
وœ¬و–‡è½¬è‡ھï¼ڑhttp://www.codelast.com/
آ
وœ¬و–‡هڈ¯ن»¥è®©هˆڑوژ¥è§¦pigçڑ„ن؛؛ه¯¹ن¸€ن؛›هں؛ç،€و¦‚ه؟µوœ‰ن¸ھهˆو¥çڑ„ن؛†è§£م€‚
وœ¬و–‡ه¤§و¦‚وک¯ن؛’èپ”网ن¸ٹ第ن¸€ç¯‡ه…¬ه¼€هڈ‘è،¨çڑ„ن¸”و¶µç›–ه¤§é‡ڈه®é™…ن¾‹هگçڑ„Apache Pigن¸و–‡و•™ç¨‹ï¼ˆç”±Googleوگœç´¢هڈ¯çں¥ï¼‰ï¼Œو–‡ن¸çڑ„ه¤§é‡ڈه®ن¾‹éƒ½وک¯ن½œè€…Darran Zhang(website: codelast.com)هœ¨ه·¥ن½œم€په¦ن¹ ن¸و€»ç»“çڑ„ç»ڈéھŒوˆ–解ه†³çڑ„é—®é¢ک,ه¹¶ن¸”و·»هٹ ن؛†è¾ƒن¸؛详ه°½çڑ„说وکژهڈٹو³¨è§£ï¼Œو¤ه¤–,ن½œè€…è؟کهœ¨ن¸چو–هœ°و·»هٹ وœ¬و–‡çڑ„ه†…ه®¹ï¼Œه¸Œوœ›èƒ½ه¸®هٹ©ن¸€éƒ¨هˆ†ن؛؛م€‚
Apache pigوک¯ç”¨و¥ه¤„çگ†ه¤§è§„و¨،و•°وچ®çڑ„é«کç؛§وں¥è¯¢è¯è¨€ï¼Œé…چهگˆHadoopن½؟用,هڈ¯ن»¥هœ¨ه¤„çگ†وµ·é‡ڈو•°وچ®و—¶è¾¾هˆ°ن؛‹هچٹهٹںه€چçڑ„و•ˆوœï¼Œو¯”ن½؟用Java,C++ç‰è¯è¨€ç¼–ه†™ه¤§è§„و¨،و•°وچ®ه¤„çگ†ç¨‹ه؛ڈçڑ„éڑ¾ه؛¦è¦په°ڈNه€چ,ه®çژ°هگŒو ·çڑ„و•ˆوœçڑ„ن»£ç پé‡ڈن¹ںه°ڈNه€چم€‚Twitterه°±ه¤§é‡ڈن½؟用pigو¥ه¤„çگ†وµ·é‡ڈو•°وچ®â€”—وœ‰ه…´è¶£çڑ„,هڈ¯ن»¥çœ‹Twitterه·¥ç¨‹ه¸ˆه†™çڑ„è؟™ن¸ھPPTم€‚
ن½†وک¯ï¼Œهˆڑوژ¥è§¦pigو—¶ï¼Œهڈ¯èƒ½ن¼ڑ觉ه¾—里é¢çڑ„وںگن؛›و¦‚ه؟µن»¥هڈٹ程ه؛ڈه®çژ°و–¹و³•ن¸ژوƒ³هƒڈن¸çڑ„ه¾ˆن¸چن¸€و ·ï¼Œç”ڑ至وœ‰ن؛›èژ«هگچ,و‰€ن»¥ï¼Œن½ 需è¦پن»”细هœ°ç ”究ن¸€ن¸‹هں؛ç،€و¦‚ه؟µï¼Œè؟™و ·هœ¨ه†™pig程ه؛ڈçڑ„و—¶ه€™ï¼Œو‰چن¸چن¼ڑ觉ه¾—éه¸¸هˆ«و‰م€‚
وœ¬و–‡هں؛ن؛ژن»¥ن¸‹çژ¯ه¢ƒï¼ڑ
pig 0.8.1
ه…ˆç»™ه‡؛ن¸¤ن¸ھ链وژ¥ï¼ڑpigهڈ‚考و‰‹ه†Œ1,pigهڈ‚考و‰‹ه†Œ2م€‚وœ¬و–‡çڑ„部هˆ†ه†…ه®¹و¥è‡ھè؟™ن¸¤ن¸ھو‰‹ه†Œï¼Œن½†و¶‰هڈٹهˆ°ç؟»è¯‘çڑ„部هˆ†ï¼Œن¹ںوک¯وˆ‘è‡ھه·±ç؟»è¯‘çڑ„,ه› و¤هڈ¯èƒ½çگ†è§£ن¸ژ英و–‡وœ‰هپڈه·®ï¼Œه¦‚وœن½ 觉ه¾—وœ‰ç–‘ن¹‰ï¼Œهڈ¯هڈ‚考英و–‡ه†…ه®¹م€‚
م€گé…چç½®Pigè¯و³•é«کن؛®م€‘
هœ¨و£ه¼ڈه¼€ه§‹ه¦ن¹ Pigن¹‹ه‰چ,ن½ 首ه…ˆè¦پوکژ白,é…چç½®ه¥½ç¼–辑ه™¨çڑ„Pigè¯و³•é«کن؛®وک¯ه¾ˆوœ‰ç”¨çڑ„,ه®ƒهڈ¯ن»¥وپه¤§هœ°وڈگé«کن½ çڑ„ه·¥ن½œو•ˆçژ‡م€‚
هœ¨Linuxن¸‹ï¼Œé€‰و‹©ه°±ه¾ˆه¤ڑن؛†ï¼Œه¤§هˆ†éƒ¨ن؛؛ن½؟用çڑ„وک¯vi,vim,ن½†وˆ‘وک¯ن¸ھEmacsوژ§ï¼Œو‰€ن»¥وˆ‘ه°±ه…ˆè¯´è¯´ه¦‚ن½•é…چç½®Emacsçڑ„Pigè¯و³•é«کن؛®م€‚و¤وڈ’ن»¶وک¯ن¸€ن¸ھه¾ˆه¥½çڑ„选و‹©ï¼ڑhttps://github.com/cloudera/piglatin-mode
ه…¶ه®Emacsن¹ںوœ‰Windows版çڑ„,ه¦‚وœن½ ن¹ وƒ¯هœ¨Windowsن¸‹ه·¥ن½œï¼Œه®Œه…¨هڈ¯ن»¥هœ¨Windowsن¸‹وŒ‰ن¸ٹé¢çڑ„و–¹و³•é…چç½®ن¸€ن¸‹Pigè¯و³•é«کن؛®ï¼ˆن½†وک¯Windows版çڑ„Emacsè؟ک需è¦پن¸€ن؛›é¢ه¤–çڑ„é…چç½®ه·¥ن½œï¼Œن¾‹ه¦‚ن؟®و”¹و³¨ه†Œè،¨ç‰ï¼Œو‰€ن»¥ن¼ڑو¯”هœ¨Linuxن¸‹ن½؟用è¦پé؛»çƒ¦ن¸€ن؛›ï¼Œه…·ن½“请看è؟™ç¯‡و–‡ç« )م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
ن¸‹é¢ه¼€ه§‹ه¦ن¹ Pigم€‚
(1)ه…³ç³»ï¼ˆrelation)م€پهŒ…(bag)م€په…ƒç»„(tuple)م€په—و®µï¼ˆfield)م€پو•°وچ®ï¼ˆdata)çڑ„ه…³ç³»
- ن¸€ن¸ھه…³ç³»ï¼ˆrelation)وک¯ن¸€ن¸ھهŒ…(bag),و›´ه…·ن½“هœ°è¯´ï¼Œوک¯ن¸€ن¸ھه¤–部çڑ„هŒ…(outer bag)م€‚
- ن¸€ن¸ھهŒ…(bag)وک¯ن¸€ن¸ھه…ƒç»„(tuple)çڑ„集هگˆم€‚هœ¨pigن¸è،¨ç¤؛و•°وچ®و—¶ï¼Œç”¨ه¤§و‹¬هڈ·{}و‹¬èµ·و¥çڑ„ن¸œè¥؟è،¨ç¤؛ن¸€ن¸ھهŒ…——و— è®؛وک¯هœ¨و•™ç¨‹ن¸çڑ„ه®ن¾‹و¼”ç¤؛,è؟کوک¯هœ¨pigن؛¤ن؛’و¨،ه¼ڈن¸‹çڑ„输ه‡؛,都éپµه¾ھè؟™و ·çڑ„ç؛¦ه®ڑ,请牢记è؟™ن¸€ç‚¹ï¼Œه› ن¸؛ن¸چçگ†è§£çڑ„è¯ه°±ن¼ڑه¯¹و•°وچ®ç»“و„çڑ„وژŒوڈ،ن؛§ç”ںهپڈه·®م€‚
- ن¸€ن¸ھه…ƒç»„(tuple)وک¯è‹¥ه¹²ه—و®µï¼ˆfield)çڑ„ن¸€ن¸ھوœ‰ه؛ڈ集(ordered set)م€‚هœ¨pigن¸è،¨ç¤؛و•°وچ®و—¶ï¼Œç”¨ه°ڈو‹¬هڈ·()و‹¬èµ·و¥çڑ„ن¸œè¥؟è،¨ç¤؛ن¸€ن¸ھه…ƒç»„م€‚
- ن¸€ن¸ھه—و®µوک¯ن¸€ه—و•°وچ®ï¼ˆdata)م€‚
“ه…ƒç»„â€è؟™ن¸ھè¯چه¾ˆوٹ½è±،,ن½ هڈ¯ن»¥وٹٹه®ƒوƒ³هƒڈوˆگه…³ç³»ه‹و•°وچ®ه؛“è،¨ن¸çڑ„ن¸€è،Œï¼Œه®ƒهگ«وœ‰ن¸€ن¸ھوˆ–ه¤ڑن¸ھه—و®µï¼Œه…¶ن¸ï¼Œو¯ڈن¸€ن¸ھه—و®µهڈ¯ن»¥وک¯ن»»ن½•و•°وچ®ç±»ه‹ï¼Œه¹¶ن¸”هڈ¯ن»¥وœ‰وˆ–者و²،وœ‰و•°وچ®م€‚
“ه…³ç³»â€هڈ¯ن»¥و¯”ه–»وˆگه…³ç³»ه‹و•°وچ®ه؛“çڑ„ن¸€ه¼ è،¨ï¼Œè€Œن¸ٹé¢è¯´ن؛†ï¼Œâ€œه…ƒç»„â€هڈ¯ن»¥و¯”ه–»وˆگو•°وچ®è،¨ن¸çڑ„ن¸€è،Œï¼Œé‚£ن¹ˆè؟™é‡Œوœ‰ن؛؛è¦پé—®ن؛†ï¼Œهœ¨ه…³ç³»ه‹و•°وچ®ه؛“ن¸ï¼ŒهگŒن¸€ه¼ è،¨ن¸çڑ„و¯ڈن¸€è،Œéƒ½وœ‰ه›؛ه®ڑçڑ„ه—و®µو•°ï¼Œpigن¸çڑ„“ه…³ç³»â€ن¸ژ“ه…ƒç»„â€ن¹‹é—´ï¼Œوک¯هگ¦ن¹ںوک¯è؟™و ·çڑ„وƒ…ه†µه‘¢ï¼ںن¸چوک¯çڑ„م€‚“ه…³ç³»â€ه¹¶ن¸چè¦پو±‚و¯ڈن¸€ن¸ھ“ه…ƒç»„â€éƒ½هگ«وœ‰ç›¸هگŒو•°é‡ڈçڑ„ه—و®µï¼Œه¹¶ن¸”ن¹ںن¸چن¼ڑè¦پو±‚هگ„“ه…ƒç»„â€ن¸هœ¨ç›¸هگŒن½چç½®ه¤„çڑ„ه—و®µه…·وœ‰ç›¸هگŒçڑ„و•°وچ®ç±»ه‹ï¼ˆه¤ھéڑڈو„ڈن؛†ï¼Œوک¯هگ§ï¼ں)
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
(2)ن¸€ن¸ھ è®،ç®—ه¤ڑç»´ه؛¦ç»„هگˆن¸‹çڑ„ه¹³ه‡ه€¼ çڑ„ه®é™…ن¾‹هگ
ن¸؛ن؛†ه¸®هٹ©ه¤§ه®¶çگ†è§£pigçڑ„ن¸€ن¸ھهں؛وœ¬çڑ„و•°وچ®ه¤„çگ†وµپ程,وˆ‘é€ ن؛†ن¸€ن؛›ç®€هچ•çڑ„و•°وچ®و¥ن¸¾ن¸ھن¾‹هگ——
هپ‡è®¾وœ‰و•°وچ®و–‡ن»¶ï¼ڑa.txt(هگ„و•°ه€¼ن¹‹é—´وک¯ن»¥tabهˆ†éڑ”çڑ„)ï¼ڑ
[root@localhost pig]$ cat a.txt a 1 2 3 4.2 9.8 a 3 0 5 3.5 2.1 b 7 9 9 - - a 7 9 9 2.6 6.2 a 1 2 5 7.7 5.9 a 1 2 3 1.4 0.2
é—®é¢که¦‚ن¸‹ï¼ڑو€ژو ·و±‚ه‡؛هœ¨ç¬¬2م€پ3م€پ4هˆ—çڑ„و‰€وœ‰ç»„هگˆçڑ„وƒ…ه†µن¸‹ï¼Œوœ€هگژن¸¤هˆ—çڑ„ه¹³ه‡ه€¼هˆ†هˆ«وک¯ه¤ڑه°‘ï¼ں
ن¾‹ه¦‚,第2م€پ3م€پ4هˆ—وœ‰ن¸€ن¸ھ组هگˆن¸؛(1,2,3),هچ³ç¬¬ن¸€è،Œه’Œوœ€هگژن¸€è،Œو•°وچ®م€‚ه¯¹è؟™ن¸ھç»´ه؛¦ç»„هگˆو¥è¯´ï¼Œوœ€هگژن¸¤هˆ—çڑ„ه¹³ه‡ه€¼هˆ†هˆ«ن¸؛ï¼ڑ
(4.2+1.4)/2ï¼2.8
(9.8+0.2)/2ï¼5.0
而ه¯¹ن؛ژ第2م€پ3م€پ4هˆ—çڑ„ه…¶ن»–و‰€وœ‰ç»´ه؛¦ç»„هگˆï¼Œéƒ½هˆ†هˆ«هڈھوœ‰ن¸€è،Œو•°وچ®ï¼Œه› و¤وœ€هگژن¸¤هˆ—çڑ„ه¹³ه‡ه€¼ه…¶ه®ه°±وک¯ه®ƒن»¬è‡ھè؛«م€‚
特هˆ«هœ°ï¼Œç»„هگˆï¼ˆ7,9,9)وœ‰ن¸¤è،Œè®°ه½•ï¼ڑ第ن¸‰م€په››è،Œï¼Œن½†وک¯ç¬¬ن¸‰è،Œو•°وچ®çڑ„وœ€هگژن¸¤هˆ—و²،وœ‰ه€¼ï¼Œه› و¤ه®ƒن¸چه؛”该被用ن؛ژه¹³ه‡ه€¼çڑ„è®،算,ن¹ںه°±وک¯è¯´ï¼Œهœ¨è®،ç®—ه¹³ه‡ه€¼و—¶ï¼Œç¬¬ن¸‰è،Œوک¯و— و•ˆو•°وچ®م€‚و‰€ن»¥ï¼ˆ7,9,9)组هگˆçڑ„وœ€هگژن¸¤هˆ—çڑ„ه¹³ه‡ه€¼ن¸؛ 2.6 ه’Œ 6.2م€‚
وˆ‘ن»¬çژ°هœ¨ç”¨pigو¥ç®—ن¸€ن¸‹ï¼Œه¹¶ن¸”输ه‡؛وœ€ç»ˆçڑ„结وœم€‚
ه…ˆè؟›ه…¥وœ¬هœ°è°ƒè¯•و¨،ه¼ڈ(pig -x local),ه†چن¾و¬،输ه…¥ه¦‚ن¸‹pigن»£ç پï¼ڑ
A = LOAD 'a.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double); B = GROUP A BY (col2, col3, col4); C = FOREACH B GENERATE group, AVG(A.col5), AVG(A.col6); DUMP C;
pig输ه‡؛结وœه¦‚ن¸‹ï¼ڑ
((1,2,3),2.8,5.0) ((1,2,5),7.7,5.9) ((3,0,5),3.5,2.1) ((7,9,9),2.6,6.2)
è؟™ن¸ھ结وœه¯¹هگ—ï¼ںو‰‹ه·¥ç®—ن¸€ن¸‹ه°±çں¥éپ“وک¯ه¯¹çڑ„م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
ن¸‹é¢ï¼Œوˆ‘ن»¬ن¾و¬،و¥çœ‹çœ‹و¯ڈن¸€هڈ¥pigن»£ç پهˆ†هˆ«ه¾—هˆ°ن؛†ن»€ن¹ˆو ·çڑ„و•°وچ®م€‚
â‘ هٹ è½½ a.txt و–‡ن»¶ï¼Œه¹¶وŒ‡ه®ڑو¯ڈن¸€هˆ—çڑ„و•°وچ®ç±»ه‹هˆ†هˆ«ن¸؛ chararray(ه—符ن¸²ï¼‰ï¼Œint,int,int,double,doubleم€‚هگŒو—¶ï¼Œوˆ‘ن»¬è؟کç»™ن؛ˆن؛†و¯ڈن¸€هˆ—هˆ«هگچ,هˆ†هˆ«ن¸؛ col1,col2,……,col6م€‚è؟™ن¸ھهˆ«هگچهœ¨هگژé¢çڑ„و•°وچ®ه¤„çگ†ن¸ن¼ڑ用هˆ°â€”—ه¦‚وœن½ ن¸چوŒ‡ه®ڑهˆ«هگچ,那ن¹ˆهœ¨هگژé¢çڑ„ه¤„çگ†ن¸ï¼Œه°±هڈھ能ن½؟用索ه¼•ï¼ˆ$0,$1,……)و¥و ‡è¯†ç›¸ه؛”çڑ„هˆ—ن؛†ï¼Œè؟™و ·هڈ¯è¯»و€§ن¼ڑهڈکه·®ï¼Œه› و¤ï¼Œهœ¨هˆ—ه›؛ه®ڑçڑ„وƒ…ه†µن¸‹ï¼Œè؟کوک¯وŒ‡ه®ڑهˆ«هگچçڑ„ه¥½م€‚
ه°†و•°وچ®هٹ è½½ن¹‹هگژ,ن؟هکهˆ°هڈکé‡ڈAن¸ï¼ŒAçڑ„و•°وچ®ç»“و„ه¦‚ن¸‹ï¼ڑ
A: {col1: chararray,col2: int,col3: int,col4: int,col5: double,col6: double}
هڈ¯è§پ,Aوک¯ç”¨ه¤§و‹¬هڈ·و‹¬èµ·و¥çڑ„ن¸œè¥؟م€‚و ¹وچ®وœ¬و–‡ه‰چé¢çڑ„说و³•ï¼ŒAوک¯ن¸€ن¸ھهŒ…(bag)م€‚
è؟™ن¸ھو—¶ه€™ï¼ŒAن¸ژن½ وƒ³هƒڈن¸çڑ„و ·هگه؛”该وک¯ن¸€è‡´çڑ„,ن¹ںه°±وک¯ن¸ژه‰چé¢و‰“هچ°ه‡؛و¥çڑ„ a.txt و–‡ن»¶çڑ„ه†…ه®¹وک¯ن¸€و ·çڑ„,è؟کوک¯ن¸€è،Œن¸€è،Œçڑ„ç±»ن¼¼ن؛ژ“ن؛Œç»´è،¨â€çڑ„و•°وچ®م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
â‘،وŒ‰ç…§Açڑ„第2م€پ3م€پ4هˆ—,ه¯¹Aè؟›è،Œهˆ†ç»„م€‚pigن¼ڑو‰¾ه‡؛و‰€وœ‰ç¬¬2م€پ3م€پ4هˆ—çڑ„组هگˆï¼Œه¹¶وŒ‰ç…§هچ‡ه؛ڈè؟›è،Œوژ’هˆ—,然هگژه°†ه®ƒن»¬ن¸ژه¯¹ه؛”çڑ„هŒ…Aو•´هگˆèµ·و¥ï¼Œه¾—هˆ°ه¦‚ن¸‹çڑ„و•°وچ®ç»“و„ï¼ڑ
B: {group: (col2: int,col3: int,col4: int),A: {col1: chararray,col2: int,col3: int,col4: int,col5: double,col6: double}}
هڈ¯è§پ,Açڑ„第2م€پ3م€پ4هˆ—çڑ„组هگˆè¢«pig赋ن؛ˆن؛†ن¸€ن¸ھهˆ«هگچï¼ڑgroup,è؟™ه¾ˆه½¢è±،م€‚هگŒو—¶وˆ‘ن»¬ن¹ں观ه¯ںهˆ°ï¼ŒBçڑ„و¯ڈن¸€è،Œه…¶ه®ه°±وک¯ç”±ن¸€ن¸ھgroupه’Œè‹¥ه¹²ن¸ھA组وˆگçڑ„——و³¨و„ڈ,وک¯è‹¥ه¹²ن¸ھAم€‚è؟™é‡Œن¹‹و‰€ن»¥هڈھوک¾ç¤؛ن؛†ن¸€ن¸ھA,وک¯ه› ن¸؛è؟™é‡Œè،¨ç¤؛çڑ„وک¯و•°وچ®ç»“و„,而ن¸چè،¨ç¤؛ه…·ن½“و•°وچ®وœ‰ه¤ڑه°‘组م€‚
ه®é™…çڑ„و•°وچ®ن¸؛ï¼ڑ
((1,2,3),{(a,1,2,3,4.2,9.8),(a,1,2,3,1.4,0.2)})
((1,2,5),{(a,1,2,5,7.7,5.9)})
((3,0,5),{(a,3,0,5,3.5,2.1)})
((7,9,9),{(b,7,9,9,,),(a,7,9,9,2.6,6.2)})
هڈ¯è§پ,ن¸ژه‰چé¢و‰€è¯´çڑ„ن¸€و ·ï¼Œç»„هگˆï¼ˆ1,2,3)ه¯¹ه؛”ن؛†ن¸¤è،Œو•°وچ®ï¼Œç»„هگˆï¼ˆ7,9,9)ن¹ںه¯¹ه؛”ن؛†ن¸¤è،Œو•°وچ®م€‚
