
Our follower graph has millions of nodes and billions of edges, making it an interesting challenge to maintain and scale data as we build out the interest graph. The model is similar to those of Twitter or Facebook, but with some key differences based around interests that we account for in the product development and design phases.
The final version of the Pinterest follower service was developed, migrated and deployed in about 8 weeks with one full time engineer and 2-3 part time engineers.
Here I’ll explain how the service-oriented architecture has helped us develop and maintain the service as a unit of its own.
The Pinterest following model and interest graph
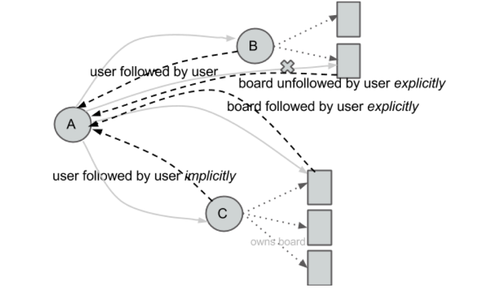
Facebook’s primary follower relationship is mutual and between two users, while Twitter’s is typically one-to-many. On Pinterest, following can be one-way, but goes beyond the individual and extends to interests. As people follow more boards and people, their home feed becomes more tailored to their interests, and the interest graph builds out further.
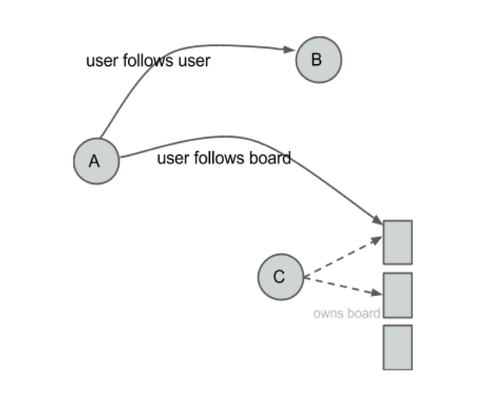
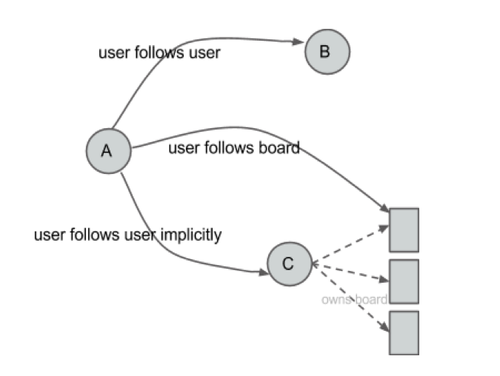
For example, if Andrea follows Bob, she’ll follow all of his boards, and if he creates a new board, she’ll automatically follow that board. If Andrea follows Bob’s Recipes board, she’ll see all of his pins from that board in her home feed. Andrea will also be listed as a follower of that board. We term the board followers as implicit followers (while the previous type of user-to-user follower is an explicit follower).
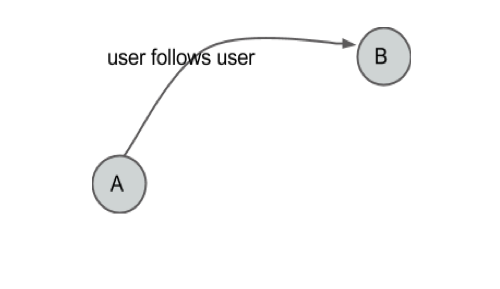
Action: follow user
Action: follow board
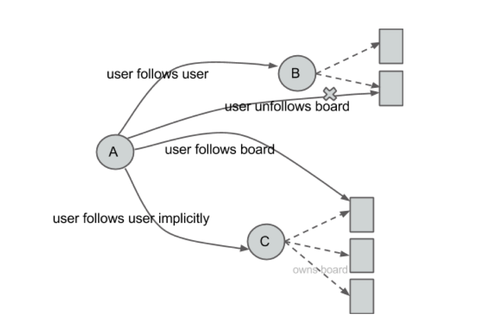
Action: unfollow board
Implicit relationships (in the reverse direction)
The follower model may seem complicated, but it allows for an easier experience for the pinner.
Low latency for common queries such as "Does user A follow user B?", and acceptable latency for paging through the entire list of potentially millions of followers is needed. The UI also shows the accurate counts and paginated lists of a user’s followers and followings and board’s followers. We want acceptable latencies because the scenarios that page through all the followers are typically part of offline jobs like fanning out the pins.
Almost all pages either show a count for followers/following, or perform checks to see if the logged-in user follows the board or user being viewed. This requires the follower service to handle high throughputs and scale with the site. Ideally the service should leave headroom for additional throughput to support internal experiments, as well as adhere to the common distributed systems patterns: be horizontally scalable, be highly available, no data loss, and have no single points of failure (SPOF).
