
 
иљђиЗ™пЉЪhttp://blog.csdn.net/czmao1985/article/details/6411667
жХ∞жНЃеЇУиЃЊиЃ°5ж≠•й™§
Five Steps to design the Database
 
 
1.з°ЃеЃЪentitiesеПКrelationships
a)жШОз°ЃеЃПиІВи°МдЄЇгАВжХ∞жНЃеЇУжШѓзФ®жЭ•еБЪдїАдєИзЪДпЉЯжѓФе¶ВпЉМзЃ°зРЖйЫЗеСШзЪДдњ°жБѓгАВ
b)з°ЃеЃЪentitiesгАВеѓєдЇОдЄАз≥їеИЧзЪДи°МдЄЇпЉМз°ЃеЃЪжЙАзЃ°зРЖдњ°жБѓжЙАжґЙеПКеИ∞зЪДдЄїйҐШиМГеЫігАВињЩе∞ЖеПШжИРtableгАВжѓФе¶ВпЉМйЫЗзФ®еСШеЈ•пЉМжМЗеЃЪеЕЈдљУйГ®йЧ®пЉМз°ЃеЃЪжКАиГљз≠ЙзЇІгАВ
c)з°ЃеЃЪrelationshipsгАВеИЖжЮРи°МдЄЇпЉМз°ЃеЃЪtablesдєЛйЧіжЬЙдљХзІНеЕ≥з≥їгАВжѓФе¶ВпЉМйГ®йЧ®дЄОйЫЗеСШдєЛйЧіе≠ШеЬ®дЄАзІНеЕ≥з≥їгАВзїЩињЩзІНеЕ≥з≥їеСљеРНгАВ
d)зїЖеМЦи°МдЄЇгАВдїОеЃПиІВи°МдЄЇеЉАеІЛпЉМзО∞еЬ®дїФзїЖж£АжЯ•ињЩдЇЫи°МдЄЇпЉМзЬЛжЬЙеУ™дЇЫи°МдЄЇиГљиљђдЄЇеЊЃиІВи°МдЄЇгАВжѓФе¶ВпЉМзЃ°зРЖйЫЗеСШзЪДдњ°жБѓеПѓзїЖеМЦдЄЇпЉЪ
¬ЈеҐЮеК†жЦ∞еСШеЈ•
¬ЈдњЃжФєе≠ШеЬ®еСШеЈ•дњ°жБѓ
¬ЈеИ†йЩ§и∞Гиµ∞зЪДеСШеЈ•
e)з°ЃеЃЪдЄЪеК°иІДеИЩгАВеИЖжЮРдЄЪеК°иІДеИЩпЉМз°ЃеЃЪдљ†и¶БйЗЗеПЦеУ™зІНгАВжѓФе¶ВпЉМеПѓиГљжЬЙињЩж†ЈдЄАзІНиІДеИЩпЉМдЄАдЄ™йГ®йЧ®жЬЙдЄФеП™иГљжЬЙдЄАдЄ™йГ®йЧ®йҐЖеѓЉгАВињЩдЇЫиІДеИЩе∞Ж襀职聰еИ∞жХ∞жНЃеЇУзЪДзїУжЮДдЄ≠гАВ
 
====================================================================
иМГдЊЛпЉЪ
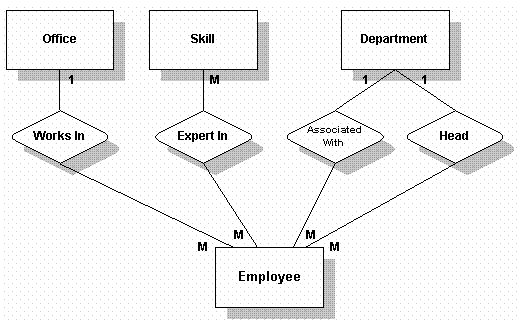
ACMEжШѓдЄАдЄ™е∞ПеЕђеПЄпЉМеЬ®5дЄ™еЬ∞жЦєйГљиЃЊжЬЙеКЮдЇЛе§ДгАВељУеЙНпЉМжЬЙ75еРНеСШеЈ•гАВеЕђеПЄеЗЖе§ЗењЂйАЯжЙ©е§ІиІДж®°пЉМеИТеИЖдЇЖ9дЄ™йГ®йЧ®пЉМжѓПдЄ™йГ®йЧ®йГљжЬЙеЕґйҐЖеѓЉгАВ
дЄЇжЬЙеК©дЇОеѓїж±ВжЦ∞зЪДеСШеЈ•пЉМдЇЇдЇЛйГ®йЧ®иІДеИТдЇЖ68зІНжКАиГљпЉМдЄЇе∞ЖжЭ•дЇЇдЇЛзЃ°зРЖдљЬе•љеЗЖе§ЗгАВеСШ壕襀жЛЫињЫжЧґпЉМжѓПдЄАзІНжКАиГљзЪДдЄУдЄЪз≠ЙзЇІйÚ襀簁еЃЪгАВ
еЃЪдєЙеЃПиІВи°МдЄЇ
дЄАдЇЫACMEеЕђеПЄзЪДеЃПиІВи°МдЄЇеМЕжЛђпЉЪ
вЧП жЛЫиБШеСШеЈ•
вЧП иІ£йЫЗеСШеЈ•
вЧП зЃ°зРЖеСШеЈ•дЄ™дЇЇдњ°жБѓ
вЧП зЃ°зРЖеЕђеПЄжЙАйЬАзЪДжКАиГљдњ°жБѓ
вЧП зЃ°зРЖеУ™дљНеСШеЈ•жЬЙеУ™дЇЫжКАиГљ
вЧП зЃ°зРЖйГ®йЧ®дњ°жБѓ
вЧП зЃ°зРЖеКЮдЇЛе§Ддњ°жБѓ
з°ЃеЃЪentitiesеПКrelationships
жИСдїђеПѓдї•з°ЃеЃЪи¶Бе≠ШжФЊдњ°жБѓзЪДдЄїйҐШйҐЖеЯЯ(и°®)еПКеЕґеЕ≥з≥їпЉМеєґеИЫеїЇдЄАдЄ™еЯЇдЇОеЃПиІВи°МдЄЇеПКжППињ∞зЪДеЫЊи°®гАВ
жИСдїђзФ®жЦєж°ЖжЭ•дї£и°®tableпЉМзФ®иП±ељҐдї£и°®relationshipгАВжИСдїђеПѓдї•з°ЃеЃЪеУ™дЇЫrelationshipжШѓдЄАеѓєе§ЪпЉМдЄАеѓєдЄАпЉМеПКе§Ъеѓєе§ЪгАВ
ињЩжШѓдЄАдЄ™E-RиНЙеЫЊпЉМдї•еРОдЉЪзїЖеМЦгАВ
 
зїЖеМЦеЃПиІВи°МдЄЇ
дї•дЄЛеЊЃиІВи°МдЄЇеЯЇдЇОдЄКйЭҐеЃПиІВи°МдЄЇиАМ嚥жИРпЉЪ
вЧП еҐЮеК†жИЦеИ†йЩ§дЄАдЄ™еСШеЈ•
вЧП еҐЮеК†жИЦеИ†йЩ§дЄАдЄ™еКЮдЇЛе§Д
вЧП еИЧеЗЇдЄАдЄ™йГ®йЧ®дЄ≠зЪДжЙАжЬЙеСШеЈ•
вЧП еҐЮеК†дЄАй°єжКАиГљ
вЧП еҐЮеК†дЄАдЄ™еСШеЈ•зЪДдЄАй°єжКАиГљ
вЧП з°ЃеЃЪдЄАдЄ™еСШеЈ•зЪДжКАиГљ
вЧП з°ЃеЃЪдЄАдЄ™еСШеЈ•жѓПй°єжКАиГљзЪДз≠ЙзЇІ
вЧП з°ЃеЃЪжЙАжЬЙжЛ•жЬЙзЫЄеРМз≠ЙзЇІзЪДжЯРй°єжКАиГљзЪДеСШеЈ•
вЧП дњЃжФєеСШеЈ•зЪДжКАиГљз≠ЙзЇІ
ињЩдЇЫеЊЃиІВи°МдЄЇеПѓзФ®жЭ•з°ЃеЃЪйЬАи¶БеУ™дЇЫtableжИЦrelationshipгАВ
з°ЃеЃЪдЄЪеК°иІДеИЩ
дЄЪеК°иІДеИЩеЄЄзФ®дЇОз°ЃеЃЪдЄАеѓєе§ЪпЉМдЄАеѓєдЄАпЉМеПКе§Ъеѓєе§ЪеЕ≥з≥їгАВ
зЫЄеЕ≥зЪДдЄЪеК°иІДеИЩеПѓиГљжЬЙпЉЪ
вЧП зО∞еЬ®жЬЙ5дЄ™еКЮдЇЛе§ДпЉЫжЬАе§ЪеЕБиЃЄжЙ©е±ХеИ∞10дЄ™гАВ
вЧП еСШеЈ•еПѓдї•жФєеПШйГ®йЧ®жИЦеКЮдЇЛе§Д
вЧП жѓПдЄ™йГ®йЧ®жЬЙдЄАдЄ™йГ®йЧ®йҐЖеѓЉ
вЧП жѓПдЄ™еКЮдЇЛе§ДиЗ≥е§ЪжЬЙ3дЄ™зФµиѓЭеПЈз†Б
вЧП жѓПдЄ™зФµиѓЭеПЈз†БжЬЙдЄАдЄ™жИЦе§ЪдЄ™жЙ©е±Х
вЧП еСШ壕襀жЛЫињЫжЧґпЉМжѓПдЄАзІНжКАиГљзЪДдЄУдЄЪз≠ЙзЇІйÚ襀簁еЃЪгАВ
вЧП жѓПдљНеСШеЈ•жЛ•жЬЙ3еИ∞20дЄ™жКАиГљ
вЧП жЯРдљНеСШеЈ•еПѓиÚ襀еЃЙжОТеЬ®дЄАдЄ™еКЮдЇЛе§ДпЉМдєЯеПѓиГљдЄНеЃЙжОТеКЮдЇЛе§ДгАВ
2.з°ЃеЃЪжЙАйЬАжХ∞жНЃ
и¶Бз°ЃеЃЪжЙАйЬАжХ∞жНЃпЉЪ
a)з°ЃеЃЪжФѓжМБжХ∞жНЃ
b)еИЧеЗЇжЙАи¶БиЈЯиЄ™зЪДжЙАжЬЙжХ∞жНЃгАВжППињ∞table(дЄїйҐШ)зЪДжХ∞жНЃеЫЮз≠ФињЩдЇЫйЧЃйҐШпЉЪи∞БпЉМдїАдєИпЉМеУ™йЗМпЉМдљХжЧґпЉМдї•еПКдЄЇдїАдєИ
c)дЄЇжѓПдЄ™tableеїЇзЂЛжХ∞жНЃ
d)еИЧеЗЇжѓПдЄ™tableзЫЃеЙНзЬЛиµЈжЭ•еРИйАВзЪДеПѓзФ®жХ∞жНЃ
e)дЄЇжѓПдЄ™relationshipиЃЊзљЃжХ∞жНЃ
f)е¶ВжЮЬжЬЙпЉМдЄЇжѓПдЄ™relationshipеИЧеЗЇйАВзФ®зЪДжХ∞жНЃ
 
