
õĖĆ.Õ║ÅĶ©Ć
┬Ā ┬Ā õ╗źÕēŹõĖĆĶĮ¼Ķ┐ćõĖĆõ║øµ¢ćń½Ā’╝īĶ┐ÖķćīÕŹÜõĖ╗ÕåÖõ╗źÕÅŖµ¢ćõĖŁńÜäõĖĆõ║øķōŠµÄź’╝īķāĮµī║ÕźĮńÜä’╝īĶĮ¼ń╗ÖÕż¦Õ«Č
┬Ā ┬Ā ÕĤµ¢ćÕ£░ÕØĆ’╝Ühttp://my.oschina.net/geecoodeer/blog/202693
┬Ā
µ£¼µ¢ćµŚ©Õ£©ń«ĆÕŹĢõ╗ŗń╗ŹÕż¦Õ×ŗõ║ÆĶüöńĮæńÜäµ×ȵ×äÕÆīµĀĖÕ┐āń╗äõ╗ČÕ«×ńÄ░ÕĤńÉåŃĆé ńÉåĶ«║õĖŖĶ«▓’╝īõ╗ÄÕ«ēĶŻģķģŹńĮ«’╝īµ£ĆõĮ│Õ«×ĶĘĄõ╗źÕÅŖµ║ÉńĀüµØźÕē¢µ×ÉÕÉäõĖ¬ń╗äõ╗Č’╝īĶ┐ÖõĖ¬Ķć¬ńäȵś»µ×üÕźĮńÜäŃĆéńö▒õ║Äń¼öĶĆģµŚČķŚ┤õ╗źÕÅŖń¤źĶ»åµ£ēķÖÉ’╝īµ£ēÕŠłÕżÜń¤źĶ»åµ▓Īµ£ēÕ£©ÕĘźõĮ£õĖŁõ║▓Ķć¬Õ«×ĶĘĄńÜäµ£║õ╝ÜŃĆéµēĆõ╗źµ£ēõ║øÕ£░µ¢╣Ķ»ŁńäēõĖŹĶ»”’╝īĶ┐śĶ»ĘÕż¦Õ«ČÕżÜÕżÜµīćµĢÖŃĆé
Õż¦Õ×ŗõ║ÆĶüöńĮæµ×ȵ×ä
Ķ¦ŻÕå│ķŚ«ķóśńÜäķĆÜńö©µĆØĶĘ»µś»Õ░åÕłåĶĆīµ▓╗õ╣ŗ’╝łdivide-and-conquer’╝ē’╝īÕ░åÕż¦ķŚ«ķóśÕłåõĖ║ĶŗźÕ╣▓õĖ¬Õ░ÅķŚ«ķóś’╝īÕÉäõĖ¬Õć╗ńĀ┤ŃĆéÕ£©Õż¦Õ×ŗõ║ÆĶüöńĮæńÜäµ×ȵ×äÕ«×ĶĘĄõĖŁ’╝īµŚĀõĖĆõĖŹõĮōńÄ░Ķ┐Öń¦ŹµĆصā│ŃĆé
µ×ȵ×äńø«µĀć
- õĮĵłÉµ£¼:õ╗╗õĮĢÕģ¼ÕÅĖÕŁśÕ£©ńÜäõ╗ĘÕĆ╝ķāĮµś»õĖ║õ║åĶÄĘÕÅ¢ÕĢåõĖÜÕł®ńøŖŃĆéÕ£©ÕÅ»ĶāĮńÜäµāģÕåĄõĖŗ’╝īÕĖīµ£øõĖĆÕłćķāĮµś»õĮĵłÉµ£¼ńÜäŃĆé
- ķ½śµĆ¦ĶāĮ:ńĮæń½ÖµĆ¦ĶāĮµś»Õ«óĶ¦éńÜäµīćµĀć’╝īÕÅ»õ╗źÕģĘõĮōõĮōńÄ░Õł░ÕōŹÕ║öµŚČķŚ┤ŃĆüÕÉ×ÕÉÉķćÅńŁēµŖƵ£»µīćµĀćŃĆéń│╗ń╗¤ńÜäÕōŹÕ║öÕ╗ČĶ┐¤’╝īµīćń│╗ń╗¤Õ«īµłÉµ¤ÉõĖĆÕŖ¤ĶāĮķ£ĆĶ”üõĮ┐ńö©ńÜ䵌ČķŚ┤’╝øń│╗ń╗¤ńÜäÕÉ×ÕÉÉķćÅ’╝īµīćń│╗ń╗¤Õ£©µ¤ÉõĖƵŚČķŚ┤ÕÅ»õ╗źÕżäńÉåńÜäµĢ░µŹ«µĆ╗ķćÅ’╝īķĆÜÕĖĖÕÅ»õ╗źńö©ń│╗ń╗¤µ»Åń¦ÆÕżäńÉåńÜäµĆ╗ńÜäµĢ░µŹ«ķćÅµØźĶĪĪķćÅ’╝øń│╗ń╗¤ńÜäÕ╣ČÕÅæĶāĮÕŖø’╝īµīćń│╗ń╗¤ÕÅ»õ╗źÕÉīµŚČÕ«īµłÉµ¤ÉõĖĆÕŖ¤ĶāĮńÜäĶāĮÕŖø’╝īķĆÜÕĖĖõ╣¤ńö© QPS(query per second)µØźĶĪĪķćÅŃĆé
- ķ½śÕÅ»ńö©’╝Üń│╗ń╗¤ńÜäÕÅ»ńö©µĆ¦(availability)µīćń│╗ń╗¤Õ£©ķØóÕ»╣ÕÉäń¦ŹÕ╝éÕĖĖµŚČÕÅ»õ╗źµŁŻńĪ«µÅÉõŠøµ£ŹÕŖĪńÜäĶāĮÕŖøŃĆéń│╗ń╗¤ńÜäÕÅ»ńö©µĆ¦ÕÅ»┬Ā
õ╗źńö©ń│╗ń╗¤Õü£µ£ŹÕŖĪńÜ䵌ČķŚ┤õĖĵŁŻÕĖĖµ£ŹÕŖĪńÜ䵌ČķŚ┤ńÜäµ»öõŠŗµØźĶĪĪķćÅ’╝īõ╣¤ÕÅ»õ╗źńö©µ¤ÉÕŖ¤ĶāĮńÜäÕż▒Ķ┤źµ¼ĪµĢ░õĖĵłÉÕŖ¤µ¼ĪµĢ░ńÜäµ»öõŠŗµØźĶĪĪķćÅŃĆé - µśōõ╝Ėń╝®’╝ܵ│©ķćŹń║┐µĆ¦µē®Õ▒Ģ’╝īµś»ÕÉ”ÕÅ»õ╗źÕ«╣µśōķĆÜĶ┐ćÕŖĀÕģźµ£║ÕÖ©µØźÕżäńÉåõĖŹµ¢ŁõĖŖÕŹćńÜäńö©µłĘĶ«┐ķŚ«ÕÄŗÕŖøŃĆéń│╗ń╗¤ńÜäõ╝Ėń╝®µĆ¦(scalability)µīćÕłåÕĖāÕ╝Åń│╗ń╗¤ķĆÜĶ┐ćµē®Õ▒ĢķøåńŠżµ£║ÕÖ©Ķ¦äµ©ĪµÅÉķ½śń│╗ń╗¤µĆ¦ĶāĮ’╝łÕÉ×ÕÉÉŃĆüÕ╗ČĶ┐¤ŃĆüÕ╣ČÕÅæ’╝ēŃĆüÕŁśÕé©Õ«╣ķćÅŃĆüĶ«Īń«ŚĶāĮÕŖøńÜäńē╣µĆ¦ŃĆé
- ķ½śÕ«ēÕģ©’╝ÜńÄ░Õ£©ÕĢåõĖÜńÄ»ÕóāõĖŁ’╝īń╗ÅÕĖĖÕć║ńÄ░Ķó½ńĮæń½ÖĶó½µŗ¢Õ║ō’╝īńö©µłĘĶ┤”µłĘĶó½ńøŚńŁēńÄ░Ķ▒ĪŃĆéńĮæń½ÖńÜäÕ«ēÕģ©µĆ¦õĖŹĶ©ĆĶĆīÕ¢╗ŃĆé
ÕģĖÕ×ŗÕ«×ńÄ░
õĖŗķØóÕģĖÕ×ŗńÜäõĖƵ¼Īwebõ║żõ║ÆĶ»Ęµ▒éńż║µäÅÕøŠŃĆé
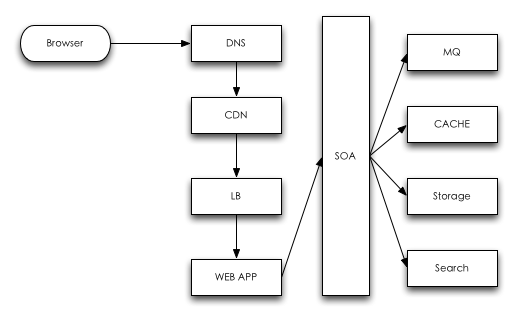
DNS
- ÕĮōńö©µłĘÕ£©µĄÅĶ¦łÕÖ©õĖŁĶŠōÕģźńĮæń½ÖÕ£░ÕØĆÕÉÄ’╝īµĄÅĶ¦łÕÖ©õ╝ܵŻĆµ¤źµĄÅĶ¦łÕÖ©ń╝ōÕŁśõĖŁµś»ÕÉ”ÕŁśÕ£©Õ»╣Õ║öÕ¤¤ÕÉŹńÜäĶ¦Żµ×Éń╗ōµ×£ŃĆéÕ”éµ×£µ£ē’╝īÕłÖĶ¦Żµ×ÉĶ┐ćń©ŗń╗ōµØ¤’╝øÕÉ”ÕłÖĶ┐øÕģźõĖŗõĖĆõĖ¬µŁźķ¬ż
