
Nearest Common Ancestors
| Time Limit: 1000MS | Memory Limit: 10000K | |
| Total Submissions: 18912 | Accepted: 10007 |
Description
A rooted tree is a well-known data structure in computer science and engineering. An example is shown below:
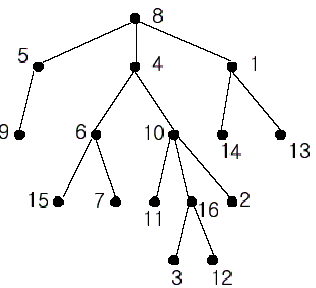
In the figure, each node is labeled with an integer from {1, 2,...,16}. Node 8 is the root of the tree. Node x is an ancestor of node y if node x is in the path between the root and node y. For example, node 4 is an ancestor of node 16. Node 10 is also an ancestor of node 16. As a matter of fact, nodes 8, 4, 10, and 16 are the ancestors of node 16. Remember that a node is an ancestor of itself. Nodes 8, 4, 6, and 7 are the ancestors of node 7. A node x is called a common ancestor of two different nodes y and z if node x is an ancestor of node y and an ancestor of node z. Thus, nodes 8 and 4 are the common ancestors of nodes 16 and 7. A node x is called the nearest common ancestor of nodes y and z if x is a common ancestor of y and z and nearest to y and z among their common ancestors. Hence, the nearest common ancestor of nodes 16 and 7 is node 4. Node 4 is nearer to nodes 16 and 7 than node 8 is.
For other examples, the nearest common ancestor of nodes 2 and 3 is node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and the nearest common ancestor of nodes 4 and 12 is node 4. In the last example, if y is an ancestor of z, then the nearest common ancestor of y and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
In the figure, each node is labeled with an integer from {1, 2,...,16}. Node 8 is the root of the tree. Node x is an ancestor of node y if node x is in the path between the root and node y. For example, node 4 is an ancestor of node 16. Node 10 is also an ancestor of node 16. As a matter of fact, nodes 8, 4, 10, and 16 are the ancestors of node 16. Remember that a node is an ancestor of itself. Nodes 8, 4, 6, and 7 are the ancestors of node 7. A node x is called a common ancestor of two different nodes y and z if node x is an ancestor of node y and an ancestor of node z. Thus, nodes 8 and 4 are the common ancestors of nodes 16 and 7. A node x is called the nearest common ancestor of nodes y and z if x is a common ancestor of y and z and nearest to y and z among their common ancestors. Hence, the nearest common ancestor of nodes 16 and 7 is node 4. Node 4 is nearer to nodes 16 and 7 than node 8 is.
For other examples, the nearest common ancestor of nodes 2 and 3 is node 10, the nearest common ancestor of nodes 6 and 13 is node 8, and the nearest common ancestor of nodes 4 and 12 is node 4. In the last example, if y is an ancestor of z, then the nearest common ancestor of y and z is y.
Write a program that finds the nearest common ancestor of two distinct nodes in a tree.
Input
The input consists of T test cases. The number of test cases (T) is given in the first line of the input file. Each test case starts with a line containing an integer N , the number of nodes in a tree, 2<=N<=10,000. The nodes are labeled with integers 1, 2,..., N. Each of the next N -1 lines contains a pair of integers that represent an edge --the first integer is the parent node of the second integer. Note that a tree with N nodes has exactly N - 1 edges. The last line of each test case contains two distinct integers whose nearest common ancestor is to be computed.
Output
Print exactly one line for each test case. The line should contain the integer that is the nearest common ancestor.
Sample Input
2 16 1 14 8 5 10 16 5 9 4 6 8 4 4 10 1 13 6 15 10 11 6 7 10 2 16 3 8 1 16 12 16 7 5 2 3 3 4 3 1 1 5 3 5
Sample Output
4 3
题意:
给出 T 组 case,输入 N(2 ~ 10000),代表有 N 个结点,后输入 N -1 条边,最后询问 a 和 b 的最近公共祖先。
思路:
LCA。DFS + 并查集的离线算法。不需要保存每个节点对的最近公共祖先,只需要保存需要询问的结果就好了。建图的时候建成单向边,故 DFS 的时要找到根节点才开始往下。
AC:
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <vector>
using namespace std;
const int VMAX = 10005;
int n, f ,t, res;
int ind[VMAX], root[VMAX];
vector<int> G[VMAX];
void init () {
for (int i = 1; i <= n; ++i) {
ind[i] = 0;
root[i] = -1;
G[i].clear();
}
}
int Find (int x) {
return x == root[x] ? x : root[x] = Find(root[x]);
}
void dfs (int u) {
root[u] = u;
for (int i = 0; i < G[u].size(); ++i) {
int v = G[u][i];
dfs(v);
root[ Find(v) ] = Find(u);
}
if (u == f && root[t] != -1) res = Find(t);
else if (u == t && root[f] != -1) res = Find(f);
}
int main() {
int T;
scanf("%d", &T);
while (T--) {
scanf("%d", &n);
init();
for (int i = 1; i <= n - 1; ++i) {
int a, b;
scanf("%d%d", &a, &b);
G[a].push_back(b);
++ind[b];
}
scanf("%d%d", &f, &t);
for (int i = 1; i <= n; ++i) {
if (!ind[i]) dfs(i);
}
printf("%d\n", res);
}
return 0;
}



相关推荐
KNN(K-Nearest Neighbors, K近邻算法)是机器学习中一种经典的监督学习算法,常用于分类和回归问题。其基本思想可以通过一句俗语概括——“近朱者赤,近墨者黑”,即根据目标数据点附近的样本来决定其类别或值。KNN...
