
原文链接:http://blog.csdn.net/zgyulongfei/article/details/7909006
有时候由于种种原因,我们需要采集某个网站的数据,但由于不同网站对数据的显示方式略有不同!
本文就用Java给大家演示如何抓取网站的数据:(1)抓取原网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原网页。
这个例子我们准备从http://ip.chinaz.com上抓取ip查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,就可以看到网页显示的结果:

第二步:查看网页源码,我们看到源码中有这么一段:

从这里可以看出,查询的结果,是重新请求一个网页之后显示的。
再看看查询之后的网页地址:
也就是说,我们只要访问形如这样的网址,就可以得到ip查询的结果,接下来看代码:
- public void captureHtml(String ip) throws Exception {
- String strURL = "http://ip.chinaz.com/?IP=" + ip;
- URL url = new URL(strURL);
- HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
- InputStreamReader input = new InputStreamReader(httpConn
- .getInputStream(), "utf-8");
- BufferedReader bufReader = new BufferedReader(input);
- String line = "";
- StringBuilder contentBuf = new StringBuilder();
- while ((line = bufReader.readLine()) != null) {
- contentBuf.append(line);
- }
- String buf = contentBuf.toString();
- int beginIx = buf.indexOf("查询结果[");
- int endIx = buf.indexOf("上面四项依次显示的是");
- String result = buf.substring(beginIx, endIx);
- System.out.println("captureHtml()的结果:\n" + result);
- }
使用HttpURLConnection连接网站,用bufReader保存网页返回的数据,然后通过自定义的一个解析方式将结果显示出来。
这里我只是随便的解析了一下,要解析的非常准确的话自己需再处理。
解析结果如下:
captureHtml()的结果:
查询结果[1]: 111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市 移动</strong><br />
二、抓取网页JavaScript返回的结果。
有时候网站为了保护自己的数据,并没有把数据直接放在网页源码中返回,而是采用异步的方式,用JS返回数据,这样可以避免搜索引擎等工具对网站数据的抓取。
首先看一下这个网页:
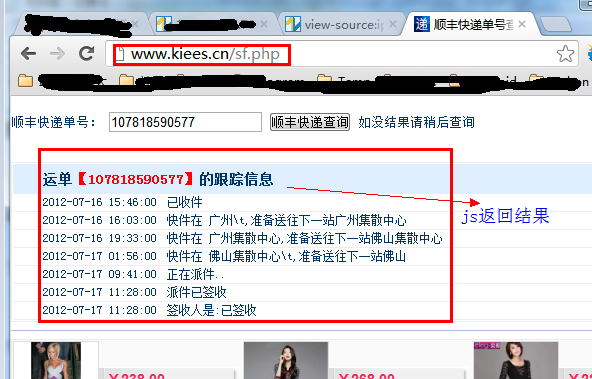
用第一种方式查看该网页的源码,却没有发现该运单的跟踪信息,因为它是通过JS的方式获取结果的。
但有时候我们很需要获取到JS的数据,这个时候要怎么办呢?
这个时候我们需要用到一个工具:HTTP Analyzer,这个工具可以截获Http的交互内容,我们通过这个工具来达到我们的目的。
首先点击Start按钮之后,它就开始监听网页的交互行为了。
我们打开网页:http://www.kiees.cn/sf.php ,可以看到HTTP Analyzer列出了所有该网页的请求数据以及结果:
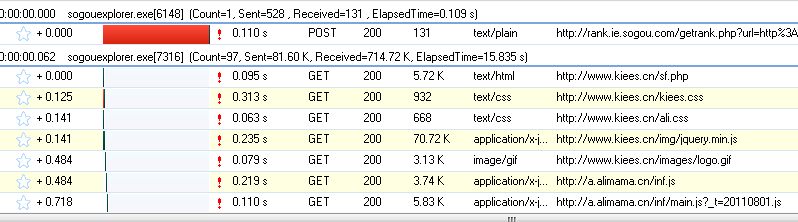
为了更方便的查看JS的结果,我们先清空这些数据,然后再网页中输入快递单号:107818590577,点击查询按钮,然后查看HTTP Analyzer的结果:

这个就是点击查询按钮之后,HTTP Analyzer的结果,我们继续查看:
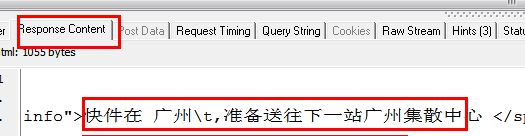
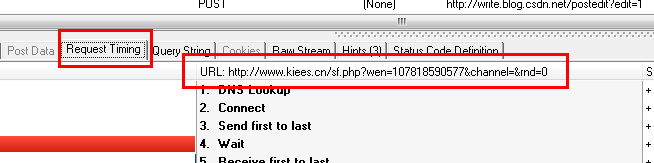
从上面两幅图中可以看出,HTTP Analyzer可以截获JS返回的数据,并在Response Content中显示,同时可以看到JS请求的网页地址。
既然如此,我们只要分析HTTP Analyzer的结果,然后模拟JS的行为就可获取到数据,即我们只要访问JS请求的网页地址来获取数据,当然前提是这些数据是没有经过加密的,我们记下JS请求的URL:http://www.kiees.cn/sf.php?wen=107818590577&channel=&rnd=0
然后让程序去请求这个网页的结果即可!
