
з®ҖиҰҒз»ҷеӨ§е®¶д»Ӣз»ҚдёҖдёӢиҜӯйҹіжҖҺд№ҲеҸҳж–Үеӯ—зҡ„еҗ§гҖӮ
йҰ–е…ҲиҜҙдёҖдёӢдҪңдёәиҫ“е…Ҙзҡ„ж—¶еҹҹжіўеҪўгҖӮжҲ‘们зҹҘйҒ“еЈ°йҹіе®һйҷ…дёҠжҳҜдёҖз§ҚжіўгҖӮеёёи§Ғзҡ„mp3гҖҒwmvзӯүж јејҸйғҪжҳҜеҺӢзј©ж јејҸпјҢеҝ…йЎ»иҪ¬жҲҗйқһеҺӢзј©зҡ„зәҜжіўеҪўж–Ү件пјҢжҜ”еҰӮWindows PCMж–Ү件пјҢеҚіwavж–Ү件жқҘеӨ„зҗҶгҖӮwavж–Ү件йҮҢеӯҳеӮЁзҡ„йҷӨдәҶдёҖдёӘж–Ү件еӨҙд»ҘеӨ–пјҢе°ұжҳҜеЈ°йҹіжіўеҪўзҡ„дёҖдёӘдёӘзӮ№дәҶгҖӮйҮҮж ·зҺҮи¶ҠеӨ§пјҢжҜҸжҜ«з§’иҜӯйҹідёӯеҢ…еҗ«зҡ„зӮ№зҡ„дёӘж•°е°ұи¶ҠеӨҡгҖӮеҸҰеӨ–еЈ°йҹіжңүеҚ•йҖҡйҒ“еҸҢйҖҡйҒ“д№ӢеҲҶпјҢиҝҳжңүеӣӣйҖҡйҒ“зҡ„зӯүзӯүгҖӮеҜ№иҜӯйҹіиҜҶеҲ«д»»еҠЎжқҘиҜҙпјҢеҚ•йҖҡйҒ“е°ұи¶іеӨҹдәҶпјҢеӨҡдәҶжөӘиҙ№пјҢеӣ жӯӨдёҖиҲ¬иҰҒжҠҠеЈ°йҹіиҪ¬жҲҗеҚ•йҖҡйҒ“зҡ„жқҘеӨ„зҗҶгҖӮдёӢеӣҫжҳҜдёҖдёӘжіўеҪўзҡ„зӨәдҫӢгҖӮ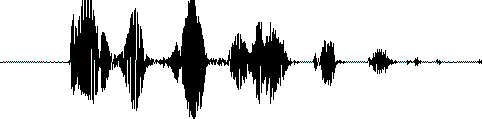
еҸҰеӨ–пјҢйҖҡеёёиҝҳйңҖиҰҒеҒҡдёӘVADеӨ„зҗҶпјҢд№ҹе°ұжҳҜжҠҠйҰ–е°ҫз«Ҝзҡ„йқҷйҹіеҲҮйҷӨпјҢйҷҚдҪҺеҜ№еҗҺз»ӯжӯҘйӘӨйҖ жҲҗзҡ„е№Іжү°пјҢиҝҷйңҖиҰҒз”ЁеҲ°дҝЎеҸ·еӨ„зҗҶзҡ„дёҖдәӣжҠҖжңҜгҖӮ
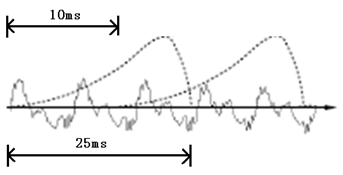
ж—¶еҹҹзҡ„жіўеҪўеҝ…йЎ»иҰҒеҲҶеё§пјҢд№ҹе°ұжҳҜжҠҠжіўеҪўеҲҮејҖжҲҗдёҖе°Ҹж®өдёҖе°Ҹж®өпјҢжҜҸе°Ҹж®өз§°дёәдёҖеё§гҖӮеҲҶеё§ж“ҚдҪңйҖҡеёёдҪҝ用移еҠЁзӘ—еҮҪж•°жқҘе®һзҺ°пјҢеҲҶеё§д№ӢеүҚиҝҳиҰҒеҒҡдёҖдәӣйў„еҠ йҮҚзӯүж“ҚдҪңпјҢиҝҷйҮҢдёҚиҜҰиҝ°гҖӮеё§дёҺеё§д№Ӣй—ҙжҳҜжңүдәӨеҸ зҡ„пјҢе°ұеғҸдёӢеӣҫиҝҷж ·пјҡ
еӣҫдёӯпјҢжҜҸеё§зҡ„й•ҝеәҰдёә25жҜ«з§’пјҢжҜҸдёӨеё§д№Ӣй—ҙжңү25-10=15жҜ«з§’зҡ„дәӨеҸ гҖӮжҲ‘们称дёәд»Ҙеё§й•ҝ25msгҖҒ帧移10msеҲҶеё§гҖӮ