K近邻(K-Nearest Neighbors, KNN)算法,并用python代码举例
K邻近算法(K-Nearest Neighbour,KNN)** KNN是一种基于实例的学习,也是监督学习中的非参数方法。它的基本思想是:对于未知类别的数据点,我们将其分类到与其最接近的K个已知类别数据点的多数类别中。这个“最...
KNN(K-最近邻,K-Nearest Neighbors)是一种简单而强大的机器学习算法,主要应用于分类任务。在Java编程环境下,KNN算法的实现是数据挖掘和机器学习领域中常见的需求。本篇文章将详细解释KNN算法的原理、步骤以及...
最邻近规则分类(K-Nearest Neighbor,简称KNN)是机器学习领域中最基础的算法之一,尤其在监督学习中扮演着重要角色。KNN算法应用广泛,尤其是在分类问题中,例如图像识别、文本分类等。这个压缩包文件可能包含了...
KNN(K-Nearest Neighbors)算法,即K最近邻算法,是一种基本且广泛使用的监督学习算法,主要用于分类和回归问题。它的核心思想是通过测量不同特征点之间的距离来进行分类或回归。 KNN(K-Nearest Neighbors)算法...
图像线性插值算法的汇总,VS2008工程,可编译,设置不同参数可以使用不同算法进行bmp图像的插值放大,可选放大算法包括: nearest nearest neighbor (pixel duplication) bilinear standard bilinear interpolation ...
4.1 最邻近规则分类(K-Nearest Neighbor)KNN算法
K近邻(K-Nearest Neighbors, KNN)算法既可处理分类问题,也可处理回归问题,其中分类和回归的主要区别在于最后做预测时的决策方式不同。KNN做分类预测时一般采用多数表决法,即训练集里和预测样本特征最近的K个样本...
knn算法实现鸢尾花分类在上面的代码中,我们首先使用`load_iris`函数加载鸢尾花数据集,并将特征数据存储在`X`数组中,将标签存储在`y`数组中。然后,通过`train_test_split`函数将数据集划分为训练集和测试集,其中...
K近邻(K-Nearest Neighbors, KNN)算法既可处理分类问题,也可处理回归问题,其中分类和回归的主要区别在于最后做预测时的决策方式不同。KNN做回归预测时一般采用平均法,预测结果为最近的K个样本数据的平均值。
4.2 最邻近规则分类(K-Nearest Neighbor)KNN算法应用
《深度学习中的K-最近邻(K-Nearest Neighbor,KNN)算法详解》 K-最近邻(K-Nearest Neighbor,KNN)算法是机器学习领域中最基础且直观的分类方法之一,尤其在非参数学习中占有重要地位。KNN算法基于实例的学习,...
k-最近邻(k-Nearest Neighbors, 简称k-NN)算法是一种基础且重要的机器学习方法,主要用于分类和回归问题。在给定一个未知类别的数据点时,k-NN算法会根据其特征,找出训练集中与该数据点最接近的k个已知类别数据点...
近似最近邻(Approximate Nearest Neighbors, ANN)算法在机器学习和数据挖掘领域中占有重要地位,特别是在大数据和高维度空间的处理上。它是一种用于查找数据集中与给定查询点最相似(或最接近)点的有效方法。在传统...
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。 kNN算法的核心思想是...
使用K近邻算法进行聚类。
C#,机器学习的KNN(K Nearest Neighbour)算法与源代码 KNN(K- Nearest Neighbor)法即K最邻近法,最初由 Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路非常...
K近邻(K-Nearest Neighbor,简称KNN)算法是机器学习领域中最基础且重要的分类算法之一。它基于实例学习,通过查找训练集中与待分类样本最接近的K个邻居,依据邻居的类别进行投票,从而决定待分类样本的类别归属。...
K-近邻算法(K Nearest Neighbor,KNN)是一种基本分类与回归方法。在机器学习领域,KNN算法的核心思想是通过测量不同特征值之间的距离来进行分类。基于输入样本与样本集中已知类别的样本之间的距离,将其归类于最近...