
原文:http://blog.csdn.net/shirdrn/article/details/7055355
附件为配置的core之间的索引数据复制,其中core0为master,core1为slave,在core0中提交数据和优化数据时,core1复制core0中的索引数据。
Solr作为一个搜索服务器,在并发搜索请求的场景下,可能一台服务器很容易就垮掉,这是我们可以通过使用集群技术,设置多台Solr搜索服务器同时对外提供搜索服务,在前端使用类似Nginx的负载均衡软件,可以通过配置使得并发到达的搜索请求均匀地反向代理到Solr集群中的每一台服务器上,这样每台Solr搜索服务器搜索请求的压力可以大大减小,增强了每台服务器能够持续提供服务器的能力。
然而,这时我们面临的问题有:
- 集群中的每台服务器在线上要保证索引数据都能很好地的同步,使得每台搜索服务器的索引数据在一定可以承受的程度上保持一致性;
- 集群中某台服务器宕机离线,人工干预重启后继续与集群中其它服务器索引数据保持一致,继续提供搜索服务;
- 集群中某台服务器的索引数据,由于硬盘故障或人为原因无法提供搜索服务,需要一种数据恢复机制;
- 集群中最先接受数据更新的Master服务器,在将索引更新传播到Slave服务器上时,避免多台Slave服务器同一时间占用大量网络带宽,从而影响了Master提供搜索服务。
事实上,Solr框架在上面的几个方面都能做到不错的支持,具有很大的灵活性。基于上述的几个问题,我们来配置Solr集群的Replication,并实践集群复制的功能。
单机实例Replication
Solr支持在单机上配置多个实例(MultiCore),每个实例都可以独立对外提供服务,共享同一网络带宽。同时,也可以实现单机实例之间Replication,在实例之间复制数据,保证数据的可用性,从而提高系统的服务能力。
我们看一下,这种复制模式的结构图,如下所示:
上图,在同一台服务器上,启动Solr的多个实例,将这些实例(通过Core来区分)作为单机上的伪分布式集群,这些Core实例都是在同一个JVM中。选择其中的一个实例Core0作为Master,每次索引更新都首先从这个实例Core0进行传播,直到Master实例Core0与Slave实例Core1、Core2、Core3上的数据同步为止。其中,每个实例都可以独立对外提供服务,因为这种模式保证多个实例上的数据都是同一份数据,起到数据备份的作用,一般不建议让多个实例同时提供服务。下面给出上图复制模式下Solr的配置。
Core0作为Master,对应的solrconfig.xml配置内容,如下所示:
- <?xml version="1.0" encoding="UTF-8" ?>
- <config>
- <luceneMatchVersion>LUCENE_35</luceneMatchVersion>
- <directoryFactory name="DirectoryFactory" class="${solr.directoryFactory:solr.StandardDirectoryFactory}" />
- <updateHandler class="solr.DirectUpdateHandler2" />
- <requestDispatcher handleSelect="true">
- <requestParsers enableRemoteStreaming="false" multipartUploadLimitInKB="2048" />
- </requestDispatcher>
- <requestHandler name="standard" class="solr.StandardRequestHandler" default="true" />
- <requestHandler name="/update" class="solr.JsonUpdateRequestHandler" />
- <requestHandler name="/admin/" class="org.apache.solr.handler.admin.AdminHandlers" />
- <queryParser name="dismax" class="solr.DisMaxQParserPlugin" />
- <requestHandler name="/dismax" class="solr.SearchHandler">
- <lst name="defaults">
- <str name="defType">dismax</str>
- <str name="qf">title content</str>
- <bool name="hl">true</bool>
- <str name="hl.fl">title content</str>
- <int name="hl.fragsize">200</int>
- <int name="hl.snippets">1</int>
- <str name="fl">*,score</str>
- <str name="qt">standard</str>
- <str name="wt">standard</str>
- <str name="version">2.2</str>
- <str name="echoParams">explicit</str>
- <str name="indent">true</str>
- <str name="debugQuery">on</str>
- <str name="explainOther">on</str>
- </lst>
- </requestHandler>
- <requestHandler name="/replication" class="solr.ReplicationHandler">
- <lst name="master">
- <str name="replicateAfter">startup</str>
- <str name="replicateAfter">commit</str>
- <str name="commitReserveDuration">00:00:10</str>
- </lst>
- </requestHandler>
- <admin>
- <defaultQuery>solr</defaultQuery>
