
2006еєізЪДOSDIжЬЙдЄ§зѓЗgoogleзЪДиЃЇжЦЗпЉМеИЖеИЂ жШѓBigTableеТМChubbyгАВChubbyжШѓдЄАдЄ™еИЖеЄГеЉПйФБжЬНеК°пЉМеЯЇдЇОPaxosзЃЧж≥ХпЉЫBigTableжШѓдЄАдЄ™зФ®дЇОзЃ°зРЖзїУжЮДеМЦжХ∞жНЃзЪДеИЖеЄГеЉПе≠ШеВ®з≥їзїЯпЉМ жЮДеїЇеЬ®GFSгАБChubbyгАБSSTableз≠ЙgoogleжКАжЬѓдєЛдЄКгАВзЫЄељУе§ЪзЪДgoogleеЇФзФ®дљњзФ®дЇЖBigTableпЉМжѓФе¶ВGoogle EarthеТМGoogle AnalyticsпЉМеЫ†ж≠§еЃГеТМGFSгАБMapReduceеєґзІ∞дЄЇи∞Јж≠МжКАжЬѓ"дЄЙеЃЭ"гАВ
дЄОGFSеТМMapReduceзЪДиЃЇжЦЗзЫЄжѓФпЉМжИСиІЙеЊЧBigTableзЪДиЃЇжЦЗйЪЊжЗВдЄАдЇЫгАВдЄАжЦєйЭҐжШѓеЫ†дЄЇиЗ™еЈ±еѓєжХ∞жНЃеЇУдЄН姙дЇЖиІ£пЉМеП¶дЄАжЦєйЭҐеПИжШѓеЫ†дЄЇеѓєжХ∞жНЃеЇУзЪДзРЖиІ£е±АйЩРдЇОеЕ≥з≥їеЮЛжХ∞жНЃеЇУгАВе∞ЭиѓХзФ®еЕ≥з≥їеЮЛжХ∞жНЃж®°еЮЛеОїзРЖиІ£BigTableе∞±еЃєжШУ"иµ∞зБЂеЕ•й≠Ф"гАВеЬ®ињЩйЗМжО®иНРдЄАзѓЗжЦЗзЂ†пЉЪUnderstanding HBase and BigTableпЉМзЫЄдњ°ињЩзѓЗжЦЗзЂ†еѓєзРЖиІ£BigTable/HBaseзЪДжХ∞жНЃж®°еЮЛжЬЙеЊИе§ІеЄЃеК©гАВ
1 дїАдєИжШѓBigTable
Bigtable жШѓдЄАдЄ™дЄЇзЃ°зРЖе§ІиІДж®°зїУжЮДеМЦжХ∞жНЃиАМиЃЊиЃ°зЪДеИЖеЄГеЉПе≠ШеВ®з≥їзїЯпЉМеПѓдї•жЙ©е±ХеИ∞PBзЇІжХ∞жНЃеТМдЄКеНГеП∞жЬНеК°еЩ®гАВеЊИе§ЪgoogleзЪДй°єзЫЃдљњзФ®Bigtableе≠ШеВ®жХ∞жНЃпЉМињЩдЇЫ еЇФзФ®еѓєBigtableжПРеЗЇдЇЖдЄНеРМзЪДжМСжИШпЉМжѓФе¶ВжХ∞жНЃиІДж®°зЪДи¶Бж±ВгАБеїґињЯзЪДи¶Бж±ВгАВBigtableиГљжї°иґ≥ињЩдЇЫе§ЪеПШзЪДи¶Бж±ВпЉМдЄЇињЩдЇЫдЇІеУБжИРеКЯеЬ∞жПРдЊЫдЇЖзБµжіїгАБйЂШжАІиГљ зЪДе≠ШеВ®иІ£еЖ≥жЦєж°ИгАВ
BigtableзЬЛиµЈжЭ•еГПдЄАдЄ™жХ∞жНЃеЇУпЉМйЗЗзФ®дЇЖеЊИе§ЪжХ∞жНЃ еЇУзЪДеЃЮзО∞з≠ЦзХ•гАВдљЖжШѓBigtableеєґдЄНжФѓжМБеЃМжХізЪДеЕ≥з≥їеЮЛжХ∞жНЃж®°еЮЛпЉЫиАМжШѓдЄЇеЃҐжИЈзЂѓжПРдЊЫдЇЖдЄАзІНзЃАеНХзЪДжХ∞жНЃж®°еЮЛпЉМеЃҐжИЈзЂѓеПѓдї•еК®жАБеЬ∞жОІеИґжХ∞жНЃзЪДеЄГе±АеТМж†ЉеЉПпЉМеєґдЄФ еИ©зФ®еЇХе±ВжХ∞жНЃе≠ШеВ®зЪДе±АйГ®жАІзЙєеЊБгАВBigtableе∞ЖжХ∞жНЃзїЯзїЯзЬЛжИРжЧ†жДПдєЙзЪДе≠ЧиКВдЄ≤пЉМеЃҐжИЈзЂѓйЬАи¶Бе∞ЖзїУжЮДеМЦеТМйЭЮзїУжЮДеМЦжХ∞жНЃдЄ≤и°МеМЦеЖНе≠ШеЕ•BigtableгАВ
дЄЛжЦЗеѓєBigTableзЪДжХ∞жНЃж®°еЮЛеТМеЯЇжЬђеЈ•дљЬеОЯзРЖињЫи°МдїЛзїНпЉМиАМеРДзІНдЉШеМЦжКАжЬѓпЉИе¶ВеОЛзЉ©гАБBloom Filterз≠ЙпЉЙдЄНеЬ®иЃ®иЃЇиМГеЫігАВ
2 BigTableзЪДжХ∞жНЃж®°еЮЛ
BigtableдЄНжШѓеЕ≥з≥їеЮЛжХ∞жНЃеЇУпЉМдљЖжШѓеНіж≤њзФ®дЇЖеЊИе§ЪеЕ≥з≥їеЮЛжХ∞жНЃеЇУзЪДжЬѓиѓ≠пЉМеГПtableпЉИи°®пЉЙгАБrowпЉИи°МпЉЙгАБcolumnпЉИеИЧпЉЙз≠ЙгАВињЩеЃєжШУиЃ©иѓїиАЕиѓѓеЕ•ж≠ІйАФпЉМе∞ЖеЕґдЄОеЕ≥з≥їеЮЛжХ∞жНЃеЇУзЪДж¶ВењµеѓєеЇФиµЈжЭ•пЉМдїОиАМйЪЊдї•зРЖиІ£иЃЇжЦЗгАВUnderstanding HBase and BigTableжШѓзѓЗеЊИдЉШзІАзЪДжЦЗзЂ†пЉМеПѓдї•еЄЃеК©иѓїиАЕдїОеЕ≥з≥їеЮЛжХ∞жНЃж®°еЮЛзЪДжАЭзїіеЃЪеКњдЄ≠иµ∞еЗЇжЭ•гАВ
жЬђиі®дЄКиѓіпЉМBigtableжШѓдЄАдЄ™йФЃеАЉпЉИkey-valueпЉЙжШ†е∞ДгАВжМЙдљЬиАЕзЪДиѓіж≥ХпЉМBigtableжШѓдЄАдЄ™з®АзЦПзЪДпЉМеИЖеЄГеЉПзЪДпЉМжМБдєЕеМЦзЪДпЉМе§ЪзїізЪДжОТеЇПжШ†е∞ДгАВ
