
参考:http://blog.csdn.net/shirdrn/article/details/4634119
NameNode节点是就是HDFS的大脑。想了解HDFS文件系统,必须了解大脑结构。 咱们就从NameNode节点开始。NameNode类中,关于HDFS文件系统的存储和管理都交给了FSNamesystem负责。下面介绍一下 FSNamesystem的逻辑组成和类图。
1. FSNameSystem层次结构
一些概念
INode: 它用来存放文件及目录的基本信息:名称,父节点、修改时间,访问时间以及UGI信息等。
INodeFile: 继承自INode,除INode信息外,还有组成这个文件的Blocks列表,重复因子,Block大小
INodeDirectory:继承自INode,此外还有一个INode列表来组成文件或目录树结构
Block(BlockInfo):组成文件的物理存储,有BlockId,size ,以及时间戳
BlocksMap: 保存数据块到INode和DataNode的映射关系
FSDirectory:保存文件树结构,HDFS整个文件系统是通过FSDirectory来管理
FSImage:保存的是文件系统的目录树
FSEditlog: 文件树上的操作日志
FSNamesystem: HDFS文件系统管理
这些概念之间的层次关系:
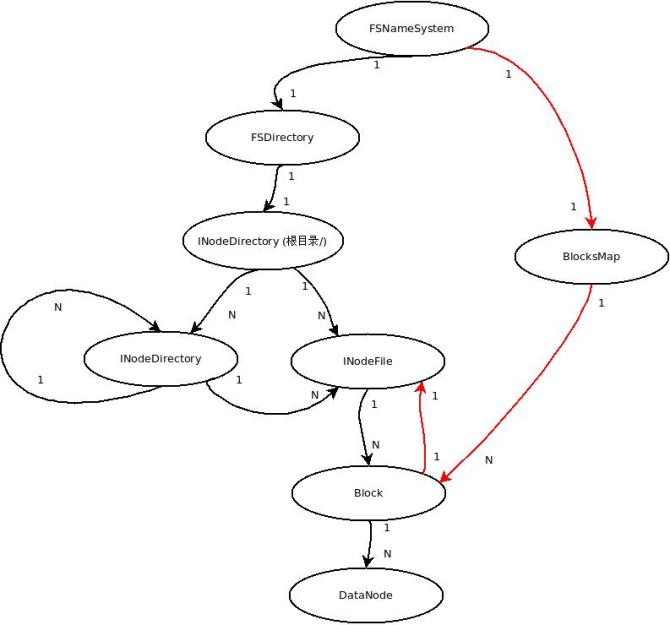
我们都知道,在NameNode内存中存在两张很重要的映射表:
1. 文件系统的命名空间(文件目录树) 主要是 文件和Block映射关系 (保存在FSDirectory)
2. Block 和 INodeFile & DataNode的映射关系 (保存在FSNamesystem)
在上图中,左边黑线部分是1 数据结构的层次关系;红线部分是 2 关系的层次结构
(其中block & DataNode这个共用)
下面详细的介绍上图所表示的关系:
文件系统 FSNamesystem
FSNamesystem 主要有两个对象:文件系统(FSDirectory)根节点rootDir 和BlocksMap映射表 (Block -> { INode, datanodes, self ref } )
文件系统目录FSDirectory
保存文件目录结构(INodeDirectory树),实现FSImage和FSEditLog操作实现。
INode ( INodeFile & INodeDirectory )
在HDFS中,无论目录还是文件,都是INode。INode有两个派生类INodeFile和INodeDirectory。
INodeFile是INode文件类,INodeDirectory是INode目录类。每一 INodeDirectory孩子节点都是由INodeDirectory目录或INodeFile文件列表构成。这样就形成了一棵INode树形结构。
NameNode内存中保存着HDFS整个文件系统形成的树,这棵树保存在FSDirectory对象内。
Block & BlocksMap & BlockInfo
HDFS物理存储单元是Block(缺省的Block大小为64M),每个Block会有几个副本(缺省是3个),这些Block都是存储在不同数据节点上的。映射关系保存在BlocksMap。
Block & INodeFile
每个INodeFile都有一个Block列表组成。每一个block有多个副本(缺省3个副本), 各副本保存在不同的数据节点上。 这样在文件与Block和DataNode之间形成一个映射关系表。这张关系表就保存在FSDirectory对象 .