- </admin>
- </config>
上述配置中,提供了一个/dismax搜索接口,对外提供搜索服务。配置中name为/Replication的requestHandler,即为Solr提供的复制请求处理接口,配置中replicateAfter表示在startup和commit之后才允许Slave的复制请求。
Solr支持索引数据Replication,同时也支持配置数据的复制。如果需要复制配置数据做好配置备份,可以在Master的solrconfig.xml中配置如下内容:
- <str name="confFiles">schema.xml,stopwords.txt,solrconfig.xml,synonyms.txt</str>
指定需要从Master上复制的配置文件名即可。
对于Core1~Core3都为Slave,即请求复制数据,我们拿Core1为例,其它配置均相同,但是我们不希望Slave实例对外提供服务,所以只需要配置Slave的/replication复制请求处理接口即可,配置内容如下所示:
- <?xml version="1.0" encoding="UTF-8" ?>
- <config>
- <luceneMatchVersion>LUCENE_35</luceneMatchVersion>
- <directoryFactory name="DirectoryFactory" class="${solr.directoryFactory:solr.StandardDirectoryFactory}" />
- <updateHandler class="solr.DirectUpdateHandler2" />
- <requestDispatcher handleSelect="true">
- <requestParsers enableRemoteStreaming="false" multipartUploadLimitInKB="2048" />
- </requestDispatcher>
- <requestHandler name="standard" class="solr.StandardRequestHandler" default="true" />
- <requestHandler name="/update" class="solr.JsonUpdateRequestHandler" />
- <requestHandler name="/admin/" class="org.apache.solr.handler.admin.AdminHandlers" />
- <requestHandler name="/replication" class="solr.ReplicationHandler">
- <lst name="slave">
- <str name="masterUrl">http://192.168.0.195:8080/solr35/core0/replication</str>
- <str name="pollInterval">00:00:20</str>
- <str name="compression">internal</str>
- <str name="httpConnTimeout">5000</str>
- <str name="httpReadTimeout">10000</str>
- <str name="httpBasicAuthUser">username</str>
- <str name="httpBasicAuthPassword">password</str>
- </lst>
- </requestHandler>
- <admin>
- <defaultQuery>solr</defaultQuery>
- </admin>
- </config>
Slave配置中masterUrl和pollInterval是必选的,masterUrl指定为core0的复制请求接口,pollInterval是指Slave周期地向Master询问是否数据有所更新,如果发生变更则进行复制。其它的参数可以根据需要进行配置。一般情况下,单机多个实例之间的Replication不需要配置上述httpBasicAuth*的参数的。
启动Solr之前,没有任何索引数据。只有执行了commit和optimize操作,才会触发Slave复制Master的索引数据。我测试了一下通过solr管理页面增加一条数据也不能触发复制,但是通过solrj调用commit提交数据后能够触发复制。
在Master和Slave数据同步的情况下,Master收到Slave的Replication请求:
- 2011-12-9 15:18:00 org.apache.solr.core.SolrCore execute
- 信息: [core0] webapp=/solr35 path=/replication params={command=indexversion&wt=javabin} status=0 QTime=0
- 2011-12-9 15:18:20 org.apache.solr.core.SolrCore execute
- 信息: [core0] webapp=/solr35 path=/replication params={command=indexversion&wt=javabin} status=0 QTime=0
- 2011-12-9 15:18:40 org.apache.solr.core.SolrCore execute
- 信息: [core0] webapp=/solr35 path=/replication params={command=indexversion&wt=javabin} status=0 QTime=0
- 2011-12-9 15:19:00 org.apache.solr.core.SolrCore execute
- 信息: [core0] webapp=/solr35 path=/replication params={command=indexversion&wt=javabin} status=0 QTime=0
每隔20s间隔,Slave请求一次,这个时间间隔可以根据需要进行配置。
