|
и§ЈйҮҠеҷЁжЁЎејҸжҳҜе№іж—¶е·ҘдҪңеҪ“дёӯзӣёеҜ№еҶ·й—Ёзҡ„дёҖдёӘи®ҫи®ЎжЁЎејҸпјҢд№ҹйқһеёёзҡ„йҡҫдәҺзҗҶи§ЈпјҢзҷҫеәҰзҷҫ科дёҠзҡ„и§ЈйҮҠд№ҹйқһеёёд№Ӣе°‘пјҢеҸӘжҳҜз®ҖеҚ•зҡ„д»Ӣз»ҚдәҶдёҖдёӢпјҢ并且иҜҙдәҶдёҖеҸҘпјҢеҸҜд»ҘеҸӮиҖғжӯЈеҲҷиЎЁиҫҫејҸдёәдёҖдёӘе®һйҷ…зҡ„еә”з”ЁдҫӢеӯҗгҖӮ
дёҚиҝҮиө„ж–ҷзҡ„еҢ®д№Ҹ并дёҚиғҪйҳ»жӯўжҲ‘们еҜ№зңҹзҗҶзҡ„жҺўзҙўпјҢдёӢйқўLZе…Ҳе°ҶзҷҫеәҰзҷҫ科дёҠзҡ„е®ҡд№үд»ҘеҸҠи§ЈеҶізҡ„й—®йўҳжӢ”еҲ°иҝҷйҮҢпјҢж–№дҫҝеҗ„дҪҚи§ӮзңӢгҖӮ
е®ҡд№үпјҡз»ҷе®ҡдёҖдёӘиҜӯиЁҖпјҢе®ҡд№үе®ғзҡ„ж–Үжі•зҡ„дёҖз§ҚиЎЁзӨәпјҢ并е®ҡд№үдёҖдёӘи§ЈйҮҠеҷЁпјҢиҝҷдёӘи§ЈйҮҠеҷЁдҪҝз”ЁиҜҘиЎЁзӨәжқҘи§ЈйҮҠиҜӯиЁҖдёӯзҡ„еҸҘеӯҗгҖӮ
дҪҝз”ЁеңәжҷҜпјҡи§ЈйҮҠеҷЁжЁЎејҸйңҖиҰҒи§ЈеҶізҡ„жҳҜпјҢеҰӮжһңдёҖз§Қзү№е®ҡзұ»еһӢзҡ„й—®йўҳеҸ‘з”ҹзҡ„йў‘зҺҮи¶іеӨҹй«ҳпјҢйӮЈд№ҲеҸҜиғҪе°ұеҖјеҫ—е°ҶиҜҘй—®йўҳзҡ„еҗ„дёӘе®һдҫӢиЎЁиҝ°дёәдёҖдёӘз®ҖеҚ•иҜӯиЁҖдёӯзҡ„еҸҘеӯҗгҖӮиҝҷж ·е°ұеҸҜд»Ҙжһ„е»әдёҖдёӘи§ЈйҮҠеҷЁпјҢиҜҘи§ЈйҮҠеҷЁйҖҡиҝҮи§ЈйҮҠиҝҷдәӣеҸҘеӯҗжқҘи§ЈеҶіиҜҘй—®йўҳгҖӮ
LZе…Ҳз»ҷеҗ„дҪҚи§ЈйҮҠдёҖдёӢе®ҡд№үеҪ“дёӯжүҖжҸҗеҲ°зҡ„ж–Үжі•гҖӮж–Үжі•д№ҹз§°дёәиҜӯжі•пјҢжҢҮзҡ„жҳҜиҜӯиЁҖзҡ„з»“жһ„ж–№ејҸгҖӮеҢ…жӢ¬иҜҚзҡ„жһ„жҲҗе’ҢеҸҳеҢ–пјҢиҜҚз»„е’ҢеҸҘеӯҗзҡ„з»„з»ҮгҖӮеҜ№дәҺж–Үжі•жқҘиҜҙпјҢжҲ‘们еҸҜд»Ҙз®ҖеҚ•зҡ„зҗҶи§ЈдёәдёҖз§ҚиҜӯиЁҖзҡ„规еҲҷпјҢйӮЈд№Ҳд»Һи§ЈйҮҠеҷЁжЁЎејҸзҡ„е®ҡд№үеҸҜд»ҘзңӢеҮәпјҢйҰ–е…ҲжҲ‘们иҰҒе…Ҳи®ҫи®ЎдёҖз§ҚиҜӯиЁҖпјҢ然еҗҺз»ҷеҮәиҜӯиЁҖзҡ„ж–Үжі•зҡ„иЎЁзӨәпјҢиҖҢеңЁжӯӨеҹәзЎҖдёҠпјҢжҲ‘们йҮҮз”Ёи§ЈйҮҠеҷЁжЁЎејҸеҺ»и§ЈйҮҠиҜӯиЁҖдёӯзҡ„еҸҘеӯҗгҖӮ
иҰҒжғіеҪ»еә•зҡ„зҗҶи§Ји§ЈйҮҠеҷЁжЁЎејҸпјҢLZеҝ…йЎ»иҰҒе…Ҳжҷ®еҸҠдёҖдёӢж–Үжі•зҡ„е®ҡд№үпјҢиҜ·еҗ„дҪҚжҡӮдё”еҝҚеҸ—дҪҸжһҜзҮҘзҡ„зҗҶи®әзҹҘиҜҶпјҢеҗҺйқўLZдјҡе°ҶиҝҷдәӣзҗҶи®әз”Ёеҗ„дҪҚзҶҹжӮүзҡ„д»Јз ҒиҜ йҮҠдёҖйҒҚгҖӮ
йҰ–е…ҲжҲ‘们жқҘи®Ёи®әдёҖдёӢдёҠдёӢж–Үж— е…іж–Үжі•зҡ„з»„жҲҗпјҢжңүеӣӣз§Қз»„жҲҗйғЁеҲҶгҖӮ
1пјҢйқһз»Ҳз»“з¬ҰеҸ·йӣҶпјҲLZж ҮжіЁпјҡеғҸJAVAиҜӯиЁҖдёӯзҡ„иЎЁиҫҫејҸпјҢзЁӢеәҸиҜӯеҸҘпјҢж ҮиҜҶз¬Ұзӯүпјү
2пјҢз»Ҳз»“з¬ҰеҸ·йӣҶпјҲLZж ҮжіЁпјҡзұ»дјјJAVAиҜӯиЁҖдёӯзҡ„+пјҢ-пјҢ*пјҢ\пјҢ=зӯүпјү
3пјҢдә§з”ҹејҸйӣҶеҗҲпјҢд№ҹеҸҜд»Ҙз§°дёә规еҲҷйӣҶеҗҲпјҲLZж ҮжіЁпјҡеҒҮи®ҫжҲ‘们记JAVAдёӯзҡ„ж ҮиҜҶз¬ҰдёәidпјҢйӮЈд№ҲдёӢйқўиҝҷеҸҘиҜқеҸҜд»Ҙиў«жҲҗи§ҶдёәдёҖжқЎи§„еҲҷ id->a|b...|z|0..|9|_пјҢе…¶дёӯ|жҳҜжҲ–иҖ…зҡ„ж„ҸжҖқпјү
4пјҢдёҖдёӘиө·е§Ӣз¬ҰеҸ·пјҢиҝҷдёӘз¬ҰеҸ·жҳҜйқһз»Ҳз»“з¬ҰеҸ·йӣҶзҡ„дёҖдёӘе…ғзҙ пјҲLZж ҮжіЁпјҡJAVAиҜӯиЁҖдҪҝз”ЁCompilationUnitпјҲзј–иҜ‘еҚ•е…ғпјүдҪңдёәиө·е§Ӣз¬ҰеҸ·гҖӮпјү
дёҠйқўжүҖиҜҙзҡ„е®ҡд№үжңүдәӣжҠҪиұЎпјҢжүҖд»ҘLZеңЁеҗҺйқўеҠ дәҶдёҖдәӣж ҮжіЁпјҢйӮЈд№ҲдёҠдёӢж–Үж— е…іж–Үжі•зҡ„дҪңз”ЁжҳҜд»Җд№Ҳе‘ўпјҹ
е®ғеҸҜд»Ҙз”ҹжҲҗдёҖз»„з”ұж–Үжі•еҜјеҮәзҡ„иҜӯеҸҘпјҢиҝҷдәӣиҜӯеҸҘеҸҜд»Ҙж №жҚ®ж–Үжі•зҡ„дә§з”ҹејҸиҝӣиЎҢеҲҶжһҗпјҢдёӢйқўLZз»ҷдёҖдёӘгҖҠзј–иҜ‘еҺҹзҗҶгҖӢдёҖд№Ұдёӯзҡ„з®ҖеҚ•дҫӢеӯҗпјҢдёәдәҶж–№дҫҝзҗҶи§ЈпјҢLZе°Ҷз¬ҰеҸ·зЁҚеҫ®жӣҙж”№дәҶдёҖдёӢгҖӮ
еҒҮи®ҫжңүдёҖдёҠдёӢж–Үж— е…іж–Үжі•еҰӮдёӢпјҡ
arithmetic -> arithmetic + number | arithmetic - number | number
number -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
жҲ‘д»¬ж №жҚ®иҝҷдёӘж–Үжі•еҸҜд»Ҙеҫ—еҲ°жүҖжңүдёӘдҪҚж•°зҡ„еҠ еҮҸиЎЁиҫҫејҸпјҢжҜ”еҰӮеҜ№дәҺ 9 + 2 - 1 пјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮд»ҘдёӢжӯҘйӘӨжҺЁеҜјеҮәжқҘгҖӮ
