
一致性Hash算法背景
一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。
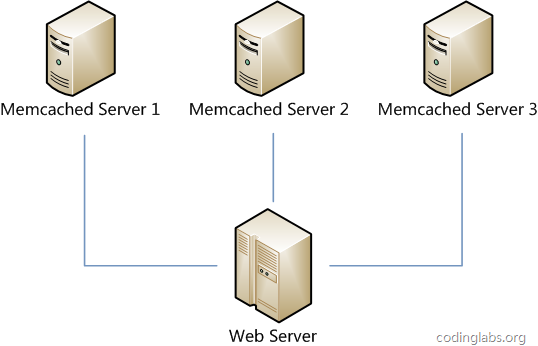
但现在一致性hash算法在分布式系统中也得到了广泛应用,研究过memcached缓存数据库的人都知道,memcached服务器端本身不提供分布式cache的一致性,而是由客户端来提供,具体在计算一致性hash时采用如下步骤:
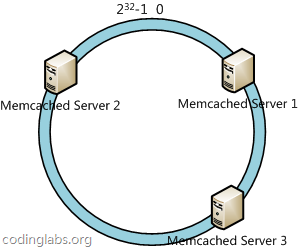
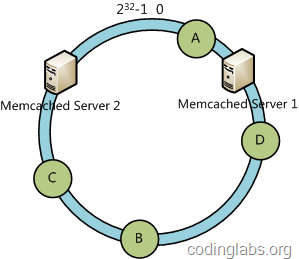
- 首先求出memcached服务器(节点)的哈希值,并将其配置到0~232的圆(continuum)上。
- 然后采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。
- 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。

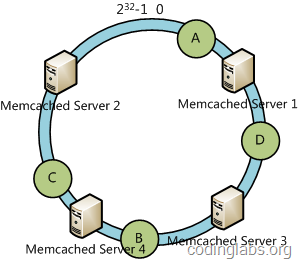
从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Hashing中,只有在园(continuum)上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响,如下图所示:

一致性Hash性质
考虑到分布式系统每个节点都有可能失效,并且新的节点很可能动态的增加进来,如何保证当系统的节点数目发生变化时仍然能够对外提供良好的服务,这是值得考虑的,尤其实在设计分布式缓存系统时,如果某台服务器失效,对于整个系统来说如果不采用合适的算法来保证一致性,那么缓存于系统中的所有数据都可能会失效(即由于系统节点数目变少,客户端在请求某一对象时需要重新计算其hash值(通常与系统中的节点数目有关),由于hash值已经改变,所以很可能找不到保存该对象的服务器节点),因此一致性hash就显得至关重要,良好的分布式cahce系统中的一致性hash算法应该满足以下几个方面:
- 平衡性(Balance)
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
- 单调性(Monotonicity)
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。简单的哈希算法往往不能满足单调性的要求,如最简单的线性哈希:x = (ax + b) mod (P),在上式中,P表示全部缓冲的大小。不难看出,当缓冲大小发生变化时(从P1到P2),原来所有的哈希结果均会发生变化,从而不满足单调性的要求。哈希结果的变化意味着当缓冲空间发生变化时,所有的映射关系需要在系统内全部更新。而在P2P系统内,缓冲的变化等价于Peer加入或退出系统,这一情况在P2P系统中会频繁发生,因此会带来极大计算和传输负荷。单调性就是要求哈希算法能够应对这种情况。
- 分散性(Spread)
在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
- 负载(Load)
负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
- 平滑性(Smoothness)
平滑性是指缓存服务器的数目平滑改变和缓存对象的平滑改变是一致的。
原理
基本概念
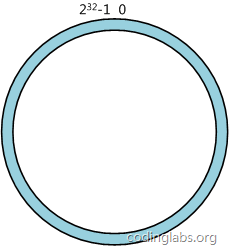
一致性哈希算法(Consistent Hashing)最早在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:

整个空间按顺时针方向组织。0和232-1在零点中方向重合。
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用ip地址哈希后在环空间的位置如下:

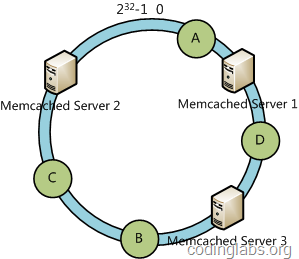
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:

根据一致性哈希算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
下面分析一致性哈希算法的容错性和可扩展性。现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果在系统中增加一台服务器Node X,如下图所示:

此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X 。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
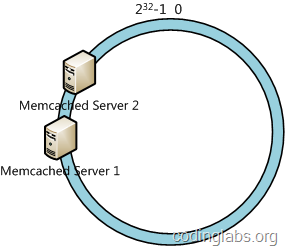
另外,一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如系统中只有两台服务器,其环分布如下,

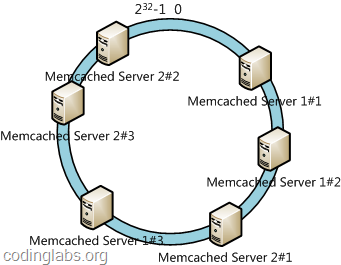
此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:

