
1 概述
1.1 什么是捕获组
捕获组就是把正则表达式中子表达式匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用。当然,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部。
捕获组有两种形式,一种是普通捕获组,另一种是命名捕获组,通常所说的捕获组指的是普通捕获组。语法如下:
普通捕获组:(Expression)
命名捕获组:(?<name>Expression)
普通捕获组在大多数支持正则表达式的语言或工具中都是支持的,而命名捕获组目前只有.NET、PHP、Python等部分语言支持,据说Java会在7.0中提供对这一特性的支持。上面给出的命名捕获组的语法是.NET中的语法,另外在.NET中使用(?’name’Expression)与使用(?<name>Expression)是等价的。在PHP和Python中命名捕获组语法为:(?P<name>Expression)。
另外需要说明的一点是,除(Expression)和(?<name>Expression)语法外,其它的(?...)语法都不是捕获组。
1.2 捕获组编号规则
编号规则指的是以数字为捕获组进行编号的规则,在普通捕获组或命名捕获组单独出现的正则表达式中,编号规则比较清晰,在普通捕获组与命名捕获组混合出现的正则表达式中,捕获组的编号规则稍显复杂。
在展开讨论之前,需要说明的是,编号为0的捕获组,指的是正则表达式整体,这一规则在支持捕获组的语言中,基本上都是适用的。下面对其它编号规则逐一展开讨论。
1.2.1 普通捕获组编号规则
如果没有显式为捕获组命名,即没有使用命名捕获组,那么需要按数字顺序来访问所有捕获组。在只有普通捕获组的情况下,捕获组的编号是按照“(”出现的顺序,从左到右,从1开始进行编号的 。
正则表达式:(\d{4})-(\d{2}-(\d\d))

上面的正则表达式可以用来匹配格式为yyyy-MM-dd的日期,为了在下表中得以区分,月和日分别采用了\d{2}和\d\d这两种写法。
用以上正则表达式匹配字符串:2008-12-31,匹配结果为:
|
编号 |
命名 |
捕获组 |
匹配内容 |
|
0 |
(\d{4})-(\d{2}-(\d\d)) |
2008-12-31 |
|
|
1 |
(\d{4}) |
2008 |
|
|
2 |
|
(\d{2}-(\d\d)) |
12-31 |
|
3 |
|
(\d\d) |
31 |
1.2.2 命名捕获组编号规则
命名捕获组通过显式命名,可以通过组名方便的访问到指定的组,而不需要去一个个的数编号,同时避免了在正则表达式扩展过程中,捕获组的增加或减少对引用结果导致的不可控。
不过容易忽略的是,命名捕获组也参与了编号的,在只有命名捕获组的情况下,捕获组的编号也是按照“(”出现的顺序,从左到右,从1开始进行编号的 。
正则表达式:(?<year>\d{4})-(?<date>\d{2}-(?<day>\d\d))

用以上正则表达式匹配字符串:2008-12-31
匹配结果为:
|
编号 |
命名 |
捕获组 |
匹配内容 |
|
0 |
(?<year>\d{4})-(?<date>\d{2}-(?<day>\d\d)) |
2008-12-31 |
|
|
1 |
year |
(?<year>\d{4}) |
2008 |
|
2 |
date |
(?<date>\d{2}-(?<day>\d\d)) |
12-31 |
|
3 |
day |
(?<day>\d\d) |
31 |
1.2.3 普通捕获组与命名捕获组混合编号规则
当一个正则表达式中,普通捕获组与命名捕获组混合出现时,捕获组的编号规则稍显复杂。对于其中的命名捕获组,随时都可以通过组名进行访问,而对于普通捕获组,则只能通过确定其编号后进行访问。