arithmetic - >arithmetic - number -> arithmetic + number - number -> number + number - number -> 9 + number -number -> 9 + 2 - number -> 9 + 2 - 1
еҜ№дәҺж–Үжі•жқҘиҜҙпјҢдёҖдёӘиҜӯеҸҘеҰӮжһңиғҪеӨҹжҢүз…§дә§з”ҹејҸжҺЁеҜјеҮәиҜҘиҜӯеҸҘпјҢе°ұз§°иҜҘиҜӯеҸҘжҳҜз¬ҰеҗҲж–Үжі•зҡ„пјҢжүҖд»Ҙ9 + 2 - 1жҳҜз¬ҰеҗҲдёҠиҝ°ж–Үжі•зҡ„дёҖдёӘиҜӯеҸҘгҖӮ
еңЁиҝҷдёӘж–Үжі•еҪ“дёӯпјҢе…¶дёӯйқһз»Ҳз»“иҖ…з¬ҰеҸ·жҳҜ arithmetic е’Ң numberпјҢ иҖҢз»Ҳз»“иҖ…з¬ҰеҸ·жҳҜ 0 - 9 гҖҒ-гҖҒ+ гҖӮ
жҲ‘们д»Һж–Үжі•дёӯеҸҜд»Ҙеҫ—зҹҘз”ұиҜҘж–Үжі•з»„жҲҗзҡ„иҜӯеҸҘжңүд»ҘдёӢ规еҲҷгҖӮ
1гҖҒoperatorзҡ„еҸіиҫ№еҝ…йЎ»жҳҜдёҖдёӘnumberгҖӮ
2гҖҒoperatorзҡ„е·Ұиҫ№еҝ…йЎ»жҳҜдёҖдёӘarithmeticгҖӮ
3гҖҒarithmeticзҡ„жңҖеҸіиҫ№дёҖе®ҡжҳҜдёҖдёӘnumberгҖӮ
4гҖҒз”ұ2е’Ң3пјҢoperatorзҡ„е·Ұиҫ№еҝ…йЎ»жҳҜnumberгҖӮ
5гҖҒз”ұ4пјҢnumberзҡ„еҸіиҫ№еҝ…йЎ»жҳҜз©әжҲ–иҖ…operatorгҖӮ
6гҖҒnumberеҸӘиғҪжҳҜ 0 е’Ң 1 - 9 зҡ„жӯЈж•ҙж•°гҖӮ
7гҖҒoperatorеҸӘиғҪжҳҜ - е’Ң + гҖӮ
й’ҲеҜ№иҝҷдёӘж–Үжі•пјҢжҲ‘们еҸҜд»ҘеҶҷдёҖдёӘи§ЈйҮҠеҷЁпјҢеҺ»и®Ўз®—иЎЁиҫҫејҸзҡ„з»“жһңпјҢиҖҢиҝҷдёӘи§ЈйҮҠеҷЁе°ұеҸҜд»ҘдҪҝз”Ёи§ЈйҮҠеҷЁжЁЎејҸзј–еҶҷгҖӮиҖҢеңЁзј–еҶҷзҡ„иҝҮзЁӢдёӯпјҢжҲ‘们йңҖиҰҒйӘҢиҜҒд»ҘдёҠзҡ„规еҲҷпјҢеҰӮжһңиҝқеҸҚдәҶ规еҲҷпјҢеҲҷиЎЁиҫҫејҸжҳҜйқһжі•зҡ„гҖӮдёәдәҶдҫҝдәҺдҪҝз”ЁзЁӢеәҸиҜӯиЁҖиЎЁзӨәпјҢжҲ‘们еҸӘйӘҢиҜҒд»ҘдёҠзҡ„еҗҺеӣӣжқЎи§„еҲҷпјҢиҝҷд№ҹжҳҜз”ұеҺҹжң¬зҡ„дә§з”ҹејҸжҺЁз®—еҮәжқҘзҡ„规еҲҷгҖӮ
жҲ‘们е…ҲжқҘзңӢдёӢи§ЈйҮҠеҷЁжЁЎејҸзҡ„зұ»еӣҫпјҢеј•иҮӘгҖҠеӨ§иҜқи®ҫи®ЎжЁЎејҸгҖӢгҖӮ
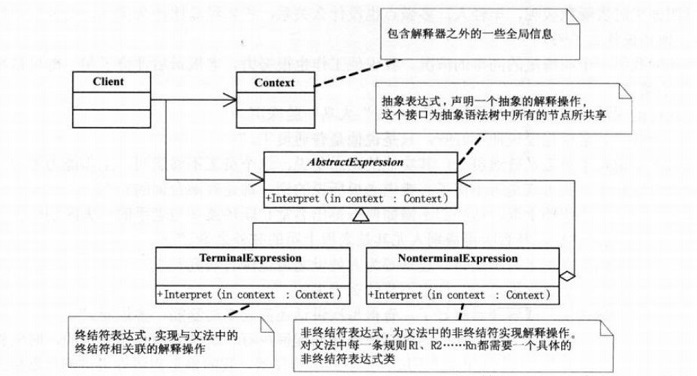
еҸҜд»ҘзңӢеҲ°зұ»еӣҫдёӯжңүеӣӣдёӘи§’иүІпјҢжҠҪиұЎиЎЁиҫҫејҸпјҲAbstractExpressionпјүгҖҒз»Ҳз»“з¬ҰиЎЁиҫҫејҸпјҲTerminalExpressionпјүгҖҒйқһз»Ҳз»“з¬ҰиЎЁиҫҫејҸпјҲNonterminalExpressionпјүд»ҘеҸҠдёҠдёӢж–ҮпјҲContextпјүгҖӮ
еӣӣдёӘи§’иүІжүҖиҙҹиҙЈзҡ„д»»еҠЎеңЁзұ»еӣҫдёӯе·Іжңүи§ЈйҮҠпјҢLZиҝҷйҮҢдёҚеҶҚйҮҚеӨҚпјҢиҝҷйҮҢиҰҒиҜҙзҡ„жҳҜпјҢиҝҷйҮҢе…·дҪ“зҡ„иЎЁиҫҫејҸзұ»дёӘж•°жҳҜдёҚе®ҡзҡ„гҖӮ
жҚўеҸҘиҜқиҜҙпјҢз»Ҳз»“з¬ҰиЎЁиҫҫејҸпјҲTerminalExpressionпјүе’Ңйқһз»Ҳз»“з¬ҰиЎЁиҫҫејҸпјҲNonterminalExpressionпјүзҡ„дёӘж•°йғҪжҳҜж №жҚ®ж–Үжі•йңҖиҰҒиҖҢе®ҡзҡ„пјҢ并йқһжҳҜдёҖжҲҗдёҚеҸҳгҖӮ
дёӢйқўжҲ‘们е°ұдҪҝз”ЁдёҠиҝ°зҡ„и§ЈйҮҠеҷЁжЁЎејҸзҡ„з»“жһ„еҺ»еҶҷдёҖдёӘи§ЈйҮҠеҷЁпјҢз”ЁдәҺи§ЈйҮҠдёҠйқўзҡ„еҠ еҮҸиЎЁиҫҫејҸпјҢйҰ–е…ҲжҲ‘们е…ҲеҶҷдёҖдёӘдёҠдёӢж–ҮпјҢе®ғи®°еҪ•дәҶдёҖдәӣе…ЁеұҖдҝЎжҒҜпјҢжҸҗдҫӣз»ҷиЎЁиҫҫејҸзұ»дҪҝз”ЁпјҢеҰӮдёӢгҖӮ
package com.interpreter;
import java.util.ArrayList;
import java.util.List;
//дёҠдёӢж–Ү
public class Context {
private int result;//з»“жһң
private int index;//еҪ“еүҚдҪҚзҪ®
private int mark;//ж Үеҝ—дҪҚ
private char[] inputChars;//иҫ“е…Ҙзҡ„еӯ—з¬Ұж•°з»„
private List operateNumbers = new ArrayList(2);//ж“ҚдҪңж•°
private char operator;//иҝҗз®—з¬Ұ
public Context(char[] inputChars) {
super();
this.inputChars = inputChars;
}
public int getResult() {
return result;
}
public void setResult(int result) {
this.result = result;
}
public boolean hasNext(){
return index != inputChars.length;
}
public char next() {
return inputChars[index++];
}
public char current(){
return inputChars[index];
}
public List getOperateNumbers() {
return operateNumbers;
}
public void setLeftOperateNumber(int operateNumber) {
