
В
flume-ng+Kafka+Storm+HDFS е®һж—¶зі»з»ҹз»„еҗҲ
В
1пјү.ж•°жҚ®йҮҮйӣҶ
иҙҹиҙЈд»Һеҗ„иҠӮзӮ№дёҠе®һж—¶йҮҮйӣҶж•°жҚ®пјҢйҖүз”Ёclouderaзҡ„flumeжқҘе®һзҺ°
2пјү.ж•°жҚ®жҺҘе…Ҙ
з”ұдәҺйҮҮйӣҶж•°жҚ®зҡ„йҖҹеәҰе’Ңж•°жҚ®еӨ„зҗҶзҡ„йҖҹеәҰдёҚдёҖе®ҡеҗҢжӯҘпјҢеӣ жӯӨж·»еҠ дёҖдёӘж¶ҲжҒҜдёӯй—ҙ件жқҘдҪңдёәзј“еҶІпјҢйҖүз”Ёapacheзҡ„kafka
3пјү.жөҒејҸи®Ўз®—
еҜ№йҮҮйӣҶеҲ°зҡ„ж•°жҚ®иҝӣиЎҢе®һж—¶еҲҶжһҗпјҢйҖүз”Ёapacheзҡ„storm
4пјү.ж•°жҚ®иҫ“еҮә
еҜ№еҲҶжһҗеҗҺзҡ„з»“жһңжҢҒд№…еҢ–пјҢжҡӮе®ҡз”Ёmysql
еҸҰдёҖж–№йқўжҳҜжЁЎеқ—еҢ–д№ӢеҗҺпјҢеҒҮеҰӮеҪ“StormжҢӮжҺүдәҶд№ӢеҗҺпјҢж•°жҚ®йҮҮйӣҶе’Ңж•°жҚ®жҺҘе…ҘиҝҳжҳҜ继з»ӯеңЁи·‘зқҖпјҢж•°жҚ®дёҚдјҡдёўеӨұпјҢstormиө·жқҘд№ӢеҗҺеҸҜд»Ҙ继з»ӯиҝӣиЎҢжөҒејҸи®Ўз®—пјӣ
В
йӮЈд№ҲжҺҘдёӢжқҘжҲ‘们жқҘзңӢдёӢж•ҙдҪ“зҡ„жһ¶жһ„еӣҫ
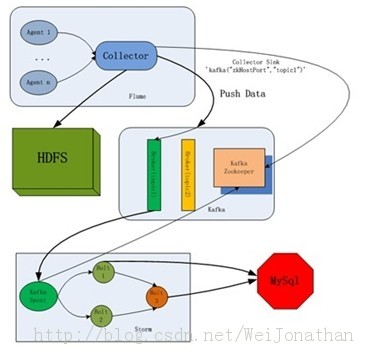
В
иҜҰз»Ҷд»Ӣз»Қеҗ„дёӘ组件еҸҠе®үиЈ…й…ҚзҪ®пјҡ
ж“ҚдҪңзі»з»ҹпјҡubuntu
В
Flume
FlumeжҳҜClouderaжҸҗдҫӣзҡ„дёҖдёӘеҲҶеёғејҸгҖҒеҸҜйқ гҖҒе’Ңй«ҳеҸҜз”Ёзҡ„жө·йҮҸж—Ҙеҝ—йҮҮйӣҶгҖҒиҒҡеҗҲе’Ңдј иҫ“зҡ„ж—Ҙеҝ—收йӣҶзі»з»ҹпјҢж”ҜжҢҒеңЁж—Ҙеҝ—зі»з»ҹдёӯе®ҡеҲ¶еҗ„зұ»ж•°жҚ®еҸ‘йҖҒж–№пјҢз”ЁдәҺ收йӣҶж•°жҚ®;еҗҢж—¶пјҢFlumeжҸҗдҫӣеҜ№ж•°жҚ®иҝӣиЎҢз®ҖеҚ•еӨ„зҗҶпјҢ并еҶҷеҲ°еҗ„з§Қж•°жҚ®жҺҘеҸ—ж–№(еҸҜе®ҡеҲ¶)зҡ„иғҪеҠӣгҖӮ
дёӢеӣҫдёәflumeе…ёеһӢзҡ„дҪ“зі»з»“жһ„пјҡ
Flumeж•°жҚ®жәҗд»ҘеҸҠиҫ“еҮәж–№ејҸ:
Flume жҸҗдҫӣдәҶд»Һconsole(жҺ§еҲ¶еҸ°)гҖҒRPC(Thrift-RPC)гҖҒtext(ж–Ү件)гҖҒtail(UNIX tail)гҖҒsyslog(syslogж—Ҙеҝ—зі»з»ҹпјҢж”ҜжҢҒTCPе’ҢUDPзӯү2з§ҚжЁЎејҸ)пјҢexec(е‘Ҫд»Өжү§иЎҢ)зӯүж•°жҚ®жәҗдёҠ收йӣҶж•°жҚ®зҡ„иғҪеҠӣ,еңЁжҲ‘们зҡ„зі»з»ҹдёӯзӣ®еүҚ дҪҝз”Ёexecж–№ејҸиҝӣиЎҢж—Ҙеҝ—йҮҮйӣҶгҖӮ
Flumeзҡ„ж•°жҚ®жҺҘеҸ—ж–№пјҢеҸҜд»ҘжҳҜconsole(жҺ§еҲ¶еҸ°)гҖҒtext(ж–Ү件)гҖҒdfs(HDFSж–Ү件)гҖҒRPC(Thrift-RPC)е’ҢsyslogTCP(TCP syslogж—Ҙеҝ—зі»з»ҹ)зӯүгҖӮеңЁжҲ‘们系з»ҹдёӯз”ұkafkaжқҘжҺҘ收гҖӮ
FlumeдёӢиҪҪеҸҠж–ҮжЎЈпјҡ
http://flume.apache.org/
Flumeе®үиЈ…пјҡ
- $tar zxvf apache-flume-1.4.0-bin.tar.gz/usr/local
- $bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name producer -Dflume.root.logger=INFO,console
В
kafkaжҳҜдёҖз§Қй«ҳеҗһеҗҗйҮҸзҡ„еҲҶеёғејҸеҸ‘еёғи®ўйҳ…ж¶ҲжҒҜзі»з»ҹпјҢеҘ№жңүеҰӮдёӢзү№жҖ§пјҡ
- йҖҡиҝҮO(1)зҡ„зЈҒзӣҳж•°жҚ®з»“жһ„жҸҗдҫӣж¶ҲжҒҜзҡ„жҢҒд№…еҢ–пјҢиҝҷз§Қз»“жһ„еҜ№дәҺеҚідҪҝж•°д»ҘTBзҡ„ж¶ҲжҒҜеӯҳеӮЁд№ҹиғҪеӨҹдҝқжҢҒй•ҝж—¶й—ҙзҡ„зЁіе®ҡжҖ§иғҪгҖӮ
- й«ҳеҗһеҗҗйҮҸпјҡеҚідҪҝжҳҜйқһеёёжҷ®йҖҡзҡ„硬件kafkaд№ҹеҸҜд»Ҙж”ҜжҢҒжҜҸз§’ж•°еҚҒдёҮзҡ„ж¶ҲжҒҜгҖӮ
- ж”ҜжҢҒйҖҡиҝҮkafkaжңҚеҠЎеҷЁе’Ңж¶Ҳиҙ№жңәйӣҶзҫӨжқҘеҲҶеҢәж¶ҲжҒҜгҖӮ
- ж”ҜжҢҒHadoop并иЎҢж•°жҚ®еҠ иҪҪгҖӮ