еҲҶеё§еҗҺпјҢиҜӯйҹіе°ұеҸҳжҲҗдәҶеҫҲеӨҡе°Ҹж®өгҖӮдҪҶжіўеҪўеңЁж—¶еҹҹдёҠеҮ д№ҺжІЎжңүжҸҸиҝ°иғҪеҠӣпјҢеӣ жӯӨеҝ…йЎ»е°ҶжіўеҪўдҪңеҸҳжҚўгҖӮеёёи§Ғзҡ„дёҖз§ҚеҸҳжҚўж–№жі•жҳҜжҸҗеҸ–MFCCзү№еҫҒпјҢжҠҠжҜҸдёҖеё§жіўеҪўеҸҳжҲҗдёҖдёӘ12з»ҙеҗ‘йҮҸгҖӮиҝҷ12дёӘзӮ№жҳҜж №жҚ®дәәиҖізҡ„з”ҹзҗҶзү№жҖ§жҸҗеҸ–зҡ„пјҢеҸҜд»ҘзҗҶи§Јдёәиҝҷ12дёӘзӮ№еҢ…еҗ«дәҶиҝҷеё§иҜӯйҹізҡ„еҶ…е®№дҝЎжҒҜгҖӮиҝҷдёӘиҝҮзЁӢеҸ«еҒҡеЈ°еӯҰзү№еҫҒжҸҗеҸ–гҖӮе®һйҷ…еә”з”ЁдёӯпјҢиҝҷдёҖжӯҘжңүеҫҲеӨҡз»ҶиҠӮпјҢжҜ”еҰӮе·®еҲҶгҖҒеқҮеҖјж–№е·®и§„ж•ҙгҖҒй«ҳж–ҜеҢ–гҖҒйҷҚз»ҙеҺ»еҶ—дҪҷзӯүпјҢеЈ°еӯҰзү№еҫҒд№ҹдёҚжӯўжңүMFCCиҝҷдёҖз§ҚпјҢе…·дҪ“е°ұдёҚиҜҰиҝ°дәҶгҖӮ
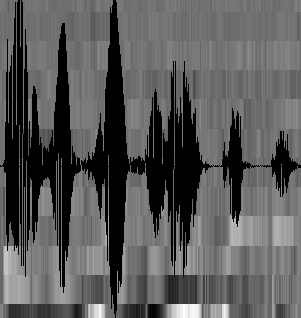
иҮіжӯӨпјҢеЈ°йҹіе°ұжҲҗдәҶдёҖдёӘ12иЎҢпјҲеҒҮи®ҫеЈ°еӯҰзү№еҫҒжҳҜ12з»ҙпјүгҖҒNеҲ—зҡ„дёҖдёӘзҹ©йҳөпјҢз§°д№Ӣдёәи§ӮеҜҹеәҸеҲ—пјҢиҝҷйҮҢNдёәжҖ»её§ж•°гҖӮи§ӮеҜҹеәҸеҲ—еҰӮдёӢеӣҫжүҖзӨәпјҢеӣҫдёӯпјҢжҜҸдёҖеё§йғҪз”ЁдёҖдёӘ12з»ҙзҡ„еҗ‘йҮҸиЎЁзӨәпјҢиүІеқ—зҡ„йўңиүІж·ұжө…иЎЁзӨәеҗ‘йҮҸеҖјзҡ„еӨ§е°ҸгҖӮ
жҺҘдёӢжқҘе°ұиҰҒд»Ӣз»ҚжҖҺж ·жҠҠиҝҷдёӘзҹ©йҳөеҸҳжҲҗж–Үжң¬дәҶгҖӮйҰ–е…ҲиҰҒд»Ӣз»ҚдёүдёӘжҰӮеҝөпјҡ
- еҚ•иҜҚпјҡиӢұиҜӯдёӯе°ұжҳҜеҚ•иҜҚпјҢжұүиҜӯдёӯжҳҜжұүеӯ—гҖӮ
- йҹізҙ пјҡеҚ•иҜҚзҡ„еҸ‘йҹіз”ұйҹізҙ жһ„жҲҗгҖӮеҜ№иӢұиҜӯпјҢдёҖз§Қеёёз”Ёзҡ„йҹізҙ йӣҶжҳҜеҚЎеҶ…еҹәжў…йҡҶеӨ§еӯҰзҡ„дёҖеҘ—з”ұ39дёӘйҹізҙ жһ„жҲҗзҡ„йҹізҙ йӣҶпјҢеҸӮи§ҒThe CMU Pronouncing DictionaryвҖҺгҖӮжұүиҜӯдёҖиҲ¬зӣҙжҺҘз”Ёе…ЁйғЁеЈ°жҜҚе’ҢйҹөжҜҚдҪңдёәйҹізҙ йӣҶпјҢеҸҰеӨ–жұүиҜӯиҜҶеҲ«иҝҳеҲҶжңүи°ғж— и°ғпјҢдёҚиҜҰиҝ°гҖӮ
- зҠ¶жҖҒпјҡжҜ”йҹізҙ жӣҙз»ҶиҮҙзҡ„иҜӯйҹіеҚ•дҪҚгҖӮйҖҡеёёдёҖдёӘйҹізҙ з”ұ3дёӘзҠ¶жҖҒжһ„жҲҗгҖӮ
иҜӯйҹіиҜҶеҲ«жҳҜжҖҺд№Ҳе·ҘдҪңзҡ„е‘ўпјҹе®һйҷ…дёҠдёҖзӮ№йғҪдёҚзҘһз§ҳпјҢж— йқһжҳҜпјҡ
第дёҖжӯҘпјҢжҠҠеё§иҜҶеҲ«жҲҗзҠ¶жҖҒпјҲйҡҫзӮ№пјүгҖӮ
第дәҢжӯҘпјҢжҠҠзҠ¶жҖҒз»„еҗҲжҲҗйҹізҙ гҖӮ
第дёүжӯҘпјҢжҠҠйҹізҙ з»„еҗҲжҲҗеҚ•иҜҚгҖӮ
