pyzheng
- 浏览: 3462727 次
- 性别:

- 来自: 珠海
-

文章分类
- 全部博客 (1633)
- Java (250)
- Android&HTML5 (111)
- Struts (10)
- Spring (236)
- Hibernate&MyBatis (115)
- SSH (49)
- jQuery插件收集 (55)
- Javascript (145)
- PHP (77)
- REST&WebService (18)
- BIRT (27)
- .NET (7)
- Database (105)
- 设计模式 (16)
- 自动化和测试 (19)
- Maven&Ant (43)
- 工作流 (36)
- 开源应用 (156)
- 其他 (16)
- 前台&美工 (119)
- 工作积累 (0)
- OS&Docker (83)
- Python&爬虫 (28)
- 工具软件 (157)
- 问题收集 (61)
- OFbiz (6)
- noSQL (12)
最新评论
-
HEZR曾嶸:
你好博主,这个不是很理解,能解释一下嘛//左边+1,上边+1, ...
java 两字符串相似度计算算法 -
天使建站:
写得不错,可以看这里,和这里的这篇文章一起看,有 ...
jquery 遍历对象、数组、集合 -
xue88ming:
很有用,谢谢
@PathVariable映射出现错误: Name for argument type -
jnjeC:
厉害,困扰了我很久
MyBatis排序时使用order by 动态参数时需要注意,用$而不是# -
TopLongMan:
非常好,很实用啊。。
PostgreSQL递归查询实现树状结构查询
新版文档地址 http://webmagic.io/docs/zh/, http://webmagic.io/docs/zh/posts/ch1-overview/README.html
webmagic的使用文档:https://github.com/code4craft/webmagic/blob/master/user-manual.md
webmagic的设计文档:webmagic的设计机制及原理-如何开发一个Java爬虫 http://my.oschina.net/flashsword/blog/145796
XPath 语法 http://www.w3school.com.cn/xpath/xpath_syntax.asp
Xsoup: 抽取工具简介 http://webmagic.io/docs/zh/posts/ch4-basic-page-processor/xsoup.html
如何用爬虫webmagic采集图片(demo附源代码) http://www.oschina.net/code/snippet_1397325_35514
一些错误解决办法:
code error 403 http://www.oschina.net/question/989118_154456
使用Maven
WebMagic基于Maven进行构建,推荐使用Maven来安装WebMagic。在项目中添加以下坐标即可:
WebMagic使用slf4j-log4j12作为slf4j的实现.如果你自己定制了slf4j的实现,请在项目中去掉此依赖。
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
以下是爬取oschina博客的一段代码:
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
webmagic包含强大的页面抽取功能,开发者可以便捷的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。例如:
webmagic也可以很方便的作为一个模块,嵌入Java项目中运行。webmagic的使用可以参考:oschina openapi 应用:博客搬家 http://my.oschina.net/oscfox/blog/194507
第一个项目
在你的项目中添加了WebMagic的依赖之后,即可开始第一个爬虫的开发了!我们这里拿一个抓取Github信息的例子:
webmagic的使用文档:https://github.com/code4craft/webmagic/blob/master/user-manual.md
webmagic的设计文档:webmagic的设计机制及原理-如何开发一个Java爬虫 http://my.oschina.net/flashsword/blog/145796
XPath 语法 http://www.w3school.com.cn/xpath/xpath_syntax.asp
Xsoup: 抽取工具简介 http://webmagic.io/docs/zh/posts/ch4-basic-page-processor/xsoup.html
如何用爬虫webmagic采集图片(demo附源代码) http://www.oschina.net/code/snippet_1397325_35514
一些错误解决办法:
code error 403 http://www.oschina.net/question/989118_154456
使用Maven
WebMagic基于Maven进行构建,推荐使用Maven来安装WebMagic。在项目中添加以下坐标即可:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.4.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.4.3</version>
</dependency>
WebMagic使用slf4j-log4j12作为slf4j的实现.如果你自己定制了slf4j的实现,请在项目中去掉此依赖。
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.4.3</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
以下是爬取oschina博客的一段代码:
Spider.create(new SimplePageProcessor("http://my.oschina.net/",
"http://my.oschina.net/*/blog/*")).thread(5).run();
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
webmagic包含强大的页面抽取功能,开发者可以便捷的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。例如:
String extractResult = Html.create(html).$("div.body")
.xpath("//a/@href").regex(".*blog.*").toString();
webmagic也可以很方便的作为一个模块,嵌入Java项目中运行。webmagic的使用可以参考:oschina openapi 应用:博客搬家 http://my.oschina.net/oscfox/blog/194507
第一个项目
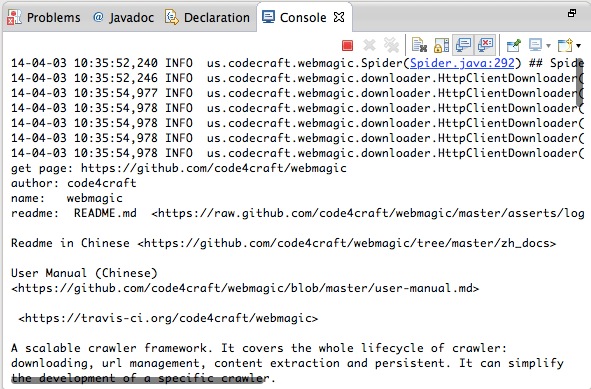
在你的项目中添加了WebMagic的依赖之后,即可开始第一个爬虫的开发了!我们这里拿一个抓取Github信息的例子:
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class GithubRepoPageProcessor implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
@Override
public void process(Page page) {
page.addTargetRequests(page.getHtml().links().regex("(https://github\\.com/\\w+/\\w+)").all());
page.putField("author", page.getUrl().regex("https://github\\.com/(\\w+)/.*").toString());
page.putField("name", page.getHtml().xpath("//h1[@class='entry-title public']/strong/a/text()").toString());
if (page.getResultItems().get("name")==null){
//skip this page
page.setSkip(true);
}
page.putField("readme", page.getHtml().xpath("//div[@id='readme']/tidyText()"));
}
@Override
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new GithubRepoPageProcessor()).addUrl("https://github.com/code4craft").thread(5).run();
}
}
分享到:


发表评论

-
Htmlunit使用
2015-04-11 20:12 1135http://my.oschina.net/u/852445/ ... -
python Tkinter的一些记录
2013-10-14 11:06 18141. Label里面的文本对齐方式:http://www.hi ... -
Python中执行外部命令并捕获双向输出
2013-10-12 15:08 2453原文:http://my.oschina.net/qihh/b ... -
python: 界面开发Tkinter
2013-10-10 16:38 1698python GUI开发 工具选择 http://blog.c ... -
Python多线程学习
2013-10-08 09:39 1473http://www.cnblogs.com/tqsummer ... -
问题: Max retries exceeded with url
2013-10-07 11:36 29500解决一: http://stackoverflow.com/q ... -
python + request + lxml的几个例子
2013-10-06 22:09 4514例子没有加入失败后重做的功能,这个也可以考虑增加。 第三个例子 ... -
python对文件的创建等处理
2013-10-06 21:24 1197http://www.qttc.net/201209207.h ... -
python: json,base64 的使用
2013-10-06 19:12 3000JSON 1. import json 2. json.dum ... -
python requests 下载图片和数据库读取
2013-10-02 15:56 18610python requests 下载图片 de ... -
python类型转换
2013-10-01 14:12 1090http://jayzotion.iteye.com/blog ... -
python字符串编码判断
2013-09-30 14:13 2258Python 字符编码判断 http://blog.sina. ... -
Python:数组、列表(list)、字典(dict)、字符串(string)常用基本操作小结
2013-09-30 13:07 13738连接 list 与分割字符串h ... -
Python模块学习 ---- datetime
2013-09-30 09:39 2232[Python Tip]如何计算时间� ... -
python html parser库lxml的介绍和使用
2013-09-30 09:39 7453使用由 Python 编写的 lxml 实现高性能 XML 解 ... -
用Python操作Mysql和中文问题
2013-09-29 13:55 2664http://www.iteye.com/topic/5730 ... -
Python 字符串操作(截取/替换/查找/分割)
2013-09-29 13:01 6254python字符串连接 先介绍下效率比较低的,有些新手朋友就会 ... -
Python中使用中文
2013-09-29 10:25 1171http://blog.csdn.net/kernelspir ... -
Beautiful Soup 中文教程
2013-09-29 09:36 2850http://www.pythonclub.org/modul ... -
python + request + pyquery[安装失败]
2013-09-28 20:51 2209比urllib好用的requests http://www.b ...
相关推荐
webporter 是一个基于垂直爬虫框架 webmagic 的 Java 爬虫应用,旨在提供一套完整的数据爬取,持久化存储和可视化展示的实践样例。 webporter 寓意“我们不生产数据,我们只是互联网的搬运工~” 如果觉得不错,请...