kafkaзҡ„зӣ®зҡ„жҳҜжҸҗдҫӣдёҖдёӘеҸ‘еёғи®ўйҳ…и§ЈеҶіж–№жЎҲпјҢе®ғеҸҜд»ҘеӨ„зҗҶж¶Ҳиҙ№иҖ…规模зҡ„зҪ‘з«ҷдёӯзҡ„жүҖжңүеҠЁдҪңжөҒж•° жҚ®гҖӮ иҝҷз§ҚеҠЁдҪңпјҲзҪ‘йЎөжөҸи§ҲпјҢжҗңзҙўе’Ңе…¶д»–з”ЁжҲ·зҡ„иЎҢеҠЁпјүжҳҜеңЁзҺ°д»ЈзҪ‘з»ңдёҠзҡ„и®ёеӨҡзӨҫдјҡеҠҹиғҪзҡ„дёҖдёӘе…ій”®еӣ зҙ гҖӮ иҝҷдәӣж•°жҚ®йҖҡеёёжҳҜз”ұдәҺеҗһеҗҗйҮҸзҡ„иҰҒжұӮиҖҢйҖҡиҝҮеӨ„зҗҶж—Ҙеҝ—е’Ңж—Ҙеҝ—иҒҡеҗҲжқҘи§ЈеҶігҖӮ еҜ№дәҺеғҸHadoopзҡ„дёҖж ·зҡ„ж—Ҙеҝ—ж•°жҚ®е’ҢзҰ»зәҝеҲҶжһҗзі»з»ҹпјҢдҪҶеҸҲиҰҒжұӮе®һж—¶еӨ„зҗҶзҡ„йҷҗеҲ¶пјҢиҝҷжҳҜдёҖдёӘеҸҜиЎҢзҡ„и§ЈеҶіж–№жЎҲгҖӮkafkaзҡ„зӣ®зҡ„жҳҜйҖҡиҝҮHadoopзҡ„并иЎҢеҠ иҪҪжңә еҲ¶жқҘз»ҹдёҖзәҝдёҠе’ҢзҰ»зәҝзҡ„ж¶ҲжҒҜеӨ„зҗҶпјҢд№ҹжҳҜдёәдәҶйҖҡиҝҮйӣҶзҫӨжңәжқҘжҸҗдҫӣе®һж—¶зҡ„ж¶Ҳиҙ№гҖӮ
kafkaеҲҶеёғејҸи®ўйҳ…жһ¶жһ„еҰӮдёӢеӣҫпјҡ--еҸ–иҮӘKafkaе®ҳзҪ‘
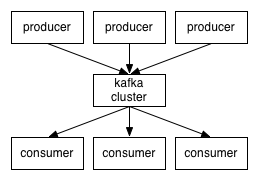
зҪ—е®қе…„ејҹж–Үз« дёҠзҡ„жһ¶жһ„еӣҫжҳҜиҝҷж ·зҡ„
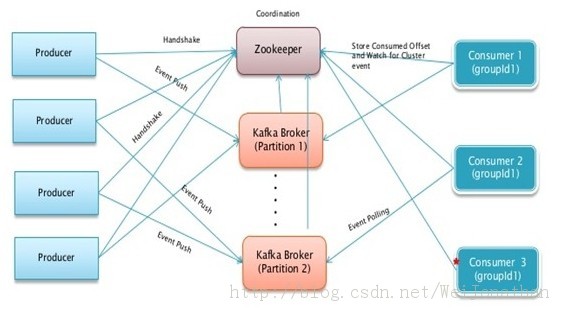
е…¶е®һдёӨиҖ…жІЎжңүеӨӘеӨ§еҢәеҲ«пјҢе®ҳзҪ‘зҡ„жһ¶жһ„еӣҫеҸӘжҳҜжҠҠKafkaз®ҖжҙҒзҡ„иЎЁзӨәжҲҗдёҖдёӘKafka ClusterпјҢиҖҢдёҠйқўжһ¶жһ„еӣҫе°ұзӣёеҜ№иҜҰз»ҶдёҖдәӣпјӣ
В
KafkaзүҲжң¬пјҡ0.8.0
KafkaдёӢиҪҪеҸҠж–ҮжЎЈпјҡhttp://kafka.apache.org/
Kafkaе®үиЈ…пјҡ
- > tar xzf kafka-<VERSION>.tgz
- > cd kafka-<VERSION>
- > ./sbt update
- > ./sbt package
- > ./sbt assembly-package-dependency
иҝҷйҮҢеҸҜиғҪжңүеҫҲеӨҡз«ҘйһӢжү§иЎҢsbtзҡ„ж—¶еҖҷдјҡжҠҘжүҫдёҚеҲ°иҝҷдёӘе‘Ҫд»Ө
[plain] view plaincopy
No command 'sbt' found, did you mean:В
В Command 'skt' from package 'latex-sanskrit' (main)В
В Command 'sb2' from package 'scratchbox2' (universe)В
В Command 'sbd' from package 'cluster-glue' (main)В
В Command 'mbt' from package 'mbt' (universe)В
В Command 'sbmt' from package 'atfs' (universe)В
В Command 'lbt' from package 'lbt' (universe)В
В Command 'st' from package 'suckless-tools' (universe)В
В Command 'sb' from package 'lrzsz' (universe)В
sbt: command not foundВ
иҝҷдёӘжҳҜйңҖиҰҒиҮӘе·ұе®үиЈ…зҡ„пјҢе®үиЈ…еҢ…еҸҜд»ҘеҲ°sbtе®ҳзҪ‘дёӢиҪҪгҖӮжҲ‘иҝҷиҫ№з”Ёзҡ„ubuntuзі»з»ҹпјҢжүҖд»ҘжҲ‘дёӢиҪҪдәҶдёӘdebеҢ…пјҢе®ҳзҪ‘ең°еқҖпјҡhttp://www.scala-sbt.org/
debеҢ…ең°еқҖпјҡhttp://repo.scala-sbt.org/scalasbt/sbt-native-packages/org/scala-sbt/sbt/0.13.1/sbt.deb
rpmеҢ…ең°еқҖпјҡhttp://repo.scala-sbt.org/scalasbt/sbt-native-packages/org/scala-sbt/sbt/0.13.1/sbt.rpm
[plain] view plaincopy
No command 'sbt' found, did you mean:В
В Command 'skt' from package 'latex-sanskrit' (main)В
В Command 'sb2' from package 'scratchbox2' (universe)В
В Command 'sbd' from package 'cluster-glue' (main)В
В Command 'mbt' from package 'mbt' (universe)В
В Command 'sbmt' from package 'atfs' (universe)В
В Command 'lbt' from package 'lbt' (universe)В
В Command 'st' from package 'suckless-tools' (universe)В
В Command 'sb' from package 'lrzsz' (universe)В
sbt: command not foundВ
иҝҷдёӘжҳҜйңҖиҰҒиҮӘе·ұе®үиЈ…зҡ„пјҢе®үиЈ…еҢ…еҸҜд»ҘеҲ°sbtе®ҳзҪ‘дёӢиҪҪгҖӮжҲ‘иҝҷиҫ№з”Ёзҡ„ubuntuзі»з»ҹпјҢжүҖд»ҘжҲ‘дёӢиҪҪдәҶдёӘdebеҢ…пјҢе®ҳзҪ‘ең°еқҖпјҡhttp://www.scala-sbt.org/
debеҢ…ең°еқҖпјҡhttp://repo.scala-sbt.org/scalasbt/sbt-native-packages/org/scala-sbt/sbt/0.13.1/sbt.deb
