环视(Lookaround)
http://blog.csdn.net/lxcnn/article/details/4304754
1
环视基础
环视只进行子表达式的匹配,不占有字符,匹配到的内容不保存到最终的匹配结果,是零宽度的。环视匹配的最终结果就是一个位置。
环视的作用相当于对所在位置加了一个附加条件,只有满足这个条件,环视子表达式才能匹配成功。
环视按照方向划分有顺序和逆序两种,按照是否匹配有肯定和否定两种,组合起来就有四种环视。顺序环视相当于在当前位置右侧附加一个条件,而逆序环视相当于在当前位置左侧附加一个条件。
|
表达式
|
说明
|
|
(?<=Expression)
|
逆序肯定环视,表示所在位置左侧能够匹配Expression
|
|
(?<!Expression)
|
逆序否定环视,表示所在位置左侧不能匹配Expression
|
|
(?=Expression)
|
顺序肯定环视,表示所在位置右侧能够匹配Expression
|
|
(?!Expression)
|
顺序否定环视,表示所在位置右侧不能匹配Expression
|
对于环视的叫法,有的文档里叫预搜索,有的叫什么什么断言的,这里使用了更多人容易接受的《精通正则表达式》中“环视”的叫法,其实叫什么无所谓,只要知道是什么作用就是了,就这么几个语法规则,还是很容易记的
2
环视匹配原理
环视是正则中的一个难点,对于环视的理解,可以从应用和原理两个角度理解,如果想理解得更清晰、深入一些,还是从原理的角度理解好一些,正则匹配基本原理参考
NFA引擎匹配原理。
上面提到环视相当于对“所在位置”附加了一个条件,环视的难点在于找到这个“位置”,这一点解决了,环视也就没什么秘密可言了。
顺序环视匹配过程
对于顺序肯定环视(?=Expression)来说,当子表达式Expression匹配成功时,(?=Expression)匹配成功,并报告(?=Expression)匹配当前位置成功。
对于顺序否定环视(?!Expression)来说,当子表达式Expression匹配成功时,(?!Expression)匹配失败;当子表达式Expression匹配失败时,(?!Expression)匹配成功,并报告(?!Expression)匹配当前位置成功;
顺序肯定环视的例子已在NFA引擎匹配原理中讲解过了,这里再讲解一下顺序否定环视。
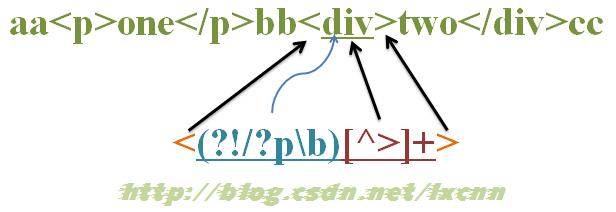
源字符串:aa<p>one</p>bb<div>two</div>cc
正则表达式:<(?!/?p\b)[^>]+>
这个正则的意义就是匹配除<p…>或</p>之外的其余标签。
匹配过程:

首先由字符“<”取得控制权,从位置0开始匹配,由于“<”匹配“a”失败,在位置0处整个表达式匹配失败,第一次迭代匹配失败,正则引擎向前传动,由位置1处开始尝试第二次迭代匹配。
重复以上过程,直到位置2,“<”匹配“<”成功,控制权交给“(?!/?p\b)”;“(?!/?p\b)”子表达式取得控制权后,进行内部子表达式的匹配。首先由“/?”取得控制权,尝试匹配“p”失败,进行回溯,不匹配,控制权交给“p”;由“p”来尝试匹配“p”,匹配成功,控制权交给“\b”;由“\b”来尝试匹配位置4,匹配成功。此时子表达式匹配完成,“/?p\b”匹配成功,那么环视表达式“(?!/?p\b)”就匹配失败。在位置2处整个表达式匹配失败,新一轮迭代匹配失败,正则引擎向前传动,由位置3处开始尝试下一轮迭代匹配。
在位置8处也会遇到一轮“/?p\b”匹配“/p”成功,而导致环视表达式“(?!/?p\b)”匹配失败,从而导致整个表达式匹配失败的过程。
重复以上过程,直到位置14,“<”匹配“<”成功,控制权交给“(?!/?p\b)”;“/?”尝试匹配“d”失败,进行回溯,不匹配,控制权交给“p”;由“p”来尝试匹配“d”,匹配失败,已经没有备选状态可供回溯,匹配失败。此时子表达式匹配完成,“/?p\b”匹配失败,那么环视表达式“(?!/?p\b)”就匹配成功。匹配的结果是位置15,然后控制权交给“[^>]+”;由“[^>]+”从位置15进行尝试匹配,可以成功匹配到“div”,控制权交给“>”;由“>”来匹配“>”。