FSImage & FSEditlog(FSDirectory)
由于目录树(FSDirectory)在NameNode内存中保存,机器也有掉电的时候。若只保存在内存那势必会造成数据的丢失。因此,系统会周期性的保存文件目录树到NameNode本地文件系统,生成FSImage。主要由FSImage和FSEditLog,这两个类负责目录树持久化。
当 HDFS系统非常庞大时,FSImage也会非常大,这样不能文件系统发生任何操作时,就更新到FSImage,所以一段时间内文件系统的操作日志会记录到FSEditLog。到一定时间会把操作日志FSEditLog同步到FSImage,这样就形成完整的文件目录树。
2. FSNameSystem 主要类关系图
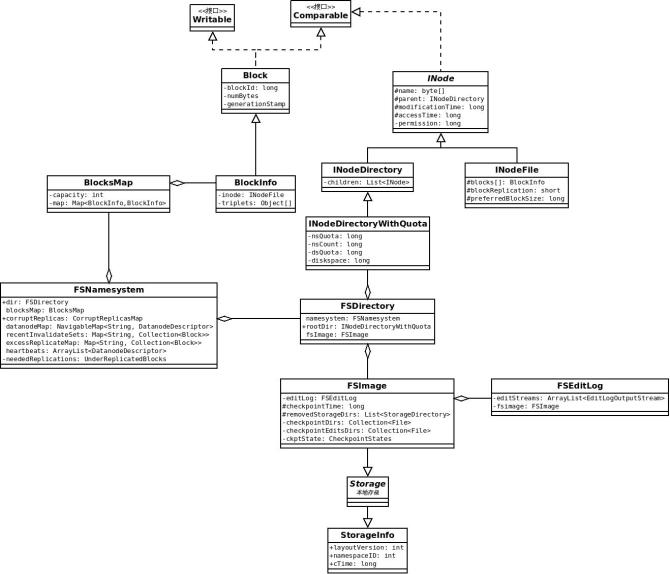
这个类图可以分成三个部分
Bock相关的部分(BlocksMap & BlockInof & Block)
INode相关的部分(INode & INodeDirectory & INodeFile & INodeDirectoryWithQuota)
FSImage & FSEditLog (Storage & StorageInfo)
其中
BlockInfo是Block的加强类,增加了INodeFile的引用和DataNode列表
INodeFirectoryWithQuota 是INodeDirectory的增强类,增加了Quota限制功能
从层次关系图和类图中,可以看出FSNamesystem中各数据结构之间的关系。了解FSNamesystem, 那么HDFS的文件系统就了解了90%。



相关推荐
Delphi 12.3控件之TraeSetup-stable-1.0.12120.exe
基于GPRS,GPS的电动汽车远程监控系统的设计与实现.pdf
内容概要:本文详细介绍了如何利用MATLAB/Simulink 2018a进行单机无穷大系统的暂态稳定性仿真。主要内容包括搭建同步发电机模型、设置无穷大系统等效电源、配置故障模块及其控制信号、优化求解器设置以及绘制和分析转速波形和摇摆曲线。文中还提供了多个实用脚本,如故障类型切换、摇摆曲线计算和极限切除角的求解方法。此外,作者分享了一些实践经验,如避免常见错误和提高仿真效率的小技巧。 适合人群:从事电力系统研究和仿真的工程师和技术人员,尤其是对MATLAB/Simulink有一定基础的用户。 使用场景及目标:适用于需要进行电力系统暂态稳定性分析的研究项目或工程应用。主要目标是帮助用户掌握单机无穷大系统的建模和仿真方法,理解故障对系统稳定性的影响,并能够通过仿真结果评估系统的性能。 其他说明:文中提到的一些具体操作和脚本代码对于初学者来说可能会有一定的难度,建议结合官方文档或其他教程一起学习。同时,部分技巧和经验来自于作者的实际操作,具有一定的实用性。
KUKA机器人相关资料
基于DLR模型的PM10–能见度–湿度相关性 研究.pdf
内容概要:本文详细介绍了如何使用MATLAB/Simulink进行光伏并网系统的最大功率点跟踪(MPPT)仿真,重点讨论了电导增量法的应用。首先阐述了电导增量法的基本原理,接着展示了如何在Simulink中构建光伏电池模型和MPPT控制系统,包括Boost升压电路的设计和PI控制参数的设定。随后,通过仿真分析了不同光照强度和温度条件对光伏系统性能的影响,验证了电导增量法的有效性,并提出了针对特定工况的优化措施。 适合人群:从事光伏系统研究和技术开发的专业人士,尤其是那些希望通过仿真工具深入理解MPPT控制机制的人群。 使用场景及目标:适用于需要评估和优化光伏并网系统性能的研发项目,旨在提高系统在各种环境条件下的最大功率点跟踪效率。 其他说明:文中提供了详细的代码片段和仿真结果图表,帮助读者更好地理解和复现实验过程。此外,还提到了一些常见的仿真陷阱及解决方案,如变步长求解器的问题和PI参数整定技巧。
KUKA机器人相关文档