rpmеҢ…ең°еқҖпјҡhttp://repo.scala-sbt.org/scalasbt/sbt-native-packages/org/scala-sbt/sbt/0.13.1/sbt.rpm
еҗҜеҠЁеҸҠжөӢиҜ•е‘Ҫд»Өпјҡ
пјҲ1пјү start server
В
- > bin/zookeeper-server-start.shconfig/zookeeper.properties
- > bin/kafka-server-start.shconfig/server.properties
В
й…ҚзҪ®зӢ¬з«Ӣзҡ„zookeeperйӣҶзҫӨйңҖиҰҒй…ҚзҪ®server.propertiesж–Ү件пјҢи®Іzookeeper.connectдҝ®ж”№дёәзӢ¬з«ӢйӣҶзҫӨзҡ„IPе’Ңз«ҜеҸЈ
В
- zookeeper.connect=nutch1:2181
В
- > bin/kafka-create-topic.sh --zookeeper localhost:2181 --replica 1 --partition 1 --topic test
- > bin/kafka-list-topic.sh --zookeeperlocalhost:2181
В
- > bin/kafka-console-producer.sh--broker-list localhost:9092 --topic test
В
- > bin/kafka-console-consumer.sh--zookeeper localhost:2181 --topic test --from-beginning
kafka-console-producer.shе’Ңkafka-console-cousumer.shеҸӘжҳҜзі»з»ҹжҸҗдҫӣзҡ„е‘Ҫд»ӨиЎҢе·Ҙе…·гҖӮиҝҷйҮҢеҗҜеҠЁжҳҜдёәдәҶжөӢиҜ•жҳҜеҗҰиғҪжӯЈеёёз”ҹдә§ж¶Ҳиҙ№пјӣйӘҢиҜҒжөҒзЁӢжӯЈзЎ®жҖ§
еңЁе®һйҷ…ејҖеҸ‘дёӯиҝҳжҳҜиҰҒиҮӘиЎҢејҖеҸ‘иҮӘе·ұзҡ„з”ҹдә§иҖ…дёҺж¶Ҳиҙ№иҖ…пјӣ
Storm
Twitter е°ҶStormжӯЈејҸејҖжәҗдәҶпјҢиҝҷжҳҜдёҖдёӘеҲҶеёғејҸзҡ„гҖҒе®№й”ҷзҡ„е®һж—¶и®Ўз®—зі»з»ҹпјҢе®ғиў«жүҳз®ЎеңЁGitHubдёҠпјҢйҒөеҫӘВ В Eclipse Public License 1.0гҖӮStormжҳҜз”ұBackTypeејҖеҸ‘зҡ„е®һж—¶еӨ„зҗҶзі»з»ҹпјҢBackTypeзҺ°еңЁе·ІеңЁTwitterйәҫдёӢгҖӮGitHubдёҠзҡ„жңҖж–°зүҲжң¬жҳҜStorm 0.5.2пјҢеҹәжң¬жҳҜз”ЁClojureеҶҷзҡ„гҖӮ
В
Stormзҡ„дё»иҰҒзү№зӮ№еҰӮдёӢпјҡ
- з®ҖеҚ•зҡ„зј–зЁӢжЁЎеһӢгҖӮзұ»дјјдәҺMapReduceйҷҚдҪҺдәҶ并иЎҢжү№еӨ„зҗҶеӨҚжқӮжҖ§пјҢStormйҷҚдҪҺдәҶиҝӣиЎҢе®һж—¶еӨ„зҗҶзҡ„еӨҚжқӮжҖ§гҖӮ
- еҸҜд»ҘдҪҝз”Ёеҗ„з§Қзј–зЁӢиҜӯиЁҖгҖӮдҪ еҸҜд»ҘеңЁStormд№ӢдёҠдҪҝз”Ёеҗ„з§Қзј–зЁӢиҜӯиЁҖгҖӮй»ҳи®Өж”ҜжҢҒClojureгҖҒJavaгҖҒRubyе’ҢPythonгҖӮиҰҒеўһеҠ еҜ№е…¶д»–иҜӯиЁҖзҡ„ж”ҜжҢҒпјҢеҸӘйңҖе®һзҺ°дёҖдёӘз®ҖеҚ•зҡ„StormйҖҡдҝЎеҚҸи®®еҚіеҸҜгҖӮ
- е®№й”ҷжҖ§гҖӮStormдјҡз®ЎзҗҶе·ҘдҪңиҝӣзЁӢе’ҢиҠӮзӮ№зҡ„ж•…йҡңгҖӮ
- ж°ҙе№іжү©еұ•гҖӮи®Ўз®—жҳҜеңЁеӨҡдёӘзәҝзЁӢгҖҒиҝӣзЁӢе’ҢжңҚеҠЎеҷЁд№Ӣй—ҙ并иЎҢиҝӣиЎҢзҡ„гҖӮ
- еҸҜйқ зҡ„ж¶ҲжҒҜеӨ„зҗҶгҖӮStormдҝқиҜҒжҜҸдёӘж¶ҲжҒҜиҮіе°‘иғҪеҫ—еҲ°дёҖж¬Ўе®Ңж•ҙеӨ„зҗҶгҖӮд»»еҠЎеӨұиҙҘж—¶пјҢе®ғдјҡиҙҹиҙЈд»Һж¶ҲжҒҜжәҗйҮҚиҜ•ж¶ҲжҒҜгҖӮ
- еҝ«йҖҹгҖӮзі»з»ҹзҡ„и®ҫи®ЎдҝқиҜҒдәҶж¶ҲжҒҜиғҪеҫ—еҲ°еҝ«йҖҹзҡ„еӨ„зҗҶпјҢдҪҝз”ЁØMQдҪңдёәе…¶еә•еұӮж¶ҲжҒҜйҳҹеҲ—гҖӮпјҲ0.9.0.1зүҲжң¬ж”ҜжҢҒØMQе’ҢnettyдёӨз§ҚжЁЎејҸпјү
- жң¬ең°жЁЎејҸгҖӮStormжңүдёҖдёӘвҖңжң¬ең°жЁЎејҸвҖқпјҢеҸҜд»ҘеңЁеӨ„зҗҶиҝҮзЁӢдёӯе®Ңе…ЁжЁЎжӢҹStormйӣҶзҫӨгҖӮиҝҷи®©дҪ еҸҜд»Ҙеҝ«йҖҹиҝӣиЎҢејҖеҸ‘е’ҢеҚ•е…ғжөӢиҜ•гҖӮ
з”ұдәҺзҜҮе№…й—®йўҳпјҢе…·дҪ“зҡ„е®үиЈ…жӯҘйӘӨеҸҜд»ҘеҸӮиҖғпјҡStorm-0.9.0.1е®үиЈ…йғЁзҪІ жҢҮеҜј
жҺҘдёӢжқҘйҮҚеӨҙжҲҸејҖе§ӢжӢүпјҒйӮЈе°ұжҳҜжЎҶжһ¶д№Ӣй—ҙзҡ„ж•ҙеҗҲе•Ұ
В
flumeе’Ңkafkaж•ҙеҗҲ
1.дёӢиҪҪflume-kafka-plus:https://github.com/beyondj2ee/flumeng-kafka-plugin
