
1. LRU
1.1.¬†еОЯзРЖ
LRUпЉИLeast¬†recently¬†usedпЉМжЬАињСжЬАе∞СдљњзФ®пЉЙзЃЧж≥Хж†єжНЃжХ∞жНЃзЪДеОЖеП≤иЃњйЧЃиЃ∞ељХжЭ•ињЫи°МжЈШж±∞жХ∞жНЃпЉМеЕґж†ЄењГжАЭжГ≥жШѓвАЬе¶ВжЮЬжХ∞жНЃжЬАињС襀聜йЧЃињЗпЉМйВ£дєИе∞Жжݕ襀聜йЧЃзЪДеЗ†зОЗдєЯжЫійЂШвАЭгАВ
1.2.¬†еЃЮзО∞
жЬАеЄЄиІБзЪДеЃЮзО∞жШѓдљњзФ®дЄАдЄ™йУЊи°®дњЭе≠ШзЉУе≠ШжХ∞жНЃпЉМиѓ¶зїЖзЃЧж≥ХеЃЮзО∞е¶ВдЄЛпЉЪ
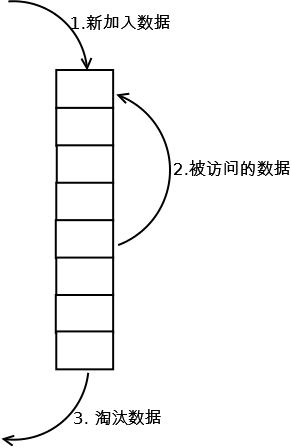
1.¬†жЦ∞жХ∞жНЃжПТеЕ•еИ∞йУЊи°®е§ійГ®пЉЫ
2.¬†жѓПељУзЉУе≠ШеСљдЄ≠пЉИеН≥зЉУе≠ШжХ∞ж́襀聜йЧЃпЉЙпЉМеИЩе∞ЖжХ∞жНЃзІїеИ∞йУЊи°®е§ійГ®пЉЫ
3.¬†ељУйУЊи°®жї°зЪДжЧґеАЩпЉМе∞ЖйУЊи°®е∞ЊйГ®зЪДжХ∞жНЃдЄҐеЉГгАВ
1.3.¬†еИЖжЮР
гАРеСљдЄ≠зОЗгАС
ељУе≠ШеЬ®зГ≠зВєжХ∞жНЃжЧґпЉМLRUзЪДжХИзОЗеЊИе•љпЉМдљЖеБґеПСжАІзЪДгАБеС®жЬЯжАІзЪДжЙєйЗПжУНдљЬдЉЪеѓЉиЗіLRUеСљдЄ≠зОЗжА•еЙІдЄЛйЩНпЉМзЉУе≠Шж±°жЯУжГЕеЖµжѓФиЊГдЄ•йЗНгАВ
гАРе§НжЭВеЇ¶гАС
еЃЮзО∞зЃАеНХгАВ
гАРдї£дїЈгАС
еСљдЄ≠жЧґйЬАи¶БйБНеОЖйУЊи°®пЉМжЙЊеИ∞еСљдЄ≠зЪДжХ∞жНЃеЭЧ糥еЉХпЉМзДґеРОйЬАи¶Бе∞ЖжХ∞жНЃзІїеИ∞е§ійГ®гАВ
 
2. LRU-K
2.1.¬†еОЯзРЖ
LRU-KдЄ≠зЪДKдї£и°®жЬАињСдљњзФ®зЪДжђ°жХ∞пЉМеЫ†ж≠§LRUеПѓдї•иЃ§дЄЇжШѓLRU-1гАВLRU-KзЪДдЄїи¶БзЫЃзЪДжШѓдЄЇдЇЖиІ£еЖ≥LRUзЃЧж≥ХвАЬзЉУе≠Шж±°жЯУвАЭзЪДйЧЃйҐШпЉМеЕґж†ЄењГжАЭжГ≥жШѓе∞ЖвАЬжЬАињСдљњзФ®ињЗ1жђ°вАЭзЪДеИ§жЦ≠ж†ЗеЗЖжЙ©е±ХдЄЇвАЬжЬАињСдљњзФ®ињЗKжђ°вАЭгАВ
2.2.¬†еЃЮзО∞
зЫЄжѓФLRUпЉМLRU-KйЬАи¶Бе§ЪзїіжК§дЄАдЄ™йШЯеИЧпЉМзФ®дЇОиЃ∞ељХжЙАжЬЙзЉУе≠ШжХ∞ж́襀聜йЧЃзЪДеОЖеП≤гАВеП™жЬЙељУжХ∞жНЃзЪДиЃњйЧЃжђ°жХ∞иЊЊеИ∞Kжђ°зЪДжЧґеАЩпЉМжЙНе∞ЖжХ∞жНЃжФЊеЕ•зЉУе≠ШгАВељУйЬАи¶БжЈШж±∞жХ∞жНЃжЧґпЉМLRU-KдЉЪжЈШж±∞зђђKжђ°иЃњйЧЃжЧґйЧіиЈЭељУеЙНжЧґйЧіжЬАе§ІзЪДжХ∞жНЃгАВиѓ¶зїЖеЃЮзО∞е¶ВдЄЛпЉЪ
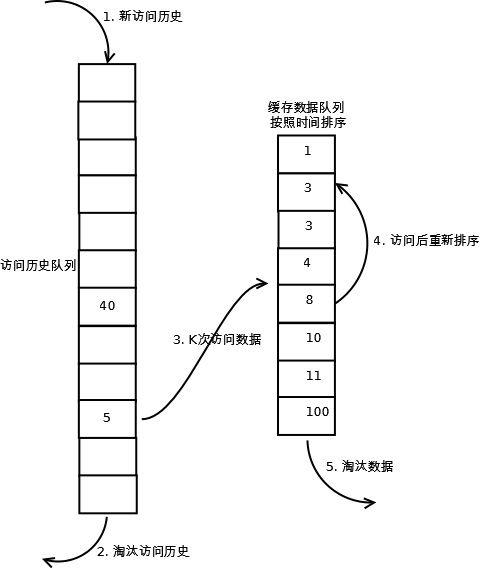
1.¬†жХ∞жНЃзђђдЄА搰襀聜йЧЃпЉМеК†еЕ•еИ∞иЃњйЧЃеОЖеП≤еИЧи°®пЉЫ
2.¬†е¶ВжЮЬжХ∞жНЃеЬ®иЃњйЧЃеОЖеП≤еИЧи°®йЗМеРОж≤°жЬЙиЊЊеИ∞Kжђ°иЃњйЧЃпЉМеИЩжМЙзЕІдЄАеЃЪиІДеИЩпЉИFIFOпЉМLRUпЉЙжЈШж±∞пЉЫ
3.¬†ељУиЃњйЧЃеОЖеП≤йШЯеИЧдЄ≠зЪДжХ∞жНЃиЃњйЧЃжђ°жХ∞иЊЊеИ∞Kжђ°еРОпЉМе∞ЖжХ∞ж́糥еЉХдїОеОЖеП≤йШЯеИЧеИ†йЩ§пЉМе∞ЖжХ∞жНЃзІїеИ∞зЉУе≠ШйШЯеИЧдЄ≠пЉМеєґзЉУе≠Шж≠§жХ∞жНЃпЉМзЉУе≠ШйШЯеИЧйЗНжЦ∞жМЙзЕІжЧґйЧіжОТеЇПпЉЫ
4.¬†зЉУе≠ШжХ∞жНЃйШЯеИЧдЄ≠襀еЖНжђ°иЃњйЧЃеРОпЉМйЗНжЦ∞жОТеЇПпЉЫ
5.¬†йЬАи¶БжЈШж±∞жХ∞жНЃжЧґпЉМжЈШж±∞зЉУе≠ШйШЯеИЧдЄ≠жОТеЬ®жЬЂе∞ЊзЪДжХ∞жНЃпЉМеН≥пЉЪжЈШж±∞вАЬеАТжХ∞зђђKжђ°иЃњйЧЃз¶їзО∞еЬ®жЬАдєЕвАЭзЪДжХ∞жНЃгАВ
LRU-KеЕЈжЬЙLRUзЪДдЉШзВєпЉМеРМжЧґиГље§ЯйБњеЕНLRUзЪДзЉЇзВєпЉМеЃЮйЩЕеЇФзФ®дЄ≠LRU-2жШѓзїЉеРИеРДзІНеЫ†зі†еРОжЬАдЉШзЪДйАЙжЛ©пЉМLRU-3жИЦиАЕжЫіе§ІзЪДKеАЉеСљдЄ≠зОЗдЉЪйЂШпЉМдљЖйАВеЇФжАІеЈЃпЉМйЬАи¶Бе§ІйЗПзЪДжХ∞жНЃиЃњйЧЃжЙНиГље∞ЖеОЖеП≤иЃњйЧЃиЃ∞ељХжЄЕйЩ§жОЙгАВ
