
Hive是基于Hadoop平台的,它提供了类似SQL一样的查询语言HQL。有了Hive,如果使用过SQL语言,并且不理解Hadoop MapReduce运行原理,也就无法通过编程来实现MR,但是你仍然可以很容易地编写出特定查询分析的HQL语句,通过使用类似SQL的语法,将HQL查询语句提交Hive系统执行查询分析,最终Hive会帮你转换成底层Hadoop能够理解的MR Job。
对于最基本的HQL查询我们不再累述,这里主要说明Hive中进行统计分析时使用到的JOIN操作。在说明Hive JOIN之前,我们先简单说明一下,Hadoop执行MR Job的基本过程(运行机制),能更好的帮助我们理解HQL转换到底层的MR Job后是如何执行的。我们重点说明MapReduce执行过程中,从Map端到Reduce端这个过程(Shuffle)的执行情况,如图所示(来自《Hadoop: The Definitive Guide》):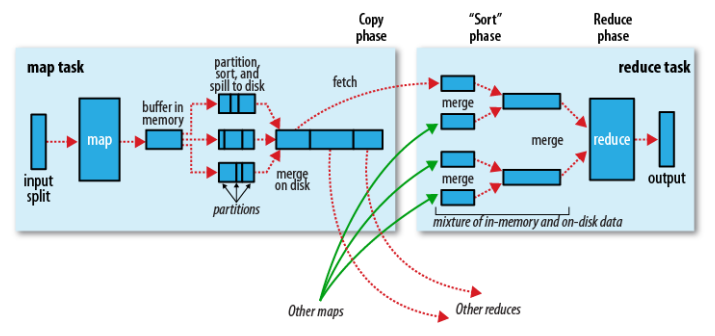
基本执行过程,描述如下:
- 一个InputSplit输入到map,会运行我们实现的Mapper的处理逻辑,对数据进行映射操作。
- map输出时,会首先将输出中间结果写入到map自带的buffer中(buffer默认大小为100M,可以通过io.sort.mb配置)。
- map自带的buffer使用容量达到一定门限(默认0.80或80%,可以通过io.sort.spill.percent配置),一个后台线程会准备将buffer中的数据写入到磁盘。
- 这个后台线程在将buffer中数据写入磁盘之前,会首先将buffer中的数据进行partition(分区,partition数为Reducer的个数),对于每个的数据会基于Key进行一个in-memory排序。
- 排序后,会检查是否配置了Combiner,如果配置了则直接作用到已排序的每个partition的数据上,对map输出进行化简压缩(这样写入磁盘的数据量就会减少,降低I/O操作开销)。
- 现在可以将经过处理的buffer中的数据写入磁盘,生成一个文件(每次buffer容量达到设置的门限,都会对应着一个写入到磁盘的文件)。
- map任务结束之前,会对输出的多个文件进行合并操作,合并成一个文件(若map输出至少3个文件,在多个文件合并后写入之前,如果配置了Combiner,则会运行来化简压缩输出的数据,文件个数可以通过min.num.splits.for.combine配置;如果指定了压缩map输出,这里会根据配置对数据进行压缩写入磁盘),这个文件仍然保持partition和排序的状态。
- reduce阶段,每个reduce任务开始从多个map上拷贝属于自己partition(map阶段已经做好partition,而且每个reduce任务知道应该拷贝哪个partition;拷贝过程是在不同节点之间,Reducer上拷贝线程基于HTTP来通过网络传输数据)。
- 每个reduce任务拷贝的map任务结果的指定partition,也是先将数据放入到自带的一个buffer中(buffer默认大小为Heap内存的70%,可以通过mapred.job.shuffle.input.buffer.percent配置),如果配置了map结果进行压缩,则这时要先将数据解压缩后放入buffer中。
- reduce自带的buffer使用容量达到一定门限(默认0.66或66%,可以通过mapred.job.shuffle.merge.percent配置),或者buffer中存放的map的输出的数量达到一定门限(默认1000,可以通过mapred.inmem.merge.threshold配置),buffer中的数据将会被写入到磁盘中。
- 在将buffer中多个map输出合并写入磁盘之前,如果设置了Combiner,则会化简压缩合并的map输出。
- 当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件,这时开始执行合并操作,并保持每个map输出数据中Key的有序性,将多个文件合并成一个文件(在reduce端可能存在buffer和磁盘上都有数据的情况,这样在buffer中的数据可以减少一定量的I/O写入操作开销)。
- 最后,执行reduce阶段,运行我们实现的Reducer中化简逻辑,最终将结果直接输出到HDFS中(因为Reducer运行在DataNode上,输出结果的第一个replica直接在存储在本地节点上)。
通过上面的描述我们看到,在MR执行过程中,存在Shuffle过程的MR需要在网络中的节点之间(Mapper节点和Reducer节点)拷贝数据,如果传输的数据量很大会造成一定的网络开销。而且,Map端和Reduce端都会通过一个特定的buffer来在内存中临时缓存数据,如果无法根据实际应用场景中数据的规模来使用Hive,尤其是执行表的JOIN操作,有可能很浪费资源,降低了系统处理任务的效率,还可能因为内存不足造成OOME问题,导致计算任务失败。
