
本文之所以称之为经验,是因为我们经常碰到莫名其妙的问题,从原理上是说不通的。但是我们却确确实实碰到了。
在刚开始运行的时候,碰到了下文所表示的错误。本想作为经验总结留下来。为了让错误重现,所以又重新操作了一遍。这时候已经换环境,但是环境与原先没做任何的更改,也就是说他们的配置完全是一样的,神奇的是mapreduce执行的完全正确。对于如果碰到下面问题的同学,可以参考。对于原理性的内容,以后在更新。
对于新手,经常遇到,在eclipse中是可以运行的,但是打包放到集群上,不可行,问题如下:
- Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/conf/Configuration
- at mapreduce.mapreduce.main(mapreduce.java:24)
- Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.conf.Configuration
- at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
- at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
- at java.security.AccessController.doPrivileged(Native Method)
- at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
- at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
- at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
- at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
- ... 1 more
- hadoop jar '/home/user/Desktop/mapreduce.jar' mapreduce
- 14/03/05 05:35:09 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
- 14/03/05 05:35:09 WARN mapred.JobClient: No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).
- 14/03/05 05:35:09 INFO input.FileInputFormat: Total input paths to process : 1
- 14/03/05 05:35:09 INFO util.NativeCodeLoader: Loaded the native-hadoop library
- 14/03/05 05:35:10 WARN snappy.LoadSnappy: Snappy native library not loaded
- 14/03/05 05:35:10 INFO mapred.JobClient: Running job: job_201402280238_0011
- 14/03/05 05:35:11 INFO mapred.JobClient: map 0% reduce 0%
- 14/03/05 05:35:25 INFO mapred.JobClient: Task Id : attempt_201402280238_0011_m_000000_0, Status : FAILED
- java.lang.RuntimeException: java.lang.ClassNotFoundException: mapreduce.mapreduce$MyMapper
- at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:867)
- at org.apache.hadoop.mapreduce.JobContext.getMapperClass(JobContext.java:199)
- at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:719)
- at org.apache.hadoop.mapred.MapTask.run(MapTask.java:370)
- at org.apache.hadoop.mapred.Child$4.run(Child.java:255)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:415)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1121)
- at org.apache.hadoop.mapred.Child.main(Child.java:249)
- Caused by: java.lang.ClassNotFoundException: mapreduce.mapreduce$MyMapper
- at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
- at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
- at java.security.AccessController.doPrivileged(Native Method)
- at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
- at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
- at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
- at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
- at java.lang.Class.forName0(Native Method)
- at java.lang.Class.forName(Class.java:270)
- at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:820)
- at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:865)
- ... 8 more
- 14/03/05 05:35:31 INFO mapred.JobClient: Task Id : attempt_201402280238_0011_m_000000_1, Status : FAILED
- java.lang.RuntimeException: java.lang.ClassNotFoundException: mapreduce.mapreduce$MyMapper
- at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:867)
- at org.apache.hadoop.mapreduce.JobContext.getMapperClass(JobContext.java:199)
- at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:719)
- at org.apache.hadoop.mapred.MapTask.run(MapTask.java:370)
- at org.apache.hadoop.mapred.Child$4.run(Child.java:255)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:415)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1121)
- at org.apache.hadoop.mapred.Child.main(Child.java:249)
- Caused by: java.lang.ClassNotFoundException: mapreduce.mapreduce$MyMapper
- at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
- at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
- at java.security.AccessController.doPrivileged(Native Method)
- at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
- at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
- at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
- at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
- at java.lang.Class.forName0(Native Method)
- at java.lang.Class.forName(Class.java:270)
- at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:820)
- at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:865)
- ... 8 more
- 14/03/05 05:35:37 INFO mapred.JobClient: Task Id : attempt_201402280238_0011_m_000000_2, Status : FAILED
- java.lang.RuntimeException: java.lang.ClassNotFoundException: mapreduce.mapreduce$MyMapper
- at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:867)
- at org.apache.hadoop.mapreduce.JobContext.getMapperClass(JobContext.java:199)
- at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:719)
- at org.apache.hadoop.mapred.MapTask.run(MapTask.java:370)
- at org.apache.hadoop.mapred.Child$4.run(Child.java:255)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:415)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1121)
- at org.apache.hadoop.mapred.Child.main(Child.java:249)
- Caused by: java.lang.ClassNotFoundException: mapreduce.mapreduce$MyMapper
- at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
- at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
- at java.security.AccessController.doPrivileged(Native Method)
- at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
- at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
- at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
- at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
- at java.lang.Class.forName0(Native Method)
- at java.lang.Class.forName(Class.java:270)
- at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:820)
- at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:865)
- ... 8 more
- 14/03/05 05:35:49 INFO mapred.JobClient: Job complete: job_201402280238_0011
- 14/03/05 05:35:49 INFO mapred.JobClient: Counters: 7
- 14/03/05 05:35:49 INFO mapred.JobClient: Job Counters
- 14/03/05 05:35:49 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=33927
- 14/03/05 05:35:49 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
- 14/03/05 05:35:49 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
- 14/03/05 05:35:49 INFO mapred.JobClient: Launched map tasks=4
- 14/03/05 05:35:49 INFO mapred.JobClient: Data-local map tasks=4
- 14/03/05 05:35:49 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=0
- 14/03/05 05:35:49 INFO mapred.JobClient: Failed map tasks=1
我们需要分析上面是什么错误,其实就是找不到类,为什么会找不到类,是我们打包问题吗?是因为没有环境不正确吗?
