- жөҸи§Ҳ: 97759 ж¬Ў
- жҖ§еҲ«:

- жқҘиҮӘ: ж·ұеңі
-

ж–Үз« еҲҶзұ»
зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 0)
- жҲ‘зҡ„й—®зӯ” ( 0)
еӯҳжЎЈеҲҶзұ»
- 2015-03 ( 3)
- 2014-12 ( 2)
- 2014-11 ( 1)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
-
qing_lu_nanпјҡ
и§ЈеҶідәҶжҲ‘зҡ„й—®йўҳпјҢеҚҒеҲҶж„ҹи°ўВ
linux дёӢservletз”»еӣҫдёҚжҳҫзӨәй—®йўҳ
JVMи°ғдјҳжҖ»з»“
JVMи°ғдјҳжҖ»з»“пјҲдёҖпјү-- дёҖдәӣжҰӮеҝө
ж•°жҚ®зұ»еһӢ
JavaиҷҡжӢҹжңәдёӯпјҢж•°жҚ®зұ»еһӢеҸҜд»ҘеҲҶдёәдёӨзұ»пјҡеҹәжң¬зұ»еһӢе’Ңеј•з”Ёзұ»еһӢгҖӮеҹәжң¬зұ»еһӢзҡ„еҸҳйҮҸдҝқеӯҳеҺҹе§ӢеҖјпјҢеҚіпјҡд»–д»ЈиЎЁзҡ„еҖје°ұжҳҜж•°еҖјжң¬иә«пјӣиҖҢеј•з”Ёзұ»еһӢзҡ„еҸҳйҮҸдҝқеӯҳеј•з”ЁеҖјгҖӮвҖңеј•з”ЁеҖјвҖқд»ЈиЎЁдәҶжҹҗдёӘеҜ№иұЎзҡ„еј•з”ЁпјҢиҖҢдёҚжҳҜеҜ№иұЎжң¬иә«пјҢеҜ№иұЎжң¬иә«еӯҳж”ҫеңЁиҝҷдёӘеј•з”ЁеҖјжүҖиЎЁзӨәзҡ„ең°еқҖзҡ„дҪҚзҪ®гҖӮ
еҹәжң¬зұ»еһӢеҢ…жӢ¬пјҡbyte,short,int,long,char,float,double,Boolean,returnAddress
еј•з”Ёзұ»еһӢеҢ…жӢ¬пјҡзұ»зұ»еһӢпјҢжҺҘеҸЈзұ»еһӢе’Ңж•°з»„гҖӮ
е ҶдёҺж Ҳ
е Ҷе’Ңж ҲжҳҜзЁӢеәҸиҝҗиЎҢзҡ„е…ій”®пјҢеҫҲжңүеҝ…иҰҒжҠҠ他们зҡ„е…ізі»иҜҙжё…жҘҡгҖӮ
ж ҲжҳҜиҝҗиЎҢж—¶зҡ„еҚ•дҪҚпјҢиҖҢе ҶжҳҜеӯҳеӮЁзҡ„еҚ•дҪҚгҖӮ
ж Ҳи§ЈеҶізЁӢеәҸзҡ„иҝҗиЎҢй—®йўҳпјҢеҚізЁӢеәҸеҰӮдҪ•жү§иЎҢпјҢжҲ–иҖ…иҜҙеҰӮдҪ•еӨ„зҗҶж•°жҚ®пјӣе Ҷи§ЈеҶізҡ„жҳҜж•°жҚ®еӯҳеӮЁзҡ„й—®йўҳпјҢеҚіж•°жҚ®жҖҺд№Ҳж”ҫгҖҒж”ҫеңЁе“Әе„ҝгҖӮ
еңЁJavaдёӯдёҖдёӘзәҝзЁӢе°ұдјҡзӣёеә”жңүдёҖдёӘзәҝзЁӢж ҲдёҺд№ӢеҜ№еә”пјҢиҝҷзӮ№еҫҲе®№жҳ“зҗҶи§ЈпјҢеӣ дёәдёҚеҗҢзҡ„зәҝзЁӢжү§иЎҢйҖ»иҫ‘жңүжүҖдёҚеҗҢпјҢеӣ жӯӨйңҖиҰҒдёҖдёӘзӢ¬з«Ӣзҡ„зәҝзЁӢж ҲгҖӮиҖҢе ҶеҲҷжҳҜжүҖжңүзәҝзЁӢе…ұдә«зҡ„гҖӮж Ҳеӣ дёәжҳҜиҝҗиЎҢеҚ•дҪҚпјҢеӣ жӯӨйҮҢйқўеӯҳеӮЁзҡ„дҝЎжҒҜйғҪжҳҜи·ҹеҪ“еүҚзәҝзЁӢпјҲжҲ–зЁӢеәҸпјүзӣёе…ідҝЎжҒҜзҡ„гҖӮеҢ…жӢ¬еұҖйғЁеҸҳйҮҸгҖҒзЁӢеәҸиҝҗиЎҢзҠ¶жҖҒгҖҒж–№жі•иҝ”еӣһеҖјзӯүзӯүпјӣиҖҢе ҶеҸӘиҙҹиҙЈеӯҳеӮЁеҜ№иұЎдҝЎжҒҜгҖӮ
дёәд»Җд№ҲиҰҒжҠҠе Ҷе’Ңж ҲеҢәеҲҶеҮәжқҘе‘ўпјҹж ҲдёӯдёҚжҳҜд№ҹеҸҜд»ҘеӯҳеӮЁж•°жҚ®еҗ—пјҹ
第дёҖпјҢд»ҺиҪҜ件и®ҫи®Ўзҡ„и§’еәҰзңӢпјҢж Ҳд»ЈиЎЁдәҶеӨ„зҗҶйҖ»иҫ‘пјҢиҖҢе Ҷд»ЈиЎЁдәҶж•°жҚ®гҖӮиҝҷж ·еҲҶејҖпјҢдҪҝеҫ—еӨ„зҗҶйҖ»иҫ‘жӣҙдёәжё…жҷ°гҖӮеҲҶиҖҢжІ»д№Ӣзҡ„жҖқжғігҖӮиҝҷз§Қйҡ”зҰ»гҖҒжЁЎеқ—еҢ–зҡ„жҖқжғіеңЁиҪҜ件и®ҫи®Ўзҡ„ж–№ж–№йқўйқўйғҪжңүдҪ“зҺ°гҖӮ
第дәҢпјҢе ҶдёҺж Ҳзҡ„еҲҶзҰ»пјҢдҪҝеҫ—е Ҷдёӯзҡ„еҶ…е®№еҸҜд»Ҙиў«еӨҡдёӘж Ҳе…ұдә«пјҲд№ҹеҸҜд»ҘзҗҶи§ЈдёәеӨҡдёӘзәҝзЁӢи®ҝй—®еҗҢдёҖдёӘеҜ№иұЎпјүгҖӮиҝҷз§Қе…ұдә«зҡ„收зӣҠжҳҜеҫҲеӨҡзҡ„гҖӮдёҖж–№йқўиҝҷз§Қе…ұдә«жҸҗдҫӣдәҶдёҖз§Қжңүж•Ҳзҡ„ж•°жҚ®дәӨдә’ж–№ејҸ(еҰӮпјҡе…ұдә«еҶ…еӯҳ)пјҢеҸҰдёҖж–№йқўпјҢе Ҷдёӯзҡ„е…ұдә«еёёйҮҸе’Ңзј“еӯҳеҸҜд»Ҙиў«жүҖжңүж Ҳи®ҝй—®пјҢиҠӮзңҒдәҶз©әй—ҙгҖӮ
第дёүпјҢж Ҳеӣ дёәиҝҗиЎҢж—¶зҡ„йңҖиҰҒпјҢжҜ”еҰӮдҝқеӯҳзі»з»ҹиҝҗиЎҢзҡ„дёҠдёӢж–ҮпјҢйңҖиҰҒиҝӣиЎҢең°еқҖж®өзҡ„еҲ’еҲҶгҖӮз”ұдәҺж ҲеҸӘиғҪеҗ‘дёҠеўһй•ҝпјҢеӣ жӯӨе°ұдјҡйҷҗеҲ¶дҪҸж ҲеӯҳеӮЁеҶ…е®№зҡ„иғҪеҠӣгҖӮиҖҢе ҶдёҚеҗҢпјҢе Ҷдёӯзҡ„еҜ№иұЎжҳҜеҸҜд»Ҙж №жҚ®йңҖиҰҒеҠЁжҖҒеўһй•ҝзҡ„пјҢеӣ жӯӨж Ҳе’Ңе Ҷзҡ„жӢҶеҲҶпјҢдҪҝеҫ—еҠЁжҖҒеўһй•ҝжҲҗдёәеҸҜиғҪпјҢзӣёеә”ж ҲдёӯеҸӘйңҖи®°еҪ•е Ҷдёӯзҡ„дёҖдёӘең°еқҖеҚіеҸҜгҖӮ
第еӣӣпјҢйқўеҗ‘еҜ№иұЎе°ұжҳҜе Ҷе’Ңж Ҳзҡ„е®ҢзҫҺз»“еҗҲгҖӮе…¶е®һпјҢйқўеҗ‘еҜ№иұЎж–№ејҸзҡ„зЁӢеәҸдёҺд»ҘеүҚз»“жһ„еҢ–зҡ„зЁӢеәҸеңЁжү§иЎҢдёҠжІЎжңүд»»дҪ•еҢәеҲ«гҖӮдҪҶжҳҜпјҢйқўеҗ‘еҜ№иұЎзҡ„еј•е…ҘпјҢдҪҝеҫ—еҜ№еҫ…й—®йўҳзҡ„жҖқиҖғж–№ејҸеҸ‘з”ҹдәҶж”№еҸҳпјҢиҖҢжӣҙжҺҘиҝ‘дәҺиҮӘ然方ејҸзҡ„жҖқиҖғгҖӮеҪ“жҲ‘们жҠҠеҜ№иұЎжӢҶејҖпјҢдҪ дјҡеҸ‘зҺ°пјҢеҜ№иұЎзҡ„еұһжҖ§е…¶е®һе°ұжҳҜж•°жҚ®пјҢеӯҳж”ҫеңЁе ҶдёӯпјӣиҖҢеҜ№иұЎзҡ„иЎҢдёәпјҲж–№жі•пјүпјҢе°ұжҳҜиҝҗиЎҢйҖ»иҫ‘пјҢж”ҫеңЁж ҲдёӯгҖӮжҲ‘们еңЁзј–еҶҷеҜ№иұЎзҡ„ж—¶еҖҷпјҢе…¶е®һеҚізј–еҶҷдәҶж•°жҚ®з»“жһ„пјҢд№ҹзј–еҶҷзҡ„еӨ„зҗҶж•°жҚ®зҡ„йҖ»иҫ‘гҖӮдёҚеҫ—дёҚжүҝи®ӨпјҢйқўеҗ‘еҜ№иұЎзҡ„и®ҫи®ЎпјҢзЎ®е®һеҫҲзҫҺгҖӮ
еңЁJavaдёӯпјҢMainеҮҪж•°е°ұжҳҜж Ҳзҡ„иө·е§ӢзӮ№пјҢд№ҹжҳҜзЁӢеәҸзҡ„иө·е§ӢзӮ№гҖӮ
зЁӢеәҸиҰҒиҝҗиЎҢжҖ»жҳҜжңүдёҖдёӘиө·зӮ№зҡ„гҖӮеҗҢCиҜӯиЁҖдёҖж ·пјҢjavaдёӯзҡ„Mainе°ұжҳҜйӮЈдёӘиө·зӮ№гҖӮж— и®әд»Җд№ҲjavaзЁӢеәҸпјҢжүҫеҲ°mainе°ұжүҫеҲ°дәҶзЁӢеәҸжү§иЎҢзҡ„е…ҘеҸЈпјҡпјү
е Ҷдёӯеӯҳд»Җд№Ҳпјҹж Ҳдёӯеӯҳд»Җд№Ҳпјҹ
е Ҷдёӯеӯҳзҡ„жҳҜеҜ№иұЎгҖӮж Ҳдёӯеӯҳзҡ„жҳҜеҹәжң¬ж•°жҚ®зұ»еһӢе’Ңе ҶдёӯеҜ№иұЎзҡ„еј•з”ЁгҖӮдёҖдёӘеҜ№иұЎзҡ„еӨ§е°ҸжҳҜдёҚеҸҜдј°и®Ўзҡ„пјҢжҲ–иҖ…иҜҙжҳҜеҸҜд»ҘеҠЁжҖҒеҸҳеҢ–зҡ„пјҢдҪҶжҳҜеңЁж ҲдёӯпјҢдёҖдёӘеҜ№иұЎеҸӘеҜ№еә”дәҶдёҖдёӘ4btyeзҡ„еј•з”ЁпјҲе Ҷж ҲеҲҶзҰ»зҡ„еҘҪеӨ„пјҡпјүпјүгҖӮ
дёәд»Җд№ҲдёҚжҠҠеҹәжң¬зұ»еһӢж”ҫе Ҷдёӯе‘ўпјҹеӣ дёәе…¶еҚ з”Ёзҡ„з©әй—ҙдёҖиҲ¬жҳҜ1~8дёӘеӯ—иҠӮвҖ”вҖ”йңҖиҰҒз©әй—ҙжҜ”иҫғе°‘пјҢиҖҢдё”еӣ дёәжҳҜеҹәжң¬зұ»еһӢпјҢжүҖд»ҘдёҚдјҡеҮәзҺ°еҠЁжҖҒеўһй•ҝзҡ„жғ…еҶөвҖ”вҖ”й•ҝеәҰеӣәе®ҡпјҢеӣ жӯӨж ҲдёӯеӯҳеӮЁе°ұеӨҹдәҶпјҢеҰӮжһңжҠҠд»–еӯҳеңЁе ҶдёӯжҳҜжІЎжңүд»Җд№Ҳж„Ҹд№үзҡ„пјҲиҝҳдјҡжөӘиҙ№з©әй—ҙпјҢеҗҺйқўиҜҙжҳҺпјүгҖӮеҸҜд»Ҙиҝҷд№ҲиҜҙпјҢеҹәжң¬зұ»еһӢе’ҢеҜ№иұЎзҡ„еј•з”ЁйғҪжҳҜеӯҳж”ҫеңЁж ҲдёӯпјҢиҖҢдё”йғҪжҳҜеҮ дёӘеӯ—иҠӮзҡ„дёҖдёӘж•°пјҢеӣ жӯӨеңЁзЁӢеәҸиҝҗиЎҢж—¶пјҢ他们зҡ„еӨ„зҗҶж–№ејҸжҳҜз»ҹдёҖзҡ„гҖӮдҪҶжҳҜеҹәжң¬зұ»еһӢгҖҒеҜ№иұЎеј•з”Ёе’ҢеҜ№иұЎжң¬иә«е°ұжңүжүҖеҢәеҲ«дәҶпјҢеӣ дёәдёҖдёӘжҳҜж Ҳдёӯзҡ„ж•°жҚ®дёҖдёӘжҳҜе Ҷдёӯзҡ„ж•°жҚ®гҖӮжңҖеёёи§Ғзҡ„дёҖдёӘй—®йўҳе°ұжҳҜпјҢJavaдёӯеҸӮж•°дј йҖ’ж—¶зҡ„й—®йўҳгҖӮ
Javaдёӯзҡ„еҸӮж•°дј йҖ’ж—¶дј еҖје‘ўпјҹиҝҳжҳҜдј еј•з”Ёпјҹ
иҰҒиҜҙжҳҺиҝҷдёӘй—®йўҳпјҢе…ҲиҰҒжҳҺзЎ®дёӨзӮ№пјҡ
1. дёҚиҰҒиҜ•еӣҫдёҺCиҝӣиЎҢзұ»жҜ”пјҢJavaдёӯжІЎжңүжҢҮй’Ҳзҡ„жҰӮеҝө
2. зЁӢеәҸиҝҗиЎҢж°ёиҝңйғҪжҳҜеңЁж ҲдёӯиҝӣиЎҢзҡ„пјҢеӣ иҖҢеҸӮж•°дј йҖ’ж—¶пјҢеҸӘеӯҳеңЁдј йҖ’еҹәжң¬зұ»еһӢе’ҢеҜ№иұЎеј•з”Ёзҡ„й—®йўҳгҖӮдёҚдјҡзӣҙжҺҘдј еҜ№иұЎжң¬иә«гҖӮ
жҳҺзЎ®д»ҘдёҠдёӨзӮ№еҗҺгҖӮJavaеңЁж–№жі•и°ғз”Ёдј йҖ’еҸӮж•°ж—¶пјҢеӣ дёәжІЎжңүжҢҮй’ҲпјҢжүҖд»Ҙе®ғйғҪжҳҜиҝӣиЎҢдј еҖји°ғз”ЁпјҲиҝҷзӮ№еҸҜд»ҘеҸӮиҖғCзҡ„дј еҖји°ғз”ЁпјүгҖӮеӣ жӯӨпјҢеҫҲеӨҡд№ҰйҮҢйқўйғҪиҜҙJavaжҳҜиҝӣиЎҢдј еҖји°ғз”ЁпјҢиҝҷзӮ№жІЎжңүй—®йўҳпјҢиҖҢдё”д№ҹз®ҖеҢ–зҡ„CдёӯеӨҚжқӮжҖ§гҖӮ
дҪҶжҳҜдј еј•з”Ёзҡ„й”ҷи§үжҳҜеҰӮдҪ•йҖ жҲҗзҡ„е‘ўпјҹеңЁиҝҗиЎҢж ҲдёӯпјҢеҹәжң¬зұ»еһӢе’Ңеј•з”Ёзҡ„еӨ„зҗҶжҳҜдёҖж ·зҡ„пјҢйғҪжҳҜдј еҖјпјҢжүҖд»ҘпјҢеҰӮжһңжҳҜдј еј•з”Ёзҡ„ж–№жі•и°ғз”ЁпјҢд№ҹеҗҢж—¶еҸҜд»ҘзҗҶи§ЈдёәвҖңдј еј•з”ЁеҖјвҖқзҡ„дј еҖји°ғз”ЁпјҢеҚіеј•з”Ёзҡ„еӨ„зҗҶи·ҹеҹәжң¬зұ»еһӢжҳҜе®Ңе…ЁдёҖж ·зҡ„гҖӮдҪҶжҳҜеҪ“иҝӣе…Ҙиў«и°ғз”Ёж–№жі•ж—¶пјҢиў«дј йҖ’зҡ„иҝҷдёӘеј•з”Ёзҡ„еҖјпјҢиў«зЁӢеәҸи§ЈйҮҠпјҲжҲ–иҖ…жҹҘжүҫпјүеҲ°е Ҷдёӯзҡ„еҜ№иұЎпјҢиҝҷдёӘж—¶еҖҷжүҚеҜ№еә”еҲ°зңҹжӯЈзҡ„еҜ№иұЎгҖӮеҰӮжһңжӯӨж—¶иҝӣиЎҢдҝ®ж”№пјҢдҝ®ж”№зҡ„жҳҜеј•з”ЁеҜ№еә”зҡ„еҜ№иұЎпјҢиҖҢдёҚжҳҜеј•з”Ёжң¬иә«пјҢеҚіпјҡдҝ®ж”№зҡ„жҳҜе Ҷдёӯзҡ„ж•°жҚ®гҖӮжүҖд»ҘиҝҷдёӘдҝ®ж”№жҳҜеҸҜд»ҘдҝқжҢҒзҡ„дәҶгҖӮ
еҜ№иұЎпјҢд»Һжҹҗз§Қж„Ҹд№үдёҠиҜҙпјҢжҳҜз”ұеҹәжң¬зұ»еһӢз»„жҲҗзҡ„гҖӮеҸҜд»ҘжҠҠдёҖдёӘеҜ№иұЎзңӢдҪңдёәдёҖжЈөж ‘пјҢеҜ№иұЎзҡ„еұһжҖ§еҰӮжһңиҝҳжҳҜеҜ№иұЎпјҢеҲҷиҝҳжҳҜдёҖйў—ж ‘пјҲеҚійқһеҸ¶еӯҗиҠӮзӮ№пјүпјҢеҹәжң¬зұ»еһӢеҲҷдёәж ‘зҡ„еҸ¶еӯҗиҠӮзӮ№гҖӮзЁӢеәҸеҸӮж•°дј йҖ’ж—¶пјҢиў«дј йҖ’зҡ„еҖјжң¬иә«йғҪжҳҜдёҚиғҪиҝӣиЎҢдҝ®ж”№зҡ„пјҢдҪҶжҳҜпјҢеҰӮжһңиҝҷдёӘеҖјжҳҜдёҖдёӘйқһеҸ¶еӯҗиҠӮзӮ№пјҲеҚідёҖдёӘеҜ№иұЎеј•з”ЁпјүпјҢеҲҷеҸҜд»Ҙдҝ®ж”№иҝҷдёӘиҠӮзӮ№дёӢйқўзҡ„жүҖжңүеҶ…е®№гҖӮ
е Ҷе’Ңж ҲдёӯпјҢж ҲжҳҜзЁӢеәҸиҝҗиЎҢжңҖж №жң¬зҡ„дёңиҘҝгҖӮзЁӢеәҸиҝҗиЎҢеҸҜд»ҘжІЎжңүе ҶпјҢдҪҶжҳҜдёҚиғҪжІЎжңүж ҲгҖӮиҖҢе ҶжҳҜдёәж ҲиҝӣиЎҢж•°жҚ®еӯҳеӮЁжңҚеҠЎпјҢиҜҙзҷҪдәҶе Ҷе°ұжҳҜдёҖеқ—е…ұдә«зҡ„еҶ…еӯҳгҖӮдёҚиҝҮпјҢжӯЈжҳҜеӣ дёәе Ҷе’Ңж Ҳзҡ„еҲҶзҰ»зҡ„жҖқжғіпјҢжүҚдҪҝеҫ—Javaзҡ„еһғеңҫеӣһ收жҲҗдёәеҸҜиғҪгҖӮ
JavaдёӯпјҢж Ҳзҡ„еӨ§е°ҸйҖҡиҝҮ-XssжқҘи®ҫзҪ®пјҢеҪ“ж ҲдёӯеӯҳеӮЁж•°жҚ®жҜ”иҫғеӨҡж—¶пјҢйңҖиҰҒйҖӮеҪ“и°ғеӨ§иҝҷдёӘеҖјпјҢеҗҰеҲҷдјҡеҮәзҺ°java.lang.StackOverflowErrorејӮеёёгҖӮеёёи§Ғзҡ„еҮәзҺ°иҝҷдёӘејӮеёёзҡ„жҳҜж— жі•иҝ”еӣһзҡ„йҖ’еҪ’пјҢеӣ дёәжӯӨж—¶ж Ҳдёӯдҝқеӯҳзҡ„дҝЎжҒҜйғҪжҳҜж–№жі•иҝ”еӣһзҡ„и®°еҪ•зӮ№гҖӮ
JVMи°ғдјҳжҖ»з»“пјҲдәҢпјү-дёҖдәӣжҰӮеҝө
JavaеҜ№иұЎзҡ„еӨ§е°Ҹ
еҹәжң¬ж•°жҚ®зҡ„зұ»еһӢзҡ„еӨ§е°ҸжҳҜеӣәе®ҡзҡ„пјҢиҝҷйҮҢе°ұдёҚеӨҡиҜҙдәҶгҖӮеҜ№дәҺйқһеҹәжң¬зұ»еһӢзҡ„JavaеҜ№иұЎпјҢе…¶еӨ§е°Ҹе°ұеҖјеҫ—е•ҶжҰ·гҖӮ
еңЁJavaдёӯпјҢдёҖдёӘз©әObjectеҜ№иұЎзҡ„еӨ§е°ҸжҳҜ8byteпјҢиҝҷдёӘеӨ§е°ҸеҸӘжҳҜдҝқеӯҳе ҶдёӯдёҖдёӘжІЎжңүд»»дҪ•еұһжҖ§зҡ„еҜ№иұЎзҡ„еӨ§е°ҸгҖӮзңӢдёӢйқўиҜӯеҸҘпјҡ
Object ob = new Object();
иҝҷж ·еңЁзЁӢеәҸдёӯе®ҢжҲҗдәҶдёҖдёӘJavaеҜ№иұЎзҡ„з”ҹе‘ҪпјҢдҪҶжҳҜе®ғжүҖеҚ зҡ„з©әй—ҙдёәпјҡ4byte+8byteгҖӮ4byteжҳҜдёҠйқўйғЁеҲҶжүҖиҜҙзҡ„Javaж Ҳдёӯдҝқеӯҳеј•з”Ёзҡ„жүҖйңҖиҰҒзҡ„з©әй—ҙгҖӮиҖҢйӮЈ8byteеҲҷжҳҜJavaе ҶдёӯеҜ№иұЎзҡ„дҝЎжҒҜгҖӮеӣ дёәжүҖжңүзҡ„Javaйқһеҹәжң¬зұ»еһӢзҡ„еҜ№иұЎйғҪйңҖиҰҒй»ҳи®Ө继жүҝObjectеҜ№иұЎпјҢеӣ жӯӨдёҚи®әд»Җд№Ҳж ·зҡ„JavaеҜ№иұЎпјҢе…¶еӨ§е°ҸйғҪеҝ…йЎ»жҳҜеӨ§дәҺ8byteгҖӮ
жңүдәҶObjectеҜ№иұЎзҡ„еӨ§е°ҸпјҢжҲ‘们е°ұеҸҜд»Ҙи®Ўз®—е…¶д»–еҜ№иұЎзҡ„еӨ§е°ҸдәҶгҖӮ
Class NewObject{ int count; Boolean flag; Object ob; }
