
 
Úźśň┐źšťüšÜäŠÄĺň║Ćš«ŚŠ│Ľ
ŠťëŠ▓튝늌óńŞŹŠÁ¬Ŕ┤╣šę║ÚŚ┤ňĆłňĆ»ń╗ąň┐źńŞÇšé╣šÜäŠÄĺň║Ćš«ŚŠ│ĽňĹó´╝čÚéúň░▒Šś»ÔÇťň┐źÚÇčŠÄĺň║ĆÔÇŁňĽŽ´╝üňůëňÉČŔ┐ÖńެňÉŹňşŚŠś»ńŞŹŠś»ň░▒ŔžëňżŚňżłÚźśšź»ňĹóŃÇé
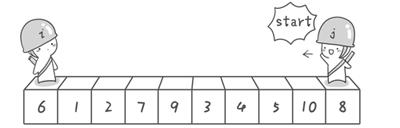
ňüçŔ«żŠłĹń╗ČšÄ░ňťĘň»╣ÔÇť6 ┬á1 ┬á2 7 ┬á9 ┬á3 ┬á4 ┬á5 10 ┬á8ÔÇŁŔ┐Öńެ10ńެŠĽ░Ŕ┐ŤŔíîŠÄĺň║ĆŃÇéÚŽľňůłňťĘŔ┐Öńެň║ĆňłŚńŞşÚÜĆńż┐ŠëżńŞÇńެŠĽ░ńŻťńŞ║ňč║ňç押░´╝łńŞŹŔŽüŔóźŔ┐ÖńެňÉŹŔ»ŹňÉôňł░ń║ć´╝îň░▒Šś»ńŞÇńެšöĘŠŁąňĆéšůžšÜ䊼░´╝îňżůń╝ÜńŻáň░▒ščąÚüôň«âšöĘŠŁąňüÜňĽąšÜäń║ć´╝ëŃÇéńŞ║ń║抾╣ńż┐´╝îň░▒Ŕ«ęšČČńŞÇńެŠĽ░6ńŻťńŞ║ňč║ňç押░ňÉžŃÇéŠÄąńŞőŠŁą´╝îÚťÇŔŽüň░ćŔ┐Öńެň║ĆňłŚńŞşŠëÇŠťëŠ»öňč║ňç押░ňĄžšÜ䊼░ŠöżňťĘ6šÜäňĆ│Ŕż╣´╝öňč║ňç押░ň░ĆšÜ䊼░ŠöżňťĘ6šÜäňĚŽŔż╣´╝îš▒╗ń╝╝ńŞőÚŁóŔ┐ÖšžŹŠÄĺňłŚ´╝Ü
3  1  2 5  4  6  9 7  10  8
ňťĘňłŁňžőšŐŠÇüńŞő´╝░ňşŚ6ňťĘň║ĆňłŚšÜäšČČ1ńŻŹŃÇ銳Ĺń╗ČšÜ䚍«Šá犜»ň░ć6Šî¬ňł░ň║ĆňłŚńŞşÚŚ┤šÜäŠčÉńެńŻŹšŻ«´╝îňüçŔ«żŔ┐ÖńެńŻŹšŻ«Šś»kŃÇéšÄ░ňťĘň░▒ÚťÇŔŽüň»╗ŠëżŔ┐Öńެk´╝îň╣ÂńŞöń╗ąšČČkńŻŹńŞ║ňłćšĽîšé╣´╝îňĚŽŔż╣šÜ䊼░ÚâŻň░Ćń║Äšşëń║Ä6´╝îňĆ│Ŕż╣šÜ䊼░ÚâŻňĄžń║Äšşëń║Ä6ŃÇéŠâ│ńŞÇŠâ│´╝îńŻáŠťëňŐ׊│ĽňĆ»ń╗ąňüÜňł░Ŕ┐Öšé╣ňÉŚ´╝č
ŠÄĺň║Ćš«ŚŠ│ĽŠśżšą×ňĘü
Šľ╣Š│ĽňůÂň«×ňżłš«ÇňŹĽ´╝Üňłćňłźń╗ÄňłŁňžőň║ĆňłŚÔÇť6 ┬á1 ┬á2 7 ┬á9 ┬á3 ┬á4 ┬á5 10 ┬á8ÔÇŁńŞĄšź»ň╝ÇňžőÔÇťŠÄóŠÁőÔÇŁŃÇéňůłń╗ÄňĆ│ňżÇňĚŽŠëżńŞÇńެň░Ćń║Ä6šÜ䊼░´╝îňćŹń╗ÄňĚŽňżÇňĆ│ŠëżńŞÇńެňĄžń║Ä6šÜ䊼░´╝îšäÂňÉÄń║ĄŠŹóń╗ľń╗ČŃÇéŔ┐ÖÚçîňĆ»ń╗ąšöĘńŞĄńެňĆśÚçĆiňĺîj´╝îňłćňłźŠîçňÉĹň║ĆňłŚŠťÇňĚŽŔż╣ňĺÇňĆ│Ŕż╣ŃÇ銳Ĺń╗ČńŞ║Ŕ┐ÖńŞĄńެňĆśÚçĆŔÁĚńެňąŻňÉČšÜäňÉŹňşŚÔÇťňôĘňůÁiÔÇŁňĺîÔÇťňôĘňůÁjÔÇŁŃÇéňłÜň╝ÇňžőšÜ䊌ÂňÇÖŔ«ęňôĘňůÁiŠîçňÉĹň║ĆňłŚšÜ䊝ÇňĚŽŔż╣´╝łňŹ│i=1´╝ë´╝îŠîçňÉĹŠĽ░ňşŚ6ŃÇéŔ«ęňôĘňůÁjŠîçňÉĹň║ĆňłŚšÜ䊝ÇňĆ│Ŕż╣´╝łňŹ│=10´╝ë´╝îŠîçňÉĹŠĽ░ňşŚŃÇé
 
ÚŽľňůłňôĘňůÁjň╝Çňžőňç║ňŐĘŃÇéňŤáńŞ║ŠşĄňĄäŔ«żšŻ«šÜäňč║ňç押░Šś»ŠťÇňĚŽŔż╣šÜ䊼░´╝îŠëÇń╗ąÚťÇŔŽüŔ«ęňôĘňůÁjňůłňç║ňŐĘ´╝îŔ┐ÖńŞÇšé╣ÚŁ×ňŞŞÚçŹŔŽü´╝łŔ»ĚŔç¬ňĚ▒Šâ│ńŞÇŠâ│ńŞ║ń╗Çń╣ł´╝ëŃÇéňôĘňůÁjńŞÇŠşąńŞÇŠşąňť░ňÉĹňĚŽŠî¬ňŐĘ´╝łňŹ│j--´╝ë´╝┤ňł░Šëżňł░ńŞÇńެň░Ćń║Ä6šÜ䊼░ňüťńŞőŠŁąŃÇéŠÄąńŞőŠŁąňôĘňůÁiňćŹńŞÇŠşąńŞÇŠşąňÉĹňĆ│Šî¬ňŐĘ´╝łňŹ│i++´╝ë´╝┤ňł░Šëżňł░ńŞÇńެŠĽ░ňĄžń║Ä6šÜ䊼░ňüťńŞőŠŁąŃÇ銝ÇňÉÄňôĘňůÁjňüťňťĘń║押░ňşŚ5ÚŁóň돴╝îňôĘňůÁiňüťňťĘń║押░ňşŚ7ÚŁóňëŹŃÇé


