
Hadoop伪分布模式搭建首先要了解一下Hadoop的运行模式:单机模式(standalone)
单机模式是Hadoop的默认模式。当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置。在这种默认模式下所有3个XML文件均为空。当配置文件为空时,Hadoop会完全运行在本地。因为不需要与其他节点交互,单机模式就不使用HDFS,也不加载任何Hadoop的守护进程。该模式主要用于开发调试MapReduce程序的应用逻辑。
伪分布模式(Pseudo-Distributed Mode)
伪分布模式在“单节点集群”上运行Hadoop,其中所有的守护进程都运行在同一台机器上。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
全分布模式(Fully Distributed Mode)
Hadoop守护进程运行在一个集群上。
1. 配置conf文件夹下hadoop-env.sh文件的JAVA_HOME环境变量指向Java安装目录<SPAN class=link_title><SPAN class=link_title></SPAN></SPAN>2. 安装SSH:包括ssh, sshd, ssh-keygen;
3. 生成SSH密钥对,不设置口令:
ssh-keygen -t rsa
4. 设置授权密钥:
01.ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
02.cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
5. 配置conf下的几个XML文件
core-site.xml
core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation.
</description>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
<description>The host and port that the MapReduce job tracker runs at.
</description>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>The actual number of replication can be specified when the file is created.
</description>
</property>
</configuration>
6. 启动Hadoop的几个守护进程
bin/start-all.sh
7. 查看Hadoop的几个守护进程,
jps
如果正常应该可以看到以下结果,包括NameNode, DataNode, SecondaryNameNode, JobTracker, TaskTracker。
- 16982 DataNode
- 17249 SecondaryNameNode
