
写在前面:索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点。考虑如下情况,假设数据库中一个表有10^6条记 录,DBMS的页面大小为4K,并存储100条记录。如果没有索引,查询将对整个表进行扫描,最坏的情况下,如果所有数据页都不在内存,需要读取10^4 个页面,如果这10^4个页面在磁盘上随机分布,需要进行10^4次I/O,假设磁盘每次I/O时间为10ms(忽略数据传输时间),则总共需要 100s(但实际上要好很多很多)。如果对之建立B-Tree索引,则只需要进行log100(10^6)=3次页面读取,最坏情况下耗时30ms。这就 是索引带来的效果,很多时候,当你的应用程序进行SQL查询速度很慢时,应该想想是否可以建索引。进入正题:
第二章、索引与优化
1、选择索引的数据类型
MySQL支持很多数据类型,选择合适的数据类型存储数据对性能有很大的影响。通常来说,可以遵循以下一些指导原则:
(1)越小的数据类型通常更好:越小的数据类型通常在磁盘、内存和CPU缓存中都需要更少的空间,处理起来更快。
(2)简单的数据类型更好:整型数据比起字符,处理开销更小,因为字符串的比较更复杂。在MySQL中,应该用内置的日期和时间数据类型,而不是用字符串来存储时间;以及用整型数据类型存储IP地址。
(3)尽量避免NULL:应该指定列为NOT NULL,除非你想存储NULL。在MySQL中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值。
1.1、选择标识符
选择合适的标识符是非常重要的。选择时不仅应该考虑存储类型,而且应该考虑MySQL是怎样进行运算和比较的。一旦选定数据类型,应该保证所有相关的表都使用相同的数据类型。
(1) 整型:通常是作为标识符的最好选择,因为可以更快的处理,而且可以设置为AUTO_INCREMENT。
(2) 字符串:尽量避免使用字符串作为标识符,它们消耗更好的空间,处理起来也较慢。而且,通常来说,字符串都是随机的,所以它们在索引中的位置也是随机的,这会导致页面分裂、随机访问磁盘,聚簇索引分裂(对于使用聚簇索引的存储引擎)。
2、索引入门
对于任何DBMS,索引都是进行优化的最主要的因素。对于少量的数据,没有合适的索引影响不是很大,但是,当随着数据量的增加,性能会急剧下降。
如果对多列进行索引(组合索引),列的顺序非常重要,MySQL仅能对索引最左边的前缀进行有效的查找。例如:
假 设存在组合索引it1c1c2(c1,c2),查询语句select * from t1 where c1=1 and c2=2能够使用该索引。查询语句select * from t1 where c1=1也能够使用该索引。但是,查询语句select * from t1 where c2=2不能够使用该索引,因为没有组合索引的引导列,即,要想使用c2列进行查找,必需出现c1等于某值。
2.1、索引的类型
索引是在存储引擎中实现的,而不是在服务器层中实现的。所以,每种存储引擎的索引都不一定完全相同,并不是所有的存储引擎都支持所有的索引类型。
2.1.1、B-Tree索引
假设有如下一个表:
|
CREATE TABLE People ( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m', 'f') not null, key(last_name, first_name, dob) ); |
其索引包含表中每一行的last_name、first_name和dob列。其结构大致如下:
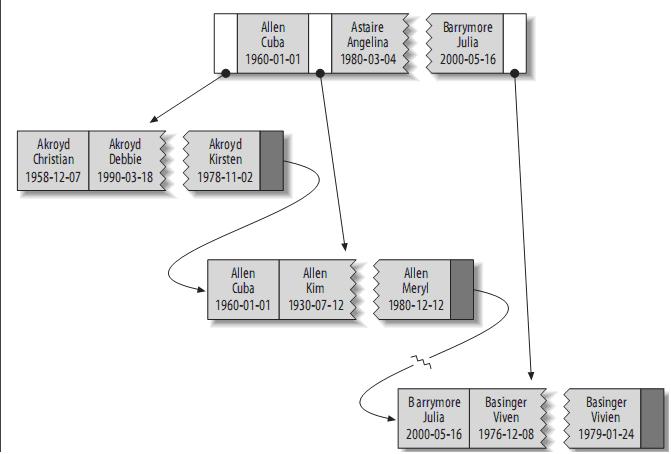
索引存储的值按索引列中的顺序排列。可以利用B-Tree索引进行全关键字、关键字范围和关键字前缀查询,当然,如果想使用索引,你必须保证按索引的最左边前缀(leftmost prefix of the index)来进行查询。
(1)匹配全值(Match the full value):对索引中的所有列都指定具体的值。例如,上图中索引可以帮助你查找出生于1960-01-01的Cuba Allen。
(2)匹配最左前缀(Match a leftmost prefix):你可以利用索引查找last name为Allen的人,仅仅使用索引中的第1列。
(3)匹配列前缀(Match a column prefix):例如,你可以利用索引查找last name以J开始的人,这仅仅使用索引中的第1列。
(4)匹配值的范围查询(Match a range of values):可以利用索引查找last name在Allen和Barrymore之间的人,仅仅使用索引中第1列。
