
最近研究了一下关于文件下载的相关内容,觉得还是写些东西记下来比较好。起初只是想研究研究,但后来发现写个可重用性比较高的模块还是很有必要的,我想这也是大多数开发人员的习惯吧。
对于HTTP协议,向服务器请求某个文件时,只要发送类似如下的请求即可:
GET /Path/FileName HTTP/1.0
Host: www.server.com:80
Accept: */*
User-Agent: GeneralDownloadApplication
Connection: close
每行用一个“回车换行”分隔,末尾再追加一个“回车换行”作为整个请求的结束。
第一行中的GET是HTTP协议支持的方法之一,方法名是大小写敏感的,HTTP协议还支持OPTIONS、HAED、POST、PUT、DELETE、TRACE、CONNECT等方法,而GET和HEAD这两个方法通常被认为是“安全的”,也就是说任何实现了HTTP协议的服务器程序都会实现这两个方法。对于文件下载功能,GET足矣。GET后面是一个空格,其后紧跟的是要下载的文件从WEB服务器根开始的绝对路径。该路径后又有一个空格,然后是协议名称及协议版本。
除第一行以外,其余行都是HTTP头的字段部分。Host字段表示主机名和端口号,如果端口号是默认的80则可以不写。Accept字段中的*/*表示接收任何类型的数据。User-Agent表示用户代理,这个字段可有可无,但强烈建议加上,因为它是服务器统计、追踪以及识别客户端的依据。Connection字段中的close表示使用非持久连接。
关于HTTP协议更多的细节可以参考RFC2616(HTTP 1.1)。因为我只是想通过HTTP协议实现文件下载,所以也只看了一部分,并没有看全。
如果服务器成功收到该请求,并且没有出现任何错误,则会返回类似下面的数据:
HTTP/1.0 200 OK
Content-Length: 13057672
Content-Type: application/octet-stream
Last-Modified: Wed, 10 Oct 2005 00:56:34 GMT
Accept-Ranges: bytes
ETag: "2f38a6cac7cec51:160c"
Server: Microsoft-IIS/6.0
X-Powered-By: ASP.NET
Date: Wed, 16 Nov 2005 01:57:54 GMT
Connection: close
不用逐一解释,很多东西一看几乎就明白了,只说我们大家都关心内容吧。
第一行是协议名称及版本号,空格后面会有一个三位数的数字,是HTTP协议的响应状态码,200表示成功,OK是对状态码的简短文字描述。状态码共有5类:
1xx属于通知类;
2xx属于成功类;
3xx属于重定向类;
4xx属于客户端错误类;
5xx属于服务端错误类。
对于状态码,相信大家对404应该很熟悉,如果向一个服务器请求一个不存在的文件,就会得到该错误,通常浏览器也会显示类似“HTTP 404 - 未找到文件”这样的错误。Content-Length字段是一个比较重要的字段,它标明了服务器返回数据的长度,这个长度是不包含HTTP头长度的。换句话说,我们的请求中并没有Range字段(后面会说到),表示我们请求的是整个文件,所以Content-Length就是整个文件的大小。其余各字段是一些关于文件和服务器的属性信息。
这段返回数据同样是以最后一行的结束标志(回车换行)和一个额外的回车换行作为结束,即“\r\n\r\n”。而“\r\n\r\n”后面紧接的就是文件的内容了,这样我们就可以找到“\r\n\r\n”,并从它后面的第一个字节开始,源源不断的读取,再写到文件中了。
以上就是通过HTTP协议实现文件下载的全过程。但还不能实现断点续传,而实际上断点续传的实现非常简单,只要在请求中加一个Range字段就可以了。
假如一个文件有1000个字节,那么其范围就是0-999,则:
Range: bytes=500- 表示读取该文件的500-999字节,共500字节。
Range: bytes=500-599 表示读取该文件的500-599字节,共100字节。
Range还有其它几种写法,但上面这两种是最常用的,对于断点续传也足矣了。如果HTTP请求中包含Range字段,那么服务器会返回206(Partial Content),同时HTTP头中也会有一个相应的Content-Range字段,类似下面的格式:
Content-Range: bytes 500-999/1000
Content-Range字段说明服务器返回了文件的某个范围及文件的总长度。这时Content-Length字段就不是整个文件的大小了,而是对应文件这个范围的字节数,这一点一定要注意。
一切好像基本上没有什么问题了,本来我也是这么认为的,但事实并非如此。如果我们请求的文件的URL是类似http://www.server.com/filename.exe这样的文件,则不会有问题。但是很多软件下载网站的文件下载链接都是通过程序重定向的,比如pchome的ACDSee的HTTP下载地址是:
http://download.pchome.net/php/tdownload2.php?sid=5547&url=/multimedia/viewer/acdc31sr1b051007.exe&svr=1&typ=0