2.жҸҗеҸ–жҸ’件дёӯзҡ„flume-conf.propertiesж–Ү件
дҝ®ж”№иҜҘж–Ү件пјҡ#source section
producer.sources.s.type = exec
producer.sources.s.command = tail -f -n+1 /mnt/hgfs/vmshare/test.log
producer.sources.s.channels = c
producer.sources.s.command = tail -f -n+1 /mnt/hgfs/vmshare/test.log
producer.sources.s.channels = c
дҝ®ж”№жүҖжңүtopicзҡ„еҖјж”№дёәtest
е°Ҷж”№еҗҺзҡ„й…ҚзҪ®ж–Ү件ж”ҫиҝӣflume/confзӣ®еҪ•дёӢ
еңЁиҜҘйЎ№зӣ®дёӯжҸҗеҸ–д»ҘдёӢjarеҢ…ж”ҫе…ҘзҺҜеўғдёӯflumeзҡ„libдёӢпјҡ

жіЁпјҡиҝҷйҮҢзҡ„flumeng-kafka-plugin.jarиҝҷдёӘеҢ…пјҢеҗҺйқўеңЁgithubйЎ№зӣ®дёӯе·Із»Ҹ移еҠЁеҲ°packageзӣ®еҪ•дәҶгҖӮжүҫдёҚеҲ°зҡ„з«ҘйһӢеҸҜд»ҘеҲ°packageзӣ®еҪ•иҺ·еҸ–гҖӮ
В
е®ҢжҲҗдёҠйқўзҡ„жӯҘйӘӨд№ӢеҗҺпјҢжҲ‘们жқҘжөӢиҜ•дёӢflume+kafkaиҝҷдёӘжөҒзЁӢжңүжІЎжңүиө°йҖҡпјӣ
жҲ‘们е…ҲеҗҜеҠЁflumeпјҢ然еҗҺеҶҚеҗҜеҠЁkafkaпјҢеҗҜеҠЁжӯҘйӘӨжҢүд№ӢеүҚзҡ„жӯҘйӘӨжү§иЎҢпјӣжҺҘдёӢжқҘжҲ‘们дҪҝз”Ёkafkaзҡ„kafka-console-consumer.shи„ҡжң¬жҹҘзңӢжҳҜеҗҰжңүflumeжңүжІЎжңүеҫҖKafkaдј иҫ“ж•°жҚ®пјӣ
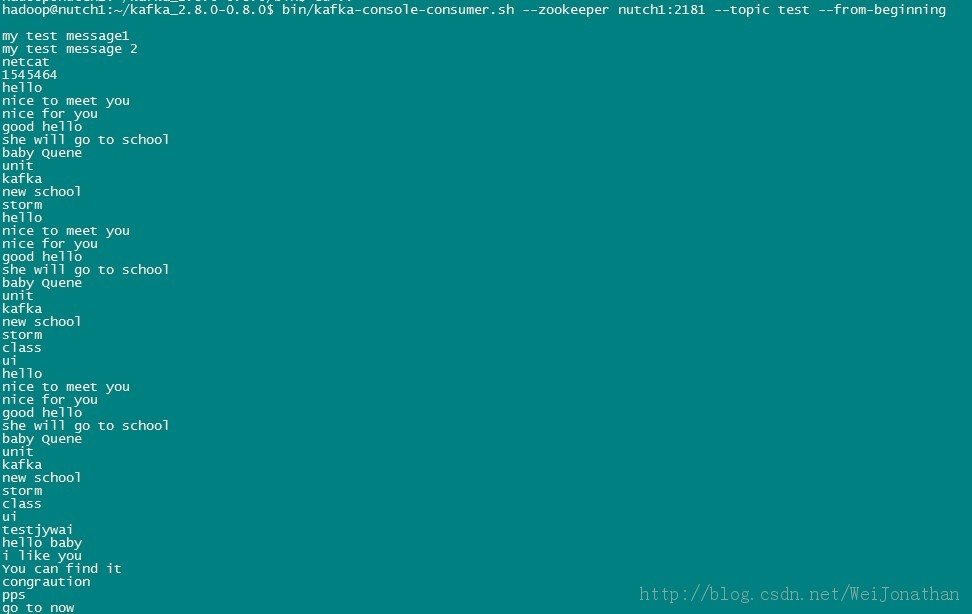
д»ҘдёҠиҝҷдёӘжҳҜжҲ‘зҡ„test.logж–Ү件йҖҡиҝҮflumeжҠ“еҸ–дј еҲ°kafkaзҡ„ж•°жҚ®пјӣиҜҙжҳҺжҲ‘们зҡ„flumeе’ҢkafkaжөҒзЁӢиө°йҖҡдәҶпјӣ
еӨ§е®¶иҝҳи®°еҫ—еҲҡејҖе§ӢжҲ‘们зҡ„жөҒзЁӢеӣҫд№ҲпјҢе…¶дёӯжңүдёҖжӯҘжҳҜйҖҡиҝҮflumeеҲ°kafkaпјҢиҝҳжңүдёҖжӯҘжҳҜеҲ°hdfsзҡ„пјӣиҖҢжҲ‘们иҝҷиҫ№иҝҳжІЎжңүжҸҗеҲ°еҰӮдҪ•еӯҳе…Ҙkafkaдё”еҗҢж—¶еӯҳеҰӮhdfsпјӣ
flumeжҳҜж”ҜжҢҒж•°жҚ®еҗҢжӯҘеӨҚеҲ¶пјҢеҗҢжӯҘеӨҚеҲ¶жөҒзЁӢеӣҫеҰӮдёӢпјҢеҸ–иҮӘдәҺflumeе®ҳзҪ‘пјҢе®ҳзҪ‘з”ЁжҲ·жҢҮеҚ—ең°еқҖпјҡhttp://flume.apache.org/FlumeUserGuide.html

жҖҺд№Ҳи®ҫзҪ®еҗҢжӯҘеӨҚеҲ¶е‘ўпјҢзңӢдёӢйқўзҡ„й…ҚзҪ®пјҡ
В
- #2дёӘchannelе’Ң2дёӘsinkзҡ„й…ҚзҪ®ж–Ү件  иҝҷйҮҢжҲ‘们еҸҜд»Ҙи®ҫзҪ®дёӨдёӘsinkпјҢдёҖдёӘжҳҜkafkaзҡ„пјҢдёҖдёӘжҳҜhdfsзҡ„пјӣ
- a1.sources = r1
- a1.sinks = k1 k2
- a1.channels = c1 c2
В
kafkaе’Ңstormзҡ„ж•ҙеҗҲ
В
1.дёӢиҪҪkafka-storm0.8жҸ’件пјҡhttps://github.com/wurstmeister/storm-kafka-0.8-plus
2.дҪҝз”Ёmaven packageиҝӣиЎҢзј–иҜ‘пјҢеҫ—еҲ°storm-kafka-0.8-plus-0.3.0-SNAPSHOT.jarеҢ…В В --жңүиҪ¬иҪҪзҡ„з«ҘйһӢжіЁж„ҸдёӢпјҢиҝҷйҮҢзҡ„еҢ…еҗҚд№ӢеүҚеҶҷй”ҷдәҶпјҢзҺ°еңЁж”№жӯЈзЎ®дәҶпјҒдёҚеҘҪж„ҸжҖқпјҒ
3.е°ҶиҜҘjarеҢ…еҸҠkafka_2.9.2-0.8.0-beta1.jarгҖҒmetrics-core-2.2.0.jarгҖҒscala-library-2.9.2.jar (иҝҷдёүдёӘjarеҢ…еңЁkafkaйЎ№зӣ®дёӯиғҪжүҫеҲ°)
еӨҮжіЁпјҡеҰӮжһңејҖеҸ‘зҡ„йЎ№зӣ®йңҖиҰҒе…¶д»–jarпјҢи®°еҫ—д№ҹиҰҒж”ҫиҝӣstormзҡ„LibдёӯжҜ”еҰӮз”ЁеҲ°дәҶmysqlе°ұиҰҒж·»еҠ mysql-connector-java-5.1.22-bin.jarеҲ°stormзҡ„libдёӢ
йӮЈд№ҲжҺҘдёӢжқҘжҲ‘们жҠҠstormд№ҹйҮҚеҗҜдёӢпјӣ
е®ҢжҲҗд»ҘдёҠжӯҘйӘӨд№ӢеҗҺпјҢжҲ‘们иҝҳжңүдёҖ件дәӢжғ…иҰҒеҒҡпјҢе°ұжҳҜдҪҝз”Ёkafka-storm0.8жҸ’件пјҢеҶҷдёҖдёӘиҮӘе·ұзҡ„StormзЁӢеәҸпјӣ
иҝҷйҮҢжҲ‘з»ҷеӨ§дјҷйҷ„дёҠдёҖдёӘжҲ‘еј„зҡ„stormзЁӢеәҸпјҢд»Јз Ғпјҡ
public class KafkaSpout implements IRichSpout {
