
 
LMAXжШѓдЄАзІНжЦ∞еЮЛйЫґеФЃйЗСиЮНдЇ§жШУеє≥еП∞пЉМеЃГиГље§Ядї•еЊИдљОзЪДеїґињЯ(latency)дЇІзФЯе§ІйЗПдЇ§жШУ(еРЮеРРйЗП). ињЩдЄ™з≥їзїЯжШѓеїЇзЂЛеЬ®JVMеє≥еП∞дЄКпЉМж†ЄењГжШѓдЄАдЄ™дЄЪеК°йАїиЊСе§ДзРЖеЩ®пЉМеЃГиГље§ЯеЬ®дЄАдЄ™зЇњз®ЛйЗМжѓПзІТе§ДзРЖ6зЩЊдЄЗиЃҐеНХ. дЄЪеК°йАїиЊСе§ДзРЖеЩ®еЃМеЕ®жШѓињРи°МеЬ®еЖЕе≠ШдЄ≠(in-memory)пЉМдљњзФ®дЇЛдїґжЇРй©±еК®жЦєеЉП(event sourcing). дЄЪеК°йАїиЊСе§ДзРЖеЩ®зЪДж†ЄењГжШѓDisruptorsпЉМињЩжШѓдЄАдЄ™еєґеПСзїДдїґпЉМиГље§ЯеЬ®жЧ†йФБзЪДжГЕеЖµдЄЛеЃЮзО∞зљСзїЬзЪДQueueеєґеПСжУНдљЬгАВдїЦдїђзЪДз†Фз©ґи°®жШОпЉМзО∞еЬ®зЪДжЙАи∞УйЂШжАІиГљз†Фз©ґжЦєеРСдЉЉдєОеТМзО∞дї£CPUиЃЊиЃ°жШѓзЫЄеЈ¶зЪДгАВ(иІБеП¶е§ЦдЄАзѓЗжЦЗзЂ†пЉЪJVMдЉ™еЕ±дЇЂ)
ињЗеОїеЗ†еєіжИСдїђдЄНжЦ≠жПРдЊЫињЩж†Је£∞йЯ≥пЉЪеЕНиієеНИй§РеЈ≤зїПзїУжЭЯгАВжИСдїђдЄНеЖНиГљжЬЯжЬЫеЬ®еНХдЄ™CPUдЄКиОЈеЊЧжЫіењЂзЪДжАІиГљпЉМеЫ†ж≠§жИСдїђйЬАи¶БеЖЩдљњзФ®е§Ъж†Єе§ДзРЖзЪДеєґеПСиљѓдїґпЉМдЄНеєЄзЪДжШѓпЉМ зЉЦеЖЩеєґеПСиљѓдїґжШѓеЊИйЪЊзЪДпЉМйФБеТМдњ°еПЈйЗПжШѓеЊИйЪЊзРЖиІ£зЪДеТМйЪЊдї•жµЛиѓХпЉМињЩжДПеС≥зЭАжИСдїђи¶БиК±жЫіе§ЪжЧґйЧіеЬ®иЃ°зЃЧжЬЇдЄКпЉМиАМдЄНжШѓжИСдїђзЪДйҐЖеЯЯйЧЃйҐШпЉМеРДзІНеєґеПСж®°еЮЛпЉМе¶ВActors еТМиљѓдЇЛеК°STM(Software Transactional Memory), зЫЃзЪДжШѓжЫіеК†еЃєжШУдљњзФ®пЉМдљЖжШѓжМЙдЄЛиСЂиК¶й£ШиµЈзУҐпЉМињШжШѓеЄ¶жЭ•дЇЖbugsеТМе§НжЭВжАІ.
жИСеЊИжГКиЃґеРђеИ∞еОїеєі3жЬИQConдЄКдЄАдЄ™жЉФиЃ≤пЉМ LMAXжШѓдЄАзІНжЦ∞зЪДйЫґеФЃзЪДйЗСиЮНдЇ§жШУеє≥еП∞гАВеЃГзЪДдЄЪеК°еИЫжЦ∞ - еЕБиЃЄдїїдљХдЇЇеЬ®дЄАз≥їеИЧзЪДйЗСиЮНи°НзФЯдЇІеУБдЇ§жШУгАВињЩе∞±йЬАи¶БйЭЮеЄЄдљОзЪДеїґињЯпЉМйЭЮеЄЄењЂйАЯзЪДе§ДзРЖпЉМеЫ†дЄЇеЄВеЬЇеПШеМЦеЊИењЂпЉМињЩдЄ™йЫґеФЃеє≥еП∞еЫ†дЄЇжЬЙеЊИе§ЪдЇЇеРМжЧґжУНдљЬиЗ™зДґеЕЈе§ЗдЇЖе§НжЭВжАІпЉМзФ®жИЈиґКе§ЪпЉМдЇ§жШУйЗПиґКе§ІпЉМдЄНжЦ≠ењЂйАЯеҐЮйХњгАВ
йЙідЇОе§Ъж†ЄењГжАЭжГ≥зЪДиљђеПШпЉМињЩзІНиЛЫеИїзЪДжАІиГљиЗ™зДґдЉЪжПРеЗЇдЄАдЄ™жШОз°ЃзЪДеєґи°МзЉЦз®Лж®°еЮЛ пЉМдљЖжШѓдїЦдїђеНіжПРеЗЇзФ®дЄАдЄ™зЇњз®Ле§ДзРЖ6зЩЊдЄЗиЃҐеНХпЉМиАМдЄФжШѓжѓПзІТпЉМеЬ®йАЪзФ®зЪДз°ђдїґдЄКгАВ
йАЪињЗдљОеїґињЯе§ДзРЖе§ІйЗПдЇ§жШУпЉМеПЦеЊЧдљОеїґињЯеТМйЂШеРЮеРРйЗПпЉМиАМдЄФж≤°жЬЙеєґеПСдї£з†БзЪДе§НжЭВжАІпЉМдїЦдїђжШѓжАОдєИеБЪеИ∞еСҐпЉЯзО∞еЬ®LMAXеЈ≤зїПдЇІеУБеМЦдЄАжЃµжЧґйЧідЇЖпЉМзО∞еЬ®еЇФиѓ•еПѓдї•жП≠еЉАеЕґз•ЮзІШиАМињЈдЇЇзЪДйЭҐзЇ±дЇЖгАВ
зїУжЮДе¶ВеЫЊпЉЪ
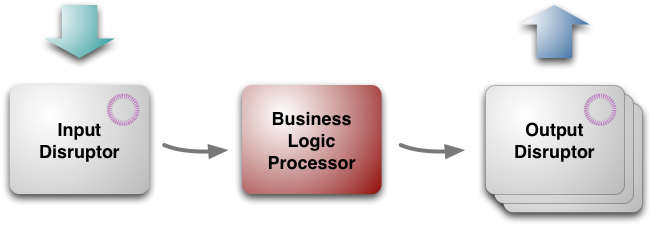
дїОжЬАйЂШе±Вжђ°зЬЛпЉМжЮґжЮДжЬЙдЄЙдЄ™йГ®еИЖпЉЪ
дЄЪеК°йАїиЊСе§ДзРЖеЩ®business logic processor[5]
иЊУеЕ•input disruptor
иЊУеЗЇoutput disruptors
дЄЪеК°йАїиЊСе§ДзРЖеЩ®е§ДзРЖжЙАжЬЙзЪДеЇФзФ®з®ЛеЇПзЪДдЄЪеК°йАїиЊСпЉМињЩжШѓдЄАдЄ™еНХзЇњз®ЛзЪДJavaз®ЛеЇПпЉМзЇѓз≤єзЪДжЦєж≥Хи∞ГзФ®пЉМеєґињФеЫЮиЊУеЗЇгАВдЄНйЬАи¶БдїїдљХеє≥еП∞ж°ЖжЮґпЉМињРи°МеЬ®JVMйЗМпЉМињЩе∞±дњЭиѓБеЕґеЊИеЃєжШУињРи°МжµЛиѓХзОѓеҐГгАВ
дЄЪеК°йАїиЊСе§ДзРЖеЩ®
еЕ®йГ®й©їзХЩеЬ®еЖЕе≠ШдЄ≠
дЄЪеК°йАїиЊСе§ДзРЖеЩ®жЬЙжђ°еЇПеЬ∞еПЦеЗЇжґИжБѓпЉМзДґеРОињРи°МеЕґдЄ≠зЪДдЄЪеК°йАїиЊСпЉМзДґеРОдЇІзФЯиЊУеЗЇдЇЛдїґпЉМжХідЄ™жУНдљЬйГљжШѓеЬ®еЖЕе≠ШдЄ≠пЉМж≤°жЬЙжХ∞жНЃеЇУжИЦеЕґдїЦжМБдєЕе≠ШеВ®гАВе∞ЖжЙАжЬЙжХ∞жНЃй©їзХЩеЬ®еЖЕе≠ШдЄ≠жЬЙдЄ§дЄ™йЗНи¶Бе•ље§ДпЉЪй¶ЦеЕИжШѓењЂпЉМж≤°жЬЙIOпЉМдєЯж≤°жЬЙдЇЛеК°пЉМеЕґжђ°жШѓзЃАеМЦзЉЦз®ЛпЉМж≤°жЬЙеѓєи±°/еЕ≥з≥їжХ∞жНЃеЇУзЪДжШ†е∞ДпЉМжЙАжЬЙдї£з†БйГљжШѓдљњзФ®Javaеѓєи±°ж®°еЮЛ(еєњеСКпЉЪеЉАжЇРж°ЖжЮґJdonframeworkеТМJiveJdonдєЯжШѓеЕ®йГ®еЯЇдЇОеЖЕе≠ШеТМдЇЛдїґжЇРпЉМеЖЕе≠ШйҐЖеЯЯеѓєи±°+дЇЛдїґй©±еК®пЉМзЬЛжЭ•ињЩжЭ°иЈѓзЪДжЦєеРСжШѓеѓєзЪД)гАВ