2.3.¬†еИЖжЮР
гАРеСљдЄ≠зОЗгАС
LRU-KйЩНдљОдЇЖвАЬзЉУе≠Шж±°жЯУвАЭеЄ¶жЭ•зЪДйЧЃйҐШпЉМеСљдЄ≠зОЗжѓФLRUи¶БйЂШгАВ
гАРе§НжЭВеЇ¶гАС
LRU-KйШЯеИЧжШѓдЄАдЄ™дЉШеЕИзЇІйШЯеИЧпЉМзЃЧж≥Хе§НжЭВеЇ¶еТМдї£дїЈжѓФиЊГйЂШгАВ
гАРдї£дїЈгАС
зФ±дЇОLRU-KињШйЬАи¶БиЃ∞ељХйВ£дЇЫ襀聜йЧЃињЗгАБдљЖињШж≤°жЬЙжФЊеЕ•зЉУе≠ШзЪДеѓєи±°пЉМеЫ†ж≠§еЖЕе≠ШжґИиАЧдЉЪжѓФLRUи¶Бе§ЪпЉЫељУжХ∞жНЃйЗПеЊИе§ІзЪДжЧґеАЩпЉМеЖЕе≠ШжґИиАЧдЉЪжѓФиЊГеПѓиІВгАВ
LRU-KйЬАи¶БеЯЇдЇОжЧґйЧіињЫи°МжОТеЇПпЉИеПѓдї•йЬАи¶БжЈШж±∞жЧґеЖНжОТеЇПпЉМдєЯеПѓдї•еН≥жЧґжОТеЇПпЉЙпЉМCPUжґИиАЧжѓФLRUи¶БйЂШгАВ
3.¬†Two¬†queuesпЉИ2QпЉЙ
3.1.¬†еОЯзРЖ
Two¬†queuesпЉИдї•дЄЛдљњзФ®2Qдї£жЫњпЉЙзЃЧж≥Хз±їдЉЉдЇОLRU-2пЉМдЄНеРМзВєеЬ®дЇО2Qе∞ЖLRU-2зЃЧж≥ХдЄ≠зЪДиЃњйЧЃеОЖеП≤йШЯеИЧпЉИж≥®жДПињЩдЄНжШѓзЉУе≠ШжХ∞жНЃзЪДпЉЙжФєдЄЇдЄАдЄ™FIFOзЉУе≠ШйШЯеИЧпЉМеН≥пЉЪ2QзЃЧж≥ХжЬЙдЄ§дЄ™зЉУе≠ШйШЯеИЧпЉМдЄАдЄ™жШѓFIFOйШЯеИЧпЉМдЄАдЄ™жШѓLRUйШЯеИЧгАВ
3.2.¬†еЃЮзО∞
ељУжХ∞жНЃзђђдЄАжђ°иЃњйЧЃжЧґпЉМ2QзЃЧж≥Хе∞ЖжХ∞жНЃзЉУе≠ШеЬ®FIFOйШЯеИЧйЗМйЭҐпЉМељУжХ∞жНЃзђђдЇМ搰襀聜йЧЃжЧґпЉМеИЩе∞ЖжХ∞жНЃдїОFIFOйШЯеИЧзІїеИ∞LRUйШЯеИЧйЗМйЭҐпЉМдЄ§дЄ™йШЯеИЧеРДиЗ™жМЙзЕІиЗ™еЈ±зЪДжЦєж≥ХжЈШж±∞жХ∞жНЃгАВиѓ¶зїЖеЃЮзО∞е¶ВдЄЛпЉЪ
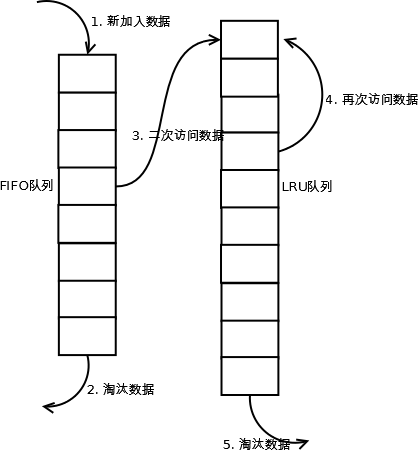
1.¬†жЦ∞иЃњйЧЃзЪДжХ∞жНЃжПТеЕ•еИ∞FIFOйШЯеИЧпЉЫ
2.¬†е¶ВжЮЬжХ∞жНЃеЬ®FIFOйШЯеИЧдЄ≠дЄАзЫіж≤°жЬЙ襀еЖНжђ°иЃњйЧЃпЉМеИЩжЬАзїИжМЙзЕІFIFOиІДеИЩжЈШж±∞пЉЫ
3.¬†е¶ВжЮЬжХ∞жНЃеЬ®FIFOйШЯеИЧдЄ≠襀еЖНжђ°иЃњйЧЃпЉМеИЩе∞ЖжХ∞жНЃзІїеИ∞LRUйШЯеИЧе§ійГ®пЉЫ
4.¬†е¶ВжЮЬжХ∞жНЃеЬ®LRUйШЯеИЧеЖН搰襀聜йЧЃпЉМеИЩе∞ЖжХ∞жНЃзІїеИ∞LRUйШЯеИЧе§ійГ®пЉЫ
5.¬†LRUйШЯеИЧжЈШж±∞жЬЂе∞ЊзЪДжХ∞жНЃгАВ
 
ж≥®пЉЪдЄКеЫЊдЄ≠FIFOйШЯеИЧжѓФLRUйШЯеИЧзЯ≠пЉМдљЖеєґдЄНдї£и°®ињЩжШѓзЃЧж≥Хи¶Бж±ВпЉМеЃЮйЩЕеЇФзФ®дЄ≠дЄ§иАЕжѓФдЊЛж≤°жЬЙз°ђжАІиІДеЃЪгАВ
3.3.¬†еИЖжЮР
гАРеСљдЄ≠зОЗгАС
2QзЃЧж≥ХзЪДеСљдЄ≠зОЗи¶БйЂШдЇОLRUгАВ
гАРе§НжЭВеЇ¶гАС
йЬАи¶БдЄ§дЄ™йШЯеИЧпЉМдљЖдЄ§дЄ™йШЯеИЧжЬђиЇЂйГљжѓФиЊГзЃАеНХгАВ
гАРдї£дїЈгАС
FIFOеТМLRUзЪДдї£дїЈдєЛеТМгАВ
2QзЃЧж≥ХеТМLRU-2зЃЧж≥ХеСљдЄ≠зОЗз±їдЉЉпЉМеЖЕе≠ШжґИиАЧдєЯжѓФиЊГжО•ињСпЉМдљЖеѓєдЇОжЬАеРОзЉУе≠ШзЪДжХ∞жНЃжЭ•иѓіпЉМ2QдЉЪеЗПе∞СдЄАжђ°дїОеОЯеІЛе≠ШеВ®иѓїеПЦжХ∞жНЃжИЦиАЕиЃ°зЃЧжХ∞жНЃзЪДжУНдљЬгАВ
4.¬†Multi¬†QueueпЉИMQпЉЙ
4.1.¬†еОЯзРЖ
MQзЃЧж≥Хж†єжНЃиЃњйЧЃйҐСзОЗе∞ЖжХ∞жНЃеИТеИЖдЄЇе§ЪдЄ™йШЯеИЧпЉМдЄНеРМзЪДйШЯеИЧеЕЈжЬЙдЄНеРМзЪДиЃњйЧЃдЉШеЕИзЇІпЉМеЕґж†ЄењГжАЭжГ≥жШѓпЉЪдЉШеЕИзЉУе≠ШиЃњйЧЃжђ°жХ∞е§ЪзЪДжХ∞жНЃгАВ
4.2.¬†еЃЮзО∞
MQзЃЧж≥Хе∞ЖзЉУе≠ШеИТеИЖдЄЇе§ЪдЄ™LRUйШЯеИЧпЉМжѓПдЄ™йШЯеИЧеѓєеЇФдЄНеРМзЪДиЃњйЧЃдЉШеЕИзЇІгАВиЃњйЧЃдЉШеЕИзЇІжШѓж†єжНЃиЃњйЧЃжђ°жХ∞иЃ°зЃЧеЗЇжЭ•зЪДпЉМдЊЛе¶В