此时正则表达式匹配完成,报告匹配成功。匹配结果为“<div>”,开始位置为14,结束位置为19。其中“<”匹配“<”,“(?!/?p\b)”匹配位置15,“[^>]+”匹配字符串“div”,“>”匹配“>”。
逆序环视基础
对于逆序肯定环视(?<=Expression)来说,当子表达式Expression匹配成功时,(?<=Expression)匹配成功,并报告(?<=Expression)匹配当前位置成功。
对于逆序否定环视(?<!Expression)来说,当子表达式Expression匹配成功时,(?<!Expression)匹配失败;当子表达式Expression匹配失败时,(?<!Expression)匹配成功,并报告(?<!Expression)匹配当前位置成功;
顺序环视相当于在当前位置右侧附加一个条件,所以它的匹配尝试是从当前位置开始的,然后向右尝试匹配,直到某一位置使得匹配成功或失败为止。而逆序环视的特殊处在于,它相当于在当前位置左侧附加一个条件,所以它不是在当前位置开始尝试匹配的,而是从当前位置左侧某一位置开始,匹配到当前位置为止,报告匹配成功或失败。
顺序环视尝试匹配的起点是确定的,就是当前位置,而匹配的终点是不确定的。逆序环视匹配的起点是不确定的,是当前位置左侧某一位置,而匹配的终点是确定的,就是当前位置。
所以顺序环视相对是简单的,而逆序环视相对是复杂的。这也就是为什么大多数语言和工具都提供了对顺序环视的支持,而只有少数语言提供了对逆序环视支持的原因。
JavaScript中只支持顺序环视,不支持逆序环视。
Java中虽然顺序环视和逆序环视都支持,但是逆序环视只支持长度确定的表达式,逆序环视中量词只支持“?”,不支持其它长度不定的量词。长度确定时,引擎可以向左查找固定长度的位置作为起点开始尝试匹配,而如果长度不确定时,就要从当前位置向左逐个位置开始尝试匹配,不成功则回溯,再向左侧位置进行尝试匹配,然后重复以上过程,直到匹配成功,或是尝试到位置0处以后,报告匹配失败,处理的复杂度是显而易见的。
目前只有.NET中支持不确定长度的逆序环视。
逆序环视匹配过程

源字符串:<div>a test</div>
正则表达式:(?<=<div>)[^<]+(?=</div>)
这个正则的意义就是匹配<div>和</div>标签之间的内容,而不包括<div>和</div>标签本身。
匹配过程:
首先由“(?<=<div>)”取得控制权,从位置0开始匹配,由于位置0是起始位置,左侧没有任何内容,所以“<div>”必然匹配失败,从而环视表达式“(?<=<div>)”匹配失败,导致整个表达式在位置0处匹配失败。第一轮迭代匹配失败,正则引擎向前传动,由位置1处开始尝试第二次迭代匹配。
直到传动到位置5,“(?<=<div>)”取得控制权,向左查找5个位置,由位置0开始匹配,由“<div>”匹配“<div>”成功,从而“(?<=<div>)”匹配成功,匹配的结果为位置5,控制权交给“[^<]+”;“[^<]+”从位置5开始尝试匹配,匹配“a
test”成功,控制权交给“(?=</div>)”;由“</div>”匹配“</div>”成功,从而“(?=</div>)”匹配成功,匹配结果为位置11。
此时正则表达式匹配完成,报告匹配成功。匹配结果为“a
test”,开始位置为5,结束位置为11。其中“(?<=<div>)”匹配位置5,“[^<]+”匹配“a
test”,“(?=</div>)”匹配位置11。
逆序否定环视的匹配过程与上述过程类似,区别只是当Expression匹配失败时,逆序否定表达式(?<!Expression)才匹配成功。
到此环视的匹配原理已基本讲解完,环视也就没有什么秘密可言了,所需要的,也只是多加练习而已。
3
环视应用
今天写累了,暂时就给出一个环视的综合应用实例吧,至于环视的应用场景和技巧,后面再整理。
需求:数字格式化成用“,”的货币格式。
正则表达式:(?n)(?<=\d)(?<!\.\d*)(?=(\d{3})+(\.|$))
测试代码:
double[] data = new double[] { 0, 12, 123, 1234, 12345, 123456, 1234567, 123456789, 1234567890, 12.345, 123.456, 1234.56, 12345.6789, 123456.789, 1234567.89, 12345678.9 };
foreach (double d in data)
