
HTTP请求流程
首先,http属于Tcp/Ip模型中的应用层协议,而两个应用程序(我们这里指的就是浏览器与服务器)之间要进行互相通信,首先得建立Tcp连接,然后浏览器才能向服务器发送请求信息,服务器在接受到请求信息后,返回相应的应答信息,浏览器接收到来自服务器的应答信息后,对这些数据进行解释执行。
在http 1.0的版本中,浏览器的每次请求(也就是对每一个页面的访问)都要求建立一次单独的连接,在处理完每一次的请求后,就自动释放连接。(这点我们应该都有感觉,比如我们访问一个页面,当该页面在浏览器中显示出来的时候,我们可以拔掉网线,此时该页面上的信息并不会丢失。)而当我们请求的网页文件中有很多图片、音乐、电影等信息时,服务器返回的信息中并不直接包含图片数据,而只是保存该图片的链接,当浏览器进行解释的时候,遇到图片的url时,才向服务器发出对图片的请求信息。可见如果一个网页中包含多个图片数据时,将会频繁的与服务器建立连接,与释放连接,这无疑会造成资源的浪费。

http 1.0 请求模式
而http 1.1则可以在一次连接中处理多个请求,并且多个请求可以重叠进行,不需要等待一个请求结束后再发送下一个请求。
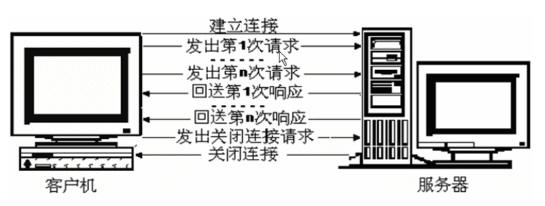
1次完整的http请求消息包括:一个请求行、若干消息头以及实体内容,而消息头和实体内容可以没有,消息头和实体内容间有一个空行。
我们来看一个例子(为了便于说明,我在每行前加了序号):
1 Get /mattmarg/ HTTP/1.0
2 User-Agent: Mozilla/2.0 (Macintosh; I; PPC)
3 Accept: text/html; */*
4 Cookie: name = value
5 Referer: http://www.XXX.com/a.html
其中,第1行就是请求行:请求方式为Get(除了Get之外,还有Post、Put、Delete方式),请求的文件位于"根目录/mattmarg/"下,当然也可以直接给出需要的页面(如:/mattmarg/index.asp,也可以加上一些其它字段 如:/mattmarg/index.asp?id=1&uid=xxx。当我们通过Get请求时,提交给服务器的请求行长度不能超过1K,而如果利用Post方式,则是把所提交的信息以实体内容形式发送给服务器,所以如果服务器没有限制的话,原则上讲可以传输无限大的内容),HTTP/1.0 表示了http的版本为1.0。其余几行就是消息头了,消息头主要是用来向服务器传达某种信息或指示。如告诉服务器自己的终端(User-Agent)是什么(如果是浏览器则返回相应的浏览器型号),终端所可以解释的类型(Accept)是什么,是从哪个页面提交的请求(Referer),以及浏览器所能解释的语言(Accept-Language)等等。我们这里拿Accept-Language来举个例子,大家都知道google在中国大陆显示的是简体中文,而在其它的国家则显示对应的语言,这个是怎么做到的呢?其实就是浏览器向服务器递交的请求信息中包含了Accept-Language,而我们的浏览器默认是zh-cn,然后服务器在接受到该信息时返回对应的页面。
我们可以通过以下方法来验证一下:
1、打开浏览器->工具->internet选项->常规选项卡
2、选择"语言",可见默认的语言是中文
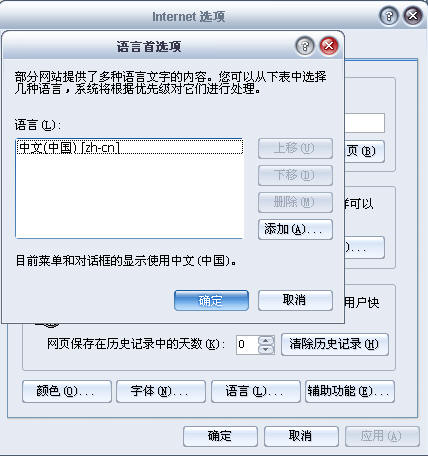
3、选择"添加",选择一种语言,然后调节一下优先顺序
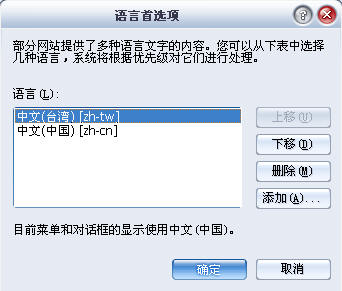
4、确定之后,我们再访问一下http://www.google.com/,是不是发现原来的简体中文全都成了繁体字了。
