
ńŞÇšŤ┤ŔÁ×ňĆ╣Sunň»╣ňżůŠŐÇŠť»šÜäńŞąŔ░Ęňĺîń╝śÚŤů´╝łbless Sun´╝ëŃÇéSun JDKńŞşJavaň║ôšÜäŠ║Éń╗úšáü´╝îŔ┐׊│ĘÚçŐÚ⯊ŞůŠŞůŠąÜŠąÜŃÇüŔžäŔžäŔîâŔîâ´╝îjavadocŠ│ĘŔžúšÜäńŻ┐šöĘń╣čńŞÇńŞŁńŞŹŔőč´╝îŔ»╗ŔÁĚŠŁąňżłšćčŔłĺŠťŹŃÇéňŤáŠşĄ´╝îňťĘŠŚąňŞŞňĚąńŻťňĺîňşŽń╣áńŞş´╝îš╗ĆňŞŞŔ»╗Ŕ»╗ Javaň║ôšÜäŠ║Éń╗úšáü´╝îńŞŹń║Žń╣Éń╣Ä´╝čňŽéŠ×ťÚüçňł░Ŕ»íň╝éÚŚ«Úóś´╝îŠ║Éń╗úšáüšÜäňŞ«ňŐęň░▒ŠŤ┤ňĄžń║ćŃÇé
ÚŚ▓Ŕ»Łň░ĹŔ»┤´╝îňŤ×ňŻĺŠşúÚóśŃÇéŔ┐ÖňçáňĄę´╝îńŞÇšŤ┤ňťĘńŞ║JavašÜäÔÇťňćůňşśŠ│äÚť▓ÔÇŁÚŚ«Úóśš║áš╗ôŃÇéJavaň║öšöĘšĘőň║ĆňŹášöĘšÜäňćůňşśňťĘńŞŹŠľşšÜäŃÇüŠťëŔžäňżőšÜäńŞŐŠÂĘ´╝ǚ╗łŔÂůŔ┐çń║暍ŊĞڜłňÇ╝ŃÇé šŽĆň░öŠĹꊾ»ńŞŹňżŚńŞŹňç║Šëőń║ć´╝ü
Ŕ»┤ŔÁĚJavašÜäňćůňşśŠ│äÚť▓´╝îňůÂň«×ň«Üń╣ëńŞŹŠś»Úéúń╣łŠśÄší«ŃÇéÚŽľňůł´╝îňŽéŠ×ťJVMŠ▓튝ëbug´╝îÚéúń╣łšÉćŔ«║ńŞŐŠś»ńŞŹń╝Üňç║šÄ░ÔÇťŠŚáŠ│ĽňŤ×ŠöšÜäňáćšę║ÚŚ┤ÔÇŁ´╝îń╣čň░▒Šś»Ŕ»┤C/C++ńŞşšÜä ÚéúšžŹňćůňşśŠ│äÚť▓ňťĘJavańŞşńŞŹňşśňťĘšÜäŃÇéňůŠČí´╝îňŽéŠ×ťšö▒ń║ÄJavašĘőň║ĆńŞÇšŤ┤ŠîüŠťëŠčÉńެň»╣Ŕ▒íšÜäň╝ĽšöĘ´╝îńŻćŠś»ń╗ÄšĘőň║ĆÚÇ╗ŔżĹńŞŐšťő´╝îŔ┐Öńެň»╣Ŕ▒íňćŹń╣čńŞŹń╝ÜŔóźšöĘňł░ń║ć´╝îÚéúń╣łŠłĹń╗ČňĆ»ń╗ąŔ«Ą ńŞ║Ŕ┐Öńެň»╣Ŕ▒íŔóźŠ│äÚť▓ń║ćŃÇéňŽéŠ×ťŔ┐ÖŠáĚšÜäň»╣Ŕ▒튼░ÚçĆňżłňĄÜ´╝îÚéúń╣łňżłŠśÄŠśż´╝îňĄžÚçĆšÜäňćůňşśšę║ÚŚ┤ň░▒ŔóźŠ│äÚť▓´╝łÔÇťŠÁ¬Ŕ┤╣ÔÇŁŠŤ┤ňçćší«ńŞÇń║Ť´╝ëń║ćŃÇé
ńŞŹŔ┐ç´╝ȊľçŔŽüŔ»┤šÜäňćůňşśŠ│äÚť▓´╝îň╣ÂńŞŹň▒×ń║ÄńŞŐŔ┐░ňÄčňŤá´╝îňŤáŠşĄŠëôńŞŐń║ćň╝ĽňĆĚŃÇéňůÂňůĚńŻôňÄčňŤá´╝îší«ň«×ňç║ń╣ÄŠäĆŠľÖŃÇéŠČ▓ščąŔ»ŽŠâů´╝îŔ»ĚšťőńŞőÚŁóŔ«▓ŔžúŃÇé
ňłćŠ×ÉňćůňşśŠ│äÚť▓šÜäńŞÇŔłČŠşąÚ¬Ą
 
ňŽéŠ×ťňĆĹšÄ░Javaň║öšöĘšĘőň║ĆňŹášöĘšÜäňćůňşśňç║šÄ░ń║ćŠ│äÚť▓šÜäŔ┐╣Ŕ▒í´╝îÚéúń╣łŠłĹń╗ČńŞÇŔłČÚççšöĘńŞőÚŁóšÜ䊺ąÚ¬ĄňłćŠ×É
- ŠŐŐJavaň║öšöĘšĘőň║ĆńŻ┐šöĘšÜäheap dumpńŞőŠŁą
- ńŻ┐šöĘJava heapňłćŠ×ÉňĚąňůĚ´╝îŠëżňç║ňćůňşśňŹášöĘŔÂůňç║Úó䊝č´╝łńŞÇŔłČŠś»ňŤáńŞ║ŠĽ░ÚçĆňĄ¬ňĄÜ´╝ëšÜäňźîšľĹň»╣Ŕ▒í
- ň┐ůŔŽüŠŚÂ´╝îÚťÇŔŽüňłćŠ×ÉňźîšľĹň»╣Ŕ▒íňĺîňůÂń╗ľň»╣Ŕ▒íšÜäň╝ĽšöĘňů│š│╗ŃÇé
- ŠčąšťőšĘőň║ĆšÜäŠ║Éń╗úšáü´╝îŠëżňç║ňźîšľĹň»╣Ŕ▒튼░ÚçĆŔ┐çňĄÜšÜäňÄčňŤáŃÇé
dump heap
ňŽéŠ×ťJavaň║öšöĘšĘőň║Ćňç║šÄ░ń║ćňćůňşśŠ│äÚť▓´╝îňŹâńŞçňłźšŁÇŠÇąšŁÇŠŐŐň║öšöĘŠŁÇŠÄë´╝îŔÇ»ŔŽüń┐ŁňşśšÄ░ňť║ŃÇéňŽéŠ×ťŠś»ń║ĺŔüöšŻĹň║öšöĘ´╝îňĆ»ń╗ąŠŐŐŠÁüÚçĆňłçňł░ňůÂń╗ľŠťŹňŐíňÖĘŃÇéń┐ŁňşśšÄ░ňť║šÜ䚍«šÜäň░▒Šś» ńŞ║ń║ćŠŐŐŔ┐ÉŔíîńŞşJVMšÜäheap dumpńŞőŠŁąŃÇé
JDKŔç¬ňŞŽšÜäjmapňĚąňůĚ´╝îňĆ»ń╗ąňüÜŔ┐Öń╗Âń║őŠâůŃÇéň«âšÜäŠëžŔí╣Š│ĽŠś»´╝Ü
jmap -dump:format=b,file=heap.bin <pid>
format=bšÜäňÉźń╣늜»´╝îdumpňç║ŠŁąšÜ䊾çń╗ŠŚÂń║îŔ┐ŤňłÂŠá╝ň╝ĆŃÇé
