
mapreduceŠś»hadoopšÜäŠáŞň┐âń╣őńŞÇ´╝îmapreduceš╗ĆňŞŞŔ«ęŠłĹń╗Čń║žšöčňÉäšžŹňŤ░ŠâĹ´╝Ĺń╗ČňƬŠś»ščąÚüôń╗Çń╣łŠś»map´╝îń╗Çń╣łŠś»renduce´╝îšöÜŔç│ŠłĹń╗ČňĚ▓š╗ĆšćčŠéëń║ćmapreduceš╝ľšĘő´╝îńŻćŠś»ňćůÚâĘšÜäňÄčšÉćŔ┐śŠś»ńŞŹŠśÄšÖŻ,ŠťČŠľçŔ«░ňŻĽšÜ䊜»ňĄžŠŽéšÜäňÄčšÉćŠĚ▒ňůąšÜäš╗ćŔŐéńŞŹňüÜŠĆĆŔ┐░´╝îŔ»ĚŠčąšťőšŤŞňů│ŔÁ䊾ÖŃÇé
 
┬á ┬á ┬á ┬á ShufflešÜ䊺úňŞŞŠäĆŠÇŁŠś»Š┤Śšëľň╝äń╣▒´╝îňĆ»ŔâŻňĄžň«ÂŠŤ┤šćčŠéëšÜ䊜»Java APIÚçîšÜäCollections.shuffle(List)Šľ╣Š│Ľ´╝îň«âń╝ÜÚÜĆŠť║ňť░Šëôń╣▒ňĆ銼░listÚçîšÜäňůâš┤áÚí║ň║ĆŃÇéňŽéŠ×ťńŻáńŞŹščąÚüôMapReduceÚçîShuffleŠś»ń╗Çń╣ł´╝îÚéúń╣łŔ»ĚšťőŔ┐Öň╝áňŤż´╝Ü┬á
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-weight: normal;">  
 
┬á ┬á┬á ┬á┬á┬áŔ┐Öň╝ኜ»ň«śŠľ╣ň»╣ShuffleŔ┐çšĘőšÜäŠĆĆŔ┐░ŃÇéńŻćŠłĹňĆ»ń╗ąŔé»ň«ÜšÜ䊜»´╝îňŹĽń╗ÄŔ┐Öň╝áňŤżńŻáňč║ŠťČńŞŹňĆ»Ŕ⯊śÄšÖŻShufflešÜäŔ┐çšĘő´╝îňŤáńŞ║ň«âńŞÄń║őň«×šŤŞňĚ«Šî║ňĄÜ´╝îš╗ćŔŐéń╣芜»ÚöÖń╣▒šÜäŃÇéňÉÄÚŁóŠłĹń╝ÜňůĚńŻôŠĆĆŔ┐░ShufflešÜäń║őň«×ŠâůňćÁ´╝îŠëÇń╗ąŔ┐ÖÚçîńŻáňƬŔŽüŠŞůŠąÜShufflešÜäňĄžŔç┤ŔîâňŤ┤ň░▒ŠłÉ´╝ŹŠÇÄŠáĚŠŐŐmap taskšÜäŔżôňç║š╗ôŠ×ťŠťëŠĽłňť░ń╝áÚÇüňł░reducešź»ŃÇéń╣čňĆ»ń╗ąŔ┐ÖŠáĚšÉćŔžú´╝î ShuffleŠĆĆŔ┐░šŁÇŠĽ░ŠŹ«ń╗Ämap taskŔżôňç║ňł░reduce taskŔżôňůąšÜäŔ┐ÖŠ«ÁŔ┐çšĘőŃÇé┬á
┬á ┬á┬á ┬á┬á┬áňťĘHadoopŔ┐ÖŠáĚšÜäÚŤćšżĄšÄ»ňóâńŞş´╝îňĄžÚâĘňłćmap taskńŞÄreduce taskšÜäŠëžŔí»ňťĘńŞŹňÉîšÜäŔŐéšé╣ńŞŐŃÇéňŻôšäÂňżłňĄÜŠâůňćÁńŞőReduceŠëžŔíÂÚťÇŔŽüŔĚĘŔŐéšé╣ňÄ╗ŠőëňĆľňůÂň«âŔŐéšé╣ńŞŐšÜämap taskš╗ôŠ×ťŃÇéňŽéŠ×ťÚŤćšżĄŠşúňťĘŔ┐ÉŔíîšÜäjobŠťëňżłňĄÜ´╝îÚéúń╣łtaskšÜ䊺úňŞŞŠëžŔíîň»╣ÚŤćšżĄňćůÚâĘšÜ䚯Ś╗ťŔÁäŠ║ÉŠÂłŔÇŚń╝ÜňżłńŞąÚçŹŃÇéŔ┐ÖšžŹšŻĹš╗ťŠÂłŔÇŚŠś»ŠşúňŞŞšÜä´╝Ĺń╗ČńŞŹŔâŻÚÖÉňłÂ´╝îŔâŻňüÜšÜäň░▒Šś»ŠťÇňĄžňîľňť░ňçĆň░ĹńŞŹň┐ůŔŽüšÜäŠÂłŔÇŚŃÇéŔ┐śŠťëňťĘŔŐéšé╣ňćů´╝îšŤŞŠ»öń║Äňćůňşś´╝îšúüšŤśIOň»╣jobň«îŠłÉŠŚÂÚŚ┤šÜäňŻ▒ňôŹń╣芜»ňĆ»ŔžéšÜäŃÇéń╗ÄŠťÇňč║ŠťČšÜäŔŽüŠ▒銣ąŔ»┤´╝Ĺń╗Čň»╣ShuffleŔ┐çšĘőšÜ䊝芝ŤňĆ»ń╗ąŠťë´╝Ü┬á
- ň«îŠĽ┤ňť░ń╗Ämap taskšź»ŠőëňĆľŠĽ░ŠŹ«ňł░reduce šź»ŃÇé
- ňťĘŔĚĘŔŐéšé╣ŠőëňĆľŠĽ░ŠŹ«ŠŚÂ´╝îň░ŻňĆ»ŔâŻňť░ňçĆň░Ĺň»╣ňŞŽň«ŻšÜäńŞŹň┐ůŔŽüŠÂłŔÇŚŃÇé
- ňçĆň░ĹšúüšŤśIOň»╣taskŠëžŔíîšÜäňŻ▒ňôŹŃÇé
┬á ┬á┬á ┬á┬á┬áOK´╝îšťőňł░Ŕ┐ÖÚç´╝îňĄžň«ÂňĆ»ń╗ąňůłňüťńŞőŠŁąŠâ│Šâ│´╝îňŽéŠ×ťŠś»Ŕç¬ňĚ▒ŠŁąŔ«żŔ«íŔ┐ÖŠ«ÁShuffleŔ┐çšĘő´╝îÚéúń╣łńŻášÜäŔ«żŔ«íšŤ«Šá犜»ń╗Çń╣łŃÇ銳Ŋâ│ŔâŻń╝śňîľšÜäňť░Šľ╣ńŞ╗ŔŽüňťĘń║ÄňçĆň░ĹŠőëňĆľŠĽ░ŠŹ«šÜäÚçĆňĆŐň░ŻÚçĆńŻ┐šöĘňćůňşśŔÇîńŞŹŠś»šúüšŤśŃÇé┬á