- 16730 NameNode
- 17746 Jps
- 17364 JobTracker
- 17629 TaskTracker
由于我之前配置的时候,SSH没有设置密钥授权,所以每次启动一个守护进程时总要手动输入一次机器密码,进行步骤4之后可以解决这个问题。 第一次启动时可以看到NameNode,关掉再启动时通过jps看不到NameNode,解决方法:关掉这些进程(bin/stop-all.sh),重新格式化,再启动,这时发现少了DataNode这个守护进程,重新格式化还是没有,又重头开始配置Hadoop,结果还是不行。
上网搜了一下,找到了解决方法:
上网搜了一下,找到了解决方法:
有时数据结构出现问题会产生无法启动datanode的问题。
然后用 hadoop namenode -format 重新格式化后仍然无效,/tmp中的文件并没有清除。
其实还需要清除/tmp/hadoop*里的文件。
执行步骤:
一、先删除hadoop:/tmp
bin/hadoop fs -rmr /tmp
二、停止 hadoop
bin/stop-all.sh
三、删除/tmp/hadoop*
rm -rf /tmp/hadoop*
四、格式化hadoop
bin/hadoop namenode -format
五、启动hadoop
bin/start-all.sh
之后即可解决这个datanode没法启动的问题
8. 检查运行状态
Hadoop管理界面:http://localhost:50030
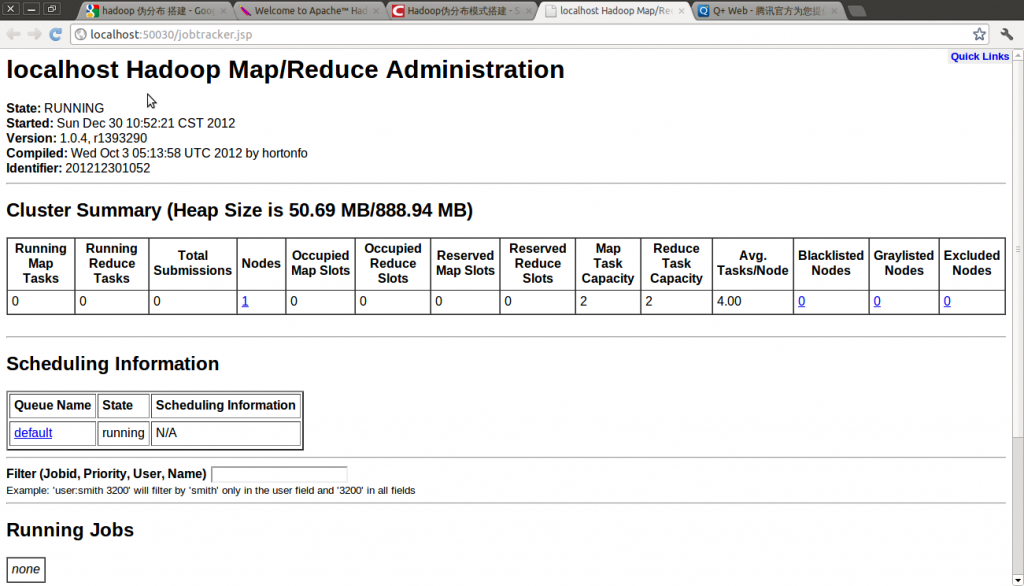
Hadoop Task Tracker 状态:http://localhost:50060
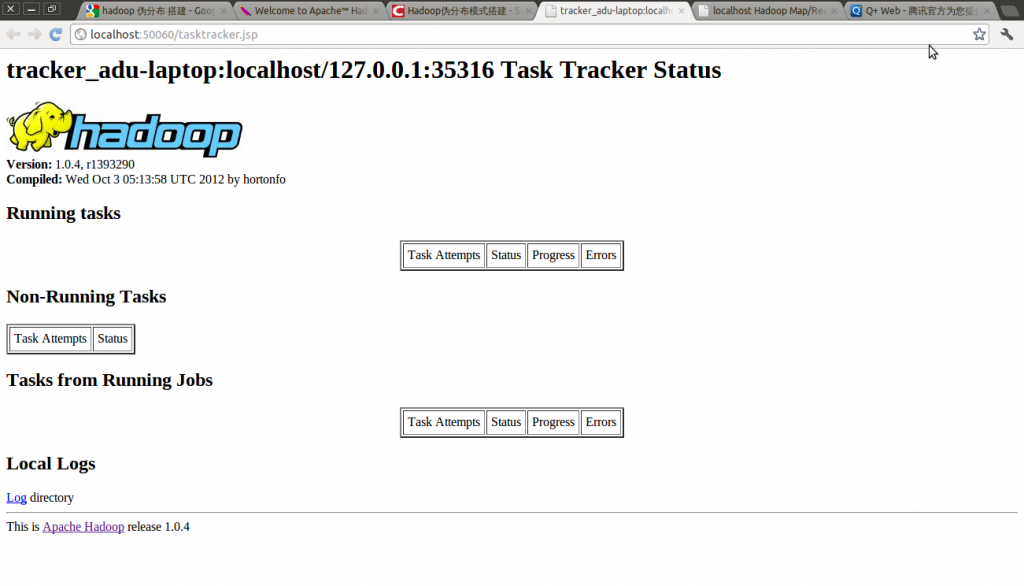
Hadoop DFS 状态:http://localhost:50070
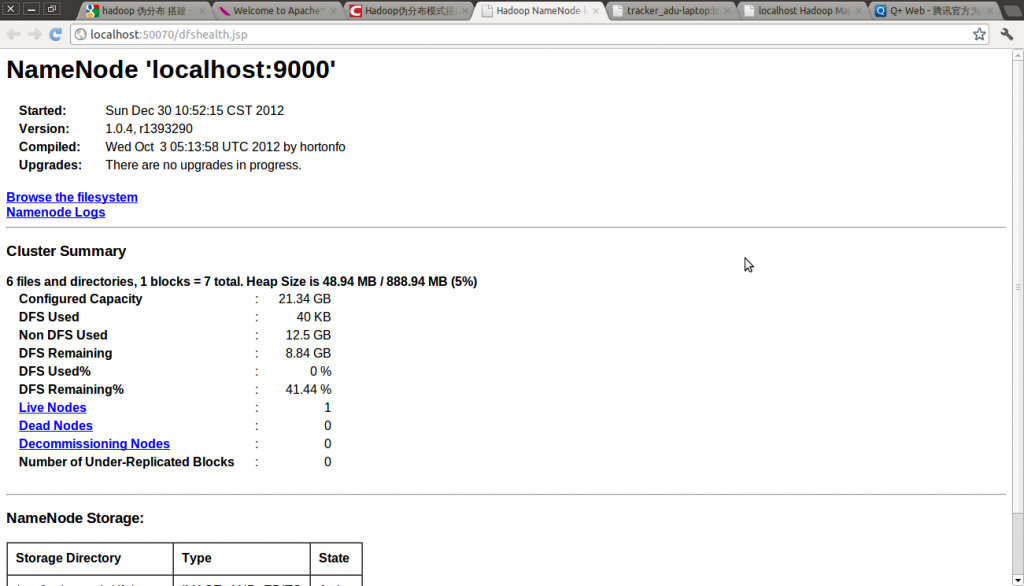
9. 结束Hadoop
Hadoop管理界面:http://localhost:50030
Hadoop Task Tracker 状态:http://localhost:50060
Hadoop DFS 状态:http://localhost:50070
9. 结束Hadoop
bin/stop-all.sh
Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程
历时一周多,终于搭建好最新版本hadoop2.2集群,期间遇到各种问题,作为菜鸟真心被各种折磨,不过当wordcount给出结果的那一刻,兴奋的不得了~~(文当中若有错误之处或疑问欢迎指正,互相学习)
PS:
第一部分 Hadoop 2.2 下载
Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2。官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译。
如下图所示,下载红色标记部分即可。如果要自行编译则下载src.tar.gz.

