hive在建表是,可以通过‘STORED AS FILE_FORMAT’ 指定存储文件格式
例如:
- >CREATEEXTERNALTABLEMYTEST(numINT,nameSTRING)
- >ROWFORMATDELIMITEDFIELDSTERMINATEDBY'\t'
- >STOREDASTEXTFILE
- >LOCATION'/data/test';
指定文件存储格式为“TEXTFILE”。
hive文件存储格式包括以下几类:
- TEXTFILE
- SEQUENCEFILE
- RCFILE
- 自定义格式
TEXTFIEL
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
实例:
- >createtabletest1(strSTRING)
- >STOREDASTEXTFILE;
- OK
- Timetaken:0.786seconds
- #写脚本生成一个随机字符串文件,导入文件:
- >LOADDATALOCALINPATH'/home/work/data/test.txt'INTOTABLEtest1;
- Copyingdatafromfile:/home/work/data/test.txt
- Copyingfile:file:/home/work/data/test.txt
- Loadingdatatotabledefault.test1
- OK
- Timetaken:0.243seconds
SEQUENCEFILE:
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
示例:
- >createtabletest2(strSTRING)
- >STOREDASSEQUENCEFILE;
- OK
- Timetaken:5.526seconds
- hive>SEThive.exec.compress.output=true;
- hive>SETio.seqfile.compression.type=BLOCK;
- hive>INSERTOVERWRITETABLEtest2SELECT*FROMtest1;
RCFILE
RCFILE是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。RCFILE文件示例:
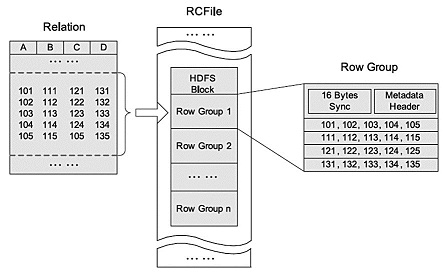
实例:
- >createtabletest3(strSTRING)
- >STOREDASRCFILE;
- OK
- Timetaken:0.184seconds
- >INSERTOVERWRITETABLEtest3SELECT*FROMtest1;
自定义格式
当用户的数据文件格式不能被当前 Hive 所识别的时候,可以自定义文件格式。
用户可以通过实现
inputformat和outputformat来自定义输入输出格式,参考代码:
.\hive-0.8.1\src\contrib\src\java\org\apache\hadoop\hive\contrib\fileformat\base64
实例:
建表
- >createtabletest4(strSTRING)
- >storedas
- >inputformat'org.apache.hadoop.hive.contrib.fileformat.base64.Base64TextInputFormat'
- >outputformat'org.apache.hadoop.hive.contrib.fileformat.base64.Base64TextOutputFormat';
$ cat test1.txt
aGVsbG8saGl2ZQ==
aGVsbG8sd29ybGQ=
aGVsbG8saGFkb29w
test1文件为base64编码后的内容,decode后数据为:
hello,hive
hello,world
hello,hadoop
load数据并查询:
- hive>LOADDATALOCALINPATH'/home/work/test1.txt'INTOTABLEtest4;
- Copyingdatafromfile:/home/work/test1.txt
- Copyingfile:file:/home/work/test1.txt
- Loadingdatatotabledefault.test4
- OK
- Timetaken:4.742seconds
- hive>select*fromtest4;
- OK
- hello,hive
- hello,world
- hello,hadoop
- Timetaken:1.953seconds
总结:
相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
分享到:





相关推荐
hive测试数据,其中为日志类型,用于验证在hive中主流文件存储格式对比实验
Hive 文件存储格式详解 Hive 文件存储格式是 Hive 中非常重要的概念,它直接影响着数据的存储和查询效率。在 Hive 中,常用的文件存储格式有 TextFile、ORC 和 Parquet 三种。下面我们将详细介绍这三种存储格式的...
### CDH550下Hive的存储格式与HQL详解 #### 一、Hive存储格式概述 在CDH550版本中,Hive提供了多种存储格式选项,以满足不同场景的需求。这些存储格式的选择直接影响着数据的读写性能、存储效率以及查询响应时间。...
而“Hive”是注册表的物理存储单元,主要有几个核心的Hive文件,如HKEY_LOCAL_MACHINE (HKLM) 和 HKEY_CURRENT_USER (HKCU)。本篇将探讨如何使用C++编程语言直接解析Windows注册表的Hive文件,而不依赖于系统提供的...
