
В В JAVAе Ҷзҡ„жҸҸиҝ°еҰӮдёӢпјҡ
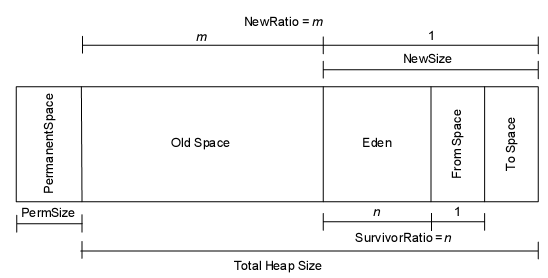
еҶ…еӯҳз”ұ Perm е’Ң Heap з»„жҲҗ. е…¶дёӯ
Heap = {Old + NEW = { Eden , from, to } }
JVMеҶ…еӯҳжЁЎеһӢдёӯеҲҶдёӨеӨ§еқ—пјҢдёҖеқ—жҳҜ NEW Generation, еҸҰдёҖеқ—жҳҜOld Generation. еңЁNew GenerationдёӯпјҢжңүдёҖдёӘеҸ«Edenзҡ„з©әй—ҙпјҢдё»иҰҒжҳҜз”ЁжқҘеӯҳж”ҫж–°з”ҹзҡ„еҜ№иұЎпјҢиҝҳжңүдёӨдёӘSurvivor SpacesпјҲfrom,toпјү, е®ғ们用жқҘеӯҳж”ҫжҜҸж¬Ўеһғеңҫеӣһ收еҗҺеӯҳжҙ»дёӢжқҘзҡ„еҜ№иұЎгҖӮеңЁOld GenerationдёӯпјҢдё»иҰҒеӯҳж”ҫеә”з”ЁзЁӢеәҸдёӯз”ҹе‘Ҫе‘Ёжңҹй•ҝзҡ„еҶ…еӯҳеҜ№иұЎпјҢиҝҳжңүдёӘPermanent GenerationпјҢдё»иҰҒз”ЁжқҘж”ҫJVMиҮӘе·ұзҡ„еҸҚе°„еҜ№иұЎпјҢжҜ”еҰӮзұ»еҜ№иұЎе’Ңж–№жі•еҜ№иұЎзӯүгҖӮ
еһғеңҫеӣһ收жҸҸиҝ°пјҡ
еңЁNew Generationеқ—дёӯпјҢеһғеңҫеӣһ收дёҖиҲ¬з”ЁCopyingзҡ„з®—жі•пјҢйҖҹеәҰеҝ«гҖӮжҜҸж¬ЎGCзҡ„ж—¶еҖҷпјҢеӯҳжҙ»дёӢжқҘзҡ„еҜ№иұЎйҰ–е…Ҳз”ұEdenжӢ·иҙқеҲ°жҹҗдёӘSurvivor Space, еҪ“Survivor Spaceз©әй—ҙж»ЎдәҶеҗҺ, еү©дёӢзҡ„liveеҜ№иұЎе°ұиў«зӣҙжҺҘжӢ·иҙқеҲ°Old GenerationдёӯеҺ»гҖӮеӣ жӯӨпјҢжҜҸж¬ЎGCеҗҺпјҢEdenеҶ…еӯҳеқ—дјҡиў«жё…з©әгҖӮеңЁOld Generationеқ—дёӯпјҢеһғеңҫеӣһ收дёҖиҲ¬з”Ёmark-compactзҡ„з®—жі•пјҢйҖҹеәҰж…ўдәӣпјҢдҪҶеҮҸе°‘еҶ…еӯҳиҰҒжұӮ.
еһғеңҫеӣһ收еҲҶеӨҡзә§пјҢ0зә§дёәе…ЁйғЁ(Full)зҡ„еһғеңҫеӣһ收пјҢдјҡеӣһ收OLDж®өдёӯзҡ„еһғеңҫпјӣ1зә§жҲ–д»ҘдёҠдёәйғЁеҲҶеһғеңҫеӣһ收пјҢеҸӘдјҡеӣһ收NEWдёӯзҡ„еһғеңҫпјҢеҶ…еӯҳжәўеҮәйҖҡеёёеҸ‘з”ҹдәҺOLDж®өжҲ–Permж®өеһғеңҫеӣһ收еҗҺпјҢд»Қз„¶ж— еҶ…еӯҳз©әй—ҙе®№зәіж–°зҡ„JavaеҜ№иұЎзҡ„жғ…еҶөгҖӮ
еҪ“дёҖдёӘURLиў«и®ҝй—®ж—¶пјҢеҶ…еӯҳз”іиҜ·иҝҮзЁӢеҰӮдёӢпјҡ
A. JVMдјҡиҜ•еӣҫдёәзӣёе…іJavaеҜ№иұЎеңЁEdenдёӯеҲқе§ӢеҢ–дёҖеқ—еҶ…еӯҳеҢәеҹҹ
B. еҪ“Edenз©әй—ҙи¶іеӨҹж—¶пјҢеҶ…еӯҳз”іиҜ·з»“жқҹгҖӮеҗҰеҲҷеҲ°дёӢдёҖжӯҘ
C. JVMиҜ•еӣҫйҮҠж”ҫеңЁEdenдёӯжүҖжңүдёҚжҙ»и·ғзҡ„еҜ№иұЎпјҲиҝҷеұһдәҺ1жҲ–жӣҙй«ҳзә§зҡ„еһғеңҫеӣһ收пјү, йҮҠж”ҫеҗҺиӢҘEdenз©әй—ҙд»Қ然дёҚи¶ід»Ҙж”ҫе…Ҙж–°еҜ№иұЎпјҢеҲҷиҜ•еӣҫе°ҶйғЁеҲҶEdenдёӯжҙ»и·ғеҜ№иұЎж”ҫе…ҘSurvivorеҢә
D. SurvivorеҢәиў«з”ЁжқҘдҪңдёәEdenеҸҠOLDзҡ„дёӯй—ҙдәӨжҚўеҢәеҹҹпјҢеҪ“OLDеҢәз©әй—ҙи¶іеӨҹж—¶пјҢSurvivorеҢәзҡ„еҜ№иұЎдјҡ被移еҲ°OldеҢәпјҢеҗҰеҲҷдјҡиў«дҝқз•ҷеңЁSurvivorеҢә
E. еҪ“OLDеҢәз©әй—ҙдёҚеӨҹж—¶пјҢJVMдјҡеңЁOLDеҢәиҝӣиЎҢе®Ңе…Ёзҡ„еһғеңҫ收йӣҶпјҲ0зә§пјү
F. е®Ңе…Ёеһғеңҫ收йӣҶеҗҺпјҢиӢҘSurvivorеҸҠOLDеҢәд»Қз„¶ж— жі•еӯҳж”ҫд»ҺEdenеӨҚеҲ¶иҝҮжқҘзҡ„йғЁеҲҶеҜ№иұЎпјҢеҜјиҮҙJVMж— жі•еңЁEdenеҢәдёәж–°еҜ№иұЎеҲӣе»әеҶ…еӯҳеҢәеҹҹпјҢеҲҷеҮәзҺ°вҖқout of memoryй”ҷиҜҜвҖқ
JVMи°ғдјҳе»әи®®:
ms/mxпјҡе®ҡд№үYOUNG+OLDж®өзҡ„жҖ»е°әеҜёпјҢmsдёәJVMеҗҜеҠЁж—¶YOUNG+OLDзҡ„еҶ…еӯҳеӨ§е°ҸпјӣmxдёәжңҖеӨ§еҸҜеҚ з”Ёзҡ„YOUNG+OLDеҶ…еӯҳеӨ§е°ҸгҖӮеңЁз”ЁжҲ·з”ҹдә§зҺҜеўғдёҠдёҖиҲ¬е°ҶиҝҷдёӨдёӘеҖји®ҫдёәзӣёеҗҢпјҢд»ҘеҮҸе°‘иҝҗиЎҢжңҹй—ҙзі»з»ҹеңЁеҶ…еӯҳз”іиҜ·дёҠжүҖиҠұзҡ„ејҖй”ҖгҖӮ
NewSize/MaxNewSizeпјҡе®ҡд№үYOUNGж®өзҡ„е°әеҜёпјҢNewSizeдёәJVMеҗҜеҠЁж—¶YOUNGзҡ„еҶ…еӯҳеӨ§е°ҸпјӣMaxNewSizeдёәжңҖеӨ§еҸҜеҚ з”Ёзҡ„YOUNGеҶ…еӯҳеӨ§е°ҸгҖӮеңЁз”ЁжҲ·з”ҹдә§зҺҜеўғдёҠдёҖиҲ¬е°ҶиҝҷдёӨдёӘеҖји®ҫдёәзӣёеҗҢпјҢд»ҘеҮҸе°‘иҝҗиЎҢжңҹй—ҙзі»з»ҹеңЁеҶ…еӯҳз”іиҜ·дёҠжүҖиҠұзҡ„ејҖй”ҖгҖӮ
PermSize/MaxPermSizeпјҡе®ҡд№үPermж®өзҡ„е°әеҜёпјҢPermSizeдёәJVMеҗҜеҠЁж—¶Permзҡ„еҶ…еӯҳеӨ§е°ҸпјӣMaxPermSizeдёәжңҖеӨ§еҸҜеҚ з”Ёзҡ„PermеҶ…еӯҳеӨ§е°ҸгҖӮеңЁз”ЁжҲ·з”ҹдә§зҺҜеўғдёҠдёҖиҲ¬е°ҶиҝҷдёӨдёӘеҖји®ҫдёәзӣёеҗҢпјҢд»ҘеҮҸе°‘иҝҗиЎҢжңҹй—ҙзі»з»ҹеңЁеҶ…еӯҳз”іиҜ·дёҠжүҖиҠұзҡ„ејҖй”ҖгҖӮ
SurvivorRatioпјҡи®ҫзҪ®Survivorз©әй—ҙе’ҢEdenз©әй—ҙзҡ„жҜ”дҫӢ
еҶ…еӯҳжәўеҮәзҡ„еҸҜиғҪжҖ§
1. OLDж®өжәўеҮә
иҝҷз§ҚеҶ…еӯҳжәўеҮәжҳҜжңҖеёёи§Ғзҡ„жғ…еҶөд№ӢдёҖпјҢдә§з”ҹзҡ„еҺҹеӣ еҸҜиғҪжҳҜпјҡ
1) и®ҫзҪ®зҡ„еҶ…еӯҳеҸӮж•°иҝҮе°Ҹ(ms/mx, NewSize/MaxNewSize)
2) зЁӢеәҸй—®йўҳ
еҚ•дёӘзЁӢеәҸжҢҒз»ӯиҝӣиЎҢж¶ҲиҖ—еҶ…еӯҳзҡ„еӨ„зҗҶпјҢеҰӮеҫӘзҺҜеҮ еҚғж¬Ўзҡ„еӯ—з¬ҰдёІеӨ„зҗҶпјҢеҜ№еӯ—з¬ҰдёІеӨ„зҗҶеә”е»әи®®дҪҝз”ЁStringBufferгҖӮжӯӨж—¶дёҚдјҡжҠҘеҶ…еӯҳжәўеҮәй”ҷпјҢеҚҙдјҡдҪҝзі»з»ҹжҢҒз»ӯеһғеңҫ收йӣҶпјҢж— жі•еӨ„зҗҶе…¶е®ғиҜ·жұӮпјҢзӣёе…ій—®йўҳзЁӢеәҸеҸҜйҖҡиҝҮThread DumpиҺ·еҸ–пјҲи§Ғзі»з»ҹй—®йўҳиҜҠж–ӯдёҖз« пјүеҚ•дёӘзЁӢеәҸжүҖз”іиҜ·еҶ…еӯҳиҝҮеӨ§пјҢжңүзҡ„зЁӢеәҸдјҡз”іиҜ·еҮ еҚҒд№ғиҮіеҮ зҷҫе…ҶеҶ…еӯҳпјҢжӯӨж—¶JVMд№ҹдјҡеӣ ж— жі•з”іиҜ·еҲ°иө„жәҗиҖҢеҮәзҺ°еҶ…еӯҳжәўеҮәпјҢеҜ№жӯӨйҰ–е…ҲиҰҒжүҫеҲ°зӣёе…іеҠҹиғҪпјҢ然еҗҺдәӨдәҲзЁӢеәҸе‘ҳдҝ®ж”№пјҢиҰҒжүҫеҲ°зӣёе…ізЁӢеәҸпјҢеҝ…йЎ»еңЁApacheж—Ҙеҝ—дёӯеҜ»жүҫгҖӮ
еҪ“JavaеҜ№иұЎдҪҝз”Ёе®ҢжҜ•еҗҺпјҢе…¶жүҖеј•з”Ёзҡ„еҜ№иұЎеҚҙжІЎжңүй”ҖжҜҒпјҢдҪҝеҫ—JVMи®Өдёәд»–иҝҳжҳҜжҙ»и·ғзҡ„еҜ№иұЎиҖҢдёҚиҝӣиЎҢеӣһ收пјҢиҝҷж ·зҙҜи®ЎеҚ з”ЁдәҶеӨ§йҮҸеҶ…еӯҳиҖҢж— жі•йҮҠж”ҫгҖӮз”ұдәҺзӣ®еүҚеёӮйқўдёҠиҝҳжІЎжңүеҜ№зі»з»ҹеҪұе“Қе°Ҹзҡ„еҶ…еӯҳеҲҶжһҗе·Ҙе…·пјҢж•…жӯӨж—¶еҸӘиғҪе’ҢзЁӢеәҸе‘ҳдёҖиө·е®ҡдҪҚгҖӮ
2. Permж®өжәўеҮә
йҖҡеёёз”ұдәҺPermж®өиЈ…иҪҪдәҶеӨ§йҮҸзҡ„Servletзұ»иҖҢеҜјиҮҙжәўеҮәпјҢзӣ®еүҚзҡ„и§ЈеҶіеҠһжі•пјҡ
1) е°ҶPermSizeжү©еӨ§пјҢдёҖиҲ¬256MиғҪеӨҹж»Ўи¶іиҰҒжұӮ
2) иӢҘеҲ«ж— йҖүжӢ©пјҢеҲҷеҸӘиғҪе°Ҷservletзҡ„и·Ҝеҫ„еҠ еҲ°CLASSPATHдёӯпјҢдҪҶдёҖиҲ¬дёҚе»әи®®иҝҷд№ҲеӨ„зҗҶ
3. C HeapжәўеҮә
зі»з»ҹеҜ№C HeapжІЎжңүйҷҗеҲ¶пјҢж•…C HeapеҸ‘з”ҹй—®йўҳж—¶пјҢJavaиҝӣзЁӢжүҖеҚ еҶ…еӯҳдјҡжҢҒз»ӯеўһй•ҝпјҢзӣҙеҲ°еҚ з”ЁжүҖжңүеҸҜз”Ёзі»з»ҹеҶ…еӯҳ
е…¶д»–пјҡ
JVMжңү2дёӘGCзәҝзЁӢгҖӮ第дёҖдёӘзәҝзЁӢиҙҹиҙЈеӣһ收Heapзҡ„YoungеҢәгҖӮ第дәҢдёӘзәҝзЁӢеңЁHeapдёҚи¶іж—¶пјҢйҒҚеҺҶHeapпјҢе°ҶYoung еҢәеҚҮзә§дёәOlderеҢәгҖӮOlderеҢәзҡ„еӨ§е°ҸзӯүдәҺ-XmxеҮҸеҺ»-XmnпјҢдёҚиғҪе°Ҷ-Xmsзҡ„еҖји®ҫзҡ„иҝҮеӨ§пјҢеӣ дёә第дәҢдёӘзәҝзЁӢиў«иҝ«иҝҗиЎҢдјҡйҷҚдҪҺJVMзҡ„жҖ§иғҪгҖӮ