- µĄÅĶ¦łÕÖ©µ¤źµēŠµōŹõĮ£ń│╗ń╗¤ń╝ōÕŁśõĖŁµś»ÕÉ”ÕŁśÕ£©Ķ┐ÖõĖ¬Õ¤¤ÕÉŹńÜäĶ¦Żµ×Éń╗ōµ×£ŃĆéĶ┐ÖõĖ¬ń╝ōÕŁśńÜäÕåģÕ«╣µØźµ║ÉÕ░▒µś»µōŹõĮ£ń│╗ń╗¤ńÜähostsµ¢ćõ╗ČŃĆéÕ”éµ×£µ£ē’╝īÕłÖĶ¦Żµ×ÉĶ┐ćń©ŗń╗ōµØ¤’╝øÕÉ”ÕłÖĶ┐øÕģźõĖŗõĖĆõĖ¬µŁźķ¬ż
- ÕēŹõĖżõĖ¬µŁźķ¬żķāĮµś»µ£¼Õ£░µ¤źµēŠ’╝īµ▓Īµ£ēÕÅæńö¤ńĮæń╗£õ║żõ║ÆŃĆéÕ£©µ£¼µŁźķ¬żõĖŁ’╝īõ╝ÜõĮ┐ńö©Õł░Õ£©ńĮæń╗£ķģŹńĮ«ńÜäõĖŁDNSÕ£░ÕØĆŃĆéĶ┐ÖõĖ¬Õ£░ÕØƵłæõ╗¼ķĆÜÕĖĖń¦░õ╣ŗõĖ║LDNS’╝łLocal DNS’╝ēŃĆéµōŹõĮ£ń│╗ń╗¤õ╝ܵŖŖÕ¤¤ÕÉŹÕÅæķĆüń╗ÖLDNSĶ¦Żµ×ÉŃĆéÕ”éµ×£Ķ¦Żµ×ɵłÉÕŖ¤’╝īÕłÖĶ¦Żµ×ÉĶ┐ćń©ŗń╗ōµØ¤’╝øÕÉ”ÕłÖĶ┐øÕģźõĖŗõĖĆõĖ¬µŁźķ¬ż
- LDNSÕ░åĶ»Ęµ▒éĶ┐öÕø×ń╗ÖGTLD’╝łGlobal Top Level Domain’╝ēµ£ŹÕŖĪÕÖ©’╝īGTLDµ£ŹÕŖĪÕÖ©µ¤źµēŠµŁżÕ¤¤ÕÉŹÕ»╣Õ║öńÜäName ServerÕ¤¤ÕÉŹńÜäÕ£░ÕØĆŃĆéĶ┐ÖõĖ¬Name ServerķĆÜÕĖĖÕ░▒µś»õĮĀńÜäÕ¤¤ÕÉŹµÅÉõŠøÕĢåńÜäµ£ŹÕŖĪÕÖ©ŃĆéName ServerµĀ╣µŹ«Õ«óµłĘĶ»Ęµ▒é’╝īĶ┐öÕø×Ķ»źÕ¤¤ÕÉŹÕ»╣Õ║öńÜäIPÕ£░ÕØĆÕÆīTTL(Time To Live)ÕĆ╝ŃĆé
- µĄÅĶ¦łÕÖ©µĀ╣µŹ«TTLÕĆ╝’╝īµŖŖĶ┐ÖõĖ¬Õ¤¤ÕÉŹÕ»╣Õ║öńÜäIPń╝ōÕŁśÕ£©µ£¼Õ£░ń│╗ń╗¤õĖŁŃĆéÕ¤¤ÕÉŹĶć│µŁżĶ¦Żµ×Éń╗ōµØ¤ŃĆé
CDN
CDN’╝łContent Delivery Network’╝īÕåģÕ«╣ÕłåÕÅæńĮæń╗£’╝ēķā©ńĮ▓Õ£©ńĮæń╗£µÅÉõŠøÕĢåńÜäµ£║µł┐ķćīķØóŃĆéÕ£©ńö©µłĘĶ»Ęµ▒éńĮæń½Öµ£ŹÕŖĪµŚČ’╝īÕÅ»õ╗źõ╗ÄĶĘØń”╗Ķć¬ÕĘ▒µ£ĆĶ┐æńÜäńĮæń╗£µÅÉõŠøÕĢåĶÄĘÕÅ¢µĢ░µŹ«ŃĆéµ»öÕ”éĶ¦åķóæńĮæń½ÖÕÆīÕåģÕ«╣ńĮæń½ÖńÜäńāŁńé╣ÕåģÕ«╣ŃĆé
Õ”éµ×£ķ£ĆĶ”üĶć¬ÕĘ▒µÉŁÕ╗║CDNń│╗ń╗¤’╝īµ£ē3ń¦ŹõĖ╗µĄüµ¢╣µĪłÕÅ»õ╗źķĆēµŗ®:
- squidµś»ń╝ōÕŁśµ£ŹÕŖĪÕÖ©ń¦æńÅŁÕć║ńö¤,Ķć¬ÕĘ▒Õ«×ńÄ░õ║åõĖĆÕźŚÕåģÕŁśķĪĄ/ńŻüńøśķĪĄńÜäń«ĪńÉåń│╗ń╗¤
- varnishµś»Ķ¦ēÕŠŚsquidµĆ¦ĶāĮõĖŹĶĪī’╝īvarnishĶ¦ēÕŠŚlinuxÕåģµĀĖÕĘ▓ń╗ŵŖŖĶÖܵŗ¤ÕåģÕŁśń«ĪńÉåÕüÜÕŠŚÕŠłÕźĮõ║å’╝īsquidńÜäÕżÜµŁżõĖĆõĖŠÕÅŹĶĆīÕĮ▒ÕōŹõ║åµĆ¦ĶāĮŃĆé
- nginx cacheµś»Õ▒×õ║ÄõĖŹÕŖĪµŁŻõĖÜ’╝īÕŠŚńøŖõ║ÄnginxÕ╝║Õż¦ńÜäµÅÆõ╗ȵ£║ÕłČŃĆé
LB
LB(Load Balance’╝īĶ┤¤ĶĮĮÕØćĶĪĪ)Õ░▒µś»Õ░åĶ┤¤ĶĮĮ’╝łńö©µłĘńÜäĶ»Ęµ▒é’╝ēµĀ╣µŹ«µ¤Éõ║øńŁ¢ńĢź’╝īÕ░åĶ┤¤ĶĮĮÕłåµæŖń╗ÖÕżÜõĖ¬µōŹõĮ£ÕŹĢÕģāµē¦ĶĪīŃĆéĶ»źµŖƵ£»ÕÅ»õ╗źµÅÉõŠøµ£ŹÕŖĪÕÖ©ńÜäÕōŹÕ║öķƤÕ║”õ╗źÕÅŖÕł®ńö©µĢłńÄć’╝īķü┐ÕģŹÕć║ńÄ░ÕŹĢńé╣Õż▒µĢłŃĆé
Ķ┐ÖķćīÕø×ķĪŠõĖŗÕēŹķØóõ╗ŗń╗ŹńÜäõĖżõĖ¬Õ░ÅĶŖé’╝īÕģČÕ«×µ£¼Ķ┤©õĖŖµŖŖµĢ░µŹ«Õłåń▒╗’╝łµĀ╣µŹ«µĢ░µŹ«µø┤µ¢░ķóæńÄć’╝īÕłåõĖ║ÕŖ©µĆüµ¢ćõ╗Č’╝īķØÖµĆüµ¢ćõ╗Č’╝ē’╝īÕ╣ȵŖŖµĢ░µŹ«µöŠÕ£©ń”╗ĶĘØń”╗ńö©µłĘµ£ĆĶ┐æńÜäÕ£░µ¢╣ŃĆéÕÅ”Õż¢õĖĆńé╣Õ░▒µś»’╝īÕ£©DNSÕÆīCDNÕģĘõĮōÕ«×ńÄ░µŚČ’╝īõ╣¤µś»Õż¦ķćÅõĮ┐ńö©õ║åĶ┤¤ĶĮĮÕØćĶĪĪµŖƵ£»ŃĆé
ÕĖĖĶ¦üńÜäĶ┤¤ĶĮĮÕØćĶĪĪń«Śµ│Ģńö▒’╝ÜRR’╝łRound Robin’╝īĶĮ«Ķ»ó’╝ē,WRR’╝łWeighted RR’╝īÕŖĀµØāĶĮ«Ķ»ó’╝ē’╝īRandom’╝łķÜŵ£║’╝ē’╝īLC’╝łLeast Connection’╝īµ£ĆÕ░æĶ┐׵ğ’╝ē’╝īSH’╝łSource Hash,µ║ÉÕØĆÕōłÕĖī’╝ē
