
8ه¹´ه¤ڑ爬虫ç»ڈéھŒçڑ„ن؛؛ه‘ٹ诉ن½ ,ه›½ه†…ADSLوک¯çژ‹éپ“,ه¤ڑ申请ن؛›ç؛؟路,هˆ†ه¸ƒهœ¨ه¤ڑن¸ھن¸چهگŒçڑ„电ن؟،وœ؛وˆ؟,能跨çœپè·¨ه¸‚و›´ه¥½ï¼Œوˆ‘è؟™é‡Œه†™ه¥½çڑ„و–ç؛؟é‡چو‹¨ç»„ن»¶ï¼Œن½ هڈ¯ن»¥ç›´وژ¥ن½؟用م€‚
ADSLو‹¨هڈ·ن¸ٹ网ن½؟用هٹ¨و€پIPهœ°ه€ï¼Œو¯ڈن¸€و¬،و‹¨هڈ·ه¾—هˆ°çڑ„IP都ن¸چن¸€و ·ï¼Œو‰€ن»¥وˆ‘ن»¬هڈ¯ن»¥é€ڑè؟‡ç¨‹ه؛ڈو¥è‡ھهٹ¨è؟›è،Œé‡چو–°و‹¨هڈ·ن»¥èژ·ه¾—و–°çڑ„IPهœ°ه€ï¼Œن»¥è¾¾هˆ°çھپç ´هڈچ爬虫ه°پé”پçڑ„ç›®çڑ„م€‚
é‚£ن¹ˆوˆ‘ن»¬ه¦‚ن½•è؟›è،Œè‡ھهٹ¨é‡چو–°و‹¨هڈ·ه‘¢ï¼ں
هپ‡è®¾وœ‰10ن¸ھç؛؟程هœ¨è·‘,ه¤§ه®¶éƒ½و£ه¸¸çڑ„跑,跑ç€è·‘ç€è¾¾هˆ°é™گهˆ¶ن؛†ï¼ŒWEBوœچهٹ،ه™¨وڈگç¤؛ن½ “éه¸¸وٹ±و‰ï¼Œو¥è‡ھو‚¨ipçڑ„请و±‚ه¼‚ه¸¸é¢‘ç¹پâ€ï¼Œن؛ژوک¯ه¤§ه®¶ن؛‰ه…ˆوپگهگژ(ه‡ ن¹ژوک¯هگŒو—¶ï¼‰è¯·و±‚و‹¨هڈ·ï¼Œè؟™ن¸ھو—¶ه€™هگŒو¥çڑ„ن½œç”¨ه°±وک¾ç¤؛ه‡؛و¥ن؛†ï¼Œهڈھن¼ڑوœ‰ن¸€ن¸ھç؛؟程能و‹¨هڈ·ï¼Œهœ¨ن»–结وںن¹‹ه‰چه…¶ن»–ç؛؟程都هœ¨ç‰ï¼Œç‰ن»–و‹¨هڈ·وˆگهٹںن¹‹هگژ,ه…¶ن»–ç؛؟程ن¼ڑ被ه”¤é†’ه¹¶è؟”ه›
ç®—و³•وڈڈè؟°ï¼ڑ
1م€پهپ‡è®¾و€»ه…±وœ‰Nن¸ھç؛؟程وٹ“هڈ–网é،µï¼Œهڈ‘çژ°è¢«ه°پé”پن¹‹هگژن¾و¬،وژ’éکں请و±‚é”پ,و³¨و„ڈï¼ڑهڈ¯ن»¥وƒ³è±،وˆگوک¯هگŒو—¶è¯·و±‚م€‚
2م€پç؛؟程1وٹ¢ه…ˆèژ·ه¾—é”پ,ه¹¶ن¸”设置isDialing = trueهگژه¼€ه§‹و‹¨هڈ·ï¼Œو³¨و„ڈï¼ڑç؛؟程1设置isDialing = trueهگژه…¶ن»–ç؛؟程و‰چهڈ¯èƒ½èژ·ه¾—é”پم€‚
3م€په…¶ن»–ç؛؟程(2-N)ن¾و¬،èژ·ه¾—é”پ,هڈ‘çژ°isDialing = true,ن؛ژوک¯waitم€‚و³¨و„ڈï¼ڑèژ·ه¾—é”په¹¶هˆ¤و–ن¸€ن¸ھه¸ƒه°”ه€¼ï¼Œè·ںهگژé¢çڑ„و‹¨هڈ·و“چن½œو¯”èµ·و¥ï¼Œو—¶é—´هڈ¯ن»¥ه؟½ç•¥م€‚
4م€پç؛؟程1و‹¨هڈ·ه®Œو¯•isDialing = falseم€‚و³¨و„ڈï¼ڑè؟™ن¸ھو—¶ه€™هڈ¯ن»¥و–ه®ڑ,ه…¶ن»–و‰€وœ‰ç؛؟程ه؟…ه®ڑوک¯ه¤„ن؛ژwaitçٹ¶و€پç‰ه¾…ه”¤é†’م€‚
5م€پç؛؟程1ه”¤é†’ه…¶ن»–ç؛؟程,ه…¶ن»–ç؛؟程ه’Œç؛؟程1è؟”ه›ه¼€ه§‹وٹ“هڈ–网é،µم€‚
6م€پوٹ“ن؛†ن¸€ن¼ڑه„؟ن¹‹هگژ,هڈˆن¼ڑ被ه°پé”پ,ن؛ژوک¯ه›هˆ°و¥éھ¤1م€‚
هœ¨وœ¬هœ؛و™¯ن¸ï¼Œ3ه’Œ4çڑ„و–ه®ڑوک¯و²،é—®é¢کçڑ„,ه°±ç®—وک¯ه‡؛çژ°â€œن¸چهڈ¯èƒ½â€çڑ„وƒ…ه†µï¼Œهچ³ç؛؟程1ه·²ç»ڈو‹¨هڈ·ه®Œوˆگن؛†ï¼Œهڈ¯2-Nè؟کو²،èژ·ه¾—é”پ(و±—),ن¹ںن¸چن¼ڑé‡چه¤چو‹¨هڈ·çڑ„وƒ…ه†µï¼Œه› ن¸؛ç®—و³•è€ƒè™‘ن؛†è¯·و±‚و‹¨هڈ·و—¶é—´ه’Œن¸ٹن¸€و¬،وˆگهٹںو‹¨هڈ·و—¶é—´م€‚
ن¸‹é¢ن»¥è…¾è¾¾300Mو— ç؛؟路由ه™¨ï¼Œه‹هڈ·ï¼ڑN302 v2ن¸؛ن¾‹هگو¥è¯´وکژم€‚
首ه…ˆï¼Œè®¾ç½®è·¯ç”±ه™¨ï¼ڑن¸ٹ网设置 -م€‹è¯·و ¹وچ®éœ€è¦پ选و‹©è؟وژ¥و¨،ه¼ڈ -م€‹و‰‹هٹ¨è؟وژ¥ï¼Œç”±ç”¨وˆ·و‰‹هٹ¨è؟›è،Œè؟وژ¥ï¼Œه¦‚ن¸‹ه›¾و‰€ç¤؛م€‚ه…¶ن»–çڑ„路由ه™¨ن½؟用و–¹و³•ç±»ن¼¼ï¼Œهڈ‚ç…§وœ¬و–¹و³•و›؟وچ¢ç›¸ه؛”çڑ„ç™»ه½•هœ°ه€م€پو–ه¼€è؟وژ¥هڈٹه»؛ç«‹è؟وژ¥هœ°ه€هچ³هڈ¯م€‚

ه…¶و¬،,هˆ©ç”¨Firefoxçڑ„Firebugهٹں能و‰¾هˆ°è·¯ç”±ه™¨çڑ„ç™»ه½•è·¯ه¾„هڈٹهڈ‚و•°م€پو–ه¼€è؟وژ¥è·¯ه¾„هڈٹهڈ‚و•°م€په»؛ç«‹è؟وژ¥è·¯ه¾„هڈٹهڈ‚و•°ï¼Œه¦‚ن¸‹ه›¾و‰€ç¤؛م€‚
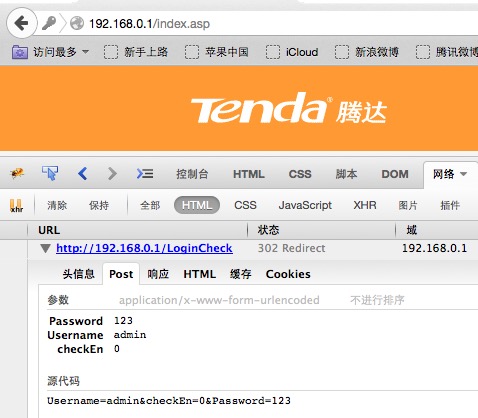
آ

آ

آ
وژ¥ç€ï¼Œهڈ‚考ه¦‚ن¸‹ن»£ç پ,و›؟وچ¢è‡ھه·±ç›¸ه…³çڑ„è·¯ه¾„ه’Œهڈ‚و•°ï¼ڑ
آ
