CDH安装有四种方式
- Cloudera manager
- Tarball
- Yum
- Rpm
下面是四种方式分别介绍:
Cloudera Manager和CDH4.1的安装
Cloudera Manager的安装需要先修改机器的三个配置:
关闭防火墙:service iptables stop;
关闭selinux:setenforce 0或修改/etc/selinux/config:SELINUX=disabled;
配置代理:在/etc/yum.conf加入如下内容:http_proxy=http://server:port。
最好在/etc/yum.conf增加timeout时间,timeout=55555。自己设置长点就行。
准备安装文件cloudera-manager-installer.bin,这是个二进制文件,下载地址:https://ccp.cloudera.com/display ... a+Manager+Downloads,这个要在64位的机器上运行,我让它运行在CentOS-6.2,x86_64上。然后设置下执行权限,chmod u+x cloudera-manager-installer.bin,接着就直接执行它./ cloudera-manager-installer.bin。这里有个问题,在我自己的虚拟机上一直运行不了,出现的问题:cannot execute binary file,可能因为它是32位的吧。
在整个安装过程中,要确保你的机器能够联网,会出现让你选择的画面,一般就ENTER,next,accpet就行了,然后慢慢等待等到它自行安装结束。
启动cloudera manager:在浏览器输入你的主机,我的是http:192.168.20.195:7180。注册一个账号登陆如(admin,admin),进去后,会让我们选择主机,我就装了伪分布式,然后安装CDH4.1和impala,这个安装过程时间比较长,因为它是外国的网站,网络稳定与否对安装的影响很大,我装这个花费很长时间,期间如果出现某个安装包错误,就必须重新开始安装,因此强调下,最好使用一个干净的系统(没装过hadoop相关程序),它会去网上下载很多rpm包,默认地把hadoop,hbase,zookeeper,hive,impala等都装到了user/lib底下,耐心等待吧。
安装好了之后,我们就可以启动自己需要的服务,当然某些服务彼此会有依赖,没关系的cloudera manager太强大了,它能帮你识别,帮助你开启相关服务。我开启的服务界面如下图所示:
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun; font-size: 14px; line-height: 21px;">
在开启服务的过程中,其他的服务都正常开启了,但是最关键的我需要的服务却一直显示不良状态,如下图:
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun; font-size: 14px; line-height: 21px;">
Impala没正常启动,这是我这次研究的重中之重。出现问题,就开始找问题,后来发现是impala和数据库(我用的是mysql)没连接成功。下面着重讲述下配置mysql连接impala。
Impala的运行需要有配置了Mysql或PostgreSQL的hive metastore,hive本身支持的derby数据库,impala不支持。
一、配置远程数据库作为Hive Mestastore。
A:安装MySQL JDBC连接器,从'http://www.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.22.tar.gz下载连接器,并把解压后的mysql-connector-java-5.1.22-bin.jar文件拷贝至/usr/lib/hive/lib下。
B:MySQL管理员需要用hive-schema-0.9.0.mysql.sql来建立初始数据库:
- mysql –u root –p
- mysql > CREATE DATABASE hivemetastoredb;
- mysql > USE hivemetastoredb;
- mysql > SOURCE /usr/lib/hive/scripts/metastore/upgrade/mysql/
- hive-schema-0.9.0.mysql.sql;
- mysql > CREATE USER ‘hive’@’%’ IDENTIFIED BY ‘hive’;
- mysql > CREATE ALL PRIVILEGES ON hivemetastoredb.* TO ‘hive’@’%’ WITH GRANT OPTION;