混合方式的捕获组编号,首先按照普通捕获组中“(”出现的先后顺序,从左到右,从1开始进行编号,当普通捕获组编号完成后,再按命名捕获组中“(”出现的先后顺序,从左到右,接着普通捕获组的编号值继续进行编号。
也就是先忽略命名捕获组,对普通捕获组进行编号,当普通捕获组完成编号后,再对命名捕获组进行编号。
正则表达式:(\d{4})-(?<date>\d{2}-(\d\d))
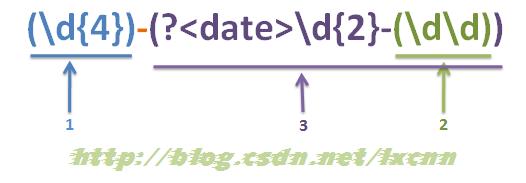
用以上正则表达式匹配字符串:2008-12-31,匹配结果为:
|
编号 |
命名 |
捕获组 |
匹配内容 |
|
0 |
(\d{4})-(?<date>\d{2}-(\d\d)) |
2008-12-31 |
|
|
1 |
(\d{4}) |
2008 |
|
|
3 |
date |
(?<date>\d{2}-(\d\d)) |
12-31 |
|
2 |
|
(\d\d) |
31 |
2 捕获组的引用
对捕获组的引用一般有以下几种:
1) 正则表达式中,对前面捕获组捕获的内容进行引用,称为反向引用;
2) 正则表达式中,(?(name)yes|no)的条件判断结构;
3) 在程序中,对捕获组捕获内容的引用。
2.1 反向引用
捕获组捕获到的内容,不仅可以在正则表达式外部通过程序进行引用,也可以在正则表达式内部进行引用,这种引用方式就是反向引用。
反向引用的作用通常是用来查找或限定重复,限定指定标识配对出现等等。
对于普通捕获组和命名捕获组的引用,语法如下:
普通捕获组反向引用:\k<number>,通常简写为\number
命名捕获组反向引用:\k<name>或者\k'name'
普通捕获组反向引用中number是十进制的数字,即捕获组的编号;命名捕获组反向引用中的name为命名捕获组的组名。
反向引用涉及到的内容比较多,后续单独说明。
2.2 条件判断表达式
条件判断结构在平衡组中谈到过,基本应用和扩展应用都可以在其中找到例子,这里不再赘述,请参考 .NET正则基础之——平衡组。
2.3 程序中引用
根据语言的不同,程序中对捕获组引用的方式也有所不同,下面就JavaScript和.NET进行举例说明。
2.3.1 JavaScript中的引用
由于JavaScript中不支持命名捕获组,所以对于捕获组的引用就只支持普通捕获组的反向引用和$number方式的引用。程序中的引用一般在替换和匹配时使用。
注:以下应用举例仅考虑简单应用场景,对于<a href="javascript:document.write('<b>hello</b>')"/>这种复杂场景暂不考虑。
1) 在Replace中引用,通常是通过$number方式引用。
举例:替换掉html标签中的属性。
<textareaid="result"rows="10"cols="100"></textarea>
<scripttype="text/javascript">
var data = "<table id=\"test\"><tr class=\"light\"><td> test </td></tr></table>";
var reg = /<([a-z]+)[^>]*>/ig;
document.getElementById("result").value = data.replace(reg, "<$1>");
</script>
//输出
<table><tr><td> test </td></tr></table>
2) 在匹配时的引用,通常通过RegExp.$number方式引用。
举例:同时获取<img…>中的src和name属性值,属性的顺序不固定。参考 一条正则能不能同时取出一个img标记的src和name?