这种地址并没有直接标识文件的位置,而是通过程序进行了重定向。如果向服务器请求这样的URL,服务器就会返回302(Moved Temporarily),意思就是需要重定向,同时在HTTP头中会包含一个Location字段,Location字段的值就是重定向后的目的URL。这时就需要断开当前的连接,而向这个重定向后的服务器发请求。
好了,原理基本上就是这些了。其实装个Sniffer好好分析一下,很容易就可以分析出来的。不过NetAnts也帮了我一些忙,它的文件下载日志对开发人员还是很有帮助的。
annegu做了一个简单的Http多线程的下载程序,来讨论一下多线程并发下载以及断点续传的问题。
这个程序的功能,就是可以分多个线程从目标地址上下载数据,每个线程负责下载一部分,并可以支持断点续传和超时重连。
下载的方法是download(),它接收两个参数,分别是要下载的页面的url和编码方式。在这个负责下载的方法中,主要分了三个步骤。第一步是用来设置断点续传时候的一些信息的,第二步就是主要的分多线程来下载了,最后是数据的合并。
1、多线程下载:
- public String download(String urlStr, String charset) {
- this.charset = charset;
- long contentLength = 0;
- ① CountDownLatch latch = new CountDownLatch(threadNum);
- long[] startPos = new long[threadNum];
- long endPos = 0;
- try {
- // 从url中获得下载的文件格式与名字
- this.fileName = urlStr.substring(urlStr.lastIndexOf("/") + 1, urlStr.lastIndexOf("?")>0 ? urlStr.lastIndexOf("?") : urlStr.length());
- if("".equalsIgnoreCase(this.fileName)){
- this.fileName = UUID.randomUUID().toString();
- }
- this.url = new URL(urlStr);
- URLConnection con = url.openConnection();
- setHeader(con);
- // 得到content的长度
- contentLength = con.getContentLength();
- // 把context分为threadNum段的话,每段的长度。
- this.threadLength = contentLength / threadNum;
- // 第一步,分析已下载的临时文件,设置断点,如果是新的下载任务,则建立目标文件。在第4点中说明。
- startPos = setThreadBreakpoint(fileDir, fileName, contentLength, startPos);
- //第二步,分多个线程下载文件
- ExecutorService exec = Executors.newCachedThreadPool();
- for (int i = 0; i < threadNum; i++) {
- // 创建子线程来负责下载数据,每段数据的起始位置为(threadLength * i + 已下载长度)
- startPos[i] += threadLength * i;
- /*设置子线程的终止位置,非最后一个线程即为(threadLength * (i + 1) - 1)
- 最后一个线程的终止位置即为下载内容的长度*/
- if (i == threadNum - 1) {
- endPos = contentLength;
- } else {
- endPos = threadLength * (i + 1) - 1;
- }
- // 开启子线程,并执行。
- ChildThread thread = new ChildThread(this, latch, i, startPos[i], endPos);
- childThreads[i] = thread;
- exec.execute(thread);
- }
- try {
- // 等待CountdownLatch信号为0,表示所有子线程都结束。
- ② latch.await();
- exec.shutdown();
- // 第三步,把分段下载下来的临时文件中的内容写入目标文件中。在第3点中说明。
- tempFileToTargetFile(childThreads);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
首先来看最主要的步骤:多线程下载。
首先从url中提取目标文件的名称,并在对应的目录创建文件。然后取得要下载的文件大小,根据分成的下载线程数量平均分配每个线程需要下载的数据量,就是threadLength。然后就可以分多个线程来进行下载任务了。
在这个例子中,并没有直接显示的创建Thread对象,而是用Executor来管理Thread对象,并且用CachedThreadPool来创建的线程池,当然也可以用FixedThreadPool。CachedThreadPool在程序执行的过程中会创建与所需数量相同的线程,当程序回收旧线程的时候就停止创建新线程。FixedThreadPool可以预先新建参数给定个数的线程,这样就不用在创建任务的时候再来创建线程了,可以直接从线程池中取出已准备好的线程。下载线程的数量是通过一个全局变量threadNum来控制的,默认为5。