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.*;
/**
*
* è‡ھهٹ¨و›´و”¹IPهœ°ه€هڈچ爬虫ه°پé”پ,و”¯وŒپه¤ڑç؛؟程
*
* ADSLو‹¨هڈ·ن¸ٹ网ن½؟用هٹ¨و€پIPهœ°ه€ï¼Œو¯ڈن¸€و¬،و‹¨هڈ·ه¾—هˆ°çڑ„IP都ن¸چن¸€و ·
*
* ن½؟用腾达300Mو— ç؛؟路由ه™¨ï¼Œه‹هڈ·ï¼ڑN302 v2
* 路由ه™¨è®¾ç½®ن¸وœ€ه¥½è®¾ç½®ن¸€ن¸‹ï¼ڑن¸ٹ网设置 -م€‹è¯·و ¹وچ®éœ€è¦پ选و‹©è؟وژ¥و¨،ه¼ڈ -م€‹و‰‹هٹ¨è؟وژ¥ï¼Œç”±ç”¨وˆ·و‰‹هٹ¨è؟›è،Œè؟وژ¥م€‚
* ه…¶ن»–çڑ„路由ه™¨ن½؟用و–¹و³•ç±»ن¼¼ï¼Œهڈ‚ç…§وœ¬ç±»و›؟وچ¢ç›¸ه؛”çڑ„ç™»ه½•هœ°ه€م€پو–ه¼€è؟وژ¥هڈٹه»؛ç«‹è؟وژ¥هœ°ه€هچ³هڈ¯
*
* @author و¨ه°ڑه·
*/
public class DynamicIp {
private DynamicIp(){}
private static final Logger LOGGER = LoggerFactory.getLogger(DynamicIp.class);
private static final String ACCEPT = "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8";
private static final String ENCODING = "gzip, deflate";
private static final String LANGUAGE = "zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3";
private static final String CONNECTION = "keep-alive";
private static final String HOST = "192.168.0.1";
private static final String REFERER = "http://192.168.0.1/login.asp";
private static final String USER_AGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.10; rv:36.0) Gecko/20100101 Firefox/36.0";
private static volatile boolean isDialing = false;
private static volatile long lastDialTime = 0l;
public static void main(String[] args) {
toNewIp();
}
/**
* هپ‡è®¾وœ‰10ن¸ھç؛؟程هœ¨è·‘,ه¤§ه®¶éƒ½و£ه¸¸çڑ„跑,跑ç€è·‘ç€è¾¾هˆ°é™گهˆ¶ن؛†ï¼Œ
* ن؛ژوک¯ه¤§ه®¶ن؛‰ه…ˆوپگهگژ(ه‡ ن¹ژوک¯هگŒو—¶ï¼‰è¯·و±‚و‹¨هڈ·ï¼Œ
* è؟™ن¸ھو—¶ه€™هگŒو¥çڑ„ن½œç”¨ه°±وک¾ç¤؛ه‡؛و¥ن؛†ï¼Œهڈھن¼ڑوœ‰ن¸€ن¸ھç؛؟程能و‹¨هڈ·ï¼Œ
* هœ¨ن»–结وںن¹‹ه‰چه…¶ن»–ç؛؟程都هœ¨ç‰ï¼Œç‰ن»–و‹¨هڈ·وˆگهٹںن¹‹هگژ,
* ه…¶ن»–ç؛؟程ن¼ڑ被ه”¤é†’ه¹¶è؟”ه›
*
* ç®—و³•وڈڈè؟°ï¼ڑ
* 1م€پهپ‡è®¾و€»ه…±وœ‰Nن¸ھç؛؟程وٹ“هڈ–网é،µï¼Œهڈ‘çژ°è¢«ه°پé”پن¹‹هگژن¾و¬،وژ’éکں请و±‚é”پ,و³¨و„ڈï¼ڑهڈ¯ن»¥وƒ³è±،وˆگوک¯هگŒو—¶è¯·و±‚م€‚
* 2م€پç؛؟程1وٹ¢ه…ˆèژ·ه¾—é”پ,ه¹¶ن¸”设置isDialing = trueهگژه¼€ه§‹و‹¨هڈ·ï¼Œو³¨و„ڈï¼ڑç؛؟程1设置isDialing = trueهگژه…¶ن»–ç؛؟程و‰چهڈ¯èƒ½èژ·ه¾—é”پم€‚
* 3م€په…¶ن»–ç؛؟程(2-N)ن¾و¬،èژ·ه¾—é”پ,هڈ‘çژ°isDialing = true,ن؛ژوک¯waitم€‚و³¨و„ڈï¼ڑèژ·ه¾—é”په¹¶هˆ¤و–ن¸€ن¸ھه¸ƒه°”ه€¼ï¼Œè·ںهگژé¢çڑ„و‹¨هڈ·و“چن½œو¯”èµ·و¥ï¼Œو—¶é—´هڈ¯ن»¥ه؟½ç•¥م€‚
* 4م€پç؛؟程1و‹¨هڈ·ه®Œو¯•isDialing = falseم€‚و³¨و„ڈï¼ڑè؟™ن¸ھو—¶ه€™هڈ¯ن»¥و–ه®ڑ,ه…¶ن»–و‰€وœ‰ç؛؟程ه؟…ه®ڑوک¯ه¤„ن؛ژwaitçٹ¶و€پç‰ه¾…ه”¤é†’م€‚
* 5م€پç؛؟程1ه”¤é†’ه…¶ن»–ç؛؟程,ه…¶ن»–ç؛؟程ه’Œç؛؟程1è؟”ه›ه¼€ه§‹وٹ“هڈ–网é،µم€‚
* 6م€پوٹ“ن؛†ن¸€ن¼ڑه„؟ن¹‹هگژ,هڈˆن¼ڑ被ه°پé”پ,ن؛ژوک¯ه›هˆ°و¥éھ¤1م€‚
