
本文转载自CSDN博客,纯为技术资料备份!
MapReduce的名字源于函数式编程模型中的两项核心操作:Map和Reduce。也许熟悉Functional Programming(FP)的人见到这两个词会倍感亲切。因为Map和Reduce这两个术语源自Lisp语言和函数式编程。Map是把一组数据一对一的映射为另外的一组数据,其映射的规则由一个函数来指定。Reduce是对一组数据进行归约,这个归约的规则由一个函数指定。Map是一个把数据分开的过程,Reduce则是把分开的数据合并的过程。如Hadoop的wordcount例子:用Map把[one,word,one,dream]进行映射就变成了[{one,1}, {word,1}, {one,1}, {dream,1}],再用Reduce把[{one,1}, {word,1}, {one,1}, {dream,1}]归约变成[{one,2}, {word,1}, {dream,1}]的结果集。
对数组里的每个元素进行相同操作的一段代码:
a = [1, 2, 3];
for (i = 0; i < a.length; i++){
a[i] = a[i] * 2;
}
for (i = 0; i < a.length; i++){
print(a[i]);
}
常常要对数组里的所有元素做同一件事情,因此你可以写个这样的函数:
function map(fn, a){
for (i = 0; i < a.length; i++){
fn(a[i]);
}
}
现在可以把上面的东西改成:
map(function(x) { return x * 2; }, a);
map(print, a);
另一个常见的任务是将数组内的所有元素按照某种方式汇总起来:
function sum(a){
s = 0;
for (i = 0; i < a.length; i++){
s += a[i];
}
return s;
}
function join(a){
s = "";
for (i = 0; i < a.length; i++){
s = s .. a[i]; // ..是字符串连接操作符
}
return s;
}
print(sum([1,2,3]));
print(join(["a","b","c"]));
注意sum和join长得很像,你也许想把它们抽象为一个将数组内的所有元素按某种算法汇总起來的泛型函数:
function reduce(fn, a, init){
s = init;
for (i = 0; i < a.length; i++){
s = fn(s, a[i]);
}
return s;
}
这样sum和join就变成下面的样子了:
function sum(a){
return reduce(function(a, b) { return a + b; }, a, 0 );
}
function join(a){
return reduce(function(a, b) { return a .. b; }, a, "" );
}
让我们看回map函数。当你要对数组内的每个元素做一些事,你很可能不在乎哪个元素先做。无论由第一个元素开始执行,还是是由最后一个元素开始执行,你的结果都是一样的。这样如果你手头上有2个CPU,你可以写段代码,使它们各自处理1/2的元素,于是乎map快了两倍。设想你在全球有千千万万台服务器,恰好你有一个真的很大很大的数组,现在你可以在几千台服务器上同时执行map,让每台服务器都来解决同一个问题的一小部分。
Map的定义:
Map, written by the user, takes an input pair and produces a set of intermediate key/value pairs. The MapReduce library groups together all intermediate values associated with the same intermediate key I and passes them to the Reduce function.
Reduce的定义:
The Reduce function, also written by the user, accepts an intermediate key I and a set of values for that key. It merges together these values to form a possibly smaller set of values. Typically just zero or one output value is produced per Reduce invocation. The intermediate values are supplied to the user’s reduce function via an iterator. This allows us to handle lists of values that are too large to fit in memory.