е…¶еӨ§е°Ҹдёәпјҡз©әеҜ№иұЎеӨ§е°Ҹ(8byte)+intеӨ§е°Ҹ(4byte)+BooleanеӨ§е°Ҹ(1byte)+з©әObjectеј•з”Ёзҡ„еӨ§е°Ҹ (4byte)=17byteгҖӮдҪҶжҳҜеӣ дёәJavaеңЁеҜ№еҜ№иұЎеҶ…еӯҳеҲҶй…Қж—¶йғҪжҳҜд»Ҙ8зҡ„ж•ҙж•°еҖҚжқҘеҲҶпјҢеӣ жӯӨеӨ§дәҺ17byteзҡ„жңҖжҺҘиҝ‘8зҡ„ж•ҙж•°еҖҚзҡ„жҳҜ24пјҢеӣ жӯӨжӯӨеҜ№иұЎзҡ„еӨ§е°Ҹдёә24byteгҖӮ
иҝҷйҮҢйңҖиҰҒжіЁж„ҸдёҖдёӢеҹәжң¬зұ»еһӢзҡ„еҢ…иЈ…зұ»еһӢзҡ„еӨ§е°ҸгҖӮеӣ дёәиҝҷз§ҚеҢ…иЈ…зұ»еһӢе·Із»ҸжҲҗдёәеҜ№иұЎдәҶпјҢеӣ жӯӨйңҖиҰҒжҠҠ他们дҪңдёәеҜ№иұЎжқҘзңӢеҫ…гҖӮеҢ…иЈ…зұ»еһӢзҡ„еӨ§е°ҸиҮіе°‘жҳҜ12byteпјҲеЈ°жҳҺдёҖдёӘз©әObjectиҮіе°‘йңҖиҰҒзҡ„з©әй—ҙпјүпјҢиҖҢдё”12byteжІЎжңүеҢ…еҗ«д»»дҪ•жңүж•ҲдҝЎжҒҜпјҢеҗҢж—¶пјҢеӣ дёәJavaеҜ№иұЎеӨ§е°ҸжҳҜ8зҡ„ж•ҙж•°еҖҚпјҢеӣ жӯӨдёҖдёӘеҹәжң¬зұ»еһӢеҢ…иЈ…зұ»зҡ„еӨ§е°ҸиҮіе°‘жҳҜ16byteгҖӮиҝҷдёӘеҶ…еӯҳеҚ з”ЁжҳҜеҫҲжҒҗжҖ–зҡ„пјҢе®ғжҳҜдҪҝз”Ёеҹәжң¬зұ»еһӢзҡ„NеҖҚпјҲN>2пјүпјҢжңүдәӣзұ»еһӢзҡ„еҶ…еӯҳеҚ з”ЁжӣҙжҳҜеӨёеј пјҲйҡҸдҫҝжғідёӢе°ұзҹҘйҒ“дәҶпјүгҖӮеӣ жӯӨпјҢеҸҜиғҪзҡ„иҜқеә”е°ҪйҮҸе°‘дҪҝз”ЁеҢ…иЈ…зұ»гҖӮеңЁJDK5.0д»ҘеҗҺпјҢеӣ дёәеҠ е…ҘдәҶиҮӘеҠЁзұ»еһӢиЈ…жҚўпјҢеӣ жӯӨпјҢJavaиҷҡжӢҹжңәдјҡеңЁеӯҳеӮЁж–№йқўиҝӣиЎҢзӣёеә”зҡ„дјҳеҢ–гҖӮ
еј•з”Ёзұ»еһӢ
еҜ№иұЎеј•з”Ёзұ»еһӢеҲҶдёәејәеј•з”ЁгҖҒиҪҜеј•з”ЁгҖҒејұеј•з”Ёе’Ңиҷҡеј•з”ЁгҖӮ
ејәеј•з”Ё:е°ұжҳҜжҲ‘们дёҖиҲ¬еЈ°жҳҺеҜ№иұЎжҳҜж—¶иҷҡжӢҹжңәз”ҹжҲҗзҡ„еј•з”ЁпјҢејәеј•з”ЁзҺҜеўғдёӢпјҢеһғеңҫеӣһ收时йңҖиҰҒдёҘж јеҲӨж–ӯеҪ“еүҚеҜ№иұЎжҳҜеҗҰиў«ејәеј•з”ЁпјҢеҰӮжһңиў«ејәеј•з”ЁпјҢеҲҷдёҚдјҡиў«еһғеңҫеӣһ收
иҪҜеј•з”Ё:иҪҜеј•з”ЁдёҖиҲ¬иў«еҒҡдёәзј“еӯҳжқҘдҪҝз”ЁгҖӮдёҺејәеј•з”Ёзҡ„еҢәеҲ«жҳҜпјҢиҪҜеј•з”ЁеңЁеһғеңҫеӣһ收时пјҢиҷҡжӢҹжңәдјҡж №жҚ®еҪ“еүҚзі»з»ҹзҡ„еү©дҪҷеҶ…еӯҳжқҘеҶіе®ҡжҳҜеҗҰеҜ№иҪҜеј•з”ЁиҝӣиЎҢеӣһ收гҖӮеҰӮжһңеү©дҪҷеҶ…еӯҳжҜ”иҫғзҙ§еј пјҢеҲҷиҷҡжӢҹжңәдјҡеӣһ收иҪҜеј•з”ЁжүҖеј•з”Ёзҡ„з©әй—ҙпјӣеҰӮжһңеү©дҪҷеҶ…еӯҳзӣёеҜ№еҜҢиЈ•пјҢеҲҷдёҚдјҡиҝӣиЎҢеӣһ收гҖӮжҚўеҸҘиҜқиҜҙпјҢиҷҡжӢҹжңәеңЁеҸ‘з”ҹOutOfMemoryж—¶пјҢиӮҜе®ҡжҳҜжІЎжңүиҪҜеј•з”ЁеӯҳеңЁзҡ„гҖӮ
ејұеј•з”Ё:ејұеј•з”ЁдёҺиҪҜеј•з”Ёзұ»дјјпјҢйғҪжҳҜдҪңдёәзј“еӯҳжқҘдҪҝз”ЁгҖӮдҪҶдёҺиҪҜеј•з”ЁдёҚеҗҢпјҢејұеј•з”ЁеңЁиҝӣиЎҢеһғеңҫеӣһ收时пјҢжҳҜдёҖе®ҡдјҡиў«еӣһ收жҺүзҡ„пјҢеӣ жӯӨе…¶з”ҹе‘Ҫе‘ЁжңҹеҸӘеӯҳеңЁдәҺдёҖдёӘеһғеңҫеӣһ收周жңҹеҶ…гҖӮ
ејәеј•з”ЁдёҚз”ЁиҜҙпјҢжҲ‘们系з»ҹдёҖиҲ¬еңЁдҪҝз”Ёж—¶йғҪжҳҜз”Ёзҡ„ејәеј•з”ЁгҖӮиҖҢвҖңиҪҜеј•з”ЁвҖқе’ҢвҖңејұеј•з”ЁвҖқжҜ”иҫғе°‘и§ҒгҖӮ他们дёҖиҲ¬иў«дҪңдёәзј“еӯҳдҪҝз”ЁпјҢиҖҢдё”дёҖиҲ¬жҳҜеңЁеҶ…еӯҳеӨ§е°ҸжҜ”иҫғеҸ—йҷҗзҡ„жғ…еҶөдёӢеҒҡдёәзј“еӯҳгҖӮеӣ дёәеҰӮжһңеҶ…еӯҳи¶іеӨҹеӨ§зҡ„иҜқпјҢеҸҜд»ҘзӣҙжҺҘдҪҝз”Ёејәеј•з”ЁдҪңдёәзј“еӯҳеҚіеҸҜпјҢеҗҢж—¶еҸҜжҺ§жҖ§жӣҙй«ҳгҖӮеӣ иҖҢпјҢ他们常и§Ғзҡ„жҳҜиў«дҪҝз”ЁеңЁжЎҢйқўеә”з”Ёзі»з»ҹзҡ„зј“еӯҳгҖӮ
JVMи°ғдјҳжҖ»з»“пјҲдёүпјү-еҹәжң¬еһғеңҫеӣһ收算法
еҸҜд»Ҙд»ҺдёҚеҗҢзҡ„зҡ„и§’еәҰеҺ»еҲ’еҲҶеһғеңҫеӣһ收算法пјҡ
жҢүз…§еҹәжң¬еӣһ收зӯ–з•ҘеҲҶ
еј•з”Ёи®Ўж•°пјҲReference Countingпјү:
жҜ”иҫғеҸӨиҖҒзҡ„еӣһ收算法гҖӮеҺҹзҗҶжҳҜжӯӨеҜ№иұЎжңүдёҖдёӘеј•з”ЁпјҢеҚіеўһеҠ дёҖдёӘи®Ўж•°пјҢеҲ йҷӨдёҖдёӘеј•з”ЁеҲҷеҮҸе°‘дёҖдёӘи®Ўж•°гҖӮеһғеңҫеӣһ收时пјҢеҸӘ用收йӣҶи®Ўж•°дёә0зҡ„еҜ№иұЎгҖӮжӯӨз®—жі•жңҖиҮҙе‘Ҫзҡ„жҳҜж— жі•еӨ„зҗҶеҫӘзҺҜеј•з”Ёзҡ„й—®йўҳгҖӮ
ж Үи®°-жё…йҷӨпјҲMark-Sweepпјү:

жӯӨз®—жі•жү§иЎҢеҲҶдёӨйҳ¶ж®өгҖӮ第дёҖйҳ¶ж®өд»Һеј•з”Ёж №иҠӮзӮ№ејҖе§Ӣж Үи®°жүҖжңүиў«еј•з”Ёзҡ„еҜ№иұЎпјҢ第дәҢйҳ¶ж®өйҒҚеҺҶж•ҙдёӘе ҶпјҢжҠҠжңӘж Үи®°зҡ„еҜ№иұЎжё…йҷӨгҖӮжӯӨз®—жі•йңҖиҰҒжҡӮеҒңж•ҙдёӘеә”з”ЁпјҢеҗҢж—¶пјҢдјҡдә§з”ҹеҶ…еӯҳзўҺзүҮгҖӮ
еӨҚеҲ¶пјҲCopyingпјү:

жӯӨз®—жі•жҠҠеҶ…еӯҳз©әй—ҙеҲ’дёәдёӨдёӘзӣёзӯүзҡ„еҢәеҹҹпјҢжҜҸж¬ЎеҸӘдҪҝз”Ёе…¶дёӯдёҖдёӘеҢәеҹҹгҖӮеһғеңҫеӣһ收时пјҢйҒҚеҺҶеҪ“еүҚдҪҝз”ЁеҢәеҹҹпјҢжҠҠжӯЈеңЁдҪҝз”Ёдёӯзҡ„еҜ№иұЎеӨҚеҲ¶еҲ°еҸҰеӨ–дёҖдёӘеҢәеҹҹдёӯгҖӮж¬Ўз®—жі•жҜҸж¬ЎеҸӘеӨ„зҗҶжӯЈеңЁдҪҝз”Ёдёӯзҡ„еҜ№иұЎпјҢеӣ жӯӨеӨҚеҲ¶жҲҗжң¬жҜ”иҫғе°ҸпјҢеҗҢж—¶еӨҚеҲ¶иҝҮеҺ»д»ҘеҗҺиҝҳиғҪиҝӣиЎҢзӣёеә”зҡ„еҶ…еӯҳж•ҙзҗҶпјҢдёҚдјҡеҮәзҺ°вҖңзўҺзүҮвҖқй—®йўҳгҖӮеҪ“然пјҢжӯӨз®—жі•зҡ„зјәзӮ№д№ҹжҳҜеҫҲжҳҺжҳҫзҡ„пјҢе°ұжҳҜйңҖиҰҒдёӨеҖҚеҶ…еӯҳз©әй—ҙгҖӮ
ж Үи®°-ж•ҙзҗҶпјҲMark-Compactпјү:
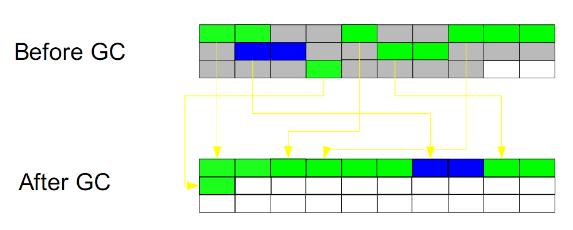
жӯӨз®—жі•з»“еҗҲдәҶвҖңж Үи®°-жё…йҷӨвҖқе’ҢвҖңеӨҚеҲ¶вҖқдёӨдёӘз®—жі•зҡ„дјҳзӮ№гҖӮд№ҹжҳҜеҲҶдёӨйҳ¶ж®өпјҢ第дёҖйҳ¶ж®өд»Һж №иҠӮзӮ№ејҖе§Ӣж Үи®°жүҖжңүиў«еј•з”ЁеҜ№иұЎпјҢ第дәҢйҳ¶ж®өйҒҚеҺҶж•ҙдёӘе ҶпјҢжҠҠжё…йҷӨжңӘж Үи®°еҜ№иұЎе№¶дё”жҠҠеӯҳжҙ»еҜ№иұЎвҖңеҺӢзј©вҖқеҲ°е Ҷзҡ„е…¶дёӯдёҖеқ—пјҢжҢүйЎәеәҸжҺ’ж”ҫгҖӮжӯӨз®—жі•йҒҝе…ҚдәҶвҖңж Үи®°-жё…йҷӨвҖқзҡ„зўҺзүҮй—®йўҳпјҢеҗҢж—¶д№ҹйҒҝе…ҚдәҶвҖңеӨҚеҲ¶вҖқз®—жі•зҡ„з©әй—ҙй—®йўҳгҖӮ
жҢүеҲҶеҢәеҜ№еҫ…зҡ„ж–№ејҸеҲҶ
еўһйҮҸ收йӣҶпјҲIncremental Collectingпјү:е®һж—¶еһғеңҫеӣһ收算法пјҢеҚіпјҡеңЁеә”з”ЁиҝӣиЎҢзҡ„еҗҢж—¶иҝӣиЎҢеһғеңҫеӣһ收гҖӮдёҚзҹҘйҒ“д»Җд№ҲеҺҹеӣ JDK5.0дёӯзҡ„收йӣҶеҷЁжІЎжңүдҪҝз”Ёиҝҷз§Қз®—жі•зҡ„гҖӮ
еҲҶ代收йӣҶпјҲGenerational Collectingпјү:еҹәдәҺеҜ№еҜ№иұЎз”ҹе‘Ҫе‘ЁжңҹеҲҶжһҗеҗҺеҫ—еҮәзҡ„еһғеңҫеӣһ收算法гҖӮжҠҠеҜ№иұЎеҲҶдёәе№ҙйқ’д»ЈгҖҒе№ҙиҖҒд»ЈгҖҒжҢҒд№…д»ЈпјҢеҜ№дёҚеҗҢз”ҹе‘Ҫе‘Ёжңҹзҡ„еҜ№иұЎдҪҝз”ЁдёҚеҗҢзҡ„з®—жі•пјҲдёҠиҝ°ж–№ејҸдёӯзҡ„дёҖдёӘпјүиҝӣиЎҢеӣһ收гҖӮзҺ°еңЁзҡ„еһғеңҫеӣһ收еҷЁпјҲд»ҺJ2SE1.2ејҖе§ӢпјүйғҪжҳҜдҪҝз”ЁжӯӨз®—жі•зҡ„гҖӮ
жҢүзі»з»ҹзәҝзЁӢеҲҶ
дёІиЎҢ收йӣҶ:дёІиЎҢ收йӣҶдҪҝз”ЁеҚ•зәҝзЁӢеӨ„зҗҶжүҖжңүеһғеңҫеӣһ收е·ҘдҪңпјҢеӣ дёәж— йңҖеӨҡзәҝзЁӢдәӨдә’пјҢе®һзҺ°е®№жҳ“пјҢиҖҢдё”ж•ҲзҺҮжҜ”иҫғй«ҳгҖӮдҪҶжҳҜпјҢе…¶еұҖйҷҗжҖ§д№ҹжҜ”иҫғжҳҺжҳҫпјҢеҚіж— жі•дҪҝз”ЁеӨҡеӨ„зҗҶеҷЁзҡ„дјҳеҠҝпјҢжүҖд»ҘжӯӨ收йӣҶйҖӮеҗҲеҚ•еӨ„зҗҶеҷЁжңәеҷЁгҖӮеҪ“然пјҢжӯӨ收йӣҶеҷЁд№ҹеҸҜд»Ҙз”ЁеңЁе°Ҹж•°жҚ®йҮҸпјҲ100Mе·ҰеҸіпјүжғ…еҶөдёӢзҡ„еӨҡеӨ„зҗҶеҷЁжңәеҷЁдёҠгҖӮ
并иЎҢ收йӣҶ:并иЎҢ收йӣҶдҪҝз”ЁеӨҡзәҝзЁӢеӨ„зҗҶеһғеңҫеӣһ收е·ҘдҪңпјҢеӣ иҖҢйҖҹеәҰеҝ«пјҢж•ҲзҺҮй«ҳгҖӮиҖҢдё”зҗҶи®әдёҠCPUж•°зӣ®и¶ҠеӨҡпјҢи¶ҠиғҪдҪ“зҺ°еҮә并иЎҢ收йӣҶеҷЁзҡ„дјҳеҠҝгҖӮ
并еҸ‘收йӣҶ:зӣёеҜ№дәҺдёІиЎҢ收йӣҶе’Ң并иЎҢ收йӣҶиҖҢиЁҖпјҢеүҚйқўдёӨдёӘеңЁиҝӣиЎҢеһғеңҫеӣһ收е·ҘдҪңж—¶пјҢйңҖиҰҒжҡӮеҒңж•ҙдёӘиҝҗиЎҢзҺҜеўғпјҢиҖҢеҸӘжңүеһғеңҫеӣһ收зЁӢеәҸеңЁиҝҗиЎҢпјҢеӣ жӯӨпјҢзі»з»ҹеңЁеһғеңҫеӣһ收时дјҡжңүжҳҺжҳҫзҡ„жҡӮеҒңпјҢиҖҢдё”жҡӮеҒңж—¶й—ҙдјҡеӣ дёәе Ҷи¶ҠеӨ§иҖҢи¶Ҡй•ҝгҖӮ
JVMи°ғдјҳжҖ»з»“пјҲеӣӣпјү-еһғеңҫеӣһ收йқўдёҙзҡ„й—®йўҳ
еҰӮдҪ•еҢәеҲҶеһғеңҫ
дёҠйқўиҜҙеҲ°зҡ„вҖңеј•з”Ёи®Ўж•°вҖқжі•пјҢйҖҡиҝҮз»ҹи®ЎжҺ§еҲ¶з”ҹжҲҗеҜ№иұЎе’ҢеҲ йҷӨеҜ№иұЎж—¶зҡ„еј•з”Ёж•°жқҘеҲӨж–ӯгҖӮеһғеңҫеӣһ收зЁӢеәҸ收йӣҶи®Ўж•°дёә0зҡ„еҜ№иұЎеҚіеҸҜгҖӮдҪҶжҳҜиҝҷз§Қж–№жі•ж— жі•и§ЈеҶіеҫӘзҺҜеј•з”ЁгҖӮжүҖд»ҘпјҢеҗҺжқҘе®һзҺ°зҡ„еһғеңҫеҲӨж–ӯз®—жі•дёӯпјҢйғҪжҳҜд»ҺзЁӢеәҸиҝҗиЎҢзҡ„ж №иҠӮзӮ№еҮәеҸ‘пјҢйҒҚеҺҶж•ҙдёӘеҜ№иұЎеј•з”ЁпјҢжҹҘжүҫеӯҳжҙ»зҡ„еҜ№иұЎгҖӮйӮЈд№ҲеңЁиҝҷз§Қж–№ејҸзҡ„е®һзҺ°дёӯпјҢ еһғеңҫеӣһ收д»Һе“Әе„ҝејҖе§Ӣзҡ„е‘ўпјҹеҚіпјҢд»Һе“Әе„ҝејҖе§ӢжҹҘжүҫе“ӘдәӣеҜ№иұЎжҳҜжӯЈеңЁиў«еҪ“еүҚзі»з»ҹдҪҝз”Ёзҡ„гҖӮдёҠйқўеҲҶжһҗзҡ„е Ҷе’Ңж Ҳзҡ„еҢәеҲ«пјҢе…¶дёӯж ҲжҳҜзңҹжӯЈиҝӣиЎҢзЁӢеәҸжү§иЎҢең°ж–№пјҢжүҖд»ҘиҰҒиҺ·еҸ–е“ӘдәӣеҜ№иұЎжӯЈеңЁиў«дҪҝз”ЁпјҢеҲҷйңҖиҰҒд»ҺJavaж ҲејҖе§ӢгҖӮеҗҢж—¶пјҢдёҖдёӘж ҲжҳҜдёҺдёҖдёӘзәҝзЁӢеҜ№еә”зҡ„пјҢеӣ жӯӨпјҢеҰӮжһңжңүеӨҡдёӘзәҝзЁӢзҡ„иҜқпјҢеҲҷеҝ…йЎ»еҜ№иҝҷдәӣзәҝзЁӢеҜ№еә”зҡ„жүҖжңүзҡ„ж ҲиҝӣиЎҢжЈҖжҹҘгҖӮ

еҗҢж—¶пјҢйҷӨдәҶж ҲеӨ–пјҢиҝҳжңүзі»з»ҹиҝҗиЎҢж—¶зҡ„еҜ„еӯҳеҷЁзӯүпјҢд№ҹжҳҜеӯҳеӮЁзЁӢеәҸиҝҗиЎҢж•°жҚ®зҡ„гҖӮиҝҷж ·пјҢд»Ҙж ҲжҲ–еҜ„еӯҳеҷЁдёӯзҡ„еј•з”Ёдёәиө·зӮ№пјҢжҲ‘们еҸҜд»ҘжүҫеҲ°е Ҷдёӯзҡ„еҜ№иұЎпјҢеҸҲд»ҺиҝҷдәӣеҜ№иұЎжүҫеҲ°еҜ№е Ҷдёӯе…¶д»–еҜ№иұЎзҡ„еј•з”ЁпјҢиҝҷз§Қеј•з”ЁйҖҗжӯҘжү©еұ•пјҢжңҖз»Ҳд»Ҙnullеј•з”ЁжҲ–иҖ…еҹәжң¬зұ»еһӢз»“жқҹпјҢиҝҷж ·е°ұеҪўжҲҗдәҶдёҖйў—д»ҘJavaж Ҳдёӯеј•з”ЁжүҖеҜ№еә”зҡ„еҜ№иұЎдёәж №иҠӮзӮ№зҡ„дёҖйў—еҜ№иұЎж ‘пјҢеҰӮжһңж ҲдёӯжңүеӨҡдёӘеј•з”ЁпјҢеҲҷжңҖз»ҲдјҡеҪўжҲҗеӨҡйў—еҜ№иұЎж ‘гҖӮеңЁиҝҷдәӣеҜ№иұЎж ‘дёҠзҡ„еҜ№иұЎпјҢйғҪжҳҜеҪ“еүҚзі»з»ҹиҝҗиЎҢжүҖйңҖиҰҒзҡ„еҜ№иұЎпјҢдёҚиғҪиў«еһғеңҫеӣһ收гҖӮиҖҢе…¶д»–еү©дҪҷеҜ№иұЎпјҢеҲҷеҸҜд»Ҙи§Ҷдёәж— жі•иў«еј•з”ЁеҲ°зҡ„еҜ№иұЎпјҢеҸҜд»Ҙиў«еҪ“еҒҡеһғеңҫиҝӣиЎҢеӣһ收гҖӮ
еӣ жӯӨпјҢ еһғеңҫеӣһ收зҡ„иө·зӮ№жҳҜдёҖдәӣж №еҜ№иұЎпјҲjavaж Ҳ, йқҷжҖҒеҸҳйҮҸ, еҜ„еӯҳеҷЁ...пјүгҖӮиҖҢжңҖз®ҖеҚ•зҡ„Javaж Ҳе°ұжҳҜJavaзЁӢеәҸжү§иЎҢзҡ„mainеҮҪж•°гҖӮиҝҷз§Қеӣһ收方ејҸпјҢд№ҹжҳҜдёҠйқўжҸҗеҲ°зҡ„вҖңж Үи®°-жё…йҷӨвҖқзҡ„еӣһ收方ејҸ
еҰӮдҪ•еӨ„зҗҶзўҺзүҮ
з”ұдәҺдёҚеҗҢJavaеҜ№иұЎеӯҳжҙ»ж—¶й—ҙжҳҜдёҚдёҖе®ҡзҡ„пјҢеӣ жӯӨпјҢеңЁзЁӢеәҸиҝҗиЎҢдёҖж®өж—¶й—ҙд»ҘеҗҺпјҢеҰӮжһңдёҚиҝӣиЎҢеҶ…еӯҳж•ҙзҗҶпјҢе°ұдјҡеҮәзҺ°йӣ¶ж•Јзҡ„еҶ…еӯҳзўҺзүҮгҖӮзўҺзүҮжңҖзӣҙжҺҘзҡ„й—®йўҳе°ұжҳҜдјҡеҜјиҮҙж— жі•еҲҶй…ҚеӨ§еқ—зҡ„еҶ…еӯҳз©әй—ҙпјҢд»ҘеҸҠзЁӢеәҸиҝҗиЎҢж•ҲзҺҮйҷҚдҪҺгҖӮжүҖд»ҘпјҢеңЁдёҠйқўжҸҗеҲ°зҡ„еҹәжң¬еһғеңҫеӣһ收算法дёӯпјҢвҖңеӨҚеҲ¶вҖқж–№ејҸе’ҢвҖңж Үи®°-ж•ҙзҗҶвҖқж–№ејҸпјҢйғҪеҸҜд»Ҙи§ЈеҶізўҺзүҮзҡ„й—®йўҳгҖӮ
еҰӮдҪ•и§ЈеҶіеҗҢж—¶еӯҳеңЁзҡ„еҜ№иұЎеҲӣе»әе’ҢеҜ№иұЎеӣһ收问йўҳ
еһғеңҫеӣһ收зәҝзЁӢжҳҜеӣһ收еҶ…еӯҳзҡ„пјҢиҖҢзЁӢеәҸиҝҗиЎҢзәҝзЁӢеҲҷжҳҜж¶ҲиҖ—пјҲжҲ–еҲҶй…ҚпјүеҶ…еӯҳзҡ„пјҢ дёҖдёӘеӣһ收еҶ…еӯҳпјҢдёҖдёӘеҲҶй…ҚеҶ…еӯҳпјҢд»ҺиҝҷзӮ№зңӢпјҢдёӨиҖ…жҳҜзҹӣзӣҫзҡ„гҖӮеӣ жӯӨпјҢеңЁзҺ°жңүзҡ„еһғеңҫеӣһ收方ејҸдёӯпјҢиҰҒиҝӣиЎҢеһғеңҫеӣһ收еүҚпјҢдёҖиҲ¬йғҪйңҖиҰҒжҡӮеҒңж•ҙдёӘеә”з”ЁпјҲеҚіпјҡжҡӮеҒңеҶ…еӯҳзҡ„еҲҶй…ҚпјүпјҢ然еҗҺиҝӣиЎҢеһғеңҫеӣһ收пјҢеӣһ收е®ҢжҲҗеҗҺеҶҚ继з»ӯеә”з”ЁгҖӮиҝҷз§Қе®һзҺ°ж–№ејҸжҳҜжңҖзӣҙжҺҘпјҢиҖҢдё”жңҖжңүж•Ҳзҡ„и§ЈеҶідәҢиҖ…зҹӣзӣҫзҡ„ж–№ејҸгҖӮ