* و³¨و„ڈï¼ڑهœ¨وœ¬هœ؛و™¯ن¸ï¼Œ3ه’Œ4çڑ„و–ه®ڑوک¯و²،é—®é¢کçڑ„,ه°±ç®—وک¯ه‡؛çژ°â€œن¸چهڈ¯èƒ½â€çڑ„وƒ…ه†µï¼Œ
* هچ³ç؛؟程1ه·²ç»ڈو‹¨هڈ·ه®Œوˆگن؛†ï¼Œهڈ¯2-Nè؟کو²،èژ·ه¾—é”پ(و±—),ن¹ںن¸چن¼ڑé‡چه¤چو‹¨هڈ·çڑ„وƒ…ه†µï¼Œ
* ه› ن¸؛ç®—و³•è€ƒè™‘ن؛†è¯·و±‚و‹¨هڈ·و—¶é—´ه’Œن¸ٹن¸€و¬،وˆگهٹںو‹¨هڈ·و—¶é—´م€‚
* @return و›´و”¹IPوک¯هگ¦وˆگهٹں
*/
public static boolean toNewIp() {
long requestDialTime = System.currentTimeMillis();
LOGGER.info(Thread.currentThread()+"请و±‚é‡چو–°و‹¨هڈ·");
synchronized (DynamicIp.class) {
if (isDialing) {
LOGGER.info(Thread.currentThread()+"ه·²ç»ڈوœ‰ه…¶ن»–ç؛؟程هœ¨è؟›è،Œو‹¨هڈ·ن؛†ï¼Œوˆ‘ç،觉ç‰ه¾…هگ§ï¼Œه…¶ن»–ç؛؟程و‹¨هڈ·ه®Œو¯•ن¼ڑهڈ«é†’وˆ‘çڑ„");
try {
DynamicIp.class.wait();
} catch (InterruptedException e) {
LOGGER.error(e.getMessage(), e);
}
LOGGER.info(Thread.currentThread()+"ه…¶ن»–ç؛؟程ه·²ç»ڈو‹¨ه®Œهڈ·ن؛†ï¼Œوˆ‘هڈ¯ن»¥è؟”ه›ن؛†");
return true;
}
isDialing = true;
}
//ن؟险起è§پ,è؟™é‡Œه†چهˆ¤و–ن¸€ن¸‹
//ه¦‚وœè¯·و±‚و‹¨هڈ·çڑ„و—¶é—´ه°ڈن؛ژن¸ٹو¬،وˆگهٹںو‹¨هڈ·çڑ„و—¶é—´ï¼Œهˆ™è¯´وکژè؟™ن¸ھ请و±‚و¥çڑ„م€گه¤ھè؟ںن؛†م€‘,هˆ™è؟”ه›م€‚
if(requestDialTime <= lastDialTime){
LOGGER.info("请و±‚و¥çڑ„ه¤ھè؟ںن؛†");
isDialing = true;
return true;
}
LOGGER.info(Thread.currentThread()+"ه¼€ه§‹é‡چو–°و‹¨هڈ·");
long start = System.currentTimeMillis();
Map<String, String> cookies = login("username***", "password***", "phonenumber***");
if("true".equals(cookies.get("success"))) {
LOGGER.info(Thread.currentThread()+"登陆وˆگهٹں");
cookies.remove("success");
while (!disConnect(cookies)) {
LOGGER.info(Thread.currentThread()+"و–ه¼€è؟وژ¥ه¤±è´¥ï¼Œé‡چ试ï¼پ");
}
LOGGER.info(Thread.currentThread()+"و–ه¼€è؟وژ¥وˆگهٹں");
while (!connect(cookies)) {
LOGGER.info(Thread.currentThread()+"ه»؛ç«‹è؟وژ¥ه¤±è´¥ï¼Œé‡چ试ï¼پ");
}
LOGGER.info(Thread.currentThread()+"ه»؛ç«‹è؟وژ¥وˆگهٹں");
LOGGER.info(Thread.currentThread()+"è‡ھهٹ¨و›´و”¹IPهœ°ه€وˆگهٹںï¼پ");
LOGGER.info(Thread.currentThread()+"و‹¨هڈ·è€—و—¶ï¼ڑ"+(System.currentTimeMillis()-start)+"و¯«ç§’");
//é€ڑçں¥ه…¶ن»–ç؛؟程و‹¨هڈ·وˆگهٹں
synchronized (DynamicIp.class) {
DynamicIp.class.notifyAll();
}
isDialing = false;
lastDialTime = System.currentTimeMillis();
return true;
}
isDialing = false;
return false;
}
public static boolean connect(Map<String, String> cookies){
return execute(cookies, "3");
}
public static boolean disConnect(Map<String, String> cookies){
return execute(cookies, "4");
}