иѓ¶зїЖзЪДзЃЧж≥ХзїУжЮДеЫЊе¶ВдЄЛпЉМQ0пЉМQ1....Qkдї£и°®дЄНеРМзЪДдЉШеЕИзЇІйШЯеИЧпЉМQ-historyдї£и°®дїОзЉУе≠ШдЄ≠жЈШж±∞жХ∞жНЃпЉМдљЖиЃ∞ељХдЇЖжХ∞жНЃзЪД糥еЉХеТМеЉХзФ®жђ°жХ∞зЪДйШЯеИЧпЉЪ
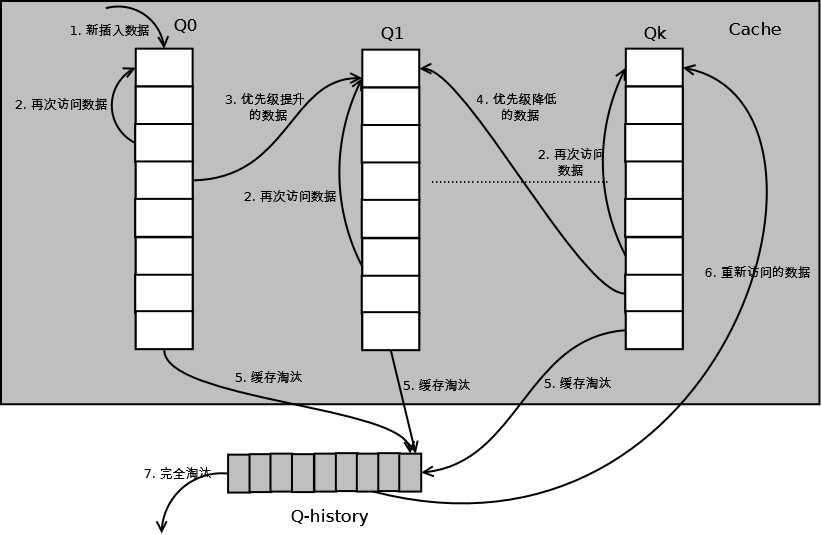
 
е¶ВдЄКеЫЊпЉМзЃЧж≥Хиѓ¶зїЖжППињ∞е¶ВдЄЛпЉЪ
1.¬†жЦ∞жПТеЕ•зЪДжХ∞жНЃжФЊеЕ•Q0пЉЫ
2.¬†жѓПдЄ™йШЯеИЧжМЙзЕІLRUзЃ°зРЖжХ∞жНЃпЉЫ
3.¬†ељУжХ∞жНЃзЪДиЃњйЧЃжђ°жХ∞иЊЊеИ∞дЄАеЃЪжђ°жХ∞пЉМйЬАи¶БжПРеНЗдЉШеЕИзЇІжЧґпЉМе∞ЖжХ∞жНЃдїОељУеЙНйШЯеИЧеИ†йЩ§пЉМеК†еЕ•еИ∞йЂШдЄАзЇІйШЯеИЧзЪДе§ійГ®пЉЫ
4.¬†дЄЇдЇЖйШ≤ж≠ҐйЂШдЉШеЕИзЇІжХ∞жНЃж∞ЄињЬдЄН襀жЈШж±∞пЉМељУжХ∞жНЃеЬ®жМЗеЃЪзЪДжЧґйЧійЗМиЃњйЧЃж≤°жЬЙ襀聜йЧЃжЧґпЉМйЬАи¶БйЩНдљОдЉШеЕИзЇІпЉМе∞ЖжХ∞жНЃдїОељУеЙНйШЯеИЧеИ†йЩ§пЉМеК†еЕ•еИ∞дљОдЄАзЇІзЪДйШЯеИЧе§ійГ®пЉЫ
5.¬†йЬАи¶БжЈШж±∞жХ∞жНЃжЧґпЉМдїОжЬАдљОдЄАзЇІйШЯеИЧеЉАеІЛжМЙзЕІLRUжЈШж±∞пЉЫжѓПдЄ™йШЯеИЧжЈШж±∞жХ∞жНЃжЧґпЉМе∞ЖжХ∞жНЃдїОзЉУе≠ШдЄ≠еИ†йЩ§пЉМе∞ЖжХ∞ж́糥еЉХеК†еЕ•Q-historyе§ійГ®пЉЫ
6.¬†е¶ВжЮЬжХ∞жНЃеЬ®Q-historyдЄ≠襀йЗНжЦ∞иЃњйЧЃпЉМеИЩйЗНжЦ∞иЃ°зЃЧеЕґдЉШеЕИзЇІпЉМзІїеИ∞зЫЃж†ЗйШЯеИЧзЪДе§ійГ®пЉЫ
7.¬†Q-historyжМЙзЕІLRUжЈШж±∞жХ∞жНЃзЪД糥еЉХгАВ
4.3.¬†еИЖжЮР
гАРеСљдЄ≠зОЗгАС
MQйЩНдљОдЇЖвАЬзЉУе≠Шж±°жЯУвАЭеЄ¶жЭ•зЪДйЧЃйҐШпЉМеСљдЄ≠зОЗжѓФLRUи¶БйЂШгАВ
гАРе§НжЭВеЇ¶гАС
MQйЬАи¶БзїіжК§е§ЪдЄ™йШЯеИЧпЉМдЄФйЬАи¶БзїіжК§жѓПдЄ™жХ∞жНЃзЪДиЃњйЧЃжЧґйЧіпЉМе§НжЭВеЇ¶жѓФLRUйЂШгАВ
гАРдї£дїЈгАС
MQйЬАи¶БиЃ∞ељХжѓПдЄ™жХ∞жНЃзЪДиЃњйЧЃжЧґйЧіпЉМйЬАи¶БеЃЪжЧґжЙЂжППжЙАжЬЙйШЯеИЧпЉМдї£дїЈжѓФLRUи¶БйЂШгАВ
ж≥®пЉЪиЩљзДґMQзЪДйШЯеИЧзЬЛиµЈжЭ•жХ∞йЗПжѓФиЊГе§ЪпЉМдљЖзФ±дЇОжЙАжЬЙйШЯеИЧдєЛеТМеПЧйЩРдЇОзЉУе≠ШеЃєйЗПзЪДе§Іе∞ПпЉМеЫ†ж≠§ињЩйЗМе§ЪдЄ™йШЯеИЧйХњеЇ¶дєЛеТМеТМдЄАдЄ™LRUйШЯеИЧжШѓдЄАж†ЈзЪДпЉМеЫ†ж≠§йШЯеИЧжЙЂжППжАІиГљдєЯзЫЄињСгАВ
 
5.¬†LRUз±їзЃЧж≥ХеѓєжѓФ
зФ±дЇОдЄНеРМзЪДиЃњйЧЃж®°еЮЛеѓЉиЗіеСљдЄ≠зОЗеПШеМЦиЊГе§ІпЉМж≠§е§ДеѓєжѓФдїЕеЯЇдЇОзРЖиЃЇеЃЪжАІеИЖжЮРпЉМдЄНеБЪеЃЪйЗПеИЖжЮРгАВ
|
еѓєжѓФзВє |
еѓєжѓФ |
|
еСљдЄ≠зОЗ |
LRU-2 > MQ(2) > 2Q > LRU |
|
е§НжЭВеЇ¶ |
LRU-2 > MQ(2) > 2Q > LRU |
|
дї£дїЈ |
LRU-2  > MQ(2) > 2Q > LRU |
еЃЮйЩЕеЇФзФ®дЄ≠йЬАи¶Бж†єжНЃдЄЪеК°зЪДйЬАж±ВеТМеѓєжХ∞жНЃзЪДиЃњйЧЃжГЕеЖµињЫи°МйАЙжЛ©пЉМеєґдЄНжШѓеСљдЄ≠зОЗиґКйЂШиґКе•љгАВдЊЛе¶ВпЉЪиЩљзДґLRUзЬЛиµЈжЭ•еСљдЄ≠зОЗдЉЪдљОдЄАдЇЫпЉМдЄФе≠ШеЬ®вАЭзЉУе≠Шж±°жЯУвАЬзЪДйЧЃйҐШпЉМдљЖзФ±дЇОеЕґзЃАеНХеТМдї£дїЈе∞ПпЉМеЃЮйЩЕеЇФзФ®дЄ≠еПНиАМеЇФзФ®жЫіе§ЪгАВ
 
javaдЄ≠жЬАзЃАеНХзЪДLRUзЃЧж≥ХеЃЮзО∞пЉМе∞±жШѓеИ©зФ®jdkзЪДLinkedHashMapпЉМи¶ЖеЖЩеЕґдЄ≠зЪДremoveEldestEntry(Map.Entry)жЦєж≥ХеН≥еПѓ
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
|
import java.util.ArrayList; 