(5)匹配部分精确而其它部分进行范围匹配(Match one part exactly and match a range on another part):可以利用索引查找last name为Allen,而first name以字母K开始的人。
(6)仅对索引进行查询(Index-only queries):如果查询的列都位于索引中,则不需要读取元组的值。
由于B-树中的节点都是顺序存储的,所以可以利用索引进行查找(找某些值),也可以对查询结果进行ORDER BY。当然,使用B-tree索引有以下一些限制:
(1) 查询必须从索引的最左边的列开始。关于这点已经提了很多遍了。例如你不能利用索引查找在某一天出生的人。
(2) 不能跳过某一索引列。例如,你不能利用索引查找last name为Smith且出生于某一天的人。
(3) 存储引擎不能使用索引中范围条件右边的列。例如,如果你的查询语句为WHERE last_name="Smith" AND first_name LIKE 'J%' AND dob='1976-12-23',则该查询只会使用索引中的前两列,因为LIKE是范围查询。
2.1.2、Hash索引
MySQL 中,只有Memory存储引擎显示支持hash索引,是Memory表的默认索引类型,尽管Memory表也可以使用B-Tree索引。Memory存储 引擎支持非唯一hash索引,这在数据库领域是罕见的,如果多个值有相同的hash code,索引把它们的行指针用链表保存到同一个hash表项中。
假设创建如下一个表:
CREATE TABLE testhash (
fname VARCHAR(50) NOT NULL,
lname VARCHAR(50) NOT NULL,
KEY USING HASH(fname)
) ENGINE=MEMORY;
包含的数据如下: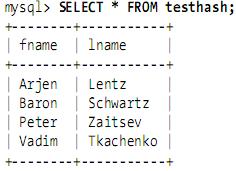
假设索引使用hash函数f( ),如下:
|
f('Arjen') = 2323 f('Baron') = 7437 f('Peter') = 8784 f('Vadim') = 2458 |
此时,索引的结构大概如下:
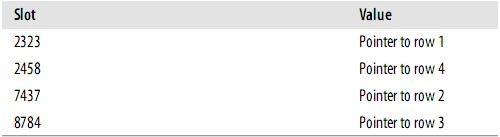
Slots是有序的,但是记录不是有序的。当你执行
mysql> SELECT lname FROM testhash WHERE fname='Peter';
MySQL会计算’Peter’的hash值,然后通过它来查询索引的行指针。因为f('Peter') = 8784,MySQL会在索引中查找8784,得到指向记录3的指针。
因为索引自己仅仅存储很短的值,所以,索引非常紧凑。Hash值不取决于列的数据类型,一个TINYINT列的索引与一个长字符串列的索引一样大。
Hash索引有以下一些限制:
(1)由于索引仅包含hash code和记录指针,所以,MySQL不能通过使用索引避免读取记录。但是访问内存中的记录是非常迅速的,不会对性造成太大的影响。
(2)不能使用hash索引排序。
(3)Hash索引不支持键的部分匹配,因为是通过整个索引值来计算hash值的。
(4)Hash索引只支持等值比较,例如使用=,IN( )和<=>。对于WHERE price>100并不能加速查询。
2.1.3、空间(R-Tree)索引
MyISAM支持空间索引,主要用于地理空间数据类型,例如GEOMETRY。
2.1.4、全文(Full-text)索引
全文索引是MyISAM的一个特殊索引类型,主要用于全文检索。
3、高性能的索引策略
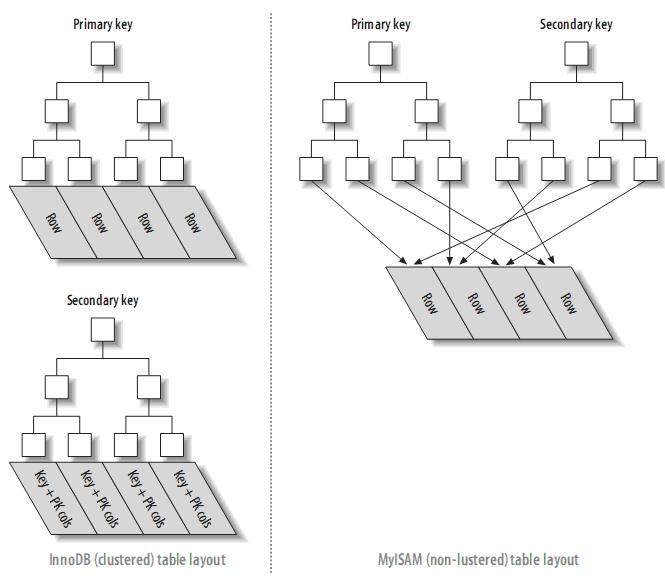
3.1、聚簇索引(Clustered Indexes)
聚 簇索引保证关键字的值相近的元组存储的物理位置也相同(所以字符串类型不宜建立聚簇索引,特别是随机字符串,会使得系统进行大量的移动操作),且一个表只 能有一个聚簇索引。因为由存储引擎实现索引,所以,并不是所有的引擎都支持聚簇索引。目前,只有solidDB和InnoDB支持。
聚簇索引的结构大致如下: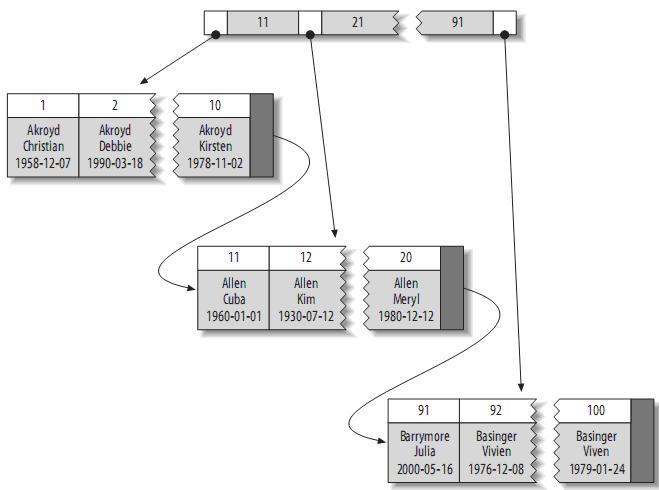
注: 叶子页面包含完整的元组,而内节点页面仅包含索引的列(索引的列为整型)。一些DBMS允许用户指定聚簇索引,但是MySQL的存储引擎到目前为止都不支 持。InnoDB对主键建立聚簇索引。如果你不指定主键,InnoDB会用一个具有唯一且非空值的索引来代替。如果不存在这样的索引,InnoDB会定义 一个隐藏的主键,然后对其建立聚簇索引。一般来说,DBMS都会以聚簇索引的形式来存储实际的数据,它是其它二级索引的基础。
