
Storm 概念梳理
刚接触storm,梳理了一些概念性的东西,对于 storm 中提到的一些名词做一些解释,重点在于搞清楚 storm 中很多组件设置的并发度,在实际的运行时是怎么体现出来的,另外对于设置 Stream 和 tuple 的 Grouping 方式相对于已有的文档,做了一些补充,这个对于写程序时设置Topology时会有帮助,有理解的不对的地方,欢迎指正。
1. storm
Storm是一个分布式实时计算系统。
全量数据处理一般使用Hadoop,但是Hadoop擅长海量数据批处理,不擅长实时计算,无法实时计算数据,并把结果反馈到系统。所以有很多的实时计算系统冒出来,Storm是其中之一。Jstorm是用Java 重写的Storm。
从应用的角度,JStorm 应用是一种遵守某种编程规范的分布式应用。从系统角度, JStorm一套类似MapReduce的调度系统。 从数据的角度, 是一套基于流水线的消息处理机制。--参考Jstorm 官方文档概叙
2. Stream
Storm中最核心的是Stream的概念:
从数据的角度,Storm是流水线式的,Tuple是基本的数据单元,由于Storm的计算过程是没有终止状态的,所以可以认为Tuple是源源不断的,没有边界的,一连串无边界的Tuple序列就构成了Stream。例如:一个Spout不断的发送tuple,一个Bolt订阅了这些tuple,之间就构成了一个Stream,Bolt处理完这些tuple,还可以把结果放在tuple中发出去,放进一个新的Stream中。
代码示例,如何声明Stream:
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 默认Stream
declarer.declare(new Fields("MessageExt"));
// id为directStream的stream
declarer.declareStream("directStream", false, new Fields("MessageExt"));
}
注意
如果声明Stream,或者订阅Stream的时候,没有显示指定Stream 的Id的,那么对应的Stream默认的Id是“default”
下图中的每一条边都代表一个Stream:
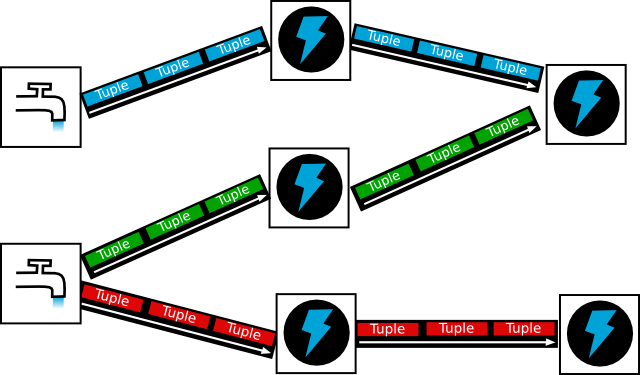
3. Jstorm中构建Topology的一些概念
-
Spot:每个stream都有一个stream源,也就是原始tuple的源头,像水龙头一样,所以将这个源头抽象为spout,tuple最开始是从这个节点发出。 -
Bolt:tuple的中间处理过程抽象为Bolt。只要Bolt订阅了流,上一级的Spot或Bolt一定会把tuple发送给它进行处理。 -
Tuple:发送数据的基本单元。 -
Stream Grouping:规定了tuple的发送方式
如果定义好了Spout和Bolt,以及它们之间的订阅关系,可以构成一个有向无环图,如下:

如果在项目中定义好了Spout、Bolt以及它们的订阅关系,从逻辑上构成了这个有向无环图(在storm/Jstorm中称为一个Topology),可以提交给Jstorm集群执行。
Storm/Jstorm集群的结构大概是这个样子:

Nimbus是master节点,负责分布代码,分发任务,监听失败。Jstorm可以有Nimbus集群,但是同一时刻只有一个有效,这里可以看成只有一个节点。Supervisor是Worker节点,负责执行具体数据处理的任务。Zookeeper集群负责协调整个Jstorm集群。
4. Worker、Executor、Tasks以及并发度
关于Topology在Jstorm具体的机器上的执行情况需要弄清楚Topology、Worker、Executor、Tasks这几个的概念和关系以及为它们设置的并发度:
-
Worker 运行在Supervisor节点上面,被Supervisor守护进程创建的用来干活的进程。每个Worker对应于一个给定topology的全部执行任务的一个子集。就是说,一个Worker里面不会运行属于不同的topology的执行任务。
Config.setNumWorkers(conf, 5);上面的代码相当于在集群中设置了5个Worker进程来执行Topology。
-
Executor可以理解成一个Worker进程中的工作线程(一个Worker进程中可以有一个或多个Executor线程)。一个Executor中只能运行隶属于同一个component(Spout/Bolt)的task。在默认情况下,一个Executor运行一个task。Spout和Bolt设置的并发度默认就是指的Executor的数量。