- <textarea id="result" rows="10" cols="100"></textarea>
- <script type="text/javascript">
- var data = [' <img alt="" border="0" name="g6-o44-1" onload="DrawImage" src="/bmp/foo1.jpg" />', ' <img src="/bmp/foo2.jpg" alt="" border="0" name="g6-o44-2" onload="DrawImage" />'] ;
- var reg = /<img\b(?=(?:(?!name=).)*name=(['"]?)([^'"\s>]+)\1)(?:(?!src=).)*src=(['"]?)([^'"\s>]+)\3[^>]*>/i;
- for(var i=0;i<data.length;i++)
- {
- var s = data[i];
- document.getElementById("result").value += "源字符串:" + s + "\n";
- document.write("<br />");
- if(reg.test(s))
- {
- document.getElementById("result").value += "name: " + RegExp.$2 + "\n";
- document.getElementById("result").value += "src: " + RegExp.$4 + "\n";
- }
- }
- </script>
2.3.2 .NET中的引用
由于.NET支持命名捕获组,所以在.NET中的引用方式会多一些。通常也是在两种场景下应用,一是替换,一是匹配。
1) 替换中的引用
普通捕获组:$number
命名捕获组:${name}
替换中应用,仍是上面的例子。
举例:替换掉html标签中的属性。使用普通捕获组。
string data = "<table id=\"test\"><tr class=\"light\"><td> test </td></tr></table>";
richTextBox2.Text = Regex.Replace(data, @"(?i)<([a-z]+)[^>]*>", "<$1>");
//输出
<table><tr><td> test </td></tr></table>
使用命名捕获组。
string data = "<table id=\"test\"><tr class=\"light\"><td> test </td></tr></table>";
richTextBox2.Text = Regex.Replace(data, @"(?i)<(?<tag>[a-z]+)[^>]*>", "<${tag}>");
//输出
<table><tr><td> test </td></tr></table>
2) 匹配后的引用
对于匹配结果中捕获组捕获内容的引用,可以通过Groups和Result对象进行引用。
string test = "<a href=\"http://www.csdn.net\">CSDN</a>";
Regex reg = new Regex(@"(?is)<a(?:(?!href=).)*href=(['""]?)(?<url>[^""'\s>]*)\1[^>]*>(?<text>(?:(?!</a>).)*)</a>");
MatchCollection mc = reg.Matches(test);
foreach (Match m in mc)
{
richTextBox2.Text += "m.Value:".PadRight(25) + m.Value + "\n";
richTextBox2.Text += "m.Result(\"$0\"):".PadRight(25) + m.Result("$0") + "\n";
richTextBox2.Text += "m.Groups[0].Value:".PadRight(25) + m.Groups[0].Value + "\n";
richTextBox2.Text += "m.Result(\"$2\"):".PadRight(25) + m.Result("$2") + "\n";
richTextBox2.Text += "m.Groups[2].Value:".PadRight(25) + m.Groups[2].Value + "\n";
richTextBox2.Text += "m.Result(\"${url}\"):".PadRight(25) + m.Result("${url}") + "\n";
richTextBox2.Text += "m.Groups[\"url\"].Value:".PadRight(25) + m.Groups["url"].Value + "\n";
richTextBox2.Text += "m.Result(\"$3\"):".PadRight(25) + m.Result("$3") + "\n";
richTextBox2.Text += "m.Groups[3].Value:".PadRight(25) + m.Groups[3].Value + "\n";
richTextBox2.Text += "m.Result(\"${text}\"):".PadRight(25) + m.Result("${text}") + "\n";
richTextBox2.Text += "m.Groups[\"text\"].Value:".PadRight(25) + m.Groups["text"].Value + "\n";
}
//输出
m.Value: <a href="http://www.csdn.net">CSDN</a>
m.Result("$0"): <a href="http://www.csdn.net">CSDN</a>
m.Groups[0].Value: <a href="http://www.csdn.net">CSDN</a>
m.Result("$2"): http://www.csdn.net
m.Groups[2].Value: http://www.csdn.net
m.Result("${url}"): http://www.csdn.net
m.Groups["url"].Value: http://www.csdn.net
m.Result("$3"): CSDN
m.Groups[3].Value: CSDN
m.Result("${text}"): CSDN
m.Groups["text"].Value: CSDN
对于捕获组0的引用,可以简写作m.Value。



相关推荐
本文件“正则基础之——捕获组(capture group)”将深入讲解正则表达式中的一个重要概念——捕获组,这是理解和运用正则表达式不可或缺的一部分。 捕获组是正则表达式中的一种机制,它允许我们将一个模式分隔成多...
在正则表达式中,捕获组(Capture Group)和反向引用是两个非常重要的概念,它们能帮助我们更加精确地控制匹配规则。 首先,我们来了解捕获组。捕获组是通过圆括号 "(...)" 来定义的,它允许我们将一个正则表达式的...