šÄ░ňťĘń║ĄŠŹóňôĘňůÁiňĺîňôĘňůÁjŠëÇŠîçňÉĹšÜäňůâš┤ášÜäňÇ╝ŃÇéń║ĄŠŹóń╣őňÉÄšÜäň║ĆňłŚňŽéńŞő´╝Ü
6  1  2  5  9 3  4  7  10  8


ňł░ŠşĄ´╝îšČČńŞÇŠČíń║ĄŠŹóš╗ôŠŁčŃÇéŠÄąńŞőŠŁąň╝ÇňžőňôĘňůÁjš╗žš╗şňÉĹňĚŽŠî¬ňŐĘ´╝łňćŹňĆőŠâůŠĆÉÚćĺ´╝ƊČíň┐ůÚí╗Šś»ňôĘňůÁjňůłňç║ňĆĹ´╝ëŃÇéń╗ľňĆĹšÄ░ń║ć4´╝łŠ»öňč║ňç押░6ŔŽüň░Ć´╝îŠ╗íŔÂ│ŔŽüŠ▒é´╝ëń╣őňÉÄňüťń║ćńŞőŠŁąŃÇéňôĘňůÁiń╣čš╗žš╗şňÉĹňĆ│Šî¬ňŐĘšÜä´╝îń╗ľňĆĹšÄ░ń║ć9´╝łŠ»öňč║ňç押░6ŔŽüňĄž´╝îŠ╗íŔÂ│ŔŽüŠ▒é´╝ëń╣őňÉÄňüťń║ćńŞőŠŁąŃÇ銺ĄŠŚÂň揊ČíŔ┐ŤŔíîń║ĄŠŹó´╝îń║ĄŠŹóń╣őňÉÄšÜäň║ĆňłŚňŽéńŞő´╝Ü
6  1  2 5  4  3  9  7 10  8
šČČń║îŠČíń║ĄŠŹóš╗ôŠŁč´╝îÔÇťŠÄóŠÁőÔÇŁš╗žš╗şŃÇéňôĘňůÁjš╗žš╗şňÉĹňĚŽŠî¬ňŐĘ´╝îń╗ľňĆĹšÄ░ń║ć3´╝łŠ»öňč║ňç押░6ŔŽüň░Ć´╝îŠ╗íŔÂ│ŔŽüŠ▒é´╝ëń╣őňÉÄňĆłňüťń║ćńŞőŠŁąŃÇéňôĘňůÁiš╗žš╗şňÉĹňĆ│šž╗ňŐĘ´╝îš│čňĽŽ´╝üŠşĄŠŚÂňôĘňůÁiňĺîňôĘňůÁjšŤŞÚüçń║ć´╝îňôĘňůÁiňĺîňôĘňůÁjÚâŻŔÁ░ňł░3ÚŁóňëŹŃÇéŔ»┤ŠśÄŠşĄŠŚÂÔÇťŠÄóŠÁőÔÇŁš╗ôŠŁčŃÇ銳Ĺń╗Čň░ćňč║ňç押░6ňĺî3Ŕ┐ŤŔíîń║ĄŠŹóŃÇéń║ĄŠŹóń╣őňÉÄšÜäň║ĆňłŚňŽéńŞő´╝Ü
3  1 2  5  4  6  9 7  10  8



ňł░ŠşĄšČČńŞÇŔŻ«ÔÇťŠÄóŠÁőÔÇŁšťčŠşúš╗ôŠŁčŃÇ銺ĄŠŚÂń╗ąňč║ňç押░6ńŞ║ňłćšĽîšé╣´╝î6ňĚŽŔż╣šÜ䊼░ÚâŻň░Ćń║Äšşëń║Ä6´╝î6ňĆ│Ŕż╣šÜ䊼░ÚâŻňĄžń║Äšşëń║Ä6ŃÇéňŤ×ÚíżńŞÇńŞőňłÜŠëŹšÜäŔ┐çšĘő´╝îňůÂň«×ňôĘňůÁjšÜäńŻ┐ňĹŻň░▒Šś»ŔŽüŠëżň░Ćń║Äňč║ňç押░šÜ䊼░´╝îŔÇîňôĘňůÁišÜäńŻ┐ňĹŻň░▒Šś»ŔŽüŠëżňĄžń║Äňč║ňç押░šÜ䊼░´╝┤ňł░iňĺîjšó░ňĄ┤ńŞ║ŠşóŃÇé
OK´╝îŔžúÚçŐň«îŠ»ĽŃÇéšÄ░ňťĘňč║ňç押░6ňĚ▓š╗ĆňŻĺńŻŹ´╝îň«âŠşúňąŻňĄäňťĘň║ĆňłŚšÜäšČČ6ńŻŹŃÇ銺ĄŠŚÂŠłĹń╗ČňĚ▓š╗Ćň░ćňÄ芣ąšÜäň║ĆňłŚ´╝îń╗ą6ńŞ║ňłćšĽîšé╣ŠőćňłćŠłÉń║ćńŞĄńެň║ĆňłŚ´╝îňĚŽŔż╣šÜäň║ĆňłŚŠś»ÔÇť3 ┬á1 2 ┬á5 ┬á4ÔÇŁ´╝îňĆ│Ŕż╣šÜäň║ĆňłŚŠś»ÔÇť9 ┬á7 ┬á10 ┬á8ÔÇŁŃÇéŠÄąńŞőŠŁąŔ┐śÚťÇŔŽüňłćňłźňĄäšÉćŔ┐ÖńŞĄńެň║ĆňłŚŃÇéňŤáńŞ║6ňĚŽŔż╣ňĺîňĆ│Ŕż╣šÜäň║ĆňłŚšŤ«ňëŹÚâŻŔ┐śŠś»ňżłŠĚĚń╣▒šÜäŃÇéńŞŹŔ┐çńŞŹŔŽüš┤ž´╝Ĺń╗ČňĚ▓š╗ĆŠÄîŠĆíń║抾╣Š│Ľ´╝îŠÄąńŞőŠŁąňƬŔŽüŠĘíŠőčňłÜŠëŹšÜ䊾╣Š│ĽňłćňłźňĄäšÉć6ňĚŽŔż╣ňĺîňĆ│Ŕż╣šÜäň║ĆňłŚňŹ│ňĆ»ŃÇéšÄ░ňťĘňůłŠŁąňĄäšÉć6ňĚŽŔż╣šÜäň║ĆňłŚšÄ░ňÉžŃÇé
ňĚŽŔż╣šÜäň║ĆňłŚŠś»ÔÇť3 ┬á1 ┬á2 5 ┬á4ÔÇŁŃÇéŔ»Ěň░ćŔ┐Öńެň║ĆňłŚń╗ą3ńŞ║ňč║ňç押░Ŕ┐ŤŔíîŔ░⊼┤´╝îńŻ┐ňżŚ3ňĚŽŔż╣šÜ䊼░ÚâŻň░Ćń║Äšşëń║Ä3´╝î3ňĆ│Ŕż╣šÜ䊼░ÚâŻňĄžń║Äšşëń║Ä3ŃÇéňąŻń║ćň╝ÇňžőňŐĘšČöňÉž
