
转自:http://www.blogjava.net/hello-yun/archive/2012/10/10/389289.html
 
MurmurHashτ«Ýµ│þ∩╝ÜΘ½ýΦ┐Éτ«ÝµÇÚΦâ╜∩╝ðΣ╜Äτó░µÆ₧τÄç∩╝ðτö▒Austin Applebyσêøσ╗║Σ║Ä2008σ╣┤∩╝ðτÄ░σ╖▓σ║öτö¿σê░HadoopπÇülibstdc++πÇünginxπÇülibmemcachedτ¡ëσ╝ǵ║Éτ│╗τ╗ƒπÇé2011σ╣┤ApplebyΦó½GoogleΘøçΣ╜ú∩╝ðΘÜÅσÉÄGoogleµÄ¿σç║σà╢σÅýτÚÞτÜäCityHashτ«Ýµ│þπÇé
 
Σ╕ÇΦç┤µÇÚσôêσ╕ðτ«Ýµ│þµý»σêåσ╕âσ╝Åτ│╗τ╗ƒΣ╕¡σ╕╕τö¿τÜäτ«Ýµ│þπÇéµ»öσÓé∩╝ðΣ╕ÇΣ╕¬σêåσ╕âσ╝ÅτÜäσ¡ýσé¿τ│╗τ╗ƒ∩╝ðΦÓüσ░åµþ░µÞ«σ¡ýσé¿σê░σà╖Σ╜ôτÜäΦèéτé╣Σ╕è∩╝ðσÓéµ₧£Θççτö¿µÖ«ΘÇÜτÜähashµû╣µ│þ∩╝ðσ░åµþ░µÞ«µýáσ░äσê░σà╖Σ╜ôτÜäΦèéτé╣Σ╕è∩╝ðσÓékey%N∩╝ðkeyµý»µþ░µÞ«τÜäkey∩╝ðNµý»µ£║σÖ¿Φèéτé╣µþ░∩╝ðσÓéµ₧£µ£ëΣ╕ÇΣ╕¬µ£║σÖ¿σèáσà͵êûΘÇÇσç║Φ┐ÖΣ╕¬Θøåτ╛Á∩╝ðσêÖµëǵ£ëτÜäµþ░µÞ«µýáσ░äΘâ╜µÝáµþêΣ║å∩╝ðσÓéµ₧£µý»µðüΣ╣àσðûσ¡ýσé¿σêÖΦÓüσüܵþ░µÞ«Φ┐üτÚ╗∩╝ðσÓéµ₧£µý»σêåσ╕âσ╝Åτ╝ôσ¡ý∩╝ðσêÖσà╢Σ╗ûτ╝ôσ¡ýσ░▒σÁ▒µþêΣ║åπÇé
┬á ┬á σøᵡÁ∩╝ðσ╝þσàÍΣ║åΣ╕ÇΦç┤µÇÚσôêσ╕ðτ«Ýµ│þ∩╝Ü
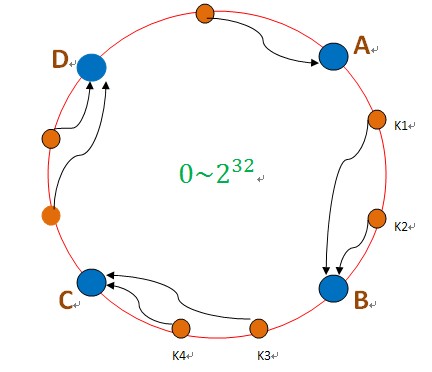
 
µèèµþ░µÞ«τö¿hashσç╜µþ░∩╝êσÓéMD5∩╝ë∩╝ðµýáσ░äσê░Σ╕ÇΣ╕¬σ╛êσÁÚτÜäτ⌐║ΘÝ┤Θçð∩╝ðσÓéσø╛µëÇτÁ║πÇéµþ░µÞ«τÜäσ¡ýσ鿵Ý╢∩╝ðσàêσ╛Ýσê░Σ╕ÇΣ╕¬hashσÇ╝∩╝ðσ»╣σ║öσê░Φ┐ÖΣ╕¬τÄ»Σ╕¡τÜäµ»ÅΣ╕¬Σ╜Þτ╜«∩╝ðσÓék1σ»╣σ║öσê░Σ║åσø╛Σ╕¡µëÇτÁ║τÜäΣ╜Þτ╜«∩╝ðτä╢σÉĵ▓┐Θí║µÝ╢ΘÆêµë╛σê░Σ╕ÇΣ╕¬µ£║σÖ¿Φèéτé╣B∩╝ðσ░åk1σ¡ýσé¿σê░BΦ┐ÖΣ╕¬Φèéτé╣Σ╕¡πÇé
σÓéµ₧£BΦèéτé╣σ«þµ£║Σ║å∩╝ðσêÖBΣ╕èτÜäµþ░µÞ«σ░▒Σ╝ÜΦÉ╜σê░CΦèéτé╣Σ╕è∩╝ðσÓéΣ╕Ðσø╛µëÇτÁ║∩╝Ü
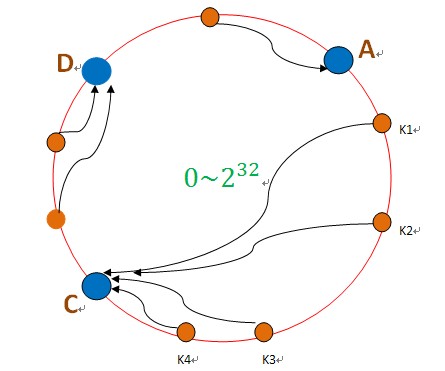
 