- mysql > FLUSH PRIVILEGES;
- mysql > QUIT;
C:配置mysql用utf8作为默认的字符编码。
- $ vim /etc/my.cnf
- 在[mysqld]下加入
- Default-character-set=utf8
这是因为,impala去连接mysql时所用到的连接字符串为:URL="jdbc:mysql://localhost:3306/hivemetastoredb?useUnicode=true&characterEncoding=UTF-8”,它默认用的就是utf8。
二、新增Impala服务
进入cloudera manager管理界面,新增impala服务,点击impala,点击配置,可看到如下界面:
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun; font-size: 14px; line-height: 21px;">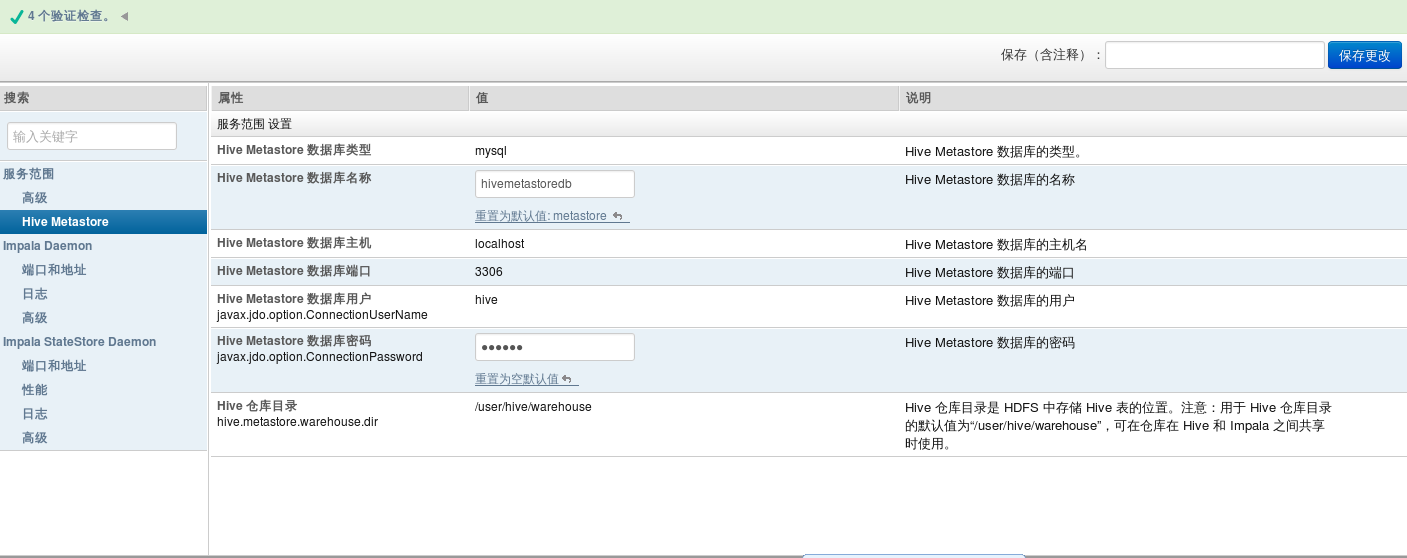
在这个配置里面,需要配置如下参数:
| Property |
Value |
| DataNode Local Path Access Users dfs.block.local-path-access.user |
impala |
| DataNode Data Directory Permissions dfs.datanode.data.dir.perm |
755 |
| Enable HDFS Block Metadata API dfs.datanode.hdfs-blocks-metadata.enabled |
true |
| Enable HDFS Short Circuit Read dfs.client.read.shortcircuit |
true |
Hive Metastore的配置如上图所示,数据库连接密码:hive。
三、配置好impala后,点击重新启动impala。启动成功后可以看到如下界面:
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun; font-size: 14px; line-height: 21px;">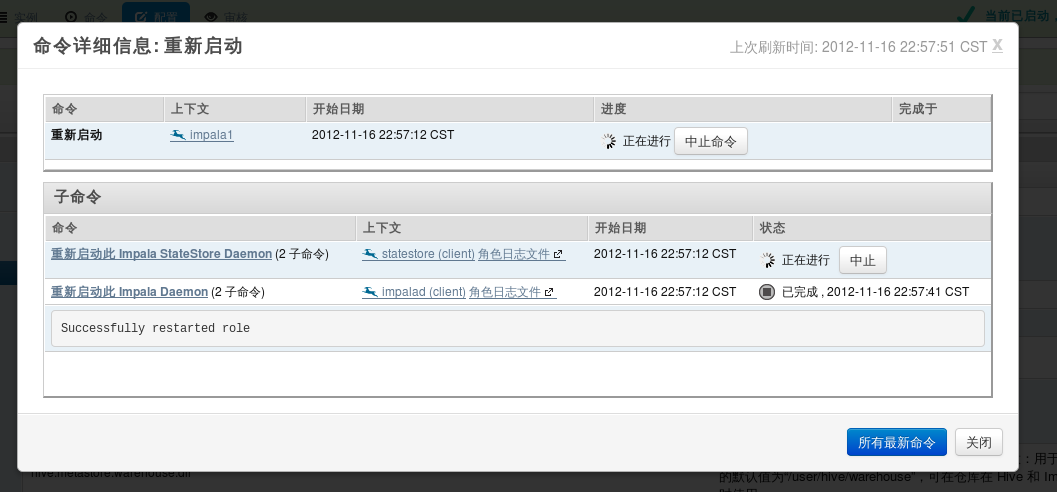
两个服务都完成,才算impala启动成功。
配置Hue Beeswax连接到Impala。
这个配置是为了让Hue Beeswax网站接口来执行Impala语句。修改/etc/hue/hue.ini,如下内容:
- [beeswax]
- beeswax_server_host=192.168.20.195
- beeswax_server_port=8003
重启Hue服务。至此,impala这个服务也算是正常启动了。
最后说明一下,这次配置遇到的问题及解决方法。
问题一:无法安装hadoop-hdfs包。
如下图所示:
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun; font-size: 14px; line-height: 21px;">
图中说明的错误是:事务验证出错,后面的信息显示了是版本冲突问题。也就是说,本来电脑里面已经有装了hadoop-1.0.3现在和cloudera的hadoop-hdfs-2.0.0冲突,导致hadoo-hdfs无法安装,也就使得安装失败,又得重新来一次了,悲剧啊。
解决问题,我找到了系统里安装hadoop-1.0.3的所有包,然后把它们全部删掉,包括安装的目录。
- $ rpm –qa | grep –i hadoop-1.0.3
- hadoop-1.0.3+20.38283-1.el6.x86_64
- $ rpm –ql hadoop-1.0.3+20.38283-1.el6.x86_64(查找安装的位置)
- $ rpm –e hadoop-1.0.3+20.38283-1.el6.x86_64(卸载)
卸载过程中,可能会有包依赖,没关系,继续按照上述方法把他们全部删光,重新安装就行啦。
问题二:启动impala时,impala daemon无法启动,查看日志出现如下问题。
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun; font-size: 14px; line-height: 21px;">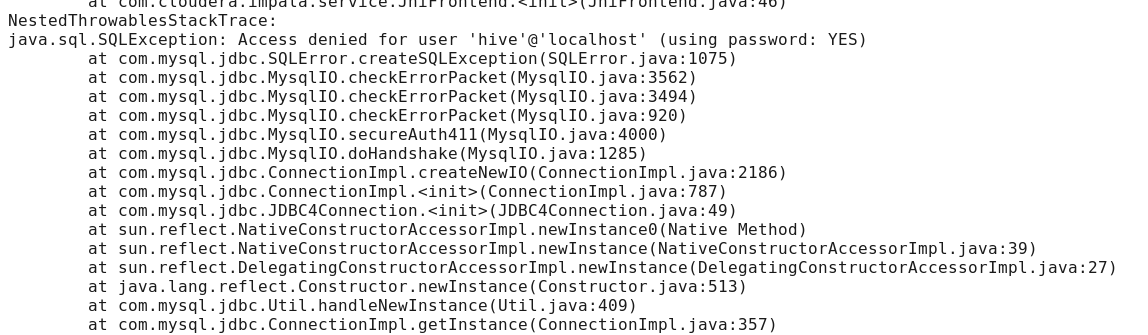
这个问题,说是连接到mysql被禁止,但是我用java自己做了个程序去连接mysql没有问题,很奇怪,
