
HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统。
一、HDFS的主要设计理念
1、存储超大文件
这里的“超大文件”是指几百MB、GB甚至TB级别的文件。
2、最高效的访问模式是 一次写入、多次读取(流式数据访问)
HDFS存储的数据集作为hadoop的分析对象。在数据集生成后,长时间在此数据集上进行各种分析。每次分析都将设计该数据集的大部分数据甚至全部数据,因此读取整个数据集的时间延迟比读取第一条记录的时间延迟更重要。
3、运行在普通廉价的服务器上
HDFS设计理念之一就是让它能运行在普通的硬件之上,即便硬件出现故障,也可以通过容错策略来保证数据的高可用。
二、HDFS的忌讳
1、将HDFS用于对数据访问要求低延迟的场景
由于HDFS是为高数据吞吐量应用而设计的,必然以高延迟为代价。
2、存储大量小文件
HDFS中元数据(文件的基本信息)存储在namenode的内存中,而namenode为单点,小文件数量大到一定程度,namenode内存就吃不消了。
三、HDFS基本概念
数据块(block):大文件会被分割成多个block进行存储,block大小默认为64MB。每一个block会在多个datanode上存储多份副本,默认是3份。
namenode:namenode负责管理文件目录、文件和block的对应关系以及block和datanode的对应关系。
datanode:datanode就负责存储了,当然大部分容错机制都是在datanode上实现的。
四、HDFS基本架构图
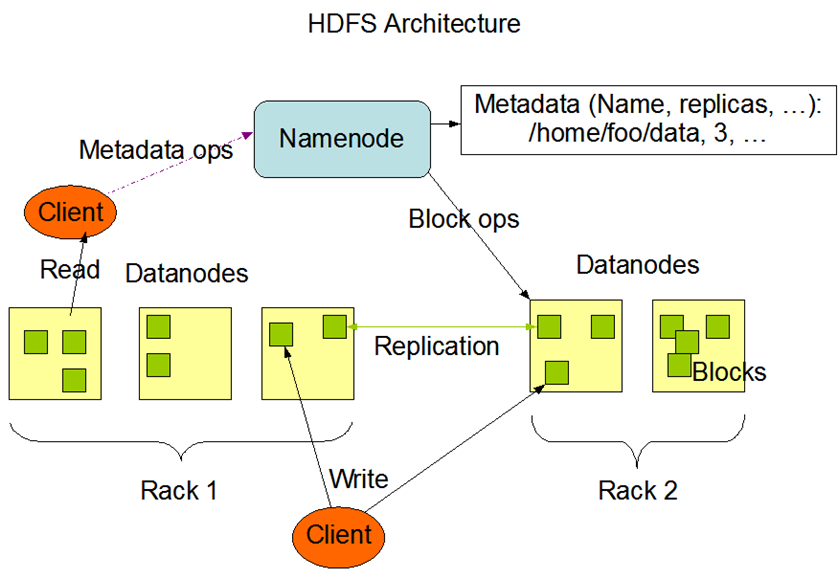
图中有几个概念需要介绍一下
Rack 是指机柜的意思,一个block的三个副本通常会保存到两个或者两个以上的机柜中(当然是机柜中的服务器),这样做的目的是做防灾容错,因为发生一个机柜掉电或者一个机柜的交换机挂了的概率还是蛮高的。
五、HDFS写文件流程
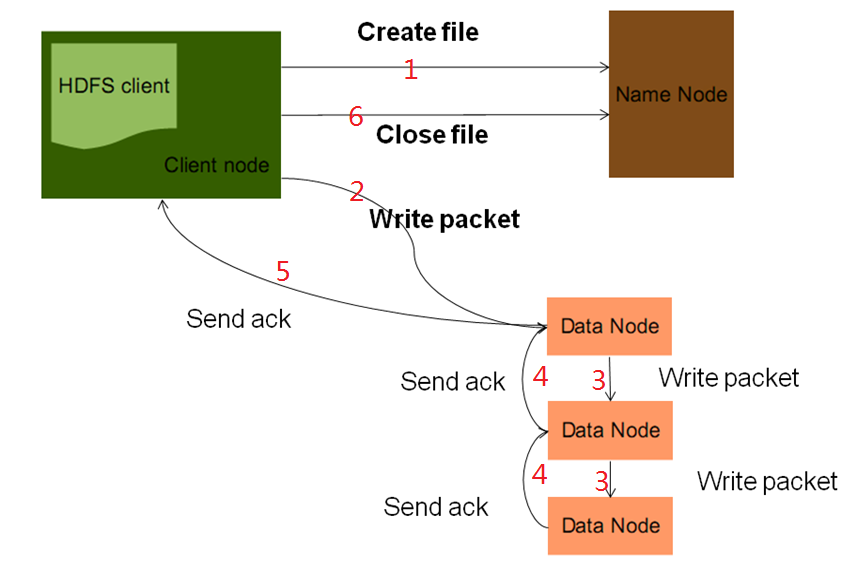
思考:
在datanode执行create file后,namenode采用什么策略给client分配datanode?
