
| Time Limit: 8000MS | Memory Limit: 65536K | |
| Total Submissions: 5288 | Accepted: 1431 | |
| Case Time Limit: 2000MS | Special Judge |
Description
Demy has n jewels. Each of her jewels has some value vi and weight wi.
Since her husband John got broke after recent financial crises, Demy has decided to sell some jewels. She has decided that she would keep k best jewels for herself. She decided to keep such jewels that their specific value is as large as possible. That is, denote the specific value of some set of jewels S = {i1, i2, …, ik} as
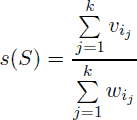 .
.
Demy would like to select such k jewels that their specific value is maximal possible. Help her to do so.
Input
The first line of the input file contains n — the number of jewels Demy got, and k — the number of jewels she would like to keep (1 ≤ k ≤ n ≤ 100 000).
The following n lines contain two integer numbers each — vi and wi (0 ≤ vi ≤ 106, 1 ≤ wi ≤ 106, both the sum of all vi and the sum of all wi do not exceed 107).
Output
Output k numbers — the numbers of jewels Demy must keep. If there are several solutions, output any one.
Sample Input
3 2 1 1 1 2 1 3
Sample Output
1 2
题意:
给出 N , K,代表有 N 颗宝石,要求从中选择 K 颗,使等式 的 S 值达到最大,输出应该选择哪几颗宝石。
思路:
二分搜索。求 v - s * w >= 0 情况下前 K 个的最大值。二分 S 后,对 v - s * w 由大到小排序即可。double 输入是 %lf。
AC:
#include <cstdio>
#include <algorithm>
#include <cstring>
using namespace std;
typedef struct {
double v, w, h;
int num;
}node;
const int INF = 10000005;
node jew[100005];
int n, k;
int cmp(node a, node b) { return a.h > b.h; }
bool C(double s) {
for (int i = 0 ; i < n; ++i)
jew[i].h = jew[i].v - s * jew[i].w;
sort(jew, jew + n, cmp);
double sum = 0;
for (int i = 0; i < k; ++i)
sum += jew[i].h;
return sum >= 0;
}
void solve() {
double l = 0, r = INF;
for (int i = 0; i < 50; ++i) {
double mid = (l + r) / 2;
if (C(mid)) l = mid;
else r = mid;
}
for (int i = 0 ; i < k; ++i) {
printf("%d", jew[i].num);
i == k - 1 ? printf("\n") : printf(" ");
}
}
int main () {
scanf("%d%d", &n, &k);
for (int i = 0; i < n; ++i) {
scanf("%lf%lf", &jew[i].v, &jew[i].w);
jew[i].num = i + 1;
}
solve();
return 0;
}



相关推荐
- **Charniak和Johnson(ACL2005)**的研究:采用了多遍扫描(coarse-to-fine k-best)的技术,先进行粗粒度搜索以找到大致正确的候选结果,然后再逐步细化。这种方法显著提升了F值得分,从89.7%提高到了91.0%。 - **...
一、二分搜索 二分搜索是信息学奥赛中最基本、最重要的搜索算法之一。其基本思想是将搜索空间分为两个部分,然后不断地缩小搜索范围,直到找到目标元素。二分搜索的时间复杂度为 O(logn),因此它非常适合解决大规模...
kd树是一种适用于多维空间的二叉树,其构建过程类似于二分搜索树,但每次分割是在当前维度上进行的。kd树的构建过程包括以下步骤:首先选择一个分割维度,然后根据该维度上的值将数据集一分为二,接着对每个子集递归...
此外,还可以讨论其他可能的解决方案,比如二分搜索或贪心策略,并分析它们的优劣。 总结: 本题主要考察了动态规划、问题建模和优化策略的能力。通过解题,可以提升对算法的理解,增强解决实际问题的技巧,对...
常见的交叉策略是binomial crossover(二进制交叉)或best/1 crossover。例如,对于best/1 crossover,新个体的部分或全部参数可能被种群中当前最优个体的相应参数替换。 4. **选择**:最后,选择操作决定哪个个体...
二分查找 深度优先搜索 广度优先搜索 递归 json 漂亮的打印 过滤中文文件 位操作 获得最大 1 号 获取最大序列号 1 号 交换整数值 大数据 获得前 k DP 斐波那契 最长公共子序列 堆 堆栈结构 中缀表达式到后缀表达式 ...
二分查找 深度优先搜索 广度优先搜索 递归 json 漂亮的打印 过滤中文文件 位操作 获得最大 1 号 获取最大序列号 1 号 交换整数值 大数据 获得前 k DP 斐波那契 最长公共子序列 堆 堆栈结构 中缀表达式到后缀表达式 ...
例如,在二维空间中,K=2(x轴和y轴);在三维空间中,K=3(x轴、y轴和z轴)。 2. **节点与分裂**:KD-Tree由根节点开始,每个内部节点代表一个超平面,将当前空间分为两个子空间。每个节点包含一个分割维度和一个...
在MATLAB中,可以采用binomial crossover(二进制交叉)或best/1 crossover策略,根据随机数决定保留原始个体还是变异个体的对应元素。 5. **选择操作**:选择操作决定了种群的进化方向,通常采用适应度值作为选择...
K-Best解码器是一种有效的候选路径选择算法,它能够在搜索树中选择出最佳的K条路径。这种方法相比于传统的最大似然解码(MLD),显著降低了计算复杂度。 - **低复杂度优势**:K-Best解码器通过减少搜索树的遍历,...
- 单峰向量问题,通过分治或二分查找策略可以在O(logn)时间内找到分界点k。 - 最大和区间问题,需要设计O(n)或O(n^2)的算法求解连续子序列的最大和。 二、计算机原理 1. CPU与程序执行: - 提高CPU主频可以加快...
leetcode题库 keep-hungry-stay-foolish ...常见题型:二分、kmp、lcs、topK、排序、搜索 daily-bugs 记录日常开发中遇到的bug以及对应的解决方案。 knowledge-graph 记录常用的思维逻辑图和脑图。
\[x_i^{j,new} = x_{\text{best}}^j + r_1 \cdot (\overline{x}^j - x_i^j) + r_2 \cdot (x_k^j - x_l^j)\] 其中,\(x_{\text{best}}^j\) 表示组内最优狼的位置;\(\overline{x}^j\) 是所有组内郊狼对应社会因子的...
算法的核心是两个更新规则:个人最好位置(Personal Best, pBest)和全局最好位置(Global Best, gBest)。 二、MATLAB实现粒子群聚类算法 1. 初始化:首先,需要初始化粒子群的大小、粒子的位置和速度。在聚类...
算法通过迭代更新每个粒子的速度和位置,使得粒子趋向于搜索过程中的最优解——全局最佳位置(Global Best,GB)。公式如下: 1. 速度更新:\( v_{id}^{t+1} = w \cdot v_{id}^t + c_1 \cdot r_1 \cdot (pbest_{id}...
3. **基于二元分类的模型**:通过训练一系列二分类器,每个分类器负责判断一个特定标签是否与样本相关,如基于嵌入的算法如ML-KNN(Multi-label K-Nearest Neighbors)和基于树的算法如BR(Binary Relevance)。...
26. **binary** ['baɪnərɪ] search - 二分搜寻法:一种高效的搜索算法,通过不断将搜索区间减半来查找目标值。 27. **binary tree** [triː] - 二元树:每个节点最多有两个子节点的树形数据结构,也称为二叉树。...