javax.jdo.JDOFatalDataStoreException: Access denied for user 'hive'@'localhost' (using password: YES),最主要是这句话,我本来连接数据库是,用root登录mysql建立了个新用户hive,然后不使用密码,同时在impala中的配置目录里,默认数据库用户hive登录也是不需要密码的,但是却始终连不上,后来经过分析这句话,using password:YES,也就是说,本来不需要密码,你却用了密码登陆到mysql,这就有问题了,也就是说,虽然配置里的密码是空的,但是impala默认还是以有密码的形式登录到mysql,这样连接就一直被禁止了。解决的方案是:删掉hive用户,建立一个用户名和密码都是hive的用户接着,把配置里密码也输入hive,问题终于解决了。
----------------------------------------------------------------------------------------------------------------------------------------------------------------
hadoop CDH3U5 使用tarball完整安装过程
用在线安装的方式, 需要依赖于外部网络, 等待时间够长的, 不利于重复部署. 用tarball的方式重新部署了一下. 牵扯到以前是root用户做的, 本次按要求用非root用户遇到了些权限控制方面的问题
统一说明
部署:
| ip |
Hostname |
安装组件 |
| 10.0.0.123 |
Hadoop-master |
-namenode, JobTracker,datanode,taskTracker
-hbase-master,hbase-thrift
-secondarynamenode
-zookeeper-server |
| 10.0.0.125 |
Hadoop-lave |
-datanode,taskTracker
-hbase-regionServer
-zookeeper-server
|
| |
|
|
下载
从https://ccp.cloudera.com/display ... wnloadable+Tarballs下载需要的组件
hadoop,hbase,Hive,zookeeper
http://archive.cloudera.com/cdh/3/hadoop-0.20.2-cdh3u5.tar.gz
http://archive.cloudera.com/cdh/3/zookeeper-3.3.5-cdh3u5.tar.gz
http://archive.cloudera.com/cdh/3/hive-0.7.1-cdh3u5.tar.gz
http://archive.cloudera.com/cdh/3/hbase-0.90.6-cdh3u5.tar.gz
将压缩包放到/hadoop/cdh3中去.
计划如下
| 目录 |
所有者 |
权限 |
|
| /hadoop/cdh3 |
hadoop |
755 |
Hadoop及其组件的运行环境 |
| /hadoop/data |
hadoop |
755 |
见下 |
| /hadoop/data/hdfs |
hadoop |
700 |
数据节点存放数据的地方, 后续由hdfs-site.xml中的dfs.data.dir指定
|
| /hadoop/data/storage |
hadoop |
777 |
所有上传到Hadoop的文件的存放目录,所以要确保这个目录足够大后续由hadoop.tmp.dir 指定 |
| 用户名 |
Home |
用途 |
| hadoop |
/home/hadoop |
[1]用于启动停止hadoop等维护
[2] /hadoop/data/hdfs目录的700权限拥有者. 也可以另选用户 |
| |
|
|
| |
|
|
| |
|
|
安装过程
[1]下载JDK
此时选的是jdk1.6.0_43
http://www.oracle.com/technetwork/java/javase/downloads/jdk6downloads-1902814.html
Linux x64 68.7 MB jdk-6u43-linux-x64.bin
放到/usr/local/share/下并执行 ./ jdk-6u43-linux-x64.bin
然后设置JAVA_HOME及PATH环境变量,注意PATH要增加, 不要覆盖
root@hadoop-master:~# which java