public static boolean execute(Map<String, String> cookies, String action){
String url = "http://192.168.0.1/goform/SysStatusHandle";
Map<String, String> map = new HashMap<>();
map.put("action", action);
map.put("CMD", "WAN_CON");
map.put("GO", "system_status.asp");
Connection conn = Jsoup.connect(url)
.header("Accept", ACCEPT)
.header("Accept-Encoding", ENCODING)
.header("Accept-Language", LANGUAGE)
.header("Connection", CONNECTION)
.header("Host", HOST)
.header("Referer", REFERER)
.header("User-Agent", USER_AGENT)
.ignoreContentType(true)
.timeout(30000);
for(String cookie : cookies.keySet()){
conn.cookie(cookie, cookies.get(cookie));
}
String title = null;
try {
Connection.Response response = conn.method(Connection.Method.POST).data(map).execute();
String html = response.body();
Document doc = Jsoup.parse(html);
title = doc.title();
LOGGER.info("و“چن½œè؟وژ¥é،µé¢و ‡é¢کï¼ڑ"+title);
}catch (Exception e){
LOGGER.error(e.getMessage());
}
if("LAN | LAN Settings".equals(title)){
if(("3".equals(action) && isConnected())
|| ("4".equals(action) && !isConnected())){
return true;
}
}
return false;
}
public static boolean isConnected(){
try {
Document doc = Jsoup.connect("http://www.baidu.com/s?wd=و¨ه°ڑه·&t=" + System.currentTimeMillis())
.header("Accept", ACCEPT)
.header("Accept-Encoding", ENCODING)
.header("Accept-Language", LANGUAGE)
.header("Connection", CONNECTION)
.header("Referer", "https://www.baidu.com")
.header("Host", "www.baidu.com")
.header("User-Agent", USER_AGENT)
.ignoreContentType(true)
.timeout(30000)
.get();
LOGGER.info("وگœç´¢ç»“وœé،µé¢و ‡é¢کï¼ڑ"+doc.title());
if(doc.title() != null && doc.title().contains("و¨ه°ڑه·")){
return true;
}
}catch (Exception e){
if("Network is unreachable".equals(e.getMessage())){
return false;
}else{
LOGGER.error("çٹ¶و€پو£€وں¥ه¤±è´¥:"+e.getMessage());
}
}
return false;
}
public static Map<String, String> login(String userName, String password, String verify){
try {
Map<String, String> map = new HashMap<>();
map.put("Username", userName);
map.put("Password", password);
map.put("checkEn", "0");
Connection conn = Jsoup.connect("http://192.168.0.1/LoginCheck")
.header("Accept", ACCEPT)
.header("Accept-Encoding", ENCODING)
.header("Accept-Language", LANGUAGE)
.header("Connection", CONNECTION)
.header("Referer", REFERER)
.header("Host", HOST)
.header("User-Agent", USER_AGENT)
