
本文通过对Apache Commons Collections 项目中LRUMap这个集合类的源代码进行详细解读,为帮助大家更好的了解这个集合类的实现原理以及使用如何该集合类。
首先介绍一下LRU算法. LRU是由Least Recently Used的首字母组成,表示最近最少使用的含义,一般使用在对象淘汰算法上。也是比较常见的一种淘汰算法。
LRUMap 则是实现的LRP算法的Map集合类,它继承于AbstractLinkedMap 抽象类。LRUMap的使用说明如下:
LRUMap的初始化时需要指定最大集合元素个数,新增的元素个数大于允许的最大集合个数时,则会执行LRU淘汰算法。所有的元素在LRUMap中会根据最近使用情况进行排序。最近使用的会放在元素的最前面(LRUMap是通过链表来存储元素内容). 所以LRUMap进行淘汰时只需要删除链表最后一个即可(即header.after所指的元素对象)
那么那些操作会影响元素的使用情况:
1. put 当新增加一个集合元素对象,则表示该对象是最近被访问的
2. get 操作会把当前访问的元素对象作为最近被访问的,会被移到链接表头
注:当执行containsKey和containsValue操作时,不会影响元素的访问情况。
LRUMap也是非线程安全。在多线程下使用可通过 Collections.synchronizedMap(Map)操作来保证线程安全。
LRUMap的一个简单使用示例:
public static void main(String[] args) {
LRUMap lruMap = new LRUMap(2);
lruMap.put("a1", "1");
lruMap.put("a2", "2");
lruMap.get("a1");//mark as recent used
lruMap.put("a3", "3");
System.out.println(lruMap);
}
上面的示例,当增加”a3”值时,会淘汰最近最少使用的”a2”, 最后输出的结果为:
{a1=1, a3=3}
下面根据LRUMap的源码来解读一下LRUMap的实现原理
整体类图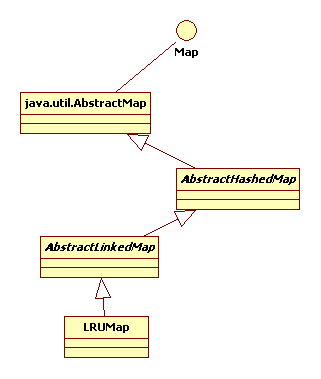
类图:
LRUMap类的关键代码说明如下:
1. get操作
public Object get(Object key) {
LinkEntry entry = (LinkEntry) getEntry(key);
if (entry == null) {
return null;
}
moveToMRU(entry); //执行LRU操作
return entry.getValue();
}
moveToMRU方法代码如下:
protected void moveToMRU(LinkEntry entry) {
if (entry.after != header) {
modCount++;
// remove 从链接中移除当前节点
entry.before.after = entry.after;
entry.after.before = entry.before;
// add first 把节点增加到链接头部
entry.after = header;
entry.before = header.before;
header.before.after = entry;
header.before = entry;
} else if (entry == header) {
throw new IllegalStateException("Can't move header to MRU" +
" (please report this to commons-dev@jakarta.apache.org)");
}
}
2. put新增操作
由于继承的AbstractLinkedMap,所以put操作会调用addMapping 方法,完整代码如下:
protected void addMapping(int hashIndex, int hashCode, Object key, Object value) {
if (isFull()) {
LinkEntry reuse = header.after;
boolean removeLRUEntry = false;
if (scanUntilRemovable) {
while (reuse != header && reuse != null) {
if (removeLRU(reuse)) {
removeLRUEntry = true;
break;
}
reuse = reuse.after;
}
if (reuse == null) {
throw new IllegalStateException(
"Entry.after=null, header.after" + header.after + " header.before" + header.before +
" key=" + key + " value=" + value + " size=" + size + " maxSize=" + maxSize +
" Please check that your keys are immutable, and that you have used synchronization properly." +
" If so, then please report this to commons-dev@jakarta.apache.org as a bug.");
}
} else {
removeLRUEntry = removeLRU(reuse);
}
if (removeLRUEntry) {
if (reuse == null) {
throw new IllegalStateException(
"reuse=null, header.after=" + header.after + " header.before" + header.before +
" key=" + key + " value=" + value + " size=" + size + " maxSize=" + maxSize +
" Please check that your keys are immutable, and that you have used synchronization properly." +
" If so, then please report this to commons-dev@jakarta.apache.org as a bug.");