/usr/local/share/jdk1.6.0_43/bin/java
root@hadoop-master:~# echo $JAVA_HOME
/usr/local/share/jdk1.6.0_43
master与slave都要安装, 为了配置方便拷贝, 一定给要一样的目录
[2]建立hadoop操作用户
root@hadoop-master:/hadoop/cdh3/hadoop-0.20.2-cdh3u5/bin# useradd hadoop -m
root@hadoop-master:/hadoop/cdh3/hadoop-0.20.2-cdh3u5/bin# su - hadoop
$ bash
hadoop@hadoop-master:~$
hadoop@hadoop-master:~$ pwd
/home/hadoop
hadoop@hadoop-master:~$ ll
total 28
drwxr-xr-x 3 hadoop hadoop 4096 2013-03-07 05:03 ./
drwxr-xr-x 4 root root 4096 2013-03-07 05:02 ../
-rw-r--r-- 1 hadoop hadoop 220 2011-05-18 03:00 .bash_logout
-rw-r--r-- 1 hadoop hadoop 3353 2011-05-18 03:00 .bashrc
-rw-r--r-- 1 hadoop hadoop 179 2011-06-22 15:51 examples.desktop
-rw-r--r-- 1 hadoop hadoop 675 2011-05-18 03:00 .profile
|
执行ssh授信
hadoop@hadoop-master:~$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
17:cc:2b:9c:81:5b:48:53:ee:d6:35:bc:1b:0f:9a:14 hadoop@hadoop-master
The key's randomart image is:
+--[ RSA 2048]----+
| o.. |
| . = o . |
| o + E + |
| = + = o |
| . S = + |
| . + o = |
| o . . |
| |
| |
+-----------------+
hadoop@hadoop-master:~$
hadoop@hadoop-master:~$ cd .ssh
hadoop@hadoop-master:~/.ssh$ ll
total 16
drwxr-xr-x 2 hadoop hadoop 4096 2013-03-07 05:04 ./
drwxr-xr-x 3 hadoop hadoop 4096 2013-03-07 05:04 ../
-rw------- 1 hadoop hadoop 1675 2013-03-07 05:04 id_rsa
-rw-r--r-- 1 hadoop hadoop 402 2013-03-07 05:04 id_rsa.pub
hadoop@hadoop-master:~/.ssh$ cat id_rsa.pub >> authorized_keys
|
在hadoop-slave添加hadoop用户, 用户名要与master相同
然后将master的id_rsa.pub 追加到slave机器的/home/hadoop/.ssh/authorized_keys中
到此, master应该可以ssh免密码登录slave了 |
[3]安装hadoop-0.20.2-cdh3u5
解压缩:
cd /hadoop/cdh3
tar zxvf hadoop-0.20.2-cdh3u5.tar.gz
修改配置文件
cdh3\hadoop-0.20.2-cdh3u5\conf\core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!--- global properties -->
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/data/storage</value>
<description>A directory for other temporary directories.</description>
</property>
<!-- file system properties -->
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master:8020</value>