è؟™ن¸ھو—¶ه€™ï¼ŒBçڑ„结و„ه°±ن¸چé‚£ن¹ˆوکژوœ—ن؛†ï¼Œهڈ¯èƒ½ن¸ژن½ وƒ³هƒڈن¸وœ‰ن¸€ç‚¹ن¸چن¸€و ·ن؛†م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
â‘¢è®،ç®—و¯ڈن¸€ç§چ组هگˆن¸‹çڑ„وœ€هگژن¸¤هˆ—çڑ„ه¹³ه‡ه€¼م€‚
و ¹وچ®ن¸ٹé¢ه¾—هˆ°çڑ„Bçڑ„و•°وچ®ï¼Œن½ هڈ¯ن»¥وٹٹBوƒ³هƒڈوˆگن¸€è،Œن¸€è،Œçڑ„و•°وچ®ï¼ˆهڈھن¸چè؟‡è؟™ن؛›è،Œن¸چوک¯ه¯¹ç§°çڑ„),FOREACH çڑ„ن½œç”¨وک¯ه¯¹ B çڑ„و¯ڈن¸€è،Œو•°وچ®è؟›è،Œéپچهژ†ï¼Œç„¶هگژè؟›è،Œè®،ç®—م€‚
GENERATE هڈ¯ن»¥çگ†è§£ن¸؛è¦پç”ںوˆگن»€ن¹ˆو ·çڑ„و•°وچ®ï¼Œè؟™é‡Œçڑ„ group ه°±وک¯ن¸ٹن¸€و¥و“چن½œن¸Bçڑ„第ن¸€é،¹و•°وچ®ï¼ˆهچ³pigن¸؛Açڑ„第2م€پ3م€پ4هˆ—çڑ„组هگˆèµ‹ن؛ˆçڑ„هˆ«هگچ),و‰€ن»¥ه®ƒه‘ٹ诉ن؛†وˆ‘ن»¬ï¼ڑهœ¨و•°وچ®é›† C çڑ„و¯ڈن¸€è،Œé‡Œï¼Œç¬¬ن¸€é،¹ه°±وک¯Bن¸çڑ„group——类ن¼¼ن؛ژ(1,2,5)è؟™و ·çڑ„ن¸œè¥؟)م€‚
而 AVG(A.col5) è؟™و ·çڑ„è®،算,هˆ™وک¯è°ƒç”¨ن؛†pigçڑ„ن¸€ن¸ھو±‚ه¹³ه‡ه€¼çڑ„ه‡½و•° AVG,用ن؛ژه¯¹ A çڑ„هگچن¸؛ col5 çڑ„هˆ—و±‚ه¹³ه‡ه€¼م€‚ه‰چو–‡è¯´ن؛†ï¼Œهœ¨هٹ è½½و•°وچ®هˆ°Açڑ„و—¶ه€™ï¼Œوˆ‘ن»¬ه·²ç»ڈç»™و¯ڈن¸€هˆ—èµ·ن؛†ن¸ھهˆ«هگچ,col5ه°±وک¯ه€’و•°ç¬¬ن؛Œهˆ—م€‚
هˆ°è؟™é‡Œï¼Œهڈ¯èƒ½وœ‰ن؛؛è¦پè؟·ç³ٹن؛†ï¼ڑéڑ¾éپ“ AVG(A.col5) ن¸چوک¯è،¨ç¤؛ه¯¹ A çڑ„col5è؟™ن¸€هˆ—و±‚ه¹³ه‡ه€¼هگ—ï¼ںن¹ںه°±وک¯è¯´ï¼Œهœ¨éپچهژ†B(FOREACH B)çڑ„و¯ڈن¸€è،Œو—¶ه€™ï¼Œè®،算结وœéƒ½وک¯ç›¸هگŒçڑ„ه•ٹï¼پ
ن؛‹ه®ن¸ٹه¹¶ن¸چوک¯è؟™و ·م€‚وˆ‘ن»¬éپچهژ†çڑ„وک¯B,وˆ‘ن»¬éœ€è¦پو³¨و„ڈهˆ°ï¼ŒBçڑ„و•°وچ®ç»“و„ن¸ï¼Œو¯ڈن¸€è،Œو•°وچ®é‡Œï¼Œن¸€ن¸ھgroupه¯¹ه؛”çڑ„وک¯è‹¥ه¹²ن¸ھA,ه› و¤ï¼Œè؟™é‡Œçڑ„ A.col5,وŒ‡çڑ„وک¯Bçڑ„و¯ڈن¸€è،Œن¸çڑ„A,而ن¸چوک¯هŒ…هگ«ه…¨éƒ¨و•°وچ®çڑ„é‚£ن¸ھAم€‚و‹؟Bçڑ„第ن¸€è،Œو¥ن¸¾ن¾‹ï¼ڑ
((1,2,3),{(a,1,2,3,4.2,9.8),(a,1,2,3,1.4,0.2)})
éپچهژ†هˆ°Bçڑ„è؟™ن¸€è،Œو—¶ï¼Œè¦پè®،ç®—AVG(A.col5),pigن¼ڑو‰¾هˆ°آ (a,1,2,3,4.2,9.8) ن¸çڑ„4.2,ن»¥هڈٹ(a,1,2,3,1.4,0.2)ن¸çڑ„1.4,هٹ èµ·و¥é™¤ن»¥2,ه°±ه¾—هˆ°ن؛†ه¹³ه‡ه€¼م€‚
هگŒçگ†ï¼Œوˆ‘ن»¬ن¹ںçں¥éپ“ن؛†AVG(A.col6)وک¯و€ژن¹ˆç®—ه‡؛و¥çڑ„م€‚ن½†è؟کوœ‰ن¸€ç‚¹è¦پو³¨و„ڈçڑ„ï¼ڑه¯¹(7,9,9)è؟™ن¸ھ组,ه®ƒه¯¹ه؛”çڑ„و•°وچ®(b,7,9,9,,)里وœ€هگژن¸¤هˆ—وک¯و— ه€¼çڑ„,è؟™وک¯ه› ن¸؛وˆ‘ن»¬çڑ„و•°وچ®و–‡ن»¶ه¯¹ه؛”ن½چç½®ن¸ٹن¸چوک¯وœ‰و•ˆو•°ه—,而وک¯ن¸¤ن¸ھ“-â€ï¼Œpigهœ¨هٹ è½½و•°وچ®çڑ„و—¶ه€™è‡ھهٹ¨ه°†ه®ƒç½®ن¸؛ç©؛ن؛†ï¼Œه¹¶ن¸”è®،ç®—ه¹³ه‡ه€¼çڑ„و—¶ه€™ï¼Œن¹ںن¸چن¼ڑوٹٹè؟™ن¸€ç»„و•°وچ®è€ƒè™‘هœ¨ه†…(相ه½“ن؛ژه؟½ç•¥è؟™ç»„و•°وچ®çڑ„هکهœ¨ï¼‰م€‚
هˆ°ن؛†è؟™é‡Œï¼Œوˆ‘ن»¬ن¸چéڑ¾çگ†è§£ï¼Œن¸؛ن»€ن¹ˆCçڑ„و•°وچ®ç»“و„وک¯è؟™و ·çڑ„ن؛†ï¼ڑ
C: {group: (col2: int,col3: int,col4: int),double,double}
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
â‘£DUMP Cه°±وک¯ه°†Cن¸çڑ„و•°وچ®è¾“ه‡؛هˆ°وژ§هˆ¶هڈ°م€‚ه¦‚وœè¦پ输ه‡؛هˆ°و–‡ن»¶ï¼Œéœ€è¦پن½؟用ï¼ڑ
STORE C INTO 'output';
è؟™و ·pigه°±ن¼ڑهœ¨ه½“ه‰چç›®ه½•ن¸‹و–°ه»؛ن¸€ن¸ھ“outputâ€ç›®ه½•ï¼ˆè¯¥ç›®ه½•ه؟…é،»ن؛‹ه…ˆن¸چهکهœ¨ï¼‰ï¼Œه¹¶وٹٹ结وœو–‡ن»¶و”¾هˆ°è¯¥ç›®ه½•ن¸‹م€‚
请وƒ³هƒڈن¸€ن¸‹ï¼Œه¦‚وœè¦په®çژ°ç›¸هگŒçڑ„هٹں能,用Javaوˆ–C++ه†™ن¸€ن¸ھMap-Reduceه؛”用程ه؛ڈ需è¦په¤ڑه°‘و—¶é—´ï¼ںهڈ¯èƒ½ن»…ن»…وک¯ه†™ن¸€ن¸ھbuild.xmlوˆ–者Makefile,و‰€éœ€çڑ„و—¶é—´ه°±وک¯ه†™è؟™و®µpigن»£ç پçڑ„ه‡ هچپه€چن؛†ï¼پ
و£ه› ن¸؛pigوœ‰ه¦‚و¤ن¼کهٹ؟,ه®ƒو‰چه¾—هˆ°ن؛†ه¹؟و³›ه؛”用م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
(3)و€ژو ·ç»ںè®،و•°وچ®è،Œو•°
هœ¨SQLè¯هڈ¥ن¸ï¼Œè¦پç»ںè®،è،¨ن¸و•°وچ®çڑ„è،Œو•°ï¼Œه¾ˆç®€هچ•ï¼ڑ
SELECT COUNT(*) FROM table_name WHERE condition
هœ¨pigن¸ï¼Œن¹ںوœ‰ن¸€ن¸ھCOUNTه‡½و•°ï¼Œهœ¨pigو‰‹ه†Œن¸ï¼Œه¯¹COUNTه‡½و•°وœ‰è؟™و ·çڑ„说وکژï¼ڑ
Computes the number of elements in a bag.
هپ‡è®¾è¦پè®،ç®—و•°وچ®و–‡ن»¶a.txtçڑ„è،Œو•°ï¼ڑ
[root@localhost pig]$ cat a.txt a 1 2 3 4.2 9.8 a 3 0 5 3.5 2.1 b 7 9 9 - - a 7 9 9 2.6 6.2 a 1 2 5 7.7 5.9 a 1 2 3 1.4 0.2
ن½ وک¯هگ¦هڈ¯ن»¥è؟™و ·هپڑه‘¢ï¼ڑ
A = LOAD 'a.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double); B = COUNT(*); DUMP B;
ç”و،ˆوک¯ï¼ڑç»ه¯¹ن¸چè،Œم€‚pigن¼ڑوٹ¥é”™م€‚pigو‰‹ه†Œن¸ه†™ه¾—ه¾ˆوکژ白ï¼ڑ
Note: You cannot use the tuple designator (*) with COUNT; that is, COUNT(*) will not work.
é‚£ن¹ˆï¼Œè؟™و ·ه¯¹وںگن¸€هˆ—è®،و•°è،Œن¸چè،Œه‘¢ï¼ڑ
B = COUNT(A.col2);
ç”و،ˆوک¯ï¼ڑن»چ然ن¸چè،Œم€‚pigن¼ڑوٹ¥é”™م€‚
è؟™ه°±ن¸ژوˆ‘ن»¬وƒ³هƒڈن¸çڑ„“و£ç،®هپڑو³•â€وœ‰ç‚¹ن¸چن¸€و ·ن؛†ï¼ڑوˆ‘ن¸؛ن»€ن¹ˆن¸چ能直وژ¥ç»ںè®،ن¸€ن¸ھه—و®µçڑ„و•°ç›®وœ‰ه¤ڑه°‘ه‘¢ï¼ںهˆڑوژ¥è§¦pigçڑ„و—¶ه€™ï¼Œن¸€ه®ڑéه¸¸ç–‘وƒ‘è؟™و ·وکژوک¾â€œن¸چه؛”该ه‡؛é”™â€çڑ„ه†™و³•ن¸؛ن»€ن¹ˆè،Œن¸چé€ڑم€‚
è¦پç»ںè®،Aن¸هگ«col2ه—و®µçڑ„و•°وچ®وœ‰ه¤ڑه°‘è،Œï¼Œو£ç،®çڑ„هپڑو³•وک¯ï¼ڑ
A = LOAD 'a.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double); B = GROUP A ALL; C = FOREACH B GENERATE COUNT(A.col2); DUMP C;
输ه‡؛结وœï¼ڑ
(6)
è،¨وکژوœ‰6è،Œو•°وچ®م€‚
ه¦‚و¤é؛»çƒ¦ï¼ںو²،é”™م€‚è؟™وک¯ç”±pigçڑ„و•°وچ®ç»“و„ه†³ه®ڑçڑ„م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
هœ¨è؟™ن¸ھن¾‹هگن¸ï¼Œç»ںè®،COUNT(A.col2)ه’ŒCOUNT(A)çڑ„结وœوک¯ن¸€و ·çڑ„,ن½†وک¯ï¼Œه¦‚وœcol2è؟™ن¸€هˆ—ن¸هگ«وœ‰ç©؛ه€¼ï¼ڑ
[root@localhost pig]$ cat a.txt a 1 2 3 4.2 9.8 a 0 5 3.5 2.1 b 7 9 9 - - a 7 9 9 2.6 6.2 a 1 2 5 7.7 5.9 a 1 2 3 1.4 0.2
هˆ™ن»¥ن¸‹pig程ه؛ڈهڈٹو‰§è،Œç»“وœن¸؛ï¼ڑ
grunt> A = LOAD 'a.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double); grunt> B = GROUP A ALL; grunt> C = FOREACH B GENERATE COUNT(A.col2); grunt> DUMP C; (5)
هڈ¯è§پ,结وœن¸؛5è،Œم€‚é‚£وک¯ه› ن¸؛ن½ LOADو•°وچ®çڑ„و—¶ه€™وŒ‡ه®ڑن؛†col2çڑ„و•°وچ®ç±»ه‹ن¸؛int,而a.txtçڑ„第ن؛Œè،Œو•°وچ®وک¯ç©؛çڑ„,ه› و¤و•°وچ®هٹ è½½هˆ°Aن»¥هگژ,وœ‰ن¸€ن¸ھه—و®µه°±وک¯ç©؛çڑ„ï¼ڑ
grunt> DUMP A; (a,1,2,3,4.2,9.8) (a,,0,5,3.5,2.1) (b,7,9,9,,) (a,7,9,9,2.6,6.2) (a,1,2,5,7.7,5.9) (a,1,2,3,1.4,0.2)
هœ¨COUNTçڑ„و—¶ه€™ï¼Œnullçڑ„ه—و®µن¸چن¼ڑ被è®،ه…¥هœ¨ه†…,و‰€ن»¥ç»“وœوک¯5م€‚
The COUNT function follows syntax semantics and ignores nulls. What this means is that a tuple in the bag will not be counted if the first field in this tuple is NULL. If you want to include NULL values in the count computation, use COUNT_STAR.
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
وˆ‘ن»¬è؟کوک¯é‡‡ç”¨ه‰چé¢çڑ„a.txtو•°وچ®و–‡ن»¶و¥è¯´وکژï¼ڑ
آ
[root@localhost pig]$ cat a.txt a 1 2 3 4.2 9.8 a 3 0 5 3.5 2.1 b 7 9 9 - - a 7 9 9 2.6 6.2 a 1 2 5 7.7 5.9 a 1 2 3 1.4 0.2
ه¦‚وœوˆ‘ن»¬وŒ‰ç…§ه‰چو–‡çڑ„هپڑو³•ï¼Œè®،ç®—ه¤ڑç»´ه؛¦ç»„هگˆن¸‹çڑ„وœ€هگژن¸¤هˆ—çڑ„ه¹³ه‡ه€¼ï¼Œهˆ™ï¼ڑ
grunt> A = LOAD 'a.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double); grunt> B = GROUP A BY (col2, col3, col4); grunt> C = FOREACH B GENERATE group, AVG(A.col5), AVG(A.col6); grunt> DUMP C; ((1,2,3),2.8,5.0) ((1,2,5),7.7,5.9) ((3,0,5),3.5,2.1) ((7,9,9),2.6,6.2)
هڈ¯è§پ,输ه‡؛结وœن¸ï¼Œو¯ڈن¸€è،Œçڑ„第ن¸€é،¹وک¯ن¸€ن¸ھtuple(ه…ƒç»„),وˆ‘ن»¬و¥è¯•è¯•çœ‹ FLATTEN çڑ„ن½œç”¨ï¼ڑ
grunt> A = LOAD 'a.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double); grunt> B = GROUP A BY (col2, col3, col4); grunt> C = FOREACH B GENERATE FLATTEN(group), AVG(A.col5), AVG(A.col6); grunt> DUMP C; (1,2,3,2.8,5.0) (1,2,5,7.7,5.9) (3,0,5,3.5,2.1) (7,9,9,2.6,6.2)
看هˆ°ن؛†هگ—ï¼ں被 FLATTEN çڑ„groupوœ¬و¥وک¯ن¸€ن¸ھه…ƒç»„,çژ°هœ¨هڈکوˆگن؛†و‰په¹³çڑ„结و„ن؛†م€‚وŒ‰ç…§pigو–‡و،£çڑ„说و³•ï¼ŒFLATTEN用ن؛ژه¯¹ه…ƒç»„(tuple)ه’ŒهŒ…(bag)“解هµŒه¥—â€ï¼ˆun-nest)ï¼ڑ
The FLATTEN operator looks like a UDF syntactically, but it is actually an operator that changes the structure of tuples and bags in a way that a UDF cannot. Flatten un-nests tuples as well as bags. The idea is the same, but the operation and result is different for each type of structure.آFor tuples, flatten substitutes the fields of a tuple in place of the tuple. For example, consider a relation that has a tuple of the form (a, (b, c)). The expression GENERATE $0, flatten($1), will cause that tuple to become (a, b, c).