┬á ┬á┬á ┬á┬á┬ኳŚÜäňłćŠ×ÉŠś»ňč║ń║ÄHadoop0.21.0šÜäŠ║Éšáü´╝îňŽéŠ×ťńŞÄńŻáŠëÇŔ«ĄŔ»ćšÜäShuffleŔ┐çšĘőŠťëňĚ«ňłź´╝îńŞŹňÉŁŠîçňç║ŃÇ銳Ĺń╝Üń╗ąWordCountńŞ║ńżő´╝îň╣ÂňüçŔ«żň«âŠťë8ńެmap taskňĺî3ńެreduce taskŃÇéń╗ÄńŞŐňŤżšťőňç║´╝îShuffleŔ┐çšĘőŠĘ¬ŔĚĘmapńŞÄreduceńŞĄšź»´╝îŠëÇń╗ąńŞőÚŁóŠłĹń╣čń╝ÜňłćńŞĄÚâĘňłćŠŁąň▒Ľň╝ÇŃÇé┬á
┬á ┬á┬á ┬á┬á┬áňůłšťőšťőmapšź»šÜäŠâůňćÁ´╝îňŽéńŞőňŤż´╝Ü┬á
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-weight: normal;">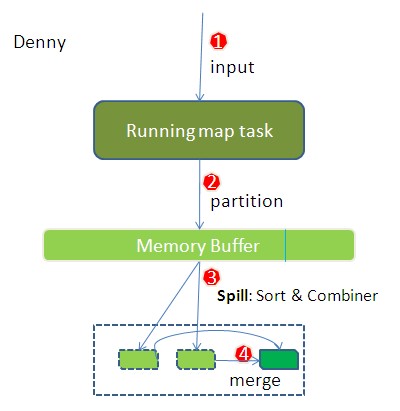  
 
       
┬á ┬á┬á ┬á┬á┬áńŞŐňŤżňĆ»Ŕ⯊ś»ŠčÉńެmap taskšÜäŔ┐ÉŔíîŠâůňćÁŃÇéŠő┐ň«âńŞÄň«śŠľ╣ňŤżšÜäňĚŽňŹŐŔż╣Š»öŔżâ´╝îń╝ÜňĆĹšÄ░ňżłňĄÜńŞŹńŞÇŔç┤ŃÇéň«śŠľ╣ňŤżŠ▓튝늪ůŠąÜňť░Ŕ»┤ŠśÄpartition´╝î sortńŞÄcombinerňł░ň║ĽńŻťšöĘňťĘňô¬ńŞ¬ÚśÂŠ«ÁŃÇ銳Śö╗ń║ćŔ┐Öň╝áňŤż´╝îňŞîŠťŤŔ«ęňĄžň«ÂŠŞůŠÖ░ňť░ń║ćŔžúń╗ÄmapŠĽ░ŠŹ«Ŕżôňůąňł░mapšź»ŠëÇŠťëŠĽ░ŠŹ«ňçćňĄçňąŻšÜäňůĘŔ┐çšĘőŃÇé┬á
┬á ┬á┬á ┬á┬á┬ኼ┤ńެŠÁüšĘőŠłĹňłćń║ćňŤŤŠşąŃÇéš«ÇňŹĽń║ŤňĆ»ń╗ąŔ┐ÖŠáĚŔ»┤´╝Ćńެmap taskÚ⯊ťëńŞÇńެňćůňşśš╝ôňć▓ňî║´╝îňşśňéĘšŁÇmapšÜäŔżôňç║š╗ôŠ×ť´╝îňŻôš╝ôňć▓ňî║ň┐źŠ╗íšÜ䊌ÂňÇÖÚťÇŔŽüň░ćš╝ôňć▓ňî║šÜ䊼░ŠŹ«ń╗ąńŞÇńެńŞ┤ŠŚÂŠľçń╗šÜ䊾╣ň╝ĆňşśŠöżňł░šúüšŤś´╝îňŻôŠĽ┤ńެmap taskš╗ôŠŁčňÉÄňćŹň»╣šúüšŤśńŞşŔ┐Öńެmap taskń║žšöčšÜäŠëÇŠťëńŞ┤ŠŚÂŠľçń╗ÂňüÜňÉłň╣´╝îšö芳ɊťÇš╗łšÜ䊺úň╝ĆŔżôňç║Šľçń╗´╝îšäÂňÉÄšşëňżůreduce taskŠŁąŠő늼░ŠŹ«ŃÇé┬á
┬á ┬á┬á ┬á┬á┬áňŻôšäÂŔ┐ÖÚçîšÜ䊻ĆńŞÇŠşąÚâŻňĆ»ŔâŻňîůňÉźšŁÇňĄÜńެŠşąÚ¬ĄńŞÄš╗ćŔŐé´╝îńŞőÚŁóŠłĹň»╣š╗ćŔŐ銣ąńŞÇńŞÇŔ»┤ŠśÄ´╝Ü┬á
1.┬á ┬á┬á ┬á┬á┬áňťĘmap taskŠëžŔí´╝îň«âšÜäŔżôňůąŠĽ░ŠŹ«ŠŁąŠ║Éń║ÄHDFSšÜäblock´╝îňŻôšäÂňťĘMapReduceŠŽéň┐ÁńŞş´╝îmap taskňƬŔ»╗ňĆľsplitŃÇéSplitńŞÄblockšÜäň»╣ň║öňů│š│╗ňĆ»Ŕ⯊ś»ňĄÜň»╣ńŞÇ´╝îÚ╗śŔ«ĄŠś»ńŞÇň»╣ńŞÇŃÇéňťĘWordCountńżőňşÉÚçî´╝îňüçŔ«żmapšÜäŔżôňůąŠĽ░ŠŹ«Ú⯊ś»ňâĆÔÇťaaaÔÇŁŔ┐ÖŠáĚšÜäňşŚšČŽńŞ▓ŃÇé┬á
2.┬á ┬á┬á ┬á┬á┬áňťĘš╗ĆŔ┐çmapperšÜäŔ┐ÉŔíîňÉÄ´╝Ĺń╗ČňżŚščąmapperšÜäŔżôňç║Šś»Ŕ┐ÖŠáĚńŞÇńެkey/valueň»╣´╝Ü keyŠś»ÔÇťaaaÔÇŁ´╝î valueŠś»ŠĽ░ňÇ╝1ŃÇéňŤáńŞ║ňŻôňëŹmapšź»ňƬňüÜňŐá1šÜäŠôŹńŻť´╝îňťĘreduce taskÚçîŠëŹňÄ╗ňÉłň╣š╗ôŠ×ťÚŤćŃÇéňëŹÚŁóŠłĹń╗ČščąÚüôŔ┐ÖńެjobŠťë3ńެreduce task´╝îňł░ň║ĽňŻôň돚ÜäÔÇťaaaÔÇŁň║öŔ»ąń║Ąšö▒ňô¬ńެreduceňÄ╗ňüÜňĹó´╝»ÚťÇŔŽüšÄ░ňťĘňć│ň«ÜšÜäŃÇé┬á