еЕИжЭ•зЬЛзЬЛе§ЪзїігАБжОТеЇПгАБжШ†е∞ДгАВBigtableзЪДйФЃжЬЙдЄЙзїіпЉМеИЖеИЂжШѓи°МйФЃпЉИrow keyпЉЙгАБеИЧйФЃпЉИcolumn keyпЉЙеТМжЧґйЧіжИ≥пЉИtimestampпЉЙпЉМи°МйФЃеТМеИЧйФЃйГљжШѓе≠ЧиКВдЄ≤пЉМжЧґйЧіжИ≥жШѓ64дљНжХіеЮЛпЉЫиАМеАЉжШѓдЄАдЄ™е≠ЧиКВдЄ≤гАВеПѓдї•зФ®¬†(row:string, column:string, time:int64)вЖТstring¬†жЭ•и°®з§ЇдЄАжЭ°йФЃеАЉеѓєиЃ∞ељХгАВ
и°МйФЃеПѓдї•жШѓдїїжДПе≠ЧиКВдЄ≤пЉМйАЪеЄЄжЬЙ10-100е≠ЧиКВгАВи°МзЪДиѓїеЖЩйГљжШѓеОЯе≠РжАІзЪДгАВBigtableжМЙзЕІи°МйФЃзЪДе≠ЧеЕЄеЇПе≠ШеВ®жХ∞жНЃгАВBigtableзЪДи°®дЉЪж†єжНЃи°МйФЃиЗ™еК®еИТеИЖдЄЇзЙЗпЉИtabletпЉЙпЉМзЙЗжШѓиіЯиљљеЭЗи°°зЪДеНХеЕГгАВжЬАеИЭи°®йГљеП™жЬЙдЄАдЄ™зЙЗпЉМдљЖйЪПзЭАи°®дЄНжЦ≠еҐЮе§ІпЉМзЙЗдЉЪиЗ™еК®еИЖи£ВпЉМзЙЗзЪДе§Іе∞ПжОІеИґеЬ®100-200MBгАВи°МжШѓи°®зЪДзђђдЄА篲糥еЉХпЉМжИСдїђеПѓдї•жККиѓ•и°МзЪДеИЧгАБжЧґйЧіеТМеАЉзЬЛжИРдЄАдЄ™жХідљУпЉМзЃАеМЦдЄЇдЄАзїійФЃеАЉжШ†е∞ДпЉМз±їдЉЉдЇОпЉЪ
 
- table{  
- ¬†¬†"1"¬†:¬†{sth.},//дЄАи°М¬†¬†
-   "aaaaa" : {sth.},  
-   "aaaab" : {sth.},  
-   "xyz" : {sth.},  
-   "zzzzz" : {sth.}  
- }  
еИЧ жШѓзђђдЇМ篲糥еЉХпЉМжѓПи°МжЛ•жЬЙзЪДеИЧжШѓдЄНеПЧйЩРеИґзЪДпЉМеПѓдї•йЪПжЧґеҐЮеК†еЗПе∞СгАВдЄЇдЇЖжЦєдЊњзЃ°зРЖпЉМеИЧ襀еИЖдЄЇе§ЪдЄ™еИЧжЧПпЉИcolumn familyпЉМжШѓиЃњйЧЃжОІеИґзЪДеНХеЕГпЉЙпЉМдЄАдЄ™еИЧжЧПйЗМзЪДеИЧдЄАиИђе≠ШеВ®зЫЄеРМз±їеЮЛзЪДжХ∞жНЃгАВдЄАи°МзЪДеИЧжЧПеЊИе∞СеПШеМЦпЉМдљЖжШѓеИЧжЧПйЗМзЪДеИЧеПѓдї•йЪПжДПжЈїеК†еИ†йЩ§гАВеИЧйФЃжМЙзЕІ family:qualifierж†ЉеЉПеСљеРНзЪДгАВињЩжђ°жИСдїђе∞ЖеИЧжЛњеЗЇжЭ•пЉМе∞ЖжЧґйЧіеТМеАЉзЬЛжИРдЄАдЄ™жХідљУпЉМзЃАеМЦдЄЇдЇМзїійФЃеАЉжШ†е∞ДпЉМз±їдЉЉдЇОпЉЪ
 
- table{  
-   // ...  
- ¬†¬†"aaaaa"¬†:¬†{¬†//дЄАи°М¬†¬†
- ¬†¬†¬†¬†"A:foo"¬†:¬†{sth.},//дЄАеИЧ¬†¬†
- ¬†¬†¬†¬†"A:bar"¬†:¬†{sth.},//дЄАеИЧ¬†¬†
- ¬†¬†¬†¬†"B:"¬†:¬†{sth.}¬†//дЄАеИЧпЉМеИЧжЧПеРНдЄЇBпЉМдљЖжШѓеИЧеРНжШѓз©Їе≠ЧдЄ≤¬†¬†
-   },  
- ¬†¬†"aaaab"¬†:¬†{¬†//дЄАи°М¬†¬†
-     "A:foo" : {sth.},  
-     "B:" : {sth.}  
-   },  
-   // ...  
- }  
жИЦиАЕеПѓдї•е∞ЖеИЧжЧПељУдљЬдЄАе±ВжЦ∞зЪД糥еЉХпЉМз±їдЉЉдЇОпЉЪ
 
- table{  
-   // ...  
- ¬†¬†"aaaaa"¬†:¬†{¬†//дЄАи°М¬†¬†
- ¬†¬†¬†¬†"A"¬†:¬†{¬†//еИЧжЧПA¬†¬†
- ¬†¬†¬†¬†¬†¬†"foo"¬†:¬†{sth.},¬†//дЄАеИЧ¬†¬†
-       "bar" : {sth.}  
-     },  
- ¬†¬†¬†¬†"B"¬†:¬†{¬†//еИЧжЧПB¬†¬†
-       "" : {sth.}  
-     }  
-   },  
- ¬†¬†"aaaab"¬†:¬†{¬†//дЄАи°М¬†¬†
-     "A" : {  
-       "foo" : {sth.},  
-     },  
-     "B" : {  
-       "" : "ocean"  
-     }  
-   },  
-   // ...  
- }  
жЧґ йЧіжИ≥жШѓзђђдЄЙ篲糥еЉХгАВBigtableеЕБиЃЄдњЭе≠ШжХ∞жНЃзЪДе§ЪдЄ™зЙИжЬђпЉМзЙИжЬђеМЇеИЖзЪДдЊЭжНЃе∞±жШѓжЧґйЧіжИ≥гАВжЧґйЧіжИ≥еПѓдї•зФ±BigtableиµЛеАЉпЉМдї£и°®жХ∞жНЃињЫеЕ• BigtableзЪДеЗЖз°ЃжЧґйЧіпЉМдєЯеПѓдї•зФ±еЃҐжИЈзЂѓиµЛеАЉгАВжХ∞жНЃзЪДдЄНеРМзЙИжЬђжМЙзЕІжЧґйЧіжИ≥йЩНеЇПе≠ШеВ®пЉМеЫ†ж≠§еЕИиѓїеИ∞зЪДжШѓжЬАжЦ∞зЙИжЬђзЪДжХ∞жНЃгАВжИСдїђеК†еЕ•жЧґйЧіжИ≥еРОпЉМе∞±еЊЧеИ∞дЇЖ BigtableзЪДеЃМжХіжХ∞жНЃж®°еЮЛпЉМз±їдЉЉдЇОпЉЪ
 
- table{  
-   // ...  
