
Twitter-Snowflakeń«Śµ│Ģõ║¦ńö¤ńÜäĶāīµÖ»ńøĖÕĮōń«ĆÕŹĢ’╝īõĖ║õ║åµ╗ĪĶČ│Twitterµ»Åń¦ÆõĖŖõĖćµØĪµČłµü»ńÜäĶ»Ęµ▒é’╝īµ»ÅµØĪµČłµü»ķāĮÕ┐ģķĪ╗ÕłåķģŹõĖƵØĪÕö»õĖĆńÜäid’╝īĶ┐Öõ║øidĶ┐śķ£ĆĶ”üõĖĆõ║øÕż¦Ķć┤ńÜäķĪ║Õ║Å’╝łµ¢╣õŠ┐Õ«óµłĘń½»µÄÆÕ║Å’╝ē’╝īÕ╣ČõĖöÕ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁõĖŹÕÉīµ£║ÕÖ©õ║¦ńö¤ńÜäidÕ┐ģķĪ╗õĖŹÕÉīŃĆé
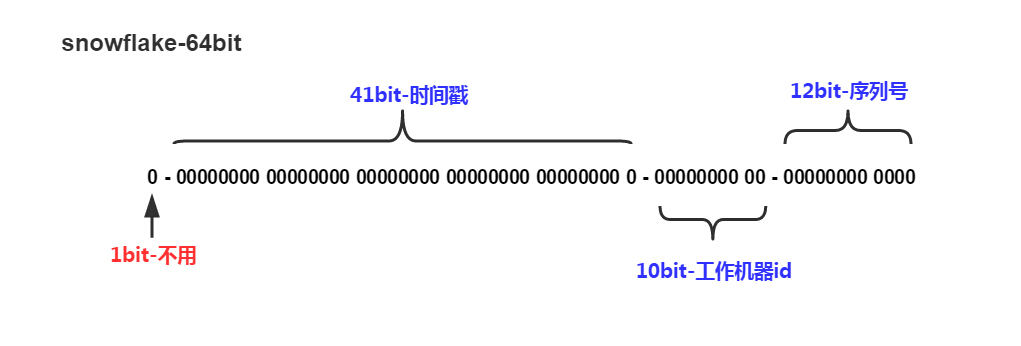
Snowflakeń«Śµ│ĢµĀĖÕ┐ā
µŖŖµŚČķŚ┤µł│’╝īÕĘźõĮ£µ£║ÕÖ©id’╝īÕ║ÅÕłŚÕÅĘń╗äÕÉłÕ£©õĖĆĶĄĘŃĆé
┬Ā
┬Ā
ķÖżõ║åµ£Ćķ½śõĮŹbitµĀćĶ«░õĖ║õĖŹÕÅ»ńö©õ╗źÕż¢’╝īÕģČõĮÖõĖēń╗äbitÕŹĀõĮŹÕØćÕÅ»µĄ«ÕŖ©’╝īń£ŗÕģĘõĮōńÜäõĖÜÕŖĪķ£Ćµ▒éĶĆīÕ«ÜŃĆéķ╗śĶ«żµāģÕåĄõĖŗ41bitńÜ䵌ČķŚ┤µł│ÕÅ»õ╗źµö»µīüĶ»źń«Śµ│ĢõĮ┐ńö©Õł░2082Õ╣┤’╝ī10bitńÜäÕĘźõĮ£µ£║ÕÖ©idÕÅ»õ╗źµö»µīü1023ÕÅ░µ£║ÕÖ©’╝īÕ║ÅÕłŚÕÅʵö»µīü1µ»½ń¦Æõ║¦ńö¤4095õĖ¬Ķć¬Õó×Õ║ÅÕłŚidŃĆéõĖŗµ¢ćõ╝ÜÕģĘõĮōÕłåµ×ÉŃĆé
┬Ā
Snowflake ŌĆō µŚČķŚ┤µł│
Ķ┐ÖķćīµŚČķŚ┤µł│ńÜäń╗åÕ║”µś»µ»½ń¦Æń║¦’╝īÕģĘõĮōõ╗ŻńĀüÕ”éõĖŗ’╝īÕ╗║Ķ««õĮ┐ńö©64õĮŹlinuxń│╗ń╗¤µ£║ÕÖ©’╝īÕøĀõĖ║µ£ēvdso’╝īgettimeofday()Õ£©ńö©µłĘµĆüÕ░▒ÕÅ»õ╗źÕ«īµłÉµōŹõĮ£’╝īÕćÅÕ░æõ║åĶ┐øÕģźÕåģµĀĖµĆüńÜ䵏¤ĶĆŚŃĆé
|
1
2
3
4
5
6
|
uint64_t generateStamp(){┬Ā┬Ā┬Ā┬Ātimeval tv;
┬Ā┬Ā┬Ā┬Āgettimeofday(&tv, 0);
┬Ā┬Ā┬Ā┬Āreturn (uint64_t)tv.tv_sec * 1000 + (uint64_t)tv.tv_usec / 1000;
} |
ķ╗śĶ«żµāģÕåĄõĖŗµ£ē41õĖ¬bitÕÅ»õ╗źõŠøõĮ┐ńö©’╝īķéŻõ╣łõĖĆÕģ▒µ£ēT’╝ł1llu << 41’╝ēµ»½ń¦ÆõŠøõĮĀõĮ┐ńö©ÕłåķģŹ’╝īÕ╣┤õ╗Į = T / (3600 * 24 * 365 * 1000) = 69.7Õ╣┤ŃĆéÕ”éµ×£õĮĀÕŬń╗ÖµŚČķŚ┤µł│ÕłåķģŹ39õĖ¬bitõĮ┐ńö©’╝īķéŻõ╣łµĀ╣µŹ«ÕÉīµĀĘńÜäń«Śµ│Ģµ£ĆÕÉÄÕ╣┤õ╗Į = 17.4Õ╣┤ŃĆé
Snowflake ŌĆō ÕĘźõĮ£µ£║ÕÖ©id