}
reuseMapping(reuse, hashIndex, hashCode, key, value);
} else {
super.addMapping(hashIndex, hashCode, key, value);
}
} else {
super.addMapping(hashIndex, hashCode, key, value);
}
}
当集合的个数超过指定的最大个数时,会调用 reuseMapping函数,把要删除的对象的key和value更新为新加入的值,并再次加入到链接表中,并重新排定次序。
reuseMapping函数代码如下:
protected void reuseMapping(LinkEntry entry, int hashIndex, int hashCode, Object key, Object value) {
// find the entry before the entry specified in the hash table
// remember that the parameters (except the first) refer to the new entry,
// not the old one
try {
int removeIndex = hashIndex(entry.hashCode, data.length);
HashEntry[] tmp = data; // may protect against some sync issues
HashEntry loop = tmp[removeIndex];
HashEntry previous = null;
while (loop != entry && loop != null) {
previous = loop;
loop = loop.next;
}
if (loop == null) {
throw new IllegalStateException(
"Entry.next=null, data[removeIndex]=" + data[removeIndex] + " previous=" + previous +
" key=" + key + " value=" + value + " size=" + size + " maxSize=" + maxSize +
" Please check that your keys are immutable, and that you have used synchronization properly." +
" If so, then please report this to commons-dev@jakarta.apache.org as a bug.");
}
// reuse the entry
modCount++;
removeEntry(entry, removeIndex, previous);
reuseEntry(entry, hashIndex, hashCode, key, value);
addEntry(entry, hashIndex);
} catch (NullPointerException ex) {
throw new IllegalStateException(
"NPE, entry=" + entry + " entryIsHeader=" + (entry==header) +
" key=" + key + " value=" + value + " size=" + size + " maxSize=" + maxSize +
" Please check that your keys are immutable, and that you have used synchronization properly." +
" If so, then please report this to commons-dev@jakarta.apache.org as a bug.");
}
}
上面的代码中:
removeEntry 方法是删除最近最少使用的节点在链接中的引用
reuseEntry方法则把该节点的key和value赋新加入的节点的key和value值
addEntry 方法则把该节点加入到链接表,并保障相关的链接顺序
/**
* Adds an entry into this map, maintaining insertion order.
* <p>
* This implementation adds the entry to the data storage table and
* to the end of the linked list.
*
* @param entry the entry to add
* @param hashIndex the index into the data array to store at
*/
protected void addEntry(HashEntry entry, int hashIndex) {
LinkEntry link = (LinkEntry) entry;
link.after = header;
link.before = header.before;
header.before.after = link;
header.before = link;
data[hashIndex] = entry;
}
LRUMap的主要源码实现就解读到这里,实现思路还是比较好理解的。
LRUMap的使用场景会比较多,例如可以很方便的帮我们实现基于内存的 LRU 缓存服务实现。



相关推荐
(1) LRU:内存管理的一种页面置换算法,对于在内存中但又不用的数据块(内存块)叫做LRU,操作系统会根据哪些数据属于LRU而将其移出内存而腾出空间来加载另外的数据。 (2) LRU算法:LRU是Least Recently Used的...
这是自己在os课实验上自己写的一个页面替换算法cpp文件,里面包含了FIFO与LRU置换算法的实现程序。简单正确,同时加上了代码注释,一目了然。
在`lru.c`和`lru.h`中,你可以看到C语言实现的LRU算法的源代码。`lru.h`可能包含了LRU缓存的接口声明,如`init_lru()`, `add_to_lru()`, `get_from_lru()`, `remove_lru()`等函数,它们分别用于初始化LRU缓存、添加...