MapReduce论文中给出了这样一个例子:在一个文档集合中统计每个单词出现的次数。Map操作的输入是每一篇文档,将输入文档中每一个单词的出现输出到中间文件中去。
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
比如我们有两篇文档,内容分别是
A - "I love programming"
B - "I am a blogger, you are also a blogger"
A文档经过Map运算后输出的中间文件将会是:
I,1
love,1
programming,1
B文档经过Map运算后输出的中间文件将会是:
I,1
am,1
a,1
blogger,1
you,1
are,1
also,1
a,1
blogger,1
Reduce操作的输入是单词和出现次数的序列。用上面的例子来说,就是 (I, [1, 1]), (love, [1]), (programming, [1]), (am, [1]), (a, [1,1]) 等。然后根据每个单词,算出总的出现次数。
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
最终结果是:("I", "2"), ("a", "2"), ……
实际的执行顺序是:
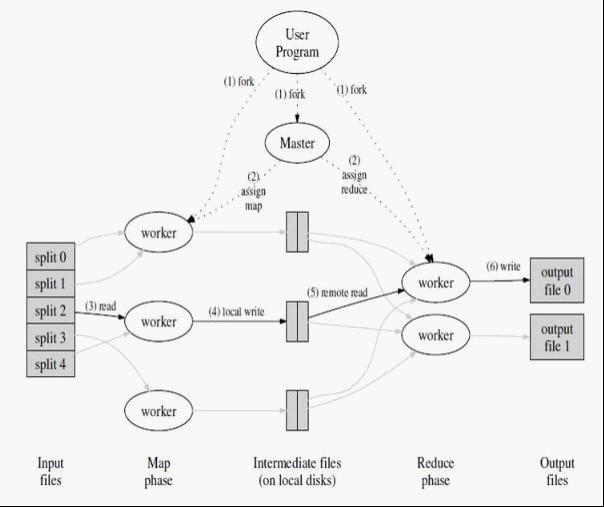
MapReduce Library将Input分成M份。这里的Input Splitter也可以是多台机器并行Split。
Master将M份Job分给Idle状态的M个worker来处理;
对于输入中的每一个<key, value> pair 进行Map操作,将中间结果Buffer在Memory里;
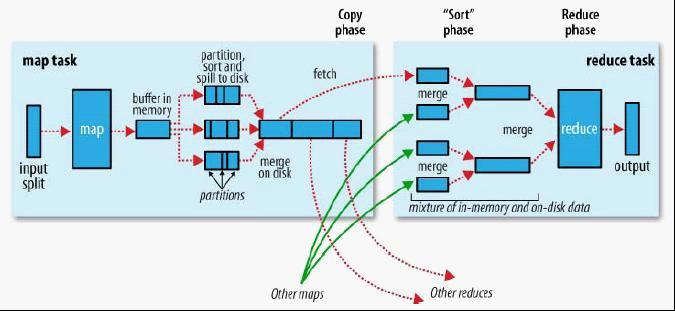
定期的(或者根据内存状态),将Buffer中的中间信息Dump到本地磁盘上,并且把文件信息传回给Master(Master需要把这些信息发送给Reduce worker)。这里最重要的一点是,在写磁盘的时候,需要将中间文件做Partition(比如R个)。拿上面的例子来举例,如果把所有的信息存到一个文件,Reduce worker又会变成瓶颈。我们只需要保证相同Key能出现在同一个Partition里面就可以把这个问题分解。
R个Reduce worker开始工作,从不同的Map worker的Partition那里拿到数据(read the buffered data from the local disks of the map workers),用key进行排序(如果内存中放不下需要用到外部排序 – external sort)。很显然,排序(或者说Group)是Reduce函数之前必须做的一步。 这里面很关键的是,每个Reduce worker会去从很多Map worker那里拿到X(0<X<R) Partition的中间结果,这样,所有属于这个Key的信息已经都在这个worker上了。
Reduce worker遍历中间数据,对每一个唯一Key,执行Reduce函数(参数是这个key以及相对应的一系列Value)。
执行完毕后,唤醒用户程序,返回结果(最后应该有R份Output,每个Reduce Worker一个)。
可见,这里的分(Divide)体现在两步,分别是将输入分成M份,以及将Map的中间结果分成R份。将输入分开通常很简单,Map的中间结果通常用”hash(key) mod R”这个结果作为标准,保证相同的Key出现在同一个Partition里面。当然,使用者也可以指定自己的Partition Function,比如,对于Url Key,如果希望同一个Host的URL出现在同一个Partition,可以用”hash(Hostname(urlkey)) mod R”作为Partition Function。
对于上面的例子来说,每个文档中都可能会出现成千上万的 ("the", 1)这样的中间结果,琐碎的中间文件必然导致传输上的损失。因此,MapReduce还支持用户提供Combiner Function。这个函数通常与Reduce Function有相同的实现,不同点在于Reduce函数的输出是最终结果,而Combiner函数的输出是Reduce函数的某一个输入的中间文件。



相关推荐
计算机二级公共基础知识模 拟试题及答案详解.pdf
内容概要:本文档详细介绍了语音发射机的设计与实现,涵盖了从硬件电路到具体元件的选择和连接方式。文档提供了详细的电路图,包括电源管理、信号处理、音频输入输出接口以及射频模块等关键部分。此外,还展示了各个引脚的功能定义及其与其他组件的连接关系,确保了系统的稳定性和高效性能。通过这份文档,读者可以全面了解语音发射机的工作原理和技术细节。 适合人群:对电子工程感兴趣的初学者、从事嵌入式系统开发的技术人员以及需要深入了解语音发射机制的专业人士。 使用场景及目标:适用于希望构建自己的语音发射设备的研究人员或爱好者,帮助他们掌握相关技术和实际操作技能。同时,也为教学机构提供了一个很好的案例研究材料。 其他说明:文档不仅限于理论讲解,还包括具体的实施步骤,使读者能够动手实践并验证所学知识。