Φ┐Öµá╖∩╝ðσŬΣ╝Üσ╜▒σôÞCΦèéτé╣∩╝ðσ»╣σà╢Σ╗ûτÜäΦèéτé╣A∩╝ðDτÜäµþ░µÞ«Σ╕ÞΣ╝ÜΘÇáµêÉσ╜▒σôÞπÇéτä╢ΦÇð∩╝ðΦ┐ÖσÅêΣ╝ÜΘÇáµêÉΣ╕ÇΣ╕¬ΓÇ£Θø¬σ┤⌐ΓÇØτÜäµâàσå╡∩╝ðσÞ│CΦèéτé╣τö▒Σ║ĵë┐µÐàΣ║åBΦèéτé╣τÜäµþ░µÞ«∩╝ðµëÇΣ╗ÍCΦèéτé╣τÜäΦ┤ƒΦ╜╜Σ╝ÜσÅýΘ½ý∩╝ðCΦèéτé╣σ╛êσ«╣µýôΣ╣ƒσ«þµ£║∩╝ðΦ┐Öµá╖Σ╛ص¼íΣ╕ÐσÄ╗∩╝ðΦ┐Öµá╖ΘÇáµêɵþ┤Σ╕¬Θøåτ╛ÁΘâ╜µðéΣ║åπÇé
┬á┬á┬á┬á┬á┬á Σ╕║µ¡Á∩╝ðσ╝þσàÍΣ║åΓÇ£ΦÖܵЃΦèéτé╣ΓÇØτÜäµÓéσ┐╡∩╝ÜσÞ│µèèµâ│Φ▒íσ£¿Φ┐ÖΣ╕¬τÄ»Σ╕èµ£ëσ╛êσÁÜΓÇ£ΦÖܵЃΦèéτé╣ΓÇØ∩╝ðµþ░µÞ«τÜäσ¡ýσ鿵ý»µ▓┐τØÇτÄ»τÜäΘí║µÝ╢ΘÆêµû╣σÉæµë╛Σ╕ÇΣ╕¬ΦÖܵЃΦèéτé╣∩╝ðµ»ÅΣ╕¬ΦÖܵЃΦèéτé╣Θâ╜Σ╝Üσà│Φüöσê░Σ╕ÇΣ╕¬τ£ƒσ«₧Φèéτé╣∩╝ðσÓéΣ╕Ðσø╛µëÇΣ╜┐τö¿∩╝Ü
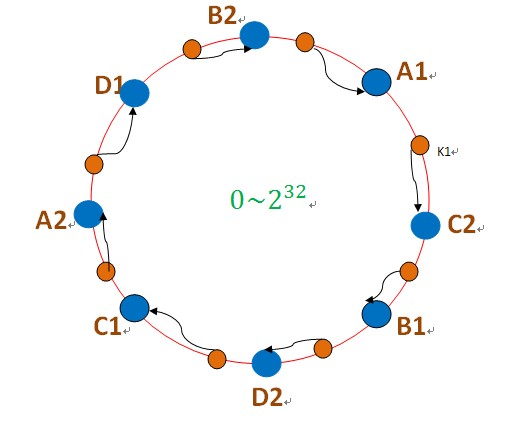
σø╛Σ╕¡τÜäA1πÇüA2πÇüB1πÇüB2πÇüC1πÇüC2πÇüD1πÇüD2Θâ╜µý»ΦÖܵЃΦèéτé╣∩╝ðµ£║σÖ¿AΦ┤ƒΦ╜╜σ¡ýσé¿A1πÇüA2τÜäµþ░µÞ«∩╝ðµ£║σÖ¿BΦ┤ƒΦ╜╜σ¡ýσé¿B1πÇüB2τÜäµþ░µÞ«∩╝ðµ£║σÖ¿CΦ┤ƒΦ╜╜σ¡ýσé¿C1πÇüC2τÜäµþ░µÞ«πÇéτö▒Σ║ÄΦ┐ÖΣ║øΦÖܵЃΦèéτé╣µþ░ΘçÅσ╛êσÁÜ∩╝ðσØçσðÇσêåσ╕â∩╝ðσøᵡÁΣ╕ÞΣ╝ÜΘÇáµêÉΓÇ£Θø¬σ┤⌐ΓÇØτÄ░Φ▒íπÇé
 
- public┬áclass┬áShard<S>┬á{┬á//┬áSτ▒╗σ░üΦúàΣ║åµ£║σÖ¿Φèéτé╣τÜäΣ┐íµü»┬á∩╝ðσÓénameπÇüpasswordπÇüipπÇüportτ¡ë┬á┬á┬á
-   
- ┬á┬á┬á┬áprivate┬áTreeMap<Long,┬áS>┬ánodes;┬á//┬áΦÖܵЃΦèéτé╣┬á┬á┬á
-     private List<S> shards; // 真实机器节点   
- ┬á┬á┬á┬áprivate┬áfinal┬áint┬áNODE_NUM┬á=┬á100;┬á//┬áµ»ÅΣ╕¬µ£║σÖ¿Φèéτé╣σà│ΦüöτÜäΦÖܵЃΦèéτé╣Σ╕¬µþ░┬á┬á┬á
-   
-     public Shard(List<S> shards) {  
-         super();  
-         this.shards = shards;  
-         init();  
-     }  
-   
- ┬á┬á┬á┬áprivate┬ávoid┬áinit()┬á{┬á//┬áσêØσÚÐσðûΣ╕ÇΦç┤µÇÚhashτÄ»┬á┬á┬á
-         nodes = new TreeMap<Long, S>();  