</property>
</configuration> |
cdh3\hadoop-0.20.2-cdh3u5\conf\hadoop-env.sh
将# export JAVA_HOME=/usr/lib/j2sdk1.6-sun
修改为
export JAVA_HOME=/usr/local/share/jdk1.6.0_43 |
cdh3\hadoop-0.20.2-cdh3u5\conf\hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/hadoop/data/hdfs</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
</configuration> |
cdh3\hadoop-0.20.2-cdh3u5\conf\mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://hadoop-master:8021</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>/mapred/system</value>
</property>
</configuration> |
cdh3\hadoop-0.20.2-cdh3u5\conf\masters
hadoop-master |
cdh3\hadoop-0.20.2-cdh3u5\conf\slaves
hadoop-slave
注:如果将hadoop-master也加进来, 那在master机器上也启动一个datanode, 如果机器规划多的话就不要加了, |
Hadoop用户下创建目录
sudo mkdir -p /hadoop/data/storage
sudo mkdir -p /hadoop/data/hdfs
sudo chmod 700 /hadoop/data/hdfs
sudo chown -R hadoop:hadoop /hadoop/data/hdfs
sudo chmod 777 /hadoop/data/storage
sudo chmod o+t /hadoop/data/storage
Hadoop用户下执行格式化
hadoop@hadoop-master:~$ hadoop namenode -format |
启动hadoop
hadoop@hadoop-master:~$ cd /hadoop/cdh3/hadoop-0.20.2-cdh3u5/bin
hadoop@hadoop-master:/hadoop/cdh3/hadoop-0.20.2-cdh3u5/bin$ ./start-all.sh
starting namenode, logging to /mnt/hgfs/hadoop/cdh3/hadoop-0.20.2-cdh3u5/bin/../logs/hadoop-hadoop-namenode-hadoop-master.out
hadoop-slave: starting datanode, logging to /mnt/hgfs/hadoop/cdh3/hadoop-0.20.2-cdh3u5/bin/../logs/hadoop-hadoop-datanode-hadoop-slave.out
hadoop-master: starting secondarynamenode, logging to /mnt/hgfs/hadoop/cdh3/hadoop-0.20.2-cdh3u5/bin/../logs/hadoop-hadoop-secondarynamenode-hadoop-master.out
starting jobtracker, logging to /mnt/hgfs/hadoop/cdh3/hadoop-0.20.2-cdh3u5/bin/../logs/hadoop-hadoop-jobtracker-hadoop-master.out
hadoop-slave: starting tasktracker, logging to /mnt/hgfs/hadoop/cdh3/hadoop-0.20.2-cdh3u5/bin/../logs/hadoop-hadoop-tasktracker-hadoop-slave.out
|
查看启动结果
hadoop@hadoop-master:/hadoop/cdh3/hadoop-0.20.2-cdh3u5/bin$ jps
5759 SecondaryNameNode
5462 NameNode
5832 JobTracker
5890 Jps