{
richTextBox2.Text += "源字符串:" + d.ToString().PadRight(15) + "格式化:"
+ Regex.Replace(d.ToString(), @"(?n)(?<=\d)(?<!\.\d*)(?=(\d{3})+(\.|$))", ",") + "\n";
}
输出结果:
源字符串:0
格式化:0
源字符串:12
格式化:12
源字符串:123
格式化:123
源字符串:1234
格式化:1,234
源字符串:12345
格式化:12,345
源字符串:123456
格式化:123,456
源字符串:1234567
格式化:1,234,567
源字符串:123456789
格式化:123,456,789
源字符串:1234567890
格式化:1,234,567,890
源字符串:12.345
格式化:12.345
源字符串:123.456
格式化:123.456
源字符串:1234.56
格式化:1,234.56
源字符串:12345.6789
格式化:12,345.6789
源字符串:123456.789
格式化:123,456.789
源字符串:1234567.89
格式化:1,234,567.89
源字符串:12345678.9
格式化:12,345,678.9
实现分析:
首先根据需求可以确定是把一些特定的位置替换为“,”,接下来就是分析并找到这些位置的规律,并抽象出来以正则表达式来表示。
1、
这个位置的左侧必须为数字
2、
这个位置右侧到出现“.”或结尾为止,必须是数字,且数字的个数必须为3的倍数
3、
这个位置左侧相隔任意个数字不能出现“.”
由以上三条,就可以完全确定这些位置,只要实现以上三条,组合一下正则表达式就可以了。
根据分析,最终匹配的结果是一个位置,所以所有子表达式都要求是零宽度。
1、
是对当前所在位置左侧附加的条件,所以要用到逆序环视,因为要求必须出现,所以是肯定的,符合这一条件的子表达式即为“(?<=\d)”
2、
是对当前所在位置右侧附加的条件,所以要用到顺序环视,也是要求出现,所以是肯定的,是数字,且个数为3的倍数,即“(?=(\d{3})+)”,到出现“.”或结尾为止,即“(?=(\d{3})+(\.|$))”
3、
是对当前所在位置左侧附加的条件,所以要用到逆序环视,因为要求不能出现,所以是否定的,即“(?<!\.\d*)”
因为零宽度的子表达式是非互斥的,最后匹配的都是同一个位置,所以先后顺序是不影响最后的匹配结果的,可以任意组合,只是习惯上把逆序环视写在左侧,顺序环视写在右侧。
说明:这里只是为了说明环视的使用而举的一个例子,实际上这个需求直接用string.Format就可以做到
环视(Lookaround)
http://blog.csdn.net/lxcnn/article/details/4304754
1
环视基础
环视只进行子表达式的匹配,不占有字符,匹配到的内容不保存到最终的匹配结果,是零宽度的。环视匹配的最终结果就是一个位置。
环视的作用相当于对所在位置加了一个附加条件,只有满足这个条件,环视子表达式才能匹配成功。
环视按照方向划分有顺序和逆序两种,按照是否匹配有肯定和否定两种,组合起来就有四种环视。顺序环视相当于在当前位置右侧附加一个条件,而逆序环视相当于在当前位置左侧附加一个条件。
|
表达式
|
说明
|
|
(?<=Expression)
|
逆序肯定环视,表示所在位置左侧能够匹配Expression
|
|
(?<!Expression)
|
逆序否定环视,表示所在位置左侧不能匹配Expression
|
|
(?=Expression)
|
顺序肯定环视,表示所在位置右侧能够匹配Expression
|
|
(?!Expression)
|
顺序否定环视,表示所在位置右侧不能匹配Expression
|
对于环视的叫法,有的文档里叫预搜索,有的叫什么什么断言的,这里使用了更多人容易接受的《精通正则表达式》中“环视”的叫法,其实叫什么无所谓,只要知道是什么作用就是了,就这么几个语法规则,还是很容易记的
2
环视匹配原理
环视是正则中的一个难点,对于环视的理解,可以从应用和原理两个角度理解,如果想理解得更清晰、深入一些,还是从原理的角度理解好一些,正则匹配基本原理参考
NFA引擎匹配原理。