如果正则表达式同时包含普通捕获组和命名捕获组,系统会先为普通捕获组编号,然后再对命名捕获组编号。在这种情况下,命名捕获组仍然可以通过它们的名字进行引用。 捕获组的引用是正则表达式中的一个重要功能。它...
您可以对Java 7中的命名捕获组使用相同的构造(即(?<name>patt)等),如以下示例所示: import com.google.code.regexp.Pattern ; import com.google.code.regexp.Matcher ; public class NamedRegexpTest { ...
捕获组(Capture Group) 捕获组允许我们将部分模式标记为一个单独的单元,并可以引用该单元。语法通常为`(...)`。例如: - `(abc)`:将"abc"作为一个整体进行匹配。 ##### 2. 非捕获组 非捕获组类似于捕获组,但...
2. 捕获组(Capture Group): - 捕获组是使用圆括号括起来的正则表达式的一部分,它的作用是将一部分匹配的文本保存为一个子匹配结果。在Java正则表达式中,捕获组通过其左括号的顺序来编号,左括号出现的第一个...
- **GroupCollection类**:包含一组`Group`对象,通常用于表示一个匹配结果中的所有捕获组。 - **Capture类**:表示捕获组内的具体匹配。 - **CaptureCollection类**:包含一组`Capture`对象,表示一个捕获组内的...
3. **Group类**:Group类表示单个捕获组的结果,捕获组是由括号()`定义的子表达式。一个Match可能包含零个或多个Group,每个Group可能包含零个或多个捕获(Capture)。 4. **Capture类**:Capture类表示单个捕获的...
4. `Group`类代表一个捕获组,捕获的是正则表达式中圆括号包围的部分。 5. `GroupCollection`是`Group`对象的集合,用于存储所有捕获的组。 6. `Capture`类代表单个捕获的子字符串。 7. `CaptureCollection`包含了一...
4. **Group类**:表示正则表达式中的捕获组。 - `Group::Value`:获取组的匹配值。 - `Group::Captures`:获取CaptureCollection,包含组内的所有捕获。 5. **Capture类**:表示正则表达式中一个特定的捕获实例。...
`Capture`类表示正则表达式匹配中捕获到的一个片段,而`CaptureCollection`则是`Capture`对象的集合,通常用于存储多个捕获结果。 #### 2. `Group`和`GroupCollection` `Group`用于表示正则表达式中的一个分组,...
对于复杂的正则表达式,可能包含捕获组(capture group),即使用括号`()`定义的部分。这些组可以捕获匹配的子串,并且可以通过`Match.Groups`属性访问。该工具还可能实现了高亮显示匹配部分的功能,以直观地呈现...
- **Group**: 表示一个捕获组的匹配结果。 - **GroupCollection**: 包含一组捕获组的结果集合。 - **Match**: 表示单个正则表达式的匹配结果。 - **MatchCollection**: 存储多次应用正则表达式到字符串后得到的所有...
精通正则表达式第三版 搜集于网络 前言..........I 第1章:正则表达式入门.... 1 解决实际问题... 2 作为编程语言的正则表达式... 4 以文件名做类比... 4 以语言做类比... 5 正则表达式的知识框架... 6 对于...
- **`Group`类**:表示正则表达式中的组匹配结果,继承自`Capture`类。 - **`Capture`类**:表示单次匹配的一部分结果。 - **`CaptureCollection`类**:表示`Capture`对象的集合。 #### 静态方法介绍 - **`Regex....
除了`Regex`类,`System.Text.RegularExpressions`命名空间还包括其他辅助类,如`Capture`(单次匹配结果)、`CaptureCollection`(Capture的集合)、`Group`(一组匹配结果,包括捕获组)和`GroupCollection`(所有...
捕获组(Capture Group)是正则表达式中用括号`()`包裹的部分,可以保存匹配的子串,以便后续使用。`lastParen`属性就是用来访问最后一个成功捕获的括号中的文本。 在JavaScript 1.2之前,如果想要获取捕获组的值,...
Deelx库还支持捕获组(capture group),这意味着你可以获取匹配模式内的特定部分。例如,如果你的正则表达式中有圆括号包围的部分,可以通过索引来访问这些匹配的子串。 此外,Deelx还提供了`replace`函数,可以...