з°ЃеЃЪжФѓжМБжХ∞жНЃ
дљ†жЙАз°ЃеЃЪзЪДжФѓжМБжХ∞жНЃе∞ЖдЉЪжИРдЄЇtableдЄ≠зЪДе≠ЧжЃµеРНгАВжѓФе¶ВпЉМдЄЛеИЧжХ∞жНЃе∞ЖйАВзФ®дЇОи°®EmployeeпЉМи°®SkillпЉМи°®Expert InгАВ
 
|
Employee |
Skill |
Expert In |
|
ID |
ID |
Level |
|
Last Name |
Name |
Date acquired |
|
First Name |
Description |
  |
|
Department |
  |   |
|
Office |
  |   |
|
Address |
  |   |
е¶ВжЮЬе∞ЖињЩдЇЫжХ∞жНЃзФїжИРеЫЊи°®пЉМе∞±еГПпЉЪ
 
 
йЬАи¶Бж≥®жДПпЉЪ
вЧП еЬ®з°ЃеЃЪжФѓжМБжХ∞жНЃжЧґпЉМиѓЈдЄАеЃЪи¶БеПВиАГдљ†дєЛеЙНжЙАз°ЃеЃЪзЪДеЃПиІВи°МдЄЇпЉМдї•жЄЕж•Ъе¶ВдљХеИ©зФ®ињЩдЇЫжХ∞жНЃгАВ
вЧП жѓФе¶ВпЉМе¶ВжЮЬдљ†зЯ•йБУдљ†йЬАи¶БжЙАжЬЙеСШеЈ•зЪДжМЙеІУж∞ПжОТеЇПзЪДеИЧи°®пЉМз°ЃдњЭдљ†е∞ЖжФѓжМБжХ∞жНЃеИЖиІ£дЄЇеРНе≠ЧдЄОеІУж∞ПпЉМињЩжѓФзЃАеНХеЬ∞жПРдЊЫдЄАдЄ™еРНе≠ЧдЉЪжЫіе•љгАВ
вЧП дљ†жЙАйАЙжЛ©зЪДеРНзІ∞жЬАе•љдњЭжМБдЄАиЗіжАІгАВињЩе∞ЖжЫіжШУдЇОзїіжК§жХ∞жНЃеЇУпЉМдєЯжЫіжШУдЇОйШЕиѓїжЙАиЊУеЗЇзЪДжК•и°®гАВ
вЧП жѓФе¶ВпЉМе¶ВжЮЬдљ†еЬ®жЯРдЇЫеЬ∞жЦєзФ®дЇЖдЄАдЄ™зЉ©еЖЩеРНзІ∞Emp_statusпЉМдљ†е∞±дЄНеЇФиѓ•еЬ®еП¶е§ЦдЄАдЄ™еЬ∞жЦєдљњзФ®еЕ®еРН(Empolyee_ID)гАВзЫЄеПНпЉМињЩдЇЫеРНзІ∞еЇФељУжШѓEmp_statusеПКEmp_idгАВ
вЧП жХ∞жНЃжШѓеР¶дЄОж≠£з°ЃзЪДtableзЫЄеѓєеЇФжЧ†еЕ≥зіІи¶БпЉМдљ†еПѓдї•ж†єжНЃиЗ™еЈ±зЪДеЦЬе•љжЭ•еЃЪгАВеЬ®дЄЛиКВдЄ≠пЉМдљ†дЉЪйАЪињЗжµЛиѓХеѓєж≠§дљЬеЗЇеИ§жЦ≠гАВ
 