this.operateNumbers.add(0, operateNumber);
}
public void setRightOperateNumber(int operateNumber) {
this.operateNumbers.add(1, operateNumber);
}
public char getOperator() {
return operator;
}
public void setOperator(char operator) {
this.operator = operator;
}
public void mark(){
mark = index;
}
public void reset(){
index = mark;
}
}
|
дёҠдёӢж–Үзҡ„еҗ„дёӘеұһжҖ§пјҢйғҪжҳҜиЎЁиҫҫејҸеңЁи®Ўз®—иҝҮзЁӢдёӯйңҖиҰҒдҪҝз”Ёзҡ„пјҢд№ҹе°ұжҳҜзұ»еӣҫдёӯжүҖиҜҙзҡ„е…ЁеұҖдҝЎжҒҜпјҢе…¶дёӯзҡ„ж“ҚдҪңж•°е’Ңиҝҗз®—з¬ҰжҳҜжЁЎжӢҹзҡ„и®Ўз®—жңәдёӯеҜ„еӯҳеҷЁеҠ еҮҸжҢҮд»Өзҡ„жү§иЎҢж–№ејҸгҖӮдёӢйқўжҲ‘们з»ҷеҮәжҠҪиұЎзҡ„иЎЁиҫҫејҸпјҢе®ғеҸӘжҳҜе®ҡд№үдёҖдёӘи§ЈйҮҠж“ҚдҪңгҖӮ
package com.interpreter;
//жҠҪиұЎиЎЁиҫҫејҸпјҢе®ҡд№үдёҖдёӘи§ЈйҮҠж“ҚдҪң
public interface Expression {
void interpreter(Context context);
}
|
дёӢйқўдҫҝжҳҜжңҖйҮҚиҰҒзҡ„еӣӣдёӘе…·дҪ“иЎЁиҫҫејҸдәҶпјҢиҝҷе…¶дёӯеҜ№еә”дәҺдёҠйқўж–Үжі•жҸҗеҲ°зҡ„з»Ҳз»“з¬Ұе’Ңйқһз»Ҳз»“з¬ҰпјҢеҰӮдёӢгҖӮ
package com.interpreter;
//з®—ж•°иЎЁиҫҫејҸпјҲйқһз»Ҳз»“з¬ҰиЎЁиҫҫејҸпјҢеҜ№еә”arithmeticпјү
public class ArithmeticExpression implements Expression {
public void interpreter(Context context) {
context.setResult(getResult(context));//и®Ўз®—з»“жһң
context.getOperateNumbers().clear();//жё…з©әж“ҚдҪңж•°
context.setLeftOperateNumber(context.getResult());//е°Ҷз»“жһңеҺӢе…Ҙе·Ұж“ҚдҪңж•°
}
private int getResult(Context context){
int result = 0;
switch (context.getOperator()) {
case '+':
result = context.getOperateNumbers().get(0) + context.getOperateNumbers().get(1);
break;
case '-':
result = context.getOperateNumbers().get(0) - context.getOperateNumbers().get(1);
break;
default:
break;
}
return result;
}
}
|
package com.interpreter;
//йқһз»Ҳз»“з¬ҰиЎЁиҫҫејҸпјҢеҜ№еә”number
public class NumberExpression implements Expression{
public void interpreter(Context context) {
//и®ҫзҪ®ж“ҚдҪңж•°
Integer operateNumber = Integer.valueOf(String.valueOf(context.current()));
if (context.getOperateNumbers().size() == 0) {
context.setLeftOperateNumber(operateNumber);
context.setResult(operateNumber);
}else {
context.setRightOperateNumber(operateNumber);
Expression expression = new ArithmeticExpression();//иҪ¬жҚўжҲҗз®—ж•°иЎЁиҫҫејҸ
expression.interpreter(context);
}
}
}
|
package com.interpreter;
//з»Ҳз»“з¬ҰиЎЁиҫҫејҸпјҢеҜ№еә”-гҖҒ+
public class OperatorExpression implements Expression{
public void interpreter(Context context) {
context.setOperator(context.current());//и®ҫзҪ®иҝҗз®—з¬Ұ
}
}
|
package com.interpreter;
//з»Ҳз»“з¬ҰиЎЁиҫҫејҸпјҢеҜ№еә”0гҖҒ1гҖҒ2гҖҒ3гҖҒ4гҖҒ5гҖҒ6гҖҒ7гҖҒ8гҖҒ9
public class DigitExpression implements Expression{
public void interpreter(Context context) {
Expression expression = new NumberExpression();//еҰӮжһңжҳҜж•°еӯ—пјҢеҲҷзӣҙжҺҘиҪ¬дёәnumberиЎЁиҫҫејҸ
expression.interpreter(context);
}
}
|
иҝҷеӣӣдёӘзұ»е°ұжҳҜз®ҖеҚ•зҡ„и§ЈйҮҠж“ҚдҪңпјҢеҖјеҫ—дёҖжҸҗзҡ„е°ұжҳҜе…¶дёӯзҡ„дёӨж¬ЎиҪ¬жҚўпјҢиҝҷдёӘеңЁзЁҚеҗҺLZдјҡи§ЈйҮҠдёҖдёӢгҖӮ