3.1.1、InnoDB和MyISAM的数据布局的比较
为了更加理解聚簇索引和非聚簇索引,或者primary索引和second索引(MyISAM不支持聚簇索引),来比较一下InnoDB和MyISAM的数据布局,对于如下表:
|
CREATE TABLE layout_test ( col1 int NOT NULL, col2 int NOT NULL, PRIMARY KEY(col1), KEY(col2) ); |
假设主键的值位于1---10,000之间,且按随机顺序插入,然后用OPTIMIZE TABLE进行优化。col2随机赋予1---100之间的值,所以会存在许多重复的值。
(1) MyISAM的数据布局
其布局十分简单,MyISAM按照插入的顺序在磁盘上存储数据,如下: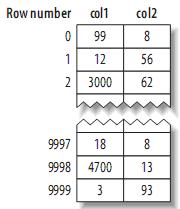
注:左边为行号(row number),从0开始。因为元组的大小固定,所以MyISAM可以很容易的从表的开始位置找到某一字节的位置。
据些建立的primary key的索引结构大致如下: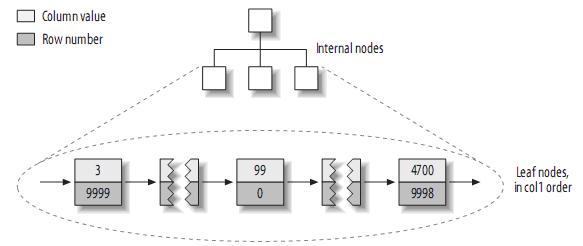
注:MyISAM不支持聚簇索引,索引中每一个叶子节点仅仅包含行号(row number),且叶子节点按照col1的顺序存储。
来看看col2的索引结构: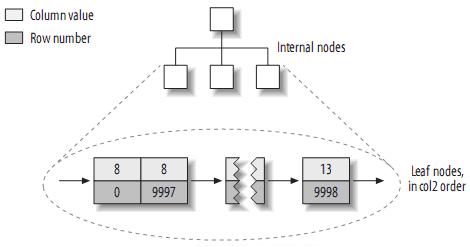
实际上,在MyISAM中,primary key和其它索引没有什么区别。Primary key仅仅只是一个叫做PRIMARY的唯一,非空的索引而已。
(2) InnoDB的数据布局
InnoDB按聚簇索引的形式存储数据,所以它的数据布局有着很大的不同。它存储表的结构大致如下: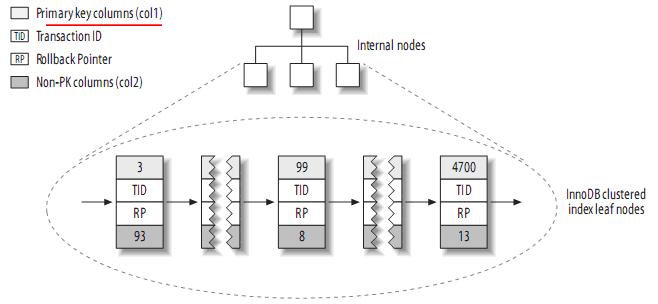
注:聚簇索引中的每个叶子节点包含primary key的值,事务ID和回滚指针(rollback pointer)——用于事务和MVCC,和余下的列(如col2)。
相 对于MyISAM,二级索引与聚簇索引有很大的不同。InnoDB的二级索引的叶子包含primary key的值,而不是行指针(row pointers),这减小了移动数据或者数据页面分裂时维护二级索引的开销,因为InnoDB不需要更新索引的行指针。其结构大致如下: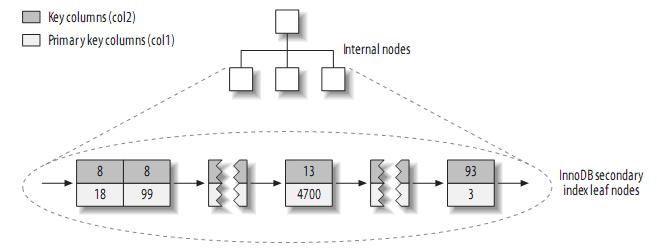
聚簇索引和非聚簇索引表的对比:
3.1.2、按primary key的顺序插入行(InnoDB)
如 果你用InnoDB,而且不需要特殊的聚簇索引,一个好的做法就是使用代理主键(surrogate key)——独立于你的应用中的数据。最简单的做法就是使用一个AUTO_INCREMENT的列,这会保证记录按照顺序插入,而且能提高使用 primary key进行连接的查询的性能。应该尽量避免随机的聚簇主键,例如,字符串主键就是一个不好的选择,它使得插入操作变得随机。
3.2、覆盖索引(Covering Indexes)
如果索引包含满足查询的所有数据,就称为覆盖索引。覆盖索引是一种非常强大的工具,能大大提高查询性能。只需要读取索引而不用读取数据有以下一些优点:
(1)索引项通常比记录要小,所以MySQL访问更少的数据;
(2)索引都按值的大小顺序存储,相对于随机访问记录,需要更少的I/O;
(3)大多数据引擎能更好的缓存索引。比如MyISAM只缓存索引。
(4)覆盖索引对于InnoDB表尤其有用,因为InnoDB使用聚集索引组织数据,如果二级索引中包含查询所需的数据,就不再需要在聚集索引中查找了。
覆盖索引不能是任何索引,只有B-TREE索引存储相应的值。而且不同的存储引擎实现覆盖索引的方式都不同,并不是所有存储引擎都支持覆盖索引(Memory和Falcon就不支持)。
对 于索引覆盖查询(index-covered query),使用EXPLAIN时,可以在Extra一列中看到“Using index”。例如,在sakila的inventory表中,有一个组合索引(store_id,film_id),对于只需要访问这两列的查 询,MySQL就可以使用索引,如下:
|
