ขๅฎไน็ๆญฃๅ่กจ่พพๅผ,็จๆฅๅน้ ๅๅฒๆๆฌๅนถๆ ๅฐๅฐๅ ณ้ฎๅญ็ๅทฅๅ ทใ้ๅธธ็จๆฅๅฏนๆฅๅฟๆฐๆฎ่ฟ่ก้ขๅค็ใ
้่ฟไฝฟ็จ`python_logstash_async_dwn`๏ผๅผๅ่ ๅฏไปฅๅจPythonๅบ็จ็จๅบไธญๆ ็ผ้ๆLogstash๏ผๅฎ็ฐ้ซๆไธๅฏ้ ็ๆฅๅฟๆตไผ ่พใๆญคๅบ็`py2.py3-none-any`ๆ ่ฏๆๅณ็ๅฎๅ ผๅฎนPython 2ๅPython 3็ๅค็งๅนณๅฐ๏ผๆ ่ฎบๆฏๅจWindowsใ...
logstash_linux-x86_64(v8.3.3)
logstash-8.1.0-x86_64.rpm
logstash-output-amazon_es ๅผนๆงๆ็ดข6.4.0+ 6.5+Amazon Elasticsearch Service่พๅบๆไปถ็้ ็ฝฎ่ฆ่ฟ่กLogstash่พๅบAmazon Elasticsearch Serviceๆไปถ๏ผๅช้ๆ็ งไปฅไธๆๆกฃๆทปๅ ้ ็ฝฎใ ้ ็ฝฎ็คบไพ๏ผ output {
6. **ๅฎๅ จๆงไธๆง่ฝไผๅ**๏ผ้ ็ฝฎ่ๆฌไธญๅฏ่ฝๅ ๅซไบๅ ณไบๅฎๅ จ่ฎพ็ฝฎๅๆง่ฝไผๅ็้จๅ๏ผๅฆ้ๅถ่ฏทๆฑ้็ใๅฏ็จHTTP/2ใ้ ็ฝฎSSL/TLS่ฏไนฆใไฝฟ็จGZIPๅ็ผฉ็ญ๏ผ่ฟไบ้ฝๆฏๆๅ็ฝ็ซๅฎๅ จๆงๅ็จๆทไฝ้ช็้่ฆๆชๆฝใ 7. **ๆ ้ๆๆฅไธ...
4. ๅฏๅจ Logstash ๆๅก๏ผไฝฟ็จๅฝไปค `bin/logstash -f config.conf`ใ ไธบไบๅ ๅๅฉ็จ Logstash๏ผ็จๆท้่ฆ็ๆ้ ็ฝฎๆไปถ่ฏญๆณ๏ผไปฅๅๅฆไฝ็ผๅๆไปถ้ ็ฝฎใๆญคๅค๏ผ็ๆง Logstash ็่ฟ่ก็ถๆๅๆฅๅฟไนๆฏ็ปดๆคๅ ถๆญฃๅธธ่ฟ่ก็ๅ ณ้ฎใ ...
Logstashๆไปถ ่ฟๆฏ็ๆไปถใ ๅฎๆฏๅฎๅ จๅ ่ดนๅๅฎๅ จๅผๆบ็ใ ่ฎธๅฏ่ฏๆฏ Apache 2.0๏ผ่ฟๆๅณ็ๆจๅฏไปฅ้ๆไปฅไปปไฝๆนๅผไฝฟ็จๅฎใ JDBC ๆต่ฟๆปคๅจๆไปถๅทฒ็งปๅจ ่ฟไธช JDBC Streaming Filter Plugin ็ฐๅจๆฏ็ไธ้จๅ๏ผ ๅจๅฏ่ฝ็ๆ ๅต...
ไพๅฆ๏ผๆไปฌๅฏไปฅไฝฟ็จTerms่ๅๆฅ็ป่ฎกnginx-qps็่ถๅฟๅพใ Kibanaๅฏ่งๅ ๅจKibanaไธญ๏ผๆไปฌๅฏไปฅไฝฟ็จไธฐๅฏ็ๅพ่กจๅไปช่กจ็ๅ่ฝๆฅๅฏ่งๅnginx-qps็็ๆงๆฐๆฎใไพๅฆ๏ผๆไปฌๅฏไปฅไฝฟ็จLine Chartๆฅๅฑ็คบnginx-qps็่ถๅฟๅพใ ...