好了,这5个子线程已经通过Executor来创建了,下面它们就会各自为政,互不干涉的执行了。线程有两种实现方式:实现Runnable接口;继承Thread类。
ChildThread就是子线程,它作为DownloadTask的内部类,继承了Thread,它的构造方法需要5个参数,依次是一个对DownloadTask的引用,一个CountDownLatch,id(标识线程的id号),startPosition(下载内容的开始位置),endPosition(下载内容的结束位置)。
这个CountDownLatch是做什么用的呢?
现在我们整理一下思路,要实现分多个线程来下载数据的话,我们肯定还要把这多个线程下载下来的数据进行合。主线程必须等待所有的子线程都执行结束之后,才能把所有子线程的下载数据按照各自的id顺序进行合并。CountDownLatch就是来做这个工作的。
CountDownLatch用来同步主线程,强制主线程等待所有的子线程执行的下载操作完成。在主线程中,CountDownLatch对象被设置了一个初始计数器,就是子线程的个数5个,代码①处。在新建了5个子线程并开始执行之后,主线程用CountDownLatch的await()方法来阻塞主线程,直到这个计数器的值到达0,才会进行下面的操作,代码②处。
对每个子线程来说,在执行完下载指定区间与长度的数据之后,必须通过调用CountDownLatch的countDown()方法来把这个计数器减1。
2、在全面开启下载任务之后,主线程就开始阻塞,等待子线程执行完毕,所以下面我们来看一下具体的下载线程ChildThread。
- public class ChildThread extends Thread {
- public static final int STATUS_HASNOT_FINISHED = 0;
- public static final int STATUS_HAS_FINISHED = 1;
- public static final int STATUS_HTTPSTATUS_ERROR = 2;
- private DownloadTask task;
- private int id;
- private long startPosition;
- private long endPosition;
- private final CountDownLatch latch;
- // private RandomAccessFile tempFile = null;
- private File tempFile = null;
- //线程状态码
- private int status = ChildThread.STATUS_HASNOT_FINISHED;
- public ChildThread(DownloadTask task, CountDownLatch latch, int id, long startPos, long endPos) {
- super();
- this.task = task;
- this.id = id;
- this.startPosition = startPos;
- this.endPosition = endPos;
- this.latch = latch;
- try {
- tempFile = new File(this.task.fileDir + this.task.fileName + "_" + id);
- if(!tempFile.exists()){
- tempFile.createNewFile();
- }
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- public void run() {
- System.out.println("Thread " + id + " run ...");
- HttpURLConnection con = null;
- InputStream inputStream = null;
- BufferedOutputStream outputStream = null;
- long count = 0;
- long threadDownloadLength = endPosition - startPosition;
- try {
- outputStream = new BufferedOutputStream(new FileOutputStream(tempFile.getPath(), true));
- } catch (FileNotFoundException e2) {
- e2.printStackTrace();
- }
- ③ for(int k = 0; k < 10; k++){
- if(k > 0)
- System.out.println("Now thread " + id + "is reconnect, start position is " + startPosition);
- try {
- //打开URLConnection