mysql> EXPLAIN SELECT store_id, film_id FROM sakila.inventory\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: inventory type: index possible_keys: NULL key: idx_store_id_film_id key_len: 3 ref: NULL rows: 5007 Extra: Using index 1 row in set (0.17 sec) |
在 大多数引擎中,只有当查询语句所访问的列是索引的一部分时,索引才会覆盖。但是,InnoDB不限于此,InnoDB的二级索引在叶子节点中存储了 primary key的值。因此,sakila.actor表使用InnoDB,而且对于是last_name上有索引,所以,索引能覆盖那些访问actor_id的查 询,如:
|
mysql> EXPLAIN SELECT actor_id, last_name -> FROM sakila.actor WHERE last_name = 'HOPPER'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: ref possible_keys: idx_actor_last_name key: idx_actor_last_name key_len: 137 ref: const rows: 2 Extra: Using where; Using index |
3.3、利用索引进行排序
MySQL 中,有两种方式生成有序结果集:一是使用filesort,二是按索引顺序扫描。利用索引进行排序操作是非常快的,而且可以利用同一索引同时进行查找和排 序操作。当索引的顺序与ORDER BY中的列顺序相同且所有的列是同一方向(全部升序或者全部降序)时,可以使用索引来排序。如果查询是连接多个表,仅当ORDER BY中的所有列都是第一个表的列时才会使用索引。其它情况都会使用filesort。
|
create table actor( actor_id int unsigned NOT NULL AUTO_INCREMENT, name varchar(16) NOT NULL DEFAULT '', password varchar(16) NOT NULL DEFAULT '', PRIMARY KEY(actor_id), KEY (name) ) ENGINE=InnoDB insert into actor(name,password) values('cat01','1234567'); insert into actor(name,password) values('cat02','1234567'); insert into actor(name,password) values('ddddd','1234567'); insert into actor(name,password) values('aaaaa','1234567'); |
|
mysql> explain select actor_id from actor order by actor_id \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: index possible_keys: NULL key: PRIMARY key_len: 4 ref: NULL rows: 4 Extra: Using index 1 row in set (0.00 sec)
mysql> explain select actor_id from actor order by password \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 4 Extra: Using filesort 1 row in set (0.00 sec)
mysql> explain select actor_id from actor order by name \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: index possible_keys: NULL key: name key_len: 18 ref: NULL rows: 4 Extra: Using index 1 row in set (0.00 sec) |
当 MySQL不能使用索引进行排序时,就会利用自己的排序算法(快速排序算法)在内存(sort buffer)中对数据进行排序,如果内存装载不下,它会将磁盘上的数据进行分块,再对各个数据块进行排序,然后将各个块合并成有序的结果集(实际上就是 外排序)。对于filesort,MySQL有两种排序算法。