Our biggest challenges while building the service
- We didn’t find any off-the-shelf open source projects that met our requirements (such as efficient graph operations at this scale).
- The traditional model of storing the sharded graph on MySQL and caching it with memcached was reaching its limits.
- Caching the graph data is hard because the cache is useful only if the entire subgraph of a user (vertex) is in cache, however this can quickly result in an attempt to cache the entire graph!
- Caching also implies that queries like "Does user A follow user B?" are either in the cache or not. But more often than not the answer is 'No' (i.e. user A is not following user B), which results in a cache miss requiring expensive lookups to the persistent store.
The inner workings of the follower graph
The corpus size of the entire Pinterest follower graph is relatively small, so loading the entire graph in memory is feasible.
Redis stores the graph, which is sharded by user IDs, and the Redis AOF feature updates to disk every second to avoid significant data loss. Since Redis is single threaded, we run multiple instances of Redis to fully utilize the CPU cores. Each Redis instance serves one virtual shard, which allows easy splitting of shards when the instances on one machine reach capacity.
Digging into the data model
Before understanding the data model we chose, let’s sum up the common operations the follower service needs. We need to efficiently respond to point queries such as “Does user A follow user B”, support filtering queries used on a search page such as “Which of these 25 users are followed by me?”, and get all users followed by users or boards to fan out the incoming pins. In order to respond to such queries, we maintain these relationships per user:
- list of users who are followed explicitly by the given user (recall that explicitly means that all the current and future boards of the user are followed)
- list of users who are followed implicitly by the given user, i.e. one or more boards are followed by the user
- list of followers for a given user (explicit followers)
- list of followers for a given user’s one or more boards (implicit followers)
- list of boards followed explicitly by a given user
- list of boards unfollowed explicitly by a given user (many users follow another user but then unfollow a few boards that don’t match their interests)
- board’s explicit followers
- board’s explicit unfollowers
The corresponding Redis data structures used to materialize these relationships are (per user):
- Redis SortedSet, with timestamp as the score, is used to store the users followed explicitly. We use a SortedSet for two reasons: first, the product requirements state that the users should be listed in reverse chronological order and second, having a sorted set allows us to paginate through the list of ids
- Redis SortedSet, with timestamp as the score, is used to store the users followed implicitly
- Redis SortedSet, with timestamp as the score, is used to store the user’s explicit followers
- Redis SortedSet, with timestamp as the score, is used to store the user’s implicit followers
- Redis Set is used to store boards followed explicitly
- Redis Set is used to store boards unfollowed explicitly
- Redis Hash is used to store a board’s explicit followers
- Redis Set is used to store a board’s explicit unfollowers
The entire user id space is split into 8192 virtual shards. We place one virtual shard per Redis DB, and run multiple Redis instances (ranging from 8 to 32) on each machine depending on the memory and CPU consumption of the shards on those instances. Similarly, we run multiple Redis DBs per Redis instance.
When a Redis machine reaches either the memory or CPU thresholds, we split it either horizontally orvertically. Vertical sharding a Redis machine is simply cutting the number of running Redis instances on the machine by half. We bring up a new master as a slave of the existing master and once the slaving is complete, we make it the new master for half of the Redis instances leaving the old master as the master for the other half.
We use Zookeeper to store the shard configurations. Since Redis is single-threaded server, it’s important to be able to split the instances horizontally to fully utilize all the machine cores.
Avoiding the Panic Button: Backups and failure scenarios
We run our cluster in a Redis master-slave configuration, and the slaves act as hot backups. Upon a master failure, we failover the slave as the new master and either bring up a new slave or reuse the old master as the new slave. We rely on ZooKeeper to make this as quick as possible.
Each master Redis instance (and slave instance) is configured to write to AOF on Amazon EBS. This ensures that if the Redis instances terminate unexpectedly then the loss of data is limited to 1 second of updates. The slave Redis instances also perform BGsave hourly which is then loaded to a more permanent store (Amazon S3). This copy is also used by Map Reduce jobs for analytics.
As a production system, we need many failure modes to guard ourselves. As mentioned, if the master host is down, we will manually failover to slave. If a single master Redis instance reboots, monit restart restores from AOF, implying a 1 second window of data loss on the shards on that instance. If the slave host goes down, we bring up a replacement. If a single slave Redis instance goes down, we rely on monit to restart using the AOF data. Because we may encounter AOF or BGsave file corruption, we BGSave and copy hourly backups to S3. Note that large file sizes can cause BGsave induced delays but in our cluster this is mitigated by smaller Redis data due to the sharding scheme.
Lessons from late-night hacking
- Broad and deep coverage on unit tests saves time in the long run. It’s also ideal to plan a longer bake time for such service launches.