file-heap.binšÜäňÉźń╣늜»´╝îdumpňç║ŠŁąšÜ䊾çń╗ÂňÉŹŠś»heap.binŃÇé
<pid>ň░▒Šś»JVMšÜäŔ┐ŤšĘőňĆĚŃÇé
´╝łňťĘlinuxńŞő´╝ëňůłŠëžŔíîps aux | grep java´╝îŠëżňł░JVMšÜäpid´╝ŤšäÂňÉÄň揊ëžŔíîjmap -dump:format=b,file=heap.bin <pid>´╝îňżŚňł░heap dumpŠľçń╗ÂŃÇé
analyze heap
ň░ćń║îŔ┐ŤňłÂšÜäheap dumpŠľçń╗ÂŔžúŠ×ÉŠłÉhuman-readablešÜäń┐íŠü»´╝îŔ笚䊜»ÚťÇŔŽüńŞôńŞÜňĚąňůĚšÜäňŞ«ňŐę´╝îŔ┐ÖÚçîŠÄĘŔŹÉMemory Analyzer ŃÇé
Memory Analyzer´╝îš«Çšž░MAT´╝»Eclipseňč║ÚçĹń╝ÜšÜäň╝ÇŠ║ÉÚí╣šŤ«´╝îšö▒SAPňĺîIBMŠŹÉňŐęŃÇéňĚĘňĄ┤ňůČňĆŞňç║ňôüšÜäŔŻ»ń╗ÂŔ┐śŠś»ňżłńŞşšöĘšÜä´╝îMATňĆ»ń╗ąňłćŠ×ÉňîůňÉźŠĽ░ń║┐š║žň»╣ Ŕ▒íšÜäheapŃÇüň┐źÚÇčŔ«íš«ŚŠ»Ćńެň»╣Ŕ▒íňŹášöĘšÜäňćůňşśňĄžň░ĆŃÇüň»╣Ŕ▒íń╣őÚŚ┤šÜäň╝ĽšöĘňů│š│╗ŃÇüŔç¬ňŐĘŠúÇŠÁőňćůňşśŠ│äÚť▓šÜäňźîšľĹň»╣Ŕ▒í´╝îňŐčŔâŻň╝║ňĄž´╝îŔÇîńŞöšĽîÚŁóňĆőňąŻŠśôšöĘŃÇé
MATšÜ䚼îÚŁóňč║ń║ÄEclipseň╝ÇňĆĹ´╝îń╗ąńŞĄšžŹňŻóň╝ĆňĆĹňŞâ´╝ÜEclipseŠĆĺń╗ÂňĺîEclipe RCPŃÇéMATšÜäňłćŠ×Éš╗ôŠ×ťń╗ąňŤżšëçňĺîŠŐąŔíĘšÜäňŻóň╝ĆŠĆÉńżŤ´╝îńŞÇšŤ«ń║ćšäÂŃÇéŠÇ╗ń╣őńެń║║Ŕ┐śŠś»ÚŁ×ňŞŞňľťŠČóŔ┐ÖńެňĚąňůĚšÜäŃÇéńŞőÚŁóňůłŔ┤┤ńŞĄň╝áň«śŠľ╣šÜäscreenshots´╝Ü
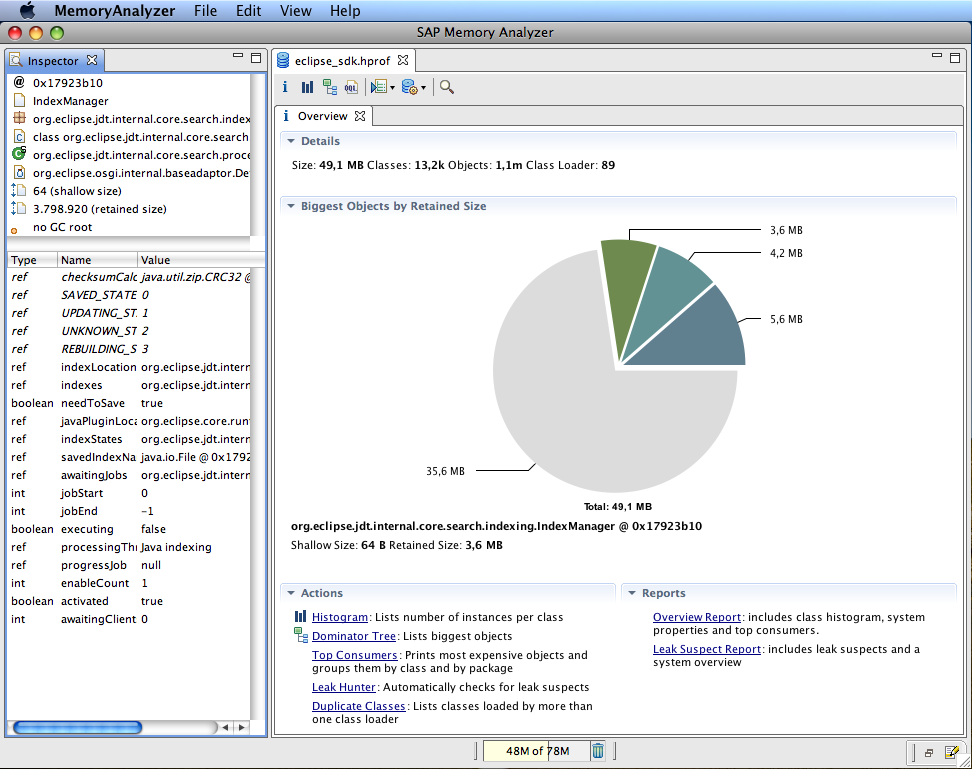

ŔĘÇňŻĺŠşúń╝á´╝ŚöĘMATŠëôň╝Çń║ćheap.bin´╝îňżłň«╣Šśôšťőňç║´╝îchar[]šÜ䊼░ÚçĆňç║ňůŠäĆŠľÖšÜäňĄÜ´╝îňŹášöĘ90%ń╗ąńŞŐšÜäňćůňşś ŃÇéńŞÇŔłČŠŁąŔ»┤´╝îchar[]ňťĘJVMší«ň«×ń╝ÜňŹášöĘňżłňĄÜňćůňşś´╝░ÚçĆń╣čÚŁ×ňŞŞňĄÜ´╝îňŤáńŞ║Stringň»╣Ŕ▒íń╗ąchar[]ńŻťńŞ║ňćůÚâĘňşśňéĘŃÇéńŻćŠś»Ŕ┐ÖŠČíšÜächar[]ňĄ¬Ŕ┤¬ňę¬ ń║ć´╝îń╗öš╗ćńŞÇŔžéň»č´╝îňĆĹšÄ░ŠťëŠĽ░ńŞçŔ«íšÜächar[]´╝ĆńެÚâŻňŹášöĘŠĽ░šÖżKšÜäňćůňşś ŃÇéŔ┐ÖńެšÄ░Ŕ▒íŔ»┤ŠśÄ´╝îJavašĘőň║Ćń┐Łňşśń║押░ń╗ąńŞçŔ«íšÜäňĄžStringň»╣Ŕ▒í ŃÇéš╗ôňÉłšĘőň║ĆšÜäÚÇ╗ŔżĹ´╝îŔ┐ÖńެŠś»ńŞŹň║öŔ»ąšÜä´╝îŔé»ň«ÜňťĘŠčÉńެňť░Šľ╣ňç║ń║ćÚŚ«ÚóśŃÇé
Úí║ŔŚĄŠĹŞšôť
ňťĘňĆ»šľĹšÜächar[]ńŞş´╝îń╗╗ŠäĆŠîĹń║ćńŞÇńެ´╝îńŻ┐šöĘPath To GC RootňŐčŔ⯴╝îŠëżňł░Ŕ»ąchar[]šÜäň╝ĽšöĘŔĚ»ňżä´╝îňĆĹšÄ░Stringň»╣Ŕ▒튜»ŔóźńŞÇńެHashMapńŞşň╝ĽšöĘšÜä ŃÇéŔ┐Öńެń╣芜»ŠäĆŠľÖńŞşšÜäń║őŠâů´╝îJavašÜäňćůňşśŠ│äÚť▓ňĄÜňŹŐŠś»ňŤáńŞ║ň»╣Ŕ▒íŔóźÚüŚšĽÖňťĘňůĘň▒ÇšÜäHashMapńŞşňżŚńŞŹňł░ÚçŐŠöżŃÇéńŞŹŔ┐ç´╝îŔ»ąHashMapŔóźšöĘńŻťńŞÇńެš╝ôňşś´╝îŔ«żšŻ«ń║ćš╝ô ňşśŠŁíšŤ«šÜäÚśłňÇ╝´╝îň»╝Ŕżżňł░ÚśłňÇ╝ňÉÄń╝ÜŔç¬ňŐĘŠĚśŠ▒░ŃÇéń╗ÄŔ┐ÖńެÚÇ╗ŔżĹňłćŠ×É´╝îň║öŔ»ąńŞŹń╝Üňç║šÄ░ňćůňşśŠ│äÚť▓šÜäŃÇéŔÖŻšäš╝ôňşśńŞşšÜäStringň»╣Ŕ▒íňĚ▓š╗ĆŔżżňł░ŠĽ░ńŞçŔ«í´╝îńŻćń╗ŹšäŠ▓튝ëŔżżňł░ÚóäňůłŔ«żšŻ« šÜäÚśłňÇ╝´╝łÚśłňÇ╝Ŕ«żšŻ«ňť░Š»öŔżâňĄž´╝îňŤáńŞ║ňŻôŠŚÂÚóäń╝░Stringň»╣Ŕ▒íÚ⯊»öŔżâň░Ć´╝ëŃÇé