еҰӮдёӢеӣҫжүҖзӨәпјҡ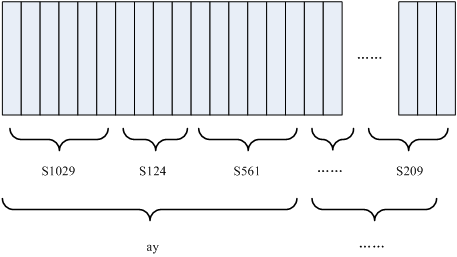 еӣҫдёӯпјҢжҜҸдёӘе°Ҹз«–жқЎд»ЈиЎЁдёҖеё§пјҢиӢҘе№Іеё§иҜӯйҹіеҜ№еә”дёҖдёӘзҠ¶жҖҒпјҢжҜҸдёүдёӘзҠ¶жҖҒз»„еҗҲжҲҗдёҖдёӘйҹізҙ пјҢиӢҘе№ІдёӘйҹізҙ з»„еҗҲжҲҗдёҖдёӘеҚ•иҜҚгҖӮд№ҹе°ұжҳҜиҜҙпјҢеҸӘиҰҒзҹҘйҒ“жҜҸеё§иҜӯйҹіеҜ№еә”е“ӘдёӘзҠ¶жҖҒдәҶпјҢиҜӯйҹіиҜҶеҲ«зҡ„з»“жһңд№ҹе°ұеҮәжқҘдәҶгҖӮ
еӣҫдёӯпјҢжҜҸдёӘе°Ҹз«–жқЎд»ЈиЎЁдёҖеё§пјҢиӢҘе№Іеё§иҜӯйҹіеҜ№еә”дёҖдёӘзҠ¶жҖҒпјҢжҜҸдёүдёӘзҠ¶жҖҒз»„еҗҲжҲҗдёҖдёӘйҹізҙ пјҢиӢҘе№ІдёӘйҹізҙ з»„еҗҲжҲҗдёҖдёӘеҚ•иҜҚгҖӮд№ҹе°ұжҳҜиҜҙпјҢеҸӘиҰҒзҹҘйҒ“жҜҸеё§иҜӯйҹіеҜ№еә”е“ӘдёӘзҠ¶жҖҒдәҶпјҢиҜӯйҹіиҜҶеҲ«зҡ„з»“жһңд№ҹе°ұеҮәжқҘдәҶгҖӮ
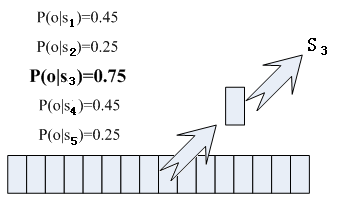
йӮЈжҜҸеё§йҹізҙ еҜ№еә”е“ӘдёӘзҠ¶жҖҒе‘ўпјҹжңүдёӘе®№жҳ“жғіеҲ°зҡ„еҠһжі•пјҢзңӢжҹҗеё§еҜ№еә”е“ӘдёӘзҠ¶жҖҒзҡ„жҰӮзҺҮжңҖеӨ§пјҢйӮЈиҝҷеё§е°ұеұһдәҺе“ӘдёӘзҠ¶жҖҒпјҢиҝҷеҸ«еҒҡвҖңжңҖеӨ§дјјз„¶вҖқгҖӮжҜ”еҰӮдёӢйқўзҡ„зӨәж„ҸеӣҫпјҢиҝҷеё§еҜ№еә”S3зҠ¶жҖҒзҡ„жҰӮзҺҮжңҖеӨ§пјҢеӣ жӯӨе°ұи®©иҝҷеё§еұһдәҺS3зҠ¶жҖҒгҖӮ
йӮЈиҝҷдәӣз”ЁеҲ°зҡ„жҰӮзҺҮд»Һе“ӘйҮҢиҜ»еҸ–е‘ўпјҹжңүдёӘеҸ«вҖңеЈ°еӯҰжЁЎеһӢвҖқзҡ„дёңиҘҝпјҢйҮҢйқўеӯҳдәҶдёҖеӨ§е ҶеҸӮж•°пјҢйҖҡиҝҮиҝҷдәӣеҸӮж•°пјҢе°ұеҸҜд»ҘзҹҘйҒ“её§е’ҢзҠ¶жҖҒеҜ№еә”зҡ„жҰӮзҺҮгҖӮеЈ°еӯҰжЁЎеһӢжҳҜдҪҝз”Ёе·ЁеӨ§ж•°йҮҸзҡ„иҜӯйҹіж•°жҚ®и®ӯз»ғеҮәжқҘзҡ„пјҢи®ӯз»ғзҡ„ж–№жі•жҜ”иҫғз№ҒзҗҗпјҢиҝҷйҮҢдёҚи®ІгҖӮ
дҪҶиҝҷж ·еҒҡжңүдёҖдёӘй—®йўҳпјҡжҜҸдёҖеё§йғҪдјҡеҫ—еҲ°дёҖдёӘзҠ¶жҖҒеҸ·пјҢжңҖеҗҺж•ҙдёӘиҜӯйҹіе°ұдјҡеҫ—еҲ°дёҖе Ҷд№ұдёғе…«зіҹзҡ„зҠ¶жҖҒеҸ·пјҢзӣёйӮ»дёӨеё§й—ҙзҡ„зҠ¶жҖҒеҸ·еҹәжң¬йғҪдёҚзӣёеҗҢгҖӮеҒҮи®ҫиҜӯйҹіжңү1000её§пјҢжҜҸеё§еҜ№еә”1дёӘзҠ¶жҖҒпјҢжҜҸ3дёӘзҠ¶жҖҒз»„еҗҲжҲҗдёҖдёӘйҹізҙ пјҢйӮЈд№ҲеӨ§жҰӮдјҡз»„еҗҲжҲҗ300дёӘйҹізҙ пјҢдҪҶиҝҷж®өиҜӯйҹіе…¶е®һж №жң¬жІЎжңүиҝҷд№ҲеӨҡйҹізҙ гҖӮеҰӮжһңзңҹиҝҷд№ҲеҒҡпјҢеҫ—еҲ°зҡ„зҠ¶жҖҒеҸ·еҸҜиғҪж №жң¬ж— жі•з»„еҗҲжҲҗйҹізҙ гҖӮе®һйҷ…дёҠпјҢзӣёйӮ»её§зҡ„зҠ¶жҖҒеә”иҜҘеӨ§еӨҡж•°йғҪжҳҜзӣёеҗҢзҡ„жүҚеҗҲзҗҶпјҢеӣ дёәжҜҸеё§еҫҲзҹӯгҖӮ
