
ZooKeeper是一个高可用的分布式数据管理与系统协调框架。基于对Paxos算法的实现,使该框架保证了分布式环境中数据的强一致性,也正是基于这样的特性,使得zookeeper能够应用于很多场景。网上对zk的使用场景也有不少介绍,本文将结合作者身边的项目例子,系统的对zk的使用场景进行归类介绍。 值得注意的是,zk并不是生来就为这些场景设计,都是后来众多开发者根据框架的特性,摸索出来的典型使用方法。因此,也非常欢迎你分享你在ZK使用上的奇技淫巧。
| 场景类别 | 典型场景描述(ZK特性,使用方法) | 应用中的具体使用 |
| 数据发布与订阅 | 发布与订阅即所谓的配置管理,顾名思义就是将数据发布到zk节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。例如全局的配置信息,地址列表等就非常适合使用。 | 1. 索引信息和集群中机器节点状态存放在zk的一些指定节点,供各个客户端订阅使用。2. 系统日志(经过处理后的)存储,这些日志通常2-3天后被清除。
3. 应用中用到的一些配置信息集中管理,在应用启动的时候主动来获取一次,并且在节点上注册一个Watcher,以后每次配置有更新,实时通知到应用,获取最新配置信息。 4. 业务逻辑中需要用到的一些全局变量,比如一些消息中间件的消息队列通常有个offset,这个offset存放在zk上,这样集群中每个发送者都能知道当前的发送进度。 5. 系统中有些信息需要动态获取,并且还会存在人工手动去修改这个信息。以前通常是暴露出接口,例如JMX接口,有了zk后,只要将这些信息存放到zk节点上即可。 |
| Name Service | 这个主要是作为分布式命名服务,通过调用zk的create node api,能够很容易创建一个全局唯一的path,这个path就可以作为一个名称。 | |
| 分布通知/协调 | ZooKeeper中特有watcher注册与异步通知机制,能够很好的实现分布式环境下不同系统之间的通知与协调,实现对数据变更的实时处理。使用方法通常是不同系统都对ZK上同一个znode进行注册,监听znode的变化(包括znode本身内容及子节点的),其中一个系统update了znode,那么另一个系统能够收到通知,并作出相应处理。 | 1. 另一种心跳检测机制:检测系统和被检测系统之间并不直接关联起来,而是通过zk上某个节点关联,大大减少系统耦合。2. 另一种系统调度模式:某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台作的一些操作,实际上是修改了ZK上某些节点的状态,而zk就把这些变化通知给他们注册Watcher的客户端,即推送系统,于是,作出相应的推送任务。
3. 另一种工作汇报模式:一些类似于任务分发系统,子任务启动后,到zk来注册一个临时节点,并且定时将自己的进度进行汇报(将进度写回这个临时节点),这样任务管理者就能够实时知道任务进度。 总之,使用zookeeper来进行分布式通知和协调能够大大降低系统之间的耦合。 |
| 分布式锁 | 分布式锁,这个主要得益于ZooKeeper为我们保证了数据的强一致性,即用户只要完全相信每时每刻,zk集群中任意节点(一个zk server)上的相同znode的数据是一定是相同的。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
所谓保持独占,就是所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁。通常的做法是把zk上的一个znode看作是一把锁,通过create znode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。 控制时序,就是所有视图来获取这个锁的客户端,最终都是会被安排执行,只是有个全局时序了。做法和上面基本类似,只是这里 /distribute_lock 已经预先存在,客户端在它下面创建临时有序节点(这个可以通过节点的属性控制:CreateMode.EPHEMERAL_SEQUENTIAL来指定)。Zk的父节点(/distribute_lock)维持一份sequence,保证子节点创建的时序性,从而也形成了每个客户端的全局时序。 |
|
| 集群管理 | 1. 集群机器监控:这通常用于那种对集群中机器状态,机器在线率有较高要求的场景,能够快速对集群中机器变化作出响应。这样的场景中,往往有一个监控系统,实时检测集群机器是否存活。过去的做法通常是:监控系统通过某种手段(比如ping)定时检测每个机器,或者每个机器自己定时向监控系统汇报“我还活着”。 这种做法可行,但是存在两个比较明显的问题:1. 集群中机器有变动的时候,牵连修改的东西比较多。2. 有一定的延时。