дҪҶжҳҜ иҝҷз§Қж–№ејҸжңүдёҖдёӘеҫҲжҳҺжҳҫзҡ„ејҠз«ҜпјҢе°ұжҳҜеҪ“е Ҷз©әй—ҙжҢҒз»ӯеўһеӨ§ж—¶пјҢеһғеңҫеӣһ收зҡ„ж—¶й—ҙд№ҹе°Ҷдјҡзӣёеә”зҡ„жҢҒз»ӯеўһеӨ§пјҢеҜ№еә”еә”з”ЁжҡӮеҒңзҡ„ж—¶й—ҙд№ҹдјҡзӣёеә”зҡ„еўһеӨ§гҖӮдёҖдәӣеҜ№зӣёеә”ж—¶й—ҙиҰҒжұӮеҫҲй«ҳзҡ„еә”з”ЁпјҢжҜ”еҰӮжңҖеӨ§жҡӮеҒңж—¶й—ҙиҰҒжұӮжҳҜеҮ зҷҫжҜ«з§’пјҢйӮЈд№ҲеҪ“е Ҷз©әй—ҙеӨ§дәҺеҮ дёӘGж—¶пјҢе°ұеҫҲжңүеҸҜиғҪи¶…иҝҮиҝҷдёӘйҷҗеҲ¶пјҢеңЁиҝҷз§Қжғ…еҶөдёӢпјҢеһғеңҫеӣһ收е°ҶдјҡжҲҗдёәзі»з»ҹиҝҗиЎҢзҡ„дёҖдёӘ瓶йўҲгҖӮдёәи§ЈеҶіиҝҷз§ҚзҹӣзӣҫпјҢжңүдәҶ 并еҸ‘еһғеңҫеӣһ收算法пјҢдҪҝз”Ёиҝҷз§Қз®—жі•пјҢеһғеңҫеӣһ收зәҝзЁӢдёҺзЁӢеәҸиҝҗиЎҢзәҝзЁӢеҗҢж—¶иҝҗиЎҢгҖӮеңЁиҝҷз§Қж–№ејҸдёӢпјҢи§ЈеҶідәҶжҡӮеҒңзҡ„й—®йўҳпјҢдҪҶжҳҜеӣ дёәйңҖиҰҒеңЁж–°з”ҹжҲҗеҜ№иұЎзҡ„еҗҢж—¶еҸҲиҰҒеӣһ收еҜ№иұЎпјҢз®—жі•еӨҚжқӮжҖ§дјҡеӨ§еӨ§еўһеҠ пјҢзі»з»ҹзҡ„еӨ„зҗҶиғҪеҠӣд№ҹдјҡзӣёеә”йҷҚдҪҺпјҢеҗҢж—¶пјҢвҖңзўҺзүҮвҖқй—®йўҳе°ҶдјҡжҜ”иҫғйҡҫи§ЈеҶігҖӮ
JVMи°ғдјҳжҖ»з»“пјҲдә”пјү-еҲҶд»Јеһғеңҫеӣһ收иҜҰиҝ°1
дёәд»Җд№ҲиҰҒеҲҶд»Ј
еҲҶд»Јзҡ„еһғеңҫеӣһ收зӯ–з•ҘпјҢжҳҜеҹәдәҺиҝҷж ·дёҖдёӘдәӢе®һпјҡдёҚеҗҢзҡ„еҜ№иұЎзҡ„з”ҹе‘Ҫе‘ЁжңҹжҳҜдёҚдёҖж ·зҡ„гҖӮеӣ жӯӨпјҢдёҚеҗҢз”ҹе‘Ҫе‘Ёжңҹзҡ„еҜ№иұЎеҸҜд»ҘйҮҮеҸ–дёҚеҗҢзҡ„收йӣҶж–№ејҸпјҢд»ҘдҫҝжҸҗй«ҳеӣһ收ж•ҲзҺҮгҖӮ
еңЁJavaзЁӢеәҸиҝҗиЎҢзҡ„иҝҮзЁӢдёӯпјҢдјҡдә§з”ҹеӨ§йҮҸзҡ„еҜ№иұЎпјҢе…¶дёӯжңүдәӣеҜ№иұЎжҳҜдёҺдёҡеҠЎдҝЎжҒҜзӣёе…іпјҢжҜ”еҰӮHttpиҜ·жұӮдёӯзҡ„SessionеҜ№иұЎгҖҒзәҝзЁӢгҖҒSocketиҝһжҺҘпјҢиҝҷзұ»еҜ№иұЎи·ҹдёҡеҠЎзӣҙжҺҘжҢӮй’©пјҢеӣ жӯӨз”ҹе‘Ҫе‘ЁжңҹжҜ”иҫғй•ҝгҖӮдҪҶжҳҜиҝҳжңүдёҖдәӣеҜ№иұЎпјҢдё»иҰҒжҳҜзЁӢеәҸиҝҗиЎҢиҝҮзЁӢдёӯз”ҹжҲҗзҡ„дёҙж—¶еҸҳйҮҸпјҢиҝҷдәӣеҜ№иұЎз”ҹе‘Ҫе‘ЁжңҹдјҡжҜ”иҫғзҹӯпјҢжҜ”еҰӮпјҡStringеҜ№иұЎпјҢз”ұдәҺе…¶дёҚеҸҳзұ»зҡ„зү№жҖ§пјҢзі»з»ҹдјҡдә§з”ҹеӨ§йҮҸзҡ„иҝҷдәӣеҜ№иұЎпјҢжңүдәӣеҜ№иұЎз”ҡиҮіеҸӘз”ЁдёҖж¬ЎеҚіеҸҜеӣһ收гҖӮ
иҜ•жғіпјҢеңЁдёҚиҝӣиЎҢеҜ№иұЎеӯҳжҙ»ж—¶й—ҙеҢәеҲҶзҡ„жғ…еҶөдёӢпјҢжҜҸж¬Ўеһғеңҫеӣһ收йғҪжҳҜеҜ№ж•ҙдёӘе Ҷз©әй—ҙиҝӣиЎҢеӣһ收пјҢиҠұиҙ№ж—¶й—ҙзӣёеҜ№дјҡй•ҝпјҢеҗҢж—¶пјҢеӣ дёәжҜҸж¬Ўеӣһ收йғҪйңҖиҰҒйҒҚеҺҶжүҖжңүеӯҳжҙ»еҜ№иұЎпјҢдҪҶе®һйҷ…дёҠпјҢеҜ№дәҺз”ҹе‘Ҫе‘Ёжңҹй•ҝзҡ„еҜ№иұЎиҖҢиЁҖпјҢиҝҷз§ҚйҒҚеҺҶжҳҜжІЎжңүж•Ҳжһңзҡ„пјҢеӣ дёәеҸҜиғҪиҝӣиЎҢдәҶеҫҲеӨҡж¬ЎйҒҚеҺҶпјҢдҪҶжҳҜ他们дҫқж—§еӯҳеңЁгҖӮеӣ жӯӨпјҢеҲҶд»Јеһғеңҫеӣһ收йҮҮз”ЁеҲҶжІ»зҡ„жҖқжғіпјҢиҝӣиЎҢд»Јзҡ„еҲ’еҲҶпјҢжҠҠдёҚеҗҢз”ҹе‘Ҫе‘Ёжңҹзҡ„еҜ№иұЎж”ҫеңЁдёҚеҗҢд»ЈдёҠпјҢдёҚеҗҢд»ЈдёҠйҮҮз”ЁжңҖйҖӮеҗҲе®ғзҡ„еһғеңҫеӣһ收方ејҸиҝӣиЎҢеӣһ收гҖӮ
еҰӮдҪ•еҲҶд»Ј
еҰӮеӣҫжүҖзӨәпјҡ

иҷҡжӢҹжңәдёӯзҡ„е…ұеҲ’еҲҶдёәдёүдёӘд»Јпјҡе№ҙиҪ»д»ЈпјҲYoung GenerationпјүгҖҒе№ҙиҖҒзӮ№пјҲOld Generationпјүе’ҢжҢҒд№…д»ЈпјҲPermanent GenerationпјүгҖӮе…¶дёӯжҢҒд№…д»Јдё»иҰҒеӯҳж”ҫзҡ„жҳҜJavaзұ»зҡ„зұ»дҝЎжҒҜпјҢдёҺеһғеңҫ收йӣҶиҰҒ收йӣҶзҡ„JavaеҜ№иұЎе…ізі»дёҚеӨ§гҖӮе№ҙиҪ»д»Је’Ңе№ҙиҖҒд»Јзҡ„еҲ’еҲҶжҳҜеҜ№еһғеңҫ收йӣҶеҪұе“ҚжҜ”иҫғеӨ§зҡ„гҖӮ
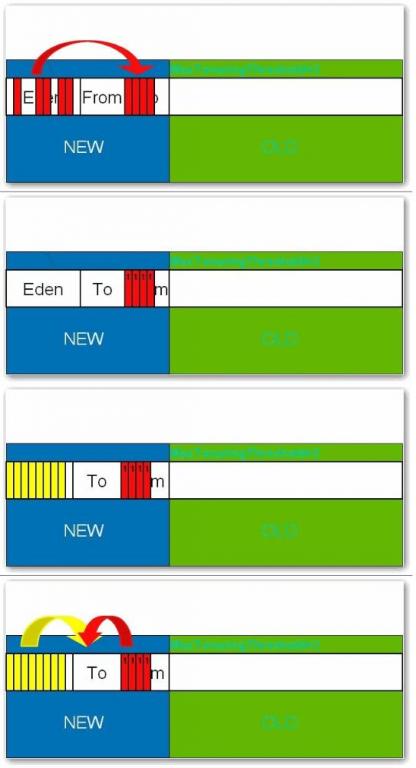
е№ҙиҪ»д»Ј:
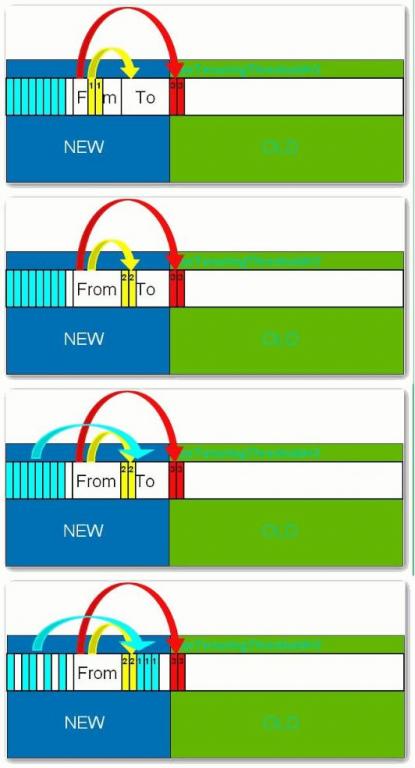
жүҖжңүж–°з”ҹжҲҗзҡ„еҜ№иұЎйҰ–е…ҲйғҪжҳҜж”ҫеңЁе№ҙиҪ»д»Јзҡ„гҖӮе№ҙиҪ»д»Јзҡ„зӣ®ж Үе°ұжҳҜе°ҪеҸҜиғҪеҝ«йҖҹзҡ„收йӣҶжҺүйӮЈдәӣз”ҹе‘Ҫе‘Ёжңҹзҹӯзҡ„еҜ№иұЎгҖӮе№ҙиҪ»д»ЈеҲҶдёүдёӘеҢәгҖӮдёҖдёӘEdenеҢәпјҢдёӨдёӘ SurvivorеҢә(дёҖиҲ¬иҖҢиЁҖ)гҖӮеӨ§йғЁеҲҶеҜ№иұЎеңЁEdenеҢәдёӯз”ҹжҲҗгҖӮеҪ“EdenеҢәж»Ўж—¶пјҢиҝҳеӯҳжҙ»зҡ„еҜ№иұЎе°Ҷиў«еӨҚеҲ¶еҲ°SurvivorеҢәпјҲдёӨдёӘдёӯзҡ„дёҖдёӘпјүпјҢеҪ“иҝҷдёӘ SurvivorеҢәж»Ўж—¶пјҢжӯӨеҢәзҡ„еӯҳжҙ»еҜ№иұЎе°Ҷиў«еӨҚеҲ¶еҲ°еҸҰеӨ–дёҖдёӘSurvivorеҢәпјҢеҪ“иҝҷдёӘSurvivorеҺ»д№ҹж»ЎдәҶзҡ„ж—¶еҖҷпјҢд»Һ第дёҖдёӘSurvivorеҢәеӨҚеҲ¶иҝҮжқҘзҡ„并且жӯӨж—¶иҝҳеӯҳжҙ»зҡ„еҜ№иұЎпјҢе°Ҷиў«еӨҚеҲ¶вҖңе№ҙиҖҒеҢә(Tenured)вҖқгҖӮйңҖиҰҒжіЁж„ҸпјҢSurvivorзҡ„дёӨдёӘеҢәжҳҜеҜ№з§°зҡ„пјҢжІЎе…ҲеҗҺе…ізі»пјҢжүҖд»ҘеҗҢдёҖдёӘеҢәдёӯеҸҜиғҪеҗҢж—¶еӯҳеңЁд»ҺEdenеӨҚеҲ¶иҝҮжқҘеҜ№иұЎпјҢе’Ңд»ҺеүҚдёҖдёӘSurvivorеӨҚеҲ¶иҝҮжқҘзҡ„еҜ№иұЎпјҢиҖҢеӨҚеҲ¶еҲ°е№ҙиҖҒеҢәзҡ„еҸӘжңүд»Һ第дёҖдёӘSurvivorеҺ»иҝҮжқҘзҡ„еҜ№иұЎгҖӮиҖҢдё”пјҢSurvivorеҢәжҖ»жңүдёҖдёӘжҳҜз©әзҡ„гҖӮеҗҢж—¶пјҢж №жҚ®зЁӢеәҸйңҖиҰҒпјҢSurvivorеҢәжҳҜеҸҜд»Ҙй…ҚзҪ®дёәеӨҡдёӘзҡ„пјҲеӨҡдәҺдёӨдёӘпјүпјҢиҝҷж ·еҸҜд»ҘеўһеҠ еҜ№иұЎеңЁе№ҙиҪ»д»Јдёӯзҡ„еӯҳеңЁж—¶й—ҙпјҢеҮҸе°‘иў«ж”ҫеҲ°е№ҙиҖҒд»Јзҡ„еҸҜиғҪгҖӮ
е№ҙиҖҒд»Ј:
еңЁе№ҙиҪ»д»Јдёӯз»ҸеҺҶдәҶNж¬Ўеһғеңҫеӣһ收еҗҺд»Қ然еӯҳжҙ»зҡ„еҜ№иұЎпјҢе°ұдјҡиў«ж”ҫеҲ°е№ҙиҖҒд»ЈдёӯгҖӮеӣ жӯӨпјҢеҸҜд»Ҙи®Өдёәе№ҙиҖҒд»Јдёӯеӯҳж”ҫзҡ„йғҪжҳҜдёҖдәӣз”ҹе‘Ҫе‘Ёжңҹиҫғй•ҝзҡ„еҜ№иұЎгҖӮ
жҢҒд№…д»Ј:
з”ЁдәҺеӯҳж”ҫйқҷжҖҒж–Ү件пјҢеҰӮд»ҠJavaзұ»гҖҒж–№жі•зӯүгҖӮжҢҒд№…д»ЈеҜ№еһғеңҫеӣһ收没жңүжҳҫи‘—еҪұе“ҚпјҢдҪҶжҳҜжңүдәӣеә”з”ЁеҸҜиғҪеҠЁжҖҒз”ҹжҲҗжҲ–иҖ…и°ғз”ЁдёҖдәӣclassпјҢдҫӢеҰӮHibernate зӯүпјҢеңЁиҝҷз§Қж—¶еҖҷйңҖиҰҒи®ҫзҪ®дёҖдёӘжҜ”иҫғеӨ§зҡ„жҢҒд№…д»Јз©әй—ҙжқҘеӯҳж”ҫиҝҷдәӣиҝҗиЎҢиҝҮзЁӢдёӯж–°еўһзҡ„зұ»гҖӮжҢҒд№…д»ЈеӨ§е°ҸйҖҡиҝҮ-XX:MaxPermSize=<N>иҝӣиЎҢи®ҫзҪ®гҖӮ
д»Җд№Ҳжғ…еҶөдёӢи§ҰеҸ‘еһғеңҫеӣһ收
з”ұдәҺеҜ№иұЎиҝӣиЎҢдәҶеҲҶд»ЈеӨ„зҗҶпјҢеӣ жӯӨеһғеңҫеӣһ收еҢәеҹҹгҖҒж—¶й—ҙд№ҹдёҚдёҖж ·гҖӮGCжңүдёӨз§Қзұ»еһӢпјҡScavenge GCе’ҢFull GCгҖӮ
Scavenge GC
дёҖиҲ¬жғ…еҶөдёӢпјҢеҪ“ж–°еҜ№иұЎз”ҹжҲҗпјҢ并且еңЁEdenз”іиҜ·з©әй—ҙеӨұиҙҘж—¶пјҢе°ұдјҡи§ҰеҸ‘Scavenge GCпјҢеҜ№EdenеҢәеҹҹиҝӣиЎҢGCпјҢжё…йҷӨйқһеӯҳжҙ»еҜ№иұЎпјҢ并且жҠҠе°ҡдё”еӯҳжҙ»зҡ„еҜ№иұЎз§»еҠЁеҲ°SurvivorеҢәгҖӮ然еҗҺж•ҙзҗҶSurvivorзҡ„дёӨдёӘеҢәгҖӮиҝҷз§Қж–№ејҸзҡ„GCжҳҜеҜ№е№ҙиҪ»д»Јзҡ„EdenеҢәиҝӣиЎҢпјҢдёҚдјҡеҪұе“ҚеҲ°е№ҙиҖҒд»ЈгҖӮеӣ дёәеӨ§йғЁеҲҶеҜ№иұЎйғҪжҳҜд»ҺEdenеҢәејҖе§Ӣзҡ„пјҢеҗҢж—¶EdenеҢәдёҚдјҡеҲҶй…Қзҡ„еҫҲеӨ§пјҢжүҖд»ҘEdenеҢәзҡ„GCдјҡйў‘з№ҒиҝӣиЎҢгҖӮеӣ иҖҢпјҢдёҖиҲ¬еңЁиҝҷйҮҢйңҖиҰҒдҪҝз”ЁйҖҹеәҰеҝ«гҖҒж•ҲзҺҮй«ҳзҡ„з®—жі•пјҢдҪҝEdenеҺ»иғҪе°Ҫеҝ«з©әй—ІеҮәжқҘгҖӮ
Full GC
еҜ№ж•ҙдёӘе ҶиҝӣиЎҢж•ҙзҗҶпјҢеҢ…жӢ¬YoungгҖҒTenuredе’ҢPermгҖӮFull GCеӣ дёәйңҖиҰҒеҜ№ж•ҙдёӘеҜ№иҝӣиЎҢеӣһ收пјҢжүҖд»ҘжҜ”Scavenge GCиҰҒж…ўпјҢеӣ жӯӨеә”иҜҘе°ҪеҸҜиғҪеҮҸе°‘Full GCзҡ„ж¬Ўж•°гҖӮеңЁеҜ№JVMи°ғдјҳзҡ„иҝҮзЁӢдёӯпјҢеҫҲеӨ§дёҖйғЁеҲҶе·ҘдҪңе°ұжҳҜеҜ№дәҺFullGCзҡ„и°ғиҠӮгҖӮжңүеҰӮдёӢеҺҹеӣ еҸҜиғҪеҜјиҮҙFull GCпјҡ
В· е№ҙиҖҒд»ЈпјҲTenuredпјүиў«еҶҷж»Ў
В· жҢҒд№…д»ЈпјҲPermпјүиў«еҶҷж»Ў
В· System.gc()иў«жҳҫзӨәи°ғз”Ё
В·дёҠдёҖж¬ЎGCд№ӢеҗҺHeapзҡ„еҗ„еҹҹеҲҶй…Қзӯ–з•ҘеҠЁжҖҒеҸҳеҢ–
JVMи°ғдјҳжҖ»з»“пјҲе…ӯпјү-еҲҶд»Јеһғеңҫеӣһ收иҜҰиҝ°2
еҲҶд»Јеһғеңҫеӣһ收жөҒзЁӢзӨәж„Ҹ


йҖүжӢ©еҗҲйҖӮзҡ„еһғеңҫ收йӣҶз®—жі•
дёІиЎҢ收йӣҶеҷЁ
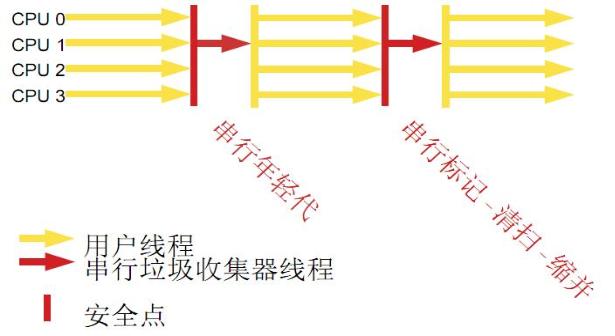
з”ЁеҚ•зәҝзЁӢеӨ„зҗҶжүҖжңүеһғеңҫеӣһ收е·ҘдҪңпјҢеӣ дёәж— йңҖеӨҡзәҝзЁӢдәӨдә’пјҢжүҖд»Ҙж•ҲзҺҮжҜ”иҫғй«ҳгҖӮдҪҶжҳҜпјҢд№ҹж— жі•дҪҝз”ЁеӨҡеӨ„зҗҶеҷЁзҡ„дјҳеҠҝпјҢжүҖд»ҘжӯӨ收йӣҶеҷЁйҖӮеҗҲеҚ•еӨ„зҗҶеҷЁжңәеҷЁгҖӮеҪ“然пјҢжӯӨ收йӣҶеҷЁд№ҹеҸҜд»Ҙз”ЁеңЁе°Ҹж•°жҚ®йҮҸпјҲ100Mе·ҰеҸіпјүжғ…еҶөдёӢзҡ„еӨҡеӨ„зҗҶеҷЁжңәеҷЁдёҠгҖӮеҸҜд»ҘдҪҝз”Ё-XX:+UseSerialGCжү“ејҖгҖӮ
并иЎҢ收йӣҶеҷЁ
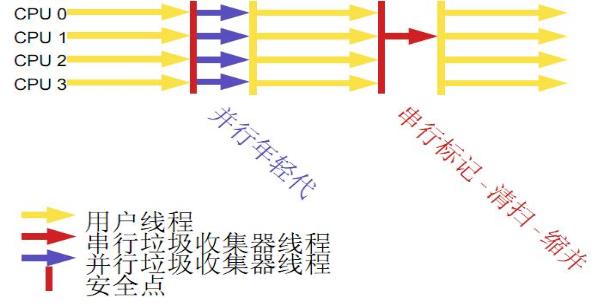
JVMи°ғдјҳжҖ»з»“пјҲдёғпјү-е…ёеһӢй…ҚзҪ®дёҫдҫӢ1
дёӢй…ҚзҪ®дё»иҰҒй’ҲеҜ№еҲҶд»Јеһғеңҫеӣһ收算法иҖҢиЁҖгҖӮ
е ҶеӨ§е°Ҹи®ҫзҪ®
е№ҙиҪ»д»Јзҡ„и®ҫзҪ®еҫҲе…ій”®
JVMдёӯжңҖеӨ§е ҶеӨ§е°Ҹжңүдёүж–№йқўйҷҗеҲ¶пјҡзӣёе…іж“ҚдҪңзі»з»ҹзҡ„ж•°жҚ®жЁЎеһӢпјҲ32-btиҝҳжҳҜ64-bitпјүйҷҗеҲ¶пјӣзі»з»ҹзҡ„еҸҜз”ЁиҷҡжӢҹеҶ…еӯҳйҷҗеҲ¶пјӣзі»з»ҹзҡ„еҸҜз”Ёзү©зҗҶеҶ…еӯҳйҷҗеҲ¶гҖӮ32дҪҚзі»з»ҹдёӢпјҢдёҖиҲ¬йҷҗеҲ¶еңЁ1.5G~2Gпјӣ64дёәж“ҚдҪңзі»з»ҹеҜ№еҶ…еӯҳж— йҷҗеҲ¶гҖӮеңЁWindows Server 2003 зі»з»ҹпјҢ3.5Gзү©зҗҶеҶ…еӯҳпјҢJDK5.0дёӢжөӢиҜ•пјҢжңҖеӨ§еҸҜи®ҫзҪ®дёә1478mгҖӮ
е…ёеһӢи®ҫзҪ®пјҡ
java-Xmx3550m -Xms3550m -Xmn2g вҖ“Xss128k
-Xmx3550mпјҡи®ҫзҪ®JVMжңҖеӨ§еҸҜз”ЁеҶ…еӯҳдёә3550MгҖӮ
-Xms3550mпјҡи®ҫзҪ®JVMдҝғдҪҝеҶ…еӯҳдёә3550mгҖӮжӯӨеҖјеҸҜд»Ҙи®ҫзҪ®дёҺ-XmxзӣёеҗҢпјҢд»ҘйҒҝе…ҚжҜҸж¬Ўеһғеңҫеӣһ收е®ҢжҲҗеҗҺJVMйҮҚж–°еҲҶй…ҚеҶ…еӯҳгҖӮ
-Xmn2gпјҡи®ҫзҪ®е№ҙиҪ»д»ЈеӨ§е°Ҹдёә2GгҖӮж•ҙдёӘе ҶеӨ§е°Ҹ=е№ҙиҪ»д»ЈеӨ§е°Ҹ + е№ҙиҖҒд»ЈеӨ§е°Ҹ + жҢҒд№…д»ЈеӨ§е°ҸгҖӮжҢҒд№…д»ЈдёҖиҲ¬еӣәе®ҡеӨ§е°Ҹдёә64mпјҢжүҖд»ҘеўһеӨ§е№ҙиҪ»д»ЈеҗҺпјҢе°ҶдјҡеҮҸе°Ҹе№ҙиҖҒд»ЈеӨ§е°ҸгҖӮжӯӨеҖјеҜ№зі»з»ҹжҖ§иғҪеҪұе“ҚиҫғеӨ§пјҢSunе®ҳж–№жҺЁиҚҗй…ҚзҪ®дёәж•ҙдёӘе Ҷзҡ„3/8гҖӮ
-Xss128kпјҡи®ҫзҪ®жҜҸдёӘзәҝзЁӢзҡ„е Ҷж ҲеӨ§е°ҸгҖӮJDK5.0д»ҘеҗҺжҜҸдёӘзәҝзЁӢе Ҷж ҲеӨ§е°Ҹдёә1MпјҢд»ҘеүҚжҜҸдёӘзәҝзЁӢе Ҷж ҲеӨ§е°Ҹдёә 256KгҖӮжӣҙе…·еә”з”Ёзҡ„зәҝзЁӢжүҖйңҖеҶ…еӯҳеӨ§е°ҸиҝӣиЎҢи°ғж•ҙгҖӮеңЁзӣёеҗҢзү©зҗҶеҶ…еӯҳдёӢпјҢеҮҸе°ҸиҝҷдёӘеҖјиғҪз”ҹжҲҗжӣҙеӨҡзҡ„зәҝзЁӢгҖӮдҪҶжҳҜж“ҚдҪңзі»з»ҹеҜ№дёҖдёӘиҝӣзЁӢеҶ…зҡ„зәҝзЁӢж•°иҝҳжҳҜжңүйҷҗеҲ¶зҡ„пјҢдёҚиғҪж— йҷҗз”ҹжҲҗпјҢз»ҸйӘҢеҖјеңЁ3000~5000е·ҰеҸігҖӮ
java -Xmx3550m -Xms3550m -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0
-XX:NewRatio=4:и®ҫзҪ®е№ҙиҪ»д»ЈпјҲеҢ…жӢ¬Edenе’ҢдёӨдёӘSurvivorеҢәпјүдёҺе№ҙиҖҒд»Јзҡ„жҜ”еҖјпјҲйҷӨеҺ»жҢҒд№…д»ЈпјүгҖӮи®ҫзҪ®дёә4пјҢеҲҷе№ҙиҪ»д»ЈдёҺе№ҙиҖҒд»ЈжүҖеҚ жҜ”еҖјдёә1пјҡ4пјҢе№ҙиҪ»д»ЈеҚ ж•ҙдёӘе Ҷж Ҳзҡ„1/5
JVMи°ғдјҳжҖ»з»“пјҲе…«пјү-е…ёеһӢй…ҚзҪ®дёҫдҫӢ2
еёёи§Ғй…ҚзҪ®жұҮжҖ»