import java.util.Collection; 
import java.util.LinkedHashMap; 
import java.util.concurrent.locks.Lock; 
import java.util.concurrent.locks.ReentrantLock; 
import java.util.Map; 
¬†¬†¬†¬†¬†¬†/** ¬†* з±їиѓіжШОпЉЪеИ©зФ®LinkedHashMapеЃЮзО∞зЃАеНХзЪДзЉУе≠ШпЉМ ењЕй°їеЃЮзО∞removeEldestEntryжЦєж≥ХпЉМеЕЈдљУеПВиІБJDKжЦЗж°£
 * 
 * @author dennis
 * 
 * @param <K>
 * @param <V>
 */ public class LRULinkedHashMap<K, V> extends LinkedHashMap<K, V> { 
    private final int maxCapacity; 
       private static final float DEFAULT_LOAD_FACTOR = 0.75f; 
       private final Lock lock = new ReentrantLock(); 
       public LRULinkedHashMap(int maxCapacity) { 
        super(maxCapacity, DEFAULT_LOAD_FACTOR, true); 
        this.maxCapacity = maxCapacity; 
    } 
       @Override     protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) { 
        return size() > maxCapacity; 
    } 
    @Override     public boolean containsKey(Object key) { 
        try { 
            lock.lock(); 
            return super.containsKey(key); 
        } finally { 
            lock.unlock(); 
        } 
    } 
              @Override     public V get(Object key) { 
        try { 
            lock.lock(); 
            return super.get(key); 
        } finally { 
            lock.unlock(); 
        } 
    } 
       @Override     public V put(K key, V value) { 
        try { 
            lock.lock(); 
            return super.put(key, value); 
        } finally { 
            lock.unlock(); 
        } 
    } 
       public int size() { 
        try { 
            lock.lock(); 
            return super.size(); 
        } finally { 
            lock.unlock(); 
        } 
    } 
       public void clear() { 
        try { 
            lock.lock(); 
            super.clear(); 
        } finally { 
            lock.unlock(); 
        } 
    } 
       public Collection<Map.Entry<K, V>> getAll() { 
        try { 
            lock.lock(); 
            return new ArrayList<Map.Entry<K, V>>(super.entrySet()); 
        } finally { 
            lock.unlock(); 
        } 
    } 
}       |
 
еЯЇдЇОеПМйУЊи°® зЪДLRUеЃЮзО∞:
гААгААдЉ†зїЯжДПдєЙзЪДLRUзЃЧж≥ХжШѓдЄЇжѓПдЄАдЄ™Cacheеѓєи±°иЃЊзљЃдЄАдЄ™иЃ°жХ∞еЩ®пЉМжѓПжђ°CacheеСљдЄ≠еИЩзїЩиЃ°жХ∞еЩ®+1пЉМиАМCacheзФ®еЃМпЉМйЬАи¶БжЈШж±∞жЧІеЖЕеЃєпЉМжФЊзљЃжЦ∞еЖЕеЃєжЧґпЉМе∞±жЯ•зЬЛжЙАжЬЙзЪДиЃ°жХ∞еЩ®пЉМеєґе∞ЖжЬАе∞СдљњзФ®зЪДеЖЕеЃєжЫњжНҐжОЙгАВ