дёәд»Җд№ҲдёҖдәӣзЁӢеәҸйў‘з№ҒеҸ‘з”ҹGCпјҹжңүеҰӮдёӢеҺҹеӣ пјҡ
l В В В В зЁӢеәҸеҶ…и°ғз”ЁдәҶSystem.gc()жҲ–Runtime.gc()гҖӮ
l В В В В дёҖдәӣдёӯй—ҙ件иҪҜ件и°ғз”ЁиҮӘе·ұзҡ„GCж–№жі•пјҢжӯӨж—¶йңҖиҰҒи®ҫзҪ®еҸӮж•°зҰҒжӯўиҝҷдәӣGCгҖӮ
l В В В В Javaзҡ„HeapеӨӘе°ҸпјҢдёҖиҲ¬й»ҳи®Өзҡ„HeapеҖјйғҪеҫҲе°ҸгҖӮ
l В В В В йў‘з№Ғе®һдҫӢеҢ–еҜ№иұЎпјҢReleaseеҜ№иұЎгҖӮжӯӨж—¶е°ҪйҮҸдҝқеӯҳ并йҮҚз”ЁеҜ№иұЎпјҢдҫӢеҰӮдҪҝз”ЁStringBuffer()е’ҢString()гҖӮ
еҰӮжһңдҪ еҸ‘зҺ°жҜҸж¬ЎGCеҗҺпјҢHeapзҡ„еү©дҪҷз©әй—ҙдјҡжҳҜжҖ»з©әй—ҙзҡ„50%пјҢиҝҷиЎЁзӨәдҪ зҡ„HeapеӨ„дәҺеҒҘеә·зҠ¶жҖҒгҖӮи®ёеӨҡServerз«Ҝзҡ„JavaзЁӢеәҸжҜҸж¬ЎGCеҗҺжңҖеҘҪиғҪжңү65%зҡ„еү©дҪҷз©әй—ҙгҖӮ
з»ҸйӘҢд№Ӣи°Ҳпјҡ
1пјҺServerз«ҜJVMжңҖеҘҪе°Ҷ-Xmsе’Ң-Xmxи®ҫдёәзӣёеҗҢеҖјгҖӮдёәдәҶдјҳеҢ–GCпјҢжңҖеҘҪи®©-XmnеҖјзәҰзӯүдәҺ-Xmxзҡ„1/3[2]гҖӮ
2пјҺдёҖдёӘGUIзЁӢеәҸжңҖеҘҪжҳҜжҜҸ10еҲ°20з§’й—ҙиҝҗиЎҢдёҖж¬ЎGCпјҢжҜҸж¬ЎеңЁеҚҠз§’д№ӢеҶ…е®ҢжҲҗ[2]гҖӮ
жіЁж„Ҹпјҡ
1пјҺеўһеҠ Heapзҡ„еӨ§е°ҸиҷҪ然дјҡйҷҚдҪҺGCзҡ„йў‘зҺҮпјҢдҪҶд№ҹеўһеҠ дәҶжҜҸж¬ЎGCзҡ„ж—¶й—ҙгҖӮ并且GCиҝҗиЎҢж—¶пјҢжүҖжңүзҡ„з”ЁжҲ·зәҝзЁӢе°ҶжҡӮеҒңпјҢд№ҹе°ұжҳҜGCжңҹй—ҙпјҢJavaеә”з”ЁзЁӢеәҸдёҚеҒҡд»»дҪ•е·ҘдҪңгҖӮ
2пјҺHeapеӨ§е°Ҹ并дёҚеҶіе®ҡиҝӣзЁӢзҡ„еҶ…еӯҳдҪҝз”ЁйҮҸгҖӮиҝӣзЁӢзҡ„еҶ…еӯҳдҪҝз”ЁйҮҸиҰҒеӨ§дәҺ-Xmxе®ҡд№үзҡ„еҖјпјҢеӣ дёәJavaдёәе…¶д»–д»»еҠЎеҲҶй…ҚеҶ…еӯҳпјҢдҫӢеҰӮжҜҸдёӘзәҝзЁӢзҡ„StackзӯүгҖӮ
2пјҺStackзҡ„и®ҫе®ҡ
жҜҸдёӘзәҝзЁӢйғҪжңүд»–иҮӘе·ұзҡ„StackгҖӮ
В
|
-Xss
|
жҜҸдёӘзәҝзЁӢзҡ„StackеӨ§е°Ҹ
|
В
3пјҺ硬件зҺҜеўғ
硬件зҺҜеўғд№ҹеҪұе“ҚGCзҡ„ж•ҲзҺҮпјҢдҫӢеҰӮжңәеҷЁзҡ„з§Қзұ»пјҢеҶ…еӯҳпјҢswapз©әй—ҙпјҢе’ҢCPUзҡ„ж•°йҮҸгҖӮ
еҰӮжһңдҪ зҡ„зЁӢеәҸйңҖиҰҒйў‘з№ҒеҲӣе»әеҫҲеӨҡtransientеҜ№иұЎпјҢдјҡеҜјиҮҙJVMйў‘з№ҒGCгҖӮиҝҷз§Қжғ…еҶөдҪ еҸҜд»ҘеўһеҠ жңәеҷЁзҡ„еҶ…еӯҳпјҢжқҘеҮҸе°‘Swapз©әй—ҙзҡ„дҪҝз”Ё[2]гҖӮ
4пјҺ4з§ҚGC
第дёҖз§ҚдёәеҚ•зәҝзЁӢGCпјҢд№ҹжҳҜй»ҳи®Өзҡ„GCгҖӮпјҢиҜҘGCйҖӮз”ЁдәҺеҚ•CPUжңәеҷЁгҖӮ
第дәҢз§ҚдёәThroughput GCпјҢжҳҜеӨҡзәҝзЁӢзҡ„GCпјҢйҖӮз”ЁдәҺеӨҡCPUпјҢдҪҝз”ЁеӨ§йҮҸзәҝзЁӢзҡ„зЁӢеәҸгҖӮ第дәҢз§ҚGCдёҺ第дёҖз§ҚGCзӣёдјјпјҢдёҚеҗҢеңЁдәҺGCеңЁж”¶йӣҶYoungеҢәжҳҜеӨҡзәҝзЁӢзҡ„пјҢдҪҶеңЁOldеҢәе’Ң第дёҖз§ҚдёҖж ·пјҢд»Қ然йҮҮз”ЁеҚ•зәҝзЁӢгҖӮ-XX:+UseParallelGCеҸӮж•°еҗҜеҠЁиҜҘGCгҖӮ
第дёүз§ҚдёәConcurrent Low Pause GCпјҢзұ»дјјдәҺ第дёҖз§ҚпјҢйҖӮз”ЁдәҺеӨҡCPUпјҢ并иҰҒжұӮзј©зҹӯеӣ GCйҖ жҲҗзЁӢеәҸеҒңж»һзҡ„ж—¶й—ҙгҖӮиҝҷз§ҚGCеҸҜд»ҘеңЁOldеҢәзҡ„еӣһ收еҗҢж—¶пјҢиҝҗиЎҢеә”з”ЁзЁӢеәҸгҖӮ-XX:+UseConcMarkSweepGCеҸӮж•°еҗҜеҠЁиҜҘGCгҖӮ
第еӣӣз§ҚдёәIncremental Low Pause GCпјҢйҖӮз”ЁдәҺиҰҒжұӮзј©зҹӯеӣ GCйҖ жҲҗзЁӢеәҸеҒңж»һзҡ„ж—¶й—ҙгҖӮиҝҷз§ҚGCеҸҜд»ҘеңЁYoungеҢәеӣһ收зҡ„еҗҢж—¶пјҢеӣһ收дёҖйғЁеҲҶOldеҢәеҜ№иұЎгҖӮ-XincgcеҸӮж•°еҗҜеҠЁиҜҘGCгҖӮ
жҢүз…§еҹәжң¬еӣһ收зӯ–з•ҘеҲҶ
еј•з”Ёи®Ўж•°пјҲReference Countingпјү:
жҜ”иҫғеҸӨиҖҒзҡ„еӣһ收算法гҖӮеҺҹзҗҶжҳҜжӯӨеҜ№иұЎжңүдёҖдёӘеј•з”ЁпјҢеҚіеўһеҠ дёҖдёӘи®Ўж•°пјҢеҲ йҷӨдёҖдёӘеј•з”ЁеҲҷеҮҸе°‘дёҖдёӘи®Ўж•°гҖӮеһғеңҫеӣһ收时пјҢеҸӘ用收йӣҶи®Ўж•°дёә0зҡ„еҜ№иұЎгҖӮжӯӨз®—жі•жңҖиҮҙе‘Ҫзҡ„жҳҜж— жі•еӨ„зҗҶеҫӘзҺҜеј•з”Ёзҡ„й—®йўҳгҖӮ
В
ж Үи®°-жё…йҷӨпјҲMark-Sweepпјү:
В
В 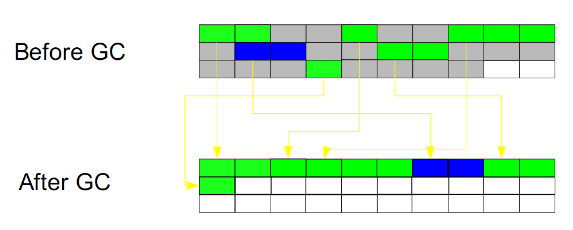
В
жӯӨз®—жі•жү§иЎҢеҲҶдёӨйҳ¶ж®өгҖӮ第дёҖйҳ¶ж®өд»Һеј•з”Ёж №иҠӮзӮ№ејҖе§Ӣж Үи®°жүҖжңүиў«еј•з”Ёзҡ„еҜ№иұЎпјҢ第дәҢйҳ¶ж®өйҒҚеҺҶж•ҙдёӘе ҶпјҢжҠҠжңӘж Үи®°зҡ„еҜ№иұЎжё…йҷӨгҖӮжӯӨз®—жі•йңҖиҰҒжҡӮеҒңж•ҙдёӘеә”з”ЁпјҢеҗҢж—¶пјҢдјҡдә§з”ҹеҶ…еӯҳзўҺзүҮгҖӮ
В
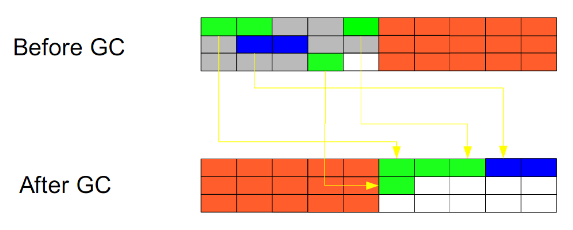
еӨҚеҲ¶пјҲCopyingпјү:
В
 В
В
В
жӯӨз®—жі•жҠҠеҶ…еӯҳз©әй—ҙеҲ’дёәдёӨдёӘзӣёзӯүзҡ„еҢәеҹҹпјҢжҜҸж¬ЎеҸӘдҪҝз”Ёе…¶дёӯдёҖдёӘеҢәеҹҹгҖӮеһғеңҫеӣһ收时пјҢйҒҚеҺҶеҪ“еүҚдҪҝз”ЁеҢәеҹҹпјҢжҠҠжӯЈеңЁдҪҝз”Ёдёӯзҡ„еҜ№иұЎеӨҚеҲ¶еҲ°еҸҰеӨ–дёҖдёӘеҢәеҹҹдёӯгҖӮз®—жі•жҜҸж¬ЎеҸӘеӨ„зҗҶжӯЈеңЁдҪҝз”Ёдёӯзҡ„еҜ№иұЎпјҢеӣ жӯӨеӨҚеҲ¶жҲҗжң¬жҜ”иҫғе°ҸпјҢеҗҢж—¶еӨҚеҲ¶иҝҮеҺ»д»ҘеҗҺиҝҳиғҪиҝӣиЎҢзӣёеә”зҡ„еҶ…еӯҳж•ҙзҗҶпјҢдёҚдјҡеҮәзҺ°вҖңзўҺзүҮвҖқй—®йўҳгҖӮеҪ“然пјҢжӯӨз®—жі•зҡ„зјәзӮ№д№ҹжҳҜеҫҲжҳҺжҳҫзҡ„пјҢе°ұжҳҜйңҖиҰҒдёӨеҖҚеҶ…еӯҳз©әй—ҙгҖӮ
В
ж Үи®°-ж•ҙзҗҶпјҲMark-Compactпјү:
В
В
В
жӯӨз®—жі•з»“еҗҲдәҶвҖңж Үи®°-жё…йҷӨвҖқе’ҢвҖңеӨҚеҲ¶вҖқдёӨдёӘз®—жі•зҡ„дјҳзӮ№гҖӮд№ҹжҳҜеҲҶдёӨйҳ¶ж®өпјҢ第дёҖйҳ¶ж®өд»Һж №иҠӮзӮ№ејҖе§Ӣж Үи®°жүҖжңүиў«еј•з”ЁеҜ№иұЎпјҢ第дәҢйҳ¶ж®өйҒҚеҺҶж•ҙдёӘе ҶпјҢжҠҠжё…йҷӨжңӘж Үи®°еҜ№иұЎе№¶дё”жҠҠеӯҳжҙ»еҜ№иұЎвҖңеҺӢзј©вҖқеҲ°е Ҷзҡ„е…¶дёӯдёҖеқ—пјҢжҢүйЎәеәҸжҺ’ж”ҫгҖӮжӯӨз®—жі•йҒҝе…ҚдәҶвҖңж Үи®°-жё…йҷӨвҖқзҡ„зўҺзүҮй—®йўҳпјҢеҗҢж—¶д№ҹйҒҝе…ҚдәҶвҖңеӨҚеҲ¶вҖқз®—жі•зҡ„з©әй—ҙй—®йўҳгҖӮ
В
жҢүеҲҶеҢәеҜ№еҫ…зҡ„ж–№ејҸеҲҶ
еўһйҮҸ收йӣҶпјҲIncremental Collectingпјү:е®һж—¶еһғеңҫеӣһ收算法пјҢеҚіпјҡеңЁеә”з”ЁиҝӣиЎҢзҡ„еҗҢж—¶иҝӣиЎҢеһғеңҫеӣһ收гҖӮдёҚзҹҘйҒ“д»Җд№ҲеҺҹеӣ JDK5.0дёӯзҡ„收йӣҶеҷЁжІЎжңүдҪҝз”Ёиҝҷз§Қз®—жі•зҡ„гҖӮ
В
еҲҶ代收йӣҶпјҲGenerational Collectingпјү:еҹәдәҺеҜ№еҜ№иұЎз”ҹе‘Ҫе‘ЁжңҹеҲҶжһҗеҗҺеҫ—еҮәзҡ„еһғеңҫеӣһ收算法гҖӮжҠҠеҜ№иұЎеҲҶдёәе№ҙйқ’д»ЈгҖҒе№ҙиҖҒд»ЈгҖҒжҢҒд№…д»ЈпјҢеҜ№дёҚеҗҢз”ҹе‘Ҫе‘Ёжңҹзҡ„еҜ№иұЎдҪҝз”ЁдёҚеҗҢзҡ„з®—жі•пјҲдёҠиҝ°ж–№ејҸдёӯзҡ„дёҖдёӘпјүиҝӣиЎҢеӣһ收гҖӮзҺ°еңЁзҡ„еһғеңҫеӣһ收еҷЁпјҲд»ҺJ2SE1.2ејҖе§ӢпјүйғҪжҳҜдҪҝз”ЁжӯӨз®—жі•зҡ„гҖӮ
В
жҢүзі»з»ҹзәҝзЁӢеҲҶ
дёІиЎҢ收йӣҶ:дёІиЎҢ收йӣҶдҪҝз”ЁеҚ•зәҝзЁӢеӨ„зҗҶжүҖжңүеһғеңҫеӣһ收е·ҘдҪңпјҢеӣ дёәж— йңҖеӨҡзәҝзЁӢдәӨдә’пјҢе®һзҺ°е®№жҳ“пјҢиҖҢдё”ж•ҲзҺҮжҜ”иҫғй«ҳгҖӮдҪҶжҳҜпјҢе…¶еұҖйҷҗжҖ§д№ҹжҜ”иҫғжҳҺжҳҫпјҢеҚіж— жі•дҪҝз”ЁеӨҡеӨ„зҗҶеҷЁзҡ„дјҳеҠҝпјҢжүҖд»ҘжӯӨ收йӣҶйҖӮеҗҲеҚ•еӨ„зҗҶеҷЁжңәеҷЁгҖӮеҪ“然пјҢжӯӨ收йӣҶеҷЁд№ҹеҸҜд»Ҙз”ЁеңЁе°Ҹж•°жҚ®йҮҸпјҲ100Mе·ҰеҸіпјүжғ…еҶөдёӢзҡ„еӨҡеӨ„зҗҶеҷЁжңәеҷЁдёҠгҖӮ
