
1.┬ĀLRU
1.1.┬ĀÕĤńÉå
LRU’╝łLeast┬Ārecently┬Āused’╝īµ£ĆĶ┐æµ£ĆÕ░æõĮ┐ńö©’╝ēń«Śµ│ĢµĀ╣µŹ«µĢ░µŹ«ńÜäÕÄåÕÅ▓Ķ«┐ķŚ«Ķ«░ÕĮĢµØźĶ┐øĶĪīµĘśµ▒░µĢ░µŹ«’╝īÕģȵĀĖÕ┐āµĆصā│µś»ŌĆ£Õ”éµ×£µĢ░µŹ«µ£ĆĶ┐æĶó½Ķ«┐ķŚ«Ķ┐ć’╝īķéŻõ╣łÕ░åµØźĶó½Ķ«┐ķŚ«ńÜäÕćĀńÄćõ╣¤µø┤ķ½śŌĆØŃĆé
1.2.┬ĀÕ«×ńÄ░
µ£ĆÕĖĖĶ¦üńÜäÕ«×ńÄ░µś»õĮ┐ńö©õĖĆõĖ¬ķōŠĶĪ©õ┐ØÕŁśń╝ōÕŁśµĢ░µŹ«’╝īĶ»”ń╗åń«Śµ│ĢÕ«×ńÄ░Õ”éõĖŗ’╝Ü
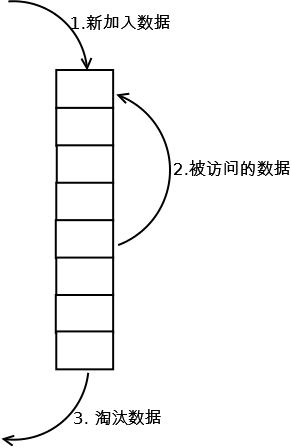
1.┬Āµ¢░µĢ░µŹ«µÅÆÕģźÕł░ķōŠĶĪ©Õż┤ķā©’╝ø
2.┬Āµ»ÅÕĮōń╝ōÕŁśÕæĮõĖŁ’╝łÕŹ│ń╝ōÕŁśµĢ░µŹ«Ķó½Ķ«┐ķŚ«’╝ē’╝īÕłÖÕ░åµĢ░µŹ«ń¦╗Õł░ķōŠĶĪ©Õż┤ķā©’╝ø
3.┬ĀÕĮōķōŠĶĪ©µ╗ĪńÜ䵌ČÕĆÖ’╝īÕ░åķōŠĶĪ©Õ░Šķā©ńÜäµĢ░µŹ«õĖóÕ╝āŃĆé
1.3.┬ĀÕłåµ×É
ŃĆÉÕæĮõĖŁńÄćŃĆæ
ÕĮōÕŁśÕ£©ńāŁńé╣µĢ░µŹ«µŚČ’╝īLRUńÜäµĢłńÄćÕŠłÕźĮ’╝īõĮåÕüČÕÅæµĆ¦ńÜäŃĆüÕ橵£¤µĆ¦ńÜäµē╣ķćŵōŹõĮ£õ╝ÜÕ»╝Ķć┤LRUÕæĮõĖŁńÄćµĆźÕē¦õĖŗķÖŹ’╝īń╝ōÕŁśµ▒Īµ¤ōµāģÕåĄµ»öĶŠāõĖźķćŹŃĆé
ŃĆÉÕżŹµØéÕ║”ŃĆæ
Õ«×ńÄ░ń«ĆÕŹĢŃĆé
ŃĆÉõ╗Żõ╗ĘŃĆæ
ÕæĮõĖŁµŚČķ£ĆĶ”üķüŹÕÄåķōŠĶĪ©’╝īµēŠÕł░ÕæĮõĖŁńÜäµĢ░µŹ«ÕØŚń┤óÕ╝Ģ’╝īńäČÕÉÄķ£ĆĶ”üÕ░åµĢ░µŹ«ń¦╗Õł░Õż┤ķā©ŃĆé
┬Ā
2.┬ĀLRU-K’╝łµÅÅĶ┐░µ£ēĶ»»’╝īĶ»ĘÕŗ┐ÕÅéĶĆā’╝ē
2.1.┬ĀÕĤńÉå
LRU-KõĖŁńÜäKõ╗ŻĶĪ©µ£ĆĶ┐æõĮ┐ńö©ńÜäµ¼ĪµĢ░’╝īÕøĀµŁżLRUÕÅ»õ╗źĶ«żõĖ║µś»LRU-1ŃĆéLRU-KńÜäõĖ╗Ķ”üńø«ńÜ䵜»õĖ║õ║åĶ¦ŻÕå│LRUń«Śµ│ĢŌĆ£ń╝ōÕŁśµ▒Īµ¤ōŌĆØńÜäķŚ«ķóś’╝īÕģȵĀĖÕ┐āµĆصā│µś»Õ░åŌĆ£µ£ĆĶ┐æõĮ┐ńö©Ķ┐ć1µ¼ĪŌĆØńÜäÕłżµ¢ŁµĀćÕćåµē®Õ▒ĢõĖ║ŌĆ£µ£ĆĶ┐æõĮ┐ńö©Ķ┐ćKµ¼ĪŌĆØŃĆé
2.2.┬ĀÕ«×ńÄ░
ńøĖµ»öLRU’╝īLRU-Kķ£ĆĶ”üÕżÜń╗┤µŖżõĖĆõĖ¬ķś¤ÕłŚ’╝īńö©õ║ÄĶ«░ÕĮĢµēƵ£ēń╝ōÕŁśµĢ░µŹ«Ķó½Ķ«┐ķŚ«ńÜäÕÄåÕÅ▓ŃĆéÕŬµ£ēÕĮōµĢ░µŹ«ńÜäĶ«┐ķŚ«µ¼ĪµĢ░ĶŠŠÕł░Kµ¼ĪńÜ䵌ČÕĆÖ’╝īµēŹÕ░åµĢ░µŹ«µöŠÕģźń╝ōÕŁśŃĆéÕĮōķ£ĆĶ”üµĘśµ▒░µĢ░µŹ«µŚČ’╝īLRU-Kõ╝ܵʜµ▒░ń¼¼Kµ¼ĪĶ«┐ķŚ«µŚČķŚ┤ĶĘØÕĮōÕēŹµŚČķŚ┤µ£ĆÕż¦ńÜäµĢ░µŹ«ŃĆéĶ»”ń╗åÕ«×ńÄ░Õ”éõĖŗ’╝Ü