¬†¬† еЃГзЪДеЉКзЂѓеЊИжШОжШЊпЉМе¶ВжЮЬCacheзЪДжХ∞йЗПе∞СпЉМйЧЃйҐШдЄНдЉЪеЊИе§ІпЉМ дљЖжШѓе¶ВжЮЬCacheзЪДз©ЇйЧіињЗе§ІпЉМиЊЊеИ∞10WжИЦиАЕ100Wдї•дЄКпЉМдЄАжЧ¶йЬАи¶БжЈШж±∞пЉМеИЩйЬАи¶БйБНеОЖжЙАжЬЙиЃ°зЃЧеЩ®пЉМеЕґжАІиГљдЄОиµДжЇРжґИиАЧжШѓеЈ®е§ІзЪДгАВжХИзОЗдєЯе∞±йЭЮеЄЄзЪДжЕҐдЇЖгАВ
¬†¬†¬† еЃГзЪДеОЯзРЖпЉЪ е∞ЖCacheзЪДжЙАжЬЙдљНзљЃйГљзФ®еПМињЮи°®ињЮжО•иµЈжЭ•пЉМељУдЄАдЄ™дљН皁襀еСљдЄ≠дєЛеРОпЉМе∞±е∞ЖйАЪињЗи∞ГжХійУЊи°®зЪДжМЗеРСпЉМе∞Жиѓ•дљНзљЃи∞ГжХіеИ∞йУЊи°®е§ізЪДдљНзљЃпЉМжЦ∞еК†еЕ•зЪДCacheзЫіжО•еК†еИ∞йУЊи°®е§ідЄ≠гАВ
¬†¬†¬†¬† ињЩж†ЈпЉМеЬ®е§Ъжђ°ињЫи°МCacheжУНдљЬеРОпЉМжЬАињС襀еСљдЄ≠зЪДпЉМе∞±дЉЪ襀еРСйУЊи°®е§іжЦєеРСзІїеК®пЉМиАМж≤°жЬЙеСљдЄ≠зЪДпЉМиАМжГ≥йУЊи°®еРОйЭҐзІїеК®пЉМйУЊи°®е∞ЊеИЩи°®з§ЇжЬАињСжЬАе∞СдљњзФ®зЪДCacheгАВ
¬†¬†¬†¬† ељУйЬАи¶БжЫњжНҐеЖЕеЃєжЧґеАЩпЉМйУЊи°®зЪДжЬАеРОдљНзљЃе∞±жШѓжЬАе∞С襀еСљдЄ≠зЪДдљНзљЃпЉМжИСдїђеП™йЬАи¶БжЈШж±∞йУЊи°®жЬАеРОзЪДйГ®еИЖеН≥еПѓгАВ
¬† дЄКйЭҐиѓідЇЖињЩдєИе§ЪзЪДзРЖиЃЇпЉМ дЄЛйЭҐзФ®дї£з†БжЭ•еЃЮзО∞дЄАдЄ™LRUз≠ЦзХ•зЪДзЉУе≠ШгАВ
¬†¬†¬† жИСдїђзФ®дЄАдЄ™еѓєи±°жЭ•и°®з§ЇCacheпЉМеєґеЃЮзО∞еПМйУЊи°®пЉМ
public class LRUCache {
/**
* йУЊи°®иКВзВє
* @author Administrator
*
*/
class CacheNode {
вА¶вА¶
}
private int cacheSize;//зЉУе≠Ше§Іе∞П
private Hashtable nodes;//зЉУе≠ШеЃєеЩ®
private int currentSize;//ељУеЙНзЉУе≠Шеѓєи±°жХ∞йЗП
private CacheNode first;//(еЃЮзО∞еПМйУЊи°®)йУЊи°®е§і
private CacheNode last;//(еЃЮзО∞еПМйУЊи°®)йУЊи°®е∞Њ
}
¬†дЄЛйЭҐзїЩеЗЇеЃМжХізЪДеЃЮзО∞пЉМињЩдЄ™з±їдєЯ襀TomcatжЙАдљњзФ®пЉИ org.apache.tomcat.util.collections.LRUCacheпЉЙпЉМдљЖжШѓеЬ®tomcat6.xзЙИжЬђдЄ≠пЉМеЈ≤зїП襀еЉГзФ®пЉМдљњзФ®еП¶е§ЦеЕґдїЦзЪДзЉУе≠Шз±їжЭ•жЫњдї£еЃГгАВ
public class LRUCache {
/**
* йУЊи°®иКВзВє
* @author Administrator
*
*/
class CacheNode {
CacheNode prev;//еЙНдЄАиКВзВє
CacheNode next;//еРОдЄАиКВзВє
Object value;//еАЉ
Object key;//йФЃ
CacheNode() {
}
}
public LRUCache(int i) {
currentSize = 0;
cacheSize = i;
nodes = new Hashtable(i);//зЉУе≠ШеЃєеЩ®
}
/**
* иОЈеПЦзЉУе≠ШдЄ≠еѓєи±°
* @param key
* @return
*/
public Object get(Object key) {
CacheNode node = (CacheNode) nodes.get(key);
if (node != null) {
moveToHead(node);
return node.value;
} else {
return null;
}
}
/**
* жЈїеК†зЉУе≠Ш
* @param key
* @param value
*/
public void put(Object key, Object value) {
CacheNode node = (CacheNode) nodes.get(key);
if (node == null) {
//зЉУе≠ШеЃєеЩ®жШѓеР¶еЈ≤зїПиґЕињЗе§Іе∞П.