Õ£©ÕĖĖĶ¦üńÜäõ║ÆĶüöńĮæµ×ȵ×äõĖŁ’╝īķĆÜÕĖĖõĮ┐ńö©ĶĮ»õ╗ČĶ┤¤ĶĮĮ’╝ÜLVS+HAproxy+WebServer’╝łNginx’╝ēŃĆéÕ£©ķā©ńĮ▓µŚČ’╝īLVS’╝īHAProxy’╝īWebServerķāĮõ╝Üķā©ńĮ▓õĖĆõĖ¬ķøåńŠż’╝īńö©µØźĶ┐øĶĪīĶ┤¤ĶĮĮÕØćĶĪĪŃĆéLVSÕĘźõĮ£Õ£©ń¼¼4Õ▒é’╝īÕ£©ńĮæń╗£Õ▒éÕł®ńö©IPÕ£░ÕØĆĶ┐øĶĪīĶĮ¼ÕÅæŃĆéHAProxyÕĘźõĮ£Õ£©ń¼¼7Õ▒é’╝īµĀ╣µŹ«ńö©µłĘńÜäHTTPĶ»Ęµ▒é’╝łµ»öÕ”éµĀ╣µŹ«URL’╝īµČłµü»Õż┤’╝ēµØźĶ┐øĶĪīĶĮ¼ÕÅæŃĆé
Õ£©õĖŖĶ┐░Õ«×ńÄ░õĖŁ’╝īķĆÜÕĖĖĶ┐śõ╝ÜõĮ┐ńö©Keepalived+VIP(ĶÖÜIP) µŖƵ£»ŃĆéKeepalived µÅÉõŠøÕüźÕ║ʵŻĆµ¤ź’╝īµĢģķÜ£ĶĮ¼ń¦╗’╝īµÅÉķ½śń│╗ń╗¤ńÜäÕÅ»ńö©µĆ¦ŃĆéķĆÜĶ┐ćVIP’╝łķģŹńĮ«DNS ń╗æÕ«ÜÕ¤¤ÕÉŹ’╝ēńÜäÕĮóÕ╝ÅÕ»╣ńĮæń½ÖĶ┐øĶĪīĶ«┐ķŚ«ŃĆé
WEB APP
ÕēŹń½»µŖƵ£»’╝ÜķüĄÕŠ¬Õ¤║µ£¼ńÜäWebÕēŹń½»õ╝śÕī¢ń╗Åķ¬ī’╝īĶ»”Ķ¦üWebÕēŹń½»õ╝śÕī¢µ£ĆõĮ│Õ«×ĶĘĄÕÅŖÕĘźÕģĘķøåķö”┬Ā
õ╗ŗń╗ŹŃĆéÕÅ”Õż¢Ķ┐śÕÅ»õ╗źõĮ┐ńö©BigPipe’╝īÕŖ©µĆüķĪĄķØóķØÖµĆüÕī¢’╝īµŚĀķÖɵ╗ÜÕŖ©ńÜäń┐╗ķĪĄµŖƵ£»ńŁēµŖƵ£»µÅÉõŠøµø┤ÕźĮńÜäńö©µłĘõĮōķ¬īŃĆéÕÅ”Õż¢õĖĆķā©ÕłåÕ░▒µś»ĶĆāĶÖæmobileµŖƵ£»õ║å’╝īĶ┐ÖÕØŚń¼öĶĆģµÜ鵌ČĶ┐śµ▓ĪµČēĶČ│’╝īÕ░▒õĖŹĶ░łõ║åŃĆé
ÕÉÄń½»µŖƵ£»’╝Ü
- HTTPÕŹÅĶ««’╝ÜHTTPÕŹÅĶ««Õż¦µ”éÕłåõĖ║Ķ»Ęµ▒éÕż┤’╝īĶ»Ęµ▒éõĮō’╝īÕōŹÕ║öÕż┤’╝īÕōŹÕ║öõĮōŃĆ鵌ĀĶ«║µś»WebServerĶ┐śµś»ApplicationServer’╝īÕŠłÕżÜĶŖ▒µĀĘķāĮµś»Õ¤║õ║ÄĶ»Ęµ▒éÕż┤ńÜäĶ»Ęµ▒éĶĘ»ÕŠäµØźńÄ®ńÜäŃĆé
- APIµÄźÕÅŻ:õĮ┐ńö©RESTFUL API’╝īµÜ┤ķ£▓µÄźÕÅŻŃĆéÕ«āÕģʵ£ēÕ”éõĖŗÕźĮÕżä’╝Ü1.ÕģģÕłåÕł®ńö© HTTP ÕŹÅĶ««µ£¼Ķ║½Ķ»Łõ╣ēŃĆé2.ķØóÕÉæĶĄäµ║É’╝īõĖĆńø«õ║åńäČ’╝īÕģʵ£ēĶć¬Ķ¦ŻķćŖµĆ¦ŃĆé3.µŚĀńŖȵĆü’╝īÕ£©Ķ░āńö©õĖĆõĖ¬µÄźÕÅŻ’╝łĶ«┐ķŚ«ŃĆüµōŹõĮ£ĶĄäµ║É’╝ēńÜ䵌ČÕĆÖ’╝īÕÅ»õ╗źõĖŹńö©ĶĆāĶÖæõĖŖõĖŗµ¢ć’╝īµ×üÕż¦ńÜäķÖŹõĮÄõ║åÕżŹµØéÕ║”ŃĆé
- Application Server’╝ÜÕ£©JavaõĖŁ’╝īõĖ║õ║åõ┐ØĶ»üń©ŗÕ║ÅĶāĮÕż¤Õ£©ÕÉäõĖ¬ÕÄéÕĢåńÜäASõĖŁÕģ╝Õ«╣Ķ┐ÉĶĪī’╝īSunÕģ¼ÕÅĖõĖ║ÕłČÕ«Üõ║åJ2EEĶ¦äĶīāŃĆéõ╗ĵŖƵ£»ÕÅæÕ▒ĢĶĘ»ÕŠäµØźń£ŗ’╝ī Serverlet,JSPµ╝öÕÅśķāĮµś»õĖ║õ║åµø┤ÕźĮÕ£░µ¢╣õŠ┐ń©ŗÕ║ÅÕæśõ╗¼ń╝¢ń©ŗŃĆéõ╗źÕģĖÕ×ŗńÜäTomcatõĖ║õŠŗ’╝īConnectorÕÆīContainerń╗䵳ÉõĖĆõĖ¬Service’╝īÕżÜõĖ¬Serviceń╗䵳ÉõĖĆõĖ¬ServerŃĆéConnectorõĖ╗Ķ”üĶ┤¤Ķ┤ŻµÄźÕÅŚÕż¢ķā©Ķ»Ęµ▒é’╝īContainerĶ┤¤Ķ┤ŻÕżäńÉåĶ»Ęµ▒éŃĆéServerµÅÉõŠøõ║åńö¤ÕæĮÕ橵£¤ń«ĪńÉå’╝īÕ”éÕÉ»ÕŖ©’╝īÕü£µŁóńŁēŃĆé
- Session Framework’╝ÜÕ£©Õż¦Õ×ŗõ║ÆĶüöńĮæµ×ȵ×äõĖŁ’╝īÕŹĢÕÅ░µ£║ÕÖ©ÕĘ▓ń╗ÅÕŁśµöŠõĖŹõ║åńö©µłĘńÜäńÖ╗ÕĮĢõ┐Īµü»ŃĆéÕÉīµŚČõĖ║õ║åµö»µīüµĢģķÜ£ĶĮ¼ń¦╗ńŁēńē╣µĆ¦’╝īķ£ĆĶ”üõĖĆÕźŚsessionń«ĪńÉåµ£║ÕłČ’╝īµö»µīüµĄĘķćÅńö©µłĘÕÉīµŚČÕ£©ń║┐ŃĆéķĆÜÕĖĖÕÅ»õ╗źÕ£©ķüĄÕŠ¬J2EEńÜäÕ«╣ÕÖ©Õåģ’╝īõĮ┐ńö©Filterµ©ĪÕ╝ÅÕÆīÕłåÕĖāÕ╝Åń╝ōÕŁśń│╗ń╗¤µØźÕ«×ńÄ░ŃĆé