ňŽéŠ×ťńŻáŠĘíŠőčšÜäŠ▓튝ëÚöÖ´╝îŔ░⊼┤ň«îŠ»Ľń╣őňÉÄšÜäň║ĆňłŚšÜäÚí║ň║Ćň║öŔ»ąŠś»´╝Ü
 
2  1  3  5  4
OK´╝îšÄ░ňťĘ3ňĚ▓š╗ĆňŻĺńŻŹŃÇéŠÄąńŞőŠŁąÚťÇŔŽüňĄäšÉć3ňĚŽŔż╣šÜäň║ĆňłŚÔÇť2 1ÔÇŁňĺîňĆ│Ŕż╣šÜäň║ĆňłŚÔÇť5 4ÔÇŁŃÇéň»╣ň║ĆňłŚÔÇť2 1ÔÇŁń╗ą2ńŞ║ňč║ňç押░Ŕ┐ŤŔíîŔ░⊼┤´╝îňĄäšÉćň«îŠ»Ľń╣őňÉÄšÜäň║ĆňłŚńŞ║ÔÇť1 2ÔÇŁ´╝îňł░ŠşĄ2ňĚ▓š╗ĆňŻĺńŻŹŃÇéň║ĆňłŚÔÇť1ÔÇŁňƬŠťëńŞÇńެŠĽ░´╝îń╣čńŞŹÚťÇŔŽüŔ┐ŤŔíîń╗╗ńŻĽňĄäšÉćŃÇéŔç│ŠşĄŠłĹń╗Čň»╣ň║ĆňłŚÔÇť2 1ÔÇŁňĚ▓ňůĘÚâĘňĄäšÉćň«îŠ»Ľ´╝îňżŚňł░ň║ĆňłŚŠś»ÔÇť1 2ÔÇŁŃÇéň║ĆňłŚÔÇť5 4ÔÇŁšÜäňĄäšÉćń╣čń╗┐šůžŠşĄŠľ╣Š│Ľ´╝ÇňÉÄňżŚňł░šÜäň║ĆňłŚňŽéńŞő´╝Ü
 
1  2  3 4  5  6 9  7  10  8
ň»╣ń║Äň║ĆňłŚÔÇť9 ┬á7 ┬á10 ┬á8ÔÇŁń╣čŠĘíŠőčňłÜŠëŹšÜäŔ┐çšĘő´╝┤ňł░ńŞŹňĆ»Šőćňłćňç║Šľ░šÜäňşÉň║ĆňłŚńŞ║ŠşóŃÇ銝ǚ╗łň░ćń╝ÜňżŚňł░Ŕ┐ÖŠáĚšÜäň║ĆňłŚ´╝îňŽéńŞő
1  2  3 4  5  6  7  8 9  10
ňł░ŠşĄ´╝îŠÄĺň║Ćň«îňůĘš╗ôŠŁčŃÇéš╗ćň┐âšÜäňÉîňşŽňĆ»ŔâŻňĚ▓š╗ĆňĆĹšÄ░´╝îň┐źÚÇčŠÄĺň║ĆšÜ䊻ĆńŞÇŔŻ«ňĄäšÉćňůÂň«×ň░▒Šś»ň░ćŔ┐ÖńŞÇŔŻ«šÜäňč║ňç押░ňŻĺńŻŹ´╝┤ňł░ŠëÇŠťëšÜ䊼░ÚâŻňŻĺńŻŹńŞ║Šşó´╝îŠÄĺň║Ćň░▒š╗ôŠŁčń║ćŃÇéńŞőÚŁóńŞŐńŞ¬ÚťŞŠ░öšÜäňŤżŠŁąŠĆĆŔ┐░ńŞőŠĽ┤ńެš«ŚŠ│ĽšÜäňĄäšÉćŔ┐çšĘőŃÇé

Ŕ┐ÖŠś»ńŞ║ń╗Çń╣łňĹó´╝č
ň┐źÚÇčŠÄĺň║Ćń╣őŠëÇŠ»öŔżâň┐ź´╝îňŤáńŞ║šŤŞŠ»öňćĺŠ│íŠÄĺň║Ć´╝ƊČíń║ĄŠŹóŠś»ŔĚ│ŔĚâň╝ĆšÜäŃÇ銻ƊČíŠÄĺň║ĆšÜ䊌ÂňÇÖŔ«żšŻ«ńŞÇńެňč║ňçćšé╣´╝îň░ćň░Ćń║Äšşëń║Äňč║ňçćšé╣šÜ䊼░ňůĘÚâĘŠöżňł░ňč║ňçćšé╣šÜäňĚŽŔż╣´╝îň░ćňĄžń║Äšşëń║Äňč║ňçćšé╣šÜ䊼░ňůĘÚâĘŠöżňł░ňč║ňçćšé╣šÜäňĆ│Ŕż╣ŃÇéŔ┐ÖŠáĚňťĘŠ»ĆŠČíń║ĄŠŹóšÜ䊌ÂňÇÖň░▒ńŞŹń╝ÜňâĆňćĺŠ│íŠÄĺň║ĆńŞÇŠáĚŠ»ĆŠČíňƬŔâŻňťĘšŤŞÚé╗šÜ䊼░ń╣őÚŚ┤Ŕ┐ŤŔíîń║ĄŠŹó´╝îń║ĄŠŹóšÜäŔĚŁšŽ╗ň░▒ňĄžšÜäňĄÜń║ćŃÇéňŤáŠşĄŠÇ╗šÜ䊻öŔżâňĺîń║ĄŠŹóŠČ튼░ň░▒ň░Ĺń║ć´╝îÚÇčň║ŽŔ笚äÂň░▒ŠĆÉÚźśń║ćŃÇéňŻôšäÂňťĘŠťÇňŁĆšÜäŠâůňćÁńŞő´╝îń╗ŹňĆ»Ŕ⯊ś»šŤŞÚé╗šÜäńŞĄńެŠĽ░Ŕ┐ŤŔíîń║ćń║ĄŠŹóŃÇéňŤáŠşĄň┐źÚÇčŠÄĺň║ĆšÜ䊝ÇňĚ«ŠŚÂÚŚ┤ňĄŹŠŁéň║ŽňĺîňćĺŠ│íŠÄĺň║ĆŠś»ńŞÇŠáĚšÜäÚ⯊ś»O(N2)´╝îň«âšÜäň╣│ňŁçŠŚÂÚŚ┤ňĄŹŠŁéň║ŽńŞ║O(NlogN)ŃÇéňůÂň«×ň┐źÚÇčŠÄĺň║ĆŠś»ňč║ń║ÄńŞÇšžŹňĆźňüÜÔÇťń║îňłćÔÇŁšÜäŠÇŁŠâ│ŃÇ銳Ĺń╗ČňÉÄÚŁóŔ┐śń╝ÜÚüçňł░ÔÇťń║îňłćÔÇŁŠÇŁŠâ│´╝îňł░ŠŚÂňÇÖňćŹŔüŐŃÇéňůłńŞŐń╗úšáü´╝îňŽéńŞő