е Ҷи®ҫзҪ®
-Xms:еҲқе§Ӣе ҶеӨ§е°Ҹ
-Xmx:жңҖеӨ§е ҶеӨ§е°Ҹ
-XX:NewSize=n:и®ҫзҪ®е№ҙиҪ»д»ЈеӨ§е°Ҹ
-XX:NewRatio=n:и®ҫзҪ®е№ҙиҪ»д»Је’Ңе№ҙиҖҒд»Јзҡ„жҜ”еҖјгҖӮеҰӮ:дёә3пјҢиЎЁзӨәе№ҙиҪ»д»ЈдёҺе№ҙиҖҒд»ЈжҜ”еҖјдёә1пјҡ3пјҢе№ҙиҪ»д»ЈеҚ ж•ҙдёӘе№ҙиҪ»д»Је№ҙиҖҒд»Је’Ңзҡ„1/4
-XX:SurvivorRatio=n:е№ҙиҪ»д»ЈдёӯEdenеҢәдёҺдёӨдёӘSurvivorеҢәзҡ„жҜ”еҖјгҖӮжіЁж„ҸSurvivorеҢәжңүдёӨдёӘгҖӮеҰӮпјҡ3пјҢиЎЁзӨәEdenпјҡSurvivor=3пјҡ2пјҢдёҖдёӘSurvivorеҢәеҚ ж•ҙдёӘе№ҙиҪ»д»Јзҡ„1/5
-XX:MaxPermSize=n:и®ҫзҪ®жҢҒд№…д»ЈеӨ§е°Ҹ
收йӣҶеҷЁи®ҫзҪ®
-XX:+UseSerialGC:и®ҫзҪ®дёІиЎҢ收йӣҶеҷЁ
-XX:+UseParallelGC:и®ҫзҪ®е№¶иЎҢ收йӣҶеҷЁ
-XX:+UseParalledlOldGC:и®ҫзҪ®е№¶иЎҢе№ҙиҖҒ代收йӣҶеҷЁ
-XX:+UseConcMarkSweepGC:и®ҫзҪ®е№¶еҸ‘收йӣҶеҷЁ
еһғеңҫеӣһ收з»ҹи®ЎдҝЎжҒҜ
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:filename
并иЎҢ收йӣҶеҷЁи®ҫзҪ®
-XX:ParallelGCThreads=n:и®ҫзҪ®е№¶иЎҢ收йӣҶеҷЁж”¶йӣҶж—¶дҪҝз”Ёзҡ„CPUж•°гҖӮ并иЎҢ收йӣҶзәҝзЁӢж•°гҖӮ
-XX:MaxGCPauseMillis=n:и®ҫзҪ®е№¶иЎҢ收йӣҶжңҖеӨ§жҡӮеҒңж—¶й—ҙ
-XX:GCTimeRatio=n:и®ҫзҪ®еһғеңҫеӣһ收时й—ҙеҚ зЁӢеәҸиҝҗиЎҢж—¶й—ҙзҡ„зҷҫеҲҶжҜ”гҖӮе…¬ејҸдёә1/(1+n)
并еҸ‘收йӣҶеҷЁи®ҫзҪ®
-XX:+CMSIncrementalMode:и®ҫзҪ®дёәеўһйҮҸжЁЎејҸгҖӮйҖӮз”ЁдәҺеҚ•CPUжғ…еҶөгҖӮ
-XX:ParallelGCThreads=n:и®ҫзҪ®е№¶еҸ‘收йӣҶеҷЁе№ҙиҪ»д»Јж”¶йӣҶж–№ејҸдёә并иЎҢ收йӣҶж—¶пјҢдҪҝз”Ёзҡ„CPUж•°гҖӮ并иЎҢ收йӣҶзәҝзЁӢж•°гҖӮ
и°ғдјҳжҖ»з»“
е№ҙиҪ»д»ЈеӨ§е°ҸйҖүжӢ©
е“Қеә”ж—¶й—ҙдјҳе…Ҳзҡ„еә”з”Ёпјҡе°ҪеҸҜиғҪи®ҫеӨ§пјҢзӣҙеҲ°жҺҘиҝ‘зі»з»ҹзҡ„жңҖдҪҺе“Қеә”ж—¶й—ҙйҷҗеҲ¶пјҲж №жҚ®е®һйҷ…жғ…еҶөйҖүжӢ©пјүгҖӮеңЁжӯӨз§Қжғ…еҶөдёӢпјҢе№ҙиҪ»д»Јж”¶йӣҶеҸ‘з”ҹзҡ„йў‘зҺҮд№ҹжҳҜжңҖе°Ҹзҡ„гҖӮеҗҢж—¶пјҢеҮҸе°‘еҲ°иҫҫе№ҙиҖҒд»Јзҡ„еҜ№иұЎгҖӮ
еҗһеҗҗйҮҸдјҳе…Ҳзҡ„еә”з”Ёпјҡе°ҪеҸҜиғҪзҡ„и®ҫзҪ®еӨ§пјҢеҸҜиғҪеҲ°иҫҫGbitзҡ„зЁӢеәҰгҖӮеӣ дёәеҜ№е“Қеә”ж—¶й—ҙжІЎжңүиҰҒжұӮпјҢеһғеңҫ收йӣҶеҸҜд»Ҙ并иЎҢиҝӣиЎҢпјҢдёҖиҲ¬йҖӮеҗҲ8CPUд»ҘдёҠзҡ„еә”з”ЁгҖӮ
е№ҙиҖҒд»ЈеӨ§е°ҸйҖүжӢ©
е“Қеә”ж—¶й—ҙдјҳе…Ҳзҡ„еә”з”Ёпјҡе№ҙиҖҒд»ЈдҪҝ用并еҸ‘收йӣҶеҷЁпјҢжүҖд»Ҙе…¶еӨ§е°ҸйңҖиҰҒе°Ҹеҝғи®ҫзҪ®пјҢдёҖиҲ¬иҰҒиҖғиҷ‘并еҸ‘дјҡиҜқзҺҮе’ҢдјҡиҜқжҢҒз»ӯж—¶й—ҙзӯүдёҖдәӣеҸӮж•°гҖӮеҰӮжһңе Ҷи®ҫзҪ®е°ҸдәҶпјҢеҸҜд»ҘдјҡйҖ жҲҗеҶ…еӯҳзўҺзүҮгҖҒй«ҳеӣһ收频зҺҮд»ҘеҸҠеә”з”ЁжҡӮеҒңиҖҢдҪҝз”Ёдј з»ҹзҡ„ж Үи®°жё…йҷӨж–№ејҸпјӣеҰӮжһңе ҶеӨ§дәҶпјҢеҲҷйңҖиҰҒиҫғй•ҝзҡ„收йӣҶж—¶й—ҙгҖӮжңҖдјҳеҢ–зҡ„ж–№жЎҲпјҢдёҖиҲ¬йңҖиҰҒеҸӮиҖғд»ҘдёӢж•°жҚ®иҺ·еҫ—пјҡ
1. 并еҸ‘еһғеңҫ收йӣҶдҝЎжҒҜ
2. жҢҒ久代并еҸ‘收йӣҶж¬Ўж•°
3. дј з»ҹGCдҝЎжҒҜ
4. иҠұеңЁе№ҙиҪ»д»Је’Ңе№ҙиҖҒд»Јеӣһ收дёҠзҡ„ж—¶й—ҙжҜ”дҫӢ
еҮҸе°‘е№ҙиҪ»д»Је’Ңе№ҙиҖҒд»ЈиҠұиҙ№зҡ„ж—¶й—ҙпјҢдёҖиҲ¬дјҡжҸҗй«ҳеә”з”Ёзҡ„ж•ҲзҺҮ
еҗһеҗҗйҮҸдјҳе…Ҳзҡ„еә”з”Ё
дёҖиҲ¬еҗһеҗҗйҮҸдјҳе…Ҳзҡ„еә”з”ЁйғҪжңүдёҖдёӘеҫҲеӨ§зҡ„е№ҙиҪ»д»Је’ҢдёҖдёӘиҫғе°Ҹзҡ„е№ҙиҖҒд»ЈгҖӮеҺҹеӣ жҳҜпјҢиҝҷж ·еҸҜд»Ҙе°ҪеҸҜиғҪеӣһ收жҺүеӨ§йғЁеҲҶзҹӯжңҹеҜ№иұЎпјҢеҮҸе°‘дёӯжңҹзҡ„еҜ№иұЎпјҢиҖҢе№ҙиҖҒд»Је°Ҫеӯҳж”ҫй•ҝжңҹеӯҳжҙ»еҜ№иұЎгҖӮ
иҫғе°Ҹе Ҷеј•иө·зҡ„зўҺзүҮй—®йўҳ
еӣ дёәе№ҙиҖҒд»Јзҡ„并еҸ‘收йӣҶеҷЁдҪҝз”Ёж Үи®°гҖҒжё…йҷӨз®—жі•пјҢжүҖд»ҘдёҚдјҡеҜ№е ҶиҝӣиЎҢеҺӢзј©гҖӮеҪ“收йӣҶеҷЁеӣһ收时пјҢд»–дјҡжҠҠзӣёйӮ»зҡ„з©әй—ҙиҝӣиЎҢеҗҲ并пјҢиҝҷж ·еҸҜд»ҘеҲҶй…Қз»ҷиҫғеӨ§зҡ„еҜ№иұЎгҖӮдҪҶжҳҜпјҢеҪ“е Ҷз©әй—ҙиҫғе°Ҹж—¶пјҢиҝҗиЎҢдёҖж®өж—¶й—ҙд»ҘеҗҺпјҢе°ұдјҡеҮәзҺ°вҖңзўҺзүҮвҖқпјҢеҰӮжһң并еҸ‘收йӣҶеҷЁжүҫдёҚеҲ°и¶іеӨҹзҡ„з©әй—ҙпјҢйӮЈд№Ҳ并еҸ‘收йӣҶеҷЁе°ҶдјҡеҒңжӯўпјҢ然еҗҺдҪҝз”Ёдј з»ҹзҡ„ж Үи®°гҖҒжё…йҷӨж–№ејҸиҝӣиЎҢеӣһ收гҖӮеҰӮжһңеҮәзҺ°вҖңзўҺзүҮвҖқпјҢеҸҜиғҪйңҖиҰҒиҝӣиЎҢеҰӮдёӢй…ҚзҪ®пјҡ
1. -XX:+UseCMSCompactAtFullCollectionпјҡдҪҝ用并еҸ‘收йӣҶеҷЁж—¶пјҢејҖеҗҜеҜ№е№ҙиҖҒд»Јзҡ„еҺӢзј©гҖӮ
2. -XX:CMSFullGCsBeforeCompaction=0пјҡдёҠйқўй…ҚзҪ®ејҖеҗҜзҡ„жғ…еҶөдёӢпјҢиҝҷйҮҢи®ҫзҪ®еӨҡе°‘ж¬ЎFull GCеҗҺпјҢеҜ№е№ҙиҖҒд»ЈиҝӣиЎҢеҺӢзј©
JVMи°ғдјҳжҖ»з»“пјҲд№қпјү-ж–°дёҖд»Јзҡ„еһғеңҫеӣһ收算法
еһғеңҫеӣһ收зҡ„瓶йўҲ
дј з»ҹеҲҶд»Јеһғеңҫеӣһ收方ејҸпјҢе·Із»ҸеңЁдёҖе®ҡзЁӢеәҰдёҠжҠҠеһғеңҫеӣһ收з»ҷеә”з”ЁеёҰжқҘзҡ„иҙҹжӢ…йҷҚеҲ°дәҶжңҖе°ҸпјҢжҠҠеә”з”Ёзҡ„еҗһеҗҗйҮҸжҺЁеҲ°дәҶдёҖдёӘжһҒйҷҗгҖӮдҪҶжҳҜд»–ж— жі•и§ЈеҶізҡ„дёҖдёӘй—®йўҳпјҢе°ұжҳҜFull GCжүҖеёҰжқҘзҡ„еә”з”ЁжҡӮеҒңгҖӮеңЁдёҖдәӣеҜ№е®һж—¶жҖ§иҰҒжұӮеҫҲй«ҳзҡ„еә”з”ЁеңәжҷҜдёӢпјҢGCжҡӮеҒңжүҖеёҰжқҘзҡ„иҜ·жұӮе Ҷз§Ҝе’ҢиҜ·жұӮеӨұиҙҘжҳҜж— жі•жҺҘеҸ—зҡ„гҖӮиҝҷзұ»еә”з”ЁеҸҜиғҪиҰҒжұӮиҜ·жұӮзҡ„иҝ”еӣһж—¶й—ҙеңЁеҮ зҷҫз”ҡиҮіеҮ еҚҒжҜ«з§’д»ҘеҶ…пјҢеҰӮжһңеҲҶд»Јеһғеңҫеӣһ收方ејҸиҰҒиҫҫеҲ°иҝҷдёӘжҢҮж ҮпјҢеҸӘиғҪжҠҠжңҖеӨ§е Ҷзҡ„и®ҫзҪ®йҷҗеҲ¶еңЁдёҖдёӘзӣёеҜ№иҫғе°ҸиҢғеӣҙеҶ…пјҢдҪҶжҳҜиҝҷж ·жңүйҷҗеҲ¶дәҶеә”з”Ёжң¬иә«зҡ„еӨ„зҗҶиғҪеҠӣпјҢеҗҢж ·д№ҹжҳҜдёҚеҸҜжҺҘ收зҡ„гҖӮ
еҲҶд»Јеһғеңҫеӣһ收方ејҸзЎ®е®һд№ҹиҖғиҷ‘дәҶе®һж—¶жҖ§иҰҒжұӮиҖҢжҸҗдҫӣдәҶ并еҸ‘еӣһ收еҷЁпјҢж”ҜжҢҒжңҖеӨ§жҡӮеҒңж—¶й—ҙзҡ„и®ҫзҪ®пјҢдҪҶжҳҜеҸ—йҷҗдәҺеҲҶд»Јеһғеңҫеӣһ收зҡ„еҶ…еӯҳеҲ’еҲҶжЁЎеһӢпјҢе…¶ж•Ҳжһңд№ҹдёҚжҳҜеҫҲзҗҶжғігҖӮ
дёәдәҶиҫҫеҲ°е®һж—¶жҖ§зҡ„иҰҒжұӮпјҲе…¶е®һJavaиҜӯиЁҖжңҖеҲқзҡ„и®ҫи®Ўд№ҹжҳҜеңЁеөҢе…ҘејҸзі»з»ҹдёҠзҡ„пјүпјҢдёҖз§Қж–°еһғеңҫеӣһ收方ејҸе‘јд№Ӣж¬ІеҮәпјҢе®ғж—ўж”ҜжҢҒзҹӯзҡ„жҡӮеҒңж—¶й—ҙпјҢеҸҲж”ҜжҢҒеӨ§зҡ„еҶ…еӯҳз©әй—ҙеҲҶй…ҚгҖӮеҸҜд»ҘеҫҲеҘҪзҡ„и§ЈеҶідј з»ҹеҲҶд»Јж–№ејҸеёҰжқҘзҡ„й—®йўҳгҖӮ
еўһйҮҸ收йӣҶзҡ„жј”иҝӣ
еўһйҮҸ收йӣҶзҡ„ж–№ејҸеңЁзҗҶи®әдёҠеҸҜд»Ҙи§ЈеҶідј з»ҹеҲҶд»Јж–№ејҸеёҰжқҘзҡ„й—®йўҳгҖӮеўһйҮҸ收йӣҶжҠҠеҜ№е Ҷз©әй—ҙеҲ’еҲҶжҲҗдёҖзі»еҲ—еҶ…еӯҳеқ—пјҢдҪҝз”Ёж—¶пјҢе…ҲдҪҝз”Ёе…¶дёӯдёҖйғЁеҲҶпјҲдёҚдјҡе…ЁйғЁз”Ёе®ҢпјүпјҢеһғеңҫ收йӣҶж—¶жҠҠд№ӢеүҚз”ЁжҺүзҡ„йғЁеҲҶдёӯзҡ„еӯҳжҙ»еҜ№иұЎеҶҚж”ҫеҲ°еҗҺйқўжІЎжңүз”Ёзҡ„з©әй—ҙдёӯпјҢиҝҷж ·еҸҜд»Ҙе®һзҺ°дёҖзӣҙиҫ№дҪҝз”Ёиҫ№ж”¶йӣҶзҡ„ж•ҲжһңпјҢйҒҝе…ҚдәҶдј з»ҹеҲҶд»Јж–№ејҸж•ҙдёӘдҪҝз”Ёе®ҢдәҶеҶҚжҡӮеҒңзҡ„еӣһ收зҡ„жғ…еҶөгҖӮ
еҪ“然пјҢдј з»ҹеҲҶ代收йӣҶж–№ејҸд№ҹжҸҗдҫӣдәҶ并еҸ‘收йӣҶпјҢдҪҶжҳҜд»–жңүдёҖдёӘеҫҲиҮҙе‘Ҫзҡ„ең°ж–№пјҢе°ұжҳҜжҠҠж•ҙдёӘе ҶеҒҡдёәдёҖдёӘеҶ…еӯҳеқ—пјҢиҝҷж ·дёҖж–№йқўдјҡйҖ жҲҗзўҺзүҮпјҲж— жі•еҺӢзј©пјүпјҢеҸҰдёҖж–№йқўд»–зҡ„жҜҸ次收йӣҶйғҪжҳҜеҜ№ж•ҙдёӘе Ҷзҡ„收йӣҶпјҢж— жі•иҝӣиЎҢйҖүжӢ©пјҢеңЁжҡӮеҒңж—¶й—ҙзҡ„жҺ§еҲ¶дёҠиҝҳжҳҜеҫҲејұгҖӮиҖҢеўһйҮҸж–№ејҸпјҢйҖҡиҝҮеҶ…еӯҳз©әй—ҙзҡ„еҲҶеқ—пјҢжҒ°жҒ°еҸҜд»Ҙи§ЈеҶідёҠйқўй—®йўҳгҖӮ
JVMи°ғдјҳжҖ»з»“пјҲеҚҒпјү-и°ғдјҳж–№жі•
JVMи°ғдјҳе·Ҙе…·
JconsoleпјҢjProfileпјҢVisualVM
Jconsole : jdkиҮӘеёҰпјҢеҠҹиғҪз®ҖеҚ•пјҢдҪҶжҳҜеҸҜд»ҘеңЁзі»з»ҹжңүдёҖе®ҡиҙҹиҚ·зҡ„жғ…еҶөдёӢдҪҝз”ЁгҖӮеҜ№еһғеңҫеӣһ收算法жңүеҫҲиҜҰз»Ҷзҡ„и·ҹиёӘгҖӮиҜҰз»ҶиҜҙжҳҺеҸӮиҖғиҝҷйҮҢ
JProfilerпјҡе•ҶдёҡиҪҜ件пјҢйңҖиҰҒд»ҳиҙ№гҖӮеҠҹиғҪејәеӨ§гҖӮиҜҰз»ҶиҜҙжҳҺеҸӮиҖғиҝҷйҮҢ
VisualVMпјҡJDKиҮӘеёҰпјҢеҠҹиғҪејәеӨ§пјҢдёҺJProfilerзұ»дјјгҖӮжҺЁиҚҗгҖӮ
еҰӮдҪ•и°ғдјҳ
и§ӮеҜҹеҶ…еӯҳйҮҠж”ҫжғ…еҶөгҖҒйӣҶеҗҲзұ»жЈҖжҹҘгҖҒеҜ№иұЎж ‘
дёҠйқўиҝҷдәӣи°ғдјҳе·Ҙе…·йғҪжҸҗдҫӣдәҶејәеӨ§зҡ„еҠҹиғҪпјҢдҪҶжҳҜжҖ»зҡ„жқҘиҜҙдёҖиҲ¬еҲҶдёәд»ҘдёӢеҮ зұ»еҠҹиғҪ
е ҶдҝЎжҒҜжҹҘзңӢ
гҖҖ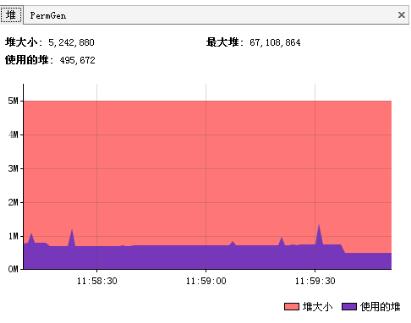
еҸҜжҹҘзңӢе Ҷз©әй—ҙеӨ§е°ҸеҲҶй…ҚпјҲе№ҙиҪ»д»ЈгҖҒе№ҙиҖҒд»ЈгҖҒжҢҒд№…д»ЈеҲҶй…Қпјү
жҸҗдҫӣеҚіж—¶зҡ„еһғеңҫеӣһ收еҠҹиғҪ
еһғеңҫзӣ‘жҺ§пјҲй•ҝж—¶й—ҙзӣ‘жҺ§еӣһ收жғ…еҶөпјү
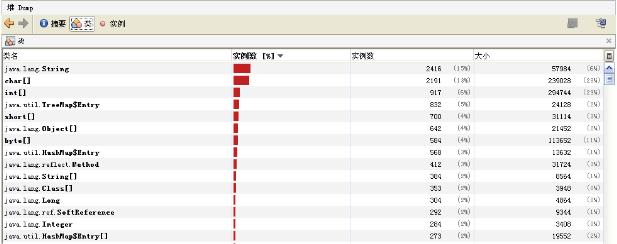
жҹҘзңӢе ҶеҶ…зұ»гҖҒеҜ№иұЎдҝЎжҒҜжҹҘзңӢпјҡж•°йҮҸгҖҒзұ»еһӢзӯү

еҜ№иұЎеј•з”Ёжғ…еҶөжҹҘзңӢ
жңүдәҶе ҶдҝЎжҒҜжҹҘзңӢж–№йқўзҡ„еҠҹиғҪпјҢжҲ‘们дёҖиҲ¬еҸҜд»ҘйЎәеҲ©и§ЈеҶід»ҘдёӢй—®йўҳпјҡ
--е№ҙиҖҒд»Је№ҙиҪ»д»ЈеӨ§е°ҸеҲ’еҲҶжҳҜеҗҰеҗҲзҗҶ
--еҶ…еӯҳжі„жјҸ
JVMи°ғдјҳжҖ»з»“-йҷ„еҪ•
е ҶеӨ§е°Ҹи®ҫзҪ®
JVM дёӯжңҖеӨ§е ҶеӨ§е°Ҹжңүдёүж–№йқўйҷҗеҲ¶пјҡзӣёе…іж“ҚдҪңзі»з»ҹзҡ„ж•°жҚ®жЁЎеһӢпјҲ32-btиҝҳжҳҜ64-bitпјүйҷҗеҲ¶пјӣзі»з»ҹзҡ„еҸҜз”ЁиҷҡжӢҹеҶ…еӯҳйҷҗеҲ¶пјӣзі»з»ҹзҡ„еҸҜз”Ёзү©зҗҶеҶ…еӯҳйҷҗеҲ¶гҖӮ32дҪҚзі»з»ҹдёӢпјҢдёҖиҲ¬йҷҗеҲ¶еңЁ1.5G~2Gпјӣ64дёәж“ҚдҪңзі»з»ҹеҜ№еҶ…еӯҳж— йҷҗеҲ¶гҖӮжҲ‘еңЁWindows Server 2003 зі»з»ҹпјҢ3.5Gзү©зҗҶеҶ…еӯҳпјҢJDK5.0дёӢжөӢиҜ•пјҢжңҖеӨ§еҸҜи®ҫзҪ®дёә1478mгҖӮ
е…ёеһӢи®ҫзҪ®пјҡ
1.
o java -Xmx3550m -Xms3550m -Xmn2g -Xss128k
-Xmx3550mпјҡи®ҫзҪ®JVMжңҖеӨ§еҸҜз”ЁеҶ…еӯҳдёә3550MгҖӮ
-Xms3550mпјҡи®ҫзҪ®JVMдҝғдҪҝеҶ…еӯҳдёә3550mгҖӮжӯӨеҖјеҸҜд»Ҙи®ҫзҪ®дёҺ-XmxзӣёеҗҢпјҢд»ҘйҒҝе…ҚжҜҸж¬Ўеһғеңҫеӣһ收е®ҢжҲҗеҗҺJVMйҮҚж–°еҲҶй…ҚеҶ…еӯҳгҖӮ
-Xmn2gпјҡи®ҫзҪ®е№ҙиҪ»д»ЈеӨ§е°Ҹдёә2GгҖӮж•ҙдёӘJVMеҶ…еӯҳеӨ§е°Ҹ=е№ҙиҪ»д»ЈеӨ§е°Ҹ + е№ҙиҖҒд»ЈеӨ§е°Ҹ + жҢҒд№…д»ЈеӨ§е°ҸгҖӮжҢҒд№…д»ЈдёҖиҲ¬еӣәе®ҡеӨ§е°Ҹдёә64mпјҢжүҖд»ҘеўһеӨ§е№ҙиҪ»д»ЈеҗҺпјҢе°ҶдјҡеҮҸе°Ҹе№ҙиҖҒд»ЈеӨ§е°ҸгҖӮжӯӨеҖјеҜ№зі»з»ҹжҖ§иғҪеҪұе“ҚиҫғеӨ§пјҢSunе®ҳж–№жҺЁиҚҗй…ҚзҪ®дёәж•ҙдёӘе Ҷзҡ„3/8гҖӮ
-Xss128kпјҡи®ҫзҪ®жҜҸдёӘзәҝзЁӢзҡ„е Ҷж ҲеӨ§е°ҸгҖӮJDK5.0д»ҘеҗҺжҜҸдёӘзәҝзЁӢе Ҷж ҲеӨ§е°Ҹдёә1MпјҢд»ҘеүҚжҜҸдёӘзәҝзЁӢе Ҷж ҲеӨ§е°Ҹдёә256KгҖӮжӣҙе…·еә”з”Ёзҡ„зәҝзЁӢжүҖйңҖеҶ…еӯҳеӨ§е°ҸиҝӣиЎҢи°ғж•ҙгҖӮеңЁзӣёеҗҢзү©зҗҶеҶ…еӯҳдёӢпјҢеҮҸе°ҸиҝҷдёӘеҖјиғҪз”ҹжҲҗжӣҙеӨҡзҡ„зәҝзЁӢгҖӮдҪҶжҳҜж“ҚдҪңзі»з»ҹеҜ№дёҖдёӘиҝӣзЁӢеҶ…зҡ„зәҝзЁӢж•°иҝҳжҳҜжңүйҷҗеҲ¶зҡ„пјҢдёҚиғҪж— йҷҗз”ҹжҲҗпјҢз»ҸйӘҢеҖјеңЁ3000~5000е·ҰеҸігҖӮ
o java -Xmx3550m -Xms3550m -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0