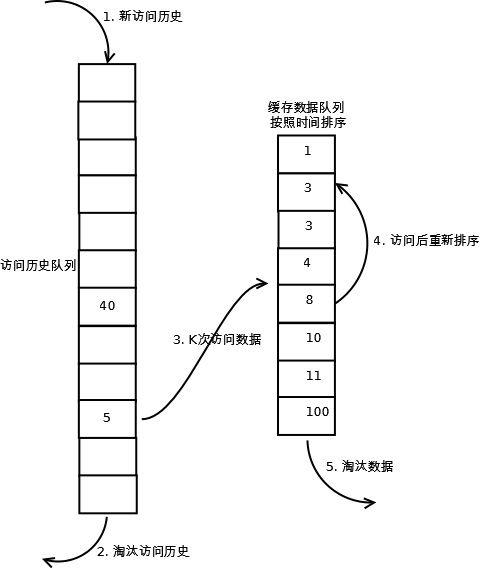
1.┬ĀµĢ░µŹ«ń¼¼õĖƵ¼ĪĶó½Ķ«┐ķŚ«’╝īÕŖĀÕģźÕł░Ķ«┐ķŚ«ÕÄåÕÅ▓ÕłŚĶĪ©’╝ø
2.┬ĀÕ”éµ×£µĢ░µŹ«Õ£©Ķ«┐ķŚ«ÕÄåÕÅ▓ÕłŚĶĪ©ķćīÕÉĵ▓Īµ£ēĶŠŠÕł░Kµ¼ĪĶ«┐ķŚ«’╝īÕłÖµīēńģ¦õĖĆÕ«ÜĶ¦äÕłÖ’╝łFIFO’╝īLRU’╝ēµĘśµ▒░’╝ø
3.┬ĀÕĮōĶ«┐ķŚ«ÕÄåÕÅ▓ķś¤ÕłŚõĖŁńÜäµĢ░µŹ«Ķ«┐ķŚ«µ¼ĪµĢ░ĶŠŠÕł░Kµ¼ĪÕÉÄ’╝īÕ░åµĢ░µŹ«ń┤óÕ╝Ģõ╗ÄÕÄåÕÅ▓ķś¤ÕłŚÕłĀķÖż’╝īÕ░åµĢ░µŹ«ń¦╗Õł░ń╝ōÕŁśķś¤ÕłŚõĖŁ’╝īÕ╣Čń╝ōÕŁśµŁżµĢ░µŹ«’╝īń╝ōÕŁśķś¤ÕłŚķ揵¢░µīēńģ¦µŚČķŚ┤µÄÆÕ║Å’╝ø
4.┬Āń╝ōÕŁśµĢ░µŹ«ķś¤ÕłŚõĖŁĶó½ÕåŹµ¼ĪĶ«┐ķŚ«ÕÉÄ’╝īķ揵¢░µÄÆÕ║Å’╝ø
5.┬Āķ£ĆĶ”üµĘśµ▒░µĢ░µŹ«µŚČ’╝īµĘśµ▒░ń╝ōÕŁśķś¤ÕłŚõĖŁµÄÆÕ£©µ£½Õ░ŠńÜäµĢ░µŹ«’╝īÕŹ│’╝ܵʜµ▒░ŌĆ£ÕĆƵĢ░ń¼¼Kµ¼ĪĶ«┐ķŚ«ń”╗ńÄ░Õ£©µ£Ćõ╣ģŌĆØńÜäµĢ░µŹ«ŃĆé
LRU-KÕģʵ£ēLRUńÜäõ╝śńé╣’╝īÕÉīµŚČĶāĮÕż¤ķü┐ÕģŹLRUńÜäń╝║ńé╣’╝īÕ«×ķÖģÕ║öńö©õĖŁLRU-2µś»ń╗╝ÕÉłÕÉäń¦ŹÕøĀń┤ĀÕÉĵ£Ćõ╝śńÜäķĆēµŗ®’╝īLRU-3µł¢ĶĆģµø┤Õż¦ńÜäKÕĆ╝ÕæĮõĖŁńÄćõ╝Üķ½ś’╝īõĮåķĆéÕ║öµĆ¦ÕĘ«’╝īķ£ĆĶ”üÕż¦ķćÅńÜäµĢ░µŹ«Ķ«┐ķŚ«µēŹĶāĮÕ░åÕÄåÕÅ▓Ķ«┐ķŚ«Ķ«░ÕĮĢµĖģķÖżµÄēŃĆé
2.3.┬ĀÕłåµ×É
ŃĆÉÕæĮõĖŁńÄćŃĆæ
LRU-KķÖŹõĮÄõ║åŌĆ£ń╝ōÕŁśµ▒Īµ¤ōŌĆØÕĖ”µØźńÜäķŚ«ķóś’╝īÕæĮõĖŁńÄćµ»öLRUĶ”üķ½śŃĆé
ŃĆÉÕżŹµØéÕ║”ŃĆæ
LRU-Kķś¤ÕłŚµś»õĖĆõĖ¬õ╝śÕģłń║¦ķś¤ÕłŚ’╝īń«Śµ│ĢÕżŹµØéÕ║”ÕÆīõ╗Żõ╗ʵ»öĶŠāķ½śŃĆé
ŃĆÉõ╗Żõ╗ĘŃĆæ
ńö▒õ║ÄLRU-KĶ┐śķ£ĆĶ”üĶ«░ÕĮĢķéŻõ║øĶó½Ķ«┐ķŚ«Ķ┐ćŃĆüõĮåĶ┐śµ▓Īµ£ēµöŠÕģźń╝ōÕŁśńÜäÕ»╣Ķ▒Ī’╝īÕøĀµŁżÕåģÕŁśµČłĶĆŚõ╝ܵ»öLRUĶ”üÕżÜ’╝øÕĮōµĢ░µŹ«ķćÅÕŠłÕż¦ńÜ䵌ČÕĆÖ’╝īÕåģÕŁśµČłĶĆŚõ╝ܵ»öĶŠāÕÅ»Ķ¦éŃĆé
LRU-Kķ£ĆĶ”üÕ¤║õ║ĵŚČķŚ┤Ķ┐øĶĪīµÄÆÕ║Å’╝łÕÅ»õ╗źķ£ĆĶ”üµĘśµ▒░µŚČÕåŹµÄÆÕ║Å’╝īõ╣¤ÕÅ»õ╗źÕŹ│µŚČµÄÆÕ║Å’╝ē’╝īCPUµČłĶĆŚµ»öLRUĶ”üķ½śŃĆé
3.┬ĀTwo┬Āqueues’╝ł2Q’╝ē
3.1.┬ĀÕĤńÉå