hadoop@hadoop-master:/hadoop/cdh3/hadoop-0.20.2-cdh3u5/bin$
|
----------------------------------------------------------------------------------------------------------------------------------------
对于Yum,Rpm的方式就不详细介绍了,下面总体介绍一下:
Redhat/Centos系列可以下载rpm包安装,也可以配置repo,使用Yum方式一键安装:
Redhat/Centos/Oracle 5
- wget http://archive.cloudera.com/cdh4/redhat/5/x86_64/cdh/cdh4-repository-1-0.noarch.rpm
- sudo rpm --import http://archive.cloudera.com/cdh4/redhat/5/x86_64/cdh/RPM-GPG-KEY-cloudera
Redhat/Centos 6 wget http://archive.cloudera.com/cdh4/redhat/6/x8664/cdh/cdh4- repository-1-0.noarch.rpm sudo rpm --import http://archive.cloudera.com/cdh4 ... PM-GPG-KEY-cloudera
然后安装各组件:
- $ sudo yum install hadoop-yarn-resourcemanager
- $ sudo yum install hadoop-hdfs-namenode
- $ sudo yum install hadoop-hdfs-secondarynamenode
- $ sudo yum install hadoop-yarn-nodemanager hadoop-hdfs-datanode hadoop-mapreduce
- $ sudo yum install hadoop-mapreduce
----------------------------------------------------------------------------------------------------------------------------------------
CDH5已经使用了Hadoop2.2.0,我们介绍一下如何手动安装:
Hadoop CDH5 手动安装伪分布式模式
由于Cloudera强烈建议使用rmp包或者apt-get的方式安装,一时半刻我都没有找到手动安装的说明,在安装的遇到多个问题,稍作记录
首先环境要求
JDK1.7_u25+
Maven3.0.5
protoc2.5
cmake
ant
zlib1g-dev
在安装完protocbuf后无法正常运行protoc命令,报错
protoc: error while loading shared libraries: libprotoc.so.8: cannot open shared object file: No such file or directory
解决方案是在make install后再执行一句sudo ldconfig
修改配置文件
etc/hadoop/core-site.xml
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://localhost</value>
- </property>
etc/hadoop/hdfs-site.xml
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/home/username/src/cdh5/hadoop/hdfs</value>
- </property>
- <property>
- <name>dfs.namenode.http-address</name>
- <value>localhost:50070</value>
- </property>
-
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>localhost:50090</value>
- </property>
etc/hadoop/yarn-site.xml
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>localhost</value>
- </property>
-
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
-