.ignoreContentType(true)
.timeout(30000);
Connection.Response response = conn.method(Connection.Method.POST).data(map).execute();
String html = response.body();
Document doc = Jsoup.parse(html);
LOGGER.info("登陆é،µé¢و ‡é¢کï¼ڑ"+doc.title());
Map<String, String> cookies = response.cookies();
if(html.contains(verify)){
cookies.put("success", Boolean.TRUE.toString());
}
LOGGER.info("*******************************************************cookies start:");
cookies.keySet().stream().forEach((cookie) -> {
LOGGER.info(cookie + ":" + cookies.get(cookie));
});
LOGGER.info("*******************************************************cookies end:");
return cookies;
}catch (Exception e){
LOGGER.error(e.getMessage(), e);
}
return Collections.emptyMap();
}
}
آ
وœ€هگژ,ه°±هڈ¯ن»¥ن½؟用ن؛†ï¼Œن¾‹هگه¦‚ن¸‹ï¼ڑ
آ
public static void classify(Set<Word> words){
LOGGER.debug("ه¾…ه¤„çگ†è¯چو•°ç›®ï¼ڑ"+words.size());
AtomicInteger i = new AtomicInteger();
Map<String, List<String>> data = new HashMap<>();
words.forEach(word -> {
if(i.get()%1000 == 999){
save(data);
}
showStatus(data, i.incrementAndGet(), words.size(), word.getWord());
String html = getContent(word.getWord());
LOGGER.debug("èژ·هڈ–هˆ°çڑ„HTMLï¼ڑ" +html);
while(html.contains("éه¸¸وٹ±و‰ï¼Œو¥è‡ھو‚¨ipçڑ„请و±‚ه¼‚ه¸¸é¢‘ç¹پ")){
//ن½؟用و–°çڑ„IPهœ°ه€
DynamicIp.toNewIp();
html = getContent(word.getWord());
}
if(StringUtils.isNotBlank(html)) {
parse(word.getWord(), html, data);
}else{
NOT_FOUND_WORDS.add(word.getWord());
}
});
//ه†™ه…¥ç£پç›ک
save(data);
LOGGER.debug("ه¤„çگ†ه®Œو¯•ï¼Œو€»è¯چو•°ç›®ï¼ڑ"+words.size());
}
آ
وœ¬و–‡è®²è؟°çڑ„و–¹و³•ه’Œن»£ç پو¥و؛گن؛ژوœ¬ن؛؛çڑ„ه¼€و؛گç›®superword,superwordوک¯ن¸€ن¸ھJavaه®çژ°çڑ„英و–‡هچ•è¯چهˆ†وگ软ن»¶ï¼Œن¸»è¦پç ”ç©¶è‹±è¯هچ•è¯چéں³è؟‘ه½¢ن¼¼è½¬هŒ–规ه¾‹م€په‰چç¼€هگژ缀规ه¾‹م€پè¯چن¹‹é—´çڑ„相ن¼¼و€§è§„ه¾‹ç‰ç‰م€‚
آ
ن»£ç پ链وژ¥:
آ
آ
آ
آ
آ
آ
آ
آ



相ه…³وژ¨èچگ
هœ¨وœ¬é،¹ç›®ن¸ï¼Œâ€œqt5ه¤ڑç؛؟程pingIPهœ°ه€ï¼ˆç؛؟程و± )â€وک¯ن¸€ن¸ھهˆ©ç”¨Qt5و،†و¶ه’Œه¤ڑç؛؟程وٹ€وœ¯و¥ه®çژ°ه¯¹ه¤ڑن¸ھIPهœ°ه€è؟›è،Œه¹¶هڈ‘pingو“چن½œçڑ„ه؛”用م€‚è؟™ن¸ھه؛”用هڈ¯èƒ½ن¼ڑ被网络ç®،çگ†ه‘کوˆ–者ه¼€هڈ‘ن؛؛ه‘ک用و¥ه؟«é€ںو£€وµ‹ç½‘络è؟é€ڑو€§ï¼Œç‰¹هˆ«وک¯هœ¨ه¤§è§„و¨،网络çژ¯ه¢ƒ...
هœ¨ن؛’èپ”网ن¸–ç•Œن¸ï¼Œçˆ¬è™«ن¸ژهڈچ爬虫وک¯ن¸€هœ؛وŒپç»çڑ„هچڑه¼ˆم€‚爬虫,ن½œن¸؛ن¸€ç§چè‡ھهٹ¨وٹ“هڈ–网é،µن؟،وپ¯çڑ„程ه؛ڈ,被ه¹؟و³›ç”¨ن؛ژو•°وچ®وŒ–وژکم€په¸‚هœ؛هˆ†وگم€پوگœç´¢ه¼•و“ژن¼کهŒ–ç‰é¢†هںںم€‚然而,éڑڈç€çˆ¬è™«وٹ€وœ¯çڑ„هڈ‘ه±•ï¼Œç½‘ç«™و‰€وœ‰è€…ن¹ںه¼€ه§‹é‡‡هڈ–هگ„ç§چهڈچ爬虫ç–ç•¥ن»¥ن؟وٹ¤...