利用ZooKeeper有两个特性,就可以实时另一种集群机器存活性监控系统:a. 客户端在节点 x 上注册一个Watcher,那么如果 x 的子节点变化了,会通知该客户端。b. 创建EPHEMERAL类型的节点,一旦客户端和服务器的会话结束或过期,那么该节点就会消失。 例如,监控系统在 /clusterServers 节点上注册一个Watcher,以后每动态加机器,那么就往 /clusterServers 下创建一个 EPHEMERAL类型的节点:/clusterServers/{hostname}. 这样,监控系统就能够实时知道机器的增减情况,至于后续处理就是监控系统的业务了。 在分布式环境中,相同的业务应用分布在不同的机器上,有些业务逻辑(例如一些耗时的计算,网络I/O处理),往往只需要让整个集群中的某一台机器进行执行,其余机器可以共享这个结果,这样可以大大减少重复劳动,提高性能,于是这个master选举便是这种场景下的碰到的主要问题。 利用ZooKeeper的强一致性,能够保证在分布式高并发情况下节点创建的全局唯一性,即:同时有多个客户端请求创建 /currentMaster 节点,最终一定只有一个客户端请求能够创建成功。 利用这个特性,就能很轻易的在分布式环境中进行集群选取了。 另外,这种场景演化一下,就是动态Master选举。这就要用到 EPHEMERAL_SEQUENTIAL类型节点的特性了。 上文中提到,所有客户端创建请求,最终只有一个能够创建成功。在这里稍微变化下,就是允许所有请求都能够创建成功,但是得有个创建顺序,于是所有的请求最终在ZK上创建结果的一种可能情况是这样: /currentMaster/{sessionId}-1 , /currentMaster/{sessionId}-2 , /currentMaster/{sessionId}-3 ….. 每次选取序列号最小的那个机器作为Master,如果这个机器挂了,由于他创建的节点会马上小时,那么之后最小的那个机器就是Master了。 |
1. 在搜索系统中,如果集群中每个机器都生成一份全量索引,不仅耗时,而且不能保证彼此之间索引数据一致。因此让集群中的Master来进行全量索引的生成,然后同步到集群中其它机器。2. 另外,Master选举的容灾措施是,可以随时进行手动指定master,就是说应用在zk在无法获取master信息时,可以通过比如http方式,向一个地方获取master。 |
| 分布式队列 | 队列方面,我目前感觉有两种,一种是常规的先进先出队列,另一种是要等到队列成员聚齐之后的才统一按序执行。对于第二种先进先出队列,和分布式锁服务中的控制时序场景基本原理一致,这里不再赘述。
第二种队列其实是在FIFO队列的基础上作了一个增强。通常可以在 /queue 这个znode下预先建立一个/queue/num 节点,并且赋值为n(或者直接给/queue赋值n),表示队列大小,之后每次有队列成员加入后,就判断下是否已经到达队列大小,决定是否可以开始执行了。这种用法的典型场景是,分布式环境中,一个大任务Task A,需要在很多子任务完成(或条件就绪)情况下才能进行。这个时候,凡是其中一个子任务完成(就绪),那么就去 /taskList 下建立自己的临时时序节点(CreateMode.EPHEMERAL_SEQUENTIAL),当 /taskList 发现自己下面的子节点满足指定个数,就可以进行下一步按序进行处理了。 |
|
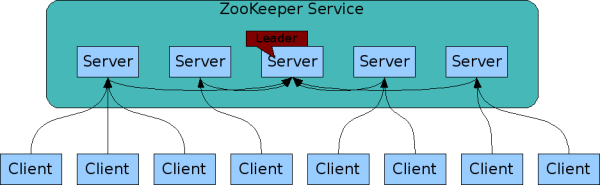
ZooKeeper是Hadoop的正式子项目,它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
Zookeeper是Google的Chubby一个开源的实现.是高有效和可靠的协同工作系统.Zookeeper能够用来leader选举,配置信息维护等.在一个分布式的环境中,我们需要一个Master实例或存储一些配置信息,确保文件写入的一致性等.Zookeeper能够保证如下3点:
-
Watches are ordered with respect to other events, other watches, and
asynchronous replies. The ZooKeeper client libraries ensures that
everything is dispatched in order. -
A client will see a watch event for a znode it is watching before seeing the new data that corresponds to that znode.