-XX:NewRatio=4:и®ҫзҪ®е№ҙиҪ»д»ЈпјҲеҢ…жӢ¬Edenе’ҢдёӨдёӘSurvivorеҢәпјүдёҺе№ҙиҖҒд»Јзҡ„жҜ”еҖјпјҲйҷӨеҺ»жҢҒд№…д»ЈпјүгҖӮи®ҫзҪ®дёә4пјҢеҲҷе№ҙиҪ»д»ЈдёҺе№ҙиҖҒд»ЈжүҖеҚ жҜ”еҖјдёә1пјҡ4пјҢе№ҙиҪ»д»ЈеҚ ж•ҙдёӘе Ҷж Ҳзҡ„1/5
-XX:SurvivorRatio=4пјҡи®ҫзҪ®е№ҙиҪ»д»ЈдёӯEdenеҢәдёҺSurvivorеҢәзҡ„еӨ§е°ҸжҜ”еҖјгҖӮи®ҫзҪ®дёә4пјҢеҲҷдёӨдёӘSurvivorеҢәдёҺдёҖдёӘEdenеҢәзҡ„жҜ”еҖјдёә2:4пјҢдёҖдёӘSurvivorеҢәеҚ ж•ҙдёӘе№ҙиҪ»д»Јзҡ„1/6
-XX:MaxPermSize=16m:и®ҫзҪ®жҢҒд№…д»ЈеӨ§е°Ҹдёә16mгҖӮ
-XX:MaxTenuringThreshold=0пјҡи®ҫзҪ®еһғеңҫжңҖеӨ§е№ҙйҫ„гҖӮеҰӮжһңи®ҫзҪ®дёә0зҡ„иҜқпјҢеҲҷе№ҙиҪ»д»ЈеҜ№иұЎдёҚз»ҸиҝҮSurvivorеҢәпјҢзӣҙжҺҘиҝӣе…Ҙе№ҙиҖҒд»ЈгҖӮеҜ№дәҺе№ҙиҖҒд»ЈжҜ”иҫғеӨҡзҡ„еә”з”ЁпјҢеҸҜд»ҘжҸҗй«ҳж•ҲзҺҮгҖӮеҰӮжһңе°ҶжӯӨеҖји®ҫзҪ®дёәдёҖдёӘиҫғеӨ§еҖјпјҢеҲҷе№ҙиҪ»д»ЈеҜ№иұЎдјҡеңЁSurvivorеҢәиҝӣиЎҢеӨҡж¬ЎеӨҚеҲ¶пјҢиҝҷж ·еҸҜд»ҘеўһеҠ еҜ№иұЎеҶҚе№ҙиҪ»д»Јзҡ„еӯҳжҙ»ж—¶й—ҙпјҢеўһеҠ еңЁе№ҙиҪ»д»ЈеҚіиў«еӣһ收зҡ„жҰӮи®әгҖӮ
2. еӣһ收еҷЁйҖүжӢ©
JVMз»ҷдәҶдёүз§ҚйҖүжӢ©пјҡдёІиЎҢ收йӣҶеҷЁгҖҒ并иЎҢ收йӣҶеҷЁгҖҒ并еҸ‘收йӣҶеҷЁпјҢдҪҶжҳҜдёІиЎҢ收йӣҶеҷЁеҸӘйҖӮз”ЁдәҺе°Ҹж•°жҚ®йҮҸзҡ„жғ…еҶөпјҢжүҖд»ҘиҝҷйҮҢзҡ„йҖүжӢ©дё»иҰҒй’ҲеҜ№е№¶иЎҢ收йӣҶеҷЁе’Ң并еҸ‘收йӣҶеҷЁгҖӮй»ҳи®Өжғ…еҶөдёӢпјҢJDK5.0д»ҘеүҚйғҪжҳҜдҪҝз”ЁдёІиЎҢ收йӣҶеҷЁпјҢеҰӮжһңжғідҪҝ用其他收йӣҶеҷЁйңҖиҰҒеңЁеҗҜеҠЁж—¶еҠ е…Ҙзӣёеә”еҸӮж•°гҖӮJDK5.0д»ҘеҗҺпјҢJVMдјҡж №жҚ®еҪ“еүҚзі»з»ҹй…ҚзҪ®иҝӣиЎҢеҲӨж–ӯгҖӮ
1. еҗһеҗҗйҮҸдјҳе…Ҳзҡ„并иЎҢ收йӣҶеҷЁ
еҰӮдёҠж–ҮжүҖиҝ°пјҢ并иЎҢ收йӣҶеҷЁдё»иҰҒд»ҘеҲ°иҫҫдёҖе®ҡзҡ„еҗһеҗҗйҮҸдёәзӣ®ж ҮпјҢйҖӮз”ЁдәҺ科еӯҰжҠҖжңҜе’ҢеҗҺеҸ°еӨ„зҗҶзӯүгҖӮ
е…ёеһӢй…ҚзҪ®пјҡ
В§ java -Xmx3800m -Xms3800m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20
-XX:+UseParallelGCпјҡйҖүжӢ©еһғеңҫ收йӣҶеҷЁдёә并иЎҢ收йӣҶеҷЁгҖӮжӯӨй…ҚзҪ®д»…еҜ№е№ҙиҪ»д»Јжңүж•ҲгҖӮеҚідёҠиҝ°й…ҚзҪ®дёӢпјҢе№ҙиҪ»д»ЈдҪҝ用并еҸ‘收йӣҶпјҢиҖҢе№ҙиҖҒд»Јд»Қж—§дҪҝз”ЁдёІиЎҢ收йӣҶгҖӮ
-XX:ParallelGCThreads=20пјҡй…ҚзҪ®е№¶иЎҢ收йӣҶеҷЁзҡ„зәҝзЁӢж•°пјҢеҚіпјҡеҗҢж—¶еӨҡе°‘дёӘзәҝзЁӢдёҖиө·иҝӣиЎҢеһғеңҫеӣһ收гҖӮжӯӨеҖјжңҖеҘҪй…ҚзҪ®дёҺеӨ„зҗҶеҷЁж•°зӣ®зӣёзӯүгҖӮ
В§ java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20 -XX:+UseParallelOldGC
-XX:+UseParallelOldGCпјҡй…ҚзҪ®е№ҙиҖҒд»Јеһғеңҫ收йӣҶж–№ејҸдёә并иЎҢ收йӣҶгҖӮJDK6.0ж”ҜжҢҒеҜ№е№ҙиҖҒ代并иЎҢ收йӣҶгҖӮ
В§ java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100
-XX:MaxGCPauseMillis=100:и®ҫзҪ®жҜҸж¬Ўе№ҙиҪ»д»Јеһғеңҫеӣһ收зҡ„жңҖй•ҝж—¶й—ҙпјҢеҰӮжһңж— жі•ж»Ўи¶іжӯӨж—¶й—ҙпјҢJVMдјҡиҮӘеҠЁи°ғж•ҙе№ҙиҪ»д»ЈеӨ§е°ҸпјҢд»Ҙж»Ўи¶іжӯӨеҖјгҖӮ
В§ java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100 -XX:+UseAdaptiveSizePolicy
-XX:+UseAdaptiveSizePolicyпјҡи®ҫзҪ®жӯӨйҖүйЎ№еҗҺпјҢ并иЎҢ收йӣҶеҷЁдјҡиҮӘеҠЁйҖүжӢ©е№ҙиҪ»д»ЈеҢәеӨ§е°Ҹе’Ңзӣёеә”зҡ„SurvivorеҢәжҜ”дҫӢпјҢд»ҘиҫҫеҲ°зӣ®ж Үзі»з»ҹ规е®ҡзҡ„жңҖдҪҺзӣёеә”ж—¶й—ҙжҲ–иҖ…收йӣҶйў‘зҺҮзӯүпјҢжӯӨеҖје»әи®®дҪҝ用并иЎҢ收йӣҶеҷЁж—¶пјҢдёҖзӣҙжү“ејҖгҖӮ
2. е“Қеә”ж—¶й—ҙдјҳе…Ҳзҡ„并еҸ‘收йӣҶеҷЁ
еҰӮдёҠж–ҮжүҖиҝ°пјҢ并еҸ‘收йӣҶеҷЁдё»иҰҒжҳҜдҝқиҜҒзі»з»ҹзҡ„е“Қеә”ж—¶й—ҙпјҢеҮҸе°‘еһғеңҫ收йӣҶж—¶зҡ„еҒңйЎҝж—¶й—ҙгҖӮйҖӮз”ЁдәҺеә”з”ЁжңҚеҠЎеҷЁгҖҒз”өдҝЎйўҶеҹҹзӯүгҖӮ
е…ёеһӢй…ҚзҪ®пјҡ
В§ java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
-XX:+UseConcMarkSweepGCпјҡи®ҫзҪ®е№ҙиҖҒд»Јдёә并еҸ‘收йӣҶгҖӮжөӢиҜ•дёӯй…ҚзҪ®иҝҷдёӘд»ҘеҗҺпјҢ-XX:NewRatio=4зҡ„й…ҚзҪ®еӨұж•ҲдәҶпјҢеҺҹеӣ дёҚжҳҺгҖӮжүҖд»ҘпјҢжӯӨж—¶е№ҙиҪ»д»ЈеӨ§е°ҸжңҖеҘҪз”Ё-Xmnи®ҫзҪ®гҖӮ
-XX:+UseParNewGC:и®ҫзҪ®е№ҙиҪ»д»Јдёә并иЎҢ收йӣҶгҖӮеҸҜдёҺCMS收йӣҶеҗҢж—¶дҪҝз”ЁгҖӮJDK5.0д»ҘдёҠпјҢJVMдјҡж №жҚ®зі»з»ҹй…ҚзҪ®иҮӘиЎҢи®ҫзҪ®пјҢжүҖд»Ҙж— йңҖеҶҚи®ҫзҪ®жӯӨеҖјгҖӮ
В§ java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseConcMarkSweepGC -XX:CMSFullGCsBeforeCompaction=5 -XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompactionпјҡз”ұдәҺ并еҸ‘收йӣҶеҷЁдёҚеҜ№еҶ…еӯҳз©әй—ҙиҝӣиЎҢеҺӢзј©гҖҒж•ҙзҗҶпјҢжүҖд»ҘиҝҗиЎҢдёҖж®өж—¶й—ҙд»ҘеҗҺдјҡдә§з”ҹвҖңзўҺзүҮвҖқпјҢдҪҝеҫ—иҝҗиЎҢж•ҲзҺҮйҷҚдҪҺгҖӮжӯӨеҖји®ҫзҪ®иҝҗиЎҢеӨҡе°‘ж¬ЎGCд»ҘеҗҺеҜ№еҶ…еӯҳз©әй—ҙиҝӣиЎҢеҺӢзј©гҖҒж•ҙзҗҶгҖӮ
-XX:+UseCMSCompactAtFullCollectionпјҡжү“ејҖеҜ№е№ҙиҖҒд»Јзҡ„еҺӢзј©гҖӮеҸҜиғҪдјҡеҪұе“ҚжҖ§иғҪпјҢдҪҶжҳҜеҸҜд»Ҙж¶ҲйҷӨзўҺзүҮ
3. иҫ…еҠ©дҝЎжҒҜ
JVMжҸҗдҫӣдәҶеӨ§йҮҸе‘Ҫд»ӨиЎҢеҸӮж•°пјҢжү“еҚ°дҝЎжҒҜпјҢдҫӣи°ғиҜ•дҪҝз”ЁгҖӮдё»иҰҒжңүд»ҘдёӢдёҖдәӣпјҡ
o -XX:+PrintGC
иҫ“еҮәеҪўејҸпјҡ[GC 118250K->113543K(130112K), 0.0094143 secs]
[Full GC 121376K->10414K(130112K), 0.0650971 secs]
o -XX:+PrintGCDetails
иҫ“еҮәеҪўејҸпјҡ[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs]
[GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs]
o -XX:+PrintGCTimeStamps -XX:+PrintGCпјҡPrintGCTimeStampsеҸҜдёҺдёҠйқўдёӨдёӘж··еҗҲдҪҝз”Ё
иҫ“еҮәеҪўејҸпјҡ11.851: [GC 98328K->93620K(130112K), 0.0082960 secs]
o -XX:+PrintGCApplicationConcurrentTime:жү“еҚ°жҜҸж¬Ўеһғеңҫеӣһ收еүҚпјҢзЁӢеәҸжңӘдёӯж–ӯзҡ„жү§иЎҢж—¶й—ҙгҖӮеҸҜдёҺдёҠйқўж··еҗҲдҪҝз”Ё
иҫ“еҮәеҪўејҸпјҡApplication time: 0.5291524 seconds
o -XX:+PrintGCApplicationStoppedTimeпјҡжү“еҚ°еһғеңҫеӣһ收жңҹй—ҙзЁӢеәҸжҡӮеҒңзҡ„ж—¶й—ҙгҖӮеҸҜдёҺдёҠйқўж··еҗҲдҪҝз”Ё
иҫ“еҮәеҪўејҸпјҡTotal time for which application threads were stopped: 0.0468229 seconds
o -XX:PrintHeapAtGC:жү“еҚ°GCеүҚеҗҺзҡ„иҜҰз»Ҷе Ҷж ҲдҝЎжҒҜ
иҫ“еҮәеҪўејҸпјҡ
34.702: [GC {Heap before gc invocations=7:
def new generation total 55296K, used 52568K [0x1ebd0000, 0x227d0000, 0x227d0000)
eden space 49152K, 99% used [0x1ebd0000, 0x21bce430, 0x21bd0000)
from space 6144K, 55% used [0x221d0000, 0x22527e10, 0x227d0000)
to space 6144K, 0% used [0x21bd0000, 0x21bd0000, 0x221d0000)
tenured generation total 69632K, used 2696K [0x227d0000, 0x26bd0000, 0x26bd0000)
the space 69632K, 3% used [0x227d0000, 0x22a720f8, 0x22a72200, 0x26bd0000)
compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
34.735: [DefNew: 52568K->3433K(55296K), 0.0072126 secs] 55264K->6615K(124928K)Heap after gc invocations=8:
def new generation total 55296K, used 3433K [0x1ebd0000, 0x227d0000, 0x227d0000)
eden space 49152K, 0% used [0x1ebd0000, 0x1ebd0000, 0x21bd0000)
from space 6144K, 55% used [0x21bd0000, 0x21f2a5e8, 0x221d0000)
to space 6144K, 0% used [0x221d0000, 0x221d0000, 0x227d0000)
tenured generation total 69632K, used 3182K [0x227d0000, 0x26bd0000, 0x26bd0000)
the space 69632K, 4% used [0x227d0000, 0x22aeb958, 0x22aeba00, 0x26bd0000)
compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
}
, 0.0757599 secs]
o -Xloggc:filename:дёҺдёҠйқўеҮ дёӘй…ҚеҗҲдҪҝз”ЁпјҢжҠҠзӣёе…іж—Ҙеҝ—дҝЎжҒҜи®°еҪ•еҲ°ж–Ү件д»ҘдҫҝеҲҶжһҗгҖӮ
4. еёёи§Ғй…ҚзҪ®жұҮжҖ»
0. е Ҷи®ҫзҪ®
В§ -Xms:еҲқе§Ӣе ҶеӨ§е°Ҹ
В§ -Xmx:жңҖеӨ§е ҶеӨ§е°Ҹ
В§ -XX:NewSize=n:и®ҫзҪ®е№ҙиҪ»д»ЈеӨ§е°Ҹ
В§ -XX:NewRatio=n:и®ҫзҪ®е№ҙиҪ»д»Је’Ңе№ҙиҖҒд»Јзҡ„жҜ”еҖјгҖӮеҰӮ:дёә3пјҢиЎЁзӨәе№ҙиҪ»д»ЈдёҺе№ҙиҖҒд»ЈжҜ”еҖјдёә1пјҡ3пјҢе№ҙиҪ»д»ЈеҚ ж•ҙдёӘе№ҙиҪ»д»Је№ҙиҖҒд»Је’Ңзҡ„1/4
В§ -XX:SurvivorRatio=n:е№ҙиҪ»д»ЈдёӯEdenеҢәдёҺдёӨдёӘSurvivorеҢәзҡ„жҜ”еҖјгҖӮжіЁж„ҸSurvivorеҢәжңүдёӨдёӘгҖӮеҰӮпјҡ3пјҢиЎЁзӨәEdenпјҡSurvivor=3пјҡ2пјҢдёҖдёӘSurvivorеҢәеҚ ж•ҙдёӘе№ҙиҪ»д»Јзҡ„1/5
В§ -XX:MaxPermSize=n:и®ҫзҪ®жҢҒд№…д»ЈеӨ§е°Ҹ
1. 收йӣҶеҷЁи®ҫзҪ®
В§ -XX:+UseSerialGC:и®ҫзҪ®дёІиЎҢ收йӣҶеҷЁ
В§ -XX:+UseParallelGC:и®ҫзҪ®е№¶иЎҢ收йӣҶеҷЁ
В§ -XX:+UseParalledlOldGC:и®ҫзҪ®е№¶иЎҢе№ҙиҖҒ代收йӣҶеҷЁ
В§ -XX:+UseConcMarkSweepGC:и®ҫзҪ®е№¶еҸ‘收йӣҶеҷЁ
2. еһғеңҫеӣһ收з»ҹи®ЎдҝЎжҒҜ
В§ -XX:+PrintGC
В§ -XX:+PrintGCDetails
В§ -XX:+PrintGCTimeStamps
В§ -Xloggc:filename
3. 并иЎҢ收йӣҶеҷЁи®ҫзҪ®
В§ -XX:ParallelGCThreads=n:и®ҫзҪ®е№¶иЎҢ收йӣҶеҷЁж”¶йӣҶж—¶дҪҝз”Ёзҡ„CPUж•°гҖӮ并иЎҢ收йӣҶзәҝзЁӢж•°гҖӮ
В§ -XX:MaxGCPauseMillis=n:и®ҫзҪ®е№¶иЎҢ收йӣҶжңҖеӨ§жҡӮеҒңж—¶й—ҙ
В§ -XX:GCTimeRatio=n:и®ҫзҪ®еһғеңҫеӣһ收时й—ҙеҚ зЁӢеәҸиҝҗиЎҢж—¶й—ҙзҡ„зҷҫеҲҶжҜ”гҖӮе…¬ејҸдёә1/(1+n)
4. 并еҸ‘收йӣҶеҷЁи®ҫзҪ®
В§ -XX:+CMSIncrementalMode:и®ҫзҪ®дёәеўһйҮҸжЁЎејҸгҖӮйҖӮз”ЁдәҺеҚ•CPUжғ…еҶөгҖӮ
В§ -XX:ParallelGCThreads=n:и®ҫзҪ®е№¶еҸ‘收йӣҶеҷЁе№ҙиҪ»д»Јж”¶йӣҶж–№ејҸдёә并иЎҢ收йӣҶж—¶пјҢдҪҝз”Ёзҡ„CPUж•°гҖӮ并иЎҢ收йӣҶзәҝзЁӢж•°гҖӮ
еӣӣгҖҒи°ғдјҳжҖ»з»“
1. е№ҙиҪ»д»ЈеӨ§е°ҸйҖүжӢ©
o е“Қеә”ж—¶й—ҙдјҳе…Ҳзҡ„еә”з”Ёпјҡе°ҪеҸҜиғҪи®ҫеӨ§пјҢзӣҙеҲ°жҺҘиҝ‘зі»з»ҹзҡ„жңҖдҪҺе“Қеә”ж—¶й—ҙйҷҗеҲ¶пјҲж №жҚ®е®һйҷ…жғ…еҶөйҖүжӢ©пјүгҖӮеңЁжӯӨз§Қжғ…еҶөдёӢпјҢе№ҙиҪ»д»Јж”¶йӣҶеҸ‘з”ҹзҡ„йў‘зҺҮд№ҹжҳҜжңҖе°Ҹзҡ„гҖӮеҗҢж—¶пјҢеҮҸе°‘еҲ°иҫҫе№ҙиҖҒд»Јзҡ„еҜ№иұЎгҖӮ
o еҗһеҗҗйҮҸдјҳе…Ҳзҡ„еә”з”Ёпјҡе°ҪеҸҜиғҪзҡ„и®ҫзҪ®еӨ§пјҢеҸҜиғҪеҲ°иҫҫGbitзҡ„зЁӢеәҰгҖӮеӣ дёәеҜ№е“Қеә”ж—¶й—ҙжІЎжңүиҰҒжұӮпјҢеһғеңҫ收йӣҶеҸҜд»Ҙ并иЎҢиҝӣиЎҢпјҢдёҖиҲ¬йҖӮеҗҲ8CPUд»ҘдёҠзҡ„еә”з”ЁгҖӮ
2. е№ҙиҖҒд»ЈеӨ§е°ҸйҖүжӢ©