- ¬†¬†"aaaaa"¬†:¬†{¬†//дЄАи°М¬†¬†
- ¬†¬†¬†¬†"A:foo"¬†:¬†{¬†//дЄАеИЧ¬†¬†
- ¬†¬†¬†¬†¬†¬†¬†¬†15¬†:¬†"y",¬†//дЄАдЄ™зЙИжЬђ¬†¬†
-         4 : "m"  
-       },  
- ¬†¬†¬†¬†"A:bar"¬†:¬†{¬†//дЄАеИЧ¬†¬†
-         15 : "d",  
-       },  
- ¬†¬†¬†¬†"B:"¬†:¬†{¬†//дЄАеИЧ¬†¬†
-         6 : "w"  
-         3 : "o"  
-         1 : "w"  
-       }  
-   },  
-   // ...  
- }  
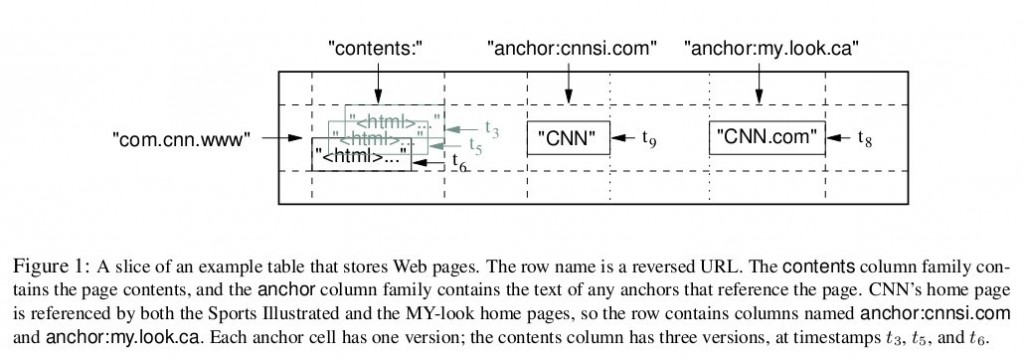
еЫЊ 1жШѓBigtableиЃЇжЦЗйЗМзїЩеЗЇзЪДдЊЛе≠РпЉМWebtableи°®е≠ШеВ®дЇЖе§ІйЗПзЪДзљСй°µеТМзЫЄеЕ≥дњ°жБѓгАВеЬ®WebtableпЉМжѓПдЄАи°Ме≠ШеВ®дЄАдЄ™зљСй°µпЉМеЕґеПНиљђзЪДurlдљЬдЄЇи°М йФЃпЉМжѓФе¶Вmaps.google.com/index.htmlзЪДжХ∞жНЃе≠ШеВ®еЬ®йФЃдЄЇcom.google.maps/index.htmlзЪДи°МйЗМпЉМеПНиљђзЪДеОЯ еЫ†жШѓдЄЇдЇЖиЃ©еРМдЄАдЄ™еЯЯеРНдЄЛзЪДе≠РеЯЯеРНзљСй°µиГљиБЪйЫЖеЬ®дЄАиµЈгАВеЫЊ1дЄ≠зЪДеИЧжЧП"anchor"дњЭе≠ШдЇЖиѓ•зљСй°µзЪДеЉХзФ®зЂЩзВєпЉИжѓФе¶ВеЉХзФ®дЇЖCNNдЄїй°µзЪДзЂЩзВєпЉЙпЉМqualifierжШѓеЉХзФ®зЂЩзВєзЪДеРНзІ∞пЉМиАМжХ∞жНЃжШѓйУЊжО•жЦЗжЬђпЉЫеИЧжЧП"contents"дњЭе≠ШзЪДжШѓзљСй°µзЪДеЖЕеЃєпЉМињЩдЄ™еИЧжЧПеП™жЬЙдЄАдЄ™з©ЇеИЧ"contents:"гАВеЫЊ1дЄ≠"contents:"еИЧдЄЛдњЭе≠ШдЇЖзљСй°µзЪДдЄЙдЄ™зЙИжЬђпЉМжИСдїђеПѓдї•зФ®("com.cnn.www", "contents:", t5)жЭ•жЙЊеИ∞CNNдЄїй°µеЬ®t5жЧґеИїзЪДеЖЕеЃєгАВ
еЖНжЭ•зЬЛзЬЛдљЬиАЕиѓізЪДеЕґеЃГзЙєеЊБпЉЪз®АзЦПпЉМеИЖеЄГеЉПпЉМжМБдєЕеМЦгАВжМБдєЕеМЦзЪДжДПжАЭеЊИзЃАеНХпЉМBigtableзЪДжХ∞жНЃжЬАзїИдЉЪдї•жЦЗдїґзЪД嚥еЉПжФЊеИ∞GFSеОїгАВBigtableеїЇзЂЛеЬ®GFSдєЛдЄКжЬђиЇЂе∞±жДПеС≥зЭАеИЖеЄГеЉПпЉМељУзДґеИЖеЄГеЉПзЪДжДПдєЙињШдЄНдїЕйЩРдЇОж≠§гАВз®АзЦПзЪДжДПжАЭжШѓпЉМдЄАдЄ™и°®йЗМдЄНеРМзЪДи°МпЉМеИЧеПѓиГљеЃМеЃМеЕ®еЕ®дЄНдЄАж†ЈгАВ
3 жФѓжТСжКАжЬѓ
BigtableдЊЭиµЦдЇОgoogleзЪДеЗ†й°єжКАжЬѓгАВзФ®GFSжЭ•е≠ШеВ®жЧ•ењЧеТМжХ∞жНЃжЦЗдїґпЉЫжМЙSSTableжЦЗдїґж†ЉеЉПе≠ШеВ®жХ∞жНЃпЉЫзФ®ChubbyзЃ°зРЖеЕГжХ∞жНЃгАВ
GFSеПВиІБи∞Јж≠МжКАжЬѓ"дЄЙеЃЭ"дєЛи∞Јж≠МжЦЗдїґз≥їзїЯгАВBigTableзЪДжХ∞жНЃеТМжЧ•ењЧйГљжШѓеЖЩеЕ•GFSзЪДгАВ
SSTableзЪДеЕ®зІ∞жШѓSorted Strings TableпЉМжШѓ дЄАзІНдЄНеПѓдњЃжФєзЪДжЬЙеЇПзЪДйФЃеАЉжШ†е∞ДпЉМжПРдЊЫдЇЖжߕ胥гАБйБНеОЖз≠ЙеКЯиГљгАВжѓПдЄ™SSTableзФ±дЄАз≥їеИЧзЪДеЭЧпЉИblockпЉЙзїДжИРпЉМBigtableе∞ЖеЭЧйїШиЃ§иЃЊдЄЇ64KBгАВеЬ® SSTableзЪДе∞ЊйГ®е≠ШеВ®зЭАеЭЧ糥еЉХпЉМеЬ®иЃњйЧЃSSTableжЧґпЉМжճ䪙糥еЉХдЉЪ襀胿еЕ•еЖЕе≠ШгАВBigTableиЃЇжЦЗж≤°жЬЙжПРеИ∞SSTableзЪДеЕЈдљУзїУжЮДпЉМLevelDbжЧ•зЯ•ељХдєЛеЫЫпЉЪ SSTableжЦЗдїґињЩзѓЗжЦЗзЂ†еѓєLevelDbзЪДSSTableж†ЉеЉПињЫи°МдЇЖдїЛзїНпЉМеЫ†дЄЇLevelDBзЪДдљЬиАЕJeffreyDeanж≠£жШѓBigTableзЪДиЃЊиЃ°еЄИпЉМжЙАдї•жЮБеЕЈеПВиАГдїЈеАЉгАВжѓПдЄАдЄ™зЙЗпЉИtabletпЉЙеЬ®GFSйЗМйГљжШѓжМЙзЕІSSTableзЪДж†ЉеЉПе≠ШеВ®зЪДпЉМжѓПдЄ™зЙЗеПѓиГљеѓєеЇФе§ЪдЄ™SSTableгАВ
