
иљђиЗ™:MySQLжАІиГљдЉШеМЦзЪДжЬАдљ≥20+жЭ°зїПй™М
¬†дїК姩пЉМжХ∞жНЃеЇУзЪДжУНдљЬиґКжЭ•иґКжИРдЄЇжХідЄ™еЇФзФ®зЪДжАІиГљзУґйҐИдЇЖпЉМињЩзВєеѓєдЇОWebеЇФзФ®е∞§еЕґжШОжШЊгАВеЕ≥дЇОжХ∞жНЃеЇУзЪДжАІиГљпЉМињЩеєґдЄНеП™жШѓDBAжЙНйЬАи¶БжЛЕењГзЪДдЇЛпЉМиАМињЩжЫіжШѓжИСдїђз®ЛеЇПеСШйЬАи¶БеОїеЕ≥ж≥®зЪДдЇЛжГЕгАВељУжИСдїђеОїиЃЊиЃ°жХ∞жНЃеЇУи°®зїУжЮДпЉМеѓєжУНдљЬжХ∞жНЃеЇУжЧґпЉИе∞§еЕґжШѓжЯ•и°®жЧґзЪДSQLиѓ≠еП•пЉЙпЉМжИСдїђйГљйЬАи¶Бж≥®жДПжХ∞жНЃжУНдљЬзЪДжАІиГљгАВињЩйЗМпЉМжИСдїђдЄНдЉЪиЃ≤ињЗе§ЪзЪДSQLиѓ≠еП•зЪДдЉШеМЦпЉМиАМеП™жШѓйТИеѓєMySQLињЩдЄАWebеЇФзФ®жЬАе§ЪзЪДжХ∞жНЃеЇУгАВеЄМжЬЫдЄЛйЭҐзЪДињЩдЇЫдЉШеМЦжКАеЈІеѓєдљ†жЬЙзФ®гАВ
1. дЄЇжߕ胥зЉУе≠ШдЉШеМЦдљ†зЪДжߕ胥
е§Іе§ЪжХ∞зЪДMySQLжЬНеК°еЩ®йГљеЉАеРѓдЇЖжߕ胥зЉУе≠ШгАВињЩжШѓжПРйЂШжАІжЬАжЬЙжХИзЪДжЦєж≥ХдєЛдЄАпЉМиАМдЄФињЩж؃襀MySQLзЪДжХ∞жНЃеЇУеЉХжУОе§ДзРЖзЪДгАВељУжЬЙеЊИе§ЪзЫЄеРМзЪДжߕ胥襀жЙІи°МдЇЖе§Ъжђ°зЪДжЧґеАЩпЉМињЩдЇЫжߕ胥зїУжЮЬдЉЪ襀жФЊеИ∞дЄАдЄ™зЉУе≠ШдЄ≠пЉМињЩж†ЈпЉМеРОзї≠зЪДзЫЄеРМзЪДжߕ胥е∞±дЄНзФ®жУНдљЬи°®иАМзЫіжО•иЃњйЧЃзЉУе≠ШзїУжЮЬдЇЖгАВ
ињЩйЗМжЬАдЄїи¶БзЪДйЧЃйҐШжШѓпЉМеѓєдЇОз®ЛеЇПеСШжЭ•иѓіпЉМињЩдЄ™дЇЛжГЕжШѓеЊИеЃєжШУ襀圚зХ•зЪДгАВеЫ†дЄЇпЉМжИСдїђжЯРдЇЫжߕ胥иѓ≠еП•дЉЪиЃ©MySQLдЄНдљњзФ®зЉУе≠ШгАВиѓЈзЬЛдЄЛйЭҐзЪДз§ЇдЊЛпЉЪ

дЄКйЭҐдЄ§жЭ°SQLиѓ≠еП•зЪДеЈЃеИЂе∞±жШѓ CURDATE() пЉМMySQLзЪДжߕ胥зЉУе≠ШеѓєињЩдЄ™еЗљжХ∞дЄНиµЈдљЬзФ®гАВжЙАдї•пЉМеГП NOW() еТМ RAND() жИЦжШѓеЕґеЃГзЪДиѓЄе¶Вж≠§з±їзЪДSQLеЗљжХ∞йГљдЄНдЉЪеЉАеРѓжߕ胥зЉУе≠ШпЉМеЫ†дЄЇињЩдЇЫеЗљжХ∞зЪДињФеЫЮжШѓдЉЪдЄНеЃЪзЪДжШУеПШзЪДгАВжЙАдї•пЉМдљ†жЙАйЬАи¶БзЪДе∞±жШѓзФ®дЄАдЄ™еПШйЗПжЭ•дї£жЫњMySQLзЪДеЗљжХ∞пЉМдїОиАМеЉАеРѓзЉУе≠ШгАВ
2. EXPLAIN дљ†зЪД SELECT жߕ胥
дљњзФ® EXPLAIN еЕ≥йФЃе≠ЧеПѓдї•иЃ©дљ†зЯ•йБУMySQLжШѓе¶ВдљХе§ДзРЖдљ†зЪДSQLиѓ≠еП•зЪДгАВињЩеПѓдї•еЄЃдљ†еИЖжЮРдљ†зЪДжߕ胥иѓ≠еП•жИЦжШѓи°®зїУжЮДзЪДжАІиГљзУґйҐИгАВ
EXPLAIN зЪДжߕ胥зїУжЮЬињШдЉЪеСКиѓЙдљ†дљ†зЪД糥еЉХдЄїйԁ襀е¶ВдљХеИ©зФ®зЪДпЉМдљ†зЪДжХ∞жНЃи°®жШѓе¶ВдљХ襀жРЬ糥еТМжОТеЇПзЪДвА¶вА¶з≠Йз≠ЙпЉМз≠Йз≠ЙгАВ
жМСдЄАдЄ™дљ†зЪДSELECTиѓ≠еП•пЉИжО®иНРжМСйАЙйВ£дЄ™жЬАе§НжЭВзЪДпЉМжЬЙе§Ъи°®иБФжО•зЪДпЉЙпЉМжККеЕ≥йФЃе≠ЧEXPLAINеК†еИ∞еЙНйЭҐгАВдљ†еПѓдї•дљњзФ®phpmyadminжЭ•еБЪињЩдЄ™дЇЛгАВзДґеРОпЉМдљ†дЉЪзЬЛеИ∞дЄАеЉ†и°®ж†ЉгАВдЄЛйЭҐзЪДињЩдЄ™з§ЇдЊЛдЄ≠пЉМжИСдїђењШиЃ∞еК†дЄКдЇЖgroup_id糥еЉХпЉМеєґдЄФжЬЙи°®иБФжО•пЉЪ
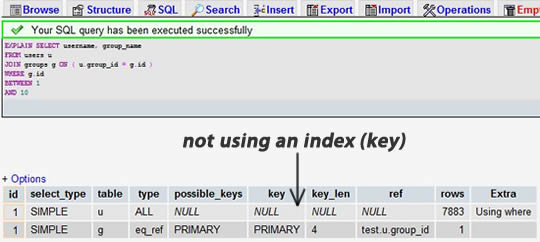
ељУжИСдїђдЄЇ group_id е≠ЧжЃµеК†дЄК糥еЉХеРОпЉЪ
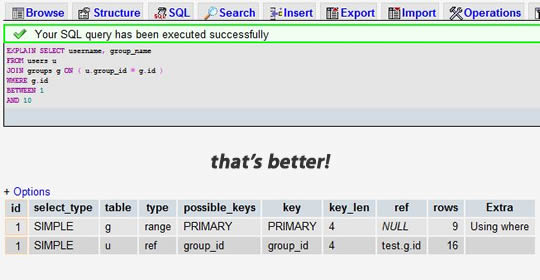
жИСдїђеПѓдї•зЬЛеИ∞пЉМеЙНдЄАдЄ™зїУжЮЬжШЊз§ЇжРЬ糥дЇЖ 7883 и°МпЉМиАМеРОдЄАдЄ™еП™жШѓжРЬ糥дЇЖдЄ§дЄ™и°®зЪД 9 еТМ 16 и°МгАВжЯ•зЬЛrowsеИЧеПѓдї•иЃ©жИСдїђжЙЊеИ∞жљЬеЬ®зЪДжАІиГљйЧЃйҐШгАВ
3. ељУеП™и¶БдЄАи°МжХ∞жНЃжЧґдљњзФ® LIMIT 1
ељУдљ†жߕ胥谮зЪДжЬЙдЇЫжЧґеАЩпЉМдљ†еЈ≤зїПзЯ•йБУзїУжЮЬеП™дЉЪжЬЙдЄАжЭ°зїУжЮЬпЉМдљЖеЫ†дЄЇдљ†еПѓиГљйЬАи¶БеОїfetchжЄЄж†ЗпЉМжИЦжШѓдљ†дєЯиЃЄдЉЪеОїж£АжЯ•ињФеЫЮзЪДиЃ∞ељХжХ∞гАВ
еЬ®ињЩзІНжГЕеЖµдЄЛпЉМеК†дЄК LIMIT 1 еПѓдї•еҐЮеК†жАІиГљгАВињЩж†ЈдЄАж†ЈпЉМMySQLжХ∞жНЃеЇУеЉХжУОдЉЪеЬ®жЙЊеИ∞дЄАжЭ°жХ∞жНЃеРОеБЬж≠ҐжРЬ糥пЉМиАМдЄНжШѓзїІзї≠еЊАеРОжЯ•е∞СдЄЛдЄАжЭ°зђ¶еРИиЃ∞ељХзЪДжХ∞жНЃгАВ
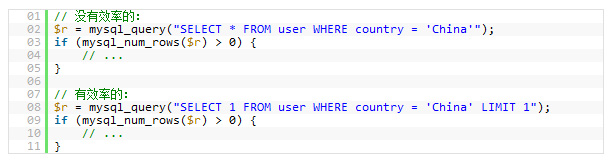
дЄЛйЭҐзЪДз§ЇдЊЛпЉМеП™жШѓдЄЇдЇЖжЙЊдЄАдЄЛжШѓеР¶жЬЙвАЬдЄ≠еЫљвАЭзЪДзФ®жИЈпЉМеЊИжШОжШЊпЉМеРОйЭҐзЪДдЉЪжѓФеЙНйЭҐзЪДжЫіжЬЙжХИзОЗгАВпЉИиѓЈж≥®жДПпЉМзђђдЄАжЭ°дЄ≠жШѓSelect *пЉМзђђдЇМжЭ°жШѓSelect 1пЉЙ
4. дЄЇжРЬ糥е≠Ч恵忯糥еЉХ
糥еЉХеєґдЄНдЄАеЃЪе∞±жШѓзїЩдЄїйФЃжИЦжШѓеФѓдЄАзЪДе≠ЧжЃµгАВе¶ВжЮЬеЬ®дљ†зЪДи°®дЄ≠пЉМжЬЙжЯРдЄ™е≠ЧжЃµдљ†жАїи¶БдЉЪзїПеЄЄзФ®жЭ•еБЪжРЬ糥пЉМйВ£дєИпЉМиѓЈдЄЇеЕґеїЇзЂЛ糥еЉХеРІгАВ
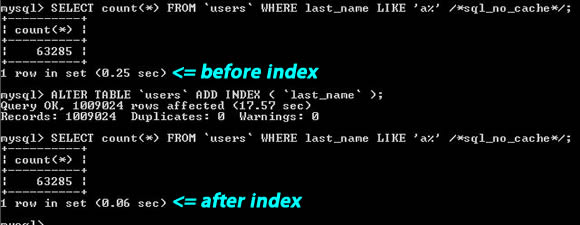
дїОдЄКеЫЊдљ†еПѓдї•зЬЛеИ∞йВ£дЄ™жРЬ糥е≠ЧдЄ≤ вАЬlast_name LIKE вАШa%вАЩвАЭпЉМдЄАдЄ™жШѓеїЇдЇЖ糥еЉХпЉМдЄАдЄ™жШѓж≤°жЬЙ糥еЉХпЉМжАІиГљеЈЃдЇЖ4еАНеЈ¶еП≥гАВ
еП¶е§ЦпЉМдљ†еЇФиѓ•дєЯйЬАи¶БзЯ•йБУдїАдєИж†ЈзЪДжРЬ糥жШѓдЄНиГљдљњзФ®ж≠£еЄЄзЪД糥еЉХзЪДгАВдЊЛе¶ВпЉМељУдљ†йЬАи¶БеЬ®дЄАзѓЗе§ІзЪДжЦЗзЂ†дЄ≠жРЬ糥дЄАдЄ™иѓНжЧґпЉМе¶ВпЉЪ вАЬWHERE post_content LIKE вАШ%apple%вАЩвАЭпЉМ糥еЉХеПѓиГљжШѓж≤°жЬЙжДПдєЙзЪДгАВдљ†еПѓиГљйЬАи¶БдљњзФ®MySQLеЕ®жЦЗ糥еЉХ жИЦжШѓиЗ™еЈ±еБЪдЄА䪙糥еЉХпЉИжѓФе¶ВиѓіпЉЪжРЬ糥еЕ≥йФЃиѓНжИЦжШѓTagдїАдєИзЪДпЉЙ
5. еЬ®Joinи°®зЪДжЧґеАЩдљњзФ®зЫЄељУз±їеЮЛзЪДдЊЛпЉМеєґе∞ЖеŴ糥еЉХ
е¶ВжЮЬдљ†зЪДеЇФзФ®з®ЛеЇПжЬЙеЊИе§Ъ JOIN жߕ胥пЉМдљ†еЇФиѓ•з°ЃиЃ§дЄ§дЄ™и°®дЄ≠JoinзЪДе≠ЧжЃµж؃襀忯ињЗ糥еЉХзЪДгАВињЩж†ЈпЉМMySQLеЖЕйГ®дЉЪеРѓеК®дЄЇдљ†дЉШеМЦJoinзЪДSQLиѓ≠еП•зЪДжЬЇеИґгАВ
иАМдЄФпЉМињЩдЇЫ襀зФ®жЭ•JoinзЪДе≠ЧжЃµпЉМеЇФиѓ•жШѓзЫЄеРМзЪДз±їеЮЛзЪДгАВдЊЛе¶ВпЉЪе¶ВжЮЬдљ†и¶БжКК DECIMAL е≠ЧжЃµеТМдЄАдЄ™ INT е≠ЧжЃµJoinеЬ®дЄАиµЈпЉМMySQLе∞±жЧ†ж≥ХдљњзФ®еЃГдїђзЪД糥еЉХгАВеѓєдЇОйВ£дЇЫSTRINGз±їеЮЛпЉМињШйЬАи¶БжЬЙзЫЄеРМзЪДе≠Чзђ¶йЫЖжЙНи°МгАВпЉИдЄ§дЄ™и°®зЪДе≠Чзђ¶йЫЖжЬЙеПѓиГљдЄНдЄАж†ЈпЉЙ

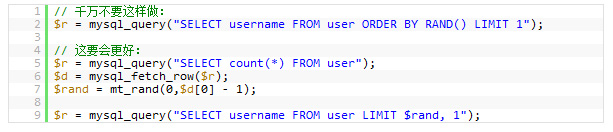
6. еНГдЄЗдЄНи¶Б ORDER BY RAND()
жГ≥жЙУдє±ињФеЫЮзЪДжХ∞жНЃи°МпЉЯйЪПжЬЇжМСдЄАдЄ™жХ∞жНЃпЉЯзЬЯдЄНзЯ•йБУи∞БеПСжШОдЇЖињЩзІНзФ®ж≥ХпЉМдљЖеЊИе§ЪжЦ∞жЙЛеЊИеЦЬ搥ињЩж†ЈзФ®гАВдљЖдљ†з°ЃдЄНдЇЖиІ£ињЩж†ЈеБЪжЬЙе§ЪдєИеПѓжАХзЪДжАІиГљйЧЃйҐШгАВ