3.ж†ЗеЗЖеМЦжХ∞жНЃ
ж†ЗеЗЖеМЦжШѓдљ†зФ®дї•жґИйЩ§жХ∞жНЃеЖЧдљЩеПКз°ЃдњЭжХ∞жНЃдЄОж≠£з°ЃзЪДtableжИЦrelationshipзЫЄеЕ≥иБФзЪДдЄАз≥їеИЧжµЛиѓХгАВеЕ±жЬЙ5дЄ™жµЛиѓХгАВжЬђиКВдЄ≠пЉМжИСдїђе∞ЖиЃ®иЃЇзїПеЄЄдљњзФ®зЪД3дЄ™гАВ
еЕ≥дЇОж†ЗеЗЖеМЦжµЛиѓХзЪДжЫіе§Ъдњ°жБѓпЉМиѓЈеПВиАГжЬЙеЕ≥жХ∞жНЃеЇУиЃЊиЃ°зЪДдє¶з±НгАВ
ж†ЗеЗЖеМЦж†ЉеЉП
ж†ЗеЗЖеМЦж†ЉеЉПжШѓж†ЗеЗЖеМЦжХ∞жНЃзЪДеЄЄзФ®жµЛиѓХжЦєеЉПгАВдљ†зЪДжХ∞жНЃйАЪињЗзђђдЄАйБНжµЛиѓХеРОпЉМе∞±иҐЂиЃ§дЄЇжШѓиЊЊеИ∞зђђдЄАж†ЗеЗЖеМЦж†ЉеЉПпЉЫйАЪињЗзђђдЇМйБНжµЛиѓХпЉМиЊЊеИ∞зђђдЇМж†ЗеЗЖеМЦж†ЉеЉПпЉЫйАЪињЗзђђдЄЙйБНжµЛиѓХпЉМиЊЊеИ∞зђђдЄЙж†ЗеЗЖеМЦж†ЉеЉПгАВ
е¶ВдљХж†ЗеЗЖж†ЉеЉПпЉЪ
1пЉОеИЧеЗЇжХ∞жНЃ
2пЉОдЄЇжѓПдЄ™и°®з°ЃеЃЪиЗ≥е∞СдЄАдЄ™йФЃгАВжѓПдЄ™и°®ењЕй°їжЬЙдЄАдЄ™дЄїйФЃгАВ
3пЉОз°ЃеЃЪrelationshipsзЪДйФЃгАВrelationshipsзЪДйФЃжШѓињЮжО•дЄ§дЄ™и°®зЪДйФЃгАВ
4пЉОж£АжЯ•жФѓжМБжХ∞жНЃеИЧи°®дЄ≠зЪДиЃ°зЃЧжХ∞жНЃгАВиЃ°зЃЧжХ∞жНЃйАЪеЄЄдЄНдњЭе≠ШеЬ®жХ∞жНЃеЇУдЄ≠гАВ
5пЉОе∞ЖжХ∞жНЃжФЊеЬ®зђђдЄАйБНзЪДж†ЗеЗЖеМЦж†ЉеЉПдЄ≠пЉЪ
6пЉОдїОtablesеПКrelationshipsйЩ§еОїйЗНе§НзЪДжХ∞жНЃгАВ
7пЉОдї•дљ†жЙАйЩ§еОїжХ∞жНЃеИЫеїЇдЄАдЄ™жИЦжЫіе§ЪзЪДtablesеПКrelationshipsгАВ
8пЉОе∞ЖжХ∞жНЃжФЊеЬ®зђђдЇМйБНзЪДж†ЗеЗЖеМЦж†ЉеЉПдЄ≠пЉЪ
9пЉОзФ®е§ЪдЇОдЄАдЄ™дї•дЄКзЪДйФЃз°ЃеЃЪtablesеПКrelationshipsгАВ
10пЉОйЩ§еОїеП™дЊЭиµЦдЇОйФЃдЄАйГ®еИЖзЪДжХ∞жНЃгАВ
11пЉОдї•дљ†жЙАйЩ§еОїжХ∞жНЃеИЫеїЇдЄАдЄ™жИЦжЫіе§ЪзЪДtablesеПКrelationshipsгАВ
12пЉОе∞ЖжХ∞жНЃжФЊеЬ®зђђдЄЙйБНзЪДж†ЗеЗЖеМЦж†ЉеЉПдЄ≠пЉЪ
13пЉОйЩ§еОїйВ£дЇЫдЊЭиµЦдЇОtablesжИЦrelationshipsдЄ≠еЕґдїЦжХ∞жНЃпЉМеєґдЄФдЄНжШѓйФЃзЪДжХ∞жНЃгАВ
14пЉОдї•дљ†жЙАйЩ§еОїжХ∞жНЃеИЫеїЇдЄАдЄ™жИЦжЫіе§ЪзЪДtablesеПКrelationshipsгАВ
жХ∞жНЃдЄОйФЃ
еЬ®дљ†еЉАеІЛж†ЗеЗЖеМЦпЉИжµЛиѓХжХ∞жНЃпЉЙеЙНпЉМзЃАеНХеЬ∞еИЧеЗЇжХ∞жНЃпЉМеєґдЄЇжѓПеЉ†и°®з°ЃеЃЪдЄАдЄ™еФѓдЄАзЪДдЄїйФЃгАВињЩдЄ™йФЃеПѓдї•зФ±дЄАдЄ™е≠ЧжЃµжИЦеЗ†дЄ™е≠ЧжЃµпЉИињЮйФБйФЃпЉЙзїДжИРгАВ
дЄїйФЃжШѓдЄАеЉ†и°®дЄ≠еФѓдЄАеМЇеИЖеРДи°МзЪДдЄАзїДе≠ЧжЃµгАВEmployeeи°®зЪДдЄїйФЃжШѓEmployee IDе≠ЧжЃµгАВWorks In relationshipдЄ≠зЪДдЄїйФЃеМЕжЛђOffice CodeеПКEmployee IDе≠ЧжЃµгАВзїЩжХ∞жНЃеЇУдЄ≠жѓПдЄАrelationshipзїЩеЗЇдЄАдЄ™йФЃпЉМдїОеЕґжЙАињЮжО•зЪДжѓПдЄАдЄ™tableдЄ≠жКљеПЦеЕґйФЃдЇІзФЯгАВ
|
RelationShip |
Key |
|
Office |
*Office code |
|   |
Office address |
|   |
Phone number |
|
Works in |
*Office code |
|   |
*Employee ID |
|
Department |
*Department ID |
|   |
Department name |
|
Heads |
*Department ID |
|   |
*Employee ID |
|
Assoc with |
*Department ID |
|   |
*EmployeeID |
|
Skill |
*Skill ID |
|   |
Skill name |
|   |
Skill description |
|
Expert In |
*Skill ID |
|   |
*Employee ID |
|   |
Skill level |
|   |
Date acquired |
|
Employee |
*Employee ID |
|   |
Last Name |
|   |
First Name |
|   |
Social security number |
|   |
Employee street |
|   |
Employee city |
|   |
Employee state |
|   |
Employee phone |
|   |
Date of birth |
е∞ЖжХ∞жНЃжФЊеЬ®зђђдЄАйБНзЪДж†ЗеЗЖеМЦж†ЉеЉПдЄ≠
вЧП йЩ§еОїйЗНе§НзЪДзїД
вЧП и¶БжµЛиѓХзђђдЄАйБНж†ЗеЗЖеМЦж†ЉеЉПпЉМйЩ§еОїйЗНе§НзЪДзїДпЉМеєґе∞ЖеЃГдїђжФЊињЫдїЦдїђеРДиЗ™зЪДдЄАеЉ†и°®дЄ≠гАВ
вЧП еЬ®дЄЛйЭҐзЪДдЊЛе≠РдЄ≠пЉМPhone NumberеПѓдї•йЗНе§НгАВпЉИдЄАдЄ™еЈ•дљЬдЇЇеСШеПѓдї•жЬЙе§ЪдЇОдЄАдЄ™зЪДзФµиѓЭеПЈз†БгАВпЉЙе∞ЖйЗНе§НзЪДзїДйЩ§еОїпЉМеИЫеїЇдЄАдЄ™еРНдЄЇTelephoneзЪДжЦ∞и°®гАВеЬ®TelephoneдЄОOfficeеИЫеїЇдЄАдЄ™еРНдЄЇAssociated WithзЪДrelationshipгАВ
е∞ЖжХ∞жНЃжФЊеЬ®зђђдЇМйБНзЪДж†ЗеЗЖеМЦж†ЉеЉПдЄ≠
вЧП йЩ§еОїйВ£дЇЫдЄНдЊЭиµЦдЇОжХідЄ™йФЃзЪДжХ∞жНЃгАВ
вЧП еП™зЬЛйВ£дЇЫжЬЙдЄАдЄ™дї•дЄКйФЃзЪДtablesеПКrelationshipsгАВи¶БжµЛиѓХзђђдЇМйБНж†ЗеЗЖеМЦж†ЉеЉПпЉМйЩ§еОїйВ£дЇЫдЄНдЊЭиµЦдЇОжХідЄ™йФЃзЪДдїїдљХжХ∞жНЃпЉИзїДжИРйФЃзЪДжЙАжЬЙе≠ЧжЃµпЉЙгАВ
вЧП еЬ®ж≠§дЊЛдЄ≠пЉМеОЯEmployeeи°®жЬЙдЄАдЄ™зФ±дЄ§дЄ™е≠ЧжЃµзїДжИРзЪДйФЃгАВдЄАдЇЫжХ∞жНЃдЄНдЊЭиµЦдЇОжХідЄ™йФЃпЉЫдЊЛе¶ВпЉМdepartment nameеП™дЊЭиµЦдЇОеЕґдЄ≠дЄАдЄ™йФЃпЉИDepartment IDпЉЙгАВеЫ†ж≠§пЉМDepartment IDпЉМеЕґдїЦEmployeeжХ∞жНЃеєґдЄНдЊЭиµЦдЇОеЃГпЉМеЇФзІїиЗ≥дЄАдЄ™еРНдЄЇDepartmentзЪДжЦ∞и°®дЄ≠пЉМеєґдЄЇEmployeeеПКDepartmentеїЇзЂЛдЄАдЄ™еРНдЄЇAssigned ToзЪДrelationshipгАВ

е∞ЖжХ∞жНЃжФЊеЬ®зђђдЄЙйБНзЪДж†ЗеЗЖеМЦж†ЉеЉПдЄ≠
вЧП йЩ§еОїйВ£дЇЫдЄНзЫіжО•дЊЭиµЦдЇОйФЃзЪДжХ∞жНЃгАВ
вЧП и¶БжµЛиѓХзђђдЄЙйБНж†ЗеЗЖеМЦж†ЉеЉПпЉМйЩ§еОїйВ£дЇЫдЄНжШѓзЫіжО•дЊЭиµЦдЇОйФЃпЉМиАМжШѓдЊЭиµЦдЇОеЕґдїЦжХ∞жНЃзЪДжХ∞жНЃгАВ
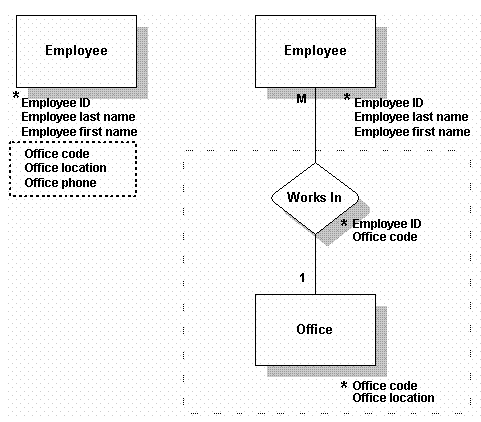
вЧП еЬ®ж≠§дЊЛдЄ≠пЉМеОЯEmployeeи°®жЬЙдЊЭиµЦдЇОеЕґйФЃпЉИEmployee IDпЉЙзЪДжХ∞жНЃгАВзДґиАМпЉМoffice locationеПКoffice phoneдЊЭиµЦдЇОеЕґдїЦе≠ЧжЃµпЉМеН≥Office CodeгАВеЃГдїђдЄНзЫіжО•дЊЭиµЦдЇОEmployee IDйФЃгАВе∞ЖињЩзїДжХ∞жНЃпЉМеМЕжЛђOffice CodeпЉМзІїиЗ≥дЄАдЄ™еРНдЄЇOfficeзЪДжЦ∞и°®дЄ≠пЉМеєґдЄЇEmployeeеПКOfficeеїЇзЂЛдЄАдЄ™еРНдЄЇWorks InзЪДrelationshipгАВ
 