内容概要:本文详细探讨了双馈风力发电机(DFIG)在Simulink环境下的建模方法及其在不同风速条件下的电流与电压波形特征。首先介绍了DFIG的基本原理,即定子直接接入电网,转子通过双向变流器连接电网的特点。接着阐述了Simulink模型的具体搭建步骤,包括风力机模型、传动系统模型、DFIG本体模型和变流器模型的建立。文中强调了变流器控制算法的重要性,特别是在应对风速变化时,通过实时调整转子侧的电压和电流,确保电流和电压波形的良好特性。此外,文章还讨论了模型中的关键技术和挑战,如转子电流环控制策略、低电压穿越性能、直流母线电压脉动等问题,并提供了具体的解决方案和技术细节。最终,通过对故障工况的仿真测试,验证了所建模型的有效性和优越性。 适用人群:从事风力发电研究的技术人员、高校相关专业师生、对电力电子控制系统感兴趣的工程技术人员。 使用场景及目标:适用于希望深入了解DFIG工作原理、掌握Simulink建模技能的研究人员;旨在帮助读者理解DFIG在不同风速条件下的动态响应机制,为优化风力发电系统的控制策略提供理论依据和技术支持。 其他说明:文章不仅提供了详细的理论解释,还附有大量Matlab/Simulink代码片段,便于读者进行实践操作。同时,针对一些常见问题给出了实用的调试技巧,有助于提高仿真的准确性和可靠性。
linux之用户管理教程.md
内容概要:本文详细介绍了利用三菱PLC(特别是FX系列)和组态王软件构建3x3书架式堆垛式立体库的方法。首先阐述了IO分配的原则,明确了输入输出信号的功能,如仓位检测、堆垛机运动控制等。接着深入解析了梯形图编程的具体实现,包括基本的左右移动控制、复杂的自动寻址逻辑,以及确保安全性的限位保护措施。还展示了接线图和原理图的作用,强调了正确的电气连接方式。最后讲解了组态王的画面设计技巧,通过图形化界面实现对立体库的操作和监控。 适用人群:从事自动化仓储系统设计、安装、调试的技术人员,尤其是熟悉三菱PLC和组态王的工程师。 使用场景及目标:适用于需要提高仓库空间利用率的小型仓储环境,旨在帮助技术人员掌握从硬件选型、电路设计到软件编程的全流程技能,最终实现高效稳定的自动化仓储管理。 其他说明:文中提供了多个实用的编程技巧和注意事项,如避免常见错误、优化性能参数等,有助于减少实际应用中的故障率并提升系统的可靠性。
基于STM32的循迹避障小车 主控:STM32 显示:OLED 电源模块 舵机云台 超声波测距 红外循迹模块(3个,左中右) 蓝牙模块 按键(6个,模式和手动控制小车状态) TB6612驱动的双电机 功能: 该小车共有3种模式: 自动模式:根据红外循迹和超声波测距模块决定小车的状态 手动模式:根据按键的状态来决定小车的状态 蓝牙模式:根据蓝牙指令来决定小车的状态 自动模式: 自动模式下,检测距离低于5cm小车后退 未检测到任何黑线,小车停止 检测到左边或左边+中间黑线,小车左转 检测到右边或右边+中间黑线,小车右转 检测到中边或左边+中间+右边黑线,小车前进 手动模式:根据按键的状态来决定小车的状态 蓝牙模式: //需切换为蓝牙模式才能指令控制 *StatusX X取值为0-4 0:小车停止 1:小车前进 2:小车后退 3:小车左转 4:小车右转
矢量边界,行政区域边界,精确到乡镇街道,可直接导入arcgis使用
内容概要:本文探讨了基于IEEE33节点的主动配电网优化方法,旨在通过合理的调度模型降低配电网的总运行成本。文中详细介绍了模型的构建,包括风光发电、储能装置、柴油发电机和燃气轮机等多种分布式电源的集成。为了实现这一目标,作者提出了具体的约束条件,如储能充放电功率限制和潮流约束,并采用了粒子群算法进行求解。通过一系列实验验证,最终得到了优化的分布式电源运行计划,显著降低了总成本并提高了系统的稳定性。 适合人群:从事电力系统优化、智能电网研究的专业人士和技术爱好者。 使用场景及目标:适用于需要优化配电网运行成本的研究机构和企业。主要目标是在满足各种约束条件下,通过合理的调度策略使配电网更加经济高效地运行。 其他说明:文章不仅提供了详细的理论推导和算法实现,还分享了许多实用的经验技巧,如储能充放电策略、粒子群算法参数选择等。此外,通过具体案例展示了不同电源之间的协同作用及其经济效益。
KUKA机器人相关文档