е¶ВжЮЬдљ†зЬЯзЪДжГ≥жККињФеЫЮзЪДжХ∞жНЃи°МжЙУдє±дЇЖпЉМдљ†жЬЙNзІНжЦєж≥ХеПѓдї•иЊЊеИ∞ињЩдЄ™зЫЃзЪДгАВињЩж†ЈдљњзФ®еП™иЃ©дљ†зЪДжХ∞жНЃеЇУзЪДжАІиГљеСИжМЗжХ∞зЇІзЪДдЄЛйЩНгАВињЩйЗМзЪДйЧЃйҐШжШѓпЉЪMySQLдЉЪдЄНеЊЧдЄНеОїжЙІи°МRAND()еЗљжХ∞пЉИеЊИиАЧCPUжЧґйЧіпЉЙпЉМиАМдЄФињЩжШѓдЄЇдЇЖжѓПдЄАи°МиЃ∞ељХеОїиЃ∞и°МпЉМзДґеРОеЖНеѓєеЕґжОТеЇПгАВе∞±зЃЧжШѓдљ†зФ®дЇЖLimit 1дєЯжЧ†жµОдЇОдЇЛпЉИеЫ†дЄЇи¶БжОТеЇПпЉЙ
дЄЛйЭҐзЪДз§ЇдЊЛжШѓйЪПжЬЇжМСдЄАжЭ°иЃ∞ељХ
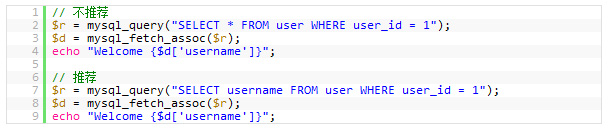
7. йБњеЕН SELECT *
дїОжХ∞жНЃеЇУйЗМиѓїеЗЇиґКе§ЪзЪДжХ∞жНЃпЉМйВ£дєИжߕ胥е∞±дЉЪеПШеЊЧиґКжЕҐгАВеєґдЄФпЉМе¶ВжЮЬдљ†зЪДжХ∞жНЃеЇУжЬНеК°еЩ®еТМWEBжЬНеК°еЩ®жШѓдЄ§еП∞зЛђзЂЛзЪДжЬНеК°еЩ®зЪДиѓЭпЉМињЩињШдЉЪеҐЮеК†зљСзїЬдЉ†иЊУзЪДиіЯиљљгАВ
жЙАдї•пЉМдљ†еЇФиѓ•еЕїжИРдЄАдЄ™йЬАи¶БдїАдєИе∞±еПЦдїАдєИзЪДе•љзЪДдє†жГѓгАВ
8. ж∞ЄињЬдЄЇжѓПеЉ†и°®иЃЊзљЃдЄАдЄ™ID
жИСдїђеЇФиѓ•дЄЇжХ∞жНЃеЇУйЗМзЪДжѓПеЉ†и°®йГљиЃЊзљЃдЄАдЄ™IDеБЪдЄЇеЕґдЄїйФЃпЉМиАМдЄФжЬАе•љзЪДжШѓдЄАдЄ™INTеЮЛзЪДпЉИжО®иНРдљњзФ®UNSIGNEDпЉЙпЉМеєґиЃЊзљЃдЄКиЗ™еК®еҐЮеК†зЪДAUTO_INCREMENTж†ЗењЧгАВ
е∞±зЃЧжШѓдљ† users и°®жЬЙдЄАдЄ™дЄїйФЃеПЂ вАЬemailвАЭзЪДе≠ЧжЃµпЉМдљ†дєЯеИЂиЃ©еЃГжИРдЄЇдЄїйФЃгАВдљњзФ® VARCHAR з±їеЮЛжЭ•ељУдЄїйФЃдЉЪдљњзФ®еЊЧжАІиГљдЄЛйЩНгАВеП¶е§ЦпЉМеЬ®дљ†зЪДз®ЛеЇПдЄ≠пЉМдљ†еЇФиѓ•дљњзФ®и°®зЪДIDжЭ•жЮДйА†дљ†зЪДжХ∞жНЃзїУжЮДгАВ
иАМдЄФпЉМеЬ®MySQLжХ∞жНЃеЉХжУОдЄЛпЉМињШжЬЙдЄАдЇЫжУНдљЬйЬАи¶БдљњзФ®дЄїйФЃпЉМеЬ®ињЩдЇЫжГЕеЖµдЄЛпЉМдЄїйФЃзЪДжАІиГљеТМиЃЊзљЃеПШеЊЧйЭЮеЄЄйЗНи¶БпЉМжѓФе¶ВпЉМйЫЖзЊ§пЉМеИЖеМЇвА¶вА¶
еЬ®ињЩйЗМпЉМеП™жЬЙдЄАдЄ™жГЕеЖµжШѓдЊЛе§ЦпЉМйВ£е∞±жШѓвАЬеЕ≥иБФи°®вАЭзЪДвАЬе§ЦйФЃвАЭпЉМдєЯе∞±жШѓиѓіпЉМињЩдЄ™и°®зЪДдЄїйФЃпЉМйАЪињЗиЛ•еє≤дЄ™еИЂзЪДи°®зЪДдЄїйФЃжЮДжИРгАВжИСдїђжККињЩдЄ™жГЕеЖµеПЂеБЪвАЬе§ЦйФЃвАЭгАВжѓФе¶ВпЉЪжЬЙдЄАдЄ™вАЬе≠¶зФЯи°®вАЭжЬЙе≠¶зФЯзЪДIDпЉМжЬЙдЄАдЄ™вАЬиѓЊз®Ли°®вАЭжЬЙиѓЊз®ЛIDпЉМйВ£дєИпЉМвАЬжИРзї©и°®вАЭе∞±жШѓвАЬеЕ≥иБФи°®вАЭдЇЖпЉМеЕґеЕ≥иБФдЇЖе≠¶зФЯи°®еТМиѓЊз®Ли°®пЉМеЬ®жИРзї©и°®дЄ≠пЉМе≠¶зФЯIDеТМиѓЊз®ЛIDеПЂвАЬе§ЦйФЃвАЭеЕґеЕ±еРМзїДжИРдЄїйФЃгАВ
9. дљњзФ® ENUM иАМдЄНжШѓ VARCHAR
ENUM з±їеЮЛжШѓйЭЮеЄЄењЂеТМзіІеЗСзЪДгАВеЬ®еЃЮйЩЕдЄКпЉМеЕґдњЭе≠ШзЪДжШѓ TINYINTпЉМдљЖеЕґе§Ци°®дЄКжШЊз§ЇдЄЇе≠Чзђ¶дЄ≤гАВињЩж†ЈдЄАжЭ•пЉМзФ®ињЩдЄ™е≠ЧжЃµжЭ•еБЪдЄАдЇЫйАЙй°єеИЧи°®еПШеЊЧзЫЄељУзЪДеЃМзЊОгАВ
е¶ВжЮЬдљ†жЬЙдЄАдЄ™е≠ЧжЃµпЉМжѓФе¶ВвАЬжАІеИЂвАЭпЉМвАЬеЫљеЃґвАЭпЉМвАЬж∞СжЧПвАЭпЉМвАЬзКґжАБвАЭжИЦвАЬйГ®йЧ®вАЭпЉМдљ†зЯ•йБУињЩдЇЫе≠ЧжЃµзЪДеПЦеАЉжШѓжЬЙйЩРиАМдЄФеЫЇеЃЪзЪДпЉМйВ£дєИпЉМдљ†еЇФиѓ•дљњзФ® ENUM иАМдЄНжШѓ VARCHARгАВ
MySQLдєЯжЬЙдЄАдЄ™вАЬеїЇиЃЃвАЭпЉИиІБзђђеНБжЭ°пЉЙеСКиѓЙдљ†жАОдєИеОїйЗНжЦ∞зїДзїЗдљ†зЪДи°®зїУжЮДгАВељУдљ†жЬЙдЄАдЄ™ VARCHAR е≠ЧжЃµжЧґпЉМињЩдЄ™еїЇиЃЃдЉЪеСКиѓЙдљ†жККеЕґжФєжИР ENUM з±їеЮЛгАВдљњзФ® PROCEDURE ANALYSE() дљ†еПѓдї•еЊЧеИ∞зЫЄеЕ≥зЪДеїЇиЃЃгАВ
10. дїО PROCEDURE ANALYSE() еПЦеЊЧеїЇиЃЃ
PROCEDURE ANALYSE() дЉЪиЃ© MySQL еЄЃдљ†еОїеИЖжЮРдљ†зЪДе≠ЧжЃµеТМеЕґеЃЮйЩЕзЪДжХ∞жНЃпЉМеєґдЉЪзїЩдљ†дЄАдЇЫжЬЙзФ®зЪДеїЇиЃЃгАВеП™жЬЙи°®дЄ≠жЬЙеЃЮйЩЕзЪДжХ∞жНЃпЉМињЩдЇЫеїЇиЃЃжЙНдЉЪеПШеЊЧжЬЙзФ®пЉМеЫ†дЄЇи¶БеБЪдЄАдЇЫе§ІзЪДеЖ≥еЃЪжШѓйЬАи¶БжЬЙжХ∞жНЃдљЬдЄЇеЯЇз°АзЪДгАВ
дЊЛе¶ВпЉМе¶ВжЮЬдљ†еИЫеїЇдЇЖдЄАдЄ™ INT е≠ЧжЃµдљЬдЄЇдљ†зЪДдЄїйФЃпЉМзДґиАМеєґж≤°жЬЙ姙е§ЪзЪДжХ∞жНЃпЉМйВ£дєИпЉМPROCEDURE ANALYSE()дЉЪеїЇиЃЃдљ†жККињЩдЄ™е≠ЧжЃµзЪДз±їеЮЛжФєжИР MEDIUMINT гАВжИЦжШѓдљ†дљњзФ®дЇЖдЄАдЄ™ VARCHAR е≠ЧжЃµпЉМеЫ†дЄЇжХ∞жНЃдЄНе§ЪпЉМдљ†еПѓиГљдЉЪеЊЧеИ∞дЄАдЄ™иЃ©дљ†жККеЃГжФєжИР ENUM зЪДеїЇиЃЃгАВињЩдЇЫеїЇиЃЃпЉМйГљжШѓеПѓиГљеЫ†дЄЇжХ∞жНЃдЄНе§Яе§ЪпЉМжЙАдї•еЖ≥з≠ЦеБЪеЊЧе∞±дЄНе§ЯеЗЖгАВ
еЬ®phpmyadminйЗМпЉМдљ†еПѓдї•еЬ®жЯ•зЬЛи°®жЧґпЉМзВєеЗї вАЬPropose table structureвАЭ жЭ•жЯ•зЬЛињЩдЇЫеїЇиЃЃ
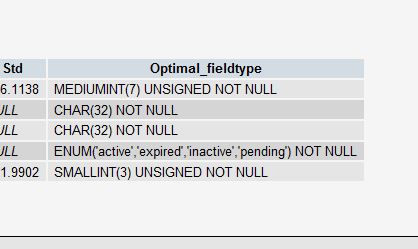
дЄАеЃЪи¶Бж≥®жДПпЉМињЩдЇЫеП™жШѓеїЇиЃЃпЉМеП™жЬЙељУдљ†зЪДи°®йЗМзЪДжХ∞жНЃиґКжЭ•иґКе§ЪжЧґпЉМињЩдЇЫеїЇиЃЃжЙНдЉЪеПШеЊЧеЗЖз°ЃгАВдЄАеЃЪи¶БиЃ∞дљПпЉМдљ†жЙНжШѓжЬАзїИеБЪеЖ≥еЃЪзЪДдЇЇгАВ
11. е∞љеПѓиГљзЪДдљњзФ® NOT NULL
йЩ§йЭЮдљ†жЬЙдЄАдЄ™еЊИзЙєеИЂзЪДеОЯеЫ†еОїдљњзФ® NULL еАЉпЉМдљ†еЇФиѓ•жАїжШѓиЃ©дљ†зЪДе≠ЧжЃµдњЭжМБ NOT NULLгАВињЩзЬЛиµЈжЭ•е•љеГПжЬЙзВєдЇЙиЃЃпЉМиѓЈеЊАдЄЛзЬЛгАВ
й¶ЦеЕИпЉМйЧЃйЧЃдљ†иЗ™еЈ±вАЬEmptyвАЭеТМвАЬNULLвАЭжЬЙе§Ъе§ІзЪДеМЇеИЂпЉИе¶ВжЮЬжШѓINTпЉМйВ£е∞±жШѓ0еТМNULLпЉЙпЉЯе¶ВжЮЬдљ†иІЙеЊЧеЃГдїђдєЛйЧіж≤°жЬЙдїАдєИеМЇеИЂпЉМйВ£дєИдљ†е∞±дЄНи¶БдљњзФ®NULLгАВпЉИдљ†зЯ•йБУеРЧпЉЯеЬ® Oracle йЗМпЉМNULL еТМ Empty зЪДе≠Чзђ¶дЄ≤жШѓдЄАж†ЈзЪДпЉБ)
дЄНи¶Бдї•дЄЇ NULL дЄНйЬАи¶Бз©ЇйЧіпЉМеЕґйЬАи¶БйҐЭе§ЦзЪДз©ЇйЧіпЉМеєґдЄФпЉМеЬ®дљ†ињЫи°МжѓФиЊГзЪДжЧґеАЩпЉМдљ†зЪДз®ЛеЇПдЉЪжЫіе§НжЭВгАВ ељУзДґпЉМињЩйЗМеєґдЄНжШѓиѓідљ†е∞±дЄНиГљдљњзФ®NULLдЇЖпЉМзО∞еЃЮжГЕеЖµжШѓеЊИе§НжЭВзЪДпЉМдЊЭзДґдЉЪжЬЙдЇЫжГЕеЖµдЄЛпЉМдљ†йЬАи¶БдљњзФ®NULLеАЉгАВ
дЄЛйЭҐжСШиЗ™MySQLиЗ™еЈ±зЪДжЦЗж°£пЉЪ

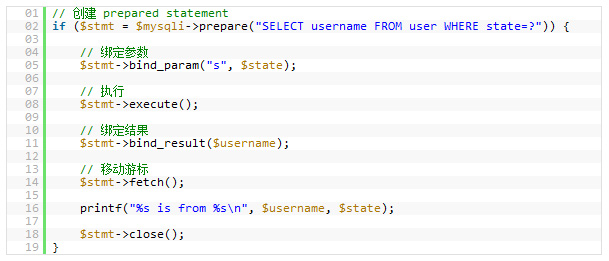
12. Prepared Statements
Prepared StatementsеЊИеГПе≠ШеВ®ињЗз®ЛпЉМжШѓдЄАзІНињРи°МеЬ®еРОеП∞зЪДSQLиѓ≠еП•йЫЖеРИпЉМжИСдїђеПѓдї•дїОдљњзФ® prepared statements иОЈеЊЧеЊИе§Ъе•ље§ДпЉМжЧ†иЃЇжШѓжАІиГљйЧЃйҐШињШжШѓеЃЙеЕ®йЧЃйҐШгАВ
Prepared Statements еПѓдї•ж£АжЯ•дЄАдЇЫдљ†зїСеЃЪе•љзЪДеПШйЗПпЉМињЩж†ЈеПѓдї•дњЭжК§дљ†зЪДз®ЛеЇПдЄНдЉЪеПЧеИ∞вАЬSQLж≥®еЕ•еЉПвАЭжФїеЗїгАВељУзДґпЉМдљ†дєЯеПѓдї•жЙЛеК®еЬ∞ж£АжЯ•дљ†зЪДињЩдЇЫеПШйЗПпЉМзДґиАМпЉМжЙЛеК®зЪДж£АжЯ•еЃєжШУеЗЇйЧЃйҐШпЉМиАМдЄФеЊИзїПеЄЄдЉЪ襀з®ЛеЇПеСШењШдЇЖгАВељУжИСдїђдљњзФ®дЄАдЇЫframeworkжИЦжШѓORMзЪДжЧґеАЩпЉМињЩж†ЈзЪДйЧЃйҐШдЉЪе•љдЄАдЇЫгАВ