Webmagic是一个由国人开发的Java语言编写、开源的垂直爬虫框架,它的设计宗旨是让爬虫的开发过程变得更加简单高效,从而使得开发者能够将更多的精力放在爬虫逻辑的实现上,而非重复性的工作。Webmagic框架的出现,很...
webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。webmagic的核心非常简单,但是覆盖爬虫的整个流程,也是很好的学习爬虫开发的材料。webmagic是一个开源的Java垂直...
WebMagic是一个开源的Java爬虫框架,专为快速、灵活地构建垂直爬虫而设计。版本v0.7.5提供了稳定性和效率的良好平衡,是许多开发者进行网页抓取和数据挖掘的首选工具。该压缩包包含的核心内容如下: 1. **源码源...
webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发 webmagic的核心 webmagic的主要特色: 完全模块化的设计,强大的可扩展性。 核心简单但是涵盖爬虫的全部流程,灵活...
为您提供webmagic垂直爬虫下载,webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。webmagic的核心非常简单,但是覆盖爬虫的整个流程,也是很好的学习爬虫开发的材料...
webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。webmagic的核心非常简单,但是覆盖爬虫的整个流程,也是很好的学习爬虫开发的材料。 本项目的主要特色: 完全...
基于WebMagic封装的垂直爬虫高分项目+详细文档+全部资料.zip 【备注】 1、该项目是个人高分项目源码,已获导师指导认可通过,答辩评审分达到95分 2、该资源内项目代码都经过测试运行成功,功能ok的情况下才上传的,...
webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。webmagic的核心非常简单,但是覆盖爬虫的整个流程,也是很好的学习爬虫开发的材料。webmagic的主要特色:1、完全...
网络搬运工webporter 是一个基于webmagic的垂直爬虫框架的 Java 爬虫应用程序,旨在提供一套完整的数据爬虫、持久化存储和可视化展示的样例实践示例。webporter寓意“我们不是生产数据,我们只是互联网的搬运工”...
【标题】基于Lucene+WebMagic实现的垂直搜索引擎 在这个项目中,我们探索了如何结合Apache Lucene和WebMagic这两个强大的工具来构建一个专门针对交通领域的垂直搜索引擎。Apache Lucene是一个开源全文搜索引擎库,...
这里的爬虫是垂直爬虫,意味着它专注于特定领域的信息,即军事新闻,而不是遍历整个网站。 WebMagic框架的核心组件包括以下几个部分: 1. **PageFetcher**:负责获取网页内容,执行HTTP请求。 2. **PageProcessor**...
Webmagic的作者曾经在前公司参与了一年的垂直爬虫开发工作,这个框架的产生正是为了解决爬虫开发过程中的那些重复劳动。Webmagic的核心虽然非常简单,但它覆盖了爬虫开发的整个流程,既可以用于学习网络爬虫技术,也...
核心简单但是涵盖爬虫的全部流程,灵活而强大,也是学习爬虫入门的好材料。 提供丰富的抽取页面API。 无配置,但是可通过POJO+注解形式实现一个爬虫。 支持多线程。 支持分布式。 支持爬取js动态渲染的页面。 无框架...
webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。 最新版:WebMagic-0.7.3 Maven依赖: <groupId>us.codecraft <artifactId>webmagic-core <version>0.7.3 ...
在本文档中,我们使用 Webmagic 框架来搭建基于网络爬虫的垂直搜索引擎。Webmagic 是一个基于 Java 的爬虫框架,提供了爬虫的基本功能,例如页面抓取、链接跟踪、数据处理等。我们使用 Webmagic 框架来搭建爬虫,...
综上所述,新闻垂直搜索引擎的爬虫部分通过Webmagic框架高效抓取新闻网站数据,而分类部分则利用Classifier4j进行文本分类,确保新闻内容能准确地按类别组织,提升用户体验。这两个环节的协同工作,使得搜索引擎能够...
webporterwebporter 是一个基于垂直爬虫框架 的 Java 爬虫应用,旨在提供一套完整的数据爬取,持久化存储和可视化展示的实践样例。webporter 寓意“我们不生产数据,我们只是互联网的搬运工~”如果觉得不错,请先在...
总结来说,这个基于网络爬虫的垂直搜索引擎设计与实现项目,通过创新的算法和定制化的爬虫技术,实现了对人工智能领域信息的精准采集和处理,建立高效索引,提供了专业化的搜索服务。同时,系统的用户管理和后台管理...
再者,`WebMagic`是一个Java实现的轻量级网络爬虫框架,它设计简洁、易于扩展。WebMagic支持自动化的网页解析、链接提取和数据提取,使得开发者无需深入了解HTML和CSS选择器,就能高效地抓取网页内容。在这个项目中...