дёӢйқўжң¬жқҘиҜҘжҳҜе®ўжҲ·з«ҜзЁӢеәҸдәҶпјҢдёҚиҝҮз”ұдәҺжҲ‘们зҡ„дҫӢеӯҗиҫғдёәеӨҚжқӮпјҢе®ўжҲ·з«Ҝзҡ„д»Јз ҒдјҡжҜ”иҫғиҮғиӮҝпјҢжүҖд»ҘLZжҠҪеҮәдәҶдёҖдёӘиҜӯжі•еҲҶжһҗзұ»пјҢеҲҶжӢ…дәҶдёҖдәӣе®ўжҲ·з«Ҝзҡ„д»»еҠЎпјҢеңЁж ҮеҮҶи§ЈйҮҠеҷЁжЁЎејҸзҡ„зұ»еӣҫдёӯжҳҜжІЎжңүиҝҷдёӘзұ»зҡ„гҖӮ
еҗ„дҪҚеҸҜд»ҘжҠҠе®ғзҡ„д»Јз ҒжғіиұЎжҲҗеңЁе®ўжҲ·з«ҜйҮҢйқўе°ұеҘҪпјҢиҝҷ并дёҚеҪұе“Қеҗ„дҪҚзҗҶи§Ји§ЈйҮҠеҷЁжЁЎејҸжң¬иә«пјҢиҜӯжі•еҲҶжһҗеҷЁзҡ„д»Јз ҒеҰӮдёӢгҖӮ
package com.interpreter;
//иҜӯжі•и§ЈжһҗеҷЁпјҲеҰӮжһңжҢүз…§и§ЈйҮҠеҷЁжЁЎејҸзҡ„и®ҫи®ЎпјҢиҝҷдәӣд»Јз Ғеә”иҜҘжҳҜеңЁе®ўжҲ·з«ҜпјҢдёәдәҶжӣҙеҠ жё…жҷ°пјҢжҲ‘们添еҠ дёҖдёӘиҜӯжі•и§ЈжһҗеҷЁпјү
public class GrammarParser {
//иҜӯжі•и§Јжһҗ
public void parse(Context context) throws Exception{
while (context.hasNext()) {
Expression expression = null;
switch (context.current()) {
case '+':
case '-':
checkGrammar(context);
expression = new OperatorExpression();
break;
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
context.mark();
checkGrammar(context, context.current());
context.reset();
expression = new DigitExpression();
break;
default:
throw new RuntimeException("иҜӯжі•й”ҷиҜҜпјҒ");//ж— ж•Ҳз¬ҰеҸ·
}
expression.interpreter(context);
context.next();
}
}
//жЈҖжҹҘиҜӯжі•
private void checkGrammar(Context context,char current){
context.next();
if (context.hasNext() && context.current() != '+' && context.current() != '-') {
throw new RuntimeException("иҜӯжі•й”ҷиҜҜпјҒ");//第5жқЎ
}
try {
Integer.valueOf(String.valueOf(current));
} catch (Exception e) {
throw new RuntimeException("иҜӯжі•й”ҷиҜҜпјҒ");//第6жқЎ
}
}
//жЈҖжҹҘиҜӯжі•
private void checkGrammar(Context context){
if (context.getOperateNumbers().size() == 0) {//第4жқЎ
throw new RuntimeException("иҜӯжі•й”ҷиҜҜпјҒ");
}
if (context.current() != '+' && context.current() != '-') {//第7жқЎ
throw new RuntimeException("иҜӯжі•й”ҷиҜҜпјҒ");
}
}
}
|
еҸҜд»ҘзңӢеҲ°пјҢжҲ‘们зҡ„иҜӯжі•еҲҶжһҗеҷЁдёҚд»…еҒҡдәҶз®ҖеҚ•зҡ„еҲҶжһҗиҜӯеҸҘпјҢд»ҺиҖҢеҫ—еҮәзӣёеә”иЎЁиҫҫејҸзҡ„е·ҘдҪңпјҢиҝҳеҒҡдәҶдёҖдёӘе·ҘдҪңпјҢе°ұжҳҜиҜӯжі•зҡ„жӯЈзЎ®жҖ§жЈҖжҹҘгҖӮ
дёӢйқўжҲ‘们еҶҷдёӘе®ўжҲ·з«ҜеҺ»и®Ўз®—еҮ дёӘиЎЁиҫҫејҸиҜ•дёҖдёӢгҖӮ
package com.interpreter;
import java.util.ArrayList;
import java.util.List;
public class Client {
public static void main(String[] args) {
List inputList = new ArrayList();
//дёүдёӘжӯЈзЎ®зҡ„пјҢдёүдёӘй”ҷиҜҜзҡ„
inputList.add("1+2+3+4+5+6+7+8+9");
inputList.add("1-2+3-4+5-6+7-8+9");
inputList.add("9");
inputList.add("-1+2+3+5");
inputList.add("1*2");
inputList.add("11+2+3+9");
GrammarParser grammarParser = new GrammarParser();//иҜӯжі•еҲҶжһҗеҷЁ
for (String input : inputList) {
Context context = new Context(input.toCharArray());
try {
grammarParser.parse(context);//иҜӯжі•еҲҶжһҗеҷЁдјҡи°ғз”Ёи§ЈйҮҠеҷЁи§ЈйҮҠиЎЁиҫҫејҸ
System.out.println(input + "=" + context.getResult());
} catch (Exception e) {
System.out.println("иҜӯжі•й”ҷиҜҜпјҢиҜ·иҫ“е…ҘжӯЈзЎ®зҡ„иЎЁиҫҫејҸпјҒ");
}
}
}
}
|
иҫ“еҮәз»“жһңпјҡ
1+2+3+4+5+6+7+8+9=45
1-2+3-4+5-6+7-8+9=5
9=9
иҜӯжі•й”ҷиҜҜпјҢиҜ·иҫ“е…ҘжӯЈзЎ®зҡ„иЎЁиҫҫејҸпјҒ