еЬ®жАІиГљжЦєйЭҐпЉМељУдЄАдЄ™зЫЄеРМзЪДжߕ胥襀䚜зФ®е§Ъжђ°зЪДжЧґеАЩпЉМињЩдЉЪдЄЇдљ†еЄ¶жЭ•еПѓиІВзЪДжАІиГљдЉШеКњгАВдљ†еПѓдї•зїЩињЩдЇЫPrepared StatementsеЃЪдєЙдЄАдЇЫеПВжХ∞пЉМиАМMySQLеП™дЉЪиІ£жЮРдЄАжђ°гАВ
иЩљзДґжЬАжЦ∞зЙИжЬђзЪДMySQLеЬ®дЉ†иЊУPrepared StatementsжШѓдљњзФ®дЇМињЫеȴ嚥еКњпЉМжЙАдї•ињЩдЉЪдљњеЊЧзљСзїЬдЉ†иЊУйЭЮеЄЄжЬЙжХИзОЗгАВ
ељУзДґпЉМдєЯжЬЙдЄАдЇЫжГЕеЖµдЄЛпЉМжИСдїђйЬАи¶БйБњеЕНдљњзФ®Prepared StatementsпЉМеЫ†дЄЇеЕґдЄНжФѓжМБжߕ胥зЉУе≠ШгАВдљЖжНЃиѓізЙИжЬђ5.1еРОжФѓжМБдЇЖгАВ
еЬ®PHPдЄ≠и¶БдљњзФ®prepared statementsпЉМдљ†еПѓдї•жЯ•зЬЛеЕґдљњзФ®жЙЛеЖМпЉЪmysqli жЙ©е±Х жИЦжШѓдљњзФ®жХ∞жНЃеЇУжКљи±°е±ВпЉМе¶ВпЉЪ PDO.
13. жЧ†зЉУеЖ≤зЪДжߕ胥
ж≠£еЄЄзЪДжГЕеЖµдЄЛпЉМељУдљ†еЬ®ељУдљ†еЬ®дљ†зЪДиДЪжЬђдЄ≠жЙІи°МдЄАдЄ™SQLиѓ≠еП•зЪДжЧґеАЩпЉМдљ†зЪДз®ЛеЇПдЉЪеБЬеЬ®йВ£йЗМзЫіеИ∞ж≤°ињЩдЄ™SQLиѓ≠еП•ињФеЫЮпЉМзДґеРОдљ†зЪДз®ЛеЇПеЖНеЊАдЄЛзїІзї≠жЙІи°МгАВдљ†еПѓдї•дљњзФ®жЧ†зЉУеЖ≤жߕ胥жЭ•жФєеПШињЩдЄ™и°МдЄЇгАВ
еЕ≥дЇОињЩдЄ™дЇЛжГЕпЉМеЬ®PHPзЪДжЦЗж°£дЄ≠жЬЙдЄАдЄ™йЭЮеЄЄдЄНйФЩзЪДиѓіжШОпЉЪ mysql_unbuffered_query() еЗљжХ∞пЉЪ

дЄКйЭҐйВ£еП•иѓЭзњїиѓСињЗжЭ•жШѓиѓіпЉМmysql_unbuffered_query() еПСйАБдЄАдЄ™SQLиѓ≠еП•еИ∞MySQLиАМеєґдЄНеГПmysql_query()дЄАж†ЈеОїиЗ™еК®fethchеТМзЉУе≠ШзїУжЮЬгАВињЩдЉЪзЫЄељУиКВзЇ¶еЊИе§ЪеПѓиІВзЪДеЖЕе≠ШпЉМе∞§еЕґжШѓйВ£дЇЫдЉЪдЇІзФЯе§ІйЗПзїУжЮЬзЪДжߕ胥иѓ≠еП•пЉМеєґдЄФпЉМдљ†дЄНйЬАи¶Бз≠ЙеИ∞жЙАжЬЙзЪДзїУжЮЬйГљињФеЫЮпЉМеП™йЬАи¶БзђђдЄАи°МжХ∞жНЃињФеЫЮзЪДжЧґеАЩпЉМдљ†е∞±еПѓдї•еЉАеІЛй©ђдЄКеЉАеІЛеЈ•дљЬдЇОжߕ胥зїУжЮЬдЇЖгАВ
зДґиАМпЉМињЩдЉЪжЬЙдЄАдЇЫйЩРеИґгАВеЫ†дЄЇдљ†и¶БдєИжККжЙАжЬЙи°МйГљиѓїиµ∞пЉМжИЦжШѓдљ†и¶БеЬ®ињЫи°МдЄЛдЄАжђ°зЪДжߕ胥еЙНи∞ГзФ® mysql_free_result() жЄЕйЩ§зїУжЮЬгАВиАМдЄФпЉМ mysql_num_rows() жИЦ mysql_data_seek() е∞ЖжЧ†ж≥ХдљњзФ®гАВжЙАдї•пЉМжШѓеР¶дљњзФ®жЧ†зЉУеЖ≤зЪДжߕ胥䚆йЬАи¶БдїФзїЖиАГиЩСгАВ
14. жККIPеЬ∞еЭАе≠ШжИР UNSIGNED INT
еЊИе§Ъз®ЛеЇПеСШйГљдЉЪеИЫеїЇдЄАдЄ™ VARCHAR(15) е≠ЧжЃµжЭ•е≠ШжФЊе≠Чзђ¶дЄ≤嚥еЉПзЪДIPиАМдЄНжШѓжճ嚥зЪДIPгАВе¶ВжЮЬдљ†зФ®жճ嚥жЭ•е≠ШжФЊпЉМеП™йЬАи¶Б4дЄ™е≠ЧиКВпЉМеєґдЄФдљ†еПѓдї•жЬЙеЃЪйХњзЪДе≠ЧжЃµгАВиАМдЄФпЉМињЩдЉЪдЄЇдљ†еЄ¶жЭ•жߕ胥дЄКзЪДдЉШеКњпЉМе∞§еЕґжШѓељУдљ†йЬАи¶БдљњзФ®ињЩж†ЈзЪДWHEREжЭ°дїґпЉЪIP between ip1 and ip2гАВ
жИСдїђењЕйЬАи¶БдљњзФ®UNSIGNED INTпЉМеЫ†дЄЇ IPеЬ∞еЭАдЉЪдљњзФ®жХідЄ™32дљНзЪДжЧ†зђ¶еПЈжճ嚥гАВ
иАМдљ†зЪДжߕ胥пЉМдљ†еПѓдї•дљњзФ® INET_ATON() жЭ•жККдЄАдЄ™е≠Чзђ¶дЄ≤IPиљђжИРдЄАдЄ™жճ嚥пЉМеєґдљњзФ® INET_NTOA() жККдЄАдЄ™жճ嚥蚐жИРдЄАдЄ™е≠Чзђ¶дЄ≤IPгАВеЬ®PHPдЄ≠пЉМдєЯжЬЙињЩж†ЈзЪДеЗљжХ∞ ip2long() еТМ long2ip()гАВ
![]()
15. еЫЇеЃЪйХњеЇ¶зЪДи°®дЉЪжЫіењЂ
е¶ВжЮЬи°®дЄ≠зЪДжЙАжЬЙе≠ЧжЃµйГљжШѓвАЬеЫЇеЃЪйХњеЇ¶вАЭзЪДпЉМжХідЄ™и°®дЉЪ襀聧䪯жШѓ вАЬstaticвАЭ жИЦ вАЬfixed-lengthвАЭгАВ дЊЛе¶ВпЉМи°®дЄ≠ж≤°жЬЙе¶ВдЄЛз±їеЮЛзЪДе≠ЧжЃµпЉЪ VARCHARпЉМTEXTпЉМBLOBгАВеП™и¶Бдљ†еМЕжЛђдЇЖеЕґдЄ≠дЄАдЄ™ињЩдЇЫе≠ЧжЃµпЉМйВ£дєИињЩдЄ™и°®е∞±дЄНжШѓвАЬеЫЇеЃЪйХњеЇ¶йЭЩжАБи°®вАЭдЇЖпЉМињЩж†ЈпЉМMySQL еЉХжУОдЉЪзФ®еП¶дЄАзІНжЦєж≥ХжЭ•е§ДзРЖгАВ
еЫЇеЃЪйХњеЇ¶зЪДи°®дЉЪжПРйЂШжАІиГљпЉМеЫ†дЄЇMySQLжРЬеѓїеЊЧдЉЪжЫіењЂдЄАдЇЫпЉМеЫ†дЄЇињЩдЇЫеЫЇеЃЪзЪДйХњеЇ¶жШѓеЊИеЃєжШУиЃ°зЃЧдЄЛдЄАдЄ™жХ∞жНЃзЪДеБПзІїйЗПзЪДпЉМжЙАдї•иѓїеПЦзЪДиЗ™зДґдєЯдЉЪеЊИењЂгАВиАМе¶ВжЮЬе≠ЧжЃµдЄНжШѓеЃЪйХњзЪДпЉМйВ£дєИпЉМжѓПдЄАжђ°и¶БжЙЊдЄЛдЄАжЭ°зЪДиѓЭпЉМйЬАи¶Бз®ЛеЇПжЙЊеИ∞дЄїйФЃгАВ
еєґдЄФпЉМеЫЇеЃЪйХњеЇ¶зЪДи°®дєЯжЫіеЃєжШУ襀зЉУе≠ШеТМйЗНеїЇгАВдЄНињЗпЉМеФѓдЄАзЪДеЙѓдљЬзФ®жШѓпЉМеЫЇеЃЪйХњеЇ¶зЪДе≠ЧжЃµдЉЪжµ™иієдЄАдЇЫз©ЇйЧіпЉМеЫ†дЄЇеЃЪйХњзЪДе≠ЧжЃµжЧ†иЃЇдљ†зФ®дЄНзФ®пЉМдїЦйГљжШѓи¶БеИЖйЕНйВ£дєИе§ЪзЪДз©ЇйЧігАВ
дљњзФ®вАЬеЮВзЫіеИЖеЙ≤вАЭжКАжЬѓпЉИиІБдЄЛдЄАжЭ°пЉЙпЉМдљ†еПѓдї•еИЖеЙ≤дљ†зЪДи°®жИРдЄЇдЄ§дЄ™дЄАдЄ™жШѓеЃЪйХњзЪДпЉМдЄАдЄ™еИЩжШѓдЄНеЃЪйХњзЪДгАВ
16. еЮВзЫіеИЖеЙ≤
вАЬеЮВзЫіеИЖеЙ≤вАЭжШѓдЄАзІНжККжХ∞жНЃеЇУдЄ≠зЪДи°®жМЙеИЧеПШжИРеЗ†еЉ†и°®зЪДжЦєж≥ХпЉМињЩж†ЈеПѓдї•йЩНдљОи°®зЪДе§НжЭВеЇ¶еТМе≠ЧжЃµзЪДжХ∞зЫЃпЉМдїОиАМиЊЊеИ∞дЉШеМЦзЪДзЫЃзЪДгАВпЉИдї•еЙНпЉМеЬ®йУґи°МеБЪињЗй°єзЫЃпЉМиІБињЗдЄАеЉ†и°®жЬЙ100е§ЪдЄ™е≠ЧжЃµпЉМеЊИжБРжАЦпЉЙ
з§ЇдЊЛдЄАпЉЪеЬ®Usersи°®дЄ≠жЬЙдЄАдЄ™е≠ЧжЃµжШѓеЃґеЇ≠еЬ∞еЭАпЉМињЩдЄ™е≠ЧжЃµжШѓеПѓйАЙе≠ЧжЃµпЉМзЫЄжѓФиµЈпЉМиАМдЄФдљ†еЬ®жХ∞жНЃеЇУжУНдљЬзЪДжЧґеАЩйЩ§дЇЖдЄ™дЇЇдњ°жБѓе§ЦпЉМдљ†еєґдЄНйЬАи¶БзїПеЄЄиѓїеПЦжИЦжШѓжФєеЖЩињЩдЄ™е≠ЧжЃµгАВйВ£дєИпЉМдЄЇдїАдєИдЄНжККдїЦжФЊеИ∞еП¶е§ЦдЄАеЉ†и°®дЄ≠еСҐпЉЯ ињЩж†ЈдЉЪиЃ©дљ†зЪДи°®жЬЙжЫіе•љзЪДжАІиГљпЉМе§ІеЃґжГ≥жГ≥жШѓдЄНжШѓпЉМе§ІйЗПзЪДжЧґеАЩпЉМжИСеѓєдЇОзФ®жИЈи°®жЭ•иѓіпЉМеП™жЬЙзФ®жИЈIDпЉМзФ®жИЈеРНпЉМеП£дї§пЉМзФ®жИЈиІТиЙ≤з≠ЙдЉЪ襀зїПеЄЄдљњзФ®гАВе∞ПдЄАзВєзЪДи°®жАїжШѓдЉЪжЬЙе•љзЪДжАІиГљгАВ
з§ЇдЊЛдЇМпЉЪ дљ†жЬЙдЄАдЄ™еПЂ вАЬlast_loginвАЭ зЪДе≠ЧжЃµпЉМеЃГдЉЪеЬ®жѓПжђ°зФ®жИЈзЩїељХж״襀жЫіжЦ∞гАВдљЖжШѓпЉМжѓПжђ°жЫіжЦ∞жЧґдЉЪеѓЉиЗіиѓ•и°®зЪДжߕ胥зЉУе≠Ш襀жЄЕз©ЇгАВжЙАдї•пЉМдљ†еПѓдї•жККињЩдЄ™е≠ЧжЃµжФЊеИ∞еП¶дЄАдЄ™и°®дЄ≠пЉМињЩж†Је∞±дЄНдЉЪељ±еУНдљ†еѓєзФ®жИЈIDпЉМзФ®жИЈеРНпЉМзФ®жИЈиІТиЙ≤зЪДдЄНеБЬеЬ∞иѓїеПЦдЇЖпЉМеЫ†дЄЇжߕ胥зЉУе≠ШдЉЪеЄЃдљ†еҐЮеК†еЊИе§ЪжАІиГљгАВ
еП¶е§ЦпЉМдљ†йЬАи¶Бж≥®жДПзЪДжШѓпЉМињЩдЇЫ襀еИЖеЗЇеОїзЪДе≠ЧжЃµжЙА嚥жИРзЪДи°®пЉМдљ†дЄНдЉЪзїПеЄЄжАІеЬ∞еОїJoinдїЦдїђпЉМдЄНзДґзЪДиѓЭпЉМињЩж†ЈзЪДжАІиГљдЉЪжѓФдЄНеИЖеЙ≤жЧґињШи¶БеЈЃпЉМиАМдЄФпЉМдЉЪжШѓжЮБжХ∞зЇІзЪДдЄЛйЩНгАВ
