
先介绍hadoop2.0 HA的基本原理和2种方式。
一、概述
在hadoop2.0之前,namenode只有一个,存在单点问题(虽然hadoop1.0有secondarynamenode,checkpointnode,buckcupnode这些,但是单点问题依然存在),对于只有一个NameNode 的集群,如果NameNode 机器出现故障,那么整个集群将无法使用,直到NameNode 重新启动。
NameNode 主要在以下两个方面影响HDFS 集群:
(1). NameNode 机器发生意外,比如宕机,集群将无法使用,直到管理员重启NameNode
(2). NameNode 机器需要升级,包括软件、硬件升级,此时集群也将无法使用HDFS 的HA 功能通过配置Active/Standby 两个NameNodes 实现在集群中对NameNode 的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode 很快的切换到另外一台机器。
在hadoop2.0引入了HA机制。hadoop2.0的HA机制官方介绍了有2种方式,一种是NFS(Network File System)方式,另外一种是QJM(Quorum Journal Manager)方式。
二、基本原理
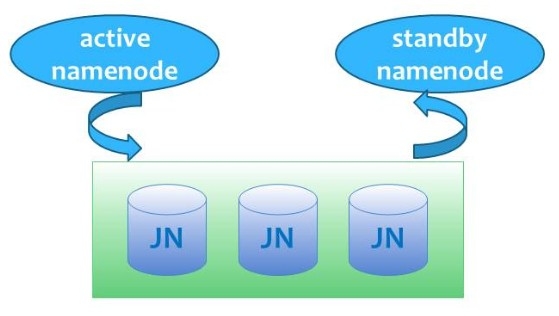
hadoop2.0的HA 机制有两个namenode,一个是active namenode,状态是active;另外一个是standby namenode,状态是standby。两者的状态是可以切换的,但不能同时两个都是active状态,最多只有1个是active状态。只有active namenode提供对外的服务,standby namenode是不对外服务的。active namenode和standby namenode之间通过NFS或者JN(journalnode,QJM方式)来同步数据。

active namenode会把最近的操作记录写到本地的一个edits文件中(edits file),并传输到NFS或者JN中。standby namenode定期的检查,从NFS或者JN把最近的edit文件读过来,然后把edits文件和fsimage文件合并成一个新的fsimage,合并完成之后会通知active namenode获取这个新fsimage。active namenode获得这个新的fsimage文件之后,替换原来旧的fsimage文件。
这样,保持了active namenode和standby namenode的数据的实时同步,standby namenode可以随时切换成active namenode(譬如active namenode挂了)。而且还有一个原来hadoop1.0的secondarynamenode,checkpointnode,buckcupnode的功能:合并edits文件和fsimage文件,使fsimage文件一直保持更新。所以启动了hadoop2.0的HA机制之后,secondarynamenode,checkpointnode,buckcupnode这些都不需要了。
三、NFS方式
NFS作为active namenode和standby namenode之间数据共享的存储。active namenode会把最近的edits文件写到NFS,而standby namenode从NFS中把数据读过来。这个方式的缺点是,如果active namenode或者standby namenode有一个和NFS之间网络有问题,则会造成他们之前数据的同步出问题。

四、QJM(Quorum Journal Manager )方式
QJM的方式可以解决上述NFS容错机制不足的问题。active namenode和standby namenode之间是通过一组journalnode(数量是奇数,可以是3,5,7...,2n+1)来共享数据。active namenode把最近的edits文件写到2n+1个journalnode上,只要有n+1个写入成功就认为这次写入操作成功了,然后standby namenode就可以从journalnode上读取了。可以看到,QJM方式有容错的机制,可以容忍n个journalnode的失败。
五、主备节点的切换
active namenode和standby namenode可以随时切换。当active namenode挂掉后,也可以把standby namenode切换成active状态,成为active namenode。可以人工切换和自动切换。人工切换是通过执行HA管理的命令来改变namenode的状态,从standby到active,或者从active到standby。自动切换则在active namenode挂掉的时候,standby namenode自动切换成active状态,取代原来的active namenode成为新的active namenode,HDFS继续正常工作。
主备节点的自动切换需要配置zookeeper。active namenode和standby namenode把他们的状态实时记录到zookeeper中,zookeeper监视他们的状态变化。当zookeeper发现active namenode挂掉后,会自动把standby namenode切换成active namenode。

六、实战tips
QJM方式有明显的优点,一是本身就有fencing的功能,二是通过多个journal节点增强了系统的健壮性,所以建议在生成环境中采用QJM的方式。
journalnode消耗的资源很少,不需要额外的机器专门来启动journalnode,可以从hadoop集群中选几台机器同时作为journalnode。