4.иАГйЗПеЕ≥з≥ї
ељУдљ†еЃМжИРж†ЗеЗЖеМЦињЫз®ЛеРОпЉМдљ†зЪДиЃЊиЃ°еЈ≤зїПеЈЃдЄНе§ЪеЃМжИРдЇЖгАВдљ†жЙАйЬАи¶БеБЪзЪДпЉМе∞±жШѓиАГйЗПеЕ≥з≥їгАВ
иАГйЗПеЄ¶жЬЙжХ∞жНЃзЪДеЕ≥з≥ї
дљ†зЪДдЄАдЇЫrelationshipеПѓиГљйЫЖеРЂжЬЙжХ∞жНЃгАВињЩзїПеЄЄеПСзФЯеЬ®е§Ъеѓєе§ЪзЪДеЕ≥з≥їдЄ≠гАВ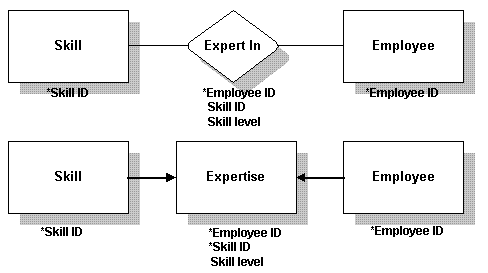
йБЗеИ∞ињЩзІНжГЕеЖµпЉМе∞ЖrelationshipиљђеМЦдЄЇдЄАдЄ™tableгАВrelationshipзЪДйФЃдЊЭжЧІжИРдЄЇtableдЄ≠зЪДйФЃгАВ
иАГйЗПж≤°жЬЙжХ∞жНЃзЪДеЕ≥з≥ї
и¶БеЃЮзО∞ж≤°жЬЙжХ∞жНЃзЪДеЕ≥з≥їпЉМдљ†йЬАи¶БеЃЪдєЙе§ЦйГ®йФЃгАВе§ЦйГ®йФЃжШѓеРЂжЬЙеП¶е§ЦдЄАдЄ™и°®дЄ≠дЄїйФЃзЪДдЄАдЄ™жИЦе§ЪдЄ™е≠ЧжЃµгАВе§ЦйГ®йФЃдљњдљ†иГљеРМжЧґињЮжО•е§Ъи°®жХ∞жНЃгАВ
жЬЙдЄАдЇЫеЯЇжЬђеОЯеИЩиГљеЄЃеК©дљ†еЖ≥еЃЪе∞ЖињЩдЇЫйФЃжФЊеЬ®еУ™йЗМпЉЪ
дЄАеѓєе§ЪеЬ®дЄАеѓєе§ЪеЕ≥з≥їдЄ≠пЉМвАЬдЄАвАЭдЄ≠зЪДдЄїйФЃжФЊеЬ®вАЬе§ЪвАЭдЄ≠гАВж≠§дЊЛдЄ≠пЉМе§ЦйГ®йФЃжФЊеЬ®Employeeи°®дЄ≠гАВ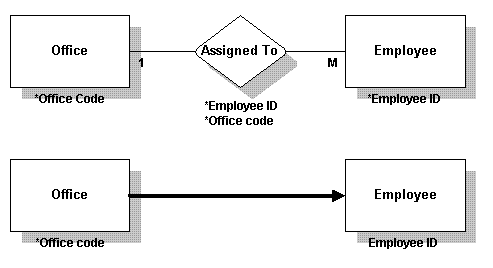
дЄАеѓєдЄАеЬ®дЄАеѓєдЄАеЕ≥з≥їдЄ≠пЉМе§ЦйГ®йФЃеПѓдї•жФЊињЫдїїдЄАи°®дЄ≠гАВе¶ВжЮЬењЕй°їи¶БжФЊеЬ®жЯРдЄАиЊєпЉМиАМдЄНиГљжФЊеЬ®еП¶дЄАиЊєпЉМеЇФиѓ•жФЊеЬ®ењЕй°їзЪДдЄАиЊєгАВж≠§дЊЛдЄ≠пЉМе§ЦйГ®йФЃпЉИHead IDпЉЙеЬ®Departmentи°®дЄ≠пЉМеЫ†дЄЇињЩжШѓењЕйЬАзЪДгАВ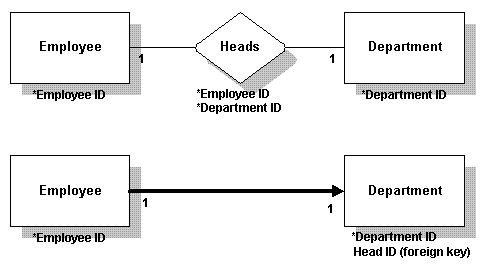
е§Ъеѓєе§ЪеЬ®е§Ъеѓєе§ЪеЕ≥з≥їдЄ≠пЉМзФ®дЄ§дЄ™е§ЦйГ®йФЃжЭ•еИЫеїЇдЄАдЄ™жЦ∞и°®гАВеЈ≤е≠ШзЪДжЧІи°®йАЪињЗињЩдЄ™жЦ∞и°®жЭ•еПСзФЯиБФз≥їгАВ