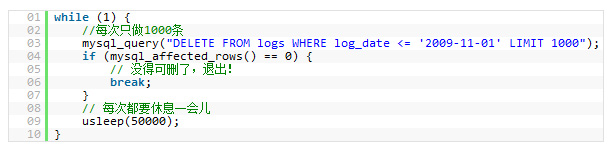
17. жЛЖеИЖе§ІзЪД DELETE жИЦ INSERT иѓ≠еП•
е¶ВжЮЬдљ†йЬАи¶БеЬ®дЄАдЄ™еЬ®зЇњзЪДзљСзЂЩдЄКеОїжЙІи°МдЄАдЄ™е§ІзЪД DELETE жИЦ INSERT жߕ胥пЉМдљ†йЬАи¶БйЭЮеЄЄе∞ПењГпЉМи¶БйБњеЕНдљ†зЪДжУНдљЬиЃ©дљ†зЪДжХідЄ™зљСзЂЩеБЬж≠ҐзЫЄеЇФгАВеЫ†дЄЇињЩдЄ§дЄ™жУНдљЬжШѓдЉЪйФБи°®зЪДпЉМи°®дЄАйФБдљПдЇЖпЉМеИЂзЪДжУНдљЬйГљињЫдЄНжЭ•дЇЖгАВ
Apache дЉЪжЬЙеЊИе§ЪзЪДе≠РињЫз®ЛжИЦзЇњз®ЛгАВжЙАдї•пЉМеЕґеЈ•дљЬиµЈжЭ•зЫЄељУжЬЙжХИзОЗпЉМиАМжИСдїђзЪДжЬНеК°еЩ®дєЯдЄНеЄМжЬЫжЬЙ姙е§ЪзЪДе≠РињЫз®ЛпЉМзЇњз®ЛеТМжХ∞жНЃеЇУйУЊжО•пЉМињЩжШѓжЮБе§ІзЪДеН†жЬНеК°еЩ®иµДжЇРзЪДдЇЛжГЕпЉМе∞§еЕґжШѓеЖЕе≠ШгАВ
е¶ВжЮЬдљ†жККдљ†зЪДи°®йФБдЄКдЄАжЃµжЧґйЧіпЉМжѓФе¶В30зІТйТЯпЉМйВ£дєИеѓєдЇОдЄАдЄ™жЬЙеЊИйЂШиЃњйЧЃйЗПзЪДзЂЩзВєжЭ•иѓіпЉМињЩ30зІТжЙАзІѓзіѓзЪДиЃњйЧЃињЫз®Л/зЇњз®ЛпЉМжХ∞жНЃеЇУйУЊжО•пЉМжЙУеЉАзЪДжЦЗдїґжХ∞пЉМеПѓиГљдЄНдїЕдїЕдЉЪиЃ©дљ†ж≥КWEBжЬНеК°CrashпЉМињШеПѓиГљдЉЪиЃ©дљ†зЪДжХіеП∞жЬНеК°еЩ®й©ђдЄКжОЫдЇЖгАВ
жЙАдї•пЉМе¶ВжЮЬдљ†жЬЙдЄАдЄ™е§ІзЪДе§ДзРЖпЉМдљ†еЃЪдљ†дЄАеЃЪжККеЕґжЛЖеИЖпЉМдљњзФ® LIMIT жЭ°дїґжШѓдЄАдЄ™е•љзЪДжЦєж≥ХгАВдЄЛйЭҐжШѓдЄАдЄ™з§ЇдЊЛпЉЪ
18. иґКе∞ПзЪДеИЧдЉЪиґКењЂ
еѓєдЇОе§Іе§ЪжХ∞зЪДжХ∞жНЃеЇУеЉХжУОжЭ•иѓіпЉМз°ђзЫШжУНдљЬеПѓиГљжШѓжЬАйЗНе§ІзЪДзУґйҐИгАВжЙАдї•пЉМжККдљ†зЪДжХ∞жНЃеПШеЊЧзіІеЗСдЉЪеѓєињЩзІНжГЕеЖµйЭЮеЄЄжЬЙеЄЃеК©пЉМеЫ†дЄЇињЩеЗПе∞СдЇЖеѓєз°ђзЫШзЪДиЃњйЧЃгАВ
еПВзЬЛ MySQL зЪДжЦЗж°£ Storage Requirements жЯ•зЬЛжЙАжЬЙзЪДжХ∞жНЃз±їеЮЛгАВ
е¶ВжЮЬдЄАдЄ™и°®еП™дЉЪжЬЙеЗ†еИЧ皥дЇЖпЉИжѓФе¶Виѓіе≠ЧеЕЄи°®пЉМйЕНзљЃи°®пЉЙпЉМйВ£дєИпЉМжИСдїђе∞±ж≤°жЬЙзРЖзФ±дљњзФ® INT жЭ•еБЪдЄїйФЃпЉМдљњзФ® MEDIUMINT, SMALLINT жИЦжШѓжЫіе∞ПзЪД TINYINT дЉЪжЫізїПжµОдЄАдЇЫгАВе¶ВжЮЬдљ†дЄНйЬАи¶БиЃ∞ељХжЧґйЧіпЉМдљњзФ® DATE и¶БжѓФ DATETIME е•љеЊЧе§ЪгАВ
ељУзДґпЉМдљ†дєЯйЬАи¶БзХЩе§Яиґ≥е§ЯзЪДжЙ©е±Хз©ЇйЧіпЉМдЄНзДґпЉМдљ†жЧ•еРОжЭ•еє≤ињЩдЄ™дЇЛпЉМдљ†дЉЪж≠їзЪДеЊИйЪЊзЬЛпЉМеПВзЬЛSlashdotзЪДдЊЛе≠РпЉИ2009еєі11жЬИ06жЧ•пЉЙпЉМдЄАдЄ™зЃАеНХзЪДALTER TABLEиѓ≠еП•иК±дЇЖ3дЄ™е§Ъе∞ПжЧґпЉМеЫ†дЄЇйЗМйЭҐжЬЙдЄАеНГеЕ≠зЩЊдЄЗжЭ°жХ∞жНЃгАВ
19. йАЙжЛ©ж≠£з°ЃзЪДе≠ШеВ®еЉХжУО
еЬ® MySQL дЄ≠жЬЙдЄ§дЄ™е≠ШеВ®еЉХжУО MyISAM еТМ InnoDBпЉМжѓПдЄ™еЉХжУОйГљжЬЙеИ©жЬЙеЉКгАВйЕЈе£≥дї•еЙНжЦЗзЂ†гАКMySQL: InnoDB ињШжШѓ MyISAM?гАЛиЃ®иЃЇеТМињЩдЄ™дЇЛжГЕгАВ
MyISAM йАВеРИдЇОдЄАдЇЫйЬАи¶Бе§ІйЗПжߕ胥зЪДеЇФзФ®пЉМдљЖеЕґеѓєдЇОжЬЙе§ІйЗПеЖЩжУНдљЬеєґдЄНжШѓеЊИе•љгАВзФЪиЗ≥дљ†еП™жШѓйЬАи¶БupdateдЄАдЄ™е≠ЧжЃµпЉМжХідЄ™и°®йГљдЉЪ襀йФБиµЈжЭ•пЉМиАМеИЂзЪДињЫз®ЛпЉМе∞±зЃЧжШѓиѓїињЫз®ЛйГљжЧ†ж≥ХжУНдљЬзЫіеИ∞иѓїжУНдљЬеЃМжИРгАВеП¶е§ЦпЉМMyISAM еѓєдЇО SELECT COUNT(*) ињЩз±їзЪДиЃ°зЃЧжШѓиґЕењЂжЧ†жѓФзЪДгАВ
InnoDB зЪДиґЛеКњдЉЪжШѓдЄАдЄ™йЭЮеЄЄе§НжЭВзЪДе≠ШеВ®еЉХжУОпЉМеѓєдЇОдЄАдЇЫе∞ПзЪДеЇФзФ®пЉМеЃГдЉЪжѓФ MyISAM ињШжЕҐгАВдїЦжШѓеЃГжФѓжМБвАЬи°МйФБвАЭ пЉМдЇОжШѓеЬ®еЖЩжУНдљЬжѓФиЊГе§ЪзЪДжЧґеАЩпЉМдЉЪжЫідЉШзІАгАВеєґдЄФпЉМдїЦињШжФѓжМБжЫіе§ЪзЪДйЂШзЇІеЇФзФ®пЉМжѓФе¶ВпЉЪдЇЛеК°гАВ
дЄЛйЭҐжШѓMySQLзЪДжЙЛеЖМ
- target=вАЭ_blankвАЭMyISAM Storage Engine
- InnoDB Storage Engine
20. дљњзФ®дЄАдЄ™еѓєи±°еЕ≥з≥їжШ†е∞ДеЩ®пЉИObject Relational MapperпЉЙ
дљњзФ® ORM (Object Relational Mapper)пЉМдљ†иГље§ЯиОЈеЊЧеПѓйЭ†зЪДжАІиГљеҐЮжґ®гАВдЄАдЄ™ORMеПѓдї•еБЪзЪДжЙАжЬЙдЇЛжГЕпЉМдєЯиÚ襀жЙЛеК®зЪДзЉЦеЖЩеЗЇжЭ•гАВдљЖжШѓпЉМињЩйЬАи¶БдЄАдЄ™йЂШзЇІдЄУеЃґгАВ
ORM зЪДжЬАйЗНи¶БзЪДжШѓвАЬLazy LoadingвАЭпЉМдєЯе∞±жШѓиѓіпЉМеП™жЬЙеЬ®йЬАи¶БзЪДеОїеПЦеАЉзЪДжЧґеАЩжЙНдЉЪеОїзЬЯж≠£зЪДеОїеБЪгАВдљЖдљ†дєЯйЬАи¶Бе∞ПењГињЩзІНжЬЇеИґзЪДеЙѓдљЬзФ®пЉМеЫ†дЄЇињЩеЊИжЬЙеПѓиГљдЉЪеЫ†дЄЇи¶БеОїеИЫеїЇеЊИе§ЪеЊИе§Ъе∞ПзЪДжߕ胥еПНиАМдЉЪйЩНдљОжАІиГљгАВ
ORM ињШеПѓдї•жККдљ†зЪДSQLиѓ≠еП•жЙУеМЕжИРдЄАдЄ™дЇЛеК°пЉМињЩдЉЪжѓФеНХзЛђжЙІи°МдїЦдїђењЂеЊЧе§ЪеЊЧе§ЪгАВ
зЫЃеЙНпЉМдЄ™дЇЇжЬАеЦЬ搥зЪДPHPзЪДORMжШѓпЉЪDoctrineгАВ
21. е∞ПењГвАЬж∞ЄдєЕйУЊжО•вАЭ
вАЬж∞ЄдєЕйУЊжО•вАЭзЪДзЫЃзЪДжШѓзФ®жЭ•еЗПе∞СйЗНжЦ∞еИЫеїЇMySQLйУЊжО•зЪДжђ°жХ∞гАВељУдЄАдЄ™йУЊжΕ襀еИЫеїЇдЇЖпЉМеЃГдЉЪж∞ЄињЬе§ДеЬ®ињЮжО•зЪДзКґжАБпЉМе∞±зЃЧжШѓжХ∞жНЃеЇУжУНдљЬеЈ≤зїПзїУжЭЯдЇЖгАВиАМдЄФпЉМиЗ™дїОжИСдїђзЪДApacheеЉАеІЛйЗНзФ®еЃГзЪДе≠РињЫз®ЛеРОвАФвАФдєЯе∞±жШѓиѓіпЉМдЄЛдЄАжђ°зЪДHTTPиѓЈж±ВдЉЪйЗНзФ®ApacheзЪДе≠РињЫз®ЛпЉМеєґйЗНзФ®зЫЄеРМзЪД MySQL йУЊжО•гАВ
PHPжЙЛеЖМпЉЪmysql_pconnect()
еЬ®зРЖиЃЇдЄКжЭ•иѓіпЉМињЩеРђиµЈжЭ•йЭЮеЄЄзЪДдЄНйФЩгАВдљЖжШѓдїОдЄ™дЇЇзїПй™МпЉИдєЯжШѓе§Іе§ЪжХ∞дЇЇзЪДпЉЙдЄКжЭ•иѓіпЉМињЩдЄ™еКЯиГљеИґйА†еЗЇжЭ•зЪДйЇїзГ¶дЇЛжЫіе§ЪгАВеЫ†дЄЇпЉМдљ†еП™жЬЙжЬЙйЩРзЪДйУЊжО•жХ∞пЉМеЖЕе≠ШйЧЃйҐШпЉМжЦЗдїґеП•жЯДжХ∞пЉМз≠Йз≠ЙгАВ
иАМдЄФпЉМApache ињРи°МеЬ®жЮБзЂѓеєґи°МзЪДзОѓеҐГдЄ≠пЉМдЉЪеИЫеїЇеЊИе§ЪеЊИе§ЪзЪДдЇЖињЫз®ЛгАВињЩе∞±жШѓдЄЇдїАдєИињЩзІНвАЬж∞ЄдєЕйУЊжО•вАЭзЪДжЬЇеИґеЈ•дљЬеЬ∞дЄНе•љзЪДеОЯеЫ†гАВеЬ®дљ†еЖ≥еЃЪи¶БдљњзФ®вАЬж∞ЄдєЕйУЊжО•вАЭдєЛеЙНпЉМдљ†йЬАи¶Бе•ље•љеЬ∞иАГиЩСдЄАдЄЛдљ†зЪДжХідЄ™з≥їзїЯзЪДжЮґжЮДгАВ
еОЯжЦЗйУЊжО•:http://net.tutsplus.com/tutorials/other/top-20-mysql-best-practices/
 
  
 
- 2010-01-25 16:47
- жµПиІИ 2596
- иѓДиЃЇ(3)
- жФґиЧП
- еИЖз±ї:жХ∞жНЃеЇУ
- зЫЄеЕ≥жО®иНР
иѓДиЃЇ
From: http://hi.baidu.com/xiaohuo37/blog/item/07b2512c37deb8ec8a139907.html
