
byte buffer一般在网络交互过程中java使用得比较多,尤其是以NIO的框架中;
看名字就知道是以字节码作为缓冲的,先buffer一段,然后flush到终端。
而本文要说的一个重点就是HeapByteBuffer与DirectByteBuffer,以及如何合理使用DirectByteBuffer。
1、HeapByteBuffer与DirectByteBuffer,在原理上,前者可以看出分配的buffer是在heap区域的,其实真正flush到远程的时候会先拷贝得到直接内存,再做下一步操作(考虑细节还会到OS级别的内核区直接内存),其实发送静态文件最快速的方法是通过OS级别的send_file,只会经过OS一个内核拷贝,而不会来回拷贝;在NIO的框架下,很多框架会采用DirectByteBuffer来操作,这样分配的内存不再是在java heap上,而是在C heap上,经过性能测试,可以得到非常快速的网络交互,在大量的网络交互下,一般速度会比HeapByteBuffer要快速好几倍。
最基本的情况下
分配HeapByteBuffer的方法是:
- ByteBuffer.allocate(int capacity);参数大小为字节的数量
ByteBuffer.allocate(int capacity);参数大小为字节的数量
分配DirectByteBuffer的方法是:
- ByteBuffer.allocateDirect(int capacity);//可以看到分配内存是通过unsafe.allocateMemory()来实现的,这个unsafe默认情况下java代码是没有能力可以调用到的,不过你可以通过反射的手段得到实例进而做操作,当然你需要保证的是程序的稳定性,既然叫unsafe的,就是告诉你这不是安全的,其实并不是不安全,而是交给程序员来操作,它可能会因为程序员的能力而导致不安全,而并非它本身不安全。
ByteBuffer.allocateDirect(int capacity);//可以看到分配内存是通过unsafe.allocateMemory()来实现的,这个unsafe默认情况下java代码是没有能力可以调用到的,不过你可以通过反射的手段得到实例进而做操作,当然你需要保证的是程序的稳定性,既然叫unsafe的,就是告诉你这不是安全的,其实并不是不安全,而是交给程序员来操作,它可能会因为程序员的能力而导致不安全,而并非它本身不安全。
由于HeapByteBuffer和DirectByteBuffer类都是default类型的,所以你无法字节访问到,你只能通过ByteBuffer间接访问到它,因为JVM不想让你访问到它,对了,JVM不想让你访问到它肯定就有它不可告人的秘密;后面我们来跟踪下他的秘密吧。
2、前面说到了,这块区域不是在java heap上,那么这块内存的大小是多少呢?默认是一般是64M,可以通过参数:-XX:MaxDirectMemorySize来控制,你够牛的话,还可以用代码控制,呵呵,这里就不多说了。
3、直接内存好,我们为啥不都用直接内存?请注意,这个直接内存的释放并不是由你控制的,而是由full gc来控制的,直接内存会自己检测情况而调用system.gc(),但是如果参数中使用了DisableExplicitGC 那么这是个坑了,所以啊,这玩意,设置不设置都是一个坑坑,所以java的优化有没有绝对的,只有针对实际情况的,针对实际情况需要对系统做一些拆分做不同的优化。
4、那么full gc不触发,我想自己释放这部分内存有方法吗?可以的,在这里没有什么是不可以的,呵呵!私有属性我们都任意玩他,还有什么不可以玩的;我们看看它的源码中DirectByteBuffer发现有一个:Cleaner,貌似是用来搞资源回收的,经过查证,的确是,而且又看到这个对象是sun.misc开头的了,此时既惊喜又郁闷,呵呵,只要我能拿到它,我就能有希望消灭掉了;下面第五步我们来做个试验。
5、因为我们的代码全是私有的,所以我要访问它不能直接访问,我需要通过反射来实现,OK,我知道要调用cleaner()方法来获取它Cleaner对象,进而通过该对象,执行clean方法;(付:以下代码大部分也取自网络上的一篇copy无数次的代码,但是那个代码是有问题的,有问题的部分,我将用红色标识出来,如果没有哪条代码是无法运行的)
- import java.nio.ByteBuffer;
- import sun.nio.ch.DirectBuffer;
- public class DirectByteBufferCleaner {
- public static void clean(final ByteBuffer byteBuffer) {
- if (byteBuffer.isDirect()) {
- ((DirectBuffer)byteBuffer).cleaner().clean();