private static final Log logger = LogFactory.getLog(KafkaSpout.class);
/**
*
*/
private static final long serialVersionUID = -5569857211173547938L;
SpoutOutputCollector collector;
private ConsumerConnectorconsumer;
private Stringtopic;
public KafkaSpout(String topic) {
this.topic = topic;
}
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
this.collector = collector;
}
private static ConsumerConfig createConsumerConfig() {
Properties props = newProperties();
props.put("zookeeper.connect","xx.xx.xx.xx:2181");
props.put("group.id","0");
props.put("zookeeper.session.timeout.ms","10000");
//props.put("zookeeper.sync.time.ms", "200");
//props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
@Override
public void close() {
// TODOAuto-generated method stub
}
@Override
public void activate() {
this.consumer = Consumer.createJavaConsumerConnector(createConsumerConfig());
Map<String, Integer> topickMap = newHashMap<String, Integer>();
topickMap.put(topic,new Integer(1));
Map<String, List<KafkaStream<byte[],byte[]>>>streamMap =consumer.createMessageStreams(topickMap);
KafkaStream<byte[],byte[]>stream = streamMap.get(topic).get(0);
ConsumerIterator<byte[],byte[]> it =stream.iterator();
while (it.hasNext()) {
String value = newString(it.next().message());
System.out.println("(consumer)-->" + value);
collector.emit(new Values(value), value);
}
}
@Override
public void deactivate() {
// TODOAuto-generated method stub
}
private boolean isComplete;
@Override
public void nextTuple() {
}
@Override
public void ack(Object msgId) {
// TODOAuto-generated method stub
}
@Override
public void fail(Object msgId) {
// TODOAuto-generated method stub
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("KafkaSpout"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
// TODOAuto-generated method stub
return null;
}
}
public class FileBlots implementsIRichBolt{
OutputCollector collector;
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple input) {
String line = input.getString(0);
for(String str : line.split("\\s+")){
List a = newArrayList();
a.add(input);
this.collector.emit(a,newValues(str));
}
this.collector.ack(input);
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("words"));
}
public Map<String, Object> getComponentConfiguration() {
// TODOAuto-generated method stub
return null;
}
}
public class WordsCounterBlots implementsIRichBolt{
OutputCollector collector;
Map<String, Integer> counter;
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
this.counter =new HashMap<String, Integer>();
}
public void execute(Tuple input) {