上面提到环视相当于对“所在位置”附加了一个条件,环视的难点在于找到这个“位置”,这一点解决了,环视也就没什么秘密可言了。
顺序环视匹配过程
对于顺序肯定环视(?=Expression)来说,当子表达式Expression匹配成功时,(?=Expression)匹配成功,并报告(?=Expression)匹配当前位置成功。
对于顺序否定环视(?!Expression)来说,当子表达式Expression匹配成功时,(?!Expression)匹配失败;当子表达式Expression匹配失败时,(?!Expression)匹配成功,并报告(?!Expression)匹配当前位置成功;
顺序肯定环视的例子已在NFA引擎匹配原理中讲解过了,这里再讲解一下顺序否定环视。
源字符串:aa<p>one</p>bb<div>two</div>cc
正则表达式:<(?!/?p\b)[^>]+>
这个正则的意义就是匹配除<p…>或</p>之外的其余标签。
匹配过程:
首先由字符“<”取得控制权,从位置0开始匹配,由于“<”匹配“a”失败,在位置0处整个表达式匹配失败,第一次迭代匹配失败,正则引擎向前传动,由位置1处开始尝试第二次迭代匹配。
重复以上过程,直到位置2,“<”匹配“<”成功,控制权交给“(?!/?p\b)”;“(?!/?p\b)”子表达式取得控制权后,进行内部子表达式的匹配。首先由“/?”取得控制权,尝试匹配“p”失败,进行回溯,不匹配,控制权交给“p”;由“p”来尝试匹配“p”,匹配成功,控制权交给“\b”;由“\b”来尝试匹配位置4,匹配成功。此时子表达式匹配完成,“/?p\b”匹配成功,那么环视表达式“(?!/?p\b)”就匹配失败。在位置2处整个表达式匹配失败,新一轮迭代匹配失败,正则引擎向前传动,由位置3处开始尝试下一轮迭代匹配。
在位置8处也会遇到一轮“/?p\b”匹配“/p”成功,而导致环视表达式“(?!/?p\b)”匹配失败,从而导致整个表达式匹配失败的过程。
重复以上过程,直到位置14,“<”匹配“<”成功,控制权交给“(?!/?p\b)”;“/?”尝试匹配“d”失败,进行回溯,不匹配,控制权交给“p”;由“p”来尝试匹配“d”,匹配失败,已经没有备选状态可供回溯,匹配失败。此时子表达式匹配完成,“/?p\b”匹配失败,那么环视表达式“(?!/?p\b)”就匹配成功。匹配的结果是位置15,然后控制权交给“[^>]+”;由“[^>]+”从位置15进行尝试匹配,可以成功匹配到“div”,控制权交给“>”;由“>”来匹配“>”。
此时正则表达式匹配完成,报告匹配成功。匹配结果为“<div>”,开始位置为14,结束位置为19。其中“<”匹配“<”,“(?!/?p\b)”匹配位置15,“[^>]+”匹配字符串“div”,“>”匹配“>”。
逆序环视基础
对于逆序肯定环视(?<=Expression)来说,当子表达式Expression匹配成功时,(?<=Expression)匹配成功,并报告(?<=Expression)匹配当前位置成功。
对于逆序否定环视(?<!Expression)来说,当子表达式Expression匹配成功时,(?<!Expression)匹配失败;当子表达式Expression匹配失败时,(?<!Expression)匹配成功,并报告(?<!Expression)匹配当前位置成功;
顺序环视相当于在当前位置右侧附加一个条件,所以它的匹配尝试是从当前位置开始的,然后向右尝试匹配,直到某一位置使得匹配成功或失败为止。而逆序环视的特殊处在于,它相当于在当前位置左侧附加一个条件,所以它不是在当前位置开始尝试匹配的,而是从当前位置左侧某一位置开始,匹配到当前位置为止,报告匹配成功或失败。
顺序环视尝试匹配的起点是确定的,就是当前位置,而匹配的终点是不确定的。逆序环视匹配的起点是不确定的,是当前位置左侧某一位置,而匹配的终点是确定的,就是当前位置。
所以顺序环视相对是简单的,而逆序环视相对是复杂的。这也就是为什么大多数语言和工具都提供了对顺序环视的支持,而只有少数语言提供了对逆序环视支持的原因。
JavaScript中只支持顺序环视,不支持逆序环视。