- }
- }
- }
import java.nio.ByteBuffer;
import sun.nio.ch.DirectBuffer;
public class DirectByteBufferCleaner {
public static void clean(final ByteBuffer byteBuffer) {
if (byteBuffer.isDirect()) {
((DirectBuffer)byteBuffer).cleaner().clean();
}
}
}
上述类你可以在任何位置建立都可以,这里多谢一楼的回复,以前我的写法是见到DirectByteBuffer类是Default类型的,因此这个类无法直接引用到,是通过反射去找到cleaner的实例,进而调用内部的clean方法,那样做麻烦了,其实并不需要那么麻烦,因为DirectByteBuffer implements了DirectBuffer,而DirectBuffer本身是public的,所以通过接口去调用内部的Clear对象来做clean方法。
我们下面来做测试来证明这个程序是有效地回收的:
在任意一个地方写一段main方法来调用,我这里就直接写在这个类里面了:
- public static void sleep(long i) {
- try {
- Thread.sleep(i);
- }catch(Exception e) {
- /*skip*/
- }
- }
- public static void main(String []args) throws Exception {
- ByteBuffer buffer = ByteBuffer.allocateDirect(1024 * 1024 * 100);
- System.out.println("start");
- sleep(10000);
- clean(buffer);
- System.out.println("end");
- sleep(10000);
- }
public static void sleep(long i) {
try {
Thread.sleep(i);
}catch(Exception e) {
/*skip*/
}
}
public static void main(String []args) throws Exception {
ByteBuffer buffer = ByteBuffer.allocateDirect(1024 * 1024 * 100);
System.out.println("start");
sleep(10000);
clean(buffer);
System.out.println("end");
sleep(10000);
}
这里分配了100M内存,为了将结果看清楚,在执行前,执行后分别看看延迟10s,当然你可以根据你的要求自己改改。请提前将OS的资源管理器打开,看看当前使用的内存是多少,如果你是linux当然是看看free或者用top等命令来看;本地程序我是用windows完成,在运行前机器的内存如下图所示:
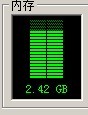
开始运行在输入start后,但是未输出end前,内存直接上升将近100m。
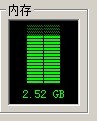
在输入end后发现内存立即降低到2.47m,说明回收是有效的。
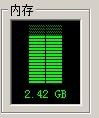
此时可以观察JVM堆的内存,不会有太多的变化,注意:JVM本身启动后也有一些内存开销,所以不要将那个开销和这个绑定在一起;这里之所以一次性申请100m也是为了看清楚过程,其余的可以做实验玩玩了。



相关推荐
与HeapByteBuffer不同,DirectByteBuffer的读写速度通常更快,因为它避免了Java对象之间的复制。 4. **性能优化**:在处理大量数据或高并发的网络传输时,使用DirectByteBuffer可以减少不必要的内存拷贝和提高效率...
### NIO Trick and Trap:构建高性能Java NIO网络框架 #### 概述 NIO(New I/O),作为Java平台的一项重要技术革新,为开发者提供了更高效的数据处理方式。相较于传统的IO模型,NIO通过非阻塞式I/O操作、多路复用...
- **类型**:主要分为两种类型:`DirectByteBuffer` 和 `HeapByteBuffer`。 - **HeapByteBuffer**:在JVM堆上分配空间,使用简单但效率较低。 - **DirectByteBuffer**:直接在本机内存中分配空间,避免了JVM堆和...