第二部分 集群环境搭建
1、这里我们搭建一个由三台机器组成的集群:
192.168.0.1 hduser/passwd cloud001 nn/snn/rm CentOS6 64bit
192.168.0.2 hduser/passwd cloud002 dn/nm Ubuntu13.04 32bit
192.168.0.3 hduser/passwd cloud003 dn/nm Ubuntu13.0432bit
1.1 上面各列分别为IP、user/passwd、hostname、在cluster中充当的角色(namenode, secondary namenode, datanode , resourcemanager, nodemanager)
1.2 Hostname可以在/etc/hostname中修改(ubuntu是在这个路径下,redhat稍有不同)
1.3 这里我们为每台机器新建了一个账户hduser.这里需要给每个账户分配sudo的权限。(切换到root账户,修改/etc/sudoers文件,增加:hduser ALL=(ALL) ALL )
2、修改/etc/hosts 文件,增加三台机器的ip和hostname的映射关系
192.168.0.1 cloud001
192.168.0.2 cloud002
192.168.0.3 cloud003
3、打通cloud001到cloud002、cloud003的SSH无密码登陆
3.1 安装ssh
一般系统是默认安装了ssh命令的。如果没有,或者版本比较老,则可以重新安装:
sodu apt-get install ssh
3.2设置local无密码登陆
安装完成后会在~目录(当前用户主目录,即这里的/home/hduser)下产生一个隐藏文件夹.ssh(ls -a 可以查看隐藏文件)。如果没有这个文件,自己新建即可(mkdir .ssh)。
具体步骤如下:
1、 进入.ssh文件夹
2、 ssh-keygen -t rsa 之后一路回 车(产生秘钥)
3、 把id_rsa.pub 追加到授权的 key 里面去(cat id_rsa.pub >> authorized_keys)
4、 重启 SSH 服 务命令使其生效 :service sshd restart(这里RedHat下为sshdUbuntu下为ssh)
此时已经可以进行ssh localhost的无密码登陆
【注意】:以上操作在每台机器上面都要进行。
3.3设置远程无密码登陆
这里只有cloud001是master,如果有多个namenode,或者rm的话则需要打通所有master都其他剩余节点的免密码登陆。(将001的authorized_keys追加到002和003的authorized_keys)
进入001的.ssh目录
scp authorized_keys hduser@cloud002:~/.ssh/ authorized_keys_from_cloud001
进入002的.ssh目录
cat authorized_keys_from_cloud001>> authorized_keys
至此,可以在001上面sshhduser@cloud002进行无密码登陆了。003的操作相同。
4、安装jdk(建议每台机器的JAVA_HOME路径信息相同)
注意:这里选择下载jdk并自行安装,而不是通过源直接安装(apt-get install)



相关推荐
hadoop伪分布模式搭建(详细步骤)_hadoop伪分布式搭建全过程-CSDN博客.mhtml
Hadoop伪分布模式环境搭建 Hadoop伪分布模式环境搭建是指在单个节点上搭建Hadoop集群环境,主要用于开发调试MapReduce应用逻辑。以下是搭建伪分布模式环境的步骤: 一、SSH协议介绍 SSH(Secure Shell)是一种...
### Hadoop伪分布模式搭建详解 #### 一、概述 Hadoop是一款开源的大数据处理框架,主要用于处理海量数据。在实际应用中,Hadoop通常运行在由多台计算机组成的集群环境中,但在学习或测试阶段,我们往往会在一台...
以下为文章部分标题 1.搭建单机模式Hadoop (1)关闭防火墙(2)关闭selinux防火墙(3)设置主机名(4)映射主机名与ip地址 2.安装JDK(2)上传JDK至服务器(4)配置JAVA环境变量...验证伪分布模式Hadoop是否安装部署成功
Hadoop伪分布模式是一种在单台机器上模拟分布式环境的方式,通常用于开发测试阶段。这种方式既能够体验到Hadoop的分布式特性,又不需要复杂的多节点集群配置。本文将详细介绍如何在Ubuntu系统上搭建Hadoop伪分布环境...