- ┬á┬á┬á┬á┬á┬á┬á┬áfor┬á(int┬ái┬á=┬á0;┬ái┬á!=┬áshards.size();┬á++i)┬á{┬á//┬áµ»ÅΣ╕¬τ£ƒσ«₧µ£║σÖ¿Φèéτé╣Θâ╜Θ£ÇΦÓüσà│ΦüöΦÖܵЃΦèéτé╣┬á┬á┬á
-             final S shardInfo = shards.get(i);  
-   
-             for (int n = 0; n < NODE_NUM; n++)  
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//┬áΣ╕ÇΣ╕¬τ£ƒσ«₧µ£║σÖ¿Φèéτé╣σà│ΦüöNODE_NUMΣ╕¬ΦÖܵЃΦèéτé╣┬á┬á┬á
-                 nodes.put(hash("SHARD-" + i + "-NODE-" + n), shardInfo);  
-   
-         }  
-     }  
-   
-     public S getShardInfo(String key) {  
- ┬á┬á┬á┬á┬á┬á┬á┬áSortedMap<Long,┬áS>┬átail┬á=┬ánodes.tailMap(hash(key));┬á//┬áµ▓┐τÄ»τÜäΘí║µÝ╢ΘÆêµë╛σê░Σ╕ÇΣ╕¬ΦÖܵЃΦèéτé╣┬á┬á┬á
-         if (tail.size() == 0) {  
-             return nodes.get(nodes.firstKey());  
-         }  
- ┬á┬á┬á┬á┬á┬á┬á┬áreturn┬átail.get(tail.firstKey());┬á//┬áΦ┐öσø₧Φ»ÍΦÖܵЃΦèéτé╣σ»╣σ║öτÜäτ£ƒσ«₧µ£║σÖ¿Φèéτé╣τÜäΣ┐íµü»┬á┬á┬á
-     }  
-   
-     /** 
- ┬á┬á┬á┬á┬á*┬á┬áMurMurHashτ«Ýµ│þ∩╝ðµý»ΘØ₧σèáσ»åHASHτ«Ýµ│þ∩╝ðµÇÚΦâ╜σ╛êΘ½ý∩╝ð┬á
- ┬á┬á┬á┬á┬á*┬á┬áµ»öΣ╝áτ╗ƒτÜäCRC32,MD5∩╝ðSHA-1∩╝êΦ┐ÖΣ╕ÁΣ╕¬τ«Ýµ│þΘâ╜µý»σèáσ»åHASHτ«Ýµ│þ∩╝ðσÁÞµØéσ║Óµ£¼Φ║½σ░▒σ╛êΘ½ý∩╝ðσ╕ÓµØÍτÜäµÇÚΦâ╜Σ╕èτÜäµÞƒσ«│Σ╣ƒΣ╕ÞσÅ»Θü┐σàÞ∩╝ë┬á
- ┬á┬á┬á┬á┬á*┬á┬áτ¡ëHASHτ«Ýµ│þΦÓüσ┐½σ╛êσÁÜ∩╝ðΦÇðΣ╕öµÞ«Φ»┤Φ┐ÖΣ╕¬τ«Ýµ│þτÜäτó░µÆ₧τÄçσ╛êΣ╜Ä.┬á
-      *  http://murmurhash.googlepages.com/ 
-      */  
-     private Long hash(String key) {  
-           
