
本文我们介绍一个网络机器人的识别与攻防的经典案例(也即爬虫与反爬虫的经典案例)。使用到的代码见本人的superword项目:
https://github.com/ysc/superword/blob/master/src/main/java/org/apdplat/superword/tools/ProxyIp.java
我们的目的是要使用机器人自动获取站点http://ip.qiaodm.com/ 和站点http://proxy.goubanjia.com/ 的免费高速HTTP代理IP和端口号。
不过他们未对机器人进行识别,如通过如下代码就可以获取网页内容:
public static void main(String[] args) {
try {
String url = "http://proxy.goubanjia.com/";
HttpURLConnection connection = (HttpURLConnection)new URL(url).openConnection();
connection.setConnectTimeout(10000);
connection.setReadTimeout(10000);
connection.setUseCaches(false);
BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream()));
StringBuilder html = new StringBuilder();
String line = null;
while ((line=reader.readLine()) != null){
html.append(line);
}
LOGGER.info("HTML:"+html);
}catch (Exception e){
LOGGER.error(e.getMessage());
}
}
尽管如此,但是他们却考虑到了机器人的防范,通过分析发现,两个站点的防范措施是一致的,所以破一得二。
他们是如何防范的呢?我们看看IP:163.125.217.56和端口:9797,我们利用FIREFOX的FIREBUG插件进行分析,如下图所示:
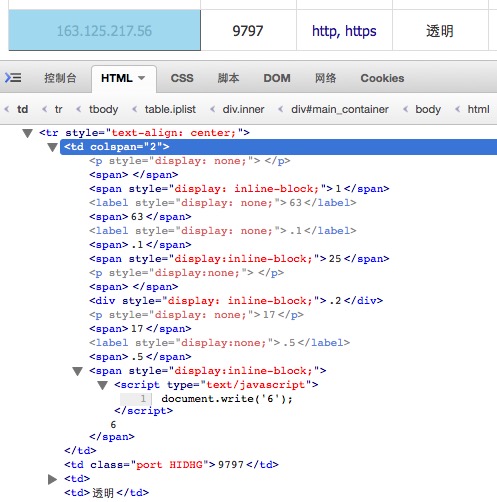
这里,如果我们直接调用选中的td节点的Jsoup的Element的text()方法,那么得到的值就会是 16363.1.125 25.21717.5.5,而不是我们在页面上看到的IP:163.125.217.56,还有<script>下面的那个6我们在源代码中是看不到的,这是<script>里面的JS执行之后动态生成的结果,对于端口9797也一样,在源代码中所有的端口全部是8080,我们这里之所以在上图中看到了6和9797,这是因为FIREBUG插件看到的是网页加载完毕且所有JS执行完毕之后的视图。
通过上面的分析,我们知道,防范的方法是将IP拆开在中间加入一些隐藏字符,并利用JS动态生成部分字符,而端口全部都是利用JS生成的。
那么我们如何来应对这种防范方法呢?首先的第一个要求是我们的机器人要能动态执行JS,其次是我们需要对IP字段进行逐节点分析,忽略隐藏节点中的字符。下面用代码说明:
1、动态执行JS。
引入htmlunit依赖,注意的是如果你是使用slf4j日志的话,需要排除commons-logging依赖。 <dependency> <groupId>net.sourceforge.htmlunit</groupId> <artifactId>htmlunit</artifactId> <version>2.14</version> <exclusions> <exclusion> <groupId>commons-logging</groupId> <artifactId>commons-logging</artifactId> </exclusion> </exclusions> </dependency>
接下来看代码,这里获取到的html就是执行JS之后的内容:
private static final WebClient WEB_CLIENT = new WebClient(BrowserVersion.INTERNET_EXPLORER_11); String html = ((HtmlPage)WEB_CLIENT.getPage(url)).getBody().asXml();
2、对IP字段进行逐节点分析,忽略隐藏节点中的字符。
引入jsoup依赖。 <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.8.1</version> </dependency>
接下来看代码:
private static String getIps(Element element){
StringBuilder ip = new StringBuilder();
Elements all = element.children();
LOGGER.info("");
LOGGER.info("开始解析IP地址,机器读到的文本:"+element.text());
AtomicInteger count = new AtomicInteger();
all.forEach(ele -> {
String html = ele.outerHtml();
LOGGER.info(count.incrementAndGet() + "、" + "原始HTML:"+html.replaceAll("[\n\r]", ""));
String text = ele.text();
if(ele.hasAttr("style")
&& (ele.attr("style").equals("display: none;")