ńŻćŠś»´╝îňĆŽńŞÇńŞ¬ÚŚ«Úóśň╝ĽŔÁĚń║抳ŚÜäŠ│ĘŠäĆ´╝ÜńŞ║ń╗Çń╣łš╝ôňşśšÜäStringň»╣Ŕ▒íňŽéŠşĄňĚĘňĄž´╝čňćůÚâĘchar[]šÜäÚĽ┐ň║ŽŔżżŠĽ░šÖżKŃÇéŔÖŻšäš╝ôňşśńŞşšÜäStringň»╣Ŕ▒튼░ ÚçĆŔ┐śŠ▓튝ëŔżżňł░ÚśłňÇ╝´╝îńŻćŠś»Stringň»╣Ŕ▒íňĄžň░ĆŔ┐ťŔ┐ťŔÂůňç║ń║抳Ĺń╗ČšÜäÚó䊝č´╝ǚ╗łň»╝Ŕç┤ňćůňşśŔóźňĄžÚçĆŠÂłŔÇŚ´╝îňŻóŠłÉňćůňşśŠ│äÚť▓šÜäŔ┐╣Ŕ▒í´╝łňçćší«Ŕ»┤ň║öŔ»ąŠś»ňćůňşśŠÂłŔÇŚŔ┐çňĄÜ´╝ë ŃÇé
ň░▒Ŕ┐ÖńŞ¬ÚŚ«ÚóśŔ┐ŤńŞÇŠşąÚí║ŔŚĄŠĹŞšôť´╝îšťőšťőStringňĄžň»╣Ŕ▒튜»ňŽéńŻĽŔóźŠöżňł░HashMapńŞşšÜäŃÇéÚÇÜŔ┐çŠčąšťőšĘőň║ĆšÜäŠ║Éń╗úšáü´╝ĹňĆĹšÄ░´╝îší«ň«×ŠťëStringňĄžň»╣Ŕ▒í´╝îńŞŹ Ŕ┐çň╣Š▓튝ëŠŐŐStringňĄžň»╣Ŕ▒íŠöżňł░HashMapńŞş´╝îŔÇ»ŠŐŐStringňĄžň»╣Ŕ▒íŔ┐ŤŔíîsplit´╝łŔ░âšöĘString.splitŠľ╣Š│Ľ´╝ë´╝îšäÂňÉÄň░ćsplitňç║ ŠŁąšÜäStringň░Ćň»╣Ŕ▒íŠöżňł░HashMapńŞş ń║ćŃÇé
Ŕ┐Öň░▒ňąçŠÇ¬ń║ć´╝îŠöżňł░HashMapńŞşŠśÄŠśÄŠś»splitń╣őňÉÄšÜäStringň░Ćň»╣Ŕ▒í´╝îŠÇÄń╣łń╝ÜňŹášöĘÚéúń╣łňĄžšę║ÚŚ┤ňĹó´╝čÚÜżÚüôŠś»Stringš▒╗šÜäsplitŠľ╣Š│ĽŠťëÚŚ« Úóś´╝č
Ščąšťőń╗úšáü
ňŞŽšŁÇńŞŐŔ┐░šľĹÚŚ«´╝ŊčąÚśůń║ćSun JDK6ńŞşStringš▒╗šÜäń╗úšáü´╝îńŞ╗ŔŽüŠś»Šś»splitŠľ╣Š│ĽšÜäň«×šÄ░´╝Ü
- public   
- String[] split(String regex, int limit) {  
-     return Pattern.compile(regex).split(this, limit);  
- }  
 
ňĆ»ń╗ąšťőňç║´╝îStirng.splitŠľ╣Š│ĽŔ░âšöĘń║ćPattern.splitŠľ╣Š│ĽŃÇéš╗žš╗şšťőPattern.splitŠľ╣Š│ĽšÜäń╗úšáü´╝Ü
- public   
- String[] split(CharSequence input, int limit) {  
-         int index = 0;  
-         boolean matchLimited = limit > 0;  
-         ArrayList<String> matchList = new   
- ArrayList<String>();  
-         Matcher m = matcher(input);  
-         // Add segments before each match found  
-         while(m.find()) {  
-             if (!matchLimited || matchList.size() < limit - 1) {  
-                 String match = input.subSequence(index,   
- m.start()).toString();  
-                 matchList.add(match);  
-                 index = m.end();  
-             } else if (matchList.size() == limit - 1) { // last one  
-                 String match = input.subSequence(index,  
-                                                    
- input.length()).toString();  
-                 matchList.add(match);  