дї•дЄЛжШѓ MySQL дЉШеМЦзЫЄеЕ≥зЪДдЄАдЇЫиѓіжШОпЉЪ
1гАБж£Ай™М key_buffer_size еПВжХ∞е§Іе∞ПжШѓеР¶еРИйАВпЉИйАВзФ® MyISAM и°®пЉЙ
key_buffer_sizeжМЗеЃЪ糥еЉХзЉУеЖ≤еМЇзЪДе§Іе∞ПпЉМеЃГеЖ≥еЃЪ糥еЉХе§ДзРЖзЪДйАЯеЇ¶пЉМе∞§еЕґж؃糥еЉХиѓїзЪДйАЯеЇ¶гАВйАЪињЗж£АжЯ•зКґжАБеАЉKey_read_requestsеТМKey_readsпЉМеПѓдї•зЯ•йБУkey_buffer_sizeиЃЊзљЃжШѓеР¶еРИзРЖгАВжѓФдЊЛkey_reads / key_read_requestsеЇФиѓ•е∞љеПѓиГљзЪДдљОпЉМиЗ≥е∞СжШѓ1:100пЉМ1:1000жЫіе•љпЉИдЄКињ∞зКґжАБеАЉеПѓдї•дљњзФ®SHOW STATUS LIKE вАШkey_read%вАЩиОЈеЊЧпЉЙпЉИж£АжЯ•зКґжАБеАЉпЉМеЬ®жߕ胥壕еЕЈйЗМиЊУеЕ• SHOW STATUS пЉМжЙІи°МпЉЙгАВ
key_buffer_sizeеП™еѓєMyISAMи°®иµЈдљЬзФ®гАВеН≥дљњдљ†дЄНдљњзФ®MyISAMи°®пЉМдљЖжШѓеЖЕйГ®зЪДдЄіжЧґз£БзЫШи°®жШѓMyISAMи°®пЉМдєЯи¶БдљњзФ®иѓ•еАЉгАВеПѓдї•дљњзФ®ж£АжЯ•зКґжАБеАЉcreated_tmp_disk_tablesеЊЧзЯ•иѓ¶жГЕгАВ
еѓєдЇО1GеЖЕе≠ШзЪДжЬЇеЩ®пЉМе¶ВжЮЬдЄНдљњзФ®MyISAMи°®пЉМжО®иНРеАЉжШѓ16MпЉИ8-64MпЉЙгАВ
ж°ИдЊЛ1пЉЪеБ•еЇЈзКґеЖµ
key_buffer_size вАУ 402649088 (384M)
key_read_requests вАУ 597579931
key_reads - 56188
ж°ИдЊЛ2пЉЪи≠¶жК•зКґжАБ
key_buffer_size вАУ 16777216 (16M)
key_read_requests вАУ 597579931
key_reads - 53832731
ж°ИдЊЛ1дЄ≠жѓФдЊЛдљОдЇО1:10000пЉМжШѓеБ•еЇЈзЪДжГЕеЖµпЉЫж°ИдЊЛ2дЄ≠жѓФдЊЛиЊЊеИ∞1:11пЉМи≠¶жК•еЈ≤зїПжЛЙеУНгАВ
2гАБжߕ胥зЉУе≠Ш query_cache_size иЃЊзљЃ
дїО 4.0.1 еЉАеІЛпЉМMySQL жПРдЊЫдЇЖжߕ胥зЉУеЖ≤жЬЇеИґгАВеЬ®еРѓзФ®жߕ胥зЉУеЖ≤зЪДжГЕеЖµдЄЛпЉМMySQL е∞Ж SELECT иѓ≠еП•еТМжߕ胥зїУжЮЬе≠ШжФЊеЬ®зЉУеЖ≤еМЇдЄ≠пЉИеЖЕе≠ШпЉЙпЉМдєЛеРОеѓєдЇОеРМж†ЈзЪД SELECT жߕ胥иѓ≠еП•пЉИеМЇеИЖе§Іе∞ПеЖЩпЉЙпЉМе∞ЖзЫіжО•дїОзЉУеЖ≤еМЇдЄ≠иѓїеПЦзїУжЮЬпЉМйБњеЕНдЇЖйЗНе§Нжߕ胥зЪДжЧ†и∞УеЉАйФАгАВеТМжߕ胥зЉУе≠ШзЫЄеЕ≥зЪДеПВжХ∞еМЕжЛђпЉЪQcache_free_blocksгАБQcache_lowmem_prunesгАБQcache_free_memoryгАБQcache_not_cachedгАБQcache_total_blocksгАБQcache_queries_in_cacheгАБQcache_hitsгАБQcache_insertsгАВеЕґдЄ≠пЉМе¶ВжЮЬ Qcache_lowmem_prunes зЪДеАЉеЊИе§ІпЉМиѓіжШОзїПеЄЄеЗЇзО∞зЉУеЖ≤дЄНе§ЯзЪДжГЕеЖµпЉИжЬАе•љдњЭжМБеЬ®йЫґпЉЙпЉМеРМжЧґ Qcache_hits зЪДеАЉйЭЮеЄЄе§ІпЉМеИЩи°®жШОжߕ胥зЉУеЖ≤дљњзФ®йЭЮеЄЄйҐСзєБпЉМж≠§жЧґйЬАи¶БеҐЮеК†зЉУеЖ≤е§Іе∞П Qcache_hits зЪДеАЉдЄНе§ІпЉМеИЩи°®жШОдљ†зЪДжߕ胥йЗНе§НзОЗеЊИдљОпЉМињЩзІНжГЕеЖµдЄЛдљњзФ®жߕ胥зЉУеЖ≤еПНиАМдЉЪељ±еУНжХИзОЗпЉМйВ£дєИеПѓдї•иАГиЩСдЄНзФ®жߕ胥зЉУеЖ≤гАВеП¶е§ЦпЉМе¶ВжЮЬ Qcache_free_blocks зЪДеАЉйЭЮеЄЄе§ІпЉМеИЩи°®жШОзЉУеЖ≤еМЇдЄ≠зҐОзЙЗеЊИе§ЪгАВ
3гАБtable_cache
еРіе®Б (16:59:27):
table_cache 
The number of open tables for all threads пЉЯпЉЯпЉЯпЉЯ
For more information about the table cache, see section 7.4.8 How MySQL Opens and Closes Tables
table_cache зФ®дЇОжМЗеЃЪи°®йЂШйАЯзЉУе≠ШзЪДе§Іе∞ПгАВжѓПељУ MySQL иЃњйЧЃдЄАдЄ™и°®жЧґпЉМе¶ВжЮЬеЬ®и°®зЉУеЖ≤еМЇдЄ≠ињШжЬЙз©ЇйЧіпЉМиѓ•и°®е∞±иҐЂжЙУеЉАеєґжФЊеЕ•еЕґдЄ≠пЉМињЩж†ЈеПѓдї•жЫіењЂеЬ∞иЃњйЧЃи°®еЖЕеЃєгАВйАЪињЗж£АжЯ•ињРи°Ме≥∞еАЉжЧґйЧізЪД Open_tables еТМ Opened_tables зКґжАБеАЉпЉМеПѓдї•еЖ≥еЃЪжШѓеР¶йЬАи¶Би∞ГжХі table_cache зЪДеАЉгАВе¶ВжЮЬдљ†еПСзО∞ open_tables зЪДеАЉз≠ЙдЇО table_cacheпЉМеєґдЄФеПСзО∞ opened_tables зКґжАБеАЉеЬ®дЄНжЦ≠еҐЮйХњпЉМйВ£дєИдљ†е∞±йЬАи¶БеҐЮеК† table_cache еПВжХ∞еАЉдЇЖпЉИдЄКињ∞зКґжАБеАЉеПѓдї•дљњзФ® SHOW STATUS LIKE вАШOpen%tablesвАЩ еСљдї§иОЈеЊЧпЉЙгАВж≥®жДПпЉМдЄНиГљзЫ≤зЫЃеЬ∞жКК table_cache еПВжХ∞иЃЊзљЃжИРеЊИе§ІзЪДеАЉпЉМе¶ВжЮЬиЃЊзљЃеЊЧ姙йЂШпЉМеПѓиГљдЉЪйА†жИРжЦЗдїґжППињ∞зђ¶дЄНиґ≥пЉМдїОиАМйА†жИРжАІиГљдЄНз®≥еЃЪжИЦиАЕињЮжΕ姱賕гАВ
еѓєдЇОжЬЙ1GеЖЕе≠ШзЪДжЬЇеЩ®пЉМжО®иНРеАЉжШѓ128пЉН256гАВ
ж°ИдЊЛ1пЉЪиѓ•ж°ИдЊЛжЭ•иЗ™дЄАдЄ™дЄНжШѓзЙєеИЂзєБењЩзЪДжЬНеК°еЩ®
table_cache вАУ 512
open_tables вАУ 103
opened_tables вАУ 1273
uptime вАУ 4021421 (measured in seconds)
иѓ•ж°ИдЊЛдЄ≠table_cacheдЉЉдєОиЃЊзљЃеЊЧ姙йЂШдЇЖгАВеЬ®е≥∞еАЉжЧґйЧіпЉМжЙУеЉАи°®зЪДжХ∞зЫЃжѓФtable_cacheи¶Бе∞СеЊЧе§ЪгАВ
ж°ИдЊЛ2пЉЪиѓ•ж°ИдЊЛжЭ•иЗ™дЄАеП∞еЉАеПСжЬНеК°еЩ®гАВ
table_cache вАУ 64
open_tables вАУ 64
opened-tables вАУ 431
uptime вАУ 1662790 (measured in seconds)
иЩљзДґopen_tablesеЈ≤зїПз≠ЙдЇОtable_cacheпЉМдљЖжШѓзЫЄеѓєдЇОжЬНеК°еЩ®ињРи°МжЧґйЧіжЭ•иѓіпЉМopened_tablesзЪДеАЉдєЯйЭЮеЄЄдљОгАВеЫ†ж≠§пЉМеҐЮеК†table_cacheзЪДеАЉеЇФиѓ•зФ®е§ДдЄНе§ІгАВ
ж°ИдЊЛ3пЉЪиѓ•ж°ИдЊЛжЭ•иЗ™дЄАдЄ™upderperformingзЪДжЬНеК°еЩ®
table_cache вАУ 64
open_tables вАУ 64
opened_tables вАУ 22423
uptime вАУ 19538
иѓ•ж°ИдЊЛдЄ≠table_cacheиЃЊзљЃеЊЧ姙дљОдЇЖгАВиЩљзДґињРи°МжЧґйЧідЄНеИ∞6е∞ПжЧґпЉМopen_tablesиЊЊеИ∞дЇЖжЬАе§ІеАЉпЉМopened_tablesзЪДеАЉдєЯйЭЮеЄЄйЂШгАВињЩж†Је∞±йЬАи¶БеҐЮеК†table_cacheзЪДеАЉгАВ
4гАБMeasuring Key Buffer Usage
When you add indexes to your data, it enables MySQL to find data faster. However, ideally you want to have these indexes stored in RAM for maximum speed, and the variable key_buffer_size defines how much RAM MySQL can allocate for index key caching. If MySQL cannot store its indexes in RAM, you will experience serious performance problems. Fortunately, most databases have relatively small key buffer requirements, but you should measure your usage to see what work needs to be done.