Two┬Āqueues’╝łõ╗źõĖŗõĮ┐ńö©2Qõ╗Żµø┐’╝ēń«Śµ│Ģń▒╗õ╝╝õ║ÄLRU-2’╝īõĖŹÕÉīńé╣Õ£©õ║Ä2QÕ░åLRU-2ń«Śµ│ĢõĖŁńÜäĶ«┐ķŚ«ÕÄåÕÅ▓ķś¤ÕłŚ’╝łµ│©µäÅĶ┐ÖõĖŹµś»ń╝ōÕŁśµĢ░µŹ«ńÜä’╝ēµö╣õĖ║õĖĆõĖ¬FIFOń╝ōÕŁśķś¤ÕłŚ’╝īÕŹ│’╝Ü2Qń«Śµ│Ģµ£ēõĖżõĖ¬ń╝ōÕŁśķś¤ÕłŚ’╝īõĖĆõĖ¬µś»FIFOķś¤ÕłŚ’╝īõĖĆõĖ¬µś»LRUķś¤ÕłŚŃĆé
3.2.┬ĀÕ«×ńÄ░
ÕĮōµĢ░µŹ«ń¼¼õĖƵ¼ĪĶ«┐ķŚ«µŚČ’╝ī2Qń«Śµ│ĢÕ░åµĢ░µŹ«ń╝ōÕŁśÕ£©FIFOķś¤ÕłŚķćīķØó’╝īÕĮōµĢ░µŹ«ń¼¼õ║īµ¼ĪĶó½Ķ«┐ķŚ«µŚČ’╝īÕłÖÕ░åµĢ░µŹ«õ╗ÄFIFOķś¤ÕłŚń¦╗Õł░LRUķś¤ÕłŚķćīķØó’╝īõĖżõĖ¬ķś¤ÕłŚÕÉäĶ欵īēńģ¦Ķć¬ÕĘ▒ńÜäµ¢╣µ│ĢµĘśµ▒░µĢ░µŹ«ŃĆéĶ»”ń╗åÕ«×ńÄ░Õ”éõĖŗ’╝Ü
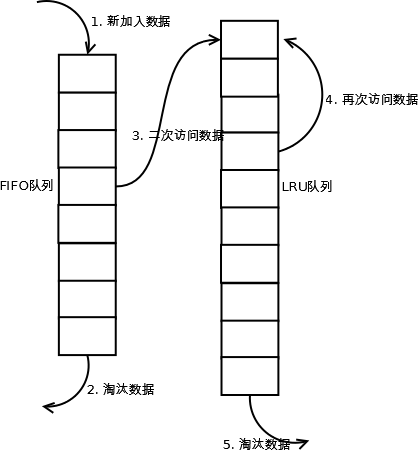
1.┬Āµ¢░Ķ«┐ķŚ«ńÜäµĢ░µŹ«µÅÆÕģźÕł░FIFOķś¤ÕłŚ’╝ø
2.┬ĀÕ”éµ×£µĢ░µŹ«Õ£©FIFOķś¤ÕłŚõĖŁõĖĆńø┤µ▓Īµ£ēĶó½ÕåŹµ¼ĪĶ«┐ķŚ«’╝īÕłÖµ£Ćń╗łµīēńģ¦FIFOĶ¦äÕłÖµĘśµ▒░’╝ø
3.┬ĀÕ”éµ×£µĢ░µŹ«Õ£©FIFOķś¤ÕłŚõĖŁĶó½ÕåŹµ¼ĪĶ«┐ķŚ«’╝īÕłÖÕ░åµĢ░µŹ«ń¦╗Õł░LRUķś¤ÕłŚÕż┤ķā©’╝ø
4.┬ĀÕ”éµ×£µĢ░µŹ«Õ£©LRUķś¤ÕłŚÕåŹµ¼ĪĶó½Ķ«┐ķŚ«’╝īÕłÖÕ░åµĢ░µŹ«ń¦╗Õł░LRUķś¤ÕłŚÕż┤ķā©’╝ø
5.┬ĀLRUķś¤ÕłŚµĘśµ▒░µ£½Õ░ŠńÜäµĢ░µŹ«ŃĆé
┬Ā
µ│©’╝ÜõĖŖÕøŠõĖŁFIFOķś¤ÕłŚµ»öLRUķś¤ÕłŚń¤Ł’╝īõĮåÕ╣ČõĖŹõ╗ŻĶĪ©Ķ┐Öµś»ń«Śµ│ĢĶ”üµ▒é’╝īÕ«×ķÖģÕ║öńö©õĖŁõĖżĶĆģµ»öõŠŗµ▓Īµ£ēńĪ¼µĆ¦Ķ¦äÕ«ÜŃĆé
3.3.┬ĀÕłåµ×É
ŃĆÉÕæĮõĖŁńÄćŃĆæ
2Qń«Śµ│ĢńÜäÕæĮõĖŁńÄćĶ”üķ½śõ║ÄLRUŃĆé
ŃĆÉÕżŹµØéÕ║”ŃĆæ
ķ£ĆĶ”üõĖżõĖ¬ķś¤ÕłŚ’╝īõĮåõĖżõĖ¬ķś¤ÕłŚµ£¼Ķ║½ķāĮµ»öĶŠāń«ĆÕŹĢŃĆé
ŃĆÉõ╗Żõ╗ĘŃĆæ
FIFOÕÆīLRUńÜäõ╗Żõ╗Ęõ╣ŗÕÆīŃĆé
2Qń«Śµ│ĢÕÆīLRU-2ń«Śµ│ĢÕæĮõĖŁńÄćń▒╗õ╝╝’╝īÕåģÕŁśµČłĶĆŚõ╣¤µ»öĶŠāµÄźĶ┐æ’╝īõĮåÕ»╣õ║ĵ£ĆÕÉÄń╝ōÕŁśńÜäµĢ░µŹ«µØźĶ»┤’╝ī2Qõ╝ÜÕćÅÕ░æõĖƵ¼Īõ╗ÄÕĤզŗÕŁśÕé©Ķ»╗ÕÅ¢µĢ░µŹ«µł¢ĶĆģĶ«Īń«ŚµĢ░µŹ«ńÜäµōŹõĮ£ŃĆé
4.┬ĀMulti┬ĀQueue’╝łMQ’╝ē
4.1.┬ĀÕĤńÉå
MQń«Śµ│ĢµĀ╣µŹ«Ķ«┐ķŚ«ķóæńÄćÕ░åµĢ░µŹ«ÕłÆÕłåõĖ║ÕżÜõĖ¬ķś¤ÕłŚ’╝īõĖŹÕÉīńÜäķś¤ÕłŚÕģʵ£ēõĖŹÕÉīńÜäĶ«┐ķŚ«õ╝śÕģłń║¦’╝īÕģȵĀĖÕ┐āµĆصā│µś»’╝Üõ╝śÕģłń╝ōÕŁśĶ«┐ķŚ«µ¼ĪµĢ░ÕżÜńÜäµĢ░µŹ«ŃĆé