ChubbyжШѓдЄАзІНйЂШеПѓзФ®зЪДеИЖеЄГеЉПйФБжЬН еК°пЉМChubbyжЬЙдЇФдЄ™жіїиЈГеЙѓжЬђпЉМеРМжЧґеП™жЬЙдЄАдЄ™дЄїеЙѓжЬђжПРдЊЫжЬНеК°пЉМеЙѓжЬђдєЛйЧізФ®PaxosзЃЧж≥ХзїіжМБдЄАиЗіжАІпЉМChubbyжПРдЊЫдЇЖдЄАдЄ™еСљеРНз©ЇйЧіпЉИеМЕжЛђдЄАдЇЫзЫЃељХеТМжЦЗ дїґпЉЙпЉМжѓПдЄ™зЫЃељХеТМжЦЗдїґе∞±жШѓдЄАдЄ™йФБпЉМChubbyзЪДеЃҐжИЈзЂѓењЕй°їеТМChubbyдњЭжМБдЉЪиѓЭпЉМеЃҐжИЈзЂѓзЪДдЉЪиѓЭиЛ•ињЗжЬЯеИЩдЉЪ䪥姱жЙАжЬЙзЪДйФБгАВеЕ≥дЇОChubbyзЪДиѓ¶зїЖдњ°жБѓеПѓ дї•зЬЛgoogleзЪДеП¶дЄАзѓЗиЃЇжЦЗпЉЪThe Chubby lock service for loosely-coupled distributed systemsгАВChubbyзФ®дЇОзЙЗеЃЪдљНпЉМзЙЗжЬНеК°еЩ®зЪДзКґжАБзЫСжОІпЉМиЃњйЧЃжОІеИґеИЧи°®е≠ШеВ®з≠ЙдїїеК°гАВ
4 BigtableйЫЖзЊ§
BigtableйЫЖзЊ§еМЕжЛђдЄЙдЄ™дЄїи¶БйГ®еИЖпЉЪдЄАдЄ™дЊЫеЃҐжИЈзЂѓдљњзФ®зЪДеЇУпЉМдЄАдЄ™дЄїжЬНеК°еЩ®пЉИmaster serverпЉЙпЉМиЃЄе§ЪзЙЗжЬНеК°еЩ®пЉИtablet serverпЉЙгАВ
ж≠£е¶ВжХ∞жНЃж®°еЮЛе∞ПиКВжЙАиѓіпЉМBigtableдЉЪе∞Жи°®пЉИtableпЉЙињЫи°МеИЖзЙЗпЉМзЙЗпЉИtabletпЉЙзЪДе§Іе∞ПзїіжМБеЬ®100-200MBиМГеЫіпЉМдЄАжЧ¶иґЕеЗЇиМГеЫіе∞±е∞ЖеИЖи£ВжИРжЫіе∞ПзЪДзЙЗпЉМжИЦиАЕеРИеєґжИРжЫіе§ІзЪДзЙЗгАВжѓПдЄ™зЙЗжЬНеК°еЩ®иіЯиі£дЄАеЃЪйЗПзЪДзЙЗпЉМе§ДзРЖеѓєеЕґзЙЗзЪДиѓїеЖЩиѓЈж±ВпЉМдї•еПКзЙЗзЪДеИЖи£ВжИЦеРИеєґгАВзЙЗжЬНеК°еЩ®еПѓдї•ж†єжНЃиіЯиљљйЪПжЧґжЈїеК†еТМеИ†йЩ§гАВињЩйЗМзЙЗжЬНеК°еЩ®еєґдЄНзЬЯеЃЮе≠ШеВ®жХ∞жНЃпЉМиАМзЫЄељУдЇОдЄАдЄ™ињЮжО•BigtableеТМGFSзЪДдї£зРЖпЉМеЃҐжИЈзЂѓзЪДдЄАдЇЫжХ∞жНЃжУНдљЬйГљйАЪињЗзЙЗжЬНеК°еЩ®дї£зРЖйЧіжО•иЃњйЧЃGFSгАВ
дЄїжЬНеК°еЩ®иіЯиі£е∞ЖзЙЗеИЖйЕНзїЩзЙЗжЬНеК°еЩ®пЉМзЫСжОІзЙЗжЬНеК°еЩ®зЪДжЈїеК†еТМеИ†йЩ§пЉМеє≥и°°зЙЗжЬНеК°еЩ®зЪДиіЯиљљпЉМе§ДзРЖи°®еТМеИЧжЧПзЪДеИЫеїЇз≠ЙгАВж≥®жДПпЉМдЄїжЬНеК°еЩ®дЄНе≠ШеВ®дїїдљХзЙЗпЉМдЄНжПРдЊЫдїїдљХжХ∞жНЃжЬНеК°пЉМдєЯдЄНжПРдЊЫзЙЗзЪДеЃЪдљНдњ°жБѓгАВ
еЃҐжИЈзЂѓйЬАи¶БиѓїеЖЩжХ∞жНЃжЧґпЉМзЫіжО•дЄОзЙЗжЬНеК°еЩ®иБФз≥їгАВеЫ†дЄЇеЃҐжИЈзЂѓеєґдЄНйЬАи¶БдїОдЄїжЬНеК°еЩ®иОЈеПЦзЙЗзЪДдљНзљЃдњ°жБѓпЉМжЙАдї•е§Іе§ЪжХ∞еЃҐжИЈзЂѓдїОжЭ•дЄНйЬАи¶БиЃњйЧЃдЄїжЬНеК°еЩ®пЉМдЄїжЬНеК°еЩ®зЪДиіЯиљљдЄАиИђеЊИиљїгАВ
5 зЙЗзЪДеЃЪдљН
еЙНйЭҐжПРеИ∞дЄїжЬНеК°еЩ®дЄНжПРдЊЫзЙЗзЪДдљНзљЃдњ°жБѓпЉМйВ£дєИеЃҐжИЈзЂѓжШѓе¶ВдљХиЃњйЧЃзЙЗзЪДеСҐпЉЯжЭ•зЬЛзЬЛиЃЇжЦЗзїЩзЪДз§ЇжДПеЫЊпЉМBigtableдљњзФ®дЄАдЄ™з±їдЉЉB+ж†СзЪДжХ∞жНЃзїУжЮДе≠ШеВ®зЙЗзЪДдљНзљЃдњ°жБѓгАВ
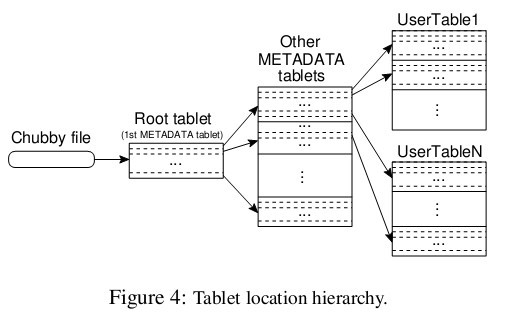
й¶ЦеЕИжШѓзђђдЄАе±ВпЉМChubby fileгАВињЩдЄАе±ВжШѓдЄАдЄ™ChubbyжЦЗдїґпЉМеЃГдњЭе≠ШзЭАroot tabletзЪДдљНзљЃгАВињЩдЄ™ChubbyжЦЗдїґе±ЮдЇОChubbyжЬНеК°зЪДдЄАйГ®еИЖпЉМдЄАжЧ¶ChubbyдЄНеПѓзФ®пЉМе∞±жДПеС≥зЭА䪥姱дЇЖroot tabletзЪДдљНзљЃпЉМжХідЄ™BigtableдєЯе∞±дЄНеПѓзФ®дЇЖгАВ
зђђдЇМе±ВжШѓroot tabletгАВroot tabletеЕґеЃЮжШѓеЕГжХ∞жНЃи°®пЉИMETADATA tableпЉЙзЪДзђђдЄАдЄ™еИЖзЙЗпЉМеЃГдњЭе≠ШзЭАеЕГжХ∞жНЃи°®еЕґеЃГзЙЗзЪДдљНзљЃгАВroot tabletеЊИзЙєеИЂпЉМдЄЇдЇЖдњЭиѓБж†СзЪДжЈ±еЇ¶дЄНеПШпЉМroot tabletдїОдЄНеИЖи£ВгАВ
зђђдЄЙе±ВжШѓеЕґеЃГзЪДеЕГжХ∞жНЃзЙЗпЉМеЃГдїђеТМroot tabletдЄАиµЈзїДжИРеЃМжХізЪДеЕГжХ∞жНЃи°®гАВжѓПдЄ™еЕГжХ∞жНЃзЙЗйГљеМЕеРЂдЇЖиЃЄе§ЪзФ®жИЈзЙЗзЪДдљНзљЃдњ°жБѓгАВ