В
并иЎҢ收йӣҶ:并иЎҢ收йӣҶдҪҝз”ЁеӨҡзәҝзЁӢеӨ„зҗҶеһғеңҫеӣһ收е·ҘдҪңпјҢеӣ иҖҢйҖҹеәҰеҝ«пјҢж•ҲзҺҮй«ҳгҖӮиҖҢдё”зҗҶи®әдёҠCPUж•°зӣ®и¶ҠеӨҡпјҢи¶ҠиғҪдҪ“зҺ°еҮә并иЎҢ收йӣҶеҷЁзҡ„дјҳеҠҝгҖӮпјҲдёІеһӢ收йӣҶзҡ„并еҸ‘зүҲжң¬пјҢйңҖиҰҒжҡӮеҒңjvmпјү 并иЎҢparaliseжҢҮзҡ„жҳҜеӨҡдёӘд»»еҠЎеңЁеӨҡдёӘcpuдёӯдёҖиө·е№¶иЎҢжү§иЎҢпјҢжңҖеҗҺе°Ҷз»“жһңеҗҲ并гҖӮж•ҲзҺҮжҳҜNеҖҚгҖӮ
В
并еҸ‘收йӣҶ:зӣёеҜ№дәҺдёІиЎҢ收йӣҶе’Ң并иЎҢ收йӣҶиҖҢиЁҖпјҢеүҚйқўдёӨдёӘеңЁиҝӣиЎҢеһғеңҫеӣһ收е·ҘдҪңж—¶пјҢйңҖиҰҒжҡӮеҒңж•ҙдёӘиҝҗиЎҢзҺҜеўғпјҢиҖҢеҸӘжңүеһғеңҫеӣһ收зЁӢеәҸеңЁиҝҗиЎҢпјҢеӣ жӯӨпјҢзі»з»ҹеңЁеһғеңҫеӣһ收时дјҡжңүжҳҺжҳҫзҡ„жҡӮеҒңпјҢиҖҢдё”жҡӮеҒңж—¶й—ҙдјҡеӣ дёәе Ҷи¶ҠеӨ§иҖҢи¶Ҡй•ҝгҖӮпјҲе’Ң并иЎҢ收йӣҶдёҚеҗҢпјҢ并еҸ‘еҸӘжңүеңЁејҖеӨҙе’Ңз»“е°ҫдјҡжҡӮеҒңjvmпјү并еҸ‘concurrentжҢҮзҡ„жҳҜеӨҡдёӘд»»еҠЎеңЁдёҖдёӘcpuдјӘеҗҢжӯҘжү§иЎҢпјҢдҪҶе…¶е®һжҳҜдёІиЎҢи°ғеәҰзҡ„пјҢж•ҲзҺҮ并йқһзӣҙжҺҘжҳҜNеҖҚгҖӮ
В
еҲҶд»Јеһғеңҫеӣһ收
В В В еҲҶд»Јзҡ„еһғеңҫеӣһ收зӯ–з•ҘпјҢжҳҜеҹәдәҺиҝҷж ·дёҖдёӘдәӢе®һпјҡдёҚеҗҢзҡ„еҜ№иұЎзҡ„з”ҹе‘Ҫе‘ЁжңҹжҳҜдёҚдёҖж ·зҡ„гҖӮеӣ жӯӨпјҢдёҚеҗҢз”ҹе‘Ҫе‘Ёжңҹзҡ„еҜ№иұЎеҸҜд»ҘйҮҮеҸ–дёҚеҗҢзҡ„收йӣҶж–№ејҸпјҢд»ҘдҫҝжҸҗй«ҳеӣһ收ж•ҲзҺҮгҖӮ
В
В В В еңЁJavaзЁӢеәҸиҝҗиЎҢзҡ„иҝҮзЁӢдёӯпјҢдјҡдә§з”ҹеӨ§йҮҸзҡ„еҜ№иұЎпјҢе…¶дёӯжңүдәӣеҜ№иұЎжҳҜдёҺдёҡеҠЎдҝЎжҒҜзӣёе…іпјҢжҜ”еҰӮHttpиҜ·жұӮдёӯзҡ„SessionеҜ№иұЎгҖҒзәҝзЁӢгҖҒSocketиҝһжҺҘпјҢиҝҷзұ»еҜ№иұЎи·ҹдёҡеҠЎзӣҙжҺҘжҢӮй’©пјҢеӣ жӯӨз”ҹе‘Ҫе‘ЁжңҹжҜ”иҫғй•ҝгҖӮдҪҶжҳҜиҝҳжңүдёҖдәӣеҜ№иұЎпјҢдё»иҰҒжҳҜзЁӢеәҸиҝҗиЎҢиҝҮзЁӢдёӯз”ҹжҲҗзҡ„дёҙж—¶еҸҳйҮҸпјҢиҝҷдәӣеҜ№иұЎз”ҹе‘Ҫе‘ЁжңҹдјҡжҜ”иҫғзҹӯпјҢжҜ”еҰӮпјҡStringеҜ№иұЎпјҢз”ұдәҺе…¶дёҚеҸҳзұ»зҡ„зү№жҖ§пјҢзі»з»ҹдјҡдә§з”ҹеӨ§йҮҸзҡ„иҝҷдәӣеҜ№иұЎпјҢжңүдәӣеҜ№иұЎз”ҡиҮіеҸӘз”ЁдёҖж¬ЎеҚіеҸҜеӣһ收гҖӮ
В
В В В иҜ•жғіпјҢеңЁдёҚиҝӣиЎҢеҜ№иұЎеӯҳжҙ»ж—¶й—ҙеҢәеҲҶзҡ„жғ…еҶөдёӢпјҢжҜҸж¬Ўеһғеңҫеӣһ收йғҪжҳҜеҜ№ж•ҙдёӘе Ҷз©әй—ҙиҝӣиЎҢеӣһ收пјҢиҠұиҙ№ж—¶й—ҙзӣёеҜ№дјҡй•ҝпјҢеҗҢж—¶пјҢеӣ дёәжҜҸж¬Ўеӣһ收йғҪйңҖиҰҒйҒҚеҺҶжүҖжңүеӯҳжҙ»еҜ№иұЎпјҢдҪҶе®һйҷ…дёҠпјҢеҜ№дәҺз”ҹе‘Ҫе‘Ёжңҹй•ҝзҡ„еҜ№иұЎиҖҢиЁҖпјҢиҝҷз§ҚйҒҚеҺҶжҳҜжІЎжңүж•Ҳжһңзҡ„пјҢеӣ дёәеҸҜиғҪиҝӣиЎҢдәҶеҫҲеӨҡж¬ЎйҒҚеҺҶпјҢдҪҶжҳҜ他们дҫқж—§еӯҳеңЁгҖӮеӣ жӯӨпјҢеҲҶд»Јеһғеңҫеӣһ收йҮҮз”ЁеҲҶжІ»зҡ„жҖқжғіпјҢиҝӣиЎҢд»Јзҡ„еҲ’еҲҶпјҢжҠҠдёҚеҗҢз”ҹе‘Ҫе‘Ёжңҹзҡ„еҜ№иұЎж”ҫеңЁдёҚеҗҢд»ЈдёҠпјҢдёҚеҗҢд»ЈдёҠйҮҮз”ЁжңҖйҖӮеҗҲе®ғзҡ„еһғеңҫеӣһ收方ејҸиҝӣиЎҢеӣһ收гҖӮ
В
В
В
В
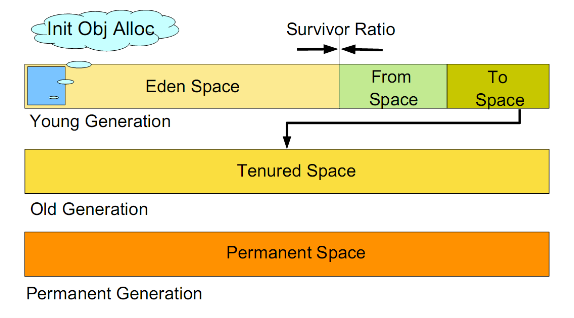
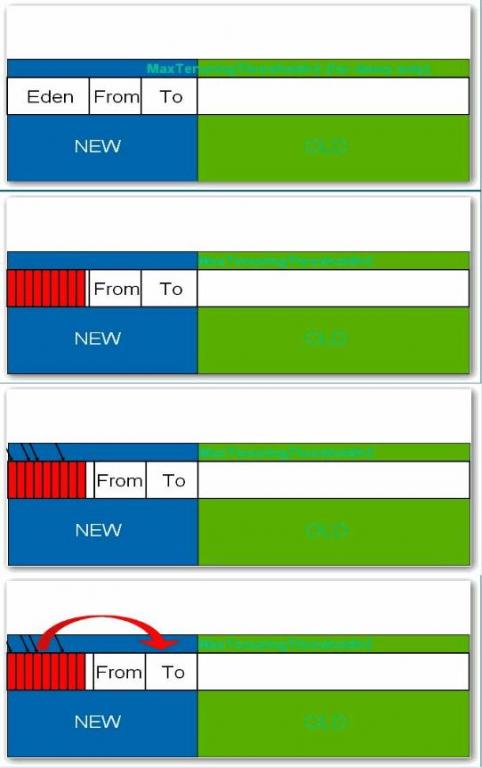
еҰӮеӣҫжүҖзӨәпјҡ
В
В В В иҷҡжӢҹжңәдёӯзҡ„е…ұеҲ’еҲҶдёәдёүдёӘд»Јпјҡе№ҙиҪ»д»ЈпјҲYoung GenerationпјүгҖҒе№ҙиҖҒзӮ№пјҲOld Generationпјүе’ҢжҢҒд№…д»ЈпјҲPermanent GenerationпјүгҖӮе…¶дёӯжҢҒд№…д»Јдё»иҰҒеӯҳж”ҫзҡ„жҳҜJavaзұ»зҡ„зұ»дҝЎжҒҜпјҢдёҺеһғеңҫ收йӣҶиҰҒ收йӣҶзҡ„JavaеҜ№иұЎе…ізі»дёҚеӨ§гҖӮе№ҙиҪ»д»Је’Ңе№ҙиҖҒд»Јзҡ„еҲ’еҲҶжҳҜеҜ№еһғеңҫ收йӣҶеҪұе“ҚжҜ”иҫғеӨ§зҡ„гҖӮ
В
В
е№ҙиҪ»д»Ј:
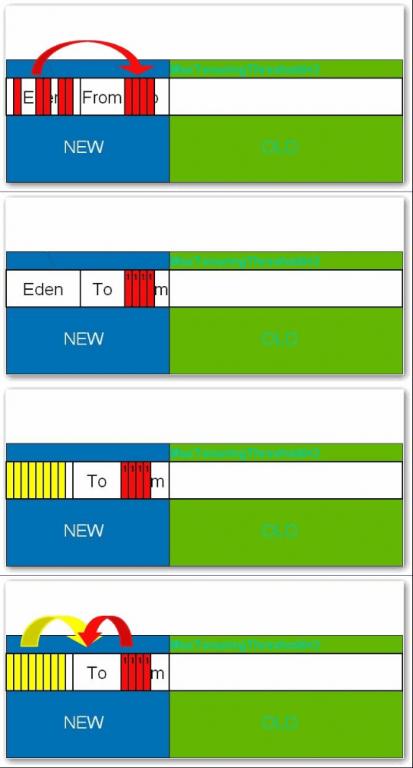
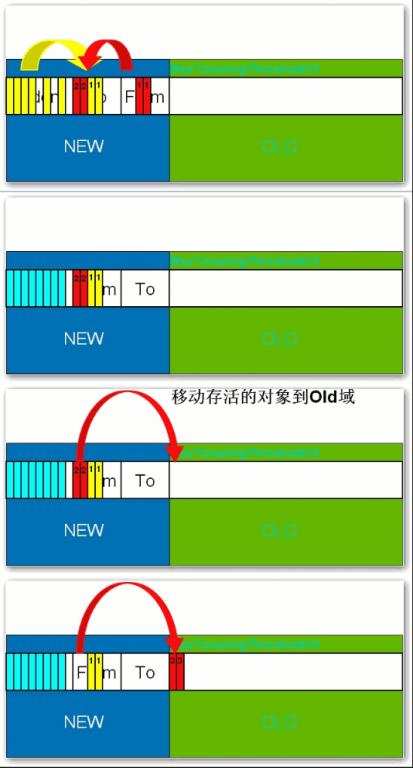
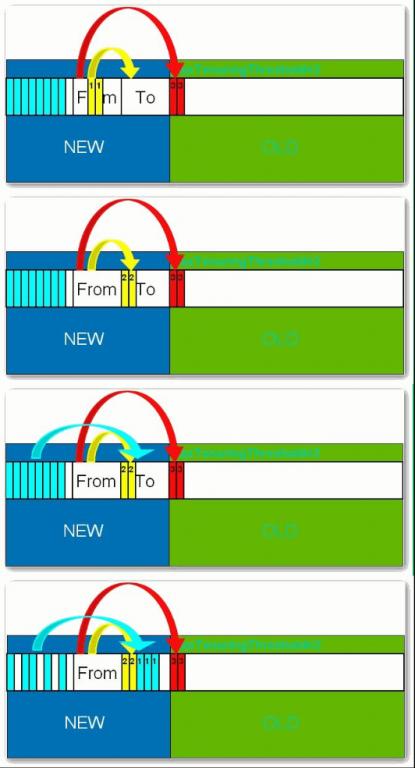
В В В жүҖжңүж–°з”ҹжҲҗзҡ„еҜ№иұЎйҰ–е…ҲйғҪжҳҜж”ҫеңЁе№ҙиҪ»д»Јзҡ„гҖӮе№ҙиҪ»д»Јзҡ„зӣ®ж Үе°ұжҳҜе°ҪеҸҜиғҪеҝ«йҖҹзҡ„收йӣҶжҺүйӮЈдәӣз”ҹе‘Ҫе‘Ёжңҹзҹӯзҡ„еҜ№иұЎгҖӮе№ҙиҪ»д»ЈеҲҶдёүдёӘеҢәгҖӮдёҖдёӘEdenеҢәпјҢдёӨдёӘSurvivorеҢә(дёҖиҲ¬иҖҢиЁҖ)гҖӮеӨ§йғЁеҲҶеҜ№иұЎеңЁEdenеҢәдёӯз”ҹжҲҗгҖӮеҪ“EdenеҢәж»Ўж—¶пјҢиҝҳеӯҳжҙ»зҡ„еҜ№иұЎе°Ҷиў«еӨҚеҲ¶еҲ°SurvivorеҢәпјҲдёӨдёӘдёӯзҡ„дёҖдёӘпјүпјҢеҪ“иҝҷдёӘSurvivorеҢәж»Ўж—¶пјҢжӯӨеҢәзҡ„еӯҳжҙ»еҜ№иұЎе°Ҷиў«еӨҚеҲ¶еҲ°еҸҰеӨ–дёҖдёӘSurvivorеҢәпјҢеҪ“иҝҷдёӘSurvivorеҢәд№ҹж»ЎдәҶзҡ„ж—¶еҖҷпјҢд»Һ第дёҖдёӘSurvivorеҢәеӨҚеҲ¶иҝҮжқҘзҡ„并且жӯӨж—¶иҝҳеӯҳжҙ»зҡ„еҜ№иұЎпјҢе°Ҷиў«еӨҚеҲ¶вҖңе№ҙиҖҒеҢә(Tenured)вҖқгҖӮйңҖиҰҒжіЁж„ҸпјҢSurvivorзҡ„дёӨдёӘеҢәжҳҜеҜ№з§°зҡ„пјҢжІЎе…ҲеҗҺе…ізі»пјҢжүҖд»ҘеҗҢдёҖдёӘеҢәдёӯеҸҜиғҪеҗҢж—¶еӯҳеңЁд»ҺEdenеӨҚеҲ¶иҝҮжқҘ еҜ№иұЎпјҢе’Ңд»ҺеүҚдёҖдёӘSurvivorеӨҚеҲ¶иҝҮжқҘзҡ„еҜ№иұЎпјҢиҖҢеӨҚеҲ¶еҲ°е№ҙиҖҒеҢәзҡ„еҸӘжңүд»Һ第дёҖдёӘSurvivorеҺ»иҝҮжқҘзҡ„еҜ№иұЎгҖӮиҖҢдё”пјҢSurvivorеҢәжҖ»жңүдёҖдёӘжҳҜз©әзҡ„гҖӮеҗҢж—¶пјҢж №жҚ®зЁӢеәҸйңҖиҰҒпјҢSurvivorеҢәжҳҜеҸҜд»Ҙй…ҚзҪ®дёәеӨҡдёӘзҡ„пјҲеӨҡдәҺдёӨдёӘпјүпјҢиҝҷж ·еҸҜд»ҘеўһеҠ еҜ№иұЎеңЁе№ҙиҪ»д»Јдёӯзҡ„еӯҳеңЁж—¶й—ҙпјҢеҮҸе°‘иў«ж”ҫеҲ°е№ҙиҖҒд»Јзҡ„еҸҜиғҪгҖӮ
В
е№ҙиҖҒд»Ј:
В В В еңЁе№ҙиҪ»д»Јдёӯз»ҸеҺҶдәҶNж¬Ўеһғеңҫеӣһ收еҗҺд»Қ然еӯҳжҙ»зҡ„еҜ№иұЎпјҢе°ұдјҡиў«ж”ҫеҲ°е№ҙиҖҒд»ЈдёӯгҖӮеӣ жӯӨпјҢеҸҜд»Ҙи®Өдёәе№ҙиҖҒд»Јдёӯеӯҳж”ҫзҡ„йғҪжҳҜдёҖдәӣз”ҹе‘Ҫе‘Ёжңҹиҫғй•ҝзҡ„еҜ№иұЎгҖӮ
В
жҢҒд№…д»Ј:
В В В з”ЁдәҺеӯҳж”ҫйқҷжҖҒж–Ү件пјҢеҰӮд»ҠJavaзұ»гҖҒж–№жі•зӯүгҖӮжҢҒд№…д»ЈеҜ№еһғеңҫеӣһ收没жңүжҳҫи‘—еҪұе“ҚпјҢдҪҶжҳҜжңүдәӣеә”з”ЁеҸҜиғҪеҠЁжҖҒз”ҹжҲҗжҲ–иҖ…и°ғз”ЁдёҖдәӣclassпјҢдҫӢеҰӮHibernateзӯүпјҢеңЁиҝҷз§Қж—¶еҖҷйңҖиҰҒи®ҫзҪ®дёҖдёӘжҜ”иҫғеӨ§зҡ„жҢҒд№…д»Јз©әй—ҙжқҘеӯҳж”ҫиҝҷдәӣиҝҗиЎҢиҝҮзЁӢдёӯж–°еўһзҡ„зұ»гҖӮжҢҒд№…д»ЈеӨ§е°ҸйҖҡиҝҮ-XX:MaxPermSize=<N>иҝӣиЎҢи®ҫзҪ®гҖӮ
В
д»Җд№Ҳжғ…еҶөдёӢи§ҰеҸ‘еһғеңҫеӣһ收В
з”ұдәҺеҜ№иұЎиҝӣиЎҢдәҶеҲҶд»ЈеӨ„зҗҶпјҢеӣ жӯӨеһғеңҫеӣһ收еҢәеҹҹгҖҒж—¶й—ҙд№ҹдёҚдёҖж ·гҖӮGCжңүдёӨз§Қзұ»еһӢпјҡScavenge GCе’ҢFull GCгҖӮ
В
Scavenge GC
В В В дёҖиҲ¬жғ…еҶөдёӢпјҢеҪ“ж–°еҜ№иұЎз”ҹжҲҗпјҢ并且еңЁEdenз”іиҜ·з©әй—ҙеӨұиҙҘж—¶пјҢе°ұдјҡи§ҰеҸ‘Scavenge GCпјҢеҜ№EdenеҢәеҹҹиҝӣиЎҢGCпјҢжё…йҷӨйқһеӯҳжҙ»еҜ№иұЎпјҢ并且жҠҠе°ҡдё”еӯҳжҙ»зҡ„еҜ№иұЎз§»еҠЁеҲ°SurvivorеҢәгҖӮ然еҗҺж•ҙзҗҶSurvivorзҡ„дёӨдёӘеҢәгҖӮиҝҷз§Қж–№ејҸзҡ„GCжҳҜеҜ№е№ҙиҪ»д»Јзҡ„EdenеҢәиҝӣиЎҢпјҢдёҚдјҡеҪұе“ҚеҲ°е№ҙиҖҒд»ЈгҖӮеӣ дёәеӨ§йғЁеҲҶеҜ№иұЎйғҪжҳҜд»ҺEdenеҢәејҖе§Ӣзҡ„пјҢеҗҢж—¶EdenеҢәдёҚдјҡеҲҶй…Қзҡ„еҫҲеӨ§пјҢжүҖд»ҘEdenеҢәзҡ„GCдјҡйў‘з№ҒиҝӣиЎҢгҖӮеӣ иҖҢпјҢдёҖиҲ¬еңЁиҝҷйҮҢйңҖиҰҒдҪҝз”ЁйҖҹеәҰеҝ«гҖҒж•ҲзҺҮй«ҳзҡ„з®—жі•пјҢдҪҝEdenеҺ»иғҪе°Ҫеҝ«з©әй—ІеҮәжқҘгҖӮ