String word = input.getString(0);
Integer integer = this.counter.get(word);
if(integer !=null){
integer +=1;
this.counter.put(word, integer);
}else{
this.counter.put(word, 1);
}
System.out.println("execute");
Jedis jedis = JedisUtils.getJedis();
jedis.incrBy(word, 1);
System.out.println("=============================================");
this.collector.ack(input);
}
public void cleanup() {
for(Entry<String, Integer> entry :this.counter.entrySet()){
System.out.println("------:"+entry.getKey()+"=="+entry.getValue());
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
public Map<String, Object> getComponentConfiguration() {
// TODOAuto-generated method stub
return null;
}
}
В е…ҲзЁҚеҫ®зңӢдёӢзЁӢеәҸзҡ„еҲӣе»әTopologyд»Јз Ғ
public class KafkaTopology {
public static void main(String[] args) {
try {
JedisUtils.initialPool("xx.xx.xx.xx", 6379);
} catch (Exception e) {
e.printStackTrace();
}
TopologyBuilder builder = newTopologyBuilder(); builder.setSpout("kafka",new KafkaSpout("kafka"));
builder.setBolt("file-blots",new FileBlots()).shuffleGrouping("kafka");
builder.setBolt("words-counter",new WordsCounterBlots(),2).fieldsGrouping("file-blots",new Fields("words"));
Config config = new Config();
config.setDebug(true);
LocalCluster local = newLocalCluster();
local.submitTopology("counter", config, builder.createTopology());
}
}
В В
- storm-0.9.0.1/bin/storm jar storm-start-demo-0.0.1-SNAPSHOT.jar com.storm.topology.KafkaTopology
е…ҲзңӢдёӢж—Ҙеҝ—пјҢиҝҷйҮҢжү“еҚ°еҮәжқҘдәҶеҫҖж•°жҚ®еә“йҮҢйқўжҸ’е…Ҙж•°жҚ®дәҶ
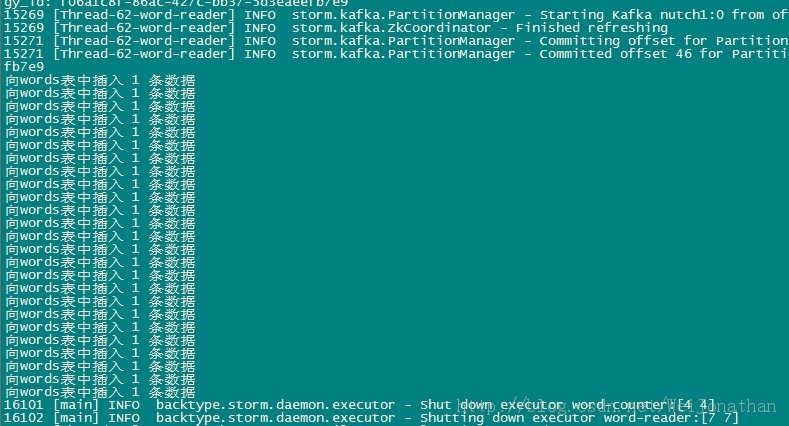
然еҗҺжҲ‘们жҹҘзңӢдёӢж•°жҚ®еә“пјӣжҸ’е…ҘжҲҗеҠҹдәҶпјҒ
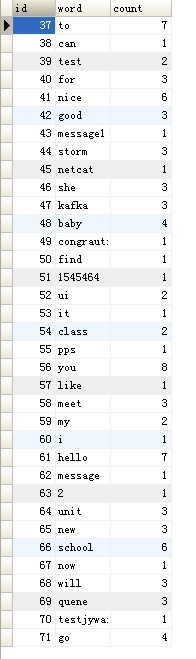
еҲ°иҝҷйҮҢжҲ‘们зҡ„ж•ҙдёӘж•ҙеҗҲе°ұе®ҢжҲҗдәҶпјҒ
дҪҶжҳҜиҝҷйҮҢиҝҳжңүдёҖдёӘй—®йўҳпјҢдёҚзҹҘйҒ“еӨ§дјҷжңүжІЎжңүеҸ‘зҺ°гҖӮ
з”ұдәҺжҲ‘们дҪҝз”ЁstormиҝӣиЎҢеҲҶеёғејҸжөҒејҸи®Ўз®—пјҢйӮЈд№ҲеҲҶеёғејҸжңҖйңҖиҰҒжіЁж„Ҹзҡ„жҳҜж•°жҚ®дёҖиҮҙжҖ§д»ҘеҸҠйҒҝе…Қи„Ҹж•°жҚ®зҡ„дә§з”ҹпјӣжүҖд»ҘжҲ‘жҸҗдҫӣзҡ„жөӢиҜ•йЎ№зӣ®еҸӘиғҪз”ЁдәҺжөӢиҜ•пјҢжӯЈејҸејҖеҸ‘дёҚиғҪиҝҷж ·еӨ„зҗҶ
В
В



зӣёе…іжҺЁиҚҗ
еңЁиҝҷдёӘиҝҮзЁӢдёӯпјҢж–ҮжЎЈгҖҠTwitter Stormзі»еҲ—гҖӢflume-ng+Kafka+Storm+HDFS е®һж—¶зі»з»ҹжҗӯе»ә.docxе’ҢгҖҠе®үиЈ…жүҺи®°.pdfгҖӢе°ҶжҸҗдҫӣиҜҰз»Ҷзҡ„жӯҘйӘӨжҢҮеҜје’Ңеёёи§Ғй—®йўҳи§ЈеҶіж–№жЎҲпјҢеё®еҠ©дҪ йЎәеҲ©е®ҢжҲҗж•ҙдёӘзі»з»ҹзҡ„жҗӯе»әе’ҢдјҳеҢ–гҖӮ жҖ»зҡ„жқҘиҜҙпјҢLNMPдёҺе®һж—¶еӨ§...
зӣҙд»ҘжқҘйғҪжғіжҺҘи§ҰStormе®һж—¶и®Ўз®—иҝҷеқ—зҡ„дёңиҘҝпјҢжңҖиҝ‘еңЁзҫӨйҮҢзңӢеҲ°дёҠжө·дёҖе“Ҙ们зҪ—е®қеҶҷзҡ„Flume+Kafka+Stormзҡ„е®һж—¶ж—Ҙеҝ—жөҒзі»з»ҹзҡ„жҗӯе»әж–ҮжЎЈпјҢиҮӘе·ұд№ҹи·ҹзқҖж•ҙдәҶдёҖйҒҚпјҢд№ӢеүҚзҪ—е®қзҡ„ж–Үз« дёӯжңүдёҖдәӣиҰҒжіЁж„ҸзӮ№жІЎжҸҗеҲ°зҡ„пјҢд»ҘеҗҺдёҖдәӣеҶҷй”ҷзҡ„зӮ№пјҢеңЁиҝҷиҫ№...