õĖźµĀ╝µäÅõ╣ēõĖŖµØźĶ»┤Ķ┐ÖõĖ¬bitµ«ĄńÜäõĮ┐ńö©ÕÅ»õ╗źµś»Ķ┐øń©ŗń║¦’╝īµ£║ÕÖ©ń║¦ńÜäĶ»ØõĮĀÕÅ»õ╗źõĮ┐ńö©MACÕ£░ÕØĆµØźÕö»õĖƵĀćńż║ÕĘźõĮ£µ£║ÕÖ©’╝īÕĘźõĮ£Ķ┐øń©ŗń║¦ÕÅ»õ╗źõĮ┐ńö©IP+PathµØźÕī║ÕłåÕĘźõĮ£Ķ┐øń©ŗŃĆéÕ”éµ×£ÕĘźõĮ£µ£║ÕÖ©µ»öĶŠāÕ░æ’╝īÕÅ»õ╗źõĮ┐ńö©ķģŹńĮ«µ¢ćõ╗ČµØźĶ«ŠńĮ«Ķ┐ÖõĖ¬idµś»õĖĆõĖ¬õĖŹķöÖńÜäķĆēµŗ®’╝īÕ”éµ×£µ£║ÕÖ©Ķ┐ćÕżÜķģŹńĮ«µ¢ćõ╗ČńÜäń╗┤µŖżµś»õĖĆõĖ¬ńüŠķÜŠµĆ¦ńÜäõ║ŗµāģŃĆé
Ķ┐ÖķćīńÜäĶ¦ŻÕå│µ¢╣µĪłµś»ķ£ĆĶ”üõĖĆõĖ¬ÕĘźõĮ£idÕłåķģŹńÜäĶ┐øń©ŗ’╝īÕÅ»õ╗źõĮ┐ńö©Ķć¬ÕĘ▒ń╝¢ÕåÖõĖĆõĖ¬ń«ĆÕŹĢĶ┐øń©ŗµØźĶ«░ÕĮĢÕłåķģŹid’╝īµł¢ĶĆģÕł®ńö©Mysql┬Āauto_incrementµ£║ÕłČõ╣¤ÕÅ»õ╗źĶŠŠÕł░µĢłµ×£ŃĆé

┬Ā
ÕĘźõĮ£Ķ┐øń©ŗõĖÄÕĘźõĮ£idÕłåķģŹÕÖ©ÕŬµś»Õ£©ÕĘźõĮ£Ķ┐øń©ŗÕÉ»ÕŖ©ńÜ䵌ČÕĆÖõ║żõ║ÆõĖƵ¼Ī’╝īńäČÕÉÄÕĘźõĮ£Ķ┐øń©ŗÕÅ»õ╗źĶć¬ĶĪīÕ░åÕłåķģŹńÜäidµĢ░µŹ«ĶÉĮµ¢ćõ╗Č’╝īõĖŗõĖƵ¼ĪÕÉ»ÕŖ©ńø┤µÄźĶ»╗ÕÅ¢µ¢ćõ╗ČķćīńÜäidõĮ┐ńö©ŃĆé
PS’╝ÜĶ┐ÖõĖ¬ÕĘźõĮ£µ£║ÕÖ©idńÜäbitµ«Ąõ╣¤ÕÅ»õ╗źĶ┐øõĖƵŁźµŗåÕłå’╝īµ»öÕ”éńö©ÕēŹ5õĖ¬bitµĀćĶ«░Ķ┐øń©ŗid’╝īÕÉÄ5õĖ¬bitµĀćĶ«░ń║┐ń©ŗidõ╣ŗń▒╗:D
Snowflake ŌĆō Õ║ÅÕłŚÕÅĘ
Õ║ÅÕłŚÕÅĘÕ░▒µś»õĖĆń│╗ÕłŚńÜäĶć¬Õó×id’╝łÕżÜń║┐ń©ŗÕ╗║Ķ««õĮ┐ńö©atomic’╝ē’╝īõĖ║õ║åÕżäńÉåÕ£©ÕÉīõĖƵ»½ń¦ÆÕåģķ£ĆĶ”üń╗ÖÕżÜµØĪµČłµü»ÕłåķģŹid’╝īĶŗźÕÉīõĖƵ»½ń¦ÆµŖŖÕ║ÅÕłŚÕÅĘńö©Õ«īõ║å’╝īÕłÖŌĆ£ńŁēÕŠģĶć│õĖŗõĖƵ»½ń¦ÆŌĆØŃĆé
|
1
2
3
4
5
6
7
8
|
uint64_t waitNextMs(uint64_t lastStamp){┬Ā┬Ā┬Ā┬Āuint64_t cur = 0;
┬Ā┬Ā┬Ā┬Ādo {
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ācur = generateStamp();
┬Ā┬Ā┬Ā┬Ā} while (cur <= lastStamp);
┬Ā┬Ā┬Ā┬Āreturn cur;
} |
┬Ā
µĆ╗õĮōµØźĶ»┤’╝īµś»õĖĆõĖ¬ÕŠłķ½śµĢłÕŠłµ¢╣õŠ┐ńÜäGUIDõ║¦ńö¤ń«Śµ│Ģ’╝īõĖĆõĖ¬int64_tÕŁŚµ«ĄÕ░▒ÕÅ»õ╗źĶā£õ╗╗’╝īõĖŹÕāÅńÄ░Õ£©õĖ╗µĄü128bitńÜäGUIDń«Śµ│Ģ’╝īÕŹ│õĮ┐µŚĀµ│Ģõ┐ØĶ»üõĖźµĀ╝ńÜäidÕ║ÅÕłŚµĆ¦’╝īõĮåµś»Õ»╣õ║Äńē╣Õ«ÜńÜäõĖÜÕŖĪ’╝īµ»öÕ”éńö©ÕüܵĖĖµłÅµ£ŹÕŖĪÕÖ©ń½»ńÜäGUIDõ║¦ńö¤õ╝ÜÕŠłµ¢╣õŠ┐ŃĆéÕÅ”Õż¢’╝īÕ£©ÕżÜń║┐ń©ŗńÜäńÄ»ÕóāõĖŗ’╝īÕ║ÅÕłŚÕÅĘõĮ┐ńö©atomicÕÅ»õ╗źÕ£©õ╗ŻńĀüÕ«×ńÄ░õĖŖµ£ēµĢłÕćÅÕ░æķöüńÜäÕ»åÕ║”ŃĆé