To do this, log in to MySQL and type SHOW STATUS LIKE вАШ%key_read%вАЩ;. That returns all the status fields that describe the hit rate of your key bufferвАФyou should get two rows back: Key_reads and Key_read_requests, which are the number of keys being read from disk and the number of keys being read from the key buffer. From these two numbers you can calculate the percentage of requests being filled from RAM and from disk, using this simple equation:
100 вАУ ((Key_reads / Key_read_requests) x 100)
That is, you divide Key_reads by Key_read_requests, multiply the result by 100 and then subtract the result from 100. For example, if you have Key_reads of 1000 and Key_read_requests of 100000, you divide 1000 by 100000 to get 0.01; then you multiply that by 100 to get 1.0, and subtract that from 100 to get 99. That number is the percentage of key reads being served from RAM, which means 99% of your keys are served from RAM.
Most people should be looking to get more than 95% served from RAM, although the primary exception is if you update or delete rows very oftenвАФMySQL canвАЩt cache what keeps changing. If your site is largely read only, this should be around 98%. Lower figures mean you might need to bump up the size of your key buffer.
If you are seeing problems, the next step is to check how much of your current key buffer is being used. Use the SHOW VARIABLES command and look up the value of the key_buffer_size variable. It is probably something like 8388600, which is eight million bytes, or 8MB. Now, use the SHOW STATUS command and look up the value of Key_blocks_used.
You can now determine how much of your key buffer is being used by multiplying Key_blocks_used by 1024, dividing by key_buffer_size, and multiplying by 100. For example, if Key_blocks_used is 8000, you multiply that by 1024 to get 8192000; then you divide that by your key_buffer_size (8388600) to get 0.97656, and finally multiplying that by 100 to get 97.656. Thus, almost 98% of your key buffer is being used.
Now, onto the important part: You have ascertained that you are reading lots of keys from disk, and you also now know that the reason for reading from disk is almost certainly because you do not have enough RAM allocated to the key buffer. A general rule of thumb is to allocate as much RAM to the key buffer as you can, up to a maximum of 25% of system RAMвАФ128MB on a 512MB system is about the ideal for systems that read heavily from keys. Beyond that, you will actually see drastic performance decreases because the system has to use virtual memory for the key buffer.
From: http://www.wangyeba.com/Article/web04/MySQL/200905/20090507084529.shtml
зЫЃеЙНweb2.0зЪДз®ЛеЇПпЉМеЊИе§ІзУґйҐИжШѓжХ∞жНЃеЇУзЪДеРЮеЇ¶йЗПгАВдЄНињЗпЉМе¶ВдљХжЙНиГљз°ЃеЃЪз≥їзїЯзЪДзУґйҐИжШѓжХ∞жНЃеЇУеСҐпЉМеЫ†дЄЇеП™жЬЙз°ЃеЃЪжХ∞жНЃеЇУжШѓжХідЄ™з≥їзїЯзЪДзУґйҐИпЉМжИСдїђжЙНжЬЙењЕи¶БеОїдЉШеМЦдїЦпЉМжѓХзЂЯпЉМињШжЬЙињЩдєИе§ЪйЬАж±Вз≠ЙеЊЕжИСдїђеОїеБЪгАВ
гААгААе¶ВдљХз°ЃеЃЪжХ∞жНЃеЇУжШѓзУґйҐИ?
гААгАА1 е¶ВжЮЬз®ЛеЇПиЃЊиЃ°иЙѓе•љпЉМжЬЙдЄАдЄ™жХ∞жНЃеЇУжУНдљЬйАїиЊСе±ВпЉМеПѓдї•дїОињЩдЄ™е±ВзЪДзїЯиЃ°жХ∞жНЃзЬЛеИ∞жѓПдЄ™иѓЈж±ВиК±иієзЪДжЧґйЧіпЉМе¶ВжЮЬеє≥еЭЗжЧґйЧіеЈ≤зїПдЄНиГљиЃ©дљ†еЃєењНзЪДиѓЭпЉМжХ∞жНЃеЇУеЈ≤зїПжШѓзУґйҐИдЇЖгАВ
гААгАА2 еЬ®жХ∞жНЃеЇУзЪДжЬНеК°еЩ®дЄКдљњзФ®topеСљдї§пЉМзЬЛзЬЛmysqlжЬНеК°еЩ®еН†зФ®иµДжЇРзЪДжГЕеЖµпЉМзЬЛзЬЛжЬЇе≠РзЪДеє≥еЭЗиіЯиљљгАВ
гААгААе¶ВжЮЬжЬНеК°еЩ®зЪДеє≥еЭЗиіЯиљљеЈ≤зїПеЊИйЂШпЉМmysqlеН†зФ®дЇЖеЭЧ100%зЪДcpuиµДжЇРпЉМиѓіжШОmysqlжЬНеК°еЩ®еЊИењЩдЇЖгАВ
гААгАА3 еЬ®жХ∞жНЃеЇУжЬНеК°еЩ®дЄКдљњзФ®iostatеСљдї§пЉМзЬЛзЬЛз£БзЫШIOпЉМе¶ВжЮЬblockдљПзЪДжУНдљЬжѓФиЊГе§ЪзЪДиѓЭпЉМиѓіжШОжХ∞жНЃеЇУжУНдљЬињШжШѓињЗдЇОйҐСзєБдЇЖпЉМз£БзЫШйГљеУНеЇФдЄНжА•дЇЖгАВ
гААгАА4 еїЇиЃЃжЙУеЉАmysqlзЪДжЕҐжߕ胥жЧ•ењЧпЉМињЩж†Јgrep selectзЬЛдЄАдЄЛжЧ•ењЧдЄ≠зЪДжЕҐжߕ胥зЪДжХ∞йЗПпЉМе¶ВжЮЬжХ∞йЗПиЊГе§ЪпЉМиѓіжШОжЕҐжߕ胥зЪДжХ∞йЗПеЊИе§ЪпЉМйЬАи¶БињЫи°Ми∞ГжХідЇЖгАВ
гААгАА5 е¶ВжЮЬжЬЙдЄА姩жХ∞жНЃеЇУжЧ†ж≥ХжПТеЕ•дЇЖпЉМйЬАи¶Бж£АжЯ•дЄАдЄЛжХ∞жНЃеЇУи°®жШѓдЄНжШѓињЗе§ІдЇЖгАВ32дљНзЪДжУНдљЬз≥їзїЯдЄКдЄАдЄ™и°®жЬАе§ІзЪДеЃєйЗПжШѓ2^32ињЩдєИе§ІгАВдЄНињЗињШжШѓеїЇиЃЃеҐЮеК†дЄАдЄ™жХ∞жНЃеЇУжУНдљЬзЪДйАїиЊСе±ВпЉМеЬ®жХ∞жНЃеЇУжУНдљЬзЪДеЙНеРОиЃ∞ељХдЄЛжУНдљЬзЪДжЧґйЧіпЉМињЫи°МзїЯиЃ°дЄКжК•пЉМеИ©зФ®зЫСжОІз®ЛеЇПжЭ•жК•и≠¶зЫЄеЕ≥иіЯиі£дЇЇпЉМињЩж†ЈеПѓдї•еПКжЧ©зЪДзЯ•йБУжХ∞жНЃеЇУжШѓзУґйҐИпЉМжПРеЙНеБЪеЗЇдЉШеМЦгАВ
гААгААзЯ•йБУжХ∞жНЃеЇУжШѓзУґйҐИдЇЖпЉМе¶ВдљХжЭ•ињЫи°МдЉШеМЦеСҐ?
гААгАА1 жИСдїђзђђдЄАдЄ™жГ≥еИ∞жШѓзЬЛзЬЛжХ∞жНЃеЇУзЪДеЃєйЗПжШѓдЄНж؃姙姲дЇЖпЉМе¶ВжЮЬжХ∞жНЃеЇУ谮姙姲зЪДиѓЭпЉМ糥еЉХжЦЗдїґдєЯдЉЪжѓФиЊГе§ІпЉМжѓПжђ°зЪДжЫіжЦ∞жУНдљЬе∞±дЉЪжЫіеК†зЪДиієжЧґгАВйЬАи¶БиАГиЩСињЫи°МеИЖеЇУеТМеИЖи°®дЇЖгАВ
гААгААеИЖеЇУеИЖи°®жМЙзЕІдЄАеЃЪзЪДиІДеИЩжЭ•еѓєжХ∞жНЃеЇУдЄ≠зЪДиЃ∞ељХињЫи°МеИЖеМЇжЭ•е≠ШеВ®пЉМдЄАжЦєйЭҐеПѓдї•еБЪеИ∞дЄАеЃЪзЪДиіЯиљљеЭЗи°°пЉМе∞ЖиѓЈж±Веє≥еИЖдЄЛжЭ•пЉМжѓПдЄ™еМЇжЃµеОїзЛђиЗ™жЙњеПЧ;еП¶дЄАжЦєйЭҐпЉМеИЖеЇУеИЖи°®еПѓдї•дљњжИСдїђе≠ШеВ®еТМжУНдљЬжЫіе§ЪзЪДжХ∞жНЃгАВ
гААгААдЄНињЗеИЖеЇУеИЖи°®йЬАи¶Бе§ЪдєЛеЙНеЯЇдЇОеНХеЇУзЪДз®ЛеЇПињЫи°МдњЃжФєпЉМе≠ШеЬ®дЄАеЃЪзЪДй£ОйЩ©пЉМеЫ†ж≠§пЉМеЬ®з®ЛеЇПиЃЊиЃ°дєЛеИЭе∞±еЇФиѓ•иАГиЩСеИ∞еИЖеЇУеИЖи°®зЪДйЬАи¶БпЉМжЬАе•љжШѓе∞ЖжХ∞жНЃеЇУжУНдљЬе±ВзЛђзЂЛеЗЇжЭ•пЉМдЊњдЇОжЙ©е±ХеТМжЫіжФєгАВ
гААгАА2 е¶ВжЮЬжХ∞жНЃеЇУи°®дЄНжШѓеЊИе§ІпЉМдљЖжШѓжߕ胥жЕҐзЪДиѓЭпЉМжИСдїђйЬАи¶Бж£АжЯ•дЄАдЄЛжИСдїђзЪДsqlжߕ胥иѓ≠еП•пЉМеИ©зФ®mysqlзЪДexplainиѓ≠еП•зЬЛзЬЛжШѓдЄНжШѓдљњзФ®дЇЖ糥еЉХпЉМе¶ВжЮЬж≤°жЬЙдљњзԮ糥еЉХпЉМйВ£жИСдїђйЬАи¶БеЬ®зЫЄеЇФзЪДе≠ЧжЃµдЄКеїЇдЄК糥еЉХпЉМеПНе§НзЪДдљњзФ®explainпЉМеѓїжЙЊеИ∞дЄ™дЄАдЄ™еРИйАВзЪД糥еЉХгАВ
гААгААеܮ忯糥еЉХжЧґйЬАи¶БиАГиЩСпЉЪ
гААгАА1)жХ∞жНЃеЇУзЪД糥еЉХи¶БеБЪеИ∞иґКе∞СиґКе•љгАВ
гААгААеЫ†дЄЇжѓПжђ°жЫіжЦ∞йГљйЬАи¶БжЫіжЦ∞糥еЉХпЉМ糥еЉХињЗе§Ъе∞±дЉЪйЩНдљОеЖЩеЕ•зЪДйАЯеЇ¶гАВ
гААгАА2)жЬАз™ДзЪДе≠ЧжЃµжФЊеЬ®йФЃзЪДеЈ¶иЊєгАВ
гААгААињЩж†ЈжПРйЂШдЇЖ糥еЉХдЄ≠жѓПдЄАдЄ™зВєзЪДеЯЇжХ∞пЉМеЄ¶жЭ•жЫіе•љзЪД糥еЉХиѓїеЖЩжАІиГљгАВ