дљњзФ®еЯЇдЇОеЖЕе≠ШзЪДж®°еЮЛжЬЙдЄАдЄ™йЗНи¶БйЧЃйҐШпЉЪдЄЗдЄАеі©жЇГжАОдєИеКЮпЉЯзФµжЇРжОЙзФµдєЯжШѓеПѓиГљеПСзФЯзЪДпЉМвАЬдЇЛдїґвАЭ(Event Sourcing )ж¶ВењµжШѓйЧЃйҐШиІ£еЖ≥зЪДж†ЄењГпЉМдЄЪеК°йАїиЊСе§ДзРЖеЩ®зЪДзКґжАБжШѓзФ±иЊУеЕ•дЇЛдїґй©±еК®зЪДпЉМеП™и¶БињЩдЇЫиЊУеЕ•дЇЛ俴襀жМБдєЕеМЦдњЭе≠ШиµЈжЭ•пЉМдљ†е∞±жАїжШѓиГље§ЯеЬ®еі©жЇГжГЕеЖµдЄЛпЉМж†єжНЃдЇЛдїґйЗНжЉФйЗНжЦ∞иОЈеЊЧељУеЙНзКґжАБгАВ(NOSQLе≠ШеВ®зЪДеЯЇдЇОдЇЛдїґзЪДдЇЛеК°еЃЮзО∞)
и¶БеЊИе•љзРЖиІ£ињЩзВєеПѓдї•йАЪињЗзЙИжЬђжОІеИґз≥їзїЯжЭ•зРЖиІ£пЉМзЙИжЬђжОІеИґз≥їзїЯжПРдЇ§зЪДеЇПеИЧпЉМеЬ®дїїдљХжЧґеАЩпЉМдљ†еПѓдї•еїЇзЂЛзФ±зФ≥иѓЈиАЕжПРдЇ§дЄАдЄ™еЈ•дљЬжЛЈиіЭпЉМзЙИжЬђжОІеИґз≥їзїЯжШѓдЄАдЄ™е§НжЭВзЪДеХЖдЄЪйАїиЊСе§ДзРЖеЩ®пЉМиАМињЩйЗМзЪДдЄЪеК°йАїиЊСе§ДзРЖеП™жШѓдЄАдЄ™зЃАеНХзЪДеЇПеИЧгАВ
еЫ†ж≠§пЉМдїОзРЖиЃЇдЄКиЃ≤пЉМдљ†жАїжШѓеПѓдї•йАЪињЗеРОе§ДзРЖзЪДжЙАжЬЙдЇЛдїґзЪДеХЖдЄЪйАїиЊСе§ДзРЖеЩ®йЗНеїЇзЪДзКґжАБпЉМдљЖжШѓеЃЮиЈµдЄ≠йЗНеїЇжЙАжЬЙдЇЛдїґжШѓиАЧжЧґзЪДпЉМйЬАи¶БеИЗеИЖпЉМLMAXжПРдЊЫдЄЪеК°йАїиЊСе§ДзРЖзЪДењЂзЕІпЉМдїОењЂзЕІињШеОЯпЉМжѓП姩жЩЪдЄКз≥їзїЯдЄНзєБењЩжЧґжЮДеїЇењЂзЕІпЉМйЗНжЦ∞еРѓеК®еХЖдЄЪйАїиЊСе§ДзРЖеЩ®зЪДйАЯеЇ¶еЊИењЂпЉМдЄАдЄ™еЃМжХізЪДйЗНжЦ∞еРѓеК® - еМЕжЛђйЗНжЦ∞еРѓеК®JVMеК†иљљжЬАињСзЪДењЂзЕІпЉМеТМйЗНжФЊдЄА姩дЇЛдїґ - дЄНеИ∞дЄАеИЖйТЯгАВ
ењЂзЕІиЩљзДґдљњеРѓеК®дЄАдЄ™жЦ∞зЪДдЄЪеК°йАїиЊСе§ДзРЖеЩ®зЪДйАЯеЇ¶пЉМдљЖйАЯеЇ¶ињШдЄНе§ЯењЂпЉМдЄЪеК°йАїиЊСе§ДзРЖеЩ®еЬ®дЄЛеНИ2жЧґе∞±йЭЮеЄЄзєБењЩзФЪиЗ≥еі©жЇГпЉМLMAXе∞±дњЭжМБе§ЪдЄ™дЄЪеК°йАїиЊСе§ДзРЖеЩ®еРМжЧґињРи°МпЉМжѓПдЄ™иЊУеЕ•дЇЛдїґзФ±е§ЪдЄ™е§ДзРЖеЩ®е§ДзРЖпЉМеП™жЬЙдЄАдЄ™е§ДзРЖеЩ®иЊУеЗЇжЬЙжХИпЉМеЕґдїЦењљзХ•пЉМе¶ВжЮЬдЄАдЄ™е§ДзРЖеٮ姱賕пЉМеИЗжНҐеИ∞еП¶е§ЦдЄАдЄ™пЉМињЩзІНжХЕйЪЬ蚐粿姱賕жБҐе§НжШѓдЇЛдїґжЇРй©±еК®(Event Sourcing)зЪДеП¶е§ЦдЄАдЄ™е•ље§ДгАВ
йАЪињЗдЇЛдїґй©±еК®(event sourcing)дїЦдїђдєЯеПѓдї•еЬ®е§ДзРЖеЩ®дєЛйЧідї•еЊЃзІТйАЯеЇ¶еИЗжНҐпЉМжѓПжЩЪеИЫеїЇењЂзЕІпЉМжѓПжЩЪйЗНеРѓдЄЪеК°йАїиЊСе§ДзРЖеЩ®пЉМ ињЩзІНе§НеИґжЦєеЉПиГље§ЯдњЭиѓБдїЦдїђж≤°жЬЙељУжЬЇжЧґйЧіпЉМеЃЮзО∞24/7.
дЇЛдїґжЦєеЉПжШѓжЬЙдїЈеАЉзЪДеЫ†дЄЇеЃГеЕБиЃЄе§ДзРЖеЩ®еПѓдї•еЃМеЕ®еЬ®еЖЕе≠ШдЄ≠ињРи°МпЉМдљЖеЃГжЬЙеП¶дЄАзІНзФ®дЇОиѓКжЦ≠зЫЄељУе§ІзЪДдЉШеКњпЉЪе¶ВжЮЬеЗЇзО∞дЄАдЇЫжДПжГ≥дЄНеИ∞зЪДи°МдЄЇпЉМдЇЛдїґеЙѓжЬђдїђиГље§ЯиЃ©дїЦдїђеЬ®еЉАеПСзОѓеҐГйЗНжФЊзФЯдЇІзОѓеҐГзЪДдЇЛдїґпЉМињЩе∞±еЃєжШУдљњдїЦдїђиГље§Яз†Фз©ґеТМеПСзО∞еЗЇеЬ®зФЯдЇІзОѓеҐГеИ∞еЇХеПСзФЯдЇЖдїАдєИдЇЛгАВ
ињЩзІНиѓКжЦ≠иГљеКЫеїґдЉЄеИ∞дЄЪеК°иѓКжЦ≠гАВжЬЙдЄАдЇЫдЉБдЄЪзЪДдїїеК°пЉМе¶ВеЬ®й£ОйЩ©зЃ°зРЖпЉМйЬАи¶Бе§ІйЗПзЪДиЃ°зЃЧпЉМдљЖжШѓдЄНе§ДзРЖиЃҐеНХгАВдЄАдЄ™дЊЛе≠РжШѓж†єжНЃеЕґзЫЃеЙНзЪДдЇ§жШУе§іеѓЄзЪДй£ОйЩ©зКґеЖµжОТеРНеЙН20дљНеЃҐжИЈеРНеНХпЉМдїЦдїђе∞±еПѓдї•еИЗеИЖеИ∞е§НеИґе•љзЪДйҐЖеЯЯж®°еЮЛдЄ≠ињЫи°МиЃ°зЃЧпЉМиАМдЄНжШѓеЬ®зФЯдЇІзОѓеҐГдЄ≠ж≠£еЬ®ињРи°МзЪДйҐЖеЯЯж®°еЮЛпЉМдЄНеРМжАІиі®зЪДйҐЖеЯЯж®°еЮЛдњЭе≠ШеЬ®дЄНеРМжЬЇеЩ®зЪДеЖЕе≠ШдЄ≠пЉМељЉж≠§дЄНељ±еУНгАВ
жАІиГљдЉШеМЦ
ж≠£е¶ВжИСиІ£йЗКпЉМдЄЪеК°йАїиЊСе§ДзРЖеЩ®зЪДжАІиГљеЕ≥йФЃжШѓжМЙй°ЇеЇПеЬ∞еБЪдЇЛ(еЕґеЃЮеєґдЄНжДЪ膥 еєґи°МеБЪе∞±иБ™жШОеРЧпЉЯ)пЉМињЩеПѓдї•иЃ©жЩЃйАЪеЉАеПСиАЕеЖЩзЪДдї£з†Бе§ДзРЖ10K TPS. е¶ВжЮЬиГљз≤ЊзЃАдї£з†БиГље§ЯеЄ¶жЭ•100K TPSжПРеНЗ. ињЩйЬАи¶БиЙѓе•љзЪДдї£з†БеТМе∞ПжЦєж≥ХпЉМељУзДґпЉМJVM HotspotзЪДзЉУе≠ШеЊЃи∞ГпЉМиЃ©еЕґжЫіеК†дЉШеМЦдєЯжШѓењЕй°їзЪДгАВ
дї•дЄЛзЬБеОїдЄ§жЃµ.......и∞ГиѓХжЦєйЭҐгАВ
зЉЦз®Лж®°еЮЛ
дї•дЄАдЄ™зЃАеНХзЪДйЭЮLMAXзЪДдЊЛе≠РжЭ•иѓіжШОгАВжГ≥и±°дЄАдЄЛпЉМдљ†ж≠£еЬ®дЄЇз≥Ци±ЖдљњзФ®дњ°зФ®еН°дЄЛиЃҐеНХгАВдЄАдЄ™зЃАеНХзЪДйЫґеФЃз≥їзїЯе∞ЖиОЈеПЦжВ®зЪДиЃҐеНХдњ°жБѓпЉМдљњзФ®дњ°зФ®еН°й™МиѓБжЬНеК°пЉМдї•ж£АжЯ•жВ®зЪДдњ°зФ®еН°еПЈз†БпЉМзДґеРОз°ЃиЃ§жВ®зЪДиЃҐеНХ - жЙАжЬЙињЩдЇЫйГљеЬ®дЄАдЄ™еНХдЄАињЗз®ЛдЄ≠жУНдљЬгАВељУињЫи°Мдњ°зФ®еН°жЬЙжХИжАІж£АжЯ•жЧґпЉМжЬНеК°еЩ®ињЩиЊєзЪДзЇњз®ЛдЉЪйШїе°Юз≠ЙеЊЕпЉМељУзДґињЩдЄ™еѓєдЇОзФ®жИЈжЭ•иѓіеБЬй°њдЄНдЉЪ姙йХњгАВ