4.2.┬ĀÕ«×ńÄ░
MQń«Śµ│ĢÕ░åń╝ōÕŁśÕłÆÕłåõĖ║ÕżÜõĖ¬LRUķś¤ÕłŚ’╝īµ»ÅõĖ¬ķś¤ÕłŚÕ»╣Õ║öõĖŹÕÉīńÜäĶ«┐ķŚ«õ╝śÕģłń║¦ŃĆéĶ«┐ķŚ«õ╝śÕģłń║¦µś»µĀ╣µŹ«Ķ«┐ķŚ«µ¼ĪµĢ░Ķ«Īń«ŚÕć║µØźńÜä’╝īõŠŗÕ”é
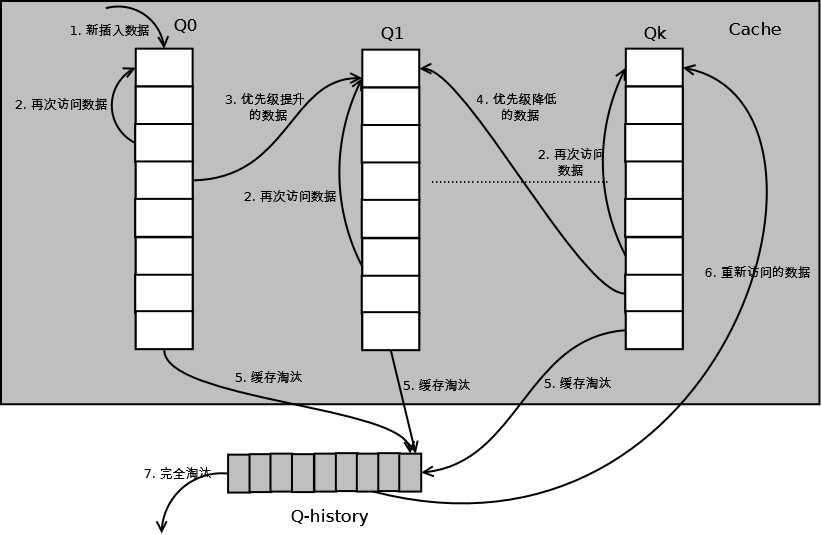
Ķ»”ń╗åńÜäń«Śµ│Ģń╗ōµ×äÕøŠÕ”éõĖŗ’╝īQ0’╝īQ1....Qkõ╗ŻĶĪ©õĖŹÕÉīńÜäõ╝śÕģłń║¦ķś¤ÕłŚ’╝īQ-historyõ╗ŻĶĪ©õ╗Äń╝ōÕŁśõĖŁµĘśµ▒░µĢ░µŹ«’╝īõĮåĶ«░ÕĮĢõ║åµĢ░µŹ«ńÜäń┤óÕ╝ĢÕÆīÕ╝Ģńö©µ¼ĪµĢ░ńÜäķś¤ÕłŚ’╝Ü
┬Ā
Õ”éõĖŖÕøŠ’╝īń«Śµ│ĢĶ»”ń╗åµÅÅĶ┐░Õ”éõĖŗ’╝Ü
1.┬Āµ¢░µÅÆÕģźńÜäµĢ░µŹ«µöŠÕģźQ0’╝ø
2.┬Āµ»ÅõĖ¬ķś¤ÕłŚµīēńģ¦LRUń«ĪńÉåµĢ░µŹ«’╝ø
3.┬ĀÕĮōµĢ░µŹ«ńÜäĶ«┐ķŚ«µ¼ĪµĢ░ĶŠŠÕł░õĖĆիܵ¼ĪµĢ░’╝īķ£ĆĶ”üµÅÉÕŹćõ╝śÕģłń║¦µŚČ’╝īÕ░åµĢ░µŹ«õ╗ÄÕĮōÕēŹķś¤ÕłŚÕłĀķÖż’╝īÕŖĀÕģźÕł░ķ½śõĖĆń║¦ķś¤ÕłŚńÜäÕż┤ķā©’╝ø
4.┬ĀõĖ║õ║åķś▓µŁóķ½śõ╝śÕģłń║¦µĢ░µŹ«µ░ĖĶ┐£õĖŹĶó½µĘśµ▒░’╝īÕĮōµĢ░µŹ«Õ£©µīćÕ«ÜńÜ䵌ČķŚ┤ķćīĶ«┐ķŚ«µ▓Īµ£ēĶó½Ķ«┐ķŚ«µŚČ’╝īķ£ĆĶ”üķÖŹõĮÄõ╝śÕģłń║¦’╝īÕ░åµĢ░µŹ«õ╗ÄÕĮōÕēŹķś¤ÕłŚÕłĀķÖż’╝īÕŖĀÕģźÕł░õĮÄõĖĆń║¦ńÜäķś¤ÕłŚÕż┤ķā©’╝ø
5.┬Āķ£ĆĶ”üµĘśµ▒░µĢ░µŹ«µŚČ’╝īõ╗ĵ£ĆõĮÄõĖĆń║¦ķś¤ÕłŚÕ╝ĆÕ¦ŗµīēńģ¦LRUµĘśµ▒░’╝øµ»ÅõĖ¬ķś¤ÕłŚµĘśµ▒░µĢ░µŹ«µŚČ’╝īÕ░åµĢ░µŹ«õ╗Äń╝ōÕŁśõĖŁÕłĀķÖż’╝īÕ░åµĢ░µŹ«ń┤óÕ╝ĢÕŖĀÕģźQ-historyÕż┤ķā©’╝ø
6.┬ĀÕ”éµ×£µĢ░µŹ«Õ£©Q-historyõĖŁĶó½ķ揵¢░Ķ«┐ķŚ«’╝īÕłÖķ揵¢░Ķ«Īń«ŚÕģČõ╝śÕģłń║¦’╝īń¦╗Õł░ńø«µĀćķś¤ÕłŚńÜäÕż┤ķā©’╝ø
7.┬ĀQ-historyµīēńģ¦LRUµĘśµ▒░µĢ░µŹ«ńÜäń┤óÕ╝ĢŃĆé
4.3.┬ĀÕłåµ×É
ŃĆÉÕæĮõĖŁńÄćŃĆæ
MQķÖŹõĮÄõ║åŌĆ£ń╝ōÕŁśµ▒Īµ¤ōŌĆØÕĖ”µØźńÜäķŚ«ķóś’╝īÕæĮõĖŁńÄćµ»öLRUĶ”üķ½śŃĆé
ŃĆÉÕżŹµØéÕ║”ŃĆæ
MQķ£ĆĶ”üń╗┤µŖżÕżÜõĖ¬ķś¤ÕłŚ’╝īõĖöķ£ĆĶ”üń╗┤µŖżµ»ÅõĖ¬µĢ░µŹ«ńÜäĶ«┐ķŚ«µŚČķŚ┤’╝īÕżŹµØéÕ║”µ»öLRUķ½śŃĆé
ŃĆÉõ╗Żõ╗ĘŃĆæ
MQķ£ĆĶ”üĶ«░ÕĮĢµ»ÅõĖ¬µĢ░µŹ«ńÜäĶ«┐ķŚ«µŚČķŚ┤’╝īķ£ĆĶ”üիܵŚČµē½µÅŵēƵ£ēķś¤ÕłŚ’╝īõ╗Żõ╗ʵ»öLRUĶ”üķ½śŃĆé