#### 一、Hive 文件存储格式 在Hive中,数据表是以文件的形式存储在HDFS (Hadoop Distributed File System) 上的。Hive支持多种文件存储格式,每种格式都有其特点,对数据加载方式、查询性能等方面有着不同的影响。...
3. **创建SequenceFile**:Hadoop的SequenceFile是一种高效的数据存储格式,适合用于合并小文件。创建一个新的SequenceFile,作为合并后的大文件的目标。 4. **读取和写入数据**:遍历获取的文件列表,使用`...
Hive文件读写是Hive核心功能之一,使得数据分析师和数据科学家能够方便地对存储在HDFS(Hadoop分布式文件系统)中的大量数据进行操作。在本篇中,我们将深入探讨如何在Linux环境下使用Hive进行文件读写,并了解BCD...
- HIVE文件是二进制格式,包含键、值对,用于存储和加载注册表信息。 - 解析库文件(如FS.DLL)可能包含用于读取、修改或解析注册表HIVE的函数。 3. FAT (File Allocation Table): - FAT是早期Windows和MS-DOS...
在大数据处理领域,Apache Hive 是一个非常重要的工具,它提供了一个SQL-like的接口来查询、管理和分析存储在分布式存储系统(如Hadoop)中的大规模数据集。本篇将重点讲解如何利用Hive对Protobuf序列化的文件进行...
在Hive 2.1.1版本中,ORC(Optimized Row Columnar)格式是一种高效的数据存储方式,尤其适用于大数据处理。它提供了压缩、索引和列式存储等特性,能够极大地提高查询性能。然而,有时候在使用ORC格式读取数据时,...
这些库可能包括Hive与HBase交互所需的连接器、Hadoop相关的库、以及其他可能的依赖,如Avro、Parquet、Thrift等,这些都是大数据处理中的常见格式和通信协议。安装这些库后,Hive就能识别和处理HBase的数据,使得...
虽然DataX的配置通常在JSON格式的配置文件中完成,但与Hive、Hadoop和Spark的集成可能会涉及上述组件的配置调整,以确保数据传输的效率和正确性。 总的来说,理解和灵活调整这些组件的配置文件信息对于优化大数据...
在大数据处理领域,Hive是一个基于Hadoop的数据仓库工具,它允许用户使用SQL类查询语言(HQL)来处理存储在Hadoop分布式文件系统(HDFS)中的大规模数据集。"HIVE操作注册表.rar"这个压缩包可能包含了与在Hive环境中...
需要注意的是,由于Hadoop和Hive主要为Linux设计,Windows上的安装和配置可能会遇到更多问题,如文件路径格式、权限控制和依赖库的不兼容等。因此,用户可能需要查阅官方文档、社区论坛或教程来解决遇到的问题。
本资料包包含了两个关键文件:2013_12.csv 和 Hive指令样例.txt,分别用于理解Hive中的数据文件格式和基本操作命令。 2013_12.csv 文件是一个CSV(Comma Separated Values)文件,这是一种常见的数据交换格式,以...
Hive支持多种数据格式,包括文本文件、SequenceFiles、RCFiles以及Parquet和ORC等列式存储格式。它也提供了对数据进行转换、聚合和一些更复杂操作的能力。Hive的任务被转换为一系列的MapReduce任务,然后执行。Hive...
通过合理选择文件格式、采用有效的压缩技术、优化MapReduce属性和Join方案、使用分区和桶表设计,以及通过Explain命令来优化查询执行计划等方法,可以让Hive在存储和性能方面达到最佳的工作状态。这对于大数据分析...
2. **hive-log4j2.properties**:这是Hive的日志配置文件,定义了日志级别、日志输出格式和目的地等。通过调整这些参数,我们可以控制Hive运行时的日志信息,这对于调试和监控系统状态至关重要。 3. **hive-env.sh*...
Hive-2.3.2是Hive的一个较新版本,提供了一些新的功能和改进,比如对ORC文件格式更好的支持、对Spark作为执行引擎的支持等。 Apache Hive资源文件,如apache-hive-2.3.2-bin.tar,是数据仓库管理和分析人员的重要...
6. **性能优化**:由于 JSON 数据解析相对较慢,为了提高性能,可以考虑预处理数据,如将 JSON 转换为 Parquet 或 ORC 格式,这两种格式都是 Hive 支持的列式存储格式,能显著提升查询速度。 7. **注意事项**:使用...