|| ele.attr("style").equals("display:none;"))) {
LOGGER.info("忽略不显示的文本:"+text);
}else{
if(StringUtils.isNotBlank(text)){
LOGGER.info("需要的文本:"+text);
ip.append(text);
}else{
LOGGER.info("忽略空文本");
}
}
});
LOGGER.info("----------------------------------------------------------------");
LOGGER.info("解析到的ip: "+ip);
LOGGER.info("----------------------------------------------------------------");
Matcher matcher = IP_PATTERN.matcher(ip.toString());
if(matcher.find()){
String _ip = matcher.group();
LOGGER.info("ip地址验证通过:"+_ip);
return _ip;
}else{
LOGGER.info("ip地址验证失败:"+ip);
}
return null;
}
接着看运行过程的输出:
开始解析IP地址,机器读到的文本:61 61 . 18 18 5. 1 1 49 .1 .1 63
1、原始HTML:<div style="display:inline-block;"> <script type="text/javascript">//<![CDATA[document.write('');//]]> </script> </div>
忽略空文本
2、原始HTML:<label style="display: none;"> 61 </label>
忽略不显示的文本:61
3、原始HTML:<span> 61 </span>
需要的文本:61
4、原始HTML:<div style="display:inline-block;"> . </div>
需要的文本:.
5、原始HTML:<div style="display:inline-block;"> <script type="text/javascript">//<![CDATA[document.write('');//]]> </script> </div>
忽略空文本
6、原始HTML:<span style="display:inline-block;"> <script type="text/javascript">//<![CDATA[document.write('');//]]> </script> </span>
忽略空文本
7、原始HTML:<p style="display: none;"> 18 </p>
忽略不显示的文本:18
8、原始HTML:<span> 18 </span>
需要的文本:18
9、原始HTML:<div style="display:inline-block;"> <script type="text/javascript">//<![CDATA[document.write('5.');//]]> </script> 5. </div>
需要的文本:5.
10、原始HTML:<p style="display: none;"> 1 </p>
忽略不显示的文本:1
11、原始HTML:<span> 1 </span>
需要的文本:1
12、原始HTML:<div style="display:inline-block;"> 49 </div>
需要的文本:49
13、原始HTML:<label style="display:none;"> .1 </label>
忽略不显示的文本:.1
14、原始HTML:<span> .1 </span>
需要的文本:.1
15、原始HTML:<div style="display:inline-block;"> <script type="text/javascript">//<![CDATA[document.write('');//]]> </script> </div>
忽略空文本
16、原始HTML:<span style="display:inline-block;"> 63 </span>
需要的文本:63
----------------------------------------------------------------
解析到的ip: 61.185.149.163
----------------------------------------------------------------
下面是通过上面的分析程序获取到的部分能隐藏自己IP的代理服务器IP和端口号:
124.88.67.33:81 183.207.224.13:80 111.161.126.101:80 183.207.228.51:80 123.138.184.228:80 120.131.128.212:85 111.12.251.199:80 111.1.36.6:80 111.206.86.76:80 120.198.243.111:80 222.138.229.17:8104 123.125.104.240:80 124.88.67.25:81 202.102.22.182:80 183.207.228.114:80 162.208.49.45:8089 183.207.228.116:80 120.192.249.74:80 124.202.177.26:8118 124.88.67.32:80 111.161.126.100:80 183.207.224.14:80 183.207.224.43:80 111.206.81.248:80 183.207.224.45:80 182.118.31.110:80 124.88.67.53:80 111.13.109.52:80 190.38.26.167:8080 118.26.183.43:80 101.226.249.237:80 202.108.50.75:82 202.106.16.36:3128 111.1.36.133:80 124.88.67.24:80