是的,这两方面可能都有问题,那么该如何解决
首先来看看我们是如何打包的:
1.单击map.java文件,弹出快捷菜单,选择Export。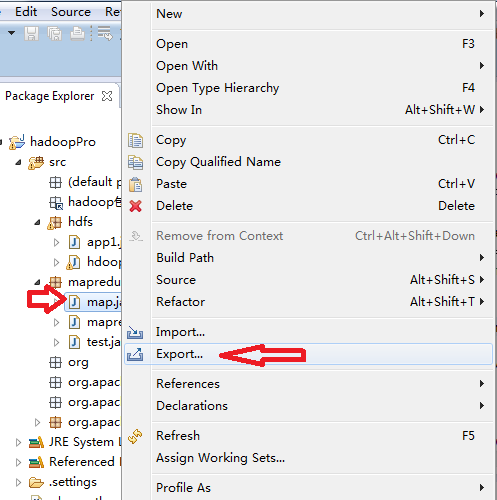
2.第一步之后,我们会看到下面,选择Java下面的JAR file。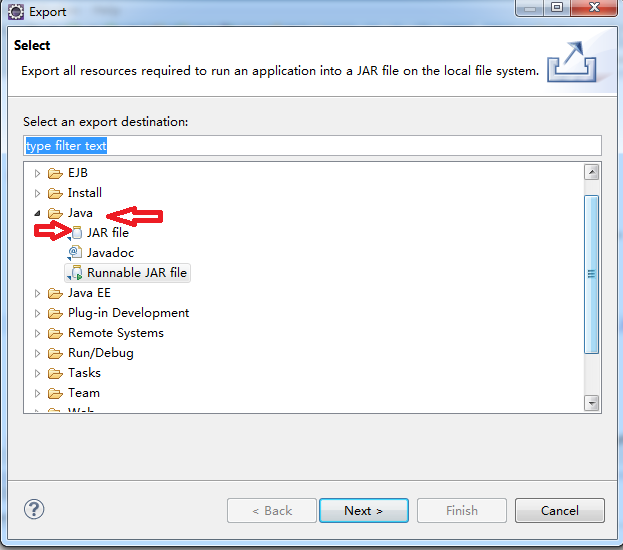
3.我们单击Next,进入JAR Export选择我们要打的包即可。
4.单击next下一步,然后在下一步,咱们会看到主类,我们选择主类到Main class
5.选择主类到Main class,我们会看到mapreduce.map,其实这是 包名.类型
6.到这一步,单击finish。我们看到了这个包。并且看到它的大小。
打包完毕,我们放到集群上运行:
出现下面情况
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/conf/Configuration
。
解决:
对于上面我们是否可以采用另外一种方法:答案是可以的。
就是我们,打成java运行jar包,是绝对可行的。
我们打完包之后,我们会看到,运行包与前面包进行对比,一个K级别,一个是M级别。
总结:
对于上面产生的问题,通用的方法就是我们可以打包成运行包,在集群上运行是没有问题的。打成运行包,是我们把程序中相关的包都打进运行包中,虽然有点冗余,可以解决初学者面临的这个问题。
但是不适用开发环境和运行环境,版本不一致的情况
http://www.aboutyun.com/thread-7086-1-1.html



相关推荐
搭建伪集群模式的Hadoop可以用于开发与测试,在这个模式下,所有节点实际上都运行在同一个物理机上,模拟集群的运行环境。同时,通过在开发IDE如Eclipse中配置Hadoop插件,可以更便捷地进行开发和调试Hadoop程序。...
1. 运行MapReduce任务:在项目中右键选择"Run As" -> "Hadoop Job",Eclipse会调用Hadoop的命令行工具提交任务到集群。你可以跟踪任务的状态,查看日志,了解任务运行情况。 2. 调试MapReduce任务:通过"Debug As" ...