µ│©’╝ÜĶÖĮńäČMQńÜäķś¤ÕłŚń£ŗĶĄĘµØźµĢ░ķćŵ»öĶŠāÕżÜ’╝īõĮåńö▒õ║ĵēƵ£ēķś¤ÕłŚõ╣ŗÕÆīÕÅŚķÖÉõ║Äń╝ōÕŁśÕ«╣ķćÅńÜäÕż¦Õ░Å’╝īÕøĀµŁżĶ┐ÖķćīÕżÜõĖ¬ķś¤ÕłŚķĢ┐Õ║”õ╣ŗÕÆīÕÆīõĖĆõĖ¬LRUķś¤ÕłŚµś»õĖƵĀĘńÜä’╝īÕøĀµŁżķś¤ÕłŚµē½µÅÅµĆ¦ĶāĮõ╣¤ńøĖĶ┐æŃĆé
┬Ā
5.┬ĀLRUń▒╗ń«Śµ│ĢÕ»╣µ»ö
ńö▒õ║ÄõĖŹÕÉīńÜäĶ«┐ķŚ«µ©ĪÕ×ŗÕ»╝Ķć┤ÕæĮõĖŁńÄćÕÅśÕī¢ĶŠāÕż¦’╝īµŁżÕżäÕ»╣µ»öõ╗ģÕ¤║õ║ÄńÉåĶ«║Õ«ÜµĆ¦Õłåµ×É’╝īõĖŹÕüÜÕ«ÜķćÅÕłåµ×ÉŃĆé
|
Õ»╣µ»öńé╣ |
Õ»╣µ»ö |
|
ÕæĮõĖŁńÄć |
LRU-2┬Ā>┬ĀMQ(2)┬Ā>┬Ā2Q┬Ā>┬ĀLRU |
|
ÕżŹµØéÕ║” |
LRU-2┬Ā>┬ĀMQ(2)┬Ā>┬Ā2Q┬Ā>┬ĀLRU |
|
õ╗Żõ╗Ę |
LRU-2┬Ā┬Ā>┬ĀMQ(2)┬Ā>┬Ā2Q┬Ā>┬ĀLRU |
Õ«×ķÖģÕ║öńö©õĖŁķ£ĆĶ”üµĀ╣µŹ«õĖÜÕŖĪńÜäķ£Ćµ▒éÕÆīÕ»╣µĢ░µŹ«ńÜäĶ«┐ķŚ«µāģÕåĄĶ┐øĶĪīķĆēµŗ®’╝īÕ╣ČõĖŹµś»ÕæĮõĖŁńÄćĶČŖķ½śĶČŖÕźĮŃĆéõŠŗÕ”é’╝ÜĶÖĮńäČLRUń£ŗĶĄĘµØźÕæĮõĖŁńÄćõ╝ÜõĮÄõĖĆõ║ø’╝īõĖöÕŁśÕ£©ŌĆØń╝ōÕŁśµ▒Īµ¤ōŌĆ£ńÜäķŚ«ķóś’╝īõĮåńö▒õ║ÄÕģČń«ĆÕŹĢÕÆīõ╗Żõ╗ĘÕ░Å’╝īÕ«×ķÖģÕ║öńö©õĖŁÕÅŹĶĆīÕ║öńö©µø┤ÕżÜŃĆé
┬Ā
µØźµ║É’╝Ühttp://blog.csdn.net/yunhua_lee/article/details/7599671



ńøĖÕģ│µÄ©ĶŹÉ
ń╝ōÕŁśµĘśµ▒░ń«Śµ│Ģõ╣ŗ LRU ń╝ōÕŁśµĘśµ▒░ń«Śµ│Ģµś»µīćÕ£©Ķ«Īń«Śµ£║ń│╗ń╗¤õĖŁ’╝īõĖ║õ║åµÅÉķ½śń╝ōÕŁśÕæĮõĖŁńÄćÕÆīÕćÅÕ░æń╝ōÕŁś pollution ĶĆīķććńö©ńÜäń«Śµ│ĢŃĆéÕģČõĖŁ’╝īLRU’╝łLeast Recently Used’╝īµ£ĆĶ┐æµ£ĆÕ░æõĮ┐ńö©’╝ēń«Śµ│Ģµś»õĖĆń¦ŹÕĖĖńö©ńÜäń╝ōÕŁśµĘśµ▒░ń«Śµ│ĢŃĆé 1. LRU ń«Śµ│ĢÕĤńÉå ...
Ķ┐Öõ║øń╝ōÕŁśµĘśµ▒░ń«Śµ│ĢÕÉäµ£ēõ╝śÕŖŻ’╝īLRU Õ«×ńÄ░ń«ĆÕŹĢõĮåÕÅ»ĶāĮÕÅŚÕł░µē╣ķćŵōŹõĮ£ńÜäÕĮ▒ÕōŹ’╝īLRU-K µÅÉķ½śõ║åÕæĮõĖŁńÄćõĮåµłÉµ£¼ĶŠāķ½ś’╝ī2Q Õ£©õĖżĶĆģõ╣ŗķŚ┤µēŠÕł░õ║åÕ╣│ĶĪĪ’╝īĶĆī MQ ÕłÖµÅÉõŠøõ║åµø┤ńüĄµ┤╗ńÜäńŁ¢ńĢźõ╗źķĆéÕ║öõĖŹÕÉīÕ£║µÖ»ńÜäķ£Ćµ▒éŃĆéķĆēµŗ®Õō¬ń¦Źń«Śµ│ĢÕÅ¢Õå│õ║ÄÕģĘõĮōńÜäÕ║öńö©Õ£║µÖ»...
