
在HBase中创建的一张表可以分布在多个Hregion,也就说一张表可以被拆分成多块,每一块称我们呼为一个Hregion。每个Hregion会保 存一个表里面某段连续的数据,用户创建的那个大表中的每个Hregion块是由Hregion服务器提供维护,访问Hregion块是要通过 Hregion服务器,而一个Hregion块对应一个Hregion服务器,一张完整的表可以保存在多个Hregion 上。HRegion Server 与Region的对应关系是一对多的关系。每一个HRegion在物理上会被分为三个部分:Hmemcache(缓存)、Hlog(日志)、HStore(持久层)。
上述这些关系在我脑海中的样子,如图所示:
1.HRegionServer、HRegion、Hmemcache、Hlog、HStore之间的关系,如图所示:

2.HBase表中的数据与HRegionServer的分布关系,如图所示:

HBase读数据
HBase读取数据优先读取HMemcache中的内容,如果未取到再去读取Hstore中的数据,提高数据读取的性能。
HBase写数据
HBase写入数据会写到HMemcache和Hlog中,HMemcache建立缓存,Hlog同步Hmemcache和Hstore的事务日志,发起Flush Cache时,数据持久化到Hstore中,并清空HMemecache。
客户端访问这些数据的时候通过Hmaster ,每个 Hregion 服务器都会和Hmaster 服务器保持一个长连接,Hmaster 是HBase分布式系统中的管理者,他的主要任务就是要告诉每个Hregion 服务器它要维护哪些Hregion。用户的这些都数据可以保存在Hadoop 分布式文件系统上。 如果主服务器Hmaster死机,那么整个系统都会无效。下面我会考虑如何解决Hmaster的SPFO的问题,这个问题有点类似Hadoop的SPFO 问题一样只有一个NameNode维护全局的DataNode,HDFS一旦死机全部挂了,也有人说采用Heartbeat来解决这个问题,但我总想找出 其他的解决方案,多点时间,总有办法的。
昨天在hadoop-0.21.0、hbase-0.20.6的环境中折腾了很久,一直报错,错误信息如下:
Exception in thread "main" java.io.IOException: Call to localhost/serv6:9000 failed on local exception: java.io.EOFException
10/11/10 15:34:34 ERROR master.HMaster: Can not start master
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:39)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:27)
at java.lang.reflect.Constructor.newInstance(Constructor.java:513)
at org.apache.hadoop.hbase.master.HMaster.doMain(HMaster.java:1233)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:1274)
死活连接不上HDFS,也无法连接HMaster,郁闷啊。
我想想啊,慢慢想,我眼前一亮 java.io.EOFException 这个异常,是不是有可能是RPC 协定格式不一致导致的?也就是说服务器端和客户端的版本不一致的问题?换了一个HDFS的服务器端以后,一切都好了,果然是版本的问题,最后采用 hadoop-0.20.2 搭配hbase-0.20.6 比较稳当。
最后的效果如图所示:
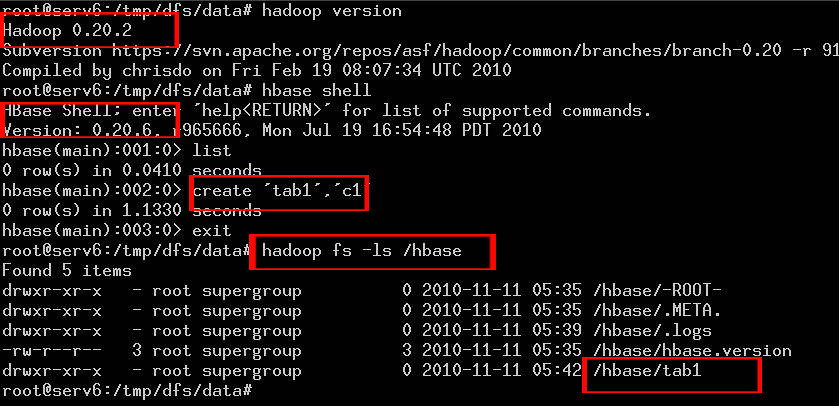
查看大图请点击这里, 上图的一些文字说明:
1.hadoop版本是0.20.2 ,
2.hbase版本是0.20.6,
3.在hbase中创建了一张表 tab1,退出hbase shell环境,
4.用hadoop命令查看,文件系统中的文件果然多了一个刚刚创建的tab1目录,
以上这张图片说明HBase在分布式文件系统Apache HDFS中运行了。