o е“Қеә”ж—¶й—ҙдјҳе…Ҳзҡ„еә”з”Ёпјҡе№ҙиҖҒд»ЈдҪҝ用并еҸ‘收йӣҶеҷЁпјҢжүҖд»Ҙе…¶еӨ§е°ҸйңҖиҰҒе°Ҹеҝғи®ҫзҪ®пјҢдёҖиҲ¬иҰҒиҖғиҷ‘并еҸ‘дјҡиҜқзҺҮе’ҢдјҡиҜқжҢҒз»ӯж—¶й—ҙзӯүдёҖдәӣеҸӮж•°гҖӮеҰӮжһңе Ҷи®ҫзҪ®е°ҸдәҶпјҢеҸҜд»ҘдјҡйҖ жҲҗеҶ…еӯҳзўҺзүҮгҖҒй«ҳеӣһ收频зҺҮд»ҘеҸҠеә”з”ЁжҡӮеҒңиҖҢдҪҝз”Ёдј з»ҹзҡ„ж Үи®°жё…йҷӨж–№ејҸпјӣеҰӮжһңе ҶеӨ§дәҶпјҢеҲҷйңҖиҰҒиҫғй•ҝзҡ„收йӣҶж—¶й—ҙгҖӮжңҖдјҳеҢ–зҡ„ж–№жЎҲпјҢдёҖиҲ¬йңҖиҰҒеҸӮиҖғд»ҘдёӢж•°жҚ®иҺ·еҫ—пјҡ
В§ 并еҸ‘еһғеңҫ收йӣҶдҝЎжҒҜ
В§ жҢҒ久代并еҸ‘收йӣҶж¬Ўж•°
В§ дј з»ҹGCдҝЎжҒҜ
В§ иҠұеңЁе№ҙиҪ»д»Је’Ңе№ҙиҖҒд»Јеӣһ收дёҠзҡ„ж—¶й—ҙжҜ”дҫӢ
еҮҸе°‘е№ҙиҪ»д»Је’Ңе№ҙиҖҒд»ЈиҠұиҙ№зҡ„ж—¶й—ҙпјҢдёҖиҲ¬дјҡжҸҗй«ҳеә”з”Ёзҡ„ж•ҲзҺҮ
o еҗһеҗҗйҮҸдјҳе…Ҳзҡ„еә”з”ЁпјҡдёҖиҲ¬еҗһеҗҗйҮҸдјҳе…Ҳзҡ„еә”з”ЁйғҪжңүдёҖдёӘеҫҲеӨ§зҡ„е№ҙиҪ»д»Је’ҢдёҖдёӘиҫғе°Ҹзҡ„е№ҙиҖҒд»ЈгҖӮеҺҹеӣ жҳҜпјҢиҝҷж ·еҸҜд»Ҙе°ҪеҸҜиғҪеӣһ收жҺүеӨ§йғЁеҲҶзҹӯжңҹеҜ№иұЎпјҢеҮҸе°‘дёӯжңҹзҡ„еҜ№иұЎпјҢиҖҢе№ҙиҖҒд»Је°Ҫеӯҳж”ҫй•ҝжңҹеӯҳжҙ»еҜ№иұЎгҖӮ
3. иҫғе°Ҹе Ҷеј•иө·зҡ„зўҺзүҮй—®йўҳ
еӣ дёәе№ҙиҖҒд»Јзҡ„并еҸ‘收йӣҶеҷЁдҪҝз”Ёж Үи®°гҖҒжё…йҷӨз®—жі•пјҢжүҖд»ҘдёҚдјҡеҜ№е ҶиҝӣиЎҢеҺӢзј©гҖӮеҪ“收йӣҶеҷЁеӣһ收时пјҢд»–дјҡжҠҠзӣёйӮ»зҡ„з©әй—ҙиҝӣиЎҢеҗҲ并пјҢиҝҷж ·еҸҜд»ҘеҲҶй…Қз»ҷиҫғеӨ§зҡ„еҜ№иұЎгҖӮдҪҶжҳҜпјҢеҪ“е Ҷз©әй—ҙиҫғе°Ҹж—¶пјҢиҝҗиЎҢдёҖж®өж—¶й—ҙд»ҘеҗҺпјҢе°ұдјҡеҮәзҺ°вҖңзўҺзүҮвҖқпјҢеҰӮжһң并еҸ‘收йӣҶеҷЁжүҫдёҚеҲ°и¶іеӨҹзҡ„з©әй—ҙпјҢйӮЈд№Ҳ并еҸ‘收йӣҶеҷЁе°ҶдјҡеҒңжӯўпјҢ然еҗҺдҪҝз”Ёдј з»ҹзҡ„ж Үи®°гҖҒжё…йҷӨж–№ејҸиҝӣиЎҢеӣһ收гҖӮеҰӮжһңеҮәзҺ°вҖңзўҺзүҮвҖқпјҢеҸҜиғҪйңҖиҰҒиҝӣиЎҢеҰӮдёӢй…ҚзҪ®пјҡ
o -XX:+UseCMSCompactAtFullCollectionпјҡдҪҝ用并еҸ‘收йӣҶеҷЁж—¶пјҢејҖеҗҜеҜ№е№ҙиҖҒд»Јзҡ„еҺӢзј©гҖӮ
o -XX:CMSFullGCsBeforeCompaction=0пјҡдёҠйқўй…ҚзҪ®ејҖеҗҜзҡ„жғ…еҶөдёӢпјҢиҝҷйҮҢи®ҫзҪ®еӨҡе°‘ж¬ЎFull GCеҗҺпјҢеҜ№е№ҙиҖҒд»ЈиҝӣиЎҢеҺӢзј©
еҹәжң¬жҰӮеҝөпјҡ
PermGen spaceпјҡе…Ёз§°жҳҜPermanent Generation spaceгҖӮе°ұжҳҜиҜҙжҳҜж°ёд№…дҝқеӯҳзҡ„еҢәеҹҹ,з”ЁдәҺеӯҳж”ҫClassе’ҢMetaдҝЎжҒҜпјҢClassеңЁиў«Loadзҡ„ж—¶еҖҷиў«ж”ҫе…ҘиҜҘеҢәеҹҹ
Heap spaceпјҡеӯҳж”ҫInstanceгҖӮGC(Garbage Collection)еә”иҜҘдёҚдјҡеҜ№PermGen spaceиҝӣиЎҢжё…зҗҶ
жүҖд»ҘеҰӮжһңдҪ зҡ„APPдјҡLOADеҫҲеӨҡCLASSзҡ„иҜқпјҢе°ұеҫҲеҸҜиғҪеҮәзҺ°PermGen spaceй”ҷиҜҜ
Java HeapеҲҶдёә3дёӘеҢәпјҢYoungпјҢOldе’ҢPermanentгҖӮYoungдҝқеӯҳеҲҡе®һдҫӢеҢ–зҡ„еҜ№иұЎгҖӮеҪ“иҜҘеҢәиў«еЎ«ж»Ўж—¶пјҢGCдјҡе°ҶеҜ№иұЎз§»еҲ°OldеҢәгҖӮPermanentеҢәеҲҷиҙҹиҙЈдҝқеӯҳеҸҚе°„еҜ№иұЎгҖӮ
JVMжңү2дёӘGCзәҝзЁӢгҖӮ
第дёҖдёӘзәҝзЁӢиҙҹиҙЈеӣһ收Heapзҡ„YoungеҢәгҖӮ
第дәҢдёӘзәҝзЁӢеңЁHeapдёҚи¶іж—¶пјҢйҒҚеҺҶHeapпјҢе°ҶYoung еҢәеҚҮзә§дёәOlderеҢәгҖӮOlderеҢәзҡ„еӨ§е°ҸзӯүдәҺ-XmxеҮҸеҺ»-XmnпјҢдёҚиғҪе°Ҷ-Xmsзҡ„еҖји®ҫзҡ„иҝҮеӨ§пјҢеӣ дёә第дәҢдёӘзәҝзЁӢиў«иҝ«иҝҗиЎҢдјҡйҷҚдҪҺJVMзҡ„жҖ§иғҪгҖӮ
дёәд»Җд№ҲдёҖдәӣзЁӢеәҸйў‘з№ҒеҸ‘з”ҹGCпјҹжңүеҰӮдёӢеҺҹеӣ пјҡ
зЁӢеәҸеҶ…и°ғз”ЁдәҶSystem.gc()жҲ–Runtime.gc()гҖӮ
дёҖдәӣдёӯй—ҙ件иҪҜ件и°ғз”ЁиҮӘе·ұзҡ„GCж–№жі•пјҢжӯӨж—¶йңҖиҰҒи®ҫзҪ®еҸӮж•°зҰҒжӯўиҝҷдәӣGCгҖӮ
Javaзҡ„HeapеӨӘе°ҸпјҢдёҖиҲ¬й»ҳи®Өзҡ„HeapеҖјйғҪеҫҲе°ҸгҖӮ
йў‘з№Ғе®һдҫӢеҢ–еҜ№иұЎпјҢReleaseеҜ№иұЎгҖӮжӯӨж—¶е°ҪйҮҸдҝқеӯҳ并йҮҚз”ЁеҜ№иұЎпјҢдҫӢеҰӮдҪҝз”ЁStringBuffer()е’ҢString()гҖӮ
еҰӮжһңдҪ еҸ‘зҺ°жҜҸж¬ЎGCеҗҺпјҢHeapзҡ„еү©дҪҷз©әй—ҙдјҡжҳҜжҖ»з©әй—ҙзҡ„50%пјҢиҝҷиЎЁзӨәдҪ зҡ„HeapеӨ„дәҺеҒҘеә·зҠ¶жҖҒгҖӮи®ёеӨҡServerз«Ҝзҡ„JavaзЁӢеәҸжҜҸж¬ЎGCеҗҺжңҖеҘҪиғҪжңү65%зҡ„еү©дҪҷз©әй—ҙгҖӮ
е»әи®®Serverз«ҜJVMжңҖеҘҪе°Ҷ-Xmsе’Ң-Xmxи®ҫдёәзӣёеҗҢеҖјгҖӮдёәдәҶдјҳеҢ–GCпјҢжңҖеҘҪи®©-XmnеҖјзәҰзӯүдәҺ-Xmxзҡ„1/3гҖӮдёҖдёӘGUIзЁӢеәҸжңҖеҘҪжҳҜжҜҸ10еҲ°20з§’й—ҙиҝҗиЎҢдёҖж¬ЎGCпјҢжҜҸж¬ЎеңЁеҚҠз§’д№ӢеҶ…е®ҢжҲҗгҖӮ
еўһеҠ Heapзҡ„еӨ§е°ҸиҷҪ然дјҡйҷҚдҪҺGCзҡ„йў‘зҺҮпјҢдҪҶд№ҹеўһеҠ дәҶжҜҸж¬ЎGCзҡ„ж—¶й—ҙгҖӮ并且GCиҝҗиЎҢж—¶пјҢжүҖжңүзҡ„з”ЁжҲ·зәҝзЁӢе°ҶжҡӮеҒңпјҢд№ҹе°ұжҳҜGCжңҹй—ҙпјҢJavaеә”з”ЁзЁӢеәҸдёҚеҒҡд»»дҪ•е·ҘдҪңгҖӮ
HeapеӨ§е°Ҹ并дёҚеҶіе®ҡиҝӣзЁӢзҡ„еҶ…еӯҳдҪҝз”ЁйҮҸгҖӮиҝӣзЁӢзҡ„еҶ…еӯҳдҪҝз”ЁйҮҸиҰҒеӨ§дәҺ-Xmxе®ҡд№үзҡ„еҖјпјҢеӣ дёәJavaдёәе…¶д»–д»»еҠЎеҲҶй…ҚеҶ…еӯҳпјҢдҫӢеҰӮжҜҸдёӘзәҝзЁӢзҡ„StackзӯүгҖӮ
Stackзҡ„и®ҫе®ҡ
жҜҸдёӘзәҝзЁӢйғҪжңүд»–иҮӘе·ұзҡ„StackгҖӮ
-Xss жҜҸдёӘзәҝзЁӢзҡ„StackеӨ§е°Ҹ
Stackзҡ„еӨ§е°ҸйҷҗеҲ¶зқҖзәҝзЁӢзҡ„ж•°йҮҸгҖӮеҰӮжһңStackиҝҮеӨ§е°ұдјҡеҜјиҮҙеҶ…еӯҳжәўжјҸгҖӮ-XssеҸӮж•°еҶіе®ҡStackеӨ§е°ҸпјҢдҫӢеҰӮ-Xss1024KгҖӮеҰӮжһңStackеӨӘе°ҸпјҢд№ҹдјҡеҜјиҮҙStackжәўжјҸгҖӮ
硬件зҺҜеўғд№ҹеҪұе“ҚGCзҡ„ж•ҲзҺҮпјҢдҫӢеҰӮжңәеҷЁзҡ„з§Қзұ»пјҢеҶ…еӯҳпјҢswapз©әй—ҙпјҢе’ҢCPUзҡ„ж•°йҮҸгҖӮ
еҰӮжһңдҪ зҡ„зЁӢеәҸйңҖиҰҒйў‘з№ҒеҲӣе»әеҫҲеӨҡtransientеҜ№иұЎпјҢдјҡеҜјиҮҙJVMйў‘з№ҒGCгҖӮиҝҷз§Қжғ…еҶөдҪ еҸҜд»ҘеўһеҠ жңәеҷЁзҡ„еҶ…еӯҳпјҢжқҘеҮҸе°‘Swapз©әй—ҙзҡ„дҪҝз”ЁгҖӮ
4з§ҚGC
1гҖҒ第дёҖз§ҚдёәеҚ•зәҝзЁӢGCпјҢд№ҹжҳҜй»ҳи®Өзҡ„GCгҖӮпјҢиҜҘGCйҖӮз”ЁдәҺеҚ•CPUжңәеҷЁгҖӮ
2гҖҒ第дәҢз§ҚдёәThroughput GCпјҢжҳҜеӨҡзәҝзЁӢзҡ„GCпјҢйҖӮз”ЁдәҺеӨҡCPUпјҢдҪҝз”ЁеӨ§йҮҸзәҝзЁӢзҡ„зЁӢеәҸгҖӮ第дәҢз§ҚGCдёҺ第дёҖз§ҚGCзӣёдјјпјҢдёҚеҗҢеңЁдәҺGCеңЁж”¶йӣҶYoungеҢәжҳҜеӨҡзәҝзЁӢзҡ„пјҢдҪҶеңЁOldеҢәе’Ң第дёҖз§ҚдёҖж ·пјҢд»Қ然йҮҮз”ЁеҚ•зәҝзЁӢгҖӮ-XX:+UseParallelGCеҸӮж•°еҗҜеҠЁиҜҘGCгҖӮ
3гҖҒ第дёүз§ҚдёәConcurrent Low Pause GCпјҢзұ»дјјдәҺ第дёҖз§ҚпјҢйҖӮз”ЁдәҺеӨҡCPUпјҢ并иҰҒжұӮзј©зҹӯеӣ GCйҖ жҲҗзЁӢеәҸеҒңж»һзҡ„ж—¶й—ҙгҖӮиҝҷз§ҚGCеҸҜд»ҘеңЁOldеҢәзҡ„еӣһ收еҗҢж—¶пјҢиҝҗиЎҢеә”з”ЁзЁӢеәҸгҖӮ-XX:+UseConcMarkSweepGCеҸӮж•°еҗҜеҠЁиҜҘGCгҖӮ
4гҖҒ第еӣӣз§ҚдёәIncremental Low Pause GCпјҢйҖӮз”ЁдәҺиҰҒжұӮзј©зҹӯеӣ GCйҖ жҲҗзЁӢеәҸеҒңж»һзҡ„ж—¶й—ҙгҖӮиҝҷз§ҚGCеҸҜд»ҘеңЁYoungеҢәеӣһ收зҡ„еҗҢж—¶пјҢеӣһ收дёҖйғЁеҲҶOldеҢәеҜ№иұЎгҖӮ-XincgcеҸӮж•°еҗҜеҠЁиҜҘGCгҖӮ
JVMеҸӮж•°й…ҚзҪ®
1: heap size
a: -Xmx<n>
жҢҮе®ҡ jvm зҡ„жңҖеӨ§ heap еӨ§е°Ҹ , еҰӮ :-Xmx=2g
b: -Xms<n>
жҢҮе®ҡ jvm зҡ„жңҖе°Ҹ heap еӨ§е°Ҹ , еҰӮ :-Xms=2g пјҢ й«ҳ并еҸ‘еә”з”ЁпјҢ е»әи®®е’Ң-XmxдёҖж ·пјҢ йҳІжӯўеӣ дёәеҶ…еӯҳ收缩пјҸзӘҒ然еўһеӨ§еёҰжқҘзҡ„жҖ§иғҪеҪұе“ҚгҖӮ
c: -Xmn<n>
жҢҮе®ҡ jvm дёӯ New Generation зҡ„еӨ§е°Ҹ , еҰӮ :-Xmn256mгҖӮ иҝҷдёӘеҸӮж•°еҫҲеҪұе“ҚжҖ§иғҪпјҢ еҰӮжһңдҪ зҡ„зЁӢеәҸйңҖиҰҒжҜ”иҫғеӨҡзҡ„дёҙж—¶еҶ…еӯҳпјҢ е»әи®®и®ҫзҪ®еҲ°512MпјҢ еҰӮжһңз”Ёзҡ„е°‘пјҢ е°ҪйҮҸйҷҚдҪҺиҝҷдёӘж•°еҖјпјҢ дёҖиҲ¬жқҘиҜҙ128пјҸ256и¶ід»ҘдҪҝз”ЁдәҶгҖӮ
d: -XX:PermSize=<n>
жҢҮе®ҡ jvm дёӯ Perm Generation зҡ„жңҖе°ҸеҖј , еҰӮ :-XX:PermSize=32mгҖӮ иҝҷдёӘеҸӮж•°йңҖиҰҒзңӢдҪ зҡ„е®һйҷ…жғ…еҶөпјҢгҖӮ еҸҜд»ҘйҖҡиҝҮjmap е‘Ҫд»ӨзңӢзңӢеҲ°еә•йңҖиҰҒеӨҡе°‘гҖӮ
e: -XX:MaxPermSize=<n>
жҢҮе®ҡ Perm Generation зҡ„жңҖеӨ§еҖј , еҰӮ :-XX:MaxPermSize=64m
f: -Xss<n>
жҢҮе®ҡзәҝзЁӢжЎҹеӨ§е°Ҹ , еҰӮ :-Xss128kпјҢ дёҖиҲ¬жқҘиҜҙпјҢwebxжЎҶжһ¶дёӢзҡ„еә”з”ЁйңҖиҰҒ256KгҖӮ еҰӮжһңдҪ зҡ„зЁӢеәҸжңүеӨ§и§„жЁЎзҡ„йҖ’еҪ’иЎҢдёәпјҢиҜ·иҖғиҷ‘и®ҫзҪ®еҲ°512KпјҸ1MгҖӮ иҝҷдёӘйңҖиҰҒе…Ёйқўзҡ„жөӢиҜ•жүҚиғҪзҹҘйҒ“гҖӮ дёҚиҝҮпјҢ256Kе·Із»ҸеҫҲеӨ§дәҶгҖӮ иҝҷдёӘеҸӮж•°еҜ№жҖ§иғҪзҡ„еҪұе“ҚжҜ”иҫғеӨ§зҡ„гҖӮ
g: -XX:NewRatio=<n>
жҢҮе®ҡ jvm дёӯ Old Generation heap size дёҺ New Generation зҡ„жҜ”дҫӢ , еңЁдҪҝз”Ё CMS GC зҡ„жғ…еҶөдёӢжӯӨеҸӮж•°еӨұж•Ҳ , еҰӮ :-XX:NewRatio=2
h: -XX:SurvivorRatio=<n>
жҢҮе®ҡ New Generation дёӯ Eden Space дёҺдёҖдёӘ Survivor Space зҡ„ heap size жҜ”дҫӢ ,-XX:SurvivorRatio=8, йӮЈд№ҲеңЁжҖ»е…ұ New Generation дёә 10m зҡ„жғ…еҶөдёӢ ,Eden Space дёә 8m
i: -XX:MinHeapFreeRatio=<n>
жҢҮе®ҡ jvm heap еңЁдҪҝз”ЁзҺҮе°ҸдәҺ n зҡ„жғ…еҶөдёӢ ,heap иҝӣиЎҢ收缩 ,Xmx==Xms зҡ„жғ…еҶөдёӢж— ж•Ҳ , еҰӮ :-XX:MinHeapFreeRatio=30
j: -XX:MaxHeapFreeRatio=<n>
жҢҮе®ҡ jvm heap еңЁдҪҝз”ЁзҺҮеӨ§дәҺ n зҡ„жғ…еҶөдёӢ ,heap иҝӣиЎҢжү©еј ,Xmx==Xms зҡ„жғ…еҶөдёӢж— ж•Ҳ , еҰӮ :-XX:MaxHeapFreeRatio=70
k: -XX:LargePageSizeInBytes=<n>
жҢҮе®ҡ Java heap зҡ„еҲҶйЎөйЎөйқўеӨ§е°Ҹ , еҰӮ :-XX:LargePageSizeInBytes=128m
2: garbage collector
a: -XX:+UseParallelGC
жҢҮе®ҡеңЁ New Generation дҪҝз”Ё parallel collector, 并иЎҢ收йӣҶ , жҡӮеҒң app threads, еҗҢж—¶еҗҜеҠЁеӨҡдёӘеһғеңҫеӣһ收 thread, дёҚиғҪе’Ң CMS gc дёҖиө·дҪҝз”Ё . зі»з»ҹеҗЁеҗҗйҮҸдјҳе…Ҳ , дҪҶжҳҜдјҡжңүиҫғй•ҝй•ҝж—¶й—ҙзҡ„ app pause, еҗҺеҸ°зі»з»ҹд»»еҠЎеҸҜд»ҘдҪҝз”ЁжӯӨ gc
b: -XX:ParallelGCThreads=<n>
жҢҮе®ҡ parallel collection ж—¶еҗҜеҠЁзҡ„ thread дёӘж•° , й»ҳи®ӨжҳҜзү©зҗҶ processor зҡ„дёӘж•° ,
c: -XX:+UseParallelOldGC
жҢҮе®ҡеңЁ Old Generation дҪҝз”Ё parallel collector
d: -XX:+UseParNewGC
жҢҮе®ҡеңЁ New Generation дҪҝз”Ё parallel collector, жҳҜ UseParallelGC зҡ„ gc зҡ„еҚҮзә§зүҲжң¬ , жңүжӣҙеҘҪзҡ„жҖ§иғҪжҲ–иҖ…дјҳзӮ№ , еҸҜд»Ҙе’Ң CMS gc дёҖиө·дҪҝз”Ё
e: -XX:+CMSParallelRemarkEnabled
еңЁдҪҝз”Ё UseParNewGC зҡ„жғ…еҶөдёӢ , е°ҪйҮҸеҮҸе°‘ mark зҡ„ж—¶й—ҙ
f: -XX:+UseConcMarkSweepGC
жҢҮе®ҡеңЁ Old Generation дҪҝз”Ё concurrent cmark sweep gc,gc thread е’Ң app thread 并иЎҢ ( еңЁ init-mark е’Ң remark ж—¶ pause app thread). app pause ж—¶й—ҙиҫғзҹӯ , йҖӮеҗҲдәӨдә’жҖ§ејәзҡ„зі»з»ҹ , еҰӮ web server
g: -XX:+UseCMSCompactAtFullCollection