еҗҜеҠЁFlumeж—¶пјҢдҪҝз”Ёflume-ngе‘Ҫд»Ө并жҢҮе®ҡй…ҚзҪ®ж–Ү件е’Ңд»ЈзҗҶеҗҚз§°гҖӮ Kafkaзҡ„е®үиЈ…е’Ңй…ҚзҪ®иҝҮзЁӢеҢ…жӢ¬дёӢиҪҪжәҗз ҒеҢ…пјҢжү§иЎҢsbtжӣҙж–°гҖҒжү“еҢ…гҖҒз»„иЈ…еҢ…дҫқиө–пјҢд»ҘеҸҠжү§иЎҢеҗҜеҠЁи„ҡжң¬гҖӮеҗҜеҠЁKafkaжңҚеҠЎйңҖиҰҒе…ҲеҗҜеҠЁZookeeperжңҚеҠЎпјҢ然еҗҺеҗҜеҠЁKafkaжңҚеҠЎ...
ж Үйўҳдёӯзҡ„вҖңеҲ©з”ЁFlumeе°ҶMySQLиЎЁж•°жҚ®еҮҶе®һж—¶жҠҪеҸ–еҲ°HDFSгҖҒMySQLгҖҒKafkaвҖқжҳҜдёҖйЎ№ж•°жҚ®йӣҶжҲҗд»»еҠЎпјҢж¶үеҸҠApache FlumeгҖҒMySQLж•°жҚ®еә“гҖҒHadoop Distributed File System (HDFS) е’ҢApache KafkaиҝҷеӣӣдёӘе…ій”®жҠҖжңҜгҖӮFlumeжҳҜApacheзҡ„дёҖ...
жң¬ж–Үе°ҶиҜҰз»Ҷд»Ӣз»ҚеҰӮдҪ•еҲ©з”ЁKafkaгҖҒFlumeNGгҖҒStormдёҺHBaseжҗӯе»әдёҖеҘ—й«ҳж•Ҳзҡ„ж•°жҚ®еӨ„зҗҶзі»з»ҹгҖӮиҜҘзі»з»ҹж—ЁеңЁе®һзҺ°д»ҘдёӢзӣ®ж Үпјҡ - е®һж—¶еӨ„зҗҶд»»ж„Ҹ规模зҡ„ж•°жҚ®йӣҶгҖӮ - ж”ҜжҢҒеӨҡз§Қзұ»еһӢзҡ„еӨ„зҗҶж“ҚдҪңгҖӮ - з»“еҗҲеӨҡз§ҚжҠҖжңҜе’Ңе·Ҙе…·пјҢжһ„е»әдёҖдёӘе…Ёж–№дҪҚзҡ„еӨ§...
еңЁеӨ§ж•°жҚ®еӨ„зҗҶйўҶеҹҹпјҢFlumeгҖҒKafkaе’ҢStormжҳҜдёүдёӘиҮіе…ійҮҚиҰҒзҡ„е·Ҙе…·пјҢе®ғ们еҲҶеҲ«еңЁж•°жҚ®йҮҮйӣҶгҖҒж•°жҚ®еҲҶеҸ‘е’Ңе®һж—¶еӨ„зҗҶж–№йқўеҸ‘жҢҘзқҖж ёеҝғдҪңз”ЁгҖӮиҝҷйҮҢжҲ‘们е°Ҷж·ұе…ҘжҺўи®ЁиҝҷдёүдёӘ组件д»ҘеҸҠеҰӮдҪ•жҗӯе»әе®ғ们гҖӮ 1. FlumeпјҡFlumeжҳҜApacheиҪҜ件еҹәйҮ‘дјҡзҡ„...
еңЁеӨ§ж•°жҚ®еӨ„зҗҶйўҶеҹҹпјҢFlumeгҖҒKafkaе’ҢStormжҳҜдёүдёӘйқһеёёйҮҚиҰҒзҡ„е·Ҙе…·пјҢе®ғ们еҲҶеҲ«иҙҹиҙЈж•°жҚ®йҮҮйӣҶгҖҒж¶ҲжҒҜдёӯй—ҙ件е’Ңе®һж—¶жөҒеӨ„зҗҶгҖӮ"flume-kafka-stormжәҗзЁӢеәҸ"иҝҷдёӘеҺӢзј©еҢ…еҫҲеҸҜиғҪжҳҜеҢ…еҗ«иҝҷдёүдёӘ组件зҡ„йӣҶжҲҗзӨәдҫӢжҲ–иҖ…жәҗд»Јз ҒпјҢз”ЁдәҺеё®еҠ©ејҖеҸ‘иҖ…...
еңЁе®һйҷ…еә”з”ЁдёӯпјҢFlume NG 1.6.0-cdh5.14.0 еёёеёёдёҺе…¶д»–еӨ§ж•°жҚ®з»„件еҰӮ HadoopгҖҒKafka е’Ң Storm з»“еҗҲдҪҝз”ЁпјҢжһ„е»әеӨҚжқӮзҡ„ж•°жҚ®еӨ„зҗҶжөҒж°ҙзәҝгҖӮдҫӢеҰӮпјҢеҸҜд»Ҙе…ҲдҪҝз”Ё Flume д»ҺеӨҡеҸ°жңҚеҠЎеҷЁж”¶йӣҶж—Ҙеҝ—ж•°жҚ®пјҢ然еҗҺйҖҡиҝҮ Kafka иҝӣиЎҢж¶ҲжҒҜйҳҹеҲ—...
- **еҗҜеҠЁFlume**пјҡжү§иЎҢ`bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name a1 -Dflume.root.logger=INFO,console`еҗҜеҠЁFlume AgentгҖӮ 2. **KafkaзҺҜеўғжһ„е»ә**пјҡ - **е®үиЈ…Zookeeper**пјҡKafkaдҫқиө–...
### е®һж—¶ж—Ҙеҝ—еҲҶжһҗзҹҘиҜҶзӮ№иҜҰи§Ј ...з»јдёҠжүҖиҝ°пјҢFlume-ng+Kafka+Storm+HDFSжһ„жҲҗдәҶдёҖдёӘејәеӨ§зҡ„е®һж—¶ж—Ҙеҝ—еҲҶжһҗзі»з»ҹпјҢдёҚд»…иғҪеӨҹж»Ўи¶іеҪ“еүҚйЎ№зӣ®зҡ„йңҖжұӮпјҢиҝҳе…·еӨҮиүҜеҘҪзҡ„жү©еұ•жҖ§е’Ңз»ҙжҠӨжҖ§пјҢйҖӮз”ЁдәҺеӨ§и§„жЁЎзҡ„ж—Ҙеҝ—еӨ„зҗҶеңәжҷҜгҖӮ
иҝҷдёӘж–ҮжЎЈжҳҜгҖҠдә‘и®Ўз®—д№ӢFlume+Kafka+Storm+Redis/Hbase+Hadoop+Hive+Mahout+Spark жҠҖжңҜж–ҮжЎЈеҲҶдә«V1.0.0гҖӢзі»еҲ—зҡ„дёҖйғЁеҲҶпјҢж¶өзӣ–дәҶеӨҡз§Қдә‘и®Ўз®—жҠҖжңҜгҖӮ йҰ–е…ҲпјҢHadoop-2.2.0жҳҜдёҖдёӘејҖжәҗзҡ„еҲҶеёғејҸи®Ўз®—жЎҶжһ¶пјҢе…¶ж ёеҝғз”ұHDFSпјҲHadoop ...