- con = (HttpURLConnection) task.url.openConnection();
- setHeader(con);
- con.setAllowUserInteraction(true);
- //设置连接超时时间为10000ms
- ④ con.setConnectTimeout(10000);
- //设置读取数据超时时间为10000ms
- con.setReadTimeout(10000);
- if(startPosition < endPosition){
- //设置下载数据的起止区间
- con.setRequestProperty("Range", "bytes=" + startPosition + "-"
- + endPosition);
- System.out.println("Thread " + id + " startPosition is " + startPosition);
- System.out.println("Thread " + id + " endPosition is " + endPosition);
- //判断http status是否为HTTP/1.1 206 Partial Content或者200 OK
- //如果不是以上两种状态,把status改为STATUS_HTTPSTATUS_ERROR
- ⑤ if (con.getResponseCode() != HttpURLConnection.HTTP_OK
- && con.getResponseCode() != HttpURLConnection.HTTP_PARTIAL) {
- System.out.println("Thread " + id + ": code = "
- + con.getResponseCode() + ", status = "
- + con.getResponseMessage());
- status = ChildThread.STATUS_HTTPSTATUS_ERROR;
- this.task.statusError = true;
- outputStream.close();
- con.disconnect();
- System.out.println("Thread " + id + " finished.");
- latch.countDown();
- break;
- }
- inputStream = con.getInputStream();
- int len = 0;
- byte[] b = new byte[1024];
- while ((len = inputStream.read(b)) != -1) {
- outputStream.write(b, 0, len);
- count += len;
- ⑥ startPosition += len;
- //每读满4096个byte(一个内存页),往磁盘上flush一下
- if(count % 4096 == 0){
- ⑦ outputStream.flush();
- }
- }
- System.out.println("count is " + count);
- if (count >= threadDownloadLength) {
- status = ChildThread.STATUS_HAS_FINISHED;
- }
- ⑧ outputStream.flush();
- outputStream.close();
- inputStream.close();
- con.disconnect();
- } else {
- status = ChildThread.STATUS_HAS_FINISHED;
- }
- System.out.println("Thread " + id + " finished.");
- latch.countDown();
- break;
- } catch (IOException e) {
- try {
- ⑨ outputStream.flush();
- ⑩ TimeUnit.SECONDS.sleep(getSleepSeconds());
- } catch (InterruptedException e1) {
- e1.printStackTrace();
- } catch (IOException e2) {
- e2.printStackTrace();
- }
- continue;
- }
- }
- }
- }
在ChildThread的构造方法中,除了设置一些从主线程中带来的id, 起始位置之外,就是新建了一个临时文件用来存放当前线程的下载数据。临时文件的命名规则是这样的:下载的目标文件名+”_”+线程编号。
现在让我们来看看从网络中读数据是怎么读的。我们通过URLConnection来获得一个http的连接。有些网站为了安全起见,会对请求的http连接进行过滤,因此为了伪装这个http的连接请求,我们给httpHeader穿一件伪装服。下面的setHeader方法展示了一些非常常用的典型的httpHeader的伪装方法。比较重要的有:Uer-Agent模拟从Ubuntu的firefox浏览器发出的请求;Referer模拟浏览器请求的前一个触发页面,例如从skycn站点来下载软件的话,Referer设置成skycn的首页域名就可以了;Range就是这个连接获取的流文件的起始区间。