еЬ®MAXжЮґжЮДдЄ≠пЉМдљ†е∞Жж≠§еНХдЄАжУНдљЬињЗз®ЛеИЖдЄЇдЄ§дЄ™пЉМзђђдЄАйГ®еИЖе∞ЖиОЈеПЦиЃҐеНХдњ°жБѓпЉМзДґеРОиЊУеЗЇдЇЛдїґ(иѓЈж±Вдњ°зФ®еН°ж£АжЯ•жЬЙжХИжАІзЪДиѓЈж±ВдЇЛдїґ)зїЩдњ°зФ®еН°еЕђеПЄ. дЄЪеК°йАїиЊСе§ДзРЖеЩ®е∞ЖзїІзї≠е§ДзРЖеЕґдїЦеЃҐжИЈзЪДиЃҐеНХпЉМзЫіиЗ≥еЃГеЬ®иЊУеЕ•дЇЛдїґдЄ≠еПСзО∞дЇЖдњ°зФ®еН°еЈ≤зїПж£АжЯ•жЬЙжХИзЪДдЇЛдїґпЉМзДґеРОиОЈеПЦиѓ•дЇЛдїґжЭ•з°ЃиЃ§иѓ•иЃҐеНХжЬЙжХИгАВ
ињЩзІНеЉВж≠•дЇЛдїґй©±еК®жЦєеЉПз°ЃеЃЮдЄНеѓїеЄЄпЉМиЩљзДґдљњзФ®еЉВж≠•жПРйЂШеЇФзФ®з®ЛеЇПзЪДеУНеЇФжШѓдЄАдЄ™зЖЯжВЙзЪДжКАжЬѓгАВеЃГињШеПѓдї•еЄЃеК©дЄЪеК°жµБз®ЛжЫіеЉєжАІпЉМеЫ†дЄЇдљ†ењЕй°їи¶БжЫіжШОз°ЃзЪДжАЭиАГдЄОињЬз®ЛеЇФзФ®з®ЛеЇПжЙУдЇ§йБУзЪДдЄНеРМдєЛе§ДгАВ
ињЩдЄ™зЉЦз®Лж®°еЮЛзђђдЇМдЄ™зЙєзВєеЬ®дЇОйФЩиѓѓе§ДзРЖгАВдЉ†зїЯж®°еЉПдЄЛдЉЪиѓЭеТМжХ∞жНЃеЇУдЇЛеК°жПРдЊЫдЇЖдЄАдЄ™жЬЙзФ®зЪДйФЩиѓѓе§ДзРЖиГљеКЫгАВе¶ВжЮЬжЬЙдїАдєИеЗЇйФЩпЉМеЊИеЃєжШУжКЫеЗЇдїїдљХдЄЬи•њпЉМињЩдЄ™дЉЪиѓЭиГље§Я襀䪥еЉГгАВе¶ВжЮЬдЄАдЄ™йФЩиѓѓеПСзФЯеЬ®жХ∞жНЃеЇУзЂѓпЉМдљ†еПѓдї•еЫЮжїЪдЇЛеК°гАВ
LMAXзЪДеЖЕе≠Шж®°еЉП(in-memory structures)еЬ®дЇОжМБдєЕеМЦиЊУеЕ•дЇЛдїґпЉМе¶ВжЮЬжЬЙйФЩиѓѓеПСзФЯдєЯдЄНдЉЪдїОеЖЕе≠ШдЄ≠з¶їеЉАйА†жИРдЄНдЄАиЗізЪДзКґжАБгАВдљЖжШѓеЫ†дЄЇж≤°жЬЙеЫЮжїЪжЬЇеИґпЉМLMAXжКХеЕ•дЇЖжЫіе§Ъз≤ЊеКЫпЉМз°ЃдњЭиЊУеЕ•дЇЛдїґеЬ®еЃЮжЦљдїїдљХеЖЕе≠ШзКґжАБељ±еУНеЙНжЬЙжХИеЬ∞жМБдєЕеМЦпЉМдїЦдїђеПСзО∞ињЩдЄ™еЕ≥йФЃжШѓжµЛиѓХпЉМеЬ®ињЫеЕ•зФЯдЇІзОѓеҐГдєЛеЙНе∞љеПѓиГљеПСзО∞еРДзІНйЧЃйҐШпЉМз°ЃдњЭжМБдєЕеМЦжЬЙжХИгАВ
е∞љзЃ°дЄЪеК°йАїиЊСжШѓеЬ®еНХдЄ™зЇњз®ЛдЄ≠еЃЮзО∞зЪДпЉМдљЖжШѓеЬ®жИСдїђи∞ГзФ®дЄАдЄ™дЄЪеК°еѓєи±°жЦєж≥ХдєЛеЙНпЉМжЬЙеЊИе§ЪдїїеК°йЬАи¶БеЃМжИР. еОЯеІЛиЊУеЕ•жЭ•иЗ™дЇОжґИжБѓељҐеЉПпЉМињЩдЄ™жґИжБѓйЬАи¶БжБҐе§НжИРдЄЪеК°йАїиЊСе§ДзРЖеЩ®иГље§Яе§ДзРЖзЪД嚥еЉПгАВдЇЛдїґжЇРEvent SourcingдЊЭиµЦдЇОиЃ©жЙАжЬЙиЊУеЕ•дЇЛдїґжМБдєЕеМЦпЉМињЩж†ЈжѓПдЄ™иЊУеЕ•жґИжБѓйЬАи¶БиГље§Яе≠ШеВ®еИ∞жМБдєЕеМЦдїЛиі®дЄКпЉМжЬАеРОжХідЄ™жЮґжЮДињШжЬЙиµЦдЇОдЄЪеК°йАїиЊСе§ДзРЖеЩ®зЪДйЫЖзЊ§. еРМж†ЈеЬ®иЊУеЗЇдЄАиЊєпЉМиЊУеЗЇдЇЛдїґдєЯйЬАи¶БињЫи°МиљђжНҐдї•дЊњиГље§ЯеЬ®зљСзїЬдЄКдЉ†иЊУгАВ
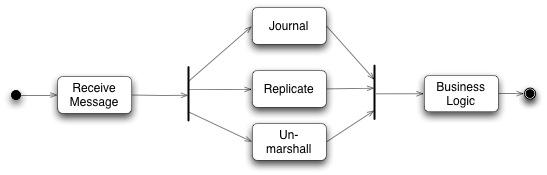
е¶ВеЫЊе§НеИґеТМжЧ•ењЧжШѓжѓФиЊГжЕҐзЪДгАВжЙАжЬЙдЄЪеК°йАїиЊСе§ДзРЖеЩ®йБњеЕНжЬАдїїдљХIOе§ДзРЖпЉМжЙАжЬЙињЩдЇЫдїїеК°йГљеЇФиѓ•зЫЄеѓєзЛђзЂЛпЉМдїЦдїђйЬАи¶БеЬ®дЄЪеК°йАїиЊСе§ДзРЖеЩ®е§ДзРЖдєЛеЙНеЃМжИРпЉМеЃГдїђеПѓдї•дї•дїїдљХжђ°еЇПжЦєеЉПеЃМжИРпЉМињЩдЄНеРМжДПдЄЪеК°йАїиЊСе§ДзРЖеЩ®йЬАи¶Бж†єжНЃдЇ§жШУиЗ™зДґеЕИеРОињЫи°МдЇ§жШУ,ињЩдЇЫйГљжШѓйЬАи¶БзЪДеєґеПСжЬЇеИґгАВ
дЄЇдЇЖињЩдЄ™еєґеПСжЬЇеИґпЉМдїЦдїђеЉАеПСдЇЖdisruptorзЪДеЉАжЇРзїДдїґгАВ
DisruptorеПѓдї•зЬЛжИРдЄАдЄ™дЇЛдїґзЫСеРђжИЦжґИжБѓжЬЇеИґпЉМеЬ®йШЯеИЧдЄ≠дЄАиЊєзФЯдЇІиАЕжФЊеЕ•жґИжБѓпЉМеП¶е§ЦдЄАиЊєжґИиієиАЕеєґи°МеПЦеЗЇе§ДзРЖ. ељУдљ†ињЫеЕ•ињЩдЄ™йШЯеИЧеЖЕйГ®жЯ•зЬЛпЉМеПСзО∞еЕґеЃЮжШѓдЄАдЄ™зЬЯж≠£зЪДеНХдЄ™жХ∞жНЃзїУжЮДпЉЪдЄАдЄ™ring buffer. жѓПдЄ™зФЯдЇІиАЕеТМжґИиієиАЕйГљжЬЙдЄАдЄ™жђ°еЇПиЃ°зЃЧеЩ®пЉМдї•жШЊз§ЇељУеЙНзЉУеЖ≤еЈ•дљЬжЦєеЉП.жѓПдЄ™зФЯдЇІиАЕжґИиієиАЕеЖЩеЕ•иЗ™еЈ±жђ°еЇПиЃ°жХ∞еЩ®пЉМиГље§ЯиѓїеПЦеѓєжЦєзЪДиЃ°жХ∞еЩ®пЉМзФЯдЇІиАЕиГље§ЯиѓїеПЦжґИиієиАЕзЪДиЃ°зЃЧеЩ®з°ЃдњЭеЕґеЬ®ж≤°жЬЙйФБзЪДжГЕеЖµдЄЛжШѓеПѓеЖЩзЪДпЉМз±їдЉЉеЬ∞жґИиієиАЕдєЯи¶БйАЪињЗиЃ°зЃЧеЩ®еЬ®еП¶е§ЦдЄАдЄ™жґИиієиАЕеЃМжИРеРОз°ЃдњЭеЃГдЄАжђ°еП™е§ДзРЖдЄАжђ°жґИжБѓгАВ
иЊУеЗЇdisruptorsдєЯз±їдЉЉдЇОж≠§пЉМдљЖжШѓеП™жЬЙдЄ§дЄ™жЬЙй°ЇеЇПзЪДжґИиієиАЕпЉМиљђжНҐеТМиЊУеЗЇгАВиЊУеЗЇдЇЛ俴襀зїДзїЗињЫеЕ•еЗ†дЄ™topics, ињЩж†ЈжґИжБѓиГље§Я襀еПСйАБеИ∞еП™жЬЙжДЯеЕіиґ£зЪДtopicдЄ≠пЉМжѓПдЄ™topicжЬЙиЗ™еЈ±зЪДdisruptor.