еПѓдї•зЬЛеЗЇжХідЄ™еЃЪдљНз≥їзїЯеЕґеЃЮеП™жШѓдЄ§йГ®еИЖпЉМдЄАдЄ™ChubbyжЦЗдїґпЉМдЄАдЄ™еЕГжХ∞жНЃи°®гАВж≥®жДПеЕГжХ∞жНЃи°®иЩљзДґзЙєжЃКпЉМдљЖдєЯдїНзДґжЬНдїОеЙНжЦЗзЪДжХ∞жНЃж®°еЮЛпЉМжѓПдЄ™еИЖзЙЗдєЯйГљжШѓзФ±дЄУйЧ®зЪДзЙЗжЬНеК°еЩ®иіЯиі£пЉМињЩе∞±жШѓдЄНйЬАи¶БдЄїжЬНеК°еЩ®жПРдЊЫдљНзљЃдњ°жБѓзЪДеОЯеЫ†гАВеЃҐжИЈзЂѓдЉЪзЉУе≠ШзЙЗзЪДдљНзљЃдњ°жБѓпЉМе¶ВжЮЬеЬ®зЉУе≠ШйЗМжЙЊдЄНеИ∞дЄАдЄ™зЙЗзЪДдљНзљЃдњ°жБѓпЉМе∞±йЬАи¶БжЯ•жЙЊињЩдЄ™дЄЙе±ВзїУжЮДдЇЖпЉМеМЕжЛђиЃњйЧЃдЄАжђ°ChubbyжЬНеК°пЉМиЃњйЧЃдЄ§жђ°зЙЗжЬНеК°еЩ®гАВ
6 зЙЗзЪДе≠ШеВ®еТМиЃњйЧЃ

ељУзЙЗжЬНеК°еЩ® жФґеИ∞дЄАдЄ™еЖЩиѓЈж±ВпЉМзЙЗжЬНеК°еЩ®й¶ЦеЕИж£АжЯ•иѓЈж±ВжШѓеР¶еРИж≥ХгАВе¶ВжЮЬеРИж≥ХпЉМеЕИе∞ЖеЖЩиѓЈж±ВжПРдЇ§еИ∞жЧ•ењЧеОїпЉМзДґеРОе∞ЖжХ∞жНЃеЖЩеЕ•еЖЕе≠ШдЄ≠зЪДmemtableгАВmemtableзЫЄељУдЇО SSTableзЪДзЉУе≠ШпЉМељУmemtableжИРйХњеИ∞дЄАеЃЪиІДж®°дЉЪ襀еЖїзїУпЉМBigtableйЪПдєЛеИЫеїЇдЄАдЄ™жЦ∞зЪДmemtableпЉМеєґдЄФе∞ЖеЖїзїУзЪДmemtableиљђ жНҐдЄЇSSTableж†ЉеЉПеЖЩеЕ•GFSпЉМињЩдЄ™жУНдљЬзІ∞дЄЇminor compactionгАВ
ељУзЙЗжЬНеК°еЩ®жФґеИ∞дЄАдЄ™иѓїиѓЈж±ВпЉМеРМж†Ји¶Бж£АжЯ•иѓЈж±ВжШѓеР¶еРИж≥ХгАВе¶ВжЮЬеРИж≥ХпЉМињЩдЄ™иѓїжУНдљЬдЉЪжЯ•зЬЛжЙАжЬЙSSTableжЦЗдїґеТМmemtableзЪДеРИеєґиІЖеЫЊпЉМеЫ†дЄЇSSTableеТМmemtableжЬђиЇЂйГљжШѓеЈ≤жОТеЇПзЪДпЉМжЙАдї•еРИеєґзЫЄељУењЂгАВ
жѓПдЄАжђ°minor compactionйГљдЉЪдЇІзФЯдЄАдЄ™жЦ∞зЪДSSTableжЦЗдїґпЉМSSTableжЦЗ俴姙е§ЪиѓїжУНдљЬзЪДжХИзОЗе∞±йЩНдљОдЇЖпЉМжЙАдї•BigtableеЃЪжЬЯжЙІи°Мmerging compactionжУНдљЬпЉМе∞ЖеЗ†дЄ™SSTableеТМmemtableеРИеєґдЄЇдЄАдЄ™жЦ∞зЪДSSTableгАВBigTableињШжЬЙдЄ™жЫіеОЙеЃ≥зЪДеПЂmajor compactionпЉМеЃГе∞ЖжЙАжЬЙSSTableеРИеєґдЄЇдЄАдЄ™жЦ∞зЪДSSTableгАВ
йБЧжЖЊзЪДжШѓпЉМBigTableдљЬиАЕж≤°жЬЙдїЛзїНmemtableеТМSSTableзЪДиѓ¶зїЖжХ∞жНЃзїУжЮДгАВ
7 BigTableеТМGFSзЪДеЕ≥з≥ї
йЫЖзЊ§еМЕжЛђдЄїжЬНеК°еЩ®еТМзЙЗжЬНеК°еЩ®пЉМдЄїжЬНеК°еЩ®иіЯиі£е∞ЖзЙЗеИЖйЕНзїЩ зЙЗжЬНеК°еЩ®пЉМиАМеЕЈдљУзЪДжХ∞жНЃжЬНеК°еИЩеЕ®жЭГзФ±зЙЗжЬНеК°еЩ®иіЯиі£гАВдљЖжШѓдЄНи¶Биѓѓдї•дЄЇзЙЗжЬНеК°еЩ®зЬЯзЪДе≠ШеВ®дЇЖжХ∞жНЃпЉИйЩ§дЇЖеЖЕе≠ШдЄ≠memtableзЪДжХ∞жНЃпЉЙпЉМжХ∞жНЃзЪДзЬЯеЃЮдљНзљЃеП™жЬЙ GFSжЙНзЯ•йБУпЉМдЄїжЬНеК°еЩ®е∞ЖзЙЗеИЖйЕНзїЩзЙЗжЬНеК°еЩ®зЪДжДПжАЭеЇФиѓ•жШѓпЉМзЙЗжЬНеК°еЩ®иОЈеПЦдЇЖзЙЗзЪДжЙАжЬЙSSTableжЦЗдїґеРНпЉМзЙЗжЬНеК°еЩ®йАЪињЗдЄАдЇЫ糥еЉХжЬЇеИґеПѓдї•зЯ•йБУжЙАйЬАи¶БзЪДжХ∞жНЃеЬ® еУ™дЄ™SSTableжЦЗдїґпЉМзДґеРОдїОGFSдЄ≠иѓїеПЦSSTableжЦЗдїґзЪДжХ∞жНЃпЉМињЩдЄ™SSTableжЦЗдїґеПѓиГљеИЖеЄГеЬ®е•љеЗ†еП∞chunkserverдЄКгАВ
8 еЕГжХ∞жНЃи°®зЪДзїУжЮД
еЕГжХ∞жНЃи°®пЉИMETADATA tableпЉЙжШѓдЄАеЉ†зЙєжЃКзЪДи°®пЉМеЃГ襀зФ®дЇОжХ∞жНЃзЪДеЃЪдљНдї•еПКдЄАдЇЫеЕГжХ∞жНЃжЬНеК°пЉМдЄНеПѓи∞УдЄНйЗНи¶БгАВдљЖжШѓBigtableиЃЇжЦЗйЗМеП™зїЩеЗЇдЇЖе∞СйЗП篜糥пЉМиАМеѓєи°®зЪДеЕЈдљУзїУжЮДж≤°жЬЙиѓіжШОгАВињЩйЗМжИСиѓХеЫЊж†єжНЃиЃЇжЦЗзЪДдЄАдЇЫ篜糥пЉМзМЬжµЛдЄАдЄЛи°®зЪДзїУжЮДгАВй¶ЦеЕИеИЧеЗЇиЃЇжЦЗдЄ≠зЪД篜糥пЉЪ
- The METADATA table stores the location of a tablet under a row key that is an encoding of the tablet's table identifier and its end row.