В
Full GC
В В В еҜ№ж•ҙдёӘе ҶиҝӣиЎҢж•ҙзҗҶпјҢеҢ…жӢ¬YoungгҖҒTenuredе’ҢPermгҖӮFull GCеӣ дёәйңҖиҰҒеҜ№ж•ҙдёӘеҜ№иҝӣиЎҢеӣһ收пјҢжүҖд»ҘжҜ”Scavenge GCиҰҒж…ўпјҢеӣ жӯӨеә”иҜҘе°ҪеҸҜиғҪеҮҸе°‘Full GCзҡ„ж¬Ўж•°гҖӮеңЁеҜ№JVMи°ғдјҳзҡ„иҝҮзЁӢдёӯпјҢеҫҲеӨ§дёҖйғЁеҲҶе·ҘдҪңе°ұжҳҜеҜ№дәҺFullGCзҡ„и°ғиҠӮгҖӮжңүеҰӮдёӢеҺҹеӣ еҸҜиғҪеҜјиҮҙFull GCпјҡ
В· е№ҙиҖҒд»ЈпјҲTenuredпјүиў«еҶҷж»Ў
В· жҢҒд№…д»ЈпјҲPermпјүиў«еҶҷж»ЎВ
В· System.gc()иў«жҳҫзӨәи°ғз”ЁВ
В·дёҠдёҖж¬ЎGCд№ӢеҗҺHeapзҡ„еҗ„еҹҹеҲҶй…Қзӯ–з•ҘеҠЁжҖҒеҸҳеҢ–
В
В
В
В
В
В
В
В
В
В
В
В
= G1 ===================================
В
В
дј иҜҙдёӯзҡ„G1пјҢдј иҜҙдёӯзҡ„low-pauseеһғеңҫ收йӣҶгҖӮJava SE 6зҡ„update14зүҲжң¬дёӯе·Із»ҸеҢ…еҗ«жөӢиҜ•зүҲпјҢеҸҜд»ҘеңЁеҗҜеҠЁж—¶еҠ JVMеҸӮж•°жқҘеҗҜз”Ё
-XX:+UnlockExperimentalVMOptions -XX:+UseG1GC
В
http://www.blogjava.net/BlueDavy/archive/2009/03/11/259230.html
жң¬ж–Үж‘ҳиҮӘгҖҠжһ„е»әй«ҳжҖ§иғҪзҡ„еӨ§еһӢеҲҶеёғејҸJavaеә”з”ЁгҖӢдёҖд№ҰпјҢGarbage Firstз®Җз§°G1пјҢе®ғзҡ„зӣ®ж ҮжҳҜиҰҒеҒҡеҲ°е°ҪйҮҸеҮҸе°‘GCжүҖеҜјиҮҙзҡ„еә”з”ЁжҡӮеҒңзҡ„ж—¶й—ҙпјҢи®©еә”з”ЁиҫҫеҲ°еҮҶе®һж—¶зҡ„ж•ҲжһңпјҢеҗҢж—¶дҝқжҢҒJVMе Ҷз©әй—ҙзҡ„еҲ©з”ЁзҺҮпјҢе°ҶдҪңдёәCMSзҡ„жӣҝд»ЈиҖ…еңЁJDK 7дёӯй—Әдә®зҷ»еңәпјҢе…¶жңҖеӨ§зҡ„зү№иүІеңЁдәҺе…Ғи®ёжҢҮе®ҡеңЁжҹҗдёӘж—¶й—ҙж®өеҶ…GCжүҖеҜјиҮҙзҡ„еә”з”ЁжҡӮеҒңзҡ„ж—¶й—ҙжңҖеӨ§дёәеӨҡе°‘пјҢдҫӢеҰӮеңЁ100з§’еҶ…жңҖеӨҡе…Ғи®ёGCеҜјиҮҙзҡ„еә”з”ЁжҡӮеҒңж—¶й—ҙдёә1з§’пјҢиҝҷдёӘзү№жҖ§еҜ№дәҺеҮҶе®һж—¶е“Қеә”зҡ„зі»з»ҹиҖҢиЁҖйқһеёёзҡ„еҗёеј•дәәпјҢиҝҷж ·е°ұеҶҚд№ҹдёҚз”ЁжӢ…еҝғзі»з»ҹзӘҒ然дјҡжҡӮеҒңдёӘдёӨдёүз§’дәҶгҖӮ
В
G1иҰҒеҒҡеҲ°иҝҷж ·зҡ„ж•ҲжһңпјҢд№ҹжҳҜжңүеүҚжҸҗзҡ„пјҢдёҖж–№йқўжҳҜ硬件зҺҜеўғзҡ„иҰҒжұӮпјҢеҝ…йЎ»жҳҜеӨҡж ёзҡ„CPUд»ҘеҸҠиҫғеӨ§зҡ„еҶ…еӯҳпјҲд»Һ规иҢғжқҘзңӢпјҢ512Mд»ҘдёҠе°ұж»Ўи¶іжқЎд»¶дәҶпјүпјҢеҸҰеӨ–дёҖж–№йқўжҳҜйңҖиҰҒжҺҘеҸ—еҗһеҗҗйҮҸзҡ„зЁҚеҫ®йҷҚдҪҺпјҢеҜ№дәҺе®һж—¶жҖ§иҰҒжұӮй«ҳзҡ„зі»з»ҹиҖҢиЁҖпјҢиҝҷзӮ№еә”иҜҘжҳҜеҸҜд»ҘжҺҘеҸ—зҡ„гҖӮ
дёәдәҶиғҪеӨҹиҫҫеҲ°иҝҷж ·зҡ„ж•ҲжһңпјҢG1еңЁеҺҹжңүзҡ„еҗ„з§ҚGCзӯ–з•ҘдёҠиҝӣиЎҢдәҶеҗёж”¶е’Ңж”№иҝӣпјҢеңЁG1дёӯеҸҜд»ҘзңӢеҲ°еўһйҮҸ收йӣҶеҷЁе’ҢCMSзҡ„еҪұеӯҗпјҢдҪҶе®ғдёҚд»…д»…жҳҜеҗёж”¶еҺҹжңүGCзӯ–з•Ҙзҡ„дјҳзӮ№пјҢ并еңЁжӯӨеҹәзЎҖдёҠеҒҡеҮәдәҶеҫҲеӨҡзҡ„ж”№иҝӣпјҢз®ҖеҚ•жқҘиҜҙпјҢG1еҗёж”¶дәҶеўһйҮҸGCд»ҘеҸҠCMSзҡ„зІҫй«“пјҢе°Ҷж•ҙдёӘjvm HeapеҲ’еҲҶдёәеӨҡдёӘеӣәе®ҡеӨ§е°Ҹзҡ„regionпјҢжү«жҸҸж—¶йҮҮз”ЁSnapshot-at-the-beginningзҡ„并еҸ‘markingз®—жі•пјҲе…·дҪ“еңЁеҗҺйқўеҶ…е®№иҜҰз»Ҷи§ЈйҮҠпјүеҜ№ж•ҙдёӘheapдёӯзҡ„regionиҝӣиЎҢmarkпјҢеӣһж”¶ж—¶ж №жҚ®regionдёӯжҙ»и·ғеҜ№иұЎзҡ„bytesиҝӣиЎҢжҺ’еәҸпјҢйҰ–е…Ҳеӣһ收жҙ»и·ғеҜ№иұЎbytesе°Ҹд»ҘеҸҠеӣһ收иҖ—ж—¶зҹӯпјҲйў„дј°еҮәжқҘзҡ„ж—¶й—ҙпјүзҡ„regionпјҢеӣһ收зҡ„ж–№жі•дёәе°ҶжӯӨregionдёӯзҡ„жҙ»и·ғеҜ№иұЎеӨҚеҲ¶еҲ°еҸҰеӨ–зҡ„regionдёӯпјҢж №жҚ®жҢҮе®ҡзҡ„GCжүҖиғҪеҚ з”Ёзҡ„ж—¶й—ҙжқҘдј°з®—иғҪеӣһ收еӨҡе°‘regionпјҢиҝҷзӮ№е’Ңд»ҘеүҚзүҲжң¬зҡ„Full GCж—¶еҫ—еӨ„зҗҶж•ҙдёӘheapйқһеёёдёҚеҗҢпјҢиҝҷж ·е°ұеҒҡеҲ°дәҶиғҪеӨҹе°ҪйҮҸзҹӯж—¶й—ҙзҡ„жҡӮеҒңеә”з”ЁпјҢеҸҲиғҪеӣһ收еҶ…еӯҳпјҢз”ұдәҺиҝҷз§Қзӯ–з•ҘеңЁеӣһ收时йҰ–е…Ҳеӣһ收зҡ„жҳҜеһғеңҫеҜ№иұЎжүҖеҚ з©әй—ҙжңҖеӨҡзҡ„regionпјҢеӣ жӯӨз§°дёәGarbage FirstгҖӮ
зңӢе®ҢдёҠйқўеҜ№дәҺG1зӯ–з•Ҙзҡ„з®ҖзҹӯжҸҸиҝ°пјҢ并дёҚиғҪжё…жҘҡзҡ„жҺҢжҸЎG1пјҢеңЁз»§з»ӯиҜҰз»ҶзңӢG1зҡ„жӯҘйӘӨд№ӢеүҚпјҢеҝ…йЎ»е…ҲжҳҺзҷҪG1еҜ№дәҺJVM Heapзҡ„ж”№йҖ пјҢиҝҷдәӣеҜ№дәҺд№ жғҜдәҶеҲ’еҲҶдёәnew generationгҖҒold generationзҡ„еӨ§е®¶жқҘиҜҙйғҪжңүдёҚе°‘зҡ„ж–°ж„ҸгҖӮ
G1е°ҶHeapеҲ’еҲҶдёәеӨҡдёӘеӣәе®ҡеӨ§е°Ҹзҡ„regionпјҢиҝҷд№ҹжҳҜG1иғҪеӨҹе®һзҺ°жҺ§еҲ¶GCеҜјиҮҙзҡ„еә”з”ЁжҡӮеҒңж—¶й—ҙзҡ„еүҚжҸҗпјҢregionд№Ӣй—ҙзҡ„еҜ№иұЎеј•з”ЁйҖҡиҝҮremembered setжқҘз»ҙжҠӨпјҢжҜҸдёӘregionйғҪжңүдёҖдёӘremembered setпјҢremembered setдёӯеҢ…еҗ«дәҶеј•з”ЁеҪ“еүҚregionдёӯеҜ№иұЎзҡ„regionзҡ„еҜ№иұЎзҡ„pointerпјҢз”ұдәҺеҗҢж—¶еә”з”Ёд№ҹдјҡйҖ жҲҗиҝҷдәӣregionдёӯеҜ№иұЎзҡ„еј•з”Ёе…ізі»дёҚж–ӯзҡ„еҸ‘з”ҹж”№еҸҳпјҢG1йҮҮз”ЁдәҶCard TableжқҘз”ЁдәҺеә”з”ЁйҖҡзҹҘregionдҝ®ж”№remembered setsпјҢCard Tableз”ұеӨҡдёӘ512еӯ—иҠӮзҡ„Cardжһ„жҲҗпјҢиҝҷдәӣCardеңЁCard Tableдёӯд»Ҙ1дёӘеӯ—иҠӮжқҘж ҮиҜҶпјҢжҜҸдёӘеә”з”Ёзҡ„зәҝзЁӢйғҪжңүдёҖдёӘе…іиҒ”зҡ„remembered set logпјҢз”ЁдәҺзј“еӯҳе’ҢйЎәеәҸеҢ–зәҝзЁӢиҝҗиЎҢж—¶йҖ жҲҗзҡ„еҜ№дәҺcardзҡ„дҝ®ж”№пјҢеҸҰеӨ–пјҢиҝҳжңүдёҖдёӘе…ЁеұҖзҡ„filled RS buffersпјҢеҪ“еә”з”ЁзәҝзЁӢжү§иЎҢж—¶дҝ®ж”№дәҶcardеҗҺпјҢеҰӮжһңйҖ жҲҗзҡ„ж”№еҸҳд»…дёәеҗҢдёҖregionдёӯзҡ„еҜ№иұЎд№Ӣй—ҙзҡ„е…іиҒ”пјҢеҲҷдёҚи®°еҪ•remembered set logпјҢеҰӮйҖ жҲҗзҡ„ж”№еҸҳдёәи·Ёregionдёӯзҡ„еҜ№иұЎзҡ„е…іиҒ”пјҢеҲҷи®°еҪ•еҲ°зәҝзЁӢзҡ„remembered set logпјҢеҰӮзәҝзЁӢзҡ„remembered set logж»ЎдәҶпјҢеҲҷж”ҫе…Ҙе…ЁеұҖзҡ„filled RS buffersдёӯпјҢзәҝзЁӢиҮӘиә«еҲҷйҮҚж–°еҲӣе»әдёҖдёӘж–°зҡ„remembered set logпјҢremembered setжң¬иә«д№ҹжҳҜдёҖдёӘз”ұдёҖе Ҷcardsжһ„жҲҗзҡ„е“ҲеёҢиЎЁгҖӮ