┬á ┬á┬á ┬á┬á┬áMapReduceŠĆÉńżŤPartitionerŠÄąňĆú´╝îň«âšÜäńŻťšöĘň░▒Šś»Šá╣ŠŹ«keyŠłľvalueňĆŐreducešÜ䊼░ÚçĆŠŁąňć│ň«ÜňŻôň돚ÜäŔ┐Öň»╣Ŕżôňç║ŠĽ░ŠŹ«ŠťÇš╗łň║öŔ»ąń║Ąšö▒ňô¬ńެreduce taskňĄäšÉćŃÇéÚ╗śŔ«Ąň»╣key hashňÉÄňćŹń╗ąreduce taskŠĽ░ÚçĆňĆľŠĘíŃÇéÚ╗śŔ«ĄšÜäňĆľŠĘ튾╣ň╝ĆňƬŠś»ńŞ║ń║ćň╣│ňŁçreducešÜäňĄäšÉćŔâŻňŐŤ´╝îňŽéŠ×ťšöĘŠłĚŔç¬ňĚ▒ň»╣PartitionerŠťëڝNJ▒é´╝îňĆ»ń╗ąŔ«óňłÂň╣ÂŔ«żšŻ«ňł░jobńŞŐŃÇé┬á
┬á ┬á┬á ┬á┬á┬áňťĘŠłĹń╗ČšÜäńżőňşÉńŞş´╝îÔÇťaaaÔÇŁš╗ĆŔ┐çPartitionerňÉÄŔ┐öňŤ×0´╝îń╣čň░▒Šś»Ŕ┐Öň»╣ňÇ╝ň║öňŻôń║Ąšö▒šČČńŞÇńެreducerŠŁąňĄäšÉćŃÇéŠÄąńŞőŠŁą´╝îÚťÇŔŽüň░押░ŠŹ«ňćÖňůąňćůňşśš╝ôňć▓ňî║ńŞş´╝îš╝ôňć▓ňî║šÜäńŻťšöĘŠś»Šë╣ÚçĆŠöÂÚŤćmapš╗ôŠ×ť´╝îňçĆň░ĹšúüšŤśIOšÜäňŻ▒ňôŹŃÇ銳Ĺń╗ČšÜäkey/valueň»╣ń╗ąňĆŐPartitionšÜäš╗ôŠ×ťÚâŻń╝ÜŔóźňćÖňůąš╝ôňć▓ňî║ŃÇéňŻôšäÂňćÖňůąń╣őň돴╝îkeyńŞÄvalueňÇ╝ÚâŻń╝ÜŔóźň║ĆňłŚňłÉňşŚŔŐ銼░š╗äŃÇé┬á
┬á ┬á┬á ┬á┬á┬ኼ┤ńެňćůňşśš╝ôňć▓ňî║ň░▒Šś»ńŞÇńެňşŚŔŐ銼░š╗ä´╝îň«âšÜäňşŚŔŐéš┤óň╝ĽňĆŐkey/valueňşśňéĘš╗ôŠ×䊳Ŋ▓튝ëšáöšęÂŔ┐çŃÇéňŽéŠ×ťŠťëŠťőňĆőň»╣ň«âŠťëšáöšę´╝îÚéúń╣łŔ»ĚňĄžŔç┤ŠĆĆŔ┐░ńŞőň«âšÜäš╗ćŔŐéňÉžŃÇé┬á
3.┬á ┬á┬á ┬á┬á┬áŔ┐Öńެňćůňşśš╝ôňć▓ňî║Šś»ŠťëňĄžň░ĆÚÖÉňłÂšÜä´╝îÚ╗śŔ«ĄŠś»100MBŃÇéňŻômap taskšÜäŔżôňç║š╗ôŠ×ťňżłňĄÜŠŚÂ´╝îň░▒ňĆ»ŔâŻń╝ÜŠĺĹšłćňćůňşś´╝îŠëÇń╗ąÚťÇŔŽüňťĘńŞÇň«ÜŠŁíń╗ÂńŞőň░ćš╝ôňć▓ňî║ńŞşšÜ䊼░ŠŹ«ńŞ┤ŠŚÂňćÖňůąšúüšŤś´╝îšäÂňÉÄÚ珊ľ░ňłęšöĘŔ┐ÖňŁŚš╝ôňć▓ňî║ŃÇéŔ┐Öńެń╗ÄňćůňşśňżÇšúüšŤśňćÖŠĽ░ŠŹ«šÜäŔ┐çšĘőŔóźšž░ńŞ║Spill´╝îńŞşŠľçňĆ»Ŕ»ĹńŞ║Š║óňćÖ´╝îňşŚÚŁóŠäĆŠÇŁňżłšŤ┤ŔžéŃÇéŔ┐ÖńެŠ║óňćÖŠś»šö▒ňŹĽšőČš║┐šĘőŠŁąň«îŠłÉ´╝îńŞŹňŻ▒ňôŹňżÇš╝ôňć▓ňî║ňćÖmapš╗ôŠ×ťšÜäš║┐šĘőŃÇéŠ║óňćÖš║┐šĘőňÉ»ňŐĘŠŚÂńŞŹň║öŔ»ąÚś╗ŠşómapšÜäš╗ôŠ×ťŔżôňç║´╝îŠëÇń╗ąŠĽ┤ńެš╝ôňć▓ňî║ŠťëńެŠ║óňćÖšÜ䊻öńżőspill.percentŃÇéŔ┐ÖńެŠ»öńżőÚ╗śŔ«ĄŠś»0.8´╝îń╣čň░▒Šś»ňŻôš╝ôňć▓ňî║šÜ䊼░ŠŹ«ňĚ▓š╗ĆŔżżňł░ÚśłňÇ╝´╝łbuffer size * spill percent = 100MB * 0.8 = 80MB´╝ë´╝îŠ║óňćÖš║┐šĘőňÉ»ňŐĘ´╝îÚöüň«ÜŔ┐Ö80MBšÜäňćůňşś´╝îŠëžŔíîŠ║óňćÖŔ┐çšĘőŃÇéMap taskšÜäŔżôňç║š╗ôŠ×ťŔ┐śňĆ»ń╗ąňżÇňëęńŞőšÜä20MBňćůňşśńŞşňćÖ´╝îń║ĺńŞŹňŻ▒ňôŹŃÇé┬á
┬á ┬á┬á ┬á┬á┬áňŻôŠ║óňćÖš║┐šĘőňÉ»ňŐĘňÉÄ´╝îÚťÇŔŽüň»╣Ŕ┐Ö80MBšę║ÚŚ┤ňćůšÜäkeyňüÜŠÄĺň║Ć(Sort)ŃÇéŠÄĺň║ĆŠś»MapReduceŠĘíň×őÚ╗śŔ«ĄšÜäŔíîńŞ║´╝îŔ┐ÖÚçîšÜäŠÄĺň║Ćń╣芜»ň»╣ň║ĆňłŚňîľšÜäňşŚŔŐéňüÜšÜäŠÄĺň║ĆŃÇé┬á