内容概要:本文详细介绍了用易语言编写的单线程全功能注册机源码,涵盖了接码平台对接、滑块验证处理、IP代理管理以及料子导入等多个核心功能。文章首先展示了主框架的初始化配置和事件驱动逻辑,随后深入探讨了接码平台(如打码兔)的API调用及其返回数据的处理方法。对于滑块验证部分,作者分享了如何利用易语言的绘图功能模拟真实用户的操作轨迹,并提高了验证通过率。IP代理模块则实现了智能切换策略,确保代理的有效性和稳定性。此外,料子导入功能支持多种格式的数据解析和去重校验,防止脏数据污染。最后,文章提到了状态机设计用于控制注册流程的状态持久化。 适合人群:有一定编程基础,尤其是熟悉易语言的开发者和技术爱好者。 使用场景及目标:适用于希望深入了解易语言注册机开发的技术细节,掌握接码、滑块验证、IP代理等关键技术的应用场景。目标是帮助读者理解并优化现有注册机的功能,提高其稳定性和效率。 其他说明:文中提到的部分技术和实现方式可能存在一定的风险,请谨慎使用。同时,建议读者在合法合规的前提下进行相关开发和测试。
计算机绘图实用教程 第三章.pdf
计算机辅助设计—AutoCAD 2018中文版基础教程 各章CAD图纸及相关说明汇总.pdf
C++相关书籍,计算机相关书籍,linux相关及http等计算机学习、面试书籍。
计算机二级mysql数据库程序设计练习题(一).pdf
计算机发展史.pdf
计算机二级课件.pdf
计算机概论第三讲:计算机组成.pdf
内容概要:本文档由中国移动通信集团终端有限公司、北京邮电大学、中国信息通信研究院和中国通信学会共同发布,旨在探讨端侧算力网络(TCAN)的概念、架构、关键技术及其应用场景。文中详细分析了终端的发展现状、基本特征和发展趋势,阐述了端侧算力网络的定义、体系架构、功能架构及其主要特征。端侧算力网络通过整合海量泛在异构终端的算力资源,实现分布式多级端侧算力资源的高效利用,提升网络整体资源利用率和服务质量。关键技术涵盖层次化端算力感知图模型、资源虚拟化、数据压缩、多粒度多层次算力调度、现场级AI推理和算力定价机制。此外,还探讨了端侧算力网络在智能家居、智能医疗、车联网、智慧教育和智慧农业等领域的潜在应用场景。 适合人群:从事通信网络、物联网、边缘计算等领域研究和开发的专业人士,以及对6G网络和端侧算力网络感兴趣的学者和从业者。 使用场景及目标:适用于希望深入了解端侧算力网络技术原理、架构设计和应用场景的读者。目标是帮助读者掌握端侧算力网络的核心技术,理解其在不同行业的应用潜力,推动端侧算力网络技术的商业化和产业化。 其他说明:本文档不仅提供了端侧算力网络的技术细节,还对其隐私与安全进行了深入探讨
学习java的心得体会.docx
计算机二级考试(南开100题齐全).pdf
内容概要:本文详细介绍了计算机二级C语言考试的内容和备考方法。首先概述了计算机二级考试的意义及其在计算机技能认证中的重要性,重点讲解了C语言的基础语法,包括程序结构、数据类型、运算符和表达式等。接着深入探讨了进阶知识,如函数、数组、指针、结构体和共用体的应用。最后分享了针对选择题、填空题和编程题的具体解题技巧,强调了复习方法和实战演练的重要性。 适合人群:准备参加计算机二级C语言考试的学生和技术爱好者。 使用场景及目标:①帮助考生系统地掌握C语言的核心知识点;②提供有效的解题策略,提高应试能力;③指导考生制定合理的复习计划,增强实战经验。 其他说明:本文不仅涵盖了理论知识,还提供了大量实例代码和详细的解释,有助于读者更好地理解和应用所学内容。此外,文中提到的解题技巧和复习建议对实际编程也有很大帮助。
论文格式及要求.doc
内容概要:本文详细介绍了如何使用三菱FX3U PLC及其485BD通信板与四台台达VFD-M系列变频器进行通信的设置与应用。主要内容涵盖硬件连接注意事项、通信参数配置、RS指令的应用、CRC校验算法的实现以及频率给定和状态读取的具体方法。文中提供了多个实用的编程示例,展示了如何通过梯形图和结构化文本编写通信程序,并讨论了常见的调试技巧和优化建议。此外,还提到了系统的扩展性和稳定性措施,如增加温度传感器通信功能和应对电磁干扰的方法。 适合人群:从事工业自动化领域的工程师和技术人员,尤其是那些熟悉三菱PLC和台达变频器的使用者。 使用场景及目标:适用于需要实现多台变频器联动控制的工业应用场景,旨在提高生产效率和系统可靠性。通过学习本文,读者可以掌握如何构建稳定的RS485通信网络,确保变频器之间的高效协同工作。 其他说明:本文不仅提供了详细的理论指导,还包括了许多来自实际项目的经验教训,帮助读者避免常见错误并提升编程技能。
计算机服务规范.pdf
Discuz_X3.2_TC_UTF8.zip LNMP搭建安装包
2023年房地产行业研究报告:缓解竣工下行加速的两大改革
win32汇编环境,网络编程入门之十五