基于Maxwell设计的经典280W 4025RPM高效率科尔摩根12极39槽TBM无框力矩电机:生产与学习双重应用案例,基于Maxwell设计的经典280W高转速科尔摩根TBM无框力矩电机:7615系列案例解析与应用实践,基于maxwwell设计的经典280W,4025RPM 内转子 科尔摩根 12极39槽 TBM无框力矩电机,7615系列。 该案例可用于生产,或者学习用,(157) ,maxwell设计; 280W; 4025RPM内转子; 科尔摩根; 12极39槽TBM无框力矩电机; 7615系列; 生产/学习用。,基于Maxwell设计,高功率280W 12极39槽TBM无框力矩电机:生产与学习双用途案例
基于碳交易的微网优化模型的Matlab设计与实现策略分析,基于碳交易的微网优化模型的Matlab设计与实现探讨,考虑碳交易的微网优化模型matlab ,考虑碳交易; 微网优化模型; MATLAB;,基于Matlab的碳交易微网优化模型研究
二级2025模拟试题(答案版)
OpenCV是一个功能强大的计算机视觉库,它提供了多种工具和算法来处理图像和视频数据。在C++中,OpenCV可以用于实现基础的人脸识别功能,包括从摄像头、图片和视频中识别人脸,以及通过PCA(主成分分析)提取图像轮廓。以下是对本资源大体的介绍: 1. 从摄像头中识别人脸:通过使用OpenCV的Haar特征分类器,我们可以实时从摄像头捕获的视频流中检测人脸。这个过程涉及到将视频帧转换为灰度图像,然后使用预训练的Haar级联分类器来识别人脸区域。 2. 从视频中识别出所有人脸和人眼:在视频流中,除了检测人脸,我们还可以进一步识别人眼。这通常涉及到使用额外的Haar级联分类器来定位人眼区域,从而实现对人脸特征的更细致分析。 3. 从图片中检测出人脸:对于静态图片,OpenCV同样能够检测人脸。通过加载图片,转换为灰度图,然后应用Haar级联分类器,我们可以在图片中标记出人脸的位置。 4. PCA提取图像轮廓:PCA是一种统计方法,用于分析和解释数据中的模式。在图像处理中,PCA可以用来提取图像的主要轮廓特征,这对于人脸识别技术中的面部特征提取尤
麻雀搜索算法(SSA)自适应t分布改进版:卓越性能与优化代码注释,适合深度学习。,自适应t分布改进麻雀搜索算法(TSSA)——卓越的学习样本,优化效果出众,麻雀搜索算法(SSA)改进——采用自适应t分布改进麻雀位置(TSSA),优化后明显要优于基础SSA(代码基本每一步都有注释,代码质量极高,非常适合学习) ,TSSA(自适应t分布麻雀位置算法);注释详尽;高质量代码;适合学习;算法改进结果优异;TSSA相比基础SSA。,自适应T分布优化麻雀搜索算法:代码详解与学习首选(TSSA改进版)
锂电池主动均衡Simulink仿真研究:多种均衡策略与电路架构的深度探讨,锂电池主动均衡与多种均衡策略的Simulink仿真研究:buckboost拓扑及多层次电路分析,锂电池主动均衡simulink仿真 四节电池 基于buckboost(升降压)拓扑 (还有传统电感均衡+开关电容均衡+双向反激均衡+双层准谐振均衡+环形均衡器+cuk+耦合电感)被动均衡电阻式均衡 、分层架构式均衡以及分层式电路均衡,多层次电路,充放电。 ,核心关键词: 锂电池; 主动均衡; Simulink仿真; 四节电池; BuckBoost拓扑; 传统电感均衡; 开关电容均衡; 双向反激均衡; 双层准谐振均衡; 环形均衡器; CUK均衡; 耦合电感均衡; 被动均衡; 电阻式均衡; 分层架构式均衡; 多层次电路; 充放电。,锂电池均衡策略研究:Simulink仿真下的多拓扑主动与被动均衡技术
S7-1500和分布式外围系统ET200MP模块数据
内置式永磁同步电机无位置传感器模型:基于滑膜观测器和MTPA技术的深度探究,内置式永磁同步电机基于滑膜观测器和MTPA的无位置传感器模型研究,基于滑膜观测器和MTPA的内置式永磁同步电机无位置传感器模型 ,基于滑膜观测器;MTPA;内置式永磁同步电机;无位置传感器模型,基于滑膜观测与MTPA算法的永磁同步电机无位置传感器模型
centos7操作系统下安装docker,及docker常用命令、在docker中运行nginx示例,包括 1.设置yum的仓库 2.安装 Docker Engine-Community 3.docker使用 4.查看docker进程是否启动成功 5.docker常用命令及nginx示例 6.常见问题
给曙光服务器安装windows2012r2时候找不到磁盘,问厂家工程师要的raid卡驱动,内含主流大多数品牌raid卡驱动
数学建模相关主题资源2