- #include <stdio.h> 
- int┬áa[101],n;//ň«Üń╣ëňůĘň▒ÇňĆśÚçĆ´╝îŔ┐ÖńŞĄńެňĆśÚçĆÚťÇŔŽüňťĘňşÉň篊Ľ░ńŞşńŻ┐šöĘ┬á
- void quicksort(int left,int right) 
- { 
-     int i,j,t,temp; 
-     if(left>right) 
-        return; 
-                                 
- ┬á┬á┬á┬átemp=a[left];┬á//tempńŞşňşśšÜäň░▒Šś»ňč║ňç押░┬á
-     i=left; 
-     j=right; 
-     while(i!=j) 
-     { 
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//Úí║ň║ĆňżłÚçŹŔŽü´╝îŔŽüňůłń╗ÄňĆ│Ŕż╣ň╝ÇňžőŠëż┬á
-                    while(a[j]>=temp && i<j) 
-                             j--; 
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//ň揊ëżňĆ│Ŕż╣šÜä┬á
-                    while(a[i]<=temp && i<j) 
-                             i++; 
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//ń║ĄŠŹóńŞĄńެŠĽ░ňťĘŠĽ░š╗äńŞşšÜäńŻŹšŻ«┬á
-                    if(i<j) 
-                    { 
-                             t=a[i]; 
-                             a[i]=a[j]; 
-                             a[j]=t; 
-                    } 
-     } 
- ┬á┬á┬á┬á//ŠťÇš╗łň░ćňč║ňç押░ňŻĺńŻŹ┬á
-     a[left]=a[i]; 
-     a[i]=temp; 
-                              
- ┬á┬á┬á┬áquicksort(left,i-1);//š╗žš╗şňĄäšÉćňĚŽŔż╣šÜä´╝îŔ┐ÖÚç»ńŞÇńެÚÇĺňŻĺšÜäŔ┐çšĘő┬á
- ┬á┬á┬á┬áquicksort(i+1,right);//š╗žš╗şňĄäšÉćňĆ│Ŕż╣šÜä┬á´╝îŔ┐ÖÚç»ńŞÇńެÚÇĺňŻĺšÜäŔ┐çšĘő┬á
- } 
- int main() 
- { 
-     int i,j,t; 
- ┬á┬á┬á┬á//Ŕ»╗ňůąŠĽ░ŠŹ«┬á
-     scanf("%d",&n); 
-     for(i=1;i<=n;i++) 
-                    scanf("%d",&a[i]); 
- ┬á┬á┬á┬áquicksort(1,n);┬á//ň┐źÚÇčŠÄĺň║ĆŔ░âšöĘ┬á
-                              
- ┬á┬á┬á┬á//Ŕżôňç║ŠÄĺň║ĆňÉÄšÜäš╗ôŠ×ť┬á
-     for(i=1;i<=n;i++) 
-         printf("%d ",a[i]); 
-     getchar();getchar(); 
-     return 0; 
- } 
1061279345108
Ŕ┐ÉŔíîš╗ôŠ×ťŠś»
12345678910
ŠÂĘňž┐ňŐ┐šÄ»ŔŐé