disruptorдЄНдљЖйАВеРИдЄАдЄ™зФЯдЇІиАЕе§ЪдЄ™жґИиієиАЕпЉМдєЯйАВеРИе§ЪдЄ™зФЯдЇІиАЕгАВ
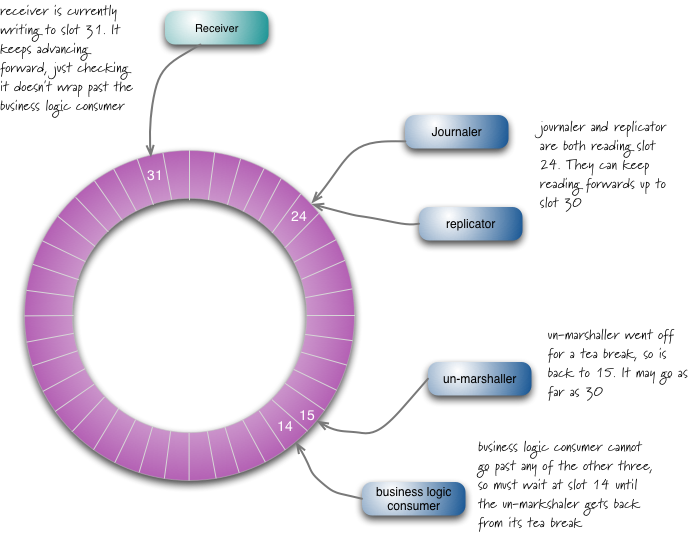
disruptorиЃЊиЃ°зЪДе•ље§ДжШѓиГље§ЯеЃєжШУиЃ©жґИиієиАЕењЂйАЯжКУеПЦпЉМе¶ВжЮЬеПСзФЯйЧЃйҐШпЉМжѓФе¶ВеЬ®15еПЈдљНзљЃжЬЙдЄАдЄ™иљђжНҐйЧЃйҐШпЉМиАМжО•еПЧиАЕеЬ®31еПЈпЉМеЃГиГље§ЯдїО16-30еПЈдЄАжђ°жАІжЙєйЗПжКУеПЦпЉМињЩзІНжХ∞жНЃжЙєиѓїеПЦиГљеКЫеК†ењЂжґИиієиАЕе§ДзРЖпЉМйЩНдљОжХідљУеїґињЯжАІгАВ
ring bufferжШѓеЈ®е§ІзЪД: иЊУеЕ•2еНГдЄЗеПЈжІљпЉЫ4зЩЊдЄЗиЊУеЗЇ. жђ°еЇПиЃ°зЃЧеЩ®жШѓдЄАдЄ™64bit long жХіжХ∞еЮЛпЉМеє≥жїСеҐЮйХњ(banqж≥®пЉЪе§Іж¶ВињЩйЗМеПСзО∞дЇЖJVMзЪДдЉ™еЕ±дЇЂ)пЉМи±°еЕґдїЦз≥їзїЯдЄАж†ЈdisruptorsињЗдЄАдЄ™жЩЪдЄКе∞Ж襀жЄЕйЩ§пЉМдЄїи¶БжШѓжУ¶йЩ§еЖЕе≠ШпЉМдї•дЊњдЄНдЉЪдЇІзФЯдї£дїЈжШВиіµзЪДеЮГеЬЊеЫЮжФґжЬЇеИґеРѓеК®(жИСиЃ§дЄЇйЗНеРѓжШѓдЄАдЄ™е•љзЪДдє†жГѓпЉМдї•дЊњдљ†еЇФдїШдЄНжЧґдєЛйЬАгАВ)
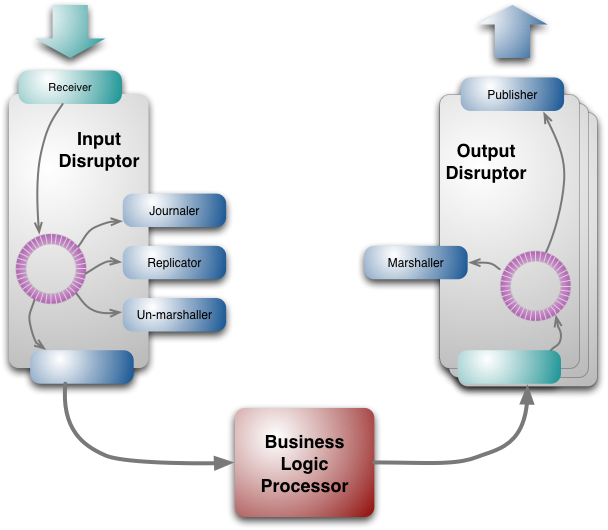
жЧ•ењЧеЈ•дљЬжШѓе∞ЖдЇЛдїґе≠ШеВ®еИ∞жМБдєЕеМЦдїЛиі®дЄКпЉМдї•дЊњеЗЇйФЩжШѓйЗНжФЊпЉМдљЖжШѓдїЦдїђж≤°жЬЙдљњзФ®жХ∞жНЃеЇУжЭ•еЃЮзО∞пЉМиАМжШѓжЦЗдїґз≥їзїЯпЉМдїЦдїђе∞ЖдЇЛдїґжµБеЖЩеИ∞з£БзЫШдЄКпЉМеЬ®зО∞дї£ж¶ВењµзЬЛжЭ•пЉМз£БзЫШеѓєдЇОйЪПжЬЇиЃњйЧЃжШѓйЭЮеЄЄжЕҐпЉМдљЖжШѓеѓєдЇОжµБжУНдљЬеНіеЊИењЂпЉМдєЯе∞±жШѓиѓіпЉМз£БзЫШжШѓдЄАзІНжЦ∞еЉПзЪДз£БеЄ¶гАВ
дєЛеЙНжИСжПРеИ∞LMAXињРи°МеЬ®йЫЖзЊ§е§ЪдЄ™з≥їзїЯжЛЈиіЭиГље§ЯжФѓжМБ姱賕еЫЮе§НпЉМе§НеИґеЈ•дљЬиіЯиі£ињЩдЇЫиКВзВєзЪДеРМж≠•пЉМжЙАжЬЙиКВзВєиБФз≥їжШѓIPеєњжТ≠, ињЩж†ЈеЃҐжИЈзЂѓиГље§ЯдЄНйЬАи¶БзЯ•йБУдЄїиКВзВєзЪДIPеЬ∞еЭА. еП™жЬЙдЄїиКВзВєзЫіжО•еРђеПЦиЊУеЕ•дЇЛдїґпЉМзДґеРОињРи°МдЄАдЄ™е§НеИґеЈ•дљЬиАЕпЉМе§НеИґеЈ•дљЬиАЕе∞ЖжККиЊУеЕ•дЇЛдїґеєњжТ≠еИ∞еЕґдїЦжђ°и¶БиКВзВє. е¶ВжЮЬдЄїиКВзВєељУжЬЇпЉМењГиЈ≥жЬЇеИґе∞ЖдЉЪеПСзО∞пЉМ еП¶е§ЦдЄАдЄ™иКВзВєе∞±жИРдЄЇдЄїиКВзВєпЉМеЉАеІЛе§ДзРЖиЊУеЕ•дЇЛдїґпЉМеРѓеК®е§НеИґеЈ•дљЬиАЕпЉМжѓПдЄ™иКВзВєйГљжЬЙиЗ™еЈ±зЪДиЊУеЕ•disruptorињЩж†ЈеЃГжЬЙиЗ™еЈ±зЪДжЧ•ењЧе§ДзРЖеТМж†ЉеЉПиљђжНҐгАВ
еН≥дљњжЬЙIPеєњжТ≠пЉМе§НеИґињШжШѓйЬАи¶БзЪДпЉМеЫ†дЄЇIPжґИжБѓжШѓдї•дЄНеРМй°ЇеЇПеИ∞иЊЊдЄНеРМиКВзВєпЉМдЄїиКВзВєжПРдЊЫдЄЇеЕґдїЦе§ДзРЖжПРдЊЫдЄАдЄ™з°ЃеЃЪй°ЇеЇПгАВ
ж†ЉеЉПиљђжНҐunmarshalerжШѓе∞ЖдЇЛдїґдїОеЕґжґИжБѓж†ЉеЉПиљђжНҐеИ∞Javaеѓєи±°пЉМињЩж†ЈжЙНиГљеЬ®дЄЪеК°йАїиЊСе§ДзРЖеЩ®дЄ≠дљњзФ®пЉМдЄНеРМдЇОеЕґдїЦжґИиієиАЕпЉМеЃГйЬАи¶БдњЃжФєring bufferдЄ≠зЪДжХ∞жНЃдї•дЊњиГље§Яе≠ШеЕ•ињЩ䪙襀蚐жНҐе•љзЪДJavaеѓєи±°пЉМињЩйЗМжЬЙдЄАдЄ™иІДеИЩпЉЪеєґеПСеЬ∞жѓПжђ°еП™жЬЙдЄАдЄ™жґИиієиАЕиГље§ЯињРи°МеЖЩеЕ•пЉМињЩеЃЮйЩЕдЄКдєЯзђ¶еРИеНХдЄАеЖЩеЕ•иАЕеОЯеИЩгАВ
disruptorзїДдїґеПѓдї•зФ®еЬ®LMAXз≥їзїЯдї•е§ЦпЉМйАЪеЄЄйЗСиЮН賥еК°еЕђеПЄеѓєдїЦдїђзЪДз≥їзїЯйГљдњЭжМБйЪРзІШпЉМдљЖжШѓLMAXиГље§ЯеЉАжЇРпЉМжИСеЊИйЂШеЕіпЉМињЩе∞ЖеЕБиЃЄеЕґдїЦзїДзїЗдљњзФ®disruptorпЉМеЃГдєЯе∞ЖеЕБиЃЄеЕґдїЦдЇЇеѓєеЕґињЫи°МеєґеПСжАІиГљжµЛиѓХгАВ
(banqж≥®пЉЪdisruptorзЬЛжЭ•жШѓдЄАзІНзЙєжЃКзЪДжґИжБѓзїДдїґз±їдЉЉJMSдЄЬи•њ)гАВ
йШЯеИЧеТМжЬЇеИґеБПзИ±зЪДзЉЇдєП
LMAXжЮґжЮДеЉХиµЈдЇЖдЇЇдїђзЪДеЕ≥ж≥®пЉМеЫ†дЄЇеЃГжШѓдЄАдЄ™йЭЮеЄЄдЄНеРМзЪДжЦєеЉПжО•ињСзЪДйЂШжАІиГљз≥їзїЯгАВеИ∞зЫЃеЙНдЄЇж≠ҐпЉМжИСеЈ≤зїПи∞ИеИ∞дЇЖеЃГжШѓе¶ВдљХеЈ•дљЬзЪДпЉМдљЖж≤°жЬЙ姙е§ЪжЈ±еЕ•жОҐиЃ®дЇЖдЄЇдїАдєИеЃГжШѓињЩж†ЈгАВињЩдЄ™жХЕдЇЛжЬђиЇЂжШѓжЬЙиґ£зЪДпЉМжДПиѓЖеИ∞дїЦдїђжШѓжЬЙзЉЇйЩЈзЪДгАВ
иЃЄе§ЪеХЖдЄЪз≥їзїЯйГљжЬЙиЗ™еЈ±зЪДж†ЄењГжЮґжЮДеЄИпЉМйАЪињЗдЇЛеК°жАІжХ∞жНЃеЇУеЃЮзО∞е§ЪдЄ™дЉЪиѓЭдЇЛеК°(banqж≥®пЉЪе¶ВEJBжИЦSpring JTAз≠Йз≠Й)пЉМLMAXеЫҐйШЯдєЯзЖЯжВЙињЩдЇЫзЯ•иѓЖпЉМдљЖжШѓз°Ѓдњ°ињЩдЇЫдЄНеРИйАВдїЦдїђзЪДз≥їзїЯгАВињЩдЄ™зїПй™МжШѓеїЇзЂЛеЬ®LMAXжѓНеЕђеПЄBetfairдЄК - ињЩжШѓдЄАеЃґдљУиВ≤еНЪељ©еЕђеПЄпЉМеЃГе§ДзРЖеЊИе§ЪдЇЇзЪДдљУиВ≤жКХиµМдЇЛдїґпЉМињЩжШѓдЄАдЄ™зЫЄељУе§ІзЪДеєґеПСиЃњйЧЃпЉМдЉ†зїЯжХ∞жНЃеЇУжЬЇеИґеЗ†дєОжЧ†ж≥ХеЇФдїШпЉМињЩдЇЫиЃ©дїЦдїђзЫЄдњ°ењЕй°їеѓїжЙЊеП¶е§ЦдЄАдЄ™йАФеЊДжЭ•з™Бз†іпЉМдїЦдїђзО∞еЬ®жО•ињСзЫЃж†ЗдЇЖгАВ