и§ЈеҶіиҝҷдёӘй—®йўҳзҡ„еёёз”Ёж–№жі•е°ұжҳҜдҪҝз”Ёйҡҗ马尔еҸҜеӨ«жЁЎеһӢпјҲHidden Markov ModelпјҢHMMпјүгҖӮиҝҷдёңиҘҝеҗ¬иө·жқҘеҘҪеғҸеҫҲй«ҳж·ұзҡ„ж ·еӯҗпјҢе®һйҷ…дёҠеҫҲз®ҖеҚ•пјҢж— йқһжҳҜпјҡ
第дёҖжӯҘпјҢжһ„е»әдёҖдёӘзҠ¶жҖҒзҪ‘з»ңгҖӮ
第дәҢжӯҘпјҢд»ҺзҠ¶жҖҒзҪ‘з»ңдёӯеҜ»жүҫдёҺеЈ°йҹіжңҖеҢ№й…Қзҡ„и·Ҝеҫ„гҖӮ
иҝҷж ·е°ұжҠҠз»“жһңйҷҗеҲ¶еңЁйў„е…Ҳи®ҫе®ҡзҡ„зҪ‘з»ңдёӯпјҢйҒҝе…ҚдәҶеҲҡжүҚиҜҙеҲ°зҡ„й—®йўҳпјҢеҪ“然д№ҹеёҰжқҘдёҖдёӘеұҖйҷҗпјҢжҜ”еҰӮдҪ и®ҫе®ҡзҡ„зҪ‘з»ңйҮҢеҸӘеҢ…еҗ«дәҶвҖңд»ҠеӨ©жҷҙеӨ©вҖқе’ҢвҖңд»ҠеӨ©дёӢйӣЁвҖқдёӨдёӘеҸҘеӯҗзҡ„зҠ¶жҖҒи·Ҝеҫ„пјҢйӮЈд№ҲдёҚз®ЎиҜҙдәӣд»Җд№ҲпјҢиҜҶеҲ«еҮәзҡ„з»“жһңеҝ…然жҳҜиҝҷдёӨдёӘеҸҘеӯҗдёӯзҡ„дёҖеҸҘгҖӮ
е…·дҪ“жҳҜиҝҷж ·зҡ„пјҢйҰ–е…Ҳжһ„йҖ еҚ•иҜҚзә§зҪ‘з»ңпјҢ然еҗҺеұ•ејҖжҲҗйҹізҙ зҪ‘з»ңпјҢ然еҗҺеұ•ејҖжҲҗзҠ¶жҖҒзҪ‘з»ңгҖӮ然еҗҺеңЁзҠ¶жҖҒзҪ‘з»ңдёӯжҗңзҙўдёҖжқЎжңҖдҪіи·Ҝеҫ„пјҢиҝҷжқЎи·Ҝеҫ„е’ҢиҜӯйҹід№Ӣй—ҙзҡ„жҰӮзҺҮпјҲз§°д№ӢдёәзҙҜз§ҜжҰӮзҺҮпјүжңҖеӨ§гҖӮжҗңзҙўзҡ„з®—жі•жҳҜдёҖз§ҚеҠЁжҖҒ规еҲ’еүӘжһқзҡ„з®—жі•пјҢз§°д№ӢдёәViterbiз®—жі•пјҢз”ЁдәҺеҜ»жүҫе…ЁеұҖжңҖдјҳи·Ҝеҫ„гҖӮж„ҹе…ҙи¶Јзҡ„еҗҢеӯҰеҸҜд»ҘеҲ°WikipediaдёҠжҗңдёҖдёӢгҖӮ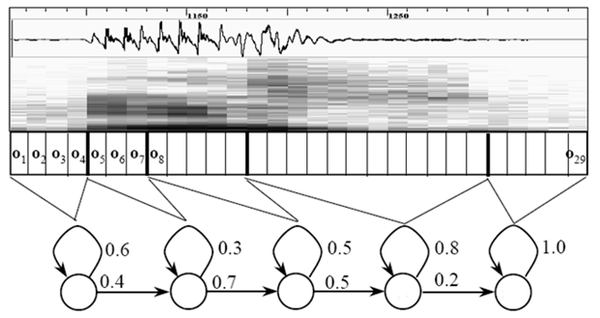
иҝҷйҮҢжүҖиҜҙзҡ„зҙҜз§ҜжҰӮзҺҮпјҢз”ұдёүйғЁеҲҶжһ„жҲҗпјҢеҲҶеҲ«жҳҜпјҡ
- и§ӮеҜҹжҰӮзҺҮпјҡжҜҸеё§е’ҢжҜҸдёӘзҠ¶жҖҒеҜ№еә”зҡ„жҰӮзҺҮ
- иҪ¬з§»жҰӮзҺҮпјҡжҜҸдёӘзҠ¶жҖҒиҪ¬з§»еҲ°иҮӘиә«жҲ–иҪ¬з§»еҲ°дёӢдёӘзҠ¶жҖҒзҡ„жҰӮзҺҮ
- иҜӯиЁҖжҰӮзҺҮпјҡж №жҚ®иҜӯиЁҖз»ҹ计规еҫӢеҫ—еҲ°зҡ„жҰӮзҺҮ
е…¶дёӯпјҢеүҚдёӨз§ҚжҰӮзҺҮд»ҺеЈ°еӯҰжЁЎеһӢдёӯиҺ·еҸ–пјҢжңҖеҗҺдёҖз§ҚжҰӮзҺҮд»ҺиҜӯиЁҖжЁЎеһӢдёӯиҺ·еҸ–гҖӮиҜӯиЁҖжЁЎеһӢжҳҜдҪҝз”ЁеӨ§йҮҸзҡ„ж–Үжң¬и®ӯз»ғеҮәжқҘзҡ„пјҢеӯҳеӮЁзҡ„жҳҜд»»ж„ҸеҚ•иҜҚгҖҒд»»ж„ҸдёӨдёӘеҚ•иҜҚгҖҒд»»ж„ҸдёүдёӘеҚ•иҜҚпјҲйҖҡеёёд№ҹе°ұеҲ°дёүдёӘеҚ•иҜҚпјүеңЁеӨ§йҮҸж–Үжң¬дёӯзҡ„еҮәзҺ°жңәзҺҮгҖӮ