·HTTP响应消息
Http响应消息的格式为:一个状态行、若干消息头和实体内容,其中消息头和实体内容可以没有,消息头和实体内容间有一个空行。
我们依旧先来看一个例子:
01 HTTP/1.1 200 OK
02 Server: Microsoft-IIS/5.1
03 X-Powered-By: ASP.NET
04 Date: Sun, 06 Jul 2008 11:01:21 GMT
05 Content-Type: text/html
06 Accept-Ranges: bytes
07 Last-Modified: Wed, 02 Jul 2008 01:01:26 GMT
08 ETag: "0f71527dfdbc81:ade"
09 Content-Length: 46
10
11 <html><head></head><body>adfasfa</body></html>
其中,01行是状态行,用于显示服务器响应的状态,HTTP/1.1显示了对应的http协议版本,200为状态数字,OK为状态信息用于解释状态数字(这里OK对应200,表示请求正常);02~09是消息头部分,10为空行,11为实体内容(也就是服务器返回的网页内容)。
好了,相信大家应该已经对这个http请求的流程有了一个大概的了解了吧,那么我们反过来回答下最初留下的问题:当我们在浏览器的地址栏中输入 "http://www.baidu.com/ " ,然后按"回车",这之后发生了什么事?。
首先,浏览器找到该网址所指向的IP,然后与其建立TCP连接,接着向百度服务器提出Get请求,当服务器接收到我们的请求后,向我们传送应答信息--百度的页面,然后断开连接。
[补充]以上文章中主要是描述HTTP请求的大致流程,至于HTTP之前所建立的一系列连接,只用了"浏览器找到该网址所指向的IP,然后与其建立TCP连接"这句话或类似的话来带过。根据朋友们的回复显得这个说法不是很恰当。所以我在这里再补充些东西。
1、获取IP。浏览器地址栏中输入"http://www.xxx.edu.cn/"并提交之后,首先它会在DNS本地缓存表中查找,如果有则直接告诉IP地址。如果没有则要求网关DNS进行查找,如此下去,当找到对应的ip后,则返回给浏览器。
2、建立TCP连接。当获取到IP之后,就开始与所请求的服务器建立TCP连接,你可以在下图中发现syn,ack,这些标识符就是用来同步用的。
3、连接建立后,就向服务器发出http请求(大家可以从图中看出来)。如果是HTTP1.0的版本则,每一次请求结束后,就释放TCP连接。
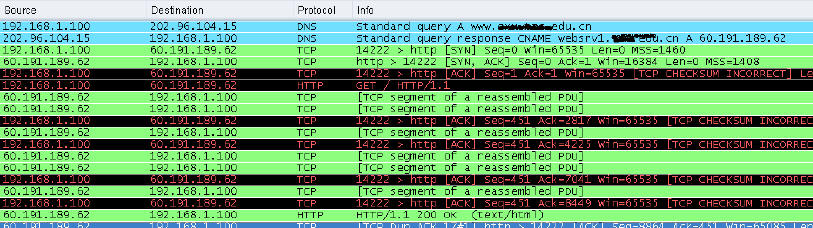
(上图中,由于是第一次访问网站,无法在本地找到对应IP)

(短时间内,第二次访问同一网站)
(短时间内,第二次访问同一网站)



相关推荐
### HTTP请求流程详解 #### 一、HTTP协议简介 HTTP(HyperText Transfer Protocol)是一种用于分布式、协作式和超媒体信息系统的应用层协议。它基于客户端-服务器模型,主要用于从Web服务器传输超文本文档(例如...
### HTTP请求的全过程详解 #### 一、输入地址与智能匹配 当用户开始在浏览器中键入网址时,浏览器就会启动一系列智能匹配机制来帮助用户快速完成URL的输入。这一过程涉及以下几个步骤: 1. **智能提示**:浏览器...
当用户发送一个HTTP请求到服务器时,Struts框架中的核心控制器——ActionServlet会首先解析该请求,并尝试找到与之相匹配的`ActionMapping`实例。`ActionMapping`用于描述请求路径、所对应的Action类以及可能的转发...