相关推荐
"HBase存储海量图片" 本文档详细描述了如何采用HBase存储海量图片,以及如何将大批量的小文件写成sequenceFile文件格式。海量图片的存储是通过HBase实现的,HBase是一种面向列的NoSQL数据库,特别适合存储海量数据...
HBase存储架构详解 HBase存储架构是HBase的核心组件之一,它们之间的关系非常复杂。本文将详细解释HBase存储架构的组件、它们之间的关系,以及它们如何工作。 HBase存储架构主要包含以下几个组件: 1. HMaster:...
简单的介绍了habse存储数据的样子和简单的hbase shell 使用
│ Day15[Hbase 基本使用及存储设计].pdf │ ├─02_视频 │ Day1501_Hbase的介绍及其发展.mp4 │ Day1502_Hbase中的特殊概念.mp4 │ Day1503_Hbase与MYSQL的存储比较.mp4 │ Day1504_Hbase部署环境准备.mp4 │ Day...
Hive的HBase存储接口就是为了解决这个问题,它使得数据可以在Hive和HBase之间无缝地交互。 Hive的Storage Handler机制是自Hive 6.0版本引入的,其目的是扩展Hive的功能,使其能够支持除HDFS之外的存储系统。Hive-...
这份“HBase存储的研究与应用-PaperAsk检测报告”很可能包含对HBase核心技术的深入探讨,以及它在实际场景中的应用案例。由于没有提供具体的报告内容,我将基于HBase的一般知识进行详细的阐述。 HBase,全称为...
【HBase 存储优化概述】 HBase 是一种基于 Hadoop 的分布式列式数据库,用于处理大规模半结构化数据。由于其对大数据的高效处理能力,尤其在亿级数据量的场景下,HBase 成为了大数据环境下的优选存储解决方案。在...
从HBase的集群搭建、HBaseshell操作、java编程、架构、原理、涉及的数据结构,并且结合陌陌海量消息存储案例来讲解实战HBase 课程亮点 1,知识体系完备,从小白到大神各阶段读者均能学有所获。 2,生动形象,化繁为...
### 支撑Facebook消息处理的HBase存储系统 #### 关于Facebook消息系统 Facebook消息系统是一种集成化的通信平台,能够支持电子邮件、聊天、短信等多种形式的信息传递方式。它旨在为用户提供一个统一的消息中心,使...
在大数据处理领域,HBase作为一个分布式、高性能的列式存储系统,被广泛应用于处理大规模结构化数据。本文将深入探讨如何使用代码实现将CSV(逗号分隔值)数据存储到HBase中,帮助你更好地理解和掌握HBase的用法。 ...
在本实验中,我们主要聚焦于HBase,这是一个基于谷歌Bigtable设计的开源NoSQL数据库,广泛应用于大数据存储场景。实验旨在让参与者熟练掌握HBase的Shell操作,包括创建表、输入数据以及进行特定查询。以下是详细步骤...
HBase存储的研究与应用_冯晓普.caj
项目1-地区销售额-基于HBase存储的State运用26.项目2-省份销售排行-双纵轴HighCharts图表开发一27.项目2-省份销售排行-双纵轴HighCharts图表开发二28.项目2-省份销售排行-双纵轴HighCharts图表开发三29.项目2-省份...
3. Hive集成:通过Hive的HBase存储过程进行数据查询。 4. Flume、Kafka集成:用于日志收集和实时流处理。 这份“HBase官方文档中文版”详细阐述了HBase的核心概念、架构、操作以及最佳实践,对于HBase的学习者和...
本文将深入探讨一个基于Hbase的海量视频存储简单模拟项目,旨在利用Hadoop和Hbase这两个强大的开源工具来解决这个问题。 首先,我们要理解Hadoop和Hbase的角色。Hadoop是分布式计算框架,其核心组件包括HDFS...
在Java编程环境中,将本地文件读取并上传到HBase是一项常见的任务,特别是在大数据处理和存储的场景下。HBase是一个分布式、版本化的NoSQL数据库,基于Apache Hadoop,适用于大规模数据存储。以下是一个详细的过程,...
- **配置hbase-site.xml**:编辑`/usr/local/hbase/conf/hbase-site.xml`,设置`hbase.rootdir`为HDFS上的存储路径,并将`hbase.cluster.distributed`设为`true`,指定HBase在分布式模式下运行。 3. **环境变量...
在大数据领域,Hbase作为一款分布式列式存储系统,常被用于处理海量的非结构化数据。本节主要探讨如何通过Hive与Hbase的交互实现数据的导入和优化存储。 1. Hive数据导入Hbase Hive可以作为数据导入Hbase的一个桥梁...
HBase大对象存储方案的设计与实现.讲诉HBase的原理及应用