从我们向Master发送索引数据更新索引请求后,在Master和Slave之间执行的数据的复制,处理日志内容可以参考后面附录的内容。
通过日志信息可以看到,Slave在Master更新索引(通过add可以看到更新了5篇文档,日志中给出了文档编号;更新时,每次发送2篇文档执行一次commit,全部发送完成后执行一次commit和optimize操作)之后,通过发送请求获取复制文件列表,然后执行复制过程,最后Slave索引数据发生变化,为保证实时能够搜索到最新内容,重新打开了一个IndexSearcher实例。日志最后面的部分,Slave的索引数据与Master保持同步,不需要复制。
集群结点Replication
在Solr集群中进行配置,与上面单机多实例的情况基本上一致,基本特点是:每个结点上的实例(Core)在同一个JVM内,不同结点之间进行复制——实际上是不同结点上的实例之间进行Replication。集群复制模式架构图,如下所示:
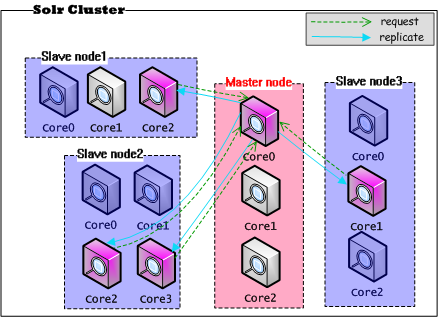
在一个Solr集群中执行Replication,复制请求与动作发生在一个网络内部。而replication的端点是不同结点上的实例(Core),很可能Slave结点上的其它实例在提供其他的服务。
通过上图可以看到,在只有一个Master的Solr集群中,如果存在大量的Slave要求Replication,势必会造成对Master服务器的压力(网络带宽、系统IO、系统CPU)。很可能因为外部大量搜索请求达到,使Master持续提供服务的能力降低,甚至宕机。Solr也考虑到这一点,通过在Master和Slave之间建立一个代理的结点来改善单点故障,代理结点既做Master的Slave,同步Master的数据,同时又做Slave的Master,将最新的数据同步复制到Slave结点,这个结点叫做Repeater,架构图如下所示:
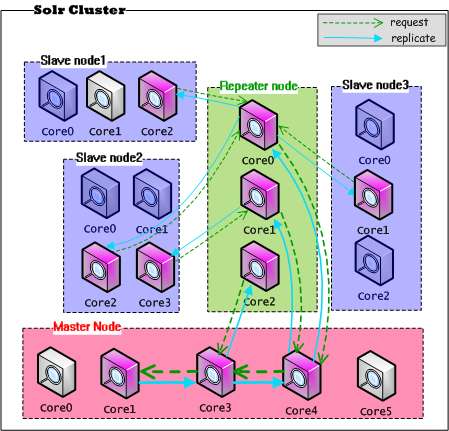
由图可见,Master的压力一下转移到了Repeater结点上,在一定程度上解决了Master的单点问题。对于Reaper结点,它具有双重角色,显而易见,在配置的时候需要配置上Master和Slave都具有的属性。我们给出一个Repeater的配置示例。
Master配置:
- <requestHandler name="/replication" class="solr.ReplicationHandler">
- <lst name="master">
- <str name="replicateAfter">startup</str>
- <str name="replicateAfter">commit</str>
- <str name="confFiles">schema.xml,stopwords.txt,solrconfig.xml,synonyms.txt</str>
- <str name="commitReserveDuration">00:00:10</str>
- </lst>
- </requestHandler>
Repeater配置:
- <requestHandler name="/replication" class="solr.ReplicationHandler">
- <lst name="master">
- <str name="replicateAfter">startup</str>
- <str name="replicateAfter">commit</str>
- <str name="commitReserveDuration">00:00:10</str>
- </lst>
- <lst name="slave">
- <str name="masterUrl">http://192.168.0.184:8080/masterapp/master/replication</str>
- <str name="pollInterval">00:00:20</str>
- <str name="compression">internal</str>
- <str name="httpConnTimeout">5000</str>
- <str name="httpReadTimeout">10000</str>
- <str name="httpBasicAuthUser">username</str>
- <str name="httpBasicAuthPassword">password</str>
- </lst>
- </requestHandler>
Slave配置:
- <requestHandler name="/replication" class="solr.ReplicationHandler" >
- <lst name="slave">
- <str name="masterUrl">http://192.168.0.174:8080/repeaterapp/repeater/replication</str>
- <str name="pollInterval">00:00:20</str>
- <str name="compression">internal</str>
- <str name="httpConnTimeout">5000</str>
- <str name="httpReadTimeout">10000</str>
- <str name="httpBasicAuthUser">username</str>
- <str name="httpBasicAuthPassword">password</str>
- </lst>
- </requestHandler>
可见,Solr能够支持这种链式Replication配置,甚至可以配置更多级,但具体如何配置还要依据你的应用的特点,以及资源条件的限制。总之,Solr Replication的目标就是让你系统的数据可用性变得更好。任何时候发生机器故障、硬盘故障、数据错误,都可以从其他的备机上同步数据。



相关推荐
6. **配置与部署**:在Solr集群中,配置通常存储在ZooKeeper中,这样可以方便地在节点之间同步配置。部署新版本的Solr或更新配置时,需确保所有节点都能正确加载并应用新的设置。 7. **负载均衡**:SolrCloud可以...