е°Ҫз®ЎG1е°ҶHeapеҲ’еҲҶдёәдәҶеӨҡдёӘregionпјҢдҪҶе…¶й»ҳи®ӨйҮҮз”Ёзҡ„д»Қ然жҳҜеҲҶд»Јзҡ„ж–№ејҸпјҢеҸӘжҳҜд»…з®ҖеҚ•зҡ„еҲ’еҲҶдёәдәҶе№ҙиҪ»д»ЈпјҲyoungпјүе’Ңйқһе№ҙиҪ»д»ЈпјҢиҝҷд№ҹжҳҜз”ұдәҺG1д»Қ然еқҡдҝЎеӨ§еӨҡж•°ж–°еҲӣе»әзҡ„еҜ№иұЎйғҪжҳҜдёҚйңҖиҰҒй•ҝзҡ„з”ҹе‘Ҫе‘Ёжңҹзҡ„пјҢеҜ№дәҺеә”з”Ёж–°еҲӣе»әзҡ„еҜ№иұЎпјҢG1е°Ҷе…¶ж”ҫе…Ҙж ҮиҜҶдёәyoungзҡ„regionдёӯпјҢеҜ№дәҺиҝҷдәӣregionпјҢ并дёҚи®°еҪ•remembered set logsпјҢжү«жҸҸж—¶еҸӘйңҖжү«жҸҸжҙ»и·ғзҡ„еҜ№иұЎпјҢG1еңЁеҲҶд»Јзҡ„ж–№ејҸдёҠиҝҳеҸҜжӣҙз»Ҷзҡ„еҲ’еҲҶдёәпјҡfully youngжҲ–partially youngпјҢfully youngж–№ејҸжҡӮеҒңзҡ„ж—¶еҖҷд»…еӨ„зҗҶyoung regionsпјҢpartiallyеҗҢж ·еӨ„зҗҶжүҖжңүзҡ„young regionsпјҢдҪҶе®ғиҝҳдјҡж №жҚ®е…Ғи®ёзҡ„GCзҡ„жҡӮеҒңж—¶й—ҙжқҘеҶіе®ҡжҳҜеҗҰиҰҒеҠ е…Ҙе…¶д»–зҡ„йқһyoung regionsпјҢG1жҳҜиҝҗиЎҢеҲ°fully-youngж–№ејҸиҝҳжҳҜpartially youngж–№ејҸпјҢеӨ–йғЁжҳҜдёҚиғҪеҶіе®ҡзҡ„пјҢеңЁеҗҜеҠЁж—¶пјҢG1йҮҮз”Ёзҡ„дёәfully-youngж–№ејҸпјҢеҪ“G1е®ҢжҲҗдёҖж¬ЎConcurrent MarkingеҗҺпјҢеҲҷеҲҮжҚўдёәpartially youngж–№ејҸпјҢйҡҸеҗҺG1и·ҹиёӘжҜҸж¬Ўеӣһ收зҡ„ж•ҲзҺҮпјҢеҰӮжһңеӣһ收fully-youngдёӯзҡ„regionsе·Із»ҸеҸҜд»Ҙж»Ўи¶іеҶ…еӯҳйңҖиҰҒзҡ„иҜқпјҢйӮЈд№Ҳе°ұеҲҮжҚўеӣһfully youngж–№ејҸпјҢдҪҶеҪ“heap sizeзҡ„еӨ§е°ҸжҺҘиҝ‘ж»Ўзҡ„жғ…еҶөдёӢпјҢG1дјҡеҲҮжҚўеҲ°partially youngж–№ејҸпјҢд»ҘдҝқиҜҒиғҪжҸҗдҫӣи¶іеӨҹзҡ„еҶ…еӯҳз©әй—ҙз»ҷеә”з”ЁдҪҝз”ЁгҖӮ
йҷӨдәҶеҲҶд»Јж–№ејҸзҡ„еҲ’еҲҶеӨ–пјҢG1иҝҳж”ҜжҢҒеҸҰеӨ–дёҖз§Қpure G1зҡ„ж–№ејҸпјҢд№ҹе°ұжҳҜдёҚиҝӣиЎҢд»Јзҡ„еҲ’еҲҶпјҢpureж–№ејҸе’ҢеҲҶд»Јж–№ејҸзҡ„е…·дҪ“дёҚеҗҢеңЁдёӢйқўзҡ„е…·дҪ“жү§иЎҢжӯҘйӘӨдёӯиҝӣиЎҢжҸҸиҝ°гҖӮ
жҺҢжҸЎдәҶиҝҷдәӣжҰӮеҝөеҗҺпјҢ继з»ӯжқҘзңӢG1зҡ„е…·дҪ“жү§иЎҢжӯҘйӘӨпјҡ
1.В В В В В В В В В Initial Marking
G1еҜ№дәҺжҜҸдёӘregionйғҪдҝқеӯҳдәҶдёӨдёӘж ҮиҜҶз”Ёзҡ„bitmapпјҢдёҖдёӘдёәprevious marking bitmapпјҢдёҖдёӘдёәnext marking bitmapпјҢbitmapдёӯеҢ…еҗ«дәҶдёҖдёӘbitзҡ„ең°еқҖдҝЎжҒҜжқҘжҢҮеҗ‘еҜ№иұЎзҡ„иө·е§ӢзӮ№гҖӮ
ејҖе§ӢInitial Markingд№ӢеүҚпјҢйҰ–е…Ҳ并еҸ‘зҡ„жё…з©әnext marking bitmapпјҢ然еҗҺеҒңжӯўжүҖжңүеә”з”ЁзәҝзЁӢпјҢ并жү«жҸҸж ҮиҜҶеҮәжҜҸдёӘregionдёӯrootеҸҜзӣҙжҺҘи®ҝй—®еҲ°зҡ„еҜ№иұЎпјҢе°Ҷregionдёӯtopзҡ„еҖјж”ҫе…Ҙnext top at mark startпјҲTAMSпјүдёӯпјҢд№ӢеҗҺжҒўеӨҚжүҖжңүеә”з”ЁзәҝзЁӢгҖӮ
и§ҰеҸ‘иҝҷдёӘжӯҘйӘӨжү§иЎҢзҡ„жқЎд»¶дёәпјҡ
lВ В G1е®ҡд№үдәҶдёҖдёӘJVM HeapеӨ§е°Ҹзҡ„зҷҫеҲҶжҜ”зҡ„йҳҖеҖјпјҢз§°дёәhпјҢеҸҰеӨ–иҝҳжңүдёҖдёӘHпјҢHзҡ„еҖјдёә(1-h)*Heap SizeпјҢзӣ®еүҚиҝҷдёӘhзҡ„еҖјжҳҜеӣәе®ҡзҡ„пјҢеҗҺз»ӯG1д№ҹи®ёдјҡе°Ҷе…¶ж”№дёәеҠЁжҖҒзҡ„пјҢж №жҚ®jvmзҡ„иҝҗиЎҢжғ…еҶөжқҘеҠЁжҖҒзҡ„и°ғж•ҙпјҢеңЁеҲҶд»Јж–№ејҸдёӢпјҢG1иҝҳе®ҡд№үдәҶдёҖдёӘuд»ҘеҸҠsoft limitпјҢsoft limitзҡ„еҖјдёәH-u*Heap SizeпјҢеҪ“HeapдёӯдҪҝз”Ёзҡ„еҶ…еӯҳи¶…иҝҮдәҶsoft limitеҖјж—¶пјҢе°ұдјҡеңЁдёҖж¬Ўclean upжү§иЎҢе®ҢжҜ•еҗҺеңЁеә”з”Ёе…Ғи®ёзҡ„GCжҡӮеҒңж—¶й—ҙиҢғеӣҙеҶ…е°Ҫеҝ«зҡ„жү§иЎҢжӯӨжӯҘйӘӨпјӣ
lВ В еңЁpureж–№ејҸдёӢпјҢG1е°ҶmarkingдёҺclean upз»„жҲҗдёҖдёӘзҺҜпјҢд»Ҙдҫҝclean upиғҪе……еҲҶзҡ„дҪҝз”Ёmarkingзҡ„дҝЎжҒҜпјҢеҪ“clean upејҖе§Ӣеӣһ收时пјҢйҰ–е…Ҳеӣһ收иғҪеӨҹеёҰжқҘжңҖеӨҡеҶ…еӯҳз©әй—ҙзҡ„regionsпјҢеҪ“з»ҸиҝҮеӨҡж¬Ўзҡ„clean upпјҢеӣһ收еҲ°жІЎеӨҡе°‘з©әй—ҙзҡ„regionsж—¶пјҢG1йҮҚж–°еҲқе§ӢеҢ–дёҖдёӘж–°зҡ„markingдёҺclean upжһ„жҲҗзҡ„зҺҜгҖӮ
2.В В В В В В В В В Concurrent Marking
жҢүз…§д№ӢеүҚInitial Markingжү«жҸҸеҲ°зҡ„еҜ№иұЎиҝӣиЎҢйҒҚеҺҶпјҢд»ҘиҜҶеҲ«иҝҷдәӣеҜ№иұЎзҡ„дёӢеұӮеҜ№иұЎзҡ„жҙ»и·ғзҠ¶жҖҒпјҢеҜ№дәҺеңЁжӯӨжңҹй—ҙеә”з”ЁзәҝзЁӢ并еҸ‘дҝ®ж”№зҡ„еҜ№иұЎзҡ„д»ҘжқҘе…ізі»еҲҷи®°еҪ•еҲ°remembered set logsдёӯпјҢж–°еҲӣе»әзҡ„еҜ№иұЎеҲҷж”ҫе…ҘжҜ”topеҖјжӣҙй«ҳзҡ„ең°еқҖеҢәй—ҙдёӯпјҢиҝҷдәӣж–°еҲӣе»әзҡ„еҜ№иұЎй»ҳи®ӨзҠ¶жҖҒеҚідёәжҙ»и·ғзҡ„пјҢеҗҢж—¶дҝ®ж”№topеҖјгҖӮ
3.В В В В В В В В В Final Marking Pause
еҪ“еә”з”ЁзәҝзЁӢзҡ„remembered set logsжңӘж»Ўж—¶пјҢжҳҜдёҚдјҡж”ҫе…Ҙfilled RS buffersдёӯзҡ„пјҢеңЁиҝҷж ·зҡ„жғ…еҶөдёӢпјҢиҝҷдәӣremebered set logsдёӯи®°еҪ•зҡ„cardзҡ„дҝ®ж”№е°ұдјҡиў«жӣҙж–°дәҶпјҢеӣ жӯӨйңҖиҰҒиҝҷдёҖжӯҘпјҢиҝҷдёҖжӯҘиҰҒеҒҡзҡ„е°ұжҳҜжҠҠеә”з”ЁзәҝзЁӢдёӯеӯҳеңЁзҡ„remembered set logsзҡ„еҶ…е®№иҝӣиЎҢеӨ„зҗҶпјҢ并зӣёеә”зҡ„дҝ®ж”№remembered setsпјҢиҝҷдёҖжӯҘйңҖиҰҒжҡӮеҒңеә”з”ЁпјҢ并иЎҢзҡ„иҝҗиЎҢгҖӮ
4.В В В В В В В В В Live Data Counting and Cleanup
еҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҢеңЁG1дёӯпјҢ并дёҚжҳҜиҜҙFinal Marking Pauseжү§иЎҢе®ҢдәҶпјҢе°ұиӮҜе®ҡжү§иЎҢCleanupиҝҷжӯҘзҡ„пјҢз”ұдәҺиҝҷжӯҘйңҖиҰҒжҡӮеҒңеә”з”ЁпјҢG1дёәдәҶиғҪеӨҹиҫҫеҲ°еҮҶе®һж—¶зҡ„иҰҒжұӮпјҢйңҖиҰҒж №жҚ®з”ЁжҲ·жҢҮе®ҡзҡ„жңҖеӨ§зҡ„GCйҖ жҲҗзҡ„жҡӮеҒңж—¶й—ҙжқҘеҗҲзҗҶзҡ„规еҲ’д»Җд№Ҳж—¶еҖҷжү§иЎҢCleanupпјҢеҸҰеӨ–иҝҳжңүеҮ з§Қжғ…еҶөд№ҹжҳҜдјҡи§ҰеҸ‘иҝҷдёӘжӯҘйӘӨзҡ„жү§иЎҢзҡ„пјҡ
lВ В G1йҮҮз”Ёзҡ„жҳҜеӨҚеҲ¶ж–№жі•жқҘиҝӣиЎҢ收йӣҶпјҢеҝ…йЎ»дҝқиҜҒжҜҸж¬Ўзҡ„вҖқto spaceвҖқзҡ„з©әй—ҙйғҪжҳҜеӨҹзҡ„пјҢеӣ жӯӨG1йҮҮеҸ–зҡ„зӯ–з•ҘжҳҜеҪ“е·Із»ҸдҪҝз”Ёзҡ„еҶ…еӯҳз©әй—ҙиҫҫеҲ°дәҶHж—¶пјҢе°ұжү§иЎҢCleanupиҝҷдёӘжӯҘйӘӨпјӣ
lВ В еҜ№дәҺfull-youngе’Ңpartially-youngзҡ„еҲҶд»ЈжЁЎејҸзҡ„G1иҖҢиЁҖпјҢеҲҷиҝҳжңүжғ…еҶөдјҡи§ҰеҸ‘Cleanupзҡ„жү§иЎҢпјҢfull-youngжЁЎејҸдёӢпјҢG1ж №жҚ®еә”з”ЁеҸҜжҺҘеҸ—зҡ„жҡӮеҒңж—¶й—ҙгҖҒеӣһ收young regionsйңҖиҰҒж¶ҲиҖ—зҡ„ж—¶й—ҙжқҘдј°з®—еҮәдёҖдёӘyound regionsзҡ„ж•°йҮҸеҖјпјҢеҪ“JVMдёӯеҲҶй…ҚеҜ№иұЎзҡ„young regionsзҡ„ж•°йҮҸиҫҫеҲ°жӯӨеҖјж—¶пјҢCleanupе°ұдјҡжү§иЎҢпјӣpartially-youngжЁЎејҸдёӢпјҢеҲҷдјҡе°ҪйҮҸйў‘з№Ғзҡ„еңЁеә”з”ЁеҸҜжҺҘеҸ—зҡ„жҡӮеҒңж—¶й—ҙиҢғеӣҙеҶ…жү§иЎҢCleanupпјҢ并жңҖеӨ§йҷҗеәҰзҡ„еҺ»жү§иЎҢnon-young regionsзҡ„CleanupгҖӮ
иҝҷдёҖжӯҘдёӯGCзәҝзЁӢ并иЎҢзҡ„жү«жҸҸжүҖжңүregionпјҢи®Ўз®—жҜҸдёӘregionдёӯдҪҺдәҺnext TAMSеҖјдёӯmarked dataзҡ„еӨ§е°ҸпјҢ然еҗҺж №жҚ®еә”з”ЁжүҖжңҹжңӣзҡ„GCзҡ„зҹӯ延时д»ҘеҸҠG1еҜ№дәҺregionеӣһ收жүҖйңҖзҡ„иҖ—ж—¶зҡ„йў„дј°пјҢжҺ’еәҸregionпјҢе°Ҷе…¶дёӯжҙ»и·ғзҡ„еҜ№иұЎеӨҚеҲ¶еҲ°е…¶д»–regionдёӯгҖӮ