иҜӯжі•й”ҷиҜҜпјҢиҜ·иҫ“е…ҘжӯЈзЎ®зҡ„иЎЁиҫҫејҸпјҒ
иҜӯжі•й”ҷиҜҜпјҢиҜ·иҫ“е…ҘжӯЈзЎ®зҡ„иЎЁиҫҫејҸпјҒ
еҸҜд»ҘзңӢеҲ°пјҢеүҚдёүдёӘиЎЁиҫҫејҸжҳҜз¬ҰеҗҲжҲ‘们зҡ„ж–Ү法规еҲҷзҡ„пјҢиҖҢеҗҺдёүдёӘйғҪдёҚз¬ҰеҗҲ规еҲҷпјҢжүҖд»ҘжҸҗзӨәдәҶй”ҷиҜҜпјҢиҝҷж ·зҡ„з»“жһңпјҢдёҺжҲ‘们ж–Үжі•жүҖиЎЁиҝ°зҡ„规еҲҷжҳҜзӣёз¬Ұзҡ„гҖӮ
LZйңҖиҰҒжҸҗзӨәзҡ„жҳҜпјҢиҝҷйҮҢйқўжң¬жқҘжҳҜе®ўжҲ·з«ҜдҪҝз”Ёи§ЈйҮҠеҷЁжқҘи§ЈйҮҠиҜӯеҸҘзҡ„пјҢдёҚиҝҮз”ұдәҺжҲ‘们жҠҪзҰ»еҮәдәҶиҜӯжі•еҲҶжһҗеҷЁпјҢжүҖд»Ҙз”ұиҜӯжі•еҲҶжһҗеҷЁи°ғз”Ёи§ЈйҮҠеҷЁжқҘи§ЈйҮҠиҜӯеҸҘпјҢиҝҷж¶ҲйҷӨдәҶе®ўжҲ·з«ҜеҜ№и§ЈйҮҠеҷЁзҡ„е…іиҒ”пјҢдёҺж ҮеҮҶзұ»еӣҫдёҚз¬ҰпјҢдёҚиҝҮиҝҷе…¶е®һеҸӘжҳҜжҲ‘们жүҖеҒҡзҡ„з®ҖеҚ•зҡ„ж”№е–„иҖҢе·ІпјҢ并дёҚеҪұе“Қи§ЈйҮҠеҷЁжЁЎејҸзҡ„з»“жһ„гҖӮ
еҸҰеӨ–пјҢдёҠйқўзҡ„дҫӢеӯҗеҪ“дёӯпјҢиҝҳжңүдёӨзӮ№жҳҜLZиҰҒжҸҗдёҖдёӢзҡ„гҖӮLZдёәдәҶж–№дҫҝзҗҶи§ЈпјҢе·Із»Ҹе°ҪйҮҸзҡ„е°ҶдҫӢеӯҗз®ҖеҢ–пјҢдёҚиҝҮе…¶дёӯжңүдёӨдёӘең°ж–№зҡ„иҪ¬жҚўжҳҜеҖјеҫ—жіЁж„Ҹзҡ„гҖӮ
1гҖҒдёҖдёӘжҳҜж“ҚдҪңж•°ж»Ўи¶іжқЎд»¶ж—¶пјҢдјҡдә§з”ҹдёҖдёӘArithmeticExpressionиЎЁиҫҫејҸгҖӮ
2гҖҒеҸҰеӨ–дёҖдёӘжҳҜд»ҺDigitExpressionзӣҙжҺҘиҪ¬жҚўжҲҗNumberExpressionзҡ„ең°ж–№пјҢиҝҷе…¶е®һе’Ң第1зӮ№дёҖж ·пјҢйғҪжҳҜеҜ№ж–Ү法规еҲҷзҡ„дҪҝз”ЁпјҢдёҚиҝҮиҝҷдёӘжӣҙеҠ жё…жҷ°гҖӮжҲ‘们еҸҜд»Ҙжё…жҘҡзҡ„зңӢеҲ°пјҢ0-9зҡ„ж•°еӯ—жҲ–иҖ…иҜҙDigitExpressionеҸӘеҜ№еә”е”ҜдёҖдёҖз§Қж–№ејҸзҡ„йқһз»Ҳз»“иҖ…з¬ҰеҸ·пјҢе°ұжҳҜnumberпјҢжүҖд»ҘжҲ‘们зӣҙжҺҘиҪ¬жҚўжҲҗNumberExpressionгҖӮ
дёҚиҝҮжҲ‘们зҡ„иҪ¬жҚўжҳҜз”ұз»Ҳз»“иҖ…з¬ҰеҸ·еҸҚеҗ‘иҪ¬жҚўжҲҗйқһз»Ҳз»“иҖ…з¬ҰеҸ·зҡ„йЎәеәҸпјҢд№ҹе°ұжҳҜзӣёеҪ“дәҺд»ҺжҠҪиұЎиҜӯжі•ж ‘зҡ„дҪҺз«Ҝеҗ‘дёҠиҪ¬жҚўзҡ„йЎәеәҸгҖӮе…¶е®һзӣёеҪ“дәҺLZзңҒеҺ»дәҶжҠҪиұЎиҜӯжі•ж ‘зҡ„жҪңеңЁжһ„е»әиҝҮзЁӢпјҢзӣҙжҺҘејҖе§Ӣи§ЈйҮҠиЎЁиҫҫејҸгҖӮ
жҲ‘们зңӢдёҠйқўзҡ„зұ»еӣҫдёӯпјҢйқһз»Ҳз»“иҖ…иЎЁиҫҫејҸжңүдёҖжқЎеҲ°жҠҪиұЎиЎЁиҫҫејҸзҡ„иҒҡеҗҲзәҝпјҢйӮЈе…¶е®һжҳҜе°Ҷйқһз»Ҳз»“иҖ…иЎЁиҫҫејҸжҢүз…§дә§з”ҹејҸеҲҶи§Јзҡ„иҝҮзЁӢпјҢиҝҷдјҡжҳҜдёҖдёӘйҖ’еҪ’зҡ„иҝҮзЁӢпјҢиҖҢжҲ‘们зңҒеҺ»дәҶиҝҷдёҖжӯҘпјҢзӣҙжҺҘйҮҮз”ЁеҸҚеҗ‘и®Ўз®—зҡ„ж–№ејҸгҖӮ
然еҗҺеҶҚиҜҙиҜҙжҲ‘们зҡ„иҜӯжі•еҲҶжһҗеҷЁпјҢе®ғзҡ„е·ҘдҪңе°ұжҳҜе°Ҷз»Ҳз»“иҖ…з¬ҰеҸ·еҜ№еә”дёҠеҜ№еә”зҡ„иЎЁиҫҫејҸпјҢеҸҜд»ҘзңӢеҲ°е®ғйҮҢйқўзҡ„swichз»“жһ„е°ұжҳҜз”ЁжқҘйҖүеҸ–иЎЁиҫҫејҸзҡ„гҖӮе®һйҷ…еҪ“дёӯпјҢжҲ‘们еҪ“然дёҚдјҡеҶҷиҝҷд№Ҳзіҹзі•зҡ„swichз»“жһ„пјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁеҫҲеӨҡж–№ејҸдјҳеҢ–е®ғгҖӮеҪ“然пјҢиҜӯжі•еҲҶжһҗеҷЁзҡ„еҸҰеӨ–дёҖдёӘе·ҘдҪңе°ұжҳҜжЈҖжҹҘиҜӯжі•зҡ„жӯЈзЎ®жҖ§пјҢиҝҷзӮ№еҸҜд»Ҙд»ҺдёӨдёӘcheckж–№жі•жҳҺжҳҫзҡ„зңӢеҲ°гҖӮ
дёҚиҝҮеҫҲйҒ—жҶҫпјҢеңЁж—Ҙеёёе·ҘдҪңеҪ“дёӯпјҢжҲ‘们дҪҝз”ЁеҲ°и§ЈйҮҠеҷЁжЁЎејҸзҡ„жҰӮзҺҮеҮ д№Һдёә0пјҢеӣ дёәеҶҷдёҖдёӘи§ЈйҮҠеҷЁе°ұеҹәжң¬зӣёеҪ“дәҺеҲӣйҖ дәҶдёҖз§ҚиҜӯиЁҖпјҢиҝҷеҜ№дәҺеӨ§еӨҡж•°дәәжқҘиҜҙпјҢжҳҜеҮ д№ҺдёҚеҸҜиғҪжҺҘеҲ°зҡ„е·ҘдҪңгҖӮдёҚиҝҮжҲ‘们дәҶи§ЈдёҖдёӢи§ЈйҮҠеҷЁжЁЎејҸпјҢиҝҳжҳҜеҜ№жҲ‘们жңүеҘҪеӨ„зҡ„гҖӮ
еүҚйқўе·Із»ҸжҸҗеҲ°иҝҮи§ЈйҮҠеҷЁжЁЎејҸйҖӮз”Ёзҡ„еңәжҷҜпјҢжҲ‘们иҝҷйҮҢз»“еҗҲдёҠйқўзҡ„дҫӢеӯҗжҖ»з»“дёҖдёӢи§ЈйҮҠеҷЁжЁЎејҸзҡ„дјҳзӮ№пјҡ
1гҖҒз”ұдәҺжҲ‘们дҪҝз”Ёе…·дҪ“зҡ„з»Ҳжӯўз¬Ұе’Ңйқһз»Ҳжӯўз¬ҰеҺ»и§ЈйҮҠж–Үжі•пјҢжүҖд»ҘдјҡжҜ”иҫғжҳ“дәҺзј–еҶҷгҖӮ
2гҖҒеҸҜд»ҘжҜ”иҫғж–№дҫҝзҡ„дҝ®ж”№е’Ңжү©еұ•ж–Ү法规еҲҷгҖӮ