5.ж£Ай™МиЃЊиЃ°
еЬ®дљ†еЃМжИРиЃЊиЃ°дєЛеЙНпЉМдљ†йЬАи¶Бз°ЃдњЭеЃГжї°иґ≥дљ†зЪДйЬАи¶БгАВж£АжЯ•дљ†еЬ®дЄАеЉАеІЛжЧґжЙАеЃЪдєЙзЪДи°МдЄЇпЉМз°ЃиЃ§дљ†еПѓдї•иОЈеПЦи°МдЄЇжЙАйЬАи¶БзЪДжЙАжЬЙжХ∞жНЃпЉЪ
вЧП дљ†иГљжЙЊеИ∞дЄАдЄ™иЈѓеЊДжЭ•з≠ЙеИ∞дљ†жЙАйЬАи¶БзЪДжЙАжЬЙдњ°жБѓеРЧпЉЯ
вЧП иЃЊиЃ°жШѓеР¶жї°иґ≥дЇЖдљ†зЪДйЬАи¶БпЉЯ
вЧП жЙАжЬЙйЬАи¶БзЪДжХ∞жНЃйГљеПѓзФ®еРЧпЉЯ
е¶ВжЮЬдљ†еѓєдї•дЄКзЪДйЧЃйҐШйГљеЫЮз≠ФжШѓпЉМдљ†еЈ≤зїПеЈЃдЄНе§ЪеЃМжИРиЃЊиЃ°дЇЖгАВ
жЬАзїИиЃЊиЃ°
жЬАзїИиЃЊиЃ°зЬЛиµЈжЭ•е∞±еГПињЩж†ЈпЉЪ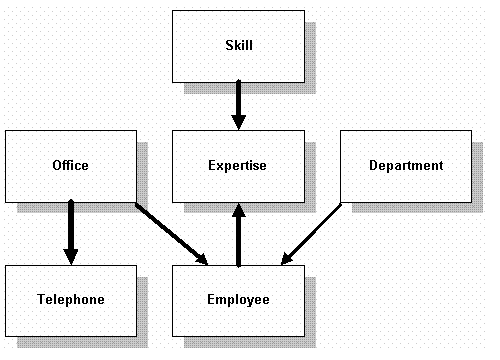
иЃЊиЃ°жХ∞жНЃеЇУзЪДи°®е±ЮжАІ
жХ∞жНЃеЇУиЃЊиЃ°йЬАи¶Бз°ЃеЃЪжЬЙдїАдєИи°®пЉМжѓПеЉ†и°®жЬЙдїАдєИе≠ЧжЃµгАВж≠§иКВиЃ®иЃЇе¶ВдљХжМЗеЃЪеРДе≠ЧжЃµзЪДе±ЮжАІгАВ
еѓєдЇОжѓПдЄАе≠ЧжЃµпЉМдљ†ењЕй°їеЖ≥еЃЪе≠ЧжЃµеРНпЉМжХ∞жНЃз±їеЮЛеПКе§Іе∞ПпЉМжШѓеР¶еЕБиЃЄNULLеАЉпЉМдї•еПКдљ†жШѓеР¶еЄМжЬЫжХ∞жНЃеЇУйЩРеИґе≠ЧжЃµдЄ≠жЙАеЕБиЃЄзЪДеАЉгАВ
йАЙжЛ©е≠ЧжЃµеРН
е≠ЧжЃµеРНеПѓдї•жШѓе≠ЧжѓНгАБжХ∞е≠ЧжИЦзђ¶еПЈзЪДдїїжДПзїДеРИгАВзДґиАМпЉМе¶ВжЮЬе≠ЧжЃµеРНеМЕжЛђдЇЖе≠ЧжѓНгАБжХ∞е≠ЧжИЦдЄЛеИТзЇњгАБжИЦеєґдЄНдї•е≠ЧжѓНжЙУе§іпЉМжИЦиАЕеЃГжШѓдЄ™еЕ≥йФЃе≠ЧпЉИиѓ¶иІБеЕ≥йФЃе≠Чи°®пЉЙпЉМйВ£дєИељУдљњзФ®е≠ЧжЃµеРНзІ∞жЧґпЉМењЕй°їзФ®еПМеЉХеПЈжЛђиµЈжЭ•гАВ
дЄЇе≠ЧжЃµйАЙжЛ©жХ∞жНЃз±їеЮЛ
SQL AnywhereжФѓжМБзЪДжХ∞жНЃз±їеЮЛеМЕжЛђпЉЪ
жХіжХ∞пЉИint, integer, smallintпЉЙ
е∞ПжХ∞пЉИdecimal, numericпЉЙ
жµЃзВєжХ∞пЉИfloat, doubleпЉЙ
е≠Чзђ¶еЮЛпЉИchar, varchar, long varcharпЉЙ
дЇМињЫеИґжХ∞жНЃз±їеЮЛпЉИbinary, long binaryпЉЙ
жЧ•жЬЯ/жЧґйЧіз±їеЮЛпЉИdate, time, timestampпЉЙ
зФ®жИЈиЗ™еЃЪдєЙз±їеЮЛ
еЕ≥дЇОжХ∞жНЃз±їеЮЛзЪДеЖЕеЃєпЉМиѓЈеПВиІБвАЬSQL AnywhereжХ∞жНЃз±їеЮЛвАЭдЄАиКВгАВе≠ЧжЃµзЪДжХ∞жНЃз±їеЮЛељ±еУНе≠ЧжЃµзЪДжЬАе§Іе∞ЇеѓЄгАВдЊЛе¶ВпЉМе¶ВжЮЬдљ†жМЗеЃЪSMALLINTпЉМж≠§е≠ЧжЃµеПѓдї•еЃєзЇ≥32,767зЪДжХіжХ∞гАВINTEGERеПѓдї•еЃєзЇ≥2,147,483,647зЪДжХіжХ∞гАВеѓєCHARжЭ•иЃ≤пЉМе≠ЧжЃµзЪДжЬАе§ІеАЉењЕй°їжМЗеЃЪгАВ
йХњдЇМињЫеИґзЪДжХ∞жНЃз±їеЮЛеПѓзФ®жЭ•еЬ®жХ∞жНЃеЇУдЄ≠дњЭе≠ШдЊЛе¶ВеЫЊеГП(е¶ВдљНеЫЊ)жИЦиАЕжЦЗе≠ЧзЉЦиЊСжЦЗж°£гАВињЩдЇЫз±їеЮЛзЪДдњ°жБѓйАЪ媪襀зІ∞дЄЇдЇМињЫеИґе§ІеЮЛеѓєи±°пЉМжИЦиАЕBLOBSгАВ
еЕ≥дЇОжѓПдЄАжХ∞жНЃз±їеЮЛзЪДеЃМжХіжППињ∞пЉМиІБвАЬSQL AnywhereжХ∞жНЃз±їеЮЛвАЭгАВ
NULLдЄОNOT NULL
е¶ВжЮЬдЄАдЄ™е≠ЧжЃµеАЉжШѓењЕе°ЂзЪДпЉМдљ†е∞±е∞Жж≠§е≠ЧжЃµеЃЪдєЙдЄЇNOT NULLгАВеР¶еИЩпЉМе≠ЧжЃµеАЉеПѓдї•дЄЇNULLеАЉпЉМеН≥еПѓдї•жЬЙз©ЇеАЉгАВSQLдЄ≠зЪДйїШиЃ§еАЉжШѓеЕБиЃЄз©ЇеАЉпЉЫдљ†еЇФиѓ•жШЊз§ЇеЬ∞е∞Же≠ЧжЃµеЃЪдєЙдЄЇNOT NULLпЉМйЩ§йЭЮдљ†жЬЙе•љзРЖзФ±е∞ЖеЕґиЃЊдЄЇеЕБиЃЄз©ЇеАЉгАВ
еЕ≥дЇОNULLеАЉзЪДеЃМжХіжППињ∞пЉМиѓЈиІБвАЬNULL valueвАЭгАВжЬЙеЕ≥еЕґеѓєжѓФзФ®ж≥ХпЉМиІБвАЬSearch conditionsвАЭгАВ
йАЙжЛ©зЇ¶жЭЯ
е∞љзЃ°е≠ЧжЃµзЪДжХ∞жНЃз±їеЮЛйЩРеИґдЇЖиГље≠ШеЬ®е≠ЧжЃµдЄ≠зЪДжХ∞жНЃпЉИдЊЛе¶ВпЉМеП™иГље≠ШжХ∞е≠ЧжИЦжЧ•жЬЯпЉЙпЉМдљ†жИЦиЃЄеЄМжЬЫжЫіињЫдЄАж≠•жЭ•зЇ¶жЭЯеЕґеЕБиЃЄеАЉгАВ
дљ†еПѓдї•йАЪињЗжМЗеЃЪдЄАдЄ™вАЬCHECKвАЭзЇ¶жЭЯжЭ•йЩРеИґдїїжДПе≠ЧжЃµзЪДеАЉгАВдљ†еПѓдї•дљњзФ®иГљеЬ®WHEREе≠РеП•дЄ≠еЗЇзО∞зЪДдїїдљХжЬЙжХИжЭ°дїґжЭ•зЇ¶жЭЯ襀еЕБиЃЄзЪДеАЉпЉМе∞љзЃ°е§Іе§ЪжХ∞CHECKзЇ¶жЭЯдљњзФ®BETWEENжИЦINжЭ°дїґгАВ
жЫіе§Ъдњ°жБѓ
жЬЙеЕ≥жЬЙжХИжЭ°дїґзЪДжЫіе§Ъдњ°жБѓпЉМиІБвАЬSearch conditionsвАЭгАВжЬЙеЕ≥е¶ВдљХдЄЇи°®еПКе≠ЧжЃµжМЗеЃЪзЇ¶жЭЯпЉМиІБвАЬEnsuring Data IntegrityвАЭгАВ
====================================================================
иМГдЊЛ
дЊЛе≠РжХ∞жНЃеЇУдЄ≠жЬЙдЄАдЄ™еРНдЄЇdepartmentзЪДи°®пЉМе≠ЧжЃµжШѓdept_id, dept_name, dept_head_idгАВеЕґеЃЪдєЙе¶ВдЄЛпЉЪ
|
Fields |
Type |
Size |
Null/Not Null |
Constraint |
|
Dept_id |
Integer |
-- |
Not null |
None |
|
Dept_name |
Char |
40 |
Not null |
None |
|
Dept_head_id |
Integer |
-- |
Not null |
None |
ж≥®жДПжѓПдЄАе≠ЧжЃµйÚ襀жМЗеЃЪдЄЇвАЬnot nullвАЭгАВињЩзІНжГЕеЖµдЄЛпЉМи°®дЄ≠жѓПдЄАиЃ∞ељХзЪДжЙАжЬЙе≠ЧжЃµзЪДжХ∞жНЃйГљењЕе°ЂгАВ
йАЙжЛ©дЄїйФЃеПКе§ЦйГ®йФЃ
дЄїйФЃжШѓеФѓдЄАиѓЖеИЂи°®дЄ≠жѓПдЄАй°єиЃ∞ељХзЪДе≠ЧжЃµгАВе¶ВдљХдљ†зЪДи°®еЈ≤зїПж≠£з°Ѓж†ЗеЗЖеМЦпЉМдЄїйФЃеЇФељУжИРдЄЇжХ∞жНЃеЇУиЃЊиЃ°зЪДдЄАйГ®еИЖгАВ
е§ЦйГ®йФЃжШѓеМЕеРЂеП¶дЄАи°®дЄ≠дЄїйФЃеАЉзЪДдЄАдЄ™жИЦдЄАзїДе≠ЧжЃµгАВе§ЦйГ®йФЃеЕ≥з≥їеЬ®жХ∞жНЃеЇУдЄ≠еїЇзЂЛдЇЖдЄАеѓєдЄАеПКдЄАеѓєе§ЪеЕ≥з≥їгАВе¶ВжЮЬдљ†зЪДиЃЊиЃ°еЈ≤зїПж≠£з°Ѓж†ЗеЗЖеМЦпЉМе§ЦйГ®йФЃеЇФељУжИРдЄЇжХ∞жНЃеЇУиЃЊиЃ°зЪДдЄАйГ®еИЖгАВ
 
 
 
There are five major steps in the design process.
 
-
Step 1: identify entities and relationships
 
-
Step 2: identify the required data
 
-
Step 3: normalize the data
 
-
Step 4: resolve the relationships
 
-
Step 5: verify the design
 
$ For information about implementing the database design, see the chapter "Working with Database Objects".
 
Step 1: identify entities and relationships
-
To identify the entities in your design and their relationship to each other:
 
-
Define high-level activities. Identify the general activities you will use this database for. For example, you may want to keep track of information about employees.
 
-
Identify entities. For the list of activities, identify the subject areas you need to maintain information about. These will become tables. For example, hire employees, assign to a department, and determine a skill level.
 
-
Identify relationships. Look at the activities and determine what the relationships will be between the tables. For example, there is a relationship between departments and employees. We give this relationship a name.
 
-
Break down the activities. You started out with high-level activities. Now examine these activities more carefully to see if some of them can be broken down into lower-level activities. For example, a high-level activity such as maintain employee information can be broken down into:
-
Add new employees
 
-
Change existing employee information
 
-
Delete terminated employees
 
-
Add new employees
-
Define high-level activities. Identify the general activities you will use this database for. For example, you may want to keep track of information about employees.
-
Identify business rules. Look at your business description and see what rules you follow. For example, one business rule might be that a department has one and only one department head. These rules will be built into the structure of the database.
 
Example
ACME Corporation is a small company with offices in five locations. Currently, 75 employees work for ACME. The company is preparing for rapid growth and has identified nine departments, each with its own department head.
 
To help in its search for new employees, the personnel department has identified 68 skills that it believes the company will need in its future employee base. When an employee is hired, the employee's level of expertise for each skill is identified.
 
