
1、Spark介绍
Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目。随着Spark在大数据计算领域的暂露头角,越来越多的企业开始关注和使用。2014年11月,Spark在Daytona Gray Sort 100TB Benchmark竞赛中打破了由Hadoop MapReduce保持的排序记录。Spark利用1/10的节点数,把100TB数据的排序时间从72分钟提高到了23分钟。
Spark在架构上包括内核部分和4个官方子模块--Spark SQL、Spark Streaming、机器学习库MLlib和图计算库GraphX。图1所示为Spark在伯克利的数据分析软件栈BDAS(Berkeley Data Analytics Stack)中的位置。可见Spark专注于数据的计算,而数据的存储在生产环境中往往还是由Hadoop分布式文件系统HDFS承担。
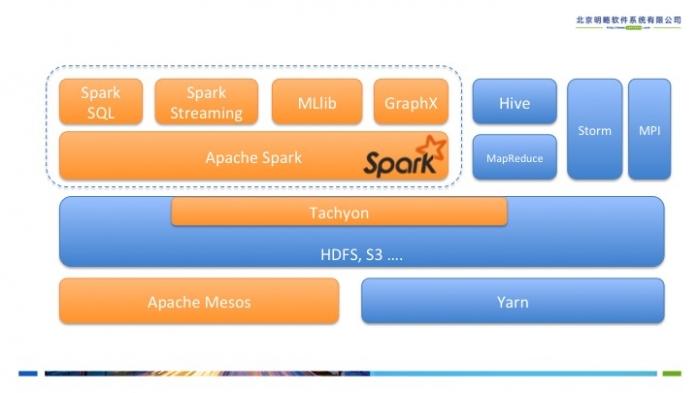
图1 Spark在BDAS中的位置
Spark被设计成支持多场景的通用大数据计算平台,它可以解决大数据计算中的批处理,交互查询及流式计算等核心问题。Spark可以从多数据源的读取数据,并且拥有不断发展的机器学习库和图计算库供开发者使用。数据和计算在Spark内核及Spark的子模块中是打通的,这就意味着Spark内核和子模块之间成为一个整体。Spark的各个子模块以Spark内核为基础,进一步支持更多的计算场景,例如使用Spark SQL读入的数据可以作为机器学习库MLlib的输入。表1列举了一些在Spark平台上的计算场景。
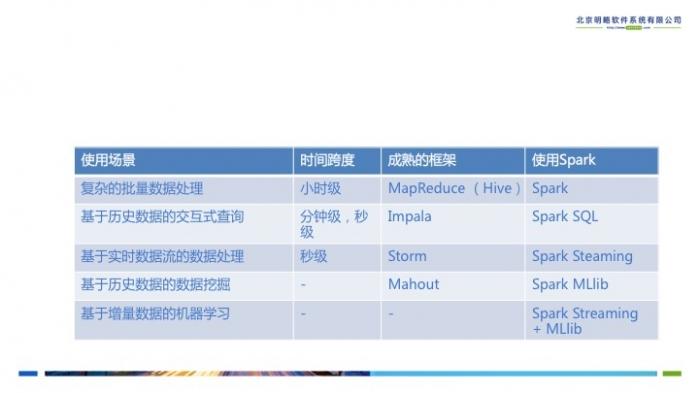
表1 Spark的应用场景举例
在本文写作是,Spark的最新版本为1.2.0,文中的示例代码也来自于这个版本。
2、Spark内核介绍
相信大数据工程师都非常了解Hadoop MapReduce一个最大的问题是在很多应用场景中速度非常慢,只适合离线的计算任务。这是由于MapReduce需要将任务划分成map和reduce两个阶段,map阶段产生的中间结果要写回磁盘,而在这两个阶段之间需要进行shuffle操作。Shuffle操作需要从网络中的各个节点进行数据拷贝,使其往往成为最为耗时的步骤,这也是Hadoop MapReduce慢的根本原因之一,大量的时间耗费在网络磁盘IO中而不是用于计算。在一些特定的计算场景中,例如像逻辑回归这样的迭代式的计算,MapReduce的弊端会显得更加明显。
那Spark是如果设计分布式计算的呢?首先我们需要理解Spark中最重要的概念--弹性分布数据集(Resilient Distributed Dataset),也就是RDD。
2.1 弹性分布数据集RDD
RDD是Spark中对数据和计算的抽象,是Spark中最核心的概念,它表示已被分片(partition),不可变的并能够被并行操作的数据集合。对RDD的操作分为两种transformation和action。Transformation操作是通过转换从一个或多个RDD生成新的RDD。Action操作是从RDD生成最后的计算结果。在Spark最新的版本中,提供丰富的transformation和action操作,比起MapReduce计算模型中仅有的两种操作,会大大简化程序开发的难度。
RDD的生成方式只有两种,一是从数据源读入,另一种就是从其它RDD通过transformation操作转换。一个典型的Spark程序就是通过Spark上下文环境(SparkContext)生成一个或多个RDD,在这些RDD上通过一系列的transformation操作生成最终的RDD,最后通过调用最终RDD的action方法输出结果。
每个RDD都可以用下面5个特性来表示,其中后两个为可选的:
- 分片列表(数据块列表)
- 计算每个分片的函数
- 对父RDD的依赖列表
- 对key-value类型的RDD的分片器(Partitioner)(可选)
- 每个数据分片的预定义地址列表(如HDFS上的数据块的地址)(可选)