-                 index = m.end();  
-             }  
-         }  
-         // If no match was found, return this  
-         if (index == 0)  
-             return new String[] {input.toString()};  
-         // Add remaining segment  
-         if (!matchLimited || matchList.size() < limit)  
-             matchList.add(input.subSequence(index,   
- input.length()).toString());  
-         // Construct result  
-         int resultSize = matchList.size();  
-         if (limit == 0)  
-             while (resultSize > 0 &&   
- matchList.get(resultSize-1).equals(""))  
-                 resultSize--;  
-         String[] result = new String[resultSize];  
-         return matchList.subList(0, resultSize).toArray(result);  
-     }  
 
Š│ĘŠäĆšťőšČČ11Ŕíî´╝ÜStirng match = input.subSequence(intdex, m.start()).toString();
Ŕ┐ÖÚçîšÜämatchň░▒Šś»splitňç║ŠŁąšÜäStringň░Ćň»╣Ŕ▒í´╝îň«âňůÂň«×Šś»StringňĄžň»╣Ŕ▒ísubSequencešÜäš╗ôŠ×ťŃÇéš╗žš╗şšťő String.subSequencešÜäń╗úšáü´╝Ü
- public   
- CharSequence subSequence(int beginIndex, int endIndex) {  
-         return this.substring(beginIndex, endIndex);  
- }  
 
String.subSequenceŠťëŔ░âšöĘń║ćString.subString´╝îš╗žš╗şšťő´╝Ü
- public String   
- substring(int beginIndex, int endIndex) {  
-     if (beginIndex < 0) {  
-         throw new StringIndexOutOfBoundsException(beginIndex);  
-     }  
-     if (endIndex > count) {  
-         throw new StringIndexOutOfBoundsException(endIndex);  
-     }  
-     if (beginIndex > endIndex) {  
-         throw new StringIndexOutOfBoundsException(endIndex - beginIndex);  
-     }  
-     return ((beginIndex == 0) && (endIndex == count)) ? this :  
-         new String(offset + beginIndex, endIndex - beginIndex, value);  
-     }  
 
šťőšČČ12ŃÇü13Ŕíî´╝Ĺń╗Čš╗łń║Äšťőňç║šťëšŤ«´╝îňŽéŠ×ťsubStringšÜäňćůň«╣ň░▒Šś»ň«îŠĽ┤šÜäňÄčňşŚšČŽńŞ▓´╝îÚéúń╣łŔ┐öňŤ×ňÄčStringň»╣Ŕ▒í´╝ŤňÉŽňłÖ´╝îň░▒ń╝ÜňłŤň╗║ńŞÇńެŠľ░šÜä Stringň»╣Ŕ▒í´╝îńŻćŠś»Ŕ┐ÖńެStringň»╣Ŕ▒íŔ▓îń╝╝ńŻ┐šöĘń║ćňÄčStringň»╣Ŕ▒íšÜächar[]ŃÇ銳Ĺń╗ČÚÇÜŔ┐çStringšÜäŠ×äÚÇáň篊Ľ░ší«Ŕ«ĄŔ┐ÖńŞÇšé╣´╝Ü
- // Package   
- private constructor which shares value array for speed.  