ň┐źÚÇčŠÄĺň║Ćšö▒ C. A. R. Hoare´╝łńŞťň░╝ÚťŹň░ö´╝îCharles Antony Richard Hoare´╝ëňťĘ1960ň╣┤ŠĆÉňç║´╝îń╣őňÉÄňĆłŠťëŔ«ŞňĄÜń║║ňüÜń║ćŔ┐ŤńŞÇŠşąšÜäń╝śňîľŃÇéňŽéŠ×ťńŻáň»╣ň┐źÚÇčŠÄĺň║ĆŠäčňů┤ŔÂúňĆ»ń╗ąňÄ╗šťőšťőńŞťň░╝ÚťŹň░ö1962ň╣┤ňťĘComputer JournalňĆĹŔíĘšÜäŔ«║ŠľçÔÇťQuicksortÔÇŁń╗ąňĆŐŃÇŐš«ŚŠ│Ľň»╝Ŕ«║ŃÇőšÜäšČČńŞâšźáŃÇéň┐źÚÇčŠÄĺň║Ćš«ŚŠ│Ľń╗ůń╗ůŠś»ńŞťň░╝ÚťŹň░öňťĘŔ«íš«ŚŠť║ÚóćňččŠëŹŔ⯚ÜäšČČńŞÇŠČ튜żÚť▓´╝îňÉÄŠŁąń╗ľňĆŚňł░ń║ćŔÇüŠŁ┐šÜäŔÁĆŔ»ćňĺîÚ珚öĘ´╝îňůČňĆŞňŞîŠťŤń╗ľńŞ║Šľ░Šť║ňÖĘŔ«żŔ«íńŞÇńެŠľ░šÜäÚźśš║žŔ»şŔĘÇŃÇéńŻáŔŽüščąÚüôňŻôŠŚÂŔ┐śŠ▓튝ëPASCALŠłľŔÇůCŔ»şŔĘÇŔ┐Öń║ŤÚźśš║žšÜäńŞťńŞťŃÇéňÉÄŠŁąńŞťň░╝ÚťŹň░öňĆéňŐáń║ćšö▒Edsger Wybe Dijkstra´╝ł1972ň╣┤ňŤżšüÁňąľňżŚńŞ╗´╝îŔ┐ÖńެňĄžšą×ŠłĹń╗ČňÉÄÚŁóŔ┐śń╝ÜÚüçňł░šÜäňł░ŠŚÂňÇÖň揚╗ćŔüŐ´╝ëńŞżňŐךÜäÔÇťALGOL 60ÔÇŁňč╣Ŕ«şšĆş´╝îń╗ľŔžëňżŚŔç¬ňĚ▒ńŞÄňůŠ▓튝ëŠŐŐŠĆíňÄ╗Ŕ«żŔ«íńŞÇńެŠľ░šÜäŔ»şŔĘÇ´╝îŔ┐śńŞŹňŽéň»╣šÄ░ŠťëšÜäÔÇťALGOL 60ÔÇŁŔ┐ŤŔíîŠö╣Ŕ┐Ť´╝îńŻ┐ń╣őŔâŻňťĘňůČňĆŞšÜ䊾░Šť║ňÖĘńŞŐńŻ┐šöĘŃÇéń║ÄŠś»ń╗ľńż┐Ŕ«żŔ«íń║ćÔÇťALGOL 60ÔÇŁšÜäńŞÇńެňşÉÚŤćšëłŠťČŃÇéŔ┐ÖńެšëłŠťČňťĘŠëžŔíłšÄçňĺîňƻڣáŠÇžńŞŐÚâŻňťĘňŻôŠŚÂÔÇťALGOL 60ÔÇŁšÜäňÉäšžŹšëłŠťČńŞşÚŽľň▒łńŞÇŠîç´╝îňŤáŠşĄńŞťň░╝ÚťŹň░öňĆŚňł░ń║ćňŤŻÚÖůňşŽŠť»šĽîšÜäÚçŹŔžćŃÇéňÉÄŠŁąń╗ľňťĘÔÇťALGOL XÔÇŁšÜäŔ«żŔ«íńŞşŔ┐śňĆĹŠśÄń║ćňĄžň«ÂšćčščąšÜäÔÇťcaseÔÇŁŔ»şňĆą´╝îňÉÄŠŁąń╣čŔóźňÉäšžŹÚźśš║žŔ»şŔĘÇň╣┐Š│ŤÚççšöĘ´╝öňŽéPASCALŃÇüCŃÇüJavaŔ»şŔĘÇšşëšşëŃÇéňŻôšä´╝îńŞťň░╝ÚťŹň░öňťĘŔ«íš«ŚŠť║ÚóćňččšÜäŔ┤íšî«Ŕ┐śŠťëňżłňĄÜňżłňĄÜ´╝îń╗ľňťĘ1980ň╣┤ŔÄĚňżŚń║ćňŤżšüÁňąľŃÇé
 
Š│ĘŠäĆ´╝ÜńŻťŔÇůŔ┐ÖńެŔ«żŔ«íŠÇŁŔ̻ڣ×ňŞŞŠśôŠçé´╝öšŻĹńŞŐňůÂń╗ľŔ«▓ň┐źÚÇčŠÄĺň║ĆšÜäš«ŚŠ│ĽÚâŻň«╣ŠśôŠçéŃÇé
ń╗úšáüŠľ╣ÚŁóń╣čňżłň«╣ŠśôŠçéŃÇé
ňůĚńŻô´╝ÜjŠîçÚĺłňżÇňĚŽŔĚĹ´╝îiŠîçÚĺłňżÇňĆ│ŔĚĹ´╝îňƬŠťëiŠëżňł░Š»öňč║ňçćňÇ╝ň░ĆšÜä´╝îjŠëżňł░Š»öňč║ňçćňÇ╝ňĄžšÜä´╝îŠëŹŔ┐ŤŔí░ŠŹ«ń║ĄŠŹóŃÇé
 
 
refurl:http://developer.51cto.com/art/201403/430986.htm



šŤŞňů│ŠÄĘŔŹÉ
### ň┐źÚÇčŠÄĺň║ĆščąŔ»ćšé╣ŔžúŠ×É #### ńŞÇŃÇüň┐źÚÇčŠÄĺň║Ćš«Çń╗ő ň┐źÚÇčŠÄĺň║ĆŠś»ńŞÇšžŹÚźśŠĽłšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îšö▒Ŕő▒ňŤŻŔ«íš«ŚŠť║šžĹňşŽň«ÂŠëśň░╝┬ĚÚťŹň░ö´╝łTony Hoare´╝ëňťĘ1960ň╣┤ŠĆÉňç║ŃÇéň«âÚççšöĘňłćŠ▓╗šşľšĽąŠŁąŠŐŐńŞÇńެň║ĆňłŚňłćńŞ║Ŕżâň░ĆňĺîŔżâňĄžšÜäńŞĄńެňşÉň║ĆňłŚ´╝îšäÂňÉÄÚÇĺňŻĺňť░...