иҝҷж ·еҹәжң¬дёҠиҜӯйҹіиҜҶеҲ«иҝҮзЁӢе°ұе®ҢжҲҗдәҶгҖӮ
д»ҘдёҠд»Ӣз»Қзҡ„жҳҜдј з»ҹзҡ„еҹәдәҺHMMзҡ„иҜӯйҹіиҜҶеҲ«гҖӮд»ҘдёҠзҡ„ж–Үеӯ—дёҚиҝҪжұӮдёҘи°ЁпјҢеҸӘжҳҜжғіи®©еӨ§е®¶е®№жҳ“зҗҶи§ЈгҖӮ
еҰӮжһңж„ҹе…ҙи¶ЈпјҢжғіиҝӣдёҖжӯҘдәҶи§ЈпјҢHTK BookжҳҜйқһеёёеҘҪзҡ„е…Ҙй—Ёд№ҰпјҢиҝҷжң¬д№Ұе®һйҷ…дёҠжҳҜеү‘жЎҘеӨ§еӯҰеҸ‘еёғзҡ„и‘—еҗҚејҖжәҗе·Ҙе…·еҢ…HTK Speech Recognition ToolkitВ зҡ„иҜҙжҳҺд№ҰпјҢиҝ‘400йЎөпјҢеҺҡеҺҡзҡ„дёҖжң¬гҖӮеҰӮжһңжңүж—¶й—ҙгҖҒжңүе…ҙи¶ЈпјҢеҸҜд»Ҙз…§зқҖд№Ұдёӯзҡ„第дәҢз« еңЁз”өи„‘дёҠеҒҡдёҖйҒҚпјҢдҪ е°Ҷжҗӯе»әеҮәдёҖдёӘз®ҖеҚ•дҪҶеҹәжң¬е®Ңж•ҙзҡ„иҜӯйҹіиҜҶеҲ«зі»з»ҹпјҢиғҪиҜҶеҲ«з®ҖеҚ•зҡ„иӢұиҜӯж•°еӯ—дёІгҖӮ



зӣёе…іжҺЁиҚҗ
дәәе·ҘжҷәиғҪиҜӯйҹіиҜҶеҲ«жҠҖжңҜеңЁй“Ғи·Ҝзі»з»ҹдёӯзҡ„еә”з”ЁжҳҜдёҖдёӘе…ҲиҝӣжҠҖжңҜдёҺиЎҢдёҡйңҖжұӮзӣёз»“еҗҲзҡ„иҢғдҫӢгҖӮеңЁиҝҷдёӘиҝҮзЁӢдёӯпјҢж¶үеҸҠеҲ°дәҶдәәе·ҘжҷәиғҪгҖҒж•°жҚ®еҲҶжһҗгҖҒдә‘и®Ўз®—зӯүеӨҡйЎ№жҠҖжңҜгҖӮжң¬ж–Үд»Һдәәе·ҘжҷәиғҪиҜӯйҹіиҜҶеҲ«жҠҖжңҜзҡ„еҹәжң¬жҰӮеҝөгҖҒй“Ғи·Ҝзі»з»ҹдёӯзҡ„е…·дҪ“еә”з”ЁгҖҒжҠҖжңҜ...
гҖҠиҜӯйҹіиҜҶеҲ«жҠҖжңҜзҷҪзҡ®д№Ұ-12еҸ‘еёғ_V1.0.2гҖӢжҳҜй’ҲеҜ№иҮӘдё»ејҖеҸ‘зҡ„иҜӯйҹіиҜҶеҲ«зі»з»ҹпјҲASRпјҡAutomatic Speech Recognitionпјүзҡ„дёҖд»ҪиҜҰз»ҶжҠҖжңҜж–ҮжЎЈгҖӮиҝҷд»Ҫж–ҮжЎЈж—ЁеңЁжҸӯзӨәиҜҘзі»з»ҹзҡ„зү№жҖ§е’ҢеҠҹиғҪпјҢдёәзӣёе…ійўҶеҹҹзҡ„ејҖеҸ‘дәәе‘ҳгҖҒз®—жі•е·ҘзЁӢеёҲгҖҒдә§е“Ғз»ҸзҗҶ...
иҜӯйҹіиҜҶеҲ«жҠҖжңҜпјҢд№ҹиў«з§°дёәиҮӘеҠЁиҜӯйҹіиҜҶеҲ«пјҢзӣ®ж ҮжҳҜд»Ҙз”өи„‘иҮӘеҠЁе°Ҷдәәзұ»зҡ„иҜӯйҹіеҶ…е®№иҪ¬жҚўдёәзӣё еә”зҡ„ж–Үеӯ—е’Ңж–Үеӯ—иҪ¬жҚўдёәиҜӯйҹіпјҢеҸҜд»ҘдҪҝз”ЁдҪҝз”Ё pyttsxпјҢSAPI пјҢSpeechLib пјҢPocketSphinx е®һзҺ°ж–Үжң¬иҪ¬жҚўиҜӯйҹіпјҢеҶ…еҗ«жңүи§Ҷйў‘и®Іи§ЈпјҢжғіиҰҒж·ұе…Ҙиҝҷ...