- MVC’╝ÜÕŹ│Model’╝īViewÕÆīControllerŃĆéModelõ╗ŻĶĪ©õĖÜÕŖĪķĆ╗ĶŠæ’╝īViewĶĪ©ńż║ķĪĄķØóĶ¦åÕøŠ’╝īControllerĶĪ©ńż║µĀ╣µŹ«ńö©µłĘĶ»Ęµ▒é’╝īµē¦ĶĪīńøĖÕ║öńÜäõĖÜÕŖĪķĆ╗ĶŠæ’╝īÕ╣ČķĆēµŗ®ķĆéÕĮōńÜäķĪĄķØóĶ¦åÕøŠĶ┐öÕø×ŃĆéńö©Ķ┐ćRORńÜäÕÉīÕŁ”ķāĮń¤źķüō’╝īķćīķØóńÜärouterķģŹńĮ«õ║åõ╗Ćõ╣łµĀĘńÜäURLÕÆīõ╗Ćõ╣łµĀĘńÜäactionńøĖÕ»╣Õ║öŃĆéńøĖÕ║öńÜä’╝īMVCńÜäµ£¼Ķ┤©Õ░▒µś»µĀ╣µŹ«õĖŹÕÉīńÜäURLķĆēµŗ®õĖŹÕÉīńÜäservletµØźµē¦ĶĪīŃĆéÕŬõĖŹĶ┐ć’╝īń╗ōÕÉłõ║åIntercepting FilterµÅÉõŠøõ║åÕ╝║Õż¦ńÜäÕŖ¤ĶāĮĶĆīÕĘ▓ŃĆé
- IOC’╝ÜĶć│õ║ÄõĖ║õ╗Ćõ╣łķ£ĆĶ”üIOC’╝īń¼öĶĆģÕ£©Ķ┐Öń»ćµ¢ćń½ĀĶ┐øĶĪīõ║åĶ«©Ķ«║ŃĆéń®ČÕģȵ£¼Ķ┤©Õ«×ńÄ░’╝īµŚĀķØ×µś»ÕÅŹÕ░ä+ÕŹĢõŠŗµ©ĪÕ╝Å+Hashń«Śµ│Ģ+ÕŁŚĶŖéńĀüÕó×Õ╝║+ThreadLocalŃĆéÕēŹ3ĶĆģńö©µØźÕ«×ńÄ░Õ»╣Ķ▒Īńö¤ÕæĮÕ橵£¤ńÜäń«ĪńÉå’╝īÕÉÄ2ĶĆģńö©µØźµö»µīüAOP’╝īÕŻ░µśÄÕ╝Åõ║ŗÕŖĪŃĆé
- ORM’╝ÜĶ┐ÖõĖ¬Ķ»ŹÕ«×ķÖģõĖŖµöŠÕ£©Ķ┐Öķćīõ╗ŗń╗ŹõĖŹÕż¬ÕÉłķĆé’╝īõĮåµś»ń¼öĶĆģńø«ÕēŹµ▓Īµā│µŖŖÕ«āÕŹĢńŗ¼µŗēÕć║ń½ĀĶŖéµØźĶ«▓ŃĆéµĀ╣µŹ«ń¼öĶĆģńÜäń╗Åķ¬ī’╝īORMõĖ╗Ķ”üÕ«īµłÉõ║åń▒╗ÕÆīĶĪ©ńÜ䵜ĀÕ░ä’╝īÕ»╣Ķ▒ĪÕÆīõĖƵØĪĶĪ©µĢ░µŹ«Ķ«░ÕĮĢńÜ䵜ĀÕ░äŃĆéÕģȵĀĖÕ┐āÕ«×ńÄ░µś»ķĆÜĶ┐ćjdbcĶÄĘÕÅ¢µĢ░µŹ«Õ║ōńÜämetaõ┐Īµü»’╝īńäČÕÉĵĀ╣µŹ«µśĀÕ░äÕģ│ń│╗’╝łĶ┐ÖķćīÕÅ»õ╗źķĆÜĶ┐ćCOC’╝łConversion Over Configuration’╝īń║”Õ«Üõ╝śõ║ÄķģŹńĮ«’╝ē’╝īµ│©Ķ¦ŻńŁēµŖƵ£»µØźń«ĆÕī¢ķģŹńĮ«’╝ēµØźÕŖ©µĆüńö¤µłÉsqlÕÆīĶ┐öÕø×µĢ░µŹ«Õ║ōńÜäµē¦ĶĪīń╗ōµ×£ŃĆé
SOA
ńĮæń½Öµ×ȵ×äńÜäµ╝öĶ┐øõ╣ŗĶĘ»’╝īõ╗ÄÕŹĢõĖĆÕ║öńö©µ×ȵ×äÕł░Õ×éńø┤Õ║öńö©µ×ȵ×ä’╝īÕłåÕĖāÕ╝ŵ£ŹÕŖĪµ×ȵ×äõ╗źÕÅŖµĄüÕŖ©Ķ«Īń«Śµ×ȵ×ä’╝īĶČŖµØźĶČŖõĮōńÄ░SOAµĪåµ×ČńÜäķćŹĶ”üµĆ¦ŃĆéĶ┐Öķćīõ╗źõ╝śń¦ĆńÜäÕ╝Ƶ║ÉÕ«×ńÄ░dubboõĖ║õŠŗ’╝īń«ĆÕŹĢõ╗ŗń╗ŹõĖŗŃĆé
dubbońÜäÕŖ¤ĶāĮõ╗ŗń╗ŹĶ¦üµ£ŹÕŖĪµ▓╗ńÉåĶ┐ćń©ŗ’╝īÕ»╣dubboµ×ȵ×äĶ»”ń╗åõ╗ŗń╗ŹńÜäµ£ēÕ”éõĮĢÕŁ”õ╣Ādubboµ║Éõ╗ŻńĀüÕÆīdubboµ║Éõ╗ŻńĀüķśģĶ»╗ŃĆé
ń«ĆĶĆīĶ©Ćõ╣ŗ’╝īÕ░▒µś»õĮ┐ńö©õ║åspringńÜäschemańÜäµē®Õ▒Ģµ£║ÕłČ’╝īĶ┐øĶĆīµö»µīüĶć¬Õ«Üõ╣ēdubboµĀćńŁŠ’╝øķĆÜĶ┐ćń▒╗õ╝╝serviceloadµ£║ÕłČķģŹńĮ«ÕżÜõĖ¬ÕÅ»ķĆēµ£ŹÕŖĪŃĆéķĆÜĶ┐ćjdkÕŖ©µĆüõ╗ŻńÉåÕÆīJavassist’╝īõĮ┐µ£ŹÕŖĪĶ░āńö©ķĆŵśÄÕī¢ŃĆéń╗ōÕÉłZooKeeperÕ«×ńÄ░ķ½śÕÅ»ńö©ÕģāµĢ░µŹ«ń«ĪńÉåŃĆé
MQ
MQ’╝łMessage Queue’╝īµČłµü»ķś¤ÕłŚ’╝ēõĮ┐µ£ŹÕŖĪĶ░āńö©Õ╝鵣źÕī¢’╝īÕÅ»õ╗źµČłķÖżÕ╣ČÕÅæĶ«┐ķŚ«µ┤¬Õ│░’╝īµÅÉÕŹćńĮæń½ÖÕōŹÕ║öķƤÕ║”ŃĆé Õ£©MQÕ«×ńÄ░õĖŁ’╝īń¼öĶĆģÕåÖĶ┐ćõĖĆń»ćõ╗ŗń╗ŹKafkańÜäÕŁ”õ╣Āń¼öĶ«░’╝īĶ»”ń╗åõ╗ŗń╗ŹĶ¦üKafka/MetaqĶ«ŠĶ«ĪµĆصā│ÕŁ”õ╣Āń¼öĶ«░’╝īõĖŹÕåŹÕżÜĶ©ĆŃĆé
CACHE
CacheÕ░▒µś»Õ░åµĢ░µŹ«µöŠÕł░ĶĘØń”╗Ķ«Īń«Śµ£ĆĶ┐æńÜäÕ£░µ¢╣’╝īńö©µØźÕŖĀÕ┐½ÕżäńÉåķƤÕ║”ŃĆéķĆÜÕĖĖÕ»╣õĖĆիܵŚČķŚ┤ÕåģńÜäńāŁńé╣µĢ░µŹ«Ķ┐øĶĪīń╝ōÕŁśŃĆé┬Ā
Õ£©õĮ┐ńö©ń╝ōÕŁśµŚČ’╝īķ£ĆĶ”üµ│©µäÅń╝ōÕŁśķóäńāŁÕÆīń╝ōÕŁśń®┐ķĆÅķŚ«ķóśŃĆé