-     String(int offset, int count, char value[]) {  
-     this.value = value;  
-     this.offset = offset;  
-     this.count = count;  
-     }  
 
ńŞ║ń║ćÚü┐ňůŹňćůňşśŠőĚŔ┤ŁŃÇüňŐáň┐źÚÇčň║Ž´╝îSun JDKšŤ┤ŠÄąňĄŹšöĘń║ćňÄčStringň»╣Ŕ▒íšÜächar[]´╝îňüĆšž╗ÚçĆňĺîÚĽ┐ň║ŽŠŁąŠáçŔ»ćńŞŹňÉîšÜäňşŚšČŽńŞ▓ňćůň«╣ŃÇéń╣čň░▒Šś»Ŕ»┤´╝îsubString ňç║šÜ䊣ąStringň░Ćň»╣Ŕ▒íń╗ŹšäÂń╝ÜŠîçňÉĹňÄčStringňĄžň»╣Ŕ▒íšÜächar[]´╝îsplitń╣芜»ňÉîŠáĚšÜäŠâůňćÁ ŃÇéŔ┐Öň░▒ŔžúÚçŐń║ć´╝îńŞ║ń╗Çń╣łHashMapńŞşStringň»╣Ŕ▒íšÜächar[]ÚâŻÚéúń╣łňĄžŃÇé
ňÄčňŤáŔžúÚçŐ
ňůÂň«×ńŞŐńŞÇŔŐéňĚ▓š╗ĆňłćŠ×Éňç║ń║ćňÄčňŤá´╝îŔ┐ÖńŞÇŔŐéň揊Ľ┤šÉćńŞÇńŞő´╝Ü
- šĘőň║Ćń╗ÄŠ»ĆńެŔ»ĚŠ▒éńŞşňżŚňł░ńŞÇńެStringňĄžň»╣Ŕ▒í´╝îŔ»ąň»╣Ŕ▒íňćůÚâĘchar[]šÜäÚĽ┐ň║ŽŔżżŠĽ░šÖżKŃÇé
- šĘőň║Ćň»╣StringňĄžň»╣Ŕ▒íňüÜsplit´╝îň░ćsplitňżŚňł░šÜäStringň░Ćň»╣Ŕ▒íŠöżňł░HashMapńŞş´╝îšöĘńŻťš╝ôňşśŃÇé
- Sun JDK6ň»╣String.splitŠľ╣Š│ĽňüÜń║ćń╝śňîľ´╝îsplitňç║ŠŁąšÜäStirngň»╣Ŕ▒획┤ŠÄąńŻ┐šöĘňÄčStringň»╣Ŕ▒íšÜächar[]
- HashMapńŞşšÜ䊻ĆńެStringň»╣Ŕ▒íňůÂň«×Ú⯊îçňÉĹń║ćńŞÇńެňĚĘňĄžšÜächar[]
- HashMapšÜäńŞŐÚÖÉŠś»ńŞçš║žšÜä´╝îňŤáŠşĄŔóźš╝ôňşśšÜäStingň»╣Ŕ▒íšÜäŠÇ╗ňĄžň░Ć=ńŞç*šÖżK=Gš║žŃÇé
- Gš║žšÜäňćůňşśŔóźš╝ôňşśňŹášöĘń║ć´╝îňĄžÚçĆšÜäňćůňşśŔóźŠÁ¬Ŕ┤╣´╝îÚÇኳÉňćůňşśŠ│äÚť▓šÜäŔ┐╣Ŕ▒íŃÇé
Ŕžúňć│Šľ╣Šíł
ňÄčňŤáŠëżňł░ń║ć´╝îŔžúňć│Šľ╣Šíłń╣čň░▒Šťëń║ćŃÇésplitŠś»ŔŽüšöĘšÜä´╝îńŻćŠś»ŠłĹń╗ČńŞŹŔŽüŠŐŐsplitňç║ŠŁąšÜäStringň»╣Ŕ▒획┤ŠÄąŠöżňł░HashMapńŞş´╝îŔÇ»Ŕ░âšöĘńŞÇńŞő StringšÜäŠőĚŔ┤ŁŠ×äÚÇáň篊Ľ░String(String original)´╝îŔ┐ÖńެŠ×äÚÇáň篊Ľ░Šś»ň«ëňůĘšÜä´╝îňůĚńŻôňĆ»ń╗ąšťőń╗úšáü´╝Ü
-     /** 
-      * Initializes a newly created {@code String} object so that it  
- represents 
-      * the same sequence of characters as the argument; in other words,  
- the 
-      * newly created string is a copy of the argument string. Unless an 
-      * explicit copy of {@code original} is needed, use of this  
- constructor is 
-      * unnecessary since Strings are immutable. 
-      * 
-      * @param  original 
-      *         A {@code String} 
-      */  
-     public String(String original) {  
-     int size = original.count;  
-     char[] originalValue = original.value;  
-     char[] v;  
-     if (originalValue.length > size) {  
-         // The array representing the String is bigger than the new  
-         // String itself.  Perhaps this constructor is being called  
-         // in order to trim the baggage, so make a copy of the array.  
-             int off = original.offset;  
-             v = Arrays.copyOfRange(originalValue, off, off+size);  
-     } else {  
-         // The array representing the String is the same  
-         // size as the String, so no point in making a copy.  