- private void setHeader(URLConnection con) {
- con.setRequestProperty("User-Agent", "Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.3) Gecko/2008092510 Ubuntu/8.04 (hardy) Firefox/3.0.3");
- con.setRequestProperty("Accept-Language", "en-us,en;q=0.7,zh-cn;q=0.3");
- con.setRequestProperty("Accept-Encoding", "aa");
- con.setRequestProperty("Accept-Charset", "ISO-8859-1,utf-8;q=0.7,*;q=0.7");
- con.setRequestProperty("Keep-Alive", "300");
- con.setRequestProperty("Connection", "keep-alive");
- con.setRequestProperty("If-Modified-Since", "Fri, 02 Jan 2009 17:00:05 GMT");
- con.setRequestProperty("If-None-Match", "\"1261d8-4290-df64d224\"");
- con.setRequestProperty("Cache-Control", "max-age=0");
- con.setRequestProperty("Referer", "http://www.dianping.com");
- }
另外,为了避免线程因为网络原因而阻塞,设置了ConnectTimeout和ReadTimeout,代码④处。setConnectTimeout设置的连接的超时时间,而setReadTimeout设置的是读取数据的超时时间,发生超时的话,就会抛出socketTimeout异常,两个方法的参数都是超时的毫秒数。
这里对超时的发生,采用的是等候一段时间重新连接的方法。整个获取网络连接并读取下载数据的过程都包含在一个循环之中(代码③处),如果发生了连接或者读取数据的超时,在抛出的异常里面就会sleep一定的时间(代码⑩处),然后continue,再次尝试获取连接并读取数据,这个时间可以通过setSleepSeconds()方法来设置。我们在迅雷等下载工具的使用中,经常可以看到状态栏会输出类似“连接超时,等待*秒后重试”的话,这个就是通过ConnectTimeout,ReadTimeout来实现的。
连接建立好之后,我们要检查一下返回响应的状态码。常见的Http Response Code有以下几种:
a) 200 OK 一切正常,对GET和POST请求的应答文档跟在后面。
b) 206 Partial Content 客户发送了一个带有Range头的GET请求,服务器完成。
c) 404 Not Found 无法找到指定位置的资源。这也是一个常用的应答。
d) 414 Request URI Too Long URI太长。
e) 416 Requested Range Not Satisfiable 服务器不能满足客户在请求中指定的Range头。
f) 500 Internal Server Error 服务器遇到了意料不到的情况,不能完成客户的请求。
g) 503 Service Unavailable 服务器由于维护或者负载过重未能应答。例如,Servlet可能在数据库连接池已满的情况下返回503。
在这些状态里面,只有200与206才是我们需要的正确的状态。所以在代码⑤处,进行了状态码的判断,如果返回不符合要求的状态码,则结束线程,返回主线程并提示报错。
假设一切正常,下面我们就要考虑从网络中读数据了。正如我之前在分析mysql的数据库驱动中看的一样,网络中发送数据都是以数据包的形式来发送的,也就是说不管是客户端向服务器发出的请求数据,还是从服务器返回给客户端的响应数据,都会被拆分成若干个小型数据包在网络中传递,等数据包到达了目的地,网络接口会依据数据包的编号来组装它们,成为完整的比特数据。因此,我们可以想到在这里也是一样的,我们用inputStream的read方法来通过网卡从网络中读取数据,并不一定一次就能把所有的数据包都读完,所以我们要不断的循环来从inputStream中读取数据。Read方法有一个int型的返回值,表示每次从inputStream中读取的字节数,如果把这个inputStream中的数据读完了,那么就返回-1。
Read方法最多可以有三个参数,byte b[]是读取数据之后存放的目标数组,off标识了目标数组中存储的开始位置,len是想要读取的数据长度,这个长度必定不能大于b[]的长度。
public synchronized int read(byte b[], int off, int len);