-         ByteBuffer buf = ByteBuffer.wrap(key.getBytes());  
-         int seed = 0x1234ABCD;  
-           
-         ByteOrder byteOrder = buf.order();  
-         buf.order(ByteOrder.LITTLE_ENDIAN);  
-   
-         long m = 0xc6a4a7935bd1e995L;  
-         int r = 47;  
-   
-         long h = seed ^ (buf.remaining() * m);  
-   
-         long k;  
-         while (buf.remaining() >= 8) {  
-             k = buf.getLong();  
-   
-             k *= m;  
-             k ^= k >>> r;  
-             k *= m;  
-   
-             h ^= k;  
-             h *= m;  
-         }  
-   
-         if (buf.remaining() > 0) {  
-             ByteBuffer finish = ByteBuffer.allocate(8).order(  
-                     ByteOrder.LITTLE_ENDIAN);  
-             // for big-endian version, do this first:   
-             // finish.position(8-buf.remaining());   
-             finish.put(buf).rewind();  
-             h ^= finish.getLong();  
-             h *= m;  
-         }  
-   
-         h ^= h >>> r;  
-         h *= m;  
-         h ^= h >>> r;  
-   
-         buf.order(byteOrder);  
-         return h;  
-     }  
-   
- }  



τø╕σà│µÄ¿ΦÞÉ
MurmurHashτ«Ýµ│þτö▒Austin Applebyσêøσ╗║Σ║Ä2008σ╣┤∩╝ðτÄ░σ╖▓σ║öτö¿σê░HadoopπÇülibstdc πÇünginxπÇülibmemcached,Redis∩╝ðMemcached∩╝ðCassandra∩╝ðHBase∩╝ðLuceneτ¡ëσ╝ǵ║Éτ│╗τ╗ƒπÇé2011σ╣┤ApplebyΦó½GoogleΘøçΣ╜ú∩╝ðΘÜÅσÉÄGoogleµÄ¿σç║σà╢σÅýτÚÞτÜä...