зӣёеҜ№дәҺдјҳзӮ№жқҘиҜҙпјҢе®ғзҡ„зјәзӮ№д№ҹйқһеёёжҳҺжҳҫпјҢйӮЈе°ұжҳҜз”ұдәҺжҲ‘们еҮ д№Һй’ҲеҜ№жҜҸдёҖдёӘ规еҲҷйғҪе®ҡд№үдәҶдёҖдёӘзұ»пјҢжүҖд»ҘеҰӮжһңдёҖдёӘж–Үжі•зҡ„规еҲҷжҜ”иҫғеӨҡпјҢйӮЈеҜ№дәҺж–Үжі•зҡ„з»ҙжҠӨе·ҘдҪңд№ҹдјҡеҸҳеҫ—йқһеёёеӣ°йҡҫгҖӮ
дёӢйқўLZе°ҶжҲ‘们дҫӢеӯҗзҡ„зұ»еӣҫиҙҙдёҠжқҘпјҢеҗ„дҪҚеҸӮиҖғдёҖдёӢгҖӮ
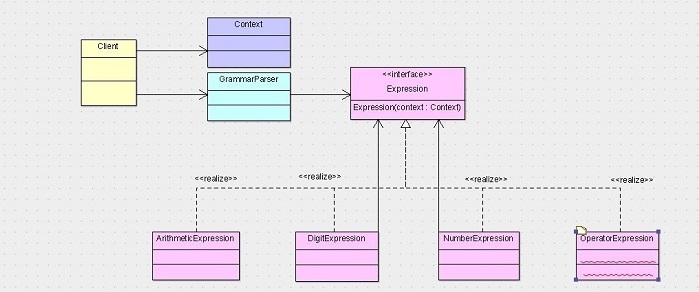
й’ҲеҜ№иҝҷдёӘзұ»еӣҫпјҢLZз®ҖеҚ•зҡ„иҜҙдёӨзӮ№гҖӮ
1гҖҒClientжң¬жқҘжҳҜе…іиҒ”зҡ„ExpressionжҺҘеҸЈпјҢдёҚиҝҮз”ұдәҺдёӯй—ҙеҠ дәҶдёӘиҜӯжі•еҲҶжһҗеҷЁпјҲGrammerParserпјүпјҢжүҖд»ҘеҸҳжҲҗдәҶClientе…іиҒ”иҜӯжі•еҲҶжһҗеҷЁпјҢиҜӯжі•еҲҶжһҗеҷЁеҶҚе…іиҒ”ExpressionжҺҘеҸЈгҖӮ
2гҖҒз”ұдәҺжҲ‘们йҮҮз”ЁеҸҚеҗ‘и®Ўз®—зҡ„ж–№ејҸпјҢжүҖд»Ҙйқһз»Ҳз»“иҖ…иЎЁиҫҫејҸжІЎжңүеҲ°ExpressionжҺҘеҸЈзҡ„иҒҡеҗҲзәҝпјҢиҖҢжҳҜз”ұдёӨжқЎе…іиҒ”зәҝд»ЈжӣҝдәҶдёӨжқЎиҒҡеҗҲзәҝгҖӮ
и§ЈйҮҠеҷЁжЁЎејҸзҡ„еҲҶдә«е°ұеҲ°жӯӨз»“жқҹдәҶпјҢеҗ„дҪҚеҸӘиҰҒеӨ§иҮҙдәҶи§ЈдёҖдёӢеҚіеҸҜпјҢеҰӮжһңе®һеңЁзҗҶи§ЈдёҚдәҶпјҢд№ҹдёҚеҝ…жӯ»жҠ иҝҷдёӘжЁЎејҸгҖӮ
еӯҰд№ и®ҫи®ЎжЁЎејҸпјҢжңүж—¶еҖҷе°ұеғҸиҝҪеҘіз”ҹдёҖж ·пјҢеҰӮжһңдҪ жҖҺд№ҲиҝҪйғҪиҝҪдёҚдёҠпјҢйӮЈиҜҙжҳҺзјҳеҲҶжңӘеҲ°пјҢиҜҘж”ҫејғзҡ„ж—¶еҖҷе°ұеҫ—ж”ҫејғпјҢиҜҙдёҚе®ҡе“ӘеӨ©зјҳеҲҶеҲ°дәҶпјҢдёҚйңҖиҰҒдҪ иҝҪпјҢдҪ еҝғдёӯзҡ„еҘ№иҮӘ然е°ұдёҠй’©дәҶгҖӮжүҖд»ҘеҰӮжһңжңүе“ӘдёҖдёӘи®ҫи®ЎжЁЎејҸдёҖж—¶еҚҠдјҡзҗҶи§ЈдёҚдәҶпјҢиҜ·дёҚиҰҒзқҖжҖҘеҺ»зҗҶи§Је®ғпјҢдёҚзҗҶи§Јзҡ„еҺҹеӣ жҳҜеӣ дёәдҪ зҡ„з§ҜзҙҜиҝҳдёҚеӨҹпјҢеҰӮжһңйңёзҺӢзЎ¬дёҠеј“зҡ„иҜқпјҢеҫҖеҫҖдјҡиў«и®ҫи®ЎжЁЎејҸжҡҙжҸҚдёҖйЎҝпјҢжңҖеҗҺиҝҳеҫ—иҮӘе·ұд»ҳеҢ»иҚҜиҙ№гҖӮ
LZеҸӘжғіиҜҙпјҢдҪ•еҝ…е‘ўпјҹ
еҲ°иҝҷзҜҮж–Үз« дёәжӯўпјҢLZе·Із»Ҹе°ҶжүҖжңү24з§Қи®ҫи®ЎжЁЎејҸе…ЁйғЁи®Іи§ЈдәҶдёҖйҒҚпјҢе…¶дёӯжңүеҘҪжңүеқҸпјҢжңүеҜ№жңүй”ҷгҖӮдёҚиҝҮдёҚз®ЎжҖҺж ·пјҢLZжң¬дәәзҡ„收иҺ·иҝҳжҳҜеҫҲеӨ§зҡ„пјҢд№ҹеҫҲж„ҹи°ўиҝҷеҪ“дёӯж”ҜжҢҒLZзҡ„зҢҝеҸӢгҖӮи®ҫи®ЎжЁЎејҸзі»еҲ—жҲ–и®ёиҝҳдјҡжңүжңҖеҗҺдёҖзҜҮпјҢеҶ…е®№иҮӘ然жҳҜеҜ№24з§Қи®ҫи®ЎжЁЎејҸзҡ„жҖ»з»“пјҢLZжңҖиҝ‘д№ҹеңЁдёәжӯӨиҖҢеҮҶеӨҮзқҖпјҢ敬иҜ·еҗ„дҪҚзҢҝеҸӢж“Ұдә®еҸҢзңјжңҹеҫ…еҗ§гҖӮ
дёҖдёӘзі»еҲ—з»“жқҹдәҶпјҢдёҚд»ЈиЎЁLZзҡ„еӯҰд№ д№Ӣи·Ҝз»“жқҹдәҶпјҢеңЁдёҠдёҖз« е·Із»ҸжҸҗеҲ°иҝҮпјҢLZжңҖиҝ‘еңЁз ”究иҷҡжӢҹжңәжәҗз ҒпјҢеңЁжҺҘдёӢжқҘзҡ„ж—¶й—ҙйҮҢпјҢLZжҲ–и®ёдјҡеҶҷдёҖдәӣдёҺиҷҡжӢҹжңәзӣёе…ізҡ„еҶ…е®№пјҢеҰӮжһңжңүе“ӘдҪҚзҢҝеҸӢеҜ№иҷҡжӢҹжңәжңүе…ҙи¶Јзҡ„иҜқпјҢеҸҜд»Ҙ继з»ӯе…іжіЁдёӢLZгҖӮ
В
иҪ¬иҮӘ:http://www.uml.org.cn/j2ee/201311044.asp
|





зӣёе…іжҺЁиҚҗ
Java дёӯ 23 з§Қи®ҫи®ЎжЁЎејҸиҜҰи§Ј еңЁиҪҜ件и®ҫи®ЎдёӯпјҢи®ҫи®ЎжЁЎејҸжҳҜи§ЈеҶізү№е®ҡй—®йўҳзҡ„йҖҡз”Ёи§ЈеҶіж–№жЎҲгҖӮ Java дёӯжңү 23 з§Қеёёи§Ғзҡ„и®ҫи®ЎжЁЎејҸпјҢдёӢйқўе°ҶеҜ№жҜҸз§Қи®ҫи®ЎжЁЎејҸиҝӣиЎҢиҜҰз»Ҷзҡ„и§ЈйҮҠпјҡ 1. жҠҪиұЎе·ҘеҺӮжЁЎејҸпјҲAbstract Factoryпјү жҠҪиұЎе·ҘеҺӮжЁЎејҸ...
и®ҫи®ЎжЁЎејҸ зҡ„еҲҶзұ» жҖ»дҪ“жқҘиҜҙи®ҫи®ЎжЁЎејҸеҲҶдёәдёүеӨ§зұ»пјҡ еҲӣе»әеһӢжЁЎејҸпјҲ5пјүпјҡ ...зӯ–з•ҘжЁЎејҸгҖҒжЁЎжқҝж–№жі•жЁЎејҸгҖҒи§ӮеҜҹиҖ…жЁЎејҸгҖҒиҝӯд»ЈеӯҗжЁЎејҸгҖҒиҙЈд»»й“ҫжЁЎејҸгҖҒе‘Ҫд»ӨжЁЎејҸгҖҒеӨҮеҝҳеҪ•жЁЎејҸгҖҒзҠ¶жҖҒжЁЎејҸгҖҒи®ҝй—®иҖ…жЁЎејҸгҖҒдёӯд»ӢиҖ…жЁЎејҸгҖҒи§ЈйҮҠеҷЁжЁЎејҸгҖӮ
- и§ЈйҮҠеҷЁжЁЎејҸпјҲInterpreterпјүпјҡз»ҷе®ҡдёҖз§ҚиҜӯиЁҖпјҢе®ҡд№үе…¶иҜӯжі•зҡ„иЎЁзӨәпјҢ并жҸҗдҫӣдёҖдёӘи§ЈйҮҠеҷЁжқҘеӨ„зҗҶиҝҷз§ҚиҜӯиЁҖдёӯзҡ„еҸҘеӯҗгҖӮ - иҝӯд»ЈеҷЁжЁЎејҸпјҲIteratorпјүпјҡжҸҗдҫӣдёҖз§Қж–№жі•йЎәеәҸи®ҝй—®иҒҡеҗҲеҜ№иұЎзҡ„е…ғзҙ пјҢиҖҢеҸҲдёҚжҡҙйңІе…¶еә•еұӮиЎЁзӨәгҖӮ - дёӯд»ӢиҖ…...