下面,我们说明Hive中的JOIN操作,针对不同的JOIN方式,应该如何来实现和优化:
生成一个MR Job
多表连接,如果多个表中每个表都使用同一个列进行连接(出现在JOIN子句中),则只会生成一个MR Job,例如:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
三个表a、b、c都分别使用了同一个字段进行连接,亦即同一个字段同时出现在两个JOIN子句中,从而只生成一个MR Job。
生成多个MR Job
多表连接,如果多表中,其中存在一个表使用了至少2个字段进行连接(同一个表的至少2个列出现在JOIN子句中),则会至少生成2个MR Job,例如:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
三个表基于2个字段进行连接,这两个字段b.key1和b.key2同时出现在b表中。连接的过程是这样的:首先a和b表基于a.key和b.key1进行连接,对应着第一个MR Job;表a和b连接的结果,再和c进行连接,对应着第二个MR Job。
表连接顺序优化
多表连接,会转换成多个MR Job,每一个MR Job在Hive中称为JOIN阶段(Stage)。在每一个Stage,按照JOIN顺序中的最后一个表应该尽量是大表,因为JOIN前一阶段生成的数据会存在于Reducer的buffer中,通过stream最后面的表,直接从Reducer的buffer中读取已经缓冲的中间结果数据(这个中间结果数据可能是JOIN顺序中,前面表连接的结果的Key,数据量相对较小,内存开销就小),这样,与后面的大表进行连接时,只需要从buffer中读取缓存的Key,与大表中的指定Key进行连接,速度会更快,也可能避免内存缓冲区溢出。例如:
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
这个JOIN语句,会生成一个MR Job,在选择JOIN顺序的时候,数据量相比应该是b < c,表a和b基于a.key = b.key1进行连接,得到的结果(基于a和b进行连接的Key)会在Reducer上缓存在buffer中,在与c进行连接时,从buffer中读取Key(a.key=b.key1)来与表c的c.key进行连接。
另外,也可以通过给出一些Hint信息来启发JOIN操作,这指定了将哪个表作为大表,从而得到优化。例如:
SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN cON (c.key = b.key1)
上述JOIN语句中,a表被视为大表,则首先会对表b和c进行JOIN,然后再将得到的结果与表a进行JOIN。
基于条件的LEFT OUTER JOIN优化
左连接时,左表中出现的JOIN字段都保留,右表没有连接上的都为空。对于带WHERE条件的JOIN语句,例如:
1 |
SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key)
|
2 |
WHERE a.ds='2009-07-07' AND b.ds='2009-07-07'
|
执行顺序是,首先完成2表JOIN,然后再通过WHERE条件进行过滤,这样在JOIN过程中可能会输出大量结果,再对这些结果进行过滤,比较耗时。可以进行优化,将WHERE条件放在ON后,例如:
1 |
SELECT a.val, b.val FROM a LEFT OUTER JOIN b
|
2 |
ON (a.key=b.key AND b.ds='2009-07-07' AND a.ds='2009-07-07')
|
这样,在JOIN的过程中,就对不满足条件的记录进行了预先过滤,可能会有更好的表现。
左半连接(LEFT SEMI JOIN)
左半连接实现了类似IN/EXISTS的查询语义,使用关系数据库子查询的方式实现查询SQL,例如:
1 |
SELECT a.key, a.value FROM a WHERE a.key IN (SELECT b.key FROM b);
|
使用Hive对应于如下语句:
1 |
SELECT a.key, a.val FROM a LEFT SEMI JOIN b ON (a.key = b.key)
|
需要注意的是,在LEFT SEMI JOIN中,表b只能出现在ON子句后面,不能够出现在SELECT和WHERE子句中。
关于子查询,这里提一下,Hive支持情况如下:
- 在0.12版本,只支持FROM子句中的子查询;
- 在0.13版本,也支持WHERE子句中的子查询。
Map Side JOIN