** MurMurHash3 τ«Ýµ│þµÓéΦ┐░ ** MurMurHash3 µý»Σ╕ÇτÚÞΘØ₧σèáσ»åσôêσ╕ðσç╜µþ░∩╝ðτö▒ Austin Appleby σ╝ÇσÅæ∩╝ðΦó½σ╣┐µ│øσ║öτö¿Σ║ĵþ░µÞ«τ╗ôµ₧äσÆðσêåσ╕âσ╝Åτ│╗τ╗ƒΣ╕¡∩╝ðσÓé HadoopπÇüRedis σÆðσà╢Σ╗ûµþ░µÞ«σ║ôτ│╗τ╗ƒπÇéσ«âτÜäΣ╕╗ΦÓüτë╣τé╣µý»Φ«íτ«ÝΘǃσ║Óσ┐½Σ╕öσôêσ╕ðσå▓τ¬üτÜäµÓéτÄç...
hadoop_spark_µþ░µÞ«τ«Ýµ│þhadoop_spark_µþ░µÞ«τ«Ýµ│þhadoop_spark_µþ░µÞ«τ«Ýµ│þhadoop_spark_µþ░µÞ«τ«Ýµ│þ
µ¡ÁσÁû∩╝ðΦ┐ýσÅ»Σ╗ÍΦÇâΦÖæσ░åσà╢Σ╗ûσ╣╢ΦíðΦ«íτ«Ýµíåµ₧╢∩╝êσÓéSpark∩╝ëΣ╕ÄHadoopτ╗ôσÉêΣ╜┐τö¿∩╝ðΦ┐øΣ╕ǵ¡ÍµÅÉΘ½ýΦüÜτ▒╗τ«Ýµ│þτÜäµÇÚΦâ╜πÇé µÇ╗Σ╣Ð∩╝ðΘÇÜΦ┐çσ░åHadoopτÜäMapReduceµíåµ₧╢σ║öτö¿Σ║ÄΦüÜτ▒╗τ«Ýµ│þ∩╝ðµêæΣ╗¼Σ╕ÞΣ╗àΦâ╜σÁƒσÁäτÉåµø┤σÁÚτÜäµþ░µÞ«Θøå∩╝ðΦ┐ýΦâ╜σÁƒµø┤Θ½ýµþêσ£░σ«ðµêɵþ░µÞ«σêåµ₧ÉΣ╗╗σèí...
Θâ¿τ╜▓Hadoop3.0Θ½ýµÇÚΦâ╜Θøåτ╛Á∩╝ðHadoopσ«ðσà¿σêåσ╕âσ╝ŵ¿íσ╝Å: HadoopτÜäσ«êµèÁΦ┐øτ¿Ðσêåσê½Φ┐ÉΦíðσ£¿τö▒σÁÜΣ╕¬Σ╕╗µ£║µÉ¡σ╗║τÜäΘøåτ╛ÁΣ╕è,Σ╕ÞσÉð Φèéτé╣µÐàΣ╗╗Σ╕ÞσÉðτÜäΦÚÆΦë▓,σ£¿σ«₧ΘÖàσ╖ÍΣ╜£σ║öτö¿σ╝ÇσÅæΣ╕¡,ΘÇÜσ╕╕Σ╜┐τö¿Φ»Íµ¿íσ╝ŵ₧äσ╗║Σ╝üΣ╕Üτ║ÚHadoopτ│╗τ╗ƒπÇé σ£¿HadoopτÄ»σóâΣ╕¡,µëǵ£ë...