õĖĆĶł¼µĄĘķćŵĢ░µŹ«ńÜäń╝ōÕŁśń│╗ń╗¤õĖŹõ╝ÜõĮ┐ńö©JavaµØźÕ«×ńÄ░’╝īµś»ÕøĀõĖ║Javaµ£ēķóØÕż¢ńÜäÕ»╣Ķ▒ĪÕż¦Õ░ÅÕ╝ĆķöĆõ╗źÕÅŖGCÕÄŗÕŖøŃĆéµēĆõ╗źõĖĆĶł¼µś»ńö©ANSI CµØźÕ«×ńÄ░ŃĆéńø«ÕēŹńö©ńÜäµ»öĶŠāńü½ńÜ䵜»Redis’╝īµø┤ÕżÜõ╗ŗń╗ŹĶ»Ęµ¤źń£ŗRedisĶĄäµ¢Öµ▒ćµĆ╗
STORAGE
Õ£©Õć║ńÄ░NOSQLõ╣ŗÕēŹ’╝īõĖĆń╗¤Õż®õĖŗńÜ䵜»MySQLÕłåÕ║ōÕłåĶĪ©µŖƵ£»ŃĆéń╗ōÕÉłń▒╗õ╝╝TDDLńŁēSQL agentµŖƵ£»’╝īõ╣¤ĶāĮÕż¤µē¦ĶĪīń▒╗õ╝╝joinńÜäµōŹõĮ£ŃĆéÕÉÄµØź’╝īÕ░▒ÕāÅÕ┐ĮÕ”éõĖĆÕż£µśźķŻÄµØź’╝īÕć║ńÄ░õ║åÕŠłÕżÜNOSQL/ÕłåÕĖāÕ╝ÅÕŁśÕé©ń│╗ń╗¤õ║¦ÕōüŃĆé
ÕłåÕĖāÕ╝ÅÕŁśÕé©ń│╗ń╗¤µś»ÕłåÕĖāÕ╝Åń│╗ń╗¤õĖŁµ£ĆÕżŹµØéńÜäõĖĆķā©Õłå’╝īńøĖµ»öĶŠāSOA,CACHEńŁēµĪåµ×Č’╝īÕ«āķ£ĆĶ”üĶ¦ŻÕå│ńÜäķŚ«ķóśµø┤ÕŖĀÕżŹµØéŃĆéÕĖĖĶ¦üńÜäķŚ«ķóśÕ”éõĖŗ’╝Ü
- µĢ░µŹ«ÕłåÕĖā Õ£©ÕżÜÕÅ░µ£ŹÕŖĪÕÖ©õ╣ŗķŚ┤õ┐ØĶ»üµĢ░µŹ«ÕłåÕĖāÕØćÕīĆ’╝īĶĘ©µ£ŹÕŖĪÕÖ©Õ”éõĮĢĶ»╗ÕåÖ
- õĖĆĶć┤µĆ¦ Õ╝éÕĖĖµāģÕåĄõĖŗÕ”éõĮĢõ┐ØĶ»üÕē»µ£¼õĖĆĶć┤µĆ¦
- Õ«╣ķöÖ µŖŖÕÅæńö¤µĢģķÜ£ÕĮōµłÉÕĖĖµĆüµØźĶ«ŠĶ«Ī’╝īÕüÜÕł░µŻĆµĄŗµś»ÕÉ”ÕÅæńö¤µĢģķÜ£Õ╣ČĶ┐øĶĪīµĢģķÜ£Ķ┐üń¦╗
- Ķ┤¤ĶĮĮÕØćĶĪĪ µ¢░Õó×ŃĆüń¦╗ķÖżµ£ŹÕŖĪÕÖ©µŚČÕ”éõĮĢĶ┤¤ĶĮĮÕØćĶĪĪ µĢ░µŹ«Ķ┐üń¦╗Õ”éõĮĢõĖŹÕĮ▒ÕōŹÕĘ▓µ£ēµ£ŹÕŖĪ
- õ║ŗÕŖĪÕ╣ČÕÅæµÄ¦ÕłČ Õ”éõĮĢÕ«×ńÄ░ÕłåÕĖāÕ╝Åõ║ŗÕŖĪ’╝īÕ”éõĮĢÕ«×ńÄ░ÕżÜńēłµ£¼Õ╣ČÕÅæµÄ¦ÕłČ
- ÕÄŗń╝®ŃĆüĶ¦ŻÕÄŗń╝® µĀ╣µŹ«µĢ░µŹ«ńē╣ńé╣ķĆēµŗ®µü░ÕĮōń«Śµ│Ģ’╝īÕ”éõĮĢÕ╣│ĶĪĪµŚČķŚ┤ÕÆīń®║ķŚ┤ńÜäÕģ│ń│╗ŃĆé
ÕĮōń¼öĶĆģķśģĶ»╗Õ«īŃĆŖÕż¦Ķ¦äµ©ĪÕłåÕĖāÕ╝ÅÕŁśÕé©ń│╗ń╗¤ÕĤńÉåĶ¦Żµ×ÉõĖĵ×ȵ×äÕ«×µłśŃĆŗÕÆīgoogleńÜäõĖżń»ćÕŁśÕé©Ķ«║µ¢ćÕÉÄ’╝īµä¤Ķ¦ēķćīķØóńÜäÕ«×ńÄ░ń╗åĶŖéÕż¬ÕżÜõ║åŃĆéÕ”éµ×£Ķ”üÕåÖńÜäĶ»Ø’╝īĶ┐śµś»ÕÉÄķØóÕŹĢńŗ¼ÕłŚõĖĆńēćµŖŖŃĆéµēĆõ╗źĶ┐ÖķćīµÜéõĖöńĢźĶ┐ćŃĆé
ÕģČõ╗¢
Ķ┐śµ£ēÕģČõ╗¢µ¢╣ķØóńÜäń¤źĶ»å’╝īńŁēÕÉÄķØóń¦»ń┤»ÕåŹÕżÜõ║ø’╝īÕåŹķćŹńé╣ÕåÖÕɦ’╝īĶ┐Öķćīõ╗ģõ╗ģµś»ń┤óÕ╝ĢõĖŗ’╝īĶ»╗ĶĆģÕÅ»õ╗źĶć¬ĶĪīńĢźĶ┐ćŃĆé
- ķģŹńĮ«µĢ░µŹ«ŃĆüÕģāµĢ░µŹ«ń«ĪńÉåń│╗ń╗¤’╝ÜÕÅ»õ╗źµ¤źń£ŗĶ┐Öń»ćZooKeeperÕÆīDiamondµ£ēõ╗Ćõ╣łõĖŹÕÉī
- µÉ£ń┤óń│╗ń╗¤’╝ܵ£║ÕÖ©ÕŁ”õ╣ĀÕłåµ×Éńö©µłĘĶĪīõĖ║’╝īń╗ōÕÉłµÉ£ń┤óĶ┐øĶĪīµÄ©ĶŹÉµÄÆÕÉŹŃĆé ÕÉäń¦ŹÕż¦µĢ░µŹ«Õłåµ×ÉÕĘźÕģĘŃĆé
- õ║æĶ«Īń«Ś’╝ÜńĪ¼õ╗ČĶÖܵŗ¤Õī¢ŃĆéÕłøõĖÜÕģ¼ÕÅĖÕÅ»õ╗źĶ┤Łõ╣░õ║æµ£ŹÕŖĪ’╝īķü┐ÕģŹÕø║Õ«ÜĶĄäõ║¦Õ╝ĆķöĆ’╝īÕÅ»ĶāĮķŚ▓ńĮ«’╝ī Ķ┤Łõ╣░’╝īń«ĪńÉå’╝īÕ«ēĶŻģĶ┤╣ńö© ’╝īµŚĀµ│ĢĶ┐ģķƤĶ┤Łõ╣░ńŁēķŚ«ķóś’╝īÕ▒×õ║ĵĄ«ÕŖ©µČłĶ┤╣’╝īń▒╗õ╝╝Õ╝ĆĶĮ”ÕÆīń¦¤ĶĮ”ńÜäÕī║Õł½’╝īõ╗ģµś»ń¦¤ńö©µ£ŹÕŖĪŃĆé õ║æÕÄéÕĢåÕ£©ĶāĮµ║É’╝īÕłČÕåĘ’╝īĶ┐Éń╗┤µłÉµ£¼’╝īķćÅÕż¦ńĪ¼õ╗ČÕ«ÜÕłČ’╝īÕģģÕłåÕł®ńö©ķŚ▓ńĮ«ĶĄäµ║ÉÕģʵ£ēõ╝śÕŖ┐ŃĆé
- ķ╣░ń£╝ń│╗ń╗¤’╝ܵŚźÕ┐ŚĶ¦äĶīāÕī¢+µēōńé╣+µĢ░µŹ«Õłåµ×É+µĀæńŖČÕ▒ĢńÄ░’╝īĶ»”ń╗åõ╗ŗń╗ŹÕÅ»õ╗źÕÅéĶĆā┬Āķ╣░ń£╝õĖŗńÜäµĘśÕ«Ø-ÕłåÕĖāÕ╝ÅĶ░āńö©ĶʤĶĖ¬ń│╗ń╗¤õ╗ŗń╗Ź
- ń│╗ń╗¤Ķ┐Éń╗┤’╝Ü ńø«µĀ浜»Ķć¬ÕŖ©Õī¢Ķ┐Éń╗┤ŃĆé