4. ไฝฟ็จๅฝไปค่กๅฏๅจLogstash๏ผ`bin/logstash -f config_path`๏ผๅ ถไธญ`config_path`ๆฏไฝ ็้ ็ฝฎๆไปถ่ทฏๅพใ ๅจWindows็ฏๅขไธ๏ผLogstash่ฟๆฏๆ้่ฟๆๅก็ๆนๅผๅฎ่ฃ ๅ็ฎก็๏ผ่ฟๆ ทๅฏไปฅๅจ็ณป็ปๅฏๅจๆถ่ชๅจๅฏๅจLogstashๆๅก๏ผ็กฎไฟ...
3. **้ ็ฝฎๆไปถ**๏ผๅจไฝฟ็จ logstash-input-jdbc ๆถ๏ผไฝ ้่ฆๅๅปบไธไธช Logstash ้ ็ฝฎๆไปถ๏ผๅ ถไธญๅ ๅซ่พๅ ฅใ่ฟๆปคๅ่พๅบ็้ ็ฝฎๆฎตใๅฏนไบ่พๅ ฅ้จๅ๏ผไฝ ้่ฆ่ฎพ็ฝฎ JDBC ้ฉฑๅจใๆฐๆฎๅบ่ฟๆฅไฟกๆฏ๏ผๅฆ URLใ็จๆทๅใๅฏ็ ๏ผไปฅๅๆฅ่ฏข...
่ตๆบๆฅ่ชpypiๅฎ็ฝใ ่ตๆบๅ จๅ๏ผpython_logstash_async_dwn-1.0.0-py2.py3-none-any.whl
็ธ่พไบ Logstash๏ผFilebeat ๆดๅ ่็่ตๆบ๏ผๅฏๅจๅฟซ้๏ผๅ ๆญคๅจๅฎๆถๆถ้ Nginx ๆฅๅฟ็ญๅบๆฏไธ๏ผFilebeat ๆไธบไบ้ฆ้ใLogstash ่ฝ็ถๅ่ฝๅผบๅคง๏ผไฝๅ ถๅ ๅญๆถ่่พๅคง๏ผๅฆๆๆๅกๅจ่ตๆบๆ้๏ผๅฏ่ฝไผๅฏนๅ ถไปๆๅก้ ๆๅฝฑๅใ ๅจ ...
4. plugins๏ผLogstash็่พๅ ฅใ่ฟๆปคๅ่พๅบๆไปถ็ฎๅฝ๏ผ่ฟไบๆไปถๅ ่ฎธๆฉๅฑLogstash็ๅ่ฝไปฅๅค็็นๅฎ็ๆฐๆฎๆบๆ็ฎๆ ใ 5. data๏ผ่ฟ่กๆถไบง็็ไธดๆถๆๆไน ๆงๆฐๆฎๅฏ่ฝๅญๅจๅจ่ฟ้๏ผๅฆๅญๅจ็ไบไปถๆ็ดขๅผใ 6. LICENSE๏ผLogstash...
3. **่ด่ฝฝๅ่กก**: ไฝฟ็จNginx็่ด่ฝฝๅ่กกๆจกๅ๏ผๅฆ`upstream`๏ผ้ ็ฝฎ่ด่ฝฝๅ่กก็ญ็ฅใ 4. **ๅฅๅบทๆฃๆฅ**: ๅฏไปฅ้่ฟ้ ็ฝฎๅฅๅบทๆฃๆฅ๏ผ็กฎไฟๅชๅฐ่ฏทๆฑ่ฝฌๅๅฐๆญฃๅธธ่ฟ่ก็ๅ็ซฏๆๅกๅจใ 5. **ไผ่ฏๆไน ๅ**: ้่ฟ`ip_hash`็ญ็ฅๆ็ฌฌไธๆน...