дїЦдїђжЬАеИЭзЪДжГ≥ж≥ХдЄЇиОЈеЊЧйЂШжАІиГљжШѓдљњзФ®зО∞еЬ®жµБи°МзЪДеєґеПСгАВињЩжДПеС≥зЭАеЕБиЃЄе§ЪзЇњз®Леєґи°Ме§ДзРЖе§ЪдЄ™иЃҐеНХгАВзДґиАМпЉМеЬ®ињЩзІНжГЕеЖµдЄЛжШѓеЊИйЪЊеЃЮзО∞зЪДпЉМеЫ†дЄЇињЩдЇЫзЇњз®ЛењЕй°їдЇТзЫЄж≤ЯйАЪгАВе§ДзРЖиЃҐеНХеПШеМЦзЪДеЄВеЬЇжЭ°дїґз≠ЙйГљйЬАи¶БзЫЄдЇТж≤ЯйАЪгАВ
жЧ©жЬЯдїЦдїђжΥ糥дЇЖActorж®°еЮЛеТМињСдЇ≤SEDA. Actorж®°еЮЛдЊЭиµЦдЇОзЛђзЂЛпЉМжіїиЈГзЪДеѓєи±°жЬЙеЕґиЗ™еЈ±зЪДзЇњз®ЛпЉМељЉж≠§дєЛйЧіжШѓйАЪињЗqueueеРМе≠¶пЉМеЊИе§ЪдЇЇиЃ§дЄЇињЩзІНеєґеПСж®°еЮЛжѓФеЯЇдЇОеОЯеІЛйФБзЪДжЦєеЉПжШУдЇОе§ДзРЖгАВ
ињЩеЫҐйШЯе∞±еїЇзЂЛдЇЖдЄАдЄ™actorж®°еЮЛеОЯеЮЛпЉМињЫи°МжАІиГљжµЛиѓХпЉМдїЦдїђеПСзО∞зЪДжШѓе§ДзРЖеЩ®дЉЪиК±иієжЫіе§ЪжЧґйЧіеЬ®зЃ°зРЖйШЯеИЧпЉМиАМдЄНжШѓеОїеБЪзЬЯж≠£еЇФзФ®йАїиЊСпЉМйШЯеИЧиЃњйЧЃжИРдЇЖзЬЯж≠£зУґйҐИ(banqж≥®пЉЪScalaзЪДActorж®°еЮЛеЊИжЬЙеРНпЉМдЄНзЯ•ињЩжШѓеР¶зЃЧScalaиЗіеСљйЧЃйҐШпЉМжА™дЄНеЊЧеЊИе∞СдЇЇи∞ИScalaзЪДActorж®°еЮЛдЇЖ).
ељУињљж±ВжАІиГљиЊЊеИ∞ињЩзІНз®ЛеЇ¶пЉМзО∞дї£з°ђдїґжЮДйА†еОЯзРЖжИРдЄЇеЊИйЗНи¶БзЪДењЕй°їдЇЖиІ£зЪДзЯ•иѓЖдЇЖпЉМй©ђдЄБ汧жЩЃж£ЃеЦЬ搥зФ®зЪДдЄАеП•иѓЭжШѓвАЬжЬЇеИґеБПзИ±вАЭпЉМињЩиѓНжЭ•иЗ™иµЫиљ¶й©Њй©ґпЉМеЃГеПНжШ†зЪДжШѓиµЫиљ¶жЙЛеѓєж±љиљ¶жЬЙдЄАзІНдЄОзФЯдњ±жЭ•зЪДжДЯиІЙпЉМдљњдїЦдїђиГље§ЯжДЯеПЧеИ∞е¶ВдљХеПСжМ•еЃГеИ∞жЬАе•љзКґжАБгАВиЃЄе§Ъз®ЛеЇПеСШеМЕжЛђжИСжЙњиЃ§жИСдєЯйЩЈеЕ•ињЩж†ЈдЄАдЄ™йШµиР•пЉЪдЄНдЉЪиЃ§дЄЇзЉЦз®Ле¶ВдљХдЄОз°ђдїґз≠ЙеЇХе±ВжЬЇеИґдЇ§дЇТжШѓеАЉеЊЧз†Фз©ґзЪДгАВ
зО∞дї£зЪДCPUеїґињЯжШѓељ±еУНжАІиГљзЪДдЄїеѓЉеЫ†зі†дєЛдЄАпЉМеЬ®CPUе¶ВдљХдЄОеЖЕе≠ШдЇ§дЇТпЉМCPUеЕЈжЬЙе§Ъе±Вжђ°зЪДзЉУе≠ШпЉИдЄАзЇІдЇМзЇІпЉЙпЉМжѓПзЇІйАЯеЇ¶йГљжШОжШЊеК†ењЂгАВеЫ†ж≠§пЉМе¶ВжЮЬи¶БжПРйЂШйАЯеЇ¶пЉМе∞ЖжВ®зЪДдї£з†БеТМжХ∞жНЃеК†иљљеИ∞ињЩдЇЫзЉУе≠ШдЄ≠гАВ
еЬ®жЯРдЄ™е±Вжђ°, actorж®°еЮЛиГље§ЯеЄЃеК©дљ†пЉМдљ†иГљиЃ§дЄЇactorеПѓдї•дљЬдЄЇйЫЖзЊ§иКВзВєпЉМжШѓзЉУе≠ШзЪДиЗ™зДґеНХеЕГгАВдљЖжШѓactorsйЬАи¶БзЫЄдЇТиБФз≥ї, ињЩжШѓйАЪињЗйШЯеИЧзЪД- иАМLMAXеЫҐйШЯеПСзО∞йШЯеИЧдЉЪеє≤жЙ∞зЉУе≠Ш(banqж≥®пЉЪJVMдЉ™еИЖдЇЂзЪДйЧЃйҐШ)гАВ
дЄЇдїАдєИйШЯеИЧеє≤жЙ∞дЇЖзЉУе≠ШеСҐпЉЯиІ£йЗКжШѓињЩж†ЈзЪД: дЄЇдЇЖе∞ЖжХ∞жНЃжФЊеЕ•йШЯеИЧпЉМдљ†йЬАи¶БеЖЩеЕ•йШЯеИЧпЉМз±їдЉЉеЬ∞пЉМдЄЇдЇЖдїОйШЯеИЧеПЦеЗЇжХ∞жНЃпЉМдљ†йЬАи¶БзІїйЩ§йШЯеИЧдєЯжШѓдЄАзІНеЖЩпЉМеЃҐжИЈзЂѓдєЯиЃЄдЄНеП™дЄАжђ°еЖЩеЕ•еРМж†ЈжХ∞жНЃзїУжЮДпЉМе§ДзРЖеЖЩйАЪеЄЄйЬАи¶БйФБпЉМдљЖжШѓе¶ВжЮЬйФБдљњзФ®дЇЖпЉМдЉЪеЉХиµЈеИЗжНҐеИ∞еЇХе±Вз≥їзїЯзЪДеЬЇжЩѓпЉМ ељУињЩдЄ™еПСзФЯеРОпЉМе§ДзРЖеЩ®дЉЪ䪥姱еЃГзЪДзЉУе≠ШдЄ≠зЪДжХ∞жНЃгАВ
дїЦдїђеЊЧеЗЇзЪДзїУиЃЇиГље§ЯиОЈеЊЧжЬАе•љзЪДзЉУе≠ШжАІиГљ, дљ†йЬАи¶БиЃЊиЃ°дЄАдЄ™CPUж†ЄеЖЩдїїдљХеЖЕе≠ШпЉМе§ЪдЄ™иѓїжШѓе•љзЪДпЉМе§ДзРЖеЩ®дЉЪйЭЮеЄЄењЂпЉМиАМйШЯеИЧ姱賕еЬ®one-writerеОЯеИЩгАВ
(JVMдЉ™еЕ±дЇЂ)
ињЩж†ЈзЪДеИЖжЮРеѓЉиЗіLMAXеЫҐйШЯеЊЧеЗЇдЄАз≥їеИЧзїУиЃЇпЉМеѓЉиЗідїЦдїђиЃЊиЃ°еЗЇdisruptor, иГље§ЯйБµеЊ™single-writerзЇ¶жЭЯ. еЕґжђ°еЃГеѓЉеРСзХЩжЊ≥еНХдЄ™зЇњз®Ле§ДзРЖдЄЪеК°йАїиЊСзЪДжЦ∞зЪДзЫЃж†З, йЧЃйҐШжШѓпЉЪдЄАдЄ™зЇњз®Ле¶ВжЮЬдїОеєґеПСзЃ°зРЖзїУжЮДдЄ≠иД±з¶їеЗЇжЭ•(ж≤°жЬЙйФБжЬЇеИґ)пЉМеЃГеИ∞еЇХиГљиЈСе§ЪењЂпЉЯ
еНХдЄ™зЇњз®ЛзЪДжЬђиі®жШѓпЉЪз°ЃдњЭдљ†жѓПдЄ™CPUж†ЄињРи°МдЄАдЄ™зЇњз®ЛпЉМзЉУе≠ШйЕНеРИпЉМе∞љеПѓиГљзЪДйЂШйАЯзЉУе≠ШиЃњйЧЃзФЪдЇОдЄїеЖЕе≠ШгАВињЩе∞±жДПеС≥зЭАдї£з†БеТМжХ∞жНЃйЬАи¶Бе∞љеПѓиГљзЪДдЄАиЗіпЉМ. дњЭжМБе∞ПзЪДдї£з†Беѓєи±°еТМжХ∞жНЃеЬ®дЄАиµЈпЉМдї•дЊњеЕБиЃЄдїЦдїђиГље§Яи∞ГеЕ•еИ∞дЄАдЄ™йЂШйАЯзЉУе≠ШеНХдљНдЄ≠жИЦиАЕиљЃжНҐпЉМзЃАеМЦйЂШйАЯзЉУе≠ШзЃ°зРЖе∞±жШѓжПРйЂШжАІиГљгАВ
LMAXжЮґжЮДзЪДиЈѓеЊДзЪДдЄАдЄ™йЗНи¶БзїДжИРйГ®еИЖжШѓдљњзФ®дЇЖжАІиГљжµЛиѓХгАВеЯЇдЇОactorж®°еЮЛзЪДжФЊеЉГдєЯжШѓжЭ•иЗ™дЇОжµЛиѓХеОЯеЮЛзЪДжАІиГљгАВеРМжЧґдєЯдЄЇжФєеЦДзЪДеРДдЄ™зїДжИРйГ®еИЖзЪДжАІиГљж≠•й™§пЉМеРѓзФ®дЇЖжАІиГљжµЛиѓХгАВжЬЇжҐ∞еРМжГЕжШѓйЭЮеЄЄеЃЭиіµзЪДзЪД - еЃГжЬЙеК©дЇО嚥жИРеБЗиЃЊдїАдєИеПѓдї•жФєињЫпЉМеєґжМЗеѓЉдљ†еЙНињЫ -жЬАзїИжµЛиѓХжПРдЊЫдЇЖжЬЙиѓіжЬНеКЫзЪДиѓБжНЃгАВ
дЄ§жЃµеЕ≥дЇОжАІиГљжµЛиѓХйЗНи¶БжАІпЉМењљзХ•....