- ńøæµÄ¦ÕÉäń¦ŹĶĄäµ║ɵīćµĀć’╝Ü
- OS:’╝łcpu’╝īmemory’╝īdisk’╝łń®║ķŚ┤’╝īĶ»╗ÕåÖµ¼ĪµĢ░’╝ē’╝ē
- ńĮæń╗£µĄüķćÅ
- õĖŁķŚ┤õ╗Č’╝Ü tomcat’╝ī jvm’╝ī
- MQ:ķĆÜĶ┐ćńøæµÄ¦ńö¤õ║¦ĶĆģ’╝ībroker’╝īµČłĶ┤╣ĶĆģõ╣ŗķŚ┤ńÜäķś¤ÕłŚµāģÕåĄ’╝īÕŖ©µĆüÕå│Õ«ÜÕó×ÕŖĀŃĆüÕćÅÕ░æµČłĶ┤╣ĶĆģ
- µ£ŹÕŖĪµĪåµ×ČĶć¬ń£ü’╝łĶ┐Éń╗┤ńøæµÄ¦’╝ē õŠØĶĄ¢Õģ│ń│╗ń╗¤Ķ«Ī’╝īÕēŹÕÅ░ń│╗ń╗¤Ķ«┐ķŚ«ĶĘ»ÕŠä’╝ī
- µśŠńż║ÕÉäń¦ŹńøæµÄ¦ń╗ōµ×£’╝ÜAgent ŌĆöŃĆŗ Explorer ’╝īAnalyze’╝īVisual’╝īDashboard’╝īShareŃĆé
- ķóäĶŁ”’╝īĶ┐Éń╗┤ Ķć¬ÕŖ©ŃĆüµēŗÕĘźķÖŹń║¦’╝īń│╗ń╗¤ķŚ«ķóśĶć¬ÕŖ©µÄƵ¤źńöÜĶć│ķŚ«ķóśĶć¬ÕŖ©õ┐«ÕżŹ’╝ī
- ńøæµÄ¦ÕÉäń¦ŹĶĄäµ║ɵīćµĀć’╝Ü
- ĶāĮµ║ÉĶŖéń£ü’╝ÜĶāĮµ║ɵȳĶĆŚ’╝łCPU,µ£║µ¤£’╝īµ░┤ÕåĘ’╝ē
- ń│╗ń╗¤Õ«ēÕģ©’╝ܵČēÕÅŖń│╗ń╗¤ńÜäµ¢╣µ¢╣ķØóķØó’╝īÕÉäń¦ŹĶäܵ£¼’╝īsqlµ│©Õģź’╝ī0dayńŁēńŁēŃĆé
- ńēłµ£¼Õ╝ĆÕÅæŃĆüńēłµ£¼ÕÅæÕĖā’╝ÜÕ╝ĆÕÅæńÄ»Õóā’╝īµĄŗĶ»ĢńÄ»Õóā’╝īµö»µīüÕ╝ĆķƤÕÅæÕĖā’╝īõĖŹńö©Õż¦ńÜäcycle’╝īńü░Ķē▓ÕÅæÕĖā’╝īÕø×µ╗ÜķÖŹń║¦µĄüń©ŗ’╝īÕæ©ĶŠ╣ÕŹÅĶ░āŃĆé Õż¦õ╝Śńé╣Ķ»äńÜäµ£ēõĖ¬Õģ│õ║ÄÕ╝ĆÕÅæńÄ»ÕóāµÉŁÕ╗║ńÜä’╝īµä¤Õģ┤ĶČŻńÜäÕÅ»õ╗źńé╣Õć╗µēōķĆĀķ½śµĢłńÜäÕŹĢµ£║Õ╝ĆÕÅæńÄ»ÕóāŃĆé
- µĢ░µŹ«õĖŁÕ┐ā’╝ÜÕ£©ŃĆŖń©ŗÕ║ÅÕæśŃĆŗ2014Õ╣┤ń¼¼õĖƵ£¤õ╗ŗń╗ŹķćīķØó’╝īµÅÉÕł░õ║åķś┐ķćīõĮ┐ńö©õ║åZONEńÜäµ”éÕ┐ĄµØźĶ¦ŻÕå│µ©¬ÕÉæµē®Õ▒ĢńÜäķŚ«ķóśŃĆéķś┐ķćīõĖ╗Ķ”üµś»õĖ║õ║åĶ¦ŻÕå│µ£║µł┐ńĮæń╗£ńōČķółÕÆīĶČģÕż¦Ķ¦äµ©Īń│╗ń╗¤ńÜäõ╝Ėń╝®µĆ¦ķŚ«ķóś’╝īµŖŖÕ«īµłÉµ¤ÉõĖĆńē╣Õ«ÜõĖÜÕŖĪķ£ĆĶ”üńÜäń│╗ń╗¤ŃĆüµĀĖÕ┐āµ£ŹÕŖĪŃĆüµĢ░µŹ«Õ║ōń╗äÕÉłµłÉõĖĆõĖ¬õĖÜÕŖĪÕŹĢÕģāŃĆé
ÕÅéĶĆā
┬Ā
- ŃĆŖµĘ▒ÕģźÕłåµ×ÉJava Web µŖƵ£»ÕåģÕ╣ĢŃĆŗ
- ŃĆŖÕż¦Ķ¦äµ©ĪÕłåÕĖāÕ╝ÅÕŁśÕé©ń│╗ń╗¤ÕĤńÉåĶ¦Żµ×ÉõĖĵ×ȵ×äÕ«×µłśŃĆŗ
- ŃĆŖÕż¦Õ×ŗńĮæń½ÖµŖƵ£»µ×ȵ×äµĀĖÕ┐āÕĤńÉåõĖĵĪłõŠŗÕłåµ×ÉŃĆŗ
- ŃĆŖÕłåÕĖāÕ╝Åń│╗ń╗¤ÕĤńÉåõ╗ŗń╗ŹŃĆŗ
- ŃĆŖÕż¦Ķ¦äµ©ĪWebµ£ŹÕŖĪÕ╝ĆÕÅæµŖƵ£»ŃĆŗ
- ŃĆŖń©ŗÕ║ÅÕæśŃĆŗ2014Õ╣┤ń¼¼õĖƵ£¤
- googleń│╗ÕłŚĶ«║µ¢ć
- varnish / squid / nginx cache µ£ēõ╗Ćõ╣łõĖŹÕÉī’╝¤
- RESTfulńÜäõ╝śńé╣



ńøĖÕģ│µÄ©ĶŹÉ
ŃĆɵĀćķóśŃĆæ’╝ÜŌĆ£µĄģµ×ÉõĖŁÕż¦Õ×ŗõ╝üõĖÜńĮæńÜäõ║ÆĶüöńĮæµ×ȵ×äŌĆØ ŃĆɵÅÅĶ┐░ŃĆæ’╝ܵ£¼µ¢ćõĖ╗Ķ”üµÄóĶ«©õ║åõĖŁÕż¦Õ×ŗõ╝üõĖÜńĮæń╗£Õ£©ķØóõĖ┤Õģ¼ńĮæIPÕ£░ÕØĆń¤Łń╝║ķŚ«ķ󜵌Ȓ╝īÕ”éõĮĢÕł®ńö©NAT’╝łńĮæń╗£Õ£░ÕØĆĶĮ¼µŹó’╝ēµŖƵ£»µØźµ×äÕ╗║õ║ÆĶüöńĮæµ×ȵ×ä’╝īõ╗źµ╗ĪĶČ│Õż¦ķćÅńö©µłĘÕÉīµŚČõĖŖńĮæńÜäķ£Ćµ▒é’╝īÕÉīµŚČĶĆāĶÖæ...
õĖĆŃĆüÕ¤║ńĪƵ×ȵ×äµ”éĶ┐░ Õż¦Õ×ŗńĮæń½ÖńÜäÕ¤║ńĪƵ×ȵ×äķĆÜÕĖĖÕīģµŗ¼ÕēŹń½»ŃĆüÕÉÄń½»ŃĆüµĢ░µŹ«Õ║ōŃĆüń╝ōÕŁśŃĆüĶ┤¤ĶĮĮÕØćĶĪĪŃĆüÕłåÕĖāÕ╝Åń│╗ń╗¤ńŁēÕżÜõĖ¬Õ▒éķØóŃĆéÕēŹń½»Ķ┤¤Ķ┤Żńö©µłĘõ║żõ║Æ’╝īÕÉÄń½»ÕżäńÉåõĖÜÕŖĪķĆ╗ĶŠæ’╝īµĢ░µŹ«Õ║ōÕŁśÕ驵Ģ░µŹ«’╝īń╝ōÕŁśµÅÉķ½śµĢ░µŹ«Ķ«┐ķŚ«ķƤÕ║”’╝īĶ┤¤ĶĮĮÕØćĶĪĪÕłåÕÅæĶ»Ęµ▒é’╝īÕłåÕĖāÕ╝Å...