**SIP协议简介** SIP(Session Initiation Protocol)协议是一种用于控制多媒体通信会话的信令协议,广泛应用于互联网电话、视频会议、即时消息等领域。由IETF(Internet Engineering Task Force)制定,旨在简化...
在Java编程中,模拟HTTP请求是一项常见的任务,尤其在网页抓取、自动化测试以及网络数据获取等场景下。本项目涉及的关键技术点是利用HTTP客户端库进行登录操作,并抓取海投网的数据,随后将这些信息存储到MySQL...
这里提到的插件,可能是基于C#编写的,专门为了简化Unity中的HTTP请求流程而设计。C#是Unity的主要编程语言,因此这个插件很可能是用C#实现的,它提供了一个友好且易于理解的接口,使得开发者可以快速地进行HTTP请求...
通过以上分析,我们可以看到基于`SoapObject`的HTTP请求调用WebService的基本流程。这不仅适用于Java环境,其基本原理也适用于其他支持SOAP的编程语言和环境。需要注意的是,在实际应用中,还需要根据具体WebService...
1. **简介**:Postman提供了一个直观的用户界面,允许用户发送各种HTTP请求(GET、POST、PUT、DELETE等),并查看服务器返回的响应。这使得开发者能够快速验证API的功能和性能,以及检查数据交互是否符合预期。 2. ...
它可以帮助我们方便地发送HTTP请求,模拟客户端与服务器之间的交互,进而测试接口的功能和性能。本文将深入讲解Postman在请求响应中的应用。 一、Postman简介 Postman是一款独立的应用程序,支持Windows、Mac、...
#### 二、GET 请求简介 GET 方法是 HTTP 协议中最常见的请求方式之一,主要用于从服务器获取资源。GET 请求通常被用来获取静态资源如图片、CSS 文件、JavaScript 文件等,也可以用来获取动态生成的数据。 #### 三...
- ** Volley/ Retrofit**: 这是两个流行的网络请求库,Volley适合简单的HTTP请求,而Retrofit提供了一种基于注解的简洁API来构建网络服务接口。 2. **SpringBoot后端服务**: - **Spring Boot简介**: SpringBoot...
5. **网络请求流程** - 在Kotlin中,通常会创建一个网络请求工具类,封装OkHttp和Gson的调用,以简化代码。 - 发起请求时,首先创建一个请求体(RequestBody),根据请求类型(GET/POST)填充必要的数据。 - 将...
在MDM9x35的工作流程中,CGI技术被用于构建Web服务器的后端,接收用户的HTTP请求,并根据这些请求执行相应的功能,如配置网络参数、获取设备状态等。 2. MDM9X35 CGI应用 在MDM9x35芯片上,CGI技术被用于实现Web...
它的工作原理基于请求-响应模型,类似于HTTP协议。 SIP协议的核心组件包括用户代理(UA)、代理服务器、重定向服务器、注册服务器和信令网关。用户代理分为两种类型:用户代理客户端(UAC)发起会话请求,用户代理...
总之,ModHeader是谷歌浏览器中不可或缺的一款实用工具,它极大地简化了开发者和测试人员对HTTP请求头的管理和操作,提升了工作流程的效率。无论是开发调试还是问题排查,都能发挥出巨大的作用。
#### 一、RTSP协议简介 实时流协议(Real Time Streaming Protocol,简称RTSP)是一种用于控制实时数据(如音频和视频)传输的网络协议。它由RealNetworks和Netscape共同开发,主要应用于通过IP网络提供实时多媒体...
1. **客户端发起请求**:用户通过浏览器或其他客户端工具向服务器发送HTTP请求。 2. **ActionServlet接收请求**:所有请求首先被转发给`ActionServlet`,它是Struts框架的核心控制器,继承自`HttpServlet`。 3. **...
本文将详细介绍如何在C++中实现HTTP请求的发送与接收,包括GET和POST两种常见的方式。 #### 二、HTTP访问的基本概念 HTTP协议主要有两种请求方式:GET和POST。GET方式通常用于获取资源,而POST方式则用于向服务器...
它提供了丰富的功能,包括HTTP请求的创建、发送、查看响应、测试、组织集合以及生成文档。通过Postman,开发者可以轻松地进行GET、POST、PUT、DELETE等HTTP方法的请求,并对请求头、查询参数、请求体等进行精细化...
接口基于HTTP POST请求,采用UTF-8编码的JSON格式数据,支持HTTP基本认证。要使用接口,需要进行相应的配置,比如在iTop配置文件中启用REST服务,并确保使用接口的脚本或应用具有“REST Services User”角色。 例如...