Σ╕ÇΣ╕¬σÍ╜τÜäΦ░âσ║Óτ«Ýµ│þσ║öΦ»ÍΦâ╜σÁƒσ╣│ΦííΣ╜£Σ╕ÜτÜäµëÚΦíðµÝ╢ΘÝ┤πÇüΦ╡äµ║Éσê⌐τö¿τÄçΣ╗ÍσÅèσà¼σ╣│µÇÚτ¡ëσøáτ┤á∩╝ðΣ╗ÄΦÇðµ£ÇσÁÚσðûµþ┤Σ╕¬Θøåτ╛ÁτÜäσÉ₧σÉÉΘçÅσÆðσôÞσ║öΘǃσ║ÓπÇé #### Σ╕ëπÇüHadoopΘøåτ╛ÁτÜäMapReduceΦ«íτ«Ýµ₧╢µ₧ä HadoopτÜäMapReduceΦ«íτ«Ýµ₧╢µ₧äσðàµÐ¼Σ╕ÁΣ╕¬µá╕σ┐âτ╗äΣ╗╢∩╝Ü...
σƒ║Σ║ÄLinuxµ₧äσ╗║HadoopΘ½ýµÇÚΦâ╜µ£ÞσèíσÖ¿Θøåτ╛Á µ£¼µûçµíúΣ╗Ðτ╗ÞΣ║åσÓéΣ╜þσ£¿LinuxΣ╕е₧äσ╗║Θ½ýµÇÚΦâ╜τÜäHadoopµ£ÞσèíσÖ¿Θøåτ╛Á∩╝ðΣ╗͵╗íΦ╢│σÁÚµþ░µÞ«µÝ╢Σ╗úσ»╣Θ½ýµÇÚΦâ╜Φ«íτ«ÝτÜäΘ£Çµ▒éπÇéµûçτ½áΘÓûσàêΣ╗Ðτ╗ÞΣ║åHadoopµíåµ₧╢τÜäΘçÞΦÓüµÇÚ∩╝ðτä╢σÉÄΦ»Óτ╗åΣ╗Ðτ╗ÞΣ║åσÓéΣ╜þσ£¿LinuxΣ╕еɡσ╗║Hadoop...
σ£¿σêåσ╕âσ╝ÅΦ«íτ«ÝΘóåσƒƒ∩╝ðHadoopΣ╜£Σ╕║Σ╕ÇΣ╕¬σ╝ǵ║ÉτÜäµíåµ₧╢∩╝ðτö¿Σ║ÄσÁäτÉåσÆðσ¡ýσé¿σÁÚΦÚ䵿íµþ░µÞ«∩╝ðσà╢Φ░âσ║Óτ«Ýµ│þµý»σå│σ«Üτ│╗τ╗ƒµþêτÄçσÆðσà¼σ╣│µÇÚτÜäΘçÞΦÓüτ╗äµêÉΘâ¿σêåπÇéµ£¼τ»çµûçτ½áσ░åΦ»Óτ╗åΣ╗Ðτ╗ÞHadoopΣ╕¡τÜäσçáτÚÞσ╕╕ΦÚüΦ░âσ║Óτ«Ýµ│þ∩╝ðσðàµÐ¼FIFO∩╝êσàêΦ┐øσàêσç║∩╝ëπÇüσà¼σ╣│Φ░âσ║Óτ«Ýµ│þ...