┬Ā
ń╗ōµ×äõĖ║’╝Ü
0---0000000000 0000000000 0000000000 0000000000 0 --- 00000 ---00000 ---0000000000 00
Õ£©õĖŖķØóńÜäÕŁŚń¼”õĖ▓õĖŁ’╝īń¼¼õĖĆõĮŹõĖ║µ£¬õĮ┐ńö©’╝łÕ«×ķÖģõĖŖõ╣¤ÕÅ»õĮ£õĖ║longńÜäń¼”ÕÅĘõĮŹ’╝ē’╝īµÄźõĖŗµØźńÜä41õĮŹõĖ║µ»½ń¦Æń║¦µŚČķŚ┤’╝īńäČÕÉÄ5õĮŹdatacenterµĀćĶ»åõĮŹ’╝ī5õĮŹµ£║ÕÖ©ID’╝łÕ╣ČõĖŹń«ŚµĀćĶ»åń¼”’╝īÕ«×ķÖģµś»õĖ║ń║┐ń©ŗµĀćĶ»å’╝ē’╝īńäČÕÉÄ12õĮŹĶ»źµ»½ń¦ÆÕåģńÜäÕĮōÕēŹµ»½ń¦ÆÕåģńÜäĶ«ĪµĢ░’╝īÕŖĀĶĄĘµØźÕłÜÕźĮ64õĮŹ’╝īõĖ║õĖĆõĖ¬LongÕ×ŗŃĆé
Ķ┐ÖµĀĘńÜäÕźĮÕżäµś»’╝īµĢ┤õĮōõĖŖµīēńģ¦µŚČķŚ┤Ķć¬Õó×µÄÆÕ║Å’╝īÕ╣ČõĖöµĢ┤õĖ¬ÕłåÕĖāÕ╝Åń│╗ń╗¤ÕåģõĖŹõ╝Üõ║¦ńö¤IDńó░µÆ×’╝łńö▒datacenterÕÆīµ£║ÕÖ©IDõĮ£Õī║Õłå’╝ē’╝īÕ╣ČõĖöµĢłńÄćĶŠāķ½ś’╝īń╗ŵĄŗĶ»Ģ’╝īsnowflakeµ»Åń¦ÆĶāĮÕż¤õ║¦ńö¤26õĖćIDÕĘ”ÕÅ│’╝īÕ«īÕģ©µ╗ĪĶČ│ķ£ĆĶ”üŃĆé
┬Ā
public class IdWorker {
private final long workerId;
private final static long twepoch = 1361753741828L;
private long sequence = 0L;
private final static long workerIdBits = 4L;
private final static long maxWorkerId = -1L ^ -1L << workerIdBits;
private final static long sequenceBits = 10L;
private final static long workerIdShift = sequenceBits;
private final static long timestampLeftShift = sequenceBits + workerIdBits;
private final static long sequenceMask = -1L ^ -1L << sequenceBits;
private long lastTimestamp = -1L;
public IdWorker(final long workerId) {
super();
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format(
"worker Id can't be greater than %d or less than 0", maxWorkerId));
}
this.workerId = workerId;
}
public synchronized long nextId() {
long timestamp = this.timeGen();
if (this.lastTimestamp == timestamp) {