ń╗╝õĖŖµēĆĶ┐░’╝īõĖŹÕÉīńÜäń╝ōÕŁśµĘśµ▒░ń«Śµ│ĢÕÉäµ£ēõ╝śÕŖŻ’╝īķĆēµŗ®Õō¬ń¦Źń«Śµ│ĢÕÅ¢Õå│õ║ÄÕģĘõĮōńÜäÕ║öńö©Õ£║µÖ»ÕÆīĶĄäµ║ÉķÖÉÕłČŃĆéLRUķĆéÕÉłń«ĆÕŹĢÕ┐½ķƤńÜäÕ«×ńÄ░’╝ī2QÕ£©µĆ¦ĶāĮÕÆīÕżŹµØéÕ║”õ╣ŗķŚ┤µēŠÕł░õ║åÕ╣│ĶĪĪ’╝īĶĆīLRU-KÕÆīMQÕłÖµÅÉõŠøõ║åµø┤ķ½śńÜäńüĄµ┤╗µĆ¦ÕÆīÕæĮõĖŁńÄć’╝īõĮåõ╗Żõ╗Ęõ╣¤µø┤ķ½śŃĆéÕ£©Õ«×ķÖģ...
LRU’╝łLeast Recently Used’╝ēń╝ōÕŁśµĘśµ▒░ń«Śµ│Ģµś»µĀ╣µŹ«µĢ░µŹ«ńÜäÕÄåÕÅ▓Ķ«┐ķŚ«Ķ«░ÕĮĢµØźÕå│Õ«ÜõĮĢµŚČµĘśµ▒░µĢ░µŹ«ńÜäńŁ¢ńĢźŃĆéÕģȵĀĖÕ┐āńÉåÕ┐Ąµś»ŌĆ£µ£ĆĶ┐æĶó½Ķ«┐ķŚ«Ķ┐ćńÜäµĢ░µŹ«Õ£©µ£¬µØźµø┤µ£ēÕÅ»ĶāĮĶó½ÕåŹµ¼ĪĶ«┐ķŚ«ŌĆØŃĆéLRUń«Śµ│ĢķĆÜÕĖĖķĆÜĶ┐ćķōŠĶĪ©µØźÕ«×ńÄ░’╝īµ¢░µĢ░µŹ«µÅÆÕģźķōŠĶĪ©Õż┤ķā©’╝īµ»Åµ¼Ī...
LRU-Kń«Śµ│Ģµö╣Ķ┐øõ║åLRUńÜäÕæĮõĖŁńÄć’╝īõĮåÕģČÕżŹµØéÕ║”ÕÆīõ╗Żõ╗Ęõ╣¤ķÜÅõ╣ŗÕó×ÕŖĀ’╝īÕøĀõĖ║ķ£ĆĶ”üķóØÕż¢ńÜäń®║ķŚ┤µØźĶ«░ÕĮĢµ£¬ĶŠŠÕł░Kµ¼ĪĶ«┐ķŚ«ńÜäµĢ░µŹ«’╝īÕ╣ČõĖöķ£ĆĶ”üń╗┤µŖżõĖĆõĖ¬õ╝śÕģłń║¦ķś¤ÕłŚŃĆé 2Qń«Śµ│Ģ’╝īÕÅłń¦░õĖ║Two Queues’╝īµś»LRU-2ńÜäõĖĆń¦ŹÕÅśõĮō’╝īÕ«āÕ░åµĢ░µŹ«ÕłåõĖ║FIFOķś¤ÕłŚÕÆī...
ÕĖĖĶ¦üńÜäń╝ōÕŁśµĘśµ▒░ń«Śµ│Ģµ£ēLFUŃĆüLRUŃĆüARCŃĆüFIFOŃĆüMRUńŁēŃĆé 1. µ£ĆõĖŹń╗ÅÕĖĖõĮ┐ńö©ń«Śµ│Ģ’╝łLFU’╝ē’╝ÜLFUń╝ōÕŁśń«Śµ│ĢõĮ┐ńö©õĖĆõĖ¬Ķ«ĪµĢ░ÕÖ©µØźĶ«░ÕĮĢµØĪńø«Ķó½Ķ«┐ķŚ«ńÜäķóæńÄćŃĆéķĆÜĶ┐ćõĮ┐ńö©LFUń╝ōÕŁśń«Śµ│Ģ’╝īµ£ĆõĮÄĶ«┐ķŚ«µĢ░ńÜäµØĪńø«ķ”¢ÕģłĶó½ń¦╗ķÖżŃĆéĶ┐ÖõĖ¬µ¢╣µ│ĢÕ╣ČõĖŹń╗ÅÕĖĖõĮ┐ńö©’╝ī...
### ķōŠĶĪ©Õ£©LRUń╝ōÕŁśµĘśµ▒░ń«Śµ│ĢõĖŁńÜäÕ║öńö© #### LRUń╝ōÕŁśµĘśµ▒░ń«Śµ│Ģń«Ćõ╗ŗ LRU’╝łLeast Recently Used’╝īµ£ĆĶ┐æµ£ĆÕ░æõĮ┐ńö©’╝ēń╝ōÕŁśµĘśµ▒░ń«Śµ│Ģµś»õĖĆń¦ŹÕĖĖńö©ńÜäń╝ōÕŁśń«ĪńÉåńŁ¢ńĢź’╝īńö©õ║ÄĶ¦ŻÕå│ń╝ōÕŁśń®║ķŚ┤µ£ēķÖÉńÜäķŚ«ķóśŃĆéÕĮōń╝ōÕŁśµ╗Īõ║åÕ╣ČõĖöµ¢░ńÜäµĢ░µŹ«ķ£ĆĶ”üÕŖĀÕģźń╝ōÕŁś...
"ķōŠĶĪ©µĢ░µŹ«ń╗ōµ×äõĖÄLRUń╝ōÕŁśµĘśµ▒░ń«Śµ│Ģ" ķōŠĶĪ©µś»õĖĆń¦ŹÕ¤║ńĪĆńÜäµĢ░µŹ«ń╗ōµ×ä’╝īÕ«āÕ╣┐µ│øÕ║öńö©õ║ÄĶĮ»õ╗ČÕ╝ĆÕÅæÕÆīńĪ¼õ╗ČĶ«ŠĶ«ĪõĖŁŃĆéõ╗ŖÕż®µłæõ╗¼Õ░åĶ«©Ķ«║Õ”éõĮĢõĮ┐ńö©ķōŠĶĪ©µØźÕ«×ńÄ░LRUń╝ōÕŁśµĘśµ▒░ń«Śµ│ĢŃĆé ķ”¢Õģł’╝īĶ«®µłæõ╗¼µØźĶ«©Ķ«║ń╝ōÕŁśńÜäµ”éÕ┐ĄŃĆéń╝ōÕŁśµś»õĖĆń¦ŹµÅÉķ½śµĢ░µŹ«Ķ»╗ÕÅ¢µĆ¦ĶāĮ...