builder.setSpout("MetaqSpout",// componentID new MetaqSpout(),// Spout 对象 2); // Parallelism hint, 相当于Executor的数量上面的代码相当于设置componentID为
MetaqSpout的Spout的Executor数量为2,相当于起两个线程。 -
Task则是 Spout 和 Bolt 中具体要干的活。一个 Executor 可以负责1个或多个 Task。同时,Task 也是各个节点之间进行grouping的单位。
默认情况,一个Executor对应一个Task,如果这样设置:
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2) .setNumTasks(4) .shuffleGrouping("blue-spout);相当于设置2个Executor 4个Task,这样会起两个线程,每个执行两个Task。
下图显示了一个拓扑在运行时 Task 在 Worker 中的分配情况。拓扑中有三个 Component:一个Blue Spout,一个Green Bolt一个Yellow Bolt。parallelism_hint分别为2,2,6。

对应的代码中的设置如下:
Config conf = new Config();
conf.setNumWorkers(2);
topologyBuilder.setSpout(“blue-spout”, new BlueSpout(), 2); // set parallelism hint to 2
topologyBuilder.setBolt(“green-bolt”, new GreenBolt(), 2) .setNumTasks(4) .shuffleGrouping(“blue-spout”);
topologyBuilder.setBolt(“yellow-bolt”, new YellowBolt(), 6) .shuffleGrouping(“green-bolt”);
StormSubmitter.submitTopology( “mytopology”, conf, topologyBuilder.createTopology() );
可以看出,并发度是10,总共设置了两个Worker进程,所以每个Worker起5个线程。green-bolt设置了4个Task,并发度是2,所以green-bolt一个线程里要执行两个Task。
更详细的内容见:Storm的基本概念
5. stream 的grouping 方式
一个 Bolt 可以设置为多个 Task 并发执行数据处理任务,假设订阅了一个 Spout 的 Stream,那么应该把 Spout 的数据发送给哪一个具体的Task执行,这个是由grouping的方式决定的。
Jstorm中的Grouping方式如下:
-
Shuffle Grouping:随机分组, 轮询的方式随机派发stream里面的tuple,它尽量保证订阅了数据的下一级的各个Task收到的tuple数量是相等的。Example:
假设有下一级有3个Task,数据源来了6个tuple,它可以保证前3个tuple是分别随机的发到了3个Task上,后3个也随机发到3个Task上。 -
Fields Grouping:类似SQL中的group by, 保证Stream中指定Field(一个或多个)上数据相同的tuple会发送到相同的Task,但是指定Field上数据不同也是有可能会发到一个Task上的。
原理是:对指定的Field上的数据做hash,然后用hash 结果求模得出目标taskId。Example:
假设Spout声明的输出是("Tags", "Message"),指定了按"Tags"分组,tuple是这样的:tuple1:["TagA","Message..."] tuple2:["TagA","Message..."] tuple3:["TagB","Message..."] tuple4:["TagA","Message..."]那么下一级Component的
Task收数据时,所有Tags为TagA的tuple都会被分到同一个Task上去,至于具体是哪一个Task是算出来的,没法手动指定。 -
All Grouping: 广播发送, 对于每一个tuple, 所有订阅了流的Bolts下所有Task都会收到. -
Global Grouping:全局分组,这个tuple被分配到拓扑中订阅了该流的Bolt的其中一个Task.再具体一点就是分配给id值最低的那个Task. -