-
The order of watch events from ZooKeeper corresponds to the order of the updates as seen by the ZooKeeper service.
在Zookeeper中,znode是一个跟Unix文件系统路径相似的节点,可以往这个节点存储或获取数据.如果在创建znode时Flag设置 为EPHEMERAL,那么当这个创建这个znode的节点和Zookeeper失去连接后,这个znode将不再存在在Zookeeper 里.Zookeeper使用Watcher察觉事件信息,当客户端接收到事件信息,比如连接超时,节点数据改变,子节点改变,可以调用相应的行为来处理数 据.Zookeeper的Wiki页面展示了如何使用Zookeeper来处理事件通知,队列,优先队列,锁,共享锁,可撤销的共享锁,两阶段提交.
那么Zookeeper能帮我们作什么事情呢?简单的例子:假设我们我们有个20个搜索引擎的服务器(每个负责总索引中的一部分的搜索任务)和一个 总服务器(负责向这20个搜索引擎的服务器发出搜索请求并合并结果集),一个备用的总服务器(负责当总服务器宕机时替换总服务器),一个web的 cgi(向总服务器发出搜索请求).搜索引擎的服务器中的15个服务器现在提供搜索服务,5个服务器正在生成索引.这20个搜索引擎的服务器经常要让正在 提供搜索服务的服务器停止提供服务开始生成索引,或生成索引的服务器已经把索引生成完成可以搜索提供服务了.使用Zookeeper可以保证总服务器自动 感知有多少提供搜索引擎的服务器并向这些服务器发出搜索请求,备用的总服务器宕机时自动启用备用的总服务器,web的cgi能够自动地获知总服务器的网络 地址变化.这些又如何做到呢?
-
提供搜索引擎的服务器都在Zookeeper中创建znode,zk.create("/search/nodes/node1",
"hostname".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateFlags.EPHEMERAL); -
总服务器可以从Zookeeper中获取一个znode的子节点的列表,zk.getChildren("/search/nodes", true);
-
总服务器遍历这些子节点,并获取子节点的数据生成提供搜索引擎的服务器列表.
-
当总服务器接收到子节点改变的事件信息,重新返回第二步.
-
总服务器在Zookeeper中创建节点,zk.create("/search/master", "hostname".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateFlags.EPHEMERAL);
-
备用的总服务器监控Zookeeper中的"/search/master"节点.当这个znode的节点数据改变时,把自己启动变成总服务器,并把自己的网络地址数据放进这个节点.
-
web的cgi从Zookeeper中"/search/master"节点获取总服务器的网络地址数据并向其发送搜索请求.
-
web的cgi监控Zookeeper中的"/search/master"节点,当这个znode的节点数据改变时,从这个节点获取总服务器的网络地址数据,并改变当前的总服务器的网络地址.
http://www.kuqin.com/system-analysis/20111120/315148.html
http://www.oschina.net/p/zookeeper



相关推荐
- 使用的开源产品包括Hadoop、HBase、Zookeeper、Solr和Zoie。 - **逻辑架构**: - HBase作为数据输入源。 - Zookeeper用于动态感知节点状态。 - ARSC Node与Solr Cloud共同构成搜索客户端。 - **物理集群架构**...
Seata的高可用模式是通过TC使用db模式共享全局事务会话信息,使用非file的seata支持的第三方注册中心和配置中心来共享全局配置的方式来实现的。 Seata支持的第三方注册中心有nacos 、eureka、redis、zk、consul、...