Define high-level activities
Some of the high-level activities for ACME Corporation are:
 
-
Hire employees
 
-
Terminate employees
 
-
Maintain personal employee information
 
-
Maintain information on skills required for the company
 
-
Maintain information on which employees have which skills
 
-
Maintain information on departments
 
-
Maintain information on offices
 
Identify the entities and relationships
We can identify the subject areas (tables) and relationships that will hold the information and create a diagram based on the description and high-level activities.
 
We use boxes to show tables and diamonds to show relationships. We can also identify which relationships are one-to-many, one-to-one, and many-to-many.
 
This is a rough E-R diagram. It will be refined throughout the chapter.
 
 
 
 
Break down the high-level activities
The lower-level activities below are based on the high-level activities listed above:
 
-
Add or delete an employee
 
-
Add or delete an office
 
-
List employees for a department
 
-
Add a skill
 
-
Add a skill for an employee
 
-
Identify skills for an employee
 
-
Identify an employee's skill level for each skill
 
-
Identify all employees that have the same skill level for a particular skill
 
-
Change an employee's skill level
 
These lower-level activities can be used to identify if any new tables or relationships are needed.
 
Identify business rules
Business rules often identify one-to-many, one-to-one, and many-to-many relationships.
 
The kind of business rules that may be relevant include the following:
 
-
There are now five offices; expansion plans allow for a maximum of 10.
 
-
Employees can change department or office
 
-
Each department has one department head
 
-
Each office has a maximum of three telephone numbers
 
-
Each telephone number has one or more extensions
 
-
When an employee is hired, the level of expertise in each of several skills is identified
 
-
Each employee can have from three to 20 skills
 
-
An employee may or may not be assigned to an office
 
Step 2: identify the required data
-
To identify the required data:
 
-
Identify supporting data.
 
-
List all the data you will need to keep track of. The data that describes the table (subject) answers the questions who, what, where, when, and why.
 
-
Set up data for each table.
 
-
List the available data for each table as it seems appropriate right now.
 
-
Set up data for each relationship.
 
- List the data that applies to each relationship (if any).
-
Identify supporting data.
Identify supporting data
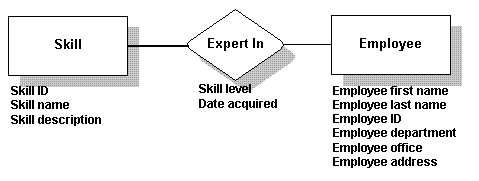
The supporting data you identify will become the names of the columns in the table. For example, the data below might apply to the Employee table, the Skill table, and the Expert In table:
| Employee ID | Skill ID | Skill level |
| Employee first name | Skill name | Date skill was acquired |
| Employee last name | Description of skill |   |
| Employee department |   |   |
| Employee office |   |   |
| Employee address |   |   |
If you make a diagram of this data, it will look like this:
 
 
 
 
Things to remember
-
When you are identifying the supporting data, be sure to refer to the activities you identified earlier to see how you will need to access the data.
 
-
For example, if you know that you will need a list of all employees sorted by last name, make sure that you specify supporting data as Last name and First name, rather than simply Name (which would contain both first and last names).
 
-
The names you choose should be consistent. Consistency makes it easier to maintain your database and easier to read reports and output windows.
 
-
For example, if you choose to use an abbreviated name such as Emp_status for one piece of data, you should not use the full name (Employee_ID) for another piece of data. Instead, the names should be Emp_status and Emp_ID.
 
-
It is not crucial that the data be associated with the correct table. You can use your intuition. In the next section, you'll apply tests to check your judgment.
 
Step 3: normalize the data
Normalization is a series of tests you use to eliminate redundancy in the data and make sure the data is associated with the correct table or relationship. There are five tests. In this section, we will talk about the three tests that are usually used.
 
For more information about the normalization tests, see a book on database design.
 
Normal forms
Normal forms are the tests you usually use to normalize data. When your data passes the first test, it is considered to be in first normal form, when it passes the second test, it is in second normal form, and when it passes the third test, it is in third normal form.
 
-
To normalize the data:
 
-
List the data:
 
-
Identify at least one key for each table. Each table must have a primary key.
 
-
Identify keys for relationships. The keys for a relationship are the keys from the two tables it joins.
 
-
Check for calculated data in your supporting data list. Calculated data is not normally stored in the database.
 
-
Put data in first normal form:
 
-
Remove repeating data from tables and relationships.
 
-
Create one or more tables and relationships with the data you remove.
 
-
Put data in second normal form:
 
-
Identify tables and relationships with more than one key.
 
-
Remove data that depends on only one part of the key.
 
-
Create one or more tables and relationships with the data you remove.
 
-
Put data in third normal form:
 
-
Remove data that depends on other data in the table or relationship and not on the key.
 
- Create one or more tables and relationships with the data you remove.
-
List the data:
Data and keys
Before you begin to normalize (test your data), simply list the data and identify a unique primary key for each table. The key can be made up of one piece of data (column) or several (a concatenated key).
 
The primary key is the set of columns that uniquely identifies rows in a table. The primary key for the Employee table is the Employee ID column. The primary key for the Works In relationship consists of the Office Code and Employee ID columns. Give a key to each relationship in your database by taking the key from each of the tables it connects. In the example, the keys identified with an asterisk are the keys for the relationship:
| Office | *Office code |
|   | Office address |
|   | Phone number |
| Works in | *Office code |
|   | *Employee ID |
| Department | *Department ID |
|   | Department name |
| Heads | *Department ID |
|   | *Employee ID |
| Assoc with | *Department ID |
|   | *Employee ID |
| Skill | *Skill ID |
|   | Skill name |
|   | Skill description |
| Expert in | *Skill ID |
|   | *Employee ID |
|   | Skill level |
|   | Date acquired |
| Employee | *Employee ID |
|   | Employee last name |
|   | Employee first name |
|   | Social security number |
|   | Employee street |
|   | Employee city |
|   | Employee state |
|   | Employee phone |
|   | Date of birth |
Putting data in first normal form
-
Remove repeating groups.
 
-
To test for first normal form, remove repeating groups and put them into a table of their own.
 
-
In the example below, Phone number can repeat. (An office can have more than one telephone number.) Remove the repeating group and make a new table called Telephone. Set up a relationship called Associated With between Telephone and Office.
 
Putting data in second normal form
-
Remove data that does not depend on the whole key.
 
-
Look only at tables and relationships that have more than one key. To test for second normal form, remove any data that does not depend on the whole key (all the columns that make up the key).
 
-
In this example, the original Employee table specifies a key composed of two columns. Some of the data does not depend on the whole key; for example, the department name depends on only one of those keys (Department ID). Therefore, the Department ID, which the other employee data does not depend on, is moved to a table of its own called Department, and a relationship called Assigned To is set up between Employee and Department.
 
 
 
 
Putting data in third normal form
-
Remove data that doesn't depend directly on the key.
 
-
To test for third normal form, remove any data that depends on other data rather than directly on the key.
 
-
In this example, the original Employee table contains data that depends on its key (Employee ID). However, data such as office location and office phone depend on another piece of data, Office code. They do not depend directly on the key, Employee ID. Remove this group of data along with Office code, which it depends on, and make another table called Office. Then we will create a relationship called Works In that connects Employee with Office.
 
 
 
 
Step 4: resolve the relationships
When you finish the normalization process, your design is almost complete. All you need to do is resolve the relationships.
 
Resolving relationships that carry data
Some of your relationships may carry data. This situation often occurs in many-to-many relationships.
 
 
When this is the case, change the relationship to a table. The key to the new table remains the same as it was for the relationship.
 
Resolving relationships that do not carry data
In order to implement relationships that do not carry data, you need to define foreign keys. A foreign key is a column or set of columns that contains primary key values from another table. The foreign key allows you to access data from more than one table at one time.
 
There are some basic rules that help you decide where to put the keys:
 
One to many In a one-to-many relationship, the primary key in the one is carried in the many. In this example, the foreign key goes into the Employee table.
 
 
 
 
One to one In a one-to-one relationship, the foreign key can go into either table. If it is mandatory on one side, but not on the other, it should go on the mandatory side. In this example, the foreign key (Head ID) is in the Department table because it is mandatory there.
 
 
Many to many In a many-to-many relationship, a new table is created with two foreign keys. The existing tables are now related to each other through this new table.
 
 
 
 
Step 5: verify the design
Before you implement your design, you need to make sure it supports your needs. Examine the activities you identified at the start of the design process and make sure you can access all the data the activities require:
 
-
Can you find a path to get all the information you need?
 
-
Does the design meet your needs?
 
-
Is all the required data available?
 
If you can answer yes to all the questions above, you are ready to implement your design.
 