Solr集群搭建是构建大规模、高可用搜索服务的基础。...以上就是搭建Solr集群的基本步骤和核心概念,实际操作中还需要根据具体需求调整配置,例如调整Shard数量、Replica比例,以及优化网络通信和性能等。
Solr集群是Apache Solr的一种分布式部署方式,它允许用户在多台服务器上分布数据,以提高搜索性能和可用性。在本场景中,我们主要关注如何在Linux环境下搭建一个基于Zookeeper的SolrCloud集群。 首先,我们需要准备...
- **配置集群管理器**:通常使用ZooKeeper作为集群管理器,负责协调Solr集群中的各个节点。 - **配置SolrCloud模式**:在`solr.xml`文件中设置Solr Cloud模式,并配置ZooKeeper的连接信息。 - **配置Sharding**:...
3. **分布式部署**:通过Sharding和Replication机制实现Solr集群的分布式部署,提高系统的可用性和扩展性。 4. **监控工具**:使用Solr提供的监控工具或者第三方工具(如Ganglia、Nagios等)对Solr集群进行监控。 #...
Solr集群环境搭建详解 Apache Solr是一款基于Java的开源搜索服务器,广泛应用于企业级的全文检索、数据索引和搜索应用。构建Solr集群可以提高系统的可用性和可扩展性,实现数据的分布式处理和存储。本文将详细介绍...
2. **Replication**: 为确保数据冗余和容错,Solr集群中的每个分片都有一个或多个副本。如果主分片发生故障,副本可以接管服务。 3. **Cores**: 在Solr中,每个索引被称为一个Core,它有自己的配置和数据。在集群中...
5. **solrcloud-config**: 当Solr运行在SolrCloud模式下,这个配置文件包含集群和集合的设置。比如,它定义了ZooKeeper的位置、Shard的数量、Replication Factor(副本因子)以及路由策略等。 6. **...
### Solr集群搭建与SolrCloud分布式搜索方案详解 #### 一、SolrCloud概述 SolrCloud 是 Apache Solr 提供的一种分布式搜索解决方案。它主要用于处理大规模数据集的索引和检索工作,并具备容错性和分布式特性。当...
- **使用Cloudera Manager**:Cloudera Manager提供了丰富的监控工具,可以直接观察到Solr集群的运行状态。 - **使用Solr Admin UI**:每个Solr节点都提供了一个Admin UI页面,可以查看该节点的状态和性能指标。 - *...
这些Node构成了Solr集群的基础。 理解这些核心概念对于正确部署和管理SolrCloud集群至关重要。 **1.2 SolrCloud的路由机制** SolrCloud提供两种主要的路由算法: - **Composite ID路由**:这是一种一致性哈希...
其次,我们要搭建主从复制的Solr集群,这是为了提高服务的可用性和数据的一致性。主节点负责接收和处理写操作,从节点则同步主节点的数据,保证在主节点故障时能无缝接管服务。Solr的Replication Handler实现了这一...
6. **Solr集群设置**:对于高可用性和负载均衡的需求,可以搭建Solr集群。集群中的每个节点称为一个SolrCloud,它们通过ZooKeeper进行协调。配置Sharding(分片)和Replication(复制),确保数据分布和容错性。 7....
在实际应用中,Solr的部署和使用不仅涉及上述基础步骤,还需要考虑集群配置、性能优化、安全设置等多个方面。例如,通过SolrCloud实现分布式部署,利用Sharding和Replication提高可用性和性能,以及通过设置过滤器、...
其中,Solrtest是FusionInsight中用于测试Solr性能和功能的工具,它可以方便地验证Solr集群的正确性和性能。 Java客户端是与Solr通信的一种常见方式,它允许开发者通过编写Java代码来执行索引操作、查询、更新和...
### Solr配置与SolrJ使用详解 #### 一、Solr简介 Solr是一款开源的、高性能的企业级全文搜索引擎,它可以独立运行并通过HTTP协议提供服务。用户可以通过发送XML文件来创建索引,或者通过HTTP GET请求来进行检索,...
1. **分布式搜索**:Solr支持在多台服务器上分布式部署,通过Sharding和Replication技术,能够处理海量数据,并实现快速的搜索响应。 2. **灵活的数据导入**:Solr提供了DataImportHandler(DIH),可以方便地从...
5. **更新配置**:如果源和目标Solr实例的配置有差异,需要确保目标实例的配置与源实例一致,以避免搜索结果不准确或无法正常运行。 6. **重启目标Solr服务**:最后,重启目标Solr服务以应用新的数据和配置。 注意...
1. **安装与配置**:在CDH集群中安装Solr和HBase,并进行相应的配置,确保它们可以协同工作。这包括设置Zookeeper地址、配置SolrCloud模式以及设置HBase-Solr连接参数。 2. **创建HBase表**:根据业务需求设计...