В
G1дёәдәҶиғҪеӨҹе°ҪйҮҸзҡ„еҒҡеҲ°еҮҶе®һж—¶зҡ„е“Қеә”пјҢдҫӢеҰӮдј°з®—жҡӮеҒңж—¶й—ҙзҡ„з®—жі•гҖҒеҜ№дәҺз»Ҹеёёиў«еј•з”Ёзҡ„еҜ№иұЎзҡ„зү№ж®ҠеӨ„зҗҶзӯүпјҢG1дёәдәҶиғҪеӨҹи®©GCж—ўиғҪеӨҹе……еҲҶзҡ„еӣһ收еҶ…еӯҳпјҢеҸҲиғҪеӨҹе°ҪйҮҸе°‘зҡ„еҜјиҮҙеә”з”Ёзҡ„жҡӮеҒңпјҢеҸҜи°“иҙ№е°ҪеҝғжҖқпјҢд»ҺG1зҡ„и®әж–Үдёӯзҡ„жҖ§иғҪиҜ„жөӢжқҘзңӢж•Ҳжһңд№ҹжҳҜдёҚй”ҷзҡ„пјҢдёҚиҝҮеҰӮжһңG1иғҪе…Ғи®ёејҖеҸ‘дәәе‘ҳеңЁзј–еҶҷд»Јз Ғж—¶жҢҮе®ҡе“ӘдәӣеҜ№иұЎжҳҜдёҚз”Ёmarkзҡ„е°ұжӣҙе®ҢзҫҺдәҶпјҢиҝҷеҜ№дәҺжңүе·ЁеӨ§зј“еӯҳзҡ„еә”з”ЁиҖҢиЁҖпјҢдјҡжңүеҫҲеӨ§зҡ„её®еҠ©пјҢG1е°ҶйҡҸJDK 6 Update 14В betaеҸ‘еёғгҖӮВ
В
= CMS ==================================
В
http://www.iteye.com/topic/1119491
В
1.жҖ»дҪ“д»Ӣз»Қпјҡ
В
CMS(Concurrent Mark-Sweep)жҳҜд»ҘзүәзүІеҗһеҗҗйҮҸдёәд»Јд»·жқҘиҺ·еҫ—жңҖзҹӯеӣһ收еҒңйЎҝж—¶й—ҙзҡ„еһғеңҫеӣһ收еҷЁгҖӮ并еҸ‘ж„Ҹе‘ізқҖйҷӨдәҶејҖеӨҙе’Ңз»“жқҹйҳ¶ж®өпјҢйңҖиҰҒжҡӮеҒңJVMпјҢе…¶е®ғж—¶й—ҙgcе’Ңеә”з”ЁдёҖиө·жү§иЎҢгҖӮеҜ№дәҺиҰҒжұӮжңҚеҠЎеҷЁе“Қеә”йҖҹеәҰзҡ„еә”з”ЁдёҠпјҢиҝҷз§Қеһғеңҫеӣһ收еҷЁйқһеёёйҖӮеҗҲгҖӮеңЁеҗҜеҠЁJVMеҸӮж•°еҠ дёҠ-XX:+UseConcMarkSweepGCВ пјҢиҝҷдёӘеҸӮж•°иЎЁзӨәеҜ№дәҺиҖҒе№ҙд»Јзҡ„еӣһ收йҮҮз”ЁCMSгҖӮCMSйҮҮз”Ёзҡ„еҹәзЎҖз®—жі•жҳҜпјҡж Үи®°вҖ”жё…йҷӨгҖӮй»ҳи®ӨдјҡејҖеҗҜ -XX :+UseParNewGCпјҢеңЁе№ҙиҪ»д»ЈдҪҝ用并иЎҢеӨҚеҲ¶ж”¶йӣҶгҖӮ
2.CMSиҝҮзЁӢпјҡ
- еҲқе§Ӣж Үи®°(STW initial mark)
- 并еҸ‘ж Үи®°(Concurrent marking)
- 并еҸ‘йў„жё…зҗҶ(Concurrent precleaning)
- йҮҚж–°ж Үи®°(STW remark)
- 并еҸ‘жё…зҗҶ(Concurrent sweeping)
- 并еҸ‘йҮҚзҪ®(Concurrent reset)
еҲқе§Ӣж Үи®°В пјҡеңЁиҝҷдёӘйҳ¶ж®өпјҢйңҖиҰҒиҷҡжӢҹжңәеҒңйЎҝжӯЈеңЁжү§иЎҢзҡ„д»»еҠЎпјҢе®ҳж–№зҡ„еҸ«жі•STW(Stop The Word)гҖӮиҝҷдёӘиҝҮзЁӢд»Һеһғеңҫеӣһ收зҡ„"ж №еҜ№иұЎ"ејҖе§ӢпјҢеҸӘжү«жҸҸеҲ°иғҪеӨҹе’Ң"ж №еҜ№иұЎ"зӣҙжҺҘе…іиҒ”зҡ„еҜ№иұЎпјҢ并дҪңж Үи®°гҖӮжүҖд»ҘиҝҷдёӘиҝҮзЁӢиҷҪ然жҡӮеҒңдәҶж•ҙдёӘJVMпјҢдҪҶжҳҜеҫҲеҝ«е°ұе®ҢжҲҗдәҶгҖӮ
并еҸ‘ж Үи®°В пјҡиҝҷдёӘйҳ¶ж®өзҙ§йҡҸеҲқе§Ӣж Үи®°йҳ¶ж®өпјҢеңЁеҲқе§Ӣж Үи®°зҡ„еҹәзЎҖдёҠ继з»ӯеҗ‘дёӢиҝҪжәҜж Үи®°гҖӮ并еҸ‘ж Үи®°йҳ¶ж®өпјҢеә”з”ЁзЁӢеәҸзҡ„зәҝзЁӢе’Ң并еҸ‘ж Үи®°зҡ„зәҝзЁӢ并еҸ‘жү§иЎҢпјҢжүҖд»Ҙз”ЁжҲ·дёҚдјҡж„ҹеҸ—еҲ°еҒңйЎҝгҖӮ
并еҸ‘йў„жё…зҗҶВ пјҡ并еҸ‘йў„жё…зҗҶйҳ¶ж®өд»Қ然жҳҜ并еҸ‘зҡ„гҖӮеңЁиҝҷдёӘйҳ¶ж®өпјҢиҷҡжӢҹжңәжҹҘжүҫеңЁжү§иЎҢ并еҸ‘ж Үи®°йҳ¶ж®өж–°иҝӣе…ҘиҖҒе№ҙд»Јзҡ„еҜ№иұЎ(еҸҜиғҪдјҡжңүдёҖдәӣеҜ№иұЎд»Һж–°з”ҹд»ЈжҷӢеҚҮеҲ°иҖҒе№ҙд»ЈпјҢ жҲ–иҖ…жңүдёҖдәӣеҜ№иұЎиў«еҲҶй…ҚеҲ°иҖҒе№ҙд»Ј)гҖӮйҖҡиҝҮйҮҚж–°жү«жҸҸпјҢеҮҸе°‘дёӢдёҖдёӘйҳ¶ж®ө"йҮҚж–°ж Үи®°"зҡ„е·ҘдҪңпјҢеӣ дёәдёӢдёҖдёӘйҳ¶ж®өдјҡStop The WorldгҖӮ
йҮҚж–°ж Үи®°В пјҡиҝҷдёӘйҳ¶ж®өдјҡжҡӮеҒңиҷҡжӢҹжңәпјҢ收йӣҶеҷЁзәҝзЁӢжү«жҸҸеңЁCMSе Ҷдёӯеү©дҪҷзҡ„еҜ№иұЎгҖӮжү«жҸҸд»Һ"и·ҹеҜ№иұЎ"ејҖе§Ӣеҗ‘дёӢиҝҪжәҜпјҢ并еӨ„зҗҶеҜ№иұЎе…іиҒ”гҖӮ
并еҸ‘жё…зҗҶВ пјҡжё…зҗҶеһғеңҫеҜ№иұЎпјҢиҝҷдёӘйҳ¶ж®ө收йӣҶеҷЁзәҝзЁӢе’Ңеә”з”ЁзЁӢеәҸзәҝзЁӢ并еҸ‘жү§иЎҢгҖӮ
并еҸ‘йҮҚзҪ®В пјҡиҝҷдёӘйҳ¶ж®өпјҢйҮҚзҪ®CMS收йӣҶеҷЁзҡ„ж•°жҚ®з»“жһ„пјҢзӯүеҫ…дёӢдёҖж¬Ўеһғеңҫеӣһ收гҖӮ
В
CSMжү§иЎҢиҝҮзЁӢпјҡВ 
3.CMSзјәзӮ№
- CMSеӣһ收еҷЁйҮҮз”Ёзҡ„еҹәзЎҖз®—жі•жҳҜMark-SweepгҖӮжүҖжңүCMSдёҚдјҡж•ҙзҗҶгҖҒеҺӢзј©е Ҷз©әй—ҙгҖӮиҝҷж ·е°ұдјҡжңүдёҖдёӘй—®йўҳпјҡз»ҸиҝҮCMS收йӣҶзҡ„е Ҷдјҡдә§з”ҹз©әй—ҙзўҺзүҮгҖӮ CMSдёҚеҜ№е Ҷз©әй—ҙж•ҙзҗҶеҺӢзј©иҠӮзәҰдәҶеһғеңҫеӣһ收зҡ„еҒңйЎҝж—¶й—ҙпјҢдҪҶд№ҹеёҰжқҘзҡ„е Ҷз©әй—ҙзҡ„жөӘиҙ№гҖӮдёәдәҶи§ЈеҶіе Ҷз©әй—ҙжөӘиҙ№й—®йўҳпјҢCMSеӣһ收еҷЁдёҚеҶҚйҮҮз”Ёз®ҖеҚ•зҡ„жҢҮй’ҲжҢҮеҗ‘дёҖеқ—еҸҜз”Ёе Ҷз©ә й—ҙжқҘдёәдёӢж¬ЎеҜ№иұЎеҲҶй…ҚдҪҝз”ЁгҖӮиҖҢжҳҜжҠҠдёҖдәӣжңӘеҲҶй…Қзҡ„з©әй—ҙжұҮжҖ»жҲҗдёҖдёӘеҲ—иЎЁпјҢеҪ“JVMеҲҶй…ҚеҜ№иұЎз©әй—ҙзҡ„ж—¶еҖҷпјҢдјҡжҗңзҙўиҝҷдёӘеҲ—иЎЁжүҫеҲ°и¶іеӨҹеӨ§зҡ„з©әй—ҙжқҘholdдҪҸиҝҷдёӘеҜ№иұЎгҖӮ
- йңҖиҰҒжӣҙеӨҡзҡ„CPUиө„жәҗгҖӮд»ҺдёҠйқўзҡ„еӣҫеҸҜд»ҘзңӢеҲ°пјҢдёәдәҶи®©еә”з”ЁзЁӢеәҸдёҚеҒңйЎҝпјҢCMSзәҝзЁӢе’Ңеә”з”ЁзЁӢеәҸзәҝзЁӢ并еҸ‘жү§иЎҢпјҢиҝҷж ·е°ұйңҖиҰҒжңүжӣҙеӨҡзҡ„CPUпјҢеҚ•зәҜйқ зәҝзЁӢеҲҮ жҚўжҳҜдёҚйқ и°ұзҡ„гҖӮ并且пјҢйҮҚж–°ж Үи®°йҳ¶ж®өпјҢдёәз©әдҝқиҜҒSTWеҝ«йҖҹе®ҢжҲҗпјҢд№ҹиҰҒз”ЁеҲ°жӣҙеӨҡзҡ„з”ҡиҮіжүҖжңүзҡ„CPUиө„жәҗгҖӮеҪ“然пјҢеӨҡж ёеӨҡCPUд№ҹжҳҜжңӘжқҘзҡ„и¶ӢеҠҝпјҒ
- CMSзҡ„еҸҰдёҖдёӘзјәзӮ№жҳҜе®ғйңҖиҰҒжӣҙеӨ§зҡ„е Ҷз©әй—ҙгҖӮеӣ дёәCMSж Үи®°йҳ¶ж®өеә”з”ЁзЁӢеәҸзҡ„зәҝзЁӢиҝҳжҳҜеңЁжү§иЎҢзҡ„пјҢйӮЈд№Ҳе°ұдјҡжңүе Ҷз©әй—ҙ继з»ӯеҲҶй…Қзҡ„жғ…еҶөпјҢдёәдәҶдҝқиҜҒеңЁCMSеӣһ 收е®Ңе Ҷд№ӢеүҚиҝҳжңүз©әй—ҙеҲҶй…Қз»ҷжӯЈеңЁиҝҗиЎҢзҡ„еә”з”ЁзЁӢеәҸпјҢеҝ…йЎ»йў„з•ҷдёҖйғЁеҲҶз©әй—ҙгҖӮд№ҹе°ұжҳҜиҜҙпјҢCMSдёҚдјҡеңЁиҖҒе№ҙд»Јж»Ўзҡ„ж—¶еҖҷжүҚејҖе§Ӣ收йӣҶгҖӮзӣёеҸҚпјҢе®ғдјҡе°қиҜ•жӣҙж—©зҡ„ејҖе§Ӣ收йӣҶпјҢе·І йҒҝе…ҚдёҠйқўжҸҗеҲ°зҡ„жғ…еҶөпјҡеңЁеӣһ收е®ҢжҲҗд№ӢеүҚпјҢе ҶжІЎжңүи¶іеӨҹз©әй—ҙеҲҶй…ҚпјҒй»ҳи®ӨеҪ“иҖҒе№ҙд»ЈдҪҝз”Ё68%зҡ„ж—¶еҖҷпјҢCMSе°ұејҖе§ӢиЎҢеҠЁдәҶгҖӮ вҖ“ XX:CMSInitiatingOccupancyFraction =n жқҘи®ҫзҪ®иҝҷдёӘйҳҖеҖјгҖӮ
жҖ»еҫ—жқҘиҜҙпјҢCMSеӣһ收еҷЁеҮҸе°‘дәҶеӣһ收зҡ„еҒңйЎҝж—¶й—ҙпјҢдҪҶжҳҜйҷҚдҪҺдәҶе Ҷз©әй—ҙзҡ„еҲ©з”ЁзҺҮгҖӮ
4.е•Ҙж—¶еҖҷз”ЁCMS
еҰӮжһңдҪ зҡ„еә”з”ЁзЁӢеәҸеҜ№еҒңйЎҝжҜ”иҫғж•Ҹж„ҹпјҢ并且еңЁеә”з”ЁзЁӢеәҸиҝҗиЎҢзҡ„ж—¶еҖҷеҸҜд»ҘжҸҗдҫӣжӣҙеӨ§зҡ„еҶ…еӯҳе’ҢжӣҙеӨҡзҡ„CPU(д№ҹе°ұжҳҜ硬件зүӣйҖј)пјҢйӮЈд№ҲдҪҝз”ЁCMSжқҘ收йӣҶдјҡз»ҷдҪ еёҰжқҘеҘҪеӨ„гҖӮиҝҳжңүпјҢеҰӮжһңеңЁJVMдёӯпјҢжңүзӣёеҜ№иҫғеӨҡеӯҳжҙ»ж—¶й—ҙиҫғй•ҝзҡ„еҜ№иұЎ(иҖҒе№ҙд»ЈжҜ”иҫғеӨ§)дјҡжӣҙйҖӮеҗҲдҪҝз”ЁCMSгҖӮ
В
В
В
= и°ғиҜ•е·Ҙе…· ==================================
В
jmap
В
jmap -heap pid В (дёҚиғҪи§ӮеҜҹG1жЁЎејҸпјү
В
using parallel threads in the new generation.