我们的目标是要把目标地址的内容下载下来,现在分了5个线程来分段下载,那么这些分段下载的数据保存在哪里呢?如果把它们都保存在内存中是非常糟糕的做法,如果文件相当之大,例如是一个视频的话,难道把这么大的数据都放在内存中吗,这样的话,万一连接中断,那前面下载的东西就都没有了?我们当然要想办法及时的把下载的数据刷到磁盘上保存下来。当用bt下载视频的时候,通常都会有个临时文件,当视频完全下载结束之后,这个临时文件就会被删除,那么下次继续下载的时候,就会接着上次下载的点继续下载。所以我们的outputStream就是往这个临时文件来输出了。
OutputStream的write方法和上面InputStream的read方法有类似的参数,byte b[]是输出数据的来源,off标识了开始位置,len是数据长度。
public synchronized void write(byte b[], int off, int len) throws IOException;
在往临时文件的outputStream中写数据的时候,我会加上一个计数器,每满4096个比特就往文件中flush一下(代码⑦处)。
对于输出流的flush,有些要注意的地方,在程序中有三个地方调用了outputStream.flush()。第一个是在循环的读取网络数据并往outputStream中写入的时候,每满4096个byte就flush一下(代码⑦处);第二个是循环之后(代码⑧处),这时候正常的读取写入操作已经完成,但是outputStream中还有没有刷入磁盘的数据,所以要flush一下才能关闭连接;第三个就是在异常中的flush(代码⑨处),因为如果发生了连接超时或者读取数据超时的话,就会直接跑到catch的exception中去,这个时候outputStream中的数据如果不flush的话,重新连接的时候这部分数据就会丢失了。另外,当抛出异常,重新连接的时候,下载的起始位置也要重新设置,所以在代码⑥处,即每次从inputStream中读取数据之后,startPosition就要重新设置,count标识了已经下载的字节数。
3、现在每个分段的下载线程都顺利结束了,也都创建了相应的临时文件,接下来在主线程中会对临时文件进行合并,并写入目标文件,最后删除临时文件。这部分很简单,就是一个对所有下载线程进行遍历的过程。这里outputStream也有两次flush,与上面类似,不再赘述。
- private void tempFileToTargetFile(ChildThread[] childThreads) {
- try {
- BufferedOutputStream outputStream = new BufferedOutputStream(
- new FileOutputStream(fileDir + fileName));
- // 遍历所有子线程创建的临时文件,按顺序把下载内容写入目标文件中
- for (int i = 0; i < threadNum; i++) {
- if (statusError) {
- for (int k = 0; k < threadNum; k++) {
- if (childThreads[k].tempFile.length() == 0)
- childThreads[k].tempFile.delete();
- }
- System.out.println("本次下载任务不成功,请重新设置线程数。");
- break;
- }
- BufferedInputStream inputStream = new BufferedInputStream(
- new FileInputStream(childThreads[i].tempFile));
- System.out.println("Now is file " + childThreads[i].id);
- int len = 0;
- long count = 0;
- byte[] b = new byte[1024];
- while ((len = inputStream.read(b)) != -1) {
- count += len;
- outputStream.write(b, 0, len);
- if ((count % 4096) == 0) {
- outputStream.flush();
- }
- // b = new byte[1024];
- }
- inputStream.close();
- // 删除临时文件
- if (childThreads[i].status == ChildThread.STATUS_HAS_FINISHED) {
- childThreads[i].tempFile.delete();
- }
- }
- outputStream.flush();
- outputStream.close();
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
4、最后,说说断点续传,前面为了实现断点续传,在每个下载线程中都创建了一个临时文件,现在我们就要利用这个临时文件来设置断点的位置。由于临时文件的命名方式都是固定的,所以我们就专门找对应下载的目标文件的临时文件,临时文件中已经下载的字节数就是我们需要的断点位置。startPos是一个数组,存放了每个线程的已下载的字节数。
- //第一步,分析已下载的临时文件,设置断点,如果是新的下载任务,则建立目标文件。
- private long[] setThreadBreakpoint(String fileDir2, String fileName2,