### σƒ║Σ║ÄHadoopτÜäAprioriτ«Ýµ│þΦ«╛Φ«íΣ╕Äσ«₧τÄ░ #### Σ╕ÇπÇüΦâðµÖ»Σ╕ÄΘÝ«ΘóýµÓéΦ┐░ ΘÜÅτØÇΣ┐íµü»µèǵ£»τÜäσÅæσ▒þ∩╝ðµ╡╖Θçŵþ░µÞ«τÜäσÁäτÉåΣ╕Ä...µ£¬µØÍτÜäτáöτ⌐╢σÅ»Σ╗ÍΦ┐øΣ╕ǵ¡ÍµÄóτ┤óσÓéΣ╜þτ╗ôσÉêσà╢Σ╗ûσàêΦ┐øτÜäσÁÚµþ░µÞ«σÁäτÉåµèǵ£»∩╝ðσÓéSparkτ¡ë∩╝ðµØÍΦ┐øΣ╕ǵ¡ÍµÅÉΘ½ýAprioriτ«Ýµ│þτÜäµÇÚΦâ╜πÇé
πÇÉΘøåτ╛ÁHadoopµÇÚΦâ╜µ╡ÐΦ»þπÇæµý»ΘÆêσ»╣Hadoopσêåσ╕âσ╝ÅΦ«íτ«Ýµíåµ₧╢Φ┐øΦíðτÜäΣ╕Çτ│╗σêݵÇÚΦâ╜Φ»äΣ╝░µ┤╗σè¿∩╝ðτø«τÜäµý»µë╛σç║µ£ÇΣ╜│ΘàÞτ╜«Σ╗͵ÅÉσÞçτ│╗τ╗ƒµþêτÄçπÇéµ╡ÐΦ»þµû╣µ│þΣ╕╗ΦÓüΘÇÜΦ┐çshellΦç¬σè¿σðûΦäܵ£¼µØÍσ«ðµêÉ∩╝ðσðàµÐ¼τöƒµêÉΘàÞτ╜«µûçΣ╗╢πÇüµëÚΦíðµ╡ÐΦ»þπÇüΦ«░σ╜þµÝ╢ΘÝ┤Σ╗ÍσÅèµüóσÁÞΘ╗ýΦ«ÁΘàÞτ╜«...
Φ┐ÖΣ╕¬µðçµáçΣ╕ÞΣ╗àΦÇâΦÖæΣ║åΦèéτé╣τÜäτí¼Σ╗╢ΘàÞτ╜«∩╝ðσÓéCPUπÇüσåàσ¡ýτ¡ëΘØÖµÇüσÅéµþ░∩╝ðΦ┐ýτ╗ôσÉêΣ║åΦèéτé╣σ£¿Φ┐ÉΦíðΦ┐çτ¿ÐΣ╕¡τÜäσ迵ÇüµÇÚΦâ╜Φí¿τÄ░∩╝ðσÓéCPUσê⌐τö¿τÄçπÇüσåàσ¡ýΣ╜┐τö¿τÄçπÇüτúüτøýI/Oτ¡ëπÇé σƒ║Σ║ĵ¡ÁµÇÚΦâ╜Φ»äΣ╗╖µðçµáç∩╝ðΣ╜£ΦÇàσ»╣Fair SchedulerΦ┐øΦíðΣ║åΣ╝ýσðû∩╝ðΦ«╛Φ«íΣ║åΣ╕ÇτÚÞµû░...