┬á ┬á┬á ┬á┬á┬áňťĘŔ┐ÖÚçĹń╗ČňĆ»ń╗ąŠâ│Šâ│´╝îňŤáńŞ║map taskšÜäŔżôňç║Šś»ÚťÇŔŽüňĆĹÚÇüňł░ńŞŹňÉîšÜäreducešź»ňÄ╗´╝îŔÇîňćůňşśš╝ôňć▓ňî║Š▓튝ëň»╣ň░ćňĆĹÚÇüňł░šŤŞňÉîreducešź»šÜ䊼░ŠŹ«ňüÜňÉłň╣´╝îÚéúń╣łŔ┐ÖšžŹňÉłň╣Âň║öŔ»ąŠś»ńŻôšÄ░Šś»šúüšŤśŠľçń╗ÂńŞşšÜäŃÇéń╗Äň«śŠľ╣ňŤżńŞŐń╣čňĆ»ń╗ąšťőňł░ňćÖňł░šúüšŤśńŞşšÜäŠ║óňćÖŠľçń╗Šś»ň»╣ńŞŹňÉîšÜäreducešź»šÜ䊼░ňÇ╝ňüÜŔ┐çňÉłň╣ÂŃÇéŠëÇń╗ąŠ║óňćÖŔ┐çšĘőńŞÇńެňżłÚçŹŔŽüšÜäš╗ćŔŐéňťĘń║Ä´╝îňŽéŠ×ťŠťëňżłňĄÜńެkey/valueň»╣ÚťÇŔŽüňĆĹÚÇüňł░ŠčÉńެreducešź»ňÄ╗´╝îÚéúń╣łÚťÇŔŽüň░ćŔ┐Öń║Ťkey/valueňÇ╝Šő╝ŠÄąňł░ńŞÇňŁŚ´╝îňçĆň░ĹńŞÄpartitionšŤŞňů│šÜäš┤óň╝ĽŔ«░ňŻĽŃÇé┬á
┬á ┬á┬á ┬á┬á┬áňťĘÚĺłň»╣Š»Ćńެreducešź»ŔÇîňÉłň╣ŠĽ░ŠŹ«ŠŚÂ´╝ëń║ŤŠĽ░ŠŹ«ňĆ»ŔâŻňâĆŔ┐ÖŠáĚ´╝ÜÔÇťaaaÔÇŁ/1´╝î ÔÇťaaaÔÇŁ/1ŃÇéň»╣ń║ÄWordCountńżőňşÉ´╝îň░▒Šś»š«ÇňŹĽňť░š╗čŔ«íňŹĽŔ»Źňç║šÄ░šÜäŠČ튼░´╝îňŽéŠ×ťňťĘňÉîńŞÇńެmap taskšÜäš╗ôŠ×ťńŞşŠťëňżłňĄÜńެňâĆÔÇťaaaÔÇŁńŞÇŠáĚňç║šÄ░ňĄÜŠČíšÜäkey´╝Ĺń╗Čň░▒ň║öŔ»ąŠŐŐň«âń╗ČšÜäňÇ╝ňÉłň╣Âňł░ńŞÇňŁŚ´╝îŔ┐ÖńެŔ┐çšĘőňĆźreduceń╣čňĆźcombineŃÇéńŻćMapReducešÜ䊝»Ŕ»şńŞş´╝îreduceňƬŠîçreducešź»ŠëžŔíîń╗ÄňĄÜńެmap taskňĆľŠĽ░ŠŹ«ňüÜŔ«íš«ŚšÜäŔ┐çšĘőŃÇéÚÖĄreduceňĄľ´╝îڣ׊şúň╝Ćňť░ňÉłň╣ŠĽ░ŠŹ«ňƬŔ⯚«ŚňüÜcombineń║ćŃÇéňůÂň«×ňĄžň«ÂščąÚüôšÜä´╝îMapReduceńŞşň░ćCombineršşëňÉîń║ÄReducerŃÇé┬á
┬á ┬á┬á ┬á┬á┬áňŽéŠ×ťclientŔ«żšŻ«Ŕ┐çCombiner´╝îÚéúń╣łšÄ░ňťĘň░▒Šś»ńŻ┐šöĘCombineršÜ䊌ÂňÇÖń║ćŃÇéň░抝뚍ŞňÉîkeyšÜäkey/valueň»╣šÜävalueňŐáŔÁĚŠŁą´╝îňçĆň░ĹŠ║óňćÖňł░šúüšŤśšÜ䊼░ŠŹ«ÚçĆŃÇéCombinerń╝Üń╝śňîľMapReducešÜäńŞşÚŚ┤š╗ôŠ×ť´╝îŠëÇń╗ąň«âňťĘŠĽ┤ńެŠĘíň×őńŞşń╝ÜňĄÜŠČíńŻ┐šöĘŃÇéÚéúňô¬ń║Ťňť║ŠÖ»ŠëŹŔâŻńŻ┐šöĘCombinerňĹó´╝čń╗ÄŔ┐ÖÚçîňłćŠ×É´╝îCombineršÜäŔżôňç║Šś»ReduceršÜäŔżôňůą´╝îCombinerš╗ŁńŞŹŔ⯊ö╣ňĆśŠťÇš╗łšÜäŔ«íš«Śš╗ôŠ×ťŃÇéŠëÇń╗ąń╗ÄŠłĹšÜäŠâ│Š│ĽŠŁąšťő´╝îCombinerňƬň║öŔ»ąšöĘń║ÄÚéúšžŹReducešÜäŔżôňůąkey/valueńŞÄŔżôňç║key/valueš▒╗ň×őň«îňůĘńŞÇŔç┤´╝îńŞöńŞŹňŻ▒ňôŹŠťÇš╗łš╗ôŠ×ťšÜäňť║ŠÖ»ŃÇ銻öňŽéš┤»ňŐá´╝ÇňĄžňÇ╝šşëŃÇéCombineršÜäńŻ┐šöĘńŞÇň«ÜňżŚŠůÄÚ珴╝îňŽéŠ×ťšöĘňąŻ´╝îň«âň»╣jobŠëžŔíłšÄ犝ëňŞ«ňŐę´╝îňĆŹń╣őń╝ÜňŻ▒ňôŹreducešÜ䊝ǚ╗łš╗ôŠ×ťŃÇé┬á
4.┬á ┬á┬á ┬á┬á┬ኻƊČíŠ║óňćÖń╝ÜňťĘšúüšŤśńŞŐšö芳ÉńŞÇńެŠ║óňćÖŠľçń╗´╝îňŽéŠ×ťmapšÜäŔżôňç║š╗ôŠ×ťšťčšÜäňżłňĄž´╝ëňĄÜŠČíŔ┐ÖŠáĚšÜäŠ║óňćÖňĆĹšöč´╝îšúüšŤśńŞŐšŤŞň║öšÜäň░▒ń╝ÜŠťëňĄÜńެŠ║óňćÖŠľçń╗ÂňşśňťĘŃÇéňŻômap taskšťčŠşúň«îŠłÉŠŚÂ´╝îňćůňşśš╝ôňć▓ňî║ńŞşšÜ䊼░ŠŹ«ń╣čňůĘÚâĘŠ║óňćÖňł░šúüšŤśńŞşňŻóŠłÉńŞÇńެŠ║óňćÖŠľçń╗ÂŃÇ銝ǚ╗łšúüšŤśńŞşń╝ÜŔç│ň░ĹŠťëńŞÇńެŔ┐ÖŠáĚšÜäŠ║óňćÖŠľçń╗ÂňşśňťĘ(ňŽéŠ×ťmapšÜäŔżôňç║š╗ôŠ×ťňżłň░Ĺ´╝îňŻômapŠëžŔíîň«îŠłÉŠŚÂ´╝îňƬń╝Üń║žšöčńŞÇńެŠ║óňćÖŠľçń╗Â)´╝îňŤáńŞ║ŠťÇš╗łšÜ䊾çń╗ÂňƬŠťëńŞÇńެ´╝îŠëÇń╗ąÚťÇŔŽüň░ćŔ┐Öń║ŤŠ║óňćÖŠľçń╗ÂňŻĺň╣Âňł░ńŞÇŔÁĚ´╝îŔ┐ÖńެŔ┐çšĘőň░▒ňĆźňüÜMergeŃÇéMergeŠś»ŠÇÄŠáĚšÜä´╝čňŽéňëŹÚŁóšÜäńżőňşÉ´╝îÔÇťaaaÔÇŁń╗ÄŠčÉńެmap