this.sequence = (this.sequence + 1) & sequenceMask;
if (this.sequence == 0) {
System.out.println("###########" + sequenceMask);
timestamp = this.tilNextMillis(this.lastTimestamp);
}
} else {
this.sequence = 0;
}
if (timestamp < this.lastTimestamp) {
try {
throw new Exception(String.format(
"Clock moved backwards. Refusing to generate id for %d milliseconds",
this.lastTimestamp - timestamp));
} catch (Exception e) {
e.printStackTrace();
}
}
this.lastTimestamp = timestamp;
long nextId = ((timestamp - twepoch << timestampLeftShift))
| (this.workerId << workerIdShift) | (this.sequence);
// System.out.println("timestamp:" + timestamp + ",timestampLeftShift:"
// + timestampLeftShift + ",nextId:" + nextId + ",workerId:"
// + workerId + ",sequence:" + sequence);
return nextId;
}
private long tilNextMillis(final long lastTimestamp) {
long timestamp = this.timeGen();
while (timestamp <= lastTimestamp) {
timestamp = this.timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
public static void main(String[] args) throws InterruptedException {
IdWorker worker2 = new IdWorker(2);
System.out.println(worker2.nextId());
Thread.sleep(1000L);
System.out.println(worker2.nextId());
}
}
┬Ā
┬Ā
Reference:



ńøĖÕģ│µÄ©ĶŹÉ
### TwitterńÜäÕłåÕĖāÕ╝ÅĶć¬Õó×IDń«Śµ│ĢSnowflake (Javańēł) #### µ”éĶ┐░ Õ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁ’╝īń╗ÅÕĖĖķ£ĆĶ”üõĮ┐ńö©Õģ©Õ▒ĆÕö»õĖĆńÜäIDµØźµĀćĶ»åõĖŹÕÉīńÜäÕ«×õĮōµł¢Ķ«░ÕĮĢŃĆéõ╝Āń╗¤ńÜä36õĮŹUUIDĶÖĮńäČĶāĮµÅÉõŠøÕģ©Õ▒ĆÕö»õĖƵƦ’╝īõĮåńö▒õ║ÄÕģČĶŠāķĢ┐ńÜäķĢ┐Õ║”ÕÅŖµŚĀÕ║Åńē╣µĆ¦’╝īÕ£©µ¤Éõ║øÕ£║µÖ»...