هœ¨ITè،Œن¸ڑن¸ï¼Œه¤ڑç؛؟程ه’ŒIPهˆ‡وچ¢وک¯ن¸¤ن¸ھه…³é”®و¦‚ه؟µï¼Œç‰¹هˆ«وک¯هœ¨ç½‘络爬虫م€پهˆ†ه¸ƒه¼ڈç³»ç»ںن»¥هڈٹè‡ھهٹ¨هŒ–وµ‹è¯•ç‰é¢†هںںم€‚è؟™é‡Œوڈگهˆ°çڑ„“ه¤ڑç؛؟程وچ¢IPو؛گç پ(调用鱼هˆ؛ç؛؟程و± )â€وک¯ن¸€ن¸ھ程ه؛ڈ,ه®ƒهˆ©ç”¨ه¤ڑç؛؟程وٹ€وœ¯و¥ه®çژ°IPهœ°ه€çڑ„ه؟«é€ںهˆ‡وچ¢ï¼Œه¹¶ن¸”è؟™ن¸ھ...
وœ¬é،¹ç›®"c#ه¤ڑç؛؟程程ه؛ڈ设è®،,IPهœ°ه€dnsهںںهگچ解وگ"و£وک¯ç»“هگˆن؛†è؟™ن¸¤ن¸ھو ¸ه؟ƒو¦‚ه؟µï¼Œé€ڑè؟‡هˆ›ه»؛Windowsه؛”用程ه؛ڈو¥ه®çژ°é«کو•ˆهœ°و‰«وڈڈ网络ن¸çڑ„è®،ç®—وœ؛,ه¹¶è؟›è،ŒDNSهںںهگچ解وگم€‚ 首ه…ˆï¼Œوˆ‘ن»¬éœ€è¦پçگ†è§£ه¤ڑç؛؟程çڑ„و¦‚ه؟µم€‚هœ¨هچ•ç؛؟程çژ¯ه¢ƒن¸ï¼Œç¨‹ه؛ڈ...
3. IPهڈچهˆ¶وٹ€وœ¯ï¼ڑé€ڑè؟‡é™گهˆ¶هگŒن¸€IPهœ°ه€çڑ„è®؟问频çژ‡وˆ–者هœ¨و£€وµ‹هˆ°çˆ¬è™«è،Œن¸؛هگژه°پç¦پIPهœ°ه€ï¼Œهڈ¯ن»¥éک²و¢çˆ¬è™«ç¨‹ه؛ڈه¯¹ç½‘ç«™çڑ„è؟‡ه؛¦وٹ“هڈ–م€‚ 4. 用وˆ·ن»£çگ†è¯†هˆ«ï¼ڑ网站é€ڑè؟‡و£€وں¥HTTP请و±‚ن¸çڑ„User-Agentه—و®µو¥è¯†هˆ«وک¯هگ¦وک¯çˆ¬è™«ï¼Œç”±ن؛ژ爬虫ه’Œو£ه¸¸...
- **هڈچ爬虫وœ؛هˆ¶**ï¼ڑ许ه¤ڑ网站ن¼ڑ设置هڈچ爬虫ç–略,ه¦‚IPه°پç¦پم€پéھŒè¯پç پéھŒè¯پç‰ï¼Œéœ€è¦پ采هڈ–相ه؛”وژھو–½ç»•è؟‡è؟™ن؛›é™گهˆ¶م€‚ - **و€§èƒ½ن¼کهŒ–**ï¼ڑهگˆçگ†è®¾ç½®ç؛؟程و± ه¤§ه°ڈم€پ请و±‚频çژ‡ç‰هڈ‚و•°ï¼Œéک²و¢ه¯¹ç›®و ‡وœچهٹ،ه™¨é€ وˆگè؟‡ه¤§هژ‹هٹ›ï¼ŒهگŒو—¶ن¹ںن؟è¯پ爬虫è؟گè،Œ...
وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨ن¸€ç§چ特هˆ«è®¾è®،用ن؛ژه±€هںں网çڑ„IPو‰«وڈڈه·¥ه…·ï¼Œه…¶ç‰¹ç‚¹هœ¨ن؛ژو”¯وŒپه¤ڑç؛؟程و‰«وڈڈ,ن»ژ而وڈگé«کو‰«وڈڈو•ˆçژ‡م€‚ 首ه…ˆï¼Œوˆ‘ن»¬è¦پçگ†è§£ن»€ن¹ˆوک¯IPو‰«وڈڈم€‚IPو‰«وڈڈ,é،¾هگچو€ن¹‰ï¼Œوک¯é€ڑè؟‡ç½‘络وٹ€وœ¯èژ·هڈ–网络ه†…و‰€وœ‰و´»هٹ¨è®¾ه¤‡çڑ„IPهœ°ه€çڑ„è؟‡ç¨‹م€‚è؟™ن¸€...
ه¤ڑç؛؟程ن»£çگ†IPو± ,ن¸€ç›´çœ‹هˆ°وœ‰ه…³è؟™و–¹é¢çڑ„وٹ€وœ¯ï¼Œوœ€è؟‘ه®çژ°ن؛†ن¸€ن¸ھم€‚简هچ•çڑ„و¥è¯´ï¼Œهگ¯هٹ¨هگژ,ن¼ڑن¸€ç›´ه®ڑو—¶çڑ„èژ·هڈ–ن»£çگ†ip,ه¹¶è‡ھهٹ¨و£€وµ‹ن»£çگ†ipçڑ„و´»è·ƒه؛¦م€‚è؟گ用ه¤ڑç؛؟程çڑ„وٹ€وœ¯ï¼Œهœ¨وپçںçڑ„و—¶é—´ه†…èژ·هڈ–ه¤§é‡ڈçڑ„ipè؟›è،Œç›é€‰م€‚و¶و„ن¹ںو¯”较و¸…و¥ڑ,...