Non Grouping:真正的随机发送tuple,和Shuffle Grouping不同的是不会尽量保证平均。 -
Direct Grouping:直接分组,这是一种比较特别的分组方法,用这种分组意味着消息的发送者知道由消息接收者的哪个task处理这个消息.如果声明了Direct Grouping的方式发送数据,则必须使用声明为Direct的Stream发送,而且这种消息的tuple必须使用emitDirect方法来发射。Direct的Stream在declareOutputFields(OutputFieldsDeclarer declarer)方法中声明。@Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(true, new Fields("MessageExt")); declarer.declareStream("directStream", true, new Fields("MessageExt")); }前一个将默认的Stream声明为
Direct,后一个将另外一个directStreamStream声明为Direct。 -
Custom Grouping:Jstorm新增的一个,没看懂要怎么用^_^ -
localOrShuffleGrouping:本worker优先,如果本worker内有目标component的task,则随机从本worker内部的目标component的task中进行选择,否则就和普通的shuffleGrouping一样。
Grouping的方式是比较多的,所以要用好需要理解用到的Grouping方式的细节,也需要更多的实际项目来积攒经验。



相关推荐
### Storm简介及安装知识点梳理 #### 一、Storm简介 **Storm** 是一款由BackType公司开发的分布式实时计算系统,后被Twitter收购并开源。它主要用于处理大规模的数据流,能够简单、高效、可靠地处理实时数据。...
标题“storm-strange-loop-***-phpapp01”暗示该文档可能涉及“Storm”和“Strange Loop”两个主要概念。Storm是一种开源的实时计算系统,它设计用于处理大量的数据流,并且具有分布式和容错特性。Strange Loop是一...
在深入探讨相关知识点之前,有必要对给定信息进行梳理。标题“models_sweetheart_storm_skin-solidworks”暗示了一个关于SolidWorks软件创建的模型项目,名为“sweetheart storm skin”。而描述部分反复强调“solid...
在软件开发过程中,用例建模是...用例建模不仅可以帮助梳理需求,还能促进团队间的沟通,降低项目风险。因此,它是软件工程中不可或缺的一部分。在实践中,不断练习和应用这些知识,将有助于提升你在IT行业的专业能力。
最后,资源中的综述文章将帮助读者梳理大数据领域的研究进展和趋势,理解各子领域的核心概念和技术,为后续的深入学习打下坚实基础。 总之,“100篇论文掌握大数据(综述加文章)”是一份全面且深度的参考资料,...
首先,让我们来梳理一下Flink的基本概念和特点。 Flink是一个分布式数据处理引擎,专门设计用于处理无边界和有边界的数据流。所谓无边界数据流,是指数据源产生数据是连续不断的,没有开始也没有结束的时间点。而有...
根据给定的文件内容,以下为知识点梳理: ...以上是根据文件内容梳理出的详细知识点,涵盖了实时数据流处理的核心概念、技术方法以及应用案例等多个方面,对理解和实施实时流数据处理具有指导意义。
本大纲主要针对大数据的基础知识进行梳理,旨在为学习者提供一个全面的入门指南。 第一章:大数据定义 大数据不仅意味着数据的量大,更体现在其多样性、高速度和价值密度低的特性。这些特性使得传统数据处理方法...
本文主要针对SBIIAUnit10《Frightening nature》中的核心词汇和句型进行了梳理,旨在帮助学生掌握与“可怕的大自然”相关的英语表达,特别是涉及恐惧、惊吓以及与之相关的动词和形容词的用法。 首先,我们来看...
大数据是21世纪信息技术领域的重要概念,它涉及的数据量巨大,结构复杂,处理速度快,且具有深度挖掘价值。本资料整理旨在提供一个全面的大数据学习框架,帮助学习者理解和掌握大数据的核心技术和应用。 首先,我们...
接下来,我们将对这些资料所涉及的大数据架构师领域的核心知识点进行梳理和总结。 ### 大数据架构师的基本概念 大数据架构师是专门负责设计、构建和维护企业级大数据处理系统的专业人员。他们需要具备深厚的技术...