ń╗╝õĖŖµēĆĶ┐░’╝īTwitterńÜäķø¬ĶŖ▒ń«Śµ│Ģ’╝łSnowflake’╝ēµÅÉõŠøõ║åõĖĆń¦Źķ½śµĢłŃĆüń«ĆÕŹĢńÜäÕłåÕĖāÕ╝ÅIDńö¤µłÉµ¢╣µĪł’╝īķĆÜĶ┐ćÕÉłńÉåńÜäń╗ōµ×äĶ«ŠĶ«Ī’╝īńĪ«õ┐Øõ║åÕģ©Õ▒ĆÕö»õĖƵƦÕÆīķĪ║Õ║ÅµĆ¦ŃĆéÕ£©JavańÄ»ÕóāõĖŗ’╝īÕÅ»õ╗źķĆÜĶ┐ćÕ«×ńÄ░ńøĖÕ║öńÜäń▒╗ÕÆīµ¢╣µ│ĢĶĮ╗µØŠÕ£░Õ╝ĢÕģźĶ┐ÖõĖƵ£║ÕłČ’╝īõĖ║ÕłåÕĖāÕ╝Åń│╗ń╗¤ńÜä...
ŃĆÉJavaÕ«×ńÄ░TwitterńÜäÕłåÕĖāÕ╝ÅĶć¬Õó×IDń«Śµ│ĢsnowflakeŃĆæ Õ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤Ķ«ŠĶ«ĪõĖŁ’╝īńö¤µłÉÕģ©Õ▒ĆÕö»õĖĆIDµś»õĖĆõĖ¬ÕĖĖĶ¦üńÜäķ£Ćµ▒éŃĆéTwitterńÜäSnowflakeń«Śµ│ĢÕ░▒µś»õĖ║õ║åĶ¦ŻÕå│Ķ┐ÖõĖ¬ķŚ«ķóśĶĆīĶ»×ńö¤ńÜä’╝īÕ«āµÅÉõŠøõ║åõĖĆń¦Źķ½śµĢłŃĆüµ£ēÕ║ÅõĖöõĖŹõ╝ÜÕå▓ń¬üńÜäIDńö¤µłÉńŁ¢ńĢźŃĆé...
Twitter Snowflakeń«Śµ│Ģ’╝īphpńēłõ╗ŻńĀü’╝ø Ķ»ĘĶ¦üÕŹÜÕ«ó’╝Ü http://blog.csdn.net/envon123/article/details/52953872
We have retired the initial release of Snowflake and working on open sourcing the next version based on Twitter-server, in a form that can run anywhere without requiring Twitter's own infrastructure ...
Õ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁ’╝īõĖ║õ║åńö¤µłÉÕģ©Õ▒ĆÕö»õĖĆńÜäĶć¬Õó×ID’╝īÕÅ»õ╗źõĮ┐ńö©Snowflakeń«Śµ│ĢŃĆüTwitterńÜäÕłåÕĖāÕ╝ÅIDńö¤µłÉµ£ŹÕŖĪ’╝īµł¢ĶĆģÕ¤║õ║ÄRedisńÜäÕ║ÅÕłŚÕÅĘńö¤µłÉµ¢╣µĪłŃĆéSpring BootÕÅ»õ╗źĶĮ╗µØŠķøåµłÉĶ┐Öõ║øµ¢╣µĪł’╝īķĆÜĶ┐ćķģŹńĮ«ÕÆīµ│©Ķ¦Żń«ĆÕī¢Õ╝ĆÕÅæµĄüń©ŗŃĆé 2. **RedisõĮ£õĖ║...
ĶĆītwitterńÜäsnowflakeĶ¦ŻÕå│õ║åĶ┐Öń¦Źķ£Ćµ▒é’╝īµ£ĆÕłØµś»TwitterµŖŖÕŁśÕé©ń│╗ń╗¤õ╗ÄMySQLĶ┐üń¦╗Õł░Cassandra’╝īÕøĀõĖ║Cassandraµ▓Īµ£ēķĪ║Õ║ÅńÜäIDńö¤µłÉµ£║ÕłČ’╝īµēĆõ╗źÕ╝ĆÕÅæõ║åĶ┐ÖµĀĘõĖĆÕźŚÕö»õĖĆńÜäIDńö¤µłÉµ£ŹÕŖĪŃĆéń╗ōµ×äķø¬ĶŖ▒ńÜäń╗ōµ×äÕ”éõĖŗ’╝łµ»Åķā©Õłåńö©-ÕłåÕ╝Ć’╝ē’╝Ü 0 - ...