taskŔ»╗ňĆľŔ┐犣ąŠŚÂňÇ╝Šś»5´╝îń╗ÄňĆŽňĄľńŞÇńެmap Ŕ»╗ňĆľŠŚÂňÇ╝Šś»8´╝îňŤáńŞ║ň«âń╗ČŠťëšŤŞňÉîšÜäkey´╝îŠëÇń╗ąňżŚmergeŠłÉgroupŃÇéń╗Çń╣łŠś»groupŃÇéň»╣ń║ÄÔÇťaaaÔÇŁň░▒Šś»ňâĆŔ┐ÖŠáĚšÜä´╝Ü{ÔÇťaaaÔÇŁ, [5, 8, 2, ÔÇŽ]}´╝░š╗äńŞşšÜäňÇ╝ň░▒Šś»ń╗ÄńŞŹňÉîŠ║óňćÖŠľçń╗ÂńŞşŔ»╗ňĆľňç║ŠŁąšÜä´╝îšäÂňÉÄň揊ŐŐŔ┐Öń║ŤňÇ╝ňŐáŔÁĚŠŁąŃÇéŔ»ĚŠ│ĘŠäĆ´╝îňŤáńŞ║mergeŠś»ň░ćňĄÜńެŠ║óňćÖŠľçń╗ÂňÉłň╣Âňł░ńŞÇńެŠľçń╗´╝îŠëÇń╗ąňĆ»ŔâŻń╣芝뚍ŞňÉîšÜäkeyňşśňťĘ´╝îňťĘŔ┐ÖńެŔ┐çšĘőńŞşňŽéŠ×ťclientŔ«żšŻ«Ŕ┐çCombiner´╝îń╣čń╝ÜńŻ┐šöĘCombinerŠŁąňÉłň╣šŤŞňÉîšÜäkeyŃÇé┬á
┬á ┬á┬á ┬á┬á┬áŔç│ŠşĄ´╝îmapšź»šÜäŠëÇŠťëňĚąńŻťÚâŻňĚ▓š╗ôŠŁč´╝ǚ╗łšö芳ɚÜäŔ┐ÖńެŠľçń╗Âń╣čňşśŠöżňťĘTaskTrackerňĄčňżŚšŁÇšÜäŠčÉńެŠťČňť░šŤ«ňŻĽňćůŃÇ銻Ćńެreduce taskńŞŹŠľşňť░ÚÇÜŔ┐çRPCń╗ÄJobTrackerÚéúÚçîŔÄĚňĆľmap taskŠś»ňÉŽň«îŠłÉšÜäń┐íŠü»´╝îňŽéŠ×ťreduce taskňżŚňł░ÚÇÜščą´╝îŔÄ̚蹊čÉňĆ░TaskTrackerńŞŐšÜämap taskŠëžŔíîň«îŠłÉ´╝îShufflešÜäňÉÄňŹŐŠ«ÁŔ┐çšĘőň╝ÇňžőňÉ»ňŐĘŃÇé┬á
┬á ┬á┬á ┬á┬á┬áš«ÇňŹĽňť░Ŕ»┤´╝îreduce taskňťĘŠëžŔíîń╣őň돚ÜäňĚąńŻťň░▒Šś»ńŞŹŠľşňť░ŠőëňĆľňŻôňëŹjobÚçĆńެmap taskšÜ䊝ǚ╗łš╗ôŠ×ť´╝îšäÂňÉÄň»╣ń╗ÄńŞŹňÉîňť░Šľ╣ŠőëňĆľŔ┐犣ąšÜ䊼░ŠŹ«ńŞŹŠľşňť░ňüÜmerge´╝îń╣芝ǚ╗łňŻóŠłÉńŞÇńެŠľçń╗ÂńŻťńŞ║reduce taskšÜäŔżôňůąŠľçń╗ÂŃÇéŔžüńŞőňŤż´╝Ü┬á
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-weight: normal;">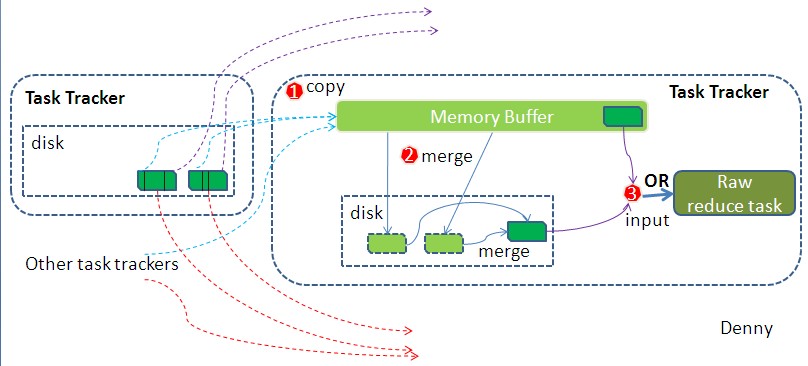  
 
┬á ┬á┬á ┬á┬á┬áňŽémap šź»šÜäš╗ćŔŐéňŤż´╝îShuffleňťĘreducešź»šÜäŔ┐çšĘőń╣čŔ⯚öĘňŤżńŞŐŠá犜ĚÜäńŞëšé╣ŠŁąŠŽéŠőČŃÇéňŻôňëŹreduce copyŠĽ░ŠŹ«šÜäň돊ĆÉŠś»ň«âŔŽüń╗ÄJobTrackerŔÄĚňżŚŠťëňô¬ń║Ťmap taskňĚ▓ŠëžŔíîš╗ôŠŁč´╝îŔ┐ÖŠ«ÁŔ┐çšĘőńŞŹŔíĘ´╝ëňů┤ŔÂúšÜ䊝őňĆőňĆ»ń╗ąňů│Š│ĘńŞőŃÇéReduceršťčŠşúŔ┐ÉŔíîń╣őň돴╝îŠëÇŠťëšÜ䊌ÂÚŚ┤Ú⯊ś»ňťĘŠőëňĆľŠĽ░ŠŹ«´╝îňüÜmerge´╝îńŞöńŞŹŠľşÚçŹňĄŹňť░ňťĘňüÜŃÇéňŽéňëŹÚŁóšÜ䊾╣ň╝ĆńŞÇŠáĚ´╝îńŞőÚŁóŠłĹń╣čňłćŠ«Áňť░ŠĆĆŔ┐░reduce šź»šÜäShuffleš╗ćŔŐé´╝Ü┬á
1.┬á ┬á┬á ┬á┬á┬áCopyŔ┐çšĘő´╝îš«ÇňŹĽňť░ŠőëňĆľŠĽ░ŠŹ«ŃÇéReduceŔ┐ŤšĘőňÉ»ňŐĘńŞÇń║ŤŠĽ░ŠŹ«copyš║┐šĘő(Fetcher)´╝îÚÇÜŔ┐çHTTPŠľ╣ň╝ĆŔ»ĚŠ▒émap taskŠëÇňťĘšÜäTaskTrackerŔÄĚňĆľmap taskšÜäŔżôňç║Šľçń╗ÂŃÇéňŤáńŞ║map taskŠŚęňĚ▓š╗ôŠŁč´╝îŔ┐Öń║ŤŠľçń╗Âň░▒ňŻĺTaskTrackerš«íšÉćňťĘŠťČňť░šúüšŤśńŞşŃÇé┬á