### иҜӯйҹіиҜҶеҲ«жҠҖжңҜеҸҠеә”з”Ё #### дёҖгҖҒеј•иЁҖ иҜӯйҹіиҜҶеҲ«жҠҖжңҜдҪңдёәдҝЎжҒҜжҠҖжңҜйўҶеҹҹзҡ„йҮҚиҰҒз»„жҲҗйғЁеҲҶпјҢеңЁиҝҮеҺ»еҮ еҚҒе№ҙйҮҢз»ҸеҺҶдәҶжҳҫи‘—зҡ„иҝӣжӯҘе’ҢеҸ‘еұ•гҖӮйҡҸзқҖдәәе·ҘжҷәиғҪжҠҖжңҜзҡ„дёҚж–ӯжҲҗзҶҹпјҢиҜӯйҹіиҜҶеҲ«жҠҖжңҜдёҚд»…жҲҗдёәдәҶдәәжңәдәӨдә’зҡ„е…ій”®жҠҖжңҜд№ӢдёҖпјҢд№ҹеңЁ...
### иҜӯйҹіиҜҶеҲ«жҠҖжңҜжҰӮиҝ° иҜӯйҹіиҜҶеҲ«жҠҖжңҜжҳҜдёҖз§ҚиғҪеӨҹи®©жңәеҷЁзҗҶ解并е“Қеә”дәәзұ»иҜӯиЁҖзҡ„жҠҖжңҜпјҢе®ғйҖҡиҝҮеӨҚжқӮзҡ„з®—жі•е’ҢжЁЎеһӢе°ҶеЈ°йҹідҝЎеҸ·иҪ¬еҢ–дёәеҸҜиҜ»зҡ„ж–Үжң¬жҲ–жҢҮд»ӨгҖӮиҝҷйЎ№жҠҖжңҜзҡ„еҸ‘еұ•е·Із»Ҹз»ҸеҺҶдәҶй•ҝжңҹзҡ„з ”з©¶е’Ңж”№иҝӣпјҢ并йҖҗжёҗд»Һе®һйӘҢе®Өйҳ¶ж®өжӯҘе…ҘдәҶ...
### иҜӯйҹіиҜҶеҲ«жҠҖжңҜиҜҰи§Ј #### жҠҖжңҜжҰӮи§ҲдёҺеә”з”Ё иҜӯйҹіиҜҶеҲ«жҠҖжңҜпјҢдҪңдёәдәәе·ҘжҷәиғҪйўҶеҹҹзҡ„йҮҚиҰҒеҲҶж”ҜпјҢиҝ‘е№ҙжқҘеҫ—еҲ°дәҶиҝ…зҢӣзҡ„еҸ‘еұ•гҖӮиҝҷйЎ№жҠҖжңҜзҡ„ж ёеҝғеңЁдәҺзҗҶи§Је’ҢиҪ¬жҚўдәәзұ»зҡ„иҜӯйҹідёәеҸҜеӨ„зҗҶзҡ„ж–Үжң¬жҲ–е‘Ҫд»ӨпјҢд»ҺиҖҢе®һзҺ°дәәжңәдәӨдә’зҡ„й«ҳж•ҲжҖ§гҖӮе…¶...
гҖҗеҹәдәҺиҜӯйҹіиҜҶеҲ«жҠҖжңҜзҡ„йҹід№җж’ӯж”ҫеҷЁи®ҫи®ЎгҖ‘ еңЁзҺ°д»Јз§‘жҠҖйЈһйҖҹеҸ‘еұ•зҡ„ж—¶д»ЈпјҢиҜӯйҹіиҜҶеҲ«жҠҖжңҜе·Із»ҸйҖҗжёҗжё—йҖҸеҲ°жҲ‘们ж—Ҙеёёз”ҹжҙ»зҡ„еҗ„дёӘйўҶеҹҹгҖӮйҹід№җж’ӯж”ҫеҷЁдҪңдёәдәә们休闲еЁұд№җзҡ„йҮҚиҰҒе·Ҙе…·пјҢз»“еҗҲиҜӯйҹіиҜҶеҲ«жҠҖжңҜпјҢеҸҜд»ҘжҸҗдҫӣжӣҙеҠ дҫҝжҚ·гҖҒдәәжҖ§еҢ–зҡ„ж“ҚдҪң...
"иҜӯйҹіиҜҶеҲ«жҠҖжңҜеҺҹзҗҶе…Ёйқўи§Јжһҗ" иҜӯйҹіиҜҶеҲ«жҠҖжңҜжҳҜи®Ўз®—жңәдҝЎжҒҜеӨ„зҗҶжҠҖжңҜдёӯзҡ„е…ій”®жҠҖжңҜпјҢиҜӯйҹіжҠҖжңҜзҡ„еә”з”Ёе·Із»ҸжҲҗдёәдёҖдёӘе…·жңүз«һдәүжҖ§зҡ„ж–°е…ҙй«ҳжҠҖжңҜдә§дёҡгҖӮиҜӯйҹіиҜҶеҲ«жҠҖжңҜзҡ„еҹәжң¬еҺҹзҗҶжҳҜе°ҶжңӘзҹҘиҜӯйҹіз»ҸиҝҮиҜқзӯ’еҸҳжҚўжҲҗз”өдҝЎеҸ·еҗҺеҠ еңЁиҜҶеҲ«зі»з»ҹзҡ„...