Map Side JOIN优化的出发点是,Map任务输出后,不需要将数据拷贝到Reducer节点,降低的数据在网络节点之间传输的开销。
多表连接,如果只有一个表比较大,其他表都很小,则JOIN操作会转换成一个只包含Map的Job,例如:
1 |
SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a JOIN b ON a.key = b.key
|
对于表a数据的每一个Map,都能够完全读取表b的数据。这里,表a与b不允许执行FULL OUTER JOIN、RIGHT OUTER JOIN。
BUCKET Map Side JOIN
我们先看两个表a和b的DDL,表a为:
1 |
CREATE TABLE a(key INT, othera STRING)
|
2 |
CLUSTERED BY(key) INTO 4 BUCKETS
|
3 |
ROW FORMAT DELIMITED |
4 |
FIELDS TERMINATED BY '\001'
|
5 |
COLLECTION ITEMS TERMINATED BY '\002'
|
6 |
MAP KEYS TERMINATED BY '\003'
|
7 |
STORED AS SEQUENCEFILE;
|
表b为:
1 |
CREATE TABLE b(key INT, otherb STRING)
|
2 |
CLUSTERED BY(key) INTO 32 BUCKETS
|
3 |
ROW FORMAT DELIMITED |
4 |
FIELDS TERMINATED BY '\001'
|
5 |
COLLECTION ITEMS TERMINATED BY '\002'
|
6 |
MAP KEYS TERMINATED BY '\003'
|
7 |
STORED AS SEQUENCEFILE;
|
现在要基于a.key和b.key进行JOIN操作,此时JOIN列同时也是BUCKET列,JOIN语句如下:
1 |
SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a JOIN b ON a.key = b.key
|
并且表a有4个BUCKET,表b有32个BUCKET,默认情况下,对于表a的每一个BUCKET,都会去获取表b中的每一个BUCKET来进行JOIN,这回造成一定的开销,因为只有表b中满足JOIN条件的BUCKET才会真正与表a的BUCKET进行连接。
这种默认行为可以进行优化,通过改变默认JOIN行为,只需要设置变量:
1 |
set hive.optimize.bucketmapjoin = true
|
这样,JOIN的过程是,表a的BUCKET 1只会与表b中的BUCKET 1进行JOIN,而不再考虑表b中的其他BUCKET 2~32。
如果上述表具有相同的BUCKET,如都是32个,而且还是排序的,亦即,在表定义中在CLUSTERED BY(key)后面增加如下约束:
1 |
SORTED BY(key)
|
则上述JOIN语句会执行一个Sort-Merge-Bucket (SMB) JOIN,同样需要设置如下参数来改变默认行为,优化JOIN时只遍历相关的BUCKET即可:
1 |
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
|
2 |
set hive.optimize.bucketmapjoin = true;
|
3 |
set hive.optimize.bucketmapjoin.sortedmerge = true;
|
关于更多的有关JOIN优化,可以参考后面的链接。



相关推荐
Hive中SQL详解 Hive是一个基于Hadoop构建的数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据。 Hive SQL支持绝大多数的语句,如DDL、DML、聚合函数、连接查询、条件查询等。 ...
【Hive QL详解1】 Hive 是一种基于 Hadoop 的数据仓库工具,它允许用户使用 SQL-like 查询语言(Hive QL)对大规模数据集进行分析和处理。本篇文章将详细探讨Hive的几个关键方面,包括Hadoop计算框架的特性、优化...
Hive SQL详解经典 在大数据处理领域,Hive是一个基于Hadoop的数据仓库工具,它允许用户使用SQL(称为HiveQL)查询存储在Hadoop分布式文件系统(HDFS)中的大型数据集。这篇博客深入探讨了Hive SQL的使用,帮助用户...
- **Join的实现原理**:在Hive中,Join操作通常通过MapReduce来实现。例如,在一个内连接中,Map阶段将不同表的数据分别标记,然后在Reduce阶段,依据标记判断并合并来自不同表的记录。这种方法确保了JOIN操作的...