гААгАА3)е∞љйЗПйБњеЕНfile sortжОТеЇПгАБдЄіжЧґи°®еТМи°®жЙЂжППгАВ
гААгААеѓєдЇОе§Іи°®пЉМеЕ®и°®жЙЂжППдЉЪеѓЉиЗіе§ІйЗПзЪДз£БзЫШIOзЪДжУНдљЬпЉМдЉЪеѓЉиЗіжУНдљЬйЭЮеЄЄзЪДзЉУжЕҐгАВ
гААгАА4)еѓєдЇОе§Іи°®пЉМе∞љйЗПдЄНи¶Бе∞Ж糥еЉХеїЇеЬ®е≠Чзђ¶дЄ≤з±їеЮЛзЪДеИЧдЄКпЉМе≠Чзђ¶дЄ≤зЪДеМєйЕНжШѓеЊИиієжЧґзЪДпЉМйЬАи¶БдїШеЗЇеЊИйЂШзЪДжАІиГљдї£дїЈпЉМе¶ВжЮЬдЄАеЃЪжЬЙењЕи¶БпЉМеїЇиЃЃеѓєе≠Чзђ¶дЄ≤еИЧињЫи°МhashеРОеПЦдЄАдЄ™жճ嚥зЪДеАЉжЭ•ињЫи°М糥еЉХгАВ
гААгАА3 е¶ВжЮЬжЫіжЦ∞жУНдљЬжЬЙзВєжЕҐпЉМиАМиѓїжУНдљЬзЪДеУНеЇФи¶Бж±ВдЄНйЬАи¶БеЊИеПКжЧґзЪДиѓЭпЉМеПѓдї•иАГиЩСеИ©зФ®mysqlзЪДдЄїдїОзГ≠е§ЗжЭ•еИЖжЛЕиѓїеЖЩзЪДеОЛеКЫгАВ
гААгААжѓХзЂЯеѓєжХ∞жНЃеЇУзЪДжУНдљЬпЉМеЖЩе∞Сиѓїе§ЪгАВеЫ†ж≠§пЉМжИСдїђе∞ЖеѓєжХ∞жНЃеЇУзЪДеЖЩжУНдљЬжФЊеИ∞mysqlзЪДдЄїжЬНеК°еЩ®дЄКпЉМеИ©зФ®mysqlзЪДзГ≠е§ЗпЉМжИСдїђеЬ®е§ЗдїљзЪДжХ∞жНЃеЇУжЬНеК°еЩ®дЄКињЫи°МиѓїжУНдљЬпЉМзФ±дЇОеПѓдї•жЬЙе§ЪдЄ™зГ≠е§ЗmysqlпЉМдЇОжШѓеПѓдї•е∞ЖиѓїжУНдљЬеИЖеЄГеЬ®е§ЪдЄ™зГ≠е§ЗдЄКйЭҐпЉМдїОиАМе∞ЖиѓїжУНдљЬеЭЗи°°еЉАжЭ•пЉМжПРйЂШиѓїжУНдљЬзЪДжАІиГљгАВ
гААгАА4 зЉУе≠ШзЪДдљњзФ®
гААгААзЉУе≠ШжШѓдЄАеИЗеРОеП∞з®ЛеЇПзЪДж†єжЬђпЉМеЫ†дЄЇ80%зЪДиѓЈж±ВжШѓеѓєеЇФ20%зЪДжХ∞жНЃпЉМжИСдїђеП™йЬАи¶Бе∞СйЗПзЪДеЖЕе≠Ше∞Ж20%зЪДжХ∞жНЃзЉУе≠ШиµЈжЭ•пЉМе∞±еПѓдї•е§Іе§ІзЪДжї°иґ≥жИСдїђз≥їзїЯйЬАж±ВпЉМдљХдєРиАМдЄНдЄЇеСҐгАВ
гААгАА1)mysqlиЃЊзљЃдЄ≠е∞љйЗПеҐЮеК†key cacheпЉМthread cacheгАБжߕ胥зЪДcacheгАВ
гААгАА2)еЬ®еЇФзФ®з®ЛеЇПе±ВеҐЮеК†дЄАдЄ™memcachedињЩж†ЈзЪДйАЪзФ®cacheгАВ
гААгАА3)еѓєдЇОе∞СйЗПжХ∞жНЃпЉМдљЖжШѓжУНдљЬйҐСзєБзЪДи°®дљњзФ®mysqlжПРдЊЫзЪДеЖЕе≠Шheapи°®пЉМеПѓдї•иОЈеЊЧжЮБйЂШзЪДеЖЩеЕ•еТМиѓїеПЦйАЯеЇ¶гАВ
гААгАА5 жХ∞жНЃеЇУзЪДиЃЊиЃ°дЄКињЫи°МдЉШеМЦ
гААгААеѓєдЇОдЉ†зїЯзЪДжХ∞жНЃеЇУиЃЊиЃ°жИСдїђиЃ≤з©ґеїЇж®°иМГеЉПпЉМйБњеЕНжХ∞жНЃзЪДеЖЧдљЩдїОиАМеѓЉиЗіиДПжХ∞жНЃгАВзДґиАМеЬ®жИСдїђеЃЮйЩЕзЪДеЇФзФ®дЄ≠йЬАи¶Бж†єжНЃжГЕеЖµжЭ•дљњзФ®зђђдЄЙиМГеЉПзЪДдЄАдЇЫиІДеИЩпЉМеѓєдЇОдЄАдЇЫйҐСзєБйЬАи¶БеЬ®е§ЪдЄ™еЬ∞жЦєеЗЇзО∞зЪДжХ∞жНЃпЉМе¶ВеРМдЄАдЄ™иЃЇеЭЫињЩзІНзФ®жИЈеТМдЄїйҐШдї•еПКеЫЮе§Нз≠ЙжЬЙеЕ≥иБФзЪДеЇФзФ®дЄ≠пЉМе¶ВжЮЬжИСдїђе∞ЖзФ®жИЈеРМдЄїйҐШеТМеЫЮе§НеИЖеЉАжЭ•е≠ШеВ®пЉМжѓПжђ°жߕ胥дЄАдЄЛдЄАзѓЗжЦЗзЂ†жИЦиАЕдЄАдЄ™еЫЮе§НзЪДжГЕеЖµйГљйЬАи¶БеѓєзФ®жИЈи°®еТМдЄїйҐШи°®жИЦиАЕеЫЮе§Ни°®ињЫи°МиБФжЯ•пЉМе¶ВжЮЬжХ∞жНЃйЗПе∞ПзЪДиѓЭпЉМињЩж†ЈиБФжЯ•зЪДжАІиГљињШжШѓеПѓдї•жО•еПЧзЪДпЉМе¶ВжЮЬи°®е§ІдЄАзВєпЉМдЄКдЇЖ3гАБ4еНБдЄЗдї•дЄКзЪДжХ∞жНЃпЉМиБФжЯ•зЪДйАЯеЇ¶е∞±дЉЪжѓФиЊГжЕҐдЇЖгАВ
гААгААиѓ•иМГеЉПеМЦзЪДеЬ∞жЦєйЬАи¶БињЫи°МиМГеЉПеМЦпЉМдљЖжШѓињШжШѓйЬАи¶Бж†єжНЃжГЕеЖµжЭ•иЃЊиЃ°жИСдїђзЪДи°®пЉМдїОиАМиЊЊеИ∞жАІиГљеТМиЙѓе•љиЃЊиЃ°зЪДжКШдЄ≠гАВ
гААгААеЕґеЃГзЪДиѓЭпЉЪ
гААгАА1 еѓєдЇОжХ∞жНЃеЇУзЪДжУНдљЬеїЇиЃЃеИЖе±Ве§ДзРЖпЉМиЗ≥е∞СеИЖдЄЇдЄ§е±ВпЉМдЄАе±ВжШѓжХ∞жНЃеЇУжУНдљЬзЪДйАїиЊСе±ВпЉМдЄАе±ВжШѓжХ∞жНЃеЇУзЪДcacheе±ВгАВ
гААгААдїОдЄАеЉАеІЛе∞±иАГиЩСе¶Вж≠§пЉМеПѓдї•еЊИжЦєдЊњеЬ®жЬ™жЭ•еѓєжХ∞жНЃеЇУињЫи°МеИТеИЖйГ®зљ≤гАБеИЖеЇУеИЖи°®жЙ©е±ХгАВ
гААгАА2 еҐЮеК†mysqlзЪДзЫСжОІпЉМзЫСжОІmysqlзЪДжЕҐжߕ胥жЧ•ењЧпЉМзЫСжОІmysqlзЪДиѓЈж±ВжГЕеЖµгАВ
гААгАА3 ж†єжНЃиЗ™еЈ±зЪДйЬАи¶БжЭ•йАЙжЛ©mysqlзЪДе≠ШеВ®еЉХжУОгАВ
гААгААmyisamжЬЙиЊГйЂШзЪДиѓїеЖЩйАЯеЇ¶пЉМдљЖжШѓзФ±дЇОи°®йФБеЃЪпЉМдЄНиГљеРМжЧґињЫи°МењЂйАЯзЪДиѓїеТМеЖЩгАВ
гААгААinnodbжФѓжМБдЇЛеК°пЉМжПРдЊЫдЇЖи°МзЇІзЪДйФБпЉМдљЖжШѓдЄЇдЇЖдљњзФ®дЇЛеК°пЉМи°®з©ЇйЧідЉЪжѓФиЊГе§ІпЉМиАМдЄФдЄНжФѓжМБеЕ®жЦЗ糥еЉХгАВ
гААгААheapе∞Жи°®жФЊеИ∞еЖЕе≠ШдЄ≠пЉМйАВеРИдЄОи°®е∞ПиАМйЬАи¶БйҐСзєБжУНдљЬзЪДжГЕеЖµпЉМе¶ВзФ®жИЈдњ°жБѓпЉМеЕґиѓїеЖЩеЊИењЂпЉМдљЖжШѓдЄНжШѓжМБдєЕзЪДпЉМйЬАи¶БиЗ™еЈ±жЭ•еЖЩеЈ•еЕЈиЃ©еЕґжМБдєЕгАВ
гААгАА4 mysqlжЬНеК°еЩ®зЪДдЄАдЇЫзКґжАБж£АжµЛзЪДеСљдї§гАВ
гААгААshow slave statusпЉЪеПѓдї•зЬЛеИ∞дЄїдїОеРМж≠•зЪДжГЕеЖµгАВ
гААгААshow [full] processlistпЉЪеПѓдї•зЬЛеИ∞mysqlжЬНеК°еЩ®зЪДиѓЈж±ВжГЕеЖµпЉМе¶ВжЮЬеПСзО∞lockжГЕеЖµеЊИе§ЪпЉМйЬАи¶Бж≥®жДПдЇЖгАВ
гААгААshow statusпЉЪеПѓдї•зЬЛеИ∞mysqlжЬНеК°еЩ®зЪДеРДзІНиѓЈж±ВжГЕеЖµгАВ
http://www.cnblogs.com/hustcat/archive/2009/10/28/1591648.html
еЖЩеЬ®еЙНйЭҐпЉЪ糥еЉХеѓєжߕ胥зЪДйАЯеЇ¶жЬЙзЭАиЗ≥еЕ≥йЗНи¶БзЪДељ±еУНпЉМзРЖиІ£зіҐеЉХдєЯжШѓињЫи°МжХ∞жНЃеЇУжАІиГљи∞ГдЉШзЪДиµЈзВєгАВиАГиЩСе¶ВдЄЛжГЕеЖµпЉМеБЗиЃЊжХ∞жНЃеЇУдЄ≠дЄАдЄ™и°®жЬЙ10^6жЭ°иЃ∞ељХпЉМDBMSзЪДй°µйЭҐе§Іе∞ПдЄЇ4KпЉМеєґе≠ШеВ®100жЭ°иЃ∞ељХгАВе¶ВжЮЬж≤°жЬЙ糥еЉХпЉМжߕ胥е∞ЖеѓєжХідЄ™и°®ињЫи°МжЙЂжППпЉМжЬАеЭПзЪДжГЕеЖµдЄЛпЉМе¶ВжЮЬжЙАжЬЙжХ∞жНЃй°µйГљдЄНеЬ®еЖЕе≠ШпЉМйЬАи¶БиѓїеПЦ10^4дЄ™й°µйЭҐпЉМе¶ВжЮЬињЩ10^4дЄ™й°µйЭҐеЬ®з£БзЫШдЄКйЪПжЬЇеИЖеЄГпЉМйЬАи¶БињЫи°М10^4жђ°I/OпЉМеБЗиЃЊз£БзЫШжѓПжђ°I/OжЧґйЧідЄЇ10ms(ењљзХ•жХ∞жНЃдЉ†иЊУжЧґйЧі)пЉМеИЩжАїеЕ±йЬАи¶Б100s(дљЖеЃЮйЩЕдЄКи¶Бе•љеЊИе§ЪеЊИе§Ъ)гАВе¶ВжЮЬеѓєдєЛеїЇзЂЛB-Tree糥еЉХпЉМеИЩеП™йЬАи¶БињЫи°Мlog100(10^6)=3жђ°й°µйЭҐиѓїеПЦпЉМжЬАеЭПжГЕеЖµдЄЛиАЧжЧґ30msгАВињЩе∞±ж؃糥еЉХеЄ¶жЭ•зЪДжХИжЮЬпЉМеЊИе§ЪжЧґеАЩпЉМељУдљ†зЪДеЇФзФ®з®ЛеЇПињЫи°МSQLжߕ胥йАЯеЇ¶еЊИжЕҐжЧґпЉМеЇФиѓ•жГ≥жГ≥жШѓеР¶еσ俕忯糥еЉХгАВињЫеЕ•ж≠£йҐШпЉЪ
зђђдЇМзЂ†гАБ糥еЉХдЄОдЉШеМЦ
1гАБйАЙж˩糥еЉХзЪДжХ∞жНЃз±їеЮЛ
MySQLжФѓжМБеЊИе§ЪжХ∞жНЃз±їеЮЛпЉМйАЙжЛ©еРИйАВзЪДжХ∞жНЃз±їеЮЛе≠ШеВ®жХ∞жНЃеѓєжАІиГљжЬЙеЊИе§ІзЪДељ±еУНгАВйАЪеЄЄжЭ•иѓіпЉМеПѓдї•йБµеЊ™дї•дЄЛдЄАдЇЫжМЗеѓЉеОЯеИЩпЉЪ
(1)иґКе∞ПзЪДжХ∞жНЃз±їеЮЛйАЪеЄЄжЫіе•љпЉЪиґКе∞ПзЪДжХ∞жНЃз±їеЮЛйАЪеЄЄеЬ®з£БзЫШгАБеЖЕе≠ШеТМCPUзЉУе≠ШдЄ≠йГљйЬАи¶БжЫіе∞СзЪДз©ЇйЧіпЉМе§ДзРЖиµЈжЭ•жЫіењЂгАВ
(2)зЃАеНХзЪДжХ∞жНЃз±їеЮЛжЫіе•љпЉЪжХіеЮЛжХ∞жНЃжѓФиµЈе≠Чзђ¶пЉМе§ДзРЖеЉАйФАжЫіе∞ПпЉМеЫ†дЄЇе≠Чзђ¶дЄ≤зЪДжѓФиЊГжЫіе§НжЭВгАВеЬ®MySQLдЄ≠пЉМеЇФиѓ•зФ®еЖЕзљЃзЪДжЧ•жЬЯеТМжЧґйЧіжХ∞жНЃз±їеЮЛпЉМиАМдЄНжШѓзФ®е≠Чзђ¶дЄ≤жЭ•е≠ШеВ®жЧґйЧіпЉЫдї•еПКзФ®жХіеЮЛжХ∞жНЃз±їеЮЛе≠ШеВ®IPеЬ∞еЭАгАВ
(3)е∞љйЗПйБњеЕНNULLпЉЪеЇФиѓ•жМЗеЃЪеИЧдЄЇNOT NULLпЉМйЩ§йЭЮдљ†жГ≥е≠ШеВ®NULLгАВеЬ®MySQLдЄ≠пЉМеРЂжЬЙз©ЇеАЉзЪДеИЧеЊИйЪЊињЫи°Мжߕ胥дЉШеМЦпЉМеЫ†дЄЇеЃГдїђдљњеЊЧ糥еЉХгАБ糥еЉХзЪДзїЯиЃ°дњ°жБѓдї•еПКжѓФиЊГињРзЃЧжЫіеК†е§НжЭВгАВдљ†еЇФиѓ•зФ®0гАБдЄАдЄ™зЙєжЃКзЪДеАЉжИЦиАЕдЄАдЄ™з©ЇдЄ≤дї£жЫњз©ЇеАЉгАВ
 



зЫЄеЕ≥жО®иНР
дї•дЄЛжШѓйТИеѓєMySQLжАІиГљдЉШеМЦзЪД20жЭ°жЬАдљ≥еЃЮиЈµзїПй™МпЉМињЩдЇЫзїПй™МиГље§ЯеЄЃеК©еЉАеПСиАЕеЬ®иЃЊиЃ°еТМзїіжК§жХ∞жНЃеЇУжЧґеБЪеЗЇжЫіжЬЙжХИзЪДеЖ≥з≠ЦгАВ 1. жߕ胥зЉУе≠ШдЉШеМЦ жߕ胥зЉУе≠ШжШѓжПРеНЗMySQLжХ∞жНЃеЇУжАІиГљзЪДжЬЙжХИжЙЛжЃµдєЛдЄАгАВељУзЫЄеРМзЪДжߕ胥襀жЙІи°Ме§Ъжђ°жЧґпЉМзїУжЮЬеПѓдї•...