- Each METADATA row stores¬†approximately 1KB of data in memoryпЉИеЫ†дЄЇиЃњйЧЃйЗПжѓФиЊГе§ІпЉМеЕГжХ∞жНЃи°®жШѓжФЊеЬ®еЖЕе≠ШйЗМзЪДпЉМињЩдЄ™дЉШеМЦеЬ®иЃЇжЦЗзЪДlocality groupsдЄ≠жПРеИ∞пЉЙ.This featureпЉИе∞Жlocality groupжФЊеИ∞еЖЕе≠ШдЄ≠зЪДзЙєжАІпЉЙ is useful for¬†small pieces of data that are accessed frequently: we¬†use it internally for the location column family in the¬†METADATA table.
- We also store secondary information in the METADATA table, including a log of all events pertaining to each tablet(such as when a server begins
serving it).
зђђдЄАжݰ篜糥пЉМеЕГжХ∞жНЃи°®зЪДи°МйФЃжШѓзФ±зЙЗжЙАе±Юи°®еРНзЪДidеТМзЙЗжЬАеРОдЄАи°МзЉЦз†БиАМжИРпЉМжЙАдї•жѓПдЄ™зЙЗеЬ®еЕГжХ∞жНЃи°®дЄ≠еН†жНЃдЄАжЭ°иЃ∞ељХпЉИдЄАи°МпЉЙпЉМиАМдЄФи°МйФЃжЧҐеМЕеРЂдЇЖеЕґжЙАе±Юи°®зЪДдњ°жБѓдєЯеМЕеРЂдЇЖеЕґжЙАжЛ•жЬЙзЪДи°МзЪДиМГеЫігАВи≠ђе¶ВйЗЗеПЦжЬАзЃАеНХзЪДзЉЦз†БжЦєеЉПпЉМеЕГжХ∞жНЃи°®зЪДи°МйФЃз≠ЙдЇОstrcat(и°®еРНпЉМзЙЗжЬАеРОдЄАи°МзЪДи°МйФЃ)гАВ
зђђдЇМзº篜糥пЉМйЩ§дЇЖзЯ•йБУеЕГжХ∞жНЃи°®зЪДеЬ∞еЭАйГ®еИЖжШѓеЄЄй©їеЖЕе≠Шдї• е§ЦпЉМињШеПѓдї•еПСзО∞еЕГжХ∞жНЃи°®жЬЙдЄАдЄ™еИЧжЧПзІ∞дЄЇlocationпЉМжИСдїђеЈ≤зїПзЯ•йБУеЕГжХ∞жНЃи°®жѓПдЄАи°Мдї£и°®дЄАдЄ™зЙЗпЉМйВ£дєИдЄЇдїАдєИйЬАи¶БдЄАдЄ™еИЧжЧПжЭ•е≠ШеВ®еЬ∞еЭАеСҐпЉЯеЫ†дЄЇжѓПдЄ™зЙЗйГљеПѓиГљ зФ±е§ЪдЄ™SSTableжЦЗдїґзїДжИРпЉМеИЧжЧПеПѓдї•зФ®жЭ•е≠ШеВ®дїїжДПе§ЪдЄ™SSTableжЦЗдїґзЪДдљНзљЃгАВдЄАдЄ™еРИзРЖзЪДеБЗиЃЊе∞±жШѓжѓПдЄ™SSTableжЦЗдїґзЪДдљНзљЃдњ°жБѓеН†жНЃдЄАеИЧпЉМеИЧеРН дЄЇlocation:filenameгАВељУзДґдЄНдЄАеЃЪйЭЮеЊЧзФ®еИЧйФЃе≠ШеВ®еЃМжХіжЦЗдїґеРНпЉМжЫіе§ІзЪДеПѓиГљжАІжШѓжККSSTableжЦЗдїґеРНе≠ШеЬ®еАЉйЗМгАВиОЈеПЦдЇЖжЦЗдїґеРНе∞±еПѓдї•еРС GFS糥и¶БжХ∞жНЃдЇЖгАВ
зђђдЄЙ䪙篜糥еСКиѓЙжИСдїђеЕГжХ∞жНЃи°®дЄНж≠Ґе≠ШеВ®дљНзљЃдњ°жБѓпЉМдєЯе∞±жШѓиѓіеИЧжЧПдЄНж≠ҐlocationпЉМињЩдЇЫжХ∞жНЃжЪВжЧґдЄНжШѓеТ±дїђеЕ≥ењГзЪДгАВ
йАЪињЗдї•дЄКдњ°жБѓпЉМжИСзФїдЇЖдЄАдЄ™зЃАеМЦзЪДBigtableзїУжЮДеЫЊпЉЪ
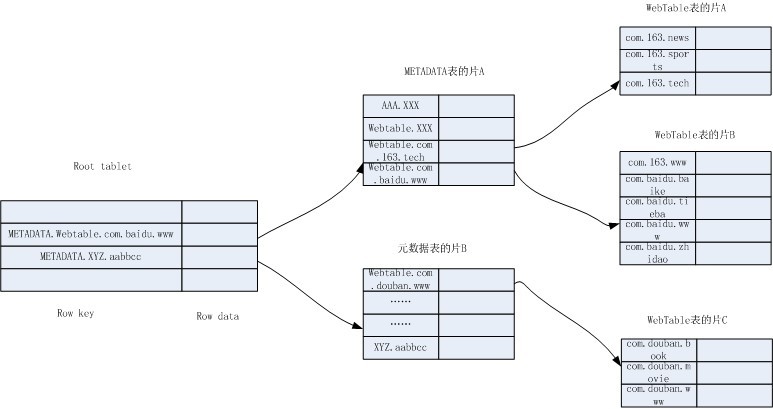
зїУжЮДеЫЊдї•Webtableи°®дЄЇдЊЛпЉМи°®дЄ≠е≠ШеВ®дЇЖзљСжШУгАБзЩЊеЇ¶еТМи±ЖзУ£зЪДеЗ†дЄ™зљСй°µгАВељУжИСдїђжГ≥жЯ•жЙЊзЩЊеЇ¶иііеРІжخ姩зЪДзљСй°µеЖЕеЃєпЉМеПѓдї•еРСBigtableеПСеЗЇжߕ胥Webtableи°®зЪД(com.baidu.tieba, contents:, yesterday)гАВ
еБЗиЃЊеЃҐжИЈзЂѓж≤°жЬЙиѓ•зЉУе≠ШпЉМйВ£дєИBigtableиЃњйЧЃ root tabletзЪДзЙЗжЬНеК°еЩ®пЉМеЄМжЬЫеЊЧеИ∞иѓ•зљСй°µжЙАе±ЮзЪДзЙЗзЪДдљНзљЃдњ°жБѓеЬ®еУ™дЄ™еЕГжХ∞жНЃзЙЗдЄ≠гАВдљњзФ®METADATA.Webtable.com.baidu.tieba дЄЇи°МйФЃеЬ®root tabletдЄ≠жЯ•жЙЊпЉМеЃЪдљНеИ∞жЬАеРОдЄАдЄ™жѓФеЃГе§ІзЪДжШѓMETADATA.Webtable.com.baidu.wwwпЉМдЇОжШѓз°ЃеЃЪйЬАи¶БзЪДе∞±жШѓеЕГжХ∞жНЃи°®зЪДзЙЗAгАВиЃњ йЧЃзЙЗAзЪДзЙЗжЬНеК°еЩ®пЉМзїІзї≠жЯ•жЙЊWebtable.com.baidu.tiebaпЉМеЃЪдљНеИ∞Webtable.com.baidu.wwwжШѓжѓФеЃГе§ІзЪДпЉМз°ЃеЃЪйЬА и¶БзЪДжШѓWebtableи°®зЪДзЙЗBгАВиЃњйЧЃзЙЗBзЪДзЙЗжЬНеК°еЩ®пЉМиОЈеЊЧжХ∞жНЃгАВ
еПВиАГжЦЗзМЃ
[1] Bigtable: A Distributed Storage System for Structured Data. In proceedings of OSDI'06.