if (currentSize >= cacheSize) {
if (last != null)//е∞ЖжЬАе∞СдљњзФ®зЪДеИ†йЩ§
nodes.remove(last.key);
removeLast();
} else {
currentSize++;
}
node = new CacheNode();
}
node.value = value;
node.key = key;
//е∞ЖжЬАжЦ∞дљњзФ®зЪДиКВзВєжФЊеИ∞йУЊи°®е§іпЉМи°®з§ЇжЬАжЦ∞дљњзФ®зЪД.
moveToHead(node);
nodes.put(key, node);
}
/**
* е∞ЖзЉУе≠ШеИ†йЩ§
* @param key
* @return
*/
public Object remove(Object key) {
CacheNode node = (CacheNode) nodes.get(key);
if (node != null) {
if (node.prev != null) {
node.prev.next = node.next;
}
if (node.next != null) {
node.next.prev = node.prev;
}
if (last == node)
last = node.prev;
if (first == node)
first = node.next;
}
return node;
}
public void clear() {
first = null;
last = null;
}
/**
* еИ†йЩ§йУЊи°®е∞ЊйГ®иКВзВє
* и°®з§Ї еИ†йЩ§жЬАе∞СдљњзФ®зЪДзЉУе≠Шеѓєи±°
*/
private void removeLast() {
//йУЊи°®е∞ЊдЄНдЄЇз©Ї,еИЩе∞ЖйУЊи°®е∞ЊжМЗеРСnull. еИ†йЩ§ињЮи°®е∞ЊпЉИеИ†йЩ§жЬАе∞СдљњзФ®зЪДзЉУе≠Шеѓєи±°пЉЙ
if (last != null) {
if (last.prev != null)
last.prev.next = null;
else
first = null;
last = last.prev;
}
}
/**
* зІїеК®еИ∞йУЊи°®е§іпЉМи°®з§ЇињЩдЄ™иКВзВєжШѓжЬАжЦ∞дљњзФ®ињЗзЪД
* @param node
*/
private void moveToHead(CacheNode node) {
if (node == first)
return;
if (node.prev != null)
node.prev.next = node.next;
if (node.next != null)
node.next.prev = node.prev;
if (last == node)
last = node.prev;
if (first != null) {
node.next = first;
first.prev = node;
}
first = node;
node.prev = null;
if (last == null)
last = first;
}
private int cacheSize;
private Hashtable nodes;//зЉУе≠ШеЃєеЩ®
private int currentSize;
private CacheNode first;//йУЊи°®е§і
private CacheNode last;//йУЊи°®е∞Њ
}



зЫЄеЕ≥жО®иНР
LRUпЉИLeast Recently UsedпЉМжЬАињСжЬАе∞СдљњзФ®пЉЙзЃЧж≥ХжШѓдЄАзІНеЄЄиІБзЪДзЉУе≠ШжЈШж±∞з≠ЦзХ•пЉМеЃГзЪДж†ЄењГжАЭжГ≥жШѓпЉЪе¶ВжЮЬдЄАдЄ™жХ∞жНЃжЬАињС襀聜йЧЃињЗпЉМйВ£дєИеЃГеЬ®жЬ™жݕ襀聜йЧЃзЪДж¶ВзОЗиЊГйЂШгАВLRU зЃЧж≥ХйАЪеЄЄйАЪињЗдЄАдЄ™йУЊи°®жЭ•еЃЮзО∞пЉМжЦ∞жХ∞жНЃжПТеЕ•йУЊи°®е§ійГ®пЉМжѓПжђ°...
еЬ®LRUзЃЧж≥ХдЄ≠пЉМељУзЉУе≠Шжї°жЧґпЉМжЬАињСжЬАе∞СдљњзФ®зЪДжХ∞жНЃе∞Ж襀粿йЩ§пЉМдї•иЕЊеЗЇз©ЇйЧізїЩжЦ∞зЪДжИЦжЬАињСйҐСзєБиЃњйЧЃзЪДжХ∞жНЃгАВ LRUзЪДеЕЈдљУеЃЮзО∞йАЪеЄЄйАЪињЗйУЊи°®жЭ•еЃМжИРгАВжЦ∞жХ∞жНЃй¶ЦеЕИжПТеЕ•йУЊи°®е§ійГ®пЉМжѓПжђ°зЉУе≠ШеСљдЄ≠пЉИеН≥жХ∞ж́襀聜йЧЃпЉЙпЉМиѓ•жХ∞жНЃдЉЪ襀粿еК®еИ∞йУЊи°®...
дЄЇдЇЖиІ£еЖ≥LRUзЃЧж≥ХдЄ≠еПѓиГљеЗЇзО∞зЪДвАЬзЉУе≠Шж±°жЯУвАЭйЧЃйҐШпЉМеЗЇзО∞дЇЖLRU-KзЃЧж≥ХгАВLRU-Kе∞ЖвАЬжЬАињСдљњзФ®ињЗ1жђ°вАЭзЪДж†ЗеЗЖжЙ©е±ХдЄЇвАЬжЬАињСдљњзФ®ињЗKжђ°вАЭгАВеЃГйЬАи¶БзїіжК§дЄАдЄ™иЃњйЧЃеОЖеП≤еИЧи°®пЉМеП™жЬЙељУжХ∞ж́襀聜йЧЃKжђ°еРОжЙНдЉЪ襀жФЊеЕ•зЉУе≠ШгАВеЬ®жЈШж±∞жХ∞жНЃжЧґпЉМLRU-...
зїЉдЄКжЙАињ∞пЉМLRUзЃЧж≥ХзЃАеНХйЂШжХИпЉМйАВзФ®дЇОе§ІйГ®еИЖеЬЇжЩѓпЉМдљЖе≠ШеЬ®зЉУе≠Шж±°жЯУзЪДйЧЃйҐШгАВLRU-KеТМ2QйАЪињЗеҐЮеК†йҐЭе§ЦзЪДжЬЇеИґжЭ•жФєеЦДињЩдЄАйЧЃйҐШпЉМжПРйЂШдЇЖеСљдЄ≠зОЗпЉМдљЖеҐЮеК†дЇЖе§НжЭВжАІеТМиµДжЇРжґИиАЧгАВMQзЃЧж≥ХеИЩйАЪињЗеИЖе±Вжђ°зЪДLRUйШЯеИЧжЭ•ињЫдЄАж≠•дЉШеМЦеСљдЄ≠зОЗпЉМеѓє...