- long contentLength, long[] startPos) {
- File file = new File(fileDir + fileName);
- long localFileSize = file.length();
- if (file.exists()) {
- System.out.println("file " + fileName + " has exists!");
- // 下载的目标文件已存在,判断目标文件是否完整
- if (localFileSize < contentLength) {
- System.out.println("Now download continue ... ");
- // 遍历目标文件的所有临时文件,设置断点的位置,即每个临时文件的长度
- File tempFileDir = new File(fileDir);
- File[] files = tempFileDir.listFiles();
- for (int k = 0; k < files.length; k++) {
- String tempFileName = files[k].getName();
- // 临时文件的命名方式为:目标文件名+"_"+编号
- if (tempFileName != null && files[k].length() > 0
- && tempFileName.startsWith(fileName + "_")) {
- int fileLongNum = Integer.parseInt(tempFileName
- .substring(tempFileName.lastIndexOf("_") + 1,
- tempFileName.lastIndexOf("_") + 2));
- // 为每个线程设置已下载的位置
- startPos[fileLongNum] = files[k].length();
- }
- }
- }
- } else {
- // 如果下载的目标文件不存在,则创建新文件
- try {
- file.createNewFile();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- return startPos;
- }
5、测试
- public class DownloadStartup {
- private static final String encoding = "utf-8";
- public static void main(String[] args) {
- DownloadTask downloadManager = new DownloadTask();
- String urlStr = "http://apache.freelamp.com/velocity/tools/1.4/velocity-tools-1.4.zip";
- downloadManager.setSleepSeconds(5);
- downloadManager.download(urlStr, encoding);
- }
- }
测试从apache下载一个velocity的压缩包,临时文件保留,看一下下载结果:
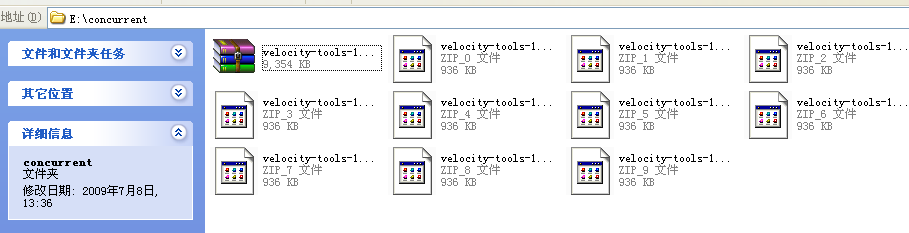
另:在测试从skycn下载软件的过程中,碰到了一个错误:
java.io.IOException: Server returned HTTP response code: 416 for URL: http://www.skycn.com/
上网查了一下:416 Requested Range Not Satisfiable 服务器不能满足客户在请求中指定的Range头,于是把threadNum改为1就可以了。
这个下载功能现在只是完成了很基础的一部分,最初的初衷就是为了演练一下CountdownLatch。CountdownLatch就是一个计数器,就像一个拦截的栅栏,用await()方法来把栅栏关上,线程就跑不下去了,只有等计数器减为0的时候,栅栏才会自动打开,被暂停的线程才会继续运行。CountdownLatch的应用场景可以有很多,分段下载就是一个很好的例子。



相关推荐
然而,实现多线程断点续传需要解决几个问题: 1. **同步管理**:多个线程可能会同时访问同一个文件的部分,因此需要使用`synchronized`关键字或`Lock`对象来确保并发安全。 2. **断点信息共享**:每个线程需要知道...
在VC++环境中,实现FTP协议的多线程断点续传,通常需要以下步骤: 1. **理解FTP协议**:首先,你需要了解FTP的基本工作原理,包括命令和响应机制,如“USER”、“PASS”用于登录,“PASV”或“PORT”用于设置数据...
本资料包“基于C#的WebAPI断点续传几种方式及WebClient断点续传下载.zip”主要探讨了两种在C#环境下实现断点续传的方法:一是通过WebAPI实现服务端的断点续传功能,二是使用WebClient类进行客户端的断点续传下载。...
在VC++环境中实现FTP协议的多线程断点续传是一项技术挑战,涉及到网络编程、FTP协议的理解以及多线程的运用。以下是一份详细的知识点解析: 1. FTP协议基础: FTP(File Transfer Protocol)是一种用于在网络上...