(1)两遍扫描算法(Two passes)
实现方式是先将须要排序的字段和可以直接定位到相关行数据的指针信息取出,然后在设定的内存(通过参数sort_buffer_size设定)中进行排序,完成排序之后再次通过行指针信息取出所需的Columns。
注:该算法是4.1之前采用的算法,它需要两次访问数据,尤其是第二次读取操作会导致大量的随机I/O操作。另一方面,内存开销较小。
(3) 一次扫描算法(single pass)
该算法一次性将所需的Columns全部取出,在内存中排序后直接将结果输出。
注: 从 MySQL 4.1 版本开始使用该算法。它减少了I/O的次数,效率较高,但是内存开销也较大。如果我们将并不需要的Columns也取出来,就会极大地浪费排序过程所需要 的内存。在 MySQL 4.1 之后的版本中,可以通过设置 max_length_for_sort_data 参数来控制 MySQL 选择第一种排序算法还是第二种。当取出的所有大字段总大小大于 max_length_for_sort_data 的设置时,MySQL 就会选择使用第一种排序算法,反之,则会选择第二种。为了尽可能地提高排序性能,我们自然更希望使用第二种排序算法,所以在 Query 中仅仅取出需要的 Columns 是非常有必要的。
当对连接操作进行排序时,如果ORDER BY仅仅引用第一个表的列,MySQL对该表进行filesort操作,然后进行连接处理,此时,EXPLAIN输出“Using filesort”;否则,MySQL必须将查询的结果集生成一个临时表,在连接完成之后进行filesort操作,此时,EXPLAIN输出 “Using temporary;Using filesort”。
3.4、索引与加锁
索引对于InnoDB非 常重要,因为它可以让查询锁更少的元组。这点十分重要,因为MySQL 5.0中,InnoDB直到事务提交时才会解锁。有两个方面的原因:首先,即使InnoDB行级锁的开销非常高效,内存开销也较小,但不管怎么样,还是存 在开销。其次,对不需要的元组的加锁,会增加锁的开销,降低并发性。
InnoDB仅对需要访问的元组加锁,而索引能够减少InnoDB访问的元组 数。但是,只有在存储引擎层过滤掉那些不需要的数据才能达到这种目的。一旦索引不允许InnoDB那样做(即达不到过滤的目的),MySQL服务器只能对 InnoDB返回的数据进行WHERE操作,此时,已经无法避免对那些元组加锁了:InnoDB已经锁住那些元组,服务器无法解锁了。
来看个例子:
|
create table actor( actor_id int unsigned NOT NULL AUTO_INCREMENT, name varchar(16) NOT NULL DEFAULT '', password varchar(16) NOT NULL DEFAULT '', PRIMARY KEY(actor_id), KEY (name) ) ENGINE=InnoDB insert into actor(name,password) values('cat01','1234567'); insert into actor(name,password) values('cat02','1234567'); insert into actor(name,password) values('ddddd','1234567'); insert into actor(name,password) values('aaaaa','1234567'); |
|
SET AUTOCOMMIT=0; BEGIN; SELECT actor_id FROM actor WHERE actor_id < 4 AND actor_id <> 1 FOR UPDATE; |
该查询仅仅返回2---3的数据,实际已经对1---3的数据加上排它锁了。InnoDB锁住元组1是因为MySQL的查询计划仅使用索引进行范围查询(而没有进行过滤操作,WHERE中第二个条件已经无法使用索引了):
|
mysql> EXPLAIN SELECT actor_id FROM test.actor -> WHERE actor_id < 4 AND actor_id <> 1 FOR UPDATE \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: index possible_keys: PRIMARY key: PRIMARY key_len: 4 ref: NULL rows: 4 Extra: Using where; Using index 1 row in set (0.00 sec)