ń╝ōÕŁśń«Śµ│Ģ’╝īÕÅłń¦░ń╝ōÕŁśµĘśµ▒░ń«Śµ│Ģ’╝īµś»µīćÕ£©ń╝ōÕŁśÕ«╣ķćÅĶŠŠÕł░õĖŖķÖɵŚČ’╝īńö©õ║ÄÕå│Õ«ÜÕō¬õ║øµĢ░µŹ«Õ║öĶ»źĶó½õ┐ØńĢÖ’╝īÕō¬õ║øµĢ░µŹ«Õ║öĶ»źĶó½µø┐µŹóÕć║ÕÄ╗ńÜäõĖĆń│╗ÕłŚń«Śµ│ĢŃĆéÕĖĖĶ¦üńÜäń╝ōÕŁśń«Śµ│ĢÕīģµŗ¼µ£ĆĶ┐æµ£ĆÕ░æõĮ┐ńö©’╝łLRU’╝ēŃĆüÕģłĶ┐øÕģłÕć║’╝łFIFO’╝ēŃĆüµŚČķƤń«Śµ│Ģ’╝łClock’╝ēńŁēŃĆéĶ┐Öõ║ø...
2. **ķ½śµĆ¦ĶāĮ**’╝ÜķĆÜĶ┐ćńø┤µÄźµōŹõĮ£ÕŁŚÕģĖńÜäÕåģķā©ń╗ōµ×ä’╝īlru-dictÕ«×ńÄ░õ║åĶ┐æõ╣ÄÕĤńö¤ÕŁŚÕģĖńÜäĶ«┐ķŚ«ķƤÕ║”’╝īÕÉīµŚČÕĖ”µ£ēń╝ōÕŁśµĘśµ▒░µ£║ÕłČŃĆé 3. **ń«ĆÕŹĢµśōńö©**’╝ÜÕ«āńÜäAPIĶ«ŠĶ«Īń«Ćµ┤ü’╝īµśōõ║ÄńÉåĶ¦ŻÕÆīķøåµłÉÕł░ķĪ╣ńø«õĖŁ’╝īÕŬķ£ĆÕćĀĶĪīõ╗ŻńĀüÕŹ│ÕŻի×ńÄ░ķ½śµĢłń╝ōÕŁśŃĆé 4. **...
ķōŠĶĪ©’╝łõĖŖ’╝ē’╝ÜÕ”éõĮĢÕ«×ńÄ░ LRU ń╝ōÕŁśµĘśµ▒░ń«Śµ│Ģ’╝¤ ķōŠĶĪ©µś»õĖĆń¦ŹÕ¤║ńĪĆńÜäµĢ░µŹ«ń╗ōµ×ä’╝īÕŁ”õ╣ĀķōŠĶĪ©µ£ēõ╗Ćõ╣łńö©Õæó’╝¤õĖ║õ║åÕø×ńŁöĶ┐ÖõĖ¬ķŚ«ķóś’╝īµłæõ╗¼µØźĶ«©Ķ«║õĖĆõĖ¬ń╗ÅÕģĖńÜäķōŠĶĪ©Õ║öńö©Õ£║µÖ»’╝īķéŻÕ░▒µś» LRU ń╝ōÕŁśµĘśµ▒░ń«Śµ│ĢŃĆéń╝ōÕŁśµś»õĖĆń¦ŹµÅÉķ½śµĢ░µŹ«Ķ»╗ÕÅ¢µĆ¦ĶāĮńÜäµŖƵ£»’╝īÕ£©...
LRU’╝łLeast Recently Used’╝īµ£ĆĶ┐æµ£ĆÕ░æõĮ┐ńö©’╝ēń«Śµ│Ģµś»õĖĆń¦ŹÕĖĖĶ¦üńÜäķĪĄķØóµø┐µŹóńŁ¢ńĢź’╝īÕ╣┐µ│øÕ║öńö©õ║Äń╝ōÕŁśń«ĪńÉåŃĆüÕåģÕŁśĶ░āÕ║”ńŁēķóåÕ¤¤ŃĆéÕ«āńÜäµĀĖÕ┐āµĆصā│µś»õ╝śÕģłµĘśµ▒░ķéŻõ║øµ£ĆķĢ┐µŚČķŚ┤µ▓Īµ£ēĶó½Ķ«┐ķŚ«Ķ┐ćńÜäµĢ░µŹ«’╝īÕüćĶ«Šµ£¬µØźµ£ĆõĖŹÕĖĖõĮ┐ńö©ńÜäµĢ░µŹ«õ╣¤Õ░åń╗¦ń╗ŁõĖŹÕĖĖĶó½...
LRU’╝łLeast Recently Used’╝ēń«Śµ│Ģµś»õĖĆń¦ŹÕĖĖńö©ńÜäķĪĄķØóµø┐µŹóńŁ¢ńĢź’╝īÕ«āÕ¤║õ║ÄŌĆ£µ£ĆĶ┐æµ£ĆÕ░æõĮ┐ńö©ŌĆØńÜäÕÄ¤ÕłÖ’╝īÕŹ│ÕĮōÕåģÕŁśń®║ķŚ┤õĖŹĶČ│µŚČ’╝īµ£ĆķĢ┐µŚČķŚ┤µ£¬Ķó½Ķ«┐ķŚ«Ķ┐ćńÜäķĪĄķØóõ╝śÕģłĶó½µĘśµ▒░ŃĆéÕ£©CĶ»ŁĶ©ĆõĖŁÕ«×ńÄ░LRUń«Śµ│Ģ’╝īķ£ĆĶ”üńÉåĶ¦ŻµĢ░µŹ«ń╗ōµ×äÕÆīń«Śµ│ĢńÜäÕ¤║ńĪĆń¤źĶ»å’╝ī...
ÕĮōBuffer PoolõĖŁńÜäń╝ōÕŁśķĪĄõĖŹÕż¤ńö©µŚČ’╝īÕ┐ģķĪ╗µĘśµ▒░õĖĆõ║øń╝ōÕŁśķĪĄµØźĶģŠÕć║ń®║ķŚ┤’╝īĶ┐ÖµŚČÕ░▒ķ£ĆĶ”üńö©Õł░ń╝ōÕŁśµĘśµ▒░ń«Śµ│ĢŃĆéĶ┐Öń»ćµ¢ćń½ĀõĖ╗Ķ”üõ╗ŗń╗Źõ║åÕ¤║õ║ÄLRU’╝łLeast Recently Used’╝īµ£ĆĶ┐æµ£ĆÕ░æõĮ┐ńö©’╝ēń«Śµ│ĢÕ£©Buffer PoolõĖŁńÜäń╝ōÕŁśķĪĄµĘśµ▒░µ£║ÕłČŃĆé ķ”¢Õģł’╝ī...