同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
相关实现
- Consistent hashing implementation in C++
- Consistent hashing implementation in Erlang
- Consistent hashing implementation in C#
- Consistent hashing implementation in Java
- Consistent hashing implementation in C
参考文献
[1].D. Darger, E. Lehman, T. Leighton, M. Levine, D. Lewin and R. Panigrahy. Consistent Hashing and Random Trees:Distributed Caching Protocols for Relieving Hot Spots On the World Wide Web. ACM Symposium on Theory of Computing, 1997. 1997:654-663.
[2].一致性哈希. http://baike.baidu.com/view/1588037.htm
[3]. memcached全面剖析–4. memcached的分布式算法. http://tech.idv2.com/2008/07/24/memcached-004/
[4].一致性哈希算法及其在分布式系统中的应用. http://www.codinglabs.org/html/consistent-hashing.html
[5].Consistent hashing. http://en.wikipedia.org/wiki/Consistent_hashing
[6].http://www.lexemetech.com/2007/11/consistent-hashing.html



相关推荐
一致性哈希算法是一种在分布式系统中用于解决数据分发和负载均衡问题的算法。随着互联网技术的快速发展,分布式系统已经成为支撑大规模服务的关键技术之一。在分布式系统中,多个节点通过网络协同工作,提供高可用性...
一致性哈希算法最初由麻省理工学院的K等人提出,并被广泛应用于分布式系统中,以解决节点动态变化时数据一致性问题。其核心思想是通过引入哈希环,将数据对象均匀分布在哈希环上的不同节点中,以此降低节点变更对...
一致性哈希算法是在分布式系统中广泛使用的一种数据定位算法,尤其适用于分布式缓存系统,如Redis。传统的哈希算法在分布式存储系统中有一个缺点,即当系统扩展或缩减节点时,数据的迁移量过大。一致性哈希算法通过...
综上所述,本文通过对一致性哈希算法及其在分布式数据库扩展中的应用进行深入研究,成功提出了一种高效扩展的方案。该方案通过合理利用预留子分区识别位和CRC32校验技术,显著提高了数据库扩展的速度和质量,对于...
本文将详细介绍一致性哈希的概念、原理以及在分布式系统中的应用。 一致性哈希为分布式系统提供了一种高效且灵活的数据分布机制。通过本文的介绍,我们学习了一致性哈希的概念、原理、应用场景以及如何实现它。一致...
一致性哈希算法由David Karger等人在1997年提出,它是一种特殊的哈希算法,主要用于分布式系统中实现负载均衡。与传统的哈希算法不同,一致性哈希算法在处理节点增减时,能够最小化重新分配数据的数量,从而提高系统...
一致性哈希算法是一种分布式哈希(Distributed Hash Table, DHT)技术,它解决了在分布式环境中数据分片和负载均衡的问题。在传统的哈希算法中,如果增加或减少服务器节点,会导致大量数据重新分配,而一致性哈希...
一致性哈希算法是一种在分布式系统中解决数据分片和负载均衡问题的算法,它主要解决了在动态添加或移除节点时,尽可能少地改变已经存在的数据分布。在云计算和大数据处理领域,一致性哈希被广泛应用,例如在分布式...
1. **一致性哈希算法**:一致性哈希是一种解决分布式系统中数据分布问题的算法,它的主要特点是能够尽可能地减少数据迁移。在WebSocket服务的分布式扩展中,一致性哈希用于确定每个连接应该路由到哪个服务器,使得在...
总的来说,Ketama一致性哈希算法是分布式系统中解决数据分布问题的重要工具,通过巧妙的设计实现了在节点变化时尽可能少的数据迁移,提高了系统的稳定性和扩展性。通过深入理解并运用这种算法,我们可以构建更加健壮...
通过运行此项目,你可以看到随着节点数量的变化,数据项的分布如何动态调整,这有助于深入理解一致性哈希算法在实际应用中的价值。此外,C#语言的实现使得代码易于阅读和学习,对于熟悉或想要学习C#编程的人来说,这...
在实际的分布式系统中,如CDN网络、分布式缓存系统等,一致性哈希算法得到了广泛应用。例如,在CDN环境中,通过一致性哈希算法可以将用户请求路由到最近的服务器,不仅减少了网络延迟,还实现了资源的高效利用。 ##...
一致性哈希算法(Consistent Hashing)是一种常用于分布式系统中的数据分片策略,它有效地解决了数据在多台服务器间均匀分布的问题,同时减少了因节点加入或离开时的数据迁移成本。 首先,一致性哈希的基本原理是将...
一致性哈希算法(Consistent Hashing)是一种在分布式系统中实现负载均衡的算法,尤其在分布式缓存如Memcached和Redis等场景下广泛使用。它解决了传统哈希算法在节点增减时导致的大量数据迁移问题,提高了系统的可用...
Mycat一致性哈希算法广泛应用于分布式缓存、负载均衡、数据库分片等场景,特别是在大数据、高并发的互联网应用中,能够有效提升系统的处理能力和稳定性。 总结,Mycat的一致性哈希分片算法是实现高效分布式数据库的...
2. **进程间通信**:分布式系统中的节点需要有效地交换信息,这就涉及到了各种进程间通信机制,包括消息传递、远程过程调用(RPC)、管道、套接字等。理解这些通信机制的原理和优缺点至关重要。 3. **分布式一致性...
在了解一致性哈希算法之前,需要了解一个经典的分布式缓存应用场景。假设,我们有三台缓存服务器,用于缓存图片,我们希望这些图片被均匀的缓存在这三台服务器上,以便它们能够分摊缓存的压力。那么,我们应该怎样做...