
维基百科(WikiPedia.org)位列世界十大网站,目前排名第八位。这是开放的力量。
来点直接的数据:
- 峰值每秒钟3万个 HTTP 请求
- 每秒钟 3Gbit 流量, 近乎375MB
- 350 台 PC 服务器
(数据来源)
架构示意图如下: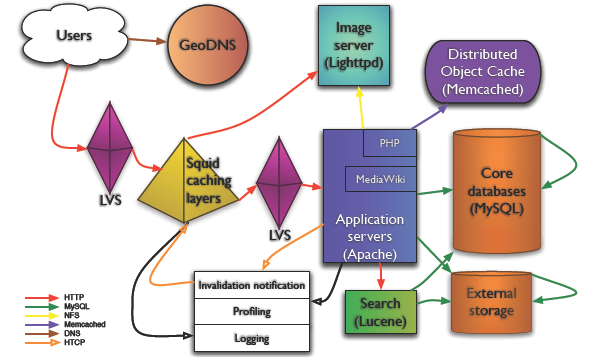 Copy @Mark Bergsma
Copy @Mark Bergsma
GeoDNS
在我写的这些网站架构的 Blog 中,GeoDNS 第一次出现,这东西是啥? “A 40-line patch for BIND to add geographical filters support to the existent views in BIND”, 把用户带到最近的服务器。GeoDNS 在 WikiPedia 架构中担当重任当然是由 WikiPedia 的内容性质决定的–面向各个国家,各个地域。
负载均衡:LVS
WikiPedia 用 LVS 做负载均衡, 是章文嵩博士发起的项目,也算中国人为数不多的在开源领域的骄傲啦。LVS 维护的一个老问题就是监控了,维基百科的技术人员用的是 pybal.
图片服务器:Lighttpd
Lighttpd 现在成了准标准图片服务器配置了。不多说。
Wiki 软件: MediaWiki
对 MediaWiki 的应用层优化细化得快到极致了。用开销相对比较小的方法定位代码热点,参见实时性能报告,瓶颈在哪里,看这样的图树展示一目了然。另外一个十分值得重视的经验是,尽可能抛弃复杂的算法、代价昂贵的查询,以及可能带来过度开销的 MediaWiki 特性。
Cache! Cache! Cache!
维基百科网站成功的第一关键要素就是 Cache 了。CDN(其实也算是 Cache) 做内容分发到不同的大洲、Squid 作为反向代理. 数据库 Cache 用 Memcached,30 台,每台 2G 。对所有可能的数据尽可能的Cache,但他们也提醒了 Cache 的开销并非永远都是最小的,尽可能使用,但不能过度使用。
数据库: MySQL
MediaWiki 用的DB 是 MySQL. MySQL 在 Web 2.0 技术上的常见的一些扩展方案他们也在使用。 复制、读写分离……应用在 DB 上的负载均衡通过 LoadBalancer.php 来做到的,可以给我们一个很好的参考。
运营这样的站点,WikiPedia 每年的开支是 200 万美元,技术人员只有 6 个,惊人的高效。
参考文档:



{kind=link}
相关推荐
### Wikipedia架构解析 #### 一、引言 维基百科(Wikipedia)自2001年启动以来,从一个简单的Perl CGI脚本发展成为一套复杂的分布式平台,该平台涵盖了多种技术栈,并且所有组件均为开源。秉承开放原则,维基百科...
亿万用户网站MySpace的成功秘密、Flickr架构、YouTube网站架构、PlentyOfFish 网站架构学习、WikiPedia技术架构学习笔记。这几个都很典型,我们可以从中获取很多有关网站架构方面的知识,看了之后你会发现你原来的...
Wikipedia2Vecsm库是一个专门用于处理和学习维基百科数据的工具,它结合了Word2Vec和Doc2Vec的概念,旨在帮助用户从大规模文本数据中提取有意义的向量表示。Word2Vec是一种词嵌入模型,它可以将词汇转化为连续的向量...
在标签中,“人工智能”和“深度学习”是现代技术的核心领域,它们已经广泛应用于自然语言处理、计算机视觉、推荐系统等多个场景。而“数据集”是这些领域研究的基础,一个高质量的数据集可以极大地推动模型的性能。...
基本用法可以通过PyPI安装Wikipedia2Vec: % pip install wikipedia2vec 使用此工具,可以通过将Wikipedia转储作为输入运行火车命令来学习嵌入。 例如,以下命令下载最新的英语维基百科转储并从该转储中学习嵌入内容...
### LATEX Wikipedia Online Tutorial知识点概述 #### 一、引言 **LaTeX**是一种基于**TeX**排版系统的文档准备系统,广泛应用于科学、工程和技术领域的文档编写中。本教程是一份非常完整且详尽的LaTeX实用指南,...
,YouTube,MySpace,Twitter,国内如优酷网等大型网站的技术架构(本文重点分析优酷网的技术架构),以飨读者。本文着重凸显每一幅图的精彩之处与其背后含义,而图的说明性文字则从简从略。ok,好好享受此
深度学习在处理大规模数据时,往往需要大量的计算资源和复杂的模型架构。对于“ml_wikipedia.csv”,我们可以使用预训练的词嵌入模型(如Word2Vec或BERT)来初始化文章内容的向量表示,然后通过GNN进一步学习和优化...
维基百科(Wikipedia)是全球最大的开源在线百科全书,它提供了丰富的信息和知识。为了方便开发者和研究人员获取和利用这些信息,维基百科提供了一套强大的API(应用程序接口)。这个API允许用户通过编程方式与维基...
wtf_wikipedia, wikipedia的维基百科标记解析器 然而,维基百科标记解析器 Kelly Kelly和许多贡献者把维基标记变成 JSON,这样获得的数据就变得更容易了。我不生气,对他们生气。解析wikiscript基本上是 np 。它的真...
Wikipedia Extractor 是意大利人用 Python 写的一个维基百科抽取器,使用非常方便。
**标题:“Wikipedia Miner”** **内容概述:** “Wikipedia Miner”是一个专门用于处理和分析维基百科数据的强大工具包。它为研究者、数据科学家以及对信息挖掘感兴趣的用户提供了一个方便的平台,来探索维基百科...
总的来说,"wikipedia_info.zip"数据集为研究者提供了一个宝贵的实验平台,促进了跨模态信息处理技术的发展,同时也推动了人工智能在理解和解释多元信息方面的能力。通过深入挖掘和利用这个数据集,我们有望创造出...
这些文件是针对人工智能和深度学习领域研究的数据集,特别是与社交网络分析和自然语言处理相关的。数据集在科研中扮演着至关重要的角色,因为它们帮助研究人员验证算法、模型和理论,推动科技进步。以下是对这些文件...
wikipedia-iphone, Wikipedia iPhone应用程序的过时版本 请使用当前版本 请访问维基百科/维基百科 iOS,了解当前维基百科的源代码官方维基百科应用程序生成备注如果你是为自己的手机构建这个,那么请注意你必须修改 ...