mysql> |
表明存储引擎从索引的起始处开始,获取所有的行,直到actor_id<4为假,服务器无法告诉InnoDB去掉元组1。
为了证明row 1已经被锁住,我们另外建一个连接,执行如下操作:
|
SET AUTOCOMMIT=0; BEGIN; SELECT actor_id FROM actor WHERE actor_id = 1 FOR UPDATE; |
该查询会被挂起,直到第一个连接的事务提交释放锁时,才会执行(这种行为对于基于语句的复制(statement-based replication)是必要的)。
如上所示,当使用索引时,InnoDB会锁住它不需要的元组。更糟糕的是,如果查询不能使用索引,MySQL会进行全表扫描,并锁住每一个元组,不管是否真正需要。
转自:http://www.cnblogs.com/hustcat/archive/2009/10/28/1591648.html



相关推荐
基于Python的天气预测与可视化(完整源码+说明文档+数据),个人经导师指导并认可通过的高分设计项目,评审分99分,代码完整确保可以运行,小白也可以亲自搞定,主要针对计算机相关专业的正在做大作业的学生和需要项目实战练习的学习者,可作为毕业设计、课程设计、期末大作业,代码资料完整,下载可用。 基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基于Python的天气预测与可视化(完整源码+说明文档+数据)基
内容概要:本文详细介绍了利用MIM(金属-介质-金属)结构进行梯度相位超表面的设计与仿真的全过程。首先,通过Au-MgF2-Au三明治结构,利用磁偶极子共振实现高效的相位控制。接着,通过FDTD仿真工具,编写参数扫描脚本来优化纳米柱尺寸,从而实现广泛的相位覆盖。然后,通过近远场变换计算异常反射效率,验证了高达85%以上的反射效率。此外,还探讨了宽带性能验证的方法以及梯度相位阵列的设计思路。最后,提供了实用的代码片段和注意事项,帮助读者理解和复现实验结果。 适合人群:从事超表面研究、光束控制、电磁仿真领域的科研人员和技术开发者。 使用场景及目标:适用于希望深入了解MIM结构在超表面设计中的应用,掌握FDTD仿真技巧,以及探索高效光束偏折机制的研究人员。目标是通过详细的步骤指导,使读者能够成功复现并优化类似实验。 其他说明:文章不仅提供了理论背景,还包括大量具体的代码实现和实践经验分享,有助于读者更好地理解和应用所学知识。
内容概要:本文探讨了利用主从博弈理论解决共享储能与综合能源微网之间的利益冲突。通过MATLAB和YALMIP+Cplex工具,构建了微网运营商、用户聚合商和共享储能服务商三者之间的博弈模型。主要内容包括系统架构介绍、核心代码解析、求解策略以及仿真结果分析。文中详细展示了如何通过Stackelberg模型实现三方利益的最大化,并提供了完整的代码实现和详细的注释。 适合人群:从事能源互联网项目的研发人员、对博弈论及其应用感兴趣的学者和技术爱好者。 使用场景及目标:适用于希望深入了解能源系统优化、主从博弈理论及其MATLAB实现的研究人员和工程师。目标是掌握如何通过编程手段解决复杂系统中的多主体利益协调问题。 其他说明:文章不仅介绍了理论背景,还提供了具体的代码实现细节,如参数初始化、目标函数构建、约束条件处理等。此外,还包括了仿真结果的可视化展示,帮助读者更好地理解模型的实际效果。
内容概要:本文深入探讨了基于FPGA平台实现直方图统计与均衡化的全过程,涵盖直方图统计、累积直方图计算和均衡化处理三大核心步骤。文中不仅提供了详细的Verilog代码实现,还介绍了关键的设计思路和技术难点,如双端口BRAM的应用、流水线控制、除法器资源优化等。此外,通过Matlab代码进行了结果验证,确保FPGA实现的准确性。 适合人群:从事FPGA开发、图像处理、计算机视觉等相关领域的工程师和技术爱好者。 使用场景及目标:适用于需要高性能、低延迟图像处理的应用场景,如实时视频处理、医学图像处理、卫星图像增强等。目标是掌握FPGA实现直方图均衡化的技术细节,提高图像对比度和清晰度。 其他说明:文章强调了FPGA相较于CPU和GPU在并行处理和硬件加速方面的优势,并提供了丰富的代码实例和测试结果,帮助读者更好地理解和应用这一技术。