2.┬á ┬á┬á ┬á┬á┬áMergeڜŠ«ÁŃÇéŔ┐ÖÚçîšÜämergeňŽémapšź»šÜämergeňŐĘńŻť´╝îňƬŠś»ŠĽ░š╗äńŞşňşśŠöżšÜ䊜»ńŞŹňÉîmapšź»copyŠŁąšÜ䊼░ňÇ╝ŃÇéCopyŔ┐犣ąšÜ䊼░ŠŹ«ń╝ÜňůłŠöżňůąňćůňşśš╝ôňć▓ňî║ńŞş´╝îŔ┐ÖÚçîšÜäš╝ôňć▓ňî║ňĄžň░ĆŔŽüŠ»ömapšź»šÜ䊍┤ńŞ║šüÁŠ┤╗´╝îň«âňč║ń║ÄJVMšÜäheap sizeŔ«żšŻ«´╝îňŤáńŞ║ShuffleڜŠ«ÁReducerńŞŹŔ┐ÉŔíî´╝îŠëÇń╗ąň║öŔ»ąŠŐŐš╗ŁňĄžÚâĘňłćšÜäňćůňşśÚ⯚╗ÖShufflešöĘŃÇéŔ┐ÖÚçîÚťÇŔŽüň╝║Ŕ░âšÜ䊜»´╝îmergeŠťëńŞëšžŹňŻóň╝Ć´╝Ü1)ňćůňşśňł░ňćůňşś┬á┬á2)ňćůňşśňł░šúüšŤś┬á┬á3)šúüšŤśňł░šúüšŤśŃÇéÚ╗śŔ«ĄŠâůňćÁńŞőšČČńŞÇšžŹňŻóň╝ĆńŞŹňÉ»šöĘ´╝îŔ«ęń║║Š»öŔżâňŤ░ŠâĹ´╝»ňÉžŃÇéňŻôňćůňşśńŞşšÜ䊼░ŠŹ«ÚçĆňł░ŔżżńŞÇň«ÜÚśłňÇ╝´╝îň░▒ňÉ»ňŐĘňćůňşśňł░šúüšŤśšÜämergeŃÇéńŞÄmap šź»š▒╗ń╝╝´╝îŔ┐Öń╣芜»Š║óňćÖšÜäŔ┐çšĘő´╝îŔ┐ÖńެŔ┐çšĘőńŞşňŽéŠ×ťńŻáŔ«żšŻ«ŠťëCombiner´╝îń╣芜»ń╝ÜňÉ»šöĘšÜä´╝îšäÂňÉÄňťĘšúüšŤśńŞşšö芳Éń║ćń╝ŚňĄÜšÜäŠ║óňćÖŠľçń╗ÂŃÇéšČČń║îšžŹmergeŠľ╣ň╝ĆńŞÇšŤ┤ňťĘŔ┐ÉŔíî´╝┤ňł░Š▓튝ëmapšź»šÜ䊼░ŠŹ«ŠŚÂŠëŹš╗ôŠŁč´╝îšäÂňÉÄňÉ»ňŐĘšČČńŞëšžŹšúüšŤśňł░šúüšŤśšÜämergeŠľ╣ň╝Ćšö芳ɊťÇš╗łšÜäÚéúńެŠľçń╗ÂŃÇé┬á
3.┬á ┬á┬á ┬á┬á┬áReduceršÜäŔżôňůąŠľçń╗ÂŃÇéńŞŹŠľşňť░mergeňÉÄ´╝ÇňÉÄń╝Üšö芳ÉńŞÇńެÔÇťŠťÇš╗łŠľçń╗ÂÔÇŁŃÇéńŞ║ń╗Çń╣łňŐáň╝ĽňĆĚ´╝čňŤáńŞ║Ŕ┐ÖńެŠľçń╗ÂňĆ»ŔâŻňşśňťĘń║ÄšúüšŤśńŞŐ´╝îń╣čňĆ»ŔâŻňşśňťĘń║ÄňćůňşśńŞşŃÇéň»╣ŠłĹń╗ČŠŁąŔ»┤´╝îňŻôšäÂňŞîŠťŤň«âňşśŠöżń║ÄňćůňşśńŞş´╝┤ŠÄąńŻťńŞ║ReduceršÜäŔżôňůą´╝îńŻćÚ╗śŔ«ĄŠâůňćÁńŞő´╝îŔ┐ÖńެŠľçń╗Šś»ňşśŠöżń║ÄšúüšŤśńŞşšÜäŃÇéňŻôReduceršÜäŔżôňůąŠľçń╗ÂňĚ▓ň«Ü´╝┤ńެShuffleŠëŹŠťÇš╗łš╗ôŠŁčŃÇéšäÂňÉÄň░▒Šś»ReducerŠëžŔíî´╝îŠŐŐš╗ôŠ×ťŠöżňł░HDFSńŞŐŃÇé┬á
 
 



šŤŞňů│ŠÄĘŔŹÉ
ShuffleڜŠ«ÁŠś»MapReducešÜäŠáŞň┐â´╝îň«âň░ćMapšÜäŔżôňç║Ŕ┐ŤŔí┤šÉć´╝îňçćňĄçń╝áÚÇĺš╗ÖReduceń╗╗ňŐíŃÇéShuffleňłćńŞ║mapšź»ňĺîreducešź»ńŞĄńެÚâĘňłćŃÇéňťĘmapšź»´╝îmapšÜäŔżôňç║ÚŽľňůłŔóźňćÖňůąňćůňşśš╝ôňć▓ňî║´╝îňŻôš╝ôňć▓ňî║ŠÄąŔ┐ĹŠ╗튌´╝░ŠŹ«ń╝ÜŔóźŠ║óňćÖňł░šúüšŤś´╝îň╣Šá╣ŠŹ«ÚóäŔ«ż...
ŠťČšźáň░ćŠĚ▒ňůąŠÄóŔ«ĘMapReducešÜäŠáŞň┐⊎éň┐ÁŃÇüňĚąńŻťňÄčšÉćń╗ąňĆŐň«×ÚÖůň║öšöĘŃÇé MapReduceňîůňÉźńŞĄńެńŞ╗ŔŽüڜŠ«Á´╝ÜMapڜŠ«ÁňĺîReduceڜŠ«Á´╝îńŞşÚŚ┤ÚÇÜŔ┐çShuffleňĺîSortŔ┐çšĘőŔ┐׊ĹŃÇéMapڜŠ«ÁŔ┤čŔ┤úň░ćŔżôňůąŠĽ░ŠŹ«ŠőćňłćŠłÉÚö«ňÇ╝ň»╣´╝łkey-value pairs´╝ë´╝îň╣ÂŔ┐ŤŔíî...
ňťĘJavańŞşň«×šÄ░MapReducešÜäShuffleŔ┐çšĘő´╝îÚŽľňůłÚťÇŔŽüšÉćŔžúń╗ąńŞőňçáńެŠáŞň┐⊎éň┐Á´╝Ü 1. **MapڜŠ«Á**´╝ÜMapڜŠ«ÁŠś»ŠĽ░ŠŹ«ňĄäšÉćšÜäŔÁĚňžőšé╣´╝îŔżôňůąŠĽ░ŠŹ«Ŕóźňłćňë▓ŠłÉňĄÜńެň░ĆňŁŚ´╝łsplit´╝ë´╝Ćńެsplitšö▒ńŞÇńެMapperń╗╗ňŐíňĄäšÉćŃÇéMapperŠÄąŠöÂÚö«ňÇ╝ň»╣´╝łkey-...