õ╗źõĖŖÕŬµś»ŃĆŖÕż¦Õ×ŗńĮæń½ÖµŖƵ£»µ×ȵ×äµĀĖÕ┐āÕĤńÉåõĖĵĪłõŠŗÕłåµ×ÉŃĆŗõĖŁķā©ÕłåµĀĖÕ┐āń¤źĶ»åńé╣ńÜäµ”éĶ┐░ŃĆéĶ┐Öµ£¼õ╣”Ķ»”ń╗åĶ«©Ķ«║õ║åĶ┐Öõ║øµŖƵ£»ńÜäÕ«×ńÄ░ń╗åĶŖéÕÆīµĪłõŠŗ’╝īÕ»╣õ║ĵÅÉÕŹćµ×ȵ×äÕĖłÕ£©Ķ«ŠĶ«ĪÕÆīõ╝śÕī¢Õż¦Õ×ŗńĮæń½ÖµŚČńÜäĶāĮÕŖøµ£ēńØƵ×üÕż¦ńÜäÕĖ«ÕŖ®ŃĆéķĆÜĶ┐ćÕ»╣Ķ┐Öõ║øń¤źĶ»åńé╣ńÜäńÉåĶ¦ŻÕÆīÕ«×ĶĘĄ’╝ī...
Õ»╣õ║ÄõĖŁÕøĮĶĆīĶ©Ć’╝īõ║ÆĶüöńĮæńĮæń╗£µ×ȵ×äńÜäÕÅæÕ▒ĢńŖČÕåĄµśŠńż║’╝īµłæÕøĮÕ¤║ńĪĆńöĄõ┐ĪĶ┐ÉĶÉźÕĢåÕÆīÕż¦Õ×ŗõ║ÆĶüöńĮæõ╝üõĖÜķāĮÕ£©ńĮæń╗£µ×äÕ╗║µ¢╣ķØóÕÅ¢ÕŠŚõ║åµśŠĶæŚĶ┐øÕ▒ĢŃĆ鵳æÕøĮÕ£©Õģ©ńÉāõ║ÆĶüöńĮæõĖŁńÜäÕ£░õĮŹõĖŹµ¢ŁµÅÉÕŹć’╝īµŚĀĶ«║µś»Õ£©ńĮæń╗£ĶāĮÕŖøŃĆüńĮæń╗£ĶĄäµ║ÉĶ┐śµś»ńĮæń╗£µĆ¦ĶāĮµ¢╣ķØó’╝īķāĮÕŹĀµŹ«õ║åÕģ©ńÉā...
1. ńĮæń½Öµ×ȵ×äµ”éĶ┐░ Õż¦Õ×ŗńĮæń½ÖµŖƵ£»µ×ȵ×äķĆÜÕĖĖµīćńÜ䵜»õĖ║µ╗ĪĶČ│Õż¦ķćÅńö©µłĘĶ«┐ķŚ«ŃĆüµĢ░µŹ«ÕżäńÉåÕÆīķ½śÕÅ»ńö©µĆ¦Ķ”üµ▒éµēĆķććńö©ńÜäõĖĆń│╗ÕłŚµŖƵ£»µ¢╣µĪłÕÆīĶ«ŠĶ«ĪÕÄ¤ÕłÖŃĆéõĖÄõ╝Āń╗¤ńÜäõĖŁÕ░ÅĶ¦äµ©ĪńĮæń½ÖńøĖµ»ö’╝īÕż¦Õ×ŗńĮæń½ÖÕ£©ńö©µłĘķćÅŃĆüµĢ░µŹ«ķćÅŃĆüĶ«┐ķŚ«ķćÅńŁēµ¢╣ķØóķāĮÕæłńÄ░Õć║ÕĘ©Õż¦ńÜäĶ¦äµ©Ī...
- **ÕŠ«µ£ŹÕŖĪµ×ȵ×ä**’╝Üķććńö©ÕŠ«µ£ŹÕŖĪµ×ȵ×ä’╝īÕ░åÕż¦Õ×ŗÕ║öńö©ÕłåĶ¦ŻõĖ║õĖĆń╗äÕ░ÅĶĆīĶ欵▓╗ńÜäµ£ŹÕŖĪ’╝īµÅÉķ½śÕ╝ĆÕÅæµĢłńÄćÕÆīń│╗ń╗¤ńüĄµ┤╗µĆ¦ŃĆé - **Ķć¬ÕŖ©Õī¢Ķ┐Éń╗┤**’╝ÜķĆÜĶ┐ćĶć¬ÕŖ©Õī¢ÕĘźÕģĘÕ«×ńÄ░ń│╗ń╗¤ńÜäķā©ńĮ▓ŃĆüńøæµÄ¦ÕÆīµĢģķÜ£µüóÕżŹ’╝īÕćÅÕ░æõ║║ÕĘźÕ╣▓ķóäŃĆé #### µŖƵ£»µ×ȵ×äÕÅśĶ┐üńÜäÕģ©...
ÕēŹÕÉÄń½»Õłåń”╗ń│╗ń╗¤µ×ȵ×äµ”éĶ┐░ µ”éĶ┐░’╝ÜÕēŹÕÉÄń½»Õłåń”╗ń│╗ń╗¤µ×ȵ×䵜»µīćÕ░å web Õ║öńö©ń©ŗÕ║ÅÕłåń”╗µłÉÕēŹń½»ÕÆīÕÉÄń½»õĖżõĖ¬ńŗ¼ń½ŗńÜäķā©Õłå’╝īõ╗źµÅÉķ½śÕ╝ĆÕÅæµĢłńÄćŃĆüńüĄµ┤╗µĆ¦ÕÆīÕÅ»ń╗┤µŖżµĆ¦ŃĆéµ£¼µ¢ćÕ░åÕ»╣ÕēŹÕÉÄń½»Õłåń”╗ń│╗ń╗¤µ×ȵ×äĶ┐øĶĪīµ”éĶ┐░’╝īõ╗ŗń╗ŹÕēŹÕÉÄń½»Õłåń”╗ńÜäÕÅæÕ▒ĢÕÄåń©ŗŃĆü MVC ...
#### õĖĆŃĆüÕż¦Õ×ŗńĮæń½Öµ×ȵ×äµ”éĶ┐░ Õż¦Õ×ŗńĮæń½ÖķĆÜÕĖĖµś»µīćķéŻõ║øĶ«┐ķŚ«ķćÅÕĘ©Õż¦ŃĆüµĢ░µŹ«ÕżäńÉåĶāĮÕŖøÕ╝║Õż¦ŃĆüÕ╣ČÕÅæńö©µłĘµĢ░ķćÅÕżÜńÜäńĮæń½ÖŃĆéĶ┐Öń▒╗ńĮæń½ÖķØóõĖ┤ńØĆÕĘ©Õż¦ńÜäµīæµłś’╝īÕīģµŗ¼õĮåõĖŹķÖÉõ║ĵĄĘķćŵĢ░µŹ«ÕŁśÕé©ŃĆüķ½śÕ╣ČÕÅæĶ«┐ķŚ«ŃĆüÕłåÕĖāÕ╝ÅĶ«Īń«ŚńŁēķŚ«ķóśŃĆéÕøĀµŁż’╝īĶ«ŠĶ«ĪÕÉłńÉåńÜä...
#### õĖĆŃĆüÕż¦Õ×ŗÕłåÕĖāÕ╝ÅńĮæń½Öµ”éĶ┐░ Õż¦Õ×ŗÕłåÕĖāÕ╝ÅńĮæń½Öµś»µīćķéŻõ║øÕżäńÉåµĄĘķćÅńö©µłĘĶ«┐ķŚ«ŃĆüÕŁśÕé©ÕÆīÕżäńÉåÕż¦ķćŵĢ░µŹ«ńÜäńĮæń½Öń│╗ń╗¤ŃĆéķÜÅńØĆõ║ÆĶüöńĮæµŖƵ£»ńÜäÕÅæÕ▒Ģ’╝īĶČŖµØźĶČŖÕżÜńÜäõ╝üõĖÜÕÆīµ£ŹÕŖĪõŠØĶĄ¢õ║ÄĶ┐Öń▒╗ń│╗ń╗¤µØźµ╗ĪĶČ│ńö©µłĘķ£Ćµ▒éŃĆéĶ┐Öõ║øń│╗ń╗¤ķĆÜÕĖĖķ£ĆĶ”üÕģĘÕżćķ½śÕÅ»ńö©µĆ¦...
### Õż¦Õ×ŗÕ║öńö©ĶĮ»õ╗ȵ×ȵ×äńÜäÕÅśĶ┐ü #### õĖĆŃĆüÕ╝ĢĶ©Ć ķÜÅńØĆõ┐Īµü»µŖƵ£»ńÜäÕ┐½ķƤÕÅæÕ▒ĢÕÆīÕ║öńö©Õ£║µÖ»ńÜäõĖŹµ¢ŁµŗōÕ▒Ģ’╝īÕż¦Õ×ŗÕ║öńö©ĶĮ»õ╗ČńÜäµ×ȵ×äõ╣¤Õ£©ń╗ÅÕÄåńØƵśŠĶæŚńÜäÕÅśÕī¢ŃĆéµ£¼µ¢ćÕ░åµĘ▒ÕģźµÄóĶ«©ńö▒µØ©ķÆóÕģłńö¤Õłåõ║½ńÜäŌĆ£Õż¦Õ×ŗÕ║öńö©ĶĮ»õ╗ȵ×ȵ×äńÜäÕÅśĶ┐üŌĆØĶ┐ÖõĖĆõĖ╗ķóś’╝īķćŹńé╣Õłåµ×É...