иҜӯйҹіиҜҶеҲ«жҠҖжңҜдҪңдёәдәәе·ҘжҷәиғҪйўҶеҹҹзҡ„дёҖдёӘйҮҚиҰҒеҲҶж”ҜпјҢе·Із»Ҹз»ҸеҺҶдәҶй•ҝжңҹзҡ„еҸ‘еұ•е’ҢеҸҳйқ©гҖӮе®ғзҡ„ж ёеҝғзӣ®ж ҮжҳҜе°Ҷдәәзұ»зҡ„иҜӯйҹідҝЎеҸ·иҪ¬жҚўжҲҗеҜ№еә”зҡ„ж–Үжң¬дҝЎжҒҜгҖӮжң¬зҜҮеҶ…е®№е°ҶеҜ№иҜӯйҹіиҜҶеҲ«жҠҖжңҜзҡ„еҺҶеҸІеҸ‘еұ•гҖҒе…ій”®жҠҖжңҜгҖҒд»ҘеҸҠжңӘжқҘи¶ӢеҠҝиҝӣиЎҢжўізҗҶе’ҢеҲҶжһҗгҖӮ ...
иҜӯйҹіиҜҶеҲ«жҠҖжңҜжҰӮиҝ° иҜӯйҹіиҜҶеҲ«жҳҜжҢҮжңәеҷЁеҜ№дәәзұ»иҜҙиҜқзҡ„иҜӯеҸҘжҲ–е‘Ҫд»ӨиҝӣиЎҢиҜҶеҲ«е’ҢзҗҶ解并еҒҡеҮәзӣёеә”зҡ„еҸҚеә”гҖӮиҜӯйҹіиҜҶеҲ«жҠҖжңҜе·Із»ҸжңүдәҶиҫғеӨ§зҡ„еҸ‘еұ•пјҢиҝ‘ 50 е№ҙзҡ„з ”з©¶еҸ‘еұ•е…·жңүж·ұиҝңзҡ„з ”з©¶д»·еҖјгҖӮжң¬ж–Үйҳҗиҝ°иҜӯйҹіиҜҶеҲ«зҡ„еҸ‘еұ•еҺҶеҸІгҖҒеҹәжң¬еҺҹзҗҶпјҢеҲҶжһҗ...
гҖҗеҹәдәҺMatlabзҡ„иҜӯйҹіиҜҶеҲ«жҠҖжңҜгҖ‘жҳҜеҲ©з”ЁMatlabиҝҷдёҖејҖеҸ‘иҜӯиЁҖжқҘе®һзҺ°зҡ„дёҖз§Қдәәе·ҘжҷәиғҪеә”з”ЁгҖӮиҜӯйҹіиҜҶеҲ«жҠҖжңҜзҡ„ж ёеҝғзӣ®ж ҮжҳҜе°Ҷдәәзұ»зҡ„иҜӯйҹідҝЎеҸ·иҪ¬еҢ–дёәеҸҜзҗҶи§Јзҡ„ж–Үеӯ—жҲ–жҢҮд»ӨпјҢж¶үеҸҠдҝЎеҸ·еӨ„зҗҶгҖҒжЁЎејҸиҜҶеҲ«е’Ңдәәе·ҘжҷәиғҪзӯүеӨҡдёӘжҠҖжңҜйўҶеҹҹгҖӮйҡҸзқҖ科жҠҖ...
йҡҸзқҖдәәе·ҘжҷәиғҪжҠҖжңҜзҡ„йЈһйҖҹеҸ‘еұ•пјҢиҜӯйҹіиҜҶеҲ«жҠҖжңҜдҪңдёәе…¶йҮҚиҰҒзҡ„еҲҶж”Ҝд№ӢдёҖпјҢе·Із»ҸйҖҗжёҗжҲҗдёәдәә们ж—Ҙеёёз”ҹжҙ»дёӯдёҚеҸҜжҲ–зјәзҡ„дёҖйғЁеҲҶгҖӮд»ҺжңҖеҲқзҡ„з®ҖеҚ•ж•°еӯ—иҜҶеҲ«еҲ°зҺ°еҰӮд»ҠеӨҚжқӮзҡ„иҝһз»ӯиҜӯйҹіеӨ„зҗҶпјҢиҜӯйҹіиҜҶеҲ«жҠҖжңҜз»ҸиҝҮдәҶж•°еҚҒе№ҙзҡ„еҸ‘еұ•еҺҶзЁӢпјҢеҸ–еҫ—дәҶе·ЁеӨ§...
жүӢжңәиҜӯйҹіиҜҶеҲ«жҠҖжңҜжҳҜиҝ‘е№ҙжқҘйҡҸзқҖ移еҠЁйҖҡдҝЎе’Ңдәәе·ҘжҷәиғҪжҠҖжңҜзҡ„еҸ‘еұ•иҖҢйҖҗжёҗе…ҙиө·зҡ„дёҖз§Қе…ій”®жҠҖжңҜпјҢе®ғдҪҝеҫ—з”ЁжҲ·еҸҜд»ҘйҖҡиҝҮиҜӯйҹіжҢҮд»ӨдёҺжүӢжңәиҝӣиЎҢдәӨдә’пјҢжһҒеӨ§ең°жҸҗеҚҮдәҶдәәжңәдәӨдә’зҡ„дҫҝеҲ©жҖ§е’Ңж•ҲзҺҮгҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁиҝҷдёҖйўҶеҹҹзҡ„ж ёеҝғжҠҖжңҜе’Ңе®һж–Ҫ...