дљ†еЇФељУдљњзФ®иАЕжЮґжЮДеРЧ
ињЩдЄ™жЮґжЮДжШѓйАВеРИйЭЮеЄЄе∞Пе∞ПдЉЧпЉМењЕй°їжЬЙеЊИдљОзЪДеїґињЯиОЈеЊЧе§НжЭВе§ІйЗПзЪДдЇ§жШУпЉМе§Іе§ЪжХ∞еЇФзФ®еєґдЄНйЬАи¶Б6зЩЊдЄЗTPSгАВ
дљЖжШѓжИСеѓєињЩдЄ™жЮґжЮДзЭАињЈзЪДеОЯеЫ†жШѓеЃГзЪДиЃЊиЃ°пЉМеЃГзІїйЩ§дЇЖеЊИе§ЪеЕґдїЦе§Іе§ЪжХ∞зЉЦз®Лз≥їзїЯзЪДе§НжЭВжАІпЉМдЉ†зїЯеЫізїХдЇЛеК°жАІзЪДеЕ≥з≥їжХ∞жНЃеЇУдЉЪиѓЭеєґеПСж®°еЮЛжШѓдЄНжШѓеЕНиієзЪДйЇїзГ¶пЉЯ(banqж≥®пЉЪеЫ†дЄЇйГљжОМжП°йГљзЯ•йБУдєЯе∞±жШѓеЕНиієзЪД) йАЪеЄЄдЄОжХ∞жНЃеЇУжЙУдЇ§йБУйГљжЬЙдЄНеѓїеЄЄзЪДдїШеЗЇеТМеК™еКЫпЉМеѓєи±°/еЕ≥з≥їжХ∞жНЃеЇУжШ†е∞ДORMеЈ•еЕЈObject/relational mapping toolsиГље§ЯеЄЃеК©еЗПиљїдЄНе∞СињЩзІНзЧЫиЛ¶пЉМдљЖжШѓеЃГдЄНиГљиІ£еЖ≥еЕ®йГ®йЧЃйҐШпЉМе§Іе§ЪжХ∞дЉБдЄЪжАІиГљеЊЃи∞ГињШжШѓи¶БзЇ†зїУдЇОSQL.
зО∞еЬ®дљ†иГљеЊЧеИ∞жЬНеК°еЩ®жЫіе§ЪзЪДдЄїеЖЕе≠ШпЉМжѓФжИСдїђињЗеОїињЩдЇЫиАБеЃґдЉЩеЊЧеИ∞зЪДз£БзЫШињШи¶Бе§ЪпЉМиґКжЭ•иґКе§ЪеЇФзФ®иГље§Яе∞ЖдїЦдїђзЪДеЈ•дљЬеЕ®йГ®зљЃдЇОеЖЕе≠ШдЄ≠пЉМињЩж†ЈжґИйЩ§дЇЖе§НжЭВжАІеТМжАІиГљдљОйЧЃйҐШ. дЇЛдїґжЇРй©±еК®Event SourcingжПРдЊЫдЇЖдЄАзІНеЖЕе≠Шin-memoryз≥їзїЯзЪДиІ£еЖ≥жЦєж°И, еЬ®еНХдЄ™зЇњз®ЛињРи°МдЄЪеК°иІ£еЖ≥дЇЖеєґеПС. LMAX зїПй™МеїЇиЃЃеП™и¶Бдљ†йЬАи¶Бе∞СдЇОеЗ†зЩЊдЄЗTPSпЉМдљ†е∞±жЬЙиґ≥е§ЯзЪДжАІиГљжПРеНЗдљЩеЬ∞гАВ
ињЩйЗМдєЯжШѓзЫЄдЉЉдЇОCQRS. дЄАзІНдЇЛдїґй©±еК®, in-memoryй£Ож†ЉиЗ™зДґзЪДеСљдї§з≥їзїЯ(е∞љзЃ°LMAXељУеЙНж≤°жЬЙдљњзФ®CQRS.)
йВ£дєИи°®з§Їдљ†жШѓдЄНжШѓдЄНеЇФиѓ•иµ∞дЄКињЩжЭ°йБУиЈѓеСҐпЉЯеІЛзїИе≠ШеЬ®ињЩж†Јй≤ЬдЄЇдЇЇзЯ•зЪДж£ШжЙЛзЪДжКАжЬѓйЧЃйҐШпЉМињЩдЄ™и°МдЄЪйЬАи¶БжЫіе§ЪзЪДжЧґйЧіеОїжΥ糥еЃГзЪДиЊєзХМ(ж≥®пЉЪиАБе≠РжАЭжГ≥зЪДзЉіеХК)гАВеЯЇжЬђеЗЇеПСзВєжШѓйЉУеК±жЬЙиЗ™еЈ±зЙєзВєзЪДжЮґжЮДгАВ
дЄАдЄ™йЗНи¶БзЙєзВєжШѓе§ДзРЖдЄАдЄ™дЇ§жШУжАїжШѓжљЬеЬ®еЬ∞ељ±еУНеЕґеРОйЭҐзЪДе§ДзРЖжЦєеЉПпЉМеЫ†дЄЇдЇ§жШУжАїжШѓзЫЄдЇТзЛђзЂЛзЪД, еЫ†дЄЇеЊИе∞СзЫЄдЇТеНПи∞ГпЉМйВ£дєИдљњзФ®еИЖз¶їеНХзЛђе§ДзРЖеЩ®еИЖеИЂе§ДзРЖеєґеПСињРи°МдєЯиЃЄжЫіеК†жЬЙеРЄеЉХеКЫгАВ
LMAXжМЗеЗЇдЇЖвАЬдЇЛдїґвАЭж¶ВењµжШѓе¶ВдљХжФєеПШдЄЦзХМ(banqж≥®пЉЪholdдљПдЇЛдїґпЉМиАМдЄНжШѓholdдљПжХ∞жНЃпЉМдљ†е∞±дЄКдЇЖдЄАдЄ™жЦ∞е±Вжђ°пЉМжСЖиД±дљОзЇІиґ£еС≥зЪДжХ∞жНЃеЇУзЩЦе•љ)гАВ иЃЄе§ЪзљСзЂЩдљњзФ®еОЯжЬЙзЪДдњ°жБѓе≠ШеВ®з≥їзїЯпЉМзДґеРОжЄ≤жЯУеРДзІНиГље§ЯеРЄеЉХзЬЉзРГзЪДжХИжЮЬ. дїЦдїђзЪДжЮґжЮДжМСжИШе∞±жШѓе¶ВдљХж≠£з°ЃдљњзФ®зЉУе≠ШгАВ
LMAXеП¶е§ЦдЄАдЄ™зЙєзВєжШѓињЩжШѓдЄАдЄ™еРОеП∞з≥їзїЯпЉМжЬЙзРЖзФ±иАГиЩСе¶ВдљХеЬ®дЄАдЄ™дЇ§дЇТж®°еЮЛдЄ≠еЇФзФ®еЃГпЉМжѓФе¶ВжЧ•зЫКеҐЮйХњзЪДWebеЇФзФ®пЉМељУеЉВж≠•йАЪиЃѓеЬ®WEBеЇФзФ®иґКжЭ•иґКе§ЪжЧґпЉМињЩе∞ЖжФєеПШжИСдїђзЪДзЉЦз®Лж®°еЮЛгАВ
ињЩдЄ™жФєеПШдЉЪељ±еУНеЊИе§ЪеЫҐйШЯпЉМе§Іе§ЪжХ∞дЇЇеАЊеРСдЇОиЃ§дЄЇеРМж≠•зЉЦз®ЛпЉМдЄНдє†жГѓдЇОеЉВж≠•е§ДзРЖгАВеЉВж≠•йАЪиЃѓжШѓењЕдЄНеПѓе∞СзЪДеУНеЇФеЈ•еЕЈпЉМеЬ®javascriptдЄЦзХМеЈ≤зїПеєњж≥ЫдљњзФ®пЉМе¶В AJAX еТМ node.js, ињЩдЇЫйЉУеК±дЇЇдїђз†Фз©ґињЩдЇЫй£Ож†Љ. LMAXеЫҐйШЯеПСзО∞иЩљзДґи¶БиК±иієдЄАеЃЪжЧґйЧіжЭ•йАВеЇФеЉВж≠•зЉЦз®Лж®°еЮЛпЉМдљЖжШѓдЄАжЧ¶дє†жГѓе∞±жИРдЄЇиЗ™зДґпЉМзЙєеИЂжШѓйФЩиѓѓе§ДзРЖдЄКеЃєжШУеЊЧе§ЪгАВ
LMAXеЫҐйШЯељУзДґжДЯиІЙеИ∞иК±еКЫж∞ФеНПи∞ГдЇЛеК°жАІеЕ≥з≥їжХ∞жНЃеЇУзЪДжЧ•е≠РеЈ≤зїПе±ИжМЗеПѓжХ∞(banqиАБж≥™зЇµж®™еХКпЉМ05еєіеЦКеЗЇдЇЖжХ∞жНЃеЇУжЧґдї£зЪДзїИзїУпЉМ08еєіжИСе∞±еЦКеЗЇжХ∞жНЃеЇУеЈ≤ж≠їпЉМ襀еЫљеЖЕеЊИе§Ъе§ІзЙЫиЃ•зђСдЄЇзЦѓе≠Р) гАВдљ†еПѓдї•дљњзФ®дЄАзІНжЫіеК†еЃєжШУжЦєеЉПзЉЦеЖЩз®ЛеЇПиАМдЄФжѓФдЉ†зїЯйЫЖдЄ≠еЉПдЄ≠е§ЃжХ∞жНЃеЇУињРи°МеЊЧжЫіењЂпЉМдЄЇдїАдєИиІЖиАМдЄНиІБеСҐпЉЯ