LRUń╝ōÕŁśń«Śµ│Ģµś»õĖĆń¦ŹÕĖĖńö©ńÜäń╝ōÕŁśµĘśµ▒░ńŁ¢ńĢź’╝īÕ«āµĀ╣µŹ«µĢ░µŹ«ķĪ╣µ£ĆĶ┐æĶó½õĮ┐ńö©ńÜ䵌ČķŚ┤µØźÕå│Õ«ÜÕō¬õ║øµĢ░µŹ«ķĪ╣Õ║öĶ»źõ╗Äń╝ōÕŁśõĖŁń¦╗ķÖż’╝īõ╗źńĪ«õ┐Øń╝ōÕŁśõĖŁÕ¦ŗń╗łÕŁśµöŠńØƵ£ĆĶ┐æµ£ĆÕÅ»ĶāĮĶó½õĮ┐ńö©ńÜäµĢ░µŹ«ķĪ╣ŃĆéĶ┐ÖõĖ¬ÕÄŗń╝®µ¢ćõ╗ČÕÅ»ĶāĮÕīģµŗ¼LRUń╝ōÕŁśńÜäÕ«×ńÄ░õ╗ŻńĀüŃĆüµĄŗĶ»ĢµĀĘõŠŗŃĆüõĮ┐ńö©...
ÕģČõĖŁ’╝īLRU’╝łLeast Recently Used’╝īµ£ĆĶ┐æµ£ĆÕ░æõĮ┐ńö©’╝ēń«Śµ│Ģµś»õĖĆń¦ŹÕĖĖńö©ńÜäń╝ōÕŁśµĘśµ▒░ńŁ¢ńĢźŃĆéµ£¼µ¢ćÕ░åĶ»”ń╗åõ╗ŗń╗ŹõĖĆõĖ¬ÕēŹń½»Õ╝Ƶ║ÉÕ║ōŌĆöŌĆö`lighter-lru-cache`’╝īÕ«āµś»õĖĆõĖ¬ĶĮ╗ķćÅń║¦ńÜäJavaScript LRUń╝ōÕŁśÕ«×ńÄ░ŃĆé `lighter-lru-cache`Õ║ōńÜäµĀĖÕ┐ā...
LRU’╝łLeast Recently Used...µĆ╗ń╗ōõĖĆõĖŗ’╝īLRUń«Śµ│Ģµś»õĖĆń¦ŹÕ¤║õ║ÄÕÄåÕÅ▓Ķ«┐ķŚ«ĶĪīõĖ║ńÜäń╝ōÕŁśńŁ¢ńĢź’╝īÕ«āķĆÜĶ┐ćµĘśµ▒░µ£ĆĶ┐æµ£ĆÕ░æõĮ┐ńö©ńÜäµĢ░µŹ«µØźõ╝śÕī¢ÕåģÕŁśõĮ┐ńö©ŃĆéÕ£©Õ«×ķÖģÕ║öńö©õĖŁ’╝īÕ”éµĢ░µŹ«Õ║ōń╝ōÕŁśŃĆüµōŹõĮ£ń│╗ń╗¤ńÜäķĪĄķØóµø┐µŹóńŁ¢ńĢźńŁē’╝īLRUń«Śµ│ĢķāĮÕ▒ĢńÄ░Õć║Ķē»ÕźĮńÜäµĆ¦ĶāĮŃĆé
µŚČķŚ┤ÕżŹµØéÕ║”µ¢╣ķØó’╝īLRUń«Śµ│ĢķĆÜÕĖĖĶĪ©ńÄ░õĖ║O(1)’╝īÕøĀõĖ║µ¤źµēŠŃĆüµÅÆÕģźÕÆīÕłĀķÖżµōŹõĮ£ķāĮÕ£©Õ╣│ÕØćµāģÕåĄõĖŗÕģʵ£ēÕĖĖµĢ░µŚČķŚ┤ÕżŹµØéÕ║”ŃĆéń®║ķŚ┤ÕżŹµØéÕ║”ÕÅ¢Õå│õ║Äń╝ōÕŁśńÜäµ£ĆÕż¦Õż¦Õ░Å’╝īÕŹ│`_max_size`ŃĆéÕ«×ńÄ░ķÜŠÕ║”Õ£©õ║ÄÕ”éõĮĢµ£ēµĢłÕ£░ń╗┤µŖżķĪĄķØóńÜäĶ«┐ķŚ«ķĪ║Õ║ÅÕÆīķĪĄķØóµśĀÕ░äŃĆé ...
Õ£©Õ«×ķÖģÕ║öńö©õĖŁ’╝īLRU ń«Śµ│ĢÕĖĖńö©õ║Äń╝ōÕŁśń«ĪńÉåÕÆīµĢ░µŹ«Õ║ōń│╗ń╗¤’╝īõ╗źõ╝śÕī¢µĢ░µŹ«ńÜäĶ«┐ķŚ«µĢłńÄćŃĆéõŠŗÕ”é’╝īÕĮōÕåģÕŁśõĖŹĶČ│õ╗źÕŁśµöŠµēƵ£ēµĢ░µŹ«µŚČ’╝īLRU ÕÅ»õ╗źÕĖ«ÕŖ®Õå│Õ«ÜÕō¬õ║øµĢ░µŹ«Õ║öĶ»źĶó½µÜ鵌Čń¦╗ķÖż’╝īõ╗źõŠ┐õĖ║µø┤ķćŹĶ”üńÜäµĢ░µŹ«ĶģŠÕć║ń®║ķŚ┤ŃĆéńö▒õ║Ä LRU ńÜäķ½śµĢłµĆ¦ÕÆīńø┤Ķ¦éµĆ¦...
ķ”¢Õģł’╝īLRUµś»õĖĆń¦ŹÕĖĖńö©ńÜäń╝ōÕŁśµĘśµ▒░ńŁ¢ńĢź’╝īÕ«āÕ¤║õ║ÄŌĆ£µ£ĆĶ┐æµ£ĆÕ░æõĮ┐ńö©ŌĆØńÜäÕÄ¤ÕłÖ’╝īÕĮōń╝ōÕŁśµ╗ĪµŚČ’╝īõ╝śÕģłµĘśµ▒░µ£ĆĶ┐æµ£ĆÕ░æõĮ┐ńö©ńÜäµĢ░µŹ«ŃĆéÕ£©ConcurrentLinkedHashMap-LRU 1.3õĖŁ’╝īĶ┐Öń¦ŹńŁ¢ńĢźĶó½ÕĘ¦Õ”ÖÕ£░Ķ׏ÕģźÕł░Õ╣ČÕÅæńÄ»ÕóāõĖŗ’╝īõ┐ØĶ»üõ║åÕ£©ÕżÜń║┐ń©ŗńÄ»ÕóāõĖŗńÜä...