еңЁдҪҝз”Ё concurrent gc зҡ„жғ…еҶөдёӢ , йҳІжӯў memory fragmention, еҜ№ live object иҝӣиЎҢж•ҙзҗҶ , дҪҝ memory зўҺзүҮеҮҸе°‘
h: -XX:CMSInitiatingOccupancyFraction=<n>
жҢҮзӨәеңЁ old generation еңЁдҪҝз”ЁдәҶ n% зҡ„жҜ”дҫӢеҗҺ , еҗҜеҠЁ concurrent collector, й»ҳи®ӨеҖјжҳҜ 68, еҰӮ :-XX:CMSInitiatingOccupancyFraction=70
i: -XX:+UseCMSInitiatingOccupancyOnly
жҢҮзӨәеҸӘжңүеңЁ old generation еңЁдҪҝз”ЁдәҶеҲқе§ӢеҢ–зҡ„жҜ”дҫӢеҗҺ concurrent collector еҗҜеҠЁж”¶йӣҶ
3:others
a: -XX:MaxTenuringThreshold=<n>
жҢҮе®ҡдёҖдёӘ object еңЁз»ҸеҺҶдәҶ n ж¬Ў young gc еҗҺиҪ¬з§»еҲ° old generation еҢә , еңЁ linux64 зҡ„ java6 дёӢй»ҳи®ӨеҖјжҳҜ 15, жӯӨеҸӮж•°еҜ№дәҺ throughput collector ж— ж•Ҳ , еҰӮ :-XX:MaxTenuringThreshold=31
b: -XX:+DisableExplicitGC
зҰҒжӯў java зЁӢеәҸдёӯзҡ„ full gc, еҰӮ System.gc() зҡ„и°ғз”Ё. жңҖеҘҪеҠ дёҠд№ҲпјҢ йҳІжӯўзЁӢеәҸеңЁд»Јз ҒйҮҢиҜҜз”ЁдәҶгҖӮеҜ№жҖ§иғҪйҖ жҲҗеҶІеҮ»гҖӮ
c: -XX:+UseFastAccessorMethods
get,set ж–№жі•иҪ¬жҲҗжң¬ең°д»Јз Ғ
d: -XX:+PrintGCDetails
жү“еә”еһғеңҫ收йӣҶзҡ„жғ…еҶөеҰӮ :
[GC 15610.466: [ParNew: 229689K->20221K(235968K), 0.0194460 secs] 1159829K->953935K(2070976K), 0.0196420 secs]
e: -XX:+PrintGCTimeStamps
жү“еә”еһғеңҫ收йӣҶзҡ„ж—¶й—ҙжғ…еҶө , еҰӮ :
[Times: user=0.09 sys=0.00, real=0.02 secs]
f: -XX:+PrintGCApplicationStoppedTime
жү“еә”еһғеңҫ收йӣҶж—¶ , зі»з»ҹзҡ„еҒңйЎҝж—¶й—ҙ , еҰӮ :
Total time for which application threads were stopped: 0.0225920 seconds
JVMеҸӮж•°и®ҫзҪ®еӨ§е…Ё
http://java.sun.com/javase/technologies/hotspot/vmoptions.jsp
JVMеҸӮж•°и®ҫзҪ®еӨ§е…ЁеҺӢзј©зүҲ
http://blogs.sun.com/watt/resource/jvm-options-list.html
JVMеҸӮж•°и°ғдјҳжҳҜдёҖдёӘеҫҲеӨҙз—ӣзҡ„й—®йўҳпјҢеҸҜиғҪе’Ңеә”з”Ёжңүе…ізі»пјҢдёӢйқўжҳҜжң¬дәәдёҖдәӣи°ғдјҳзҡ„е®һи·өз»ҸйӘҢпјҢеёҢжңӣеҜ№иҜ»иҖ…иғҪжңүеё®еҠ©пјҢзҺҜеўғLinuxAS4,resin2.1.17,JDK6.0,2CPU,4GеҶ…еӯҳ,dell2950жңҚеҠЎеҷЁпјҢзҪ‘з«ҷжҳҜhttp://shedewang.com
дёҖпјҡдёІиЎҢеһғеңҫеӣһ收пјҢд№ҹе°ұжҳҜй»ҳи®Өй…ҚзҪ®пјҢе®ҢжҲҗ10дёҮrequestз”Ёж—¶153з§’пјҢJVMеҸӮж•°й…ҚзҪ®еҰӮдёӢпјҡ
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps ";
иҝҷз§Қй…ҚзҪ®дёҖиҲ¬еңЁresinеҗҜеҠЁ24е°Ҹж—¶еҶ…дјјд№ҺжІЎжңүеӨ§й—®йўҳпјҢзҪ‘з«ҷеҸҜд»ҘжӯЈеёёи®ҝй—®пјҢдҪҶжҹҘзңӢж—Ҙеҝ—еҸ‘зҺ°пјҢеңЁжҺҘиҝ‘24е°Ҹж—¶ж—¶пјҢFull GCжү§иЎҢи¶ҠжқҘи¶Ҡйў‘з№ҒпјҢеӨ§зәҰжҜҸйҡ”3еҲҶй’ҹе°ұжңүдёҖж¬ЎFull GCпјҢжҜҸж¬ЎFull GCзі»з»ҹдјҡеҒңйЎҝ6з§’е·ҰеҸіпјҢдҪңдёәдёҖдёӘзҪ‘з«ҷжқҘиҜҙпјҢз”ЁжҲ·зӯүеҫ…6з§’жҒҗжҖ•еӨӘй•ҝдәҶпјҢжүҖд»Ҙиҝҷз§Қж–№ејҸжңүеҫ…ж”№е–„гҖӮMaxTenuringThreshold=7иЎЁзӨәдёҖдёӘеҜ№иұЎеҰӮжһңеңЁж•‘еҠ©з©әй—ҙ移еҠЁ7ж¬ЎиҝҳжІЎжңүиў«еӣһ收е°ұж”ҫе…Ҙе№ҙиҖҒд»ЈпјҢGCTimeRatio=19иЎЁзӨәjavaеҸҜд»Ҙз”Ё5%зҡ„ж—¶й—ҙжқҘеҒҡеһғеңҫеӣһ收пјҢ1/(1+19)=1 /20=5%гҖӮ
дәҢпјҡ并иЎҢеӣһ收пјҢе®ҢжҲҗ10дёҮrequestз”Ёж—¶117з§’пјҢй…ҚзҪ®еҰӮдёӢпјҡ
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xmx2048M -Xms2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseParallelGC -XX:ParallelGCThreads=20 -XX:+UseParallelOldGC -XX:MaxGCPauseMillis=500 -XX:+UseAdaptiveSizePolicy -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 ";
并иЎҢеӣһ收жҲ‘е°қиҜ•иҝҮеӨҡз§Қз»„еҗҲй…ҚзҪ®пјҢдјјд№ҺйғҪжІЎд»Җд№Ҳз”ЁпјҢresinеҗҜеҠЁ3е°Ҹж—¶е·ҰеҸіе°ұдјҡеҒңйЎҝпјҢж—¶й—ҙи¶…иҝҮ10 з§’гҖӮд№ҹжңүеҸҜиғҪжҳҜеҸӮж•°и®ҫзҪ®дёҚеӨҹеҘҪзҡ„еҺҹеӣ пјҢMaxGCPauseMillisиЎЁзӨәGCжңҖеӨ§еҒңйЎҝж—¶й—ҙпјҢеңЁresinеҲҡеҗҜеҠЁиҝҳжІЎжңүжү§иЎҢFull GCж—¶зі»з»ҹжҳҜжӯЈеёёзҡ„пјҢдҪҶдёҖж—Ұжү§иЎҢFull GCпјҢMaxGCPauseMillisж №жң¬жІЎжңүз”ЁпјҢеҒңйЎҝж—¶й—ҙеҸҜиғҪи¶…иҝҮ20з§’пјҢд№ӢеҗҺдјҡеҸ‘з”ҹд»Җд№ҲжҲ‘д№ҹдёҚеҶҚе…іеҝғдәҶпјҢиө¶зҙ§йҮҚеҗҜresinпјҢе°қиҜ•е…¶д»–еӣһ收зӯ–з•ҘгҖӮ
дёүпјҡ并еҸ‘еӣһ收пјҢе®ҢжҲҗ10дёҮrequestз”Ёж—¶60з§’пјҢжҜ”并иЎҢеӣһ收差дёҚеӨҡеҝ«дёҖеҖҚпјҢжҳҜй»ҳи®Өеӣһ收зӯ–з•ҘжҖ§иғҪзҡ„2.5еҖҚпјҢй…ҚзҪ®еҰӮдёӢпјҡ
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 ";
иҝҷдёӘй…ҚзҪ®иҷҪ然дёҚдјҡеҮәзҺ°10з§’иҝһдёҚдёҠзҡ„жғ…еҶөпјҢдҪҶзі»з»ҹйҮҚеҗҜ3дёӘе°Ҹж—¶е·ҰеҸіпјҢжҜҸйҡ”еҮ еҲҶй’ҹе°ұдјҡжңү5з§’иҝһдёҚдёҠзҡ„жғ…еҶөпјҢжҹҘзңӢgc.logпјҢеҸ‘зҺ°еңЁжү§иЎҢParNewGCж—¶жңүдёӘpromotion failedй”ҷиҜҜпјҢд»ҺиҖҢиҪ¬еҗ‘жү§иЎҢFull GCпјҢйҖ жҲҗзі»з»ҹеҒңйЎҝпјҢиҖҢдё”дјҡеҫҲйў‘з№ҒпјҢжҜҸйҡ”еҮ еҲҶй’ҹе°ұжңүдёҖж¬ЎпјҢжүҖд»Ҙиҝҳеҫ—ж”№е–„гҖӮUseCMSCompactAtFullCollectionжҳҜиЎЁжҳҜжү§иЎҢFull GCеҗҺеҜ№еҶ…еӯҳиҝӣиЎҢж•ҙзҗҶеҺӢзј©пјҢе…Қеҫ—дә§з”ҹеҶ…еӯҳзўҺзүҮпјҢCMSFullGCsBeforeCompaction=NиЎЁзӨәжү§иЎҢNж¬ЎFull GCеҗҺжү§иЎҢеҶ…еӯҳеҺӢзј©гҖӮ
еӣӣпјҡеўһйҮҸеӣһ收пјҢе®ҢжҲҗ10дёҮrequestз”Ёж—¶171з§’пјҢеӨӘж…ўдәҶпјҢй…ҚзҪ®еҰӮдёӢпјҡ
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xincgc ";
дјјд№Һеӣһ收еҫ—д№ҹдёҚеӨӘе№ІеҮҖпјҢиҖҢдё”д№ҹеҜ№жҖ§иғҪжңүиҫғеӨ§еҪұе“ҚпјҢдёҚеҖјеҫ—иҜ•гҖӮ
дә”пјҡ并еҸ‘еӣһ收зҡ„I-CMSжЁЎејҸпјҢе’ҢеўһйҮҸеӣһ收差дёҚеӨҡпјҢе®ҢжҲҗ10дёҮrequestз”Ёж—¶170з§’гҖӮ
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode -XX:+CMSIncrementalPacing -XX:CMSIncrementalDutyCycleMin=0 -XX:CMSIncrementalDutyCycle=10 -XX:-TraceClassUnloading ";
йҮҮз”ЁдәҶsunжҺЁиҚҗзҡ„еҸӮж•°пјҢеӣһ收ж•ҲжһңдёҚеҘҪпјҢз…§ж ·жңүеҒңйЎҝпјҢж•°е°Ҹж—¶д№ӢеҶ…е°ұдјҡйў‘з№ҒеҮәзҺ°еҒңйЎҝпјҢд»Җд№ҲsunжҺЁиҚҗзҡ„еҸӮж•°пјҢз…§ж ·дёҚеҘҪдҪҝгҖӮ
е…ӯпјҡйҖ’еўһејҸдҪҺжҡӮеҒң收йӣҶеҷЁпјҢиҝҳеҸ«д»Җд№ҲзҒ«иҪҰејҸеӣһ收пјҢдёҚзҹҘйҒ“еұһдәҺе“ӘдёӘзі»пјҢе®ҢжҲҗ10дёҮrequestз”Ёж—¶153з§’
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -Xloggc:log/gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseTrainGC ";
иҜҘй…ҚзҪ®ж•Ҳжһңд№ҹдёҚеҘҪпјҢеҪұе“ҚжҖ§иғҪпјҢжүҖд»ҘжІЎиҜ•гҖӮ
дёғпјҡзӣёжҜ”д№ӢдёӢпјҢиҝҳжҳҜ并еҸ‘еӣһ收жҜ”иҫғеҘҪпјҢжҖ§иғҪжҜ”иҫғй«ҳпјҢеҸӘиҰҒиғҪи§ЈеҶіParNewGCпјҲ并иЎҢеӣһ收е№ҙиҪ»д»Јпјүж—¶зҡ„promotion failedй”ҷиҜҜе°ұдёҖеҲҮеҘҪеҠһдәҶпјҢжҹҘдәҶеҫҲеӨҡж–Үз« пјҢеҸ‘зҺ°еј•иө·promotion failedй”ҷиҜҜзҡ„еҺҹеӣ жҳҜCMSжқҘдёҚеҸҠеӣһ收пјҲCMSй»ҳи®ӨеңЁе№ҙиҖҒд»ЈеҚ еҲ°90%е·ҰеҸіжүҚдјҡжү§иЎҢпјүпјҢе№ҙиҖҒд»ЈеҸҲжІЎжңүи¶іеӨҹзҡ„з©әй—ҙдҫӣGCжҠҠдёҖдәӣжҙ»зҡ„еҜ№иұЎд»Һе№ҙиҪ»д»Јз§»еҲ°е№ҙиҖҒд»ЈпјҢжүҖд»Ҙжү§иЎҢFull GCгҖӮCMSInitiatingOccupancyFraction=70иЎЁзӨәе№ҙиҖҒд»ЈеҚ еҲ°зәҰ70%ж—¶е°ұејҖе§Ӣжү§иЎҢCMSпјҢиҝҷж ·е°ұдёҚдјҡеҮәзҺ°Full GCдәҶгҖӮSoftRefLRUPolicyMSPerMBиҝҷдёӘеҸӮж•°д№ҹжҳҜжҲ‘и®ӨдёәжҜ”иҫғжңүз”Ёзҡ„пјҢе®ҳж–№и§ЈйҮҠжҳҜsoftly reachable objects will remain alive for some amount of time after the last time they were referenced. The default value is one second of lifetime per free megabyte in the heapпјҢжҲ‘и§үеҫ—жІЎеҝ…иҰҒзӯү1з§’пјҢжүҖд»Ҙи®ҫзҪ®жҲҗ0гҖӮй…ҚзҪ®еҰӮдёӢпјҡ
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms2048M -Xmx2048M -Xmn512M -XX:PermSize=256M -XX:MaxPermSize=256M -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=7 -XX:GCTimeRatio=19 -Xnoclassgc -XX:+DisableExplicitGC -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSPermGenSweepingEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCApplicationStoppedTime -Xloggc:log/gc.log ";
дёҠйқўиҝҷдёӘй…ҚзҪ®еҶ…еӯҳдёҠеҚҮзҡ„еҫҲж…ўпјҢ24е°Ҹж—¶д№ӢеҶ…еҮ д№ҺжІЎжңүеҒңйЎҝзҺ°иұЎпјҢжңҖй•ҝзҡ„еҸӘеҒңж»һдәҶ0.8sпјҢParNew GCжҜҸ30з§’е·ҰеҸіжүҚжү§иЎҢдёҖж¬ЎпјҢжҜҸж¬Ўеӣһ收зәҰ0.2з§’пјҢзңӢжқҘй—®йўҳеә”иҜҘжҡӮж—¶и§ЈеҶідәҶгҖӮ
еҸӮж•°дёҚжҳҺзҷҪзҡ„еҸҜд»ҘдёҠзҪ‘жҹҘпјҢжң¬дәәи®ӨдёәжҜ”иҫғйҮҚиҰҒзҡ„еҮ дёӘеҸӮж•°жҳҜпјҡ
-Xms -Xmx -Xmn MaxTenuringThreshold GCTimeRatio UseConcMarkSweepGC CMSInitiatingOccupancyFraction SoftRefLRUPolicyMSPerMB
JVMеҸӮж•°и°ғдјҳжҳҜдёӘеҫҲеӨҙз—ӣзҡ„й—®йўҳпјҢи®ҫзҪ®зҡ„дёҚеҘҪпјҢJVMдёҚж–ӯжү§иЎҢFull GCпјҢеҜјиҮҙж•ҙдёӘзі»з»ҹеҸҳеҫ—еҫҲж…ўпјҢзҪ‘з«ҷеҒңж»һж—¶й—ҙиғҪиҫҫ10з§’д»ҘдёҠпјҢиҝҷз§Қжғ…еҶөеҰӮжһңжІЎйҡ”еҮ еҲҶй’ҹе°ұжқҘдёҖж¬ЎпјҢиҮӘе·ұйғҪеҸ—дёҚдәҶгҖӮиҝҷз§ҚеҒңж»һеңЁжөӢиҜ•зҡ„ж—¶еҖҷзңӢдёҚеҮәжқҘпјҢеҸӘжңүзҪ‘з«ҷpvиҫҫеҲ°ж•°еҚҒдёҮ/еӨ©зҡ„ж—¶еҖҷй—®йўҳе°ұжҡҙйңІеҮәжқҘдәҶгҖӮ
иҰҒжғій…ҚзҪ®еҘҪJVMеҸӮж•°пјҢйңҖиҰҒеҜ№е№ҙиҪ»д»ЈгҖҒе№ҙиҖҒд»ЈгҖҒж•‘еҠ©з©әй—ҙе’Ңж°ёд№…д»ЈжңүдёҖе®ҡдәҶи§ЈпјҢиҝҳиҰҒдәҶи§ЈjvmеҶ…еӯҳз®ЎзҗҶйҖ»иҫ‘пјҢжңҖз»ҲиҝҳиҰҒж №жҚ®иҮӘе·ұзҡ„еә”з”ЁжқҘеҒҡи°ғж•ҙгҖӮе…ідәҺJVMеҸӮж•°дёҠзҪ‘дёҖжҗңе°ұиғҪжҗңеҮәдёҖеӨ§жҠҠпјҢд№ҹжңүеҫҲеӨҡжҸҗдҫӣе®һи·өзҡ„дҫӢеӯҗпјҢжҲ‘д№ҹжҢүз…§еҗ„з§ҚдҫӢеӯҗжөӢиҜ•иҝҮпјҢжңҖз»ҲиҝҳжҳҜдјҡеҮәзҺ°й—®йўҳгҖӮ
з»ҸиҝҮеҮ дёӘжңҲзҡ„е®һи·өж”№е–„пјҢжҲ‘е°ұзҪ‘з«ҷпјҲиҰҒжұӮж— еҒңж»һж—¶й—ҙпјүзҡ„jvmеҸӮж•°и°ғдјҳз»ҷеҮәд»ҘдёӢеҮ жқЎз»ҸйӘҢгҖӮ
1пјҡе»әи®®з”Ё64дҪҚж“ҚдҪңзі»з»ҹпјҢLinuxдёӢ64дҪҚзҡ„jdkжҜ”32дҪҚjdkиҰҒж…ўдёҖдәӣпјҢдҪҶжҳҜеҗғеҫ—еҶ…еӯҳжӣҙеӨҡпјҢеҗһеҗҗйҮҸжӣҙеӨ§гҖӮ
2пјҡXMXе’ҢXMSи®ҫзҪ®дёҖж ·еӨ§пјҢMaxPermSizeе’ҢMinPermSizeи®ҫзҪ®дёҖж ·еӨ§пјҢиҝҷж ·еҸҜд»ҘеҮҸиҪ»дјёзј©е ҶеӨ§е°ҸеёҰжқҘзҡ„еҺӢеҠӣгҖӮ