-         v = originalValue;  
-     }  
-     this.offset = 0;  
-     this.count = size;  
-     this.value = v;  
-     }  
 
ňƬŠś»´╝înew String(string)šÜäń╗úšáüňżłŠÇ¬ň╝é´╝îňŤžŃÇ銳ľŔ«Ş´╝îsubStringňĺîsplitň║öŔ»ąŠĆÉńżŤńŞÇńެÚÇëÚí╣´╝îŔ«ęšĘőň║ĆňĹśŠÄžňłÂŠś»ňÉŽňĄŹšöĘStringň»╣Ŕ▒íšÜä char[]ŃÇé
Šś»ňÉŽŠś»Bug
 
ŔÖŻšä´╝îsubStringňĺîsplitšÜäň«×šÄ░ÚÇኳÉń║ćšÄ░ňťĘšÜäÚŚ«Úóś´╝îńŻćŠś»Ŕ┐ÖŔâŻňÉŽš«ŚStringš▒╗šÜäbugňĹó´╝čńެń║║ŔžëňżŚńŞŹňąŻŔ»┤ŃÇéňŤáńŞ║Ŕ┐ÖŠáĚšÜäń╝śňś»Š»öŔżâňÉłšÉć šÜä´╝îsubStringňĺîspitšÜäš╗ôŠ×ťŔé»ň«ÜŠś»ňÄčňşŚšČŽńŞ▓šÜäŔ┐ך╗şňşÉň║ĆňłŚŃÇéňƬŔâŻŔ»┤´╝îStringńŞŹń╗ůń╗ůŠś»ńŞÇńެŠáŞň┐âš▒╗´╝îň«âň»╣ń║ÄJVMŠŁąŔ»┤Šś»ńŞÄňÄčňžőš▒╗ň×őňÉîšşëÚçŹŔŽüšÜä š▒╗ň×őŃÇé
JDKň«×šÄ░ň»╣StringňüÜňÉäšžŹňĆ»Ŕ⯚Üäń╝śňîľÚ⯊ś»ňĆ»ń╗ąšÉćŔžúšÜäŃÇéńŻćŠś»ń╝śňîľňŞŽŠŁąń║ćň┐žŠéú´╝Ĺń╗ČšĘőň║ĆňĹśŔÂ│ňĄčń║ćŔžúń╗ľń╗Č´╝îŠëŹŔ⯚öĘňąŻń╗ľń╗ČŃÇé



šŤŞňů│ŠÄĘŔŹÉ
ň╝▒ňŐ┐šżĄńŻôńŞëÚçŹň┐žŠéúšáöšęÂŔ«║Šľç.doc
šĄżń╝Ü´╝ÜŔóźAIŠÄąš«íňÉÄšÜäň┐žŠéúšĄżń╝Ü´╝ÜŔóźAIŠÄąš«íňÉÄšÜäň┐žŠéúšĄżń╝Ü´╝ÜŔóźAIŠÄąš«íňÉÄšÜäň┐žŠéúšĄżń╝Ü´╝ÜŔóźAIŠÄąš«íňÉÄšÜäň┐žŠéúšĄżń╝Ü´╝ÜŔóźAIŠÄąš«íňÉÄšÜäň┐žŠéúšĄżń╝Ü´╝ÜŔóźAIŠÄąš«íňÉÄšÜäň┐žŠéúšĄżń╝Ü´╝ÜŔóźAIŠÄąš«íňÉÄšÜäň┐žŠéúšĄżń╝Ü´╝ÜŔóźAIŠÄąš«íňÉÄšÜäň┐žŠéúšĄżń╝Ü´╝ÜŔóźAIŠÄąš«íňÉÄšÜäň┐žŠéú...
ň╣┐ňĄľšžĹňşŽŠŐÇŠť»ňĆ▓ÚźśšžĹŠŐÇŠŚÂń╗úšÜäń║║Šľçň┐žŠéúPPTŔ»żń╗Â.pptx
šöčń║Äň«ëń╣É´╝╗ń║Äň┐žŠéú´╝îŔ┐ÖŠś»ńŞşňŤŻňĆĄń╗úŠÇŁŠâ│ň«ÂňşčňşÉšĽÖš╗ÖňÉÄńŞľšÜäŠÖ║ŠůžŔşŽňĆąŃÇéŔ┐ÖňĆąŔ»ŁńŞŹń╗ůŠĆĆŔ┐░ń║ćńެń║║ŠłÉÚĽ┐šÜäŔŻĘŔ┐╣´╝îń╣芜»š╗äš╗çňĆĹň▒Ľňĺżń╝ÜŔ┐ŤŠşąšÜäš╝ęňŻ▒ŃÇéňťĘŠÄóŔ«ĘŔ┐ÖńŞÇńŞ╗ÚóśšÜäPPTńŞş´╝îÚÇÜŔ┐çňşčňşÉšÜäňô▓ňşŽŔžéšé╣ňĺîńŞÇš│╗ňłŚňÄćňĆ▓ń║║šëęšÜäŠíłńżő´╝Ĺń╗ČŔâŻňĄč...
2. ŃÇŐšşöňĆŞÚęČŔ░ĆŔ««ń╣ŽŃÇő´╝ÜšÄőň«ëšč│ńŞ╗ň╝áŠö╣ÚŁę´╝îŔ«ĄńŞ║ÔÇťŠë┐ňĄęŠÖ»ňĹŻ´╝Ěň┐žňÉ»ňťúÔÇŁ´╝îňŤŻň«Âň┐ůÚí╗Šá╣ŠŹ«ŠŚÂń╗úňĆśňîľŔ┐ŤŔíîňĆśÚŁę´╝îń╗ąň║öň»╣ŠĚ▒Ú珚Üäň┐žŠéúŃÇé ňŤŤŃÇüš╗ĆňůŞŔ»şňŻĽ´╝Ü 1. ÔÇťŔŻŻŔłčŔŽćŔłčÔÇŁ´╝Üń║║Š░ĹňŽéňÉîŠë┐ŔŻŻŔł╣ňƬšÜäŠ░┤´╝îňĆ»ń╗ąŠëŠîüňÉŤńŞ╗´╝îń╣čňĆ»ń╗ąÚóáŔŽćňůš╗čŠ▓╗...
ÚúÄÚÖęÚóäŠÁőńŞÄň┐žŠéúŠĚ▒ŠÇŁ´╝Üń║║ňĚąŠÖ║ŔâŻň»╣ŠĽÖŔé▓ňĆĹň▒ĽšÜäňć▓ňç╗ńŞÄňĆśÚŁęÔÇöÔÇöňô▓ňşŽńŞÄń╝ŽšÉćšÜäŠÇŁŔÇâ.pdf
(2) "šäÂňÉÄščąšöčń║Äň┐žŠéú´╝îŔÇ╗ń║Äň«ëń╣Éń╣č" ŔíĘšĄ║ÔÇťŔ┐ÖŠáĚń╗ąňÉÄ´╝îń║║ń╗ČŠëŹń╝ÜŠśÄšÖŻ´╝îň┐žŠéú´╝łŔ⯊┐ÇňŐ▒ń║║ňąőňĆĹ´╝ëńŻ┐ń║║Ŕ░őŠ▒éšöčňşśňĆĹň▒Ľ´╝îŔÇîň«ëÚÇŞń║źń╣Éň░▒ń╝ÜŔ«ęń║║ŔÉÄÚŁí´╝îň»╝Ŕç┤Šş╗ń║íÔÇŁŃÇé ň揊ŁąšťőšČČń║îÚâĘňłćšÜäňşčŠ»ŹŠĽÖňşÉšÜ䊼ůń║ő´╝Ü 5. Ŕ┐ÖÚçîŔžúÚçŐń║ćńŞĄńެŠľçŔĘÇŔ»ŹŔ»ş...