- <property>
- <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
- <value>org.apache.hadoop.mapred.ShuffleHandler</value>
- </property>
然后format,启动start-all.sh
启动伪分布式模式碰到的第一个问题是找不到JAVA_HOME
原因是启动命令调用sbin/slaves.sh脚本,这个脚本中有使用ssh远程调用其他机器的命令
在这种情况下bashrc中的设置环境变量的语句没有被执行,原因是bashrc中第一句语句([ -z "$PS1" ] && return)会判断调用模式是否是交互式模式,如果是非交互式模式则直接退出,所以写在下面的语句都没有被执行,解决方法有两个
1.是把设置JAVA_HOME的语句写在bashrc文件的最前面
2.是修改etc/hadoop/hadoop-evn.sh中的export JAVA_HOME=${JAVA_HOME},不要使用系统的环境变量赋值,直接改成绝对路径
修改完后再次启动成功
使用jps会看到所有的进程
3536 ResourceManager
3116 DataNode
2900 NameNode
3378 SecondaryNameNode
3755 NodeManager
2168 Jps
使用hadoop fs -ls 查看文件系统的时候会遇到报错
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
原因是缺少libhadoop.so文件
在src目录或者hadoop-common子项目中重新build,命令:mvn package -DskipTests -Pdist,native,docs -Dtar
再次遇到报错[ERROR] class file for org.mortbay.component.AbstractLifeCycle not found
- <dependency>
- <groupId>org.mortbay.jetty</groupId>
- <artifactId>jetty-util</artifactId>
- <scope>test</scope>
- </dependency>
再次编译遇到报错Failed to execute goal org.apache.maven.plugins:maven-antrun-plugin:1.6:run (make) on project hadoop-common:
这是没有安装zlib1g-dev的关系,这个可以 使用apt-get安装
最后把生成的.so文件全部拷贝到lib/native/目录下,再次运行hadoop fs -ls没有报错信息




相关推荐
在本文中,我们将深入探讨如何在Linux环境中安装Hadoop CDH5,这是一个广泛使用的Hadoop分发版,包含了多个开源大数据处理组件。CDH5提供了高效的数据存储、处理和分析功能,适合大规模数据处理场景。 首先,安装...
### Hadoop之CDH:基于Cloudera的HA部署指南 #### 关于本指南 本文档旨在提供关于如何在Cloudera Distribution Including Hadoop (CDH)上配置高可用性的详细指南。CDH是由Cloudera公司提供的一个企业级Hadoop发行...
在大数据处理领域,Hadoop是不可或缺的开源框架,而Cloudera Distribution Including Apache Hadoop (CDH) 是Hadoop的一种企业级发行版,它提供了一套完整的数据处理和存储解决方案。CDH5.5.0是CDH的一个版本,包含...
本文主要介绍Flink在Cloudera Distribution Hadoop(CDH)集群上的配置部署流程,以及如何利用Flink从Kafka中读取数据并进行处理的实例验证。在开始前,需要明白几个核心概念及其之间的关系: 1. Flink 是一个开源...
### CDH搭建Hadoop环境知识点整理 #### CDH简介 CDH(Cloudera's Distribution Including Apache Hadoop)是Cloudera公司提供的一个发行版,包含了Apache Hadoop的核心组件以及许多额外的工具和增强功能。CDH旨在...
Spark3对YARN(Hadoop的资源管理器)的优化使得在CDH平台上运行更加高效,提供了一种在Hadoop生态系统内无缝运行Spark作业的方法。 在CDH7.1.7与SPARK3的集成中,用户可以利用Spark3的高级特性,例如DataFrame和...