ň┐źÚÇčŠÄĺň║ĆŠś»ńŞÇšžŹÚźśŠĽłšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îšö▒Ŕő▒ňŤŻŔ«íš«ŚŠť║šžĹňşŽň«ÂC.A.R. HoareňťĘ1960ň╣┤ŠĆÉňç║´╝îň«âšÜäňč║ŠťČŠÇŁŠâ│Šś»ÚÇÜŔ┐çńŞÇŔÂčŠÄĺň║Ćň░ćňżůŠÄĺŔ«░ňŻĽňłćÚÜöŠłÉšőČšźőšÜäńŞĄÚâĘňłć´╝îňůÂńŞşńŞÇÚâĘňłćŔ«░ňŻĽšÜäňů│Úö«ňşŚňŁçŠ»öňĆŽńŞÇÚâĘňłćšÜäňů│Úö«ňşŚň░Ć´╝îšäÂňÉÄňłćňłźň»╣Ŕ┐ÖńŞĄÚâĘňłćŔ«░ňŻĽ...
ň┐źÚÇčŠÄĺň║Ćň┐źÚÇčŠÄĺň║Ć ň┐źÚÇčŠÄĺň║Ć ň┐źÚÇčŠÄĺň║Ć ň┐źÚÇčŠÄĺň║Ć ň┐źÚÇčŠÄĺň║Ć
ň┐źÚÇčŠÄĺň║ĆŠś»ńŞÇšžŹÚźśŠĽłšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îňťĘŔ«íš«ŚŠť║šžĹňşŽňĺ░ňşŽńŞşŔóźň╣┐Š│ŤšáöšęÂŃÇéňůÂňč║ŠťČňÄčšÉ抜»ňłćŠ▓╗Š│ĽšşľšĽą´╝îňŹ│ň░ćńŞÇš╗䊼░ŠŹ«ňłćńŞ║ńŞĄńެňşÉň║ĆňłŚň╣ÂňłćňłźŔ┐ŤŔíîŠÄĺň║ĆŃÇéň┐źÚÇčŠÄĺň║ĆŠťčŠťŤšÜ䊌ÂÚŚ┤ňĄŹŠŁéň║ŽńŞ║O(nlogn)´╝îńŻćňťĘŠťÇňŁĆšÜäŠâůňćÁńŞő´╝îň«âšÜ䊌ÂÚŚ┤ňĄŹŠŁéň║ŽňĆ»...
ň┐źÚÇčŠÄĺň║ĆŠś»ńŞÇšžŹÚźśŠĽłšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îšö▒Ŕő▒ňŤŻŔ«íš«ŚŠť║šžĹňşŽň«ÂC.A.R. HoareňťĘ1960ň╣┤ŠĆÉňç║ŃÇéň«âšÜäňč║ŠťČŠÇŁŠâ│Šś»ňłćŠ▓╗Š│Ľ´╝łDivide and Conquer´╝ë´╝îňŹ│ŠŐŐńŞÇńެňĄžÚŚ«ÚóśňłćŔžúŠłÉŔőąň╣▓ńެň░ĆÚŚ«Ú󜊣ąŔžúňć│´╝ǚ╗łň░ćň░ĆÚŚ«ÚóśšÜäš╗ôŠ×ťňÉłň╣ÂňżŚňł░ňÄčÚŚ«ÚóśšÜäŔžúŃÇéňťĘŔ┐Ö...
ŠťČńŞ╗Úóśň░ćŠĚ▒ňůąŠÄóŔ«ĘňŤŤšžŹňŞŞŔžüšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝ÜňáćŠÄĺň║ĆŃÇüň┐źÚÇčŠÄĺň║Ćń╗ąňĆŐńŞĄšžŹŠť¬ňťĘŠáçÚóśńŞşŠśÄší«ŠĆÉňł░ńŻćňÉîŠáĚÚçŹŔŽüšÜäŠÄĺň║ĆŠľ╣Š│ĽÔÇöÔÇöňč║ŠĽ░ŠÄĺň║ĆňĺîŔ«íŠĽ░ŠÄĺň║ĆŃÇé ÚŽľňůł´╝îŔ«ęŠłĹń╗ČŔ»Žš╗ćń║ćŔžúńŞÇńŞőňáćŠÄĺň║ĆŃÇéňáćŠÄĺň║ĆŠś»ńŞÇšžŹňč║ń║ÄŠ»öŔżâšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îňłęšöĘń║押░ŠŹ«...
Šá╣ŠŹ«ŠĆÉńżŤšÜ䊾çń╗Âń┐íŠü»´╝Ĺń╗ČňĆ»ń╗ąŠĚ▒ňůąŠÄóŔ«Ęň┐źÚÇčŠÄĺň║ĆŔ┐ÖńŞÇš«ŚŠ│ĽšÜ䚍Şňů│ščąŔ»ćšé╣´╝îňîůŠőČňůÂňÄčšÉćŃÇüš╝ľšĘőŠÇŁŔĚ»ŃÇüŠÂëňĆŐšÜäščąŔ»ćšé╣ń╗ąňĆŐňůĚńŻôšÜäň«×šÄ░Šľ╣ň╝ĆŃÇé ### ň┐źÚÇčŠÄĺň║ĆňÄčšÉć ň┐źÚÇčŠÄĺň║ĆŠś»ńŞÇšžŹÚźśŠĽłšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îň▒×ń║Ä**ňłćŔÇîŠ▓╗ń╣ő**šşľšĽąšÜäńŞÇšžŹňůŞň×ő...
### ň┐źÚÇčŠÄĺň║ĆšÜäň╣ÂŔíîš«ŚŠ│Ľ #### ň┐źÚÇčŠÄĺň║Ćňč║šíÇŠŽéň┐Á ň┐źÚÇčŠÄĺň║ĆŠś»ńŞÇšžŹÚŁ×ňŞŞÚźśŠĽłšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îšö▒C.A.R. HoareňťĘ1962ň╣┤ŠĆÉňç║ŃÇéň«âÚççšöĘňłćŠ▓╗Š│ĽšÜäŠÇŁŠâ│ŠŁąň»╣ŠĽ░š╗äŔ┐ŤŔíîŠÄĺň║ĆŃÇéňůĚńŻôŠôŹńŻťŠś»ÚÇëŠőęńŞÇńެňůâš┤áńŻťńŞ║ňč║ňçć´╝łpivot´╝ë´╝îšäÂňÉÄÚÇÜŔ┐çńŞÇŔÂč...