虽然Spark是基于内存的计算,但RDD不光可以存储在内存中,根据useDisk、useMemory、useOffHeap, deserialized、replication五个参数的组合Spark提供了12种存储级别,在后面介绍RDD的容错机制时,我们会进一步理解。值得注意的是当StorageLevel设置成OFF_HEAP时,RDD实际被保存到Tachyon中。Tachyon是一个基于内存的分布式文件系统,目前正在快速发展,本文不做详细介绍,可以通过其官方网站进一步了解。
- classStorageLevelprivate(
- privatevar _useDisk:Boolean,
- privatevar _useMemory:Boolean,
- privatevar _useOffHeap:Boolean,
- privatevar _deserialized:Boolean
- privatevar _replication:Int=1)
- extendsExternalizable{//… }
- val NONE =newStorageLevel(false,false,false,false)
- val DISK_ONLY =newStorageLevel(true,false,false,false)
- val DISK_ONLY_2 =newStorageLevel(true,false,false,false,2)
- val MEMORY_ONLY =newStorageLevel(false,true,false,true)
- val MEMORY_ONLY_2 =newStorageLevel(false,true,false,true,2)
- val MEMORY_ONLY_SER =newStorageLevel(false,true,false,false)
- val MEMORY_ONLY_SER_2 =newStorageLevel(false,true,false,false,2)
- val MEMORY_AND_DISK =newStorageLevel(true,true,false,true)
- val MEMORY_AND_DISK_2 =newStorageLevel(true,true,false,true,2)
- val MEMORY_AND_DISK_SER =newStorageLevel(true,true,false,false)
- val MEMORY_AND_DISK_SER_2 =newStorageLevel(true,true,false,false,2)
- val OFF_HEAP =newStorageLevel(false,false,true,false)
2.2 DAG、Stage与任务的生成
Spark的计算发生在RDD的action操作,而对action之前的所有transformation,Spark只是记录下RDD生成的轨迹,而不会触发真正的计算。
Spark内核会在需要计算发生的时刻绘制一张关于计算路径的有向无环图,也就是DAG。举个例子,在图2中,从输入中逻辑上生成A和C两个RDD,经过一系列transformation操作,逻辑上生成了F,注意,我们说的是逻辑上,因为这时候计算没有发生,Spark内核做的事情只是记录了RDD的生成和依赖关系。当F要进行输出时,也就是F进行了action操作,Spark会根据RDD的依赖生成DAG,并从起点开始真正的计算。
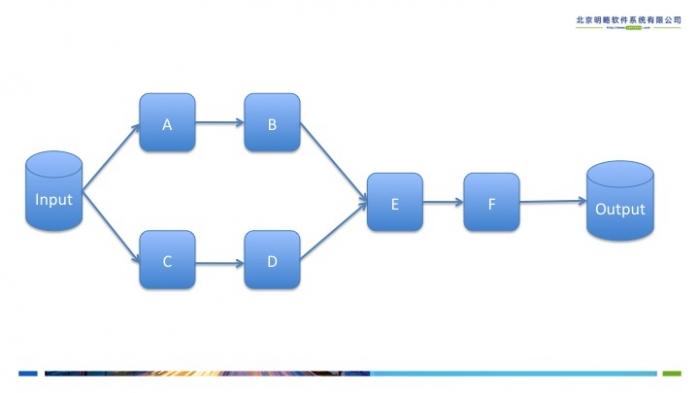
图2 逻辑上的计算过程:DAG
有了计算的DAG图,Spark内核下一步的任务就是根据DAG图将计算划分成任务集,也就是Stage,这样可以将任务提交到计算节点进行真正的计算。Spark计算的中间结果默认是保存在内存中的,Spark在划分Stage的时候会充分考虑在分布式计算中可流水线计算(pipeline)的部分来提高计算的效率,而在这个过程中,主要的根据就是RDD的依赖类型。根据不同的transformation操作,RDD的依赖可以分为窄依赖(Narrow Dependency)和宽依赖(Wide Dependency,在代码中为ShuffleDependency)两种类型。窄依赖指的是生成的RDD中每个partition只依赖于父RDD(s) 固定的partition。宽依赖指的是生成的RDD的每一个partition都依赖于父 RDD(s) 所有partition。窄依赖典型的操作有map, filter, union等,宽依赖典型的操作有groupByKey, sortByKey等。可以看到,宽依赖往往意味着shuffle操作,这也是Spark划分stage的主要边界。对于窄依赖,Spark会将其尽量划分在同一个stage中,因为它们可以进行流水线计算。