Ŕ┐ĚńŻáÚ▒╝ŔĆťňů▒šöčš│╗š╗芜»ńŞÇšžŹŠľ░ň×őšÜäňĄŹňÉłŔÇĽńŻťńŻôš│╗´╝îň«âŠŐŐŠ░┤ń║žňů╗Š«ľńŞÄŔöČŔĆťšöčń║žŔ┐ÖńŞĄšžŹňÄ芝Čň«îňůĘńŞŹňÉîšÜäňćťŔÇĽŠŐÇŠť»´╝îÚÇÜŔ┐çňĚžňŽÖšÜäšöčŠÇüŔ«żŔ«í´╝îŔżżňł░šžĹňşŽšÜäňŹĆňÉîňů▒šöč´╝îň«×šÄ░ňů╗Ú▒╝ńŞŹŠŹóŠ░┤ŔÇáŠ░┤Ŕ┤Ęň┐žŠéú´╝îšžŹŔĆťńŞŹŠľŻŔéąŔÇúňŞŞŠłÉÚĽ┐šÜäšöčŠÇüňů▒šö芼łň║öŃÇé...
ňŹŚňöÉŔ»ŹňłÖŠ│ĘňůąňúźňĄžňĄźšÜäň┐žŠéúń╣őŠäčňĺîšöčňĹŻŠäĆŔ»ć´╝îŠÇŁŠâ│ňó⚼îŔżâÚźś´╝îŔ»şŔĘÇń╣芻öŔżâŠŞůŠľ░ÚŤůńŞŻŃÇé ňŤŤŃÇüňůÂń╗ľ´╝Ü 1. ŃÇŐÚÇŹÚüąŠŞŞŃÇőšÜäŔë║Šť»šë╣Ŕë▓´╝ÜŔ┐ÉšöĘňĄžÚçĆň»ôŔĘÇÚśÉňĆĹňô▓ňşŽŠÇŁŠâ│ŃÇ銾皟áš╗ôŠ×䊝ëÔÇťŠľşš╗şÔÇŁń╣őňŽÖ´╝îšö▒ňô▓šÉćŠÇŁŠâ│Ŕ┤»šę┐ňůĘŠľçŃÇéŔ»şŔĘÇŔ笚ö▒šüÁŠ┤╗´╝î...
ŃÇŐňç║ňŞłŔíĘŃÇőŠś»ńŞëňŤŻŠŚÂŠťčŔťÇŠ▒ëńŞ×šŤŞŔ»ŞŔĹŤń║«ňťĘ...ŠÇ╗šÜ䊣ąŔ»┤´╝îŃÇŐňç║ňŞłŔíĘŃÇőŠś»Ŕ»ŞŔĹŤń║«ň»╣ňłśšŽůšÜäŔ░ćŔ░押ÖŔ»▓´╝îň▒ĽšÄ░ń║ćń╗ľŠĚ▒Š▓ëšÜäň┐žŠéúŠäĆŔ»ćňĺîňŁÜň«ÜšÜäńŻ┐ňĹŻŠäčŃÇéŔ┐Öš»çŠľçšźáńŞŹń╗ůŠś»ŠľçňşŽńŞŐšÜäšĹ░ň«Ł´╝îń╣芜»ňÄćňĆ▓ňĺîŠö┐Š▓╗ŠÖ║ŠůžšÜäš╗ôŠÖ´╝îŔç│ń╗Őń╗ŹňůĚŠťëŠĚ▒Ŕ┐ťšÜäňÉ»šĄ║ŠäĆń╣ëŃÇé
ÚÇÜŔ┐çŠ╝öŔ«▓´╝îňĆéńŞÄŔÇůňĆ»ń╗ąňŤ×ÚíżňÄćňĆ▓´╝îňó×ň╝║ň┐žŠéúŠäĆŔ»ć´╝îňÉÂň▒ĽšÄ░Šľ░ŠŚÂń╗úňĄžňşŽšöčšÜäÚúÄÚççŃÇé ńŞÇŃÇüŠ┤╗ňŐĘň«ŚŠŚĘ´╝Ü Š┤╗ňŐĘšÜäň«ŚŠŚĘňťĘń║Äš║¬ň┐ÁšąľňŤŻšÜäŔżëšůîňÄćšĘő´╝îňŐáŠĚ▒ňşŽšöčň»╣ňŤŻň«Âň«ëňůĘňĺîŠáíňŤşň«ëňůĘšÜäšÉćŔžúŃÇéŠ┤╗ňŐĘÚ╝ôňŐ▒ňşŽšöčšž»Š×üňĆéńŞÄ´╝îň╝║ňîľŔ笊łĹń┐ŁŠŐĄŠäĆŔ»ć´╝î...
1. ŠĽłňŐ│ŠäĆŔ»ćňĺîň┐žŠéúŠäĆŔ»ćŠĚíŔľä´╝ÜÚóćň»╝ň╣▓ÚâĘňĆ»ŔâŻň┐ŻŔžćń║ćńŞ║ń║║Š░ĹŠťŹňŐíšÜäň«ŚŠŚĘ´╝îš╝║ń╣ĆňŹ▒Šť║Šäč´╝îň»╝Ŕç┤ňĚąńŻťšž»Š×üŠÇžńŞŹÚźśŃÇé 2. ňşŽń╣áńŞÄň«×ÚÖůňĚąńŻťŔä▒ŔŐé´╝ÜšÉćŔ«║ňşŽń╣áńŞÄň«×ŔĚÁŠôŹńŻťń╣őÚŚ┤ňşśňťĘÚŞ┐Š▓č´╝îÚóćň»╝ň╣▓ÚâĘŠť¬ŔâŻň░ćŠëÇňşŽščąŔ»ćň║öšöĘňł░ň«×ÚÖůňĚąńŻťńŞşŃÇé 3. ňşŽń╣á...
ń╝üńŞÜň«ëňůĘň┐žŠéúŠäĆŔ»ćŠ╝öŔ«▓šĘ┐.docx
ń┐äňŤŻňłŚň«żšÜäŃÇŐń╝Ćň░öňŐáŠ▓│ńŞŐšÜäš║ĄňĄźŃÇőňĆŹŠśáń║ćňŐ│ňŐĘń║║Š░ĹšÜäŠé▓ŠâĘňĄäňóâ´╝üňç║ń║ćŠ░ĹŠŚĆšÜäň┐žŠéúŠäĆŔ»ćŃÇé 4.ňŹ░Ŕ▒íšö╗Š┤ż´╝ł19 ńŞľš║¬ňÉÄňŹŐŠťč´╝ë´╝ÜŠ│ĽňŤŻŔÄźňąłšÜäŃÇŐŠŚąňç║┬ĚňŹ░Ŕ▒íŃÇő´╝ŤŔŹĚňů░ňçíÚźś´╝łÔÇťŠëĹňÉĹňĄ¬Úś│šÜäšö╗ň«ÂÔÇŁ´╝ëšÜäŃÇŐňÉĹŠŚąŔĹÁŃÇő´╝ŤŠ│ĽňŤŻňí×ň░ÜŠôůÚĽ┐ÚŁÖšëę´╝îŔë▓ňŻę...