以下是一个简单的LRU缓存实现的Java代码框架: ```java class LRUCache, V> { private int capacity; private HashMap, Node> map; private DoublyLinkedList<Node> list; public LRUCache(int capacity) { ...
LRU 算法四种实现方式介绍 LRU 算法全称是 Least Recently Used,即最近最久未使用的意思。LRU 算法的设计原则是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。也就是说,当限定的...
标题中的“Lru缓存代码”指的是实现LRU缓存机制的源代码,可能是用特定编程语言编写的。通过这段代码,开发者可以创建一个能够在内存中保存最近最常用数据的缓存结构。 描述中的“lru资源缓存”可能是指利用LRU策略...
通过以上代码,我们已经构建了一个简单的LRU缓存系统。在实际应用中,LRU算法不仅可以用于操作系统中的页面替换,还可以应用于数据库查询缓存、编程语言的内存管理(如Java的SoftReference和WeakReference)以及Web...
近期最少使用算法
在这个名为`CacheMemory`的压缩包中,很可能包含了实现上述功能的Java源代码。通过对源码的阅读和分析,我们可以更深入地理解LRU缓存的工作原理和具体实现细节。为了进一步学习和应用,你可以尝试阅读源码,理解每个...
该设计报告的源程序文件包括了 LRU 算法的实现代码,使用的编程语言是 C 或 C++。该设计报告还包括了算法的测试代码和结果。 九、程序运行结果 该设计报告的程序运行结果包括了 LRU 算法的测试结果,包括了算法的...
本文将详细介绍一个用C语言实现的LRU算法示例代码,并对其实现细节进行深入解析。 #### 二、LRU算法概述 LRU算法的核心思想是:当缓存满时,优先淘汰最近最少使用的数据。这里的“最近最少使用”是指在最近一段...
LRU(Least Recently Used)算法是一种常用的页面替换算法,用于解决计算机内存有限而数据需求量大的问题。...在理解这个算法的基础上,可以通过阅读`LRU.cpp`文件中的具体代码,进一步了解其细节和优化点。
给定的源代码实现了一个简单的LRU缓存淘汰策略。下面将详细介绍各个部分的功能和工作原理。 #### 三、关键结构与变量定义 1. **`#define M 4`**: 定义了缓存大小为4。 2. **`#define N 17`**: 定义了请求序列...
本文将基于给定的C/C++源代码,深入解析LRU页面置换算法的工作原理及其具体实现细节。 #### LRU算法的核心思想 LRU算法的基本思想是在发生页面故障时,选择最近最久未使用的页面进行替换。这里的“最近最久未使用...
在计算机科学领域,虚拟存储是一...在提供的文档“lru.doc”中,应该详细阐述了实验的具体步骤、LRU和FIFO的实现细节,以及可能的实验结果和分析。阅读这份文档可以帮助你深入理解这两种页面替换算法的原理和实际应用。
用C语言实现的OPT和LRU算法,下载后直接用VC++6.0打开即可编译运行。亲测可用。
LRU算法实现 LRU(Least Recently Used)算法是一种常用的缓存淘汰算法,目标是在缓存中选择最近最久未使用的页面予以置换。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来经历的时间T,当须...
实验的主要数据结构是一个模板类`lru_cache`,它基于关联容器`std::unordered_map`和双向链表`std::list`实现。`unordered_map`用于快速查找页面,而`list`则保持页面的访问顺序。`put()`方法用于插入或更新页面,`...
基于python的LRU算法设计与实现
高吞吐、线程安全的 LRU 缓存详解是对 LRU 缓存的深入研究和实现,以下是对该主题的详细知识点。 1. LRU 缓存的原理 LRU 缓存是基于 Least Recently Used(最近最少使用)的原则,缓存中保存的是最近使用的数据,...