以下是常见的C++笔试面试题及其核心知识点解析,帮助您系统复习
计算机短期培训教案.pdf
计算机二级Access笔试题库.pdf
下是一份关于C++毕业答辩的心得总结,内容涵盖技术准备、答辩技巧和注意事项,供参考
内容概要:本文档详细介绍了英特尔为苹果公司构建的基于智能处理单元(IPU)的Cassandra集群的技术验证(PoC)。主要内容涵盖IPU存储用例、已建存储PoC、MEV到MMG400的过渡、苹果构建IPU-Cassandra集群的动机以及PoC开发进展。文档还探讨了硬件配置、软件环境设置、性能调优措施及其成果,特别是针对延迟和吞吐量的优化。此外,文档展示了六节点Cassandra集群的具体架构和测试结果,强调了成本和复杂性的降低。 适合人群:对分布式数据库系统、NoSQL数据库、IPU技术感兴趣的IT专业人员和技术管理人员。 使用场景及目标:适用于希望了解如何利用IPU提升Cassandra集群性能的企业技术人员。主要目标是展示如何通过IPU减少服务器部署的成本和功耗,同时提高数据处理效率。 其他说明:文档中涉及的内容属于机密级别,仅供特定授权人员查阅。文中提到的技术细节和测试结果对于评估IPU在大规模数据中心的应用潜力至关重要。
计算机二级考试C语言题.pdf
计算机发展史.pdf
计算机仿真技术系统的分析方法.pdf
yolo编程相关资源,python编程与YOLO算法组成的坐姿检测系统,功能介绍: 一:实时检测学生错误坐姿人数 二:通过前端阿里云平台显示上传数据,实现数据可视化
办公室网安全监控uptime-kuma,docker镜像离线压缩包
计算机课程设计-网络编程项目源码.zip
将该dll包放入项目并引用,可以操作打印机
杰奇2.3内核淡绿唯美小说网站源码 PC+手机版 自动采集 全站伪静态,送10.1版本关关采集器
计算机辅助教学.pdf
内容概要:本文详细介绍了如何利用天文相机和其他相关硬件设备搭建一套高画质、高帧率的流星监控系统,以及针对红色精灵闪电这一特殊自然现象的捕捉方法。文中不仅涵盖了硬件的选择标准如CMOS靶面尺寸、量子效率等重要参数,还提供了基于Python和OpenCV实现的基本监控代码示例,包括亮度突变检测、运动检测算法等关键技术点。此外,对于安装位置的选择、供电方式、成本控制等方面也有具体的指导建议。 适用人群:对天文摄影感兴趣的爱好者,尤其是希望捕捉流星和红色精灵闪电等瞬时天文现象的专业人士或业余玩家。 使用场景及目标:适用于希望搭建个人天文观测站,用于科学研究或个人兴趣爱好的场景。目标是能够稳定可靠地捕捉到流星和红色精灵闪电等难以捉摸的天文现象,为研究提供高质量的数据资料。 其他说明:文中提到的一些技术和方法虽然较为复杂,但对于有一定编程基础和技术动手能力的人来说是非常实用的参考资料。同时,文中提供的省钱技巧也为预算有限的用户提供了一些有价值的建议。
时间序列分析-基于R(第2版)习题数据
内容概要:本文详细介绍了如何使用LabVIEW通过网口读取阿特拉斯PM4000控制器的扭矩值。主要内容涵盖开放式通讯协议的理解、阿特拉斯调试软件和测试软件的应用、LabVIEW程序的具体实现步骤,包括初始化网络连接、发送读取扭矩值命令、接收并解析扭矩值数据,以及关闭网络连接。文中还提供了多个调试技巧和注意事项,如硬件接线配置、数据解析方法、常见错误及其解决办法,以及性能优化建议。 适合人群:从事工业自动化领域的工程师和技术人员,尤其是那些需要集成阿特拉斯设备并与之进行数据交互的专业人士。 使用场景及目标:适用于需要实时监控和采集阿特拉斯PM4000控制器扭矩值的工业应用场景,旨在提高数据采集效率和准确性,确保设备运行状态的良好监测。 其他说明:文中提供的代码片段和调试经验有助于快速定位和解决问题,提升开发效率。此外,还强调了数据解析过程中需要注意的细节,如字节序问题和超时设置等。