Java中虽然顺序环视和逆序环视都支持,但是逆序环视只支持长度确定的表达式,逆序环视中量词只支持“?”,不支持其它长度不定的量词。长度确定时,引擎可以向左查找固定长度的位置作为起点开始尝试匹配,而如果长度不确定时,就要从当前位置向左逐个位置开始尝试匹配,不成功则回溯,再向左侧位置进行尝试匹配,然后重复以上过程,直到匹配成功,或是尝试到位置0处以后,报告匹配失败,处理的复杂度是显而易见的。
目前只有.NET中支持不确定长度的逆序环视。
逆序环视匹配过程
源字符串:<div>a test</div>
正则表达式:(?<=<div>)[^<]+(?=</div>)
这个正则的意义就是匹配<div>和</div>标签之间的内容,而不包括<div>和</div>标签本身。
匹配过程:
首先由“(?<=<div>)”取得控制权,从位置0开始匹配,由于位置0是起始位置,左侧没有任何内容,所以“<div>”必然匹配失败,从而环视表达式“(?<=<div>)”匹配失败,导致整个表达式在位置0处匹配失败。第一轮迭代匹配失败,正则引擎向前传动,由位置1处开始尝试第二次迭代匹配。
直到传动到位置5,“(?<=<div>)”取得控制权,向左查找5个位置,由位置0开始匹配,由“<div>”匹配“<div>”成功,从而“(?<=<div>)”匹配成功,匹配的结果为位置5,控制权交给“[^<]+”;“[^<]+”从位置5开始尝试匹配,匹配“a
test”成功,控制权交给“(?=</div>)”;由“</div>”匹配“</div>”成功,从而“(?=</div>)”匹配成功,匹配结果为位置11。
此时正则表达式匹配完成,报告匹配成功。匹配结果为“a
test”,开始位置为5,结束位置为11。其中“(?<=<div>)”匹配位置5,“[^<]+”匹配“a
test”,“(?=</div>)”匹配位置11。
逆序否定环视的匹配过程与上述过程类似,区别只是当Expression匹配失败时,逆序否定表达式(?<!Expression)才匹配成功。
到此环视的匹配原理已基本讲解完,环视也就没有什么秘密可言了,所需要的,也只是多加练习而已。
3
环视应用
今天写累了,暂时就给出一个环视的综合应用实例吧,至于环视的应用场景和技巧,后面再整理。
需求:数字格式化成用“,”的货币格式。
正则表达式:(?n)(?<=\d)(?<!\.\d*)(?=(\d{3})+(\.|$))
测试代码:
double[] data = new double[] { 0, 12, 123, 1234, 12345, 123456, 1234567, 123456789, 1234567890, 12.345, 123.456, 1234.56, 12345.6789, 123456.789, 1234567.89, 12345678.9 };
foreach (double d in data)
{
richTextBox2.Text += "源字符串:" + d.ToString().PadRight(15) + "格式化:"
+ Regex.Replace(d.ToString(), @"(?n)(?<=\d)(?<!\.\d*)(?=(\d{3})+(\.|$))", ",") + "\n";
}
输出结果:
源字符串:0
格式化:0
源字符串:12
格式化:12
源字符串:123
格式化:123
源字符串:1234
格式化:1,234
源字符串:12345
格式化:12,345
源字符串:123456
格式化:123,456
源字符串:1234567
格式化:1,234,567
源字符串:123456789
格式化:123,456,789
源字符串:1234567890
格式化:1,234,567,890
源字符串:12.345
格式化:12.345
源字符串:123.456
格式化:123.456
源字符串:1234.56
格式化:1,234.56
源字符串:12345.6789
格式化:12,345.6789
源字符串:123456.789
格式化:123,456.789
源字符串:1234567.89
格式化:1,234,567.89
源字符串:12345678.9
格式化:12,345,678.9
实现分析:
首先根据需求可以确定是把一些特定的位置替换为“,”,接下来就是分析并找到这些位置的规律,并抽象出来以正则表达式来表示。
1、
这个位置的左侧必须为数字
2、
这个位置右侧到出现“.”或结尾为止,必须是数字,且数字的个数必须为3的倍数
3、
这个位置左侧相隔任意个数字不能出现“.”