Final design
The final design of the example looks like this:
 
 



зЫЄеЕ≥жО®иНР
йЬАж±ВеИЖжЮРжШѓжХ∞жНЃеЇУиЃЊиЃ°зЪДзђђдЄАж≠•й™§пЉМеЃГзЪДдЄїи¶БдїїеК°жШѓи∞ГжЯ•зљСеРІзЃ°зРЖз≥їзїЯзЪДеЇФзФ®йҐЖеЯЯпЉМжФґйЫЖдњ°жБѓпЉМеИЖжЮРзФ®жИЈдњ°жБѓеТМдЄКзљСжµБз®ЛпЉМе§ДзРЖи¶Бж±ВгАБжХ∞жНЃзЪДеЃЙеЕ®жАІдЄОеЃМжХіжАІи¶Бж±ВгАВйЬАж±ВеИЖжЮРзЪДињЗз®ЛеМЕжЛђйЬАж±ВеИЖжЮРдїїеК°гАБйЬАж±ВеИЖжЮРињЗз®ЛгАБжХ∞жНЃе≠ЧеЕЄеТМ...
жЦЗдїґеИЧи°®дЄ≠зЪД"step2"гАБ"step3"гАБ"step1"еПѓиГљдї£и°®жХ∞жНЃеЇУиЃЊиЃ°зЪДж≠•й™§пЉМдЊЭжђ°жШѓиЃЊиЃ°йШґжЃµгАБеЃЮзО∞йШґжЃµеТМеПѓиГљзЪДдЉШеМЦжИЦеЫЮй°ЊйШґжЃµгАВеЬ®иЃЊиЃ°йШґжЃµпЉМдЉЪињЫи°МйЬАж±ВеИЖжЮРгАБж¶Вењµж®°еЮЛиЃЊиЃ°пЉИе¶ВERеЫЊпЉЙпЉМзДґеРОиљђжНҐдЄЇйАїиЊСж®°еЮЛпЉИе¶ВSQLи°®зїУжЮДпЉЙгАВеЬ®...
### жХ∞жНЃеЇУиЃЊиЃ°иѓіжШОдє¶зЯ•иѓЖзВє #### 1. еЉХи®АдЄОзЫЃзЪД - **жЦЗж°£иГМжЩѓ**пЉЪињЩдїљжЦЗж°£жШѓзФ±вАЬжЮЬеЖїдЉ†е•ЗвАЭеЫҐйШЯдЄЇвАЬJellyShopеЬ®зЇњеХЖеЯОвАЭй°єзЫЃзЉЦеЖЩпЉМжЧ®еЬ®дЄЇй°єзЫЃзЪДжХ∞жНЃеЇУиЃЊиЃ°жПРдЊЫжМЗеѓЉеТМиІДиМГгАВеЃГеЉЇи∞ГдЇЖеЬ®дїїдљХжХ∞жНЃеЇУжКХеЕ•дљњзФ®дєЛеЙНињЫи°М...
### PowerDesignerеѓЉеЗЇжХ∞жНЃеЇУиЃЊиЃ°жЦЗж°£зЯ•иѓЖзВєиѓ¶иІ£ ...йАЪињЗдї•дЄКж≠•й™§пЉМжВ®еПѓдї•зЖЯзїГжОМжП°е¶ВдљХдљњзФ®PowerDesignerињЮжО•MySQLжХ∞жНЃеЇУеєґеѓЉеЗЇжХ∞жНЃеЇУиЃЊиЃ°жЦЗж°£гАВињЩдЄНдїЕжЬЙеК©дЇОжПРйЂШеЈ•дљЬжХИзОЗпЉМињШиГљз°ЃдњЭжХ∞жНЃеЇУиЃЊиЃ°жЦЗж°£зЪДеЗЖз°ЃжАІеТМиІДиМГжАІгАВ
жХ∞жНЃеЇУиЃЊиЃ°жШѓз≥їзїЯеЉАеПСзЪДеЕ≥йФЃж≠•й™§пЉМеЃГеЖ≥еЃЪдЇЖжХ∞жНЃзЪДзїДзїЗжЦєеЉПгАБе≠ШеВ®жХИзОЗдї•еПКз≥їзїЯзЪДжАІиГљгАВжЬђз≥їзїЯйЗЗзФ®зЪДжХ∞жНЃеЇУиЃЊиЃ°еМЕеРЂдЇЖеЃЮдљУеЕ≥з≥їж®°еЮЛпЉИERж®°еЮЛпЉЙгАБи°®зїУжЮДиЃЊиЃ°гАБ糥еЉХз≠ЦзХ•з≠Йе§ЪдЄ™жЦєйЭҐпЉМз°ЃдњЭдЇЖйЯ≥дєРжХ∞жНЃзЪДжЬЙжХИзЃ°зРЖеТМйЂШжХИиЃњйЧЃгАВ...
еЬ®зФµе≠РеХЖеК°з≥їзїЯдЄ≠пЉМжХ∞жНЃеЇУиЃЊиЃ°жШѓжЮДеїЇйЂШжХИгАБз®≥еЃЪдЄФеПѓжЙ©е±Хеє≥еП∞зЪДеЕ≥йФЃж≠•й™§гАВињЩзѓЗеНЪеЃҐвАЬзФµе≠РеХЖеК°з≥їзїЯжХ∞жНЃеЇУиЃЊиЃ°пЉИдЄАпЉЙвАЭеПѓиГљдЉЪжОҐиЃ®е¶ВдљХдЄЇзФµе≠РеХЖеК°з≥їзїЯжЮДеїЇеРИзРЖзЪДжХ∞жНЃж®°еЮЛпЉМдї•дЊње§ДзРЖе§ІйЗПдЇ§жШУжХ∞жНЃпЉМжФѓжМБзФ®жИЈдЇ§дЇТпЉМдї•еПКзЃ°зРЖ...
* жХ∞жНЃеЇУиЃЊиЃ°зЪДдЄїи¶Бж≠•й™§пЉЪйЬАж±ВеИЖжЮРгАБж¶ВењµиЃЊиЃ°гАБйАїиЊСиЃЊиЃ°гАБзЙ©зРЖиЃЊиЃ°гАВ * жХ∞жНЃеЇУиЃЊиЃ°зЪДдЄїи¶БзЫЃж†ЗпЉЪжХ∞жНЃзЛђзЂЛжАІгАБжХ∞жНЃеЃЙеЕ®жАІгАБжХ∞жНЃдЄАиЗіжАІгАБжХ∞жНЃеЕ±дЇЂжАІгАВ * жХ∞жНЃеЇУиЃЊиЃ°дЄ≠зЪДдЄїи¶Бж¶ВењµпЉЪеЃЮдљУгАБе±ЮжАІгАБеЕ≥з≥їгАБйФЃгАБ糥еЉХгАВ жХ∞жНЃ...
ињЩдЄ™й°єзЫЃдЄНдїЕжґµзЫЦдЇЖжХ∞жНЃеЇУиЃЊиЃ°еТМзЃ°зРЖзЪДеЯЇжЬђж¶ВењµпЉМињШжґЙеПКеИ∞дЇЖзљСзїЬзИђиЩЂжКАжЬѓгАБеЙНзЂѓеЉАеПСдї•еПКжХ∞жНЃе§ДзРЖзЪДеЃЮиЈµеЇФзФ®пЉМжШѓе≠¶дє†жХ∞жНЃеЇУжКАжЬѓзЪДдЄАдЄ™зїЉеРИжАІеЃЮдЊЛгАВйАЪињЗињЩдЄ™й°єзЫЃпЉМе≠¶зФЯеПѓдї•жЈ±еЕ•зРЖиІ£жХ∞жНЃеЇУеЬ®еЃЮйЩЕйЧЃйҐШдЄ≠зЪДеЇФзФ®пЉМжПРеНЗ...
жХ∞жНЃеїЇж®°дЄОжХ∞жНЃеЇУиЃЊиЃ°жШѓITйҐЖеЯЯдЄ≠зЪДеЕ≥йФЃжКАжЬѓзОѓиКВпЉМеЃГжґЙеПКеИ∞жХ∞жНЃзЪДзїДзїЗгАБе≠ШеВ®еТМзЃ°зРЖпЉМеѓєдЇОйЂШжХИгАБеЃЙеЕ®гАБеПѓйЭ†зЪДз≥їзїЯиЗ≥еЕ≥йЗНи¶БгАВеЬ®жЬђзѓЗеЖЕеЃєдЄ≠пЉМжИСдїђе∞ЖжЈ±еЕ•жОҐиЃ®жХ∞жНЃеїЇж®°ж¶Вињ∞гАБжХ∞жНЃеЇУиЃЊиЃ°зЪДеЯЇжЬђињЗз®Лдї•еПКUMLжХ∞жНЃеїЇж®°зЪДеЇФзФ®гАВ ...
еЬ®жЬђиКВ"MySQLжХ∞жНЃеЇУеЇФзФ®ж°ИдЊЛиІЖйҐСжХЩз®ЛдЄЛиљљзђђ22иЃ≤ иЃЇеЭЫзЃ°зРЖз≥їзїЯжХ∞жНЃеЇУиЃЊиЃ°"дЄ≠пЉМжИСдїђе∞ЖжЈ±еЕ•жОҐиЃ®е¶ВдљХдЄЇдЄАдЄ™иЃЇеЭЫзЃ°зРЖз≥їзїЯиЃЊиЃ°еРИйАВзЪДжХ∞жНЃеЇУзїУжЮДгАВињЩдЄ™дЄїйҐШжґµзЫЦдЇЖжХ∞жНЃеЇУиЃЊиЃ°зЪДеЯЇз°АзРЖиЃЇдї•еПКеЬ®еЃЮйЩЕй°єзЫЃдЄ≠зЪДеЇФзФ®пЉМеѓєдЇОзРЖиІ£еТМ...