集群的元数据需要存储在数据库中,文档中指导如何安装MySQL数据库,并覆盖原有的配置文件***f,以及创建数据库实例和用户密码。MySQL数据库的安装和配置是Cloudera Manager存储集群状态和配置信息的基础。 #### 六...
8. **Cloudera Manager安装**:提供了三种安装方式,离线安装在没有互联网连接或网络速度较慢的情况下更有优势,因为它允许预先下载所有需要的包,然后在目标系统上进行安装。 9. **Zypper包管理器**:在SUSE Linux...
总结来说,Hive-1.1.0-cdh5.9.3是CDH5.9.3中的重要组成部分,提供了高效、灵活的大数据处理能力,与CDH的其他组件紧密配合,为企业的大数据战略提供了坚实的基础。了解和掌握Hive在CDH环境中的使用,对于大数据领域...
- **知识点说明**:Cloudera提供了多种安装CDH(CDH即Cloudera Distribution Including Apache Hadoop)的方法,包括使用Cloudera Manager图形界面安装、使用脚本自动安装(Cloudera Director)以及手动安装等。...
描述中提到的"WordCount实例"是Hadoop的典型入门示例,用于统计文本文件中单词出现的次数。在Hadoop 2.6.0中,运行这个例子至少需要以下三个关键的JAR文件: 1. **commons-cli-1.2.jar**:这是Apache Commons命令行...
Parcel是Cloudera分发软件的一种方式,它允许用户以一种安全且可管理的方式在CDH集群中部署和升级组件。这个安装包包含了所有必要的文件和配置,使得Phoenix能够在EL7系统上顺利运行,提供对HBase数据库的SQL接口。 ...
本课程旨在为具备一定软件开发经验的专业人士提供一个深入学习Hadoop 2.x及大数据相关技术的机会。不同于一般的入门课程,本课程将重点放在企业级项目的实战操作上,通过真实案例的学习,使学员能够掌握大数据处理的...
本书用于Hadoop+Spark快速上手,全面解析Hadoop和Spark生态系统,通过原理解说和实例操作每一个组件,让读者能够轻松跨入大数据分析与开发的大门。 全书共12章,大致分为3个部分,第1部分(第1~7章)讲解Hadoop的...
总结来说,CDH环境中Kerberos入门与实战涉及对Kerberos协议基础的理解,体系结构和工作机制的深入认识,以及Kerberos在CDH环境中的配置、安装和应用。掌握这些知识点对于确保Hadoop集群的安全性和高效运行至关重要。
在大数据领域,它常被用作数据流处理的工具,尤其适合收集来自多个源的日志数据,然后将这些数据传输到中央存储系统,如 Hadoop HDFS 或其他实时分析系统。 "flume-ng-1.6.0-cdh5.5.0.tar.gz" 是 Apache Flume 的一...
Apache Ambari是一个基于Web的工具,用于简化Hadoop集群的安装、配置和管理过程。Ambari支持Hadoop HDFS、MapReduce、Hive、HCatalog、HBase、ZooKeeper、Oozie、Pig和Sqoop等多种Hadoop生态系统中的组件。此外,...
Cloudera Manager是一款高效的大数据集群管理工具,主要用于管理和监控CDH(Cloudera Distribution Including Apache Hadoop)环境。CDH是由Cloudera提供的开源大数据平台,包含了多种Apache Hadoop项目,如HDFS、...
CDH是Cloudera公司提供的Hadoop发行版,它包含了多个Hadoop相关的开源项目,如HDFS、MapReduce、YARN等,并且对这些组件进行了优化和整合,使得企业可以更方便地部署和管理大数据平台。CDH 5.14.2是该发行版的一个...
### CDH550@hive 使用及操作说明 #### 系统介绍 ##### 总体说明 本文档旨在详细介绍CDH 5.5.0环境下Hive的使用方法及其相关操作指南。Hive是一种建立在Hadoop之上的数据仓库工具,主要用于通过SQL查询语言来处理...