由以上三条,就可以完全确定这些位置,只要实现以上三条,组合一下正则表达式就可以了。
根据分析,最终匹配的结果是一个位置,所以所有子表达式都要求是零宽度。
1、
是对当前所在位置左侧附加的条件,所以要用到逆序环视,因为要求必须出现,所以是肯定的,符合这一条件的子表达式即为“(?<=\d)”
2、
是对当前所在位置右侧附加的条件,所以要用到顺序环视,也是要求出现,所以是肯定的,是数字,且个数为3的倍数,即“(?=(\d{3})+)”,到出现“.”或结尾为止,即“(?=(\d{3})+(\.|$))”
3、
是对当前所在位置左侧附加的条件,所以要用到逆序环视,因为要求不能出现,所以是否定的,即“(?<!\.\d*)”
因为零宽度的子表达式是非互斥的,最后匹配的都是同一个位置,所以先后顺序是不影响最后的匹配结果的,可以任意组合,只是习惯上把逆序环视写在左侧,顺序环视写在右侧。
说明:这里只是为了说明环视的使用而举的一个例子,实际上这个需求直接用string.Format就可以做到
分享到:




相关推荐
本文将深入探讨“正则基础之——环视”这一主题,旨在帮助你理解和掌握正则表达式中的环视技术。 环视(Lookaround)是正则表达式中的一个重要概念,它允许我们在不包含在最终匹配结果中的情况下,检查某个位置的...
在“正则应用之——逆序环视探索”这个主题中,我们将深入探讨这两个概念以及它们在实际应用中的价值。 肯定逆序环视(?)用于确保匹配的字符串前有某个模式,但不会包含这个模式在匹配结果内。例如,如果你想要匹配...
正则基础之——NFA引擎匹配原理 在正则表达式中,了解引擎匹配原理是非常重要的。就像音乐家一样,一个人可以演奏出动听的乐曲,但是如果不知道如何去改变音符的组合,乐曲就不会变得更动听。同样,在使用正则...
正则表达式是一种强大的文本处理工具,用于在字符串中进行模式匹配和搜索。...通过阅读《正则匹配原理之——逆序环视深入.pdf》这份文档,你可以更深入地了解这个主题,掌握逆序环视在实际应用中的技巧和策略。
实战正则表达式第2讲可能涵盖了更复杂的正则表达式构造,如环视(lookaround)——前瞻断言(lookahead)和后顾断言(lookbehind),以及更高级的用法,如使用条件语句和非捕获组等。这些高级特性能够使正则表达式...
精通正则表达式第三版 搜集于网络 前言..........I 第1章:正则表达式入门.... 1 解决实际问题... 2 作为编程语言的正则表达式... 4 以文件名做类比... 4 以语言做类比... 5 正则表达式的知识框架... 6 对于...
本文将深入探讨Delphi环境中的一款正则表达式库——DiRegEx 5.20,它专为XE5平台的Win32应用设计,提供了丰富的功能和高效性能。 DiRegEx是Delphi开发者用来实现复杂文本匹配、查找、替换等操作的重要库。其版本...
"regextester.rar" 文件提供了一个正则表达式测试工具——RegExTester,以及一个正则表达式系统教程,对于学习和掌握正则表达式非常有帮助。 RegExTester 是一款便捷的正则表达式测试工具,它允许用户输入自定义的...
Java是世界上最流行的编程语言之一,尤其在企业级应用开发领域占据主导地位。本文将深入探讨两本关于Java的经典书籍——《Java学习笔记》和《Java中正则表达式使用方法详解》,以及它们涵盖的重要知识点。 《Java...
这个名为“pcre-8.20.zip”的压缩包文件,正是PCRE库的一个特定版本——8.20版,它带来了显著的性能提升和错误修复,对于开发者来说,这是一个值得关注的更新。 首先,我们要明确PCRE 8.20版本的一个重大改进:...
14. **正则表达式深入** - 进一步研究正则表达式,学习高级用法,如后向引用、预查、环视等。 15. **文本处理与解析** - 学习如何利用Perl处理和解析各种格式的文本文件,如CSV、XML、HTML等。 16. **脚本自动化**...