Eclipse是一款流行的开源集成开发环境(IDE),适用于多种编程语言,包括Java,而Hadoop的开发通常涉及到Java编程。为了在Eclipse中方便地开发、调试和运行Hadoop项目,我们需要一个合适的插件,这就是"Hadoop ...
总结来说,Hadoop2x-eclipse-plugin-master是Hadoop开发者的得力助手,它通过与Eclipse的深度集成,提供了一站式的开发解决方案,简化了Hadoop项目的开发流程,降低了入门门槛,提升了开发效率。对于想要涉足Hadoop...
4. **测试连接**:当以上步骤都已完成并且集群运行正常时,应该能够通过Eclipse连接到Hadoop集群并加载其中的文件。 #### 六、释放Hadoop-Common库 1. **解压位置**:将`Hadoop-common.zip`解压至指定位置,例如`E...
" 指出,这个插件的主要优点在于它将Hadoop集群的监控和管理功能引入到Eclipse IDE中,使得开发者不必离开熟悉的开发环境就能查看和操作Hadoop集群。这包括但不限于查看任务状态、监控资源使用情况以及方便的数据...
通过学习和运行这些案例,开发者可以快速掌握Hadoop MapReduce编程模型,以及在Eclipse中部署和调试作业的方法。 总的来说,要使Eclipse连接并运行Hadoop项目,我们需要安装Hadoop Eclipse Plugin,并理解`hadoop....
5. **Hadoop-Eclipse插件功能**:该插件提供HDFS的浏览和文件操作功能,可以在Eclipse内创建、编辑和运行MapReduce程序,同时还可以直接提交作业到Hadoop集群进行测试和生产运行。 6. **开发环境集成**:通过...
5. **提交作业**:通过插件提供的菜单或快捷键,选择“运行” -> “在Hadoop上运行”,即可将作业提交到Hadoop集群。 三、最佳实践 1. **版本匹配**:确保插件版本与所使用的Hadoop版本兼容,以避免可能出现的问题...
Eclipse还支持远程调试,这对于解决运行时问题非常有用。 总之,要在Windows下的Eclipse环境中成功运行MapReduce程序,关键在于正确配置Hadoop环境,导入所有必要的jar包,并理解如何设置和提交MapReduce作业。这个...
- **运行配置**:可以直接在Eclipse内提交作业到Hadoop集群,无需手动执行命令行操作。 - **资源管理**:显示Hadoop集群的状态,包括节点、任务和作业信息。 - **依赖管理**:帮助管理项目中的Hadoop库和其他相关...
6. **测试与部署**: 完成开发后,可以通过Eclipse的Export功能,将MapReduce程序打包成JAR,然后在实际的Hadoop集群上运行。 **优势与注意事项** - 使用Eclipse Hadoop插件,开发者可以在熟悉的开发环境中进行...
4. **编写和运行MapReduce程序**:使用Eclipse创建Java项目,编写MapReduce代码,并使用Eclipse的Run As > Hadoop Job选项直接在Hadoop集群上运行。 5. **调试和日志查看**:Eclipse还可以帮助调试MapReduce程序,...
Eclipse Hadoop插件使得开发者能够在本地模拟Hadoop集群,编写MapReduce作业,并直接在Eclipse中提交到实际的Hadoop集群上执行。 使用这个压缩包,开发者可以: 1. 安装Eclipse Hadoop插件:将“Hadoop-Eclipse-...
本文将深入探讨如何使用Eclipse IDE结合hadoop-eclipse-plugin-2.6.0.jar插件,实现在Windows环境下进行远程连接到Hadoop集群,尤其适用于64位操作系统。 首先,我们要理解Hadoop的核心概念。Hadoop是由Apache基金...
接着,可以创建新的MapReduce项目,编写map和reduce函数,最后通过插件将程序打包并提交到Hadoop集群执行。 总之,Hadoop Eclipse Plugin 2.7.4是Hadoop开发者不可或缺的工具,它通过提供直观的图形界面和强大的...
Eclipse 配置 Hadoop 及 MapReduce 开发指南 一、Eclipse 中配置 Hadoop 插件 配置 Hadoop 插件是使用 Eclipse 进行 MapReduce 开发的第一步。首先,需要安装 Eclipse 3.3.2 和 Hadoop 0.20.2-eclipse-plugin.jar ...
Hadoop-Eclipse-Plugin-3.1.1是一款专为Eclipse集成开发环境设计的插件,用于方便地在Hadoop分布式文件系统(HDFS)上进行开发和调试MapReduce程序。这款插件是Hadoop生态系统的组成部分,它使得Java开发者能够更加...