15. **и§ЈйҮҠеҷЁжЁЎејҸ**пјҡе®ҡд№үдёҖдёӘиЎЁзӨәиҜӯиЁҖзҡ„ж–Үжі•пјҢ并з»ҷеҮәдёҖдёӘи§ЈйҮҠеҷЁпјҢз”ЁдәҺи§ЈйҮҠиҜӯиЁҖдёӯзҡ„еҸҘеӯҗгҖӮ 16. **иҝӯд»ЈеҷЁжЁЎејҸ**пјҡжҸҗдҫӣдёҖз§Қж–№жі•йЎәеәҸи®ҝй—®иҒҡеҗҲеҜ№иұЎзҡ„е…ғзҙ пјҢиҖҢеҸҲдёҚжҡҙйңІе…¶еә•еұӮиЎЁзӨәгҖӮ 17. **дёӯд»ӢиҖ…жЁЎејҸ**пјҡз”ЁдёҖдёӘдёӯд»ӢеҜ№иұЎ...
15. **и§ЈйҮҠеҷЁжЁЎејҸпјҲInterpreterпјү**пјҡз»ҷе®ҡдёҖз§ҚиҜӯиЁҖпјҢе®ҡд№үе®ғзҡ„ж–Үжі•иЎЁзӨәпјҢ并且жҸҗдҫӣдёҖдёӘи§ЈйҮҠеҷЁпјҢиҜҘи§ЈйҮҠеҷЁз”ЁдәҺж №жҚ®иҝҷз§Қж–Үжі•еӨ„зҗҶиҫ“е…ҘгҖӮ 16. **иҝӯд»ЈеҷЁжЁЎејҸпјҲIteratorпјү**пјҡжҸҗдҫӣдёҖз§Қж–№жі•йЎәеәҸи®ҝй—®иҒҡеҗҲеҜ№иұЎдёӯзҡ„е…ғзҙ пјҢиҖҢеҸҲдёҚ...
жң¬дё»йўҳе°Ҷж·ұе…ҘжҺўи®ЁJavaејҖеҸ‘дёӯзҡ„23з§Қи®ҫи®ЎжЁЎејҸпјҢиҝҷдәӣжЁЎејҸиў«е№ҝжіӣеә”з”ЁдәҺеҲӣе»әгҖҒз»“жһ„е’ҢиЎҢдёәдёүдёӘдё»иҰҒзұ»еҲ«пјҢж—ЁеңЁжҸҗй«ҳд»Јз Ғзҡ„еҸҜиҜ»жҖ§гҖҒеҸҜз»ҙжҠӨжҖ§е’ҢеӨҚз”ЁжҖ§гҖӮ дёҖгҖҒеҲӣе»әеһӢи®ҫи®ЎжЁЎејҸпјҡ 1. еҚ•дҫӢжЁЎејҸпјҡзЎ®дҝқдёҖдёӘзұ»еҸӘжңүдёҖдёӘе®һдҫӢпјҢ并жҸҗдҫӣдёҖ...
Javaдёӯзҡ„23з§Қи®ҫи®ЎжЁЎејҸиў«е№ҝжіӣеә”з”ЁдәҺжҸҗй«ҳд»Јз Ғзҡ„еҸҜиҜ»жҖ§гҖҒеҸҜз»ҙжҠӨжҖ§е’ҢзҒөжҙ»жҖ§гҖӮд»ҘдёӢжҳҜеҜ№иҝҷдәӣжЁЎејҸзҡ„иҜҰз»Ҷи§ЈйҮҠпјҡ 1. **е·ҘеҺӮжЁЎејҸ**пјҲFactory MethodпјүпјҡиҝҷжҳҜдёҖз§ҚеҲӣе»әеһӢи®ҫи®ЎжЁЎејҸпјҢе®ғжҸҗдҫӣдәҶдёҖдёӘжҺҘеҸЈжқҘеҲӣе»әеҜ№иұЎпјҢдҪҶе…Ғи®ёеӯҗзұ»еҶіе®ҡ...
гҖҗAndroidзј–зЁӢи®ҫи®ЎжЁЎејҸд№Ӣи§ЈйҮҠеҷЁжЁЎејҸиҜҰи§ЈгҖ‘ и§ЈйҮҠеҷЁжЁЎејҸпјҲInterpreter PatternпјүжҳҜи®ҫи®ЎжЁЎејҸдёӯзҡ„дёҖз§ҚиЎҢдёәжЁЎејҸпјҢдё»иҰҒз”ЁдәҺи§Јжһҗзү№е®ҡиҜӯиЁҖжҲ–иЎЁиҫҫејҸгҖӮеңЁAndroidејҖеҸ‘дёӯпјҢе°Ҫз®ЎдёҚеёёи§ҒпјҢдҪҶеҪ“йңҖиҰҒиҮӘе®ҡд№үз®ҖеҚ•зҡ„иҜӯиЁҖжҲ–иҖ…иЎЁиҫҫејҸи§ЈйҮҠ...
15. **и§ЈйҮҠеҷЁжЁЎејҸпјҲInterpreterпјү**пјҡз»ҷе®ҡдёҖдёӘиҜӯиЁҖпјҢе®ҡд№үе®ғзҡ„ж–Үжі•иЎЁзӨәпјҢ并жҸҗдҫӣдёҖдёӘи§ЈйҮҠеҷЁжқҘеӨ„зҗҶиҜҘиҜӯиЁҖдёӯзҡ„еҸҘеӯҗгҖӮ 16. **иҝӯд»ЈеҷЁжЁЎејҸпјҲIteratorпјү**пјҡжҸҗдҫӣдёҖз§Қж–№жі•йЎәеәҸи®ҝй—®иҒҡеҗҲеҜ№иұЎзҡ„е…ғзҙ пјҢиҖҢеҸҲдёҚжҡҙйңІе…¶еә•еұӮиЎЁзӨәгҖӮ ...
- **и§ЈйҮҠеҷЁжЁЎејҸпјҲInterpreterпјү**пјҡз»ҷе®ҡдёҖдёӘиҜӯиЁҖпјҢе®ҡд№үе®ғзҡ„ж–Үжі•иЎЁзӨәпјҢ并жҸҗдҫӣдёҖдёӘи§ЈйҮҠеҷЁжқҘеӨ„зҗҶиҝҷдёӘиҜӯиЁҖдёӯзҡ„еҸҘеӯҗгҖӮ - **и®ҝй—®иҖ…жЁЎејҸпјҲVisitorпјү**пјҡиЎЁзӨәдёҖдёӘдҪңз”ЁдәҺжҹҗеҜ№иұЎз»“жһ„дёӯзҡ„еҗ„е…ғзҙ зҡ„ж“ҚдҪңгҖӮе®ғдҪҝдҪ еҸҜд»ҘеңЁдёҚж”№еҸҳ...
"23з§Қи®ҫи®ЎжЁЎејҸиҜҰи§ЈеҸҠжЎҲдҫӢ"ж¶өзӣ–дәҶиҝҷдәӣжЁЎејҸзҡ„зҗҶи®әеҹәзЎҖе’Ңе®һйҷ…еә”з”ЁпјҢж—ЁеңЁеё®еҠ©ејҖеҸ‘иҖ…жӣҙеҘҪең°зҗҶи§Је’ҢжҺҢжҸЎе®ғ们гҖӮ 1. **еҚ•дҫӢжЁЎејҸ**пјҡдҝқиҜҒдёҖдёӘзұ»еҸӘжңүдёҖдёӘе®һдҫӢпјҢеёёз”ЁдәҺз®ЎзҗҶе…ұдә«иө„жәҗпјҢеҰӮж•°жҚ®еә“иҝһжҺҘгҖӮеңЁAndroidдёӯпјҢеҚ•дҫӢжЁЎејҸеёёз”ЁдәҺ...