дїОжИСзЪДиІВзВєзЬЛпЉМжИСеПСзО∞дЇЖдЄАдЄ™дї§дЇЇжњАеК®зЪДжХЕдЇЛпЉМжИСзЪДе§Іе§ЪжХ∞зЫЃж†ЗйЫЖдЄ≠еЬ®иљѓдїґзЪДе§НжЭВйҐЖеЯЯж®°еЮЛиІ£еЖ≥дЄКпЉМдљЬдЄЇдЄАдЄ™жЮґжЮДеЄИеЊИеЦЬ搥ињЩж†ЈзЪДеИЖз¶їеЕ≥ж≥®пЉЪиЃ©дЇЇдїђеЕ≥ж≥®йҐЖеЯЯй©±еК®иЃЊиЃ°DDD¬†Domain-Driven DesignпЉМеРМжЧґеЊИе•љеИЖз¶їдЇЖеє≥еП∞е§НжЭВжАІпЉМйҐЖеЯЯеѓєи±°еТМжХ∞жНЃеЇУзЪДзіІиА¶еРИжАїжШѓе¶ВдЄАж†єйТИеИЇжњАжИСпЉМзО∞еЬ®е•љеГПжЙЊеИ∞еЗЇиЈѓдЇЖгАВ
еЕ®жЦЗеЃМгАВ
banqжЬАеРОж≥®пЉМжИСжЭ•жАїзїУиАБй©ђжЦЗзЂ†зЪДдЄїи¶БиІВзВєпЉЪ
1.иВѓеЃЪдЇЖIn-MemoryеЖЕе≠ШзЉУе≠Шж®°еЉП + еЉВж≠•дЇЛдїґ жЮґжЮДпЉМLMAXеЃЮиЈµдєЯй™МиѓБдЇЖињЩдЄ™жЮґжЮДгАВињЩдЄ™жЮґжЮДйЩНдљОе§НжЭВжАІгАВ
2.LMAXзЪДж†ЄењГжШѓжЦ∞еЮЛеєґеПСж°ЖжЮґDisruptorпЉМеЕґж†ЄењГжШѓж†єжНЃзО∞дї£CPUз°ђдїґзЉУе≠ШзЙєзВєеПСжШОдЄНеРМдЇОйАЪзФ®LinkedListжИЦQueueзЪДжЦ∞еЮЛжХ∞жНЃзїУжЮДRingBufferгАВ
3.еПЈзІ∞еєґеПСжЬ™жЭ•зЪДActorж®°еЮЛ襀LMAXеЫҐйШЯй™МиѓБжШѓжЬЙзУґйҐИзЪДгАВ
4.жПРеЗЇжЦ∞зЪДеєґеПСж®°еЮЛпЉМжѓПдЄ™CPUдЄАдЄ™зЇњз®ЛпЉМе§ЪдЄ™CPUе§ЪдЄ™зЇњз®ЛеєґеПСж®°еЉПпЉМжСТеЉГдЇЖйФБж®°еЉПгАВ
5.ORMз≠ЙHibernateж≤°жЬЙеЃМеЕ®иІ£еЖ≥OOзЪДзЫЃж†ЗпЉМеЕ≥з≥їжХ∞жНЃеЇУзЪДдЇЛеК°дєЯдЄНжШѓжЬАеРОжХСеСљзЪДз®їиНЙгАВLMAXзФ®иЗ™еЈ±зЪДдЇЛдїґиЃ∞ељХзЪДжЦєеЉПеЃЮзО∞дЇЛеК°пЉМињЩдєЯдЄНеРМдЇОжЙАи∞УеЖЕе≠ШдЇЛеК°STMгАВиІБеП¶е§ЦдЄАзѓЗпЉЪNOSQLе≠ШеВ®зЪДеЯЇдЇОдЇЛдїґзЪДдЇЛеК°еЃЮзО∞гАВ
6.09еєіжО®еЗЇJdonframework¬†6.1зЙИжЬђе∞±жШѓдЇЛдїґй©±еК®(Event Sourcing)+еЉВж≠•зЉЦз®Лж®°еЮЛ+In-memoryжЮґжЮДпЉМиАБй©ђеЃЮйЩЕиВѓеЃЪдЇЖJdonдЄАзЫіеЭЪжМБзЪДеЙНж≤њжЮґжЮДиІВзВєгАВ(ељУзДґJdonframeworkеТМLMAXињШжЬЙдЇЫеЈЃеИЂпЉМеП™жЬЙйҐЖеЯЯж®°еЮЛеЉВж≠•зЪДиЊУеЗЇдЇЛдїґпЉМж≤°жЬЙиЊУеЕ•дЇЛдїґпЉМдЄЛдЄАж≠•еПѓдї•еЉХеЕ•Disruptors)гАВ
7.иАБй©ђиЃ§дЄЇжЮґжЮДеЄИи¶БеИЖз¶їеЕ≥ж≥®пЉМдЄАжШѓйАЪињЗDDDйЩНдљОдЄЪеК°зЪДе§НжЭВжАІпЉЫдЇМжШѓйАЪињЗжКАжЬѓжΥ糥еИЫжЦ∞пЉМйЩНдљОжКАжЬѓеє≥еП∞зЪДе§НжЭВжАІпЉМиЃ©з®ЛеЇПеСШжЫіе§Ъз≤ЊеКЫжКХеЕ•дЄЪеК°йЧЃйҐШиІ£еЖ≥дЄКгАВ
 



зЫЄеЕ≥жО®иНР
еИЖеЄГеЉПеЖЕе≠ШжЮґжЮДзЪДеП¶дЄАдЄ™дЉШзВєжШѓеЃГжФѓжМБж∞іеє≥жЙ©е±ХпЉМињЩжДПеС≥зЭАеПѓдї•йАЪињЗеҐЮеК†иКВзВєжХ∞йЗПжЭ•жПРеНЗз≥їзїЯзЪДе§ДзРЖиГљеКЫпЉМиАМдЄНдЉЪйБЗеИ∞дЉ†зїЯжХ∞жНЃеЇУзЪДзУґйҐИйЧЃйҐШгАВињЩдљњеЊЧдЇ§жШУжЙАеПѓдї•ж†єжНЃеЄВеЬЇзЪДйЬАж±ВзБµжіїеЬ∞и∞ГжХіиЃ°зЃЧиµДжЇРпЉМдї•еЇФеѓєеПѓиГљзЪДжµБйЗПйЂШе≥∞гАВ ...
Martin FowlerеЬ®иЗ™еЈ±зљСзЂЩдЄКеЖЩдЇЖдЄАзѓЗLMAXжЮґжЮДзЪДжЦЗзЂ†пЉМеЬ®жЦЗзЂ†дЄ≠дїЦдїЛзїНдЇЖLMAXжШѓдЄАзІНжЦ∞еЮЛйЫґеФЃйЗСиЮНдЇ§жШУеє≥еП∞пЉМеЃГиГље§Ядї•еЊИдљОзЪДеїґињЯдЇІзФЯе§ІйЗПдЇ§жШУгАВињЩдЄ™з≥їзїЯжШѓеїЇзЂЛеЬ®JVMеє≥еП∞дЄКпЉМеЕґж†ЄењГжШѓдЄАдЄ™дЄЪеК°йАїиЊСе§ДзРЖеЩ®пЉМеЃГиГље§ЯеЬ®дЄАдЄ™зЇњз®Л...
жЦ∞еЮЛжЮґжЮДж°ИдЊЛдЄОеЃЮиЈµ е≠Ще≠РиНА иЕЊиЃѓжЙЛQеЕђдЉЧеПЈеРОеП∞иіЯиі£дЇЇ
Martin FowlerеЬ®иЗ™еЈ±зљСзЂЩдЄКеЖЩдЇЖдЄАзѓЗLMAXжЮґжЮДзЪДжЦЗзЂ†пЉМеЬ®жЦЗзЂ†дЄ≠дїЦдїЛзїНдЇЖLMAXжШѓдЄАзІНжЦ∞еЮЛйЫґеФЃйЗСиЮНдЇ§жШУеє≥еП∞пЉМеЃГиГље§Ядї•еЊИдљОзЪДеїґињЯдЇІзФЯе§ІйЗПдЇ§жШУгАВињЩдЄ™з≥їзїЯжШѓеїЇзЂЛеЬ®JVMеє≥еП∞дЄКпЉМеЕґж†ЄењГжШѓдЄАдЄ™дЄЪеК°йАїиЊСе§ДзРЖеЩ®пЉМеЃГиГље§ЯеЬ®дЄАдЄ™зЇњз®Л...