зїЉдЄКжЙАињ∞пЉМеЫЊдє¶йФАеФЃзЃ°зРЖз≥їзїЯжХ∞жНЃеЇУиЃЊиЃ°жґµзЫЦдЇЖеЕ®йЭҐзЪДеКЯиГљйЬАж±ВеИЖжЮРгАБжХ∞жНЃеЇУж®°еЮЛиЃЊиЃ°дї•еПКз≥їзїЯзЪДеЃЙеЕ®зЃ°зРЖпЉМжШѓжЮДеїЇдЄАдЄ™йЂШжХИгАБеПѓйЭ†зЪДеЫЊдє¶йФАеФЃеє≥еП∞зЪДеЕ≥йФЃж≠•й™§гАВйАЪињЗињЩдЇЫиЃЊиЃ°пЉМз≥їзїЯиГље§ЯеЃЮзО∞йЂШжХИзЪДжХ∞жНЃзЃ°зРЖпЉМдЄЇзФ®жИЈжПРдЊЫжµБзХЕзЪД...
зїЉдЄКжЙАињ∞пЉМз†Фз©ґзФЯйАЙж†°дњ°жБѓжЬНеК°еє≥еП∞зЪДжХ∞жНЃеЇУиЃЊиЃ°дЄОжХ∞жНЃжУНдљЬжШѓдЄАдЄ™жґЙеПКе§ЪжЦєйЭҐжКАжЬѓзЪДеЈ•дљЬпЉМйЬАи¶БзїУеРИйЬАж±ВеИЖжЮРгАБжХ∞жНЃеЇУеїЇж®°гАБжХ∞жНЃеЃЮжЦљдЄОзїіжК§з≠Йе§ЪдЄ™ж≠•й™§пЉМжЬАзїИжЮДеїЇеЗЇдЄАдЄ™йЂШжХИгАБеЃЙеЕ®дЄФеКЯиГљдЄ∞еѓМзЪДдњ°жБѓеє≥еП∞пЉМеК©еКЫиАГзФЯеБЪеЗЇжШОжЩЇ...
гАКжХ∞жНЃеЇУиЃЊиЃ°дЄОERж®°еЮЛзїЉињ∞гАЛ еЬ®жХ∞жНЃеЇУиЃЊиЃ°дЄ≠пЉМERпЉИеЃЮдљУеЕ≥з≥їпЉЙж®°еЮЛжШѓдЄАзІНйЗНи¶БзЪДж¶ВењµиЃЊиЃ°еЈ•еЕЈпЉМеЃГеЄЃеК©жИСдїђзРЖиІ£еТМжЮДеїЇжХ∞жНЃеЇУеЇФзФ®з≥їзїЯзЪДиЃЊиЃ°ињЗз®ЛгАВERж®°еЮЛзЪДеЯЇжЬђж¶ВењµеМЕжЛђеЃЮдљУгАБиБФз≥їеТМе±ЮжАІпЉМињЩдЇЫеЕГзі†еЕ±еРМжЮДжИРдЇЖжХ∞жНЃеЇУзЪД...
4. **жХ∞жНЃеЇУиЃЊиЃ°ж≠•й™§**пЉЪ - йЬАж±ВеИЖжЮРпЉЪзРЖиІ£дЄЪеК°йЬАж±ВпЉМжШОз°Ѓз≥їзїЯзЫЃж†ЗгАВ - ж¶ВењµзїУжЮДиЃЊиЃ°пЉЪзїШеИґE-RеЫЊпЉМеЃЪдєЙеЃЮдљУгАБе±ЮжАІеТМеЕ≥з≥їгАВ - йАїиЊСзїУжЮДиЃЊиЃ°пЉЪе∞ЖE-RеЫЊиљђеМЦдЄЇеЕ≥з≥їж®°еЉПпЉМињЫи°МдЉШеМЦгАВ - зЙ©зРЖзїУжЮДиЃЊиЃ°пЉЪиАГиЩСе≠ШеВ®жХИзОЗпЉМ...
иІДиМГеМЦиЃЊиЃ°жШѓжХ∞жНЃеЇУиЃЊиЃ°дЄ≠зЪДйЗНи¶Бж≠•й™§пЉМеЃГеЗПе∞СдЇЖжХ∞жНЃеЖЧдљЩеєґдЉШеМЦдЇЖжХ∞жНЃдЄАиЗіжАІгАВеЬ®ињЩдЄ™ж°ИдЊЛдЄ≠пЉМйБµеЊ™дЇЖзђђдЄАиМГеЉПпЉИ1NFпЉЙгАБзђђдЇМиМГеЉПпЉИ2NFпЉЙеТМзђђдЄЙиМГеЉПпЉИ3NFпЉЙпЉМз°ЃдњЭдЇЖжХ∞жНЃзЛђзЂЛжАІеТМжЬАе∞ПеЖЧдљЩгАВ ж≠§е§ЦпЉМз≥їзїЯињШеПѓиГљжґЙеПКеЕґдїЦ...
### еЬ®зЇњзВєж≠Мз≥їзїЯзЪДжХ∞жНЃеЇУиЃЊиЃ°зЯ•иѓЖзВє #### дЄАгАБйЬАж±ВеИЖжЮР еЬ®зЇњзВєж≠Мз≥їзїЯзЪДжХ∞жНЃеЇУиЃЊиЃ°й¶ЦеЕИйЬАи¶БињЫи°МйЬАж±ВеИЖжЮРгАВињЩдЄАж≠•й™§жШѓжХідЄ™й°єзЫЃзЪДеЯЇз°АпЉМ...йАЪињЗињЩдЄАз≥їеИЧзЪДиЃЊиЃ°ж≠•й™§пЉМеПѓдї•з°ЃдњЭжЬАзїИзЪДжХ∞жНЃеЇУз≥їзїЯиГље§ЯйЂШжХИеЬ∞жї°иґ≥зФ®жИЈзЪДйЬАж±ВгАВ
**дЇМгАБжХ∞жНЃеЇУиЃЊиЃ°ж≠•й™§** 1. **йЬАж±ВеИЖжЮР**пЉЪдЇЖиІ£зФ®жИЈзЪДдЄЪеК°йЬАж±ВпЉМз°ЃеЃЪжХ∞жНЃзЪДз±їеЮЛгАБиМГеЫіеТМйАїиЊСеЕ≥з≥їпЉМ嚥жИРйЬАж±ВиІДиМГгАВ 2. **ж¶ВењµиЃЊиЃ°**пЉЪжЮДеїЇж¶Вењµж®°еЮЛпЉМеѓєзО∞еЃЮдЄЦзХМињЫи°МжКљи±°пЉМдљУзО∞еЃЮдљУгАБе±ЮжАІеТМеЕ≥з≥їгАВ 3. **йАїиЊСиЃЊиЃ°**пЉЪе∞Ж...
жЬђзЂ†дЄїи¶БдїЛзїНдЇЖжХ∞жНЃеЇУиЃЊиЃ°зЪДеЯЇжЬђжµБз®ЛпЉМеМЕжЛђйЬАж±ВеИЖжЮРгАБж¶ВењµзїУжЮДиЃЊиЃ°гАБйАїиЊСзїУжЮДиЃЊиЃ°гАБзЙ©зРЖиЃЊиЃ°гАБжХ∞жНЃеЇУеЃЮжЦљдї•еПКеРОжЬЯзЪДињРи°МдЄОзїіжК§гАВ 1. **йЬАж±ВеИЖжЮР**пЉЪињЩжШѓжХ∞жНЃеЇУиЃЊиЃ°зЪДзђђдЄАж≠•пЉМдЄїи¶БжШѓзРЖиІ£зФ®жИЈзЪДйЬАж±ВпЉМжФґйЫЖеТМжХізРЖдЄЪеК°...
еЬ®ITи°МдЄЪдЄ≠пЉМжХ∞жНЃеЇУиЃЊиЃ°жШѓжЮДеїЇйЂШжХИгАБз®≥еЃЪдЄФеПѓжЙ©е±ХзЪДеЇФзФ®з®ЛеЇПзЪДеЕ≥йФЃж≠•й™§гАВеЬ®ињЩдЄ™еИЭж≠•зЪДж®°еЭЧжХ∞жНЃеЇУиЃЊиЃ°1дЄ≠пЉМжИСдїђеЕ≥ж≥®зЪДжШѓзФ®жИЈж®°еЭЧгАБжЄЄиЃ∞ж®°еЭЧгАБзФ®жИЈйЧЃйҐШдЄОиІ£з≠Фж®°еЭЧгАБи°Мз®Лдњ°жБѓж®°еЭЧдї•еПКдЇІеУБжО®иНРе±Хз§Їж®°еЭЧгАВдї•дЄЛжШѓеѓєињЩдЇЫ...
**жХ∞жНЃеЇУиЃЊиЃ°**пЉЪжШѓжМЗеЬ®зЙєеЃЪзЪДеЇФзФ®зОѓеҐГдЄ≠пЉМжЮДеїЇжЬАйАВеРИзЪДжХ∞жНЃеЇУзїУжЮДпЉМеєґеЯЇдЇОж≠§еїЇзЂЛеЃМжХізЪДжХ∞жНЃеЇУеПКеЕґеЇФзФ®з≥їзїЯпЉМз°ЃдњЭеЕґиГљйЂШжХИеЬ∞е≠ШеВ®жХ∞жНЃеєґжї°иґ≥дЄНеРМзФ®жИЈзЪДйЬАж±ВгАВ 1. **йЬАж±ВеИЖжЮР**пЉЪињЩдЄАйШґжЃµзЪДзЫЃж†ЗжШѓеѓєзФ®жИЈдЄЪеК°жіїеК®еПК...