жң¬ж–ҮеҜ№еҹәдәҺ Flume зҡ„зҫҺеӣўж—Ҙеҝ—收йӣҶзі»з»ҹиҝӣиЎҢдәҶиҜҰз»Ҷзҡ„д»Ӣз»Қе’ҢеҲҶжһҗпјҢеҢ…жӢ¬ж—Ҙеҝ—收йӣҶзі»з»ҹзҡ„жһ¶жһ„и®ҫи®ЎгҖҒFlume-NG дёҺ Scribe зҡ„жҜ”иҫғгҖҒзҫҺеӣўж—Ҙеҝ—收йӣҶзі»з»ҹзҡ„жһ¶жһ„е’Ңи®ҫи®ЎгҖҒзҫҺеӣўж—Ҙеҝ—收йӣҶзі»з»ҹзҡ„и®ҫи®Ўе’ҢдјҳеҢ–зӯүж–№йқўгҖӮеҗҢж—¶пјҢжң¬ж–ҮиҝҳеҜ№ Flume...
emsiteжЎҶжһ¶йӣҶжҲҗдәҶdubboжңҚеҠЎеұӮгҖҒеҚ•зӮ№зҷ»еҪ•гҖҒAuth2.0и®ӨиҜҒгҖҒstorm+kafkaж¶ҲжҒҜеӨ„зҗҶзі»з»ҹгҖҒж—Ҙеҝ—еҲҶжһҗзі»з»ҹпјҲkafka+ flume+storm+hdfs+hadoopпјүгҖҒй…ҚзҪ®дёӯеҝғгҖҒеҲҶеёғејҸд»»еҠЎи°ғеәҰзі»з»ҹгҖҒжңҚеҠЎеҷЁе®һж—¶зӣ‘жҺ§зі»з»ҹд»ҘеҸҠжҗңзҙўеј•ж“Һзі»з»ҹпјҲelastic...
Flume-NGжҳҜдёҖдёӘй«ҳеҸҜз”ЁгҖҒй«ҳеҸҜйқ зҡ„еҲҶеёғејҸж—Ҙеҝ—йҮҮйӣҶзі»з»ҹпјҢз”ұClouderaејҖеҸ‘并已зәіе…ҘApacheйЎ№зӣ®гҖӮдёҺScribeзӣёжҜ”пјҢFlume-NGеңЁе®№й”ҷжҖ§е’ҢеҸҜжү©еұ•жҖ§ж–№йқўиЎЁзҺ°еҮәиүІгҖӮе®ғдёҚд»…еңЁAgentе’ҢCollectorд№Ӣй—ҙпјҢд№ҹеңЁCollectorе’ҢStoreд№Ӣй—ҙжҸҗдҫӣдәҶ...
- emsiteйҮҮз”ЁdubboдҪңдёәжңҚеҠЎеұӮжЎҶжһ¶пјҢеҗҺеҸ°е°ҶйӣҶжҲҗеҚ•зӮ№зҷ»еҪ•гҖҒoauth2.0гҖҒstorm+kafkaж¶ҲжҒҜеӨ„зҗҶзі»з»ҹгҖҒkafka+ flume+storm+hdfs+hadoopдҪңдёәж—Ҙеҝ—еҲҶжһҗзі»з»ҹгҖҒй…ҚзҪ®дёӯеҝғгҖҒеҲҶеёғејҸд»»еҠЎи°ғеәҰзі»з»ҹгҖҒжңҚеҠЎеҷЁе®һж—¶зӣ‘жҺ§зі»з»ҹгҖҒжҗңзҙўеј•ж“Һзі»з»ҹ...
йҮҮз”ЁdubboдҪңдёәжңҚеҠЎеұӮжЎҶжһ¶пјҢеҗҺеҸ°е°ҶйӣҶжҲҗеҚ•зӮ№зҷ»еҪ•гҖҒAuth2.0гҖҒstorm+kafkaж¶ҲжҒҜеӨ„зҗҶзі»з»ҹгҖҒkafka+ flume+storm+hdfs+hadoopдҪңдёәж—Ҙеҝ—еҲҶжһҗзі»з»ҹгҖҒй…ҚзҪ®дёӯеҝғгҖҒеҲҶеёғејҸд»»еҠЎи°ғеәҰзі»з»ҹгҖҒжңҚеҠЎеҷЁе®һж—¶зӣ‘жҺ§зі»з»ҹгҖҒжҗңзҙўеј•ж“Һзі»з»ҹ(elastic...
- **Kafka+Flume+Storm еңЁзәҝи®Ўз®—пјҡ** йҖӮз”ЁдәҺе®һж—¶ж•°жҚ®жөҒеӨ„зҗҶгҖӮ - **Flume+Kafka+HDFS з”ЁдәҺ MR зҰ»зәҝи®Ўз®—пјҡ** йҖӮз”ЁдәҺжү№еӨ„зҗҶдҪңдёҡгҖӮ - **Kafka+Spark з”ЁдәҺж•°жҚ®жҢ–жҺҳе’ҢжңәеҷЁеӯҰд№ пјҡ** дёәеӨҚжқӮзҡ„ж•°жҚ®еҲҶжһҗд»»еҠЎжҸҗдҫӣдәҶејәеӨ§зҡ„ж”ҜжҢҒгҖӮ...
гҖҗдә‘и®Ўз®—гҖ‘жӯӨеӨ–пјҢж•ҷзЁӢиҝҳж¶үеҸҠдәҶдә‘и®Ўз®—зӣёе…ізҡ„жҠҖжңҜпјҢеҰӮKafkaпјҲеҲҶеёғејҸж¶ҲжҒҜзі»з»ҹпјүгҖҒStormпјҲе®һж—¶жөҒеӨ„зҗҶпјүгҖҒSparkпјҲеҝ«йҖҹеӨ§ж•°жҚ®еӨ„зҗҶеј•ж“Һпјүд»ҘеҸҠOozieпјҲе·ҘдҪңжөҒи°ғеәҰеҷЁпјүгҖҒImpalaпјҲдәӨдә’ејҸжҹҘиҜўжңҚеҠЎпјүгҖҒSolrпјҲе…Ёж–Үжҗңзҙўеј•ж“ҺпјүзӯүпјҢ...