有了这些IP和端口号,我们在JAVA中如何使用呢?只需要设置系统属性即可。
System.setProperty("proxySet", "true");
System.setProperty("http.proxyHost", ip);
System.setProperty("http.proxyPort", port);
设置完系统属性之后,我们如何判断有没有生效呢?我们可以通过看看在ip138的眼中,自己的IP是多少,然后和自己之前的IP作比较,看是否发生变化,如果发生变化,则认为我们的代理成功为我们向外部隐藏了自己的真实IP。
如何从ip138获取自己的外部地址呢?看如下代码:
public static String getCurrentIp(){
try {
String url = "http://1111.ip138.com/ic.asp?timestamp="+System.nanoTime();
String text = Jsoup.connect(url)
.header("Accept", ACCEPT)
.header("Accept-Encoding", ENCODING)
.header("Accept-Language", LANGUAGE)
.header("Connection", CONNECTION)
.header("Host", "1111.ip138.com")
.header("Referer", "http://ip138.com/")
.header("User-Agent", USER_AGENT)
.ignoreContentType(true)
.timeout(5000)
.get()
.text();
LOGGER.info("检查自身IP地址:"+text);
Matcher matcher = IP_PATTERN.matcher(text);
if(matcher.find()){
String ip = matcher.group();
LOGGER.info("自身IP地址:"+ip);
return ip;
}
}catch (Exception e){
LOGGER.error(e.getMessage());
}
LOGGER.info("检查自身IP地址失败,返回之前的IP地址:"+ previousIp);
return previousIp;
}
最后看看程序运行的部分截图如下:
尝试使用新的代理:186.91.60.155:8080 检查自身IP地址:您的IP地址 您的IP是:[186.91.60.155] 来自:委内瑞拉 自身IP地址:186.91.60.155 Thread[main,5,main]自动更换代理成功! Thread[main,5,main]更换代理耗时:4025毫秒 将66条代理IP地址写入本地 将81条能隐藏自己的代理IP地址写入本地 将108条不能隐藏自己的代理IP地址写入本地 Thread[main,5,main]请求重新更换代理 Thread[main,5,main]开始重新更换代理 尝试使用新的代理:117.158.98.214:80 检查自身IP地址:您的IP地址 您的IP是:[117.158.98.214] 来自:河南省许昌市 移动 自身IP地址:117.158.98.214 Thread[main,5,main]自动更换代理成功! Thread[main,5,main]更换代理耗时:176毫秒 将66条代理IP地址写入本地 将81条能隐藏自己的代理IP地址写入本地 将108条不能隐藏自己的代理IP地址写入本地 Thread[main,5,main]请求重新更换代理 Thread[main,5,main]开始重新更换代理 尝试使用新的代理:120.131.128.212:85 检查自身IP地址:您的IP地址 您的IP是:[111.200.10.82] 来自:北京市 联通 自身IP地址:111.200.10.82 Thread[main,5,main]自动更换代理成功! Thread[main,5,main]更换代理耗时:240毫秒 将66条代理IP地址写入本地 将81条能隐藏自己的代理IP地址写入本地 将108条不能隐藏自己的代理IP地址写入本地
完整的代码见本人的superword项目:https://github.com/ysc/superword/blob/master/src/main/java/org/apdplat/superword/tools/ProxyIp.java



相关推荐
最后,项目支持信息表明,本研究得到了相关教育和科研机构的资助,反映出工业机器人识别方式的研究不仅具有理论价值,也获得了社会各界的关注和支持,其研究与开发对于推动产教融合和校企联合人才培养模式也具有积极...
网络爬虫,也被称为网页蜘蛛或机器人,是互联网上的一个重要工具,主要用于自动化地抓取大量网页信息。这种技术被广泛应用于搜索引擎的索引更新、数据分析、市场研究、内容监控等多种场景。网络爬虫通过模拟人类...
【机器人】机器人相关案例的简介 【机器人】机器人相关案例的简介 【机器人】机器人相关案例的简介 【机器人】机器人相关案例的简介 【机器人】机器人相关案例的简介 【机器人】机器人相关案例的简介 ...