#### õĖĆŃĆüÕż¦Õ×ŗńĮæń½Öµ×ȵ×äµ”éĶ┐░ Õż¦Õ×ŗńĮæń½Öµ×ȵ×䵜»µīćķÆłÕ»╣ķ½śÕ╣ČÕÅæŃĆüÕż¦µĄüķćÅÕ£║µÖ»õĖŗńÜäńĮæń½Öń│╗ń╗¤µēĆĶ«ŠĶ«ĪńÜäÕ¤║ńĪƵ×ȵ×äŃĆéĶ┐Öń▒╗µ×ȵ×äķĆÜÕĖĖÕģĘÕżćķ½śÕ║”ÕÅ»ķØĀµĆ¦ŃĆüÕ«ēÕģ©µĆ¦ŃĆüÕÅ»µē®Õ▒ĢµĆ¦ÕÆīµśōõ║Äń╗┤µŖżńŁēńē╣ńé╣’╝īµŚ©Õ£©ńĪ«õ┐ØńĮæń½ÖÕ£©ķØóÕ»╣µĄĘķćÅńö©µłĘĶ«┐ķŚ«µŚČõŠØńäČĶāĮÕż¤...
ńĮæń╗£µ£ŹÕŖĪÕÖ©µ×ȵ×äµ”éĶ┐░ ńĮæń╗£µ£ŹÕŖĪÕÖ©µ×ȵ×äµ”éĶ┐░µś»µīćÕ£©µĀĪÕøŁµ£ŹÕŖĪÕÖ©õĖŁ’╝īń╗ÅĶ┐ćķĢ┐µŚČķŚ┤ńÜäĶ┐ÉĶĪī’╝īµ£ŹÕŖĪÕÖ©õĖŁńÜäÕÉäń¦Źń│╗ń╗¤ÕĘ▓ń╗Åń┤Ŗõ╣▒’╝īķ£ĆĶ”üķ揵¢░Õ«ēĶŻģµōŹõĮ£ń│╗ń╗¤µł¢Õ║öńö©ĶĮ»õ╗ČŃĆéĶ┐Öń»ćµ¢ćń½ĀÕ░åĶ«▓Ķ¦ŻĶĮ»õ╗Čń╗┤µŖżĶ┐ćń©ŗõĖŁµēĆķ£Ćµ│©µäÅńÜäõĖĆõ║øķŚ«ķóśŃĆé õĖĆŃĆüÕ«ēĶŻģÕēŹńÜä...
õĖŁÕÅ░µŖƵ£»µ×ȵ×äõĖ║õ╝üõĖܵÅÉõŠøõ║åµø┤ÕŖĀńüĄµ┤╗ÕÆīķ½śµĢłńÜäITÕ¤║ńĪĆĶ«Šµ¢Į’╝īµ£ēÕŖ®õ║Äõ╝Āń╗¤õ╝üõĖÜĶĮ¼Õ×ŗÕÆīõ║ÆĶüöńĮæõ╝üõĖÜÕłøµ¢░ŃĆéńäČĶĆī’╝īÕ«×µ¢ĮõĖŁÕÅ░Õ╣ČķØ×µśōõ║ŗ’╝īķ£ĆĶ”üÕģģÕłåńÉåĶ¦ŻõĖÜÕŖĪķ£Ćµ▒é’╝īÕÉłńÉåĶ¦äÕłÆ’╝īõ╗źÕÅŖÕ»╣ńÄ░µ£ēń│╗ń╗¤Ķ┐øĶĪīķĆéķģŹÕÆīµö╣ķĆĀŃĆ鵣ŻńĪ«ńÉåĶ¦ŻÕÆīĶ┐Éńö©õĖŁÕÅ░’╝īÕÅ»õ╗źõĖ║...
õ║æÕĤńö¤µ×ȵ×äÕ╣┐µ│øÕ║öńö©õ║Äõ║ÆĶüöńĮæŃĆüķćæĶ׏ń¦æµŖĆŃĆüķøČÕö«ŃĆüÕī╗ń¢ŚńŁēÕżÜõĖ¬ĶĪīõĖÜ’╝īÕĖ«ÕŖ®õ╝üõĖÜÕ┐½ķƤµ×äÕ╗║ÕÆīĶ░āµĢ┤õĖÜÕŖĪń│╗ń╗¤’╝īÕ║öÕ»╣ÕĖéÕ£║ÕÅśÕī¢ŃĆéõŠŗÕ”é’╝īķĆÜĶ┐ćÕŠ«µ£ŹÕŖĪµ×ȵ×ä’╝īõ╝üõĖÜÕÅ»õ╗źÕ┐½ķƤÕōŹÕ║öÕ«óµłĘķ£Ćµ▒é’╝īµÄ©Õć║µ¢░ńÜäÕŖ¤ĶāĮµł¢µ£ŹÕŖĪ’╝øÕƤÕŖ®Õ«╣ÕÖ©ÕÆīKubernetes’╝īÕÅ»õ╗ź...
õĖĆõĖ¬µĀćÕćåńÜäÕż¦Õ×ŗõ║ÆĶüöńĮæķĪ╣ńø«µ¢ćµĪŻń╗ōµ×äķĆÜÕĖĖÕīģµŗ¼ķĪ╣ńø«µ”éĶ┐░ŃĆüń│╗ń╗¤µ×ȵ×äĶ«ŠĶ«ĪŃĆüÕŖ¤ĶāĮķ£Ćµ▒éĶ»┤µśÄŃĆüķØ×ÕŖ¤ĶāĮķ£Ćµ▒éĶ»┤µśÄŃĆüµŖƵ£»µĀłķĆēµŗ®ŃĆüµÄźÕÅŻÕ«Üõ╣ēŃĆüÕ«ēÕģ©ńŁ¢ńĢźŃĆüķā©ńĮ▓ńŁ¢ńĢźŃĆüµĄŗĶ»ĢĶ«ĪÕłÆõ╗źÕÅŖķĪ╣ńø«ń╗┤µŖżÕÆīÕŹćń║¦Ķ«ĪÕłÆńŁēķā©ÕłåŃĆé Õ£©ķĪ╣ńø«µ”éĶ┐░ķā©Õłå’╝īķ£ĆĶ”üµĖģµÖ░...
õĖĆŃĆüńĮæń½Öµ×ȵ×äµ”éĶ┐░ Õż¦Õ×ŗńĮæń½ÖńÜäµŖƵ£»µ×ȵ×䵜»µö»µÆæÕģČķ½śÕ╣ČÕÅæŃĆüķ½śµĆ¦ĶāĮŃĆüķ½śÕÅ»ńö©ÕÆīÕÅ»µē®Õ▒ĢµĆ¦ńÜäķćŹĶ”üÕ¤║ń¤│ŃĆéÕ«āµČēÕÅŖÕł░ÕżÜõĖ¬Õ▒éµ¼Ī’╝īÕīģµŗ¼ńĪ¼õ╗ČŃĆüµōŹõĮ£ń│╗ń╗¤ŃĆüńĮæń╗£ŃĆüµĢ░µŹ«Õ║ōŃĆüń╝ōÕŁśŃĆüÕłåÕĖāÕ╝Åń│╗ń╗¤ńŁēŃĆéµØĵÖ║µģ¦Õģłńö¤Õ£©õ╣”õĖŁĶ»”ń╗åĶ«▓Ķ¦Żõ║åĶ┐Öõ║øÕ▒éµ¼ĪńÜäĶ«ŠĶ«Ī...
ŃĆÉWindowsńĮæń╗£µ£ŹÕŖĪÕÖ©µ×ȵ×äµ”éĶ┐░ŃĆæ WindowsńĮæń╗£µ£ŹÕŖĪÕÖ©µ×ȵ×䵜»õĖĆõĖ¬ÕżŹµØéĶĆīń▓Šń╗åńÜäõĮōń│╗’╝īõĖ╗Ķ”üµČēÕÅŖµōŹõĮ£ń│╗ń╗¤Õ«ēĶŻģŃĆüń╗┤µŖżŃĆüńĮæń╗£µ£ŹÕŖĪķģŹńĮ«õ╗źÕÅŖÕÉäń¦ŹÕ║öńö©ń│╗ń╗¤ńÜäķā©ńĮ▓ŃĆéµ£¼õĖōķóśÕ░åĶ»”ń╗åķśÉĶ┐░Ķ┐ÖõĖ¬Ķ┐ćń©ŗŃĆé ķ”¢Õģł’╝īÕ«ēĶŻģÕēŹńÜäÕćåÕżćÕĘźõĮ£Ķć│Õģ│ķćŹĶ”üŃĆé...