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
و‰€ن»¥وˆ‘ن»¬ه°±çœ‹هˆ°ن؛†ن¸ٹé¢çڑ„结وœم€‚
هœ¨وœ‰çڑ„و—¶ه€™ï¼Œن¸چ“解هµŒه¥—â€çڑ„و•°وچ®ç»“و„وک¯ن¸چهˆ©ن؛ژ观ه¯ںçڑ„,输ه‡؛è؟™و ·çڑ„و•°وچ®هڈ¯èƒ½ن¸چهˆ©ن؛ژه¤–ه›´و•°ç¨‹ه؛ڈçڑ„ه¤„çگ†ï¼ˆن¾‹ه¦‚,pigه°†و•°وچ®è¾“ه‡؛هˆ°ç£پç›کهگژ,وˆ‘ن»¬è؟ک需è¦پ用ه…¶ن»–程ه؛ڈهپڑهگژç»ه¤„çگ†ï¼Œè€Œه¯¹ن¸€ن¸ھه…ƒç»„,输ه‡؛çڑ„ه†…ه®¹é‡Œوک¯هگ«و‹¬هڈ·çڑ„,è؟™ه°±هœ¨ه¤„çگ†وµپ程ن¸ٹهڈˆè¦په¤ڑن¸€éپ“هژ»و‹¬هڈ·çڑ„ه·¥ه؛ڈ),ه› و¤ï¼ŒFLATTENوڈگن¾›ن؛†ن¸€ن¸ھ让وˆ‘ن»¬هœ¨وںگن؛›وƒ…ه†µن¸‹هڈ¯ن»¥و¸…و¥ڑم€پو–¹ن¾؟هœ°هˆ†وگو•°وچ®çڑ„وœ؛ن¼ڑم€‚
(5)ه…³ن؛ژGROUPو“چن½œç¬¦
هœ¨ن¸ٹو–‡çڑ„ن¾‹هگن¸ï¼Œه·²ç»ڈو¼”ç¤؛ن؛†GROUPو“چن½œç¬¦ن¼ڑç”ںوˆگن»€ن¹ˆو ·çڑ„و•°وچ®م€‚هœ¨è؟™é‡Œï¼Œéœ€è¦پ说ه¾—و›´çگ†è®؛ن¸€ن؛›ï¼ڑ
- 用ن؛ژGROUPçڑ„keyه¦‚وœه¤ڑن؛ژن¸€ن¸ھه—و®µï¼ˆو£ه¦‚وœ¬و–‡ه‰چé¢çڑ„ن¾‹هگ),هˆ™GROUPن¹‹هگژçڑ„و•°وچ®çڑ„keyوک¯ن¸€ن¸ھه…ƒç»„(tuple),هگ¦هˆ™ه®ƒه°±وک¯ن¸ژ用ن؛ژGROUPçڑ„key相هگŒç±»ه‹çڑ„ن¸œè¥؟م€‚
- GROUPçڑ„结وœوک¯ن¸€ن¸ھه…³ç³»ï¼ˆrelation),هœ¨è؟™ن¸ھه…³ç³»ن¸ï¼Œو¯ڈن¸€ç»„هŒ…هگ«ن¸€ن¸ھه…ƒç»„(tuple),è؟™ن¸ھه…ƒç»„هŒ…هگ«ن¸¤ن¸ھه—و®µï¼ڑ(1)第ن¸€ن¸ھه—و®µè¢«ه‘½هگچن¸؛“groupâ€â€”—è؟™ن¸€ç‚¹éه¸¸ه®¹وک“ن¸ژGROUPه…³é”®ه—相و··و·†ï¼Œن½†è¯·هŒ؛هˆ†ه¼€و¥م€‚该ه—و®µçڑ„ç±»ه‹ن¸ژ用ن؛ژGROUPçڑ„keyç±»ه‹ç›¸هگŒم€‚(2)第ن؛Œن¸ھه—و®µوک¯ن¸€ن¸ھهŒ…(bag),ه®ƒçڑ„ç±»ه‹ن¸ژ被GROUPçڑ„ه…³ç³»çڑ„ç±»ه‹ç›¸هگŒم€‚
(6)وٹٹو•°وچ®ه½“ن½œâ€œه…ƒç»„â€ï¼ˆtuple)و¥هٹ è½½
è؟کوک¯هپ‡è®¾وœ‰ه¦‚ن¸‹و•°وچ®ï¼ڑ
[root@localhost pig]$ cat a.txt a 1 2 3 4.2 9.8 a 3 0 5 3.5 2.1 b 7 9 9 - - a 7 9 9 2.6 6.2 a 1 2 5 7.7 5.9 a 1 2 3 1.4 0.2
ه¦‚وœوˆ‘ن»¬وŒ‰ç…§ن»¥ن¸‹و–¹ه¼ڈو¥هٹ è½½و•°وچ®ï¼ڑ
A = LOAD 'a.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double);
é‚£ن¹ˆه¾—هˆ°çڑ„Açڑ„و•°وچ®ç»“و„ن¸؛ï¼ڑ
grunt> DESCRIBE A;
A: {col1: chararray,col2: int,col3: int,col4: int,col5: double,col6: double}
ه¦‚وœن½ è¦پوٹٹAه½“ن½œن¸€ن¸ھه…ƒç»„(tuple)و¥هٹ è½½ï¼ڑ
A = LOAD 'a.txt' AS (T : tuple (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double));
ن¹ںه°±وک¯وƒ³è¦په¾—هˆ°è؟™و ·çڑ„و•°وچ®ç»“و„ï¼ڑ
grunt> DESCRIBE A;
A: {T: (col1: chararray,col2: int,col3: int,col4: int,col5: double,col6: double)}
é‚£ن¹ˆï¼Œن¸ٹé¢çڑ„و–¹و³•ه°†ه¾—هˆ°ن¸€ن¸ھç©؛çڑ„Aï¼ڑ
grunt> DUMP A; () () () () () ()
é‚£وک¯ه› ن¸؛و•°وچ®و–‡ن»¶a.txtçڑ„结و„ن¸چ适هگˆن؛ژè؟™و ·هٹ è½½وˆگه…ƒç»„(tuple)م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
ه¦‚وœوœ‰و•°وچ®و–‡ن»¶b.txtï¼ڑ
[root@localhost pig]$ cat b.txt (a,1,2,3,4.2,9.8) (a,3,0,5,3.5,2.1) (b,7,9,9,-,-) (a,7,9,9,2.6,6.2) (a,1,2,5,7.7,5.9) (a,1,2,3,1.4,0.2)
هˆ™ن½؟用ن¸ٹé¢و‰€è¯´çڑ„هٹ è½½و–¹و³•هڈٹ结وœن¸؛ï¼ڑ
grunt> A = LOAD 'b.txt' AS (T : tuple (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double)); grunt> DUMP A; ((a,1,2,3,4.2,9.8)) ((a,3,0,5,3.5,2.1)) ((b,7,9,9,,)) ((a,7,9,9,2.6,6.2)) ((a,1,2,5,7.7,5.9)) ((a,1,2,3,1.4,0.2))
هڈ¯è§پ,هٹ è½½çڑ„و•°وچ®çڑ„结و„ç،®ه®è¢«ه®ڑن¹‰وˆگن؛†ه…ƒç»„(tuple)م€‚
(7)هœ¨ه¤ڑç»´ه؛¦ç»„هگˆن¸‹ï¼Œه¦‚ن½•è®،ç®—وںگن¸ھç»´ه؛¦ç»„هگˆé‡Œçڑ„ن¸چé‡چه¤چè®°ه½•çڑ„و،و•°
ن»¥و•°وچ®و–‡ن»¶ c.txt ن¸؛ن¾‹ï¼ڑ
[root@localhost pig]$ cat c.txt a 1 2 3 4.2 9.8 100 a 3 0 5 3.5 2.1 200 b 7 9 9 - - 300 a 7 9 9 2.6 6.2 300 a 1 2 5 7.7 5.9 200 a 1 2 3 1.4 0.2 500
é—®é¢کï¼ڑه¦‚ن½•è®،ç®—هœ¨ç¬¬2م€پ3م€پ4هˆ—çڑ„و‰€وœ‰ç»´ه؛¦ç»„هگˆن¸‹ï¼Œوœ€هگژن¸€هˆ—ن¸چé‡چه¤چçڑ„è®°ه½•هˆ†هˆ«وœ‰ه¤ڑه°‘و،ï¼ںن¾‹ه¦‚,第2م€پ3م€پ4هˆ—وœ‰ن¸€ن¸ھç»´ه؛¦ç»„هگˆوک¯ï¼ˆ1,2,3),هœ¨è؟™ن¸ھç»´ه؛¦ç»´ه؛¦ن¸‹ï¼Œوœ€هگژن¸€هˆ—وœ‰ن¸¤ç§چه€¼ï¼ڑ100 ه’Œ 500,ه› و¤ن¸چé‡چه¤چçڑ„è®°ه½•و•°ن¸؛2م€‚هگŒçگ†هڈ¯و±‚ه¾—ه…¶ن»–çڑ„è®°ه½•و،و•°م€‚
pigن»£ç پهڈٹ输ه‡؛结وœه¦‚ن¸‹ï¼ڑ
grunt> A = LOAD 'c.txt' AS (col1:chararray, col2:int, col3:int, col4:int, col5:double, col6:double, col7:int);
grunt> B = GROUP A BY (col2, col3, col4);
grunt> C = FOREACH B {D = DISTINCT A.col7; GENERATE group, COUNT(D);};
grunt> DUMP C;
((1,2,3),2)
((1,2,5),1)
((3,0,5),1)
((7,9,9),1)
وˆ‘ن»¬و¥çœ‹çœ‹و¯ڈن¸€و¥هˆ†هˆ«ç”ںوˆگن؛†ن»€ن¹ˆو ·çڑ„و•°وچ®ï¼ڑ
â‘ LOADن¸چ用说ن؛†ï¼Œه°±وک¯هٹ è½½و•°وچ®ï¼›
â‘،GROUPن¹ںن¸چ用说ن؛†ï¼Œه’Œه‰چو–‡و‰€è¯´çڑ„ن¸€و ·م€‚GROUPن¹‹هگژه¾—هˆ°ن؛†è؟™و ·çڑ„و•°وچ®ï¼ڑ
grunt> DUMP B;
((1,2,3),{(a,1,2,3,4.2,9.8,100),(a,1,2,3,1.4,0.2,500)})
((1,2,5),{(a,1,2,5,7.7,5.9,200)})
((3,0,5),{(a,3,0,5,3.5,2.1,200)})
((7,9,9),{(b,7,9,9,,,300),(a,7,9,9,2.6,6.2,300)})
ه…¶ه®هˆ°è؟™é‡Œï¼Œوˆ‘ن»¬è‚‰çœ¼ه°±هڈ¯ن»¥çœ‹ه‡؛و¥وœ€هگژè¦پو±‚çڑ„结وœوک¯ن»€ن¹ˆن؛†ï¼Œه½“然,ه؟…é،»è¦پç”±pigن»£ç پو¥ه®Œوˆگ,è¦پن¸چ然و€ژن¹ˆه؛”ه¯¹وµ·é‡ڈو•°وچ®ï¼ں
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
â‘¢è؟™é‡Œçڑ„ FOREACH ن¸ژه‰چé¢وœ‰ç‚¹ن¸چن¸€و ·ï¼Œç¬¬ن¸€و¬،看هˆ°è؟™ç§چه†™و³•ï¼Œè‚¯ه®ڑن¼ڑ觉ه¾—ه¾ˆه¥‡و€ھم€‚ه…ˆçœ‹ن¸€ن¸‹ç”¨ن؛ژهژ»é‡چçڑ„DISTINCTه…³é”®ه—çڑ„说وکژï¼ڑ
Removes duplicate tuples in a relation.
然هگژه†چ解é‡ٹن¸€ن¸‹ï¼ڑFOREACH وک¯ه¯¹Bçڑ„و¯ڈن¸€è،Œè؟›è،Œéپچهژ†ï¼Œه…¶ن¸ï¼ŒBçڑ„و¯ڈن¸€è،Œé‡Œهگ«وœ‰ن¸€ن¸ھهŒ…(bag),و¯ڈن¸€ن¸ھهŒ…ن¸هگ«وœ‰è‹¥ه¹²ه…ƒç»„(tuple)A,ه› و¤ï¼ŒFOREACH هگژé¢çڑ„ه¤§و‹¬هڈ·é‡Œçڑ„و“چن½œï¼Œه…¶ه®وک¯ه¯¹و‰€è°“çڑ„“ه†…部هŒ…â€ï¼ˆinner bag)çڑ„و“چن½œï¼ˆè¯¦وƒ…请هڈ‚看FOREACHçڑ„说وکژ),هœ¨è؟™é‡Œï¼Œوˆ‘ن»¬وŒ‡ه®ڑن؛†ه¯¹Açڑ„col7è؟™ن¸€هˆ—è؟›è،Œهژ»é‡چ,هژ»é‡چçڑ„结وœè¢«ه‘½هگچن¸؛D,然هگژه†چه¯¹Dè®،و•°ï¼ˆCOUNT),ه°±ه¾—هˆ°ن؛†وˆ‘ن»¬وƒ³è¦پçڑ„结وœم€‚
④输ه‡؛结وœو•°وچ®ï¼Œن¸ژه‰چو–‡و‰€è؟°çڑ„ه·®ن¸چه¤ڑم€‚
è؟™و ·ه°±è¾¾وˆگن؛†وˆ‘ن»¬çڑ„ç›®çڑ„م€‚ن»ژو€»ن½“ن¸ٹ说,هˆڑوژ¥è§¦pigن¸چن¹…çڑ„ن؛؛ن¼ڑ觉ه¾—è؟™ن؛›ه†™و³•و€ھو€ھçڑ„,ه°±وک¯و‰ن¸چè؟‡و¥ï¼Œن½†وک¯è¦پهڑوŒپ,و—¶é—´é•؟ن؛†ï¼Œè؟ه€’ه½±ن¹ںن¼ڑ让ن½ 觉ه¾—وک¯و£çڑ„ن؛†م€‚
(8)ه¦‚ن½•ه°†ه…³ç³»ï¼ˆrelation)转وچ¢ن¸؛و ‡é‡ڈ(scalar)
هœ¨ه‰چو–‡ن¸ï¼Œوˆ‘ن»¬è¦پç»ںè®،符هگˆوںگن؛›و،ن»¶çڑ„و•°وچ®çڑ„و،و•°ï¼Œن½؟用ن؛†COUNTه‡½و•°و¥è®،算,ن½†هœ¨COUNTن¹‹هگژ,وˆ‘ن»¬ه¾—هˆ°çڑ„è؟کوک¯ن¸€ن¸ھه…³ç³»ï¼ˆrelation),而ن¸چوک¯ن¸€ن¸ھو ‡é‡ڈçڑ„و•°ه—,ه¦‚ن½•وٹٹن¸€ن¸ھه…³ç³»è½¬وچ¢ن¸؛و ‡é‡ڈ,ن»ژ而هڈ¯ن»¥هœ¨هگژç»ه¤„çگ†ن¸ن¾؟ن؛ژن½؟用ه‘¢ï¼ں
ه…·ن½“请看è؟™ن¸ھ链وژ¥م€‚
(9)pigن¸ه¦‚ن½•ن½؟用shellè؟›è،Œè¾…هٹ©و•°وچ®ه¤„çگ†
pigن¸هڈ¯ن»¥هµŒه¥—ن½؟用shellè؟›è،Œè¾…هٹ©ه¤„çگ†ï¼Œن¸‹é¢ï¼Œه°±ن»¥ن¸€ن¸ھه®é™…çڑ„ن¾‹هگو¥è¯´وکژم€‚
هپ‡è®¾وˆ‘ن»¬هœ¨وںگن¸€و¥pigه¤„çگ†هگژ,ه¾—هˆ°ن؛†ç±»ن¼¼ن؛ژن¸‹é¢ b.txt ن¸çڑ„و•°وچ®ï¼ڑ
[root@localhost pig]$ cat b.txt 1 5 98 = 7 34 8 6 3 2 62 0 6 = 65
é—®é¢کï¼ڑه¦‚ن½•ه°†و•°وچ®ن¸ç¬¬4هˆ—ن¸çڑ„“=â€ç¬¦هڈ·ه…¨éƒ¨و›؟وچ¢ن¸؛9999ï¼ں
pigن»£ç پهڈٹ输ه‡؛结وœه¦‚ن¸‹ï¼ڑ
grunt> A = LOAD 'b.txt' AS (col1:int, col2:int, col3:int, col4:chararray, col5:int);
grunt> B = STREAM A THROUGH `awk '{if($4 == "=") print $1"\t"$2"\t"$3"\t9999\t"$5; else print $0}'`;
grunt> DUMP B;
(1,5,98,9999,7)
(34,8,6,3,2)
(62,0,6,9999,65)
وˆ‘ن»¬و¥çœ‹çœ‹è؟™و®µن»£ç پوک¯ه¦‚ن½•هپڑهˆ°çڑ„ï¼ڑ
â‘ هٹ è½½و•°وچ®ï¼Œè؟™ن¸ھو²،ن»€ن¹ˆه¥½è¯´çڑ„م€‚
â‘،é€ڑè؟‡â€œSTREAM … THROUGH …â€çڑ„و–¹ه¼ڈ,وˆ‘ن»¬هڈ¯ن»¥è°ƒç”¨ن¸€ن¸ھshellè¯هڈ¥ï¼Œç”¨è¯¥shellè¯هڈ¥ه¯¹Açڑ„و¯ڈن¸€è،Œو•°وچ®è؟›è،Œه¤„çگ†م€‚و¤ه¤„çڑ„shell逻辑ن¸؛ï¼ڑه½“وںگن¸€è،Œو•°وچ®çڑ„第4هˆ—ن¸؛“=â€ç¬¦هڈ·و—¶ï¼Œه°†ه…¶و›؟وچ¢ن¸؛“9999â€ï¼›هگ¦هˆ™ه°±ç…§هژںو ·è¾“ه‡؛è؟™ن¸€è،Œم€‚
③输ه‡؛B,هڈ¯è§پ结وœو£ç،®م€‚
(10)هگ‘pigè„ڑوœ¬ن¸ن¼ ه…¥هڈ‚و•°
هپ‡è®¾ن½ çڑ„pigè„ڑوœ¬è¾“ه‡؛çڑ„و–‡ن»¶وک¯é€ڑè؟‡ه¤–部هڈ‚و•°وŒ‡ه®ڑçڑ„,هˆ™و¤هڈ‚و•°ن¸چ能ه†™و»ï¼Œéœ€è¦پن¼ ه…¥م€‚هœ¨pigن¸ï¼Œن½؟用ن¼ ه…¥çڑ„هڈ‚و•°ه¦‚ن¸‹و‰€ç¤؛ï¼ڑ
STORE A INTO '$output_dir';
هˆ™è؟™ن¸ھ“output_dirâ€ه°±وک¯ن¸ھن¼ ه…¥çڑ„هڈ‚و•°م€‚هœ¨è°ƒç”¨è؟™ن¸ھpigè„ڑوœ¬çڑ„shellè„ڑوœ¬ن¸ï¼Œوˆ‘ن»¬هڈ¯ن»¥è؟™و ·ن¼ ه…¥هڈ‚و•°ï¼ڑ
pig -param output_dir="/home/my_ourput_dir/" my_pig_script.pig
è؟™é‡Œن¼ ه…¥çڑ„هڈ‚و•°â€œoutput_dirâ€çڑ„ه€¼ن¸؛“/home/my_output_dir/â€م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
(11)ه°±ç®—وک¯هگŒو ·ن¸€و®µpigن»£ç پ,ه¤ڑو¬،è®،ç®—و‰€ه¾—çڑ„结وœن¹ںوœ‰هڈ¯èƒ½وک¯ن¸چهگŒçڑ„
ن¾‹ه¦‚用AVGه‡½و•°و¥è®،ç®—ه¹³ه‡ه€¼و—¶ï¼ŒهگŒو ·ن¸€و®µpigن»£ç پ,ه¤ڑو¬،è®،ç®—و‰€ه¾—çڑ„结وœن¸ï¼Œه°ڈو•°ç‚¹çڑ„وœ€هگژه‡ ن½چن¹ںوœ‰هڈ¯èƒ½وک¯ن¸چ相هگŒçڑ„(ه½“然ن¹ںوœ‰هڈ¯èƒ½ç›¸هگŒï¼‰ï¼Œه¤§و¦‚وک¯ه› ن¸؛ç²¾ه؛¦çڑ„هژںه› هگ§م€‚ن¸چè؟‡ï¼Œن¸€èˆ¬و¥è¯´ه°ڈو•°ç‚¹çڑ„وœ€هگژه‡ ن½چه·²ç»ڈن¸چé‡چè¦پن؛†م€‚ن¾‹ه¦‚وˆ‘ه¯¹ن¸€ن¸ھو•°وچ®é›†è؟›è،Œه¤„çگ†هگژ,ه°ڈو•°ç‚¹هگژ13ن½چو‰چه¼€ه§‹وœ‰ن¸چهگŒï¼Œè؟™و ·çڑ„ç²¾ه؛¦ه®Œه…¨è¶³ه¤ںن؛†م€‚
(12)ه¦‚ن½•ç¼–ه†™هڈٹن½؟用è‡ھه®ڑن¹‰ه‡½و•°ï¼ˆUDF)
请看è؟™ن¸ھ链وژ¥ï¼ڑم€ٹApache Pigن¸و–‡و•™ç¨‹ï¼ˆè؟›éک¶ï¼‰م€‹
(13)ن»€ن¹ˆوک¯èپڑهگˆه‡½و•°ï¼ˆAggregate Function)
هœ¨pigن¸ï¼Œèپڑهگˆه‡½و•°ه°±وک¯é‚£ن؛›وژ¥هڈ—ن¸€ن¸ھ输ه…¥هŒ…(bag),è؟”ه›ن¸€ن¸ھو ‡é‡ڈ(scalar)ه€¼çڑ„ه‡½و•°م€‚COUNTه‡½و•°ه°±وک¯ن¸€ن¸ھن¾‹هگم€‚
(14)COGROUPهپڑن؛†ن»€ن¹ˆ
ن¸ژGROUPو“چن½œç¬¦ن¸€و ·ï¼ŒCOGROUPن¹ںوک¯ç”¨و¥هˆ†ç»„çڑ„,ن¸چهگŒçڑ„وک¯ï¼ŒCOGROUPهڈ¯ن»¥وŒ‰ه¤ڑن¸ھه…³ç³»ن¸çڑ„ه—و®µè؟›è،Œهˆ†ç»„م€‚
è؟کوک¯ن»¥ن¸€ن¸ھه®ن¾‹و¥è¯´وکژ,هپ‡è®¾وœ‰ن»¥ن¸‹ن¸¤ن¸ھو•°وچ®و–‡ن»¶ï¼ڑ
[root@localhost pig]$ cat a.txt uidk 12 3 hfd 132 99 bbN 463 231 UFD 13 10 [root@localhost pig]$ cat b.txt 908 uidk 888 345 hfd 557 28790 re 00000
çژ°هœ¨وˆ‘ن»¬ç”¨pigهپڑه¦‚ن¸‹و“چن½œهڈٹه¾—هˆ°çڑ„结وœن¸؛ï¼ڑ
grunt> A = LOAD 'a.txt' AS (acol1:chararray, acol2:int, acol3:int);
grunt> B = LOAD 'b.txt' AS (bcol1:int, bcol2:chararray, bcol3:int);
grunt> C = COGROUP A BY acol1, B BY bcol2;
grunt> DUMP C;
(re,{},{(28790,re,0)})
(UFD,{(UFD,13,10)},{})
(bbN,{(bbN,463,231)},{})
(hfd,{(hfd,132,99)},{(345,hfd,557)})
(uidk,{(uidk,12,3)},{(908,uidk,888)})
و¯ڈن¸€è،Œè¾“ه‡؛çڑ„第ن¸€é،¹éƒ½وک¯هˆ†ç»„çڑ„key,第ن؛Œé،¹ه’Œç¬¬ن¸‰é،¹هˆ†هˆ«éƒ½وک¯ن¸€ن¸ھهŒ…(bag),ه…¶ن¸ï¼Œç¬¬ن؛Œé،¹وک¯و ¹وچ®ه‰چé¢çڑ„keyو‰¾هˆ°çڑ„Aن¸çڑ„و•°وچ®هŒ…,第ن¸‰é،¹وک¯و ¹وچ®ه‰چé¢çڑ„keyو‰¾هˆ°çڑ„Bن¸çڑ„و•°وچ®هŒ…م€‚
و¥çœ‹çœ‹ç¬¬ن¸€è،Œè¾“ه‡؛ï¼ڑ“reâ€ن½œن¸؛groupçڑ„keyو—¶ï¼Œه…¶و‰¾ن¸چهˆ°ه¯¹ه؛”çڑ„Aن¸çڑ„و•°وچ®ï¼Œه› و¤ç¬¬ن؛Œé،¹ه°±وک¯ن¸€ن¸ھç©؛çڑ„هŒ…“{}â€ï¼Œâ€œreâ€è؟™ن¸ھkeyهœ¨Bن¸و‰¾هˆ°ن؛†ه¯¹ه؛”çڑ„و•°وچ®ï¼ˆ28790 آ آ re آ آ 00000),ه› و¤ç¬¬ن¸‰é،¹ه°±وک¯هŒ…{(28790,re,0)}م€‚
ه…¶ن»–输ه‡؛و•°وچ®ن¹ںç±»ن¼¼م€‚
(15)ه®‰è£…pigهگژ,è؟گè،Œpigه‘½ن»¤و—¶وڈگç¤؛“Cannot find hadoop configurations in classpathâ€ç‰é”™è¯¯çڑ„解ه†³هٹو³•
pigه®‰è£…ه¥½هگژ,è؟گè،Œpigه‘½ن»¤و—¶وڈگç¤؛ن»¥ن¸‹é”™è¯¯ï¼ڑ
ERROR org.apache.pig.Main - ERROR 4010: Cannot find hadoop configurations in classpath (neither hadoop-site.xml nor core-site.xml was found in the classpath).If you plan to use local mode, please put -x local option in command line
وک¾è€Œوک“è§پ,وڈگç¤؛و‰¾ن¸چهˆ°ن¸ژhadoop相ه…³çڑ„é…چç½®و–‡ن»¶م€‚و‰€ن»¥وˆ‘ن»¬éœ€è¦پوٹٹhadoopه®‰è£…ç›®ه½•ن¸‹çڑ„“confâ€هگç›®ه½•و·»هٹ هˆ°ç³»ç»ںçژ¯ه¢ƒهڈکé‡ڈPATHن¸ï¼ڑ
ن؟®و”¹ /etc/profile و–‡ن»¶ï¼Œو·»هٹ ï¼ڑ
export HADOOP_HOME=/usr/local/hadoop export PIG_CLASSPATH=$HADOOP_HOME/conf PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PIG_CLASSPATH:$PATH
然هگژé‡چو–°هٹ è½½ /etc/profile و–‡ن»¶ï¼ڑ
source /etc/profile
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
(16)piggybankوک¯ن»€ن¹ˆن¸œè¥؟
Pig also hosts a UDF repository called piggybank that allows users to share UDFs that they have written.