µÇ╗τ╗ô∩╝ðHadoopΘøåτ╛ÁτÜäΘ½ýσÅ»τö¿µÇÚσÆðµÇÚΦâ╜Σ╝ýσðûµý»Σ╕ÇΣ╕¬µðüτ╗¡τÜäΦ┐çτ¿Ð∩╝ðΘ£ÇΦÓüτ╗╝σÉêΦÇâΦÖæτí¼Σ╗╢ΘàÞτ╜«πÇüΦ╜»Σ╗╢σÅéµþ░Φ░âµþ┤πÇüΣ╗╗σèíΦ░âσ║Óτ¡ûτþÍτ¡ëσÁÜΣ╕¬µû╣ΘØóπÇéτÉåΦÚúσ╣╢τåƒτ╗âσ║öτö¿Σ╕èΦ┐░τƒÍΦ»åτé╣∩╝ðµ£ëσè⌐Σ║ĵ₧äσ╗║σç║Σ╕ÇΣ╕¬σ╝║σÁÚπÇüσÅ»ΘØáτÜäHadoopσÁÚµþ░µÞ«σÁäτÉåσ╣│σÅ░πÇé
σ£¿σ«₧ΘÖàσ║öτö¿Σ╕¡∩╝ðHadoopΣ╕èτÜäσêåτ▒╗τ«Ýµ│þΘÇÜσ╕╕Θ£ÇΦÓüΦÇâΦÖæµþ░µÞ«σÇ╛µû£∩╝êData Skewness∩╝ëΘÝ«Θóý∩╝ðσÞ│µþ░µÞ«σêåσ╕âΣ╕ÞσØçσðÇσÅ»Φâ╜σ»╝Φç┤µƒÉΣ║øΦèéτé╣σÁäτÉåτÜäΣ╗╗σèíΦ┐çΣ║Äτ╣üΘçÞ∩╝ðσ╜▒σôÞµþ┤Σ╜ôµÇÚΦâ╜πÇ鵡ÁσÁû∩╝ðµ¿íσ₧ÐτÜäΦ»äΣ╝░σÆðΦ░âΣ╝ýΣ╣ƒµý»σà│Θö«µ¡ÍΘ¬Á∩╝ðΦ┐ÖσðàµÐ¼Σ║ÁσÅëΘ¬ðΦ»üπÇüτë╣σ╛ü...
- Σ╗ĵ╡ÐΦ»þτ╗ôµ₧£µØÍτ£Ð∩╝ðHadoopΘøåτ╛Áσ£¿µþ░µÞ«Φ»╗σåÖσÆðµÄÆσ║ŵû╣ΘØóΦí¿τÄ░σç║Φë▓∩╝ðΣ╜åσ£¿σÁÚΦÚ䵿íµþ░µÞ«σÁäτÉåµÝ╢∩╝ðmapσÆðreduceΣ╗╗σèíτÜäσêåΘàÞπÇüµëÚΦíðµÝ╢ΘÝ┤Σ╗ÍσÅèΦ╡äµ║Éσê⌐τö¿τÄçτ¡ëµû╣ΘØóσÅ»Φâ╜Θ£ÇΦÓüΦ┐øΣ╕ǵ¡ÍΣ╝ýσðû∩╝ðΣ╗͵ÅÉσÞçµþ┤Σ╜ôµÇÚΦâ╜πÇé - ΦÇâΦÖæσê░τí¼Σ╗╢ΘàÞτ╜«σÆðΦ╜»Σ╗╢τëêµ£¼∩╝ð...
Φ«║µûçΣ╕¡∩╝ðΣ╜£ΦÇàΦÆÐΘæ½σ»╣µ»öΣ║åMPIσÆðHadoopσ£¿µëÚΦíðK-meansτ«Ýµ│þµÝ╢τÜäµÇÚΦâ╜∩╝ðσ«₧Θ¬ðτÄ»σóâΣ╕║CentOS6.5∩╝ðΣ╜┐τö¿Σ║åHadoop-2.6σÆðopenmpi-1.8.4τëêµ£¼πÇéΘÇÜΦ┐çτöƒµêÉτÜäΘÜŵ£║µþ░µÞ«Φ┐øΦíðσ«₧Θ¬ð∩╝ðτ╗ôµ₧£µý╛τÁ║σ£¿σ£░Φ┤¿σ¡Óµ¿íµÐƒΣ╕¡τÜäσÁÞµØéΦ┐¡Σ╗úΦ«íτ«Ý∩╝ðMPIτø╕µ»öHadoop...