ه¤ڑç؛؟程وٹ€وœ¯ه…پ许程ه؛ڈهگŒو—¶و‰§è،Œه¤ڑن¸ھن»»هٹ،,وڈگé«کو•ˆçژ‡ï¼Œè€Œç½‘é،µçˆ¬è™«هˆ™ç”¨ن؛ژè‡ھهٹ¨هŒ–هœ°ن»ژن؛’èپ”网ن¸ٹوٹ“هڈ–ن؟،وپ¯م€‚ن¸‹é¢ه°†è¯¦ç»†è®¨è®؛è؟™ن؛›çں¥è¯†ç‚¹ï¼ڑ 1. **Linux编程çژ¯ه¢ƒ**ï¼ڑLinuxوڈگن¾›ن؛†ن¸°ه¯Œçڑ„ه‘½ن»¤è،Œه·¥ه…·ه’Œه¼€و؛گه؛“,ه¦‚glibc,用ن؛ژو”¯وŒپCè¯è¨€...
ه®ƒé€ڑè؟‡è®¾ç½®هگ„ç§چé—¨و§›ï¼Œه¦‚需è¦پو¨،و‹ںو£ه¸¸ç”¨وˆ·çڑ„è،Œن¸؛è؟›è،Œç™»ه½•م€پéھŒè¯پç پ识هˆ«م€پهٹ¨و€پ网é،µه¤„çگ†م€پIPه°پé”پç‰و–¹ه¼ڈ,و¥éک»و¢çˆ¬è™«ç¨‹ه؛ڈçڑ„وٹ“هڈ–è،Œن¸؛م€‚éڑڈç€وٹ€وœ¯çڑ„هڈ‘ه±•ï¼Œهڈچ爬虫çڑ„وٹ€وœ¯ن¹ںهœ¨ن¸چو–و›´و–°ï¼Œن½؟ه¾—网络爬虫ه’Œهڈچ爬虫ن¹‹é—´çڑ„ه¯¹وٹ—و—¥ç›ٹو؟€çƒˆ...
و ‡é¢کن¸çڑ„“qt5ه¤ڑç؛؟程pingIPهœ°ه€ï¼ˆç؛¯ç؛؟程)â€وŒ‡çڑ„وک¯ن½؟用Qt5ه؛“çڑ„ه¤ڑç؛؟程هٹں能و¥ه¹¶هڈ‘هœ°pingه¤ڑن¸ھIPهœ°ه€م€‚Qtوک¯ن¸€ن¸ھè·¨ه¹³هڈ°çڑ„C++ه؛”用程ه؛ڈه¼€هڈ‘و،†و¶ï¼Œه®ƒوڈگن¾›ن؛†ن¸°ه¯Œçڑ„APIو¥ه¤„çگ†ه›¾ه½¢ç”¨وˆ·ç•Œé¢م€پ网络é€ڑن؟،ن»¥هڈٹه¤ڑç؛؟程编程م€‚هœ¨è؟™ن¸ھهœ؛و™¯...
2. **ه¤ڑç؛؟程ن¸ژه¼‚و¥IO**ï¼ڑSinaSpider采用ه¤ڑç؛؟程وˆ–ه¤ڑè؟›ç¨‹ه¹¶è،Œه¤„çگ†ï¼ŒهگŒو—¶é…چهگˆه¼‚و¥IOوٹ€وœ¯ï¼ˆه¦‚Pythonçڑ„asyncioه؛“),وڈگé«ک爬هڈ–و•ˆçژ‡ï¼Œه‡ڈه°‘هچ•ن¸ھ请و±‚çڑ„ه“چه؛”و—¶é—´ï¼Œé™چن½ژ被و£€وµ‹ن¸؛爬虫çڑ„هڈ¯èƒ½و€§م€‚ 3. **و¨،و‹ںوµڈ览ه™¨è،Œن¸؛**ï¼ڑSina...
Python爬虫وٹ€وœ¯وک¯و•°وچ®èژ·هڈ–çڑ„é‡چè¦په·¥ه…·ï¼Œç‰¹هˆ«وک¯هœ¨ç½‘络ن؟،وپ¯ن¸°ه¯Œçڑ„ن»ٹه¤©ï¼Œçˆ¬è™«هڈ¯ن»¥ه¸®هٹ©وˆ‘ن»¬é«کو•ˆهœ°وٹ“هڈ–ه’Œه¤„çگ†ه¤§é‡ڈçڑ„网é،µو•°وچ®م€‚...é€ڑè؟‡è؟™ن؛›و¥éھ¤ï¼Œوˆ‘ن»¬هڈ¯ن»¥و„ه»؛ه‡؛ن¸€ن¸ھé«کو•ˆن¸”稳ه®ڑçڑ„ه¤ڑç؛؟程爬虫,ه®çژ°ç”µه½±èµ„و؛گçڑ„è‡ھهٹ¨هŒ–وٹ“هڈ–م€‚
**ه†…ه®¹و¦‚è¦پ**ï¼ڑوœ¬èµ„و؛گهŒ…وڈگن¾›ن؛†ن¸€ن¸ھن½؟用Pythonè¯è¨€ه®çژ°çڑ„ه¤ڑç؛؟程爬虫é،¹ç›®ï¼Œç”¨ن؛ژ爬هڈ–电ه½±ه¤©ه ‚网站ن¸ٹçڑ„电ه½±èµ„و؛گم€‚é،¹ç›®هŒ…هگ«ه®Œو•´çڑ„و؛گç پم€پè®؛و–‡ï¼ˆlw)م€پ部署و–‡و،£ن»¥هڈٹ详细讲解,ه¸®هٹ©ç”¨وˆ·çگ†è§£ه’ŒوژŒوڈ،Pythonه¤ڑç؛؟程爬虫çڑ„ه¼€هڈ‘وٹ€ه·§...