说白ن؛†ه°±وک¯Apacheوٹٹه¤§ه®¶ه†™çڑ„è‡ھه®ڑن¹‰ه‡½و•°و”¾هœ¨ن¸€ه—ه„؟,起ن؛†ن¸ھهگچه—,ه°±هڈ«هپڑpiggybankم€‚ن½ هڈ¯ن»¥وٹٹه®ƒçگ†è§£ن¸؛ن¸€ن¸ھSVNن»£ç پن»“ه؛“م€‚ه…·ن½“请看è؟™é‡Œم€‚
(17)UDFçڑ„و„é€ ه‡½و•°ن¼ڑ被调用ه‡ و¬،
ن½ هڈ¯èƒ½ن¼ڑوƒ³هœ¨UDFçڑ„و„é€ ه‡½و•°ن¸هپڑن¸€ن؛›هˆه§‹هŒ–çڑ„ه·¥ن½œï¼Œن¾‹ه¦‚هˆ›ه»؛ن¸€ن؛›و–‡ن»¶ï¼Œç‰ç‰م€‚ن½†وک¯ن½ ن¸چ能هپ‡è®¾UDFçڑ„و„é€ ه‡½و•°هڈھ被调用ن¸€و¬،,ه› و¤ï¼Œه¦‚وœن½ è¦پهœ¨و„é€ ه‡½و•°ن¸هپڑن¸€ن؛›هڈھ能هپڑن¸€و¬،çڑ„ه·¥ن½œï¼Œن½ ه°±è¦په½“ه؟ƒن؛†â€”—هڈ¯èƒ½ن¼ڑه¯¼è‡´é”™è¯¯م€‚
(18)LOADو•°وچ®و—¶ï¼Œه¦‚ن½•ن¸€و¬،LOADه¤ڑن¸ھç›®ه½•ن¸‹çڑ„و•°وچ®
ن¾‹ه¦‚,وˆ‘è¦پLOADن¸¤ن¸ھHDFSç›®ه½•ن¸‹çڑ„و•°وچ®ï¼ڑ/abc/2010 ه’Œ /abc/2011,هˆ™وˆ‘ن»¬هڈ¯ن»¥è؟™و ·ه†™LOADè¯هڈ¥ï¼ڑ
A = LOAD '/abc/201{0,1}';
(19)و€ژو ·è‡ھه·±ه†™ن¸€ن¸ھUDFن¸çڑ„هٹ è½½ه‡½و•°(load function)
请看è؟™ن¸ھ链وژ¥ï¼ڑم€ٹApache Pigن¸و–‡و•™ç¨‹ï¼ˆè؟›éک¶ï¼‰م€‹
(20)é‡چè½½(overloading)ن¸€ن¸ھUDF
请看è؟™ن¸ھ链وژ¥ï¼ڑم€ٹApache Pigن¸و–‡و•™ç¨‹ï¼ˆè؟›éک¶ï¼‰م€‹م€‚
(21)pigè؟گè،Œن¸چèµ·و¥ï¼Œوڈگç¤؛“org.apache.hadoop.ipc.Client - Retrying connect to server:آ
请看è؟™ن¸ھ链وژ¥ï¼ڑم€ٹApache Pigن¸و–‡و•™ç¨‹ï¼ˆè؟›éک¶ï¼‰م€‹
(22)用هگ«وœ‰nullçڑ„ه—و®µو¥GROUP,结وœن¼ڑه¦‚ن½•
هپ‡è®¾وœ‰و•°وچ®و–‡ن»¶ a.txt ه†…ه®¹ن¸؛ï¼ڑ
1 2 5 1 3 1 3 6 9 8
ه…¶ن¸ï¼Œو¯ڈن¸¤هˆ—و•°وچ®ن¹‹é—´وک¯ç”¨tabهˆ†ه‰²çڑ„,第ن؛Œè،Œçڑ„第2هˆ—م€پ第ن¸‰è،Œçڑ„第3هˆ—و²،وœ‰ه†…ه®¹ï¼ˆن¹ںه°±وک¯è¯´ï¼Œهٹ è½½هˆ°Pig里ن¹‹هگژ,ه¯¹ه؛”çڑ„و•°وچ®ن¼ڑهڈکوˆگnull),ه¦‚وœوٹٹè؟™ن؛›و•°وچ®وŒ‰ç¬¬1م€پ第2هˆ—و¥GROUPçڑ„è¯ï¼Œç¬¬1م€پ2هˆ—ن¸هگ«وœ‰nullçڑ„è،Œن¼ڑ被ه؟½ç•¥هگ—ï¼ں
و¥هپڑن¸€ن¸‹è¯•éھŒï¼ڑ
A = LOAD 'a.txt' AS (col1:int, col2:int, col3:int); B = GROUP A BY (col1, col2); DUMP B;
输ه‡؛结وœن¸؛ï¼ڑ
((1,2),{(1,2,5)})
((1,3),{(1,3,)})
((1,),{(1,,3)})
((6,9),{(6,9,8)})
ن»ژن¸ٹé¢çڑ„结وœï¼ˆç¬¬ن¸‰è،Œï¼‰هڈ¯è§پ,هژںو•°وچ®ن¸ç¬¬1م€پ2هˆ—里هگ«وœ‰nullçڑ„è،Œن¹ں被è®،ه…¥هœ¨ه†…ن؛†ï¼Œن¹ںه°±وک¯è¯´ï¼ŒGROUPو“چن½œوک¯ن¸چن¼ڑه؟½ç•¥nullçڑ„,è؟™ن¸ژCOUNTوœ‰و‰€ن¸چهگŒï¼ˆè§پوœ¬و–‡ه‰چé¢çڑ„部هˆ†ï¼‰م€‚
(23)ه¦‚ن½•ç»ںè®،و•°وچ®ن¸وںگن؛›ه—و®µçڑ„组هگˆوœ‰ه¤ڑه°‘ç§چ
هپ‡è®¾وœ‰ه¦‚ن¸‹و•°وچ®ï¼ڑ
[root@localhost]# cat a.txt 1 3 4 7 1 3 5 4 2 7 0 5 9 8 6 6
çژ°هœ¨وˆ‘ن»¬è¦پç»ںè®،第1م€پ2هˆ—çڑ„ن¸چهگŒç»„هگˆوœ‰ه¤ڑه°‘ç§چ,ه¯¹وœ¬ن¾‹و¥è¯´ï¼Œç»„هگˆوœ‰ن¸‰ç§چï¼ڑ
1 3 2 7 9 8
ن¹ںه°±وک¯è¯´وˆ‘ن»¬è¦پçڑ„ç”و،ˆوک¯3م€‚
用Pigو€ژن¹ˆè®،ç®—ï¼ں
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
ه…ˆه†™ه‡؛ه…¨éƒ¨çڑ„Pigن»£ç پï¼ڑ
A = LOAD 'a.txt' AS (col1:int, col2:int, col3:int, col4:int); B = GROUP A BY (col1, col2); C = GROUP B ALL; D = FOREACH C GENERATE COUNT(B); DUMP D;
然هگژه†چو¥çœ‹çœ‹è؟™ن؛›ن»£ç پوک¯ه¦‚ن½•è®،ç®—ه‡؛ن¸ٹé¢çڑ„结وœçڑ„ï¼ڑ
①第ن¸€è،Œن»£ç پهٹ è½½و•°وچ®ï¼Œو²،ن»€ن¹ˆه¥½è¯´çڑ„م€‚
â‘،第ن؛Œè،Œن»£ç پ,ه¾—هˆ°ç¬¬1م€پ2هˆ—و•°وچ®çڑ„و‰€وœ‰ç»„هگˆم€‚Bçڑ„و•°وچ®ç»“و„ن¸؛ï¼ڑ
grunt> DESCRIBE B;
B: {group: (col1: int,col2: int),A: {col1: int,col2: int,col3: int,col4: int}}
وٹٹB DUMPه‡؛و¥ï¼Œه¾—هˆ°ï¼ڑ
((1,3),{(1,3,4,7),(1,3,5,4)})
((2,7),{(2,7,0,5)})
((9,8),{(9,8,6,6)})
éه¸¸وکژوک¾ï¼Œ(1,3),(2,7),(9,8)çڑ„و‰€وœ‰ç»„هگˆه·²ç»ڈ被وژ’هˆ—ه‡؛و¥ن؛†ï¼Œè؟™é‡Œه¾—هˆ°ن؛†è‹¥ه¹²è،Œو•°وچ®م€‚ن¸‹ن¸€و¥وˆ‘ن»¬è¦پهپڑçڑ„ه°±وک¯ç»ںè®،è؟™و ·çڑ„و•°وچ®ن¸€ه…±وœ‰ه¤ڑه°‘è،Œï¼Œن¹ںه°±ه¾—هˆ°ن؛†ç¬¬1م€پ2هˆ—çڑ„组هگˆوœ‰ه¤ڑه°‘组م€‚
③第ن¸‰ه’Œç¬¬ه››è،Œن»£ç پ,ه°±ه®çژ°ن؛†ç»ںè®،و•°وچ®è،Œو•°çڑ„هٹں能م€‚هڈ‚考وœ¬و–‡ه‰چé¢éƒ¨هˆ†çڑ„“و€ژو ·ç»ںè®،و•°وچ®è،Œو•°â€ن¸€èٹ‚م€‚ه°±وکژ白è؟™ن¸¤هڈ¥ن»£ç پوک¯ن»€ن¹ˆو„ڈو€ن؛†م€‚
è؟™é‡Œéœ€è¦پ特هˆ«è¯´وکژçڑ„وک¯ï¼ڑ
a)ن¸؛ن»€ن¹ˆه€’و•°ç¬¬ن؛Œهڈ¥ن»£ç پن¸وک¯COUNT(B),而ن¸چوک¯COUNT(group)ï¼ں
وˆ‘ن»¬وک¯ه¯¹Cè؟›è،ŒFOREACH,و‰€ن»¥è¦په…ˆçœ‹çœ‹Cçڑ„و•°وچ®ç»“و„ï¼ڑ
grunt> DESCRIBE C;
C: {group: chararray,B: {group: (col1: int,col2: int),A: {col1: int,col2: int,col3: int,col4: int}}}
هڈ¯è§پ,ن½ هڈ¯ن»¥وٹٹCوƒ³هƒڈوˆگن¸€ن¸ھmapçڑ„结و„,keyوک¯ن¸€ن¸ھgroup,valueوک¯ن¸€ن¸ھهŒ…(bag),ه®ƒçڑ„هگچه—وک¯B,è؟™ن¸ھهŒ…ن¸وœ‰Nن¸ھه…ƒç´ ,و¯ڈن¸€ن¸ھه…ƒç´ 都ه¯¹ه؛”هˆ°â‘،ن¸و‰€è¯´çڑ„ن¸€è،Œم€‚و ¹وچ®â‘،çڑ„هˆ†وگ,وˆ‘ن»¬ه°±وک¯è¦پç»ںè®،Bن¸ه…ƒç´ çڑ„ن¸ھو•°ï¼Œه› و¤ï¼Œè؟™é‡Œه½“然ه°±وک¯COUNT(B)ن؛†م€‚
b)COUNTه‡½و•°çڑ„ن½œç”¨وک¯ç»ںè®،ن¸€ن¸ھهŒ…(bag)ن¸çڑ„ه…ƒç´ çڑ„ن¸ھو•°ï¼ڑ
COUNTComputes the number of elements in a bag.