总的来说,"MyNetAnts.rar"是一个集成了HTTP协议、断点续传和多线程下载技术的下载工具,其设计理念是优化大文件下载的效率和用户体验。对于学习网络编程、HTTP协议以及多线程技术的开发者来说,这是一个很好的实践...
多线程断点续传原理与具体实现 断点续传是指在网络不稳定或传输过程中出现异常时,能够从断开处继续传输而不是重新开始。为了实现这一功能,需要记录文件传输的进度,并在下次传输时能够准确地从上次断开的地方...
总之,多线程断点续传在ASP.NET(C#)中的实现涉及到文件流操作、HTTP协议理解和多线程编程等多个方面,是一项技术挑战性较高的任务。掌握这一技能,不仅能提升个人编程能力,还能为用户提供更稳定、高效的网络服务...
FTP(File Transfer Protocol)协议是Internet上用于在主机之间传输文件的标准协议,它允许用户从远程主机...通过学习和理解这些源代码,开发者可以深入理解FTP协议、多线程编程以及如何结合两者来实现断点续传功能。
综上所述,在Java中实现HTTP断点续传主要依赖于对HTTP协议的理解及使用Java内置的网络编程API。通过合理的使用`HttpURLConnection`和`RandomAccessFile`等工具,开发者可以轻松地开发出支持断点续传的应用程序。
#### 一、多线程断点续传的概念及重要性 在移动互联网应用中,特别是在资源下载方面,用户体验是非常关键的一环。对于大文件的下载,传统的单线程下载方式往往无法满足用户的需求,尤其是在网络不稳定的情况下,...
标题中的“socket做的支持多线程断点上传or断点续传Java源码”涉及到的是在网络编程中,如何使用Java的Socket API实现一个能够处理断点上传和断点续传功能的服务。这是一个高级的网络编程任务,通常在大型文件传输...
多线程断点续传的实现通常需要一个下载管理器,它可以跟踪每个线程的进度,协调各个线程的下载,并在需要时进行错误恢复。此外,为了确保文件的完整性,下载管理器还需要进行校验,比如使用MD5或SHA-1等哈希算法计算...
在实现断点续传的过程中,我们需要考虑如何使用Java多线程来实现文件的分块下载和断点续传。具体步骤如下: 2.1 连接到服务器 使用Java的HttpURLConnection类连接到服务器,并发送GET请求获取要下载的文件的基本...
总的来说,Android多线程断点续传下载结合了多线程编程和HTTP协议的特性,提高了文件下载的效率和用户体验。开发者需要掌握线程管理、文件操作以及HTTP请求的相关知识,才能有效地实现这一功能。通过不断学习和实践...
除了单线程的断点续传,还可以通过多线程或并行下载来提高下载速度。每个线程负责下载文件的一部分,然后合并到同一个文件中。这种方式需要更复杂的逻辑来协调各个线程的下载进度,以确保数据的正确性。 通过以上...
以上是关于Android实现多线程断点续传下载的基本原理和实现要点。实际项目中,你可能还需要考虑网络状态变化、权限管理、文件存储路径选择等更多细节。提供的压缩包文件"MultiThreadDownloader-master"可能包含了...
多线程断点续传是一种在大文件传输中常见的优化技术,它允许用户在中断传输后从上次停止的地方继续,而无需重新下载整个文件。在Java编程中,实现这一功能通常涉及对网络I/O、多线程以及文件操作的深入理解。本实践...
这两个文件分别代表了多线程断点续传功能中的客户端和服务器端。在实际使用时,客户端负责发起请求并根据服务器端的反馈,控制文件的下载过程,实现断点续传功能。而服务器端则处理客户端的请求,负责提供文件数据...
了解并实现多线程断点下载文件的原理和技术,不仅可以提升开发者的技能,也能帮助用户更高效地管理和下载大型文件,从而提高工作效率。在实际开发中,还需要考虑如何优化资源分配,防止过多线程对系统造成过大的压力...