using thread-local object allocation.
Concurrent Mark-Sweep GC
Heap Configuration:
В В MinHeapFreeRatio = 40
В В MaxHeapFreeRatio = 70
В В MaxHeapSize В В В = 2147483648 (2048.0MB)
В В NewSize В В В В В = 268435456 (256.0MB)
В В MaxNewSize В В В = 268435456 (256.0MB)
В В OldSize В В В В В = 805306368 (768.0MB)
В В NewRatio В В В В = 7
В В SurvivorRatio В В = 8
В В PermSize В В В В = 134217728 (128.0MB)
В В MaxPermSize В В В = 134217728 (128.0MB)
Heap Usage:
New Generation (Eden + 1 Survivor Space):
В В capacity = 241631232 (230.4375MB)
В В used В В = 145793088 (139.03912353515625MB)
В В free В В = 95838144 (91.39837646484375MB)
В В 60.33702133340114% used
Eden Space:
В В capacity = 214827008 (204.875MB)
В В used В В = 132689456 (126.54252624511719MB)
В В free В В = 82137552 (78.33247375488281MB)
В В 61.7657236095752% used
From Space:
В В capacity = 26804224 (25.5625MB)
В В used В В = 13103632 (12.496597290039062MB)
В В free В В = 13700592 (13.065902709960938MB)
В В 48.886444166411984% used
To Space:
В В capacity = 26804224 (25.5625MB)
В В used В В = 0 (0.0MB)
В В free В В = 26804224 (25.5625MB)
В В 0.0% used
concurrent mark-sweep generation: пјҲoldеҢәпјү
В В capacity = 1879048192 (1792.0MB)
В В used В В = 1360638440 (1297.6059341430664MB)
В В free В В = 518409752 (494.3940658569336MB)
В В 72.41104543209076% used
Perm Generation:
В В capacity = 134217728 (128.0MB)
В В used В В = 65435064 (62.40373992919922MB)
В В free В В = 68782664 (65.59626007080078MB)
В В 48.75292181968689% used
В
В
jmap -histo:live pid
В
num В В #instances В В В В #bytes В class name
----------------------------------------------
В В 1: В В В 3148147 В В В 209172848 В [B
В В 2: В В В 2584345 В В В 144723320 В java.lang.ref.SoftReference
В В 3: В В В 2578827 В В В 123783696 В sun.misc.CacheEntry
В В 4: В В В В 781560 В В В 112544640 В com.sun.net.ssl.internal.ssl.SSLSessionImpl
В В 5: В В В 1385200 В В В 89970592 В [C
В В 6: В В В В 783287 В В В 87807200 В [Ljava.util.Hashtable$Entry;
В В 7: В В В 1421399 В В В 56855960 В java.lang.String
В В 8: В В В В В В 12 В В В 56828880 В [Lsun.misc.CacheEntry;
В В 9: В В В 2343358 В В В 56240592 В com.sun.net.ssl.internal.ssl.SessionId
В 10: В В В В 783185 В В В 50123840 В java.util.Hashtable
В 11: В В В В 783094 В В В 50118016 В java.lang.ref.Finalizer
В 12: В В В В 287243 В В В 36086720 В [Ljava.lang.Object;
В 13: В В В В 263376 В В В 33712128 В org.apache.commons.pool.impl.GenericObjectPool
В
В
jstat
В
jstat -gccause 31169 60000 1000
В
(sweep 1,2) (Eden) (Old) (Perm) (Young GC, GCTime)(Full GC, GCTime)
В S0 В В В В S1 В В E В В В В O В В В В P В В YGC В В YGCT В В FGC В В FGCT В В В GCT В В В В В В LGCC В В В В В В В В GCC В В В В В В В В В
В 48.80 В 0.00 В 68.94 В 69.55 В 48.86 В 30202 В 725.319 51835 5083.298 5808.616 unknown GCCause В В В No GC В В В В В В В В
В 47.98 В 0.00 В 37.47 В 69.61 В 48.86 В 30206 В 725.385 51835 5083.298 5808.682 unknown GCCause В В В No GC В В В В В В В В
В 50.73 В 0.00 В 51.72 В 69.65 В 48.86 В 30210 В 725.459 51835 5083.298 5808.757 unknown GCCause В В В No GC В В В В В В В В
В 0.00 В 50.02 В 82.67 В 69.60 В 48.84 В 30213 В 725.508 51836 5091.572 5817.081 unknown GCCause В В В No GC В В В В В В В В
В
jstat -gcutil $pid
В
В S0 В В В В S1 В В E В В В В O В В В P В В В YGC В В YGCT В В FGC В В FGCT В В GCT В В
В 74.79 В 0.00 В 95.15 В 0.86 В 37.35 В В В 2 В В В В 0.112 В В 0 В В В В 0.000 В В В 0.112
В
O = old occupied
YGC = young gc time ( new part )
YGCT = young gc total cost time
FGC = full gc time ( old part )
FGCT = full gc total cost time
GCT = all gc cost time
В
В
jvisualvm
windowдёӢеҗҜеҠЁиҝңзЁӢзӣ‘жҺ§пјҢ并еңЁиў«зӣ‘жҺ§жңҚеҠЎз«ҜпјҢеҗҜеҠЁjstatdжңҚеҠЎгҖӮ
В
еҲӣе»әе®үе…Ёзӯ–з•Ҙж–Ү件пјҢ并е‘ҪеҗҚдёәjstatd.all.policy
grant codebase "file:${java.home}/../lib/tools.jar" {
В В В permission java.security.AllPermission;
};
jstatd -J-Djava.security.policy=jstatd.all.policy -p 8080 &
======================== Tunning =================
-server -Xmx2g -Xms2g -Xmn512m -XX:PermSize=128m -Xss256k -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -Djava.awt.headless=true -Djava.net.preferIPv4Stack=true
3. 并еҸ‘收йӣҶеҷЁпјҲconcurrent low pause collectorпјүпјҡе‘Ҫд»ӨиЎҢеҸӮж•°пјҡ-XX:+UseConcMarkSweepGCгҖӮеңЁж—§з”ҹд»ЈдҪҝ用并еҸ‘收йӣҶзӯ–з•ҘпјҢеӨ§йғЁеҲҶ收йӣҶе·ҘдҪңйғҪжҳҜе’Ңеә”用并еҸ‘иҝӣиЎҢзҡ„пјҢеңЁиҝӣиЎҢ收йӣҶзҡ„ж—¶еҖҷпјҢеә”з”Ёзҡ„жҡӮеҒңж—¶й—ҙеҫҲзҹӯгҖӮй»ҳи®Өй…ҚеҘ—жү“ејҖ -XX:+UseParNewGCпјҢдјҡеңЁж–°з”ҹд»ЈдҪҝ用并иЎҢеӨҚеҲ¶ж”¶йӣҶгҖӮ

TheВ (original) copying collectorВ (Enabled by default). When this collector kicks in, all application threads are stopped, and the copying collection proceeds using one thread (which means only one CPU even if on a multi-CPU machine). This is known as a stop-the-world collection, because basically the JVM pauses everything else until the collection is completed.
TheВ parallel copying collectorВ (Enabled using -XX:+UseParNewGC). Like the original copying collector, this is a stop-the-world collector. However this collector parallelizes the copying collection over multiple threads, which is more efficient than the original single-thread copying collector for multi-CPU machines (though not for single-CPU machines). This algorithm potentially speeds up young generation collection by a factor equal to the number of CPUs available, when compared to the original singly-threaded copying collector.
TheВ parallel scavenge collectorВ (Enabled using -XX:UseParallelGC). This is like the previous parallel copying collector, but the algorithm is tuned for gigabyte heaps (over 10GB) on multi-CPU machines. This collection algorithm is designed to maximize throughput while minimizing pauses. It has an optional adaptive tuning policy which will automatically resize heap spaces. If you use this collector, you can only use the the original mark-sweep collector in the old generation (i.e. the newer old generation concurrent collector cannot work with this young generation collector).
В
UserParallelGCдҪҝз”ЁдәҶжӣҙй«ҳж•Ҳзҡ„з®—жі•пјҢз”ЁдәҺеӨ„зҗҶеӨ§и§„жЁЎеҶ…еӯҳ>10GеңәжҷҜпјҢжҸҗдҫӣдәҶеӨ§еҗһеҗҗйҮҸеҠҹиғҪгҖӮдҪҶжҳҜпјҢеҗҢж—¶еңЁиҖҒз”ҹд»ЈпјҢеҸӘиғҪдҪҝз”ЁдёІиЎҢзҡ„ж Үи®°жё…йҷӨж–№жі•гҖӮ
В
иҖҒз”ҹд»ЈпјҢеҝ…йЎ»еҒҡfullgcпјҢеҝ…йЎ»д»ҺrootејҖе§Ӣе…Ёйқўж ҮиҜҶ收йӣҶгҖӮ
В
- TheВ (original) mark-sweep collectorВ (Enabled by default). This uses a stop-the-world mark-and-sweep collection algorithm. The collector is single-threaded, the entire JVM is paused and the collector uses only one CPU until completed.
- TheВ concurrent collectorВ (Enabled using -XX:+UseConcMarkSweepGC). This collector tries to allow application processing to continue as much as possible during the collection. Splitting the collection into six phases described shortly, four are concurrent while two are stop-the-world:
1. the initial-mark phase (stop-the-world, snapshot the old generation so that we can run most of the rest of the collection concurrent to the application threads);
2. the mark phase (concurrent, mark the live objects traversing the object graph from the roots);
3. the pre-cleaning phase (concurrent);
4. the re-mark phase (stop-the-world, another snapshot to capture any changes to live objects since the collection started);
5. the sweep phase (concurrent, recycles memory by clearing unreferenced objects);
6. the reset phase (concurrent).
If "the rate of creation" of objects is too high, and the concurrent collector is not able to keep up with the concurrent collection, it falls back to the traditional mark-sweep collector. - TheВ incremental collectorВ (Enabled using -Xincgc). The incremental collector uses a "train" algorithm to collect small portions of the old generation at a time. This collector has higher overheads than the mark-sweep collector, but because small numbers of objects are collected each time, the (stop-the-world) garbage collection pause is minimized at the cost of total garbage collection taking longer. The "train" algorithm does not guarantee a maximum pause time, but pause times are typically less than ten milliseconds.



зӣёе…іжҺЁиҚҗ
### Javaеһғеңҫеӣһ收жңәеҲ¶иҜҰи§Ј #### дёҖгҖҒеј•иЁҖ JavaдҪңдёәдёҖз§Қе№ҝжіӣеә”з”Ёзҡ„зј–зЁӢиҜӯиЁҖпјҢе…¶иҮӘеҠЁеҶ…еӯҳз®ЎзҗҶжңәеҲ¶дёҖзӣҙжҳҜе…¶жҳҫи‘—зү№зӮ№д№ӢдёҖгҖӮеһғеңҫеӣһ收жңәеҲ¶пјҲGarbage Collection, GCпјүжҳҜJavaиҮӘеҠЁеҶ…еӯҳз®ЎзҗҶзҡ„йҮҚиҰҒз»„жҲҗйғЁеҲҶпјҢиҙҹиҙЈиҮӘеҠЁеӣһ收дёҚеҶҚ...