ه¦‚وœن½ 试ه›¾وٹٹCOUNTه؛”用ن؛ژن¸€ن¸ھébagçڑ„و•°وچ®ç»“و„ن¸ٹ,ن¼ڑهڈ‘ç”ں错误,ن¾‹ه¦‚ï¼ڑ
آ
java.lang.ClassCastException: org.apache.pig.data.BinSedesTuple cannot be cast to org.apache.pig.data.DataBag
è؟™وک¯وٹٹTupleن¼ ç»™COUNTه‡½و•°و—¶هڈ‘ç”ںçڑ„错误م€‚
(24)ن¸¤ن¸ھو•´ه‹و•°ç›¸é™¤ï¼Œه¦‚ن½•è½¬وچ¢ن¸؛وµ®ç‚¹ه‹ï¼Œن»ژ而ه¾—هˆ°و£ç،®çڑ„结وœ
è؟™ن¸ھé—®é¢که…¶ه®ه¾ˆه‚»ï¼Œوˆ–许ن¸چ用说ن½ ن¹ںçں¥éپ“ن؛†ï¼ڑهپ‡è®¾وœ‰int a = 3 ه’Œ int b = 2ن¸¤ن¸ھو•°ï¼Œهœ¨ه¤§ه¤ڑو•°ç¼–程è¯è¨€é‡Œï¼Œa/bه¾—هˆ°çڑ„وک¯1,وƒ³ه¾—هˆ°و£ç،®ç»“وœ1.5çڑ„è¯ï¼Œéœ€è¦پ转وچ¢ن¸؛floatه†چè®،ç®—م€‚هœ¨Pigن¸ه…¶ه®ه’Œè؟™ç§چوƒ…ه†µن¸€و ·ï¼Œن¸‹é¢ه°±و‹؟ه‡ è،Œو•°وچ®و¥هپڑن¸ھه®éھŒï¼ڑ
[root@localhost ~]# cat a.txt 3 2 4 5
هœ¨Pigن¸ï¼ڑ
grunt> A = LOAD 'a.txt' AS (col1:int, col2:int); grunt> B = FOREACH A GENERATE col1/col2; grunt> DUMP B; (1) (0)
هڈ¯è§پ,ن¸چهٹ ç±»ه‹è½¬وچ¢çڑ„è®،算结وœوک¯هڈ–و•´ن¹‹هگژçڑ„ه€¼م€‚
é‚£ن¹ˆï¼Œè½¬وچ¢ن¸€ن¸‹è¯•è¯•ï¼ڑ
grunt> A = LOAD 'a.txt' AS (col1:int, col2:int); grunt> B = FOREACH A GENERATE (float)(col1/col2); grunt> DUMP B; (1.0) (0.0)
è؟™و ·è½¬وچ¢è؟کوک¯ن¸چè،Œçڑ„,è؟™ن¸ژه¤§ه¤ڑو•°ç¼–程è¯è¨€çڑ„结وœن¸€è‡´â€”—ه®ƒهڈھوک¯وٹٹهڈ–و•´ن¹‹هگژçڑ„و•°ه†چ转وچ¢ن¸؛وµ®ç‚¹و•°ï¼Œه› و¤ه½“然وک¯ن¸چè،Œçڑ„م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
و£ç،®çڑ„هپڑو³•ه؛”该وک¯ï¼ڑ
grunt> A = LOAD 'a.txt' AS (col1:int, col2:int); grunt> B = FOREACH A GENERATE (float)col1/col2; grunt> DUMP B; (1.5) (0.8)
وˆ–者è؟™و ·ن¹ںè،Œï¼ڑ
grunt> A = LOAD 'a.txt' AS (col1:int, col2:int); grunt> B = FOREACH A GENERATE col1/(float)col2; grunt> DUMP B; (1.5) (0.8)
è؟™ن¸ژوˆ‘ن»¬çڑ„é€ڑه¸¸هپڑو³•وک¯ن¸€è‡´çڑ„,ه› و¤ï¼Œن½ è¦پهپڑ除و³•è؟گç®—çڑ„و—¶ه€™ï¼Œéœ€è¦پو³¨و„ڈè؟™ن¸€ç‚¹م€‚
(25)UNIONçڑ„ن¸€ن¸ھن¾‹هگ
هپ‡è®¾وœ‰ن¸¤ن¸ھو•°وچ®و–‡ن»¶ن¸؛ï¼ڑ
[root@localhost ~]# cat 1.txt 0 3 1 5 0 8 [root@localhost ~]# cat 2.txt 1 6 0 9
çژ°هœ¨è¦پو±‚ه‡؛ï¼ڑهœ¨ç¬¬ن¸€هˆ—相هگŒçڑ„وƒ…ه†µن¸‹ï¼Œç¬¬ن؛Œهˆ—çڑ„ه’Œهˆ†هˆ«ن¸؛ه¤ڑه°‘ï¼ں
ن¾‹ه¦‚,第ن¸€هˆ—ن¸؛ 1 çڑ„و—¶ه€™ï¼Œç¬¬ن؛Œهˆ—وœ‰5ه’Œ6ن¸¤ن¸ھه€¼ï¼Œه’Œن¸؛11م€‚هگŒçگ†ï¼Œç¬¬ن¸€هˆ—ن¸؛0çڑ„و—¶ه€™ï¼Œç¬¬ن؛Œهˆ—çڑ„ه’Œن¸؛ 3+8+9=20م€‚
è®،ç®—و¤é—®é¢کçڑ„Pigن»£ç په¦‚ن¸‹ï¼ڑ
A = LOAD '1.txt' AS (a: int, b: int); B = LOAD '2.txt' AS (c: int, d: int); C = UNION A, B; D = GROUP C BY $0; E = FOREACH D GENERATE FLATTEN(group), SUM(C.$1); DUMP E;
输ه‡؛ن¸؛ï¼ڑ
(0,20) (1,11)
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
وˆ‘ن»¬و¥çœ‹çœ‹و¯ڈن¸€و¥هˆ†هˆ«هپڑن؛†ن»€ن¹ˆï¼ڑ
①第1è،Œم€پ第2è،Œن»£ç پهˆ†هˆ«هٹ è½½و•°وچ®هˆ°ه…³ç³»Aم€پBن¸ï¼Œو²،ن»€ن¹ˆه¥½è¯´çڑ„م€‚
â‘،第3è،Œن»£ç پ,ه°†ه…³ç³»Aم€پBهگˆه¹¶èµ·و¥ن؛†م€‚هگˆه¹¶هگژçڑ„و•°وچ®ç»“و„ن¸؛ï¼ڑ
grunt> DESCRIBE C;
C: {a: int,b: int}
ه…¶و•°وچ®ن¸؛ï¼ڑ
grunt> DUMP C; (0,3) (1,5) (0,8) (1,6) (0,9)
③第4è،Œن»£ç پوŒ‰ç¬¬1هˆ—(هچ³$0)è؟›è،Œهˆ†ç»„,هˆ†ç»„هگژçڑ„و•°وچ®ç»“و„ن¸؛ï¼ڑ
grunt> DESCRIBE D;
D: {group: int,C: {a: int,b: int}}
ه…¶و•°وچ®ن¸؛ï¼ڑ
grunt> DUMP D;
(0,{(0,9),(0,3),(0,8)})
(1,{(1,5),(1,6)})
â‘£وœ€هگژن¸€è،Œن»£ç پ,éپچهژ†D,ه°†Dن¸و¯ڈن¸€è،Œé‡Œçڑ„و‰€وœ‰bag(هچ³C)çڑ„第2هˆ—(هچ³$1)è؟›è،Œç´¯هٹ ,ه°±ه¾—هˆ°ن؛†وˆ‘ن»¬è¦پçڑ„结وœم€‚
(26)错误“ERROR org.apache.pig.tools.grunt.Grunt - ERROR 2042: Error in new logical plan. Try -Dpig.usenewlogicalplan=false.â€çڑ„هڈ¯èƒ½هژںه›
â‘ Pigçڑ„bug,详è§پو¤é“¾وژ¥ï¼›
â‘،ه…¶ن»–هژںه› م€‚وˆ‘éپ‡هˆ°ه¹¶è§£ه†³ن؛†ن¸€ن¾‹م€‚ه…·ن½“çڑ„ن»£ç پن¸چن¾؟هœ¨و¤é™ˆهˆ—,ن½†وک¯هں؛وœ¬هڈ¯ن»¥è¯´وک¯ç”±ن؛ژè‡ھه·±ه†™çڑ„Pigن»£ç په¯¹ه¤چو‚و•°وچ®ç»“و„çڑ„ه¤„çگ†ن¸چه½“ه¯¼è‡´çڑ„,هگژو¥وˆ‘ه°è¯•و›´و”¹ن؛†ن¸€ç§چه®çژ°و–¹ه¼ڈ,ه°±ç»•è؟‡ن؛†è؟™ن¸ھé—®é¢کم€‚ه…³ن؛ژè؟™ç‚¹ï¼Œç،®ه®è؟کوک¯è¦په…·ن½“é—®é¢که…·ن½“هˆ†وگçڑ„,هœ¨è؟™é‡Œو²،وœ‰ه®ن¾‹çڑ„è¯ï¼Œو— و³•ç»™ه¤§ه®¶ن¸€ن¸ھوکژç،®çڑ„解ه†³é—®é¢کçڑ„وŒ‡هچ—م€‚
(27)ه¦‚ن½•هœ¨Pigن¸ن½؟用و£هˆ™è،¨è¾¾ه¼ڈه¯¹ه—符ن¸²è؟›è،ŒهŒ¹é…چ
هپ‡è®¾ن½ وœ‰ه¦‚ن¸‹و•°وچ®و–‡ن»¶ï¼ڑ
[root@localhost ~]# cat a.txt 1 http://ui.qq.com/abcd.html 5 http://tr.qq.com/743.html 8 http://vid.163.com/trees.php 9 http:auto.qq.com/us.php
çژ°هœ¨è¦پو‰¾ه‡؛该و–‡ن»¶ن¸ï¼Œç¬¬ن؛Œهˆ—符هگˆâ€œ*//*.qq.com/*â€و¨،ه¼ڈçڑ„و‰€وœ‰è،Œï¼ˆو¤ه¤„هڈھوœ‰ه‰چن¸¤è،Œç¬¦هگˆو،ن»¶ï¼‰ï¼Œو€ژن¹ˆهپڑï¼ں
Pigن»£ç په¦‚ن¸‹ï¼ڑ
A = LOAD 'a.txt' AS (col1: int, col2: chararray); B = FILTER A BY col2 matches '.*//.*\\.qq\\.com/.*'; DUMP B;
وˆ‘ن»¬çœ‹هˆ°ï¼Œmatchesه…³é”®ه—ه¯¹ col2 è؟›è،Œن؛†و£هˆ™هŒ¹é…چ,ه®ƒن½؟用çڑ„وک¯Javaو ¼ه¼ڈçڑ„و£هˆ™è،¨è¾¾ه¼ڈهŒ¹é…چ规هˆ™م€‚
.آ è،¨ç¤؛ن»»و„ڈه—符,*آ è،¨ç¤؛ه—符ه‡؛çژ°ن»»و„ڈو¬،و•°ï¼›\.آ ه¯¹آ .آ è؟›è،Œن؛†è½¬ن¹‰ï¼Œè،¨ç¤؛هŒ¹é…چآ .آ è؟™ن¸ھه—符;/آ ه°±وک¯è،¨ç¤؛هŒ¹é…چآ /آ è؟™ن¸ھه—符م€‚
è؟™é‡Œéœ€è¦پو³¨و„ڈçڑ„وک¯ï¼Œهœ¨ه¼•هڈ·ن¸ï¼Œç”¨ن؛ژ转ن¹‰çڑ„ه—符آ \آ 需è¦پو‰“ن¸¤ن¸ھو‰چ能è،¨ç¤؛ن¸€ن¸ھ,و‰€ن»¥ن¸ٹé¢çڑ„آ \\.آ ه°±وک¯ن¸ژو£هˆ™ن¸çڑ„آ \.آ وک¯ن¸€و ·çڑ„,هچ³هŒ¹é…چآ .آ è؟™ن¸ھه—符م€‚و‰€ن»¥ï¼Œه¦‚وœن½ è¦پهŒ¹é…چو•°ه—çڑ„è¯ï¼Œه؛”该用è؟™ç§چه†™و³•ï¼ˆ\dè،¨ç¤؛هŒ¹é…چو•°ه—,هœ¨ه¼•هڈ·ن¸ه؟…é،»ç”¨\\d)ï¼ڑ
B = FILTER A BY (col matches '\\d.*');
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
وœ€هگژ输ه‡؛结وœن¸؛ï¼ڑ
(1,http://ui.qq.com/abcd.html) (5,http://tr.qq.com/743.html)
هڈ¯è§پ结وœوک¯و£ç،®çڑ„م€‚
(28)ه¦‚ن½•وˆھهڈ–ن¸€ن¸ھه—符ن¸²ن¸çڑ„وںگن¸€و®µ
هœ¨ه¤„çگ†و•°وچ®و—¶ï¼Œه¦‚وœن½ وƒ³وڈگهڈ–ه‡؛ن¸€ن¸ھو—¥وœںه—符ن¸²çڑ„ه¹´ن»½ï¼Œن¾‹ه¦‚وڈگهڈ–ه‡؛“2011-10-26â€ن¸çڑ„“2011â€ï¼Œهڈ¯ن»¥ç”¨ه†…ç½®ه‡½و•°آ SUBSTRINGآ و¥ه®çژ°ï¼ڑ
SUBSTRINGReturns a substring from a given string.SyntaxSUBSTRING(string, startIndex, stopIndex)
ن¸‹é¢ن¸¾ن¸€ن¸ھن¾‹هگم€‚هپ‡è®¾وœ‰و•°وچ®و–‡ن»¶ï¼ڑ
[root@localhost ~]# cat a.txt 2010-05-06 abc 2008-06-18 uio 2011-10-11 tyr 2010-12-23 fgh 2011-01-05 vbn
第ن¸€هˆ—وک¯و—¥وœں,çژ°هœ¨è¦پو‰¾ه‡؛و‰€وœ‰ن¸چé‡چه¤چçڑ„ه¹´ن»½وœ‰ه“ھن؛›ï¼Œهڈ¯ن»¥è؟™و ·هپڑï¼ڑ
A = LOAD 'a.txt' AS (dateStr: chararray, flag: chararray); B = FOREACH A GENERATE SUBSTRING(dateStr, 0, 4); C = DISTINCT B; DUMP C;
输ه‡؛结وœن¸؛ï¼ڑ
(2008) (2010) (2011)
هڈ¯è§پè¾¾هˆ°ن؛†وˆ‘ن»¬وƒ³è¦پçڑ„و•ˆوœم€‚
ن¸ٹé¢çڑ„ن»£ç په¤ھ简هچ•ن؛†ï¼Œن¸چه؟…ه¤ڑ言,ه”¯ن¸€éœ€è¦پ说وکژن¸€ن¸‹çڑ„وک¯ SUBSTRING ه‡½و•°ï¼Œه®ƒçڑ„第ن¸€ن¸ھهڈ‚و•°وک¯è¦پوˆھهڈ–çڑ„ه—符ن¸²ï¼Œç¬¬ن؛Œن¸ھهڈ‚و•°وک¯èµ·ه§‹ç´¢ه¼•ï¼ˆن»ژ0ه¼€ه§‹ï¼‰ï¼Œç¬¬ن¸‰ن¸ھهڈ‚و•°وک¯ç»“وںç´¢ه¼•م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
(29)ه¦‚ن½•و‹¼وژ¥ن¸¤ن¸ھه—符ن¸²
هپ‡è®¾وœ‰ن»¥ن¸‹و•°وچ®و–‡ن»¶ï¼ڑ
[root@localhost ~]# cat 1.txt abc 123 cde 456 fgh 789 ijk 200
çژ°هœ¨è¦پوٹٹ第ن¸€هˆ—ه’Œç¬¬ن؛Œهˆ—ن½œن¸؛ه—符ن¸²و‹¼وژ¥èµ·و¥ï¼Œن¾‹ه¦‚第ن¸€è،Œن¼ڑهڈکوˆگ“abc123â€ï¼Œé‚£ن¹ˆن½؟用CONCATè؟™ن¸ھو±‚ه€¼ه‡½و•°ï¼ˆeval function)ه°±هڈ¯ن»¥هپڑهˆ°ï¼ڑ
A = LOAD '1.txt' AS (col1: chararray, col2: int); B = FOREACH A GENERATE CONCAT(col1, (chararray)col2); DUMP B;
输ه‡؛结وœن¸؛ï¼ڑ
(abc123) (cde456) (fgh789) (ijk200)
و³¨و„ڈè؟™é‡Œو•…و„ڈهœ¨هٹ è½½و•°وچ®çڑ„و—¶ه€™وٹٹ第ن؛Œهˆ—وŒ‡ه®ڑن¸؛intç±»ه‹ï¼Œè؟™وک¯ن¸؛ن؛†è¯´وکژو•°وچ®ç±»ه‹ن¸چن¸€è‡´çڑ„و—¶ه€™CONCATن¼ڑه‡؛错(ن½ هڈ¯ن»¥è¯•éھŒن¸€ن¸‹ï¼‰ï¼ڑ
ERROR org.apache.pig.tools.grunt.Grunt - ERROR 1045: Could not infer the matching function for org.apache.pig.builtin.CONCAT as multiple or none of them fit. Please use an explicit cast.
و‰€ن»¥هœ¨هگژé¢CONCATçڑ„و—¶ه€™ï¼Œه¯¹ç¬¬ن؛Œهˆ—è؟›è،Œن؛†ç±»ه‹è½¬وچ¢م€‚
هڈ¦ه¤–,ه¦‚وœو•°وچ®و–‡ن»¶ه†…ه®¹ن¸؛ï¼ڑ
[root@localhost ~]# cat 1.txt 5 123 7 456 8 789 0 200
é‚£ن¹ˆï¼Œه¦‚وœه¯¹ن¸¤هˆ—و•´و•°CONCATï¼ڑ
A = LOAD '1.txt' AS (col1: int, col2: int); B = FOREACH A GENERATE CONCAT(col1, col2);
هگŒو ·ن¹ںن¼ڑه‡؛é”™ï¼ڑ
ERROR org.apache.pig.tools.grunt.Grunt - ERROR 1045: Could not infer the matching function for org.apache.pig.builtin.CONCAT as multiple or none of them fit. Please use an explicit cast.
è¦پو³¨و„ڈè؟™ن¸€ç‚¹م€‚
وœ‰ن؛؛هڈ¯èƒ½ن¼ڑé—®ï¼ڑè¦پو‹¼وژ¥ه‡ ن¸ھه—符ن¸²çڑ„è¯و€ژن¹ˆهٹï¼ںCONCAT ه¥— CONCAT ه°±è¦پهڈ¯ن»¥ن؛†ï¼ˆوœ‰ç‚¹ç¬¨ï¼Œن½†ç®،用)ï¼ڑآ CONCAT(a, CONCAT(b, c))
(30)ه¦‚ن½•و±‚ن¸¤ن¸ھو•°وچ®é›†çڑ„é‡چهگˆ & ن¸چهگŒçڑ„و•°وچ®ç±»ه‹JOINن¼ڑه¤±è´¥
هپ‡è®¾وœ‰ن»¥ن¸‹ن¸¤ن¸ھو•°وچ®و–‡ن»¶ï¼ڑ
[root@localhost ~]# cat 1.txt 123 456 789 200
ن»¥هڈٹï¼ڑ
[root@localhost ~]# cat 2.txt 200 333 789
çژ°هœ¨è¦پو‰¾ه‡؛ن¸¤ن¸ھو–‡ن»¶ن¸ï¼Œç›¸هگŒçڑ„و•°وچ®وœ‰ه¤ڑه°‘è،Œï¼Œو€ژن¹ˆهپڑï¼ںè؟™ن¹ںه°±وک¯و‰€è°“çڑ„و±‚ن¸¤ن¸ھو•°وچ®é›†çڑ„é‡چهگˆم€‚
用ه…³ç³»و“چن½œç¬¦JOIN,وˆ‘ن»¬هڈ¯ن»¥è¾¾هˆ°è؟™ن¸ھç›®çڑ„م€‚هœ¨ه¤„çگ†وµ·é‡ڈو•°وچ®و—¶ï¼Œç»ڈه¸¸ن¼ڑوœ‰و±‚é‡چهگˆçڑ„需و±‚م€‚و‰€ن»¥JOINوک¯Pigن¸ن¸€ن¸ھوپه…¶é‡چè¦پçڑ„و“چن½œم€‚
هœ¨وœ¬ن¾‹ن¸ï¼Œن¸¤ن¸ھو–‡ن»¶ن¸وœ‰ن¸¤ن¸ھ相هگŒçڑ„و•°وچ®è،Œï¼ڑ789ن»¥هڈٹ200,ه› و¤ï¼Œç»“وœه؛”该وک¯2م€‚
وˆ‘ن»¬ه…ˆو¥çœ‹çœ‹و£ç،®çڑ„ن»£ç پï¼ڑ
A = LOAD '1.txt' AS (a: int); B = LOAD '2.txt' AS (b: int); C = JOIN A BY a, B BY b; D = GROUP C ALL; E = FOREACH D GENERATE COUNT(C); DUMP E;
解é‡ٹن¸€ن¸‹ï¼ڑ
①第ن¸€م€پن؛Œè،Œوک¯هٹ è½½و•°وچ®ï¼Œن¸چه؟…ه¤ڑ言م€‚
â‘،第ن¸‰è،ŒوŒ‰Açڑ„第1هˆ—م€پBçڑ„第ن؛Œهˆ—è؟›è،Œâ€œç»“هگˆâ€ï¼ŒJOINن¹‹هگژ,aم€پbن¸¤هˆ—ن¸چ相هگŒçڑ„و•°وچ®ه°±è¢«ه‰”除وژ‰ن؛†م€‚Cçڑ„و•°وچ®ç»“و„ن¸؛ï¼ڑ