3пјҡи°ғиҜ•зҡ„ж—¶еҖҷи®ҫзҪ®дёҖдәӣжү“еҚ°еҸӮж•°пјҢеҰӮ-XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:log/gc.logпјҢиҝҷж ·еҸҜд»Ҙд»Һgc.logйҮҢзңӢеҮәдёҖдәӣз«ҜеҖӘеҮәжқҘгҖӮ
4пјҡзі»з»ҹеҒңйЎҝзҡ„ж—¶еҖҷеҸҜиғҪжҳҜGCзҡ„й—®йўҳд№ҹеҸҜиғҪжҳҜзЁӢеәҸзҡ„й—®йўҳпјҢеӨҡз”Ёjmapе’ҢjstackжҹҘзңӢпјҢжҲ–иҖ…killall -3 javaпјҢ然еҗҺжҹҘзңӢjavaжҺ§еҲ¶еҸ°ж—Ҙеҝ—пјҢиғҪзңӢеҮәеҫҲеӨҡй—®йўҳгҖӮжңүдёҖж¬ЎпјҢзҪ‘з«ҷзӘҒ然еҫҲж…ўпјҢjstackдёҖзңӢпјҢеҺҹжқҘжҳҜиҮӘе·ұеҶҷзҡ„URLConnectionиҝһжҺҘеӨӘеӨҡжІЎжңүйҮҠж”ҫпјҢж”№дёҖдёӢзЁӢеәҸе°ұOKдәҶгҖӮ
5пјҡд»”з»ҶдәҶи§ЈиҮӘе·ұзҡ„еә”з”ЁпјҢеҰӮжһңз”ЁдәҶзј“еӯҳпјҢйӮЈд№Ҳе№ҙиҖҒд»Јеә”иҜҘеӨ§дёҖдәӣпјҢзј“еӯҳзҡ„HashMapдёҚеә”иҜҘж— йҷҗеҲ¶й•ҝпјҢе»әи®®йҮҮз”ЁLRUз®—жі•зҡ„MapеҒҡзј“еӯҳпјҢLRUMapзҡ„жңҖеӨ§й•ҝеәҰд№ҹиҰҒж №жҚ®е®һйҷ…жғ…еҶөи®ҫе®ҡгҖӮ
6пјҡеһғеңҫеӣһ收时promotion failedжҳҜдёӘеҫҲеӨҙз—ӣзҡ„й—®йўҳпјҢдёҖиҲ¬еҸҜиғҪжҳҜдёӨз§ҚеҺҹеӣ дә§з”ҹпјҢ第дёҖдёӘеҺҹеӣ жҳҜж•‘еҠ©з©әй—ҙдёҚеӨҹпјҢж•‘еҠ©з©әй—ҙйҮҢзҡ„еҜ№иұЎиҝҳдёҚеә”иҜҘ被移еҠЁеҲ°е№ҙиҖҒд»ЈпјҢдҪҶе№ҙиҪ»д»ЈеҸҲжңүеҫҲеӨҡеҜ№иұЎйңҖиҰҒж”ҫе…Ҙж•‘еҠ©з©әй—ҙпјӣ第дәҢдёӘеҺҹеӣ жҳҜе№ҙиҖҒд»ЈжІЎжңүи¶іеӨҹзҡ„з©әй—ҙжҺҘзәіжқҘиҮӘе№ҙиҪ»д»Јзҡ„еҜ№иұЎпјӣиҝҷдёӨз§Қжғ…еҶөйғҪдјҡиҪ¬еҗ‘Full GCпјҢзҪ‘з«ҷеҒңйЎҝж—¶й—ҙиҫғй•ҝгҖӮ第дёҖдёӘеҺҹеӣ жҲ‘зҡ„жңҖз»Ҳи§ЈеҶіеҠһжі•жҳҜеҺ»жҺүж•‘еҠ©з©әй—ҙпјҢи®ҫзҪ®-XX:SurvivorRatio=65536 -XX:MaxTenuringThreshold=0еҚіеҸҜпјҢ第дәҢдёӘеҺҹеӣ жҲ‘зҡ„и§ЈеҶіеҠһжі•жҳҜи®ҫзҪ®CMSInitiatingOccupancyFractionдёәжҹҗдёӘеҖјпјҲеҒҮи®ҫ70пјүпјҢиҝҷж ·е№ҙиҖҒд»Јз©әй—ҙеҲ°70%ж—¶е°ұејҖе§Ӣжү§иЎҢCMSпјҢе№ҙиҖҒд»Јжңүи¶іеӨҹзҡ„з©әй—ҙжҺҘзәіжқҘиҮӘе№ҙиҪ»д»Јзҡ„еҜ№иұЎгҖӮ
7пјҡдёҚз®ЎжҖҺж ·пјҢж°ёд№…д»ЈиҝҳжҳҜдјҡйҖҗжёҗеҸҳж»ЎпјҢжүҖд»Ҙйҡ”дёүе·®дә”йҮҚиө·javaжңҚеҠЎеҷЁжҳҜеҝ…иҰҒзҡ„пјҢжҲ‘жҜҸеӨ©йғҪиҮӘеҠЁйҮҚиө·гҖӮ
8пјҡйҮҮ用并еҸ‘еӣһ收时пјҢе№ҙиҪ»д»Је°ҸдёҖзӮ№пјҢе№ҙиҖҒд»ЈиҰҒеӨ§пјҢеӣ дёәе№ҙиҖҒеӨ§з”Ёзҡ„жҳҜ并еҸ‘еӣһ收пјҢеҚідҪҝж—¶й—ҙй•ҝзӮ№д№ҹдёҚдјҡеҪұе“Қе…¶д»–зЁӢеәҸ继з»ӯиҝҗиЎҢпјҢзҪ‘з«ҷдёҚдјҡеҒңйЎҝгҖӮ
жҲ‘зҡ„жңҖз»Ҳй…ҚзҪ®еҰӮдёӢпјҲзі»з»ҹ8GеҶ…еӯҳпјүпјҢжҜҸеӨ©еҮ зҷҫдёҮpvдёҖзӮ№й—®йўҳйғҪжІЎжңүпјҢзҪ‘з«ҷжІЎжңүеҒңйЎҝпјҢ2009е№ҙshedewang.comжІЎжңүеӣ дёәеҶ…еӯҳй—®йўҳdownиҝҮжңәгҖӮ
$JAVA_ARGS .= " -Dresin.home=$SERVER_ROOT -server -Xms6000M -Xmx6000M -Xmn500M -XX:PermSize=500M -XX:MaxPermSize=500M -XX:SurvivorRatio=65536 -XX:MaxTenuringThreshold=0 -Xnoclassgc -XX:+DisableExplicitGC -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=90 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:log/gc.log
";
иҜҙжҳҺдёҖдёӢпјҢ -XX:SurvivorRatio=65536 -XX:MaxTenuringThreshold=0е°ұжҳҜеҺ»жҺүдәҶж•‘еҠ©з©әй—ҙпјӣ
-XnoclassgcзҰҒз”Ёзұ»еһғеңҫеӣһ收пјҢжҖ§иғҪдјҡй«ҳдёҖзӮ№пјӣ
-XX:+DisableExplicitGCзҰҒжӯўSystem.gc()пјҢе…Қеҫ—зЁӢеәҸе‘ҳиҜҜи°ғз”Ёgcж–№жі•еҪұе“ҚжҖ§иғҪпјӣ
-XX:+UseParNewGCпјҢеҜ№е№ҙиҪ»д»ЈйҮҮз”ЁеӨҡзәҝзЁӢ并иЎҢеӣһ收пјҢиҝҷж ·ж”¶еҫ—еҝ«пјӣ
еёҰCMSеҸӮж•°зҡ„йғҪжҳҜе’Ң并еҸ‘еӣһ收зӣёе…ізҡ„пјҢдёҚжҳҺзҷҪзҡ„еҸҜд»ҘдёҠзҪ‘жҗңзҙўпјӣ
CMSInitiatingOccupancyFractionпјҢиҝҷдёӘеҸӮж•°и®ҫзҪ®жңүеҫҲеӨ§жҠҖе·§пјҢеҹәжң¬дёҠж»Ўи¶і(Xmx-Xmn)*(100-CMSInitiatingOccupancyFraction)/100>=Xmnе°ұдёҚдјҡеҮәзҺ°promotion failedгҖӮеңЁжҲ‘зҡ„еә”з”ЁдёӯXmxжҳҜ6000пјҢXmnжҳҜ500пјҢйӮЈд№ҲXmx-XmnжҳҜ5500е…ҶпјҢд№ҹе°ұжҳҜе№ҙиҖҒд»Јжңү5500е…ҶпјҢCMSInitiatingOccupancyFraction=90иҜҙжҳҺе№ҙиҖҒд»ЈеҲ°90%ж»Ўзҡ„ж—¶еҖҷејҖе§Ӣжү§иЎҢеҜ№е№ҙиҖҒд»Јзҡ„并еҸ‘еһғеңҫеӣһ收пјҲCMSпјүпјҢиҝҷж—¶иҝҳеү©10%зҡ„з©әй—ҙжҳҜ5500*10%=550е…ҶпјҢжүҖд»ҘеҚідҪҝXmnпјҲд№ҹе°ұжҳҜе№ҙиҪ»д»Је…ұ500е…ҶпјүйҮҢжүҖжңүеҜ№иұЎйғҪжҗ¬еҲ°е№ҙиҖҒд»ЈйҮҢпјҢ550е…Ҷзҡ„з©әй—ҙд№ҹи¶іеӨҹдәҶпјҢжүҖд»ҘеҸӘиҰҒж»Ўи¶ідёҠйқўзҡ„е…¬ејҸпјҢе°ұдёҚдјҡеҮәзҺ°еһғеңҫеӣһ收时зҡ„promotion
failedпјӣ
SoftRefLRUPolicyMSPerMBиҝҷдёӘеҸӮж•°жҲ‘и®ӨдёәеҸҜиғҪжңүзӮ№з”ЁпјҢе®ҳж–№и§ЈйҮҠжҳҜsoftly reachable objects will remain alive for some amount of time after the last time they were referenced. The default value is one second of lifetime per free megabyte in the heapпјҢжҲ‘и§үеҫ—жІЎеҝ…иҰҒзӯү1з§’пјӣ
зҪ‘дёҠе…¶д»–д»Ӣз»ҚJVMеҸӮж•°зҡ„д№ҹжҜ”иҫғеӨҡпјҢдј°и®Ўе…¶дёӯеӨ§йғЁеҲҶжҳҜжІЎжңүйҒҮеҲ°promotion failedпјҢжҲ–иҖ…и®ҝй—®йҮҸеӨӘе°ҸжІЎжңүжңәдјҡйҒҮеҲ°пјҢ(Xmx-Xmn)*(100-CMSInitiatingOccupancyFraction)/100>=XmnиҝҷдёӘе…¬ејҸз»қеҜ№жҳҜеҺҹеҲӣпјҢзңҹйҒҮеҲ°promotion failedдәҶпјҢиҝҳеҫ—иҝҷд№ҲеӨ„зҗҶгҖӮ


- 2011-11-15 16:49
- жөҸи§Ҳ 235
- иҜ„и®ә(0)
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

зӣёе…іжҺЁиҚҗ
JVMи°ғдјҳжҖ»з»“ -Xms -Xmx -Xmn -Xss JVM и°ғдјҳжҳҜ Java virtual machine зҡ„жҖ§иғҪдјҳеҢ–пјҢйҖҡиҝҮи°ғж•ҙ JVM зҡ„еҸӮж•°жқҘжҸҗй«ҳ Java еә”з”ЁзЁӢеәҸзҡ„жҖ§иғҪгҖӮе…¶дёӯпјҢ-XmsгҖҒ-XmxгҖҒ-XmnгҖҒ-Xss жҳҜеӣӣдёӘйҮҚиҰҒзҡ„еҸӮж•°пјҢеҲҶеҲ«жҺ§еҲ¶ JVM зҡ„еҲқе§Ӣе ҶеӨ§е°ҸгҖҒ...
### JVMи°ғдјҳжҖ»з»“ #### дёҖгҖҒжҰӮиҝ° JavaиҷҡжӢҹжңә(JVM)жҳҜJavaзЁӢеәҸзҡ„ж ёеҝғиҝҗиЎҢзҺҜеўғпјҢеҜ№дәҺжҸҗй«ҳJavaеә”з”ЁзЁӢеәҸжҖ§иғҪиҮіе…ійҮҚиҰҒгҖӮJVMи°ғдјҳжҳҜжҢҮйҖҡиҝҮи°ғж•ҙJVMзҡ„й…ҚзҪ®еҸӮж•°жқҘдјҳеҢ–зЁӢеәҸжҖ§иғҪзҡ„иҝҮзЁӢгҖӮжң¬ж–Үе°Ҷеӣҙз»•JVMи°ғдјҳеұ•ејҖи®Ёи®әпјҢйҮҚзӮ№еҲҶжһҗж•°жҚ®...
### JVMи°ғдјҳжҖ»з»“пјҡXmsгҖҒXmxгҖҒXmnгҖҒXss еңЁJavaиҷҡжӢҹжңәпјҲJVMпјүзҡ„иҝҗиЎҢиҝҮзЁӢдёӯпјҢеҗҲзҗҶзҡ„еҸӮж•°й…ҚзҪ®еҜ№дәҺжҸҗй«ҳзЁӢеәҸжҖ§иғҪиҮіе…ійҮҚиҰҒгҖӮжң¬ж–Үе°ҶеҜ№JVMи°ғдјҳдёӯзҡ„еҮ дёӘе…ій”®еҸӮж•°иҝӣиЎҢж·ұе…Ҙи§ЈжһҗпјҢеҢ…жӢ¬-XmsгҖҒ-XmxгҖҒ-Xmnе’Ң-XssзӯүпјҢеё®еҠ©ејҖеҸ‘иҖ…жӣҙеҘҪ...
### JVMи°ғдјҳдёҺеһғеңҫеӣһ收жңәеҲ¶иҜҰи§Ј #### дёҖгҖҒеј•иЁҖ йҡҸзқҖиҪҜ件系з»ҹзҡ„еӨҚжқӮеәҰдёҚж–ӯжҸҗй«ҳпјҢжҖ§иғҪдјҳеҢ–жҲҗдёәдәҶиҪҜ件ејҖеҸ‘дёӯзҡ„дёҖдёӘйҮҚиҰҒзҺҜиҠӮгҖӮеҜ№дәҺJavaеә”з”ЁзЁӢеәҸжқҘиҜҙпјҢJavaиҷҡжӢҹжңә(JVM)зҡ„жҖ§иғҪзӣҙжҺҘеҪұе“ҚзқҖеә”з”Ёзҡ„ж•ҙдҪ“иЎЁзҺ°гҖӮеһғеңҫеӣһ收(GC)...
JVMи°ғдјҳжҖ»з»“ JVMпјҲJava Virtual MachineпјүжҳҜ Java иҜӯиЁҖзҡ„иҝҗиЎҢзҺҜеўғпјҢиҙҹиҙЈе°Ҷ Java еӯ—иҠӮз ҒиҪ¬жҚўдёәжңәеҷЁз Ғ并жү§иЎҢгҖӮ然иҖҢпјҢйҡҸзқҖ Java еә”з”ЁзЁӢеәҸзҡ„еӨҚжқӮеәҰе’Ң规模зҡ„еўһеҠ пјҢJVM зҡ„жҖ§иғҪеҸҳеҫ—и¶ҠжқҘи¶ҠйҮҚиҰҒгҖӮеӣ жӯӨпјҢJVM и°ғдјҳжҳҜйқһеёёеҝ…иҰҒзҡ„...
"JVMи°ғдјҳжҖ»з»“" JVMи°ғдјҳжҳҜдёҖз§ҚйқһеёёйҮҚиҰҒзҡ„жҠҖжңҜпјҢиғҪеӨҹеё®еҠ©жҲ‘们жҸҗй«ҳJavaеә”з”ЁзЁӢеәҸзҡ„жҖ§иғҪе’ҢзЁіе®ҡжҖ§гҖӮеңЁиҝҷзҜҮж–Үз« дёӯпјҢжҲ‘们е°ҶжҖ»з»“JVMи°ғдјҳзҡ„дёҖдәӣеҹәжң¬жҰӮеҝөе’Ңз®—жі•гҖӮ дёҖгҖҒзӣёе…іжҰӮеҝө JVMи°ғдјҳзҡ„еҹәжң¬жҰӮеҝөеҢ…жӢ¬еј•з”Ёи®Ўж•°гҖҒж Үи®°-жё…йҷӨгҖҒ...
жң¬ж–ҮжЎЈжҖ»з»“дәҶJVMи°ғдјҳзҡ„еҹәзЎҖзҹҘиҜҶе’ҢдёҖдәӣж ёеҝғжҰӮеҝөпјҢж—ЁеңЁеё®еҠ©ејҖеҸ‘иҖ…жӣҙеҘҪең°жҺҢжҸЎJavaзЁӢеәҸзҡ„жҖ§иғҪдјҳеҢ–гҖӮ йҰ–е…ҲпјҢж–ҮжЎЈжҸҗеҲ°дәҶJavaдёӯзҡ„ж•°жҚ®зұ»еһӢеҲҶдёәеҹәжң¬зұ»еһӢе’Ңеј•з”Ёзұ»еһӢгҖӮеҹәжң¬зұ»еһӢзҡ„еҸҳйҮҸеӯҳеӮЁзҡ„жҳҜеҺҹе§Ӣж•°жҚ®еҖјпјҢиҖҢеј•з”Ёзұ»еһӢзҡ„еҸҳйҮҸ...
гҖҗJVMи°ғдјҳжҖ»з»“гҖ‘ JavaиҷҡжӢҹжңәпјҲJVMпјүжҳҜJavaзЁӢеәҸиҝҗиЎҢзҡ„еҹәзЎҖпјҢе®ғиҙҹиҙЈи§Јжһҗеӯ—иҠӮз Ғ并е°Ҷе…¶иҪ¬жҚўдёәжңәеҷЁеҸҜжү§иЎҢзҡ„жҢҮд»ӨгҖӮJVMи°ғдјҳжҳҜдјҳеҢ–Javaеә”з”ЁзЁӢеәҸжҖ§иғҪзҡ„е…ій”®жӯҘйӘӨпјҢе°Өе…¶еҜ№дәҺеӨ§еһӢеҲҶеёғејҸзі»з»ҹиҖҢиЁҖпјҢиүҜеҘҪзҡ„JVMй…ҚзҪ®еҸҜд»Ҙжҳҫи‘—жҸҗй«ҳзі»з»ҹ...
JVMи°ғдјҳжҖ»з»“ --收йӣҶжҹҗдҪҚй«ҳдәәзҡ„еҚҡе®ў.
### Java-JVMи°ғдјҳжҖ»з»“ #### дёҖгҖҒеј•иЁҖ еңЁзҺ°д»ЈиҪҜ件ејҖеҸ‘дёӯпјҢJava дҪңдёәдёҖз§Қе№ҝжіӣдҪҝз”Ёзҡ„зј–зЁӢиҜӯиЁҖпјҢе…¶еә”з”ЁзЁӢеәҸзҡ„жҖ§иғҪдјҳеҢ–иҮіе…ійҮҚиҰҒгҖӮиҖҢ JVMпјҲJava Virtual MachineпјүдҪңдёә Java зЁӢеәҸиҝҗиЎҢзҡ„еҹәзЎҖзҺҜеўғпјҢеҜ№е…¶иҝӣиЎҢеҗҲзҗҶзҡ„и°ғдјҳеҸҜд»Ҙ...
гҖҗJVMи°ғдјҳжҖ»з»“пјҡи°ғдјҳж–№жі•гҖ‘ JavaиҷҡжӢҹжңәпјҲJVMпјүи°ғдјҳжҳҜдёҖйЎ№е…ій”®зҡ„д»»еҠЎпјҢж—ЁеңЁдјҳеҢ–еә”з”ЁзЁӢеәҸзҡ„жҖ§иғҪпјҢеҮҸе°‘еҶ…еӯҳжі„жјҸпјҢ并确дҝқзі»з»ҹзЁіе®ҡиҝҗиЎҢгҖӮд»ҘдёӢжҳҜеҜ№JVMи°ғдјҳзҡ„дёҖдәӣж ёеҝғж–№жі•е’Ңе·Ҙе…·зҡ„иҜҰз»ҶиҜҙжҳҺгҖӮ ### JVMи°ғдјҳе·Ҙе…· #### 1. ...
еңЁж·ұе…Ҙи®Ёи®әJVMпјҲJavaиҷҡжӢҹжңәпјүи°ғдјҳд№ӢеүҚпјҢжҲ‘们жңүеҝ…иҰҒе…ҲдәҶи§ЈдёҖдёӢиҷҡжӢҹжңәзҡ„еҹәжң¬жҰӮеҝөе’Ңе Ҷж Ҳ...йҖҡиҝҮдёҠиҝ°зҡ„еҲҶжһҗе’ҢжҖ»з»“пјҢжҲ‘们еҸҜд»Ҙеҫ—еҮәпјҢJVMи°ғдјҳжҳҜдёҖдёӘж¶үеҸҠеӨҡж–№йқўзҹҘиҜҶзҡ„еӨҚжқӮиҝҮзЁӢпјҢйңҖиҰҒејҖеҸ‘иҖ…е…·еӨҮжүҺе®һзҡ„зҗҶи®әеҹәзЎҖе’Ңдё°еҜҢзҡ„е®һи·өз»ҸйӘҢгҖӮ
жң¬зҜҮж–Үз« е°ҶиҜҰз»Ҷи®Іи§Ј"JVMи°ғдјҳжҖ»з»“пјҲ4пјүеҲҶд»Јеһғеңҫеӣһ收"иҝҷдёҖдё»йўҳпјҢж—ЁеңЁеё®еҠ©JavaејҖеҸ‘иҖ…жҺҢжҸЎжӣҙеҠ й«ҳж•ҲгҖҒзЁіе®ҡзҡ„еә”з”ЁиҝҗиЎҢзӯ–з•ҘгҖӮ дёҖгҖҒеҲҶд»Јеһғеңҫеӣһ收зҗҶи®әеҹәзЎҖ Javaзҡ„еҶ…еӯҳз®ЎзҗҶдё»иҰҒдҫқйқ еһғеңҫеӣһ收жңәеҲ¶пјҢе®ғиҮӘеҠЁеӣһ收дёҚеҶҚдҪҝз”Ёзҡ„еҜ№иұЎпјҢ...
гҖҠJVMи°ғдјҳжҖ»з»“гҖӢдёҺгҖҠJavaиҷҡжӢҹжңәпјҡJVMй«ҳзә§зү№жҖ§дёҺжңҖдҪіе®һи·өгҖӢжҳҜдёӨжң¬ж·ұе…ҘжҺўи®ЁJavaиҷҡжӢҹжңәпјҲJVMпјүзҡ„д№ҰзұҚпјҢеҜ№дәҺJavaејҖеҸ‘иҖ…жқҘиҜҙпјҢе®ғ们жҸҗдҫӣдәҶдё°еҜҢзҡ„зҹҘиҜҶе’Ңе®һи·өз»ҸйӘҢпјҢе°Өе…¶еҜ№дәҺжғіиҰҒзҗҶи§ЈJVMе·ҘдҪңеҺҹзҗҶд»ҘеҸҠиҝӣиЎҢжҖ§иғҪдјҳеҢ–зҡ„дё“дёҡдәәеЈ«жӣҙ...