顺序写入三个datanode,写入过程中有一个datanode挂掉了,如何容错?
client往datanode写入数据时挂掉了,怎么容错?
六、HDFS读文件流程
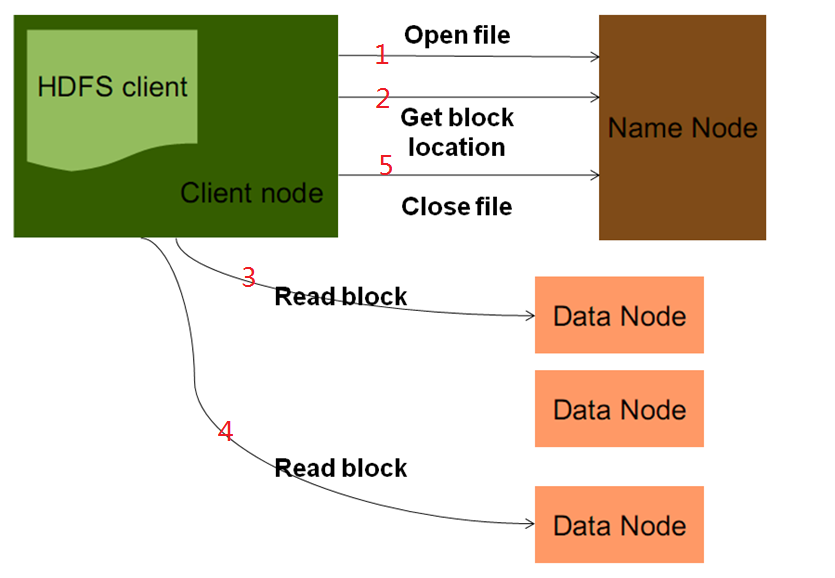
思考:namenode挂掉了怎么办,这个时候HDFS是否有相应的容错方案。



相关推荐
"Hadoop HDFS原理分析" HDFS(Hadoop Distributed File System)是Hadoop项目的一部分,是一个分布式文件管理系统。HDFS的设计理念是为了存储和管理大量的数据,具有高容错性、可扩展性和高性能的特点。 HDFS的...
【HDFS原理篇】 在大数据领域,分布式文件系统HDFS(Hadoop Distributed File System)扮演着至关重要的角色。HDFS是Apache Hadoop项目的核心组成部分,它设计为在廉价硬件上运行,提供高容错性和高吞吐量的数据...
5. 分析实验结果,理解HDFS操作的底层逻辑。 七、实验总结与思考 实验结束后,学生应反思实验过程中遇到的问题,分享解决策略,并探讨未解决的问题,以加深对HDFS的理解和应用能力。 总之,这个实验项目全方位覆盖...