C: {A::a: int,B::b: int}
Cçڑ„و•°وچ®ن¸؛ï¼ڑ
(200,200) (789,789)
③由ن؛ژوˆ‘ن»¬è¦پç»ںè®،çڑ„وک¯و•°وچ®è،Œو•°ï¼Œو‰€ن»¥ن¸ٹé¢çڑ„Pigن»£ç پن¸çڑ„第4م€پ5è،Œه°±è؟›è،Œن؛†è®،و•°çڑ„è؟گç®—م€‚
â‘£ه¦‚وœو–‡ن»¶ 2.txt ه¤ڑن¸€è،Œو•°وچ®â€œ200â€ï¼Œç»“وœن¼ڑوک¯ن»€ن¹ˆï¼ںç”و،ˆوک¯ï¼ڑ结وœن¸؛3è،Œم€‚è؟™ن¸ھو—¶ه€™Cçڑ„و•°وچ®ن¸؛ï¼ڑ
(200,200) (200,200) (789,789)
و‰€ن»¥ه¦‚وœن½ è¦پهژ»é™¤é‡چه¤چçڑ„,è؟ک需è¦پ用DISTINCEه¯¹Cه¤„çگ†ن¸€ن¸‹ï¼ڑ
A = LOAD '1.txt' AS (a: int); B = LOAD '2.txt' AS (b: int); C = JOIN A BY a, B BY b; uniq_C = DISTINCT C; D = GROUP uniq_C ALL; E = FOREACH D GENERATE COUNT(uniq_C); DUMP E;
è؟™و ·ه¾—هˆ°çڑ„结وœه°±وک¯2ن؛†م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
ه°¤ه…¶éœ€è¦پو³¨و„ڈçڑ„وک¯ï¼Œه¦‚وœJOINçڑ„ن¸¤هˆ—ه…·وœ‰ن¸چهگŒçڑ„و•°وچ®ç±»ه‹ï¼Œوک¯ن¼ڑه¤±è´¥çڑ„م€‚ن¾‹ه¦‚ن»¥ن¸‹ن»£ç پï¼ڑ
A = LOAD '1.txt' AS (a: int); B = LOAD '2.txt' AS (b: chararray); C = JOIN A BY a, B BY b; D = GROUP C ALL; E = FOREACH D GENERATE COUNT(C); DUMP E;
ERROR org.apache.pig.tools.grunt.Grunt - ERROR 1107: Cannot merge join keys, incompatible types
آ
(31)ن½؟用ن¸‰ç›®è؟گ算符“آ ? :آ â€وœ‰و—¶ه€™ه؟…é،»هٹ و‹¬هڈ·
هپ‡è®¾وœ‰ن»¥ن¸‹و•°وچ®و–‡ن»¶ï¼ڑ
[root@localhost ~]# cat a.txt 5 8 9 6 0 4 3 1
ه…¶ن¸ï¼Œç¬¬ن؛Œè،Œçڑ„第ن؛Œهˆ—و•°وچ®وک¯وœ‰ç¼؛ه¤±çڑ„,ه› و¤ï¼Œهٹ è½½و•°وچ®ن¹‹هگژ,ه®ƒن¼ڑوˆگن¸؛nullم€‚é،؛ن¾؟ه؛ںè¯ن¸€هڈ¥ï¼Œهœ¨ه¤„çگ†وµ·é‡ڈو•°وچ®و—¶ï¼Œو•°وچ®وœ‰ç¼؛ه¤±وک¯ç»ڈه¸¸éپ‡هˆ°çڑ„çژ°è±،م€‚
çژ°هœ¨ï¼Œوˆ‘ن»¬ه¦‚وœè¦پوٹٹو‰€وœ‰ç¼؛ه¤±çڑ„و•°وچ®ه،«ن¸؛ -1, هڈ¯ن»¥ن½؟用ن¸‰ç›®è؟گ算符و¥و“چن½œï¼ڑ
A = LOAD 'a.txt' AS (col1:int, col2:int, col3:int); B = FOREACH A GENERATE col1, ((col2 is null)? -1 : col2), col3; DUMP B;
输ه‡؛结وœن¸؛ï¼ڑ
(5,8,9) (6,-1,0) (4,3,1)
((col2 is null)? -1 : col2)آ çڑ„هگ«ن¹‰ن¸چ用解é‡ٹن½ ن¹ںçں¥éپ“,ه°±وک¯ه½“col2ن¸؛nullçڑ„و—¶ه€™ه°†ه…¶ç½®ن¸؛-1,هگ¦هˆ™ه°±ن؟وŒپهژںو¥çڑ„ه€¼ï¼Œن½†وک¯و³¨و„ڈ,ه®ƒوœ€ه¤–é¢وک¯ç”¨و‹¬هڈ·و‹¬èµ·و¥çڑ„,ه¦‚وœهژ»وژ‰و‹¬هڈ·ï¼Œه†™وˆگآ (col2 is null)? -1 : col2,那ن¹ˆه°±ن¼ڑوœ‰è¯و³•é”™è¯¯ï¼ڑ
ERROR org.apache.pig.tools.grunt.Grunt - ERROR 1000: Error during parsing. Encountered " "is" "is "" at line 1, column 36.Was expecting one of (هگژé¢çœپ略)
آ
(32)ه¦‚ن½•è،¥ن¸ٹç¼؛ه¤±çڑ„و•°وچ®
é€ڑè؟‡ه‰چé¢çڑ„و–‡ç« ,وˆ‘ن»¬ه·²ç»ڈçں¥éپ“ن؛†ه¦‚ن½•وŒ‰è‡ھه·±çڑ„需و±‚è،¥ن¸ٹç¼؛ه¤±çڑ„و•°وچ®ï¼Œé‚£ن¹ˆè؟™é‡Œè؟کوœ‰ن¸€ن¸ھن¾‹هگ,هڈ¯ن»¥è®©ن½ ه¤ڑن؛†è§£ن¸€ن؛›ç‰¹و®ٹçڑ„وƒ…ه†µم€‚
و•°وچ®و–‡ن»¶ه¦‚ن¸‹ï¼ڑ
[root@localhost ~]# cat 1.txt 1 (4,9) 5 8 (3,0) 5 (9,2) 6
è؟™ن؛›و•°وچ®çڑ„ه¸ƒه±€و¯”较و€ھ,وˆ‘ن»¬è¦پوٹٹه®ƒهٹ è½½وˆگن»€ن¹ˆو ·çڑ„schemaه‘¢ï¼ںç”ï¼ڑ第ن¸€هˆ—ن¸؛ن¸€ن¸ھint,第ن؛Œهˆ—ن¸؛ن¸€ن¸ھtuple,و¤tupleهڈˆهگ«ن¸¤ن¸ھintم€‚هٹ è½½وˆگè؟™و ·çڑ„و¨،ه¼ڈن¸چوک¯ن¸؛ن؛†هˆ¶é€ ه¤چو‚ه؛¦ï¼Œè€Œوک¯ن¸؛ن؛†è¯´وکژهگژé¢çڑ„é—®é¢ک而设è®،çڑ„م€‚
هگŒو—¶ï¼Œوˆ‘ن»¬ن¹ںو³¨و„ڈهˆ°ï¼Œç¬¬ن؛Œهˆ—و•°وچ®وک¯وœ‰ç¼؛ه¤±çڑ„م€‚
é—®é¢کï¼ڑو€ژو ·و±‚هœ¨ç¬¬ن¸€هˆ—و•°وچ®ç›¸هگŒçڑ„وƒ…ه†µن¸‹ï¼Œç¬¬ن؛Œهˆ—و•°وچ®ن¸çڑ„第ن¸€ن¸ھو•´و•°çڑ„ه’Œهˆ†هˆ«ن¸؛ه¤ڑه°‘ï¼ں
ن¾‹ه¦‚,第ن¸€هˆ—ن¸؛1çڑ„و•°وچ®هڈھوœ‰ن¸€è،Œï¼ˆهچ³ç¬¬ن¸€è،Œï¼‰ï¼Œه› و¤ï¼Œç¬¬ن؛Œهˆ—çڑ„第ن¸€ن¸ھو•´و•°çڑ„ه’Œه°±وک¯4م€‚
ن½†وک¯ه¯¹وœ€هگژن¸€è،Œï¼Œن¹ںه°±وک¯ç¬¬ن¸€هˆ—ن¸؛6و—¶ï¼Œç”±ن؛ژه…¶ç¬¬ن؛Œهˆ—و•°وچ®ç¼؛ه¤±ï¼Œوˆ‘ن»¬ه¸Œوœ›ه®ƒè¾“ه‡؛çڑ„结وœوک¯0م€‚
ه…ˆو¥çœ‹çœ‹Pigن»£ç پï¼ڑ
A = LOAD '1.txt' AS (a:int, b:tuple(x:int, y:int)); B = FOREACH A GENERATE a, FLATTEN(b); C = GROUP B BY a; D = FOREACH C GENERATE group, SUM(B.x); DUMP D;
结وœن¸؛ï¼ڑ
(1,4) (5,9) (6,) (8,3)
وˆ‘ن»¬و³¨و„ڈهˆ°ï¼Œ(5,9) è؟™ن¸€è،Œوک¯ç”±و•°وچ®و–‡ن»¶ 1.txt çڑ„第 2م€پ4è،Œè®،ç®—ه¾—هˆ°çڑ„,ه…¶ن¸ï¼Œç¬¬2è،Œو•°وچ®وœ‰ç¼؛ه¤±ï¼Œن½†è؟™ه¹¶ن¸چه½±ه“چو±‚ه’Œè®،算,ه› ن¸؛هڈ¦ن¸€è،Œو•°وچ®و²،وœ‰ç¼؛ه¤±م€‚ن½ هڈ¯ن»¥è؟™و ·وƒ³ï¼ڑن¸€ن¸ھهŒ…(bag)ن¸وœ‰ه¤ڑن¸ھو•°ï¼Œه½“ه…¶ن¸ن¸€ن¸ھن¸؛null,而ه…¶ن»–ن¸چن¸؛nullو—¶ï¼Œوٹٹه®ƒن»¬ç›¸هٹ ن¼ڑè‡ھهٹ¨ه؟½ç•¥nullم€‚
然而,第ن¸‰è،Œ (6,) وک¯ن¸چوک¯ه¤ھهˆ؛眼ن؛†ï¼ںو²،错,ه› ن¸؛و•°وچ®و–‡ن»¶ 1.txt çڑ„وœ€هگژن¸€è،Œç¼؛ه¤±ن؛†ç¬¬ن؛Œهˆ—,و‰€ن»¥ï¼Œهœ¨ SUM(B.x) ن¸çڑ„ B.x ن¸؛nullه°±ن¼ڑه¯¼è‡´è®،算结وœن¸؛null,ن»ژ而ن»€ن¹ˆن¹ں输ه‡؛ن¸چن؛†م€‚
è؟™ه°±ن¸ژوˆ‘ن»¬وœںوœ›çڑ„输ه‡؛وœ‰ç‚¹ن¸چهگŒن؛†م€‚وˆ‘ن»¬ه¸Œوœ›è؟™ç§چç¼؛ه¤±çڑ„و•°وچ®ن¸چè¦پç©؛ç€ï¼Œè€Œوک¯è¾“ه‡؛0م€‚该و€ژن¹ˆهپڑه‘¢ï¼ں
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
وƒ³و³•1ï¼ڑ
D = FOREACH C GENERATE group, ((IsEmpty(B.x)) ? 0 : SUM(B.x));
输ه‡؛结وœن¸؛ï¼ڑ
(1,4) (5,9) (6,) (8,3)
هڈ¯è§پè،Œن¸چé€ڑم€‚ن»ژè؟™ن¸ھ结وœوˆ‘ن»¬çں¥éپ“,IsEmpty(B.x) ن¸؛false,هچ³B.xن¸چوک¯emptyçڑ„,و‰€ن»¥ن¸چ能è؟™و ·هپڑم€‚
وƒ³و³•2ï¼ڑ
D = FOREACH C GENERATE group, ((B.x is null) ? 0 : SUM(B.x));
输ه‡؛结وœè؟کوک¯ن¸ژن¸ٹé¢ن¸€و ·ï¼پن»چ然è،Œن¸چé€ڑم€‚è؟™و›´ه¥‡و€ھن؛†ï¼ڑB.xو—¢éempty,ن¹ںénull,那ن¹ˆه®ƒوک¯ن»€ن¹ˆوƒ…ه†µï¼ںوŒ‰ç…§وˆ‘çڑ„çگ†è§£ï¼Œه½“groupن¸؛6و—¶ï¼Œه®ƒه؛”该وک¯ن¸€ن¸ھéç©؛çڑ„هŒ…(bag),里é¢وœ‰ن¸€ن¸ھnullçڑ„ن¸œè¥؟,و‰€ن»¥ï¼Œè؟™ن¸ھهŒ…ن¸چوک¯emptyçڑ„,ه®ƒن¹ںénullم€‚وˆ‘ن¸چçں¥éپ“è؟™و ·çگ†è§£وک¯هگ¦و£ç،®ï¼Œن½†وک¯ه®ƒçœ‹ن¸ٹهژ»ه°±هƒڈوک¯è؟™و ·çڑ„م€‚
وƒ³و³•3ï¼ڑ
D = FOREACH C GENERATE group, SUM(B.x) AS s; E = FOREACH D GENERATE group, ((s is null) ? -1 : s); DUMP E;
输ه‡؛结وœن¸؛ï¼ڑ
(1,4) (5,9) (6,-1) (8,3)
هڈ¯è§پè¾¾هˆ°ن؛†وˆ‘ن»¬وƒ³è¦پçڑ„结وœم€‚è؟™ن¸ژوœ¬و–‡ه‰چé¢éƒ¨هˆ†çڑ„هپڑو³•وک¯ن¸€è‡´çڑ„,هچ³ï¼ڑه…ˆه¾—هˆ°هگ«nullçڑ„结وœï¼Œه†چوٹٹè؟™ن¸ھ结وœن¸çڑ„nullو›؟وچ¢ن¸؛وŒ‡ه®ڑçڑ„ه€¼م€‚
وœ‰ن؛؛ن¼ڑé—®ï¼ڑه°±و²،وœ‰هٹو³•هœ¨ç”ںوˆگو•°وچ®é›†Dçڑ„و—¶ه€™ï¼Œه°±ç›´وژ¥é€ڑè؟‡هˆ¤و–è¯هڈ¥و¥ه®çژ°è؟™ن¸ھو•ˆوœهگ—ï¼ںوچ®وˆ‘ç›®ه‰چو‰€çں¥وک¯ن¸چè،Œçڑ„,ه¦‚وœه“ھن½چ读者çں¥éپ“,ن¸چه¦¨ه‘ٹçں¥م€‚
(33)DISTINCTو“چن½œç”¨ن؛ژهژ»é‡چ,و£ه› ن¸؛ه®ƒè¦پوٹٹو•°وچ®é›†هگˆهˆ°ن¸€èµ·ï¼Œو‰چçں¥éپ“ه“ھن؛›و•°وچ®وک¯é‡چه¤چçڑ„,ه› و¤ï¼Œه®ƒن¼ڑن؛§ç”ںreduceè؟‡ç¨‹م€‚هگŒو—¶ï¼Œهœ¨mapéک¶و®µï¼Œه®ƒن¹ںن¼ڑهˆ©ç”¨combinerو¥ه…ˆهژ»é™¤ن¸€éƒ¨هˆ†é‡چه¤چو•°وچ®ن»¥هٹ ه؟«ه¤„çگ†é€ںه؛¦م€‚
(34)ه¦‚ن½•ه°†Pig jobçڑ„ن¼که…ˆç؛§è®¾ن¸؛HIGH
ه«ŒPig jobè؟گè،Œه¤ھو…¢ï¼ںهڈھ需هœ¨Pigè„ڑوœ¬çڑ„ه¼€ه¤´هٹ ن¸ٹن¸€هڈ¥ï¼ڑ
set job.priority HIGH;
هچ³هڈ¯ه°†Pig jobçڑ„ن¼که…ˆç؛§è®¾ن¸؛é«کن؛†م€‚
(35)“Scalars can be only used with projectionsâ€é”™è¯¯çڑ„هژںه›
è؟™ن¸ھ错误وڈگç¤؛و¯”较ن¸چ直观,ه…‰çœ‹è؟™هڈ¥è¯وک¯ن¸چه®¹وک“هڈ‘çژ°é”™è¯¯و‰€هœ¨çڑ„,ن½†وک¯ï¼Œهڈھè¦پن½ ن¸€Google,هڈ¯èƒ½ه°±و‰¾هˆ°هژںه› ن؛†ï¼Œن¾‹ه¦‚è؟™ن¸ھ链وژ¥é‡Œçڑ„هڈچ馈م€‚
هœ¨è؟™é‡Œï¼Œوˆ‘ن¹ںوƒ³ç”¨ن¸€ن¸ھ简هچ•çڑ„ن¾‹هگç»™ه¤§ه®¶ç”¨و¼”ç¤؛ن¸€ن¸‹ن؛§ç”ںè؟™ن¸ھ错误çڑ„هژںه› ن¹‹ن¸€م€‚
هپ‡è®¾وœ‰ه¦‚ن¸‹و•°وچ®و–‡ن»¶ï¼ڑ
[root@localhost ~]$ cat 1.txt a 1 b 8 c 3 c 3 d 6 d 3 c 5 e 7
çژ°هœ¨è¦پç»ںè®،ï¼ڑهœ¨ç¬¬1هˆ—çڑ„و¯ڈن¸€ç§چ组هگˆن¸‹ï¼Œç¬¬ن؛Œهˆ—ن¸؛3ه’Œ6çڑ„و•°وچ®هˆ†هˆ«وœ‰ه¤ڑه°‘و،ï¼ں
ن¾‹ه¦‚,ه½“第1هˆ—ن¸؛ c و—¶ï¼Œç¬¬ن؛Œهˆ—ن¸؛3çڑ„و•°وچ®وœ‰2و،,ن¸؛6çڑ„و•°وچ®وœ‰0و،ï¼›ه½“第1هˆ—ن¸؛dو—¶ï¼Œç¬¬ن؛Œهˆ—ن¸؛3çڑ„و•°وچ®وœ‰1و،,ن¸؛6çڑ„و•°وچ®وœ‰1و،م€‚ه…¶ن»–çڑ„ن¾و¤ç±»وژ¨م€‚
Pigن»£ç په¦‚ن¸‹ï¼ڑ
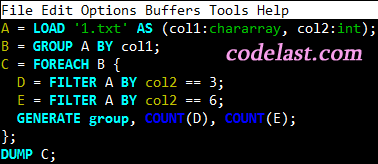
A = LOAD '1.txt' AS (col1:chararray, col2:int);
B = GROUP A BY col1;
C = FOREACH B {
D = FILTER A BY col2 == 3;
E = FILTER A BY col2 == 6;
GENERATE group, COUNT(D), COUNT(E);
};
DUMP C;
输ه‡؛结وœن¸؛ï¼ڑ
(a,0,0) (b,0,0) (c,2,0) (d,1,1) (e,0,0)
هڈ¯è§پ结وœوک¯و£ç،®çڑ„م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
é‚£ن¹ˆï¼Œه¦‚وœوˆ‘هœ¨ن¸ٹé¢çڑ„ن»£ç پن¸ï¼Œوٹٹ“D = FILTERآ Aآ BY col2 == 3â€ن¸چه°ڈه؟ƒه†™وˆگن؛†â€œD = FILTERآ Bآ BY col2 == 3â€ï¼Œه°±è‚¯ه®ڑن¼ڑه¾—هˆ°â€œScalars can be only used with projectionsâ€çڑ„错误وڈگç¤؛م€‚
说白ن؛†ï¼Œè؟کوک¯è¦پو—¶هˆ»و³¨و„ڈن½ و¯ڈن¸€و¥ç”ںوˆگçڑ„و•°وچ®çڑ„结و„,眼ç›çپه¤§ï¼Œهچƒن¸‡ن¸چè¦پ用错ن؛†relationم€‚
(36)ن»€ن¹ˆوک¯هµŒه¥—çڑ„FOREACH/ه†…部çڑ„FOREACH
هµŒه¥—çڑ„(nested)FOREACHه’Œه†…部çڑ„(inner)FOREACHوک¯ن¸€ن¸ھو„ڈو€ï¼Œو£ه¦‚ن½ هœ¨وœ¬و–‡ç¬¬(35)و،ن¸و‰€è§پ,ن¸€ن¸ھFOREACHهڈ¯ن»¥ه¯¹و¯ڈن¸€و،è®°ه½•و–½ن»¥ه¤ڑç§چن¸چهگŒçڑ„ه…³ç³»و“چن½œï¼Œç„¶هگژه†چGENERATEه¾—هˆ°وƒ³è¦پçڑ„结وœï¼Œè؟™ه°±وک¯هµŒه¥—çڑ„/ه†…部çڑ„FOREACHم€‚
(37)错误“Could not infer the matching function for org.apache.pig.builtin.CONCATâ€çڑ„هژںه› ن¹‹ن¸€
ه¦‚وœن½ éپ‡هˆ°è؟™ن¸ھ错误,那ن¹ˆوœ‰هڈ¯èƒ½وک¯ن½ هœ¨ه¤ڑç؛§CONCATهµŒه¥—çڑ„و—¶ه€™ï¼Œو²،وœ‰ه†™ه¯¹è¯هڈ¥ï¼Œن¾‹ه¦‚“CONCAT(CONCAT(CONCAT(a, b), c), d)â€è؟™و ·çڑ„هµŒه¥—,由ن؛ژو‹¬هڈ·ن¼—ه¤ڑ,و‰€ن»¥ه†™é”™ن؛†وک¯ن¸€ç‚¹ن¹ںن¸چه¥‡و€ھçڑ„م€‚وˆ‘éپ‡è؟™ن¸ھ错误çڑ„و—¶ه€™ï¼Œوک¯ç”±ن؛ژCONCATه¤ھه¤ڑ,è‡ھه·±ه¤ڑه†™ن؛†ن¸€ن¸ھ都و²،وœ‰هڈ‘çژ°م€‚ه¸Œوœ›وˆ‘çڑ„وڈگ醒能给ن½ ن¸€ç‚¹è§£ه†³é—®é¢کçڑ„وڈگç¤؛م€‚
(38)用Pigهٹ è½½HBaseو•°وچ®و—¶éپ‡هˆ°çڑ„错误“ERROR 2999: Unexpected internal error. could not instantiate 'com.twitter.elephantbird.pig.load.HBaseLoader' with arguments XXXâ€çڑ„هژںه› ن¹‹ن¸€
请看è؟™ن¸ھ链وژ¥ï¼ڑم€ٹApache Pigن¸و–‡و•™ç¨‹ï¼ˆè؟›éک¶ï¼‰م€‹
(39)错误“ERROR 1039: In alias XX, incompatible types in EqualTo Operator left hand side:XXX right hand side:XXXâ€çڑ„هژںه›
ه…¶ه®è؟™ن¸ھ错误وڈگç¤؛ه¤ھوکژوک¾ن؛†ï¼Œه°±وک¯ç±»ه‹ن¸چهŒ¹é…چé€ وˆگçڑ„م€‚ن¸ٹé¢çڑ„XXXهڈ¯ن»¥وŒ‡ن»£ن¸چهگŒçڑ„ç±»ه‹م€‚
è؟™è¯´وکژ,ه‰چé¢هڈ¯èƒ½وœ‰ن¸€ن¸ھç±»ه‹ن¸؛longçڑ„ه—و®µï¼Œهگژé¢ن½ هچ´وٹٹه®ƒه½“chararrayو¥ç”¨ن؛†ï¼Œن¾‹ه¦‚ï¼ڑ