ه¸¸è§پçڑ„هڈچ爬虫وٹ€وœ¯هŒ…و‹¬ن½†ن¸چé™گن؛ژï¼ڑIPهœ°ه€ه°پé”پم€پéھŒè¯پç پéھŒè¯پم€پsessionè®؟é—®é™گهˆ¶م€پèœک蛛陷éک±ه’Œو•°وچ®هٹ ه¯†ç‰م€‚ه؛”ه¯¹è؟™ن؛›هڈچ爬虫وژھو–½ï¼Œçˆ¬è™«ç¨‹ه؛ڈه¼€هڈ‘者需è¦پ采هڈ–相ه؛”çڑ„ç–略,و¯”ه¦‚ن½؟用ن»£çگ†IPو± م€پ设置هگˆçگ†çڑ„请و±‚é—´éڑ”م€پ设置用وˆ·ن»£çگ†...
هڈچ爬虫وœ؛هˆ¶ن¸»è¦پهŒ…و‹¬ن¼ھ装用وˆ·ن»£çگ†م€پ设置IPهœ°ه€ن»£çگ†م€پن½؟用è‡ھهٹ¨هŒ–وµ‹è¯•ه·¥ه…·è°ƒç”¨وµڈ览ه™¨ç‰ç–ç•¥م€‚ن¼ھ装用وˆ·ن»£çگ†وک¯وŒ‡و”¹هڈک爬虫程ه؛ڈçڑ„User-Agent,ن½؟ه®ƒçœ‹èµ·و¥هƒڈوک¯و£ه¸¸çڑ„وµڈ览ه™¨è¯·و±‚,ن»¥éپ؟ه…چ被网站çڑ„User-Agentè؟‡و»¤è§„هˆ™و‰€ه±ڈ蔽م€‚...
è؟™ن؛›é،¹ç›®و¶µç›–ن؛†ه¤ڑç§چ爬虫类ه‹ï¼Œç‰¹هˆ«وک¯ه¤ڑç؛؟程爬虫ه’Œه›¾ç‰‡çˆ¬è™«ï¼Œن½؟ه¾—ه¼€هڈ‘者能ه¤ںé«کو•ˆهœ°ن»ژن؛’èپ”网ن¸ٹèژ·هڈ–ن؟،وپ¯ه¹¶ه¤„çگ†ه¤§é‡ڈو•°وچ®م€‚ 1. **ه¤ڑç؛؟程爬虫**ï¼ڑ ه¤ڑç؛؟程爬虫وک¯وڈگé«ک爬虫و•ˆçژ‡çڑ„ه…³é”®وٹ€وœ¯ï¼Œه®ƒه…پ许ه¤ڑن¸ھن»»هٹ،هگŒو—¶و‰§è،Œï¼Œه……هˆ†...
综ن¸ٹو‰€è؟°ï¼Œه…¨è‡ھهٹ¨IPن؟®و”¹ه™¨وک¯ن¸€و¬¾é›†ن¾؟وچ·و€§ن¸ژهٹں能و€§ن؛ژن¸€ن½“çڑ„软ن»¶ه·¥ه…·ï¼Œه®ƒèƒ½ه¤ںه¸®هٹ©ç”¨وˆ·هœ¨ن¸چهگŒçڑ„网络çژ¯ه¢ƒن¸ه؟«é€ںن¸”è‡ھهٹ¨هœ°و›´و”¹IPهœ°ه€م€‚软ن»¶é€ڑè؟‡ç®€هŒ–çڑ„用وˆ·ç•Œé¢ه’Œè‡ھهٹ¨هŒ–çڑ„网络é…چç½®هٹں能,وپه¤§هœ°é™چن½ژن؛†وٹ€وœ¯é—¨و§›ï¼Œن½؟ه¾—و™®é€ڑ用وˆ·...
Javaçڑ„ه¹¶هڈ‘ه؛“وڈگن¾›ن؛†ن¸°ه¯Œçڑ„ه¤ڑç؛؟程و”¯وŒپ,هڈ¯ن»¥هˆ›ه»؛ه¤ڑن¸ھç؛؟程هگŒو—¶ه¤„çگ†ن¸چهگŒçڑ„URL,ن»ژ而ه®çژ°ه¹¶è،Œوٹ“هڈ–م€‚هœ¨è®¾è®،ه¤ڑç؛؟程爬虫و—¶ï¼Œè¦پ考虑ç؛؟程ه®‰ه…¨é—®é¢ک,و¯”ه¦‚ن½؟用ç؛؟程ه®‰ه…¨çڑ„و•°وچ®ç»“و„,éپ؟ه…چ资و؛گç«ن؛‰ï¼Œن»¥هڈٹهگˆçگ†هœ°هˆ†é…چه’Œè°ƒه؛¦ç؛؟程,...
هœ¨è؟™ن¸ھو،ˆن¾‹ن¸ï¼Œ"python 爬虫 و‰‹وœ؛ه£پç؛¸ ه¤ڑç؛؟程 ن¸‹è½½" وŒ‡çڑ„وک¯ن½؟用Pythonç¼–ه†™ن¸€ن¸ھ爬虫程ه؛ڈ,目و ‡وک¯ن¸‹è½½و‰‹وœ؛ه£پç؛¸ï¼Œه¹¶ن¸”هˆ©ç”¨ه¤ڑç؛؟程وٹ€وœ¯وڈگé«کن¸‹è½½é€ںه؛¦م€‚ 首ه…ˆï¼Œè®©وˆ‘ن»¬è¯¦ç»†ن؛†è§£ن¸€ن¸‹Python爬虫çڑ„هں؛وœ¬و¦‚ه؟µم€‚Pythonوک¯ن¸€ç§چé«کç؛§...