以上就是根据提供的文件内容,对Hadoop2.7.3伪分布式模式搭建的知识点的详细说明。整个搭建过程需要读者对Linux操作系统、JDK的安装和配置以及Hadoop配置有一定的了解,对于初学者来说,手把手的教学文档能够提供很...
【大数据之Hadoop伪分布模式启动】 在大数据处理领域,Hadoop是一个开源的分布式计算框架,它能够处理和存储海量数据。在学习和测试Hadoop时,为了方便,通常会采用伪分布模式(Pseudo-Distributed Mode),这种...
【Hadoop伪分布式环境搭建详解】 Hadoop作为大数据处理的核心框架,对于初学者和专业开发人员来说,理解并掌握其安装配置至关重要。Hadoop提供了多种运行模式,包括本地模式、伪分布式模式以及集群模式,每种模式都...
7. 最后,通过`help文档.txt`中的指示进行验证,确保Hadoop伪分布式环境已成功搭建并运行。 理解并掌握这些步骤和配置文件的用途,是成为Hadoop管理员或数据工程师的关键技能之一。在实际应用中,你可能需要根据...
本文将详细介绍如何在单机上搭建Hadoop伪分布式环境,并通过运行经典的WordCount示例来理解Hadoop的基本工作流程。 #### 二、Hadoop伪分布式环境简介 ##### 2.1 Hadoop分布式组件概述 Hadoop主要由两大部分构成:...
### Hadoop伪分布式集群搭建详解 #### 一、概述 Hadoop是一款开源的大数据处理框架,主要用于处理海量数据。在实际应用中,Hadoop通常运行在由多台服务器组成的集群环境中,但为了方便学习和测试,可以搭建一个伪...
### Hadoop 2.6.0 伪分布模式安装详细指南 #### 一、环境准备与常见问题 在开始安装之前,确保您的机器满足以下条件: 1. **JDK 版本确认**:Hadoop 2.6.0 对 JDK 的版本有一定要求,通常推荐使用 Oracle JDK 1.7...
在本文中,我们将深入探讨如何搭建Hadoop平台,包括单节点模式、伪分布式模式以及分布式文件系统,并在这些环境中运行MapReduce程序进行测试。Hadoop是Apache软件基金会的一个开源项目,它提供了一个分布式文件系统...
本文将详细介绍如何搭建Hadoop伪集群环境,并在Eclipse中配置插件。 首先,搭建Hadoop伪集群环境主要分为以下几个步骤: 1. 安装Hadoop环境:需要在机器上安装Java环境,因为Hadoop是用Java编写的。除此之外,还...
通过上述步骤,我们可以成功地在本地计算机上搭建起Hadoop伪分布模式。这对于初学者来说是一个非常好的学习平台,不仅能够帮助理解Hadoop的基本工作原理,还能掌握Hadoop集群的搭建过程。同时,通过实际操作,也能更...
在开始配置Hadoop伪分布式之前,需要确保已经完成了基本的环境搭建工作。主要包括: 1. **系统环境准备**:一般情况下,推荐使用Linux操作系统,因为它提供了良好的稳定性和性能。 2. **JDK安装**:Hadoop基于Java...
我们将依据《如何搭建hadoop伪分布式》这篇文章,并结合提供的配置文件来探讨相关知识点。 首先,你需要下载Hadoop的安装包,推荐选择稳定版本,如Hadoop 2.x或3.x系列。下载完成后,解压到一个合适的目录,例如`/...
搭建Hadoop伪分布式环境的步骤如下: 1. **安装JDK**:首先,你需要将JDK解压到一个适当的目录,然后设置JAVA_HOME环境变量指向JDK的安装路径。同时,确保PATH环境变量包含了JDK的bin目录,以便系统能够找到Java...
012.Hadoop配置伪分布模式.mp4 013.Hadoop配置完全分布模式之修改虚拟机名称和目录.mp4 014.Hadoop配置完全分布模式之修改登录提示和主机名.mp4 -015.Hadoop配置完全分布模式之使用符号链接实现配置分离.mp4 -016....
在Ubuntu环境下搭建Hadoop伪分布式模式,主要是为了模拟多节点Hadoop集群的环境,以便于学习和测试Hadoop的功能。这个过程涉及到多个步骤,包括必要的资源下载、软件安装、环境配置以及Hadoop服务的启动与验证。以下...