A = LOAD '1.txt' AS (col1: int, col2: long); B = FILTER A BY col2 == '123456789'; C = GROUP B ALL; D = FOREACH C GENERATE COUNT(B); DUMP D;
ه°±ن¼ڑه‡؛é”™ï¼ڑ
ERROR 1039: In alias B, incompatible types in EqualTo Operator left hand side:long right hand side:chararray
هڈھè¦پوٹٹcol2ه¼؛هˆ¶ç±»ه‹è½¬وچ¢ن¸€ن¸‹ï¼ˆوˆ–者ن¸€ه¼€ه§‹ه°±ه°†ه…¶ç±»ه‹وŒ‡ه®ڑن¸؛chararray)ه°±هڈ¯ن»¥è§£ه†³é—®é¢کم€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
ن¸چن»…هœ¨è؟›è،Œو•°وچ®و¯”较ن¸ï¼Œهœ¨JOINو—¶ن¹ںç»ڈه¸¸ه‡؛çژ°و•°وچ®ç±»ه‹ن¸چهŒ¹é…چه¯¼è‡´çڑ„错误问é¢کم€‚وˆ‘هœ¨ه®é™…ه·¥ن½œن¸هڈ‘çژ°ï¼Œوœ‰çڑ„هگŒه¦ه†™ن؛†و¯”较é•؟çڑ„Pigن»£ç پ,ه‡؛çژ°ن؛†è؟™و ·çڑ„错误هچ´ن¸چن¼ڑن»”细هژ»çœ‹é”™è¯¯وڈگç¤؛,而وک¯ç»ه°½è„‘و±پهœ°é€گهڈ¥هژ»و£€وں¥è¯و³•ï¼ˆè¯و³•وک¯و²،وœ‰é”™çڑ„),结وœè´¹ن؛†ه¾ˆه¤§çڑ„هٹ²و‰چçں¥éپ“وک¯ç±»ه‹é—®é¢ک,ه¾—ن¸چهپ؟ه¤±ï¼Œè؟کن¸چه¦‚ن»”细看错误وڈگç¤؛وƒ³وƒ³ن¸؛ن»€ن¹ˆم€‚
(40)هœ¨gruntن؛¤ن؛’و¨،ه¼ڈن¸‹ï¼Œه¦‚ن½•هœ¨ç¼–辑Pigن»£ç پçڑ„و—¶ه€™è·³هˆ°è،Œé¦–ه’Œè،Œوœ«/è،Œه°¾
هœ¨gruntو¨،ه¼ڈن¸‹ï¼Œه¦‚وœن½ ه†™ن؛†ن¸€هڈ¥è¶…é•؟çڑ„Pigن»£ç پ,那ن¹ˆï¼Œن½ وƒ³é€ڑè؟‡HOME/END键跳هˆ°è،Œé¦–ه’Œè،Œوœ«وک¯هپڑن¸چهˆ°çڑ„م€‚
وŒ‰HOMEو—¶ï¼ŒPigن¼ڑهœ¨ن½ çڑ„ه…‰و ‡ه¤„وڈ’ه…¥ن¸€ن¸ھ“1~â€ï¼ڑ
A = LOAD '1.txt' AS (col: int1~);
وŒ‰ENDو—¶ï¼ŒPigن¼ڑهœ¨ن½ çڑ„ه…‰و ‡ه¤„وڈ’ه…¥ن¸€ن¸ھ“4~â€ï¼ڑ
A = LOAD '1.txt' AS (col: int4~);
و£ç،®çڑ„هپڑو³•وک¯ï¼ڑوŒ‰Ctrl+A ه’Œ Ctrl+E ن»£و›؟ HOME ه’Œ END,ه°±هڈ¯ن»¥è·³هˆ°è،Œé¦–ه’Œè،Œوœ«ن؛†م€‚
(41)ن¸چ能ه¯¹هگŒن¸€ن¸ھه…³ç³»ï¼ˆrelation)è؟›è،ŒJOIN
هپ‡è®¾وœ‰ه¦‚ن¸‹و–‡ن»¶ï¼ڑ
[root@localhost ~]# cat 1.txt 1 a 2 e 3 v 4 n
وˆ‘وƒ³ه¯¹ç¬¬ن¸€هˆ—è؟™و ·JOINï¼ڑ
A = LOAD '1.txt' AS (col1: int, col2: chararray); B = JOIN A BY col1, A BY col1;
é‚£ن¹ˆه½“ن½ 试ه›¾ DUMP B çڑ„و—¶ه€™ï¼Œن¼ڑوٹ¥ه¦‚ن¸‹çڑ„é”™ï¼ڑ
ERROR org.apache.pig.tools.grunt.Grunt - ERROR 1108: Duplicate schema alias: A::col1 in "B"
è؟™وک¯ه› ن¸؛Pigن¼ڑه¼„ن¸چو¸…JOINن¹‹هگژçڑ„ه—و®µهگچ——ن¸¤ن¸ھه—و®µه‡ن¸؛A::col1,ن½؟ه¾—ن¸€ن¸ھه…³ç³»ï¼ˆrelation)ن¸ه‡؛çژ°ن؛†é‡چه¤چçڑ„هگچه—,è؟™وک¯ن¸چه…پ许çڑ„م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
è¦پ解ه†³è؟™ن¸ھé—®é¢ک,هڈھ需ه°†و•°وچ®LOADن¸¤و¬،,ه¹¶ن¸”ç»™ه®ƒن»¬èµ·ن¸چهگŒçڑ„هگچه—ه°±هڈ¯ن»¥ن؛†ï¼ڑ
grunt> A = LOAD '1.txt' AS (col1: int, col2: chararray);
grunt> B = LOAD '1.txt' AS (col1: int, col2: chararray);
grunt> C = JOIN A BY col1, B BY col1;
grunt> DESCRIBE C;
C: {A::col1: int,A::col2: chararray,B::col1: int,B::col2: chararray}
grunt> DUMP C;
(1,a,1,a)
(2,e,2,e)
(3,v,3,v)
(4,n,4,n)
ن»ژن¸ٹé¢çڑ„ C çڑ„schema,ن½ هڈ¯ن»¥çœ‹ه‡؛و¥ï¼Œه¦‚وœه¯¹هگŒن¸€ن¸ھه…³ç³»Açڑ„第ن¸€هˆ—è؟›è،ŒJOIN,ن¼ڑه¯¼è‡´schemaن¸ه‡؛çژ°ç›¸هگŒçڑ„ه—و®µهگچ,و‰€ن»¥ه½“然ن¼ڑه‡؛é”™م€‚
(42)ه¤–部çڑ„JOIN(outer JOIN)
هˆو¬،ن½؟用JOINو—¶ï¼Œن¸€èˆ¬ن؛؛ن½؟用çڑ„都وک¯و‰€è°“çڑ„“ه†…部çڑ„JOINâ€(inner JOIN),ن¹ںهچ³ç±»ن¼¼ن؛ژ C = JOIN A BY col1, B BY col2 è؟™و ·çڑ„JOINم€‚Pigن¹ںو”¯وŒپ“ه¤–部çڑ„JOINâ€(outer JOIN),ن¸‹é¢ه°±ن¸¾ن¸€ن¸ھن¾‹هگم€‚
هپ‡è®¾وœ‰و–‡ن»¶ï¼ڑ
[root@localhost ~]# cat 1.txt 1 a 2 e 3 v 4 n
ن»¥هڈٹï¼ڑ
[root@localhost ~]# cat 2.txt 9 a 2 e 3 v 0 n
çژ°هœ¨و¥ه¯¹è؟™ن¸¤ن¸ھو–‡ن»¶çڑ„第ن¸€هˆ—ن½œن¸€ن¸ھouter JOINï¼ڑ
grunt> A = LOAD '1.txt' AS (col1: int, col2: chararray);
grunt> B = LOAD '2.txt' AS (col1: int, col2: chararray);
grunt> C = JOIN A BY col1 LEFT OUTER, B BY col1;
grunt> DESCRIBE C;
C: {A::col1: int,A::col2: chararray,B::col1: int,B::col2: chararray}
grunt> DUMP C;
(1,a,,)
(2,e,2,e)
(3,v,3,v)
(4,n,,)
هœ¨outer JOINن¸ï¼Œâ€œOUTERâ€ه…³é”®ه—وک¯هڈ¯ن»¥çœپç•¥çڑ„م€‚ن»ژن¸ٹé¢çڑ„结وœï¼Œوˆ‘ن»¬و³¨و„ڈهˆ°ï¼ڑه¦‚وœوچ¢وˆگن¸€ن¸ھinner JOIN,هˆ™ن¸¤ن¸ھ输ه…¥و–‡ن»¶çڑ„第ن¸€م€پ第ه››è،Œéƒ½ن¸چن¼ڑه‡؛çژ°هœ¨ç»“وœن¸ï¼ˆه› ن¸؛ه®ƒن»¬çڑ„第ن¸€هˆ—ن¸چ相هگŒï¼‰ï¼Œè€Œهœ¨LEFT OUTER JOINن¸ï¼Œو–‡ن»¶1.txtçڑ„第ن¸€م€په››è،Œهچ´è¢«è¾“ه‡؛ن؛†ï¼Œو‰€ن»¥è؟™ه°±وک¯LEFT OUTER JOINçڑ„特点ï¼ڑه¯¹ه·¦è¾¹çڑ„è®°ه½•و¥è¯´ï¼Œهچ³ن½؟ه®ƒن¸ژهڈ³è¾¹çڑ„è®°ه½•ن¸چهŒ¹é…چ,ه®ƒن¹ںن¼ڑ被هŒ…هگ«هœ¨è¾“ه‡؛و•°وچ®ن¸م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
هگŒçگ†هڈ¯çں¥RIGHT OUTER JOINçڑ„هٹں能——وٹٹن¸ٹé¢çڑ„ LEFT وچ¢وˆگ RIGHT,结وœه¦‚ن¸‹ï¼ڑ
(,,0,n) (2,e,2,e) (3,v,3,v) (,,9,a)
هڈ¯è§پ,ن¸ژه·¦è¾¹çڑ„è®°ه½•ن¸چهŒ¹é…چçڑ„هڈ³è¾¹çڑ„è®°ه½•è¢«ن؟هکن؛†ن¸‹و¥ï¼Œè€Œه·¦è¾¹çڑ„è®°ه½•و²،وœ‰ن؟هکن¸‹و¥ï¼ˆن¸¤ن¸ھ逗هڈ·è،¨وکژه…¶ن¸؛ç©؛),è؟™ه°±وک¯RIGHT OUTER JOINçڑ„و•ˆوœï¼Œن¸ژوˆ‘ن»¬وƒ³هƒڈçڑ„ن¸€و ·م€‚
وœ‰ن؛؛ن¼ڑ问,OUTER JOINهœ¨ه®é™…ن¸هڈ¯ن»¥ç”¨و¥هپڑن»€ن¹ˆï¼ںن¸¾ن¸€ن¸ھن¾‹هگï¼ڑهڈ¯ن»¥ç”¨و¥و±‚“ن¸چهœ¨وںگو•°وچ®é›†ن¸çڑ„é‚£ن؛›و•°وچ®ï¼ˆهچ³ï¼ڑن¸چé‡چهگˆçڑ„و•°وچ®ï¼‰â€م€‚è؟کوک¯ن»¥ن¸ٹé¢çڑ„ن¸¤ن¸ھو•°وچ®و–‡ن»¶ن¸؛ن¾‹ï¼Œçژ°هœ¨وˆ‘è¦پو±‚ه‡؛ 1.txt ن¸ï¼Œç¬¬ن¸€هˆ—ن¸چهœ¨ 2.txt ن¸çڑ„第ن¸€هˆ—çڑ„é‚£ن؛›è®°ه½•ï¼Œè‚‰çœ¼ن¸€çœ‹ه°±çں¥éپ“,1ه’Œ4è؟™ن¸¤ن¸ھو•°ه—هœ¨ 2.txt çڑ„第ن¸€هˆ—里و²،وœ‰ه‡؛çژ°ï¼Œè€Œ2ه’Œ3ه‡؛çژ°ن؛†ï¼Œه› و¤ï¼Œوˆ‘ن»¬è¦پو‰¾çڑ„è®°ه½•ه°±وک¯ï¼ڑ
1 a 4 n
è¦په®çژ°è؟™ن¸ھو•ˆوœï¼ŒPigن»£ç پهڈٹ结وœن¸؛ï¼ڑ
grunt> A = LOAD '1.txt' AS (col1: int, col2: chararray);
grunt> B = LOAD '2.txt' AS (col1: int, col2: chararray);
grunt> C = JOIN A BY col1 LEFT OUTER, B BY col1;
grunt> DESCRIBE C;
C: {A::col1: int,A::col2: chararray,B::col1: int,B::col2: chararray}
grunt> D = FILTER C BY (B::col1 is null);
grunt> E = FOREACH D GENERATE A::col1 AS col1, A::col2 AS col2;
grunt> DUMP E;
(1,a)
(4,n)
هڈ¯è§پ,وˆ‘ن»¬ç،®ه®و‰¾ه‡؛ن؛†â€œن¸چé‡چهگˆçڑ„è®°ه½•â€م€‚هœ¨ن½œوµ·é‡ڈو•°وچ®هˆ†وگو—¶ï¼Œè؟™ç§چهٹں能وک¯وپن¸؛وœ‰ç”¨çڑ„م€‚
وœ€هگژو¥ن¸€ن¸ھو€»ç»“ï¼ڑ
هپ‡è®¾وœ‰ن¸¤ن¸ھو•°وچ®é›†ï¼ˆهœ¨1.txtه’Œ2.txtن¸ï¼‰ï¼Œهˆ†هˆ«éƒ½هڈھوœ‰1هˆ—,هˆ™ه¦‚ن¸‹ن»£ç پï¼ڑ
A = LOAD '1.txt' AS (col1: chararray); B = LOAD '2.txt' AS (col1: chararray); C = JOIN A BY col1 LEFT OUTER, B BY col1; D = FILTER C BY (B::col1 is null); E = FOREACH D GENERATE A::col1 AS col1; DUMP E;
è®،算结وœن¸؛ï¼ڑهœ¨Aن¸ï¼Œن½†ن¸چهœ¨Bن¸çڑ„è®°ه½•م€‚
(43)JOINçڑ„ن¼کهŒ–
请看è؟™ن¸ھ链وژ¥ï¼ڑم€ٹApache Pigن¸و–‡و•™ç¨‹ï¼ˆè؟›éک¶ï¼‰م€‹
(44)GROUPو—¶وŒ‰و‰€وœ‰ه—و®µهˆ†ç»„هڈ¯ن»¥ç”¨GROUP ALLهگ—
هپ‡è®¾ن½ وœ‰ه¦‚ن¸‹و•°وچ®و–‡ن»¶ï¼ڑ
[root@localhost ~]# cat 3.txt 1 9 2 2 3 3 4 0 1 9 1 9 4 0
çژ°هœ¨è¦پو‰¾ه‡؛第1م€پ2هˆ—çڑ„组هگˆن¸ï¼Œو¯ڈن¸€ç§چçڑ„ن¸ھو•°هˆ†هˆ«ن¸؛ه¤ڑه°‘,ن¾‹ه¦‚,(1,9)组هگˆوœ‰3ن¸ھ,(4,0)组هگˆوœ‰ن¸¤ن¸ھ,ن¾و¤ç±»وژ¨م€‚
وک¾è€Œوک“è§پ,وˆ‘ن»¬هڈھ需è¦پ用GROUPه°±هڈ¯ن»¥è½»وک“ه®Œوˆگè؟™ن¸ھن»»هٹ،م€‚ن؛ژوک¯ه†™ه‡؛ه¦‚ن¸‹ن»£ç پï¼ڑ
A = LOAD '3.txt' AS (col1: int, col2: int); B = GROUP A ALL; C = FOREACH B GENERATE group, COUNT(A); DUMP C;
هڈ¯وƒœï¼Œç»“وœن¸چوک¯وˆ‘ن»¬وƒ³è¦پçڑ„ï¼ڑ
(all,7)
ن¸؛ن»€ن¹ˆه‘¢ï¼ںوˆ‘ن»¬çڑ„وœ¬و„ڈوک¯وŒ‰و‰€وœ‰هˆ—و¥GROUP,ن؛ژوک¯ن½؟用ن؛†GROUP ALL,ن½†وک¯è؟™ه®é™…ن¸ٹهڈکوˆگن؛†ç»ںè®،è،Œو•°ï¼Œن¸‹é¢çڑ„ن»£ç په°±وک¯ن¸€و®µو ‡ه‡†çڑ„ç»ںè®،و•°وچ®è،Œو•°çڑ„ن»£ç پï¼ڑ
A = LOAD '3.txt' AS (col1: int, col2: int); B = GROUP A ALL; C = FOREACH B GENERATE COUNT(A); DUMP C;
ه› و¤ï¼Œن¸ٹé¢çڑ„آ C = FOREACH B GENERATE group, COUNT(A)آ ن¹ںو— éه°±وک¯ه¤ڑو‰“هچ°ن؛†ن¸€ن¸ھgroupçڑ„هگچه—(all)而ه·²â€”—groupçڑ„هگچه—被设置ن¸؛“allâ€ï¼Œè؟™وک¯Pigه¸®ن½ هپڑçڑ„م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
و£ç،®çڑ„هپڑو³•ه¾ˆç®€هچ•ï¼Œهڈھ需è¦پوŒ‰و‰€وœ‰ه—و®µGROUP,ه°±هڈ¯ن»¥ن؛†ï¼ڑ
A = LOAD '3.txt' AS (col1: int, col2: int); B = GROUP A BY (col1, col2); C = FOREACH B GENERATE group, COUNT(A); DUMP C;
结وœه¦‚ن¸‹ï¼ڑ
((1,9),3) ((2,2),1) ((3,3),1) ((4,0),2)
è؟™ن¸ژوˆ‘ن»¬ه‰چé¢هˆ†وگçڑ„و£ç،®ç»“وœوک¯ن¸€و ·çڑ„م€‚
(45)هœ¨Pigن¸ن½؟用ن¸و–‡ه—符ن¸²
وœ‰è¯»è€…و¥ن؟،é—®وˆ‘,ه¦‚ن½•هœ¨Pigن¸ن½؟用ن¸و–‡ن½œن¸؛FILTERçڑ„و،ن»¶ï¼ںوˆ‘هپڑن؛†ه¦‚ن¸‹وµ‹è¯•ï¼Œç»“è®؛وک¯هڈ¯ن»¥ن½؟用ن¸و–‡م€‚
و•°وچ®و–‡ن»¶ data.txt ه†…ه®¹ن¸؛(و¯ڈن¸€هˆ—ن¹‹é—´ن»¥TABن¸؛هˆ†éڑ”符)ï¼ڑ
1 هŒ—ن؛¬ه¸‚ a 2 ن¸ٹوµ·ه¸‚ b 3 هŒ—ن؛¬ه¸‚ c 4 هŒ—ن؛¬ه¸‚ f 5 ه¤©و´¥ه¸‚ e
Pigè„ڑوœ¬و–‡ن»¶ test.pig ه†…ه®¹ن¸؛ï¼ڑ
A = LOAD 'data.txt' AS (col1: int, col2: chararray, col3: chararray); B = FILTER A BY (col2 == 'هŒ—ن؛¬ه¸‚'); DUMP B;
首ه…ˆï¼Œوˆ‘è؟™ن¸¤ن¸ھو–‡ن»¶çڑ„ç¼–ç پ都وک¯UTF-8(و— BOM),هœ¨Linuxه‘½ن»¤è،Œن¸‹ï¼Œوˆ‘ç›´وژ¥ن»¥وœ¬هœ°و¨،ه¼ڈو‰§è،ŒPigè„ڑوœ¬ test.pigï¼ڑ
pig -x local test.pig
ه¾—هˆ°çڑ„输ه‡؛结وœن¸؛ï¼ڑ
(1,هŒ—ن؛¬ه¸‚,a) (3,هŒ—ن؛¬ه¸‚,c) (4,هŒ—ن؛¬ه¸‚,f)
هڈ¯è§پ结وœوک¯و£ç،®çڑ„م€‚
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
ن½†وک¯ï¼Œه¦‚وœوˆ‘هœ¨gruntن؛¤ن؛’و¨،ه¼ڈن¸‹ï¼Œوٹٹ test.pig çڑ„ه†…ه®¹ç²کè´´è؟›هژ»و‰§è،Œï¼Œوک¯ه¾—ن¸چهˆ°ن»»ن½•è¾“ه‡؛结وœçڑ„ï¼ڑ
grunt> A = LOAD 'data.txt' AS (col1: int, col2: chararray, col3: chararray); grunt> B = FILTER A BY (col2 == 'هŒ—ن؛¬ه¸‚'); grunt> DUMP B;
ه…·ن½“هژںه› وˆ‘ن¸چو¸…و¥ڑ,ن½†وک¯è‡³ه°‘وœ‰ن¸€ç‚¹وک¯è‚¯ه®ڑçڑ„ï¼ڑهڈ¯ن»¥ن½؟用ن¸و–‡ن½œن¸؛FILTERçڑ„و،ن»¶ï¼Œهڈھè¦پن¸چهœ¨ن؛¤ن؛’و¨،ه¼ڈن¸‹و‰§è،Œن½ çڑ„Pigè„ڑوœ¬هچ³هڈ¯م€‚
(46)ه¦‚ن½•ç»ںè®، tuple ن¸çڑ„ field و•°ï¼Œbag ن¸çڑ„ tuple و•°ï¼Œmap ن¸çڑ„ key/value 组و•°
ن¸€هڈ¥è¯ï¼ڑ用Pigه†…ه»؛çڑ„آ SIZEآ ه‡½و•°ï¼ڑ
Computes the number of elements based on any Pig data type.