зЉУе≠ШжЈШж±∞зЃЧж≥ХдєЛ LRU зЉУе≠ШжЈШж±∞зЃЧж≥ХжШѓжМЗеЬ®иЃ°зЃЧжЬЇз≥їзїЯдЄ≠пЉМдЄЇдЇЖжПРйЂШзЉУе≠ШеСљдЄ≠зОЗеТМеЗПе∞СзЉУе≠Ш pollution иАМйЗЗзФ®зЪДзЃЧж≥ХгАВеЕґдЄ≠пЉМLRUпЉИLeast Recently UsedпЉМжЬАињСжЬАе∞СдљњзФ®пЉЙзЃЧж≥ХжШѓдЄАзІНеЄЄзФ®зЪДзЉУе≠ШжЈШж±∞зЃЧж≥ХгАВ 1. LRU зЃЧж≥ХеОЯзРЖ ...
2. жЬАињСжЬАе∞СдљњзФ®зЃЧж≥ХпЉИLRUпЉЙпЉЪLRUзЉУе≠ШзЃЧж≥Хе∞ЖжЬАињСдљњзФ®зЪДжЭ°зЫЃе≠ШжФЊеИ∞йЭ†ињСзЉУе≠Шй°ґйГ®зЪДдљНзљЃгАВељУдЄАдЄ™жЦ∞жЭ°зہ襀聜йЧЃжЧґпЉМLRUе∞ЖеЃГжФЊзљЃеИ∞зЉУе≠ШзЪДй°ґйГ®гАВељУзЉУе≠ШиЊЊеИ∞жЮБйЩРжЧґпЉМиЊГжЧ©дєЛеЙНиЃњйЧЃзЪДжЭ°зЫЃе∞ЖдїОзЉУе≠ШеЇХйГ®еЉАеІЛ襀粿йЩ§гАВ LRUзЉУе≠Ш...
ељУзЉУе≠Шжї°дЇЖеєґдЄФжЦ∞зЪДжХ∞жНЃйЬАи¶БеК†еЕ•зЉУе≠ШжЧґпЉМLRUзЃЧж≥ХдЉЪйАЙжЛ©жЬАињСжЬАе∞СдљњзФ®зЪДжХ∞жНЃй°єињЫи°МжЈШж±∞пЉМдЄЇжЦ∞жХ∞жНЃиЕЊеЗЇз©ЇйЧігАВ #### зЉУе≠ШзЪДйЗНи¶БжАІдЄОжМСжИШ зЉУе≠ШдљЬдЄЇдЄАзІНжПРйЂШжХ∞жНЃиѓїеПЦжАІиГљзЪДеЕ≥йФЃжКАжЬѓпЉМеЬ®еРДдЄ™йҐЖеЯЯйГљжЬЙеєњж≥ЫеЇФзФ®пЉМдЊЛе¶ВCPUзЉУе≠Ш...
"йУЊи°®жХ∞жНЃзїУжЮДдЄОLRUзЉУе≠ШжЈШж±∞зЃЧж≥Х" йУЊи°®жШѓдЄАзІНеЯЇз°АзЪДжХ∞жНЃзїУжЮДпЉМеЃГеєњж≥ЫеЇФзФ®дЇОиљѓдїґеЉАеПСеТМз°ђдїґиЃЊиЃ°дЄ≠гАВдїК姩жИСдїђе∞ЖиЃ®иЃЇе¶ВдљХдљњзФ®йУЊи°®жЭ•еЃЮзО∞LRUзЉУе≠ШжЈШж±∞зЃЧж≥ХгАВ й¶ЦеЕИпЉМиЃ©жИСдїђжЭ•иЃ®иЃЇзЉУе≠ШзЪДж¶ВењµгАВзЉУе≠ШжШѓдЄАзІНжПРйЂШжХ∞жНЃиѓїеПЦжАІиГљ...
жАїзїУжЭ•иѓіпЉМ`LRUзЃЧж≥Х--utilsеЈ•еЕЈеМЕ`жґЙеПКеИ∞зЪДжШѓдЄАдЄ™еЃЮзФ®зЪДзЉУе≠ШзЃ°зРЖеЈ•еЕЈпЉМеЃГеИ©зФ®LRUз≠ЦзХ•йЂШжХИеЬ∞е§ДзРЖжЬЙйЩРзЪДзЉУе≠Шз©ЇйЧігАВйАЪињЗйУЊи°®еТМеУИеЄМи°®зЪДжХ∞жНЃзїУжЮДпЉМеЃЮзО∞дЇЖењЂйАЯжЯ•жЙЊеТМжЈШж±∞жЬАињСжЬАе∞СдљњзФ®жХ∞жНЃзЪДеКЯиГљгАВеЬ®еЉАеПСињЗз®ЛдЄ≠пЉМеРИзРЖињРзФ®...
йУЊи°®пЉИдЄКпЉЙпЉЪе¶ВдљХеЃЮзО∞ LRU зЉУе≠ШжЈШж±∞зЃЧж≥ХпЉЯ йУЊи°®жШѓдЄАзІНеЯЇз°АзЪДжХ∞жНЃзїУжЮДпЉМе≠¶дє†йУЊи°®жЬЙдїАдєИзФ®еСҐпЉЯдЄЇдЇЖеЫЮз≠ФињЩдЄ™йЧЃйҐШпЉМжИСдїђжЭ•иЃ®иЃЇдЄАдЄ™зїПеЕЄзЪДйУЊи°®еЇФзФ®еЬЇжЩѓпЉМйВ£е∞±жШѓ LRU зЉУе≠ШжЈШж±∞зЃЧж≥ХгАВзЉУе≠ШжШѓдЄАзІНжПРйЂШжХ∞жНЃиѓїеПЦжАІиГљзЪДжКАжЬѓпЉМеЬ®...
LRUжШѓдЄАзІНеЄЄзФ®зЪДй°µйЭҐжЫњжНҐзЃЧж≥ХпЉМељУеЖЕе≠Шз©ЇйЧідЄНиґ≥жЧґпЉМдЉЪдЉШеЕИжЈШж±∞жЬАињСжЬАе∞СдљњзФ®зЪДжХ∞жНЃгАВеЬ®PythonдЄ≠пЉМlru-dictеЕБиЃЄзФ®жИЈењЂйАЯеИЫеїЇдЄАдЄ™жЬЙйЩРеЃєйЗПзЪДе≠ЧеЕЄпЉМдЄАжЧ¶иЊЊеИ∞иЃЊеЃЪзЪДжЬАе§ІеЃєйЗПпЉМжЦ∞жЈїеК†зЪДеЕГзі†дЉЪжЫњжНҐжОЙжЬАжЧ©жЬ™дљњзФ®зЪДеЕГзі†пЉМдїОиАМ...
еЄЄиІБзЪДзЉУе≠ШзЃЧж≥ХеМЕжЛђжЬАињСжЬАе∞СдљњзФ®пЉИLRUпЉЙгАБеЕИињЫеЕИеЗЇпЉИFIFOпЉЙгАБжЧґйТЯзЃЧж≥ХпЉИClockпЉЙз≠ЙгАВињЩдЇЫзЃЧж≥ХеРДжЬЙзЙєзВєпЉМйАВзФ®дЇОдЄНеРМзЪДеЬЇжЩѓеТМйЬАж±ВгАВ зЉУе≠Шж°ЖжЮґжШѓеЃЮзО∞зЉУе≠ШжЬЇеИґзЪДиљѓдїґеє≥еП∞жИЦеЇУпЉМеЃГжПРдЊЫдЇЖдЄАз≥їеИЧжО•еП£еТМеЈ•еЕЈжЭ•зЃАеМЦзЉУе≠ШзЪДеЃЮзО∞...