Snowflakeń«Śµ│Ģµś»ńö▒TwitterÕ╝Ƶ║ÉńÜäõĖĆń¦Źķ½śµĢłõĖöÕÅ»µē®Õ▒ĢńÜäÕłåÕĖāÕ╝ÅIDńö¤µłÉµ¢╣µĪł’╝īÕ╣┐µ│øÕ║öńö©õ║ÄJavaÕÆīÕģČõ╗¢ń╝¢ń©ŗĶ»ŁĶ©ĆńÜäń│╗ń╗¤õĖŁŃĆé Snowflakeń«Śµ│ĢńÜäµĀĖÕ┐āµĆصā│µś»Õ░å64õĮŹńÜäµĢ┤µĢ░ÕłÆÕłåõĖ║õĖŹÕÉīńÜäķā©Õłå’╝īÕłåÕł½õĖ║’╝Ü 1. **µŚČķŚ┤µł│**’╝ł41õĮŹ’╝ē’╝ÜĶć¬Õ«Üõ╣ē...
3. **ÕłåÕĖāÕ╝ÅIDńö¤µłÉÕÖ©**’╝ÜÕ”éSnowflakeń«Śµ│Ģ’╝īÕ«āµś»ńö▒TwitterÕ╝Ƶ║ÉńÜäõĖĆń¦ŹÕłåÕĖāÕ╝ÅIDńö¤µłÉµ¢╣µĪłŃĆéķĆÜĶ┐浌ČķŚ┤µł│ŃĆüÕĘźõĮ£µ£║ÕÖ©IDÕÆīÕ║ÅÕłŚÕÅĘõĖēķā©Õłåń╗äÕÉł’╝īÕÅ»õ╗źńö¤µłÉÕģ©Õ▒ĆÕö»õĖĆńÜäID’╝īĶĆīõĖöµÄÆÕ║ÅµĆ¦ÕźĮŃĆéÕ£©JavaõĖŁ’╝īÕÅ»õ╗źõĮ┐ńö©Ķ»ĖÕ”éSnowflakeµł¢ĶĆģÕģČÕÅśń¦Ź...
public class SnowflakeIdGenerator { private static final SnowflakeIdWorker idWorker = new SnowflakeIdWorker(0, 0); public static long generateId() { return idWorker.nextId(); } } ``` Õ£©Ķ┐ÖõĖ¬õŠŗÕŁÉõĖŁ...
Snowflakeń«Śµ│Ģµś»ńö▒TwitterÕ╝ĆÕÅæńÜä’╝īÕ«āķĆÜĶ┐ćõĖĆõĖ¬64õĮŹńÜäµĢ┤µĢ░µØźĶĪ©ńż║ID’╝īÕģČõĖŁÕłåµłÉÕżÜõĖ¬ķā©Õłå’╝īÕīģµŗ¼µŚČķŚ┤µł│ŃĆüÕĘźõĮ£µ£║ÕÖ©IDŃĆüÕ║ÅÕłŚÕÅĘńŁēŃĆéÕģĘõĮōµØźĶ»┤’╝īÕ«āķĆÜÕĖĖÕīģÕɽõ╗źõĖŗÕćĀõĖ¬ķā©Õłå’╝Ü1õĮŹµ£¬õĮ┐ńö©ńÜäń¼”ÕÅĘõĮŹ’╝ī41õĮŹńÜ䵌ČķŚ┤µł│’╝ī10õĮŹńÜäÕĘźõĮ£µ£║ÕÖ©ID...
- ķø¬ĶŖ▒ń«Śµ│Ģńö▒TwitterµÅÉÕć║’╝īńö¤µłÉńÜäIDńö▒µŚČķŚ┤µł│ŃĆüÕĘźõĮ£ĶŖéńé╣IDÕÆīÕ║ÅÕłŚÕÅĘõĖēķā©Õłåń╗䵳ɒ╝īÕģ©Õ▒ĆÕö»õĖĆõĖöµ£ēÕ║ÅŃĆé - µŚČķŚ┤µł│ńĪ«õ┐ØIDńÜäÕģ©Õ▒ĆÕö»õĖƵƦÕÆīµŚČķŚ┤ķĪ║Õ║Å’╝øÕĘźõĮ£ĶŖéńé╣IDńĪ«õ┐ØõĖŹÕÉīĶŖéńé╣ńö¤µłÉńÜäIDõĖŹõ╝ÜÕå▓ń¬ü’╝øÕ║ÅÕłŚÕÅĘÕ£©µ»ÅõĖ¬ĶŖéńé╣Õåģķā©ńĪ«õ┐ØÕö»õĖƵƦ...