内容概要:本文详细介绍了利用LSTM模型进行高速公路车辆换道轨迹预测的研究过程。首先,作者使用来自I-80和US-101高速公路的实际换道轨迹数据,这些数据包括横向和纵向的速度、加速度以及轨迹坐标等特征。通过对数据进行预处理,如标准化、划分训练集和测试集等步骤,确保了数据的质量。然后,设计并实现了包含两层LSTM和一层全连接层的神经网络模型,采用Adam优化器进行训练,并通过交叉熵损失函数评估模型性能。实验结果显示,模型在测试集上的准确率达到85%,表明LSTM模型能够有效捕捉车辆换道的行为模式。 适合人群:从事自动驾驶技术研发的专业人士,尤其是对深度学习应用于交通预测感兴趣的工程师和技术研究人员。 使用场景及目标:本研究旨在提高自动驾驶系统的安全性与效率,具体应用场景包括但不限于城市快速路、高速公路等复杂路况下车辆换道行为的提前预测,从而辅助驾驶员或自动驾驶系统做出更好的决策。 其他说明:尽管目前模型已经取得了较好的成绩,但仍存在改进空间,例如可以通过引入更多类型的传感器数据(如摄像头图像)、优化现有模型结构等方式进一步提升预测精度。此外,考虑到实际应用中的实时性和鲁棒性要求,后续还需针对硬件平台进行针对性优化。
个人资料-111相关内容
内容概要:本文详细介绍了使用HyperWorks和LS-DYNA进行汽车碰撞仿真的方法和技术要点。从网格划分、材料属性设置、连接装配到最后的分析计算和结果处理,每个环节都配有具体的代码示例和注意事项。文中不仅涵盖了正碰、侧碰、偏置碰等多种类型的碰撞分析,还包括了座椅安全带约束等特殊部件的建模技巧。此外,作者分享了许多实践经验,如网格尺寸的选择、材料参数的设定以及求解器设置的最佳实践,帮助读者避免常见的陷阱并提高仿真效率。 适合人群:从事汽车工程领域的工程师、研究人员以及对汽车碰撞仿真感兴趣的初学者。 使用场景及目标:适用于需要掌握汽车碰撞仿真完整流程的专业人士,旨在提升其在实际项目中的应用能力,确保仿真结果的准确性和可靠性。 其他说明:附赠的源代码进一步增强了学习效果,使读者能够快速上手并在实践中不断优化自己的技能。
内容概要:本文详细介绍了如何在MATLAB/Simulink环境中搭建四分之一车被动悬架双质量(二自由度)模型。该模型主要用于研究车辆悬架系统在垂直方向上的动态特性,特别是面对路面不平度时的表现。文中不仅提供了具体的建模步骤,包括输入模块、模型主体搭建和输出模块的设计,还给出了详细的参数配置方法和仿真分析技巧。此外,文章还探讨了如何通过调整悬架系统的参数(如阻尼系数)来优化车辆的乘坐舒适性和行驶安全性。 适合人群:从事汽车动力学研究的专业人士、高校相关专业的学生以及对车辆悬架系统感兴趣的工程师。 使用场景及目标:①用于教学目的,帮助学生理解车辆悬架系统的理论知识;②用于科研实验,验证不同的悬架设计方案;③为企业产品研发提供技术支持,改进现有产品的性能。 其他说明:文中提供的代码片段和建模思路有助于读者快速上手并掌握Simulink建模技能。同时,强调了实际应用中的注意事项,如选择合适的求解器、处理代数环等问题。
内容概要:本文详细介绍了使用MATLAB进行语音数据处理的完整流程,涵盖从音频文件读取、特征提取(特别是梅尔倒谱系数MFCC)、分类器构建(支持向量机SVM)到最后的性能评估(混淆矩阵)。作者分享了许多实用技巧,如避免常见错误、优化特征提取参数以及提高分类准确性的方法。文中提供了大量具体代码示例,帮助读者快速理解和应用相关技术。 适合人群:对语音信号处理感兴趣的初学者或有一定经验的研究人员和技术爱好者。 使用场景及目标:适用于希望深入了解语音识别系统内部机制的人群,尤其是希望通过MATLAB平台实现简单而有效的语音分类任务的学习者。主要目的是掌握如何利用MATLAB工具箱完成从原始音频到分类结果可视化的全过程。 其他说明:除了介绍基本概念外,还强调了一些实践经验,例如预处理步骤的重要性、选择合适的滤波器数目、尝试不同的分类器配置等。此外,作者鼓励读者根据实际情况调整参数设置,以获得更好的实验效果。
基于python+yolov5和deepsort实现的行人或车辆跟踪计数系统+源码+项目文档+演示视频,适合毕业设计、课程设计、项目开发。项目源码已经过严格测试,可以放心参考并在此基础上延申使用,详情见md文档 项目运行环境:win10,pycharm,python3.6+ 主要需要的包:pytorch >= 1.7.0,opencv 运行main.py即可开始追踪检测,可以在控制台运行 基于python+yolov5和deepsort实现的行人或车辆跟踪计数系统+源码+项目文档+演示视频,适合毕业设计、课程设计、项目开发。项目源码已经过严格测试,可以放心参考并在此基础上延申使用,详情见md文档 项目运行环境:win10,pycharm,python3.6+ 主要需要的包:pytorch >= 1.7.0,opencv 运行main.py即可开始追踪检测,可以在控制台运行~