### MapReduce šÜäňĚąńŻťňÄčšÉć´╝Ü 1. **Ŕżôňůą**´╝ÜMapReduce ŠÄąňĆŚŔżôňůąŠĽ░ŠŹ«´╝îÚÇÜňŞŞń╗ąÚö«ňÇ╝ň»╣šÜäňŻóň╝ĆŃÇé 2. **Map ڜŠ«Á**´╝ÜŔżôňůąŠĽ░ŠŹ«Ŕóźňłćňë▓ŠłÉňĄÜńެŠĽ░ŠŹ«ňŁŚ´╝ĆńެŠĽ░ŠŹ«ňŁŚšö▒ńŞÇńެ Map ń╗╗ňŐíňĄäšÉćŃÇ銻Ćńެ Map ń╗╗ňŐíšőČšźőňť░ňĄäšÉćňůŠĽ░ŠŹ«ňŁŚ´╝îšö芳É...
### MapReducešÜäňĚąńŻťňÄčšÉć´╝Ü 1. **MapڜŠ«Á**´╝ÜŔżôňůąŠĽ░ŠŹ«Ŕóźňłćňë▓ŠłÉňĄÜńެň░ĆňŁŚ´╝îšäÂňÉÄň╣ÂŔíîňť░ń╝áÚÇĺš╗ÖMapň篊Ľ░ŃÇ銻ĆńެMapň篊Ľ░ňĄäšÉćńŞÇńެŠĽ░ŠŹ«ňŁŚ´╝îň╣Âń║žšöčńŞÇš│╗ňłŚńŞşÚŚ┤Úö«ňÇ╝ň»╣ŃÇéŔ┐Öń║ŤńŞşÚŚ┤š╗ôŠ×ťń╝ÜŔóźŠÄĺň║ĆŃÇé 2. **ShuffleڜŠ«Á**´╝ÜňťĘMapňĺî...
ŃÇŐHadoopŠŐÇŠť»ňćůň╣Ľ´╝ÜŠĚ▒ňůąŔžúŠ×ÉMapReduceŠ×Š×äŔ«żŔ«íńŞÄň«×šÄ░ňÄčšÉćŃÇőŠś»ňů│ń║ÄňĄžŠĽ░ŠŹ«ňĄäšÉćÚóćňččšÜäńŞÇŠťČš╗ĆňůŞŔĹŚńŻť´╝îńŞôŠ│Ęń║ÄŠÄóŔ«ĘHadoopšÜäŠáŞň┐âš╗äń╗ÂÔÇöÔÇöMapReduceŃÇéMapReduceŠś»GoogleŠĆÉňç║šÜäńŞÇšžŹňłćňŞâň╝ĆŔ«íš«ŚŠĘíň×ő´╝îŔóźň╣┐Š│Ťň║öšöĘń║ÄŠÁĚÚçĆŠĽ░ŠŹ«šÜä...
ŃÇŐMapReduce2.0Š║ÉšáüňłćŠ×ÉńŞÄň«×Šłśš╝ľšĘőŃÇőŠś»ńŞÇŠťČŠĚ▒ň║ŽŠÄóŔ«ĘHadoop MapReduceŠáŞň┐âŠíćŠ×šÜäń╣Žš▒Ź´╝ĘňťĘňŞ«ňŐęŔ»╗ŔÇůšÉćŔžúMapReducešÜäňĚąńŻťňÄčšÉć´╝îň╣ÂÚÇÜŔ┐çň«×ÚÖůš╝ľšĘőŠÄîŠĆíňůÂň║öšöĘŠŐÇňĚžŃÇéń╗ąńŞőŠś»ňÉäšźáŔŐéńŞ╗ŔŽüňćůň«╣šÜ䊎éŔ┐░´╝Ü šČČ1šźá´╝ÜMapReduceš«Çń╗ő ŠťČ...
1. **MapReduceš╝ľšĘőŠĘíň×ő**´╝ÜMapReducešÜäŠáŞň┐⊜»MapňĺîReduceńŞĄńެň篊Ľ░ŃÇéMapŔ┤čŔ┤úň░ćŔżôňůąŠĽ░ŠŹ«ŠőćňłćŠłÉÚö«ňÇ╝ň»╣´╝îŔ┐ŤŔíîň▒ÇÚâĘňĄäšÉć´╝ŤReduceňłÖň░ćMapڜŠ«ÁšÜäš╗ôŠ×ťŔ┐ŤŔíîŔüÜňÉł´╝îšö芳ɊťÇš╗łš╗ôŠ×ťŃÇéńŞşÚŚ┤š╗ôŠ×ťÚÇÜŔ┐ç Shuffle ňĺî Sort ڜŠ«ÁŔ┐ŤŔíîŠÄĺň║Ćňĺî...
MapReducešÜäŠáŞň┐âŠÇŁŠâ│ňĆ»ń╗ąňłćńŞ║ńŞĄńެńŞ╗ŔŽüڜŠ«Á´╝ÜMapڜŠ«ÁňĺîReduceڜŠ«ÁŃÇéMapڜŠ«ÁŔ┤čŔ┤úň░ćŔżôňůąŠĽ░ŠŹ«ňłćŔžúŠłÉňĄÜńެÚö«ňÇ╝ň»╣´╝îň╣ÂňłćňĆĹňł░ńŞŹňÉîšÜäňĚąńŻťŔŐéšé╣Ŕ┐ŤŔíîň╣ÂŔíîňĄäšÉćŃÇéReduceڜŠ«ÁňłÖň░ćMapڜŠ«ÁšÜäš╗ôŠ×ťŔ┐ŤŔíîŔüÜňÉł´╝îÚÇÜŔ┐çšë╣ň«ÜšÜäÚÇ╗ŔżĹň»╣š╗ôŠ×ťŔ┐ŤŔíî...
Šá╣ŠŹ«ŠĆÉńżŤšÜ䊾çń╗Âń┐íŠü»´╝Ȋľçň░ćŠĚ▒ňůąŔžúŠ×ÉŃÇŐHadoopŠŐÇŠť»ňćůň╣Ľ´╝ÜŠĚ▒ňůąŔžúŠ×ÉMapReduceŠ×Š×äŔ«żŔ«íńŞÄň«×šÄ░ňÄčšÉćŃÇőŔ┐ÖŠťČń╣ŽńŞşšÜäňů│Úö«ščąŔ»ćšé╣´╝îńŞ╗ŔŽüňîůŠőČHadoopšÜäŠáŞň┐âš╗äń╗ÂÔÇöÔÇöMapReducešÜäŔ«żŔ«íšÉćň┐ÁŃÇüŠ×Š×äš╗䊳ÉňĆŐňůÂňůĚńŻôšÜäň«×šÄ░ňÄčšÉćŃÇé ### Hadoop...
MapReduceŠś»Apache HadoopÚí╣šŤ«šÜäŠáŞň┐âš╗äń╗Âń╣őńŞÇ´╝îńŞ╗ŔŽüšöĘń║ÄňĄäšÉćňĄžŔžäŠĘ튼░ŠŹ«ÚŤćšÜäňłćňŞâň╝ĆŔ«íš«ŚŃÇéň«âńŞŹń╗ůŠś»ńŞÇšžŹš╝ľšĘőŠĘíň×ő´╝îŔ┐śŠś»ńŞÇňąŚŠö»ŠîüŔ┐ÖšžŹŠĘíň×őšÜäŔŻ»ń╗ŠíćŠ×ÂŃÇéMapReduceńŻ┐ňżŚň╝ÇňĆĹń║║ňĹśŔâŻňĄčŔŻ╗ŠŁżš╝ľňćÖňłćňŞâň╝Ćň║öšöĘšĘőň║Ć´╝îňĄäšÉćňĄžÚçĆŠĽ░ŠŹ«ň╣Â...