### Javaеһғеңҫеӣһ收жңәеҲ¶иҜҰи§Ј #### дёҖгҖҒеј•иЁҖ JavaдҪңдёәдёҖз§Қй«ҳзә§зј–зЁӢиҜӯиЁҖпјҢиҮӘй—®дё–д»ҘжқҘдҫҝеӣ е…¶иҮӘеҠЁеҶ…еӯҳз®ЎзҗҶе’Ңеһғеңҫеӣһ收жңәеҲ¶иҖҢеӨҮеҸ—йқ’зқҗгҖӮжң¬зҜҮж–Үз« ж—ЁеңЁж·ұе…ҘжҺўи®ЁJavaеһғеңҫеӣһ收пјҲGarbage Collection, GCпјүжңәеҲ¶зҡ„е·ҘдҪңеҺҹзҗҶеҸҠе…¶...
жң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁJavaеһғеңҫеӣһ收жңәеҲ¶зҡ„ж ёеҝғеҺҹзҗҶеҸҠе…¶е…ій”®жҠҖжңҜгҖӮ #### дәҢгҖҒJavaе ҶеҶ…еӯҳ Javaзҡ„е ҶжҳҜдёҖдёӘиҝҗиЎҢж—¶ж•°жҚ®еҢәпјҢз”ЁдәҺеӯҳеӮЁжүҖжңүеҜ№иұЎе®һдҫӢгҖӮиҝҷдәӣеҜ№иұЎжҳҜйҖҡиҝҮ`new`гҖҒ`newarray`гҖҒ`anewarray`е’Ң`multianewarray`зӯүжҢҮд»ӨеҲӣе»ә...
### Javaеһғеңҫеӣһ收еҺҹзҗҶиҜҰи§Ј #### дёҖгҖҒеј•иЁҖ еңЁзҺ°д»ЈиҪҜ件ејҖеҸ‘дёӯпјҢJavaдҪңдёәдёҖз§Қе№ҝжіӣдҪҝз”Ёзҡ„зј–зЁӢиҜӯиЁҖпјҢе…¶еһғеңҫеӣһ收жңәеҲ¶жҳҜзЎ®дҝқзЁӢеәҸй«ҳж•ҲиҝҗиЎҢзҡ„е…ій”®жҠҖжңҜд№ӢдёҖгҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁJavaдёӯзҡ„еһғеңҫеӣһ收жңәеҲ¶пјҢеҢ…жӢ¬е…¶еҹәжң¬еҺҹзҗҶгҖҒдёҚеҗҢзұ»еһӢ...
### ж·ұе…ҘJavaж ёеҝғжҺўз§ҳJavaеһғеңҫеӣһ收жңәеҲ¶ #### дёҖгҖҒеј•иЁҖ JavaдҪңдёәдёҖз§Қе№ҝжіӣеә”з”Ёзҡ„зј–зЁӢиҜӯиЁҖпјҢе…¶ејәеӨ§зҡ„иҮӘеҠЁеҶ…еӯҳз®ЎзҗҶе’Ңеһғеңҫеӣһ收жңәеҲ¶дёҖзӣҙжҳҜејҖеҸ‘иҖ…е…іжіЁзҡ„з„ҰзӮ№гҖӮеһғеңҫеӣһ收пјҲGarbage Collection, GCпјүиғҪеӨҹиҮӘеҠЁиҜҶеҲ«е’Ңжё…зҗҶдёҚеҶҚ...
жң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁJavaдёӯзҡ„еһғеңҫеӣһ收жңәеҲ¶пјҢеҢ…жӢ¬е…¶е·ҘдҪңеҺҹзҗҶгҖҒеёёз”Ёз®—жі•д»ҘеҸҠе®һйҷ…еә”з”Ёдёӯзҡ„жіЁж„ҸдәӢйЎ№гҖӮ #### дәҢгҖҒеһғеңҫеӣһ收зҡ„еҹәжң¬жҰӮеҝө **1. д»Җд№ҲжҳҜеһғеңҫеӣһ收** еһғеңҫеӣһ收пјҲGarbage Collection, GCпјүжҳҜжҢҮеңЁзЁӢеәҸиҝҗиЎҢиҝҮзЁӢдёӯиҮӘеҠЁ...
д»ҘдёӢжҳҜе…ідәҺJavaеһғеңҫеӣһ收жңәеҲ¶зҡ„иҜҰз»Ҷи§ЈйҮҠпјҡ дёҖгҖҒеһғеңҫе®ҡд№ү еңЁJVMдёӯпјҢеһғеңҫжҢҮзҡ„жҳҜйӮЈдәӣеңЁе ҶеҶ…еӯҳдёӯе·Із»Ҹж— жі•иў«д»»дҪ•еӯҳжҙ»зҡ„еј•з”ЁжүҖи§ҰеҸҠзҡ„еҜ№иұЎгҖӮд№ҹе°ұжҳҜиҜҙпјҢеҰӮжһңдёҖдёӘеҜ№иұЎдёҚеҶҚиў«зЁӢеәҸдёӯзҡ„д»»дҪ•еҸҳйҮҸзӣҙжҺҘжҲ–й—ҙжҺҘеј•з”ЁпјҢйӮЈд№Ҳе®ғе°ұиў«и®ӨдёәжҳҜ...
### Javaеһғеңҫеӣһ收жңәеҲ¶иҜҰи§Ј #### дёҖгҖҒеј•иЁҖ еңЁиҪҜ件ејҖеҸ‘йўҶеҹҹпјҢзү№еҲ«жҳҜеҜ№дәҺеғҸJavaиҝҷж ·зҡ„йқўеҗ‘еҜ№иұЎиҜӯиЁҖпјҢеҶ…еӯҳз®ЎзҗҶдёҖзӣҙжҳҜејҖеҸ‘иҖ…е…іжіЁзҡ„ж ёеҝғй—®йўҳд№ӢдёҖгҖӮJavaзҡ„еҮәзҺ°жһҒеӨ§ең°з®ҖеҢ–дәҶиҝҷдёҖиҝҮзЁӢпјҢе…¶дёӯжңҖдёәзӘҒеҮәзҡ„зү№зӮ№д№ӢдёҖе°ұжҳҜе…¶еҶ…зҪ®зҡ„...
еҗҢж—¶пјҢдёәдәҶдҪҝеҫ—еһғеңҫеӣһ收жңәеҲ¶иғҪеӨҹйҖӮеә”дёҚеҗҢзҡ„еә”з”ЁйңҖжұӮе’ҢиҝҗиЎҢзҺҜеўғпјҢJavaеһғеңҫеӣһ收жңәеҲ¶и®ҫи®ЎдәҶеӨҡз§Қеӣһ收算法пјҢжҜ”еҰӮж Үи®°-жё…йҷӨпјҲMark-SweepпјүгҖҒеӨҚеҲ¶пјҲCopyingпјүгҖҒж Үи®°-ж•ҙзҗҶпјҲMark-Compactпјүд»ҘеҸҠеҲҶ代收йӣҶпјҲGenerational ...
JVMзҡ„е·ҘдҪңеҺҹзҗҶеҸҠе…¶еһғеңҫеӣһ收жңәеҲ¶еҜ№дәҺзҗҶи§Је’ҢдјҳеҢ–Javaеә”з”ЁзЁӢеәҸиҮіе…ійҮҚиҰҒгҖӮйҖҡиҝҮеҜ№JVMеҶ…еӯҳз®ЎзҗҶзҡ„зҗҶи§ЈпјҢжҲ‘们еҸҜд»ҘжӣҙеҘҪең°жҺ§еҲ¶еҜ№иұЎзҡ„з”ҹе‘Ҫе‘ЁжңҹпјҢеҮҸе°‘дёҚеҝ…иҰҒзҡ„еҶ…еӯҳж¶ҲиҖ—пјҢ并жҸҗй«ҳзЁӢеәҸзҡ„жҖ§иғҪгҖӮжӯӨеӨ–пјҢдәҶи§ЈдёҚеҗҢзҡ„еһғеңҫеӣһ收算法еҸҜд»Ҙеё®еҠ©...
жҖ»д№ӢпјҢзҗҶ解并жҺҢжҸЎJavaеһғеңҫеӣһ收жңәеҲ¶еҜ№дәҺзј–еҶҷй«ҳж•ҲгҖҒзЁіе®ҡзҡ„JavaзЁӢеәҸиҮіе…ійҮҚиҰҒгҖӮйҖҡиҝҮе®һи·өе’Ңи°ғж•ҙпјҢжҲ‘们еҸҜд»Ҙжңүж•Ҳең°еҲ©з”ЁеҶ…еӯҳиө„жәҗпјҢжҸҗй«ҳеә”з”Ёзҡ„иҝҗиЎҢж•ҲзҺҮгҖӮеңЁе®һйҷ…йЎ№зӣ®дёӯпјҢйҖүжӢ©еҗҲйҖӮзҡ„еһғеңҫеӣһ收еҷЁе’Ңи°ғдјҳзӯ–з•ҘжҳҜжҸҗеҚҮзі»з»ҹжҖ§иғҪзҡ„е…ій”®гҖӮ
### иҜҰз»Ҷд»Ӣз»ҚJavaеһғеңҫеӣһ收...з»јдёҠжүҖиҝ°пјҢзҗҶи§ЈJavaеһғеңҫеӣһ收жңәеҲ¶зҡ„еҹәжң¬еҺҹзҗҶеҸҠе…¶е·ҘдҪңж–№ејҸеҜ№дәҺдјҳеҢ–Javaеә”з”Ёзҡ„жҖ§иғҪиҮіе…ійҮҚиҰҒгҖӮејҖеҸ‘иҖ…еҸҜд»ҘйҖҡиҝҮеҗҲзҗҶйҖүжӢ©еһғеңҫеӣһ收еҷЁд»ҘеҸҠи°ғж•ҙзӣёе…ізҡ„еҸӮж•°жқҘе№іиЎЎеҶ…еӯҳдҪҝз”Ёж•ҲзҺҮдёҺзі»з»ҹжҖ§иғҪд№Ӣй—ҙзҡ„е…ізі»гҖӮ
Javaзҡ„еһғеңҫеӣһ收жңәеҲ¶е®һдҫӢеҲҶжһҗ Javaзҡ„еһғеңҫеӣһ收жңәеҲ¶жҳҜдёҖз§ҚиҮӘеҠЁз®ЎзҗҶеҶ…еӯҳзҡ„жңәеҲ¶пјҢйҖҡиҝҮеһғеңҫеӣһ收еҷЁпјҲGarbage CollectorпјүжқҘеӣһ收е ҶеҶ…еӯҳдёӯзҡ„еҜ№иұЎпјҢд»ҺиҖҢйҒҝе…ҚеҶ…еӯҳжі„йңІе’ҢжәўеҮәгҖӮдёӢйқўжҳҜJavaзҡ„еһғеңҫеӣһ收жңәеҲ¶зҡ„иҜҰз»ҶеҲҶжһҗпјҡ дёҖгҖҒеһғеңҫ...
жң¬ж–Үж·ұе…ҘжҺўи®ЁдәҶJavaеһғеңҫеӣһ收жңәеҲ¶зҡ„зү№зӮ№еҸҠе…¶еңЁJavaиҷҡжӢҹжңәпјҲJVMпјүдёӯзҡ„еә”з”ЁпјҢ并иҜҰз»ҶеҲҶжһҗдәҶеҮ з§Қе…ёеһӢзҡ„еһғеңҫ收йӣҶз®—жі•гҖӮжӯӨеӨ–пјҢж–Үз« иҝҳд»Ӣз»ҚдәҶеҰӮдҪ•йҖҡиҝҮе‘Ҫд»ӨиЎҢеҸӮж•°жқҘи°ғж•ҙеһғеңҫеӣһ收зҡ„иЎҢдёәд»ҘеҸҠ`finalize`ж–№жі•зҡ„дҪңз”ЁгҖӮйҖҡиҝҮзҗҶи§Јиҝҷдәӣ...
Javaеһғеңҫеӣһ收жңәеҲ¶зҡ„и®ҫи®Ўе’Ңе®һзҺ°жҳҜJavaе№іеҸ°зҡ„дёҖеӨ§дә®зӮ№пјҢе®ғжһҒеӨ§ең°з®ҖеҢ–дәҶеҶ…еӯҳз®ЎзҗҶпјҢеҗҢж—¶д№ҹйңҖиҰҒејҖеҸ‘иҖ…зҗҶи§Је…¶е·ҘдҪңеҺҹзҗҶпјҢд»ҘдјҳеҢ–еә”з”ЁзЁӢеәҸзҡ„жҖ§иғҪе’ҢзЁіе®ҡжҖ§гҖӮйҖҡиҝҮйҖүжӢ©еҗҲйҖӮзҡ„еһғеңҫеӣһ收еҷЁпјҢй…ҚзҪ®йҖӮеҪ“зҡ„еҸӮж•°пјҢд»ҘеҸҠзј–еҶҷиүҜеҘҪзҡ„д»Јз Ғд№ жғҜ...
Javaеһғеңҫеӣһ收жңәеҲ¶жҳҜJavaзј–зЁӢиҜӯиЁҖдёӯзҡ„дёҖдёӘйҮҚиҰҒзү№жҖ§пјҢе®ғиҮӘеҠЁеҢ–ең°з®ЎзҗҶзЁӢеәҸиҝҗиЎҢж—¶зҡ„еҶ…еӯҳеҲҶй…ҚдёҺеӣһ收пјҢд»ҺиҖҢеҮҸиҪ»дәҶзЁӢеәҸе‘ҳзҡ„е·ҘдҪңиҙҹжӢ…гҖӮеһғеңҫеӣһ收зҡ„дё»иҰҒзӣ®ж ҮжҳҜиҜҶеҲ«е№¶йҮҠж”ҫйӮЈдәӣдёҚеҶҚиў«зЁӢеәҸдҪҝз”Ёзҡ„еҜ№иұЎжүҖеҚ з”Ёзҡ„еҶ…еӯҳпјҢд»ҘйҳІжӯўеҶ…еӯҳжі„жјҸ...
Javaеһғеңҫеӣһ收жңәеҲ¶жҳҜJavaзј–зЁӢдёӯдёҖдёӘйқһеёёйҮҚиҰҒзҡ„жҰӮеҝөпјҢе°Өе…¶еңЁйқўиҜ•е’Ңе®һйҷ…ејҖеҸ‘дёӯеёёеёёиў«и®Ёи®әгҖӮеһғеңҫеӣһ收пјҲGarbage Collection, GCпјүжҳҜJavaиҷҡжӢҹжңәиҮӘеҠЁз®ЎзҗҶеҶ…еӯҳзҡ„дёҖз§Қж–№ејҸпјҢж—ЁеңЁиҮӘеҠЁиҜҶеҲ«е№¶йҮҠж”ҫдёҚеҶҚдҪҝз”Ёзҡ„еҜ№иұЎпјҢд»ҺиҖҢйҒҝе…ҚеҶ…еӯҳ...
жҖ»з»“пјҢJavaеһғеңҫеӣһ收жңәеҲ¶жҳҜJavaе№іеҸ°зҡ„дёҖдёӘж ёеҝғзү№жҖ§пјҢе®ғдҪҝеҫ—ејҖеҸ‘иҖ…ж— йңҖе…іеҝғеҶ…еӯҳз®ЎзҗҶз»ҶиҠӮпјҢдҪҶзҗҶи§Је…¶е·ҘдҪңеҺҹзҗҶе’ҢдјҳеҢ–зӯ–з•ҘеҜ№дәҺжҸҗй«ҳеә”з”ЁжҖ§иғҪиҮіе…ійҮҚиҰҒгҖӮйҖҡиҝҮйҖүжӢ©еҗҲйҖӮзҡ„GCзұ»еһӢпјҢи°ғж•ҙеҸӮж•°пјҢд»ҘеҸҠиүҜеҘҪзҡ„зј–зЁӢд№ жғҜпјҢжҲ‘们еҸҜд»Ҙжңүж•Ҳең°...