Ķ»źń«Śµ│ĢńÜäĶ«ŠĶ«ĪńüĄµä¤µØźµ║Éõ║ÄTwitterÕĮōµŚČķØóõĖ┤ńÜäÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁIDńö¤µłÉńÜäķ£Ćµ▒éŃĆéÕ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁ’╝īµ»ÅõĖ¬µ£ŹÕŖĪÕ«×õŠŗķāĮķ£ĆĶ”üĶāĮÕż¤ńö¤µłÉĶć¬ÕĘ▒ńÜäÕö»õĖĆID’╝īĶĆīõĖŹķ£ĆĶ”üõĖÄÕģČõ╗¢µ£ŹÕŖĪĶ┐øĶĪīķĆÜõ┐ĪŃĆéÕ”éµ×£ń│╗ń╗¤õŠØĶĄ¢õ║ĵĢ░µŹ«Õ║ōµł¢ÕģČõ╗¢ķøåõĖŁÕ╝ŵ£ŹÕŖĪµØźńö¤µłÉID’╝īÕÅ»ĶāĮ...
õĖ║Ķ¦ŻÕå│µŁżķŚ«ķóś’╝īÕÅ»õ╗źõĮ┐ńö©Õģ©Õ▒ĆĶć¬Õó×Õ║ÅÕłŚ’╝īÕ”éTwitterńÜäSnowflakeń«Śµ│Ģ’╝īÕ«āń╗ōÕÉłµŚČķŚ┤µł│ŃĆüÕĘźõĮ£ĶŖéńé╣IDÕÆīÕ║ÅÕłŚÕÅĘńö¤µłÉÕģ©Õ▒ĆÕö»õĖĆńÜä64õĮŹIDŃĆé 2. UUID’╝łķĆÜńö©Õö»õĖƵĀćĶ»åń¼”’╝ē’╝ÜUUIDµś»õĖĆń¦ŹÕ╣┐µ│øõĮ┐ńö©ńÜäÕģ©Õ▒ĆÕö»õĖĆIDńö¤µłÉµ¢╣µĪł’╝īõĮåÕģČ128õĮŹķĢ┐Õ║”...
1. **Snowflakeń«Śµ│Ģ**’╝ÜĶ┐Öµś»õĖĆń¦ŹÕĖĖĶ¦üńÜäÕłåÕĖāÕ╝ÅIDńö¤µłÉńŁ¢ńĢź’╝īńö▒TwitterÕ╝Ƶ║ÉŃĆéÕ«āķĆÜĶ┐浌ČķŚ┤µł│ŃĆüÕĘźõĮ£ĶŖéńé╣IDÕÆīÕ║ÅÕłŚÕÅĘõĖēķā©Õłåń╗䵳ɒ╝īńĪ«õ┐ØÕģ©Õ▒ĆÕö»õĖƵƦŃĆéńäČĶĆī’╝īĶ┐ÖķćīńÜäµÅÅĶ┐░Õ╣ȵ▓Īµ£ēµśÄńĪ«µÅÉÕÅŖSnowflake’╝īĶĆīµś»µÜŚńż║õ║åÕÅ»ĶāĮµ£ēÕģČõ╗¢Ķć¬Õ«Üõ╣ēÕ«×ńÄ░...
TwitterńÜäSnowflakeµś»õĖĆń¦ŹÕłåÕĖāÕ╝ÅIDńö¤µłÉń«Śµ│Ģ’╝īńö©õ║ÄÕ£©Õż¦Ķ¦äµ©ĪÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁńö¤µłÉÕģ©Õ▒ĆÕö»õĖĆńÜäŃĆüµ£ēÕ║ÅńÜä64õĮŹµĢ┤µĢ░IDŃĆéĶ┐ÖõĖ¬ń«Śµ│Ģńö▒TwitterÕ╝Ƶ║É’╝īĶ¦ŻÕå│õ║åÕ£©ÕłåÕĖāÕ╝ÅńÄ»ÕóāõĖŗÕ”éõĮĢńö¤µłÉÕģʵ£ēµŚČķŚ┤Õ║ÅÕłŚÕ▒׵ƦõĖöõĖŹķćŹÕżŹńÜäIDńÜäķŚ«ķóśŃĆéńÄ░Õ£©’╝īµłæõ╗¼Õ░å...