下面是代码:
- public void captureJavascript(String postid) throws Exception {
- String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
- + "&channel=&rnd=0";
- URL url = new URL(strURL);
- HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
- InputStreamReader input = new InputStreamReader(httpConn
- .getInputStream(), "utf-8");
- BufferedReader bufReader = new BufferedReader(input);
- String line = "";
- StringBuilder contentBuf = new StringBuilder();
- while ((line = bufReader.readLine()) != null) {
- contentBuf.append(line);
- }
- System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
- }
看到了吧,抓取JS的方式和前面抓取原网页的代码一模一样,我们只不过做了一个分析JS的过程。
下面是程序执行的结果:
captureJavascript()的结果:
<div class="results"><div id="ali-itu-wl-result" class="ali-itu-wl-result"><h2 class="logisTitle">运单<span class="mail-no">【107818590577】</span>的跟踪信息</h2><div class="trace_result"><ul><li><span class="time">2012-07-16 15:46:00</span><span class="info">已收件 </span></li><li><span class="time">2012-07-16 16:03:00</span><span class="info">快件在 广州\t,准备送往下一站广州集散中心 </span></li><li><span class="time">2012-07-16 19:33:00</span><span class="info">快件在 广州集散中心,准备送往下一站佛山集散中心 </span></li><li><span class="time">2012-07-17 01:56:00</span><span class="info">快件在 佛山集散中心\t,准备送往下一站佛山 </span></li><li><span class="time">2012-07-17 09:41:00</span><span class="info">正在派件.. </span></li><li><span class="time">2012-07-17 11:28:00</span><span class="info">派件已签收 </span></li><li><span class="time">2012-07-17 11:28:00</span><span class="info">签收人是:已签收 </span></li></ul><div></div></div></div> </div>
这些数据就是JS返回的结果了,我们的目的达到了!
希望本文能够对需要的朋友有一点帮助,需要程序源码的,请点击这里下载!



相关推荐
网页抓取,也被称为网络爬虫或数据抓取,是一种自动化技术,用于从互联网上大量收集和处理数据。这项技术通常被数据分析师、研究人员、市场营销人员以及网站管理员用来获取特定类型的信息,例如市场趋势、用户行为...
网页数据比分抓取源码是一种常见的信息技术应用,主要用于自动化地从互联网上收集和处理特定的比分信息。在体育赛事如足球、篮球等中,实时比分更新对于球迷和数据分析人员至关重要。这个"网页数据比分抓取源码"演示...
本文将详细讨论如何使用Java语言来抓取网页数据,包括两种主要方法:直接抓取原网页内容和处理网页中的JavaScript返回数据。 首先,让我们探讨**抓取原网页**的方法。在Java中,我们可以使用`java.net.URL`类来建立...
JavaScript通常用于网页交互,它可以帮助解析由AJAX返回的复杂数据结构。例如,可以使用jQuery或其他库来定位和提取DOM元素中的数据。如果用户能理解基本的JavaScript语法,他们就可以根据需要定制数据提取规则,...