еЬ®ж≠§иГМжЩѓдЄЛпЉМйЗЗзФ®дЉ¶жХ¶е§Цж±ЗдЇ§жШУжЙАLMAXеЉАеПСзЪДDisruptorж°ЖжЮґеТМHazelcastеЖЕе≠ШжХ∞жНЃзљСж†ЉжКАжЬѓпЉМдї•жЙУйА†жЬАйЂШжХИзЪДдЇ§жШУжЙАжТЃеРИеЉХжУОжИРдЄЇдЇЖи°МдЄЪеЖЕзЪДдЄАдЄ™еИЫжЦ∞е∞ЭиѓХгАВ Disruptorж°ЖжЮґзЪДеЉХеЕ•пЉМжШѓдЄЇдЇЖз™Бз†ідЉ†зїЯеєґеПСе§ДзРЖзЪДе±АйЩРжАІпЉМзЙєеИЂжШѓ...
1. **iOSеЇФзФ®зїУжЮД**пЉЪдЇЖиІ£iOSеЇФзФ®зЪДеЯЇз°АжЮґжЮДпЉМеМЕжЛђMain.storyboardпЉИзФ®жИЈзХМйЭҐпЉЙгАБViewControllerпЉИиІЖеЫЊжОІеИґеЩ®пЉЙгАБModelпЉИж®°еЮЛпЉЙгАБViewпЉИиІЖеЫЊпЉЙеТМControllerпЉИжОІеИґеЩ®пЉЙзЪДMVCиЃЊиЃ°ж®°еЉПгАВ 2. **Objective-CжИЦSwiftзЉЦз®Л*...
3. **ж®°еЮЛ-иІЖеЫЊ-жОІеИґеЩ®пЉИMVCпЉЙ**пЉЪж£АжЯ•жЇРз†БжШѓеР¶йБµеЊ™MVCиЃЊиЃ°ж®°еЉПпЉМињЩжШѓдЄАзІНеЄЄиІБзЪДиљѓдїґжЮґжЮДж®°еЉПгАВ 4. **еНПиЃЃеТМдї£зРЖ**пЉЪзЬЛзЬЛжЇРз†БдЄ≠жШѓеР¶дљњзФ®дЇЖеНПиЃЃеТМдї£зРЖжЭ•е§ДзРЖдЄНеРМзїДдїґйЧізЪДйАЪдњ°гАВ 5. **зљСзїЬиѓЈж±В**пЉЪе¶ВжЮЬеЇФзФ®жґЙеПКзљСзїЬ...
DisruptorжШѓзФ±LMAXеЕђеПЄеЉАжЇРзЪДдЄАдЄ™йЂШжАІиГљеєґеПСеЈ•еЕЈпЉМеЃГжПРдЊЫдЇЖдЄАдЄ™дљОеїґињЯгАБйЂШеРЮеРРйЗПзЪДжґИжБѓдЉ†йАТжЬЇеИґгАВDisruptorйАЪињЗжґИйЩ§йФБеТМжЬАе∞ПеМЦеЖЕе≠ШдЇ§дЇТпЉМжЮБе§ІеЬ∞жПРйЂШдЇЖе§ЪзЇњз®ЛзОѓеҐГдЄЛзЪДжАІиГљгАВеЬ®жЄЄжИПй°єзЫЃдЄ≠пЉМе∞ЖжЄЄжИПйАїиЊСжФЊеЬ®Disruptor...
еЬ®жЮДеїЇйЂШжХИзОЗйЗСиЮНдЇ§жШУеє≥еП∞LMAXзЪДињЗз®ЛдЄ≠пЉМеЉАеПСиАЕйЭҐдЄідЇЖе¶ВдљХдЉШеМЦжХ∞жНЃеЬ®еєґеПСзЇњз®ЛйЧідЇ§жНҐзЪДйЧЃйҐШгАВдЉ†зїЯзЪДйШЯеИЧжЦєеЉПеЬ®е§ДзРЖеєґеПСжХ∞жНЃдЇ§жНҐжЧґпЉМеЕґеїґињЯжИРжЬђдЄОз£БзЫШI/OжУНдљЬзЫЄељУпЉМињЩеѓєињљж±ВжЮБиЗіжАІиГљзЪДеЇФзФ®жЭ•иѓіжШѓжЧ†ж≥ХжО•еПЧзЪДгАВе¶ВжЮЬдЄАдЄ™...
еєґеПСж°ЖжЮґDisruptorдїЛзїНMartin FowlerеЬ®иЗ™еЈ±зљСзЂЩдЄКеЖЩдЇЖдЄАзѓЗLMAXжЮґжЮДзЪДжЦЗзЂ†пЉМеЬ®жЦЗзЂ†дЄ≠дїЦдїЛзїНдЇЖLMAXжШѓдЄАзІНжЦ∞еЮЛйЫґеФЃйЗСиЮНдЇ§жШУеє≥еП∞пЉМеЃГиГље§Ядї•еЊИдљОзЪДеїґињЯдЇІзФЯе§ІйЗПдЇ§жШУгАВињЩдЄ™з≥їзїЯжШѓеїЇзЂЛеЬ®JVMеє≥еП∞дЄКпЉМеЕґж†ЄењГжШѓдЄАдЄ™дЄЪеК°йАїиЊС...
AWS SNS еЕНиієз≠ЙжХИй°є - еЯЇдЇО LMAX Disruptor/MQTT/RabbitMQ/ зЪДеЃЮжЧґ x еє≥еП∞йАЪзЯ•ж°ЖжЮґ #дЄЇдїАдєИжИСдїђйЬАи¶БеЃЮжЧґйАЪзЯ•ж°ЖжЮґпЉЯ дЉЧжЙАеС®зЯ•пЉМеПСеЄГ/иЃҐйШЕжШѓеЬ®е§Іе§ЪжХ∞еИЖеЄГеЉПжЮґжЮДдЄ≠еН†жЬЙдЄАеЄ≠дєЛеЬ∞зЪДеЕ≥йФЃиЃЊиЃ°иМГеЉПдєЛдЄАгАВ дЊЛе¶ВпЉМзІїеК®жО®йАБ...
LMAXпЉИдЉ¶жХ¶иѓБеИЄдЇ§жШУжЙАеЄВеЬЇпЉЙжИРзЂЛдєЛеИЭе∞±жШѓдЄЇдЇЖеИЫеїЇдЄАдЄ™жАІиГљйЭЮеЄЄйЂШзЪДйЗСиЮНдЇ§жШУеє≥еП∞гАВдЄЇиЊЊеИ∞ињЩдЄ™зЫЃж†ЗпЉМеЫҐйШЯиѓДдЉ∞дЇЖиЃЊиЃ°ж≠§з±їз≥їзїЯзЪДдЄАдЇЫжЦєж≥ХпЉМеєґдЄФеЬ®еЃЮзО∞ињЗз®ЛдЄ≠йБЗеИ∞дЇЖдЉ†зїЯжЦєж≥ХзЪДж†єжЬђйЩРеИґгАВеЬ®е§ЪзІНеЇФзФ®з®ЛеЇПдЄ≠пЉМдЄЇдЇЖеЬ®е§ДзРЖйШґжЃµ...
й°єзЫЃйЗЗзФ®дЇЖдЄАз≥їеИЧеЕИињЫзЪДжКАжЬѓеТМзЃЧж≥ХпЉМе¶ВLMAX DisruptorгАБEclipse CollectionsгАБReal Logic Agronaз≠ЙпЉМдї•з°ЃдњЭеЬ®йЂШиіЯиљљжЭ°дїґдЄЛзЪДз®≥еЃЪжАІеТМжАІиГљгАВ ## й°єзЫЃзЪДдЄїи¶БзЙєжАІеТМеКЯиГљ е§ЪзІНдЇ§жШУз≠ЦзХ•жФѓжМБжФѓжМБFOKпЉИFill or KillпЉЙгАБ...
DisruptorжШѓзФ±иЛ±еЫљйЗСиЮНжЬНеК°еЕђеПЄLMAXеЉАеПСзЪДдЄАзІНйЂШжАІиГљзЪДеєґеПСжХ∞жНЃзїУжЮДпЉМдЄїи¶Б襀职聰䪯дЄАдЄ™дљОеїґињЯгАБйЂШеРЮеРРйЗПзЪДжґИжБѓдЉ†йАТж°ЖжЮґгАВеЃГдї•еЕґеИЫжЦ∞зЪДеєґеПСе§ДзРЖжЬЇеИґеТМеЬ®еНХж†ЄCPUдЄКеЃЮзО∞жѓПзІТе§ДзРЖжХ∞зЩЊдЄЗдЇЛеК°зЪДйАЯеЇ¶иАМйЧїеРНгАВDisruptorеЬ®...
ињЩзІНжАІиГљжПРеНЗдљњеЊЧDisruptorжИРдЄЇеЉВж≠•дЇЛдїґй©±еК®жЮґжЮДзЪДзРЖжГ≥йАЙжЛ©пЉМLMAXеЕђеПЄеЈ≤зїПеЬ®иЃҐеНХеМєйЕНеЉХжУОгАБеЃЮжЧґй£ОйЩ©зЃ°зРЖеТМеЖЕе≠ШдЇЛеК°е§ДзРЖз≥їзїЯз≠Йе§ЪдЄ™еЕ≥йФЃй°єзЫЃдЄ≠жИРеКЯеЇФзФ®дЇЖDisruptorпЉМеЃЮзО∞дЇЖеЙНжЙАжЬ™жЬЙзЪДжАІиГљж∞іеє≥гАВ DisruptorеєґйЭЮдїЕйЩРдЇО...
* ж∞іеє≥зЇњзЉЖиЃ°зЃЧжЦєж≥ХпЉЪж∞іеє≥зЇњзЉЖйХњеЇ¶ A=(Lmax+Lmin)/2*1.1+DпЉМD дЄЇзЂѓжО•дљЩйЗП 6~15mгАВ * еЮВзЫізЇњзЉЖиЃ°зЃЧжЦєж≥ХпЉЪжѓПе±ВеЮВзЫізЇњзЉЖйХњеЇ¶(m)=(иЈЭ BD зЪДж•Ље±ВжХ∞*е±ВйЂШ+зЂѓжО•еЃєйЩР)*жѓПе±ВйЬАи¶Бж†єжХ∞гАВ еЕ≠гАБиЃЊе§ЗйЧі/зЃ°зРЖе≠Рз≥їзїЯиЃЊиЃ° * иЃЊе§ЗйЧі...