内容概要:本文详细介绍了将光热电站(CSP)和有机朗肯循环(ORC)集成到综合能源系统中的优化建模方法。主要内容涵盖系统的目标函数设计、关键设备的约束条件(如CSP储热罐、ORC热电耦合)、以及具体实现的技术细节。文中通过MATLAB和YALMIP工具进行建模,采用CPLEX求解器解决混合整数规划问题,确保系统在经济性和环境效益方面的最优表现。此外,文章还讨论了碳排放惩罚机制、风光弃能处理等实际应用场景中的挑战及其解决方案。 适合人群:从事综合能源系统研究的专业人士,尤其是对光热发电、余热利用感兴趣的科研工作者和技术开发者。 使用场景及目标:适用于需要评估和优化包含多种能源形式(如光伏、风电、燃气锅炉等)在内的复杂能源系统的项目。目标是在满足供电供热需求的同时,最小化运行成本并减少碳排放。 其他说明:文中提供了大量具体的MATLAB代码片段作为实例,帮助读者更好地理解和复现所提出的优化模型。对于初学者而言,建议从简单的确定性模型入手,逐渐过渡到更复杂的随机规划和鲁棒优化。
网站设计与管理作业一.ppt
内容概要:本文详细介绍了如何使用MATLAB搭建双闭环Buck电路的仿真模型。首先定义了主电路的关键参数,如输入电压、电感、电容等,并解释了这些参数的选择依据。接着分别对电压外环和电流内环进行了PI控制器的设计,强调了电流环响应速度需要显著高于电压环以确保系统的稳定性。文中还讨论了仿真过程中的一些关键技术细节,如PWM死区时间的设置、低通滤波器的应用以及参数调整的方法。通过对比单闭环和双闭环系统的性能,展示了双闭环方案在应对负载突变时的优势。最后分享了一些调试经验和常见问题的解决方案。 适合人群:从事电力电子、电源设计领域的工程师和技术人员,尤其是有一定MATLAB基础的读者。 使用场景及目标:适用于需要进行电源管理芯片设计验证、电源系统性能评估的研究人员和工程师。主要目标是提高电源系统的稳定性和响应速度,特别是在负载变化剧烈的情况下。 其他说明:文章不仅提供了详细的理论分析,还包括了大量的代码片段和具体的调试步骤,帮助读者更好地理解和应用所学知识。同时提醒读者注意仿真与实际情况之间的差异,鼓励在实践中不断探索和改进。
内容概要:本文详细探讨了MATLAB环境下冷热电气多能互补微能源网的鲁棒优化调度模型。首先介绍了多能耦合元件(如风电、光伏、P2G、燃气轮机等)的运行特性模型,展示了如何通过MATLAB代码模拟这些元件的实际运行情况。接着阐述了电、热、冷、气四者的稳态能流模型及其相互关系,特别是热电联产过程中能流的转换和流动。然后重点讨论了考虑经济成本和碳排放最优的优化调度模型,利用MATLAB优化工具箱求解多目标优化问题,确保各能源设备在合理范围内运行并保持能流平衡。最后分享了一些实际应用中的经验和技巧,如处理风光出力预测误差、非线性约束、多能流耦合等。 适合人群:从事能源系统研究、优化调度、MATLAB编程的专业人士和技术爱好者。 使用场景及目标:适用于希望深入了解综合能源系统优化调度的研究人员和工程师。目标是掌握如何在MATLAB中构建和求解复杂的多能互补优化调度模型,提高能源利用效率,降低碳排放。 其他说明:文中提供了大量MATLAB代码片段,帮助读者更好地理解和实践所介绍的内容。此外,还提及了一些有趣的发现和挑战,如多能流耦合的复杂性、鲁棒优化的应用等。
内容概要:本文详细介绍了如何利用Simulink和Carsim进行联合仿真,实现基于PID(比例-积分-微分)和MPC(模型预测控制)的自适应巡航控制系统。首先阐述了Carsim参数设置的关键步骤,特别是cpar文件的配置,包括车辆基本参数、悬架系统参数和转向系统参数的设定。接着展示了Matlab S函数的编写方法,分别针对PID控制和MPC控制提供了详细的代码示例。随后讨论了Simulink中车辆动力学模型的搭建,强调了模块间的正确连接和参数设置的重要性。最后探讨了远程指导的方式,帮助解决仿真过程中可能出现的问题。 适合人群:从事汽车自动驾驶领域的研究人员和技术人员,尤其是对Simulink和Carsim有一定了解并希望深入学习联合仿真的从业者。 使用场景及目标:适用于需要验证和优化自适应巡航控制、定速巡航及紧急避撞等功能的研究和开发项目。目标是提高车辆行驶的安全性和舒适性,确保控制算法的有效性和可靠性。 其他说明:文中不仅提供了理论知识,还有大量实用的代码示例和避坑指南,有助于读者快速上手并应用于实际工作中。此外,还提到了远程调试技巧,进一步提升了仿真的成功率。
02.第18讲一、三重积分02.mp4