Hadoop MapReduceňÄčšÉ抜»ňłćňŞâň╝ĆŔ«íš«ŚŠíćŠ×šÜäŠáŞň┐âŠŐÇŠť»ń╣őńŞÇ´╝îňůÂŔ«żŔ«íšÉćň┐ÁŠś»ńŞ║ń║ćňťĘŠÖ«ÚÇÜšÜäňĽćšöĘšíČń╗ÂÚŤćšżĄńŞŐňĄäšÉćňĄžŠĽ░ŠŹ«ÚŚ«ÚóśŃÇéMapReducešÜäńŞ╗ŔŽüŠÇŁŠâ│Šś»ň░ćń╗╗ňŐíňłćŔžúńŞ║ńŞĄńŞ¬ÚśÂŠ«Á´╝ÜMapڜŠ«ÁňĺîReduceڜŠ«ÁŃÇéňťĘń╝áš╗čMapReduceńŞş´╝îš│╗š╗čŠ×Š×ä...
MapReducešÜäŠáŞň┐âšÉćň┐ÁŠś»ÔÇťňłćŔÇîŠ▓╗ń╣őÔÇŁ´╝îÚÇÜŔ┐çň░ćňĄžŔžäŠĘ튼░ŠŹ«ŠőćňłćŠłÉňĆ»š«íšÉćšÜäň░ĆÚâĘňłć´╝îšäÂňÉÄňťĘňłćňŞâň╝ĆÚŤćšżĄšÜäńŞŹňÉîŔŐéšé╣ńŞŐň╣ÂŔíîňĄäšÉćŔ┐Öń║Ťň░ĆÚâĘňłć´╝ÇňÉÄň░ćŠëÇŠťëňĄäšÉćš╗ôŠ×ťňÉłň╣ÂňżŚňł░ŠťÇš╗łŔżôňç║ŃÇé **MapReducešÜäňč║ŠťČňÄčšÉć** MapReduceŠĘíň×ő...
ŠÇ╗š╗ôŠŁąŔ»┤´╝î`mapreduce-examples` Úí╣šŤ«ńŞ║ň╝ÇňĆĹŔÇůŠĆÉńżŤń║ćńŞÇńެŠĚ▒ňůąšÉćŔžú MapReduce ňĚąńŻťňÄčšÉćňĺîň«×ŔĚÁšÜäň╣│ňĆ░ŃÇéÚÇÜŔ┐çňşŽń╣áňĺîň«×ŔĚÁňůÂńŞşšÜ䚥║ńżő´╝Ĺń╗ČňĆ»ń╗ąŠÄîŠĆíňŽéńŻĽńŻ┐šöĘ Java API š╝ľňćÖ MapReduce ň║öšöĘ´╝îń╗ąňĆŐňŽéńŻĽÚĺłň»╣ňĄžŔžäŠĘ튼░ŠŹ«ÚŤćŔ┐ŤŔíî...
- **š╗¬Ŕ«║**´╝ÜMapReducešÜäŠáŞň┐âŠÇŁŠâ│Šś»ň░ćňĄžŔžäŠĘ튼░ŠŹ«šÜäňĄäšÉćňłćŔžúńŞ║ńŞĄńެńŞ╗ŔŽüŠôŹńŻť´╝ÜMapňĺîReduce´╝îŔ┐ÖńŞĄńެŠôŹńŻťÚ⯊ś»ń╗ąň篊Ľ░ň╝Ćš╝ľšĘőńŞşšÜ䊎éň┐ÁńŞ║ňč║šíÇŃÇéMapڜŠ«Áň░ćňÄčňžőŠĽ░ŠŹ«ňłćšëçň╣Âň║öšöĘŠśáň░äň篊Ľ░´╝îšö芳ÉńŞşÚŚ┤Úö«ňÇ╝ň»╣´╝ŤReduceڜŠ«ÁňłÖň»╣Ŕ┐Öń║Ť...
#### ńŞÇŃÇüMapReduceŠŽéŔžłńŞÄňÄčšÉć MapReduceńŻťńŞ║HadoopšÜäŠáŞň┐âš╗äń╗Âń╣őńŞÇ´╝îŠĆÉńżŤń║ćńŞÇšžŹÚźśŠĽłŃÇüňƻڣášÜäňłćňŞâň╝ĆŔ«íš«ŚŠíćŠ×ÂŃÇéň«âŠťÇňłŁšö▒Doug Cuttingňč║ń║ÄGoogleňĆĹŔíĘšÜäŔ«║ŠľçŃÇŐMapReduce: Simplified Data Processing on Large Clusters...
šÉćŔžúMapReducešÜäňĚąńŻťňÄčšÉćň»╣ń║Äň╝ÇňĆĹňĺîń╝śňîľňĄžŠĽ░ŠŹ«ňĄäšÉćň║öšöĘŔç│ňů│ÚçŹŔŽü´╝îŔ┐Öń╣芜»HadoopšöčŠÇüš│╗š╗čńŞşšÜäŠáŞň┐âŠŐÇŔâŻń╣őńŞÇŃÇéÚÇÜŔ┐çŠîüš╗şňşŽń╣áňĺîň«×ŔĚÁ´╝îň╝ÇňĆĹŔÇůňĆ»ń╗ąŠŤ┤ňąŻňť░ňłęšöĘMapReduceŔžúňć│ň«×ÚÖůÚŚ«Úóś´╝îÚężÚ꺊ÁĚÚçĆŠĽ░ŠŹ«šÜäŠîĹŠłśŃÇé
ŃÇŐŠĚ▒ňůąŔžúŠ×ÉMapReduceŠ×Š×äŔ«żŔ«íńŞÄň«×šÄ░ňÄčšÉćŃÇőŠś»Úĺłň»╣HadoopŠŐÇŠť»šÜäńŞÇŠťČńŞôńŞÜŠîçňŹŚ´╝îň░ĄňůÂńżžÚçŹń║ÄMapReduceŔ┐ÖńŞÇŠáŞň┐âš╗äń╗šÜäŠĚ▒ň║Žň뾊×ÉŃÇéMapReduceŠś»GoogleŠĆÉňç║šÜäńŞÇšžŹňłćňŞâň╝ĆŔ«íš«ŚŠĘíň×ő´╝îŔóźň╣┐Š│Ťň║öšöĘń║ÄňĄžŠĽ░ŠŹ«ňĄäšÉćÚóćňčč´╝îňŽéŠŚąň┐ŚňłćŠ×ÉŃÇü...
MapReduceňĚąńŻťňÄčšÉćŔ»ŽŔžú HadoopŠś»ńŞÇńެň╝ÇŠ║ÉšÜäňłćňŞâň╝ĆŔ«íš«ŚŠíćŠ×´╝îŔÁĚŠ║Éń║ÄApacheÚí╣šŤ«´╝îńŞôŠ│Ęń║ÄňĄžŔžäŠĘ튼░ŠŹ«šÜäňłćňŞâň╝ĆňşśňéĘňĺîňĄäšÉćŃÇéň«âšÜäŠáŞň┐âšë╣ŠÇžňîůŠőČňĆ»Šëęň▒ĽŠÇžŃÇüš╗ĆŠÁÄŠÇžŃÇüÚźśŠĽłŠÇžňĺîňƻڣáŠÇž´╝îńŻ┐ňżŚňĄäšÉćPBš║žňłźšÜ䊼░ŠŹ«ňĆśňżŚňĆ»Ŕ⯴╝îňÉÂňłęšöĘ...