对于JavaScript加载后的网页抓取,一种常见的解决方案是使用Headless浏览器,比如Google的Chrome提供了Headless模式,它可以在没有界面的情况下运行,执行JavaScript并返回渲染后的页面内容。另一种方法是使用像...
### 抓取网页数据的代码及PreparedStatement的使用详解 #### 一、抓取网页数据的基本概念 抓取网页数据通常指的是使用编程手段自动地从互联网上的网页中提取所需的信息。这种技术广泛应用于搜索引擎、数据分析、...
在IT领域,网络数据抓取是一项重要的技能,它允许我们从网页中提取所需的信息,用于数据分析、内容聚合或自动化任务。HttpClient和Jsoup是两个Java库,分别专注于HTTP通信和HTML解析,它们常被组合使用来高效地抓取...
在“java抓取网页数据”这个主题中,我们将深入探讨如何利用Java来抓取并处理互联网上的信息。 首先,我们要了解什么是网络爬虫。网络爬虫(Web Crawler)是自动遍历互联网的程序,通过抓取网页内容并存储在本地,...
网页抓取的基本步骤包括发送HTTP请求到目标网站,接收响应,然后解析返回的HTML内容,寻找并提取所需的数据。 在C#中,我们可以使用HttpClient类来发送HTTP请求,它提供了异步操作,可以更高效地处理网络通信。一旦...
1. **Python爬虫**:Python爬虫是用于自动抓取互联网数据的一种技术。在疫情可视化项目中,可能使用了如`requests`库来发送HTTP请求获取网页数据,`BeautifulSoup`或`lxml`等解析库来解析HTML内容,提取出疫情相关的...
动态网页抓取则涉及到JavaScript、AJAX等技术,因为这些网页的内容往往在客户端通过执行JavaScript代码生成。对于这类网页,MFC单纯使用HTTP请求可能无法获取完整数据,需要更复杂的处理。一种方法是使用像CMarkUp...
总结来说,抓取淘宝页面数据涉及的知识点包括:HTTP请求与响应、HTML和JavaScript解析、网页自动化工具(Selenium、Puppeteer)、反爬策略与应对、API接口利用、数据存储与处理,以及相关的法律法规遵循。...
开发者可以利用Express的灵活性和模块化设计来快速搭建服务器端的应用程序,使得爬虫服务能够对外提供接口,接收请求并返回数据。 **Cheerio**: Cheerio是一个轻量级的库,它为Node.js环境提供了类似jQuery的API,...
1. **网页抓取**:网页抓取,又称为网络爬虫或网页抓取,是一种自动化程序,用于从万维网下载大量信息。它们通过模拟浏览器发送HTTP请求到服务器,然后接收并解析返回的HTML或其它格式的网页内容。常见的网页抓取...
本项目是关于如何使用Python从ICLR(International Conference on Learning Representations)2019年的OpenReview网页抓取相关数据。ICLR是一个在机器学习和深度学习领域具有影响力的国际会议,OpenReview则是它采用...
标签"jsp网页抓取天气预报源代码"与标题一致,进一步确认了项目的核心内容:使用JSP进行网络数据抓取,特别是天气预报数据。 【文件名解析】 由于只给出了一个文件名"weather",我们可以推断这是项目的主文件或者...
在IT行业中,处理网页和抓取网页代码是网络编程中的重要技能,特别是在自动化测试、数据挖掘和信息分析等领域。本文将深入探讨这两种技术,并提供一些实用的方法和工具,以帮助您在缺乏相应命令行工具的情况下,通过...
网页爬虫,也被称为网络爬虫或数据抓取工具,是一种自动化程序,它按照特定的规则遍历互联网上的网页,收集所需的信息。在信息技术领域,爬虫被广泛应用于数据分析、市场研究、搜索引擎优化等多个场景。了解如何构建...
XMLHttpRequest适合自动化和低级别的数据抓取,QueryTable和Power Query则更适合日常数据导入,WebBrowser控件则在需要与网页交互时发挥作用。了解并掌握这些方法,将使你在处理Excel与网页数据交互时游刃有余。
【抓取整站网页】是一项技术,主要用于网络数据挖掘或备份特定网站的全部内容。这一过程通常被称为网站镜像或Web抓取。通过这项技术,我们可以获取网站的HTML代码、图片、CSS样式表、JavaScript文件等,使得在本地...