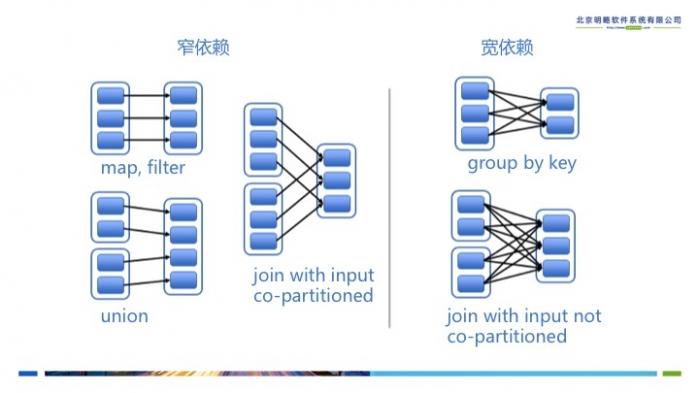
图3 RDD的宽依赖和窄依赖
我们再通过图4详细解释一下Spark中的Stage划分。我们从HDFS中读入数据生成3个不同的RDD,通过一系列transformation操作后再将计算结果保存回HDFS。可以看到这幅DAG中只有join操作是一个宽依赖,Spark内核会以此为边界将其前后划分成不同的Stage. 同时我们可以注意到,在图中Stage2中,从map到union都是窄依赖,这两步操作可以形成一个流水线操作,通过map操作生成的partition可以不用等待整个RDD计算结束,而是继续进行union操作,这样大大提高了计算的效率。
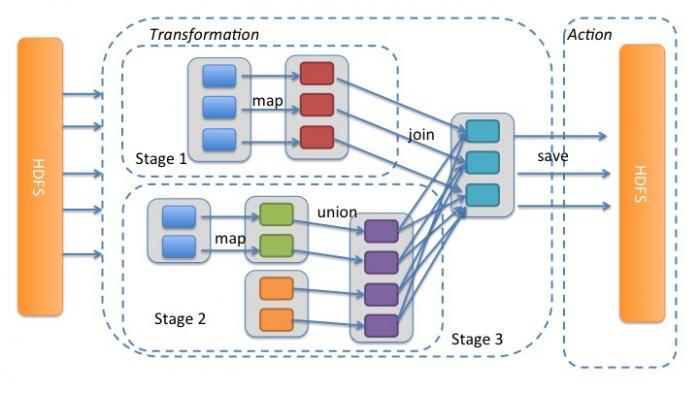
图4 Spark中的Stage划分
http://developer.51cto.com/art/201502/464742.htm



相关推荐
随着 Spark在大数据计算领域的暂露头角,越来越多的企业开始关注和使用。2014年11月,Spark在Daytona Gray Sort 100TB Benchmark
Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目。随着 Spark在大数据计算领域的暂露头角,越来越多的企业开始关注和使用。2014年11月,Spark在...
《Spark技术内幕深入解析Spark内核架构设计与实现原理》这本书深入探讨了Apache Spark这一分布式计算框架的核心架构和实现机制,旨在帮助读者全面理解Spark的工作原理,并能够有效地利用其进行大数据处理。...
深入理解Sp深入理解SPARK:核心思想与源码分析》结合大量图和示例,对Spark的架构、部署模式和工作模块的设计理念、实现源码与使用技巧进行了深入的剖析与解读。 《深入理解SPARK:核心思想与源码分析》一书对Spark...
1. 启明星辰公司副总裁潘柱廷:2016 年大数据技术发展趋势解读 2. Databricks公司联合创始人、Spark首席架构师辛湜:Spark发展:回顾2015,展望 2016 3. 京东云平台总架构师、系统技术部负责人刘海锋 :从2014 到...
该课程主要解决的问题是Spark如何设计和实现一个高性能的分布式计算框架,以及如何在处理大数据时提供更快的计算速度和更灵活的操作。 在内容上,本书可能会从以下几个方面来剖析Spark的源码: 1. Spark的设计初衷...
《Spark技术内幕》这本书...总的来说,《Spark技术内幕》是一本深度解析Spark的书籍,适合有志于在大数据领域,特别是Spark平台进行开发和优化的工程师。它将帮助读者掌握Spark的精髓,提升在实际项目中的应用能力。
在大数据和云计算方面,了解Hadoop和Spark的处理机制,掌握GPU并行计算的原理与应用,可以帮助专业人员更好地处理大规模数据集,优化计算效率。这些前沿技术的掌握,对于在行业竞争中保持领先至关重要。 开发大神...
- 对Linux 4.1内核热补丁的成功实践进行了深度解读,展示了操作系统内核在安全性与稳定性方面的持续改进。 - 华为云AI战略的解析,揭示了华为如何利用AI技术在未来的市场竞争中取得优势。 6. **挑战与应对** - ...
- **大数据**:Hadoop、Spark等大数据处理框架的应用。 - **课程资源**:各类技术培训材料、教学视频等。 - **音视频处理**:多媒体文件处理、音频编辑软件等。 - **网站开发**:包括响应式网页设计、动态网站开发等...