ÚÇÜŔ┐çňůĚńŻôšÜ䊼░ňşŚ´╝îňşŽšöčŔ⯊Ť┤šŤ┤Ŕžéňť░ŠäčňĆŚňł░Ú╗äŠ▓│ÚŚ«ÚóśšÜäńŞąÚ珊Ǟ´╝îń╗ÄŔÇîň╝ĽňĆĹń╗ľń╗ČšÜäň┐žŠéúŠäĆŔ»ćňĺîšÄ»ń┐ŁŔíîňŐĘšÜäňć│ň┐âŃÇé ŠÇ╗šÜ䊣ąŔ»┤´╝îŔ┐Öń╗ŻŠĽÖňşŽŔ«żŔ«íŠŚĘňťĘÚÇÜŔ┐çŠÄóšęÂÚ╗äŠ▓│šÜäňÄćňĆ▓ňĆśŔ┐ü´╝îň╝Ľň»╝ňşŽšöčňů│Š│ĘŔ笚äšĻňóâšÜäňĆśňîľ´╝îňč╣ňů╗ń╗ľń╗ČšÜäšÄ»ń┐ŁŠäĆŔ»ćňĺżń╝Ü...
ňşčňşÉňťĘŠłśňŤŻŠŚÂŠťčšÜäňÉŹŔĘÇÔÇťšöčń║Äň┐žŠéúŔÇ╗ń║Äň«ëń╣ÉÔÇŁńŞÄŠşĄšŤŞňĹ╝ň║ö´╝îŠĆşšĄ║ń║ćň┐žŠéúŠäĆŔ»ćň»╣ń║ÄňŤŻň«Âňşśń║íšÜäÚçŹŔŽüŠÇžŃÇé ŃÇÉšö▓ڬʊľçšáöšęšÜäÚçŹŔŽüŠÇžŃÇĹ šö▓ڬʊľçńŻťńŞ║ŠłĹňŤŻŠťÇŠŚęšÜ䊾çňşŚ´╝»ń║ćŔžúŠ«ĚňĽćňÄćňĆ▓ŠľçňîľšÜäÚçŹŔŽüš¬ŚňĆúŃÇéÚÇÜŔ┐çšáöšęšö▓ڬʊľçńŞşšÜäšüżšąŞňşŚ´╝îňŽé...
ŠÇÄń╣łňüÜňł░šÜä´╝ÜÚŽľňůł´╝ĹŔ┐Öńެń║║Šťëňżłň╝║šÜäň┐žŠéúŠäĆŔ»ć´╝îŠÇ╗Šőůň┐âŔç¬ňĚ▒Š║║Š░┤ŃÇéńŞŐŔ»żňëŹŔ«ĄšťčÚóäń╣áń║ćńŻôŔé▓ń╣ŽńŞŐŠŞŞŠ││Ŕ┐ÖńŞÇŔ»żŃÇéňůŠČí´╝îńŞŐŔ»ż´╝îŔ«ĄšťčňÉČŔ»żŃÇéŔ»żńŞŐŔ«Ąšťčš╗âń╣áŃÇ銝ÇňÉÄ´╝îŔ»żńŞőňĚęňŤ║ŃÇé ňşŽń╣áÚçĹňşŚňíöňĹŐŔ»ëŠłĹń╗Č´╝îňşŽń╣ኼłŠ×ťňťĘ30%ń╗ąńŞőšÜäňçášžŹń╝áš╗č...
ŃÇÉŠĆĆŔ┐░ŃÇĹŔ┐Öń╗ŻńŞôÚóśŔÁ䊾ÖŔüÜšäŽń║Äń╝üńŞÜňŽéńŻĽňťĘňĄŹŠŁéňĄÜňĆśšÜäňĽćńŞÜšÄ»ňóâńŞşń┐ŁŠîüňč║ńŞÜÚĽ┐ÚŁĺ´╝îšë╣ňłźŠś»ÚÇÜŔ┐çň╝║ňîľňŹ▒Šť║š«íšÉćňĺîň┐žŠéúŠäĆŔ»ćŠŁąň║öň»╣ńŞŹší«ň«ÜňŤáš┤áŃÇé ŃÇÉŠáçšşżŃÇĹŠĽÖŔé▓ŔÁ䊾ִ╝îń╝üńŞÜš«íšÉć´╝îňŹ▒Šť║š«íšÉć ŃÇÉňćůň«╣Ŕ»ŽŔžúŃÇĹ 1. ň╝║šâłšÜäňŹ▒Šť║ńŞÄň┐žŠéúŠäĆŔ»ć ...
ŃÇŐÚźśŠĽłš«íšÉćńŞÄš«íšÉćŠÁüšĘőń╝śňîľŃÇő.pptx Šś»ńŞÇń╗Żňů│ń║ÄšÄ░ń╗úń╝üńŞÜš«íšÉćšÜ䊾çŠíúŔÁ䊾ִ╝îńŞ╗ŔŽüŠÄóŔ«Ęń║ćń╝üńŞÜňŽéńŻĽň«×šÄ░ŔžäŔîâňîľš«íšÉćňĺîŠÁüšĘőń╝śňîľ´╝îń╗ąń┐âŔ┐Ťń╝üńŞÜšÜäÚźśŠĽłŔ┐ÉŔíîňĺîÚĽ┐ŠťčňĆĹň▒ĽŃÇéń╗ąńŞőŠś»ňůÂńŞşŠÂëňĆŐšÜäńŞ╗ŔŽüščąŔ»ćšé╣´╝Ü 1. šÄ░ń╗úń╝üńŞÜš«íšÉ抎éŔ┐░´╝Ü - ...
ň╣┐ňĄľšžĹňşŽŠŐÇŠť»ňĆ▓ÚźśšžĹŠŐÇŠŚÂń╗úšÜäń║║Šľçň┐žŠéúPPTňşŽń╣ኼ֊íł.pptx