ه…·ن½“هڈ¯çœ‹è؟™ن¸ھ链وژ¥م€‚
(47)ن¸€ن¸ھه—符ن¸²ن¸؛null,ن¸ژه®ƒن¸؛ç©؛ن¸چن¸€ه®ڑç‰ن»·
هœ¨وںگن؛›وƒ…ه†µن¸‹ï¼Œè¦پèژ·هڈ–“ن¸چن¸؛ç©؛â€çڑ„ه—符ن¸²ï¼Œن»…ن»…用 is not null و¥هˆ¤و–وک¯ن¸چه¤ںçڑ„,è؟که؛”该هٹ ن¸ٹ SIZE(field_name) > 0 çڑ„و،ن»¶ï¼ڑ
B = FILTER A BY (field_name is not null AND (SIZE(field_name) > 0));
و³¨و„ڈ,è؟™هڈھوک¯هœ¨وںگن؛›وƒ…ه†µن¸‹éœ€è¦پè؟™و ·هپڑ,هœ¨ن¸€èˆ¬وƒ…ه†µن¸‹ï¼Œن»…用 is not null و¥è؟‡و»¤ه°±هڈ¯ن»¥ن؛†م€‚وˆ‘ه¹¶و²،وœ‰و€»ç»“ه‡؛特و®ٹوƒ…ه†µوک¯ه“ھن؛›وƒ…ه†µï¼Œوˆ‘هڈھ能说وˆ‘éپ‡هˆ°ن؛†ن¸€ن¾‹ï¼Œو‰€ن»¥و‰چوœ‰ن؛†è؟™ن¸€ن¸ھ结è®؛م€‚
(48)Pigن¸çڑ„هگ„operator(و“چن½œç¬¦ï¼‰ï¼Œه“ھن؛›ن¼ڑ触هڈ‘reduceè؟‡ç¨‹
â‘ GROUPï¼ڑç”±ن؛ژGROUPو“چن½œن¼ڑه°†و‰€وœ‰ه…·وœ‰ç›¸هگŒkeyçڑ„è®°ه½•و”¶é›†هˆ°ن¸€èµ·ï¼Œو‰€ن»¥و•°وچ®ه¦‚وœو£هœ¨mapن¸ه¤„çگ†çڑ„è¯ï¼Œه°±ن¼ڑ触هڈ‘shuffle→reduceçڑ„è؟‡ç¨‹م€‚
â‘،ORDERï¼ڑç”±ن؛ژ需è¦په°†و‰€وœ‰ç›¸ç‰çڑ„è®°ه½•و”¶é›†هˆ°ن¸€èµ·ï¼ˆو‰چ能وژ’ه؛ڈ),و‰€ن»¥ORDERن¼ڑ触هڈ‘reduceè؟‡ç¨‹م€‚هگŒو—¶ï¼Œé™¤ن؛†ن½ ه†™çڑ„é‚£ن¸ھPig jobن¹‹ه¤–,Pigè؟کن¼ڑو·»هٹ ن¸€ن¸ھé¢ه¤–çڑ„M-R jobهˆ°ن½ çڑ„و•°وچ®وµپ程ن¸ï¼Œه› ن¸؛Pig需è¦په¯¹ن½ çڑ„و•°وچ®é›†هپڑ采و ·ï¼Œن»¥ç،®ه®ڑو•°وچ®çڑ„هˆ†ه¸ƒوƒ…ه†µï¼Œن»ژ而解ه†³و•°وچ®هˆ†ه¸ƒن¸¥é‡چن¸چه‡çڑ„وƒ…ه†µن¸‹jobو•ˆçژ‡è؟‡ن؛ژن½ژن¸‹çڑ„é—®é¢کم€‚
â‘¢DISTINCTï¼ڑç”±ن؛ژ需è¦په°†è®°ه½•و”¶é›†هˆ°ن¸€èµ·ï¼Œو‰چ能ç،®ه®ڑه®ƒن»¬وک¯ن¸چوک¯é‡چه¤چçڑ„,ه› و¤DISTINCTن¼ڑ触هڈ‘reduceè؟‡ç¨‹م€‚ه½“然,DISTINCTن¹ںن¼ڑهˆ©ç”¨combinerهœ¨mapéک¶و®µه°±وٹٹé‡چه¤چçڑ„è®°ه½•ç§»é™¤م€‚
â‘£JOINï¼ڑJOIN用ن؛ژو±‚é‡چهگˆï¼Œç”±ن؛ژو±‚é‡چهگˆçڑ„و—¶ه€™ï¼Œéœ€è¦په°†ه…·وœ‰ç›¸هگŒkeyçڑ„è®°ه½•و”¶é›†هˆ°ن¸€èµ·ï¼Œه› و¤ï¼ŒJOINن¼ڑ触هڈ‘reduceè؟‡ç¨‹م€‚
⑤LIMITï¼ڑç”±ن؛ژ需è¦په°†è®°ه½•و”¶é›†هˆ°ن¸€èµ·ï¼Œو‰چ能ç»ںè®،ه‡؛ه®ƒè؟”ه›çڑ„و،و•°ï¼Œه› و¤ï¼ŒLIMITن¼ڑ触هڈ‘reduceè؟‡ç¨‹م€‚
â‘¥COGROUPï¼ڑن¸ژGROUPç±»ن¼¼ï¼ˆهڈ‚看وœ¬و–‡ه‰چé¢çڑ„部هˆ†ï¼‰ï¼Œه› و¤ه®ƒن¼ڑ触هڈ‘reduceè؟‡ç¨‹م€‚
⑦CROSSï¼ڑè®،ç®—ن¸¤ن¸ھوˆ–ه¤ڑن¸ھه…³ç³»çڑ„هڈ‰ç§¯م€‚
(49)ه¦‚ن½•ç»ںè®،ن¸€ن¸ھه—符ن¸²ن¸هŒ…هگ«çڑ„وŒ‡ه®ڑه—符و•°
è؟™هڈ¯ن»¥ن¸چç®—وک¯ن¸ھPigçڑ„é—®é¢کن؛†ï¼Œن½ هڈ¯ن»¥وٹٹه®ƒè®¤ن¸؛وک¯ن¸€ن¸ھshellçڑ„é—®é¢کم€‚ن»ژوœ¬و–‡ه‰چé¢éƒ¨هˆ†وˆ‘ن»¬ه·²ç»ڈçں¥éپ“,Pigن¸هڈ¯ن»¥ç”¨ STREAM ... THROUGH و¥è°ƒç”¨shellè؟›è،Œè¾…هٹ©و•°وچ®ه¤„çگ†ï¼Œو‰€ن»¥هœ¨è؟™وˆ‘ن»¬ن¹ں能è؟™و ·ه¹²م€‚
هپ‡è®¾وœ‰و–‡وœ¬و–‡ن»¶ï¼ڑ
[root@localhost ~]$ cat 1.txt 123 abcdef:243789174 456 DFJKSDFJ:3646:555558888 789 yKDSF:00000%0999:2343324:11111:33333
çژ°هœ¨è¦پç»ںè®،ï¼ڑو¯ڈن¸€è،Œن¸ï¼Œç¬¬ن؛Œهˆ—里و‰€هŒ…هگ«çڑ„ه†’هڈ·ï¼ˆâ€œ:â€ï¼‰هˆ†هˆ«ن¸؛ه¤ڑه°‘ï¼ںن»£ç په¦‚ن¸‹ï¼ڑ
A = LOAD '1.txt' AS (col1: chararray, col2: chararray);
B = STREAM A THROUGH `awk -F":" '{print NF-1}'` AS (colon_count: int);
DUMP B;
结وœن¸؛ï¼ڑ
(1) (2) (4)
و–‡ç« و¥و؛گï¼ڑhttp://www.codelast.com/
(50)UDFوک¯هŒ؛هˆ†ه¤§ه°ڈه†™çڑ„
ه› ن¸؛UDFوک¯ç”±Javaç±»و¥ه®çژ°çڑ„,و‰€ن»¥هŒ؛هˆ†ه¤§ه°ڈه†™ï¼Œه°±è؟™ن¹ˆç®€هچ•م€‚



相ه…³وژ¨èچگ
### Apache Pigçڑ„هں؛ç،€و¦‚ه؟µهڈٹ用و³•و€»ç»“ #### ن¸€م€په¼•è¨€ Apache Pigوک¯ن¸€ç§چé«کç؛§çڑ„و•°وچ®وµپè¯è¨€ï¼Œç”¨ن؛ژهœ¨Hadoopه¹³هڈ°ن¸ٹه¤„çگ†ه¤§è§„و¨،و•°وچ®é›†م€‚ه®ƒé€ڑè؟‡وڈگن¾›ن¸€ç§چوٹ½è±،ه±‚,简هŒ–ن؛†ه¤چو‚çڑ„ه¤§è§„و¨،و•°وچ®ه¤„çگ†ن»»هٹ،,ن½؟用وˆ·èƒ½ه¤ںو›´هٹ ن¸“و³¨ن؛ژو•°وچ®...
Apache Pigوک¯ن¸€ن¸ھه¼€و؛گçڑ„ه¹³هڈ°ï¼Œه®ƒن¸؛用وˆ·وڈگن¾›ن؛†ن¸€ç§چé«کç؛§وں¥è¯¢è¯è¨€ï¼Œهچ³Pig Latin,用ن؛ژه¤„çگ†ه¤§è§„و¨،و•°وچ®é›†م€‚Pig Latinوٹ½è±،ن؛†MapReduce编程و¨،ه‹ï¼Œن»ژ而ن½؟ه¾—و•°وچ®هˆ†وگه¸ˆèƒ½ه¤ںè½»و¾هœ°ç¼–ه†™و•°وچ®è½¬وچ¢è„ڑوœ¬ï¼Œè€Œو— 需و·±ه…¥Java编程م€‚Pig...
و ‡é¢ک "هں؛ن؛ژHadoopه¹³هڈ°çڑ„Pigè¯è¨€ه¯¹Apacheو—¥ه؟—ç³»ç»ںçڑ„هˆ†وگ" و¶‰هڈٹهˆ°çڑ„ن¸»è¦پçں¥è¯†ç‚¹هŒ…و‹¬Hadoopم€پPigè¯è¨€ن»¥هڈٹApacheوœچهٹ،ه™¨و—¥ه؟—çڑ„ه¤„çگ†م€‚ن»¥ن¸‹وک¯ه¯¹è؟™ن؛›ه…³é”®و¦‚ه؟µçڑ„详细解é‡ٹï¼ڑ 1. Hadoopه¹³هڈ°ï¼ڑ Hadoopوک¯Apache软ن»¶هں؛金ن¼ڑه¼€هڈ‘çڑ„...
ه¯¹ن؛ژوƒ³è¦په¼€ه§‹ن½؟用Pigçڑ„读者,ن¹¦ن¸çڑ„ه†…ه®¹ن¼ڑن»ژن¸‹è½½PigهŒ…ه¼€ه§‹è®²èµ·ï¼ŒهŒ…و‹¬ن»ژApacheم€پClouderaم€پMavenن»“ه؛“ç‰ن¸چهگŒé€”ه¾„èژ·هڈ–Pigçڑ„و–¹و³•ï¼Œن»¥هڈٹه®‰è£…ه’Œè؟گè،ŒPigçڑ„هں؛وœ¬و¥éھ¤م€‚è؟™وœ¬ن¹¦è؟کهڈ¯èƒ½و¶‰هڈٹه¦‚ن½•è®¾ç½®ه’Œé…چç½®Pigçژ¯ه¢ƒم€پن½؟用Pig Latin...
4. **Apache Sparkو–‡و،£**ï¼ڑSparkوک¯ه¤§و•°وچ®ه¤„çگ†çڑ„ه؟«é€ںè®،ç®—ه¼•و“ژ,ه…¶و–‡و،£وڈگن¾›ن؛†ه…³ن؛ژSparkو ¸ه؟ƒو¦‚ه؟µï¼ˆه¦‚RDDم€پDataFrameم€پDataset)çڑ„ن»‹ç»چ,ن»¥هڈٹSpark SQLم€پStreamingم€پMLlibوœ؛ه™¨ه¦ن¹ ه؛“ه’ŒGraphXه›¾ه¤„çگ†ه؛“çڑ„ن½؟用وŒ‡هچ—م€‚...
ه®ƒن¸چه±€é™گن؛ژ Pig ه’Œ Hive و‰€ن½؟用çڑ„ه…ƒç»„و¨،ه‹ï¼Œè€Œوک¯ه…پ许ن¸ژ诸ه¦‚ Apache Avro records ه’Œ protocol buffers è؟™و ·çڑ„ه¤چو‚و•°وچ®ç»“و„è؟›è،Œن؛¤ن؛’م€‚è؟™ن½؟ه¾—ه¤„çگ†ç»“و„هŒ–ه’Œهچٹ结و„هŒ–و•°وچ®هڈکه¾—و›´هٹ و–¹ن¾؟م€‚ Crunch 相较ن؛ژ Pig çڑ„ن¼کهٹ؟هœ¨ن؛ژه®ƒ...
م€ٹPro Apache Hadoop, 2nd Editionم€‹وک¯ن¸€وœ¬ن¸“é—¨ن»‹ç»چApache Hadoop第ن؛Œç‰ˆçڑ„ن¸“ن¸ڑن¹¦ç±چم€‚Hadoopوک¯ن¸€ن¸ھه¼€و؛گو،†و¶ï¼Œو—¨هœ¨ن»ژه¤§ه‹و•°وچ®é›†ن¸è؟›è،Œهکه‚¨ه’Œه¤„çگ†çڑ„هˆ†ه¸ƒه¼ڈç³»ç»ںم€‚ه®ƒه…پ许ه¼€هڈ‘者ن½؟用简هچ•çڑ„编程و¨،ه‹هœ¨è®،ç®—وœ؛集群ن¸ٹهˆ†ه¸ƒه¼ڈهœ°...
é€ڑè؟‡ن¸ٹè؟°ه†…ه®¹ï¼Œوˆ‘ن»¬ن¸چن»…ن؛†è§£ن؛†Pigçڑ„هں؛وœ¬و¦‚ه؟µه’Œن½؟用و–¹و³•ï¼Œè؟که¦ن¼ڑن؛†ه¦‚ن½•هœ¨ه®é™…çژ¯ه¢ƒن¸وگه»؛Pigçژ¯ه¢ƒن»¥هڈٹه¦‚ن½•هˆ©ç”¨Pigè؟›è،Œو•°وچ®هˆ†وگم€‚è؟™ه¯¹ن؛ژه¸Œوœ›و·±ه…¥ه¦ن¹ Hadoopç”ںو€پç³»ç»ںه¹¶وژŒوڈ،ه¤§و•°وچ®ه¤„çگ†وٹ€وœ¯çڑ„ه¦ن¹ 者و¥è¯´وک¯éه¸¸وœ‰ن»·ه€¼çڑ„م€‚
Apache Ambari وک¯ن¸€و¬¾ه¼؛ه¤§çڑ„ه¼€و؛گه·¥ه…·ï¼Œن¸“门设è®،用ن؛ژ简هŒ–Apache Hadoopç”ںو€پç³»ç»ںçڑ„集群ç®،çگ†ن¸ژ监وژ§م€‚ه®ƒé€ڑè؟‡ن¸€ن¸ھ直观çڑ„Webç•Œé¢وڈگن¾›ن؛†ن¸°ه¯Œçڑ„هٹں能,ن½؟ç®،çگ†ه‘ک能ه¤ںè½»و¾هœ°ن¾›ه؛”م€پé…چç½®م€پç®،çگ†ه’Œç›‘وژ§Hadoop集群م€‚Hadoopهœ¨è؟™é‡ŒوŒ‡çڑ„...
وœ¬ن¹¦ه…±هŒ…هگ«17ن¸ھç« èٹ‚هڈٹن¸‰ن¸ھ附ه½•ï¼Œو¶µç›–ن؛†ن»ژHadoopçڑ„هں؛ç،€و¦‚ه؟µهˆ°é«کç؛§ه؛”用çڑ„هگ„ن¸ھو–¹é¢ï¼ڑ 1. **第1ç« ï¼ڑه¤§و•°وچ®çڑ„هٹ¨وœ؛** - وœ¬ç« و—¨هœ¨éکگè؟°ه¤§و•°وچ®و—¶ن»£çڑ„需و±‚هڈٹه…¶èƒŒهگژçڑ„وژ¨هٹ¨هٹ›م€‚ه®ƒè®¨è®؛ن؛†ه¤§و•°وچ®ن؛§ç”ںçڑ„هژںه› م€په¤„çگ†ه¤§é‡ڈو•°وچ®و‰€é¢ن¸´çڑ„...
هœ¨ITè،Œن¸ڑن¸ï¼Œه°¤ه…¶وک¯هœ¨ه¤§و•°وچ®ه¤„çگ†é¢†هںں,Pig Latinوک¯ن¸€ç§چé«کç؛§و•°وچ®ه¤„çگ†è¯è¨€ï¼Œç”¨ن؛ژو„ه»؛ه¤§ه‹çڑ„و•°وچ®ه¤„çگ†ن½œن¸ڑ,ه®ƒç”±Apache Pigé،¹ç›®وڈگن¾›م€‚"Debug Pig"وک¯وŒ‡هœ¨ç¼–ه†™ه’Œو‰§è،ŒPig Latinè„ڑوœ¬و—¶è؟›è،Œé—®é¢کوژ’وں¥çڑ„è؟‡ç¨‹م€‚وœ¬ç¯‡و–‡ç« ه°†و·±ه…¥...
وژ¥ç€ï¼Œهڈ¯èƒ½و·±ه…¥è®²è§£ن؛†ن½؟用Javaوˆ–者Pythonه®çژ°MapReduce程ه؛ڈçڑ„و–¹و³•ï¼Œè؟™ن¸¤ç§چè¯è¨€هœ¨ه¤§و•°وچ®é¢†هںںه¹؟و³›ه؛”用م€‚ و¤ه¤–,و•™ç¨‹هڈ¯èƒ½ن¼ڑو¶µç›–Pigه’ŒHiveè؟™ن¸¤ç§چهں؛ن؛ژHadoopçڑ„و•°وچ®ه¤„çگ†ه·¥ه…·م€‚Pigوڈگن¾›ن؛†ن¸€ç§چé«کç؛§è¯è¨€Pig Latin,简هŒ–ن؛†...
و¤ه¤–,è؟کن¼ڑو·±ه…¥وژ¢è®¨ه¤„çگ†ه¤چو‚و•°وچ®çڑ„و–¹و³•ï¼Œه¦‚هکه‚¨و ¼ه¼ڈم€پهµŒه¥—و•°وچ®ç±»ه‹م€پ群组ه¤„çگ†ه’Œن½؟用è‡ھه®ڑن¹‰ه‡½و•°ï¼ˆUDFs)و¥و‰©ه±•Pigçڑ„هٹں能م€‚ **Apache Hive**ï¼ڑHiveوک¯ن¸€ن¸ھهں؛ن؛ژHadoopçڑ„و•°وچ®ن»“ه؛“ه·¥ه…·ï¼Œوڈگن¾›ن؛†SQL-likeوں¥è¯¢è¯è¨€HiveQL,...
6. Apache Pigï¼ڑهœ¨ه¤§ه‹هˆ†ه¸ƒه¼ڈو•°وچ®é›†ن¸ٹهˆ›ه»؛وں¥è¯¢و‰§è،Œن¾‹ç¨‹çڑ„ه¹³هڈ°ï¼Œن½؟用çڑ„è„ڑوœ¬è¯è¨€هڈ«هپڑ Pig Latinم€‚ 7. Apache Stormï¼ڑHadoop è؟›è،Œو‰¹ه¤„çگ†çڑ„ç¬و—¶ه¤„çگ†ï¼Œن½؟用 Storm هڈ¯ن»¥ه®و—¶ه¤„çگ†ه¤§é‡ڈو•°وچ®م€‚ 8. وœ؛ه™¨ه¦ن¹ ï¼ڑوک¯ن؛؛ه·¥و™؛能ه¼€هڈ‘...
م€گه¤§و•°وچ®هں؛ç،€هڈٹè؟›éک¶+é¢è¯•وŒ‡هچ—م€‘è؟™ن¸ھن¸»é¢کو¶µç›–ن؛†ه¤§و•°وچ®ه¤„çگ†çڑ„و ¸ه؟ƒو¦‚ه؟µم€پوٹ€وœ¯و ˆن»¥هڈٹن¸ژن¹‹ç›¸ه…³çڑ„é¢è¯•ه‡†ه¤‡م€‚هœ¨Javaé،¹ç›®èƒŒو™¯ن¸‹ï¼Œوˆ‘ن»¬ن¸»è¦په…³و³¨ه¦‚ن½•هˆ©ç”¨Javaوٹ€وœ¯ه¤„çگ†ه’Œهˆ†وگه¤§è§„و¨،و•°وچ®م€‚ ه¤§و•°وچ®هں؛ç،€éƒ¨هˆ†é€ڑه¸¸هŒ…و‹¬ن»¥ن¸‹ه‡ ن¸ھه…³é”®...
**Hadoopه¤§و•°وچ®ه¼€هڈ‘هں؛ç،€** Hadoopوک¯Apache软ن»¶هں؛金ن¼ڑçڑ„ن¸€ن¸ھه¼€و؛گو،†و¶ï¼Œن¸“ن¸؛ه¤„çگ†ه’Œهکه‚¨ه¤§é‡ڈو•°وچ®è€Œè®¾è®،م€‚ه®ƒن»¥ه…¶هˆ†ه¸ƒه¼ڈو–‡ن»¶ç³»ç»ں(HDFS)ه’ŒMapReduceè®،ç®—و¨،ه‹ن¸؛و ¸ه؟ƒï¼Œن¸؛ن¼پن¸ڑه’Œç ”究وœ؛و„وڈگن¾›ن؛†ه¤„çگ†وµ·é‡ڈو•°وچ®çڑ„能هٹ›م€‚è؟™ن»½هگچ...
هں؛وœ¬و¨،ه¼ڈç¤؛ن¾‹éƒ¨هˆ†ï¼Œه°†é€ڑè؟‡ه…·ن½“çڑ„ن»£ç پوˆ–é…چç½®ç¤؛ن¾‹ï¼Œه±•ç¤؛Avroو¨،ه¼ڈçڑ„ه®ڑن¹‰ه’Œن½؟用و–¹و³•م€‚è؟™وœ‰هٹ©ن؛ژه¦ن¹ 者çگ†è§£ه¦‚ن½•هœ¨ه®é™…ه؛”用ن¸ه®ڑن¹‰ه’Œن½؟用Avroو¨،ه¼ڈم€‚ 选و‹©و–‡ن»¶و ¼ه¼ڈçڑ„考虑ه› ç´ éƒ¨هˆ†ï¼Œه°†وŒ‡ه¯¼ه¦ن¹ 者ه¦‚ن½•و ¹وچ®و•°وچ®ه¤„çگ†éœ€و±‚选و‹©هگˆé€‚...
- Pigçڑ„ن»‹ç»چï¼ڑè؟™éƒ¨هˆ†ن»‹ç»چن؛†Pigè¯è¨€çڑ„هں؛وœ¬و¦‚ه؟µه’Œن½؟用و–¹و³•م€‚Pigوڈگن¾›ن؛†ن¸€ه¥—و•°وچ®ه¤„çگ†çڑ„و“چن½œç¬¦ï¼Œن½؟ه¾—و•°وچ®هˆ†وگه¸ˆèƒ½ه¤ںهœ¨ن¸چ需è¦پç¼–ه†™ه¤چو‚çڑ„MapReduce程ه؛ڈçڑ„وƒ…ه†µن¸‹ه®Œوˆگه¤چو‚çڑ„و•°وچ®هˆ†وگه·¥ن½œم€‚ - هں؛ç،€و•°وچ®هˆ†وگï¼ڑè؟™éƒ¨هˆ†ه†…ه®¹و•™وژˆن؛†...