ň┐źÚÇčŠÄĺň║ĆŠś»ńŞÇšžŹÚźśŠĽłšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îšö▒Ŕő▒ňŤŻŔ«íš«ŚŠť║šžĹňşŽň«ÂC.A.R. HoareňťĘ1960ň╣┤ŠĆÉňç║ŃÇéň«âšÜäňč║ŠťČŠÇŁŠâ│Šś»ňłćŠ▓╗Š│Ľ´╝îÚÇÜŔ┐çńŞÇŔÂčŠÄĺň║Ćň░ćňżůŠÄĺň║ĆšÜ䊼░ŠŹ«ňłćňë▓ŠłÉšőČšźőšÜäńŞĄÚâĘňłć´╝îňůÂńŞşńŞÇÚâĘňłćšÜäŠëÇŠťëŠĽ░ŠŹ«Ú⯊»öňĆŽńŞÇÚâĘňłćšÜäŠëÇŠťëŠĽ░ŠŹ«ÚâŻŔŽüň░Ć´╝îšäÂňÉÄň揊îë...
ň┐źÚÇčŠÄĺň║ĆŠś»ńŞÇšžŹÚźśŠĽłšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îšö▒Ŕő▒ňŤŻŔ«íš«ŚŠť║šžĹňşŽň«ÂC.A.R. HoareňťĘ1960ň╣┤ŠĆÉňç║ŃÇéň«âšÜäňč║ŠťČŠÇŁŠâ│Šś»ňłćŠ▓╗šşľšĽą´╝îÚÇÜŔ┐çńŞÇŔÂčŠÄĺň║Ćň░ćňżůŠÄĺň║ĆšÜ䊼░ŠŹ«ňłćňë▓ŠłÉšőČšźőšÜäńŞĄÚâĘňłć´╝îňůÂńŞşńŞÇÚâĘňłćšÜäŠëÇŠťëŠĽ░ŠŹ«Ú⯊»öňĆŽńŞÇÚâĘňłćšÜäŠëÇŠťëŠĽ░ŠŹ«ÚâŻŔŽüň░Ć´╝îšäÂňÉÄňćŹ...
ň┐źÚÇčŠÄĺň║Ćš«ŚŠ│ĽŠś»ńŞÇšžŹŠťëŠĽłšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îŔÖŻšäš«ŚŠ│ĽňťĘŠťÇňŁĆšÜäŠâůňćÁńŞőŔ┐ÉŔíÂÚŚ┤ńŞ║ O(n^2)´╝îńŻćšö▒ń║Äň╣│ňŁçŔ┐ÉŔíÂÚŚ┤ńŞ║ O(nlogn)´╝îň╣ÂńŞöňťĘňćůňşśńŻ┐šöĘŃÇüšĘőň║Ćň«×šÄ░ňĄŹŠŁéŠÇžńŞŐŔíĘšÄ░ń╝śšžÇ´╝îň░ĄňůŠś»ň»╣ň┐źÚÇčŠÄĺň║Ćš«ŚŠ│ĽŔ┐ŤŔíîÚÜĆŠť║ňîľšÜäňĆ»Ŕ⯴╝îńŻ┐ňżŚň┐źÚÇčŠÄĺň║ĆňťĘ...
´╝ł1´╝ëšöĘÚÜĆŠť║ň┐źÚÇčŠÄĺň║ĆšÜ䊾╣Š│Ľ´╝îň»╣ŔżôňůąšÜ䊼░ňÇ╝ń╗ąń╗ÄňĄžňł░ň░ĆšÜäÚí║ň║ĆŔ┐ŤŔíîň┐źÚÇčŠÄĺň║ĆŃÇé ´╝ł2´╝ëň»╣ÚÜĆŠť║ň┐źÚÇčŠÄĺň║ĆňĺîňćĺŠ│íŠÄĺň║ĆŔ┐ÖńŞĄšžŹŠÄĺň║ĆŠľ╣Š│ĽŔ┐ŤŔíöŔżâ´╝îŠÁőŔ»ĽňůÂňťĘńŞŹňÉ░ňÇ╝ňĄžň░ĆšÜäŠâůňćÁńŞőš«ŚŠ│ĽŔ┐ÉŔíîšÜ䊌ÂÚŚ┤ňĄŹŠŁéň║ŽŃÇé ń║îŃÇü ň«×Ú¬îŔŽüŠ▒é ň┐źÚÇčŠÄĺň║Ć...
ň┐źÚÇčŠÄĺň║ĆŠś»ńŞÇšžŹÚźśŠĽłšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îšö▒Ŕő▒ňŤŻŔ«íš«ŚŠť║šžĹňşŽň«ÂC.A.R. HoareňťĘ1960ň╣┤ŠĆÉňç║ŃÇéň«âšÜäňč║ŠťČŠÇŁŠâ│Šś»ňłćŠ▓╗Š│Ľ´╝łDivide and Conquer´╝ë´╝îÚÇÜŔ┐çńŞÇŔÂčŠÄĺň║Ćň░ćňżůŠÄĺŔ«░ňŻĽňłćÚÜöŠłÉšőČšźőšÜäńŞĄÚâĘňłć´╝îňůÂńŞşńŞÇÚâĘňłćŔ«░ňŻĽšÜäňů│Úö«ňşŚňŁçŠ»öňĆŽńŞÇÚâĘňłćšÜä...
ňćĺŠ│íŠÄĺň║Ćňĺîň┐źÚÇčŠÄĺň║ĆšÜ䊌ÂÚŚ┤ŠÇžŔ⯠ňćĺŠ│íŠÄĺň║Ćňĺîň┐źÚÇčŠÄĺň║ĆŠś»ńŞĄšžŹňŞŞšöĘšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îň«âń╗ČšÜ䊌ÂÚŚ┤ŠÇžŔ⯊ś»ň╝ÇňĆĹŔÇůňĺîšáöšęÂń║║ňĹśŠëÇňů│ň┐âšÜäšâşšé╣Ŕ»ŁÚóśŃÇéňťĘŠťČŠľçńŞş´╝Ĺń╗Čň░ćň»╣ňćĺŠ│íŠÄĺň║Ćňĺîň┐źÚÇčŠÄĺň║ĆšÜ䊌ÂÚŚ┤ŠÇžŔâŻŔ┐ŤŔíîŠĚ▒ňůąňłćŠ×ÉňĺöŔżâŃÇé ňćĺŠ│íŠÄĺň║ĆŠś»ńŞÇ...