еЬ®еЃЮйЩЕеЇФзФ®дЄ≠пЉМLRUзЃЧж≥Хеєњж≥ЫеЇФзФ®дЇОжХ∞жНЃеЇУз≥їзїЯгАБжУНдљЬз≥їзїЯгАБWebжЬНеК°еЩ®зЪДзЉУе≠ШзЃ°зРЖз≠ЙйҐЖеЯЯпЉМдї•жПРйЂШжХ∞жНЃиЃњйЧЃжХИзОЗгАВйАЪињЗзРЖиІ£ињЩдЄ™Cиѓ≠и®АеЃЮзО∞зЪДLRUзЃЧж≥ХпЉМдљ†еПѓдї•жЈ±еЕ•е≠¶дє†еИ∞е¶ВдљХзїУеРИжХ∞жНЃзїУжЮДеТМзЃЧж≥ХжЭ•иІ£еЖ≥еЃЮйЩЕйЧЃйҐШгАВ
жАїзЪДжЭ•иѓіпЉМLRUзЃЧж≥ХжШѓзО∞дї£иЃ°зЃЧжЬЇз≥їзїЯдЄ≠дЉШеМЦеЖЕе≠ШдљњзФ®зЪДеЕ≥йФЃжКАжЬѓдєЛдЄАпЉМе∞§еЕґеЬ®иЩЪжЛЯеЖЕе≠ШзЃ°зРЖеТМзЉУе≠Шз≠ЦзХ•дЄ≠иµЈзЭАйЗНи¶БдљЬзФ®гАВйАЪињЗж®°жЛЯеЃЮй™МпЉМеПѓдї•жЈ±еЕ•зРЖиІ£ињЩдЄ§зІНзЃЧж≥ХзЪДеЈ•дљЬеОЯзРЖпЉМеєґеѓєжѓФеЃГдїђеЬ®дЄНеРМеЬЇжЩѓдЄЛзЪДи°®зО∞гАВ
LRUзЉУе≠ШзЃЧж≥ХжШѓдЄАзІНеЄЄзФ®зЪДзЉУе≠ШжЈШж±∞з≠ЦзХ•пЉМеЃГж†єжНЃжХ∞жНЃй°єжЬАињС襀䚜зФ®зЪДжЧґйЧіжЭ•еЖ≥еЃЪеУ™дЇЫжХ∞жНЃй°єеЇФиѓ•дїОзЉУе≠ШдЄ≠зІїйЩ§пЉМдї•з°ЃдњЭзЉУе≠ШдЄ≠еІЛзїИе≠ШжФЊзЭАжЬАињСжЬАеПѓиÚ襀䚜зФ®зЪДжХ∞жНЃй°єгАВињЩдЄ™еОЛзЉ©жЦЗдїґеПѓиГљеМЕжЛђLRUзЉУе≠ШзЪДеЃЮзО∞дї£з†БгАБжµЛиѓХж†ЈдЊЛгАБдљњзФ®...
еЕґдЄ≠пЉМLRUпЉИLeast Recently UsedпЉМжЬАињСжЬАе∞СдљњзФ®пЉЙзЃЧж≥ХжШѓдЄАзІНеЄЄзФ®зЪДзЉУе≠ШжЈШж±∞з≠ЦзХ•гАВжЬђжЦЗе∞Жиѓ¶зїЖдїЛзїНдЄАдЄ™еЙНзЂѓеЉАжЇРеЇУвАФвАФ`lighter-lru-cache`пЉМеЃГжШѓдЄАдЄ™иљїйЗПзЇІзЪДJavaScript LRUзЉУе≠ШеЃЮзО∞гАВ `lighter-lru-cache`еЇУзЪДж†ЄењГ...
еЬ®жХ∞жНЃеЇУзЃ°зРЖз≥їзїЯдЄ≠пЉМBuffer PoolпЉИзЉУеЖ≤...дї•дЄКеЖЕеЃєжґµзЫЦдЇЖBuffer PoolдЄ≠зЉУе≠Шй°µзЃ°зРЖзЪДж†ЄењГж¶ВењµпЉМеМЕжЛђLRUзЃЧж≥ХеЬ®зЉУе≠ШжЈШж±∞дЄ≠зЪДеЇФзФ®гАВињЩдЇЫзЯ•иѓЖзВєеѓєдЇОзРЖиІ£еТМдЉШеМЦжХ∞жНЃеЇУжАІиГљиЗ≥еЕ≥йЗНи¶БпЉМжШѓжХ∞жНЃеЇУзЃ°зРЖеСШеТМеЉАеПСиАЕењЕй°їжОМжП°зЪДжКАжЬѓгАВ
й¶ЦеЕИпЉМLRUжШѓдЄАзІНеЄЄзФ®зЪДзЉУе≠ШжЈШж±∞з≠ЦзХ•пЉМеЃГеЯЇдЇОвАЬжЬАињСжЬАе∞СдљњзФ®вАЭзЪДеОЯеИЩпЉМељУзЉУе≠Шжї°жЧґпЉМдЉШеЕИжЈШж±∞жЬАињСжЬАе∞СдљњзФ®зЪДжХ∞жНЃгАВеЬ®ConcurrentLinkedHashMap-LRU 1.3дЄ≠пЉМињЩзІНз≠ЦзՕ襀売е¶ЩеЬ∞иЮНеЕ•еИ∞еєґеПСзОѓеҐГдЄЛпЉМдњЭиѓБдЇЖеЬ®е§ЪзЇњз®ЛзОѓеҐГдЄЛзЪД...
LRUпЉИLeast Recently Used...жАїзїУдЄАдЄЛпЉМLRUзЃЧж≥ХжШѓдЄАзІНеЯЇдЇОеОЖеП≤иЃњйЧЃи°МдЄЇзЪДзЉУе≠Шз≠ЦзХ•пЉМеЃГйАЪињЗжЈШж±∞жЬАињСжЬАе∞СдљњзФ®зЪДжХ∞жНЃжЭ•дЉШеМЦеЖЕе≠ШдљњзФ®гАВеЬ®еЃЮйЩЕеЇФзФ®дЄ≠пЉМе¶ВжХ∞жНЃеЇУзЉУе≠ШгАБжУНдљЬз≥їзїЯзЪДй°µйЭҐжЫњжНҐз≠ЦзХ•з≠ЙпЉМLRUзЃЧж≥ХйГље±ХзО∞еЗЇиЙѓе•љзЪДжАІиГљгАВ