基于深度学习的分拣机器人目标识别与定位_解修亮基于深度学习的分拣机器人目标识别与定位_解修亮基于深度学习的分拣机器人目标识别与定位_解修亮基于深度学习的分拣机器人目标识别与定位_解修亮基于深度学习的分拣...
一个经典的机器人竞赛案例; 一个经典的机器人竞赛案例; 一个经典的机器人竞赛案例; 一个经典的机器人竞赛案例; 一个经典的机器人竞赛案例; 一个经典的机器人竞赛案例; 一个经典的机器人竞赛案例; 一个经典的...
在IT领域,网络机器人,也称为网络爬虫或网页抓取程序,是一种自动浏览互联网并收集信息的软件。本指南将深入探讨如何使用Java语言来编写网络机器人,从而帮助你理解其基本概念、设计原理以及实际操作技巧。 一、...
在IT行业,网络爬虫与反爬虫技术之间的对抗已经成为了互联网安全的重要组成部分。这份文件的标题“智能反爬虫试炼之路.pdf”以及描述“反爬虫攻击的现状 常见的反爬策略 防护新思考 智能反爬虫”暗示了文档内容将...
网络机器人和爬虫设计
《网络机器人JAVA编程指南》是一本专为Java开发者设计的深度学习资料,旨在帮助读者掌握如何使用Java语言构建网络爬虫和自动化工具,也就是我们常说的“网络机器人”。网络机器人在网络数据抓取、数据分析和自动化...
网络机器人,也称为网络爬虫或网页抓取器,是一种自动浏览互联网并收集信息的程序。在Java环境下,我们可以利用其强大的类库和跨平台特性来高效地实现这一功能。 本书可能涵盖以下关键知识点: 1. **基础概念**:...
机器人实际几何参数识别与仿真 机器人实际几何参数识别与仿真是机器人技术领域中的一个重要研究方向。机器人技术的发展使得机器人在工业、服务、医疗等领域中的应用越来越广泛。但是,机器人的实际几何参数识别和...
本文档是关于Python网络爬虫的复习大纲,涵盖了爬虫的基本概念、实现原理、技术、网页请求原理、抓取网页数据、数据解析、并发下载、抓取动态内容、图像识别与文字处理、存储爬虫数据、爬虫框架Scrapy等知识点。...
在进行基于ARM的教学用爬虫式机器人步态与控制策略研究中,首先涉及到的是机器人设计与步态规划的基本概念。爬虫式机器人是一种模仿真实爬行动物运动方式的自动化机械,通过四肢的协同动作来实现移动。其设计理念中...
"基于概率神经网络图像识别的工业机器人控制" 概率神经网络(PNN)是一种基于机器学习算法的神经网络模型,能够对图像进行分类识别和特征学习。在工业机器人控制领域,PNN被广泛应用于图像识别和机器人控制。该论文...
《网络机器人》一书主要探讨了如何理解和构建网络爬虫,即我们常说的"spider"或"bot"。网络机器人是一种自动浏览互联网并抓取信息的程序,它们在网络数据挖掘、搜索引擎优化、数据分析等领域发挥着重要作用。在这个...
文章《基于卷积神经网络的智能巡检机器人场景识别》主要探讨了如何通过卷积神经网络(CNN)来增强智能巡检机器人在变电站环境中的场景识别能力。 首先,文章回顾了机器人技术的发展,并指出了智能机器人运行的核心...
除草机器人杂草识别与视觉导航技术研究
在IT领域,爬虫机器人是一种自动化程序,用于在网络上抓取大量数据。制作自己的爬虫机器人是学习数据分析、网站抓取和信息处理的重要步骤。在这个过程中,你需要了解编程语言(如Python)、网络请求库(如requests)...
本文深入探讨了智能巡检机器人在变电站中可见光缺陷识别的应用案例,并提供了相应的问题分析与管理提升措施,为未来更好地利用智能巡检机器人实现无人巡视打下了基础。 知识点一:变电站智能化与智能巡检机器人应用...