зЫЄеЕ≥жО®иНР
иµДжЇРжЭ•иЗ™pypiеЃШзљСгАВ иµДжЇРеЕ®еРНпЉЪgoogle_cloud_bigtable-0.23.1-py2.py3-none-any.whl
жАїдєЛпЉМе§ІжХ∞жНЃгАБдЇСиЃ°зЃЧеТМеИЖеЄГеЉПжКАжЬѓзЪДзїУеРИжШѓзО∞дї£дњ°жБѓжКАжЬѓйҐЖеЯЯзЪДж†ЄењГй©±еК®еКЫдєЛдЄАгАВеЃГдїђдЄНдїЕжФєеПШдЇЖжХ∞жНЃе§ДзРЖзЪДжЦєеЉПпЉМдєЯжЈ±еИїељ±еУНдЇЖеХЖдЄЪж®°еЉПеТМз§ЊдЉЪињРи°МзЪДжЦєжЦєйЭҐйЭҐгАВйЪПзЭАжКАжЬѓзЪДдЄНжЦ≠ињЫж≠•пЉМжИСдїђжЬЯеЊЕзЬЛеИ∞жЫіе§ЪеИЫжЦ∞зЪДиІ£еЖ≥жЦєж°ИжЭ•...
Bigtable-SQLжШѓдЄАжђЊзФ®дЇОзЃ°зРЖе§ІжХ∞жНЃзЪДеПѓиІЖеМЦеЈ•еЕЈпЉМеЃГжФѓжМБдЄОе§ЪзІНе§ІжХ∞жНЃе§ДзРЖж°ЖжЮґе¶ВHiveгАБImpalaгАБSparkгАБPrestoеТМHBaseзЪДдЇ§дЇТпЉМжПРдЊЫSQLжߕ胥еКЯиГљгАВеЬ®дљњзФ®Bigtable-SQLжЧґпЉМзФ®жИЈйЬАи¶Бз°ЃдњЭеЬ®64дљНWindowsзОѓеҐГдЄЛињРи°МпЉМеЫ†дЄЇиѓ•...
еЬ®е§ІжХ∞жНЃжЧґдї£иГМжЩѓдЄЛпЉМдЇСиЃ°зЃЧжКАж܃襀府ж≥ЫеЇФзФ®дЇОеРДдЄ™йҐЖеЯЯпЉМеЕґдЄ≠пЉМеИ©зФ®е§ІжХ∞жНЃдЇСиЃ°зЃЧж®°еЮЛеѓєеЬ∞йЬЗйА†жИРзЪДжИње±ЛжНЯ姱ињЫи°МиѓДдЉ∞жШѓдЄАдЄ™йЗНи¶БзЪДз†Фз©ґжЦєеРСгАВжЬђжЦЗдїЛзїНдЇЖдЄАзІНеЯЇдЇОе§ІжХ∞жНЃдЇСиЃ°зЃЧжКАжЬѓзЪДеЬ∞йЬЗжИње±ЛжНЯ姱иѓДдЉ∞ж®°еЮЛпЉМиѓ•ж®°еЮЛдЄїи¶БеИ©зФ®...
жЇРиЗ™Google GFS,BigTable,MapReduce иЃЇжЦЗгАВ == HDFS == HDFS (Hadoop Distributed File System),Hadoop еИЖеЄГеЉПжЦЗдїґз≥їзїЯгАВ NameNode,HDFSеСљеРНжЬНеК°еЩ®,иіЯиі£дЄОDataNodeжЦЗдїґеЕГдњ°жБѓдњЭе≠ШгАВ DataNode,HDFSжХ∞жНЃиКВзВєпЉМиіЯиі£е≠ШеВ®...
HomeиЃњйЧЃжИСзЪД,иОЈеПЦжЫіе§Ъе§ІжХ∞жНЃ/дЇСиЃ°зЃЧзЪДжКАжЬѓжЦЗзЂ†пЉБеРДзІНиљђиљљжИЦдњЃжФєиѓЈж≥®жШОжЭ•иЗ™www.itweet.cnпЉБbigtable-sql-3.5.0ж≠§иљѓдїґдЄЇеЯЇдЇОSQuirreL SQLеЉАжЇРиљѓдїґдЇМжђ°еЉАеПСпЉБеИЖеЄГеЉПе§ІжХ∞жНЃSQLжߕ胥еПѓиІЖеМЦзХМйЭҐпЉБдЄ≠жЦЗзФ®жИЈжЙЛеЖМ.зЉЦиѓСзОѓеҐГ...
еЃГжШѓGoogleеЖЕйГ®BigtableжКАжЬѓзЪДдЇСзЙИжЬђпЉМеПѓе§ДзРЖжµЈйЗПжХ∞жНЃгАВ 4. **PythonеЃҐжИЈзЂѓеЇУ**: "google_cloud_bigtable" жШѓдЄАдЄ™PythonеЇУпЉМжПРдЊЫдЇЖиЃњйЧЃеТМжУНдљЬGoogle Cloud BigtableзЪДжО•еП£гАВеЉАеПСиАЕеПѓдї•дљњзФ®еЃГжЭ•еИЫеїЇгАБиѓїеПЦгАБжЫіжЦ∞еТМ...