ň┐źÚÇčŠÄĺň║ĆŠś»ńŞÇšžŹÚźśŠĽłšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îšö▒Ŕő▒ňŤŻŔ«íš«ŚŠť║šžĹňşŽň«ÂŠëśň░╝┬ĚÚťŹň░öń║Ä1960ň╣┤ŠĆÉňç║ŃÇéň«âÚççšöĘňłćŠ▓╗šşľšĽąŠŁąŠŐŐńŞÇńެň║ĆňłŚňłćńŞ║Ŕżâň░ĆšÜäńŞĄńެňşÉň║ĆňłŚ´╝îšäÂňÉÄÚÇĺňŻĺňť░ň»╣ňşÉň║ĆňłŚŔ┐ŤŔíîŠÄĺň║Ć´╝ǚ╗łňÉłň╣ÂňżŚňł░Šťëň║Ćň║ĆňłŚŃÇéň┐źÚÇčŠÄĺň║ĆňťĘň╣│ňŁçŠâůňćÁńŞőšÜ䊌ÂÚŚ┤...
ň┐źÚÇčŠÄĺň║ĆŠś»ńŞÇšžŹÚźśŠĽłšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îšö▒Ŕő▒ňŤŻŔ«íš«ŚŠť║šžĹňşŽň«ÂC.A.R. HoareňťĘ1960ň╣┤ŠĆÉňç║ŃÇéň«âňč║ń║ÄňłćŠ▓╗Š│ĽšÜäšşľšĽą´╝îÚÇÜŔ┐çÚÇëňĆľńŞÇńެňč║ňçćňÇ╝ň╣ÂÚ珊ľ░ŠÄĺňłŚŠĽ░š╗ä´╝îň░ćÚŚ«ÚóśňłćŔžúńŞ║Ŕżâň░ĆšÜäÚâĘňłć´╝îšäÂňÉÄÚÇĺňŻĺňť░ň»╣Ŕ┐Öń║ŤÚâĘňłćŔ┐ŤŔíîŠÄĺň║Ć´╝ǚ╗łŔżżňł░ŠĽ┤ńެň║ĆňłŚ...
ň┐źÚÇčŠÄĺň║ĆŠś»ńŞÇšžŹÚźśŠĽłšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îšö▒Ŕő▒ňŤŻŔ«íš«ŚŠť║šžĹňşŽň«ÂC.A.R. HoareňťĘ1960ň╣┤ŠĆÉňç║ŃÇéň«âňč║ń║ÄňłćŠ▓╗šşľšĽą´╝îÚÇÜňŞŞŠ»öňůÂń╗ľO(n^2)ŠŚÂÚŚ┤ňĄŹŠŁéň║ŽšÜäŠÄĺň║Ćš«ŚŠ│ĽŠŤ┤ň┐ź´╝îň╣│ňŁçŠŚÂÚŚ┤ňĄŹŠŁéň║ŽńŞ║O(n log n)ŃÇéňťĘŠťČÚí╣šŤ«ńŞş´╝îÔÇťň┐źÚÇčŠÄĺň║ĆŠ╝öšĄ║šĘőň║Ć/vc++/mfc...
´╝ł1´╝ë ň«îŠłÉ5šžŹňŞŞšöĘňćůÚâĘŠÄĺň║Ćš«ŚŠ│ĽšÜäŠ╝öšĄ║´╝î5šžŹŠÄĺň║Ćš«ŚŠ│ĽńŞ║´╝Üň┐źÚÇčŠÄĺň║Ć´╝┤ŠÄąŠĆĺňůąŠÄĺň║Ć´╝îÚÇëŠőęŠÄĺň║Ć´╝îňáćŠÄĺň║Ć´╝îňŞîň░öŠÄĺň║Ć´╝Ť ´╝ł2´╝ë ňżůŠÄĺň║Ćňůâš┤áńŞ║ŠĽ┤ŠĽ░´╝îŠÄĺň║Ćň║ĆňłŚňşśňéĘňťĘŠĽ░ŠŹ«Šľçń╗ÂńŞş´╝îŔŽüŠ▒éŠÄĺň║Ćňůâš┤áńŞŹň░Ĺń║Ä30ńެ´╝Ť ´╝ł3´╝ë Š╝öšĄ║šĘőň║Ćň╝Çňžő´╝î...
ňťĘŠťČŠľçńŞş´╝Ĺń╗Čň░ćŠĚ▒ňůąŠÄóŔ«Ęňč║ń║ÄFPGAšÜäň╣ÂŔíîň┐źÚÇčŠÄĺň║Ćš«ŚŠ│Ľ´╝îšë╣ňłźňů│Š│ĘÔÇťńŻŹň«ŻňĆ»Ŕ«żÔÇŁšÜäšë╣ŠÇžŃÇéŔ┐ÖšžŹš«ŚŠ│ĽŔâŻňĄčÚźśŠĽłňť░ňĄäšÉćňĄžÚçĆŠĽ░ŠŹ«´╝îň╣ÂńŞöňťĘšíČń╗Âň«×šÄ░ńŞŐňůĚŠťëňżłÚźśšÜäšüÁŠ┤╗ŠÇžŃÇ銳Ĺń╗Čň░ćń╗Äń╗ąńŞőňçáńެŠľ╣ÚŁóŠŁąÚśÉŔ┐░Ŕ┐ÖńެńŞ╗Úóś´╝Ü ńŞÇŃÇüň┐źÚÇčŠÄĺň║Ćš«ŚŠ│Ľ...
Šá╣ŠŹ«š╗Öň«ÜŠľçń╗šÜäń┐íŠü»´╝Ĺń╗ČňĆ»ń╗ąŠÇ╗š╗ôňç║ń╗ąńŞőňů│ń║ÄÔÇťŠĽ░ŠŹ«š╗ôŠ×ä ň┐źÚÇčŠÄĺň║Ć Ŕżôňç║Š»ĆńŞÇŔÂčš╗ôŠ×ťÔÇŁšÜäščąŔ»ćšé╣´╝Ü ### ńŞÇŃÇüň┐źÚÇčŠÄĺň║ĆšÜäňč║ŠťČŠŽéň┐Á ň┐źÚÇčŠÄĺň║ĆŠś»ńŞÇšžŹÚźśŠĽłšÜäŠÄĺň║Ćš«ŚŠ│Ľ´╝îÚççšöĘňłćŠ▓╗Š│ĽšşľšĽąŠŁąŠŐŐńŞÇńެň║ĆňłŚňłćńŞ║Ŕżâň░ĆňĺîŔżâňĄžšÜäńŞĄńެňşÉň║ĆňłŚ...