иЎҢдёәжЁЎејҸжҳҜжҢҮеңЁеҜ№иұЎзҡ„иЎҢдёәдёҠдҪҝз”Ёзҡ„жЁЎејҸпјҢеҢ…жӢ¬ IteratorпјҲиҝӯд»ЈжЁЎејҸпјүгҖҒTemplateпјҲжЁЎжқҝжЁЎејҸпјүгҖҒChain of ResponsibilityпјҲиҙЈд»»й“ҫжЁЎејҸпјүгҖҒMementoпјҲзәӘеҝөе“ҒжЁЎејҸпјүгҖҒMediatorпјҲдёӯд»ӢжЁЎејҸпјүгҖҒInterpreterпјҲи§ЈйҮҠеҷЁжЁЎејҸпјүгҖҒ...
жң¬ж–ҮжЎЈиҜҰз»Ҷд»Ӣз»ҚдәҶ23з§ҚC#и®ҫи®ЎжЁЎејҸпјҢеҢ…жӢ¬еҲӣе»әеһӢгҖҒз»“жһ„еһӢе’ҢиЎҢдёәеһӢдёүдёӘеӨ§зұ»гҖӮиҝҷдәӣи®ҫи®ЎжЁЎејҸжҳҜ.NETиҝӣйҳ¶еҝ…еӨҮзҡ„зҹҘиҜҶпјҢйҖҡиҝҮеӯҰд№ е’ҢжҺҢжҸЎиҝҷдәӣи®ҫи®ЎжЁЎејҸпјҢеҸҜд»ҘжҸҗй«ҳзЁӢеәҸе‘ҳзҡ„и®ҫи®Ўе’Ңзј–з ҒиғҪеҠӣгҖӮ еҲӣе»әеһӢи®ҫи®ЎжЁЎејҸ 1. еҚ•д»¶жЁЎејҸ...
д»ҘдёҠ23з§Қи®ҫи®ЎжЁЎејҸйғҪжҳҜиҪҜ件и®ҫи®Ўдёӯзҡ„е®қиҙөз»ҸйӘҢпјҢзҗҶ解并зҶҹз»ғеә”з”ЁиҝҷдәӣжЁЎејҸпјҢиғҪеё®еҠ©ејҖеҸ‘иҖ…еҶҷеҮәжӣҙй«ҳж•ҲгҖҒеҸҜз»ҙжҠӨзҡ„д»Јз ҒпјҢжҸҗеҚҮзі»з»ҹзҡ„еҸҜжү©еұ•жҖ§е’ҢзҒөжҙ»жҖ§гҖӮйҖҡиҝҮйҳ…иҜ»жҸҗдҫӣзҡ„"DesignPattern"еҺӢзј©еҢ…ж–Ү件пјҢеҸҜд»Ҙж·ұе…ҘеӯҰд№ жҜҸз§ҚжЁЎејҸзҡ„е®һзҺ°...
и§ЈйҮҠеҷЁжЁЎејҸпјҡз»ҷе®ҡдёҖдёӘиҜӯиЁҖпјҢе®ҡд№үе®ғзҡ„ж–Үжі•зҡ„дёҖз§ҚиЎЁзӨәпјҢ并е®ҡд№үдёҖдёӘи§ЈйҮҠеҷЁгҖӮ зӯ–з•ҘжЁЎејҸпјҡе®ҡд№үдёҖзі»еҲ—з®—жі•пјҢжҠҠ他们е°ҒиЈ…иө·жқҘпјҢ并且дҪҝе®ғ们еҸҜд»Ҙзӣёдә’жӣҝжҚўгҖӮ зҠ¶жҖҒжЁЎејҸпјҡе…Ғи®ёдёҖдёӘеҜ№иұЎеңЁе…¶еҜ№иұЎеҶ…йғЁзҠ¶жҖҒж”№еҸҳж—¶ж”№еҸҳе®ғзҡ„иЎҢдёәгҖӮ ...
3. и§ЈйҮҠеҷЁжЁЎејҸпјҲInterpreterпјүпјҡз»ҷе®ҡдёҖз§ҚиҜӯиЁҖпјҢе®ҡд№үе®ғзҡ„ж–Үжі•иЎЁзӨәпјҢ并жҸҗдҫӣдёҖдёӘи§ЈйҮҠеҷЁжқҘеӨ„зҗҶиҜҘиҜӯиЁҖдёӯзҡ„еҸҘеӯҗгҖӮ 4. иҝӯд»ЈеҷЁжЁЎејҸпјҲIteratorпјүпјҡжҸҗдҫӣдёҖз§Қж–№жі•йЎәеәҸи®ҝй—®иҒҡеҗҲеҜ№иұЎзҡ„е…ғзҙ пјҢиҖҢеҸҲдёҚжҡҙйңІе…¶еә•еұӮиЎЁзӨәгҖӮ 5. дёӯд»ӢиҖ…жЁЎејҸ...
Javaи®ҫи®ЎжЁЎејҸиҜҰи§Ј Javaи®ҫи®ЎжЁЎејҸжҳҜеүҚиҫҲ们еҜ№д»Јз ҒејҖеҸ‘з»ҸйӘҢзҡ„жҖ»з»“пјҢжҳҜи§ЈеҶізү№е®ҡй—®йўҳзҡ„дёҖзі»еҲ—еҘ—и·ҜгҖӮе®ғдёҚжҳҜиҜӯ法规е®ҡпјҢиҖҢжҳҜдёҖеҘ—з”ЁжқҘжҸҗй«ҳд»Јз ҒеҸҜеӨҚз”ЁжҖ§гҖҒеҸҜз»ҙжҠӨжҖ§гҖҒеҸҜиҜ»жҖ§гҖҒзЁіеҒҘжҖ§д»ҘеҸҠе®үе…ЁжҖ§зҡ„и§ЈеҶіж–№жЎҲгҖӮ... * и§ЈйҮҠеҷЁжЁЎејҸ
иҝҷ23з§Қи®ҫи®ЎжЁЎејҸеҢ…жӢ¬дҪҶдёҚйҷҗдәҺеҚ•дҫӢжЁЎејҸгҖҒе·ҘеҺӮжЁЎејҸгҖҒе»әйҖ иҖ…жЁЎејҸгҖҒеҺҹеһӢжЁЎејҸгҖҒйҖӮй…ҚеҷЁжЁЎејҸгҖҒжЎҘжҺҘжЁЎејҸгҖҒз»„еҗҲжЁЎејҸгҖҒиЈ…йҘ°жЁЎејҸгҖҒеӨ–и§ӮжЁЎејҸгҖҒдә«е…ғжЁЎејҸгҖҒд»ЈзҗҶжЁЎејҸгҖҒе‘Ҫд»ӨжЁЎејҸгҖҒиҙЈд»»й“ҫжЁЎејҸгҖҒи§ЈйҮҠеҷЁжЁЎејҸгҖҒиҝӯд»ЈеҷЁжЁЎејҸгҖҒдёӯд»ӢиҖ…жЁЎејҸгҖҒ...
и§ЈйҮҠеҷЁжЁЎејҸдёәдёҖдёӘиҜӯиЁҖе®ҡд№үе®ғзҡ„ж–Үжі•зҡ„дёҖз§ҚиЎЁзӨәпјҢ并еҗҢж—¶жҸҗдҫӣдёҖдёӘи§ЈйҮҠеҷЁгҖӮ и®ҫи®ЎжЁЎејҸзҡ„е…ӯеӨ§еҺҹеҲҷеҢ…жӢ¬пјҡејҖй—ӯеҺҹеҲҷгҖҒйҮҢж°Ҹд»ЈжҚўеҺҹеҲҷгҖҒдҫқиө–еҖ’иҪ¬еҺҹеҲҷгҖҒжҺҘеҸЈйҡ”зҰ»еҺҹеҲҷгҖҒиҝӘзұізү№жі•еҲҷпјҲжңҖе°‘зҹҘйҒ“еҺҹеҲҷпјүгҖҒз»„еҗҲ/иҒҡеҗҲеӨҚз”ЁеҺҹеҲҷгҖӮејҖй—ӯеҺҹеҲҷ...