Ķ»źń«Śµ│Ģµ£ĆÕłØńö▒TwitterµÅÉÕć║’╝īÕ«āĶāĮÕż¤õĖ║µ»ÅõĖ¬ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁńÜäĶŖéńé╣ńö¤µłÉõĖĆõĖ¬64õĮŹńÜäÕö»õĖĆIDŃĆéńö¤µłÉńÜäIDÕÅ»õ╗źõ┐ØĶ»üÕ£©ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁńÜäÕö»õĖƵƦ’╝īÕ╣ČõĖöĶČŗÕŖ┐ķĆÆÕó×’╝īķü┐ÕģŹõ║åõ╝Āń╗¤µĢ░µŹ«Õ║ōńÜäĶć¬Õó×õĖ╗ķö«µł¢ĶĆģUUIDÕĖ”µØźńÜäµĆ¦ĶāĮÕÆīÕŁśÕé©ķÖÉÕłČŃĆé Õ£©Ķ»źĶĄäµ║ÉÕīģ...
12. **ÕłåÕĖāÕ╝ÅIDńö¤µłÉÕÖ©**: Õ”éTwitterńÜäSnowflakeń«Śµ│Ģ’╝īńö¤µłÉÕģ©Õ▒ĆÕö»õĖĆõĖöķĆÆÕó×ńÜäIDŃĆéPythonÕ«×ńÄ░Õ░åÕģ│µ│©µŚČķŚ┤µł│ŃĆüµ£║ÕÖ©µĀćĶ»åÕÆīÕ║ÅÕłŚÕÅĘńÜäń╗äÕÉłŃĆé ķĪ╣ńø«õĖŁńÜäÕ«×ńö©ÕĘźÕģĘń▒╗ÕÅ»ĶāĮÕīģµŗ¼ÕōłÕĖīÕćĮµĢ░ŃĆüńĮæń╗£ķĆÜõ┐Īµ©ĪÕØŚŃĆüÕ╣ČÕÅæµÄ¦ÕłČŃĆüµŚźÕ┐ŚĶ«░ÕĮĢŃĆüķģŹńĮ«...
ķø¬ĶŖ▒ń«Śµ│Ģµś»ńö▒TwitterÕ╝Ƶ║ÉńÜäõĖĆń¦ŹÕłåÕĖāÕ╝ÅIDńö¤µłÉń«Śµ│Ģ’╝īÕ«āĶāĮÕż¤õĖ║ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁńÜäµ»ÅõĖ¬Õ«×õĮōńö¤µłÉÕģ©Õ▒ĆÕö»õĖĆńÜäŃĆüÕŹĢĶ░āķĆÆÕó×ńÜä64õĮŹµĢ┤µĢ░IDŃĆéĶ┐Öń¦Źń«Śµ│ĢÕ£©Õż¦µĢ░µŹ«ÕÆīÕłåÕĖāÕ╝ÅńÄ»ÕóāõĖŗÕ╣┐µ│øÕ║öńö©õ║ÄõĖ╗ķö«ńö¤µłÉ’╝īÕøĀõĖ║Õ«āĶ¦ŻÕå│õ║åÕ£©ÕłåÕĖāÕ╝ÅńÄ»ÕóāõĖŗńÜäIDÕö»õĖĆ...
Snowflakeń«Śµ│ĢÕ░▒µś»õĖĆń¦ŹĶó½Õ╣┐µ│øõĮ┐ńö©ńÜäÕłåÕĖāÕ╝ÅIDńö¤µłÉµ¢╣µĪł’╝īÕ«āńö▒TwitterÕ╝Ƶ║É’╝īÕģʵ£ēµŚČķŚ┤µł│ŃĆüÕĘźõĮ£µ£║ÕÖ©IDÕÆīÕ║ÅÕłŚÕÅĘõĖēķā©Õłåń╗䵳ɒ╝īĶāĮÕż¤ńĪ«õ┐ØÕ£©ÕłåÕĖāÕ╝ÅńÄ»ÕóāõĖŗńö¤µłÉńÜäIDÕģʵ£ēÕö»õĖƵƦŃĆüµ£ēÕ║ÅµĆ¦ÕÆīķ½śµĆ¦ĶāĮŃĆé Snowflakeń«Śµ│ĢńÜäµĀĖÕ┐āµĆصā│µś»Õ░å64...