【大纲】hdfs 概述hdfs 体系结构hdfs java调用RPC和HDFS调用hdfs文件读写流程分析数据回收站HA和FederationHDFS常见问题
本文主要对Hadoop HDFS的原理进行阐述。从HDFS系统架构、HDFS中守候进程、各进程之间的接口、HDFS中的关键数据结构几个方面进行分析,在此基础上,针对HDFS的启动、读、写和建立检查点几个流程进行了说明。从而可...
在Hadoop分布式文件系统(HDFS)的性能评估中,有几个经典的压测工具,如Terasort、Slive和DFSIO,它们对理解HDFS的工作原理和优化至关重要。这些工具不仅帮助开发者了解系统的吞吐率,还能揭示不同组件的性能瓶颈。 ...
HDFS,全称为Hadoop Distributed File System,是Apache Hadoop项目的核心组件之一,设计用于处理大规模数据集。...了解并熟练掌握HDFS的应用场景、工作原理、基本架构和使用方法,对于进行大数据处理和分析至关重要。
Hadoop 源码分析 HDFS 数据流 Hadoop 的 HDFS(Hadoop Distributed File System)是 Hadoop 项目中最核心...只有通过深入理解 DataXceiverServer 和 DataXceiver 的实现机制,才能更好地理解 HDFS 数据流的工作原理。
### HDFS 命令原理介绍 #### HDFS 概述 HDFS(Hadoop Distributed File System)是一种专为大规模数据处理设计的分布式文件系统。它具有高度容错性、可扩展性和高吞吐率等特点,非常适合存储和处理大规模数据集。 ...
标题中的“基于spring-boot和hdfs的网盘.zip”表明这是一个使用Spring Boot框架构建的网盘应用,它集成了Hadoop分布式文件系统...通过深入理解Spring Boot和HDFS的工作原理,我们可以更好地理解和维护这样的系统。
源码分析可以帮助我们深入理解HDFS的工作原理,例如如何处理数据复制以确保容错性,如何调度数据块的读写,以及如何在节点故障时恢复数据。此外,对于MapReduce的理解也是不可或缺的,因为MapReduce是Hadoop处理...
本文将深入探讨HDFS的基本原理和操作,以及如何通过Java API进行文件操作。 Hadoop分布式文件系统(HDFS)是Google文件系统(GFS)的一种实现,设计用于处理海量数据。HDFS的核心特点是分布式存储,它将大文件分割...
总结来说,Hadoop和HDFS是一个强大的分布式数据处理和存储平台,通过深入学习其源码可以更好地理解分布式系统的工作原理。Hadoop的可靠性和高效性得益于其容错机制、并行处理能力以及可扩展性。Hadoop适用于处理PB...
在进行源代码分析时,我们可以按照模块进行,先从外部接口开始,了解每个组件的功能和使用方法,然后深入到内部实现,探究其工作原理。对于具有研究价值的部分,如数据块的复制策略或MapReduce调度策略,我们需要...
《存储技术原理分析_基于Linux 2.6内核源代码》是一本深入探讨存储技术的书籍,尤其侧重于从Linux 2.6内核源代码的角度进行解析。该书对于理解存储系统的底层运作机制、优化存储性能以及解决相关问题具有重要的指导...
HDFS技术原理深入理解 HDFS(Hadoop Distributed File System)是一种分布式文件管理系统,旨在解决大规模数据存储和管理问题。其核心概念包括NameNode、DataNode、Block、Replication、FileSystem等。 HDFS架构 ...
Hadoop是大数据处理...通过HDFS和MapReduce的协同工作,Hadoop能够处理PB级别的数据,广泛应用于数据分析、日志处理、推荐系统、机器学习等领域。理解并掌握Hadoop的工作原理对于构建和优化大数据处理系统至关重要。
《HDFS——Hadoop分布式文件系统深度实践》这本书是针对Hadoop分布式文件系统(HDFS)的详尽指南,旨在帮助读者深入理解HDFS的工作原理、设计思想以及在实际应用中的最佳实践。HDFS是Apache Hadoop项目的核心组件之...