### иҜӯйҹіиҜҶеҲ«жҠҖжңҜиҜҰи§ЈеҸҠе…¶еә”з”ЁеүҚжҷҜ #### дёҖгҖҒеј•иЁҖ йҡҸзқҖдҝЎжҒҜжҠҖжңҜзҡ„еҝ«йҖҹеҸ‘еұ•пјҢиҜӯйҹіиҜҶеҲ«жҠҖжңҜдҪңдёәдёҖз§ҚйҮҚиҰҒзҡ„дәӨдә’ж–№ејҸпјҢжӯЈйҖҗжёҗжҲҗдёәдәәжңәжҺҘеҸЈзҡ„е…ій”®жҠҖжңҜд№ӢдёҖгҖӮжң¬ж–Үж—ЁеңЁж·ұе…ҘжҺўи®ЁиҜӯйҹіиҜҶеҲ«жҠҖжңҜзҡ„еҹәзЎҖеҺҹзҗҶгҖҒе…ій”®жҠҖжңҜеҸҠеә”з”Ё...
дәәе·ҘжҷәиғҪиҜӯйҹіиҜҶеҲ«жҠҖжңҜжҳҜзҺ°д»ЈдҝЎжҒҜжҠҖжңҜйўҶеҹҹдёӯзҡ„дёҖдёӘйҮҚиҰҒеҲҶж”ҜпјҢе®ғз»“еҗҲдәҶи®Ўз®—жңә科еӯҰгҖҒдҝЎеҸ·еӨ„зҗҶгҖҒжЁЎејҸиҜҶеҲ«гҖҒиҜӯиЁҖеӯҰзӯүеӨҡдёӘеӯҰ科зҡ„зҹҘиҜҶпјҢиҮҙеҠӣдәҺе®һзҺ°еҜ№дәәзұ»иҮӘ然иҜӯиЁҖзҡ„иҮӘеҠЁзҗҶи§Је’Ңи§ЈжһҗгҖӮиҝҷйЎ№жҠҖжңҜзҡ„е№ҝжіӣеә”з”ЁпјҢеҰӮжҷәиғҪеҠ©жүӢгҖҒжҷәиғҪ...
**дәәе·ҘжҷәиғҪиҜӯйҹіиҜҶеҲ«жҠҖжңҜ** иҜӯйҹіиҜҶеҲ«жҠҖжңҜжҳҜдәәе·ҘжҷәиғҪйўҶеҹҹзҡ„йҮҚиҰҒз»„жҲҗйғЁеҲҶпјҢе…¶зӣ®ж ҮжҳҜдҪҝи®Ўз®—жңәжҲ–жҷәиғҪи®ҫеӨҮиғҪеӨҹзҗҶи§Је’Ңжү§иЎҢдәәзұ»зҡ„еҸЈеӨҙжҢҮд»ӨпјҢе®һзҺ°дәәжңәиҮӘ然дәӨдә’гҖӮиҝҷйЎ№жҠҖжңҜзҡ„ж ёеҝғеңЁдәҺе°ҶиҜӯйҹідҝЎеҸ·иҪ¬еҢ–дёәеҸҜзҗҶи§Јзҡ„ж–Үжң¬жҲ–е‘Ҫд»ӨпјҢж¶үеҸҠ...
гҖҗеҹәдәҺиҜӯйҹіиҜҶеҲ«жҠҖжңҜзҡ„移еҠЁжңәеҷЁдәәжҺ§еҲ¶зі»з»ҹз ”еҸ‘гҖ‘ иҜӯйҹіиҜҶеҲ«жҠҖжңҜпјҢдҪңдёәдёҖз§Қдәәе·ҘжҷәиғҪзҡ„йҮҚиҰҒз»„жҲҗйғЁеҲҶпјҢе·Із»ҸеңЁз§»еҠЁжңәеҷЁдәәйўҶеҹҹеҸ‘жҢҘзқҖдёҚеҸҜжҲ–зјәзҡ„дҪңз”ЁгҖӮиҝҷйЎ№жҠҖжңҜиө·жәҗдәҺ20дё–зәӘ50е№ҙд»ЈпјҢж—ЁеңЁдҪҝжңәжў°и®ҫеӨҮзҗҶи§Је’Ңе“Қеә”дәәзұ»иҜӯйҹігҖӮе®ғ...
и°ғз”Ёеҫ®иҪҜжҠҖжңҜпјҢиҜӯйҹіиҜҶеҲ«дёҚйңҖиҒ”зҪ‘,еҸҜд»Ҙеҹәжң¬иҜҶеҲ«дәәиҜҙзҡ„иҜӯеҸҘпјҢ并且дёҚйңҖиҰҒиҒ”зҪ‘пјҢжІЎжңүи°ғз”ЁзҪ‘з»ңapi дәҢгҖҒиҸңеҚ•еҠҹиғҪ 1гҖҒе…·жңүејҖе§Ӣзӣ‘еҗ¬и®Өеҫ—иҜҙиҜқ并е®һж—¶жҳҫзӨәеңЁж–Үжң¬жЎҶдёҠ 2гҖҒе…·жңүйҳ…иҜ»еҠҹиғҪпјҢ并且еҸҜд»Ҙи°ғйҖҹ 3гҖҒејҖеҸ‘зҺҜеўғдёәVisual ...
STC11L08XEеҚ•зүҮжңә+LD3320иҜӯйҹіиҜҶеҲ«жЁЎеқ—иө„ж–ҷеҢ…жӢ¬зЎ¬д»¶еҸӮиҖғи®ҫи®Ў+иҪҜ件й©ұеҠЁжәҗз Ғ+иҜӯйҹіиҜҶеҲ«жҠҖжңҜи®әж–Үиө„ж–ҷпјҡ YS-V0.7з”өи·Ҝе…ғ件规еҲ’еӣҫ.pdf YS-V0.7иҜӯйҹіжЁЎеқ—з”өи·Ҝеӣҫ.pdf LD3320并иЎҢдёІиЎҢиҜ»еҶҷиҫ…еҠ©иҜҙжҳҺ.pdf LD3320ејҖеҸ‘жүӢеҶҢ.pdf LD3320...