- We could have prevented bugs by having a language or framework that natively supported asynchronous call framework.
- We used Redis LUA feature in a small niche feature to maintain write consistency. We expected to encounter small sized sets but discovered that this may cause high CPU usage (strcpy) in a small fraction of users who had abnormally large number of boards unfollowed.
The master-slave based solution implies that in the event of a master failure, a few shards are unavailable for writes. One future improvement might be to make the master/slave failover automatic to further reduce the window when the master is unavailable for its writes. Ideally, we also want to invest in a repair capability in case of catastrophic failures in order to restore from the S3 backups. Another potential area of improvement is connection load balancing in our thrift client.
In the end, when we migrated away from the existing sharded MySQL cluster, we saved about 30% IOps.
Moving fast and building infrastructure and products that scale is one of the best parts of the job. We hope the lessons we’ve learned can help others out there!
Abhi Khune is an engineer at Pinterest and works on Infrastructure.
http://engineering.pinterest.com/post/55272557617/building-a-follower-model-from-scratch



相关推荐
turtlebot follower void imageCb const sensor msgs::ImageConstPtr& msg { cv bridge::CvImagePtr cv ptr; try { cv ptr cv bridge::toCvCopy msg sensor msgs::image encodings::BGR8 ; } catch cv ...
This is simulation of leader follower control system.
智能交易策略"Trend Follower
在这个项目中,"riki_line_follower"是一个基于ROS的小车巡线应用,它利用了OpenCV库进行图像处理,结合Hough变换来识别车道线。下面我们将详细探讨这些关键知识点。 **OpenCV** 是一个强大的计算机视觉库,它提供...
在ROS中,"line_follower_turtlebot"是一个特定的项目,旨在实现一个使用摄像头进行巡线功能的机器人小车。在这个项目中,Turtlebot是一个流行的开源机器人平台,通常用于ROS的初学者和教育目的。 巡线任务是机器人...
此参数用在卸船起重机上的起升变频器参数的设定,两台变频器驱动两台电机,但两者之间有主从通讯,实现载荷分配,同步功能
在MATLAB中,Leader-Follower算法是一种用于聚类的数据分析方法。这个算法主要适用于处理具有相似性质的对象集合,通过寻找“领导者”(中心点或关键点)并让其他数据点跟随这些领导者,来划分数据群体。这个算法在...
This paper proposes a methodology to model FIP from a multibody Dynamics (MBD) perspective. The results from the model include the temporal behavior of driving torque, contact Hertz stress and ...
标题中的“ltc.zip_line follower_line follower robot _ltc”提到了一个与线跟随机器人相关的项目,其中“ltc”可能是项目的简称或者是某种特定技术的缩写。描述中提到的“line follower robot circuit diagram”...
Carsim与Simulink联合仿真模型说明,适合毕业设计,大作业,期末报告参考,提供指导可以互相交流,主要设计轨迹跟随横向控制,车道保持(LKA),自适应巡航(ACC),有关自动驾驶方向内容也欢迎来讨论!
在多智能体系统中,领导者-跟随者(Leader-follower)模型是一种常见的协调策略,它涉及一个或多个领导者引领一群跟随者实现特定任务。在这个基于MATLAB的项目中,我们将会探讨如何通过编程来实现这样的系统。以下是...
2follower.ms14
"Wall_follower.rar_#cwp117@#_Sharp_wall follower" 是一个与机器人技术相关的压缩包,尤其涉及到一种名为"墙跟随者"(Wall Follower)的机器人设计。这种机器人通常用于导航和路径规划,其核心原理是利用传感器来...
arduino_line_follower.ino
Implementation of Leader-Follower Formation Control of a Team of Nonholonomic Mobile Robots
根据提供的文件信息,我们可以推断出这是一组与“Follower v2.0”相关的源代码文件,它们被设计用于在Windows操作系统上运行。文件名中包含了诸如"widget", "executor", "codeeditor", "updateform", "toolmenu", ...
在多智能体系统中,"leader-follower"架构是一种常见的协调策略,其中至少有一个智能体作为领导者,其余的称为跟随者。领导者设定运动方向或目标,而跟随者通过与领导者和其他跟随者的交互来模仿领导者的行动,从而...
常见的路径规划算法包括A*算法、Dijkstra算法或者更复杂的优化方法,如RRT ( Rapidly-exploring Random Trees)。 3. **C++编程**:作为实现语言,C++提供了高效、面向对象的编程能力,适合处理实时性和性能要求高的...
下行异构网络中基于多领导者多跟随者博弈的功率控制算法,韩乔妮,杨博,异构网络(Heterogeneous networks, HetNets)是正在扩张的3G网络和新兴的4G网络的重要组成部分。然而,为了达到所有用户的服务质量(Quality ...