дї•дЄЛжШѓдїО"MySQLжАІиГљдЉШеМЦзЪДжЬАдљ≥21жЭ°зїПй™М"дЄ≠жПРеПЦзЪДдЄАдЇЫеЕ≥йФЃзЯ•иѓЖзВєпЉЪ 1. **糥еЉХдЉШеМЦ**пЉЪ糥еЉХжШѓжПРеНЗжߕ胥йАЯеЇ¶зЪДеЕ≥йФЃпЉМеРИзРЖеИЫеїЇдЄїйФЃгАБеФѓдЄАйФЃеТМжЩЃйАЪ糥еЉХпЉМйБњеЕНеЕ®и°®жЙЂжППгАВдљњзФ®и¶ЖзЫЦ糥еЉХеПѓдї•еЗПе∞Сз£БзЫШI/OгАВ 2. **йАЙжЛ©еРИйАВзЪД...
дї•дЄЛжШѓдЄАдЇЫйТИеѓєMySQLжАІиГљдЉШеМЦзЪДйЗНи¶БзїПй™МеТМжКАеЈІпЉЪ 1. **дЄЇжߕ胥зЉУе≠ШдЉШеМЦдљ†зЪДжߕ胥**пЉЪMySQLзЪДжߕ胥зЉУе≠ШеПѓдї•жШЊиСЧжПРйЂШжАІиГљпЉМзЙєеИЂжШѓеѓєдЇОйЗНе§Нжߕ胥гАВйБњеЕНеЬ®жߕ胥дЄ≠дљњзФ®MySQLеЗљжХ∞пЉМе¶ВCURDATE()пЉМеЫ†дЄЇеЃГдїђдЉЪеѓЉиЗізЉУе≠Ш姱жХИгАВжФєзФ®...
жЬђжЦЗе∞ЖйЗНзВєдїЛзїНMySQLжАІиГљдЉШеМЦзЪД20дљЩжЭ°жЬАдљ≥еЃЮиЈµзїПй™МпЉМжЧ®еЬ®еЄЃеК©иѓїиАЕжПРйЂШMySQLжХ∞жНЃеЇУзЪДињРи°МжХИзОЗгАВ #### 1. дЄЇжߕ胥зЉУе≠ШдЉШеМЦдљ†зЪДжߕ胥 жߕ胥зЉУе≠ШжШѓMySQLдЄ≠зЪДдЄАй°єеЖЕзљЃеКЯиГљпЉМеЃГиГље§ЯжШЊиСЧжПРеНЗжХ∞жНЃеЇУжАІиГљгАВељУе§ЪдЄ™зЫЄеРМзЪДжߕ胥...
"MySQLжАІиГљдЉШеМЦеТМйЂШеПѓзФ®жЮґжЮДеЃЮиЈµ" жЬђдє¶гАКMySQLжАІиГљдЉШеМЦеТМйЂШеПѓзФ®жЮґжЮДеЃЮиЈµгАЛжШѓдЄАжЬђиѓ¶зїЖдїЛзїНMySQLжАІиГљдЉШеМЦеТМйЂШеПѓзФ®жЮґжЮДеЃЮиЈµзЪДдє¶з±НпЉМжЧ®еЬ®еЄЃеК©иѓїиАЕжПРеНЗMySQLжХ∞жНЃеЇУзЪДжАІиГљеТМеПѓйЭ†жАІгАВжЬђдє¶зЪДеЖЕеЃєжґµзЫЦдЇЖжߕ胥дЉШеМЦзЪДеЯЇжЬђеОЯеИЩеТМ...
MySQLжАІиГљдЉШеМЦжШѓжПРеНЗWebеЇФзФ®жХИзОЗзЪДеЕ≥йФЃзОѓиКВпЉМе∞§еЕґжШѓеЬ®е§ДзРЖе§ІйЗПжХ∞жНЃжУНдљЬжЧґгАВдї•дЄЛжШѓеѓєж†ЗйҐШеТМжППињ∞дЄ≠жПРеИ∞зЪДдЄАдЇЫеЕ≥йФЃзЯ•иѓЖзВєзЪДиѓ¶зїЖиІ£йЗКпЉЪ 1. **жߕ胥зЉУе≠ШдЉШеМЦ** - MySQLзЪДжߕ胥зЉУе≠ШеПѓдї•жШЊиСЧжПРеНЗжАІиГљпЉМе≠ШеВ®жЙІи°МињЗзЪДSQLжߕ胥...
MySQLжАІиГљдЉШеМЦжШѓжХ∞жНЃеЇУзЃ°зРЖеСШеТМеЉАеПСдЇЇеСШзЪДеЕ≥йФЃжКАиГљпЉМеЃГжґЙеПКеИ∞е¶ВдљХжЬЙжХИеЬ∞дљњзФ®SQLиѓ≠еП•гАБе≠ШеВ®ињЗз®ЛеТМеЗљжХ∞пЉМдї•жПРйЂШжХ∞жНЃжߕ胥йАЯеЇ¶еТМз≥їзїЯжХідљУжХИзОЗгАВжЬђжЙЛеЖМе∞ЖжЈ±еЕ•жОҐиЃ®ињЩдЇЫеЕ≥йФЃйҐЖеЯЯпЉМеЄЃеК©дљ†зРЖиІ£еєґеЃЮжЦљжЬАдљ≥еЃЮиЈµгАВ еЬ®SQLиѓ≠еП•...
mysqlжАІиГљи∞ГдЉШжЬАдљ≥еЃЮиЈµ pptж†ЉеЉПгААе∞±жШѓиЃ≤жАОдєИдЉШеМЦmysqlзЪДгАВ
йТИеѓєMySQLжАІиГљдЉШеМЦињЗз®ЛдЄ≠еЄЄиІБзЪДзЦСйЧЃеТМйЧЃйҐШпЉМеїЇиЃЃињЫи°МжЈ±еЕ•з†Фз©ґеТМеЃЮиЈµпЉМдЄНжЦ≠зІѓзіѓзїПй™МпЉМдї•йАВеЇФдЄНеРМеЇФзФ®еЬЇжЩѓдЄЛзЪДдЉШеМЦйЬАж±ВгАВдЊЛе¶ВпЉМе¶ВдљХеє≥谰糥еЉХжХ∞йЗПдЄОжߕ胥жХИзОЗгАБе¶ВдљХеЬ®йЂШеєґеПСеЬЇжЩѓдЄЛињЫи°МжЬЙжХИзЪДдЇЛеК°зЃ°зРЖз≠ЙпЉМйГљжШѓеАЉеЊЧжЈ±еЕ•...
- **еЃЮжИШзїПй™М**пЉЪйАЪињЗеЕЈдљУзЪДж°ИдЊЛеИЖжЮРпЉМжИСдїђеПѓдї•е≠¶еИ∞е¶ВдљХеЬ®еЃЮйЩЕеЈ•дљЬдЄ≠еЇФзФ®MySQLжАІиГљдЉШеМЦз≠ЦзХ•гАВ - **жМБзї≠жФєињЫ**пЉЪйЪПзЭАжКАжЬѓзЪДеПСе±ХпЉМMySQLзЪДдЉШеМЦжЦєж≥ХдєЯеЬ®дЄНжЦ≠ињЫж≠•пЉМйЬАи¶БеЃЪжЬЯеЫЮй°ЊеТМжЫіжЦ∞зЯ•иѓЖгАВ - **жЦЗж°£жЫіжЦ∞**пЉЪдїО2011еєі7...
гАРж†ЗйҐШгАСпЉЪвАЬзЩЊеЇ¶mysqlжАІиГљдЉШеМЦpptвАЭжЙАжґЙеПКзЪДзЯ•иѓЖзВєжґµзЫЦдЇЖMySQLжХ∞жНЃеЇУеЬ®жАІиГљи∞ГдЉШжЦєйЭҐзЪДе§ЪдЄ™йЗНи¶БзОѓиКВгАВеЬ®MySQLжАІиГљдЉШеМЦдЄ≠пЉМжИСдїђеЕ≥ж≥®зЪДж†ЄењГжШѓжПРеНЗжХ∞жНЃе§ДзРЖйАЯеЇ¶пЉМеЗПе∞СиµДжЇРжґИиАЧпЉМдїОиАМжПРйЂШз≥їзїЯзЪДжХідљУжХИзОЗгАВ гАРжППињ∞гАСпЉЪ...
жАїзїУжЭ•иѓіпЉМMySQLжАІиГљдЉШеМЦжШѓдЄАдЄ™з≥їзїЯеЈ•з®ЛпЉМжґµзЫЦжߕ胥дЉШеМЦгАБжХ∞жНЃеЇУзїУжЮДдЉШеМЦеТМжЬНеК°еЩ®йЕНзљЃдЉШеМЦз≠Йе§ЪдЄ™е±ВйЭҐгАВйАЪињЗжОМжП°ињЩдЇЫдЉШеМЦжЙЛжЃµпЉМжИСдїђеПѓдї•жЬЙжХИеЗПе∞Сз≥їзїЯзУґйҐИпЉМжПРйЂШжХ∞жНЃеЇУеУНеЇФйАЯеЇ¶пЉМдїОиАМжПРеНЗжХідЄ™еЇФзФ®зЪДжАІиГљгАВеЬ®еЃЮйЩЕжУНдљЬдЄ≠...
MySQLжАІиГљдЉШеМЦзЪДжЬАдљ≥зїПй™М.zip
жАїзЪДжЭ•иѓіпЉМMYSQLеЕ®йЭҐйЂШзЇІжАІиГљдЉШеМЦиµДжЦЩжґµзЫЦдЇЖMYSQLжАІиГљдЉШеМЦзЪДе§ЪдЄ™йЗНи¶БжЦєйЭҐпЉМеМЕжЛђMYSQLзЪДеЕ®жЦЗжРЬ糥еКЯиГљпЉМжАІиГљеЯЇеЗЖжµЛиѓХпЉМMYSQLеЬ®дЄНеРМеє≥еП∞дЄКзЪДжАІиГљи°®зО∞пЉМMYSQL 5.0дЄО4.1зЙИжЬђжАІиГљеѓєжѓФпЉМдї•еПКMYSQLжАІиГљдЉШеМЦзЪДжЬ™жЭ•иґЛеКњз≠ЙгАВ...
# MySQLжАІиГљдЉШеМЦиѓ¶иІ£ ## дЄАгАБMySQLжАІиГљдЉШеМЦзЪДйЗНи¶БжАІеПКж¶ВиІИ ### 1.1 MySQLжАІиГљдЉШеМЦзЃАдїЛ еЬ®WebеЇФзФ®з®ЛеЇПжЮґжЮДдЄ≠пЉМжХ∞жНЃжМБдєЕе±ВпЉИйАЪеЄЄжМЗеЕ≥з≥їжХ∞жНЃеЇУпЉЙжЙЃжЉФзЭАж†ЄењГиІТиЙ≤пЉМеѓєжХідЄ™з≥їзїЯзЪДжАІиГљиЗ≥еЕ≥йЗНи¶БгАВMySQLдљЬдЄЇдЄАзІНеєњж≥ЫдљњзФ®зЪД...
MySQLжАІиГљдЉШеМЦжШѓжХ∞жНЃеЇУзЃ°зРЖеСШеТМ...йАЪињЗе≠¶дє†caozзЪДMySQLжАІиГљдЉШеМЦжХЩз®ЛпЉМдљ†е∞ЖжОМжП°дЄАз≥їеИЧеЃЮзФ®жКАеЈІпЉМдљњдљ†зЪДMySQLжХ∞жНЃеЇУиЊЊеИ∞жЬАдљ≥ињРи°МзКґжАБпЉМжї°иґ≥дЄЪеК°йЬАж±ВпЉМйЩНдљОињРзїіжИРжЬђгАВжЧ†иЃЇжШѓеИЭе≠¶иАЕињШжШѓзїПй™МдЄ∞еѓМзЪДDBAпЉМйГљиГљдїОдЄ≠иОЈзЫКеМ™жµЕгАВ