西门子四轴卧式加工中心后处理系统:828D至840D支持,四轴联动制造解决方案,图档处理与试看程序一应俱全。,西门子四轴卧加后处理系统:支持828D至840D系统,四轴联动高精度制造解决方案,西门子四轴卧加后处理,支持828D~840D系统,支持四轴联动,可制制,看清楚联系,可提供图档处理试看程序 ,核心关键词:西门子四轴卧加后处理; 828D~840D系统支持; 四轴联动; 制程; 联系; 图档处理试看程序。,西门子四轴卧加后处理程序,支持多种系统与四轴联动
MATLAB下基于列约束生成法CCG的两阶段鲁棒优化问题求解入门指南:算法验证与经典文献参考,MATLAB下基于列约束生成法CCG的两阶段鲁棒优化问题求解入门指南:算法验证与文献参考,MATLAB代码:基于列约束生成法CCG的两阶段问题求解 关键词:两阶段鲁棒 列约束生成法 CCG算法 参考文档:《Solving two-stage robust optimization problems using a column-and-constraint generation method》 仿真平台:MATLAB YALMIP+CPLEX 主要内容:代码构建了两阶段鲁棒优化模型,并用文档中的相对简单的算例,进行CCG算法的验证,此篇文献是CCG算法或者列约束生成算法的入门级文献,其经典程度不言而喻,几乎每个搞CCG的两阶段鲁棒的人都绕不过此篇文献 ,两阶段鲁棒;列约束生成法;CCG算法;MATLAB;YALMIP+CPLEX;入门级文献。,MATLAB代码实现:基于两阶段鲁棒与列约束生成法CCG的算法验证研究
“生热研究的全面解读:探究参数已配置的Comsol模型中的18650圆柱锂电池表现”,探究已配置参数的COMSOL模型下的锂电池生热现象:18650圆柱锂电池模拟分析,出一个18650圆柱锂电池comsol模型 参数已配置,生热研究 ,出模型; 18650圆柱锂电池; comsol模型; 参数配置; 生热研究,构建18650电池的COMSOL热研究模型
移动端多端运行的知识付费管理系统源码,TP6+Layui+MySQL后端支持,功能丰富,涵盖直播、点播、管理全功能及礼物互动,基于UniApp跨平台开发的移动端知识付费管理系统源码:多端互通、全功能齐备、后端采用TP6与PHP及Layui前端,搭载MySQL数据库与直播、点播、管理、礼物等功能的强大整合。,知识付费管理系统源码,移动端uniApp开发,app h5 小程序一套代码多端运行,后端php(tp6)+layui+MySQL,功能齐全,直播,点播,管理,礼物等等功能应有尽有 ,知识付费;管理系统源码;移动端uniApp开发;多端运行;后端php(tp6);layui;MySQL;直播点播;管理功能;礼物功能,知识付费管理平台:全功能多端运行系统源码(PHP+Layui+MySQL)
基于Python+Django+MySQL的个性化图书推荐系统:协同过滤推荐,智能部署,用户定制功能,基于Python+Django+MySQL的个性化图书推荐系统:协同过滤推荐,智能部署,用户定制功能,Python+Django+Mysql个性化图书推荐系统 图书在线推荐系统 基于用户、项目、内容的协同过滤推荐算法。 帮远程安装部署 一、项目简介 1、开发工具和实现技术 Python3.8,Django4,mysql8,navicat数据库管理工具,html页面,javascript脚本,jquery脚本,bootstrap前端框架,layer弹窗组件、webuploader文件上传组件等。 2、项目功能 前台用户包含:注册、登录、注销、浏览图书、搜索图书、信息修改、密码修改、兴趣喜好标签、图书评分、图书收藏、图书评论、热点推荐、个性化推荐图书等功能; 后台管理员包含:用户管理、图书管理、图书类型管理、评分管理、收藏管理、评论管理、兴趣喜好标签管理、权限管理等。 个性化推荐功能: 无论是否登录,在前台首页展示热点推荐(根据图书被收藏数量降序推荐)。 登录用户,在前台首页展示个性化推荐
STM32企业级锅炉控制器源码分享:真实项目经验,带注释完整源码助你快速掌握实战经验,STM32企业级锅炉控制器源码:真实项目经验,完整注释,助力初学者快速上手,stm32真实企业项目源码 项目要求与网上搜的那些开发板的例程完全不在一个级别,也不是那些凑合性质的项目可以比拟的。 项目是企业级产品的要求开发的,能够让初学者了解真实的企业项目是怎么样的,增加工作经验 企业真实项目网上稀缺,完整源码带注释,适合没有参与工作或者刚学stm32的增加工作经验, 这是一个锅炉的控制器,有流程图和程序协议的介绍。 ,stm32源码;企业级项目;工作经验;锅炉控制器;流程图;程序协议,基于STM32的真实企业级锅炉控制器项目源码