Hive 支持常见的 SQL 功能,如 JOIN、GROUP BY 和 DISTINCT,但这些操作在实现上可能会转化为多个 MapReduce 作业,以适应大数据处理的需要。 为了优化 Hive 的性能,可以采取一些策略,比如开启 Combiner 减少网络...
在实际使用中,Hive支持多种操作,如创建表、从本地或HDFS加载数据、查看表信息、执行JOIN、GROUP BY和DISTINCT等操作。此外,为了优化性能,Hive还提供了开启Combiner、倾斜数据二次分发等策略,以提高数据处理效率...
本文将对Hive的参数配置进行详细的解释,以便更好地使用Hive。 1. hive.exec.mode.local.auto 该参数决定Hive是否应该自动地根据输入文件大小,在本地运行(在GateWay运行)。如果设置为true,则Hive会根据输入...
50.Hive中的数据倾斜及解决方案-三种join方式 51.Hive中的数据倾斜及解决方案-group by 52.Hive中使用正则加载数据 53. Hive中使用Python脚本进行预处理 第5章:Zeus任务资源调度工具 54.资源任务调度框架介绍 55....
### Hive语法详解 #### 一、安装和配置 **1.1 要求** - **硬件需求**:为了高效地运行Hive,推荐至少具备4GB内存,并且Hive服务器应该有足够的磁盘空间来存储元数据。 - **软件需求**:Hive需要Java环境支持,...
Hive提供了多种Join类型,包括Common Join、Map Join、Bucket Map Join等,每种Join都有其适用场景: - **Common Join**:标准的Join操作,适用于大多数情况。 - **Map Join**:适用于小表参与Join的情况,可以将小...
### HiveSQL执行计划详解 #### 一、前言 在大数据处理领域,Hive作为一款广泛使用的数据仓库工具,提供了高效的数据查询与分析能力。为了更深入地理解HiveSQL的执行过程,掌握其执行计划变得尤为重要。执行计划是...
IT十八掌第三期配套课堂笔记 1、Hive工作原理、类型及特点 2、Hive架构及其文件格式 ...4、Hive的JOIN详解 5、Hive优化策略 6、Hive内置操作符与函数 7、Hive用户自定义函数接口 8、Hive的权限控制
在这个"Day08-Hive函数与HQL详解"的课程资料中,我们将深入探讨Hive的函数使用以及HQL的相关知识。 Hive的核心功能在于其强大的SQL接口,即HiveQL,它允许用户以结构化查询的方式操作存储在Hadoop HDFS中的非结构化...
《Hive大数据处理详解》 在当今的数据洪流中,Hive作为一种强大的大数据处理工具,已经成为业界的标准之一。本笔记将全面深入地探讨Hive在大数据处理中的应用、原理及其实战技巧。 一、Hive简介 Hive是Apache软件...
【Hive安装详解】 Hive是Apache软件基金会的一个开源项目,它提供了一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,使得用户可以通过类SQL的方式进行大数据处理。...
**大数据与云计算技术:Hadoop之Hive详解** 在当今数据驱动的世界中,大数据和云计算技术扮演着至关重要的角色。Hadoop是Apache软件基金会开发的一个开源框架,它为大规模数据处理提供了分布式存储和计算能力。而...
### Hive SQL优化技巧详解 #### 一、数据倾斜优化 数据倾斜是指在Hive查询过程中,数据不均匀地分布在不同的Reducer上,导致某些Reducer处理的数据量远大于其他Reducer,从而影响整个查询性能的问题。解决数据倾斜...
【Hive面试知识点详解】 Hive是大数据领域中一个重要的数据仓库工具,它设计的目标是为大规模数据集提供数据查询和分析能力。由于Hive提供了类似SQL的查询语言(HQL),使得非Java背景的分析师也能轻松进行大数据...
《Hive在CDH5.9.3中的应用与详解》 Hive是Apache软件基金会的一个开源项目,它提供了一种基于Hadoop的数据仓库工具,能够将结构化的数据文件映射为一张数据库表,并提供SQL(HQL)查询功能,方便大数据的分析处理。...
Hive 窗口函数详解 Hive 窗口函数是 Hive 中的一种强大的分析函数,它可以对数据进行分类、排序、聚合和排名等操作。下面将详细介绍 Hive 窗口函数的语法结构、分类、应用场景和实践练习。 窗口函数语法结构 窗口...