内容概要:本文详细介绍了金-氟化镁-金(MIM)结构在超表面全息领域的应用及其高效性能。首先探讨了MIM结构中磁偶极子模式的优势,特别是其低辐射损耗的特点。接着讨论了几何相位的应用,展示了纳米柱旋转角度与相位延迟之间的线性关系,并解决了相位误差的问题。随后介绍了改进的GS算法,提高了迭代收敛速度。最后,通过FDTD仿真验证了MIM结构的高效率,提供了详细的仿真参数设置和优化技巧。 适合人群:从事超表面研究、光学工程、纳米技术和FDTD仿真的研究人员和技术人员。 使用场景及目标:适用于希望深入了解MIM结构在超表面全息中的应用,以及希望通过FDTD仿真进行相关研究的专业人士。目标是提高超表面全息的转换效率,探索新的应用场景如涡旋光生成和偏振加密全息。 其他说明:文中提供了大量具体的代码片段和参数设置,帮助读者更好地理解和复现实验结果。此外,还提到了一些常见的仿真陷阱和解决方案,有助于避免常见错误并提升仿真准确性。
内容概要:文章介绍了金融科技公司信用飞如何通过关注用户信用成长,利用先进技术和专业服务为用户量身定制金融解决方案,从而实现用户资产的稳健增值。首先,信用飞通过多维度数据分析,全面了解用户的信用状况和需求,为不同信用水平的用户提供个性化服务。其次,建立了动态信用评估体系,实时监测并调整用户信用服务策略,帮助用户持续提升信用。再者,根据不同用户的需求,提供包括信用消费、理财投资、融资借贷等在内的多样化金融服务。最后,借助大数据、人工智能、区块链等技术手段,确保金融服务的安全可靠和高效便捷,持续陪伴用户实现信用与财富的双重增长。 适合人群:对个人信用管理有一定需求,希望通过科学金融规划实现资产稳健增值的个人及小微企业主。 使用场景及目标:①希望提升个人或企业信用评级的用户;②寻求合适金融产品和服务以优化财务管理的人群;③需要安全可靠的融资渠道支持业务发展的创业者和中小企业。 阅读建议:本文详细阐述了信用飞如何通过技术创新和个性化服务助力用户信用成长及资产增值,建议读者重点关注文中提到的技术应用和服务特色,结合自身情况思考如何更好地利用此类金融科技服务来优化个人或企业的财务状况。
少儿编程scratch项目源代码文件案例素材-AI战争.zip
内容概要:本文详细介绍了出口设备1200线体程序的配置与优化方法,涵盖PLC通讯控制、V90模块配置以及工艺对象与FB284的协同控制。文章强调了开源特性的优势,使得用户可以自由扩展和优化控制系统。主要内容包括:1) 出口设备1200线体程序的核心地位及其复杂控制逻辑;2) 多个PLC设备的通讯协作,确保数据可靠传输;3) V90模块的具体配置步骤,确保各模块稳定运行;4) 工艺对象与FB284的协同控制,避免逻辑冲突;5) 开源带来的便利性,便于用户进行功能扩展和学习;6) 实际应用中的优化措施,提高系统的运行效率。 适合人群:从事工业自动化领域的工程师和技术人员,尤其是那些希望深入了解PLC通讯控制和V90伺服配置的人。 使用场景及目标:适用于需要配置和优化出口设备1200线体程序的实际工程项目,帮助用户掌握PLC通讯、V90配置及工艺对象与FB284协同控制的方法,从而提升生产线的效率和稳定性。 其他说明:文章提供了大量实用的代码片段和调试技巧,有助于读者更好地理解和实施相关配置。同时,文中提到的一些具体案例和经验分享也为实际操作提供了宝贵的参考。
前端面试与vue源码讲解
少儿编程scratch项目源代码文件案例素材-green vs blue.zip
内容概要:本文详细介绍了博世汽车电驱仿真模型中同步电机和异步电机的FOC(磁场定向控制)技术及其优化方法。主要内容涵盖相电流波形生成、弱磁控制、正反转切换、滑差补偿以及铁损计算等方面的技术细节。通过MATLAB、Python和C等多种编程语言实现了对电机控制的精确模拟,展示了如何通过数学方法和智能算法提高电机性能,减少电流畸变和转矩脉动。文中特别强调了弱磁控制在高速区的应用,通过动态查表法自动调整d轴电流分量,有效解决了电压极限椭圆的问题。此外,还提到了一些创新性的技术应用,如相位预判机制、动态滑差补偿和自适应耦合系数计算等。 适合人群:从事电机控制、电动汽车研究及相关领域的工程师和技术人员。 使用场景及目标:适用于希望深入了解同步电机和异步电机FOC控制原理及其实现方法的研究人员和工程师。目标是掌握先进的电机控制技术和优化方法,应用于实际项目中,提高系统性能和可靠性。 其他说明:文章不仅提供了详细的理论解释,还附有具体的代码实现,便于读者理解和实践。同时,文中提到的一些创新性技术可以为相关领域的研究提供新的思路和方法。
少儿编程scratch项目源代码文件案例素材-RPG游戏引擎5.5c.zip
2025年6G近场技术白皮书2.0.pdf
少儿编程scratch项目源代码文件案例素材-scratch 通关游戏.zip