гАКе§ІжХ∞жНЃдЇСиЃ°зЃЧжКАжЬѓз≥їеИЧпЉЪHadoopдєЛHbaseдїОеЕ•йЧ®еИ∞з≤ЊйАЪгАЛ HBaseпЉМеЕ®зІ∞Hadoop DatabaseпЉМжШѓдЄАжђЊеЯЇдЇОHadoopзФЯжАБз≥їзїЯзЪДеИЖеЄГеЉПеИЧеЉПе≠ШеВ®з≥їзїЯпЉМжЧ®еЬ®е§ДзРЖжµЈйЗПзїУжЮДеМЦжХ∞жНЃгАВеЃГеАЯйЙідЇЖGoogle BigtableзЪДиЃЊиЃ°жАЭжГ≥пЉМдљЖеЉАжЇРеєґйАВеЇФдЇЖ...
гАРе§ІжХ∞жНЃдЇСиЃ°зЃЧжКАжЬѓ hadoopеЃЮжИШеЯєиЃ≠гАСзЪДPPTжЈ±еЕ•иІ£жЮРдЇЖе¶ВдљХеЇФеѓєжµЈйЗПжХ∞жНЃе§ДзРЖзЪДжМСжИШпЉМдї•еПКHadoopеЬ®еЕґдЄ≠зЪДеЕ≥йФЃдљЬзФ®гАВе§ІжХ∞жНЃжШѓжМЗжЧ†ж≥ХзФ®дЉ†зїЯжХ∞жНЃеЇУзЃ°зРЖеЈ•еЕЈе§ДзРЖзЪДе§ІйЗПгАБйЂШйАЯгАБе§Ъж†ЈзЪДдњ°жБѓиµДдЇІпЉМиАМдЇСиЃ°зЃЧеИЩжПРдЊЫдЇЖжМЙйЬАеИЖйЕН...
жАїзЪДжЭ•иѓіпЉМдЇСиЃ°зЃЧдЄОжХ∞жНЃжМЦжОШгАБжХ∞жНЃеИЖжЮРеѓЖеИЗзЫЄеЕ≥пЉМеЃГдїђеЕ±еРМжЮДжИРдЇЖзО∞дї£дњ°жБѓжКАжЬѓзЪДж†ЄењГзїДжИРйГ®еИЖпЉМдЄЇе§ІжХ∞жНЃжЧґдї£зЪДеХЖдЄЪеЖ≥з≠ЦгАБзІСе≠¶з†Фз©ґеТМз§ЊдЉЪињЫж≠•жПРдЊЫдЇЖеЉЇе§ІзЪДжФѓжТСгАВйАЪињЗињЩдЇЫжКАжЬѓпЉМдЉБдЄЪеТМз†Фз©ґиАЕеПѓдї•йЂШжХИеЬ∞е§ДзРЖжµЈйЗПжХ∞жНЃпЉМ...
е§ІжХ∞жНЃдЇСиЃ°зЃЧжКАжЬѓз≥їеИЧ Hbase зЃАдїЛ дЄАгАБзЃАдїЛ HbaseжЇРдЇОChad WaltersеТМJimеЬ®2006еєі11жЬИжПРеЗЇзЪДBigTableж¶ВењµпЉМеЃГжШѓдЄАдЄ™еЉАжЇРзЪДеИЖеЄГеЉПжХ∞жНЃеЇУпЉМжЬАеИЭдљЬдЄЇHadoopиі°зМЃй°єзЫЃзЪДдЄАйГ®еИЖеЬ®2007еєі2жЬИеИЫеїЇгАВ2007еєі10жЬИпЉМHbaseжИРдЄЇй¶Ц...
еЬ®ITи°МдЄЪдЄ≠пЉМGoogleжШѓжКАжЬѓеИЫжЦ∞зЪДеЈ®е§іпЉМеЕґдЄЙе§Іж†ЄењГжКАжЬѓвАФвАФMapReduceгАБGFSпЉИGoogle File SystemпЉЙеТМBigtableпЉМеѓєе§ІжХ∞жНЃе§ДзРЖеТМдЇСиЃ°зЃЧйҐЖеЯЯдЇІзФЯдЇЖжЈ±ињЬељ±еУНгАВињЩдЇЫжКАжЬѓжШѓGoogleдЄЇиІ£еЖ≥иЗ™иЇЂе§ІиІДж®°жХ∞жНЃе§ДзРЖйЧЃйҐШиАМз†ФеПСзЪДпЉМеєґ...
жАїзЪДжЭ•иѓіпЉМдЇСиЃ°зЃЧзЪДж†ЄењГжКАжЬѓжґµзЫЦдЇЖзЉЦз®Лж®°еЮЛгАБжХ∞жНЃе≠ШеВ®гАБжХ∞жНЃзЃ°зРЖгАБиЩЪжЛЯеМЦдї•еПКеє≥еП∞зЃ°зРЖз≠Йе§ЪдЄ™жЦєйЭҐпЉМеЃГдїђеЕ±еРМжЮДеїЇдЇЖдЇСиЃ°зЃЧзЪДеЯЇзЯ≥пЉМдљњеЊЧдЉБдЄЪеТМеЉАеПСиАЕиГље§Ядї•зБµжіїгАБзїПжµОйЂШжХИзЪДжЦєеЉПе§ДзРЖеТМеИ©зФ®е§ІжХ∞жНЃгАВйЪПзЭАжКАжЬѓзЪДдЄНжЦ≠еПСе±ХпЉМ...
йЪПзЭАе§ІжХ∞жНЃжКАжЬѓзЪДеПСе±ХпЉМHBaseеЬ®еЃЮжЧґеИЖжЮРгАБжХ∞жНЃдїУеЇУгАБдЇЇеЈ•жЩЇиГљз≠ЙйҐЖеЯЯжЬЙеєњйШФзЪДеЇФзФ®еЙНжЩѓгАВеРМжЧґпЉМз§ЊеМЇдЄНжЦ≠дЉШеМЦеЕґжАІиГљеТМеКЯиГљпЉМе¶ВжФѓжМБжЫідЄ∞еѓМзЪДжߕ胥иѓ≠и®АпЉМжПРеНЗе§Ъи°®еЕ≥иБФжУНдљЬзЪДжХИзОЗгАВ жАїдєЛпЉМгАКе§ІжХ∞жНЃдЇСиЃ°зЃЧжКАжЬѓз≥їеИЧпЉЪHadoop...
- еЬ®еОЯжЬЙзЪДдЇТиБФзљСеЯЇз°АиЃЊжЦљдєЛдЄКпЉМжЦ∞еҐЮеК†дЇЖдЇСзљСзЂѓпЉИдЇСиЃ°зЃЧгАБе§ІжХ∞жНЃеЯЇз°АиЃЊжЦљгАБжЩЇиГљзїИзЂѓеТМеЇФзФ®з®ЛеЇПпЉЙгАВ - дЇСиЃ°зЃЧдЄОе§ІжХ∞жНЃеЯЇз°АиЃЊжЦљзЪДеЉЇеКњеПСе±ХгАВ - дЇТиБФзљСдЄОзЙ©иБФзљСзЪДењЂйАЯжЩЃеПКгАВ - жЩЇиГљзїИзЂѓеТМеРДз±їеЇФзФ®з®ЛеЇПзЪДеєњж≥ЫдљњзФ®гАВ ...
иµДжЇРжЭ•иЗ™pypiеЃШзљСгАВ иµДжЇРеЕ®еРНпЉЪgoogle_cloud_bigtable-1.1.0-py2.py3-none-any.whl
иµДжЇРеИЖз±їпЉЪPythonеЇУ жЙАе±Юиѓ≠и®АпЉЪPython иµДжЇРеЕ®еРНпЉЪgoogle-cloud-bigtable-0.23.1.tar.gz иµДжЇРжЭ•жЇРпЉЪеЃШжЦє еЃЙи£ЕжЦєж≥ХпЉЪhttps://lanzao.blog.csdn.net/article/details/101784059