相关推荐
在Hadoop 2.0中,NameNode的High Availability(HA)和Federation是为了解决传统Hadoop架构中的两个关键问题:单点故障和集群扩展性。在Hadoop 2.0之前,NameNode作为HDFS的核心组件,它的单点故障可能导致整个...
### Hadoop2.0分布式HA环境部署 #### Hadoop2.0 HA机制概览 Hadoop2.0相比Hadoop1.0,在集群稳定性与可用性方面进行了显著增强,特别是引入了High Availability (HA)机制。Hadoop1.0中仅存在单一的NameNode作为元...
本文将详细介绍在Hadoop 2.0环境下进行集群部署的关键步骤。 1. **创建统一用户账户** 在所有节点上创建相同用户名(如 hadoop)是部署的基础,确保节点间操作的一致性。用户权限的统一有助于简化管理和权限设置。...
1. **NameNode HA**:Hadoop 2.0引入了NameNode HA机制,该机制支持两个NameNode实例——一个是处于活动状态的Active NameNode,另一个是处于备用状态的Standby NameNode。Active NameNode负责提供服务,而Standby ...
在Hadoop 2.0中,HDFS引入了NameNode HA(High Availability)和 Federation,增强了系统的可用性和可扩展性。 1. NameNode HA:通过引入两个活动的NameNode,解决了单点故障问题。当一个NameNode出现故障时,另一...
### Hadoop 2.0:从YARN到下一代大数据处理平台 #### 1. Hadoop 2.0:新时代的大数据处理平台 Hadoop 2.0是Apache Hadoop的一个重要版本,它标志着Hadoop从单一的MapReduce计算框架转变为一个更加通用、可扩展和...
所谓HA,即高可用,实现高可用最关键的是消除单点故障,hadoop-ha严格来说应该分成各个组件的HA机制——HDFS的HA、YARN的HA;通过双namenode消除单点故障;通过双namenode协调工作
2. HDFS HA(High Availability):为了解决NameNode单点故障问题,Hadoop 2.0实现了NameNode高可用,通过热备机制确保服务不间断。 3. 更强的容错性和可扩展性:通过改进的数据节点心跳机制和快速失败检测,Hadoop...
本章节我们将深入探讨Hadoop2.0的新特性,包括YARN资源管理框架和Hadoop的高可用(HA)模式。 ### 1. Hadoop2.0的改进 #### (1) 从Hadoop1.0到Hadoop2.0 Hadoop1.0由MapReduce和HDFS两大部分组成,但在高可用性和...
2. **MapReduce 2.0**:MapReduce的实现也发生了变化,`org.apache.hadoop.mapreduce`包取代了`org.apache.hadoop.mapred`,提供了一个新的、更模块化的框架。新的MapReduce API更加面向Java 7,同时也支持更灵活的...
YARN是Hadoop 2.0版本引入的资源管理系统,它的核心思想是将资源管理和任务调度功能分离。YARN中的ResourceManager负责集群资源的管理和调度,而ApplicationMaster负责监控任务的执行,并处理任务的容错。YARN允许...
开源思想,少要积分,仅供学习参考。 Hadoop2.0 从0到HA安装运行步骤。 开源思想,少要积分,仅供学习参考。 Hadoop2.0 从0到HA安装运行步骤。
Hadoop 2.0 在原有的基础上引入了关键改进,包括高可用性(HA)、YARN(Yet Another Resource Negotiator)和HDFS联邦。 1. **Hadoop 2.0 高可用性(HA)**: - HDFS HA 通过引入Active/Standby NameNode的角色,...
8. **容错与高可用**:为了确保服务的连续性和稳定性,Hadoop 2.0提供了高可用性解决方案,如NameNode HA和ResourceManager HA,降低了单点故障的风险。 通过这份PPT课件,学习者将能够深入了解Hadoop 2.0在云架构...
《Hadoop 2.0:主流开源云架构(一)》是云计算第三版精品课程中的一个重要章节,专注于介绍Hadoop这一关键的分布式计算框架。在本章中,我们将深入探讨Hadoop 2.0的核心概念、架构以及它在云环境中的应用。 Hadoop...
在Hadoop 2.0中,为了解决单点故障问题,Hadoop社区引入了一系列的高可用性(HA)解决方案,以确保系统的关键组件能够持续运行,即使在某个节点失败时也能保持服务的稳定性。Hadoop 1.0的主要缺点在于MapReduce的...
Hadoop 2.0的另一个重要组成部分是HDFS联邦和高可用性(HA)功能。HDFS联邦提高了集群的扩展性和容错性,而高可用性配置则进一步提升了集群的稳定性和可靠性。此外,Hadoop 2.0还包括其他改进,如对内存计算的支持、...
- 配置`etc/hadoop/hdfs-site.xml`来设置HDFS的副本数、HA和Erasure Coding等参数。 - 对于YARN,需要在`etc/hadoop/yarn-site.xml`中配置资源管理器和应用历史服务器的相关参数。 4. **MapReduce编程模型**: -...
在本压缩包中,我们关注的是“云计算第三版精品课程配套PPT课件含习题(26页)第5章 Hadoop 2.0 主流开源云架构(二).pptx”,这是一个关于Hadoop 2.0的深度讲解,涵盖了云计算领域的核心概念和Hadoop作为主流开源...
此外,Hadoop 2.0还引入了HDFS HA(High Availability)和 Federation,增强了HDFS的稳定性和可扩展性。 在学习Hadoop的过程中,环境搭建是至关重要的一步。这包括配置Hadoop的运行环境,如安装Java环境,设置...